
前言¶
本文档详细的描述了LiteOS结合日志信息定位死机问题的方法和思路。
本文档主要适用于LiteOS的开发者。
本文档主要适用于以下对象:
软件开发工程师
技术支持工程师
在本文中可能出现下列标志,它们所代表的含义如下。





概述¶
背景¶
在嵌入式系统中,多任务并发、资源竞争、内存管理异常、硬件驱动缺陷或配置不当等因素,系统死机问题频发,FBB-RTOS采用单进程设计且未启用MMU机制,物理内存全局可见的特性在提升效率的同时,也使得非法内存操作更易导致系统级崩溃。相较于Android/Linux等具备完善DFX工具链和日志系统的操作系统,FBB-RTOS的异常诊断面临更大挑战,死机问题往往难以快速定位,尤其是死机发生并非第一现场时,问题排查效率低。
本文旨在系统化梳理FBB-RTOS现有DFX能力及通用诊断方法,为研发团队提供结构化的问题排查思路。需要特别说明的是:
死机问题通常与具体业务场景深度耦合。
当前文档仅覆盖现有DFX工具的使用方法。
内容将随DFX能力增强持续更新。
死机日志解读¶
在FBB-RTOS运行过程中,系统发生死机时会输出关键日志信息,这些日志包含异常类型、错误地址、寄存器状态等关键调试数据。正确解读这些日志信息是定位死机根因的关键步骤。系统死机时常见日志及含义注解如下:
注:根据指令地址反查是指代在elf文件中搜索该地址,会与代码段中某行汇编的地址一样,例:
反查mepc:0x115df4,在elf中搜索115df4,说明异常时正在执行的指令为sw a0,0(a1)。
|
115de4: 00108b2a051f l.li a0,108b2a <g_xRegsMap+0x56c> 115de8: 7f0000ef jal ra,101196 115dec: 12345678051f l.li a0,12345678 <__heap_end+0x12225678> |
整体思路¶
综合历史问题处理经验,总结出FBB-RTOS死机问题的主要原因分布如下:
内存踩踏引起的Load/Store access fault
栈溢出(stack overflow)
取指异常(Instruction access fault)
看门狗超时(Watchdog Timeout)
Out Of Memory
Panic
非法内存访问:包括访问保留内存(Store/AMO access fault)、PMP保护内存(PMP access fault)
内存布局非对齐(Unaligned memory layout)
死锁(Dead Lock)
非对齐访问(Unaligned Access)
后续章节将通过典型问题案例,系统性覆盖上述各类异常,结合真实场景提供定位思路与解决方案,帮助开发者快速识别问题根源,高效修复系统异常。
针对死机问题的故障定位,可采用分层递进的分析方法,具体实施步骤如下:
根据异常类型溯源
死机日志中的异常类型信息是FBB-RTOS通过解析mcause、ccause等硬件异常寄存器生成,直接反映了触发死机的硬件级或者系统级异常事件。分析时应:
优先锁定日志中记录的异常类型(如取指异常、栈溢出等),明确最直接的异常诱因。
根据异常类型分析可能的原因(如取指异常的原因可能为函数指针异常或者代码段异常)。
针对可能的原因逐个排查分析。
排查异常上下文代码逻辑
分析关键寄存器值ra、mepc、mtval可以分别获得死机时正在执行的具体函数、具体哪条汇编指令及操作的内存地址,可排查分析异常上下文代码逻辑。
使用DFX工具进行动态诊断
