
前言¶
本文介绍 HiSpark Studio AI 插件工具,如何通过该工具进行模型量化、模型转换、模型评估,以及后续应用开发等功能。
本文档主要适用于以下工程师:
技术支持工程师
AI开发工程师
在本文中可能出现下列标志,它们所代表的含义如下。





HiSpark Studio AI简介¶
关于HiSpark Studio AI¶
HiSpark Studio AI是面向开发者提供的超轻量级AI应用开发平台,具备高集成、高专业、高易用等特征,聚焦嵌入式AI应用场景,提供模型压缩、模型转换、应用开发,端侧部署、性能调优的全流程开发平台。
高集成
一站式开发平台,支持模型压缩/转换/推理/部署/调试等功能。
统一的IDE界面和API接口,支持CPU/NPU等芯片AI应用开发和部署。
高专业
高效的模型压缩,支持ONNX/TFLite等AI模型。
超轻量的模型部署,支持KB级RAM嵌入式设备。
高易用
提供VS Code插件,方便安装和使用。
支持性能/精度可视化分析,方便调试。
功能介绍
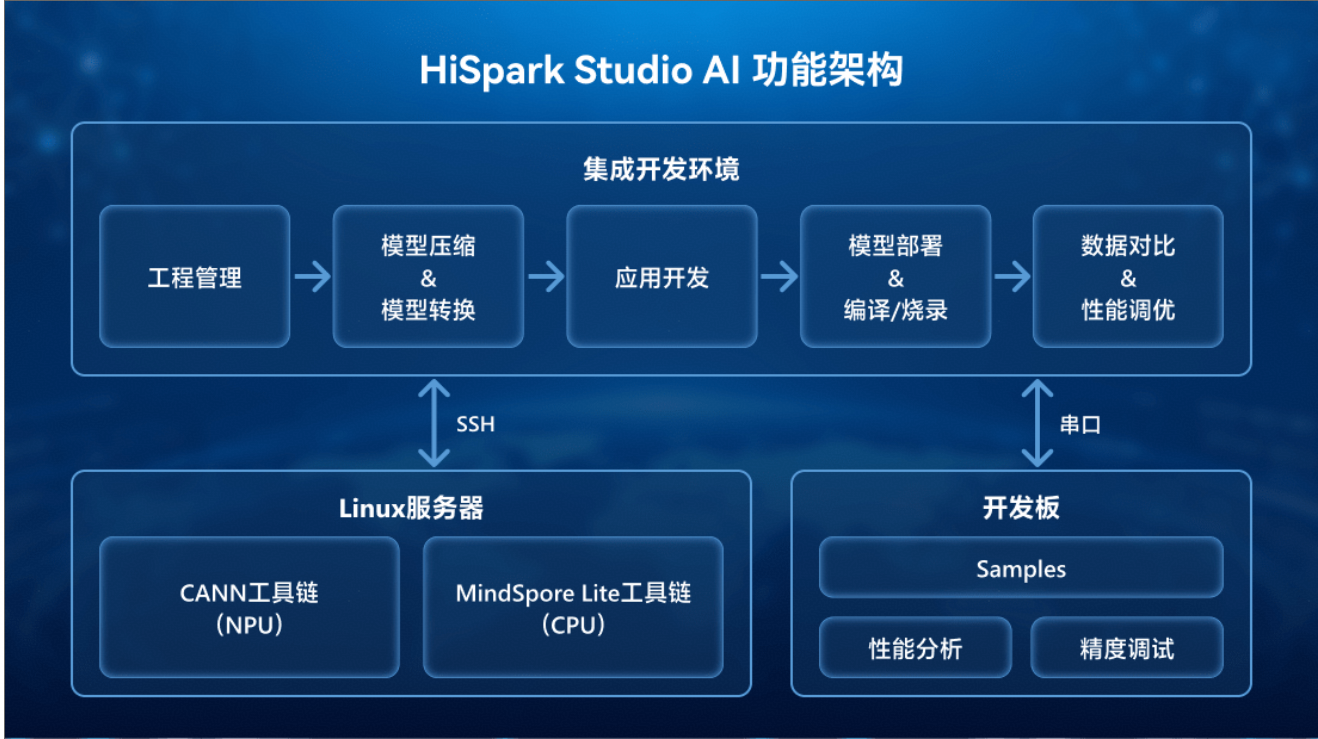
HiSpark Studio AI功能架构如下图所示。具备核心功能有:
导入ONNX/TFLite等格式的AI模型,初始化开发环境。
通过集成的NPU/CPU工具链可以进行模型压缩和转换。
导入SDK并参考Sample进行用户AI应用开发。
编译用户AI应用,烧录到嵌入式设备进行部署。
根据串口日志检测性能精度是否达成目标。
安装方案介绍¶
须知: 若之前已经安装过DevEco相关的插件,请手动禁用或者卸载所有与DevEco相关的插件,否则会与HiSpark Studio插件功能冲突。
打开VS Code插件市场。
搜索并安装HiSpark Studio AI。
为保证功能正常运行,还需安装HiSpark Studio插件。
窗口介绍¶
整体窗口介绍¶
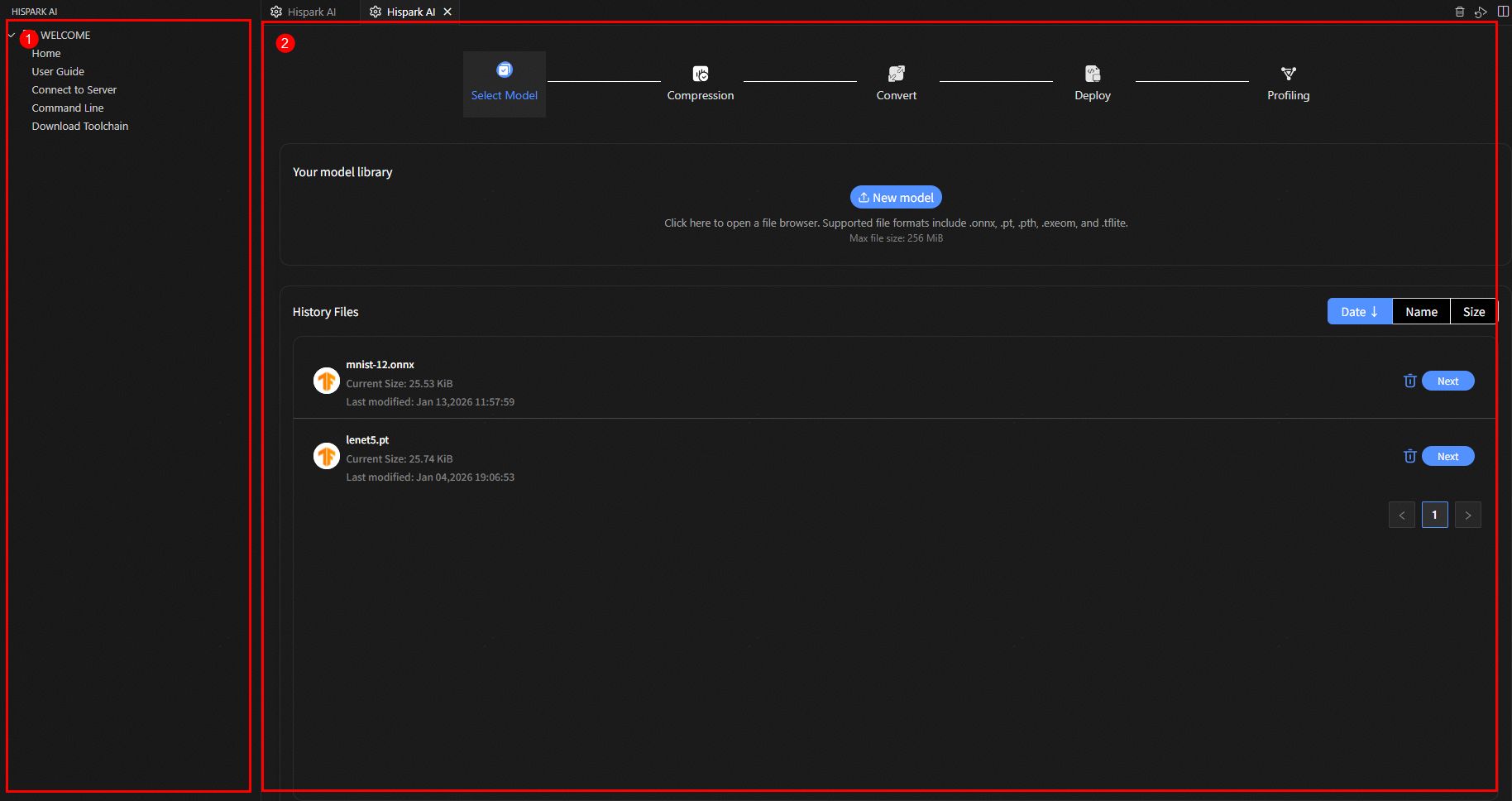
HiSpark Studio AI 整体窗口如下图所示,主要包含两个部分:
侧边栏:HiSpark Studio AI功能导航栏。
工作区:HiSpark Studio AI工作区。
侧边栏¶
侧边栏为功能导航栏,展示了HiSpark Studio AI插件提供的五个主要功能,分别为:
Home(主页):单击进入新建/导入工程,或在已打开工程的情况下进入HiSpark Studio AI模型选择主界面。
User Guide(用户指南):单击在工作区打开用户指南,提供快速入门指南。
Connect to Server(连接服务器):单击连接至服务器。
Command Line(命令行工具):单击在命令行中运行HiSpark Studio AI的量化、转换等功能。
Download Toolchain(下载工具链):单击下载运行HiSpark Studio AI插件所需要的工具链,并自动配置环境。
工作区¶
工作区为插件核心功能展示区域,详细交互逻辑请参见后续章节。
关键概念¶
本文档中涉及如下概念,在此处做统一说明。
AMCT¶
AMCT(Ascend Model Compression Toolkit,简称AMCT)是一个针对昇腾芯片亲和的深度学习模型压缩工具包,提供量化、张量分解等多种模型压缩特性,压缩后的模型体积变小,部署到NPU IP加速器上后可使能低比特运算,提高计算效率,从而实现性能提升。有关AMCT具体操作请参考《AMCT模型压缩工具用户指南》。
