
前言¶
概述
本文档主要描述HiSpark Studio AI for VS Code插件的安装及使用。该工具主要用于模型压缩、模型转换、应用开发、端侧部署、性能调优等。
读者对象
本文档主要适用于基于海思芯片进行嵌入式开发的相关人员:
软件开发工程师
技术支持工程师
硬件开发工程师
嵌入式爱好者
符号约定
在本文中可能出现下列标志,它们所代表的含义如下。
符号 |
说明 |
|---|---|
|
表示如不避免则将会导致死亡或严重伤害的具有高等级风险的危害。 |
|
表示如不避免则可能导致死亡或严重伤害的具有中等级风险的危害。 |
|
表示如不避免则可能导致轻微或中度伤害的具有低等级风险的危害。 |
|
用于传递设备或环境安全警示信息。如不避免则可能会导致设备损坏、数据丢失、设备性能降低或其它不可预知的结果。 “须知”不涉及人身伤害。 |
|
对正文中重点信息的补充说明。 “说明”不是安全警示信息,不涉及人身、设备及环境伤害信息。 |





修改记录
文档版本 |
发布日期 |
修改说明 |
|---|---|---|
01 |
2026-01-26 |
第一次正式版本发布。 |
简介¶
HiSpark Studio AI是面向开发者提供的超轻量级AI应用开发平台,具备高集成、高专业、高易用等特征,聚焦嵌入式AI应用场景,提供模型压缩、模型转换、应用开发、端侧部署、性能调优的全流程开发平台。
开发板准备¶
目前支持Hi3863以及Hi3322两款芯片,需要提前准备单板资源。
开发环境准备¶
HiSpark Studio AI准备¶
插件安装¶
从VS Code插件市场中安装插件:
安装HiSpark Studio插件
图 1 HiSpark Studio插件
安装HiSpark Studio AI插件
图 2 HiSpark Studio AI插件
环境配置¶
进入HiSpark Studio AI页面,点击“Download Toolchain”按钮。
图 1 Download Toolchain

出现如图2所示界面,即表示一键下载工具链已完成。
图 2 下载成功提示

将用户通过点击“Download Toolchain”下载环境中cmake路径配置到环境变量,路径如下:D:\xxxxxx\tools\python\Scripts
Hi3863环境准备¶
整个CPU侧环境准备步骤大致如图1所示。
图 1 CPU环境准备

Linux服务器端AI环境准备¶
使用Dockerfile准备Linux服务器端AI环境。环境安装前需要从发布包获取Dockerfile文件、MSLite安装包,并将其放置在同级目录下。
Dockerfile包括Dockerfile_mslite。Dockerfile_mslite为基础版环境准备配置文件。
环境安装前,请先检查目录下是否包含如下文件:
.
├── Dockerfile_mslite
└── HiSpark.AI_xx.xx.xx-mindspore-enterprise-lite-xx.xx.xx-linux-x64.tar.gz
须知:
请勿将多个不同版本的MSLite包放置于该目录下。
请保持Linux服务器网络畅通。
基础版环境准备¶
基础版环境准备前,请先保证Linux服务器安装Docker。
基础版环境准备步骤如下:
执行如下命令构建Docker镜像:
docker build -f Dockerfile_mslite -t {镜像名称}:{镜像标签} .如需要配置代理,请执行如下命令:
docker build -f Dockerfile_mslite --build-arg http_proxy={http代理地址} --build-arg https_proxy={https代理地址} --build-arg no_proxy={排除代理地址} -t {镜像名称}:{镜像标签} .如果打印如下类似信息,表示Docker构建成功。
Successfully built xxx Successfully tagged xxx
执行如下命令运行容器,并关联端口及挂载文件夹:
docker run -itd --ipc=host -p {服务器端口}:22 -v {服务器路径}:{容器路径} --name {容器名称} {镜像名称}:{镜像标签}其中:
--ipc=host:可选,配置后容器共享宿主机的内存。
-p参数:表示将服务器对应端口映射到容器的[服务器端口}:22端口。
-v参数:表示将服务器相应路径映射到容器内的相应路径。该参数为可选参数。
执行如下命令启动容器:
docker start {容器名称}使用如下指令查询运行的容器,如果查询的表格中包含启动的容器,则表示启动成功。
docker ps配置容器root密码。
使用如下命令进入容器:
docker exec -it {容器名称} /bin/bash配置密码:
passwd
执行如下命令测试ssh连接。按照提示输入root密码,能够顺利进入容器,则表示ssh连接正常。
ssh root@{服务器IP地址} -p {服务器端口}
说明: 由于镜像构建过程中使用的镜像源由基础镜像Ubuntu XX.XX决定,请用户根据基础镜像决定是否更换镜像源。更换镜像源可参考以下示例:
下述示例中,设置了http://mirrors.aliyun.com为镜像源,该镜像源并不一定适用所有的环境,请用户选择适合的镜像源进行替换。
#!/bin/bash
# Mirror source configuration
# The following configuration of mirror sources is for reference only.
# You need to configure proper mirror sources based on your environment requirements.
# Configure the image source according to the following example to ensure that the software package can be downloaded during image construction.
############## Modify the following information as required .##################
# cp -a /etc/apt/sources.list /etc/apt/sources.list.bak
# sed -i "s@http://.*archive.ubuntu.com@http://mirrors.aliyun.com@g" /etc/apt/sources.list
# sed -i "s@http://.*security.ubuntu.com@http://mirrors.aliyun.com@g" /etc/apt/sources.list
# mkdir -p /root/.pip/
# echo '[global]' >> /root/.pip/pip.conf
# echo 'trusted-host=mirrors.aliyun.com' >> /root/.pip/pip.conf
# echo 'index-url=http://mirrors.aliyun.com/pypi/simple' >> /root/.pip/pip.conf
Windows侧环境准备¶
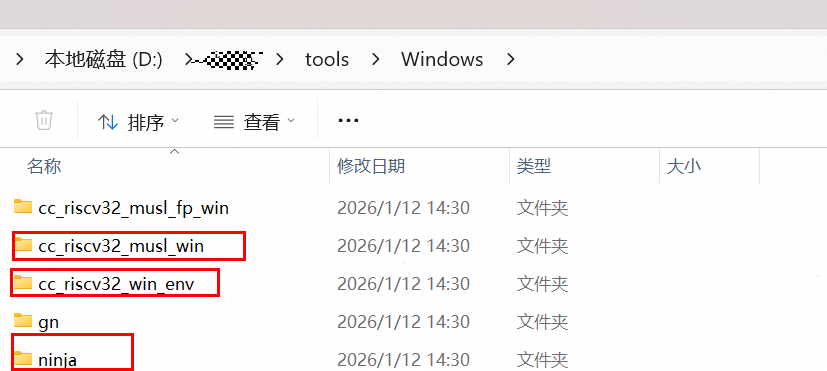
将cmake以及ninja依赖配置到环境变量
找到下载工具链中cmake、ninja等的路径,添加至环境变量并置顶。toolchain_path为用户自定义下载的路径。
${toolchain_path}\Windows\cc_riscv32_win_env ${toolchain_path}\Windows\ninja ${toolchain_path}\Windows\cc_riscv32_msul_win\bin
图 1 依赖工具包
解压MindSpore安装包到本地
图 2 MindSpore安装包