当常规分析无法定位时,可启用DFX机制,开启内核调试配置(如backtrace、内存访问监控trigger等)重新编译后复现问题,获取更详尽的运行时数据。
死机问题定位指南¶
常见关键异常信息及其对应的直接死机原因如下表所示,后文将逐个展开详细说明。
栈溢出¶
问题识别¶
FBB-RTOS默认开启栈溢出检测,检测方法分为魔术字检测和硬件栈检测。
原因分析¶
过大的局部变量:在函数内定义超大数组或复杂结构体。
栈空间分配不足:未预留安全余量,即任务栈大小设置时,未考虑最坏执行路径的栈需求(如异常处理分支)。
问题定位¶
线程识别:通过系统日志中的任务名称和任务ID(task ID:)可确定发生栈溢出的具体线程。
使用静态估算工具:利用栈估算工具估算任务/函数的栈使用峰值,识别栈消耗过大的函数(如含大型局部变量的函数),结合task命令查看任务栈当前配置的大小,确定是函数栈开销过大亦或是配置不合理。工具使用方法参见LiteOS开发指南(不足:对函数指针调用链的分析存在误差)。
根据日志中的“stack overflow”可确认是栈溢出问题。
根据日志中的"task ID: Task_A:9"可确认发生栈溢出任务为Task_A。
根据task命令获知栈大小为默认值,过小,调整栈大小后解决。
取指异常¶
问题识别¶
取指异常(Instruction Fetch Exception)通常发生在CPU尝试从非法或不可执行的内存地址读取指令,异常类型为Instruction access fault。例:
原因分析¶
使用空指针/野指针:当函数指针为空或者未初始化/未赋值时,函数指针值为随机值。
代码段被踩:程序和数据放置在相邻内存区域,当写数据操作发生越界时(memcpy/memset)会造成代码区被重写。
代码段未拷贝:设备启动时通常会从外部存储介质中读取代码,当启动时未将代码段拷贝到对应的ram中会造成代码段不存在。
**链接脚本配置问题:**链接脚本支持配置多个代码段,当将A代码段链接到B代码段时,会导致代码段搬移到错误代码段。
问题定位¶
排查函数指针:根据mtval、ra定位异常代码上下文,排查异常是否由函数指针导致,若是则检查函数指针是否为空指针、野指针。
**排查链接脚本:**检查异常函数所在代码段是否有拷贝动作,若有则检查链接脚本,查看拷贝的源地址、目的地址是否符合预期。
排查代码段拷贝:比较异常函数运行地址的内存值是否与反汇编中函数的第一条指令值相同,若不同则排查代码段被踩或者代码段未拷贝/错拷贝。
代码段监测:利用PMP将异常函数所在代码段配置为RX权限,监测代码段是否被踩。
Instruction access fault // 异常信息 |
看门狗超时¶
问题识别¶
FBB-RTOS运行时需要定期喂狗(重置定时器),若未按时喂狗,看门狗计时器溢出,会产生NMI异常,并在异常类型中输出Oops:NMI。例:
原因分析¶
CPU资源被占用
CPU资源被中断和高优先级任务占用,具体原因包括:
中断处理过长:中断处理时间过长或者中断无法正常退出。
中断风暴:某个外设产生大量中断,导致CPU忙于处理中断。
高优先级任务异常:某个高优先级任务由于bug而一直运行(比如进入死循环),导致低优先级的喂狗任务永远得不到时间片。
高优先级任务一直在抢占CPU:系统负载过高,轮不到喂狗任务。
喂狗任务调度异常
任务参数错误:喂狗任务周期大于看门狗超时阈值。
任务被误删除:错误的API调用误删除喂狗任务。
调度器故障:任务调度异常。
问题定位¶
初步分析