ATC¶
昇腾张量编译器(Ascend Tensor Compiler,简称ATC)是CANN异构计算架构体系下的模型转换工具,它可以将开源框架的网络模型转换为NPU IP加速器支持的离线模型。有关ATC具体操作请参考《ATC离线模型编译工具用户指南》。
数据准备与环境搭建¶
数据准备¶
模型的训练后量化校准、量化感知训练、量化精度评估以及上板精度评估等操作需要对应数据,请按照如下格式准备数据:
数据存储为bin或npy格式,每个文件对应一个与网络输入张量匹配的样本。当前不同流程需要不同的格式,详细请参照“Hi3863操作指南”和“Hi3322操作指南”。
若模型有多个输出,则不同的输出必须存储在不同的目录中。同一个样本不同的输出名称需要保持一致。
分类任务真值存储为csv格式。包含两列sample和label,其中sample表示样本的名称,和bin或npy文件名保持一致。label表示标签值。csv文件示例见表1。
表 1 分类真值标签csv表格示例
环境搭建¶
环境配置请参考《HiSpark.AI 快速入门指南》。
Hi3863操作指南¶
工程创建¶
约束说明¶
用户使用WS63 SDK版本需要社区版本(WS63社区链接) 或海思发布的商用版本。商用客户优先使用商用版本。
SDK存放路径必须为英文路径。
界面介绍¶
首页¶
单击HiSpark Studio AI插件中的“Home”按钮,进入首页如图1所示。
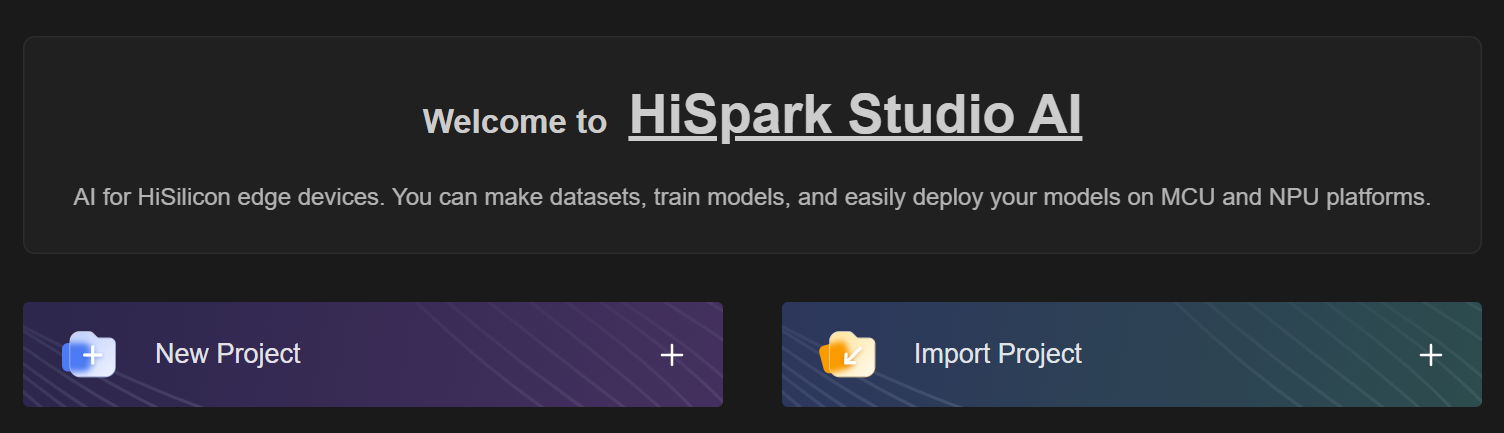
若用户首次使用HiSpark Studio AI,点击“New Project”即可创建新项目。若用户需要项目迁移,也可以选择“Import Project”导入已有项目。
新建工程配置界面¶
选择芯片为WS63,选择已准备好的SDK目录,工程项目目录选择SDK相同路径即可。
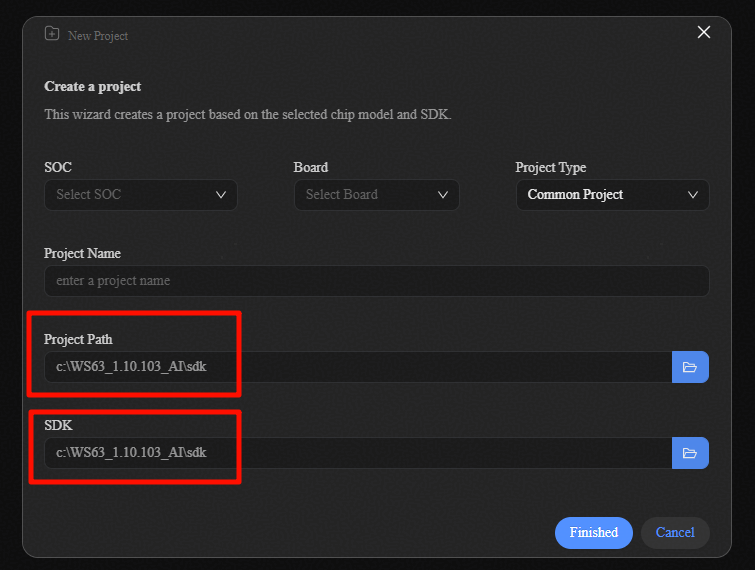
新建工程导入页面的具体逻辑如下,参数详细配置如表1所示。
选择芯片“SOC”为WS63,“Board”为WS63,“Project Type”为Common Project通用项目。
填写“Project Name”为项目名称。
配置“Project Path”以及“SDK”,一般情况下,配置为下载的SDK路径。
表 1 新建工程参数配置
用户需要提前准备WS63 SDK解压到指定目录,一级目录包含application、tools等文件夹。
通常情况下,用户将“SDK”和“Project Path”设置为相同路径即可。如果用户有将“.proj”等项目文件与SDK文件夹分开放置的需求,可以创建一个新的文件夹,专门用于放置项目文件,并单独配置到“Project Path”中。
模型导入¶
模型导入主要帮助用户将本地已经训练好的Onnx或者TFLite模型加载到HiSpark Studio AI中,并且记录之前的导入记录。
约束说明¶
Onnx模型满足Opset版本大于18。
TFLite推荐版本未Tensorflow 2.13。
Onnx以及TFLite模型中的算子必须位于列表中,具体清单请参考《HiSpark.AI 转换工具 使用指南》。
目前仅支持浮点Onnx以及TFLite模型,量化后的模型暂时不支持。