配置config.json
打开“C:\Users\用户名\.vscode\extensions\hispark.hisparkai-x.x.x\resources\config.json”。
CPU相关的字段:mindspore。
将mindspore字段对应的路径替换为本地安装路径。
{ "mindspore": "xxx" }
准备SDK¶
取Hi3863对应SDK发布包,解压SDK包到本地目录。
解压HiSpark.AI组件包并合入到SDK对应目录。
将组件包中的“HiSpark.AI_xx.xx.x.xxxx-samples.tar.gz”包解压,将ai_samples一级目录放置到SDK中“application/samples”下,目录结构如下所示:
application/samples ├─ai_samples │ ├─amct │ └─oh │ ├─gru │ │ ├─model │ │ ├─scripts │ │ └─src │ └─lenet5 │ ├─data │ ├─model │ ├─scripts │ └─src │-- ......
将组件包中的“HiSpark.AI_xx.xx.x.xxxx-adaptor.tar.gz”包解压,将adaptor以及include一级目录放置到SDK中“middleware/utils/ai_mcu”下,目录结构如下所示:
middleware/utils/ai_mcu ├─adaptor │ ├─cpu │ │ ├─dump │ │ └─include │ └─npu └─include
Hi3322环境准备¶
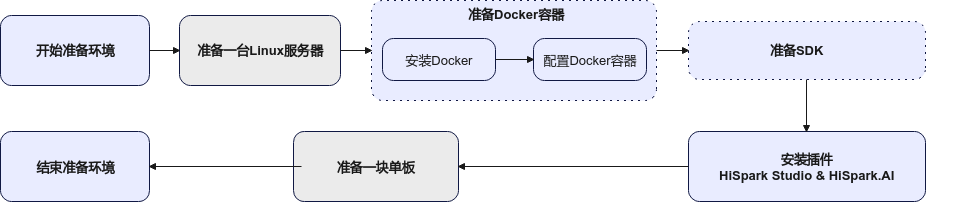
整个NPU侧环境准备步骤大致如图1所示。
图 1 NPU环境准备
Linux服务器端AI环境准备¶
使用Dockerfile准备Linux服务器端AI环境。环境安装前需要从发布包获取Dockerfile文件、ATC安装包、AMCT安装包,并将其放置在同级目录下。
Dockerfile包括Dockerfile_cann_cpu和Dockerfile_cann_gpu。其中Dockerfile_cann_cpu为基础版环境准备配置文件;Dockerfile_cann_gpu为GPU加速版环境准备配置文件。GPU可以加速量化感知训练的效率。
环境安装前,请先检查目录下是否包含如下文件:
.
├── CANN-amct-{版本号}-linux.x86_64.tar.gz
├── CANN-compiler-{版本号}-linux.x86_64.run
├── CANN-opp-{版本号}-linux.x86_64.run
├── CANN-runtime-{版本号}-linux.x86_64.run
├── CANN-toolkit-{版本号}-linux.x86_64.run
└── Dockerfile_cann_cpu或Dockerfile_cann_gpu
请勿将多个不同版本的ATC和AMCT安装包放置于该目录下。
请保持Linux服务器网络畅通。
基础版环境准备¶
基础版环境准备前,请先保证Linux服务器安装Docker。
基础版环境准备步骤如下:
执行如下命令构建Docker镜像:
docker build -f Dockerfile_cann_cpu -t {镜像名称}:{镜像标签} .如需要配置代理,请执行如下命令:
docker build -f Dockerfile_cann_cpu --build-arg http_proxy={http代理地址} --build-arg https_proxy={https代理地址} --build-arg no_proxy={排除代理地址} -t {镜像名称}:{镜像标签} .如果打印如下类似信息,表示Docker构建成功。
Successfully built 61bc7fae9f9e Successfully tagged {镜像名称}:{镜像标签}
执行如下命令运行容器,并关联端口及挂载文件夹:
docker run -itd -p {服务器端口}:22 -v {服务器路径}:{容器路径} --name {容器名称} {镜像名称}:{镜像标签}其中:
-p参数:表示将服务器对应端口映射到容器的{服务器端口}:22端口。
-v参数:表示将服务器相应路径映射到容器内的相应路径。该参数为可选参数。
执行如下命令启动容器:
docker start {容器名称}使用如下指令查询运行的容器,如果查询的表格中包含启动的容器,则表示启动成功。
docker ps配置容器root密码。
使用如下命令进入容器:
docker exec -it {容器名称} /bin/bash配置密码:
passwd
执行如下命令测试ssh连接。按照提示输入root密码,能够顺利进入容器,则表示ssh连接正常。
ssh root@{服务器IP地址} -p {服务器端口}
GPU加速版环境准备¶
GPU加速版环境准备前,请先保证Linux服务器:
安装Docker。
安装GPU驱动;并保证版本号≥525。
安装和配置NVIDIA Container Toolkit。
GPU加速版环境准备步骤如下:
执行如下命令构建Docker镜像:
docker build -f Dockerfile_cann_gpu -t {镜像名称}:{镜像标签} .如需要配置代理,请执行如下命令:
docker build -f Dockerfile_cann_gpu --build-arg http_proxy={http代理地址} --build-arg https_proxy={https代理地址} --build-arg no_proxy={排除代理地址} -t {镜像名称}:{镜像标签} .如果打印如下类似信息,表示Docker构建成功。
Successfully built 61bc7fae9f9e Successfully tagged {镜像名称}:{镜像标签}
执行如下命令运行容器,并关联端口及挂载文件夹:
docker run -itd -p {服务器端口}:22 --gpus all -v {服务器路径}:{容器路径} --name {容器名称} {镜像名称}:{镜像标签}其中:
-p参数:表示将服务器对应端口映射到容器的22端口。
--gpus参数:表示GPU对容器可见。
-v参数:表示将服务器相应路径映射到容器内的相应路径。该参数为可选参数。
执行如下命令启动容器:
docker start {容器名称}使用如下指令查询运行的容器,如果查询的表格中包含启动的容器,则表示启动成功。
docker ps配置容器root密码。
使用如下命令进入容器:
docker exec -it {容器名称} /bin/bash配置密码:
passwd
在容器内执行如下命令测试GPU是否可用。
nvidia-smi命令输出如图1类似信息,表示GPU可用。
图 1 GPU查询结果