根据MEPC查找反汇编,排查分析异常上下文代码逻辑。
问题分析
分析看门狗超时问题,需重点考察系统挂死前关键时间段内(即喂狗超时窗口期内)的任务(含中断)调度和执行情况,具体可从以下三个维度进行分析:
**CPU空闲状态检查:**若存在CPU idle时段,则表明喂狗任务调度出现异常。
**任务CPU占用分析:**若发现某个任务CPU占用显著异常,则可能是该任务陷入死循环或逻辑错误。
**系统负载评估:**若出现频繁任务切换且CPU利用率持续满载,则是系统整体负载过高导致喂狗任务无法及时调度。
上述三个维度的信息可通过系统提供的DFX工具trace或者调度统计获取,trace和调度统计具体使用方法可分别参考《LiteOS 开发指南》的“Trace”章节和“调度统计”章节内容。。
针对CPU占用异常高任务的诊断方法
若发现某任务CPU占用率异常高,需获取其完整调用栈以精确定位问题代码,可以打开系统的backtrace功能并在NMI异常中补充输出所有任务的调用栈。
根据mepc的值0x1182c4,查看反汇编
找到对应代码:
说明系统进入低功耗/待机,此时只有中断才能唤醒,分析中断间隔,发现中断频率小于喂狗时间,引起狗超时重启,属于调度异常范畴。
Panic¶
问题识别¶
软件主动Panic是系统针对不可恢复或严重违反系统规则时采取的主动终止机制,系统会输出详细的错误诊断信息,主要包括以下关键内容:
**错误描述:**panic的原因(如“ASSERT ERROR! at xxx.c:123”)。
**当前运行任务上下文:**当前任务名称、任务ID、寄存器值。
原因分析¶
**断言:**LOS_ASSERT(expr)宏在条件不满足时触发,通常指示程序逻辑错误或系统状态异常。
**LOS_Panic:**LOS_Panic()函数在检测到关键系统异常时调用,如重复内存释放、堆内存头被踩踏。
问题定位¶
定位方法
初步定位Panic源头
若日志包含文件名和行号,直接查看对应源码,确认问题位置。
搜索代码中的打印信息或结合mepc(PC寄存器值)定位挂死代码行。
若为断言失败,检查断言表达式,分析为何不成立(如空指针、越界、非法状态等)。
根据LOS_PANIC原因深入排查
根据LOS_PANIC原因如重复内存释放、堆内存头被踩踏等参考相对应章节分析方法。
例1:断言失败
根据上述异常打印信息可知:
异常位置:los_cpup.c第378行。
断言条件:LOS_ASSERT(cycles >= g_startCycles)。
直接原因:系统检测到cycles值小于g_startCycles,违反预期逻辑。
例2:LOS_PANIC示例
异常位置定位:根据mepc的值在反汇编文件反查代码段或者在源码中搜索打印信息找到Panic源头LOS_PANIC("The node:%p is not used!\n", node)。
访问PMP保护内存¶
问题识别¶
系统配置PMP后,将根据PMP的配置对总线的取指、数据访问、数据存储进行权限校验,若校验不通过则上报异常(正在执行的取指、数据访问、数据存储操作不被执行),异常信息中会输出PMP access fault,同时异常类型还会明确指出异常操作的类型。
Instruction access fault // 异常操作为“取指”
Load access fault// 异常操作为“Load”
Store/AMO access fault // 异常操作为“Store”
例:
原因分析¶
问题定位¶
通过mepc定位异常指令地址