界面介绍¶
整体界面¶
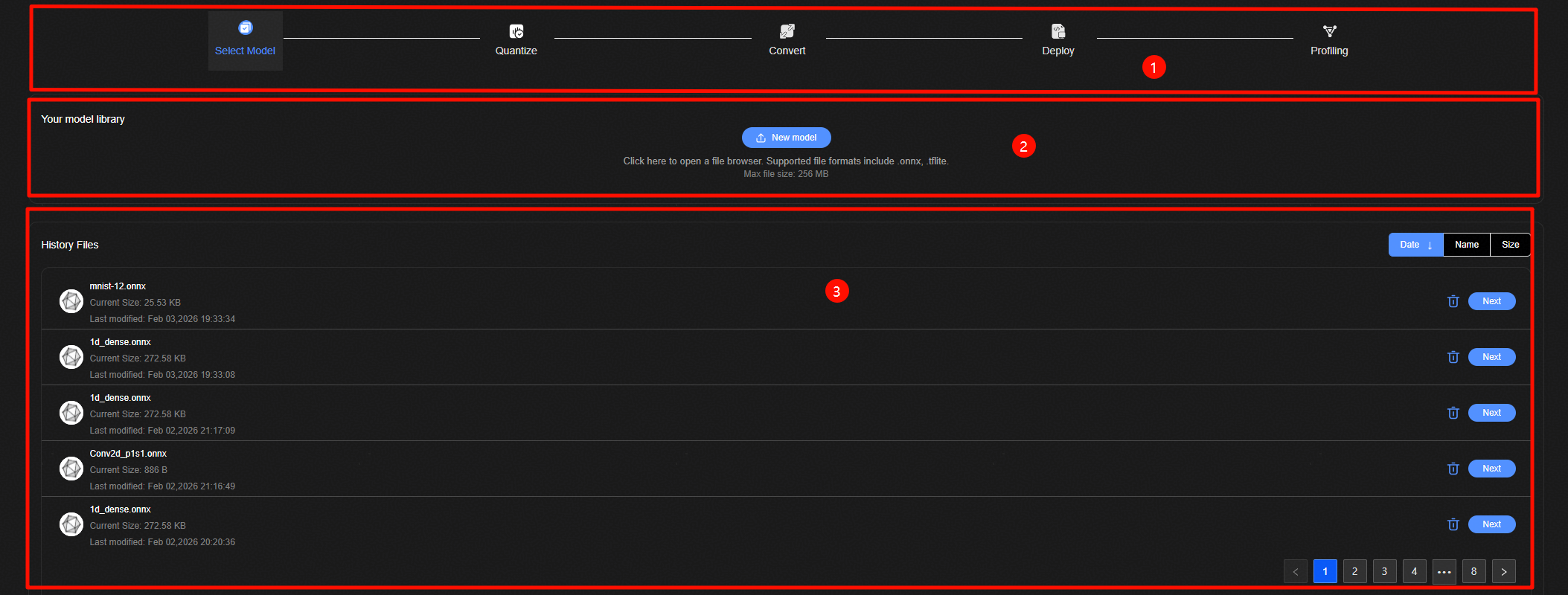
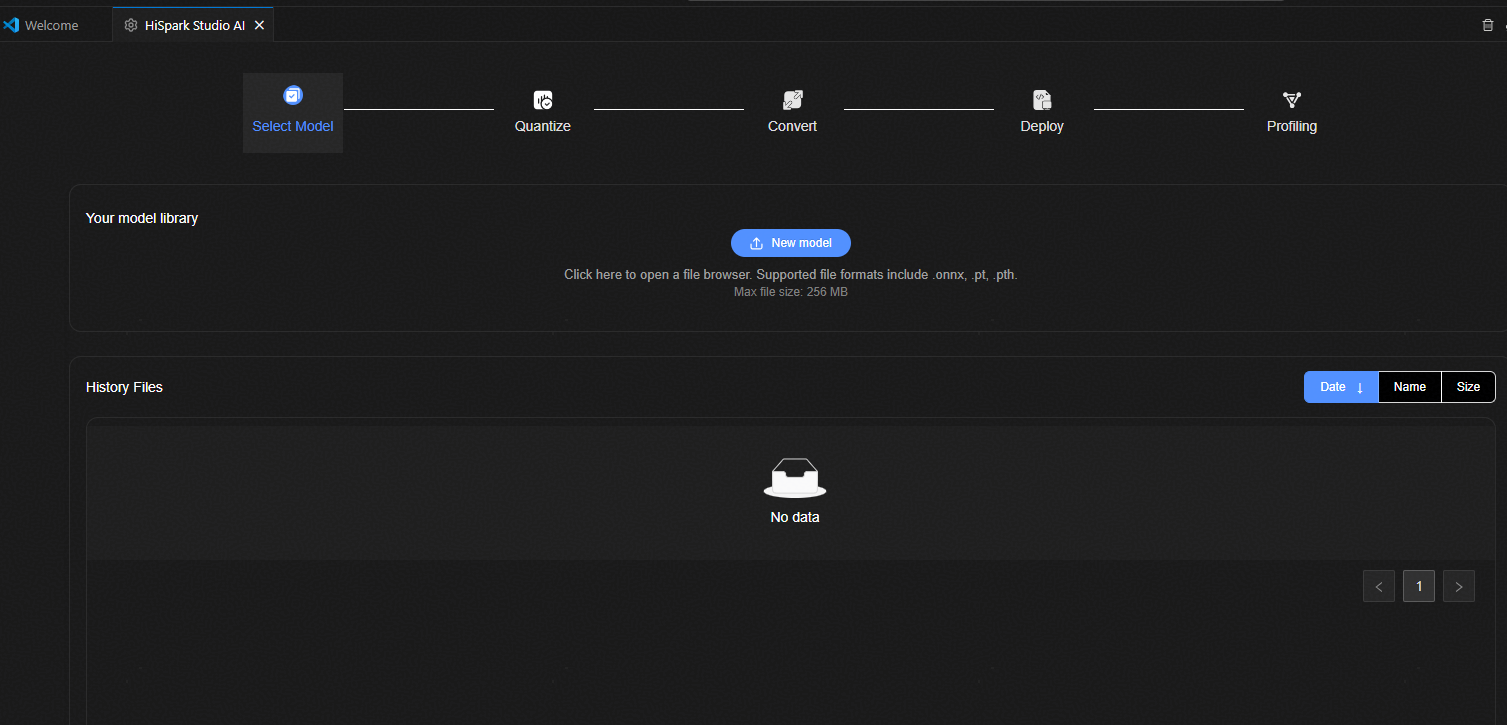
模型导入的界面如模型导入整体页面所示。主要包含以下部分:
跳转标签(Select Model -> Quantize -> Convert -> Deploy -> Profiling),当存在历史操作记录时,完成界面的切换。
模型选择页面,用于选择Linux服务器上的部署目标模型。
历史模型选择记录页面,显示所有的选择过模型的大小、修改时间,并提供回溯历史步骤以及删除功能。
模型导入步骤如下:
进入模型选择页面,点击“New Model”按钮连接Linux服务器,输入密码,选择对应的Mnist Onnx模型,测试模型请参考 Mnist-5.onnx。
连接远程服务器,输入Docker的IP、端口号、用户名、密码。
导入成功后,将跳转到量化页面。
导入配置界面¶
首次点击“New Model”按钮,需要用户填写服务器相关配置,用于连接远端服务器(需要先按照快速入门指南环境准备章节配置环境)。
点击“仅命令传输 & 待定文件下载连接”按钮
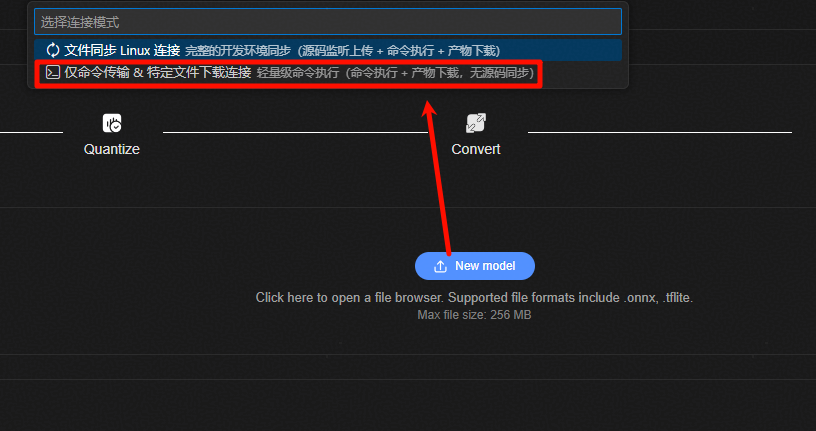
导入配置成功界面¶
模型压缩¶
约束说明¶
模型压缩仅针对Onnx以及TFLite两种格式的模型。
模型压缩仅支持未进行过量化的模型,已量化完成的Onnx以及TFLite不支持。
任何网络都会被处理为分类网络,带标签的量化精度准确率评估仅针对网络输入为[N, D]格式。
压缩前提¶
用户需要准备模型压缩的输入数据,并将数据放置到Docker环境所在的服务器上,可参考快速入门指南的样例运行章节准备。
界面介绍¶
整体界面¶
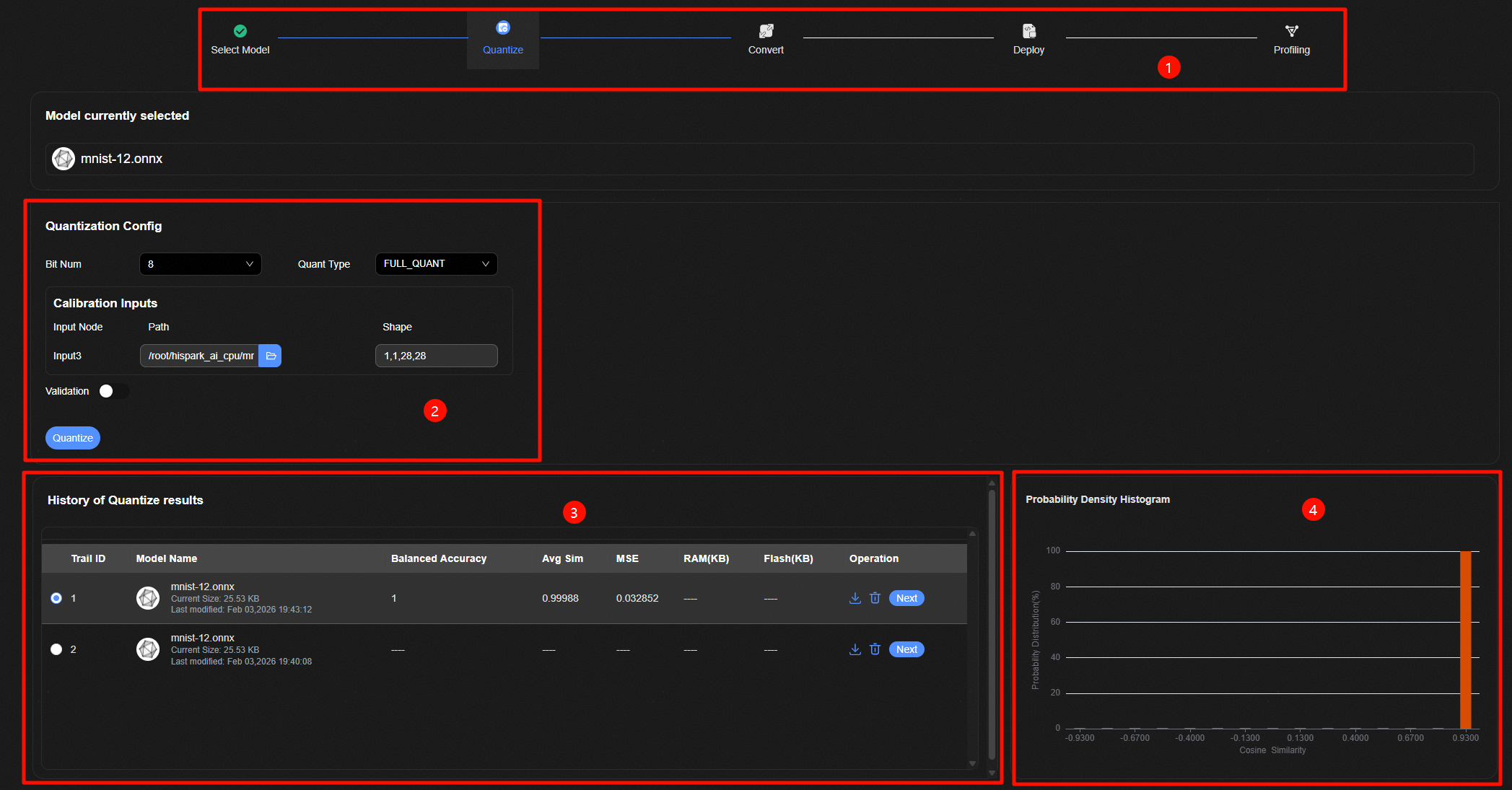
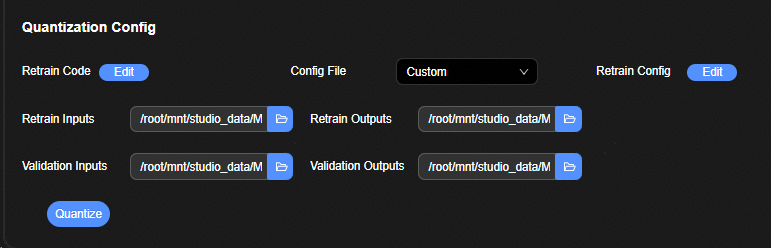
模型压缩界面如图1所示,量化整体界面主要包含四个部分:
跳转标签页面,能否跳转到该量化记录关联的前后步骤。
量化参数配置界面。
压缩历史显示界面,显示所有的压缩网络余弦相似度、MSE、准确率等指标。
样本精度分布直方图显示界面,显示验证集的直方图界面。
量化步骤如下:
进入量化页面,配置量化参数,参数详情请参见“量化参数配置页面”。
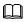 说明:
量化输入数据需要输入文件夹路径,文件夹内量化数据保持为bin格式;验证输入数据需要输入文件夹路径,文件夹内量化数据保持为npy格式。
说明:
量化输入数据需要输入文件夹路径,文件夹内量化数据保持为bin格式;验证输入数据需要输入文件夹路径,文件夹内量化数据保持为npy格式。单击“Quantize”按钮,输出量化余弦相似度、准确率以及MSE等结果。
在量化历史配置界面与验证集精度直方图分布界面,查看量化结果。
单击“Next”进入下一步。
量化参数配置页面¶
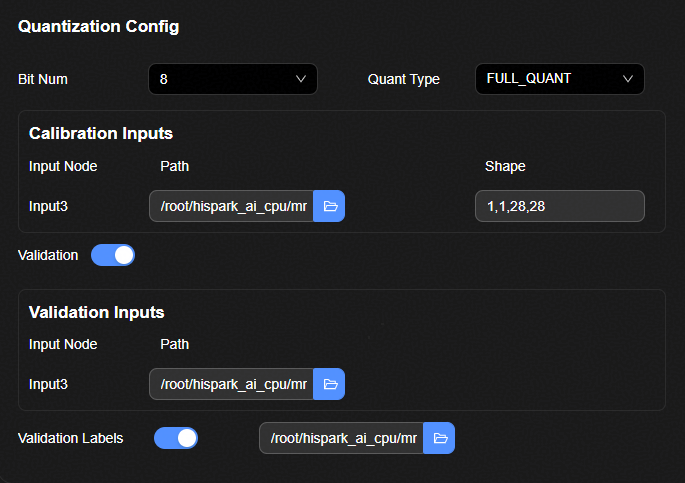
参数解释如表1所示。
表 1 量化参数配置
|
|
用户在该表格中输入量化的校准数据。表格中各列的含义如下所示:
|
|
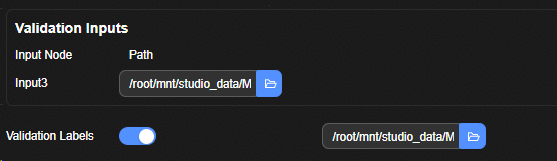