在Linux服务器执行如下命令测试ssh连接。按照提示输入root密码,能够顺利进入容器,则表示ssh连接正常。
ssh root@{服务器IP地址} -p {服务器端口}
Windows侧Bash环境准备¶
该小节仅针对于需要依赖bash环境才可以编译的Hi3322工程。
如果需要编译Hi3322的工程,用户需手动下载Git并将bash路径添加到环境变量中。
下载链接:https://github.com/git-for-windows/git/releases/download/v2.48.1.windows.1/Git-2.48.1-64-bit.exe
如果Windows系统System32下默认有“bash.exe”,需要删除其系统下的“bash.exe”,使用安装的git下内置的“bash.exe”。
完成后,重启VS Code使新环境变量生效,即可正常编译工程。
图 1 删除Windows系统库的bash
图 2 配置bash.exe的删除权限

图 3 配置bash.exe的删除权限
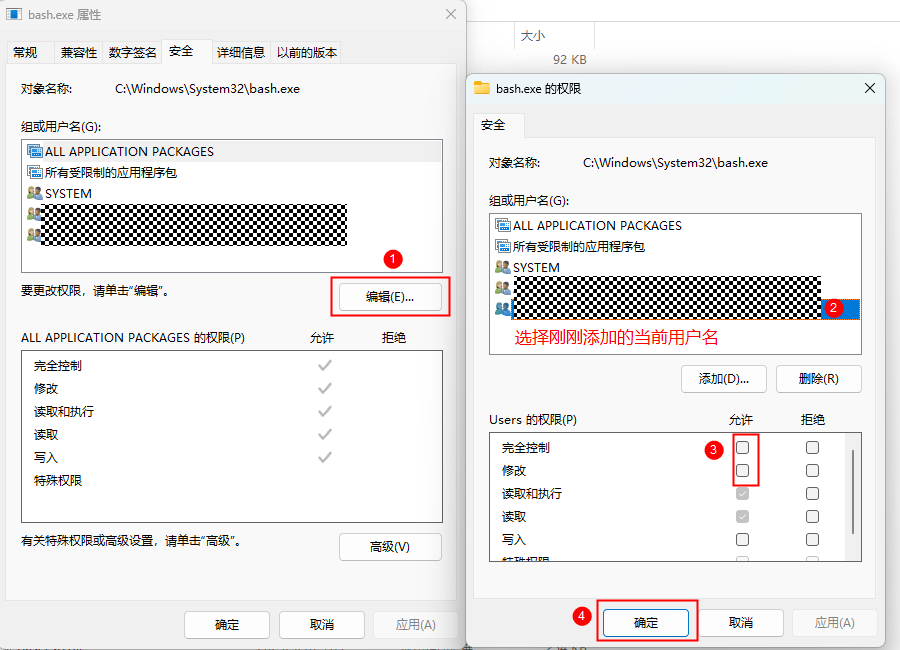
图 4 Git下的bash路径

图 5 添加到环境变量中

图 6 保证Git下的bash被调用

准备SDK¶
取Hi3322对应SDK发布包,解压SDK包到本地目录。
样例运行¶
Hi3863样例运行¶
模型与数据获取¶
模型获取并上传到容器内。
进行模型量化,请点击Link,下载ONNX模型。
点击Link,下载数据和预处理脚本“preproc_mnist_data.py”。请参考文档,在容器内执行该脚本,进行数据获取。请确保文件夹内包含如下数据和文件。
. |-- test_data | `-- npy | `-- sample_00000_7.npy | `-- ...... | `-- sample_09999_6.npy | `-- bin | `-- sample_00000_7.bin | `-- ...... | `-- sample_09999_6.bin | `-- label.csv `-- train_data | `-- bin | `-- sample_00000_5.bin | `-- ...... | `-- sample_59999_8.bin | `-- label.csv
说明:
test_data和train_data目录作为数据下载和预处理脚本的输入参数,会根据用户的输入而变化。
新建工程与模型导入¶
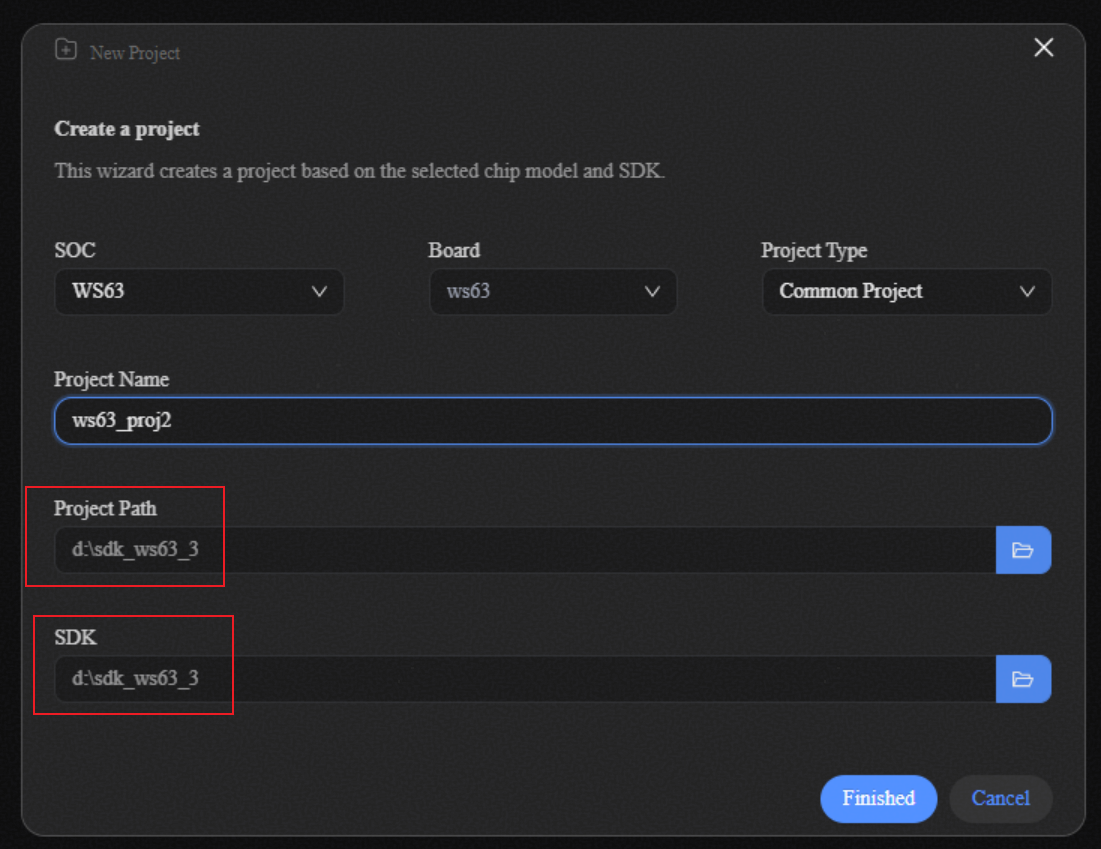
进入HiSpark Studio AI插件点击home按钮,点击“New Project”按钮。
图 1 New Project

选择芯片为WS63,选择已准备好的SDK目录,工程项目目录选择SDK相同路径即可。
图 2 工程创建示意图
进入模型选择页面,点击New Model按钮连接Linux服务器,输入密码,选择对应的LeNet onnx模型。
图 3 模型导入示意图