根据mepc寄存器值,确认异常发生时CPU试图执行的指令地址。
通过mtval确认异常访问地址
根据mtval确认异常发生时访问的内存地址(用于Load/Store异常)或指令地址(用于取指异常)。
若异常地址/指令符合内存布局预期检查PMP配置
若异常指令地址或访问地址符合系统内存布局(如位于合法代码段、数据段、堆栈等),则优先检查PMP(物理内存保护)配置是否正确。
若异常指令(取指)不符合预期参考“取指异常”章节。
若异常指令为访问非PMP配置内存区间参考踩内存章节定位。
异常地址定位:根据mepc可知异常访问的地址为0x22082444,通过mtval确认被保护的地址也为0x22082444,说明该地址并未配置可执行权限,但系统却希望从该地址取指。
排查PMP权限配置:排查代码中对该内存的PMP配置,根据业务需求确认PMP权限是否配置合理。
访问保留内存¶
问题识别¶
预留的地址空间在被访问时会触发异常,异常信息中的含有Store/AMO access fault且没有PMP access fault。
例:
原因分析¶
系统访问了预留地址空间。
问题定位¶
通过mtval定位异常访问地址并验证合法性。
通过mtval可锁定异常发生时CPU尝试访问的内存地址。结合系统提供的地址空间分配表确认该地址是否属于保留地址。若非保留地址,排查该地址是否满足内存对齐要求,针对 LINX 核架构。
lw / sw(32位加载/存储):地址必须为4字节对齐(即地址末尾为0x00、0x04、0x08等)。
lh / sh(16 位加载/存储):地址必须为2字节对齐(即地址末尾为0x00、0x02等)。
通过mepc定位异常指令地址并反查反汇编,定位异常源码。
根据mtval可以锁定异常访问的内存地址为0x1800000,确认为保留内存地址。
根据mepc反查反汇编文件可知问题代码所在行。
115de4: 00108b2a051f l.li a0,108b2a <g_xRegsMap+0x56c>
115de8: 7f0000ef jal ra,101196
115dec: 12345678051f l.li a0,12345678 <__heap_end+0x12225678>
死锁¶
问题识别¶
FBB-RTOS提供了死锁检测DFX特性,支持自旋锁、互斥锁、二值信号量和线程锁四种类型锁的死锁,以及重复上锁、错误释放和锁的深度溢出的检测。相关内核配置如下:
若相关内核配置被使能,检测到死锁时会挂死,异常信息中会输出dead lock。例:
[2025-11-17 11:20:49] lockdep check failed [2025-11-17 11:20:49] error type : dead lock |
原因分析¶
两个任务分别等待对方所占的资源。
问题定位¶
**反查请求地址定位异常锁函数:**将触发异常的request addr值复制至系统镜像的反汇编文件中,通过地址定位至具体代码行,即可识别是哪个锁函数在执行过程中发生异常。
注:request addr反查结果通常指向具体的锁函数入口,若任务中存在多个同类锁,可通过锁ID 进行进一步区分,以精确定位具体锁对象。
根据异常信息可知任务Task_A与Task_B发生死锁,Task_B持有0032的锁申请0031的锁,Task_A持有0031的锁申请0032的锁;
根据request addr的值(本例中为0x47262),在系统镜像的反汇编文件中找到该地址,可确定具体的锁函数LOS_MuxPend,进一步定位到Task A调用互斥锁位置。