使能验证开关。当开关打开时,验证数据集输入界面展开,如图2所示。 |
|
用户在该表格中输入量化评估网络的验证数据集。表格中各列的含义如下图2所示:
|
|
使能开关打开后,输入含分类真值标签的csv表格文件。文件中的表格格式如表2所示。各列的含义如下所示:
|
|
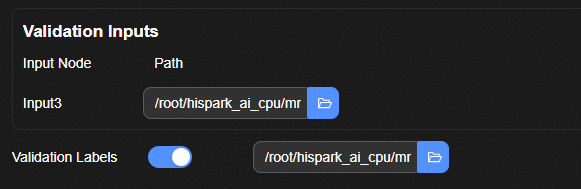
Validation Labels输入csv格式如表2所示。
表 2 label.csv文件内容
压缩历史配置界面¶
压缩历史显示窗口如图1所示。

该窗口以表格的方式显示历史压缩的结果。表头解释如表1所示。
表 1 历史压缩结果表头说明


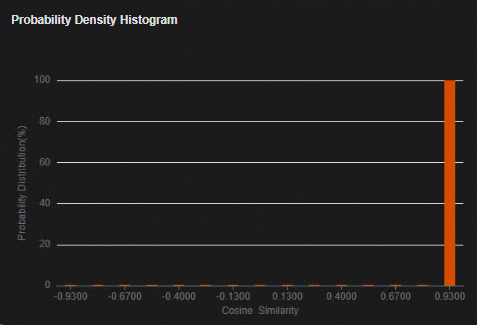
验证集精度分布直方图显示界面¶
验证集精度分布直方图显示窗口如图1所示,该窗口显示验证集的余弦相似度的分布图。横轴为余弦相似度,纵轴为验证集样本的百分比。
模型转换¶
约束说明¶
转换前提¶
用户已成功完成量化,且量化所用的校准数据位置在Docker容器上不改变。
界面介绍¶
整体界面¶
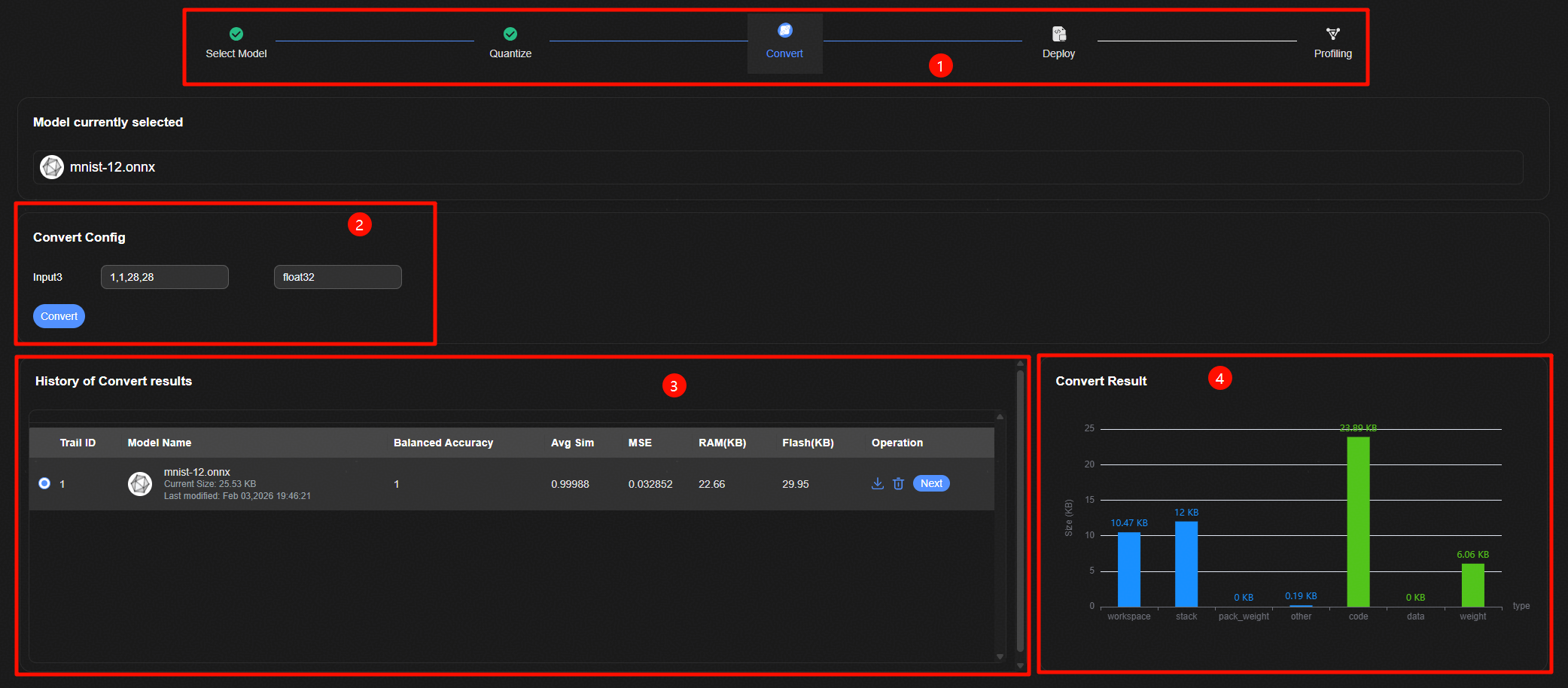
模型转换整体界面如图1所示,主要包含四个部分:
跳转标签页面,能否跳转到该量化记录关联的前后步骤。
转换参数配置界面。
历史转换记录配置界面,显示所有的转换网络余弦相似度、MSE、准确率、RAM、FLASH等指标。
转换结果RAM/FLASH对比界面,显示模型转换预估上板的各项RAM/FLASH估计。
转换步骤:
进入转换页面,配置转换参数,参数详情详见“转换参数配置页面”。
单击“Convert”按钮,输出转换RAM/FLASH等结果。
在历史转换记录配置界面 与 ,转换结果RAM/FLASH对比界面查看转换结果。
单击“Next”进入下一步。
转换参数配置页面¶
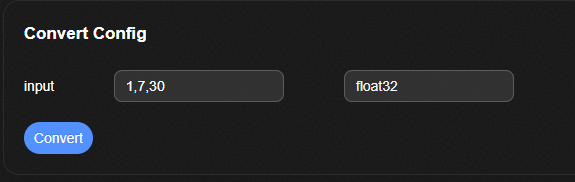
参数解释如表1所示。
表 1 转换参数配置
转换历史配置界面¶

该窗口以表格的方式显示历史压缩的结果。表头解释如表1所示。
表 1 历史转换结果表头说明


内存占用分布条形图显示界面¶
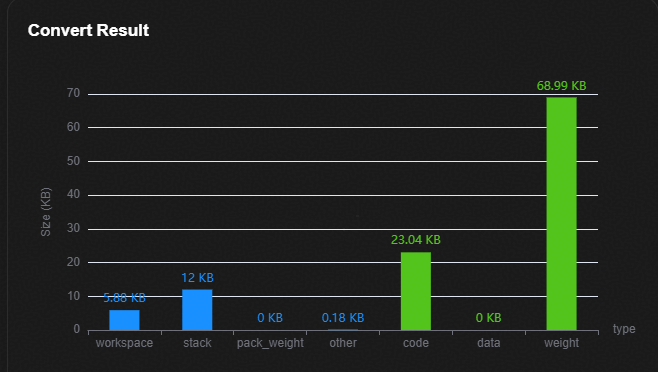
AI上板存储占比如图1所示,蓝色显示为RAM占用,绿色显示为FLASH占用,各参数显示具体含义如表1所示。
表 1 内存占用分布条形图各项含义
部署¶
约束说明¶
界面介绍¶
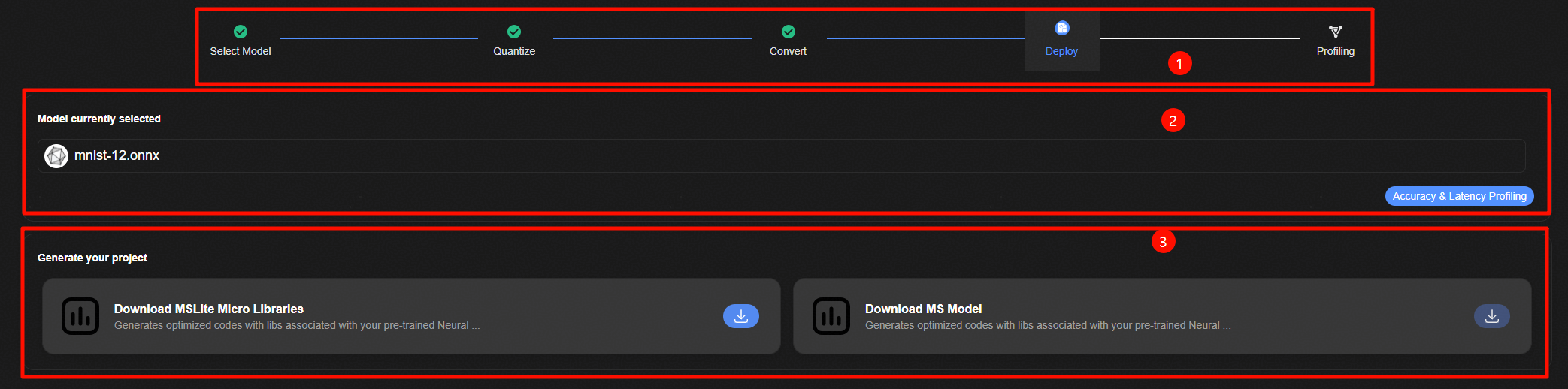
模型部署整体界面如图1所示,主要包含三个部分:
跳转标签页面,能否跳转到该量化记录关联的前后步骤。
模型部署下载配置页面。
模型转换产物下载页面。
转换步骤如下:
下载模型转换产物,用户后续应用开发部署,
单击“Accuracy & Latency Profiling”按钮,进行下一步性能 & 精度验证。
模型调优¶
约束说明¶
用户需要在环境变量中配置cmake路径、ninja路径、cmake_env路径。
用户需要在.vscode本地配置config.json中的“mindspore”字段,为mindspore包本地解压路径。
用户需要保证SDK的完成性。
用户需要准备一块WS63单板,并且使用USB串口线与本地PC连接。
调优前提¶