连接远程服务器,输入Docker的IP、端口号、用户名、密码。
图 4 连接远程服务器示意图

模型压缩¶
进入模型压缩页面,打开Validation开关,在Calibration Inputs输入框选择“Input3”(模型输入名称)为bin文件目录路径,在Validation Inputs输入框选择“Input3”为验证数据npy目录,在Validation Labels文本框选择为含标签的label文件。
Label文件数据结构如表1所示。
表 1 label.csv文件内容
sample
label
sample_00000_7.npy
7
sample_00001_2.npy
2
说明:
label.csv中为样本分类的真值标签。文件中的表格格式如表1。其中sample列表示样本的名称。label列表示样本对应的真值标签。图 1 模型压缩示意图
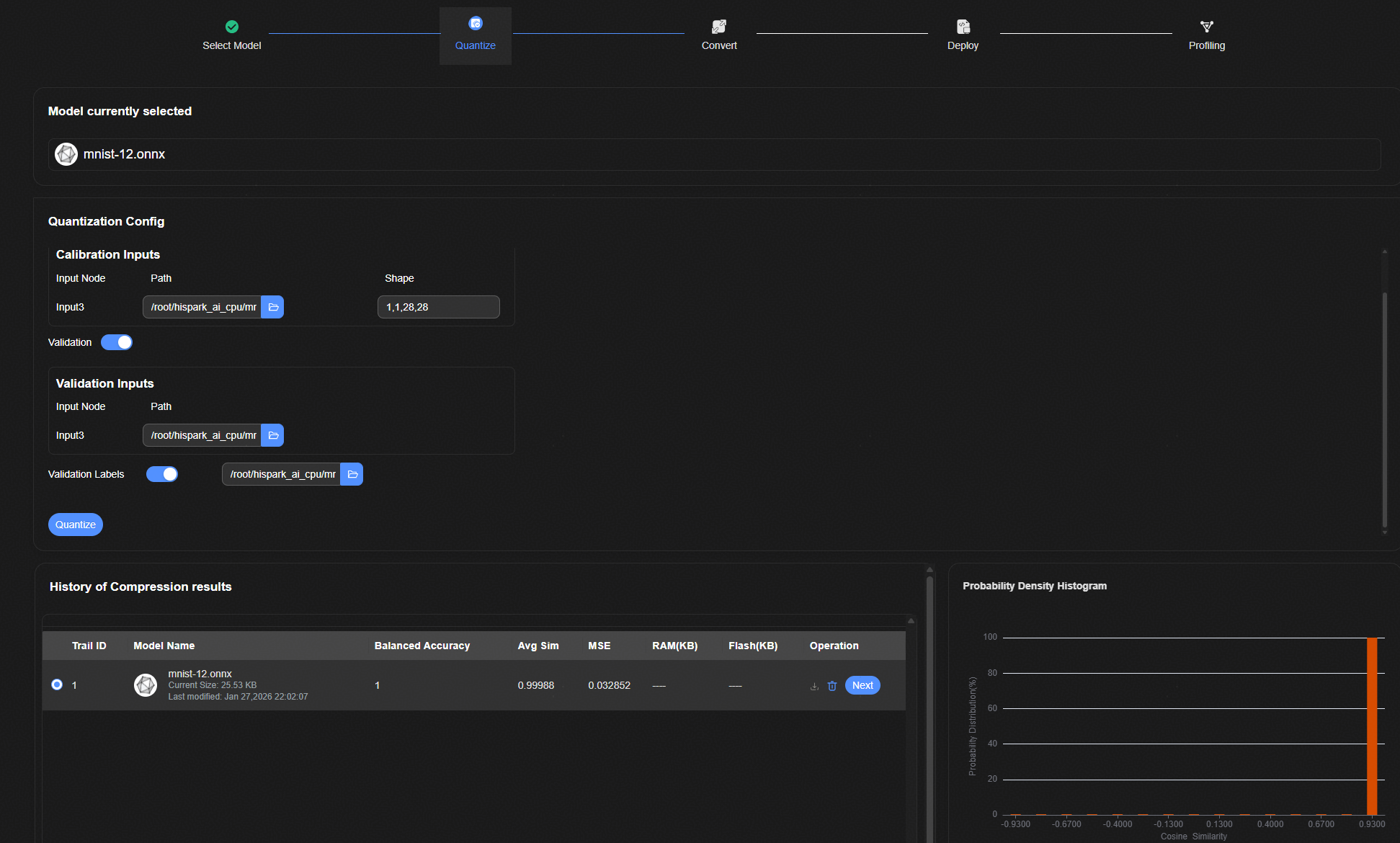
点击“Quantize”按钮,输出量化余弦相似度、准确率以及MSE等结果。
模型转换¶
点击“Convert”按钮,完成模型转换,输出对应的RAM以及FLASH值。
图 1 模型转换示意图
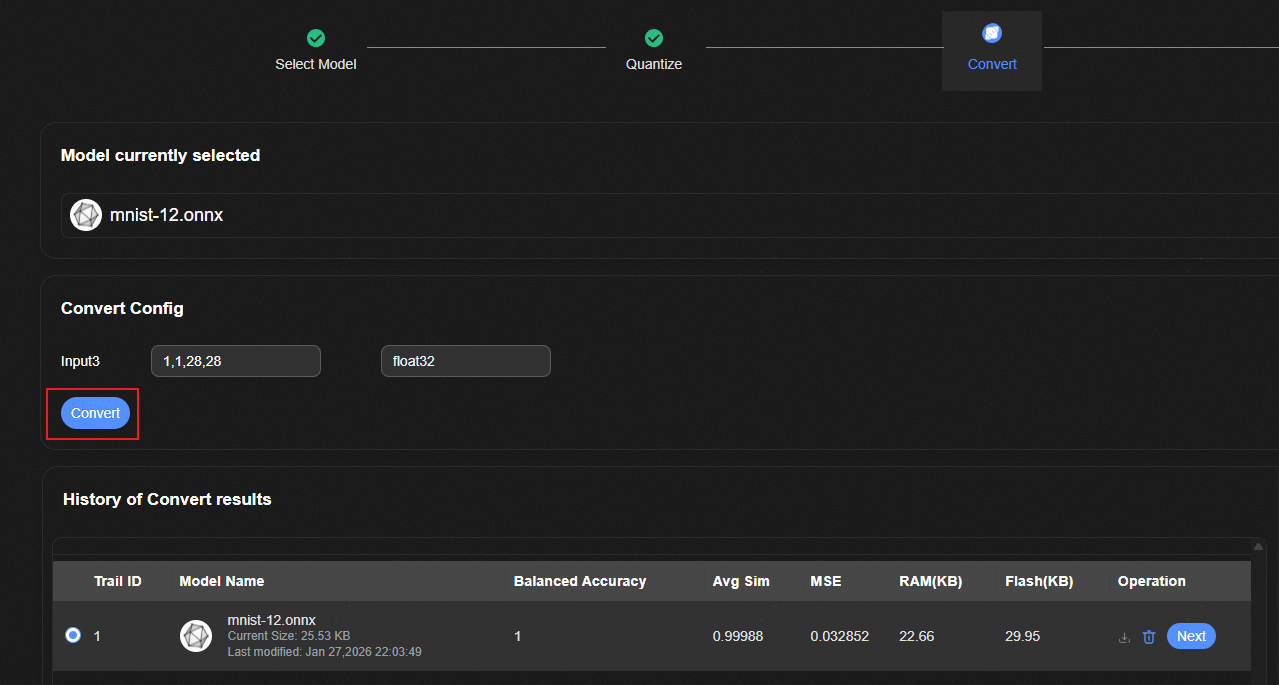
图 2 模型转换结果示意图