非对齐访问¶
问题识别¶
内存对齐访问要求:访问数据时,其物理地址必须是该数据类型字节宽度的整数倍。
32位数据(如uint32_t、float):地址必须是4的倍数(如0x0000、0x0004、0x0008);
16位数据(如uint16_t):地址必须是2的倍数;
8位数据(如uint8_t):地址可为任意值(无需对齐)。
非对齐访问即违反上述规则的访问行为,当程序尝试从非对齐地址加载或存储数据时,硬件会触发异常,死机日志中会出现关键字“Load address misaligned”或者“Store/AMO address misaligned”。例:
原因分析¶
核心原因
内存访问模型与硬件对齐要求不匹配,芯片不支持非对齐访问,而软件未考虑。常出现在代码移植至新平台后突然崩溃的场景中,尤其在客户自研芯片架构上更为突出。
典型场景
**结构体填充与对齐控制:**编译器默认会对结构体成员进行内存对齐填充,以提升访问效率。若使用 #pragma pack(1) 等指令强制取消对齐,再直接访问结构体内成员,易引发非对齐访问。
**指针类型转换:**将char*或void*指针强制转换为更严格对齐类型的指针(如int*、float*),并解引用,极易导致非对齐访问。
网络协议包/二进制文件解析:在网络通信或文件解析场景中,常将原始字节缓冲区(char[])直接映射为结构体指针。若协议定义的数据域本身未对齐,或解析时未考虑对齐,将导致非对齐访问。
问题定位¶
根据mepc(PC寄存器值)即可定位非对齐访问引起挂死的代码行。
适配J客户时由于非对齐访问产生了上述挂死,该场景属于FBB-RTOS适配其他厂商的芯片,芯片不支持非对齐访问。(客户自己提供的打印信息未指示当前的异常类型)
解决方案:非对齐访问操作转化为按照单个字节去操作。
其他异常¶
当系统异常日志与代码上下文无法直接定位根本原因,或通过上文提供的分析手段仅能锁定到某个变量、内存块或资源异常时,通常需怀疑发生了内存踩踏、内存不足或者内存布局非对齐问题。此类异常没有固定的异常类型,同时异常发生时往往非第一现场,导致问题定位困难。针对此类异常,FBB-RTOS提供了相应的DFX工具,能精准定位高频内存异常问题,包括动态分配内存越界、固定区域内存踩踏、指针重复释放引起的飞踩、内存泄露。
踩内存¶
原因分析¶
发生踩内存类问题时,第一现场通常不会挂死,直到访问到被踩的内容时,通常才出现异常,出现系统死机、变量异常值、数据传输错误、业务预期结果异常、任务异常挂起或者退出、指令无效、内存合法性校验失败等问题。
踩内存的根本原因在于数组溢出、动态内存溢出、飞踩、重复释放等。
问题定位¶
当前FBB-RTOS系统提供的DFX能力,主要解决踩内存的以下三类典型问题:
固定踩内存(每次踩踏都是同一片内存或者踩踏固定的变量)
通过trigger监控固定区域的读写操作,捕获踩内存的第一现场,首先确定被踩的内存地址,然后使能LOSCFG_TRIGGER_ENABLE内核配置,使用trigger进行监控。目前提供了两种使用方式:
方式一(推荐):针对没有适配命令行的产品,可以直接调用trigger接口。
方式二:在命令行使用命令
命令说明:设置一个trigger,保护addr地址开始的size个字节
Example:trigger set 0x1405ca4 4 表示保护从0x1405ca4地址开始的4个字节