用户已完成模型转换步骤。
界面介绍¶
整体界面¶
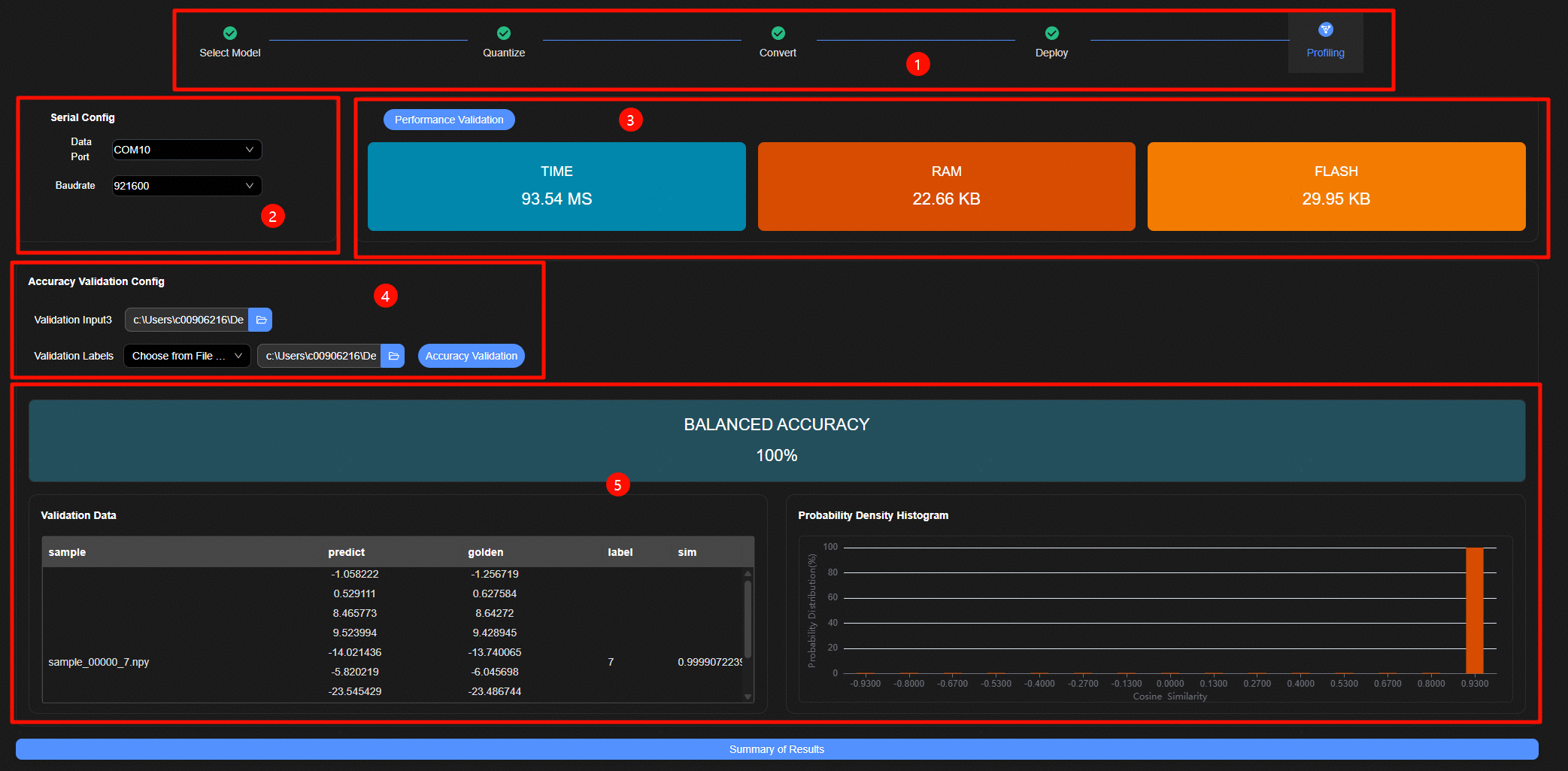
模型调优界面如图1所示,主要包含五个部分:
跳转标签页面,能否跳转到该量化记录关联的前后步骤。
性能验证参数配置页面,配置相关的串口连接相关选项。
性能验证结果评估页面,显示AI上板推理时间、RAM内存消耗、FLASH内存消耗等信息。
精度验证参数配置页面,配置相关的精度验证输入数据输入等信息。
精度验证结果评估页面,显示上板精度评估余弦相似度分布直方图 & 准确率等信息。
模型调优步骤如下:
进入模型调优页面,选择单板链接的串口以及波特率。
单击“Performance Validation”按钮,输出上板推理时间、RAM内存消耗、FLASH内存消耗等信息。
选择Windows本地相应的验证数据输入文件夹等精度验证相关的选项。
说明:
上板精度验证输入数据需要输入文件夹路径,文件夹内上板精度验证数据保持为bin格式;验证输入数据需要输入文件夹路径,文件夹内上板精度验证数据保持为npy格式。单击“Accuracy Validation”按钮,输出相关的准确率、余弦相似度分布以及上板推理的时间、精度等信息。
性能验证参数配置页面¶
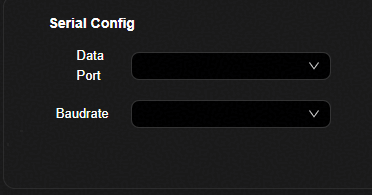
参数解释如表1所示。
表 1 转换参数配置
性能验证结果配置页面¶

具体每个参数含义如表1所示。
表 1 性能验证结果
精度验证参数配置页面¶
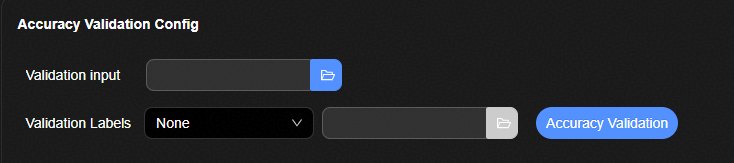
参数解释如表1所示。
表 1 转换参数配置
精度验证结果配置页面¶
上板精度验证结果页面主要分为以下三部分:
准确率信息
逐项结果展示
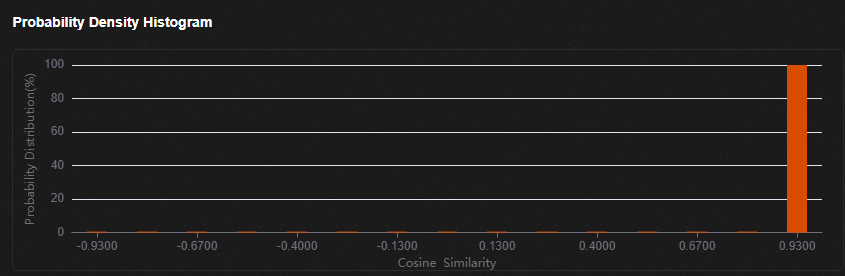
余弦相似度分布直方图
各参数如表1所示。
表 1 上板精度验证结果说明

应用开发¶
在HiSpark Studio AI中完成模型量化、转换之后,将模型导出并使用HiSpark.AI API完成应用开发。具体步骤如下。

Hi3322操作指南¶
工程创建¶
前提条件¶
在工程创建前,请先获取Hi3322 SDK,并存放于本地Windows环境。
界面介绍¶
进入HiSpark Studio AI单击“New Project”按钮进入新建工程页面。工程创建整体界面如图1所示。
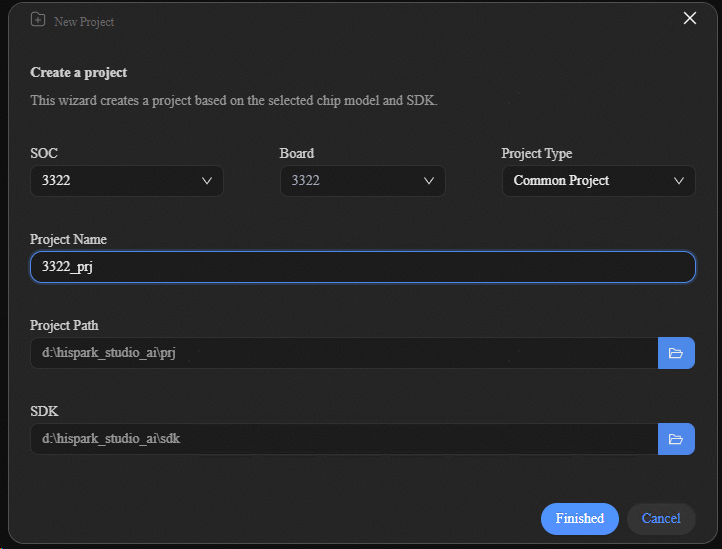
工程创建的步骤如下所示:
选择3322 SOC。
输入工程创建配置参数。
单击“Finished”按钮。
工程创建界面元素说明如表1所示。
表 1 工程创建元素说明
模型导入¶
约束说明¶
前提条件¶
完成Linux服务器环境配置。
连接Linux服务器,若未完成连接,在单击“New model”按钮时会弹出Linux服务器连接窗口。
将待处理的网络模型上传至Linux服务器。
界面介绍¶
模型导入界面整体界面如图1所示。
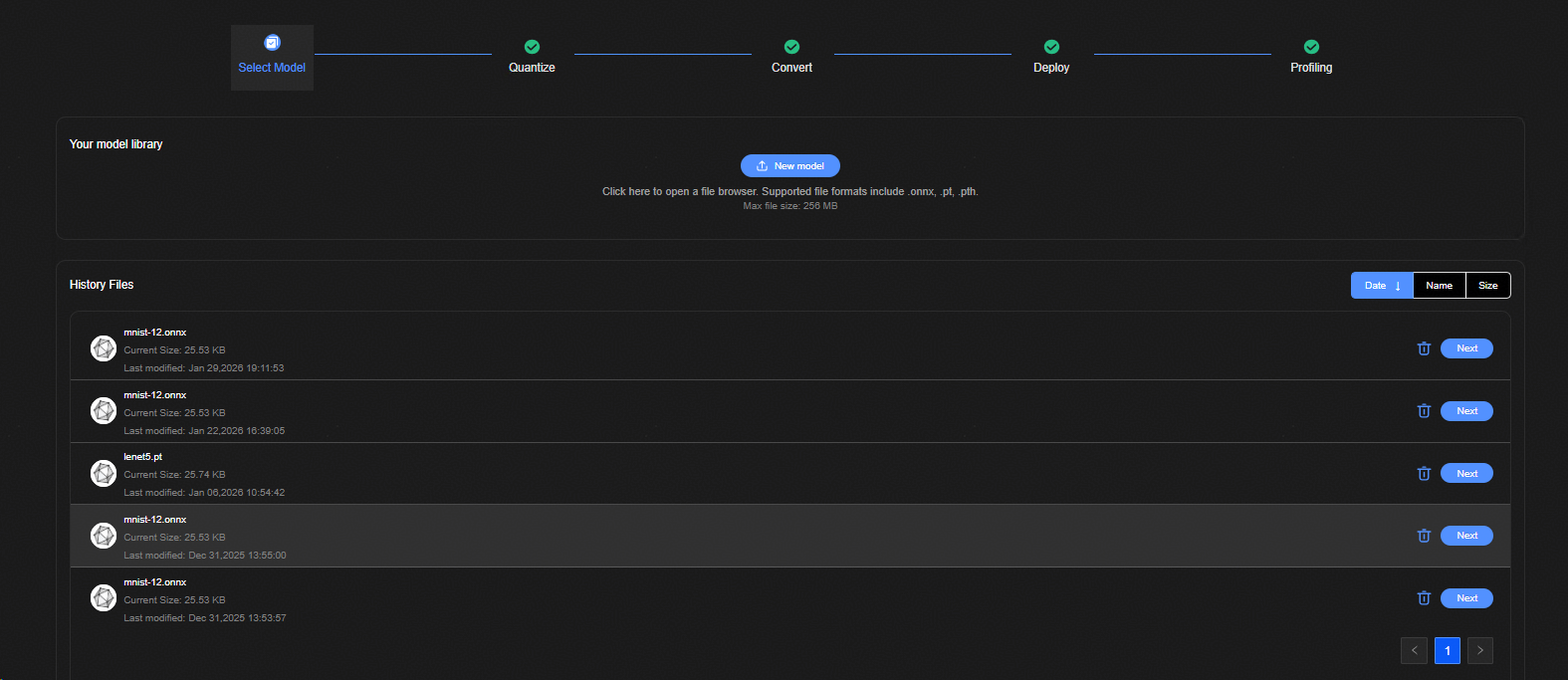
模型导入界面主要元素说明如表1。
表 1 模型导入主要元素说明
模型压缩¶
约束说明¶
支持原始框架类型为ONNX的模型训练后量化PTQ。
支持原始框架类型为PyTorch(参数后缀pt或pth)的模型量化感知训练QAT。