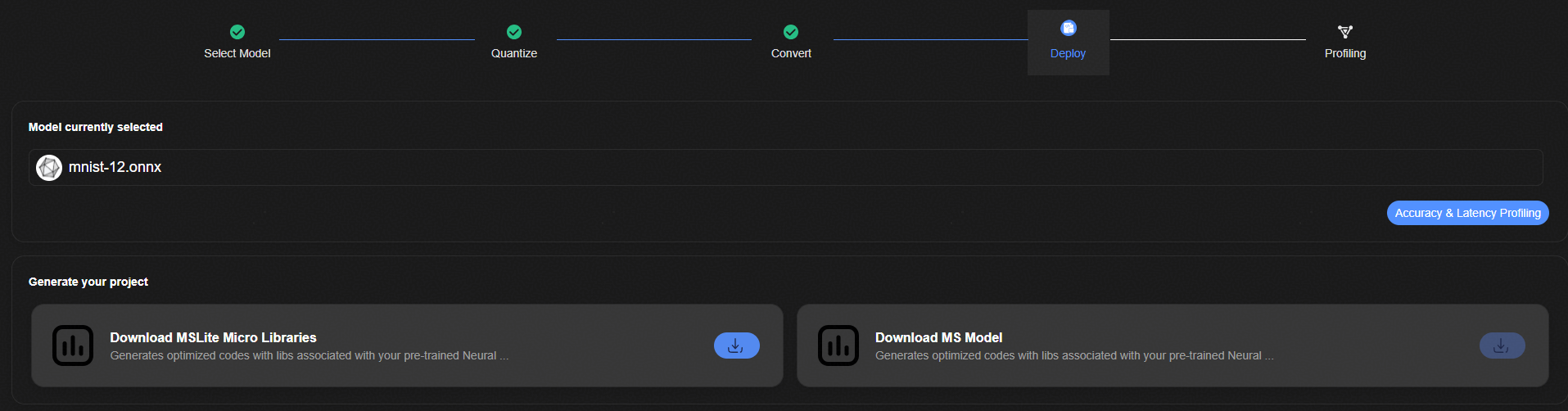
模型部署¶
点击“Accuracy & Latency Profiling”按钮,进入模型部署流程页面。
图 1 模型部署示意图
性能评估和精度评估¶
配置串口信息,点击性能验证按钮。
图 1 模型评估示意图

输出上板验证的时间、RAM、FLASH的值。
图 2 模型评估示意图

配置Validation Input的验证数据文件,配置Validation Output的label文件的值,点击精度验证。
图 3 模型评估示意图

输出验证数据结果的余弦相似度等值。
图 4 模型评估示意图

应用开发¶
在HiSpark Studio AI中完成模型量化、转换之后,将模型导出并使用HiSpark.AI API完成应用开发。具体步骤如下。
在“Deploy”页面下载转化好的Micro工程文件。
图 1 下载micro工程文件

具体API的用法请参考文档《HiSpark.AI API开发指南》
Hi3322样例运行¶
本章节以LeNet5模型为例,介绍如何使用HiSpark Studio AI工具进行模型量化、转换、性能评估以及精度评估。如果需要使用命令行工具进行如上操作,请参考《AMCT模型压缩工具用户指南》以及《ATC离线模型编译工具用户指南》。
模型与数据获取¶
模型获取,并上传到容器内。
点击Link,下载数据和预处理脚本“preproc_mnist_data.py”。请参考文档,在容器内执行该脚本,进行数据获取。请确保文件夹内包含如下数据和文件。
. |-- test_data | `-- npy | `-- sample_00000_7.npy | `-- ...... | `-- sample_09999_6.npy | `-- bin | `-- sample_00000_7.bin | `-- ...... | `-- sample_09999_6.bin | `-- label.csv `-- train_data | `-- bin | `-- sample_00000_5.bin | `-- ...... | `-- sample_59999_8.bin | `-- label.csv
说明:test_data和train_data目录作为数据下载和预处理脚本的输入参数,会根据用户的输入而变化。
label.csv中为样本分类的真值标签。文件中的表格格式如表1 label.csv格式示例。其中sample列表示样本的名称。label列表示样本对应的真值标签。
表 1 label.csv格式示例
sample
label
sample_00000_7.npy
7
sample_00001_2.npy
2
新建工程与模型导入¶
进入HiSpark Studio AI插件点击“Home”按钮,点击“New Project”按钮进入新建工程页面。在弹出框中选择SOC类型为“3322”;选择已经下载的SDK路径;并为工程设置好名字和工程文件保存地址。
图 1 新建工程页面

点击“Finished”进入“Select Model”页面。
连接远程服务器,输入Docker的IP、端口号、用户名、密码。
点击“New model”并选择“模型与数据获取”章节下载的模型。
进行训练后量化,请选择ONNX模型。
进行量化感知训练,请选择PyTorch模型。
说明:
首次连接请根据提示设置远端连接。注意端口选择映射到容器内的服务器端口。导入模型后,自动跳转到量化页面。
如果导入的模型为ONNX模型,跳转到训练后量化页面。
如果导入的模型为PyTorch模型,跳转到量化感知训练界面。
模型压缩¶
在“Quantize”模型转换页面对模型进行量化,并对量化后的评估模型进行精度验证,以帮助用户评估量化后的模型是否符合业务需求。精度验证的指标如表1 精度验证指标所示。
表 1 精度验证指标
指标 |
说明 |
|---|---|
Balanced Accuracy |
表示分类结果准确率,使用标签真值计算。 |
Avg Sim |
平均余弦相似度,使用量化评估网络的输出和原始浮点网络的输出计算。 |
MSE |
均方误差,使用量化评估网络的输出和原始浮点网络的输出计算。 |
模型压缩“Quantize”页面提供训练后量化PTQ和量化感知训练QAT两种量化方式。
训练后量化¶
在“Quantization Config”中配置输入参数。
“Calibration Inputs”文件选择框中输入量化校准数据:选择“模型与数据获取”下载的训练数据文件夹下的bin子文件夹,如“train_data/bin”。
打开“validation”开关。
在“Validation Inputs”文件选择框中输入验证数据:选择“模型与数据获取”下载的测试数据文件夹下的npy子文件夹,如:test_data/npy。
打开“validation Labels”。并在文件输入验证数据的真值:选择框选择“模型与数据获取”下载的测试数据文件夹下的“label.csv”文件。
其他参数保持默认,或按需调整。
图 1 训练后量化参数配置界面
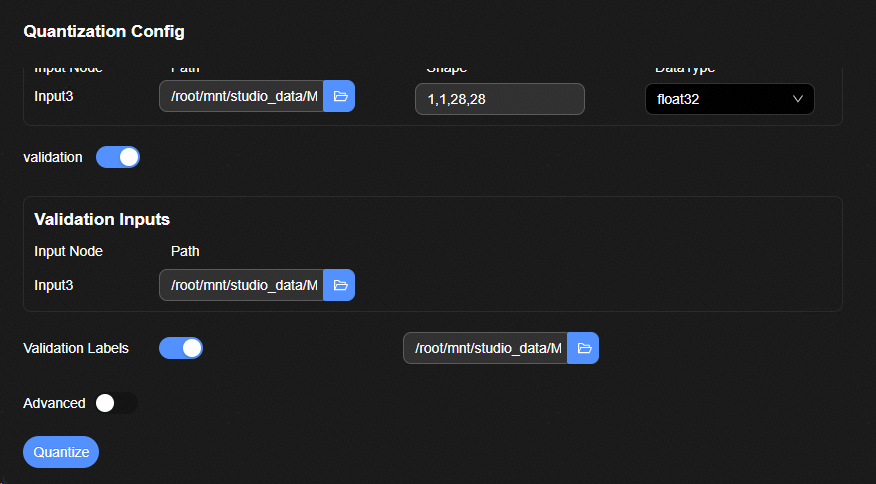
点击“Quantize”按钮开始量化。“OUTPUT”中输出如下类似信息,表示量化成功。
2026-01-04 08:14:23 - INFO - HiSpark.AI SUCCESS; Precision validation completed successfully 2026-01-04 08:14:23 - INFO - HiSpark.AI SUCCESS; All quantization workflow steps completed successfully
在“History of Convert results”中查看量化仿真模型在验证集的精度。
图 2 量化结果显示界面

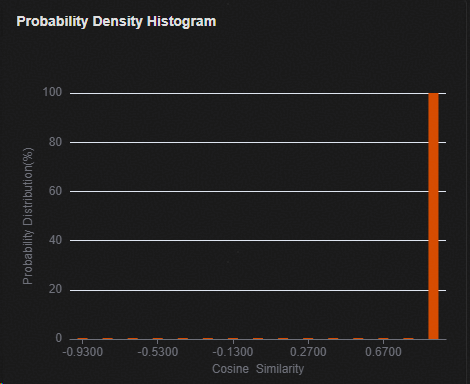
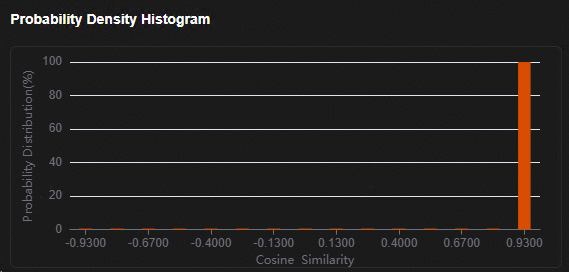
在“Probability Density Histogram”窗口查看验证样本余弦相似度的分布。
图 3 训练后量化评估网络在验证集的余弦相似度分布直方图
在“History of Compression results”的“Operation”列点击“Next”按钮,进入模型转换页面。
量化感知训练¶
点击按钮“ReTrain Code”打开重训练代码编辑框。并修改代码模板。
设定训练epoch数。
EPOCH_NUM = 1设定训练的batch_num。
BATCH_SIZE = 4设定学习率。
LEARNING_RATE = 0.00001定义网络结构。
class NNModel(nn.Module): def __init__(self) -> None: """Initialize network layers and components.""" super(NNModel, self).__init__() self.conv1 = nn.Conv2d(1, 8, kernel_size=(5, 5), padding=2) self.relu1 = nn.ReLU() self.maxpool1 = nn.MaxPool2d(kernel_size=(2, 2), stride=(2, 2), padding=(0, 0), dilation=1, ceil_mode=False) self.conv2 = nn.Conv2d(8, 16, kernel_size=(5, 5), padding=2) self.relu2 = nn.ReLU() self.maxpool2 = nn.MaxPool2d(kernel_size=(3, 3), stride=(3, 3), padding=(0, 0), dilation=1, ceil_mode=False) self.fc = torch.nn.Linear(256, 10, bias=True) def forward(self, img): """ Forward pass of the network. Args: x (torch.Tensor): Input tensor with shape (batch_size, 1, 28, 28) Returns: torch.Tensor: Output logits with shape (batch_size, 10) """ out = self.conv1(img) out = self.relu1(out) out = self.maxpool1(out) out = self.conv2(out) out = self.relu2(out) out = self.maxpool2(out) out = out.reshape(-1, 256) out = self.fc(out) return out
配置“Quantization Config”中的输入参数
“Retrain Inputs”文件选择框中选择“模型与数据获取”下载的训练数据文件夹下的bin子文件夹,如:train_data/bin。
“Retrain Outputs”文件选择框选择“模型与数据获取”下载的训练数据文件夹下的“label.csv”文件。
“Validation Inputs”文件选择框中选择“模型与数据获取”下载的测试数据文件夹下的npy子文件夹,如:test_data/npy。
“Retrain Outputs”文件选择框选择“模型与数据获取”下载的测试数据文件夹下的“label.csv”文件。
其他参数保持默认,或按需调整。
图 1 量化感知训练参数输入界面

点击“Quantize”按钮开始量化感知训练。“OUTPUT”框中出现如下类似信息,说明量化感知训练成功。
2026-01-06 06:10:42 - INFO - HiSpark.AI SUCCESS; All workflow steps completed successfully在“History of Compression results”中查看量化仿真模型在验证集的精度。
图 2 量化感知训练验证精度显示界面

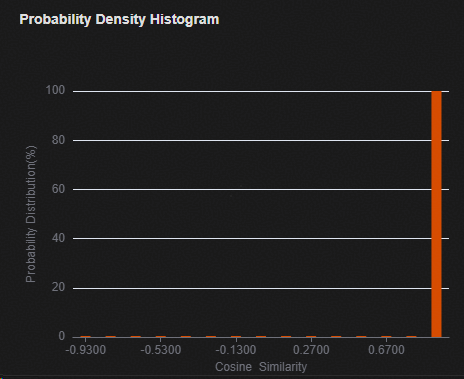
在“Probability Density Histogram”窗口查看验证样本余弦相似度的分布。
图 3 量化感知训练评估网络在验证集的余弦相似度分布直方图
在“History of Compression results”的“Operation”列点击“Next”按钮,进入模型转换页面。
模型转换¶
在“Convert”模型转换页面将量化后的模型进行转换,得到适配NPU IP加速器的离线模型。具体步骤如下。
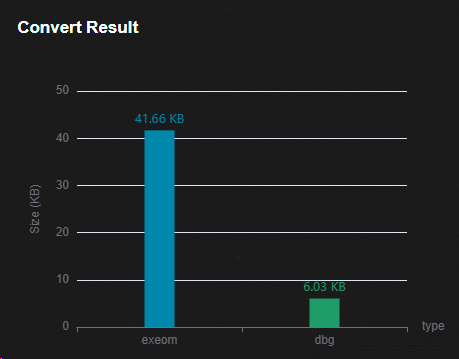
保持默认参数,点击“Convert”按钮完成模型转换。
在“Convert results”窗口查看转化后模型的大小。
图 1 转化后模型大小图示
在“History of Compression results”的“Operation”列点击“Next”按钮,进入模型部署页面。
模型部署¶
点击“Accuracy & Latency Profiling”按钮,完成SDK的编译,并进入性能评估和精度评估页面。
图 1 SDK编译和进入评估页面

性能评估和精度评估¶
HiSpark Studio AI提供连板性能评估和精度评估功能。在开始性能评估和精度评估前,请按照Hi3322硬件指导完成Hi3322硬件环境的准备。
性能评估自动将转换的模型上传到单板,在端侧推理模型并统计模型推理性能。
精度评估自动将转换的模型和验证集上传到单板,在端测推理模型;并和量化之前的模型以及真值标签对比,计算量化精度指标。
性能评估和精度评估的具体步骤如下。
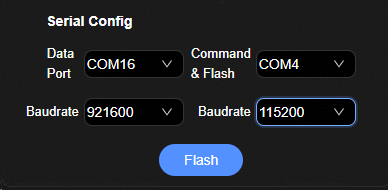
在“Serial Config”窗口配置数据传输的端口、波特率,以及命令传输和烧写的端口和波特率。
图 1 串口配置
点击“烧录”按钮,完成镜像烧录。
点击“性能验证”按钮,完成模型上板性能验证。验证完成后,在性能验证窗口显示推理时间、和模型大小。
图 2 性能验证结果

在“Accuracy Validation Config”窗口配置精度验证数据集。
将“模型与数据获取”下载的测试数据文件夹下的npy子文件夹,如“test_data/npy”,拷贝到Windows侧。“Validatioin Inputs”文件选择框中该文件夹。
将“模型与数据获取”下载的测试数据文件夹下的“label.csv”文件拷贝到Windows侧。“Validation Output”文件选择框选择该文件。
图 3 精度验证数据集配置界面

点击“精度验证”按钮,开始上板精度验证。
在“BALANCED ACCURACY”窗口查看上板精度验证的精度值。该值为使用为“label.csv”中的标签真值计算的结果。
图 4 精度评估准确率显示界面

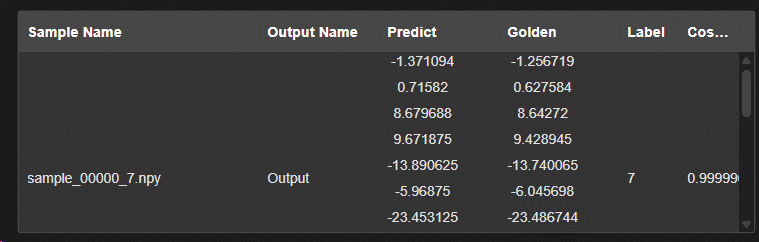
在“Validation Data”窗口查看验证集各个样本的验证结果。
图 5 验证样本的评估精度显示界面
在“Probability Density Histogram”窗口查看验证样本余弦相似度的分布。
图 6 余弦相似度分布直方图
应用开发¶
在HiSpark Studio AI中完成模型量化、转换之后,将模型导出并使用HiSpark.AI API完成应用开发。具体步骤如下。
在“Deploy”页面下载转化好的exeom模型。
图 1 下载exeom模型

具体API的用法请参考文档《HiSpark.AI API开发指南》