************************************************************************************
堆越界踩内存头
利用FBB_RTOS提供的DFX工具确定被踩内存结点,然后根据被踩内存结点中的taskId等信息进行定位。具体操作方法参考LiteOS开发指南8.3.3章节。
内存重复释放
利用FBB_RTOS提供的DFX工具确定重复释放指令,然后通过反汇编文件确定问题函数,并使用callerRA等信息逐步定位。
具体步骤为:
使能LOSCFG_MEM_DFX_DOUBLE_FREE_CHECK内核配置。
添加编译选项重新编译运行。
根据打印信息结合反汇编文件可以确定重复free函数的调用点。
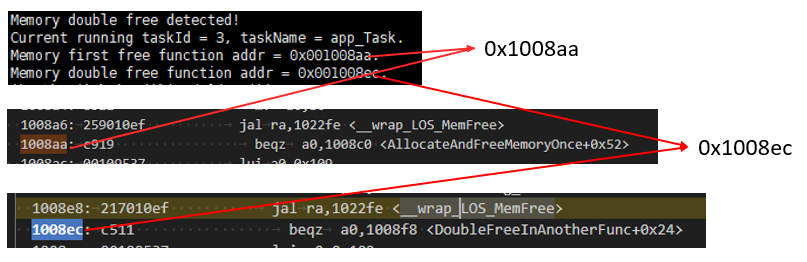
详细使用方法和介绍参考《LiteOS 开发指南》的“内存重复释放检测”章节。
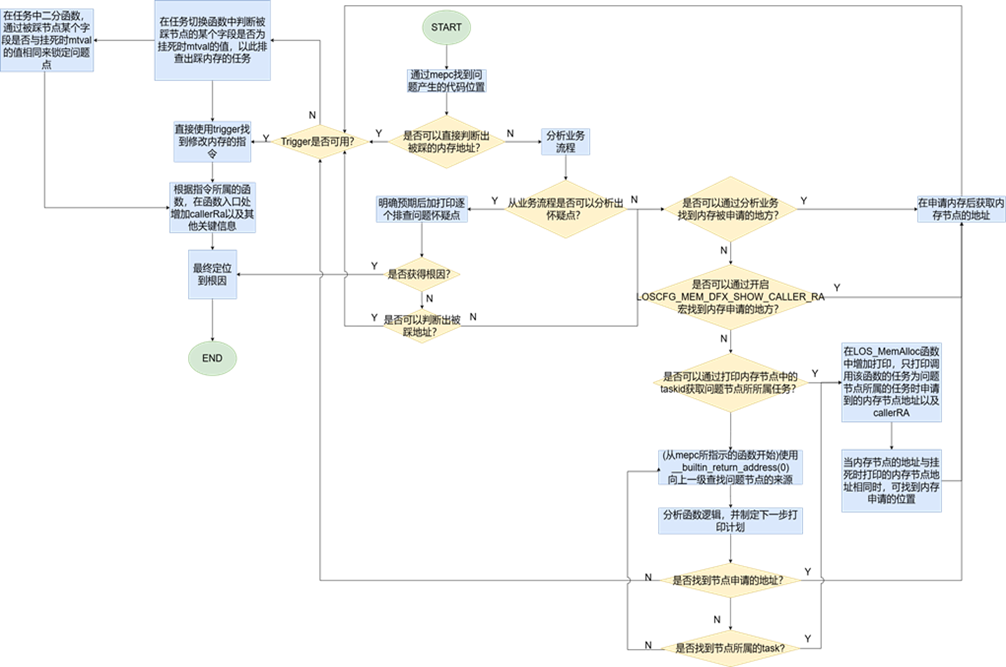
其他飞踩等问题当前并没有特别好的手段,主要通过结合异常点业务代码做进一步分析,详细分析思路参考下图。
例1(堆越界踩内存头):
The node:0x1137b4 has been damaged! node:0x1137b4 has been damaged! pre node:0x11379c,pre node CallerRA:0x100864 |
通过关键信息打印 The node:0x1137b4 has been damaged确定是堆内存被踩踏,通常是前序节点越界才会踩踏后序节点的内存头,直接通过前序节点prenode的callerRA信息确定相邻前序节点申请者,进一步通过反汇编查找callerRA地址,确定到代码行即可。
例2(通过trigger定位踩固定区域):
异常信息如下:
通过mepc: 0x102ee0找到异常发生时所运行的函数。
102eba: 3fffffff099f l.li s3,3fffffff <_heap_end+0x3fedffff>
102ec6: 05c58913 addi s2,a1,92
发现异常指令是一条load操作,并且基地址存放在s0寄存器中,结合异常信息,发现s0寄存器是一个异常地址(0xababeff2)。
结合代码和反汇编,发现异常指令处是从结构体中取某一字段时异常,因此怀疑结构体被踩。
由于被踩节点是一个动态申请的内存节点,因此通过使能CallerRA记录能力,记录内存节点申请的顶层函数地址,并在第3步中红框位置前增加打印,把内存节点的CallerRA打印出来。
结合CallerRA,找到内存节点申请的函数,并在申请到节点后使用Trigger将节点监控起来。
再次触发异常时,通过mepc可以得知踩内存的凶手为0x299f8。
task name: osMain, mepc: 0x299f8, caller: 0x2666e, diff addr: 0Ox22130304, old val: Ox0001254d, new val: 0xababeff2
Out Of Memory(oom)¶
原因分析¶
内存泄漏
通常发生在函数反复被多次调用,函数内动态申请的内存未释放,内存泄露量随时间累积到一定程度,最终耗尽系统内存,触发系统异常挂死。
申请内存过大
当程序尝试分配一块大内存,而系统提供的内存不足,内存分配函数可能会返回失败,未准确处理此类异常触发程序崩溃。
问题定位¶
检查待申请内存大小是否符合业务预期
若申请大小异常大,则需确认是否为业务逻辑错误或误操作。