只支持单输出分类网络计算量化评估网络的准确率。
压缩前提¶
界面介绍¶
整体界面¶
量化的整体界面如图 量化整体界面所示。
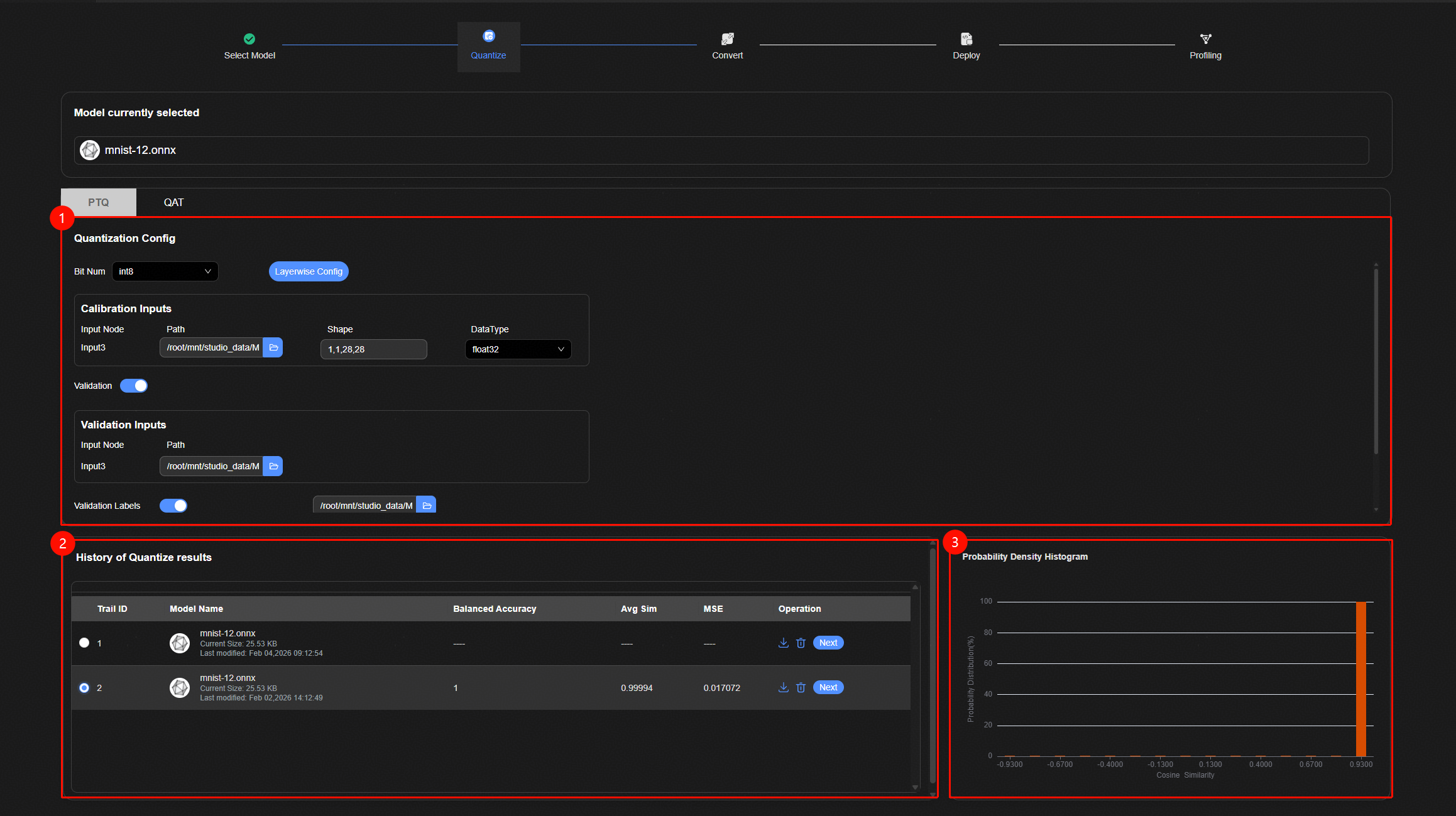
模型量化整体界面如图1所示,主要包含三个部分:
量化参数配置界面。
压缩历史显示界面,显示所有压缩的网络及其精度指标。
样本精度分布直方图显示界面,显示验证集的精度分布。
执行量化步骤如下:
在量化参数界面配置量化参数。
单击“Quantize”按钮。
压缩历史显示界面查看压缩的结果。如果使能了量化精度验证,在该表格中显示量化精度验证评估结果。
如果使能了量化精度验证,在样本精度分布直方图显示界面中查看验证集精度分布直方图。
压缩历史显示界面中选择待转换的量化模型,单击“Next”按钮进入模型转换界面。
量化参数配置界面¶
训练后量化¶
训练后量化量化参数配置窗口如图 量化参数配置界面所示。
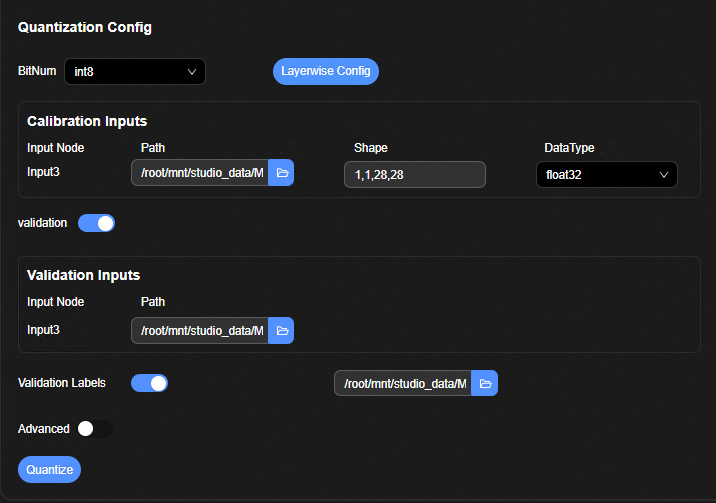
参数解释如表1所示。
表 1 训练后量化参数配置界面参数
模型量化类型。当配置为int8时,转换后模型占用空间相对较小,推理速度相对较快,精度损失相对更大。当配置为int16时,转换后模型占用空间相对较大,推理速度相对较慢,精度损失相对小。 |
|
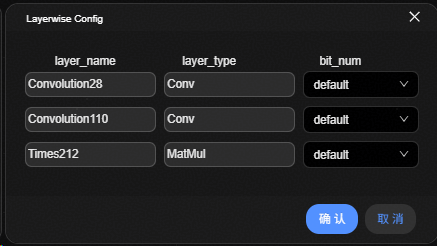
打开逐层量化配置窗口。逐层量化类型配置窗口如图2 逐层量化类型配置界面所示。表格中各列的含义如下所示:
|
|
用户在该表格中输入量化的校准数据。表格中各列的含义如下所示:
|
|
使能验证开关。当开关打开时,验证数据集输入界面展开,如图3 验证集输入界面所示。 |
|
用户在该表格中输入量化评估网络的验证数据集。表格中各列的含义如下所示:
|
|
高级模式使能开关。当开关打开时,高级模式界面展开,如图4所示。 |
|
高级模式量化配置文件输入控件。在该输入控件中输入昇腾量化配置cfg文件。昇腾量化配置文件编写格式参见文档《AMCT模型压缩工具用户指南》。点击 |
|

量化感知训练¶
量化感知训练参数配置窗口如图1所示。
参数解释如表2所示。
表 1 量化感知训练参数配置界面参数
|
量化感知训练代码模板说明见表2。 |
|
|
|
验证集输入数据目录。目录中存放和模型输入匹配的npy文件数据。若模型有多个输入,同一个训练样本的多个输入npy文件文件名必须保持一致。 |
|
表 2 量化感知训练代码模板说明
torch.nn.Module子类。在定义模型结构时请遵守如下约束:
|
压缩历史显示界面¶
压缩历史显示窗口如图 压缩历史显示界面所示。

该界面以表格的方式显示历史压缩的结果。表头解释如表1所示。
表 1 压缩历史
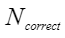
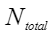
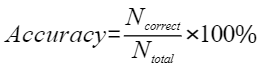
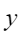
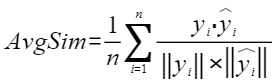
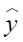
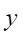
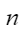
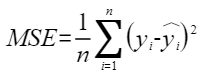


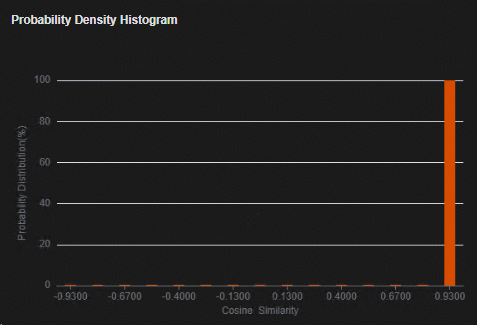
验证集精度分布直方图显示界面¶
验证集精度分布直方图显示界面如图 验证集精度分布直方图显示界面所示。该窗口显示验证集的余弦相似度的分布图,横轴为余弦相似度,纵轴为验证集样本的百分比。
模型转换¶
整体界面¶
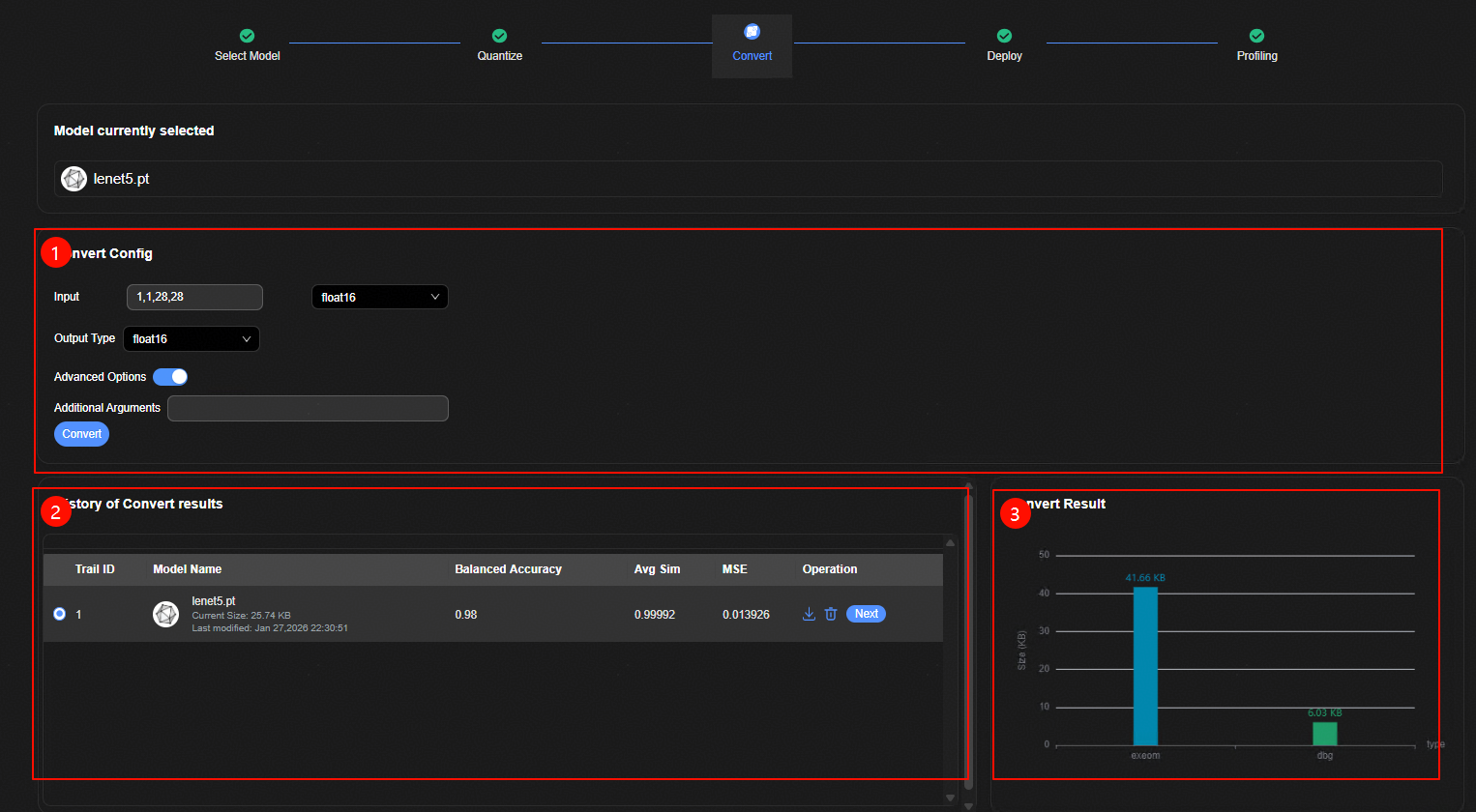
用户在模型转换界面将模型转换成昇腾NPU执行的离线模型。模型转换整体界面如图1所示。主要包含三个部分:
模型转换参数配置界面。
转换历史显示界面,显示所有转换的网络及其相关信息。
转换结果显示界面,显示转换后模型的大小。
模型转换步骤如下:
在模型转换参数配置界面配置转换参数。
单击“Convert”按钮。
转换历史显示界面查看转换的结果。
转换结果显示界面查看转换后模型的大小。
转换历史显示界面选择待评估的模型,单击“Next”按钮进入部署界面。
模型转换参数配置界面¶
模型转换参数配置界面如图1所示。
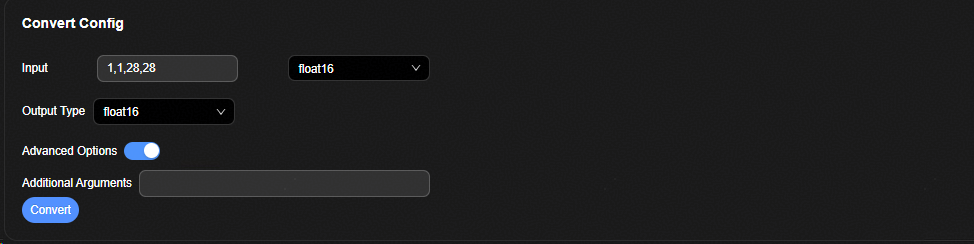
参数解释如表1所示。
表 1 模型转换参数配置界面参数
|
|
扩展参数输入框。模型转换界面不支持配置,但是ATC工具支持的参数均可通过此选项进行扩展。在该输入框中用户根据实际情况输入ATC工具可用的参数。多个参数使用空格分隔。详细参数请参见《ATC离线模型编译工具用户指南》。 |
|
转换历史显示界面¶
转换历史显示界面如图1所示。

该界面以表格的方式显示历史转换的结果。表头解释如表1所示
表 1 转换历史
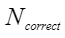
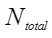
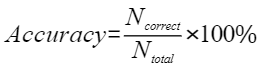
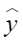
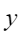
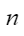
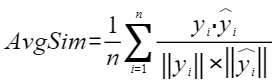
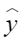
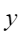
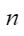
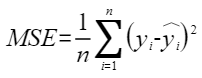


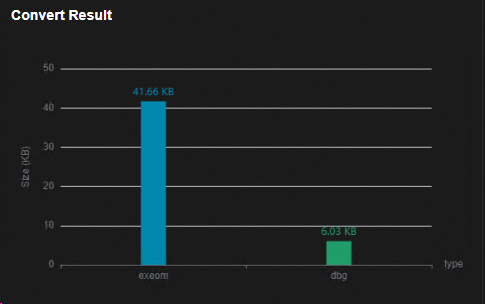
转换结果显示界面¶
转换结果显示界面如图1所示。该界面以柱状图的形式显示转换后模型以及图调试信息文件的大小。
部署¶
部署界面如图1所示。
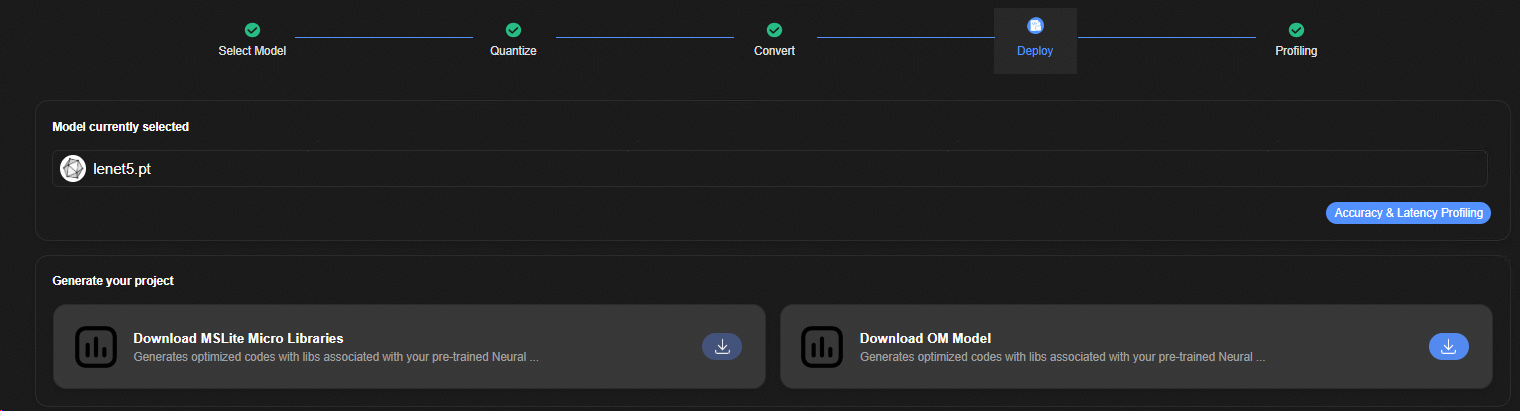
该界面主要控件如表1所示。
表 1 部署接口主要控件说明
模型调优¶
约束说明¶
调优前提¶