若申请大小合理,则需进一步排查是否存在内存泄露或系统内存资源不足。
查看当前内存状态
若freesize < 申请量,则是内存耗尽,需进一步确认是内存泄露还是堆总大小不够。
若freesize > 申请量,但某个特定mem pool内存不足,可结合业务诉求调整对应mem pool内存大小。
若freesize > 申请量,且maxfreeNodeSize < 申请量,可能为内存泄露或者碎片化。
内存泄露定位流程
使能LOSCFG_MEM_DFX_SHOW_CALLER_RA内核配置,重新编译系统,启用内存泄露追踪功能。具体参考LiteOS开发指南8.4章节。
在系统运行期间,多次执行task_mem命令,查看内存节点的使用情况,关注相同callerRA(调用栈返回地址)的内存节点数量是否持续增长,若增长,则表明存在内存泄露,结合callerRA确认泄露点。
内存碎片定位与优化
碎片化程度评估:通过LOS_MemFragInfo接口获取各内存块大小区间内的空闲块数量,若小内存空闲块数量多则碎片化严重。
碎片化优化策略:根据业务申请频次与大小,优化slab配置;高频申请/释放的业务模块独立使用内存池,降低碎片化影响。
若内存状态均正常可考虑内存小型化优化。
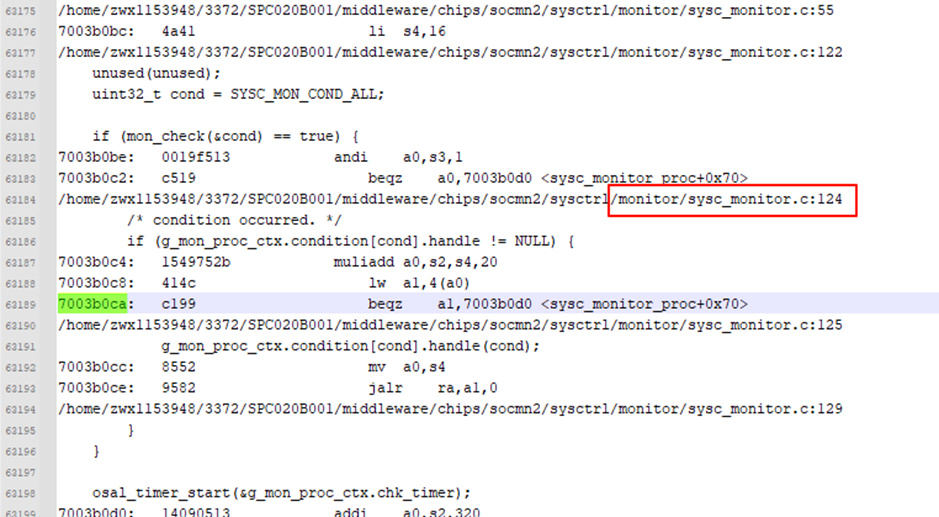
解析dump文件可知当前PC所指的位置为panic_deal,死机原因原因在g_preserve_data_lib中,死机原因code = 0x0B。
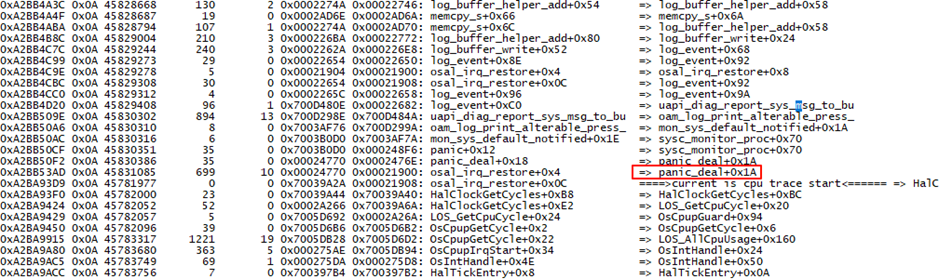
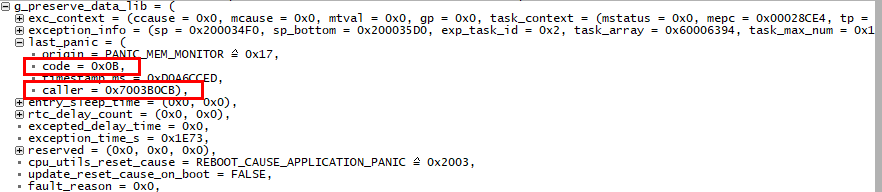
基于caller反查反汇编文件可知异常上下文为sysc_monitor.c的124行。
错误码0xB的含义REBOOT_CAUSE_MON_MEM_ALMOST_EMPTY,即死机原因内存不足。结合业务侧代码逻辑分析很大概率存在内存泄漏,排查任务的内存使用情况,发现已使用的内存大小一直增加,基本坐实为内存泄露导致的oom,使用FBB-RTOS提供的内存泄露DFX工具定位到问题代码。
内存布局非对齐¶
原因分析¶
该场景下产生异常的主要原因是链接脚本的错误配置。
问题定位与解决¶
启动阶段异常优先检查链接脚本与内存布局。
若系统异常发生在启动阶段,应首先排查链接脚本中各段(section)是否满足内存对齐要求,若满足对齐要求,使用工具dump RAM中的代码/数据段,验证其是否与链接脚本预期一致。
任务创建阶段异常优先检查栈起始地址对齐。
若异常发生在任务创建过程中,优先通过任务创建接口的返回值判断。
结构体字段读取异常优先检查动态内存节点对齐。
若异常发生在读取动态分配结构体字段时,且已排除内存踩踏等破坏性写入,优先通过打印方式将内存头结点地址打印出来,检查内存地址是否满足4bytes对齐。
使用LOS_MemTaskIdGet函数获取一个指针所属的task,返回异常(ret != taskID)。
增加打印,遍历内存节点时,出现大量非对齐内存节点(内存节点至少应该是2bytes对齐)。
检查ld文件,发现堆的起始位置未进行对齐处理,引起内存池异常。
*(.bss .bss.* .sbss* .gnu.linkonce.b.* COMMON)
__heap_end = ORIGIN(SRAM_DATA) + LENGTH(SRAM_DATA);
__startup_stack = __heap_end - 0x20;