准备精度验证数据,并保存于本地Windows环境。具体数据格式见“数据准备与环境搭建”。
准备并连接Hi3322单板。
界面介绍¶
整体界面¶
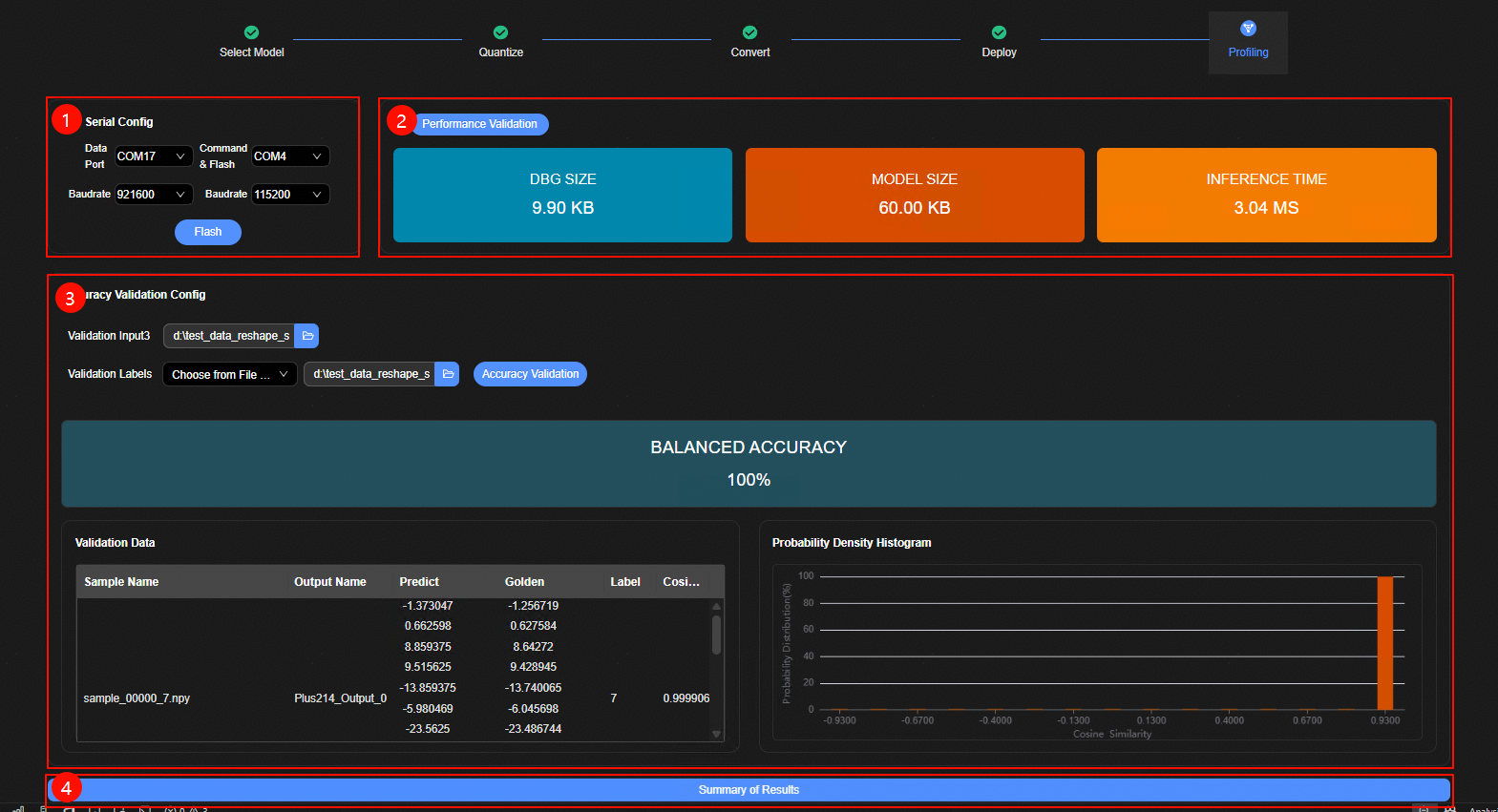
模型调优整体界面如图1所示,主要包含四个部分:
串口配置界面。在该界面配置数据传输、烧录、命令串口和波特率。
性能评估界面。
精度评估界面。
评估结果汇总按钮。
执行模型调优的步骤如下:
配置数据传输、烧录、命令串口和波特率。
可选。如需烧录镜像,单击“Flash”按钮,执行镜像烧录。
可选。单击“Performance Validation”按钮,执行上板性能评估。查看性能评估结果。
可选。配置精度验证数据集路径,单击“Accuracy Validation”按钮,执行上板精度评估。查看精度评估结果。
单击“Summary of Results”按钮,在弹窗中查看历史评估结果。
串口配置界面¶
用户在串口配置界面配置镜像烧录、数据传输、命令发送串口和波特率。串口配置界面如图1所示。
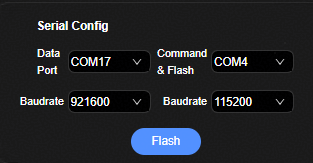
元素说明如表1所示。
表 1 串口配置界面元素说明
性能评估界面¶
用户在性能评估界面触发上板性能评估,并查看性能评估结果。性能评估界面的如图1所示。

性能评估界面元素说明如表1所示。
表 1 性能评估界面元素说明
精度评估界面¶
用户在精度评估界面配置精度评估验证数据、触发上板精度验证以及查看精度验证结果。精度评估界面如图1所示。
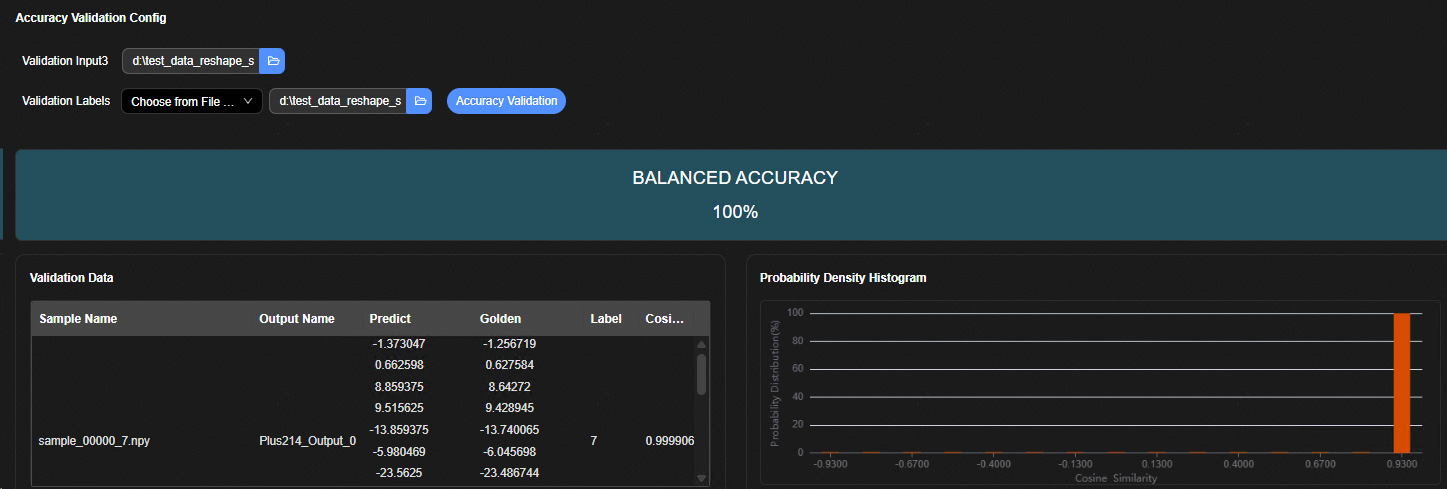
精度评估界面元素说明如表1所示。
表 1 精度评估界面元素说明
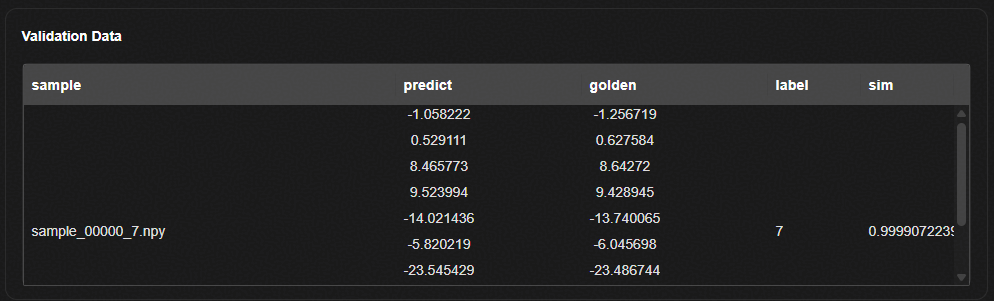
各验证样本验证结果。表格中各项说明如表2所示。 |
|
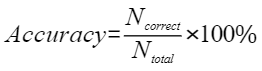
表 2 验证样本结果说明
平均余弦相似度,计算公式如下,其中 |
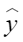
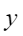
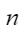
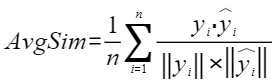
评估结果汇总界面¶
单击“Summary of Results”按钮之后弹出评估结果汇总界面,该界面汇总每次评估的结果。如图1所示。
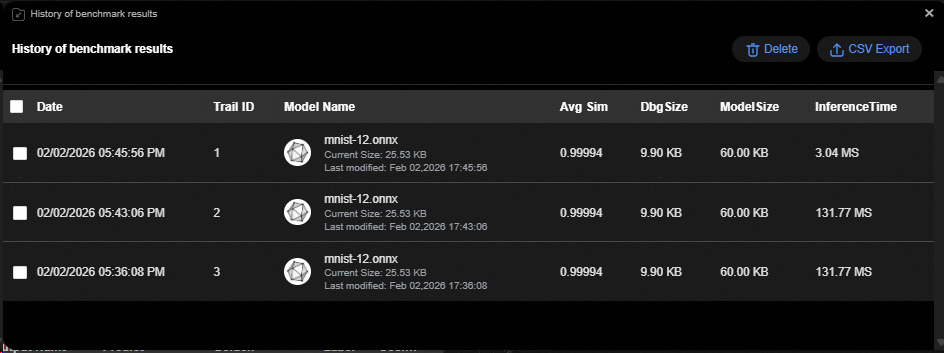
评估结果汇总界面元素说明如表1所示。
表 1 评估结果界面元素说明
平均余弦相似度,计算公式如下,其中 |
|
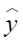
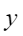
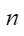
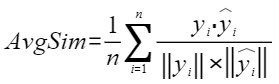
应用开发¶
在HiSpark Studio AI中完成模型量化、转换之后,将模型导出并使用HiSpark.AI API完成应用开发。具体步骤如下:
