
简介¶
本节介绍AscendCL的主要功能、基本概念,并给出本文档的学习顺序建议。
AscendCL是什么?
**AscendCL(Ascend Computing Language)**是一套C语言API库,提供运行时管理、单算子调用、模型管理、媒体数据处理等API,能够实现利用底层硬件计算资源,在CANN平台上进行深度学习推理计算、图形图像预处理、单算子加速计算等。简单来说,就是统一的API框架,实现对所有资源的调用。其中,计算资源层是NPU IP加速器的硬件算力基础,主要完成神经网络的矩阵相关计算、完成控制算子/标量/向量等通用计算和执行控制功能、完成图像和视频数据的预处理。
图 1 逻辑架构图
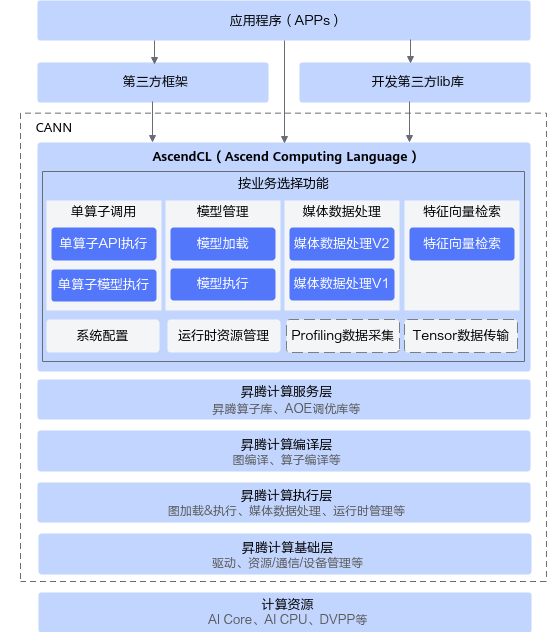
AscendCL的应用场景:
开发应用:用户可以直接调用AscendCL提供的接口开发图片分类应用、目标识别应用等。
供第三方框架调用:用户可以通过第三方框架调用AscendCL接口,以便使用NPU IP加速器的计算能力。
供第三方开发lib库:用户还可以使用AscendCL封装实现第三方lib库,以便提供NPU IP加速器的运行管理、资源管理等能力。
AscendCL的优势如下:
高度抽象:算子编译、加载、执行的API归一,相比每个算子一个API,AscendCL大幅减少API数量,降低复杂度。
向后兼容:AscendCL具备向后兼容,确保软件升级后,基于旧版本编译的程序依然可以在新版本上运行。
零感知NPU IP加速器:一套AscendCL接口可以实现应用代码统一,多款NPU IP加速器无差异。
基本概念
表 1 概念介绍
概念 |
描述 |
|---|---|
同步/异步 |
本文中提及的同步、异步是站在调用者和执行者的角度:
|
进程/线程 |
本文中提及的进程、线程,若无特别注明,则表示用户应用程序中的进程、线程。 |
通道 |
在RGB色彩模式下,图像通道就是指单独的红色R、绿色G、蓝色B部分。也就是说,一幅完整的图像,是由红色绿色蓝色三个通道组成的,它们共同作用产生了完整的图像。同样在HSV色系中指的是色调H,饱和度S,亮度V三个通道。 |
以NPU IP加速器的PCIe的工作模式进行区分,如果PCIe工作在主模式,可以扩展外设,则称为 |
文档使用建议
如果您是第一次使用本文档,已了解AscendCL做什么,但还不清楚如何开发应用时,建议:
先参考《安装指南》安装固件、驱动及CANN软件。
然后单击Link获取入门样例,按README.md中的指导下载样例源码、编译及运行应用等,再通过源码了解acl接口(接口名以acl开头)的关键代码逻辑。
再通过头文件和库文件说明、接口调用流程了解整体的接口分类以及接口调用流程。
最后通过模型管理章节的接口调用流程+示例代码展开学习,扩展进行其它应用的开发。
具备C/C++语言程序开发能力、对机器学习或深度学习有一定了解的开发者,可以更好地理解本文档。
准备环境¶
部署开发环境,请参见《开发环境安装指南》。
安装CANN软件后,使用CANN运行用户进行编译、运行时,需要以CANN运行用户登录环境,执行source ${INSTALL_DIR}/bin/setenv.bash命令设置环境变量。${INSTALL_DIR}请替换为CANN软件安装后文件存储路径。以root安装举例,安装后文件默认存储路径为:/usr/local/Ascend/latest。
部署开发环境后,才能获取调用接口所需的头文件、编译运行接口所需的库文件。
从“CANN软件安装后文件存储路径/include/acl”目录下获取头文件。
从“CANN软件安装后文件存储路径/lib64”目录下获取库文件。
编程接口与调用流程¶
本节介绍接口分类以及调用接口时依赖的头文件和库文件。 本节介绍应用开发接口调用流程。
头文件和库文件说明¶
本节介绍接口分类以及调用接口时依赖的头文件和库文件。
接口分类
接口名以acl作为前缀,命名风格为:acl+接口类别缩写+操作动词+对象,其中操作动词和对象均采用首字母大写。下文为了描述方便,将本文中的接口统称为acl接口。
表 1 接口类别列表
接口名前缀 |
描述 |
|---|---|
acl |
系统配置类接口 |
aclrt |
运行时资源管理类的接口 |
aclmdl |
模型推理类的接口 |
调用接口依赖的头文件和库文件说明
安装固件、驱动及CANN软件包后,编译、运行应用程序时才能引用到acl接口的头文件、库文件。
您需要根据实际使用的acl接口来include依赖的文件,各头文件的用途如下表所示。
acl接口的头文件在“${INSTALL_DIR}/include/”目录下,库文件在“${INSTALL_DIR}/lib64/”目录下。${INSTALL_DIR}请替换为CANN软件安装后文件存储路径。以root安装举例,安装后文件默认存储路径为:/usr/local/Ascend/latest。
须知: 编译acl接口程序时,请按照include的头文件依赖对应的库文件,如果引用多余的so文件(例如libascendcl.a),可能导致版本功能异常或后续版本升级时存在兼容性问题。
表 2 头文件列表
定义接口的头文件 |
用途 |
对应的库文件 |
|---|---|---|
acl/acl_base.h |
用于定义基本的数据类型(例如aclDataBuffer、aclTensorDesc等)及其操作接口、枚举值(例如aclFormat)、日志管理接口等。 |
libascendcl.a |
acl/acl.h |
该头文件中已包含acl/acl_mdl.h、acl/acl_rt.h、acl/acl_op.h。包含acl.h文件后,可以引用初始化/去初始化、Device管理、Context管理、Stream管理、同步等待、内存管理、算力Group查询与设置、模型加载与执行、单算子执行(含部分接口)等接口。 |
libascendcl.a |
接口调用流程¶
本节介绍应用开发接口调用流程。
接口调用流程
调用acl接口,可开发包含模型推理等功能的应用,这些功能可以独立存在,也可以组合存在。下图给出了使用acl接口开发AI应用的整体接口调用流程。
图 1 接口调用流程图
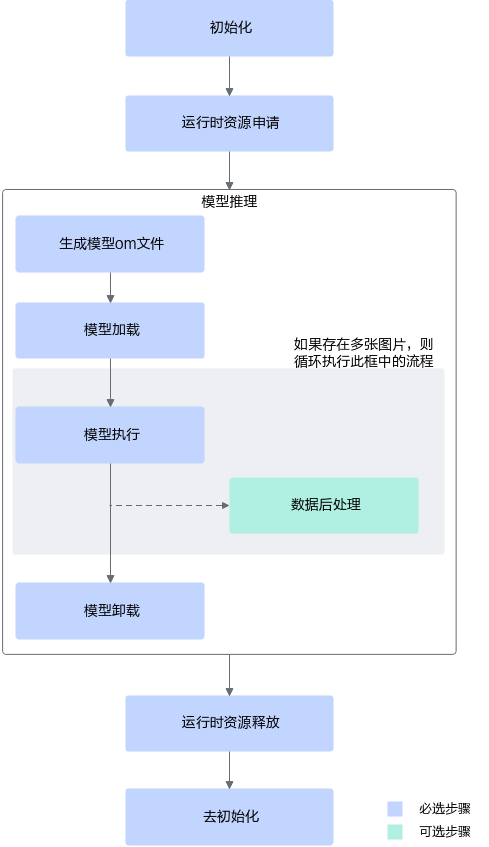
上图根据应用开发中的典型功能抽象出主要的接口调用流程,例如,如果模型对输入图片的宽高要求与用户提供的源图不一致,则需要媒体数据处理,将源图裁剪成符合模型的要求;如果需要实现模型推理的功能,则需要先加载模型,模型推理结束后,则需要卸载模型;如果模型推理后,需要从推理结果中查找最大置信度的类别标识对图片分类,则需要数据后处理。
初始化。
调用aclInit接口实现初始化。
运行时资源申请。
具体流程,请参见运行时资源申请与释放。
应用业务处理。
模型推理
模型加载:模型推理前,需要先将对应的模型加载到系统中。
接口调用流程,请参见模型加载。
但加载模型前,必须要有适配昇腾AI处理器的离线模型适配NPU IP加速器的离线模型,需提前构建模型,请参见模型构建。
模型执行:使用模型实现图片分类、目标识别等功能。
接口调用流程,请参见模型执行。
(可选)数据后处理:处理模型推理的结果,此处根据用户的实际需求来处理推理结果,例如用户可以将获取到的推理结果写入文件、从推理结果中找到每张图片最大置信度的类别标识等。
模型卸载:调用aclmdlUnload接口卸载模型。
运行时资源释放。
所有数据处理都结束后,需要依次释放运行时资源,接口调用流程,请参见运行时资源申请与释放。
去初始化。
调用aclFinalize接口实现去初始化。
说明: 在应用开发过程中,各环节都涉及内存的申请与释放、数据传输(通过内存复制实现)、数据类型的创建与销毁,因此未在图中一一标识,关于内存申请与释放、内存复制的接口请参见内存管理,数据类型的创建与销毁的接口请参见数据类型及其操作接口。
初始化与去初始化¶
本节介绍初始化与去初始化的相关接口、注意事项,并给出示例代码。
基本原理
您必须调用aclInit接口进行初始化,配置文件内容为json格式,详细的配置内容请参见aclInit中的描述。
如果当前的默认配置已满足需求,无需修改,可向aclInit接口中传入NULL,或者可将配置文件配置为空json串(即配置文件中只有{})。向aclInit接口中传入空指针的示例如下:
aclError ret = aclInit(NULL);
有初始化就有去初始化,在进程退出之前,需调用aclFinalize接口实现去初始化。
示例代码
调用接口后,需增加异常处理的分支,并记录报错日志、提示日志,此处不一一列举。以下是关键步骤的代码示例,不可以直接拷贝编译运行,仅供参考。
// 初始化
// 此处的..表示相对路径,相对可执行文件所在的目录
// 例如,编译出来的可执行文件存放在out目录下,此处的..就表示out目录的上一级目录
const char *aclConfigPath = "../src/acl.json";
aclError ret = aclInit(aclConfigPath);
// ......
// 去初始化
ret = aclFinalize();
// ......
运行时资源管理¶
本节介绍运行时资源包括哪些、如何申请&释放这些资源,并给出示例代码。 本节介绍数据传输的相关接口、注意事项,并给出示例代码。 本节介绍单Stream、多Stream的创建、销毁流程,以及多Stream同步等待的流程。 本节介绍Device、Stream、Event、Notify在异步场景下的使用示例及关键接口。
概念说明¶
基本概念
表 1 概念介绍
概念 |
描述 |
|---|---|
Device |
Device指安装了NPU IP加速器的硬件设备,提供NN计算能力。 |
Context |
Context作为一个容器,管理了所有对象(包括Stream、Event、设备内存等)的生命周期。不同Context的Stream、不同Context的Event是完全隔离的,无法建立同步等待关系。 显式创建Context:在进程或线程中调用aclrtCreateContext接口显式创建一个Context。 |
Stream |
Stream用于维护一些异步操作的执行顺序,确保同一个Stream中的任务按照应用程序中的代码调用顺序在Device上执行。 显式创建Stream:在进程或线程中调用aclrtCreateStreamV2接口显式创建一个Stream。 |
Device、Context、Stream之间的关系
图 1 Device、Context、Stream之间的关系
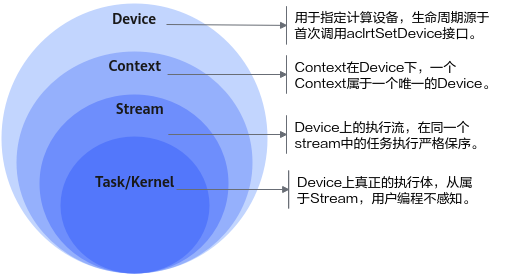
Device,表示计算设备,用户可以调用acl接口,例如aclrtSetDevice,指定当前线程中用于运算的设备。
Context,在Device下,一个Context一定属于一个唯一的Device。
显式创建的Context,调用aclrtCreateContext接口会显式创建Context,调用aclrtDestroyContext接口显式销毁Context。
若在某一进程内创建多个Context(Context的数量与Stream相关,Stream数量有限制,请参见aclrtCreateStreamV2),当前线程在同一时刻内只能使用其中一个Context,建议通过aclrtSetCurrentContext接口明确指定当前线程的Context,增加程序的可维护性**。**
进程内的Context是共享的,可以通过aclrtSetCurrentContext进行切换。
Stream,是Device上的执行流,在同一个stream中的任务执行严格保序。
用户可以显式创建Stream,调用aclrtCreateStreamV2接口显式创建Stream,调用aclrtDestroyStream接口显式销毁Stream。显式创建的Stream归属的Context被销毁后,会影响该Stream的使用,虽然此时Stream没有被销毁,但不可再用。
Task/Kernel,是Device上真正的任务执行体。
线程、Context、Stream之间的关系
一个用户线程一定会绑定一个Context,所有Device的资源使用或调度,都必须基于Context。
一个线程中当前会有一个唯一的Context在用,Context中已经关联了本线程要使用的Device。
可以通过aclrtSetCurrentContext进行Device的快速切换。示例代码如下,仅供参考,不可以直接拷贝编译运行:
// ...... aclrtCreateContext(&ctx1, 0); aclrtCreateStreamV2(&s1, &handle1); /* 执行算子 */ aclopExecuteV2(op1,...,s1); aclrtCreateContext(&ctx2,1); /* 在当前线程中,创建ctx2后,当前线程对应的Context切换为ctx2,后续计算任务在Device 1上进行 */ aclrtCreateStreamV2(&s2, &handle2); /* 执行算子 */ aclopExecuteV2(op2,...,s2); /* 在当前线程中,通过Context切换,使后续计算任务在对应的Device 0上进行 */ aclrtSetCurrentContext(ctx1); /* 执行算子 */ aclopExecuteV2(op3,...,s1); // ......
一个线程中可以创建多个Stream,不同的Stream上计算任务是可以并行执行;多线程场景下,推荐每个线程创建一个Stream,线程之间的Stream在Device上相互独立,每个Stream内部的任务是按照Stream下发的顺序执行。
多线程的调度依赖于运行应用的操作系统调度,多Stream在Device侧的调度,由Device上调度组件进行调度。
一个进程内多个线程间的Context切换
一个进程中可以创建多个Context,但一个线程同一时刻只能使用一个Context。
线程中创建的多个Context,线程缺省使用最后一次创建的Context。
进程内创建的多个Context,可以通过aclrtSetCurrentContext设置当前需要使用的Context。
图 2 接口调用流程
多线程、多stream的性能说明
线程调度依赖运行的操作系统,Stream上下发了任务后,Stream的调度由Device的调度单元调度,但如果一个进程内的多Stream上的任务在Device存在资源争抢的时候,性能可能会比单Stream低。
当前NPU IP加速器有不同的执行部件,如AI Core、AI CPU、Vector Core等,对应使用不同执行部件的任务,建议多Stream的创建按照算子执行引擎划分。
单线程多Stream与多线程多Stream(一个进程中可以包含多个线程,每个线程中一个Stream)性能上哪个更优,具体取决于应用本身的逻辑实现,一般来说前者性能略好,原因是相对后者,应用层少了线程调度开销。
运行时资源申请与释放¶
本节介绍运行时资源包括哪些、如何申请&释放这些资源,并给出示例代码。
开发应用时,应用程序中必须包含运行时资源申请的代码逻辑,关于运行时资源申请的接口调用流程,请先参见接口调用流程了解整体流程,再查看本节中的资源申请&释放流程说明、示例代码。
基本原理
您需要按顺序依次申请Device、Stream等运行时资源,确保可以使用这些资源执行运算、管理任务。所有数据处理都结束后,需要按顺序依次释放Stream、Device等运行时资源。
关于单进程、单线程、单Stream场景如下所示:
单进程:一个应用程序对应一个进程。
单线程:不创建多个线程时,默认只有一个线程。
单Stream:整个开发的过程中使用同一个Stream。
对于同一个Stream中的异步任务,会按照应用程序中任务的顺序执行任务,确保异步任务执行的顺序。
关于多线程、多Stream的场景请参见Stream管理。
运行时资源申请流程
图 1 运行时资源申请流程
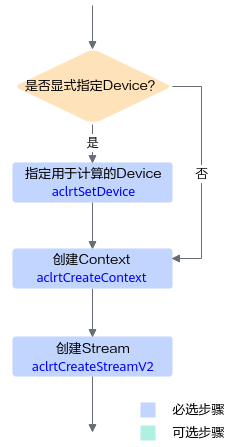
申请运行时资源时,需按顺序依次申请:Device、Context、Stream。
显式指定用于运算的Device
依次调用aclrtSetDevice接口指定Device、调用aclrtCreateContext接口显式创建Context、调用aclrtCreateStreamV2接口显式创建Stream。
隐式指定用于运算的Device
调用aclrtCreateContext接口显式创建Context,调用aclrtCreateStreamV2接口显式创建Stream。
调用aclrtCreateContext接口显式创建Context时,传入Device ID,这时系统内部会根据该Device ID指定运行的Device。
运行时资源释放流程
图 2 运行时资源释放流程
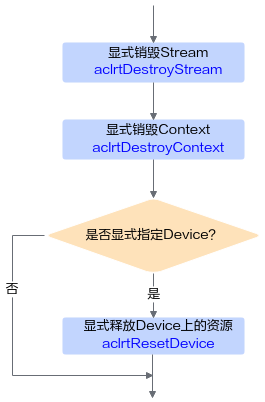
释放运行时资源时,需按顺序依次释放:Stream、Context、Device。需调用aclrtDestroyStream接口释放Stream,再调用aclrtDestroyContext接口释放Context。若显式调用aclrtSetDevice接口指定运算的Device时,还需调用aclrtResetDevice接口释放Device上的资源。
示例代码
调用接口后,需增加异常处理的分支,并记录报错日志、提示日志,此处不一一列举。以下是关键步骤的代码示例,不可以直接拷贝编译运行,仅供参考。
// 初始化变量
int32_t deviceId=0 ;
aclrtContext context;
aclrtStream stream;
extern bool g_isDevice;
// =====运行时资源申请=====
// 指定运算的Device
aclError ret = aclrtSetDevice(deviceId);
// 显式创建一个Context,用于管理Stream对象
ret = aclrtCreateContext(&context, deviceId);
// 显式创建一个Stream,此处创建Stream时以设置Stream优先级为例
// 用于维护一些异步操作的执行顺序,确保按照应用程序中的代码调用顺序执行任务
uint32_t stmPriority = 1;
aclrtStreamConfigHandle *handle = aclrtCreateStreamConfigHandle();
ret = aclrtSetStreamConfigOpt(handle, ACL_RT_STREAM_PRIORITY, &stmPriority, sizeof(stmPriority));
ret = aclrtCreateStreamV2(&stream, handle);
// =====运行时资源申请=====
// ......
// =====运行时资源释放=====
ret = aclrtDestroyStream(stream);
ret = aclrtDestroyStreamConfigHandle(handle);
ret = aclrtDestroyContext(context);
ret = aclrtResetDevice(deviceId);
// =====运行时资源释放=====
// ......
数据传输¶
本节介绍数据传输的相关接口、注意事项,并给出示例代码。
接口调用流程
数据传输的关键接口调用流程如下:
申请内存。
Device上的内存,调用aclrtMalloc接口申请内存。
将数据读入内存。
由用户自行管理数据读入内存的实现逻辑。
通过内存复制实现数据传输。
数据传输可以通过内存复制的方式实现,分为同步内存复制、异步内存复制:
同步内存复制:调用aclrtMemcpy接口。
调用同步或异步内存复制接口时,支持以下类型的复制(可单击链接查看对应类型的内存复制示例代码):
一个Device内的数据传输
调用接口后,需增加异常处理的分支,并记录报错日志、提示日志,此处不一一列举。以下是关键步骤的代码示例,不可以直接拷贝编译运行,仅供参考。
// 1. 申请内存
uint64_t size = 1 * 1024 * 1024;
void* devPtrA = NULL;
void* devPtrB = NULL;
aclrtMalloc(&devPtrA, size, ACL_MEM_MALLOC_HUGE_FIRST);
aclrtMalloc(&devPtrB, size, ACL_MEM_MALLOC_HUGE_FIRST);
// 2. 申请内存后,可向内存中读入数据,该自定义函数ReadFile由用户实现
ReadFile(fileName, devPtrA, size);
// 3. 内存复制,可以选择同步或异步
// 同步内存复制,devPtrA表示Device上源内存地址指针,devPtrB表示Device上目的内存地址指针,size表示内存大小
aclrtMemcpy(devPtrB, size, devPtrA, size, ACL_MEMCPY_DEVICE_TO_DEVICE);
// 异步内存复制
// 显式创建一个Stream,此处创建Stream时以设置Stream优先级为例
aclrtStream stream;
uint32_t stmPriority = 1;
aclrtStreamConfigHandle *handle = aclrtCreateStreamConfigHandle();
aclrtSetStreamConfigOpt(handle, ACL_RT_STREAM_PRIORITY, &stmPriority, sizeof(stmPriority));
aclrtCreateStreamV2(&stream, handle);
aclrtMemcpyAsync(devPtrB, size, devPtrA, size, ACL_MEMCPY_DEVICE_TO_DEVICE, stream);
aclrtSynchronizeStream(stream);
// 4. 使用完内存中的数据后,需及时释放资源
aclrtDestroyStream(stream);
aclrtDestroyStreamConfigHandle(handle);
aclrtFree(devPtrA);
aclrtFree(devPtrB);
// ......
Stream管理¶
本节介绍单Stream、多Stream的创建、销毁流程,以及多Stream同步等待的流程。
在AscendCL中,Stream是一个任务队列,应用程序通过Stream来管理任务的并行,一个Stream内部的任务保序执行,即Stream根据发送过来的任务依次执行;不同Stream中的任务并行执行。
当前包含以下几种Stream管理机制:
单线程单Stream
调用接口后,需增加异常处理的分支,并记录报错日志、提示日志,此处不一一列举。以下是关键步骤的代码示例,不可以直接拷贝编译运行,仅供参考。
#include "acl/acl.h"
// ......
int32_t deviceId = 0;
aclrtContext context;
/ 如果只创建了一个Context,线程默认将这个Context作为线程当前的Context;
// 如果是多个Context,则需要调用aclrtSetCurrentContext接口设置当前线程的Context
aclrtCreateContext(&context, deviceId);
// 显式创建一个Stream,此处创建Stream时以设置Stream优先级为例
aclrtStream stream;
uint32_t stmPriority = 1;
aclrtStreamConfigHandle *handle = aclrtCreateStreamConfigHandle();
aclrtSetStreamConfigOpt(handle, ACL_RT_STREAM_PRIORITY, &stmPriority, sizeof(stmPriority));
aclrtCreateStreamV2(&stream, handle);
// 调用触发任务的接口,传入stream参数
aclrtMemcpyAsync(dstPtr, dstSize, srcPtr, srcSize, ACL_MEMCPY_HOST_TO_DEVICE, stream);
// 调用aclrtSynchronizeStream接口,阻塞应用程序运行,直到指定Stream中的所有任务都完成。
aclrtSynchronizeStream(stream);
// Stream使用结束后,显式销毁Stream
aclrtDestroyStream(stream);
aclrtDestroyStreamConfigHandle(handle);
aclrtDestroyContext(context);
// ......
单线程多Stream
调用接口后,需增加异常处理的分支,并记录报错日志、提示日志,此处不一一列举。以下是关键步骤的代码示例,不可以直接拷贝编译运行,仅供参考。
#include "acl/acl.h"
// ......
int32_t deviceId = 0 ;
uint32_t modelId1 = 0;
uint32_t modelId2 = 1;
aclrtContext context;
aclrtStream stream1;
aclrtStream stream2;
// 如果只创建了一个Context,线程默认将这个Context作为线程当前的Context;
// 如果是多个Context,则需要调用aclrtSetCurrentContext接口设置当前线程的Context
aclrtCreateContext(&context, deviceId);
// 创建stream1,此处创建Stream时以设置Stream优先级为例
uint32_t stmPriority = 1;
aclrtStreamConfigHandle *handle1 = aclrtCreateStreamConfigHandle();
aclrtSetStreamConfigOpt(handle1, ACL_RT_STREAM_PRIORITY, &stmPriority, sizeof(stmPriority));
aclrtCreateStreamV2(&stream1, handle1);
// 调用触发任务的接口,例如异步模型推理,任务下发在stream1
aclmdlDataset *input1;
aclmdlDataset *output1;
aclmdlExecuteAsync(modelId1, input1, output1, stream1);
// 创建stream2,此处创建Stream时以设置Stream优先级为例
uint32_t stmPriority = 2;
aclrtStreamConfigHandle *handle2 = aclrtCreateStreamConfigHandle();
aclrtSetStreamConfigOpt(handle2, ACL_RT_STREAM_PRIORITY, &stmPriority, sizeof(stmPriority));
aclrtCreateStreamV2(&stream2, handle2);
// 调用触发任务的接口,例如异步模型推理, 任务下发在stream2
aclmdlDataset *input2;
aclmdlDataset *output2;
aclmdlExecuteAsync(modelId2, input2, output2, stream2);
// 流同步
aclrtSynchronizeStream(stream1);
aclrtSynchronizeStream(stream2);
// 释放资源
aclrtDestroyStream(stream1);
aclrtDestroyStreamConfigHandle(handle1);
aclrtDestroyStream(stream2);
aclrtDestroyStreamConfigHandle(handle2);
aclrtDestroyContext(context);
// ....
多线程多Stream
调用接口后,需增加异常处理的分支,并记录报错日志、提示日志,此处不一一列举。以下是关键步骤的代码示例,不可以直接拷贝编译运行,仅供参考。
#include "acl/acl.h"
// ......
void runThread() {
int32_t deviceId =0;
aclrtContext context;
// 如果只创建了一个Context,线程默认将这个Context作为线程当前的Context;
// 如果是多个Context,则需要调用aclrtSetCurrentContext接口设置当前线程的Context
aclrtCreateContext(&context, deviceId);
// 显式创建一个Stream,此处创建Stream时以设置Stream优先级为例
aclrtStream stream;
uint32_t stmPriority = 1;
aclrtStreamConfigHandle *handle = aclrtCreateStreamConfigHandle();
aclrtSetStreamConfigOpt(handle, ACL_RT_STREAM_PRIORITY, &stmPriority, sizeof(stmPriority));
aclrtCreateStreamV2(&stream, handle);
// 调用触发任务的接口
// ....
// 释放资源
aclrtDestroyStream(stream);
aclrtDestroyStreamConfigHandle(handle1);
aclrtDestroyContext(context);
}
// 创建2个线程,每个线程内部创建一个Stream
std::thread t1(runThread);
std::thread t2(runThread);
// 显式调用join函数确保结束线程
t1.join();
t2.join();
同步等待¶
本节介绍Device、Stream、Event、Notify在异步场景下的使用示例及关键接口。
同步机制
同步机制包含以下几种:
调用aclrtSynchronizeStream接口,阻塞应用程序运行,直到指定Stream中的所有任务都完成。 |
Stream内任务的同步等待
调用接口后,需增加异常处理的分支,并记录报错日志、提示日志,此处不一一列举。以下是关键步骤的代码示例,不可以直接拷贝编译运行,仅供参考。
#include "acl/acl.h"
// ......
// 显式创建一个Stream,此处创建Stream时以设置Stream优先级为例
aclrtStream stream;
uint32_t stmPriority = 1;
aclrtStreamConfigHandle *handle = aclrtCreateStreamConfigHandle();
aclrtSetStreamConfigOpt(handle, ACL_RT_STREAM_PRIORITY, &stmPriority, sizeof(stmPriority));
aclrtCreateStreamV2(&stream, handle);
// 调用触发任务的接口,传入stream参数
aclrtMemcpyAsync(dstPtr, dstSize, srcPtr, srcSize, ACL_MEMCPY_HOST_TO_DEVICE, stream);
// 调用aclrtSynchronizeStream接口,阻塞应用程序运行,直到指定Stream中的所有任务都完成。
aclrtSynchronizeStream(stream);
// Stream使用结束后,显式销毁Stream
aclrtDestroyStream(stream);
aclrtDestroyStreamConfigHandle(handle);
// ......
模型管理¶
本节以模型推理为例介绍基于acl接口开发应用的流程。 推理场景下,对于开源框架的网络模型(如ONNX、TensorFlow等),不能直接在NPU IP加速器上做推理,需要先使用ATC(Ascend Tensor Compiler)工具将开源框架的网络模型转换为适配昇腾AI处理器的离线模型适配NPU IP加速器的离线模型(*.om文件)。
开发流程¶
本节以模型推理为例介绍基于acl接口开发应用的流程。
图 1 开发流程
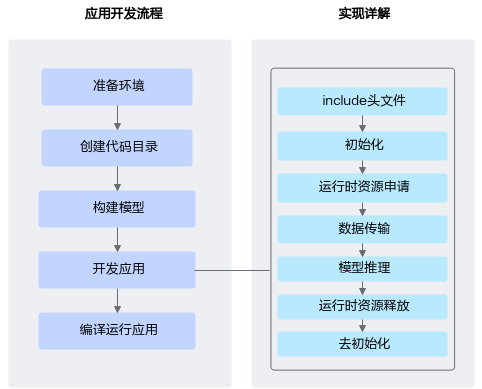
准备环境。
创建代码目录。
在开发应用前,您需要先创建目录,存放代码文件、编译脚本、测试图片数据、模型文件等。
如下仅是示例,供参考:
├App名称 ├── model // 该目录下存放模型文件 │ ├── xxxxxx ├── data │ ├── xxx.jpg // 测试数据 ├── inc // 该目录下存放声明函数的头文件 │ ├── xxx.h ├── out // 该目录下存放输出结果 ├── src │ ├── xxx.json // 系统初始化的配置文件 │ ├── CMakeLists.txt // 编译脚本 │ ├── xxx.cpp // 实现文件
构建模型。
模型推理场景下,必须要有适配昇腾AI处理器的离线模型适配NPU IP加速器的离线模型(*.om文件),请参见模型构建。
开发应用。
初始化,请参见初始化与去初始化。
使用acl接口开发应用时,必须先调用aclInit接口进行初始化,否则可能会导致后续系统内部资源初始化出错,进而导致其它业务异常。
运行时资源申请,请参见运行时资源申请与释放。
数据传输,请参见数据传输。
执行模型推理。请参见静态Shape输入模型推理。
若需要处理模型推理的结果,还需要进行数据后处理,例如对于图片分类应用,通过数据后处理从推理结果中查找最大置信度的类别标识。
模型推理结束后,需及时释放推理相关资源。
所有数据处理结束后,需及时释放运行时资源,请参见运行时资源申请与释放。
执行去初始化,请参见初始化与去初始化。
编译运行应用,包括编译代码、运行应用,请参见应用编译&运行。
模型构建¶
推理场景下,对于开源框架的网络模型(如ONNX、TensorFlow等),不能直接在NPU IP加速器上做推理,需要先使用ATC(Ascend Tensor Compiler)工具将开源框架的网络模型转换为适配昇腾AI处理器的离线模型适配NPU IP加速器的离线模型(*.om文件)。
此处以ONNX框架的ResNet-50网络为例,说明如何使用ATC工具进行模型转换,详细说明请参见《ATC离线模型编译工具用户指南》。
以运行用户登录开发环境。
执行模型转换。
执行以下命令,将原始模型转换为NPU IP加速器能识别的*.om模型文件。请注意,执行命令的用户需具有命令中相关路径的可读、可写权限。以下命令中的“<SAMPLE_DIR>”请根据实际样例包的存放目录替换、“<soc_version>”请根据实际NPU IP加速器版本替换。
cd <SAMPLE_DIR>/MyFirstApp_ONNX/model wget https://obs-9be7.obs.cn-east-2.myhuaweicloud.com/003_Atc_Models/resnet50/resnet50.onnx atc --model=resnet50.onnx --framework=5 --output=resnet50 --input_shape="actual_input_1:1,3,224,224" --soc_version=<soc_version>
各参数的解释如下,详细约束说明请参见《ATC离线模型编译工具用户指南》。
--model:ResNet-50网络的模型文件的路径。
--framework:原始框架类型。5表示ONNX。
--output:resnet50.om模型文件的路径。请注意,记录保存该om模型文件的路径,后续开发应用时需要使用。
--input_shape:模型输入数据的shape。
--soc_version:NPU IP加速器的版本。
(后续处理)如果想快速体验直接使用转换后的om离线模型文件进行推理,请准备好环境、om模型文件、符合模型输入要求的*.bin格式的输入数据,单击Link,获取msame工具,参考该工具配套的README,进行体验。
如果模型转换时,提示有算子编译相关问题,但根据报错信息无法定位问题、需要联系技术支持时,则需设置DUMP_GE_GRAPH、DUMP_GRAPH_LEVEL环境变量,再重新转换模型,收集模型转换过程中各个阶段的图描述信息。关于环境变量以及图描述信息的说明,请参见《ATC离线模型编译工具用户指南》中的“参考 > dump图详细信息”。
如果现有网络不满足您的需求,您可以使用NPU IP加速器支持的算子、调用Ascend Graph接口自行构建自己的网络,再编译成om离线模型文件。详细说明请参见《Ascend Graph开发指南》。
静态Shape输入模型推理¶
本节介绍如何加载模型,为模型执行做准备。 本节结合接口调用流程、示例代码介绍模型执行前需要准备哪些数据、模型执行接口以及模型执行之后需要释放哪些资源。 模型执行结束后,需及时卸载模型,释放模型资源。
模型加载¶
本节介绍如何加载模型,为模型执行做准备。
接口调用流程
开发应用时,如果涉及整网模型推理,则应用程序中必须包含模型加载的代码逻辑,关于模型加载的接口调用流程,请先参见接口调用流程了解整体流程,再查看本节中的流程说明。
AscendCL提供两套模型加载的接口,用户可根据编程习惯、使用场景选择对应的模型加载接口:
如图1所示,针对不同的加载方式(从文件加载、从内存加载等),只需设置接口中的配置参数,适用各种加载方式,但涉及多个接口配合使用,分别用于创建配置对象、设置对象中的属性值、加载模型。
图 1 模型加载流程(通过接口中的配置参数区分加载方式)

关键接口的说明如下:
在模型加载前,需要先构建出适配昇腾AI处理器的离线模型适配NPU IP加速器的离线模型(*.om文件),构建方式请参见模型构建。
当由用户管理内存时,为确保内存不浪费,在申请工作内存、权值内存前,需要调用aclmdlQuerySize接口查询模型运行时所需工作内存、权值内存的大小。
如果模型输入数据的Shape不确定,则不能调用aclmdlQuerySize接口查询内存大小,在加载模型时,就无法由用户管理内存,因此需选择由系统管理内存的模型加载接口。
若在构建模型时,调用Ascend Graph接口自行构建自己的网络,且没有生成om离线模型文件、只是将模型数据存放在内存中,则无法通过aclmdlQuerySize接口查询内存大小。关于Ascend Graph接口的详细说明请参见《Ascend Graph开发指南》。
支持以下方式加载模型,模型加载成功后,返回标识模型的模型ID:
使用aclmdlSetConfigOpt接口、aclmdlLoadWithConfig接口时,是通过配置对象中的属性来区分,在加载模型时是从文件加载,还是从内存加载,以及内存是由系统内部管理,还是由用户管理。
示例代码
模型加载成功,会返回标识模型的ID,在模型执行时需要使用该ID。
此处以从文件加载模型、由用户自行管理内存为例。
调用接口后,需增加异常处理的分支,并记录报错日志、提示日志,此处不一一列举。以下是关键步骤的代码示例,不可以直接拷贝编译运行,仅供参考。
// 1.初始化变量。
// 此处的..表示相对路径,相对可执行文件所在的目录
// 例如,编译出来的可执行文件存放在out目录下,此处的..就表示out目录的上一级目录
const char* omModelPath = "../model/resnet50.om";
// ......
// 2.根据模型文件获取模型执行时所需的权值内存大小、工作内存大小。
aclError ret = aclmdlQuerySize(omModelPath, &modelMemSize_, &modelWeightSize_);
// 3.根据工作内存大小,申请Device上模型执行的工作内存。
ret = aclrtMalloc(&modelMemPtr_, modelMemSize_, ACL_MEM_MALLOC_HUGE_FIRST);
// 4.根据权值内存的大小,申请Device上模型执行的权值内存。
ret = aclrtMalloc(&modelWeightPtr_, modelWeightSize_, ACL_MEM_MALLOC_HUGE_FIRST);
// 5.加载离线模型文件,由用户自行管理模型运行的内存(包括权值内存、工作内存)。
// 模型加载成功,返回标识模型的ID。
ret = aclmdlLoadFromFileWithMem(omModelPath, &modelId_, modelMemPtr_, modelMemSize_, modelWeightPtr_, modelWeightSize_);
// ......
模型执行¶
本节结合接口调用流程、示例代码介绍模型执行前需要准备哪些数据、模型执行接口以及模型执行之后需要释放哪些资源。
基本原理
开发应用时,如果涉及整网模型推理,则应用程序中必须包含模型执行的代码逻辑,关于模型执行的接口调用流程,请先参见接口调用流程了解整体流程,再查看本节中的流程说明。
在模型加载之后,模型执行之前,需要准备输入、输出数据结构,将输入数据传输到模型输入数据结构的对应内存中。
模型执行结束后,若无需使用输入数据、aclmdlDesc类型、aclmdlDataset类型、aclDataBuffer类型等相关资源,需及时释放内存、销毁对应的数据类型,防止内存异常。模型可能存在多个输入、多个输出,每个输入/输出的内存地址、内存大小用aclDataBuffer类型的数据来描述,针对每个输入/输出,需调用aclrtFree接口释放内存中的数据,再调用aclDestroyDataBuffer接口销毁相应的aclDataBuffer类型。
模型执行流程
图 1 基本的模型推理流程
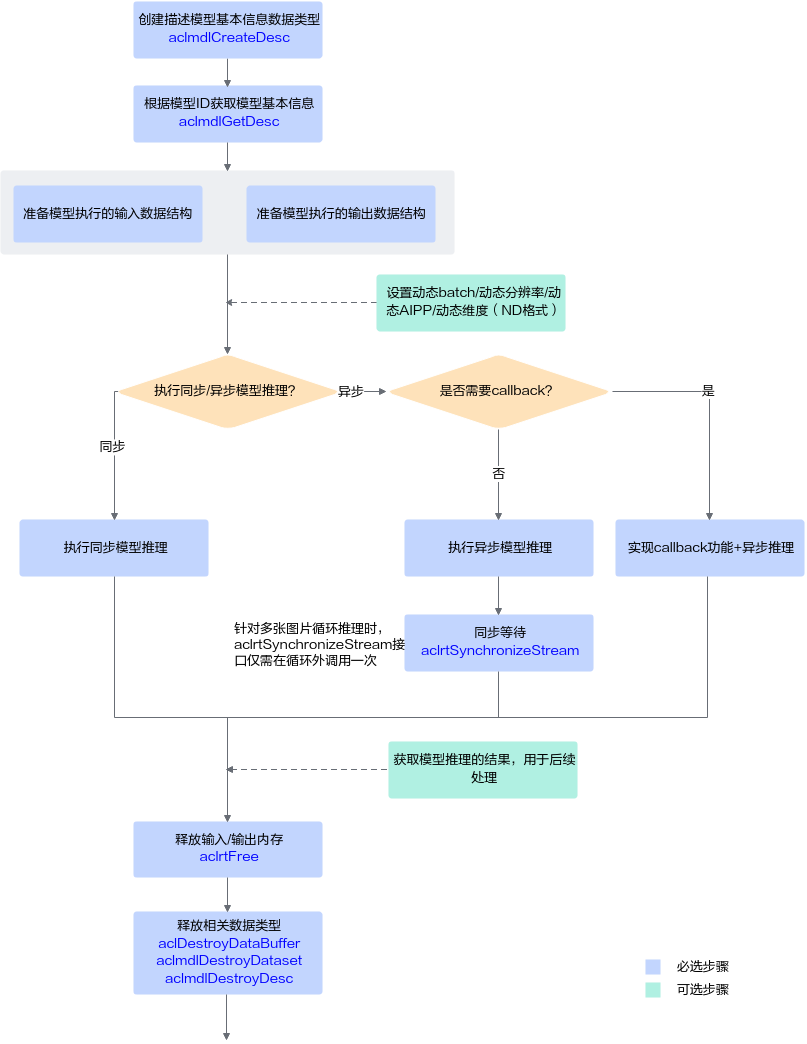
关键接口的说明如下:
调用aclmdlCreateDesc接口创建描述模型基本信息的数据类型。
调用aclmdlGetDesc接口根据模型加载中返回的模型ID获取模型基本信息。
准备模型执行的输入、输出数据结构,具体流程,请参见准备模型执行的输入/输出数据结构。
执行模型推理。
对于固定的多Batch场景,需要满足batch size后,才能将输入数据发送给模型进行推理。不满足batch size时,用户需根据自己的实际场景处理。
当前系统支持模型的同步推理和异步推理:
同步推理
调用aclmdlExecuteV2接口执行同步推理。
异步推理
调用aclmdlExecuteAsyncV2接口执行异步推理。
但对于异步接口,还需调用aclrtSynchronizeStream接口阻塞应用程序运行,直到指定Stream中的所有任务都完成。
获取模型推理的结果,用于后续处理。
对于同步推理,直接获取模型推理的输出数据即可。
对于异步推理,在实现Callback功能时,在回调函数内获取模型推理的结果,供后续使用。
释放内存。
调用aclrtFree接口释放Device上的内存。
释放相关数据类型的数据。
在模型推理结束后,需依次调用aclDestroyDataBuffer接口、aclmdlDestroyDataset接口及时释放描述模型输入、输出数据类型的数据。如果存在多个输入、输出,需调用多次aclDestroyDataBuffer接口。
准备模型执行的输入/输出数据结构
AscendCL提供了以下数据类型来描述模型、描述其输入输出以及存放数据的内存,在模型执行前,需要构造好这些数据类型,作为模型执行的输入:
使用aclmdlDesc类型的数据描述模型基本信息(例如输入/输出的个数、名称、数据类型、Format、维度信息等)。
模型加载成功后,用户可根据模型的ID,调用aclmdlGetDesc接口获取该模型的描述信息,进而从模型的描述信息中获取模型输入/输出的个数、内存大小、维度信息、Format、数据类型等信息,可参见aclmdlDesc类型下的操作接口。
使用aclmdlDataset类型的数据描述模型的输入/输出数据,模型可能存在多个输入、多个输出。
调用aclmdlDataset类型下的操作接口添加aclDataBuffer类型的数据、获取aclDataBuffer的个数等。
每个输入/输出的内存地址、内存大小用aclDataBuffer类型的数据来描述。
调用aclDataBuffer类型下的操作接口获取内存地址、内存大小等。
图 2 aclmdlDataset类型与aclDataBuffer类型的关系

了解相关的数据类型后,可以使用这些数据类型的操作接口准备模型的输入、输出数据结构,如下图所示。
图 3 模型执行的输入/输出数据结构的准备流程
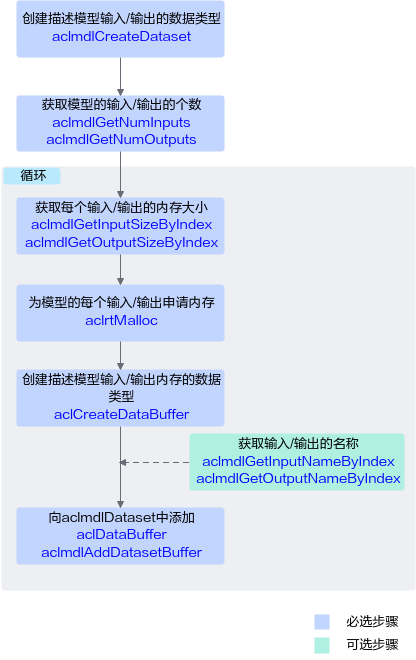
关键说明如下:
模型存在多个输入、输出时,用户可调用aclmdlGetNumInputs、aclmdlGetNumOutputs接口获取输入、输出的个数。
模型每个输入、输出所需的内存大小,用户可调用aclmdlGetInputSizeByIndex、aclmdlGetOutputSizeByIndex接口获取。
如果模型的输入涉及动态Batch、动态分辨率、动态维度(ND格式)等特性,输入tensor数据的Shape支持多种档位,在模型执行前才能确定,因此该输入所需的内存大小建议用户调用aclmdlGetInputSizeByIndex接口获取,该接口获取的是最大档位的内存,确保内存够用。
模型存在多个输入、输出时,用户在向aclmdlDataset中添加aclDataBuffer时,为避免顺序出错,可以先调用aclmdlGetInputNameByIndex、aclmdlGetOutputNameByIndex接口获取输入、输出的名称,根据输入、输出名称所对应的index的顺序添加。
示例代码
此处的示例代码是处理图片分类模型的输出结果,屏显每张图片的top5置信度的类别编号。用户可根据实际需求,自行实现模型推理输出数据的处理逻辑。
调用接口后,需增加异常处理的分支,并记录报错日志、提示日志,此处不一一列举。以下是关键步骤的代码示例,不可以直接拷贝编译运行,仅供参考。
// 1 根据模型的ID,获取该模型的描述信息。
// modelDesc_为aclmdlDesc类型。
modelDesc_ = aclmdlCreateDesc();
aclError ret = aclmdlGetDesc(modelDesc_, modelId_);
// 2 准备模型推理的输入数据结构
// (1)申请输入内存
size_t modelInputSize;
void *modelInputBuffer = nullptr;
// 当前示例代码中的模型只有一个输入,所以index为0,如果模型有多个输入,则需要先调用aclmdlGetNumInputs接口获取模型输入的数量
modelInputSize = aclmdlGetInputSizeByIndex(modelDesc_, 0);
ret = aclrtMalloc(&modelInputBuffer, modelInputSize, ACL_MEM_MALLOC_HUGE_FIRST);
// (2)准备模型的输入数据结构
// 创建aclmdlDataset类型的数据,描述模型推理的输入,input_为aclmdlDataset类型
input_ = aclmdlCreateDataset();
aclDataBuffer *inputData = aclCreateDataBuffer(modelInputBuffer, modelInputSize);
ret = aclmdlAddDatasetBuffer(input_, inputData);
// 3 准备模型推理的输出数据结构
// (1)创建aclmdlDataset类型的数据,描述模型推理的输出,output_为aclmdlDataset类型
output_ = aclmdlCreateDataset();
// (2)获取模型的输出个数.
size_t outputSize = aclmdlGetNumOutputs(modelDesc_);
// (3)循环为每个输出申请内存,并将每个输出添加到aclmdlDataset类型的数据中.
for (size_t i = 0; i < outputSize; ++i) {
size_t buffer_size = aclmdlGetOutputSizeByIndex(modelDesc_, i);
void *outputBuffer = nullptr;
ret = aclrtMalloc(&outputBuffer, buffer_size, ACL_MEM_MALLOC_HUGE_FIRST);
aclDataBuffer* outputData = aclCreateDataBuffer(outputBuffer, buffer_size);
ret = aclmdlAddDatasetBuffer(output_, outputData);
}
// 4 模型执行
string testFile[] = {
"../data/dog1_1024_683.bin",
"../data/dog2_1024_683.bin"
};
for (size_t index = 0; index < sizeof(testFile) / sizeof(testFile[0]); ++index) {
// 4.1 自定义函数ReadBinFile,调用C++标准库std::ifstream中的函数读取图片文件,输出图片文件占用的内存大小inputBuffSize以及图片文件存放在内存中的地址inputBuff
void *inputBuff = nullptr;
uint32_t inputBuffSize = 0;
auto ret1 = Utils::ReadBinFile(fileName, inputBuff, inputBuffSize);
// 4.2 准备模型推理的输入数据
// 在申请运行时资源时调用aclrtGetRunMode接口获取软件栈的运行模式
// 如果运行模式为ACL_DEVICE,则g_isDevice参数值为true,表示软件栈运行在Device侧,无需传输图片数据或在Device内传输数据 ;否则,需要调用内存复制接口将数据传输到Device
if (!g_isDevice) {
// if app is running in host, need copy data from host to device
// modelInputBuffer、modelInputSize分别表示模型推理输入数据的内存地址、内存大小,在输入/输出数据结构准备时申请该内存
ret = aclrtMemcpy(modelInputBuffer, modelInputSize, inputBuff, inputBuffSize, ACL_MEMCPY_HOST_TO_DEVICE);
(void)aclrtFreeHost(inputBuff);
} else { // app is running in device
ret = aclrtMemcpy(modelInputBuffer, modelInputSize, inputBuff, inputBuffSize, ACL_MEMCPY_DEVICE_TO_DEVICE);
(void)aclrtFree(inputBuff);
}
// 4.3 执行模型推理
// modelId_表示模型ID,在模型加载成功后,会返回标识模型的ID
// input_、output_分别表示模型推理的输入、输出数据,在准备模型推理的输入、输出数据结构时已定义
ret = aclmdlExecute(modelId_, input_, output_);
// 处理模型推理的输出数据,输出top5置信度的类别编号
// output_表示模型执行的输出
for (size_t i = 0; i < aclmdlGetDatasetNumBuffers(output_); ++i) {
// 获取每个输出的内存地址和内存大小
aclDataBuffer* dataBuffer = aclmdlGetDatasetBuffer(output_, i);
void* data = aclGetDataBufferAddr(dataBuffer);
size_t len = aclGetDataBufferSizeV2(dataBuffer);
// 将内存中的数据转换为float类型
float *outData = NULL;
outData = reinterpret_cast<float*>(data);
// 屏显每张图片的top5置信度的类别编号
map<float, int, greater<float> > resultMap;
for (int j = 0; j < len / sizeof(float); ++j) {
resultMap[*outData] = j;
outData++;
}
int cnt = 0;
for (auto it = resultMap.begin(); it != resultMap.end(); ++it) {
// print top 5
if (++cnt > 5) {
break;
}
INFO_LOG("top %d: index[%d] value[%lf]", cnt, it->second, it->first);
}
}
}
// 5 释放模型推理的输入、输出资源
// 释放输入资源,包括数据结构和内存
for (size_t i = 0; i < aclmdlGetDatasetNumBuffers(input_); ++i) {
aclDataBuffer *dataBuffer = aclmdlGetDatasetBuffer(input_, i);
(void)aclDestroyDataBuffer(dataBuffer);
}
(void)aclmdlDestroyDataset(input_);
input_ = nullptr;
aclrtFree(modelInputBuffer);
// 释放输出资源,包括数据结构和内存
for (size_t i = 0; i < aclmdlGetDatasetNumBuffers(output_); ++i) {
aclDataBuffer* dataBuffer = aclmdlGetDatasetBuffer(output_, i);
void* data = aclGetDataBufferAddr(dataBuffer);
(void)aclrtFree(data);
(void)aclDestroyDataBuffer(dataBuffer);
}
(void)aclmdlDestroyDataset(output_);
output_ = nullptr;
在构建模型时,若batchSize≥2(通过ATC工具的input_shape参数设置),在推理前,需要编写一段代码,实现逻辑为:等输入数据满足batchSize(例如:batchSize=8)的要求,申请Device上的内存存放batchSize=8的数据,作为模型推理的输入。如果最后循环遍历所有的输入数据后,仍不满足batchSize 的要求,则直接将剩余数据作为模型推理的输入。
此处的示例代码以batchSize=8为例:
uint32_t batchSize = 8;
uint32_t deviceNum = 1;
uint32_t deviceId = 0;
// 获取模型第一个输入的大小
uint32_t modelInputSize = aclmdlGetInputSizeByIndex(modelDesc, 0);
// 获取每个Batch输入数据的大小
uint32_t singleBuffSize = modelInputSize / batchSize;
// 定义该变量,用于累加batch size是否达到8 Batch
uint32_t cnt = 0;
// 定义该变量,用于描述每个文件读入内存时的位置偏移
uint32_t pos = 0;
void* p_batchDst = NULL;
std::vector<std::string>inferFile_vec;
for (int i = 0; i < files.size(); ++i)
{
// 每8个文件,申请一次Device上的内存,存放8 Batch的输入数据
if (cnt % batchSize == 0)
{
pos = 0;
inferFile_vec.clear();
// 申请Device上的内存
aclrtMalloc(&p_batchDst, modelInputSize, ACL_MEM_MALLOC_HUGE_FIRST);
}
// TODO: 从某个目录下读入文件,计算文件大小fileSize
// 根据文件大小,申请内存,存放文件数据
aclrtMallocHost(&p_imgBuf, fileSize);
// 将数据传输到Device的内存
aclrtMemcpy((uint8_t *)p_batchDst + pos, fileSize, p_imgBuf, fileSize, ACL_MEMCPY_HOST_TO_DEVICE);
pos += fileSize;
// 及时释放不使用的内存
aclrtFreeHost(p_imgBuf);
// 将第i个文件存入vector中,同时cnt+1
inferFile_vec.push_back(files[i]);
cnt++;
// 每8 Batch的输入数据送给模型进行推理
if (cnt % batchSize == 0)
{
// TODO: 创建aclmdlDataset、aclDataBuffer类型的数据,用于描述模型的输入、输出数据
// TODO: 调用aclmdlExecute接口执行模型推理
// TODO: 推理结束后,调用aclrtFree接口释放Device上的内存
}
}
// 如果最后循环遍历所有的输入数据后,仍不满足多Batch的要求,则直接将剩余数据作为模型推理的输入。
if (cnt % batchSize != 0)
{
// TODO: 创建aclmdlDataset、aclDataBuffer类型的数据,用于描述模型的输入、输出数据
// TODO: 调用aclmdlExecute接口执行模型推理
// TODO: 推理结束后,调用aclrtFree接口释放Device上的内存
}
模型卸载¶
模型执行结束后,需及时卸载模型,释放模型资源。
关于模型卸载的接口调用流程,请先参见接口调用流程了解整体流程,再查看本节中的流程说明。
基本原理
在模型推理结束后,还需要通过aclmdlUnload接口卸载模型,并销毁aclmdlDesc类型的模型描述信息、释放模型运行的工作内存和权值内存。
示例代码
// 1. 卸载模型
aclError ret = aclmdlUnload(modelId_);
// 2. 释放模型描述信息
if (modelDesc_ != nullptr) {
(void)aclmdlDestroyDesc(modelDesc_);
modelDesc_ = nullptr;
}
// 3. 释放模型运行的工作内存
if (modelWorkPtr_ != nullptr) {
(void)aclrtFree(modelWorkPtr_);
modelWorkPtr_ = nullptr;
modelWorkSize_ = 0;
}
// 4. 释放模型运行的权值内存
if (modelWeightPtr_ != nullptr) {
(void)aclrtFree(modelWeightPtr_);
modelWeightPtr_ = nullptr;
modelWeightSize_ = 0;
}
多模型串联推理¶
多模型推理的基本流程与单模型类似,请参见静态Shape输入模型推理。
多模型推理与单模型推理在acl接口使用上的不同点如下:
关于模型加载,如果涉及多个模型,需调用多次模型加载接口。模型加载请参见模型加载。
关于模型执行,如果涉及多个模型,需调用多次模型执行接口。模型执行请参见模型执行。
例如,调用aclmdlExecuteV2接口实现同步模型推理。
更多特性¶
用户通过内存管理接口申请内存后,若需二次分配管理,需关注各内存接口的约束,防止出现内存越界。
内存二次分配管理¶
用户通过内存管理接口申请内存后,若需二次分配管理,需关注各内存接口的约束,防止出现内存越界。
用户内存管理有两种管理方式:
独立内存管理,根据需要单独申请所需的内存,内存不做拆分或者二次分配。
内存池管理内存,用户一次性申请一块较大内存,并在使用时从这块较大内存中二次分配所需内存。
在内存二次分配时,使用如下接口从内存池申请对应内存,由于接口对申请的内存地址、大小有约束,在内存池管理时,需要关注,否则容易出现内存越界。
内存管理的总体说明请参见总体说明。
接口 |
用途 |
输入内存/输出内存 |
|---|---|---|
aclrtMalloc |
在Device上分配size大小的线性内存,并通过*devPtr返回已分配内存的指针。本接口分配的内存会进行字节对齐,会对用户申请的size向上对齐成32字节整数倍后再多加32字节。 |
|
溢出算子数据采集及分析¶
前提条件
使用ATC工具转换模型时,需在转换命令中增加--status_check参数,并将参数值设置为1,表示在编译算子时添加溢出检测逻辑。
关于ATC工具及其参数的详细说明,请参见《ATC离线模型编译工具用户指南》。
采集溢出算子信息
在调用aclInit接口初始化时,在json配置文件中增加溢出算子Dump配置。
json配置文件中的示例内容如下,示例中的dump_path以相对路径为例:
{
"dump":{
"dump_path":"output",
"dump_debug":"on"
}
}
当dump_path配置为相对路径时,您可以在“应用可执行文件的目录/{dump_path}”下查看导出的数据文件,针对每个溢出算子,会导出两个数据文件:
溢出算子的dump文件(文件名以{op_type}开头),您可以解析该文件后获取具体出现溢出错误的算子。
算子溢出数据文件(文件名以Opdebug开头),您可以解析该文件后获取溢出相关信息,包括溢出算子所在的模型、AICore的status寄存器状态等。
以上两类文件的解析请参见《精度调试工具用户指南》中的“扩展功能 > 溢出算子数据采集与解析”章节。
应用编译&运行¶
完成程序代码编写后,可按照本节中的指导编译程序、执行应用。
问题定位
运行应用时如果出错,您可以获取日志文件,以便查看日志文件中详细报错。根据报错初步定位后:
如果是接口约束导致接口调用逻辑不对,需查看总体的使用约束以及各接口本身的约束,再调整接口调用逻辑。
精度/性能优化¶
调优简介¶
本章重点介绍推理应用的精度、性能调优,由于是调优,因此在调优前,请确保已经完成了整网推理功能调测,功能不阻塞,只是推理精度错误、推理精度与标杆数据存在少量差距、模型推理性能不符合预期或待提升等问题。
应用的精度问题可能由于推理功能与其它功能之间的串接问题、整网中算子本身的精度问题等,可参考本章中的建议排查功能串接时的接口参数配置问题、借助工具获取详细数据定位分析问题。
应用的性能问题可能由于模型在NPU IP加速器上的算子适配或数据读写问题、DVPP接口使用问题等,可参考本章中的建议排查接口使用问题、借助工具优化模型、借助工具获取详细数据定位分析问题。
模型推理精度提升建议¶
精度提升简介¶
本文介绍整网推理场景下的精度调优流程、相关配置及典型案例等。由于是调优,因此在调优前,请确保已经完成了整网推理功能调测,功能不阻塞,只是推理精度错误,或推理精度与标杆数据存在少量差距。
在整网推理时,可能由于以下原因导致推理精度错误或者推理精度不达标:
整网中算子本身的精度问题,该类问题可以借助精度比对工具,根据下文中具体的问题定位流程获取各类数据后,再进行比对、分析,确认是配置问题,还是算子实现问题,再逐一解决问题。本文中会结合具体的比对、分析的案例,介绍如何比对、分析。
图 1 推理精度问题
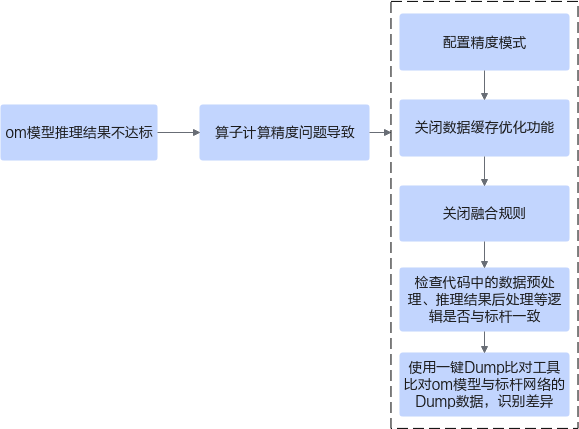
算子精度导致推理结果不达标¶
问题描述¶
推理结果不达标,包括以下两种情况:
算子精度导致推理结果错误,是指整网推理的功能已调通,但推理结果错误,例如目标检测网络MAP结果全0、om模型的推理结果与标杆网络的推理结果比对时余弦相似度为0。
算子精度导致推理精度不达标,是指整网推理的功能已调通,单次om模型的推理结果与标杆网络的推理结果比对时余弦相似度在95%以上,但数据集推理精度与标杆数据存在少量差距,例如:
分类网络om模型,Top1/Top5分别为:0.90/0.70,;标杆网络Top1/Top5分别为:0.92/0.71。
检测网络om模型MAP精度:0.54;标杆网络MAP精度:0.55。
问题定位流程¶
图 1 定位流程
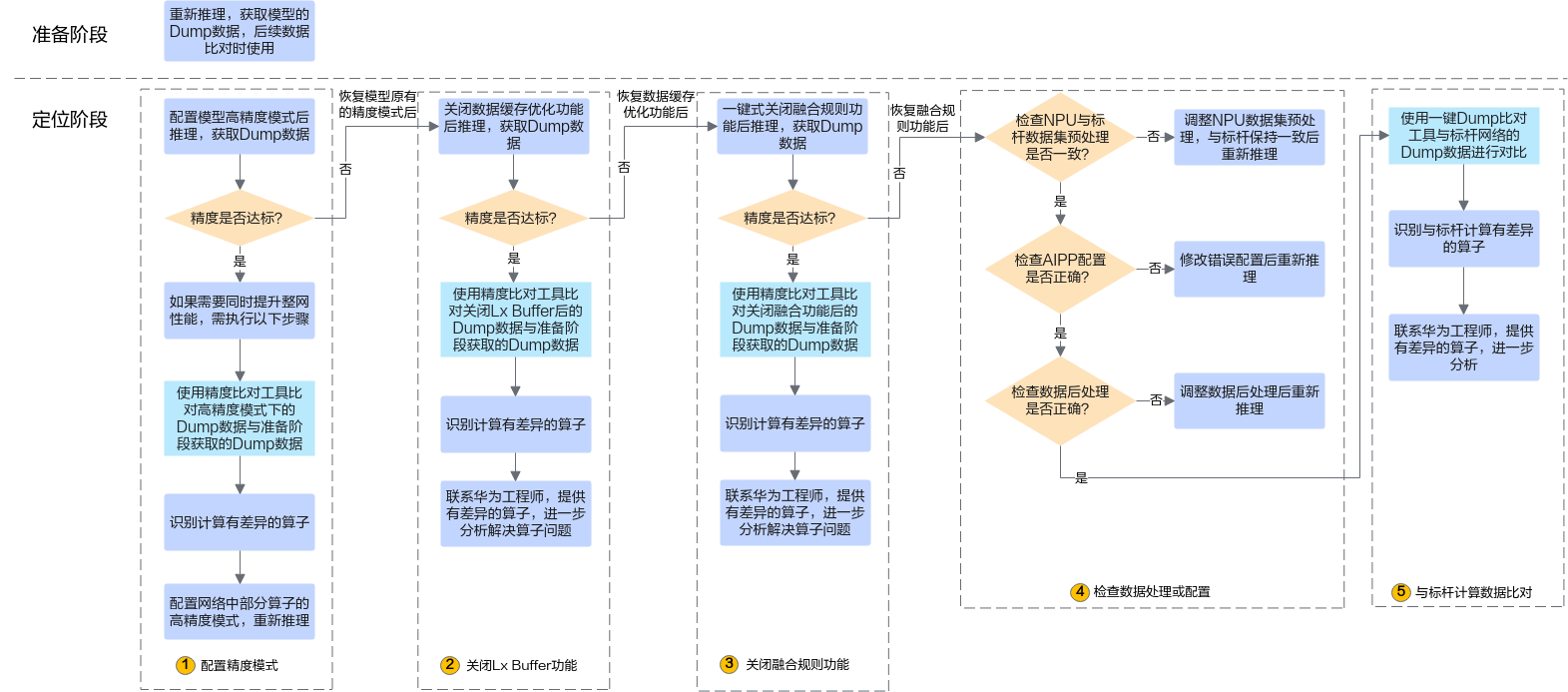
推理结果错误,为了后续定位问题,需要重新执行推理,用于获取模型的Dump数据。
获取模型的Dump数据,需要调用acl接口打开Dump开关,详细描述请参见《精度调试工具用户指南》。
配置精度模式。
配置模型高精度模式后推理,获取模型的Dump数据。推理后,如果精度达标,则进行步骤2.b;如果精度不达标,则进行步骤3。
配置模型高精度模式后推理,可能会影响推理性能,如果在精度达标的同时,需要保持性能,则执行2.b~2.d,配置部分算子保持原始网络中的数据类型。
配置模型高精度模式,请参见配置网络模型的高精度模式。
使用精度比对工具比对高精度模式下的Dump数据与1获取的Dump数据。
工具的使用请参见《精度调试工具用户指南》。
根据2.b中的比对结果识别计算有差异的算子。
一般来说,每次识别一个差异算子(首个余弦相似度较低的算子,例如低于0.95),找到差异算子后,执行2.d推理,推理的同时获取Dump数据,用来与高精度模式下的Dump数据比对,继续找到下一个差异算子。
需要循环执行该步骤,直至没有差异算子。
对于有差异的算子,配置该部分算子保持原始网络中的数据类型,再重新推理。
配置部分算子的高精度模式,请参见配置部分算子保持原始网络中的数据类型。
关闭数据缓存优化功能。
恢复模型的原有精度模式后,关闭数据缓存优化功能后推理,如果精度达标,则进行步骤3.b;如果精度不达标,则进行步骤4。
当前默认开启数据缓存优化,开启数据缓存优化可提高计算效率、提升性能,但由于部分算子在实现上可能存在未考虑的场景,导致影响精度,因此在出现精度问题时可以尝试关闭数据缓存优化。如果关闭数据缓存优化功能后,精度达标,则还是需要识别出问题算子,再联系技术支持进一步分析、解决算子问题,解决算子问题后,建议保持开启数据缓存优化。
关闭数据缓存优化功能,请参见关闭数据缓存优化。
使用精度比对工具比对关闭数据缓存优化功能后的Dump数据与1获取的Dump数据。
工具的使用请参见《精度调试工具用户指南》。
根据3.b中的比对结果识别计算有差异的算子。
联系技术支持,提供有差异的算子,进一步分析。
关闭融合规则功能。
恢复启用数据缓存优化功能,关闭融合规则功能后推理,如果精度达标,则进行步骤4.b;如果精度不达标,则进行步骤5。
当前默认开启融合规则,开启融合规则可提高计算效率、提升性能,但算子之间可能会融合,融合后的部分算子在实现上可能存在未考虑的场景,导致影响精度,因此在出现精度问题时可以尝试关闭融合规则。如果关闭融合规则功能后,精度达标,则还是需要识别出问题算子,反馈给技术支持进一步分析、解决算子问题,解决算子问题后,建议保持开启融合规则功能。
关闭融合规则功能,请参见关闭融合规则。关闭某些融合规则可能会导致功能问题,因此在配置关闭融合规则后,系统在不影响功能的前提下关闭部分融合规则,而不是全部融合规则。
使用精度比对工具比对关闭融合规则后的Dump数据与1获取的Dump数据。
工具的使用请参见《精度调试工具用户指南》。
根据4.b中的比对结果识别计算有差异的算子。
联系技术支持,提供有差异的算子,进一步分析。
检查数据处理或配置。
推理精度不达标可能是由于数据集、AIPP、后处理方式的差异导致,需逐步进行排查,恢复启用融合规则功能后,请检查数据处理或配置,参见检查数据处理或配置。
如果数据处理逻辑或数据配置有问题,则需修改后重新推理;如果数据处理逻辑或数据配置没有问题,则进行6。
与标杆计算数据比对。
使用精度比对工具将模型的Dump数据与标杆网络的Dump数据进行对比。
工具的使用请参见《精度调试工具用户指南》
根据6.a中的比对结果识别计算有差异的算子。
联系技术支持,提供有差异的算子,进一步分析。
配置精度模式¶
如果在模式转换时不指定网络模型或算子的精度模式,默认采用fp16(float16)数据类型进行计算。
配置模型高精度模式后推理,可提升精度,但可能会影响推理性能,如果在精度达标的同时,需要保持性能,则可以配置部分算子保持原始网络中的数据类型。
配置网络模型的高精度模式
使用ATC工具转换模型时,增加高级参数--precision_mode,用于指定精度模式。
参数设置如下所示,表示如果网络模型中算子支持fp32(float32),则使用fp32;如果网络模型中算子不支持fp32,则使用fp16(float16)。
--precision_mode=allow_fp32_to_fp16关于该参数的详细说明请参见《ATC离线模型编译工具用户指南》中的“参数说明 > 高级功能参数 > 算子调优选项 > --precision_mode”。
使用转换后的om模型重新推理。
配置部分算子保持原始网络中的数据类型
使用ATC工具转换模型时,增加高级参数--keep_dtype(指定部分算子计算时保持原始网络的数据类型)和--precision_mode(指定网络模型的精度模式)。
参数使用示例如下:
--keep_dtype=$HOME/exceptionlist.cfg --precision_mode=force_fp16配置文件名举例为_exceptionlist.cfg_,配置文件样例如下,文件中每一行是一个算子的名称,将配置好的_exceptionlist.cfg_文件上传到ATC工具所在服务器任意目录:
Opname1 Opname2 …
关于该参数的详细说明请参见《ATC离线模型编译工具用户指南》中的“参数说明 > 高级功能参数 > 算子调优选项 > --keep_dtype”。
使用转换后的om模型重新推理。
关闭数据缓存优化¶
如果在模型转换时不指定关闭数据缓存优化功能,当前默认开启数据缓存优化,开启数据缓存优化可提高计算效率、提升性能,但由于部分算子在实现上可能存在未考虑的场景,导致影响精度,因此在出现精度问题时可以尝试关闭数据缓存优化。
如果关闭数据缓存优化功能后,精度达标,则还是需要识别出问题算子,反馈给技术支持进一步分析、解决算子问题,解决算子问题后,建议保持开启数据缓存优化。
使用ATC工具转换模型时,增加高级参数:--buffer_optimize,用于关闭数据缓存优化。
参数设置如下所示,:
--buffer_optimize=off_optimize关于该参数的详细说明请参见《ATC离线模型编译工具用户指南》中的“参数说明 > 高级功能参数 > 模型调优选项 > --buffer_optimize”。
使用转换后的om模型重新推理。
关闭融合规则¶
如果在模型转换时不指定关闭融合规则,当前默认开启融合规则,开启融合规则可提高计算效率、提升性能,但算子之间可能会融合,融合后的部分算子在实现上可能存在未考虑的场景,导致影响精度,因此在出现精度问题时可以尝试关闭融合规则。
如果关闭融合规则功能后,精度达标,则还是需要识别出问题算子,反馈给技术支持进一步分析、解决算子问题,解决算子问题后,建议保持开启融合规则功能。
使用ATC工具转换模型时,增加高级参数:--fusion_switch_file
参数使用示例如下:
--fusion_switch_file=$HOME/module/fusion_switch.cfg配置文件名举例为_fusion_switch.cfg_,配置文件样例如下,将配置好的_fusion_switch.cfg_文件上传到ATC工具所在服务器任意目录:
{ "Switch":{ "GraphFusion":{ "ALL":"off" }, "UBFusion":{ "ALL":"off" } } }
关于该参数的详细说明请参见《ATC离线模型编译工具用户指南》中的“参数说明 > 高级功能参数 > 模型调优选项 > --fusion_switch_file”。
使用转换后的om模型重新推理。
检查数据处理或配置¶
检查om模型与标杆网络推理的输入数据以及输入数据的处理是否一致,如果不一致,需调整成一致。
检查AIPP配置。
AIPP(Artificial Intelligence Pre-Processing),用于在AI Core上完成图像预处理,包括改变图像尺寸、色域转换(转换图像格式)、减均值/乘系数(改变图像像素),数据处理之后再进行真正的模型推理。
如果AIPP配置错误可能导致模型推理的输入数据不准确,需要参见《ATC离线模型编译工具用户指南》中的“高级功能 > AIPP使能”章节检查AIPP配置,如有不正确的AIPP配置,修改正确后,重新转换模型,再重新推理。
检查om模型与标杆网络推理结果的后处理方式是否一致,如果不一致,需调整成一致。
案例介绍¶
案例描述
FastRCNN网络,模型转换时,保持默认高性能模式、force_fp16精度模式,推理出来的精度错误,MAP结果为0。
然后,在模型转换时,设置模型的高精度模式(precision_mode=allow_fp32_to_fp16),推理出来的精度正确。
案例分析
模型转换时保持默认高性能模式、force_fp16精度模式,进行推理,获取该模式下的Dump数据文件。
再次模型转换,设置模型的高精度模式(precision_mode=allow_fp32_to_fp16),再次进行推理,获取该模式下的Dump数据文件。
-
比对结果示例如下:

从图中可以看CosineSimilarity这一列,余弦相似度算法比对出来的结果,范围是[-1,1],比对的结果如果越接近1,表示两者的值越相近,越接近-1意味着两者的值越相反。对于大部分算子,值低于0.95就说明存在精度问题。
上图中AddN算子第0个输出的余弦相似度只有0.72,说明这个算子可能存在精度问题,因此需要进一步分析该算子在高精度模式下的第0个输出的Dump数据文件(2中获取的Dump数据文件)。
由于Dump数据文件无法通过文本工具直接查阅,因此在分析该Dump数据文件前,请参考《精度调试工具用户指南》的“扩展功能 > 查看dump数据文件”章节,先将dump数据文件转换为numpy格式,再将numpy格式文件转换为txt格式文件。
在将numpy格式文件为txt格式文件的过程中,可以获取AddN算子第0个输出的最大值、最小值,命令示例如下(******.npy**表示numpy格式文件的路径):
$ python3 Python 3 (default, Mar 5 2020, 16:07:54)[GCC 5.4.0 20160609] on linuxType .... >>> import numpy as np >>> a = np.load("****.npy") >>> a.max() >>> 109508.0 >>> a.min() >>> 70683.0
从5获取到的AddN算子第0个输出的最大值、最小值,可以看出高精度模式下AddN算子输出tensor的最大值为109508.0,而高性能模式(fp16)下,输出tensor的最大值为65504.0(FP16能表达的最大值域范围为(-65505~65504)),由此可以得出高精度模式下AddN算子的输出值大于fp16类型域表达范围,因此需要配置该算子走高精度模式,参见配置部分算子保持原始网络中的数据类型。
acl API参考¶
本节介绍接口分类以及调用接口时依赖的头文件和库文件。
废弃接口/返回码列表¶
接口
aclGetDataBufferSize接口
此接口后续版本会废弃,请使用aclGetDataBufferSizeV2接口。
返回码
ACL_ERROR_NONE返回码
此返回码后续版本会废弃,请使用ACL_SUCCESS返回码。
ACL_ERROR_NOT_STATIC_AIPP
此返回码后续版本会废弃,请使用ACL_ERROR_GE_AIPP_NOT_EXIST返回码。
ACL_ERROR_STREAM_NOT_SUBSCRIBE
此返回码后续版本会废弃,请使用ACL_ERROR_RT_STREAM_NO_CB_REG返回码。
ACL_ERROR_THREAD_NOT_SUBSCRIBE
此返回码后续版本会废弃,请使用ACL_ERROR_RT_THREAD_SUBSCRIBE返回码。
ACL_ERROR_WAIT_CALLBACK_TIMEOUT
此返回码后续版本会废弃,请使用ACL_ERROR_RT_REPORT_TIMEOUT返回码。
ACL_ERROR_INVALID_DEVICE
此返回码后续版本会废弃,请使用ACL_ERROR_RT_INVALID_DEVICEID返回码。
ACL_ERROR_GROUP_NOT_SET
此返回码后续版本会废弃,请使用ACL_ERROR_RT_GROUP_NOT_SET返回码。
ACL_ERROR_GROUP_NOT_CREATE
此返回码后续版本会废弃,请使用ACL_ERROR_RT_GROUP_NOT_CREATE返回码。
同步&异步API说明¶
CANN支持以下几类显式同步,调用此类接口后,主机线程会阻塞直到相关的任务执行完成。
流同步:例如aclrtSynchronizeStream
阻塞当前主机线程直到指定的Stream中完成所有下发的任务。
对于异步接口,主机线程调用异步接口后仅代表下发任务,在任务未完成前,异步接口已向主机线程返回成功。用户需要调用上面的显式同步接口阻塞主机线程,等待任务完成,否则可能会导致训练或推理等业务异常、Device断链掉卡等未知情况。
头文件和库文件说明¶
本节介绍接口分类以及调用接口时依赖的头文件和库文件。
接口分类
接口名以acl作为前缀,命名风格为:acl+接口类别缩写+操作动词+对象,其中操作动词和对象均采用首字母大写。下文为了描述方便,将本文中的接口统称为acl接口。
表 1 接口类别列表
接口名前缀 |
描述 |
|---|---|
acl |
系统配置类接口 |
aclrt |
运行时资源管理类的接口 |
aclmdl |
模型推理类的接口 |
调用接口依赖的头文件和库文件说明
安装固件、驱动及CANN软件包后,编译、运行应用程序时才能引用到acl接口的头文件、库文件。
您需要根据实际使用的acl接口来include依赖的文件,各头文件的用途如下表所示。
acl接口的头文件在“${INSTALL_DIR}/include/”目录下,库文件在“${INSTALL_DIR}/lib64/”目录下。${INSTALL_DIR}请替换为CANN软件安装后文件存储路径。以root安装举例,安装后文件默认存储路径为:/usr/local/Ascend/latest。
表 2 头文件列表
定义接口的头文件 |
用途 |
对应的库文件 |
|---|---|---|
acl/acl_base.h |
用于定义基本的数据类型(例如aclDataBuffer、aclTensorDesc等)及其操作接口、枚举值(例如aclFormat)、日志管理接口等。 |
libascendcl.a |
acl/acl.h |
该头文件中已包含acl/acl_mdl.h、acl/acl_rt.h、acl/acl_op.h。包含acl.h文件后,可以引用初始化/去初始化、Device管理、Context管理、Stream管理、同步等待、内存管理、算力Group查询与设置、模型加载与执行、单算子执行(含部分接口)等接口。 |
libascendcl.a |
系统配置¶
aclInit¶
产品支持情况
产品 |
是否支持 |
|---|---|
IPV350 |
√ |
功能说明
初始化函数。
函数原型
aclError aclInit(const char *configPath)
参数说明
参数名 |
输入/输出 |
说明 |
|---|---|---|
configPath |
输入 |
配置文件所在路径(包含文件名)的指针。配置文件内容为json格式(json文件内的“{”的层级最多为10,“[”的层级最多为10)。 初始化时,可通过该配置文件开启或设置以下功能,如果以下的默认配置已满足需求,无需修改,可向aclInit接口中传入NULL,或者可将配置文件配置为空json串(即配置文件中只有{})。
说明:
建议不要同时配置dump信息和Profiling采集信息,否则dump操作会影响系统性能,导致Profiling采集的性能数据指标不准确。 |
返回值说明
返回0表示成功,返回其他值表示失败,请参见aclError。
约束说明
使用acl接口开发应用时,必须先调用aclInit接口,否则可能会导致后续系统内部资源初始化出错,进而导致其它业务异常。
一个进程内支持多次调用aclInit接口初始化,但要求aclInit接口与aclFinalize去初始化接口数量匹配,支持以下场景:
成对调用aclInit、aclFinalize接口,分别实现初始化、去初始化,在每对aclInit和aclFinalize中正常处理业务,同时每次aclInit接口中的json配置都能生效:
aclInit-->业务处理-->aclFinalize-->aclInit-->业务处理-->aclFinalize连续调用N次aclInit接口初始化,这时也需连续调用N次aclFinalize接口才能真正去初始化,且只有第一次aclInit接口中的json配置生效:
aclInit-->aclInit-->业务处理-->aclFinalize-->aclFinalize该场景下,若在aclInit接口前调用1次或多次aclFinalize接口,此时不会触发去初始化流程;若调用N次aclInit接口后,调用aclFinalize接口的次数大于N,则多余的aclFinalize接口也不会触发去初始化流程。
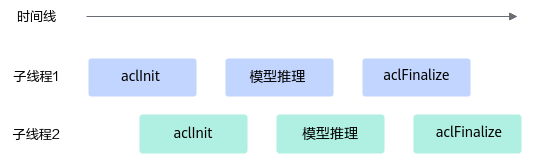
多线程场景推荐如下使用方式,否则可能导致业务异常:
主线程调用aclInit和aclFinalize、子线程调模型推理等业务处理,主线程等待子线程的业务处理结束再调用aclFinalize:
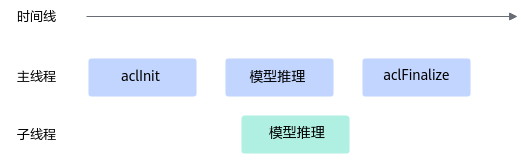
各子线程均成对调aclInit和aclFinalize:
模型推理(同步)场景下,若开启Dump功能,只支持在一个进程中对一个或多个模型执行Dump操作,由于资源限制,其它进程中不建议启动推理程序,否则可能造成Dump异常。
若对多个模型执行Dump操作,多个模型必须串行;
建议单线程内对模型执行Dump操作,否则可能出现Dump数据文件路径中的序号(即data_index)不准确,导致Dump数据存放的目录异常。
模型推理(异步)场景下,若开启Dump功能,建议一次异步推理、一次流同步,否则可能出现Dump数据文件路径中的序号(即data_index)不准确,导致Dump数据存放的目录异常。
模型Dump配置示例
模型Dump配置示例如下:
{
"dump":{
"dump_list":[
{ "model_name":"ResNet-101"
},
{
"model_name":"ResNet-50",
"layer":[
"conv1conv1_relu",
"res2a_branch2ares2a_branch2a_relu",
"res2a_branch1",
"pool1"
]
}
],
"dump_path":"/home/output",
"dump_mode":"output",
"dump_op_switch":"off",
"dump_data":"tensor"
}
}
表 1 acl.json文件格式说明
配置项 |
参数说明 |
|---|---|
dump_list |
(必选)待dump数据的整网模型列表。 创建模型dump配置信息,当存在多个模型需要dump时,需要每个模型之间用英文逗号隔开。 |
model_name |
模型名称,各个模型的model_name值须唯一。
|
layer |
IO性能相对较差时,可能会出现由于数据量过大导致执行超时,所以不建议全量dump,请指定算子进行dump。通过该字段可以指定需要dump的算子名,支持指定为ATC模型转换后的算子名,也支持指定为转换前的原始算子名,配置时需注意:
|
dump_path |
(必选)dump数据文件存储到运行环境的目录,该目录需要提前创建且确保安装时配置的运行用户具有读写权限。IPV350需要提前将编译生成的dbg文件放在该目录。 支持配置绝对路径或相对路径:
|
dump_mode |
dump数据模式。
|
dump_level |
dump数据级别,取值:
默认配置下,dump数据文件会比较多,例如有一些aclnn开头的dump文件,若用户对dump性能有要求或内存资源有限时,则可以将该参数设置为op级别,以便提升dump性能、精简dump数据文件数量。 说明:
算子是一个运算逻辑的表示(如加减乘除运算),kernel是运算逻辑真正进行计算处理的实现,需要分配具体的计算设备完成计算。 |
dump_step |
指定采集哪些迭代的Dump数据。推理场景无需配置。 不配置该参数,默认所有迭代都会产生dump数据,数据量比较大,建议按需指定迭代。 多个迭代用“|”分割,例如:0|5|10;也可以用“-”指定迭代范围,例如:0|3-5|10。 配置示例: {
"dump":{
"dump_list":[
......
],
"dump_path":"/home/output",
"dump_mode":"output",
"dump_op_switch":"off",
"dump_step": "0|3-5|10"
}
}
|
dump_data |
算子dump内容类型,取值:
通常dump数据量太大并且耗时长,可以先dump算子统计数据,根据统计数据识别可能异常的算子,然后再dump算子数据。 |
异常算子Dump配置示例
通过配置dump_scene参数值开启异常算子Dump功能,配置文件中的示例内容如下,表示开启轻量化的exception dump:
{
"dump":{
"dump_path":"output",
"dump_scene":"aic_err_brief_dump"
}
}
详细配置说明及约束如下:
dump_scene参数支持如下取值:
aic_err_brief_dump:表示轻量化exception dump,用于导出AI Core错误算子的输入&输出、workspace数据。
aic_err_norm_dump:表示普通exception dump,在轻量化exception dump基础上,还会导出Shape、Data Type、Format以及属性信息。
lite_exception:表示轻量化exception dump,为了兼容旧版本,效果等同于aic_err_brief_dump。
dump_path是可选参数,表示导出dump文件的存储路径。
dump文件存储路径的优先级如下:NPU_COLLECT_PATH环境变量 > ASCEND_WORK_PATH环境变量 > 配置文件中的dump_path > 应用程序的当前执行目录
环境变量的详细描述请参见《环境变量参考》。
将dump_scene参数设置为aic_err_detail_dump时,若需查看导出的dump文件内容,可使用msDebug工具查看文件内容,详细方法请参见《算子开发工具用户指南》。将dump_scene参数设置为其它参数值时,若需查看导出的dump文件内容,先将dump文件转换为numpy格式文件后,再通过Python查看numpy格式文件,详细转换步骤请参见《精度调试工具用户指南》中的“扩展功能 > 查看dump数据文件”章节。
异常算子Dump配置,不能与模型Dump配置或单算子Dump配置同时开启。
溢出算子Dump配置示例
将dump_debug参数设置为on表示开启溢出算子配置,配置文件中的示例内容如下:
{
"dump":{
"dump_path":"output",
"dump_debug":"on"
}
}
详细配置说明及约束如下:
不配置dump_debug或将dump_debug配置为off表示不开启溢出算子配置。
若开启溢出算子配置,则dump_path必须配置,表示导出dump文件的存储路径。
获取导出的数据文件后,文件的解析请参见《精度调试工具用户指南》中的“扩展功能 > 溢出算子数据采集与解析”章节。
dump_path支持配置绝对路径或相对路径:
绝对路径配置以“/“开头,例如:/home。
相对路径配置直接以目录名开始,例如:output。
溢出算子Dump配置,不能与模型Dump配置或单算子Dump配置同时开启,否则会返回报错。
仅支持采集AI Core算子的溢出数据。
算子Dump Watch模式配置示例
将dump_scene参数设置为watcher,开启算子Dump Watch模式,配置文件中的示例内容如下,配置效果为:(1)当执行完A算子、B算子时,会把C算子和D算子的输出Dump出来;(2)当执行完C算子、D算子时,也会把C算子和D算子的输出Dump出来。将(1)、(2)中的C算子、D算子的Dump文件进行比较,用于排查A算子、B算子是否会踩踏C算子、D算子的输出内存。
{
"dump":{
"dump_list":[
{
"layer":["A", "B"],
"watcher_nodes":["C", "D"]
}
],
"dump_path":"/home/",
"dump_mode":"output",
"dump_scene":"watcher"
}
}
详细配置说明及约束如下:
若开启算子Dump Watch模式,则不支持同时开启溢出算子Dump(配置dump_debug参数)或开启单算子模型Dump(配置dump_op_switch参数),否则报错。
在dump_list中,通过layer参数配置可能踩踏其它算子内存的算子名称,通过watcher_nodes参数配置可能被其它算子踩踏输出内存导致精度有问题的算子名称。
若不指定layer,则模型内所有支持Dump的算子在执行后,都会将watcher_nodes中配置的算子的输出Dump出来。
layer和watcher_node处配置的算子都必须是静态图、静态子图中的算子,否则不生效。
若layer和watcher_node处配置的算子名称相同,或者layer处配置的是集合通信类算子(算子类型以Hcom开头,例如HcomAllReduce),则只导出watcher_node中所配置算子的dump文件。
对于融合算子,watcher_node处配置的算子名称必须是融合后的算子名称,若配置融合前的算子名称,则不导出dump文件。
dump_list内暂不支持配置model_name。
开启算子Dump Watch模式,则dump_path必须配置,表示导出dump文件的存储路径。
此处收集的dump文件无法通过文本工具直接查看其内容,若需查看dump文件内容,先将dump文件转换为numpy格式文件后,再通过Python查看numpy格式文件,详细转换步骤请参见《精度调试工具用户指南》中的“扩展功能 > 查看dump数据文件”章节。
dump_path支持配置绝对路径或相对路径:
绝对路径配置以“/“开头,例如:/home。
相对路径配置直接以目录名开始,例如:output。
通过dump_mode参数控制导出watcher_nodes中所配置算子的哪部分数据,当前仅支持配置为output。
错误信息上报模式配置示例
err_msg_mode参数取值范围:0为默认值,表示按线程级别获取错误信息;1表示按进程级别获取错误信息。
配置文件中的示例内容如下:
{
"err_msg_mode": "1"
}
参考资源
接口调用示例,参见初始化与去初始化。
aclFinalize¶
产品支持情况
产品 |
是否支持 |
|---|---|
IPV350 |
√ |
功能说明
去初始化函数,用于释放进程内acl接口使用的相关资源。
函数原型
aclError aclFinalize()
参数说明
无
返回值说明
返回0表示成功,返回其他值表示失败,请参见aclError。
约束说明
应用进程退出前,应确保已调用aclFinalize接口完成去初始化,否则可能会导致异常,例如应用进程退出时有异常报错。
不建议在析构函数中调用aclFinalize接口,否则在进程退出时可能由于单例析构顺序未知而导致进程异常退出的问题。
参考资源
接口调用示例,参见初始化与去初始化。
aclrtGetVersion¶
产品支持情况
产品 |
是否支持 |
|---|---|
IPV350 |
√ |
功能说明
查询接口版本号,acl接口版本号命名采用:A.B.C模式,其中,A表示有不兼容修改,B表示新增接口,C表示bug修复。
函数原型
aclError aclrtGetVersion(int32_t *majorVersion, int32_t *minorVersion, int32_t *patchVersion)
参数说明
参数名 |
输入/输出 |
说明 |
|---|---|---|
majorVersion |
输出 |
主版本号的指针,从1开始,如果出现接口的不兼容变更时,加1。 |
minorVersion |
输出 |
次版本号的指针,从0开始,按照迭代周期,有新增接口时加1。 |
patchVersion |
输出 |
补丁版本号的指针,从0开始,表示本版本仅解决了问题,在majorVersion、minorVersion不变的情况下加1;但majorVersion、minorVersion增加的时候,patchVersion一般为0。 |
返回值说明
返回0表示成功,返回其他值表示失败,请参见aclError。
aclGetRecentErrMsg¶
产品支持情况
产品 |
是否支持 |
|---|---|
IPV350 |
x |
功能说明
获取并清空与本接口在同一个进程或线程中的其它acl接口调用失败时的错误描述信息。
获取进程级别、还是线程级别的错误描述信息由aclInit接口中的err_msg_mode配置控制,默认线程级别。
建议在每次调用acl接口失败时都调用aclGetRecentErrMsg接口,以便获取调用acl接口异常时的错误描述信息,用于定位问题,否则可能导致错误信息堆积、丢失。同一个进程或线程中多次调用aclGetRecentErrMsg接口后,只有最后一次调用aclGetRecentErrMsg接口返回的错误描述字符串的指针有效,之前aclGetRecentErrMsg接口返回的错误描述字符串指针不能使用,否则可能导致内存非法访问。
函数原型
const char *aclGetRecentErrMsg()
参数说明
无
返回值说明
返回错误描述字符串的指针。如果通过本接口获取到多条错误描述信息,最上面的错误描述信息为最新的。
获取错误描述信息失败时,返回nullptr。
运行时管理¶
Device管理¶
aclrtSetDevice¶
产品支持情况
产品 |
是否支持 |
|---|---|
IPV350 |
√ |
功能说明
指定当前线程中用于运算的Device。
函数原型
aclError aclrtSetDevice(int32_t deviceId)
参数说明
参数名 |
输入/输出 |
说明 |
|---|---|---|
deviceId |
输入 |
Device ID。 |
返回值说明
返回0表示成功,返回其他值表示失败,请参见aclError。
约束说明
调用aclrtSetDevice接口指定运算的Device后,若不使用Device上的资源时,可调用aclrtResetDevice接口及时释放本进程使用的Device资源(若不调用这两个接口,功能上不会有问题,因为在进程退出时也会释放本进程使用的Device资源):
若调用aclrtResetDevice接口释放Device资源:
aclrtResetDevice接口内部涉及引用计数的实现,建议aclrtResetDevice接口与aclrtSetDevice接口配对使用,aclrtSetDevice接口每被调用一次,则引用计数加一,aclrtResetDevice接口每被调用一次,则该引用计数减一,当引用计数减到0时,才会真正释放Device上的资源。
在不同进程或线程中支持调用aclrtSetDevice接口指定同一个Device用于运算。
多Device场景下,可在进程中通过aclrtSetDevice接口切换到其它Device,也可以调用aclrtSetCurrentContext接口通过切换Context来切换Device。
参考资源
接口调用流程及示例,参见运行时资源申请与释放。
aclrtResetDevice¶
产品支持情况
产品 |
是否支持 |
|---|---|
IPV350 |
√ |
功能说明
复位当前运算的Device,释放Device上的资源。
aclrtResetDevice接口内部涉及引用计数的实现,建议aclrtResetDevice接口与aclrtSetDevice接口配对使用,aclrtSetDevice接口每被调用一次,则引用计数加一,aclrtResetDevice接口每被调用一次,则该引用计数减一,当引用计数减到0时,才会真正释放Device上的资源。
如果多次调用aclrtSetDevice接口而不调用aclrtResetDevice接口释放本线程使用的Device资源,功能上不会有问题,因为在进程退出时也会释放本进程使用的Device资源。
函数原型
aclError aclrtResetDevice(int32_t deviceId)
参数说明
参数名 |
输入/输出 |
说明 |
|---|---|---|
deviceId |
输入 |
Device ID。 |
返回值说明
返回0表示成功,返回其他值表示失败,请参见aclError。
约束说明
若要复位的Device上存在显式创建的Context、Stream、Event,在复位前,建议遵循如下接口调用顺序,否则可能会导致业务异常。
**接口调用顺序:调用aclrtDestroyStream接口释放显式创建的Stream-->调用aclrtDestroyContext释放显式创建的Context-->**调用aclrtResetDevice接口
参考资源
接口调用流程及示例,参见运行时资源申请与释放。
aclrtGetDevice¶
产品支持情况
产品 |
是否支持 |
|---|---|
IPV350 |
√ |
功能说明
获取当前正在使用的Device的ID。
函数原型
aclError aclrtGetDevice(int32_t *deviceId)
参数说明
参数名 |
输入/输出 |
说明 |
|---|---|---|
deviceId |
输出 |
Device ID的指针。 |
返回值说明
返回0表示成功,返回其他值表示失败,请参见aclError。
约束说明
如果没有提前指定Device,则调用aclrtGetDevice接口时,返回错误。指定Device的方式包括:调用aclrtSetDevice接口显式指定Device、调用aclrtCreateContext接口隐式指定Device。
aclrtGetRunMode¶
产品支持情况
产品 |
是否支持 |
|---|---|
IPV350 |
√ |
功能说明
获取当前AI软件栈的运行模式。
函数原型
aclError aclrtGetRunMode(aclrtRunMode *runMode)
参数说明
参数名 |
输入/输出 |
说明 |
|---|---|---|
runMode |
输出 |
运行模式的指针。
|
返回值说明
返回0表示成功,返回其他值表示失败,请参见aclError。
参考资源
接口调用流程及示例代码,参见运行时资源申请与释放。
Context管理¶
aclrtCreateContext¶
产品支持情况
产品 |
是否支持 |
|---|---|
IPV350 |
√ |
功能说明
在当前进程或线程中显式创建一个Context。
函数原型
aclError aclrtCreateContext(aclrtContext *context, int32_t deviceId)
参数说明
参数名 |
输入/输出 |
说明 |
|---|---|---|
context |
输出 |
Context的指针。 |
deviceId |
输入 |
在指定的Device下创建Context。 |
返回值说明
返回0表示成功,返回其他值表示失败,请参见aclError。
约束说明
在某一进程中指定Device,该进程内的多个线程可共用在此Device上显式创建的Context(调用aclrtCreateContext接口显式创建Context)。
若在某一进程内创建多个Context(Context的数量与Stream相关,Stream数量有限制,请参见aclrtCreateStreamV2),当前线程在同一时刻内只能使用其中一个Context,建议通过aclrtSetCurrentContext接口明确指定当前线程的Context,增加程序的可维护性**。**
aclrtDestroyContext¶
产品支持情况
产品 |
是否支持 |
|---|---|
IPV350 |
√ |
功能说明
销毁一个Context,释放Context的资源。只能销毁通过aclrtCreateContext接口创建的Context。
函数原型
aclError aclrtDestroyContext(aclrtContext context)
参数说明
参数名 |
输入/输出 |
说明 |
|---|---|---|
context |
输入 |
需销毁的Context。 |
返回值说明
返回0表示成功,返回其他值表示失败,请参见aclError。
aclrtSetCurrentContext¶
产品支持情况
产品 |
是否支持 |
|---|---|
IPV350 |
√ |
功能说明
设置线程的Context。
函数原型
aclError aclrtSetCurrentContext(aclrtContext context)
参数说明
参数名 |
输入/输出 |
说明 |
|---|---|---|
context |
输入 |
指定线程当前的Context。 |
返回值说明
返回0表示成功,返回其他值表示失败,请参见aclError。
约束说明
支持以下场景:
如果在某线程(例如:thread1)中调用aclrtCreateContext接口显式创建一个Context(例如:ctx1),则可以不调用aclrtSetCurrentContext接口指定该线程的Context,系统默认将ctx1作为thread1的Context。
如果多次调用aclrtSetCurrentContext接口设置线程的Context,以最后一次为准。
若给线程设置的Context所对应的Device已经被复位,则不能将该Context设置为线程的Context,否则会导致业务异常。
推荐在某一线程中创建的Context,在该线程中使用。若在线程A中调用aclrtCreateContext接口创建Context,在线程B中使用该Context,则需由用户自行保证两个线程中同一个Context下同一个Stream中任务执行的顺序。
aclrtGetCurrentContext¶
产品支持情况
产品 |
是否支持 |
|---|---|
IPV350 |
√ |
功能说明
获取线程的Context。
如果用户多次调用aclrtSetCurrentContext接口设置当前线程的Context,则获取的是最后一次设置的Context。
函数原型
aclError aclrtGetCurrentContext(aclrtContext *context)
参数说明
参数名 |
输入/输出 |
说明 |
|---|---|---|
context |
输出 |
线程当前Context的指针。 |
返回值说明
返回0表示成功,返回其他值表示失败,请参见aclError。
Stream管理¶
aclrtCreateStreamV2¶
产品支持情况
产品 |
是否支持 |
|---|---|
IPV350 |
√ |
功能说明
创建一个Stream(IPV350最多支持4个Stream),支持创建Stream时增加Stream配置。
本接口需要配合其它接口一起使用,创建Stream,接口调用顺序如下:
调用aclrtCreateStreamConfigHandle接口创建Stream配置对象。
多次调用aclrtSetStreamConfigOpt接口设置配置对象中每个属性的值。
调用aclrtCreateStreamV2接口创建Stream。
Stream使用完成后,调用aclrtDestroyStreamConfigHandle接口销毁Stream配置对象,调用aclrtDestroyStream接口销毁Stream。
函数原型
aclError aclrtCreateStreamV2(aclrtStream *stream, const aclrtStreamConfigHandle *handle)
参数说明
参数名 |
输入/输出 |
说明 |
|---|---|---|
stream |
输出 |
Stream的指针。 |
handle |
输入 |
Stream配置对象的指针。与aclrtSetStreamConfigOpt中的handle保持一致。 |
返回值说明
返回0表示成功,返回其他值表示失败,请参见aclError。
aclrtSetStreamConfigOpt¶
产品支持情况
产品 |
是否支持 |
|---|---|
IPV350 |
√ |
功能说明
设置Stream配置对象中的各属性的取值。
本接口需要配合其它接口一起使用,创建Stream,接口调用顺序如下:
调用aclrtCreateStreamConfigHandle接口创建Stream配置对象。
多次调用aclrtSetStreamConfigOpt接口设置配置对象中每个属性的值。
调用aclrtCreateStreamV2接口创建Stream。
Stream使用完成后,调用aclrtDestroyStreamConfigHandle接口销毁Stream配置对象,调用aclrtDestroyStream接口销毁Stream。
函数原型
aclError aclrtSetStreamConfigOpt(aclrtStreamConfigHandle *handle, aclrtStreamConfigAttr attr, const void *attrValue, size_t valueSize)
参数说明
参数名 |
输入/输出 |
说明 |
|---|---|---|
handle |
输出 |
Stream配置对象的指针。需提前调用aclrtCreateStreamConfigHandle接口创建该对象。 |
attr |
输入 |
指定需设置的属性。 |
attrValue |
输入 |
指向属性值的指针,attr对应的属性取值。 如果属性值本身是指针,则传入该指针的地址。 |
valueSize |
输入 |
attrValue部分的数据长度。 用户可使用C/C++标准库的函数sizeof(*attrValue)查询数据长度。 |
返回值说明
返回0表示成功,返回其他值表示失败,请参见aclError。
aclrtDestroyStream¶
产品支持情况
产品 |
是否支持 |
|---|---|
IPV350 |
√ |
功能说明
销毁指定Stream,销毁通过aclrtCreateStreamV2接口创建的Stream,若Stream上有未完成的任务,会等待任务完成后再销毁Stream。
函数原型
aclError aclrtDestroyStream(aclrtStream stream)
参数说明
参数名 |
输入/输出 |
说明 |
|---|---|---|
stream |
输入 |
待销毁的Stream。 |
返回值说明
返回0表示成功,返回其他值表示失败,请参见aclError。
约束说明
在调用aclrtDestroyStream接口销毁指定Stream前,需要先调用aclrtSynchronizeStream接口确保Stream中的任务都已完成。
调用aclrtDestroyStream接口销毁指定Stream时,需确保该Stream在当前Context下。
在调用aclrtDestroyStream接口销毁指定Stream时,需确保其它接口没有正在使用该Stream。
参考资源
接口调用流程及示例,参见运行时资源申请与释放。
aclrtSynchronizeStream¶
产品支持情况
产品 |
是否支持 |
|---|---|
IPV350 |
√ |
功能说明
阻塞应用程序运行,直到指定Stream中的所有任务都完成。
函数原型
aclError aclrtSynchronizeStream(aclrtStream stream)
参数说明
参数名 |
输入/输出 |
说明 |
|---|---|---|
stream |
输入 |
指定需要完成所有任务的Stream。 不支持传NULL,否则返回报错。 |
返回值说明
返回0表示成功,返回其他值表示失败,请参见aclError。
参考资源
接口调用示例,参见Stream内任务的同步等待。
内存管理¶
总体说明¶
各产品型号在内存使用上有一些注意事项,如下表所示。
型号 |
注意事项 |
|---|---|
各型号都涉及 |
|
aclrtMalloc¶
产品支持情况
产品 |
是否支持 |
|---|---|
IPV350 |
√ |
功能说明
在Device上分配size大小的线性内存,并通过*devPtr返回已分配内存的指针,且内存首地址64字节对齐。
本接口分配的内存,会进行字节对齐,会对用户申请的size向上对齐成32字节整数倍后再多加32字节。但对于内存申请粒度为1G的大页内存,为节省大页内存,本接口会对用户申请的size仅向上对齐成32字节整数倍,不会再增加32字节。
函数原型
aclError aclrtMalloc(void **devPtr, size_t size, aclrtMemMallocPolicy policy)
参数说明
参数名 |
输入/输出 |
说明 |
|---|---|---|
devPtr |
输出 |
“Device上已分配内存的指针”的指针。 |
size |
输入 |
申请内存的大小,单位Byte。 size不能为0。 |
policy |
输入 |
内存分配规则。 若配置的内存分配规则超出aclrtMemMallocPolicy取值范围,size≥2M时,按大页申请内存,否则按普通页申请内存。 |
返回值说明
返回0表示成功,返回其他值表示失败,请参见aclError。
约束说明
本接口分配的内存不会对内容初始化,建议在使用内存前先调用aclrtMemset接口先初始化内存,清除内存中的随机数。
本接口内部不会进行隐式的Device同步或流同步。如果申请内存成功或申请内存失败会立刻返回结果。
使用aclrtMalloc接口申请的内存,需要通过aclrtFree接口释放内存。
频繁调用aclrtMalloc接口申请内存、调用aclrtFree接口释放内存,会损耗性能,建议用户提前做内存预先分配或二次管理,避免频繁申请/释放内存。
若用户需申请大块内存并自行划分、管理内存时,建议使用aclrtMallocAlign32接口,该接口相比aclrtMalloc接口,只会对用户申请的size向上对齐成32字节整数倍,不会再多加32字节。
不管是aclrtMalloc接口,还是aclrtMallocAlign32接口,若用户使用本接口申请大块内存并自行划分、管理内存时,每段内存需同时满足以下需求:
内存大小向上对齐成32整数倍+32字节(m=ALIGN_UP[len,32]+32字节);
内存起始地址需满足64字节对齐(ALIGN_UP[m,64])。
说明:
len表示某段内存的大小,ALIGN_UP[len,k]表示向上按k字节对齐:((len-1)/k+1)*k。
参考资源
接口调用示例,参见数据传输。
aclrtFree¶
产品支持情况
产品 |
是否支持 |
|---|---|
IPV350 |
√ |
功能说明
释放Device上的内存。
函数原型
aclError aclrtFree(void *devPtr)
参数说明
参数名 |
输入/输出 |
说明 |
|---|---|---|
devPtr |
输入 |
待释放内存的指针。 如果传入的devPtr为空指针,本接口会返回报错。 |
返回值说明
返回0表示成功,返回其他值表示失败,请参见aclError。
约束说明
aclrtFree接口只能释放通过aclrtMalloc接口申请的内存。
本接口会立刻释放传入的内存,函数内部不会进行隐式的Device同步或流同步。用户需要确保调用完本接口后不再对该内存指针进行访问。
参考资源
接口调用示例,参见数据传输。
aclrtMemset¶
产品支持情况
产品 |
是否支持 |
|---|---|
IPV350 |
√ |
功能说明
初始化内存,将内存中的内容设置为指定的值。
函数原型
aclError aclrtMemset(void *devPtr, size_t maxCount, int32_t value, size_t count)
参数说明
参数名 |
输入/输出 |
说明 |
|---|---|---|
devPtr |
输入 |
内存起始地址的指针。 |
maxCount |
输入 |
内存的最大长度,单位Byte。 |
value |
输入 |
设置的值。 |
count |
输入 |
需要设置为指定值的内存长度,单位Byte。 |
返回值说明
返回0表示成功,返回其他值表示失败,请参见aclError。
约束说明
本接口会立刻进行内存初始化,函数内部不会进行隐式的device同步或流同步。
aclrtMemcpy¶
产品支持情况
产品 |
是否支持 |
|---|---|
IPV350 |
√ |
功能说明
实现内存复制。
函数原型
aclError aclrtMemcpy(void *dst, size_t destMax, const void *src, size_t count, aclrtMemcpyKind kind)
参数说明
参数名 |
输入/输出 |
说明 |
|---|---|---|
dst |
输入 |
目的内存地址指针。 |
destMax |
输入 |
目的内存地址的最大内存长度,单位Byte。 |
src |
输入 |
源内存地址指针。 |
count |
输入 |
内存复制的长度,单位Byte。 |
kind |
输入 |
内存复制的类型,预留参数,配置枚举值中的值无效,系统内部会根据源内存地址指针、目的内存地址指针判断是否可以将源地址的数据复制到目的地址,如果不可以,则系统会返回报错。 |
返回值说明
返回0表示成功,返回其他值表示失败,请参见aclError。
约束说明
本接口会立刻进行内存复制,函数内部不会进行隐式的device同步或流同步。
参考资源
接口调用示例,参见数据传输。
aclrtGetMemInfo¶
产品支持情况
产品 |
是否支持 |
|---|---|
IPV350 |
√ |
功能说明
根据指定属性,获取Device上可用内存的空闲大小和总大小,不包括系统预留内存大小。
函数原型
aclError aclrtGetMemInfo(aclrtMemAttr attr, size_t *free, size_t *total)
参数说明
参数名 |
输入/输出 |
说明 |
|---|---|---|
attr |
输入 |
需要查询的内存的属性值。 |
free |
输出 |
对应属性内存空闲大小的指针,单位Byte。 |
total |
输出 |
对应属性内存总大小的指针,单位Byte。 |
返回值说明
返回0表示成功,返回其他值表示失败,请参见aclError。
约束说明
调用本接口前是必须先指定用于计算的Device(例如调用aclrtSetDevice接口指定用于计算的Device),因此本接口中不体现Device ID。
请根据实际硬件支持的情况,选择对应属性的内存,否则调用本接口获取到的空闲大小和总大小都为0。
该约束适用以下型号:
IPV350
执行控制¶
aclrtSubscribeReport¶
产品支持情况
产品 |
是否支持 |
|---|---|
IPV350 |
√ |
功能说明
异步任务场景下,注册处理Stream上回调函数的线程。
本接口需与以下其它接口配合使用,以便实现异步场景下的callback功能:
定义并实现回调函数,函数原型为:typedef void (*aclrtCallback)(void *userData);
新建线程,在线程函数内,调用aclrtProcessReport接口设置超时时间(需循环调用),等待回调任务执行;
调用aclrtSubscribeReport接口建立第2步中的线程和Stream的绑定关系,该Stream下发的回调函数将在绑定的线程中执行;
在指定Stream上执行异步任务(例如异步推理任务);
调用aclrtLaunchCallback接口在Stream的任务队列中下发回调任务,触发第2步中注册的线程处理回调函数,每调用一次aclrtLaunchCallback接口,就会触发一次回调函数的执行;
异步任务全部执行完成后,取消线程注册(aclrtUnSubscribeReport接口)。
函数原型
aclError aclrtSubscribeReport(uint64_t threadId, aclrtStream stream)
参数说明
参数名 |
输入/输出 |
说明 |
|---|---|---|
threadId |
输入 |
指定线程的ID。 |
stream |
输入 |
指定Stream。 |
返回值说明
返回0表示成功,返回其他值表示失败,请参见aclError。
约束说明
支持多次调用aclrtSubscribeReport接口给多个Stream(仅支持同一Device内的多个Stream)注册同一个处理回调函数的线程;
为确保Stream内的任务按调用顺序执行,不支持调用aclrtSubscribeReport接口给同一个Stream注册多个处理回调函数的线程;
同一个进程内,在不同的Device上注册回调函数的线程时,不能指定同一个线程ID。
aclrtLaunchCallback¶
产品支持情况
产品 |
是否支持 |
|---|---|
IPV350 |
√ |
功能说明
异步任务场景下,在Stream的任务队列中下发一个回调任务,系统内部在执行到该回调任务时,会在Stream上注册的线程(通过aclrtSubscribeReport接口注册的线程)中执行回调函数。
本接口是异步接口,调用接口成功仅表示任务下发成功,不表示任务执行成功。调用该接口后,需调用同步等待接口(例如,aclrtSynchronizeStream)确保任务已执行完成,否则可能会导致训练或推理等业务异常、Device断链掉卡等未知情况。
本接口需与以下其它接口配合使用,以便实现异步场景下的callback功能:
定义并实现回调函数,函数原型为:typedef void (*aclrtCallback)(void *userData);
新建线程,在线程函数内,调用aclrtProcessReport接口设置超时时间(需循环调用),等待回调任务执行;
调用aclrtSubscribeReport接口建立第2步中的线程和Stream的绑定关系,该Stream下发的回调函数将在绑定的线程中执行;
在指定Stream上执行异步任务(例如异步推理任务);
调用aclrtLaunchCallback接口在Stream的任务队列中下发回调任务,触发第2步中注册的线程处理回调函数,每调用一次aclrtLaunchCallback接口,就会触发一次回调函数的执行;
异步任务全部执行完成后,取消线程注册(aclrtUnSubscribeReport接口)。
函数原型
aclError aclrtLaunchCallback(aclrtCallback fn, void *userData, aclrtCallbackBlockType blockType, aclrtStream stream)
参数说明
参数名 |
输入/输出 |
说明 |
|---|---|---|
fn |
输入 |
指定要增加的回调函数。 回调函数的函数原型为: typedef void (*aclrtCallback)(void *userData) |
userData |
输入 |
待传递给回调函数的用户数据的指针。 |
blockType |
输入 |
指定回调任务是否阻塞本Stream上后续任务的执行。 typedef enum aclrtCallbackBlockType {
ACL_CALLBACK_NO_BLOCK, //非阻塞
ACL_CALLBACK_BLOCK, //阻塞
} aclrtCallbackBlockType;
|
stream |
输入 |
指定Stream。 不支持传NULL,否则返回报错。 |
返回值说明
返回0表示成功,返回其他值表示失败,请参见aclError。
aclrtProcessReport¶
产品支持情况
产品 |
是否支持 |
|---|---|
IPV350 |
√ |
功能说明
异步任务场景下,调用本接口设置超时时间,等待aclrtLaunchCallback接口下发的回调任务执行。
本接口需与以下其它接口配合使用,以便实现异步场景下的callback功能:
定义并实现回调函数,函数原型为:typedef void (*aclrtCallback)(void *userData);
新建线程,在线程函数内,调用aclrtProcessReport接口设置超时时间(需循环调用),等待回调任务执行;
调用aclrtSubscribeReport接口建立第2步中的线程和Stream的绑定关系,该Stream下发的回调函数将在绑定的线程中执行;
在指定Stream上执行异步任务(例如异步推理任务);
调用aclrtLaunchCallback接口在Stream的任务队列中下发回调任务,触发第2步中注册的线程处理回调函数,每调用一次aclrtLaunchCallback接口,就会触发一次回调函数的执行;
异步任务全部执行完成后,取消线程注册(aclrtUnSubscribeReport接口)。
函数原型
aclError aclrtProcessReport(int32_t timeout)
参数说明
参数名 |
输入/输出 |
说明 |
|---|---|---|
timeout |
输入 |
超时时间,单位为ms。 取值范围:
|
返回值说明
返回0表示成功,返回其他值表示失败,请参见aclError。
aclrtUnSubscribeReport¶
产品支持情况
产品 |
是否支持 |
|---|---|
IPV350 |
√ |
功能说明
异步任务场景下,取消线程注册,Stream上的回调函数不再由指定线程处理。
本接口需与以下其它接口配合使用,以便实现异步场景下的callback功能:
定义并实现回调函数,函数原型为:typedef void (*aclrtCallback)(void *userData);
新建线程,在线程函数内,调用aclrtProcessReport接口设置超时时间(需循环调用),等待回调任务执行;
调用aclrtSubscribeReport接口建立第2步中的线程和Stream的绑定关系,该Stream下发的回调函数将在绑定的线程中执行;
在指定Stream上执行异步任务(例如异步推理任务);
调用aclrtLaunchCallback接口在Stream的任务队列中下发回调任务,触发第2步中注册的线程处理回调函数,每调用一次aclrtLaunchCallback接口,就会触发一次回调函数的执行;
异步任务全部执行完成后,取消线程注册(aclrtUnSubscribeReport接口)。
函数原型
aclError aclrtUnSubscribeReport(uint64_t threadId, aclrtStream stream)
参数说明
参数名 |
输入/输出 |
说明 |
|---|---|---|
threadId |
输入 |
指定线程的ID。 |
stream |
输入 |
指定Stream。 不支持传NULL,否则返回报错。 |
返回值说明
返回0表示成功,返回其他值表示失败,请参见aclError。
aclrtSubscribeHostFunc¶
产品支持情况
产品 |
是否支持 |
|---|---|
IPV350 |
√ |
功能说明
模型中有CPU算子、且调用aclmdlExecuteV2或aclmdlExecuteAsyncV2接口执行模型推理时,调用本接口注册处理Stream上回调函数的线程(线程需由用户自行创建),再配合调用aclrtProcessHostFunc接口触发回调函数、在模型执行之后调用aclrtUnSubscribeHostFunc接口取消注册。
**使用场景:**模型中有CPU算子、且调用aclmdlExecuteV2或aclmdlExecuteAsyncV2接口执行模型推理时,由于IPV350上的内存限制,无法支撑CPU算子的调度框架,因此需配合aclrtSubscribeHostFunc、aclrtProcessHostFunc、aclrtUnSubscribeHostFunc接口完成CPU算子调度,完成模型推理。
函数原型
aclError aclrtSubscribeHostFunc(uint64_t hostFuncThreadId, aclrtStream exeStream)
参数说明
参数名 |
输入/输出 |
说明 |
|---|---|---|
hostFuncThreadId |
输入 |
指定线程的ID。 |
exeStream |
输入 |
指定Stream。 不支持传NULL,否则返回报错。 |
返回值说明
返回0表示成功,返回其他值表示失败,请参见aclError。
约束说明
支持多次调用aclrtSubscribeHostFunc接口给多个Stream(仅支持同一Device内的多个Stream)注册同一个处理回调函数的线程。
为确保Stream内的任务按调用顺序执行,不支持调用aclrtSubscribeHostFunc接口给同一个Stream注册多个处理回调函数的线程。
aclrtProcessHostFunc¶
产品支持情况
产品 |
是否支持 |
|---|---|
IPV350 |
√ |
功能说明
等待指定时间后,触发回调处理,由aclrtSubscribeHostFunc接口指定的线程处理回调。
线程需由用户提前自行创建,并自定义线程函数,在线程函数内调用本接口,等待指定时间后通过系统内部进行算子计算。
函数原型
aclError aclrtProcessHostFunc(int32_t timeout)
参数说明
参数名 |
输入/输出 |
说明 |
|---|---|---|
timeout |
输入 |
超时时间,单位为ms。 取值范围:
|
返回值说明
返回0表示成功,返回其他值表示失败,请参见aclError。
aclrtUnSubscribeHostFunc¶
产品支持情况
产品 |
是否支持 |
|---|---|
IPV350 |
√ |
功能说明
与aclrtSubscribeHostFunc接口配合使用,调用模型执行接口后,调用本接口取消线程注册,Stream上的回调函数不再由指定线程处理。
函数原型
aclError aclrtUnSubscribeHostFunc(uint64_t hostFuncThreadId, aclrtStream exeStream)
参数说明
参数名 |
输入/输出 |
说明 |
|---|---|---|
hostFuncThreadId |
输入 |
指定线程的ID。 |
exeStream |
输入 |
指定Stream。 不支持传NULL,否则返回报错。 |
返回值说明
返回0表示成功,返回其他值表示失败,请参见aclError。
模型管理¶
模型加载和卸载¶
aclmdlSetConfigOpt¶
产品支持情况
产品 |
是否支持 |
|---|---|
IPV350 |
√ |
功能说明
设置模型加载的配置对象中的各属性的取值,包括模型执行的优先级、模型的文件路径或内存地址、内存大小等。
本接口需要与以下其它接口配合,实现模型加载功能:
调用aclmdlCreateConfigHandle接口创建模型加载的配置对象。
多次调用aclmdlSetConfigOpt接口设置配置对象中每个属性的值。
调用aclmdlLoadWithConfig接口指定模型加载时需要的配置信息,并进行模型加载。
模型加载成功后,调用aclmdlDestroyConfigHandle接口销毁。
函数原型
aclError aclmdlSetConfigOpt(aclmdlConfigHandle *handle, aclmdlConfigAttr attr, const void *attrValue, size_t valueSize)
参数说明
参数名 |
输入/输出 |
说明 |
|---|---|---|
handle |
输出 |
模型加载的配置对象的指针。需提前调用aclmdlCreateConfigHandle接口创建该对象。 |
attr |
输入 |
指定需设置的属性。 |
attrValue |
输入 |
指向属性值的指针,attr对应的属性取值。 如果属性值本身是指针,则传入该指针的地址。 |
valueSize |
输入 |
attrValue部分的数据长度。 用户可使用C/C++标准库的函数sizeof(*attrValue)查询数据长度。 |
返回值说明
返回0表示成功,返回其他值表示失败,请参见aclError。
参考资源
使用aclmdlSetConfigOpt接口、aclmdlLoadWithConfig接口时,是通过配置对象中的属性来区分,在加载模型时是从文件加载,还是从内存加载,以及内存是由系统内部管理,还是由用户管理。
aclmdlLoadWithConfig¶
产品支持情况
产品 |
是否支持 |
|---|---|
IPV350 |
√ |
功能说明
指定模型加载时需要的配置信息,并进行模型加载。在加载前,请先根据模型文件的大小评估内存空间是否足够,内存空间不足,会导致应用程序异常。
本接口需要与以下其它接口配合,实现模型加载功能:
调用aclmdlCreateConfigHandle接口创建模型加载的配置对象。
多次调用aclmdlSetConfigOpt接口设置配置对象中每个属性的值。
调用aclmdlLoadWithConfig接口指定模型加载时需要的配置信息,并进行模型加载。
模型加载成功后,调用aclmdlDestroyConfigHandle接口销毁。
函数原型
aclError aclmdlLoadWithConfig(const aclmdlConfigHandle *handle, uint32_t *modelId)
参数说明
参数名 |
输入/输出 |
说明 |
|---|---|---|
handle |
输入 |
模型加载的配置对象的指针。需提前调用aclmdlCreateConfigHandle接口创建该对象,与aclmdlSetConfigOpt中的handle保持一致。 |
modelId |
输出 |
模型ID的指针。 系统成功加载模型后会返回的模型ID。 |
返回值说明
返回0表示成功,返回其他值表示失败,请参见aclError。
参考资源
使用aclmdlSetConfigOpt接口、aclmdlLoadWithConfig接口时,是通过配置对象中的属性来区分,在加载模型时是从文件加载,还是从内存加载,以及内存是由系统内部管理,还是由用户管理。
aclmdlUnload¶
产品支持情况
产品 |
是否支持 |
|---|---|
IPV350 |
√ |
功能说明
系统完成模型推理后,可调用本接口卸载模型,释放资源,但需确保其它接口没有正在使用该模型。
模型加载、模型执行、模型卸载的操作必须在同一个Context下(关于Context的创建请参见aclrtSetDevice或aclrtCreateContext)。
函数原型
aclError aclmdlUnload(uint32_t modelId)
参数说明
参数名 |
输入/输出 |
说明 |
|---|---|---|
modelId |
输入 |
需卸载的模型的ID。 |
返回值说明
返回0表示成功,返回其他值表示失败,请参见aclError。
参考资源
接口调用流程,参见接口调用流程。
模型执行¶
aclmdlSetExecConfigOpt¶
产品支持情况
产品 |
是否支持 |
|---|---|
IPV350 |
√ |
功能说明
设置模型执行的配置对象中的各属性的取值。
本接口需要配合其它接口一起使用,实现模型执行,接口调用顺序如下:
调用aclmdlCreateExecConfigHandle接口创建模型执行的配置对象。
多次调用aclmdlSetExecConfigOpt接口设置配置对象中每个属性的值。
调用aclmdlExecuteV2或aclmdlExecuteAsyncV2接口指定模型执行时需要的配置信息,并进行模型执行。
模型执行成功后,调用aclmdlDestroyExecConfigHandle接口销毁。
函数原型
aclError aclmdlSetExecConfigOpt(aclmdlExecConfigHandle *handle, aclmdlExecConfigAttr attr, const void *attrValue, size_t valueSize)
参数说明
参数名 |
输入/输出 |
说明 |
|---|---|---|
handle |
输出 |
模型执行的配置对象的指针。需提前调用aclmdlCreateExecConfigHandle接口创建该对象。 |
attr |
输入 |
指定需设置的属性。 |
attrValue |
输入 |
指向属性值的指针,attr对应的属性取值。 如果属性值本身是指针,则传入该指针的地址。 |
valueSize |
输入 |
attrValue部分的数据长度。 用户可使用C/C++标准库的函数sizeof(*attrValue)查询数据长度。 |
返回值说明
返回0表示成功,返回其他值表示失败,请参见aclError。
aclmdlExecuteV2¶
产品支持情况
产品 |
是否支持 |
|---|---|
IPV350 |
√ |
功能说明
根据aclmdlSetExecConfigOpt接口所配置的属性,执行模型推理,直到返回推理结果。该接口支持在执行模型推理时设置工作内存地址及大小。
本接口需要配合其它接口一起使用,实现模型执行,接口调用顺序如下:
调用aclmdlCreateExecConfigHandle接口创建模型执行的配置对象。
多次调用aclmdlSetExecConfigOpt接口设置配置对象中每个属性的值。
调用aclmdlExecuteV2接口指定模型执行时需要的配置信息,并进行模型执行。
模型执行成功后,调用aclmdlDestroyExecConfigHandle接口销毁。
函数原型
aclError aclmdlExecuteV2(uint32_t modelId, const aclmdlDataset *input, aclmdlDataset *output, aclrtStream stream, const aclmdlExecConfigHandle *handle)
参数说明
参数名 |
输入/输出 |
说明 |
|---|---|---|
modelId |
输入 |
指定需要执行推理的模型的ID。 调用模型加载接口(例如aclmdlLoadWithConfig接口)成功后,会返回模型ID,该ID作为本接口的输入。 |
input |
输入 |
模型推理的输入数据的指针。 |
output |
输出 |
模型推理的输出数据的指针。 调用aclCreateDataBuffer接口创建存放对应index输出数据的aclDataBuffer类型时,支持在data参数处传入nullptr,同时size需设置为0,表示创建一个空的aclDataBuffer类型,然后在模型执行过程中,系统内部自行计算并申请该index输出的内存。使用该方式可节省内存,但内存数据使用结束后,需由用户释放内存并重置aclDataBuffer,同时,系统内部申请内存时涉及内存拷贝,可能涉及性能损耗。 释放内存并重置aclDataBuffer的示例代码如下:
aclDataBuffer *dataBuffer = aclmdlGetDatasetBuffer(output, 0); // 根据index获取对应的dataBuffer void *data = aclGetDataBufferAddr(dataBuffer); // 获取data的Device指针 aclrtFree(data ); // 释放Device内存 aclUpdateDataBuffer(dataBuffer, nullptr, 0); // 重置dataBuffer里面内容,以便下次推理 |
stream |
输入 |
指定Stream。 不支持传NULL,否则返回报错。 |
handle |
输入 |
模型执行的配置对象的指针。与aclmdlSetExecConfigOpt中的handle保持一致。 |
返回值说明
返回0表示成功,返回其他值表示失败,请参见aclError。
约束说明
若由于业务需求,必须在多线程中使用同一个modelId,则用户线程间需加锁,保证刷新输入输出内存、保证执行是连续操作,例如:
// 线程A的接口调用顺序: lock(handle1) -> aclrtMemcpy刷新输入输出内存 -> aclmdlExecute执行推理 -> unlock(handle1) // 线程B的接口调用顺序: lock(handle1) -> aclrtMemcpy刷新输入输出内存 -> aclmdlExecute执行推理 -> unlock(handle1)
存放模型输入/输出数据的Device内存,可以使用以下接口申请:aclrtMalloc接口。
其中:
各内存申请接口的使用场景、使用约束请参见各内存申请接口的说明。
由于硬件对内存有对齐和补齐要求,若用户使用这些接口申请大块内存并自行划分、管理内存时,需满足对应接口的对齐和补齐约束,请参见内存二次分配管理。
aclmdlExecuteAsyncV2¶
产品支持情况
产品 |
是否支持 |
|---|---|
IPV350 |
√ |
功能说明
根据aclmdlSetExecConfigOpt所配置的属性,执行模型推理,直到返回推理结果。该接口支持在执行模型推理时设置工作内存地址及大小。异步接口。
本接口需要配合其它接口一起使用,实现模型执行,接口调用顺序如下:
调用aclmdlCreateExecConfigHandle接口创建模型执行的配置对象。
多次调用aclmdlSetExecConfigOpt接口设置配置对象中每个属性的值。
调用aclmdlExecuteAsyncV2接口指定模型执行时需要的配置信息,并进行模型执行。
本接口是异步接口,调用接口成功仅表示任务下发成功,不表示任务执行成功。调用该接口后,需调用同步等待接口(例如,aclrtSynchronizeStream)确保任务已执行完成,否则可能会导致训练或推理等业务异常、Device断链掉卡等未知情况。
模型执行成功后,调用aclmdlDestroyExecConfigHandle接口销毁。
函数原型
aclError aclmdlExecuteAsyncV2(uint32_t modelId, const aclmdlDataset *input, aclmdlDataset *output, aclrtStream stream, const aclmdlExecConfigHandle *handle)
参数说明
参数名 |
输入/输出 |
说明 |
|---|---|---|
modelId |
输入 |
指定需要执行推理的模型的ID。 调用aclmdlLoadWithConfig接口加载模型成功后,会返回模型ID。 |
input |
输入 |
模型推理的输入数据的指针。 |
output |
输出 |
模型推理的输出数据的指针。 |
stream |
输入 |
指定Stream。 不支持传NULL,否则返回报错。 |
handle |
输入 |
模型执行的配置对象的指针。与aclmdlSetExecConfigOpt中的handle保持一致。 |
返回值说明
返回0表示成功,返回其他值表示失败,请参见aclError。
约束说明
对同一个modelId的模型,不能调用aclmdlExecuteAsync接口执行多Stream并发场景下的模型推理。错误示例如下,该示例中,两次aclmdlExecuteAsync接口多Stream并发执行,导致报错:
//...... aclmdlExecuteAsync(modelId1, input, output, stream1); aclmdlExecuteAsync(modelId1, input, output, stream2); aclrtSynchronizeStream(stream1); aclrtSynchronizeStream(stream2); //......
若由于业务需求,必须在多线程中使用同一个modelId,则用户线程间需加锁,保证刷新输入输出内存、保证执行是连续操作,例如:
// 线程A的接口调用顺序: lock(handle1) -> aclrtMemcpyAsync(stream1)刷新输入输出内存 -> aclmdlExecuteAsync(modelId1,stream1)执行推理 -> unlock(handle1) // 线程B的接口调用顺序: lock(handle1) -> aclrtMemcpyAsync(stream1)刷新输入输出内存 -> aclmdlExecuteAsync(modelId1,stream1)执行推理 -> unlock(handle1)
若需要使用外置Allocator,则注册Allocator时的stream需与模型执行时的stream保持一致。
存放模型输入/输出数据的Device内存,可以使用以下接口申请:aclrtMalloc接口。
其中:
各内存申请接口的使用场景、使用约束请参见各内存申请接口的说明。
由于硬件对内存有对齐和补齐要求,若用户使用这些接口申请大块内存并自行划分、管理内存时,需满足对应接口的对齐和补齐约束,请参见内存二次分配管理。
aclmdlQuerySize¶
产品支持情况
产品 |
是否支持 |
|---|---|
IPV350 |
√ |
功能说明
根据模型文件获取模型执行时所需的权值内存大小、工作内存大小。
当由用户管理内存时,为确保内存不浪费,在申请工作内存、权值内存前,需要调用本接口查询模型运行时所需工作内存、权值内存的大小。如果模型输入数据的Shape不确定,则不能调用aclmdlQuerySize接口查询内存大小,在加载模型时,就无法由用户管理内存,因此需选择由系统管理内存的模型加载接口。
函数原型
aclError aclmdlQuerySize(const char *fileName, size_t *workSize, size_t *weightSize)
参数说明
参数名 |
输入/输出 |
说明 |
|---|---|---|
fileName |
输入 |
模型文件路径的指针,路径中包含文件名。运行程序(APP)的用户需要对该路径有访问权限。 此处的模型文件是适配昇腾AI处理器的离线模型适配NPU IP加速器的离线模型,即*.om文件。 说明:
关于如何获取om文件,请参见《ATC离线模型编译工具用户指南》中的“参数说明 > 基础功能参数 > 总体选项 > --mode”。 |
workSize |
输出 |
模型执行时所需的工作内存大小的指针,单位Byte。 此处的内存为Device内存,而且需要用户申请和释放。 |
weightSize |
输出 |
模型执行时所需权值内存大小的指针,单位Byte。 此处的内存为Device内存,而且需要用户申请和释放。 |
返回值说明
返回0表示成功,返回其他值表示失败,请参见aclError。
参考资源
接口调用流程及示例代码,参见模型加载。
aclmdlQueryExeOMDesc¶
产品支持情况
产品 |
是否支持 |
|---|---|
IPV350 |
√ |
功能说明
根据模型文件获取模型执行时所需的工作内存、权值内存、模型描述信息、静态和动态shape任务等的内存大小。
函数原型
aclError aclmdlQueryExeOMDesc(const char *fileName, aclmdlExeOMDesc *mdlPartitionSize)
参数说明
参数名 |
输入/输出 |
说明 |
|---|---|---|
fileName |
输入 |
模型文件路径的指针,路径中包含文件名。运行程序(APP)的用户需要对该路径有访问权限。 此处的模型文件是适配昇腾AI处理器的离线模型适配NPU IP加速器的离线模型,即*.exeom文件。 说明:
关于如何获取exeom文件,请参见《ATC离线模型编译工具用户指南》中的“参数说明 > 基础功能参数 > 总体选项 > --mode”。 |
mdlPartitionSize |
输出 |
模型执行时所需的各分区大小的结构体指针,分区大小单位为Byte。 |
返回值说明
返回0表示成功,返回其他值表示失败,请参见aclError。
数据类型及其操作接口¶
aclError¶
typedef int aclError;
规则1:开发人员的环境异常或者代码逻辑错误,可以通过优化环境或代码逻辑的方式解决问题,此时返回码定义为1XXXXX。
规则2:资源不足(Stream、内存等)、开发人员编程时使用的接口或参数与当前硬件不匹配,可以通过在编程时合理使用资源的方式解决,此时返回码定义为2XXXXX。
规则3:业务功能异常,比如队列满、队列空等,此时返回码定义为3XXXXX。
规则4:软硬件内部异常,包括软件内部错误、Device执行失败等,用户无法解决问题,需要将问题反馈给技术支持,此时返回码定义为5XXXXX。
规则5:无法识别的错误,当前都映射为500000。
表 1 acl返回码列表
返回码 |
含义 |
可能原因及解决方法 |
|---|---|---|
static const int ACL_SUCCESS = 0; |
执行成功。 |
- |
static const int ACL_ERROR_NONE = 0; 须知:
此返回码后续版本会废弃,请使用ACL_SUCCESS返回码。 |
执行成功。 |
- |
static const int ACL_ERROR_INVALID_PARAM = 100000; |
参数校验失败。 |
请检查接口的入参值是否正确。 |
static const int ACL_ERROR_UNINITIALIZE = 100001; |
未初始化。 |
|
static const int ACL_ERROR_REPEAT_INITIALIZE = 100002; |
重复初始化或重复加载。 |
请检查是否调用对应的接口重复初始化或重复加载。 |
static const int ACL_ERROR_INVALID_FILE = 100003; |
无效的文件。 |
请检查文件是否存在、文件是否能被访问等。 |
static const int ACL_ERROR_WRITE_FILE = 100004; |
写文件失败。 |
请检查文件路径是否存在、文件是否有写权限等。 |
static const int ACL_ERROR_INVALID_FILE_SIZE = 100005; |
无效的文件大小。 |
请检查文件大小是否符合接口要求。 |
static const int ACL_ERROR_PARSE_FILE = 100006; |
解析文件失败。 |
请检查文件内容是否合法。 |
static const int ACL_ERROR_FILE_MISSING_ATTR = 100007; |
文件缺失参数。 |
请检查文件内容是否完整。 |
static const int ACL_ERROR_FILE_ATTR_INVALID = 100008; |
文件参数无效。 |
请检查文件中参数值是否正确。 |
static const int ACL_ERROR_INVALID_DUMP_CONFIG = 100009; |
无效的Dump配置。 |
请检查Dump配置是否正确,详细配置请参见《精度调试工具用户指南》。 |
static const int ACL_ERROR_INVALID_PROFILING_CONFIG = 100010; |
无效的Profiling配置。 |
请检查Profiling配置是否正确。 |
static const int ACL_ERROR_INVALID_MODEL_ID = 100011; |
无效的模型ID。 |
请检查模型ID是否正确、模型是否正确加载。 |
static const int ACL_ERROR_DESERIALIZE_MODEL = 100012; |
反序列化模型失败。 |
模型可能与当前版本不匹配,请重新构建模型。 |
static const int ACL_ERROR_PARSE_MODEL = 100013; |
解析模型失败。 |
模型可能与当前版本不匹配,请重新构建模型。 |
static const int ACL_ERROR_READ_MODEL_FAILURE = 100014; |
读取模型失败。 |
请检查模型文件是否存在、模型文件是否能被访问等。 |
static const int ACL_ERROR_MODEL_SIZE_INVALID = 100015; |
无效的模型大小。 |
模型文件无效,请重新构建模型。 |
static const int ACL_ERROR_MODEL_MISSING_ATTR = 100016; |
模型缺少参数。 |
模型可能与当前版本不匹配,请重新构建模型。 |
static const int ACL_ERROR_MODEL_INPUT_NOT_MATCH = 100017; |
模型的输入不匹配。 |
请检查模型的输入是否正确。 |
static const int ACL_ERROR_MODEL_OUTPUT_NOT_MATCH = 100018; |
模型的输出不匹配。 |
请检查模型的输出是否正确。 |
static const int ACL_ERROR_MODEL_NOT_DYNAMIC = 100019; |
非动态模型。 |
请检查当前模型是否支持动态场景,如不支持,请重新构建模型。 |
static const int ACL_ERROR_OP_TYPE_NOT_MATCH = 100020; |
单算子类型不匹配。 |
请检查算子类型是否正确。 |
static const int ACL_ERROR_OP_INPUT_NOT_MATCH = 100021; |
单算子的输入不匹配。 |
请检查算子的输入是否正确。 |
static const int ACL_ERROR_OP_OUTPUT_NOT_MATCH = 100022; |
单算子的输出不匹配。 |
请检查算子的输出是否正确。 |
static const int ACL_ERROR_OP_ATTR_NOT_MATCH = 100023; |
单算子的属性不匹配。 |
请检查算子的属性是否正确。 |
static const int ACL_ERROR_OP_NOT_FOUND = 100024; |
单算子未找到。 |
请检查算子类型是否支持。 |
static const int ACL_ERROR_OP_LOAD_FAILED = 100025; |
单算子加载失败。 |
模型可能与当前版本不匹配,请重新构建单算子模型。 |
static const int ACL_ERROR_UNSUPPORTED_DATA_TYPE = 100026; |
不支持的数据类型。 |
请检查数据类型是否存在或当前是否支持。 |
static const int ACL_ERROR_FORMAT_NOT_MATCH = 100027; |
Format不匹配。 |
请检查Format是否正确。 |
static const int ACL_ERROR_INVALID_QUEUE_ID = 100032; |
无效的队列ID。 |
请检查队列ID是否正确。 |
static const int ACL_ERROR_REPEAT_SUBSCRIBE = 100033; |
重复订阅。 |
请检查针对同一个Stream,是否重复调用aclrtSubscribeReport接口。 |
static const int ACL_ERROR_STREAM_NOT_SUBSCRIBE = 100034; 须知:
此返回码后续版本会废弃,请使用ACL_ERROR_RT_STREAM_NO_CB_REG返回码。 |
Stream未订阅。 |
请检查是否已调用aclrtSubscribeReport接口。 |
static const int ACL_ERROR_THREAD_NOT_SUBSCRIBE = 100035; 须知:
此返回码后续版本会废弃,请使用ACL_ERROR_RT_THREAD_SUBSCRIBE返回码。 |
线程未订阅。 |
请检查是否已调用aclrtSubscribeReport接口。 |
static const int ACL_ERROR_WAIT_CALLBACK_TIMEOUT = 100036; 须知:
此返回码后续版本会废弃,请使用ACL_ERROR_RT_REPORT_TIMEOUT返回码。 |
等待callback超时。 |
请检查是否已调用aclrtLaunchCallback接口下发callback任务; 请检查aclrtProcessReport接口中超时时间是否合理; 请检查callback任务是否已经处理完成,如果已处理完成,但还调用aclrtProcessReport接口,则需优化代码逻辑。 |
static const int ACL_ERROR_REPEAT_FINALIZE = 100037; |
重复去初始化。 |
请检查是否重复调用aclFinalize接口进行去初始化。 |
static const int ACL_ERROR_COMPILING_STUB_MODE = 100039; |
运行应用前配置的动态库路径是编译桩的路径,不是正确的动态库路径。 |
请检查动态库路径的配置,确保使用运行模式的动态库。 |
static const int ACL_ERROR_INVALID_MAX_OPQUEUE_NUM_CONFIG = 148048; |
无效的算子缓存信息老化配置。 |
请检查算子缓存信息老化配置,参考aclInit处的配置说明及示例。 |
static const int ACL_ERROR_INVALID_OPP_PATH = 148049; |
没有设置ASCEND_OPP_PATH环境变量,或该环境变量的值设置错误。 |
请检查是否设置ASCEND_OPP_PATH环境变量,且该环境变量的值是否为opp软件包的安装路径。 |
static const int ACL_ERROR_OP_UNSUPPORTED_DYNAMIC = 148050; |
算子不支持动态Shape。 |
|
static const int ACL_ERROR_RELATIVE_RESOURCE_NOT_CLEARED = 148051; |
相关的资源尚未释放。 |
在销毁通道描述信息时,如果相关的通道尚未销毁则返回此错误码。请检查与此通道描述信息相关联的通道是否被销毁。 |
static const int ACL_ERROR_INVALID_BUNDLE_MODEL_ID = 148053; |
无效的模型ID。 |
请检查模型ID是否正确、模型是否正确加载。 |
static const int ACL_ERROR_BAD_ALLOC = 200000; |
申请内存失败。 |
请检查硬件环境上的内存剩余情况。 |
static const int ACL_ERROR_API_NOT_SUPPORT = 200001; |
接口不支持。 |
请检查调用的接口当前是否支持。 |
static const int ACL_ERROR_INVALID_DEVICE = 200002; 须知:
此返回码后续版本会废弃,请使用ACL_ERROR_RT_INVALID_DEVICEID返回码。 |
无效的Device。 |
请检查Device是否存在。 |
static const int ACL_ERROR_MEMORY_ADDRESS_UNALIGNED = 200003; |
内存地址未对齐。 |
请检查内存地址是否符合接口要求。 |
static const int ACL_ERROR_RESOURCE_NOT_MATCH = 200004; |
资源不匹配。 |
请检查调用接口时,是否传入正确的Stream、Context等资源。 |
static const int ACL_ERROR_INVALID_RESOURCE_HANDLE = 200005; |
无效的资源句柄。 |
请检查调用接口时,传入的Stream、Context等资源是否已被销毁或占用。 |
static const int ACL_ERROR_FEATURE_UNSUPPORTED = 200006; |
特性不支持。 |
请获取日志,联系技术支持。 |
static const int ACL_ERROR_STORAGE_OVER_LIMIT = 300000; |
超出存储上限。 |
请检查硬件环境上的存储剩余情况。 |
static const int ACL_ERROR_INTERNAL_ERROR = 500000; |
未知内部错误。 |
请获取日志,联系技术支持。 |
static const int ACL_ERROR_FAILURE = 500001; |
内部错误。 |
请获取日志,联系技术支持。 |
static const int ACL_ERROR_GE_FAILURE = 500002; |
GE(Graph Engine)模块的错误。 |
请获取日志,联系技术支持。 |
static const int ACL_ERROR_RT_FAILURE = 500003; |
RUNTIME模块的错误。 |
请获取日志,联系技术支持。 |
static const int ACL_ERROR_DRV_FAILURE = 500004; |
Driver模块的错误。 |
请获取日志,联系技术支持。 |
static const int ACL_ERROR_PROFILING_FAILURE = 500005; |
Profiling模块的错误。 |
请获取日志,联系技术支持。 |
表 2 透传RUNTIME的返回码列表
返回码 |
含义 |
可能原因及解决方法 |
|---|---|---|
static const int32_t ACL_ERROR_RT_PARAM_INVALID = 107000; |
参数校验失败。 |
请检查接口入参是否正确。 |
static const int32_t ACL_ERROR_RT_INVALID_DEVICEID = 107001; |
无效的Device ID。 |
请检查Device ID是否合法。 |
static const int32_t ACL_ERROR_RT_CONTEXT_NULL = 107002; |
context为空。 |
请检查是否调用aclrtSetCurrentContext或aclrtSetDevice。 |
static const int32_t ACL_ERROR_RT_STREAM_CONTEXT = 107003; |
stream不在当前context内。 |
请检查stream所在的context与当前context是否一致。 |
static const int32_t ACL_ERROR_RT_MODEL_CONTEXT = 107004; |
model不在当前context内。 |
请检查加载的模型与当前context是否一致。 |
static const int32_t ACL_ERROR_RT_STREAM_MODEL = 107005; |
stream不在当前model内。 |
请检查stream是否绑定过该模型。 |
static const int32_t ACL_ERROR_RT_EVENT_TIMESTAMP_INVALID = 107006; |
event时间戳无效。 |
请检查event是否创建。 |
static const int32_t ACL_ERROR_RT_EVENT_TIMESTAMP_REVERSAL = 107007; |
event时间戳反转。 |
请检查event是否创建。 |
static const int32_t ACL_ERROR_RT_ADDR_UNALIGNED = 107008; |
内存地址未对齐。 |
请检查所申请的内存地址是否对齐,详细内存申请接口的约束请参见内存管理。 |
static const int32_t ACL_ERROR_RT_FILE_OPEN = 107009; |
打开文件失败。 |
请检查文件是否存在。 |
static const int32_t ACL_ERROR_RT_FILE_WRITE = 107010; |
写文件失败。 |
请检查文件是否存在或者是否具备写权限。 |
static const int32_t ACL_ERROR_RT_STREAM_SUBSCRIBE = 107011; |
stream未订阅或重复订阅。 |
请检查当前stream是否订阅或重复订阅。 |
static const int32_t ACL_ERROR_RT_THREAD_SUBSCRIBE = 107012; |
线程未订阅或重复订阅。 |
请检查当前线程是否订阅或重复订阅。 |
static const int32_t ACL_ERROR_RT_STREAM_NO_CB_REG = 107015; |
该callback对应的stream未注册到线程。 |
请检查stream是否已经注册到线程,检查是否调用aclrtSubscribeReport接口。 |
static const int32_t ACL_ERROR_RT_INVALID_MEMORY_TYPE = 107016; |
无效的内存类型。 |
请检查内存类型是否合法。 |
static const int32_t ACL_ERROR_RT_INVALID_HANDLE = 107017; |
无效的资源句柄。 |
检查对应输入和使用的参数是否正确. |
static const int32_t ACL_ERROR_RT_INVALID_MALLOC_TYPE = 107018; |
申请使用的内存类型不正确。 |
检查对应输入和使用的内存类型是否正确。 |
static const int32_t ACL_ERROR_RT_WAIT_TIMEOUT = 107019; |
等待超时。 |
请尝试重新执行下发任务的接口。 |
static const int32_t ACL_ERROR_RT_TASK_TIMEOUT = 107020; |
执行任务超时。 |
请排查业务编排是否合理或者设置合理的超时时间。 |
static const int32_t ACL_ERROR_RT_STREAM_ABORT = 107023; |
正在清除Stream上的任务。 |
正在清除指定Stream上的任务,不支持同步等待该Stream上的任务执行。 |
static const int32_t ACL_ERROR_RT_STREAM_CAPTURE_IMPLICIT = 107031; |
捕获场景下不允许使用默认Stream。 |
请尝试使用其他Stream替代默认Stream。 |
static const int32_t ACL_ERROR_RT_FEATURE_NOT_SUPPORT = 207000; |
特性不支持。 |
请获取日志,联系技术支持。 |
static const int32_t ACL_ERROR_RT_MEMORY_ALLOCATION = 207001; |
内存申请失败。 |
请检查硬件环境上的存储剩余情况。 |
static const int32_t ACL_ERROR_RT_MEMORY_FREE = 207002; |
内存释放失败。 |
请获取日志,联系技术支持。 |
static const int32_t ACL_ERROR_RT_AICORE_OVER_FLOW = 207003; |
aicore算子运算溢出。 |
请检查对应的aicore算子运算是否有溢出,可以根据dump数据找到对应溢出的算子,再定位具体的算子问题。 |
static const int32_t ACL_ERROR_RT_NO_DEVICE = 207004; |
Device不可用。 |
请检查Device是否正常运行。 |
static const int32_t ACL_ERROR_RT_RESOURCE_ALLOC_FAIL = 207005; |
资源申请失败。 |
请检查Stream等资源的使用情况,及时释放不用的资源。 |
static const int32_t ACL_ERROR_RT_NO_PERMISSION = 207006; |
没有操作权限。 |
请检查运行应用的用户权限是否正确。 |
static const int32_t ACL_ERROR_RT_NO_NOTIFY_RESOURCE = 207009; |
系统内部Notify资源不足。 |
媒体数据处理的并发任务太多或模型推理时消耗资源太多,建议尝试减少并发任务或卸载部分模型。 |
static const int32_t ACL_ERROR_RT_NO_MODEL_RESOURCE = 207010; |
模型资源不足。 |
建议卸载部分模型。 |
static const int32_t ACL_ERROR_RT_NO_CDQ_RESOURCE = 207011; |
Runtime内部资源不足。 |
请获取日志,联系技术支持。 |
static const int32_t ACL_ERROR_RT_OVER_LIMIT = 207012; |
队列数目超出上限。 |
请销毁不需要的队列之后再创建新的队列。 |
static const int32_t ACL_ERROR_RT_QUEUE_EMPTY = 207013; |
队列为空。 |
不能从空队列中获取数据,请先向队列中添加数据,再获取。 |
static const int32_t ACL_ERROR_RT_QUEUE_FULL = 207014; |
队列已满。 |
不能向已满的队列中添加数据,请先从队列中获取数据,再添加。 |
static const int32_t ACL_ERROR_RT_REPEATED_INIT = 207015; |
队列重复初始化。 |
建议初始化一次队列即可,不要重复初始化。 |
static const int32_t ACL_ERROR_RT_DEVIDE_OOM = 207018; |
Device侧内存耗尽。 |
排查Device上的内存使用情况,并根据Device上的内存规格合理规划内存的使用。 |
static const int32_t ACL_ERROR_RT_INTERNAL_ERROR = 507000; |
runtime模块内部错误。 |
请获取日志,联系技术支持。 |
static const int32_t ACL_ERROR_RT_TS_ERROR = 507001; |
Device上的task scheduler模块内部错误。 |
请获取日志,联系技术支持。 |
static const int32_t ACL_ERROR_RT_STREAM_TASK_FULL = 507002; |
stream上的task数量满。 |
请获取日志,联系技术支持。 |
static const int32_t ACL_ERROR_RT_STREAM_TASK_EMPTY = 507003; |
stream上的task数量为空。 |
请获取日志,联系技术支持。 |
static const int32_t ACL_ERROR_RT_STREAM_NOT_COMPLETE = 507004; |
stream上的task未全部执行完成。 |
请获取日志,联系技术支持。 |
static const int32_t ACL_ERROR_RT_END_OF_SEQUENCE = 507005; |
AI CPU上的task执行完成。 |
请获取日志,联系技术支持。 |
static const int32_t ACL_ERROR_RT_EVENT_NOT_COMPLETE = 507006; |
event未完成。 |
请获取日志,联系技术支持。 |
static const int32_t ACL_ERROR_RT_CONTEXT_RELEASE_ERROR = 507007; |
context释放失败。 |
请获取日志,联系技术支持。 |
static const int32_t ACL_ERROR_RT_SOC_VERSION = 507008; |
获取soc version失败。 |
请获取日志,联系技术支持。 |
static const int32_t ACL_ERROR_RT_TASK_TYPE_NOT_SUPPORT = 507009; |
不支持的task类型。 |
请获取日志,联系技术支持。 |
static const int32_t ACL_ERROR_RT_LOST_HEARTBEAT = 507010; |
task scheduler丢失心跳。 |
请获取日志,联系技术支持。 |
static const int32_t ACL_ERROR_RT_MODEL_EXECUTE = 507011; |
模型执行失败。 |
请获取日志,联系技术支持。 |
static const int32_t ACL_ERROR_RT_REPORT_TIMEOUT = 507012; |
获取task scheduler的消息失败。 |
排查接口的超时时间设置是否过短,适当增长超时时间。如果增长超时时间后,依然有超时报错,再排查日志。 请获取日志,联系技术支持。 |
static const int32_t ACL_ERROR_RT_SYS_DMA = 507013; |
system dma(Direct Memory Access)硬件执行错误。 |
请获取日志,联系技术支持。 |
static const int32_t ACL_ERROR_RT_AICORE_TIMEOUT = 507014; |
aicore执行超时。 |
请获取日志,联系技术支持。 日志的详细介绍,请参见《日志参考》。 |
static const int32_t ACL_ERROR_RT_AICORE_EXCEPTION = 507015; |
aicore执行异常。 |
请获取日志,联系技术支持。 |
static const int32_t ACL_ERROR_RT_AICORE_TRAP_EXCEPTION = 507016; |
aicore trap执行异常。 |
请获取日志,联系技术支持。 |
static const int32_t ACL_ERROR_RT_AICPU_TIMEOUT = 507017; |
AI CPU执行超时。 |
请获取日志,联系技术支持。 |
static const int32_t ACL_ERROR_RT_AICPU_EXCEPTION = 507018; |
AI CPU执行异常。 |
请获取日志,联系技术支持。 |
static const int32_t ACL_ERROR_RT_AICPU_DATADUMP_RSP_ERR = 507019; |
AI CPU执行数据dump后未给task scheduler返回响应。 |
请获取日志,联系技术支持。 |
static const int32_t ACL_ERROR_RT_AICPU_MODEL_RSP_ERR = 507020; |
AI CPU执行模型后未给task scheduler返回响应。 |
请获取日志,联系技术支持。 |
static const int32_t ACL_ERROR_RT_IPC_ERROR = 507022; |
进程间通信异常。 |
请获取日志,联系技术支持。 |
static const int32_t ACL_ERROR_RT_MODEL_ABORT_NORMAL = 507023; |
模型退出。 |
请获取日志,联系技术支持。 |
static const int32_t ACL_ERROR_RT_KERNEL_UNREGISTERING = 507024; |
算子正在去注册。 |
请获取日志,联系技术支持。 |
static const int32_t ACL_ERROR_RT_RINGBUFFER_NOT_INIT = 507025; |
ringbuffer(环形缓冲区)功能未初始化。 |
请获取日志,联系技术支持。 |
static const int32_t ACL_ERROR_RT_RINGBUFFER_NO_DATA = 507026; |
ringbuffer(环形缓冲区)没有数据。 |
请获取日志,联系技术支持。 |
static const int32_t ACL_ERROR_RT_KERNEL_LOOKUP = 507027; |
RUNTIME内部的kernel未注册。 |
请获取日志,联系技术支持。 |
static const int32_t ACL_ERROR_RT_KERNEL_DUPLICATE = 507028; |
重复注册RUNTIME内部的kernel。 |
请获取日志,联系技术支持。 |
static const int32_t ACL_ERROR_RT_DEBUG_REGISTER_FAIL = 507029; |
debug功能注册失败。 |
请获取日志,联系技术支持。 |
static const int32_t ACL_ERROR_RT_DEBUG_UNREGISTER_FAIL = 507030; |
debug功能去注册失败。 |
请获取日志,联系技术支持。 |
static const int32_t ACL_ERROR_RT_LABEL_CONTEXT = 507031; |
标签不在当前context内。 |
请获取日志,联系技术支持。 |
static const int32_t ACL_ERROR_RT_PROGRAM_USE_OUT = 507032; |
注册的program数量超过限制。 |
请获取日志,联系技术支持。 |
static const int32_t ACL_ERROR_RT_DEV_SETUP_ERROR = 507033; |
Device启动失败。 |
请获取日志,联系技术支持。 |
static const int32_t ACL_ERROR_RT_VECTOR_CORE_TIMEOUT = 507034; |
vector core执行超时。 |
请获取日志,联系技术支持。 |
static const int32_t ACL_ERROR_RT_VECTOR_CORE_EXCEPTION = 507035; |
vector core执行异常。 |
请获取日志,联系技术支持。 |
static const int32_t ACL_ERROR_RT_VECTOR_CORE_TRAP_EXCEPTION = 507036; |
vector core trap执行异常。 |
请获取日志,联系技术支持。 |
static const int32_t ACL_ERROR_RT_CDQ_BATCH_ABNORMAL = 507037; |
Runtime内部资源申请异常。 |
请获取日志,联系技术支持。 |
static const int32_t ACL_ERROR_RT_DIE_MODE_CHANGE_ERROR = 507038; |
die模式修改异常,不能修改die模式。 |
请获取日志,联系技术支持。 |
static const int32_t ACL_ERROR_RT_DIE_SET_ERROR = 507039; |
单die模式不能指定die。 |
请获取日志,联系技术支持。 |
static const int32_t ACL_ERROR_RT_INVALID_DIEID = 507040; |
指定die id错误。 |
请获取日志,联系技术支持。 |
static const int32_t ACL_ERROR_RT_DIE_MODE_NOT_SET = 507041; |
die模式没有设置。 |
请获取日志,联系技术支持。 |
static const int32_t ACL_ERROR_RT_AICORE_TRAP_READ_OVERFLOW = 507042; |
aicore trap读越界异常。 |
请获取日志,联系技术支持。 |
static const int32_t ACL_ERROR_RT_AICORE_TRAP_WRITE_OVERFLOW = 507043; |
aicore trap写越界异常。 |
请获取日志,联系技术支持。 |
static const int32_t ACL_ERROR_RT_VECTOR_CORE_TRAP_READ_OVERFLOW = 507044; |
vector core trap读越界异常。 |
请获取日志,联系技术支持。 |
static const int32_t ACL_ERROR_RT_VECTOR_CORE_TRAP_WRITE_OVERFLOW = 507045; |
vector core trap写越界异常。 |
请获取日志,联系技术支持。 |
static const int32_t ACL_ERROR_RT_STREAM_SYNC_TIMEOUT = 507046; |
在指定的超时等待事件中,指定的stream中所有任务还没有执行完成。 |
请获取日志,联系技术支持。 |
static const int32_t ACL_ERROR_RT_EVENT_SYNC_TIMEOUT = 507047; |
在指定的Event同步等待中,超过指定时间,该Event还有没有执行完。 |
请获取日志,联系技术支持。 |
static const int32_t ACL_ERROR_RT_FFTS_PLUS_TIMEOUT = 507048; |
内部任务执行超时。 |
请获取日志,联系技术支持。 |
static const int32_t ACL_ERROR_RT_FFTS_PLUS_EXCEPTION = 507049; |
内部任务执行异常。 |
请获取日志,联系技术支持。 |
static const int32_t ACL_ERROR_RT_FFTS_PLUS_TRAP_EXCEPTION = 507050; |
内部任务trap异常。 |
请获取日志,联系技术支持。 |
static const int32_t ACL_ERROR_RT_SEND_MSG = 507051; |
数据入队过程中消息发送失败。 |
请获取日志,联系技术支持。 |
static const int32_t ACL_ERROR_RT_COPY_DATA = 507052; |
数据入队过程中内存拷贝失败。 |
请获取日志,联系技术支持。 |
static const int32_t ACL_ERROR_RT_HBM_MULTI_BIT_ECC_ERROR = 507054; |
HBM比特ECC故障。 |
请获取日志,联系技术支持。 |
static const int32_t ACL_ERROR_RT_SUSPECT_DEVICE_MEM_ERROR = 507055; |
多进程、多Device场景下,可能出现内存UCE错误。 |
由于当前Device访问的对端Device内存发生故障,用户需排查对端Device进程的错误信息。 |
static const int32_t ACL_ERROR_RT_LINK_ERROR = 507056; |
多Device场景下,两个Device之间的通信断链。 |
建议重试,若依然报错,则需检查两个Device之间的通信链路。 |
static const int32_t ACL_ERROR_RT_SUSPECT_REMOTE_ERROR = 507057; |
多进程、多Device场景下,对端Device内存可能出现故障,或者当前Device内存访问越界。 |
用户需排查对端Device进程的错误信息或当前Device的内存访问情况。 |
static const int32_t ACL_ERROR_RT_DRV_INTERNAL_ERROR = 507899; |
Driver模块内部错误。 |
请获取日志,联系技术支持。 |
static const int32_t ACL_ERROR_RT_AICPU_INTERNAL_ERROR = 507900; |
AI CPU模块内部错误。 |
请获取日志,联系技术支持。 |
static const int32_t ACL_ERROR_RT_SOCKET_CLOSE = 507901; |
内部HDC(Host Device Communication)会话链接断开。 |
请获取日志,联系技术支持。 |
static const int32_t ACL_ERROR_RT_AICPU_INFO_LOAD_RSP_ERR = 507902; |
AI CPU调度处理失败。 |
请获取日志,联系技术支持。 |
static const int32_t ACL_ERROR_RT_STREAM_CAPTURE_INVALIDATED = 507903; |
模型捕获异常。 |
请获取日志,联系技术支持。 |
表 3 透传GE的返回码列表
返回码 |
含义 |
可能原因及解决方法 |
|---|---|---|
uint32_t ACL_ERROR_GE_PARAM_INVALID = 145000; |
参数校验失败。 |
请检查接口的入参值是否正确。 |
uint32_t ACL_ERROR_GE_EXEC_NOT_INIT = 145001; |
未初始化。 |
|
uint32_t ACL_ERROR_GE_EXEC_MODEL_PATH_INVALID = 145002; |
无效的模型路径。 |
请检查模型路径是否正确。 |
uint32_t ACL_ERROR_GE_EXEC_MODEL_ID_INVALID = 145003; |
无效的模型ID。 |
请检查模型ID是否正确、模型是否正确加载。 |
uint32_t ACL_ERROR_GE_EXEC_MODEL_DATA_SIZE_INVALID = 145006; |
无效的模型大小。 |
模型文件无效,请重新构建模型。 |
uint32_t ACL_ERROR_GE_EXEC_MODEL_ADDR_INVALID = 145007; |
无效的模型内存地址。 |
请检查模型地址是否有效。 |
uint32_t ACL_ERROR_GE_EXEC_MODEL_QUEUE_ID_INVALID = 145008; |
无效的队列ID。 |
请检查队列ID是否正确。 |
uint32_t ACL_ERROR_GE_EXEC_LOAD_MODEL_REPEATED = 145009; |
重复初始化或重复加载。 |
请检查是否调用对应的接口重复初始化或重复加载。 |
uint32_t ACL_ERROR_GE_DYNAMIC_INPUT_ADDR_INVALID = 145011; |
无效的动态分档输入地址。 |
请检查动态分档输入地址。 |
uint32_t ACL_ERROR_GE_DYNAMIC_INPUT_LENGTH_INVALID = 145012; |
无效的动态分档输入长度。 |
请检查动态分档输入长度。 |
uint32_t ACL_ERROR_GE_DYNAMIC_BATCH_SIZE_INVALID = 145013; |
无效的动态分档Batch大小。 |
请检查动态分档Batch大小。 |
uint32_t ACL_ERROR_GE_AIPP_BATCH_EMPTY = 145014; |
无效的AIPP batch size。 |
请检查AIPP batch size是否正确。 |
uint32_t ACL_ERROR_GE_AIPP_NOT_EXIST = 145015; |
AIPP配置不存在。 |
请检查AIPP是否配置。 |
uint32_t ACL_ERROR_GE_AIPP_MODE_INVALID = 145016; |
无效的AIPP模式。 |
请检查模型转换时配置的AIPP模式是否正确。 |
uint32_t ACL_ERROR_GE_OP_TASK_TYPE_INVALID = 145017; |
无效的任务类型。 |
请检查算子类型是否正确。 |
uint32_t ACL_ERROR_GE_OP_KERNEL_TYPE_INVALID = 145018; |
无效的算子类型。 |
请检查算子类型是否正确。 |
uint32_t ACL_ERROR_GE_PLGMGR_PATH_INVALID = 145019; |
无效的so文件,包括so文件的路径层级太深、so文件被误删除等情况。 |
请检查运行应用前配置的环境变量LD_LIBRARY_PATH是否正确,详细描述请参见编译运行处的操作指导。 |
uint32_t ACL_ERROR_GE_FORMAT_INVALID = 145020; |
无效的format。 |
请检查Tensor数据的format是否有效。 |
uint32_t ACL_ERROR_GE_SHAPE_INVALID = 145021; |
无效的shape。 |
请检查Tensor数据的shape是否有效。 |
uint32_t ACL_ERROR_GE_DATATYPE_INVALID = 145022; |
无效的数据类型。 |
请检查Tensor数据的数据类型是否有效。 |
uint32_t ACL_ERROR_GE_MEMORY_ALLOCATION = 245000; |
申请内存失败。 |
请检查硬件环境上的内存剩余情况。 |
uint32_t ACL_ERROR_GE_MEMORY_OPERATE_FAILED = 245001; |
内存初始化、内存复制操作失败。 |
请检查内存地址是否正确、硬件环境上的内存是否足够等。 |
uint32_t ACL_ERROR_GE_DEVICE_MEMORY_ALLOCATION_FAILED = 245002; |
申请Device内存失败。 |
Device内存已用完,无法继续申请,请释放部分Device内存,再重新尝试。 |
uint32_t ACL_ERROR_GE_SUBHEALTHY = 345102; |
亚健康状态。 |
设备或进程异常触发的重部署动作完成后的状态为亚健康状态,亚健康状态下可以正常调用相关接口。 |
static const uint32_t ACL_ERROR_GE_USER_RAISE_EXCEPTION = 345103; |
用户自定义函数主动抛异常。 |
用户可根据DataFlowInfo中设置的UserData识别出来哪个输入的数据执行报错了,再根据报错排查问题。 |
static const uint32_t ACL_ERROR_GE_DATA_NOT_ALIGNED = 345104; |
数据未对齐。 |
若用户自定义函数存在多个输出时,需排查用户代码中是否少设置输出,缺少输出可能会导致数据对齐异常。 |
uint32_t ACL_ERROR_GE_INTERNAL_ERROR = 545000; |
未知内部错误。 |
请获取日志,联系技术支持。 |
uint32_t ACL_ERROR_GE_LOAD_MODEL = 545001; |
系统内部加载模型失败。 |
请获取日志,联系技术支持。 |
uint32_t ACL_ERROR_GE_EXEC_LOAD_MODEL_PARTITION_FAILED = 545002; |
系统内部加载模型失败。 |
请获取日志,联系技术支持。 |
uint32_t ACL_ERROR_GE_EXEC_LOAD_WEIGHT_PARTITION_FAILED = 545003; |
系统内部加载模型权值失败。 |
请获取日志,联系技术支持。 |
uint32_t ACL_ERROR_GE_EXEC_LOAD_TASK_PARTITION_FAILED = 545004; |
系统内部加载模型任务失败。 |
请获取日志,联系技术支持。 |
uint32_t ACL_ERROR_GE_EXEC_LOAD_KERNEL_PARTITION_FAILED = 545005; |
系统内部加载模型算子失败。 |
请获取日志,联系技术支持。 |
uint32_t ACL_ERROR_GE_EXEC_RELEASE_MODEL_DATA = 545006; |
系统内释放模型空间失败。 |
请获取日志,联系技术支持。 |
uint32_t ACL_ERROR_GE_COMMAND_HANDLE = 545007; |
系统内命令操作失败。 |
请获取日志,联系技术支持。 |
uint32_t ACL_ERROR_GE_GET_TENSOR_INFO = 545008; |
系统内获取张量数据失败。 |
请获取日志,联系技术支持。 |
uint32_t ACL_ERROR_GE_UNLOAD_MODEL = 545009; |
系统内卸载模型空间失败。 |
请获取日志,联系技术支持。 |
uint32_t ACL_ERROR_GE_MODEL_EXECUTE_TIMEOUT = 545601; |
模型执行超时 |
请获取日志,联系技术支持。 |
uint32_t ACL_ERROR_GE_REDEPLOYING = 545602; |
正在重部署。 |
等待重部署动作完成后重新调用相关接口。 |
aclDataType¶
typedef enum {
ACL_DT_UNDEFINED = -1, //未知数据类型,默认值
ACL_FLOAT = 0,
ACL_FLOAT16 = 1,
ACL_INT8 = 2,
ACL_INT32 = 3,
ACL_UINT8 = 4,
ACL_INT16 = 6,
ACL_UINT16 = 7,
ACL_UINT32 = 8,
ACL_INT64 = 9,
ACL_UINT64 = 10,
ACL_DOUBLE = 11,
ACL_BOOL = 12,
ACL_STRING = 13,
ACL_COMPLEX64 = 16,
ACL_COMPLEX128 = 17,
ACL_BF16 = 27,
ACL_INT4 = 29,
ACL_UINT1 = 30,
ACL_COMPLEX32 = 33,
ACL_HIFLOAT8 = 34, // 当前不支持该类型
ACL_FLOAT8_E5M2 = 35, // 当前不支持该类型
ACL_FLOAT8_E4M3FN = 36, // 当前不支持该类型
ACL_FLOAT8_E8M0 = 37, // 当前不支持该类型
ACL_FLOAT6_E3M2 = 38, // 当前不支持该类型
ACL_FLOAT6_E2M3 = 39, // 当前不支持该类型
ACL_FLOAT4_E2M1 = 40, // 当前不支持该类型
ACL_FLOAT4_E1M2 = 41, // 当前不支持该类型
} aclDataType;
aclFormat¶
typedef enum {
ACL_FORMAT_UNDEFINED = -1,
ACL_FORMAT_NCHW = 0,
ACL_FORMAT_NHWC = 1,
ACL_FORMAT_ND = 2,
ACL_FORMAT_NC1HWC0 = 3,
ACL_FORMAT_FRACTAL_Z = 4,
ACL_FORMAT_NC1HWC0_C04 = 12,
ACL_FORMAT_HWCN = 16,
ACL_FORMAT_NDHWC = 27,
ACL_FORMAT_FRACTAL_NZ = 29,
ACL_FORMAT_NCDHW = 30,
ACL_FORMAT_NDC1HWC0 = 32,
ACL_FRACTAL_Z_3D = 33,
ACL_FORMAT_NC = 35,
ACL_FORMAT_NCL = 47,
} aclFormat;
UNDEFINED:未知格式,默认值。
NCHW:4维数据格式。
NHWC:4维数据格式。
ND:表示支持任意格式,仅有Square、Tanh等这些单输入对自身处理的算子外,其它需要慎用。
NC1HWC0:5维数据格式。其中,C0与微架构强相关,该值等于cube单元的size,例如16;C1是将C维度按照C0切分:C1=C/C0, 若结果不整除,最后一份数据需要padding到C0。
FRACTAL_Z:卷积的权重的格式。
NC1HWC0_C04:5维数据格式。其中,C0固定为4,C1是将C维度按照C0切分:C1=C/C0, 若结果不整除,最后一份数据需要padding到C0。当前版本不支持。
HWCN:4维数据格式。
NDHWC:NDHWC格式。对于3维图像就需要使用带D(Depth)维度的格式。
FRACTAL_NZ:内部分形格式,用户目前无需使用。
NCDHW:NCDHW格式。对于3维图像就需要使用带D(Depth)维度的格式。
NDC1HWC0:6维数据格式。相比于NC1HWC0,仅多了D(Depth)维度。
FRACTAL_Z_3D:3D卷积权重格式,例如Conv3D/MaxPool3D/AvgPool3D这些算子都需要这种格式来表达。
NC:2维数据格式。
NCL:3维数据格式。
aclrtMemMallocPolicy¶
typedef enum aclrtMemMallocPolicy {
ACL_MEM_MALLOC_HUGE_FIRST,
ACL_MEM_MALLOC_HUGE_ONLY,
ACL_MEM_MALLOC_NORMAL_ONLY,
ACL_MEM_MALLOC_HUGE_FIRST_P2P,
ACL_MEM_MALLOC_HUGE_ONLY_P2P,
ACL_MEM_MALLOC_NORMAL_ONLY_P2P,
ACL_MEM_MALLOC_HUGE1G_ONLY,
ACL_MEM_MALLOC_HUGE1G_ONLY_P2P,
ACL_MEM_TYPE_LOW_BAND_WIDTH = 0x0100U,
ACL_MEM_TYPE_HIGH_BAND_WIDTH = 0x1000U,
ACL_MEM_ACCESS_USER_SPACE_READONLY = 0x100000U,
} aclrtMemMallocPolicy;
此处支持单个枚举项,也支持多个枚举项位或:
配置单个枚举项:
若配置ACL_MEM_TYPE_LOW_BAND_WIDTH或ACL_MEM_TYPE_HIGH_BAND_WIDTH,则系统内部会默认采取ACL_MEM_MALLOC_HUGE_FIRST,优先申请大页。
若配置除ACL_MEM_TYPE_LOW_BAND_WIDTH、ACL_MEM_TYPE_HIGH_BAND_WIDTH之外的其它值,则系统内部会根据硬件支持情况选择从高带宽或低带宽物理内存申请内存。
配置多个枚举项位或:
支持这三项(ACL_MEM_MALLOC_HUGE_FIRST、ACL_MEM_MALLOC_HUGE_ONLY、ACL_MEM_MALLOC_NORMAL_ONLY)与这两项(ACL_MEM_TYPE_LOW_BAND_WIDTH、ACL_MEM_TYPE_HIGH_BAND_WIDTH)组合,例如:ACL_MEM_MALLOC_HUGE_FIRST | ACL_MEM_TYPE_HIGH_BAND_WIDTH
表 1 枚举项说明
枚举项 |
说明 |
|---|---|
ACL_MEM_MALLOC_HUGE_FIRST |
申请大页内存,内存申请粒度为2M,不足2M的倍数,向上2M对齐。 当申请的内存小于等于1M时,即使使用该内存分配规则,也是申请普通页的内存。当申请的内存大于1M时,优先申请大页内存,如果大页内存不够,则使用普通页的内存。 |
ACL_MEM_MALLOC_HUGE_ONLY |
申请大页内存,内存申请粒度为2M,不足2M的倍数,向上2M对齐。 配置该选项时,表示仅申请大页,如果大页内存不够,则返回错误。 |
ACL_MEM_MALLOC_NORMAL_ONLY |
仅申请普通页,如果普通页内存不够,则返回错误。 |
ACL_MEM_MALLOC_HUGE_FIRST_P2P |
仅两个Device之间内存复制场景下使用该选项申请大页内存,内存申请粒度为2M,不足2M的倍数,向上2M对齐。 配置该选项时,表示优先申请大页内存,如果大页内存不够,则使用普通页的内存。 当前版本不支持该选项。 |
ACL_MEM_MALLOC_HUGE_ONLY_P2P |
仅两个Device之间内存复制场景下使用该选项申请大页内存,内存申请粒度为2M,不足2M的倍数,向上2M对齐。 配置该选项时,表示仅申请大页内存,如果大页内存不够,则返回错误。 当前版本不支持该选项。 |
ACL_MEM_MALLOC_NORMAL_ONLY_P2P |
仅两个Device之间内存复制场景下使用该选项,表示仅申请普通页的内存。 当前版本不支持该选项。 |
ACL_MEM_MALLOC_HUGE1G_ONLY |
申请大页内存,内存申请粒度为1G,不足1G的倍数,向上1G对齐。例如申请1.9G时,按向上对齐的原则,实际会申请2G。 配置为该选项时,表示仅申请大页,如果大页内存不够,则返回错误。 该选项与ACL_MEM_MALLOC_HUGE_ONLY选项相比,ACL_MEM_MALLOC_HUGE_ONLY的内存申请粒度为2M,如果要申请1G大小的大页内存,会占用1024/2=512个页表,但ACL_MEM_MALLOC_HUGE1G_ONLY的内存申请粒度为1G,1G大页内存只占用1个页表,能有效降低页表数量,有效扩大TLB(Translation Lookaside Buffer)缓存的地址范围,从而提升离散访问的性能。 当前版本不支持该选项。 |
ACL_MEM_MALLOC_HUGE1G_ONLY_P2P |
仅两个Device之间内存复制场景下使用该选项申请大页内存,内存申请粒度为1G,不足1G的倍数,向上1G对齐。例如申请1.9G时,按向上对齐的原则,实际会申请2G。 配置为该选项时,表示仅申请大页,如果大页内存不够,则返回错误。 该选项与ACL_MEM_MALLOC_HUGE_ONLY_P2P选项相比,ACL_MEM_MALLOC_HUGE_ONLY_P2P的内存申请粒度为2M,如果要申请1G大小的大页内存,会占用1024/2=512个页表,但ACL_MEM_MALLOC_HUGE1G_ONLY_P2P的内存申请粒度为1G,1G大页内存只占用1个页表,能有效降低页表数量,有效扩大TLB(Translation Lookaside Buffer)缓存的地址范围,从而提升离散访问的性能。 当前版本不支持该选项。 |
ACL_MEM_TYPE_LOW_BAND_WIDTH |
从带宽低的物理内存上申请内存。 |
ACL_MEM_TYPE_HIGH_BAND_WIDTH |
从带宽高的物理内存上申请内存。 |
ACL_MEM_ACCESS_USER_SPACE_READONLY |
用于控制申请的内存在用户态为只读,若在用户态修改此内存都会导致失败。 |
aclrtMemcpyKind¶
typedef enum aclrtMemcpyKind {
ACL_MEMCPY_HOST_TO_HOST, // Host内的内存复制
ACL_MEMCPY_HOST_TO_DEVICE, // Host到Device的内存复制
ACL_MEMCPY_DEVICE_TO_HOST, // Device到Host的内存复制
ACL_MEMCPY_DEVICE_TO_DEVICE, // Device内或两个Device间的内存复制
ACL_MEMCPY_DEFAULT, // 由系统根据源、目的内存地址自行判断拷贝方向
ACL_MEMCPY_HOST_TO_BUF_TO_DEVICE, // Host到Device的内存复制,但Host内存会暂存在Runtime管理的缓存中,内存复制接口调用成功后,就可以释放Host内存
ACL_MEMCPY_INNER_DEVICE_TO_DEVICE, // Device内的内存复制
ACL_MEMCPY_INTER_DEVICE_TO_DEVICE, // 两个Device之间的内存复制
} aclrtMemcpyKind;
aclrtContext¶
typedef void *aclrtContext;
aclrtStream¶
typedef void *aclrtStream;
aclrtRunMode¶
typedef enum aclrtRunMode {
ACL_DEVICE, // AI软件栈运行在Device的Control CPU或板端环境上
ACL_HOST, // AI软件栈运行在Host侧
} aclrtRunMode;
aclmdlIODims¶
#define ACL_MAX_DIM_CNT 128
#define ACL_MAX_TENSOR_NAME_LEN 128
typedef struct aclmdlIODims {
char name[ACL_MAX_TENSOR_NAME_LEN]; // tensor name
size_t dimCount; // Shape中的维度个数,如果为标量,则维度个数为0
int64_t dims[ACL_MAX_DIM_CNT]; // 维度信息
} aclmdlIODims;
aclmdlConfigAttr¶
typedef enum {
ACL_MDL_PRIORITY_INT32 = 0,
ACL_MDL_LOAD_TYPE_SIZET,
ACL_MDL_PATH_PTR,
ACL_MDL_MEM_ADDR_PTR,
ACL_MDL_MEM_SIZET,
ACL_MDL_WEIGHT_ADDR_PTR,
ACL_MDL_WEIGHT_SIZET,
ACL_MDL_WORKSPACE_ADDR_PTR,
ACL_MDL_WORKSPACE_SIZET,
ACL_MDL_INPUTQ_NUM_SIZET,
ACL_MDL_INPUTQ_ADDR_PTR,
ACL_MDL_OUTPUTQ_NUM_SIZET,
ACL_MDL_OUTPUTQ_ADDR_PTR,
ACL_MDL_WORKSPACE_MEM_OPTIMIZE,
ACL_MDL_WEIGHT_PATH_PTR,
ACL_MDL_MODEL_DESC_PTR,
ACL_MDL_MODEL_DESC_SIZET,
ACL_MDL_KERNEL_PTR,
ACL_MDL_KERNEL_SIZET,
ACL_MDL_KERNEL_ARGS_PTR,
ACL_MDL_KERNEL_ARGS_SIZET,
ACL_MDL_STATIC_TASK_PTR,
ACL_MDL_STATIC_TASK_SIZET,
ACL_MDL_DYNAMIC_TASK_PTR,
ACL_MDL_DYNAMIC_TASK_SIZET,
ACL_MDL_MEM_MALLOC_POLICY_SIZET,
ACL_MDL_FIFO_PTR,
ACL_MDL_FIFO_SIZET,
} aclmdlConfigAttr;
表 1 模型加载选项配置
选项 |
取值说明 |
|---|---|
ACL_MDL_PRIORITY_INT32 |
模型执行的优先级,可选项。该选项对应的值为int32类型。 数字越小优先级越高,取值[0,7],默认值为0。 |
ACL_MDL_LOAD_TYPE_SIZET |
模型加载方式,必选项。该选项对应的值为size_t类型。 ACL_MDL_LOAD_TYPE_SIZET(表示模型加载方式)的取值如下:
注意:如果将ACL_MDL_LOAD_TYPE_SIZET设置为ACL_MDL_LOAD_FROM_MEM,表示从内存加载模型数据,还支持使用ACL_MDL_WEIGHT_PATH_PTR选项指定权重文件目录。 |
ACL_MDL_PATH_PTR |
离线模型文件路径的指针,如果选择从文件加载模型,则该选项必选。 |
ACL_MDL_MEM_ADDR_PTR |
模型在内存中的起始地址,如果选择从内存加载模型,则该选项必选。 |
ACL_MDL_MEM_SIZET |
模型在内存中的大小,如果选择从内存加载模型,则该选项必选,与ACL_MDL_MEM_ADDR_PTR选项配合使用。该选项对应的值为size_t类型。 |
ACL_MDL_WEIGHT_ADDR_PTR |
Device上模型权值内存(存放权值数据)的指针,如果需要由用户管理权值内存,则该选项必选。若不配置该选项,则表示由系统管理内存。 |
ACL_MDL_WEIGHT_SIZET |
权值内存大小,单位为Byte,如果需要由用户管理权值内存,则该选项必选,与ACL_MDL_WEIGHT_ADDR_PTR选项配合使用。该选项对应的值为size_t类型。 |
ACL_MDL_WORKSPACE_ADDR_PTR |
Device上模型所需工作内存(存放模型执行过程中的临时数据)的指针,如果需要由用户管理工作内存,则该选项必选。若不配置该选项,则表示由系统管理内存。 当前版本不支持该配置。 |
ACL_MDL_WORKSPACE_SIZET |
模型所需工作内存的大小,单位为Byte,如果需要由用户管理工作内存,则该选项必选,与ACL_MDL_WORKSPACE_ADDR_PTR选项配合使用。该选项对应的值为size_t类型。 当前版本不支持该配置。 |
ACL_MDL_INPUTQ_NUM_SIZET |
模型输入队列大小 ,带队列加载模型时,该选项必选,与ACL_MDL_INPUTQ_ADDR_PTR选项配合使用。该选项对应的值为size_t类型。 当前版本不支持该配置。 |
ACL_MDL_INPUTQ_ADDR_PTR |
模型输入队列ID的指针,带队列加载模型时,该选项必选,一个模型输入对应一个队列ID。 当前版本不支持该配置。 |
ACL_MDL_OUTPUTQ_NUM_SIZET |
模型输出队列大小,带队列加载模型时,该选项必选,与ACL_MDL_OUTPUTQ_ADDR_PTR选项配合使用。该选项对应的值为size_t类型。 当前版本不支持该配置。 |
ACL_MDL_OUTPUTQ_ADDR_PTR |
模型输出队列ID的指针,带队列加载模型时,该选项必选,一个模型输出对应一个队列ID。 当前版本不支持该配置。 |
ACL_MDL_WORKSPACE_MEM_OPTIMIZE |
是否开启模型工作内存优化功能,1开启,0不开启。当前版本不支持该配置。 若关注内存规划或内存资源有限时,建议选择由系统管理内存的方式加载模型,并开启工作内存优化功能,此时工作内存中不包含存放模型输入、输出数据的内存,工作内存大小会减小,达到节省内存的目的。 在模型执行前,还需要由用户申请存放模型输入、输出数据的内存,因此即使在模型加载时开启工作内存优化功能,也不会影响后续的模型执行。 |
ACL_MDL_WEIGHT_PATH_PTR |
权重文件所在目录的指针。对om模型文件大小有限制的场景下,通过本参数可实现权重文件外置功能。 如果将ACL_MDL_LOAD_TYPE_SIZET设置为ACL_MDL_LOAD_FROM_MEM,表示从内存加载模型数据,则支持使用ACL_MDL_WEIGHT_PATH_PTR指定权重文件目录。 一般对om模型文件大小有限制或模型文件加密的场景下,需单独指定权重文件目录,但前提是需在使用ATC工具生成om文件时,将--external_weight参数设置为1(1表示将原始网络中的Const/Constant节点的权重保存在单独的文件中)。 |
ACL_MDL_MODEL_DESC_PTR |
存放模型描述信息的内存指针。 |
ACL_MDL_MODEL_DESC_SIZET |
存放模型描述信息所需的内存大小,单位Byte。该选项对应的值为size_t类型。 可提前调用aclmdlQueryExeOMDesc接口获取存放模型描述信息所需的内存大小,且本选项需与ACL_MDL_MODEL_DESC_PTR选项配合使用。 |
ACL_MDL_KERNEL_PTR |
存放TBE算子kernel(算子的*.o与*.json)的内存指针。 |
ACL_MDL_KERNEL_SIZET |
存放TBE算子kernel(算子的*.o与*.json)所需的内存大小,单位Byte。该选项对应的值为size_t类型。 可提前调用aclmdlQueryExeOMDesc接口获取存放TBE算子kernel(算子的*.o与*.json)所需的内存大小,且本选项需与ACL_MDL_KERNEL_PTR选项配合使用。 |
ACL_MDL_KERNEL_ARGS_PTR |
存放TBE算子kernel参数的内存指针。 |
ACL_MDL_KERNEL_ARGS_SIZET |
存放TBE算子kernel参数所需的内存大小,单位Byte。该选项对应的值为size_t类型。 可提前调用aclmdlQueryExeOMDesc接口获取存放TBE算子kernel参数所需的内存大小,且本选项需与ACL_MDL_KERNEL_ARGS_PTR选项配合使用。 |
ACL_MDL_STATIC_TASK_PTR |
存放静态shape任务描述信息的内存指针。 |
ACL_MDL_STATIC_TASK_SIZET |
存放静态shape任务描述信息所需的内存大小,单位Byte。该选项对应的值为size_t类型。 可提前调用aclmdlQueryExeOMDesc接口获取存放静态shape任务描述信息所需的内存大小,且本选项需与ACL_MDL_STATIC_TASK_PTR选项配合使用。 |
ACL_MDL_DYNAMIC_TASK_PTR |
存放动态shape任务描述信息的内存指针。 |
ACL_MDL_DYNAMIC_TASK_SIZET |
存放动态shape任务描述信息所需的内存大小,单位Byte。该选项对应的值为size_t类型。 可提前调用aclmdlQueryExeOMDesc接口获取存放动态shape任务描述信息所需的内存大小,且本选项需与ACL_MDL_DYNAMIC_TASK_PTR选项配合使用。 |
ACL_MDL_MEM_MALLOC_POLICY_SIZET |
内存分配规则,该选项对应的值为size_t类型。 支持如下取值:
此处支持单个取值,也支持多个取值位或:
|
ACL_MDL_FIFO_PTR |
模型级别全局内存的起始地址。此处是指Device上的内存。 若某个模型在推理时,其每一层的输入来自上一层的输出以及前面几轮推理结果拼接而成时,则需使用模型级别的全局内存将该模型所需的输入数据保存下来,供后续推理使用。 注意事项:对于同一个模型加载一次并行执行多次推理的场景,此时可能存在多个推理任务同时访问模型级别全局内存的情况,导致推理结果异常。建议加载一次模型后,串行执行多次推理。 |
ACL_MDL_FIFO_SIZET |
模型级别全局内存的大小,该选项对应的值为size_t类型。 可提前调用aclmdlQueryExeOMDesc接口获取模型级别全局内存的大小。 |
*.om文件不感知具体的硬件调度能力、包含中间态的抽象数据结构,在模型加载阶段,再根据具体执行平台的调度特性,生成运行时数据结构。
*.exeom文件感知具体的硬件调度能力、包含目标执行平台的运行时数据结构(这些数据以二进制的形式保存在*.exeom文件中),在模型加载阶段,加载恢复二进制内容,根据用户应用程序传递的数据区地址,或实际申请到的数据地址,刷新二进制中的地址指针值后,将二进制内容直接拷贝至Device,达到提升模型加载性能、降低模型加载内存峰值占用的效果。在一些资源受限的场景,建议使用*.exeom模型文件,增强产品的商用竞争力。
aclmdlExecConfigAttr¶
typedef enum {
ACL_MDL_STREAM_SYNC_TIMEOUT = 0,
ACL_MDL_EVENT_SYNC_TIMEOUT,
ACL_MDL_WORK_ADDR_PTR,
ACL_MDL_WORK_SIZET,
ACL_MDL_MPAIMID_SIZET, /** param reserved */
ACL_MDL_AICQOS_SIZET, /** param reserved */
ACL_MDL_AICOST_SIZET, /** param reserved */
ACL_MDL_MEC_TIMETHR_SIZET /** param reserved */
} aclmdlExecConfigAttr;
表 1 枚举项说明
枚举项 |
说明 |
|---|---|
ACL_MDL_STREAM_SYNC_TIMEOUT |
在执行模型推理时控制Stream任务的超时时间。该属性值为INT32类型。 取值说明如下:
当前版本不支持该配置。 |
ACL_MDL_EVENT_SYNC_TIMEOUT |
在执行模型推理时控制Event任务的超时时间。该属性值为INT32类型。 取值说明如下:
当前版本不支持该配置。 |
ACL_MDL_WORK_ADDR_PTR |
模型所需工作内存(Device上存放模型执行过程中的临时数据)的指针,由用户管理工作内存。一般用于模型一次加载、多并发执行的场景。 如果同时配置ACL_MDL_WORK_ADDR_PTR以及aclrtStreamConfigAttr中的ACL_RT_STREAM_WORK_ADDR_PTR(表示Stream上模型的工作内存),则以ACL_MDL_WORK_ADDR_PTR优先。 |
ACL_MDL_WORK_SIZET |
模型所需工作内存的大小,单位为Byte。一般用于模型一次加载、多并发执行的场景。 |
ACL_MDL_MPAIMID_SIZET |
预留配置。 |
ACL_MDL_AICQOS_SIZET |
预留配置。 |
ACL_MDL_AICOST_SIZET |
预留配置。 |
ACL_MDL_MEC_TIMETHR_SIZET |
预留配置。 |
aclrtStreamConfigAttr¶
typedef enum {
ACL_RT_STREAM_WORK_ADDR_PTR = 0,
ACL_RT_STREAM_WORK_SIZE,
ACL_RT_STREAM_FLAG,
ACL_RT_STREAM_PRIORITY,
} aclrtStreamConfigAttr;
表 1 枚举项说明
枚举项 |
说明 |
|---|---|
ACL_RT_STREAM_WORK_ADDR_PTR |
某一个Stream上的模型所需工作内存(Device上存放模型执行过程中的临时数据)的指针,由用户管理工作内存。该配置主要用于多模型在同一个Stream上串行执行时想共享工作内存的场景,此时需按多个模型中最大的工作内存来申请内存,可提前使用aclmdlQuerySize查询各模型所需的工作内存大小。 如果同时配置ACL_RT_STREAM_WORK_ADDR_PTR以及aclmdlExecConfigAttr中的ACL_MDL_WORK_ADDR_PTR(表示某个模型的工作内存),则以aclmdlExecConfigAttr中的ACL_MDL_WORK_ADDR_PTR优先。 |
ACL_RT_STREAM_WORK_SIZE |
模型所需工作内存的大小,单位为Byte。 |
ACL_RT_STREAM_FLAG |
预留配置,默认值为0。 |
ACL_RT_STREAM_PRIORITY |
Stream的优先级,数字越小优先级越高,取值[0,7]。默认值为0。 |
aclrtMemAttr¶
typedef enum aclrtMemAttr {
ACL_DDR_MEM, // 大页内存+普通内存
ACL_HBM_MEM, // 大页内存+普通内存
ACL_DDR_MEM_HUGE, // 大页内存
ACL_DDR_MEM_NORMAL, // 普通内存
ACL_HBM_MEM_HUGE, // 大页内存,内存申请粒度为2M,不足2M的倍数,向上2M对齐
ACL_HBM_MEM_NORMAL, // 普通内存
ACL_DDR_MEM_P2P_HUGE, // 用于Device间数据复制的大页内存
ACL_DDR_MEM_P2P_NORMAL, // 用于Device间数据复制的普通内存
ACL_HBM_MEM_P2P_HUGE, // 用于Device间数据复制的大页内存,内存申请粒度为2M,不足2M的倍数,向上2M对齐
ACL_HBM_MEM_P2P_NORMAL, // 用于Device间数据复制的普通内存
ACL_HBM_MEM_HUGE1G, // 大页内存,内存申请粒度为1G,不足1G的倍数,向上1G对齐,当前版本不支持该选项
ACL_HBM_MEM_P2P_HUGE1G // 用于Device间数据复制的大页内存,内存申请粒度为1G,不足1G的倍数,向上1G对齐,当前版本不支持该选项
} aclrtMemAttr;
对于申请大页内存的场景,当内存申请粒度为2M时,如果要申请1G大小的大页内存,会占用1024/2=512个页表,当内存申请粒度为1G时,1G大页内存只占用1个页表,能有效降低页表数量,有效扩大TLB(Translation Lookaside Buffer)缓存的地址范围,从而提升离散访问的性能。
aclmdlExeOMDesc¶
typedef struct aclmdlExeOMDesc {
size_t workSize;
size_t weightSize;
size_t modelDescSize;
size_t kernelSize;
size_t kernelArgsSize;
size_t staticTaskSize;
size_t dynamicTaskSize;
size_t fifoTaskSize;
size_t reserved[8];
} aclmdlExeOMDesc;
成员名称 |
描述 |
|---|---|
workSize |
模型执行时所需的工作内存的大小,单位Byte。 |
weightSize |
模型执行时所需的权值内存的大小,单位Byte。 |
modelDescSize |
存放模型描述信息所需的内存大小,单位Byte。 |
kernelSize |
存放TBE算子kernel(算子的*.o与*.json)所需的内存大小,单位Byte。 |
kernelArgsSize |
存放TBE算子kernel参数所需的内存大小,单位Byte。 |
staticTaskSize |
存放静态shape任务描述信息所需的内存大小,单位Byte。 |
dynamicTaskSize |
存放动态shape任务描述信息所需的内存大小,单位Byte。 |
fifoTaskSize |
存放模型级别的全局内存大小,单位Byte。 若某个模型在推理时,其每一层的输入来自上一层的输出以及前面几轮推理结果拼接而成时,则需使用模型级别的全局内存将该模型所需的输入数据保存下来,供后续推理使用。 |
reserved |
预留值。 |
aclDataBuffer¶
aclCreateDataBuffer¶
产品支持情况
产品 |
是否支持 |
|---|---|
IPV350 |
√ |
功能说明
创建aclDataBuffer类型的数据,该数据类型用于描述内存地址、大小等内存信息。
如需销毁aclDataBuffer类型的数据,请参见aclDestroyDataBuffer。
函数原型
aclDataBuffer *aclCreateDataBuffer(void *data, size_t size)
参数说明
参数名 |
输入/输出 |
说明 |
|---|---|---|
data |
输入 |
存放数据内存地址的指针。data参数支持传入nullptr,表示创建一个空的数据类型,此时size参数值必须设置为0。 该内存需由用户自行管理,调用aclrtMalloc接口/aclrtFree接口申请/释放内存。 |
size |
输入 |
内存大小,单位Byte。 如果用户需要使用空tensor,则在申请内存时,内存大小最小为1Byte,以保障后续业务正常运行。 |
返回值说明
返回aclDataBuffer类型的指针。
aclDestroyDataBuffer¶
产品支持情况
产品 |
是否支持 |
|---|---|
IPV350 |
√ |
功能说明
销毁通过aclCreateDataBuffer接口创建的aclDataBuffer类型的数据。
此处仅销毁aclDataBuffer类型的数据,调用aclCreateDataBuffer接口创建aclDataBuffer类型数据时传入的data的内存需由用户自行释放。
函数原型
aclError aclDestroyDataBuffer(const aclDataBuffer *dataBuffer)
参数说明
参数名 |
输入/输出 |
说明 |
|---|---|---|
dataBuffer |
输入 |
待销毁的aclDataBuffer类型的指针。 |
返回值说明
返回0表示成功,返回其他值表示失败,请参见aclError。
aclGetDataBufferAddr¶
产品支持情况
产品 |
是否支持 |
|---|---|
IPV350 |
√ |
功能说明
获取aclDataBuffer类型中的数据的内存地址。
函数原型
void *aclGetDataBufferAddr(const aclDataBuffer *dataBuffer)
参数说明
参数名 |
输入/输出 |
说明 |
|---|---|---|
dataBuffer |
输入 |
aclDataBuffer类型的指针。 需提前调用aclCreateDataBuffer接口创建aclDataBuffer类型的数据。 |
返回值说明
返回aclDataBuffer类型中的数据的内存地址。
aclGetDataBufferSize(废弃)¶
产品支持情况
产品 |
是否支持 |
|---|---|
IPV350 |
√ |
功能说明
获取aclDataBuffer类型中数据的内存大小,单位Byte。
函数原型
uint32 aclGetDataBufferSize(const aclDataBuffer *dataBuffer)
参数说明
参数名 |
输入/输出 |
说明 |
|---|---|---|
dataBuffer |
输入 |
aclDataBuffer类型的指针。 需提前调用aclCreateDataBuffer接口创建aclDataBuffer类型的数据。 |
返回值说明
aclDataBuffer类型中数据的内存大小。
aclGetDataBufferSizeV2¶
产品支持情况
产品 |
是否支持 |
|---|---|
IPV350 |
√ |
功能说明
获取aclDataBuffer类型中数据的内存大小,单位Byte。
函数原型
size_t aclGetDataBufferSizeV2(const aclDataBuffer *dataBuffer)
参数说明
参数名 |
输入/输出 |
说明 |
|---|---|---|
dataBuffer |
输入 |
aclDataBuffer类型的指针。 需提前调用aclCreateDataBuffer接口创建aclDataBuffer类型的数据。 |
返回值说明
aclDataBuffer类型中数据的内存大小。
aclmdlDataset¶
aclmdlCreateDataset¶
产品支持情况
产品 |
是否支持 |
|---|---|
IPV350 |
√ |
功能说明
创建aclmdlDataset类型的数据,该数据类型用于描述模型推理时的输入数据、输出数据,模型可能存在多个输入、多个输出,每个输入/输出的内存地址、内存大小用aclDataBuffer类型的数据来描述。
如需销毁aclmdlDataset类型的数据,请参见aclmdlDestroyDataset。
函数原型
aclmdlDataset *aclmdlCreateDataset()
参数说明
无
返回值说明
返回aclmdlDataset类型的指针。
aclmdlDestroyDataset¶
产品支持情况
产品 |
是否支持 |
|---|---|
IPV350 |
√ |
功能说明
销毁通过aclmdlCreateDataset接口创建的aclmdlDataset类型的数据。
函数原型
aclError aclmdlDestroyDataset(const aclmdlDataset *dataset)
参数说明
参数名 |
输入/输出 |
说明 |
|---|---|---|
dataset |
输入 |
待销毁的aclmdlDataset类型的指针。 |
返回值说明
返回0表示成功,返回其他值表示失败,请参见aclError。
aclmdlAddDatasetBuffer¶
产品支持情况
产品 |
是否支持 |
|---|---|
IPV350 |
√ |
功能说明
向aclmdlDataset中增加aclDataBuffer。
函数原型
aclError aclmdlAddDatasetBuffer(aclmdlDataset *dataset, aclDataBuffer *dataBuffer)
参数说明
参数名 |
输入/输出 |
说明 |
|---|---|---|
dataset |
输出 |
待增加aclDataBuffer的aclmdlDataset地址指针。 需提前调用aclmdlCreateDataset接口创建aclmdlDataset类型的数据。 |
dataBuffer |
输入 |
待增加的aclDataBuffer地址指针。 需提前调用aclCreateDataBuffer接口创建aclDataBuffer类型的数据。 |
返回值说明
返回0表示成功,返回其他值表示失败,请参见aclError。
aclmdlGetDatasetNumBuffers¶
产品支持情况
产品 |
是否支持 |
|---|---|
IPV350 |
√ |
功能说明
获取aclmdlDataset中aclDataBuffer的个数。
函数原型
size_t aclmdlGetDatasetNumBuffers(const aclmdlDataset *dataset)
参数说明
参数名 |
输入/输出 |
说明 |
|---|---|---|
dataset |
输入 |
aclmdlDataset类型的指针。 需提前调用aclmdlCreateDataset接口创建aclmdlDataset类型的数据。 |
返回值说明
aclDataBuffer的个数。
aclmdlGetDatasetBuffer¶
产品支持情况
产品 |
是否支持 |
|---|---|
IPV350 |
√ |
功能说明
获取aclmdlDataset中的第n个aclDataBuffer。
函数原型
aclDataBuffer* aclmdlGetDatasetBuffer(const aclmdlDataset *dataset, size_t index)
参数说明
参数名 |
输入/输出 |
说明 |
|---|---|---|
dataset |
输入 |
aclmdlDataset类型的指针。 需提前调用aclmdlCreateDataset接口创建aclmdlDataset类型的数据。 |
index |
输入 |
表明获取的是第几个aclDataBuffer。 |
返回值说明
获取成功,返回aclDataBuffer的地址。
获取失败返回空地址。
aclmdlDesc¶
aclmdlCreateDesc¶
产品支持情况
产品 |
是否支持 |
|---|---|
IPV350 |
√ |
功能说明
创建aclmdlDesc类型的数据,表示模型描述信息。
如需销毁aclmdlDesc类型的数据,请参见aclmdlDestroyDesc。
函数原型
aclmdlDesc* aclmdlCreateDesc()
参数说明
无
返回值说明
返回aclmdlDesc类型的指针。
aclmdlDestroyDesc¶
产品支持情况
产品 |
是否支持 |
|---|---|
IPV350 |
√ |
功能说明
销毁通过aclmdlCreateDesc接口创建的aclmdlDesc类型的数据。
函数原型
aclError aclmdlDestroyDesc(aclmdlDesc *modelDesc)
参数说明
参数名 |
输入/输出 |
说明 |
|---|---|---|
modelDesc |
输入 |
待销毁的aclmdlDesc类型的指针。 |
返回值说明
返回0表示成功,返回其他值表示失败,请参见aclError。
aclmdlGetDesc¶
产品支持情况
产品 |
是否支持 |
|---|---|
IPV350 |
√ |
功能说明
根据模型ID获取该模型的模型描述信息。
函数原型
aclError aclmdlGetDesc(aclmdlDesc *modelDesc, uint32_t modelId)
参数说明
参数名 |
输入/输出 |
说明 |
|---|---|---|
modelDesc |
输出 |
aclmdlDesc类型的指针。 需提前调用aclmdlCreateDesc接口创建aclmdlDesc类型的数据。 |
modelId |
输入 |
模型ID。 调用aclmdlLoadWithConfig接口加载模型成功后,会返回模型ID。 |
返回值说明
返回0表示成功,返回其他值表示失败,请参见aclError。
aclmdlGetNumInputs¶
产品支持情况
产品 |
是否支持 |
|---|---|
IPV350 |
√ |
功能说明
根据模型描述信息获取模型的输入个数。
函数原型
size_t aclmdlGetNumInputs(aclmdlDesc *modelDesc)
参数说明
参数名 |
输入/输出 |
说明 |
|---|---|---|
modelDesc |
输入 |
aclmdlDesc类型的指针。 需提前调用aclmdlCreateDesc接口创建aclmdlDesc类型的数据。 |
返回值说明
模型的输入个数。
aclmdlGetNumOutputs¶
产品支持情况
产品 |
是否支持 |
|---|---|
IPV350 |
√ |
功能说明
根据模型描述信息获取模型的输出个数。
函数原型
size_t aclmdlGetNumOutputs(aclmdlDesc *modelDesc)
参数说明
参数名 |
输入/输出 |
说明 |
|---|---|---|
modelDesc |
输入 |
aclmdlDesc类型的指针。 需提前调用aclmdlCreateDesc接口创建aclmdlDesc类型的数据。 |
返回值说明
模型的输出个数。
aclmdlGetInputSizeByIndex¶
产品支持情况
产品 |
是否支持 |
|---|---|
IPV350 |
√ |
功能说明
根据模型描述信息获取指定输入的大小,单位为Byte。
函数原型
size_t aclmdlGetInputSizeByIndex(aclmdlDesc *modelDesc, size_t index)
参数说明
参数名 |
输入/输出 |
说明 |
|---|---|---|
modelDesc |
输入 |
aclmdlDesc类型的指针。 需提前调用aclmdlCreateDesc接口创建aclmdlDesc类型的数据。 |
index |
输入 |
指定获取第几个输入的大小,index值从0开始。 |
返回值说明
针对动态Batch、动态分辨率(宽高)的场景,返回最大档位对应的输入的大小;静态场景下,返回指定输入的大小。单位是Byte。
约束说明
如果模型输入的Shape是动态的、且维度的取值为-1(表示此维度可以使用>=1的任意取值),则通过本接口获取的大小为0,用户需根据实际数据占用的内存大小来申请内存。
aclmdlGetOutputSizeByIndex¶
产品支持情况
产品 |
是否支持 |
|---|---|
IPV350 |
√ |
功能说明
根据模型描述信息获取指定输出的大小,单位为Byte。
函数原型
size_t aclmdlGetOutputSizeByIndex(aclmdlDesc *modelDesc, size_t index)
参数说明
参数名 |
输入/输出 |
说明 |
|---|---|---|
modelDesc |
输入 |
aclmdlDesc类型的指针。 需提前调用aclmdlCreateDesc接口创建aclmdlDesc类型的数据。 |
index |
输入 |
指定获取第几个输出的大小,index值从0开始。 |
返回值说明
针对动态Batch、动态分辨率(宽高)的场景,返回最大档位对应的输出的大小;静态场景下,返回指定输出的大小。单位是Byte。
约束说明
如果通过本接口获取的大小为0,有可能是由于输出Shape的范围不确定,当前支持以下两种处理方式:
方式一:系统内部自行申请对应index的输出内存,节省内存,但内存数据使用结束后,需由用户释放内存,同时,系统内部申请内存时涉及内存拷贝,可能涉及性能损耗。该方式仅支持在使用aclmdlExecuteV2推理接口时使用。
方式二:用户预估输出内存大小,并申请内存,由用户自行管理内存,但内存大小可能不够或超出,不够时系统会校验报错,超出时会浪费内存。
用户需先根据实际情况预估一块较大的输出内存,在模型执行过程中,系统会校验用户指定的输出内存大小是否符合要求,如果不符合要求,系统会返回报错,并在报错信息中提示具体需要多大的输出内存。您可以通过以下两种方式查看报错:
在应用程序中调用aclGetRecentErrMsg接口获取报错。
aclmdlGetInputDims¶
产品支持情况
产品 |
是否支持 |
|---|---|
IPV350 |
√ |
功能说明
根据模型描述信息获取模型的输入tensor的维度信息。
如果模型中含有静态AIPP配置信息,您可以根据实际需要选择aclmdlGetInputDims接口查询维度信息
通过aclmdlGetInputDims接口获取的维度信息,各维度的值与输入图像的各维度的值保持一致,详细规则如表1所示。
函数原型
aclError aclmdlGetInputDims(const aclmdlDesc *modelDesc, size_t index, aclmdlIODims *dims)
参数说明
参数名 |
输入/输出 |
说明 |
|---|---|---|
modelDesc |
输入 |
aclmdlDesc类型的指针。 需提前调用aclmdlCreateDesc接口创建aclmdlDesc类型的数据。 |
index |
输入 |
指定获取第几个输入的Dims,index值从0开始。 |
dims |
输出 |
输入维度信息的指针。 针对动态Batch、动态分辨率(宽高)的场景,输入tensor的dims中batch size或宽高为-1,表示其动态可变。例如,输入tensor的format为NCHW,在动态Batch场景下,动态可变的输入tensor的dims为[-1,3,224,224];在动态分辨率场景下,动态可变的输入tensor的dims为[1,3,-1,-1]。举例中的斜体部分以实际情况为准。 若tensor的name长度大于127,则在输出的dims.name时,接口会将tensor的name转换为“acl_modelId_${id}_input_${index}_${随机字符串} ”格式(如果转换后的tensor的name与模型中已有的tensor的name冲突,则会在转换后的name尾部增加“_${随机字符串} ”,否则不会增加随机字符串),并在转换后的name与原name之间建立映射关系,用户可调用aclmdlGetTensorRealName接口,传入转换后的name,获取原name(若向接口传入原name,则获取的还是原name);若tensor的name长度小于或等于127,则在输出的dims.name时,按tensor的name输出。 针对静态AIPP场景,本接口针对不同格式的图像,对应NHWC的Format格式,当前接口中明确各个维度的定义规则,如表1所示。 |
表 1 静态AIPP场景下的维度定义规则
图像格式 |
Format参考格式 |
维度定义规则 |
|---|---|---|
YUV420SP_U8 |
NHWC |
n,h,w,c |
XRGB8888_U8 |
NHWC |
n,h,w,c |
RGB888_U8 |
NHWC |
n,h,w,c |
YUV400_U8 |
NHWC |
n,h,w,c |
ARGB8888_U8 |
NHWC |
n,h,w,c |
YUYV_U8 |
NHWC |
n,h,w,c |
YUV422SP_U8 |
NHWC |
n,h,w,c |
AYUV444_U8 |
NHWC |
n,h,w,c |
返回值说明
返回0表示成功,返回其他值表示失败,请参见aclError。
aclmdlGetOutputDims¶
产品支持情况
产品 |
是否支持 |
|---|---|
IPV350 |
√ |
功能说明
根据模型描述信息获取指定的模型输出tensor的维度信息。
固定Shape场景下,通过该接口获取指定的模型输出tensor的维度信息。
动态Shape(动态Batch或动态分辨率)场景下,通过该接口获取最大档的维度信息。
函数原型
aclError aclmdlGetOutputDims(const aclmdlDesc *modelDesc, size_t index, aclmdlIODims *dims)
参数说明
参数名 |
输入/输出 |
说明 |
|---|---|---|
modelDesc |
输入 |
aclmdlDesc类型的指针。 需提前调用aclmdlCreateDesc接口创建aclmdlDesc类型的数据。 |
index |
输入 |
指定获取第几个输出的Dims,index值从0开始。 |
dims |
输出 |
输出维度信息的指针。 若tensor的name长度大于127,则在输出的dims.name时,系统会将tensor的name转换为“acl_modelId_${id}_output_${index} _${随机字符串} ”格式(如果转换后的tensor name与模型中已有的tensor name冲突,则会在转换后的name尾部增加“_${随机字符串} ”,否则不会增加随机字符串),并在转换后的name与原name之间建立映射关系,用户可调用aclmdlGetTensorRealName接口,传入转换后的name,获取原name(若向接口传入原name,则获取的还是原name);若tensor的name长度小于或等于127,则在输出的dims.name时,按tensor的name输出。 |
返回值说明
返回0表示成功,返回其他值表示失败,请参见aclError。
aclmdlGetInputNameByIndex¶
产品支持情况
产品 |
是否支持 |
|---|---|
IPV350 |
√ |
功能说明
根据模型描述信息获取模型中指定输入的输入名称。
函数原型
const char *aclmdlGetInputNameByIndex(const aclmdlDesc *modelDesc, size_t index)
参数说明
参数名 |
输入/输出 |
说明 |
|---|---|---|
modelDesc |
输入 |
aclmdlDesc类型的指针。 需提前调用aclmdlCreateDesc接口创建aclmdlDesc类型的数据。 |
index |
输入 |
指定获取第几个输入的名称,index值从0开始。 |
返回值说明
返回指定输入的输入名称。
aclmdlGetOutputNameByIndex¶
产品支持情况
产品 |
是否支持 |
|---|---|
IPV350 |
√ |
功能说明
根据模型描述信息获取模型中指定输出的输出算子名称、算子输出边的下标、top名称或输出名称。
函数原型
const char *aclmdlGetOutputNameByIndex(const aclmdlDesc *modelDesc, size_t index)
参数说明
参数名 |
输入/输出 |
说明 |
|---|---|---|
modelDesc |
输入 |
aclmdlDesc类型的指针。 需提前调用aclmdlCreateDesc接口创建aclmdlDesc类型的数据。 |
index |
输入 |
指定获取第几个输出的输出算子名称、算子输出边下标、top名称或输出名称,index值从0开始。 |
返回值说明
返回指定输出的输出算子名称、算子输出边的下标、top名称或输出名称。不同原始网络、不同构建模型的方式,调用本接口获取的返回值格式不同。
Caffe网络
返回值格式如下,各项之间以冒号分割,如果模型中包含top名称就返回,不包含就不返回:
输出算子名称 : 算子输出边下标 : top名称TensorFlow网络
使用ATC工具构建om模型的场景下,返回值格式如下,各项之间以冒号分割:
输出算子名称 : 算子输出边下标使用Ascend Graph接口构建om模型的场景下,返回值格式如下,各项之间以下划线分割:
output_网络输出下标_输出算子名称_算子输出边下标Ascend Graph接口的详细说明请参见《Ascend Graph开发指南》。
ONNX网络
在构建模型时,不指定输出节点名称(node_name)或输出名称(output的name),或者仅指定输出名称,返回值格式如下,各项之间以冒号分割:
输出算子名称 : 算子输出边下标 : 输出名称在构建模型时,指定输出节点名称(node_name):
输出算子名称可能是图融合后的算子名称,也可能是子图名称。
使用ATC工具构建om模型的场景下,返回值格式如下,各项之间以冒号分割:
输出算子名称 : 算子输出边下标使用Ascend Graph接口构建om模型的场景下,返回值格式如下,各项之间以下划线分割:
output_网络输出下标_输出算子名称_算子输出边下标Ascend Graph接口的详细说明请参见《Ascend Graph开发指南》。
同时指定输出节点名称(node_name)和输出名称(output的name),接口返回报错。
aclmdlGetInputFormat¶
产品支持情况
产品 |
是否支持 |
|---|---|
IPV350 |
√ |
功能说明
根据模型描述信息获取模型中指定输入的Format。
函数原型
aclFormat aclmdlGetInputFormat(const aclmdlDesc *modelDesc, size_t index)
参数说明
参数名 |
输入/输出 |
说明 |
|---|---|---|
modelDesc |
输入 |
aclmdlDesc类型的指针。 需提前调用aclmdlCreateDesc接口创建aclmdlDesc类型的数据。 |
index |
输入 |
指定获取第几个输入的Format,index值从0开始。 |
返回值说明
返回指定输入的Format。
aclmdlGetOutputFormat¶
产品支持情况
产品 |
是否支持 |
|---|---|
IPV350 |
√ |
功能说明
根据模型描述信息获取模型中指定输出的Format。
函数原型
aclFormat aclmdlGetOutputFormat(const aclmdlDesc *modelDesc, size_t index)
参数说明
参数名 |
输入/输出 |
说明 |
|---|---|---|
modelDesc |
输入 |
aclmdlDesc类型的指针。 需提前调用aclmdlCreateDesc接口创建aclmdlDesc类型的数据。 |
index |
输入 |
指定获取第几个输出的Format,index值从0开始。 |
返回值说明
返回指定输出的Format。
aclmdlGetInputDataType¶
产品支持情况
产品 |
是否支持 |
|---|---|
IPV350 |
√ |
功能说明
根据模型描述信息获取模型中指定输入的数据类型。
函数原型
aclDataType aclmdlGetInputDataType(const aclmdlDesc *modelDesc, size_t index)
参数说明
参数名 |
输入/输出 |
说明 |
|---|---|---|
modelDesc |
输入 |
aclmdlDesc类型的指针。 需提前调用aclmdlCreateDesc接口创建aclmdlDesc类型的数据。 |
index |
输入 |
指定获取第几个输入的数据类型,index值从0开始。 |
返回值说明
返回指定输入的数据类型。
aclmdlGetOutputDataType¶
产品支持情况
产品 |
是否支持 |
|---|---|
IPV350 |
√ |
功能说明
根据模型描述信息获取模型中指定输出的数据类型。
函数原型
aclDataType aclmdlGetOutputDataType(const aclmdlDesc *modelDesc, size_t index)
参数说明
参数名 |
输入/输出 |
说明 |
|---|---|---|
modelDesc |
输入 |
aclmdlDesc类型的指针。 需提前调用aclmdlCreateDesc接口创建aclmdlDesc类型的数据。 |
index |
输入 |
指定获取第几个输出的数据类型,index值从0开始。 |
返回值说明
返回指定输出的数据类型。
aclmdlGetInputIndexByName¶
产品支持情况
产品 |
是否支持 |
|---|---|
IPV350 |
√ |
功能说明
根据模型中的输入名称获取对应输入的索引编号。
函数原型
aclError aclmdlGetInputIndexByName(const aclmdlDesc *modelDesc, const char *name, size_t *index)
参数说明
参数名 |
输入/输出 |
说明 |
|---|---|---|
modelDesc |
输入 |
aclmdlDesc类型的指针。 需提前调用aclmdlCreateDesc接口创建aclmdlDesc类型的数据。 |
name |
输入 |
输入名称的指针。 |
index |
输出 |
输入的索引编号的指针。 |
返回值说明
返回0表示成功,返回其他值表示失败,请参见aclError。
aclmdlGetOutputIndexByName¶
产品支持情况
产品 |
是否支持 |
|---|---|
IPV350 |
√ |
功能说明
根据模型中的输出名称获取对应输出的索引编号。
函数原型
aclError aclmdlGetOutputIndexByName(const aclmdlDesc *modelDesc, const char *name, size_t *index)
参数说明
参数名 |
输入/输出 |
说明 |
|---|---|---|
modelDesc |
输入 |
aclmdlDesc类型的指针。 需提前调用aclmdlCreateDesc接口创建aclmdlDesc类型的数据。 |
name |
输入 |
输出名称的指针。 |
index |
输出 |
输出的索引编号的指针。 |
返回值说明
返回0表示成功,返回其他值表示失败,请参见aclError。
aclmdlGetTensorRealName¶
产品支持情况
产品 |
是否支持 |
|---|---|
IPV350 |
x |
功能说明
根据指定名称获取tensor的真实名称。
aclmdlGetTensorRealName接口需要与aclmdlGetInputDims/aclmdlGetOutputDims接口配合使用。
函数原型
const char *aclmdlGetTensorRealName(const aclmdlDesc *modelDesc, const char *name)
参数说明
参数名 |
输入/输出 |
说明 |
|---|---|---|
modelDesc |
输入 |
aclmdlDesc类型的指针。 需提前调用aclmdlCreateDesc接口创建aclmdlDesc类型的数据。 |
name |
输入 |
名称的指针,用于根据该名称获取tensor的真实名称。 |
返回值说明
返回指向tensor真实名称的指针,该指针的生命周期与modelDesc相同,若modelDesc资源被销毁,则该指针指向的内容也会自动被销毁。
若modelDesc或name为空,则返回nullptr。
aclmdlGetDescFromFile¶
产品支持情况
产品 |
是否支持 |
|---|---|
IPV350 |
x |
功能说明
根据模型文件获取该模型的模型描述信息。
函数原型
aclError aclmdlGetDescFromFile(aclmdlDesc *modelDesc, const char *modelPath)
参数说明
参数名 |
输入/输出 |
说明 |
|---|---|---|
modelDesc |
输出 |
aclmdlDesc类型的指针。 需提前调用aclmdlCreateDesc接口创建aclmdlDesc类型的数据。 |
modelPath |
输入 |
模型文件路径的指针,路径中包含文件名。运行程序(APP)的用户需要对该存储路径有访问权限。 此处的模型文件是适配昇腾AI处理器的离线模型适配NPU IP加速器的离线模型,即*.om文件。关于如何获取om文件,请参见《ATC离线模型编译工具用户指南》中的“参数说明 > 基础功能参数 > 总体选项 > --mode”。 |
返回值说明
返回0表示成功,返回其他值表示失败,请参见aclError。
aclmdlGetDescFromMem¶
产品支持情况
产品 |
是否支持 |
|---|---|
IPV350 |
x |
功能说明
从内存获取该模型的模型描述信息。
函数原型
aclError aclmdlGetDescFromMem(aclmdlDesc *modelDesc, const void *model, size_t modelSize)
参数说明
参数名 |
输入/输出 |
说明 |
|---|---|---|
modelDesc |
输出 |
aclmdlDesc类型的指针。 需提前调用aclmdlCreateDesc接口创建aclmdlDesc类型的数据。 |
model |
输入 |
存放模型数据的内存地址指针。 |
modelSize |
输入 |
内存中的模型数据长度,单位Byte。 |
返回值说明
返回0表示成功,返回其他值表示失败,请参见aclError。
aclmdlConfigHandle¶
aclmdlCreateConfigHandle¶
产品支持情况
产品 |
是否支持 |
|---|---|
IPV350 |
√ |
功能说明
创建aclmdlConfigHandle类型的数据,表示一个模型加载的配置对象。
如需销毁aclmdlConfigHandle类型的数据,请参见aclmdlDestroyConfigHandle。
函数原型
aclmdlConfigHandle *aclmdlCreateConfigHandle()
参数说明
无
返回值说明
返回aclmdlConfigHandle类型的指针,表示成功。
返回nullptr,表示失败。
aclmdlDestroyConfigHandle¶
产品支持情况
产品 |
是否支持 |
|---|---|
IPV350 |
√ |
功能说明
销毁通过aclmdlCreateConfigHandle接口创建的aclmdlConfigHandle类型的数据。
函数原型
aclError aclmdlDestroyConfigHandle(aclmdlConfigHandle *handle)
参数说明
参数名 |
输入/输出 |
说明 |
|---|---|---|
handle |
输入 |
待销毁的aclmdlConfigHandle类型的指针。 |
返回值说明
返回0表示成功,返回其他值表示失败,请参见aclError。
aclmdlExecConfigHandle¶
aclmdlCreateExecConfigHandle¶
产品支持情况
产品 |
是否支持 |
|---|---|
IPV350 |
√ |
功能说明
创建aclmdlExecConfigHandle类型的数据,表示一个模型执行的配置对象。
如需销毁aclmdlExecConfigHandle类型的数据,请参见aclmdlDestroyExecConfigHandle。
函数原型
aclmdlExecConfigHandle *aclmdlCreateExecConfigHandle()
参数说明
无
返回值说明
返回aclmdlExecConfigHandle类型的指针,表示成功。
返回NULL,表示失败。
aclmdlDestroyExecConfigHandle¶
产品支持情况
产品 |
是否支持 |
|---|---|
IPV350 |
√ |
功能说明
销毁通过aclmdlCreateExecConfigHandle接口创建的aclmdlExecConfigHandle类型的数据。
函数原型
aclError aclmdlDestroyExecConfigHandle(const aclmdlExecConfigHandle *handle)
参数说明
参数名 |
输入/输出 |
说明 |
|---|---|---|
handle |
输入 |
待销毁的aclmdlExecConfigHandle类型的指针。 |
返回值说明
返回0表示成功,返回其他值表示失败,请参见aclError。
aclrtStreamConfigHandle¶
aclrtCreateStreamConfigHandle¶
产品支持情况
产品 |
是否支持 |
|---|---|
IPV350 |
√ |
功能说明
创建aclrtStreamConfigHandle类型的数据,表示一个Stream的配置对象。
如需销毁aclrtStreamConfigHandle类型的数据,请参见aclrtDestroyStreamConfigHandle。
函数原型
aclrtStreamConfigHandle *aclrtCreateStreamConfigHandle(void)
参数说明
无
返回值说明
返回aclrtStreamConfigHandle类型的指针,表示成功。
返回NULL,表示失败。
aclrtDestroyStreamConfigHandle¶
产品支持情况
产品 |
是否支持 |
|---|---|
IPV350 |
√ |
功能说明
销毁通过aclrtCreateStreamConfigHandle接口创建的aclrtStreamConfigHandle类型的数据。
函数原型
aclError aclrtDestroyStreamConfigHandle(aclrtStreamConfigHandle *handle)
参数说明
参数名 |
输入/输出 |
说明 |
|---|---|---|
handle |
输入 |
待销毁的aclrtStreamConfigHandle类型的指针。 |
返回值说明
返回0表示成功,返回其他值表示失败,请参见aclError。
FAQ案例集¶
运行时资源异常问题¶
内存未释放导致内存泄漏¶
问题现象描述
测试用例长稳运行时,出现内存泄漏的现象,内存占用持续上升。如图1所示。
图 1 内存占用持续上升
可能原因
分析上述信息,可能存在以下故障原因:
系统存在只申请内存不释放内存的问题,正常情况下,内存申请与释放必须成对出现。
处理步骤
针对分析的故障可能原因,可以参考下面步骤处理:
排查所有的内存申请和释放的地方,保证申请与释放一一对应。例如aclrtMalloc与aclrtFree,aclrtMallocHost与aclrtFreeHost、aclrtCreateStream与aclrtDestroyStream等。
Event数量超过上限导致aclrtRecordEvent接口返回失败¶
问题现象描述
调用aclrtRecordEvent接口在Stream中记录一个Event时,日志中的报错如下,红框中是关键日志信息,提示Event申请失败。由于软件版本在持续优化中,新旧版本的日志不同,如下所示:
新版本日志示例如下:
275:[INFO] ASCENDCL(234708,acltest_host):2024-07-17-23:57:52.402.011 [acl_event_testcase.cpp:173]234708 acl_event_testcase.cpp:173 ACL_EVENT_0213:create events, the latest event can be created, but eventRecord failed, return ACL_ERROR_RT_DRV_INTERNAL_ERROR ! 69718:[ERROR] RUNTIME(234708,acltest_host):2024-07-18-00:06:16.739.666 [event.cc:378]234708 Record:report error module_type=0, module_name=EE9999 69719:[ERROR] RUNTIME(234708,acltest_host):2024-07-18-00:06:16.739.680 [event.cc:378]234708 Record:Event id alloc error, deviceId=0, tsId=0, retCode=0x7020019! 70241:[ERROR] RUNTIME(234708,acltest_host):2024-07-18-00:06:16.749.305 [stream.cc:1751]234708 ReleaseTimeline:report error module_type=0, module_name=EE9999 70242:[ERROR] RUNTIME(234708,acltest_host):2024-07-18-00:06:16.749.307 [stream.cc:1751]234708 ReleaseTimeline:Release timeline failed, base=0 is invalid, valid value=0x10a8c0 70244:[ERROR] RUNTIME(234708,acltest_host):2024-07-18-00:06:16.749.322 [api_error.cc:888]234708 EventRecord:Record event failed. 70245:[ERROR] RUNTIME(234708,acltest_host):2024-07-18-00:06:16.749.330 [api_c.cc:716]234708 rtEventRecord:ErrCode=207007, desc=[driver error:no event resource], InnerCode=0x7020019 70246:[ERROR] RUNTIME(234708,acltest_host):2024-07-18-00:06:16.749.332 [error_message_manage.cc:53]234708 FuncErrorReason:report error module_type=3, module_name=EE8888 70247:[ERROR] RUNTIME(234708,acltest_host):2024-07-18-00:06:16.749.335 [error_message_manage.cc:53]234708 FuncErrorReason:rtEventRecord execute failed, reason=[driver error:no event resource] 70249:[ERROR] ASCENDCL(234708,acltest_host):2024-07-18-00:06:16.749.348 [event.cpp:101]234708 aclrtRecordEvent: record event failed, runtime result = 207007
旧版本日志示例如下:
可能原因
分析上述日志信息,可能存在以下故障原因:Event ID的数量超过上限。
处理步骤
多Stream之间同步等待的场景下,Event ID的资源是可以复用的,复用Event ID的流程是:在调用aclrtRecordEvent接口+aclrtStreamWaitEvent接口后,若指定的Event已完成,则需要及时调用aclrtResetEvent接口释放Event资源。
需要用户按照复用Event ID的流程优化代码逻辑。
进程异常退出后重新执行任务失败¶
问题现象描述
进程异常退出时,包括强行终止任务(如ctrl + c或者kill命令终止进程)的场景,然后重新启动任务失败。
可能原因
进程异常退出时,只能依赖系统检测到程序退出后才进行资源释放,释放资源最长需要一分钟的执行时间。如果在未执行完资源释放前执行新的任务,可能导致新执行的任务失败。
处理步骤
进程异常退出后需要等待一分钟,才能保证下一次重新执行任务成功。
进程异常,下一次执行任务报错“unbind model stream failed”¶
问题现象描述
用户捕获异常退出信号,并在信号处理函数中释放已申请资源,下一次执行时会报执行失败。此时查看日志,会发现unbind model stream failed报错。
图 1 unbind model stream failed

可能原因
进程异常时,Host侧内核态驱动会自动检测并发起对应进程Device侧资源释放的流程,不需要用户捕获进程异常的信号并主动完成清理。若用户主动释放,会影响到系统的资源释放流程。
处理步骤
用户无需关注进程异常退出信号,不要对异常退出信号做处理。
用户进程异常退出后重启进程失败¶
问题现象描述
用户进程卡住或者用户强制退出进程后,再次重启,重启后发现进程无法正常启动。类似的日志信息如下:
acl接口的报错信息:aclrtProcessReport failed
aclrtProcessReport failed, ret = 107012
Runtime日志信息:halResourceIdAlloc xxx failed
[ERROR] RUNTIME(2086,rtstest_host):2021-06-09-02:14:46.034.380 [npu_driver.cc:285]2086 StreamIdAlloc:[driver interface] halResourceIdAlloc streamid failed: device_id=0, tsId=0, drvRetCode=48!
[ERROR] RUNTIME(2086,rtstest_host):2021-06-09-02:14:46.034.401 [stream.cc:448]2086 Setup:Failed to alloc stream id, retCode=0x702001a.
[ERROR] RUNTIME(2086,rtstest_host):2021-06-09-02:14:46.034.416 [context.cc:1251]2086 StreamCreate:Setup stream failed, retCode=0x702001a.
[ERROR] RUNTIME(2086,rtstest_host):2021-06-09-02:14:46.034.440 [logger.cc:211]2086 StreamCreate:Create stream failed, priority=7 ,flags=0.
[ERROR] RUNTIME(2086,rtstest_host):2021-06-09-02:14:46.034.458 [api_c.cc:461]2086 rtStreamCreateWithFlags:ErrCode=207008, desc=[driver error:no stream resource], InnerCode=0x702001a
[ERROR] RUNTIME(2086,rtstest_host):2021-06-09-02:14:46.034.469 [error_message_manage.cc:26]2086 ReportFuncErrorReason:rtStreamCreateWithFlags execute failed, reason=[driver error:no stream resource]
可能原因
通过日志分析无法正常重启的原因可能是public taskid、stream id、eventid等资源申请不到引起的:
资源已经被其他进程占用完。
上一个进程退出时还未完全释放完资源。
处理步骤
针对上述可能原因,可以按以下方式处理:
等待一分钟后再重新启动进程,保证上一个进程资源释放完成。
停止其他进程或者等其他进程执行完成后再启动进程。
如果通过上述方式处理后仍然申请失败,建议检查是否超过了可用的资源上限,如果未超上限,则需要重启环境强行释放资源、恢复环境。
AI应用进程未退出,导致休眠唤醒失败¶
问题现象描述
休眠失败。
查看应用类日志,系统内部的任务分发模块hwts正处于busy状态,检查发现不满足休眠条件,日志片段示例如下:
[ERROR] TSCH(-1,null):2023-01-01-02:53:45.850.781 1 (dieid:0,cpuid:0) device_management_plat.c:563 suspend_ack: suspend pre check fail, hwts is busy
[EVENT] TSCH(-1,null):2023-01-01-02:53:45.850.803 2 (dieid:0,cpuid:0) device_management.c:411 process_low_power_cmd: ts suspend ack ret=1.
原因分析
根据休眠唤醒的流程,休眠前AI应用进程必须先退出,相关硬件资源处于idle态,才允许休眠。不满足休眠条件,会有相关报错,本案例中因为AI应用进程未退出,在休眠唤醒时检测到hwts处于busy状态,因此休眠失败。
解决办法
用户需要确保AI应用进程已经运行结束或者优雅退出,推荐使用**kill -2 PID退出相关进程,PID**需替换为实际进程ID。
内存申请失败,出现OOM¶
问题现象描述
内存申请失败,Host侧日志提示EL9999返回码,有如下打印信息:
[ERROR] DRV(2936187,python3):2022-04-21-14:19:39.429.481 [curpid: 2936187, 2969960][drv][devmm][devmm_alloc_managed 182]<errno:12, 6> Heap_alloc_managed out of memory. (temp_ptr=0x1; bytesize=8592031776)
[ERROR] RUNTIME(2936187,python3):2022-04-21-14:19:39.429.491 [npu_driver.cc:780]2969960 DevMemAllocHugePageManaged:report error module_type=1, module_name=EL9999
[ERROR] RUNTIME(2936187,python3):2022-04-21-14:19:39.429.495 [npu_driver.cc:780]2969960 DevMemAllocHugePageManaged:[driver interface] halMemAlloc failed: device_id=1, size=8592031776, type=0, env_type=3, drvRetCode=6!
可能原因
根据日志信息分析,判断为内存申请失败。可能原因:
网络并行运行,导致内存不足。
网络运行需要内存过大,导致内存申请失败。
处理步骤
查看运行网络时是否存在并行情况。
查询网络运行需要内存大小或者减少batchsize,查看网络是否可以正常运行。
异步拷贝调用查询接口报错¶
问题现象描述
通过event实现H2D或D2H异步拷贝任务的同步等待时,在调用aclrtQueryEventStatus确认任务完成后,先调用aclrtFreeHost释放Host内存再调用aclrtDestroyEvent接口,可能会有如下报错信息打印:

可能原因
报错是因为使用了异步拷贝任务之后下发了一个event record任务,期望使用aclrtQueryEventStatus查询到event record任务是否完成,从而判断异步拷贝任务是否完成,而后释放内存调用aclrtFreeHost。
实际上aclrtQueryEventStatus查询到的是Device执行完任务,并未透传到Host侧,所以此时释放内存,未先销毁Event会有时序问题导致报错。
处理步骤
处理该问题可以参考以下方案:
方案一:使用aclrtSynchronizeStream接口判断任务是否执行完成。
方案二:使用aclrtQueryEventStatus接口时,先调用aclrtDestroyEvent接口,再调用aclrtFreeHost接口,保证无时序问题。
低版本内核使用asan导致单算子执行失败¶
问题现象描述
执行单算子时,算子输入数据正确,但输出数据异常,全为0,Host侧plog日志中的报错示例如下:
[ERROR] RUNTIME(2082291,python3):2024-07-04-14:14:25.036.721 [stars_engine.cc:1321]2082291 ProcLogicCqReport:[INIT][DEFAULT]Task run failed, device_id=0, stream_id=2, task_id=1, sqe_type=0(ffts), errType=0x1(task exception), sqSwStatus=0
[ERROR] RUNTIME(2082291,python3):2024-07-04-14:14:25.049.079 [device_error_proc.cc:1218]2082291 ProcessStarsCoreErrorInfo:[INIT][DEFAULT]report error module_type=5, module_name=EZ9999
[ERROR] RUNTIME(2082291,python3):2024-07-04-14:14:25.049.115 [device_error_proc.cc:1218]2082291 ProcessStarsCoreErrorInfo:[INIT][DEFAULT]The error from device(chipId:3, dieId:0), serial number is 20, there is an aivec error exception, core id is 4, error code = 0, dump info: pc start: 0x12c0c001406c, current: 0x12c0c00140fc, vec error info: 0x600ed4063d, mte error info: 0x8d0600008c, ifu error info: 0x70f016e068500, ccu error info: 0x28000037, cube error info: 0, biu error info: 0, aic error mask: 0x6500020bd00028c, para base: 0x12c0803e5000.
[ERROR] RUNTIME(2082291,python3):2024-07-04-14:14:25.049.300 [device_error_proc.cc:1230]2082291 ProcessStarsCoreErrorInfo:[INIT][DEFAULT]report error module_type=5, module_name=EZ9999
[ERROR] RUNTIME(2082291,python3):2024-07-04-14:14:25.049.321 [device_error_proc.cc:1230]2082291 ProcessStarsCoreErrorInfo:[INIT][DEFAULT]The extend info: errcode:(0, 0x200000000000000, 0) errorStr: The MPU address access is invalid. fixp_error0 info: 0x600008c, fixp_error1 info: 0x8d fsmId:1, tslot:3, thread:0, ctxid:0, blk:0, sublk:0, subErrType:4.
[ERROR] RUNTIME(2082291,python3):2024-07-04-14:14:25.049.519 [stream.cc:3084]2082291 EnterFailureAbort:[INIT][DEFAULT]stream_id=2 enter failure abort.
[ERROR] RUNTIME(2082291,python3):2024-07-04-14:14:25.049.558 [davinic_kernel_task.cc:1321]2082291 SetStarsResultForDavinciTask:[INIT][DEFAULT]AIV Kernel happen error, retCode=0x31.
[ERROR] RUNTIME(2082291,python3):2024-07-04-14:14:25.050.340 [davinic_kernel_task.cc:1219]2082291 PreCheckTaskErr:[INIT][DEFAULT]report error module_type=5, module_name=EZ9999
[ERROR] RUNTIME(2082291,python3):2024-07-04-14:14:25.050.365 [davinic_kernel_task.cc:1219]2082291 PreCheckTaskErr:[INIT][DEFAULT]Kernel task happen error, retCode=0x31, [vector core exception].
[ERROR] RUNTIME(2082291,python3):2024-07-04-14:14:25.050.474 [stream.cc:1079]2082291 GetError:[INIT][DEFAULT]Stream Synchronize failed, stream_id=2, retCode=0x31, [vector core exception].
[ERROR] RUNTIME(2082291,python3):2024-07-04-14:14:25.050.496 [stream.cc:1082]2082291 GetError:[INIT][DEFAULT]report error module_type=5, module_name=EZ9999
[ERROR] RUNTIME(2082291,python3):2024-07-04-14:14:25.050.517 [stream.cc:1082]2082291 GetError:[INIT][DEFAULT]AIV Kernel happen error, retCode=0x31.
[ERROR] RUNTIME(2082291,python3):2024-07-04-14:14:25.050.941 [davinic_kernel_task.cc:1143]2082291 PrintErrorInfoForDavinciTask:[INIT][DEFAULT]Aicore kernel execute failed, device_id=0, stream_id=2, report_stream_id=2, task_id=1, flip_num=0, fault kernel_name=Add_ee98c6628030785f610b924ab1557b31_high_performance_210000000, fault kernel info ext=none, program id=0, hash=3838710036602041089.
[ERROR] RUNTIME(2082291,python3):2024-07-04-14:14:25.051.013 [davinic_kernel_task.cc:1082]2082291 GetArgsInfo:[INIT][DEFAULT][AIC_INFO] args(0 to 9) after execute:0, 0, 0, 0, 0, 0, 0, 0, 0,
[ERROR] RUNTIME(2082291,python3):2024-07-04-14:14:25.051.046 [davinic_kernel_task.cc:1085]2082291 GetArgsInfo:[INIT][DEFAULT]tilingKey = 210000000, print 1 Times totalLen=(9*8)Bytes, argsSize=72, blockDim=1
[ERROR] RUNTIME(2082291,python3):2024-07-04-14:14:25.051.088 [davinic_kernel_task.cc:1147]2082291 PrintErrorInfoForDavinciTask:[INIT][DEFAULT][AIC_INFO] after execute:args print end
可能原因
用户程序编译选项中启动了地址消毒(-lasan),但低版本内核(5.10以下版本,不含5.10)不支持使用asan工具,导致执行算子时拷贝输出数据异常。
可使用uname -r命令查看内核版本。
处理步骤
解决方法1:升级内核版本到5.10或更高版本。
解决方法2:在用户程序编译选项中去掉地址消毒(-lasan)。
析构函数中调用去初始化接口aclFinalize导致应用进程coredump¶
问题现象描述
应用程序运行过程中出现core dump,应用程序异常终止。
原因分析
生成coredump文件。
物理机场景,执行ulimit -c unlimited命令,表示在程序崩溃时生成coredump文件:
完成问题定位后,如果不需要生成coredump文件,可执行ulimit -c 0命令。
Docker场景,在Docker启动命令中增加**--ulimit core=-1**设置。
运行应用程序,若进程崩溃,即可在当前目录下生成coredump文件。
使用gdb工具调试core文件、打印堆栈信息。
进入gdb模式,调试coredump文件,命令示例如下。其中,_main_表示产生coredump文件的可执行程序名称,可根据实际情况修改;coredump文件名需根据实际文件名称修改。
gdb main core*.*执行命令后,gdb工具会将发生异常的代码、其所在的函数、文件名和所在文件的行数打印到屏幕,堆栈信息的最上面是最底层的调用栈信息,方便定位问题。堆栈信息举例如下:
Thread 1 "main" received signal SIGSEGV, Segmentation fault. 0x0000ffffa70747c8 in ge::PluginManager::~PluginManager() () from /usr/local/Ascend/latest/lib64/libge_common.so (gdb) bt #0 0x0000ffffa70747c8 in ge::PluginManager::~PluginManager() () from /usr/local/Ascend/latest/lib64/libge_common.so #1 0x0000ffffa707c900 in ge::RuntimePluginLoader::Finalize() () from /usr/local/Ascend/latest/lib64/libge_common.so #2 0x0000ffffa29485d0 in ge::GeExecutor::FinalizeEx() () from /usr/local/Ascend/latest/lib64/libge_executor.so #3 0x0000ffffb06fabc in aclFinalize() from /usr/local/Ascend/latest/lib64/libascendcl.so #4 0x0000ffffbd5a98ec in ResourceManager::~ResourceManager() () from /home/miniconda3/envs/gly/lib/pythons3.7/site-packages/mindspore/_c_dataengine.cpython-37m-aarch64-linux-gnu.so #5 0x0000ffffbd5a9f80 in std::Sp_counted_ptr<ResourceManager*, (__gnu_cxx::Lock_policy)2>::_M_dispose() () from /home/miniconda3/envs/gly/lib/pythons3.7/site-packages/mindspore/_c_dataengine.cpython-37m-aarch64-linux-gnu.so #6 0x0000ffffbd5a97f0 in std::shared_ptr<ResourceManager>::~shared_ptr() () from /home/miniconda3/envs/gly/lib/pythons3.7/site-packages/mindspore/_c_dataengine.cpython-37m-aarch64-linux-gnu.so
注意,调试coredump文件、打印堆栈信息要在出现问题的运行环境中,如果换一套环境,可能导致调试的堆栈信息不准确。
若环境中未安装gdb,则需要安装gdb,可通过包管理(如apt-get install gdb、yum install gdb)进行安装,详细安装步骤及使用方法请参见GDB官方文档。
分析堆栈信息。
生成coredump文件、检查打印的堆栈信息后,发现应用程序在调用aclFinalize接口后异常退出,因此初步判断可能是aclFinalize接口使用问题。
排查应用程序代码中aclFinalize接口的调用逻辑。
排查代码逻辑,发现该aclFinalize接口在析构函数中被调用,但该接口存在使用约束:不建议在析构函数中调用aclFinalize接口,否则在进程退出时可能由于单例析构顺序未知而导致进程异常退出的问题。因此判断是由于在析构函数中调用aclFinalize接口导致应用进程coredump。
处理步骤
优化应用程序的代码逻辑,不能在析构函数中调用aclFinalize接口,下文给出正确、错误的代码示例。
aclFinalize接口的正确调用示例如下:
int main() { // 初始化 // 此处的..表示相对路径,相对可执行文件所在的目录,例如,编译出来的可执行文件存放在out目录下,此处的..就表示out目录的上一级目录 const char *aclConfigPath = "../src/acl.json"; aclError ret = aclInit(aclConfigPath); // 业务处理代码 // 去初始化,没有退出main函数,所有资源都可用 ret = aclFinalize(); return 0; }
aclFinalize接口的错误调用示例如下,使用单例析构去初始化:
class ResourceManager { public: ResourceManager() = default; // 单例析构 ~ResourceManager() { // 去初始化 (void) aclFinalize(); } // 单例构造 static ResourceManager &Instance() { static ResourceManager instance; return instance; } aclError Init() { // 初始化 // 此处的..表示相对路径,相对可执行文件所在的目录,例如,编译出来的可执行文件存放在out目录下,此处的..就表示out目录的上一级目录 const char *aclConfigPath = "../src/acl.json"; return aclInit(aclConfigPath); } }; int main() { // 初始化 aclError ret = ResourceManager::Instance().Init(); // 业务处理代码 // 没有显式去初始化,最后ResourceManager单例析构时调用aclFinalize // 由于单例析构是在main函数退出后才执行,单例析构和进程依赖so的卸载顺序无法控制 // 会出现aclFinalize访问的一些资源所在so已经被卸载,从而导致进程退出异常 return 0; }
aclFinalize接口的错误调用示例如下,使用全局变量析构去初始化:
class ResourceManager { public: ResourceManager() = default; // 全局变量析构 ~ResourceManager() { // 去初始化 (void) aclFinalize(); } aclError Init() { // 初始化 // 此处的..表示相对路径,相对可执行文件所在的目录,例如,编译出来的可执行文件存放在out目录下,此处的..就表示out目录的上一级目录 const char *aclConfigPath = "../src/acl.json"; return aclInit(aclConfigPath); } }; // 全局变量构造 ResourceManager g_resource_manager; int main() { // 初始化 aclError ret = g_resource_manager.Init(); // 业务处理代码 // 没有显式去初始化,最后ResourceManager全局变量析构时调用aclFinalize // 由于全局变量析构是在main函数退出后才执行,全局变量析构和进程依赖so的卸载顺序无法控制 // 会出现aclFinalize访问的一些资源所在so已经被卸载,从而导致进程退出异常 return 0; }
模型推理问题¶
使用dump功能未获取dump结果¶
问题现象描述
日志显示正确执行了Dump功能,但在Dump结果路径下没有Dump的结果。日志信息包含了以下关键字:
[INFO] ASCENDCL ****** "HandleDumpConfig end in HandleDumpConfig."
[INFO] ASCENDCL ****** "set HandleDumpConfig success in aclInit"
可能原因
分析上述日志信息,可能存在以下故障原因:Dump配置的模型名与实际的模型名不匹配。
处理步骤
针对分析的故障可能原因,可以参考下面步骤处理:
检查Dump配置文件acl.json,确保Dump配置文件合法,例如model_name是否配置正确。示例如下:
{
"dump":{
"dump_list":[
{
"model_name":"ResNet-50",
"layer":[
"convlconvl_relu"
]
},
{
"model_name":"mxnet-model"
}
],
"dump_mode":"output",
"dump_path":"/home/test/output/dump"
}
}
模型名称可以通过以下方式获取:
方式一:如果您安装了MindStudio,在MindStudio界面选择“Tools > Model Visualizer“菜单栏,选择.om模型文件,在显示该模型内容的面板空白处单击左键,此时右侧属性面板中显示模型名称属性“Model Name“,模型名称取该项对应值。
方式二:通过ATC命令生成模型的json文件,在json文件中查找“name“字段对应值,查找模型名称和算子名称,模型名称在"graph"字段外、算子名称在"graph"字段内。
注册算子数超过最大规格¶
问题现象描述
推理过程中,用户load model出现报错。
日志中包含ProgramRegister:Program register failed, program out of xxx和Register binary failed关键信息,日志示例如下:
[ERROR] RUNTIME(3093,rtstest_host):2021-06-09-02:30:34.400.124 [runtime.cc:967]3093 ProgramRegister:Program register failed, program out of 40000000
[ERROR] RUNTIME(3093,rtstest_host):2021-06-09-02:30:34.400.155 [logger.cc:23]3093 DevBinaryRegister:Register binary failed.
[ERROR] RUNTIME(3093,rtstest_host):2021-06-09-02:30:34.400.182 [api_c.cc:127]3093 rtDevBinaryRegister:ErrCode=507032, desc=[program register num out of use], InnerCode=0x7090007
[ERROR] RUNTIME(3093,rtstest_host):2021-06-09-02:30:34.400.185 [error_message_manage.cc:26]3093 ReportFuncErrorReason:rtDevBinaryRegister execute failed, reason=[program register num out of use]
可能原因
通过日志分析报错的原因可能是一个进程内算子等资源注册超过最大规格。
处理步骤
针对上述可能原因,可以按以下方式处理:
分析model,简化模型或者降低动态batch档次。
算子数是进程资源,model太大的情况下建议一个进程open一个device。
避免同一算子在不同模型中反复注册。
注册算子数不超过最大规格。
算子执行问题¶
算子插件未注册报错¶
问题现象描述
查看日志, 存在报错某个算子类型不支持:
Check op[%s]'s type[%s] failed, it is not supported.
或者
进行模型转换的时候,某个算子类型转换不符合预期,被转换成了frameworkop类型。
可能原因
根据日志分析,可能存在以下可能原因:
算子插件so未加载成功。
算子未注册映射关系,或者未编译到算子的插件so中。
解决措施
针对分析可能的故障原因,可以参考下面步骤处理:
确认算子插件so是否加载成功。
算子插件so加载成功打印类似信息:
plugin load /usr/local/Ascend/opp/built-in/framework/onnx/libops_all_onnx_plugin.so success.加载失败的告警关键信息:
dlopen failed, plugin name:%s. Message(%s).
如果算子插件so加载成功,则需要继续确认算子注册的映射关系是否编译进加载的插件so中了。
使用nm命令查看so符号表, 如果没有注册, 则需要注册该算子插件, 可以参考《TBE&AI CPU算子开发指南》中的“算子开发过程 > 算子适配”章节内容实现。
说明:
nm -D命令可查看so文件符号表。如果算子插件so未加载成功,参考失败告警中Message提示内容处理。
算子原型未注册报错¶
问题现象描述
查看日志, 存在报错某个算子没有原型定义:
op[%s] type[%s] have no ir factory.
或者
IR for op[%s] optype[%s] is not registered.
可能原因
根据日志分析,可能存在以下可能原因:
算子原型so未加载成功。
算子未定义注册该类型算子, 并编译到算子的原型so中。
解决措施
针对分析可能的故障原因,可以参考下面步骤处理:
确认算子原型so是否加载成功。
算子原型so加载成功打印类似信息:
OpsProtoManager plugin load /usr/local/Ascend/opp/built-in/op_proto/libopsproto.so success.加载失败的告警关键信息:
OpsProtoManager dlopen failed, plugin name:%s. Message(%s).
如果算子原型so加载成功, 需要确认算子原型定义是否编译进加载的so中了。
使用nm查看so符号表, 如果没有注册, 则需要注册该算子原型, 可以参考《TBE&AI CPU算子开发指南》中的“算子开发过程 > 算子原型定义”章节内容实现。
说明:
nm -D命令可查看so文件符号表。如果算子原型so未加载成功,参考失败告警中Message提示内容处理。
AI Core算子执行报错¶
问题现象描述
Runtime执行报错,在应用程序运行日志中Runtime打印了类似fault kernel_name和func_name的关键信息。
[ERROR] RUNTIME(4150867,msame):2022-09-22-09:27:46.403.262 [engine.cc:1103]4150867 ReportExceptProc:[EXEC][DEFAULT]Task exception! device_id=0, stream_id=20, task_id=1, type=13, retCode=0x91, [the model stream execute failed].
[ERROR] RUNTIME(4150867,msame):2022-09-22-09:27:46.404.423 [device_error_proc.cc:495]4150867 PrintCoreErrorInfo:[EXEC][DEFAULT]The error from device(0), serial number is 193, there is an aicore error, core id is 8, error code = 0x800000, dump info: pc start: 0x800120080047000, current: 0x1200800471cc, vec error info: 0x7cafc4e, mte error info: 0x3000052, ifu error info: 0xc33f87bd7a80, ccu error info: 0xffd2bbd5005fe9d7, cube error info: 0x84, biu error info: 0, aic error mask: 0x65000200d000288, para base: 0x120080016300, errorStr: The DDR address of the MTE instruction is out of range.
[ERROR] RUNTIME(4150867,msame):2022-09-22-09:27:46.404.443 [device_error_proc.cc:526]4150867 PrintCoreErrorInfo:[EXEC][DEFAULT]report error module_type=5, module_name=EZ9999
[ERROR] RUNTIME(4150867,msame):2022-09-22-09:27:46.404.449 [device_error_proc.cc:526]4150867 PrintCoreErrorInfo:[EXEC][DEFAULT]The extend info from device(0), serial number is 193, there is aicore error, core id is 8, aicore int: 0x10, aicore error2: 0, axi clamp ctrl: 0, axi clamp state: 0x1717, biu status0: 0x101d14000000000, biu status1: 0x80000201020000, clk gate mask: 0, dbg address: 0, ecc en: 0, mte ccu ecc 1bit error: 0x2e80000000000000, vector cube ecc 1bit error: 0, run stall: 0x1, dbg data0: 0, dbg data1: 0, dbg data2: 0, dbg data3: 0, dfx data: 0x8b
[ERROR] RUNTIME(4150867,msame):2022-09-22-09:27:46.404.607 [task.cc:1021]4150867 PrintErrorInfo:[EXEC][DEFAULT]Aicore kernel execute failed, device_id=0, stream_id=23, report_stream_id=20, task_id=24, flip_num=0, fault kernel_name=16805736118314619649-1_0_1_Add_35, func_name=te_add_729e2a87c649f49de98ac1a6fd491b3262ee7db9c1c2d6f4add7d7439aa3d22e_1__kernel0, program id=22, hash=3338199064661472585.
[ERROR] RUNTIME(4150867,msame):2022-09-22-09:27:46.404.618 [task.cc:3275]4150867 ReportErrorInfo:[EXEC][DEFAULT]model execute error, retCode=0x91, [the model stream execute failed].
[ERROR] RUNTIME(4150867,msame):2022-09-22-09:27:46.404.624 [task.cc:3247]4150867 PrintErrorInfo:[EXEC][DEFAULT]model execute task failed, device_id=0, model stream_id=20, model task_id=1, flip_num=0, model_id=3, first_task_id=65535
[ERROR] RUNTIME(4150867,msame):2022-09-22-09:27:46.404.714 [stream.cc:929]4150867 GetError:[EXEC][DEFAULT]Stream Synchronize failed, stream_id=20, retCode=0x91, [the model stream execute failed].
[ERROR] RUNTIME(4150867,msame):2022-09-22-09:27:46.404.742 [model.cc:581]4150867 SynchronizeExecute:[EXEC][DEFAULT]Fail to synchronize forbidden stream_id=20, retCode=0x7150050!
[ERROR] RUNTIME(4150867,msame):2022-09-22-09:27:46.404.748 [model.cc:605]4150867 GetStreamToSyncExecute:[EXEC][DEFAULT]report error module_type=0, module_name=EE9999
[ERROR] RUNTIME(4150867,msame):2022-09-22-09:27:46.404.753 [model.cc:605]4150867 GetStreamToSyncExecute:[EXEC][DEFAULT]Model synchronize execute failed, model_id=3!
[ERROR] RUNTIME(4150867,msame):2022-09-22-09:27:46.404.774 [logger.cc:856]4150867 ModelExecute:[EXEC][DEFAULT]Execute model failed.
[ERROR] RUNTIME(4150867,msame):2022-09-22-09:27:46.404.787 [api_c.cc:2063]4150867 rtModelExecute:[EXEC][DEFAULT]ErrCode=507011, desc=[the model stream execute failed], InnerCode=0x7150050
[ERROR] RUNTIME(4150867,msame):2022-09-22-09:27:46.404.793 [error_message_manage.cc:49]4150867 FuncErrorReason:[EXEC][DEFAULT]report error module_type=3, module_name=EE8888
[ERROR] RUNTIME(4150867,msame):2022-09-22-09:27:46.404.801 [error_message_manage.cc:49]4150867 FuncErrorReason:[EXEC][DEFAULT]rtModelExecute execute failed, reason=[the model stream execute failed]
可能原因
从日志报错可知,AI Core算子执行失败,可能算子本身代码问题:数据输入不匹配、访问越界、计算溢出等异常。
查阅plog日志,根据fault kernel_name和func_name可获取报错算子名称和报错函数名称。
[ERROR] RUNTIME(4150867,msame):2022-09-22-09:27:46.404.607 [task.cc:1021]4150867 PrintErrorInfo:[EXEC][DEFAULT]Aicore kernel execute failed, device_id=0, stream_id=23, report_stream_id=20, task_id=24, flip_num=0, fault kernel_name=16805736118314619649-1_0_1_Add_35, func_name=te_add_729e2a87c649f49de98ac1a6fd491b3262ee7db9c1c2d6f4add7d7439aa3d22e_1__kernel0, program id=22, hash=3338199064661472585.
处理步骤
该类型错误,需要联系技术支持定位排查。
可能导致的故障
模型下沉场景下,该问题可能导致acl接口报错Execute model failed,并打印在plog日志中。
[ERROR] ASCENDCL(4150867,msame):2022-09-22-09:27:46.404.834 [model.cpp:699]4150867 ModelExecute: [EXEC][DEFAULT][Exec][Model]Execute model failed, ge result[507011], modelId[1]
[ERROR] ASCENDCL(4150867,msame):2022-09-22-09:27:46.404.857 [model.cpp:1547]4150867 aclmdlExecute: [EXEC][DEFAULT][Exec][Model]modelId[1] execute failed, result[507011]
非模型下沉场景下,该问题可能导致算子执行失败,acl接口报错get op desc failed,Runtime报错Aicore kernel execute failed,并打印在plog日志中。
[ERROR] RUNTIME(2856615,xaclfk):2022-09-15-11:36:47.817.465 [task.cc:1058]2856939 PreCheckTaskErr:[EXEC][DEFAULT]Kernel task happen error, retCode=0x26, [aicore exception].
[ERROR] RUNTIME(2856615,xaclfk):2022-09-15-11:36:47.817.538 [task.cc:1029]2856939 PrintErrorInfo:[EXEC][DEFAULT]Aicore kernel execute failed, device_id=0, stream_id=0, report_stream_id=0, task_id=615, flip_num=0, fault kernel_name=12646006_1663210912148832_-1_0_while/transformer_0/decoder/layer_0/rnn/rnn/while/Select, func_name=te_select_7b314df6791292127cb82df985d04ddaf6d069cb31aaccec00e0b8ee2e997f20_1__kernel0, program id=131, hash=14736095126365135477.
[ERROR] GE(2856615,xaclfk):2022-09-15-11:36:47.818.283 [graph_execute.cc:557]2856939 GetOpDescInfo: ErrorNo: 4294967295(failed) [EXEC][DEFAULT][Get][OpDescInfo] failed, device_id:0, stream_id:0, task_id:615.
[ERROR] GE(2856615,xaclfk):2022-09-15-11:36:47.818.308 [ge_executor.cc:1332]2856939 GetOpDescInfo: ErrorNo: 4294967295(failed) [EXEC][DEFAULT][Get][OpDescInfo] failed, device_id:0, stream_id:0, task_id:615.
[ERROR] ASCENDCL(2856615,xaclfk):2022-09-15-11:36:47.818.315 [model.cpp:2216]2856939 aclmdlCreateAndGetOpDesc: [EXEC][DEFAULT][Get][OpDescInfo]get op desc failed, ge result[-1], deviceId[0], streamId[0], taskId[615]
AI CPU算子Kernel执行报错¶
问题现象描述
Runtime执行报错,在应用程序运行日志中Runtime打印了PrintAicpuErrorInfo的错误信息。
[ERROR] RUNTIME(16243,msame):2022-09-22-11:27:01.791.865 [engine.cc:1103]16282 ReportExceptProc:Task exception! device_id=0, stream_id=7, task_id=2, type=1, retCode=0x2a, [aicpu exception].
[ERROR] RUNTIME(16243,msame):2022-09-22-11:27:01.793.489 [device_error_proc.cc:669]16282 ProcessAicpuErrorInfo:report error module_type=0, module_name=E39999
[ERROR] RUNTIME(16243,msame):2022-09-22-11:27:01.793.498 [device_error_proc.cc:669]16282 ProcessAicpuErrorInfo:An exception occurred during AICPU execution, stream_id:7, task_id:2, errcode:5, msg:aicpu execute failed.
[ERROR] RUNTIME(16243,msame):2022-09-22-11:27:01.793.932 [task.cc:1050]16282 PreCheckTaskErr:report error module_type=5, module_name=EZ9999
[ERROR] RUNTIME(16243,msame):2022-09-22-11:27:01.793.941 [task.cc:1050]16282 PreCheckTaskErr:Kernel task happen error, retCode=0x2a, [aicpu exception].
[ERROR] RUNTIME(16243,msame):2022-09-22-11:27:01.793.981 [task.cc:759]16282 PrintAicpuErrorInfo:report error module_type=0, module_name=E39999
[ERROR] RUNTIME(16243,msame):2022-09-22-11:27:01.793.990 [task.cc:759]16282 PrintAicpuErrorInfo:Aicpu kernel execute failed, device_id=0, stream_id=7, task_id=2.
[ERROR] RUNTIME(16243,msame):2022-09-22-11:27:01.794.116 [task.cc:777]16282 PrintAicpuErrorInfo:Aicpu kernel execute failed, device_id=0, stream_id=7, task_id=2, flip_num=0, fault so_name=, fault kernel_name=, fault op_name=Unique, extend_info=(info_type:4, info_len:6, msg_info:Unique).
[ERROR] RUNTIME(16243,msame):2022-09-22-11:27:01.794.384 [stream.cc:929]16243 GetError:[EXEC][DEFAULT]Stream Synchronize failed, stream_id=7, retCode=0x2a, [aicpu exception].
[ERROR] RUNTIME(16243,msame):2022-09-22-11:27:01.794.407 [stream.cc:932]16243 GetError:[EXEC][DEFAULT]report error module_type=0, module_name=E39999
[ERROR] RUNTIME(16243,msame):2022-09-22-11:27:01.794.419 [stream.cc:932]16243 GetError:[EXEC][DEFAULT]Aicpu kernel execute failed, device_id=0, stream_id=7, task_id=2, flip_num=0, fault so_name=, fault kernel_name=, fault op_name=Unique, extend_info=(info_type:4, info_len:6, msg_info:Unique)
[ERROR] RUNTIME(16243,msame):2022-09-22-11:27:01.794.482 [logger.cc:305]16243 StreamSynchronize:[EXEC][DEFAULT]Stream synchronize failed, stream = 0x5643fe3e28d0
[ERROR] RUNTIME(16243,msame):2022-09-22-11:27:01.794.510 [api_c.cc:661]16243 rtStreamSynchronize:[EXEC][DEFAULT]ErrCode=507018, desc=[aicpu exception], InnerCode=0x715002a
[ERROR] RUNTIME(16243,msame):2022-09-22-11:27:01.794.519 [error_message_manage.cc:49]16243 FuncErrorReason:[EXEC][DEFAULT]report error module_type=3, module_name=EE8888
[ERROR] RUNTIME(16243,msame):2022-09-22-11:27:01.794.532 [error_message_manage.cc:49]16243 FuncErrorReason:[EXEC][DEFAULT]rtStreamSynchronize execute failed, reason=[aicpu exception]
可能原因
从日志报错可知,AI CPU算子执行失败,可能算子本身代码问题:**数据输入不匹配(例如数据格式、广播维度等)、访问越界、AI CPU线程挂死、算子执行超时(默认不超过30秒)**等问题。
若a.shape=(5, 1, 5, 1, 5, 1),b.shape=(5, 5, 5, 5, 5, 5),没有需要合并的轴,最后维度为6,广播报错。
若a.shape=(5, 1, 5, 5, 1, 1),b.shape=(5, 5, 5, 5, 5, 5),在第2和3维都不需要广播,4和5维都需要广播,分别连续合并,合并后的维度为4,广播成功。
比如通过查阅AI CPU的日志,排查具体报错原因。
样例1:UniqueExt算子输入数据维度不符合要求。
[ERROR] CCECPU(2309,aicpu_scheduler):2022-09-22-11:27:00.733.218 [aicpu_tf_kernel.cc:348][tid:2317][TFAdapter] AICPUKernelAndDevice::Run failure, kernel_id=0, op_name=Unique, op_type=UniqueExt, error=Invalid argument: unique expects a 1D vector. [ERROR] CCECPU(2309,aicpu_scheduler):2022-09-22-11:27:00.733.242 [tf_adpt_session_mgr.cc:74][tid:2317][TFAdapter] [sessionID:0] Failed to Run kernel, kernel_id=0. [ERROR] CCECPU(2309,aicpu_scheduler):2022-09-22-11:27:00.733.261 [tf_adpt_session_mgr.cc:434][tid:2317][TFAdapter] [sessionID:0] Run kernel on session failed. [ERROR] CCECPU(2309,aicpu_scheduler):2022-09-22-11:27:00.733.277 [tf_adpt_api.cc:85][tid:2317][TFAdapter] [sessionID:0] Invoke TFOperateAPI failed. [ERROR] CCECPU(2309,aicpu_scheduler):2022-09-22-11:27:00.733.296 [ae_kernel_lib_fwk.cc:229][TransformKernelErrorCode][tid:2317][AICPU_PROCESSER] Call tf api return failed:5, input param to tf api:0x124040017004 [ERROR] CCECPU(2309,aicpu_scheduler):2022-09-22-11:27:00.733.366 [aicpusd_event_process.cpp:1325][ExecuteTsKernelTask][tid:2317] Aicpu engine process failed, result[5].
样例2:BitwiseXor算子输入数据维度大于6维,不支持广播规则。
已知a.shape=[15,15,8,18,15,7,14],b.shape=[3,15,1,8,1,1,7,14],报错原因如下:
根据广播规则,首先a需要向b维度看齐,左侧补1,结果为a_new.shape[1,15,15,8,18,15,7,14]。
根据TensorFlow广播规则,a_new和b的第4和5维需要广播、第6和7维不需要广播,分别连续合并,合并后的维度为6,广播失败。
[ERROR] CCECPU(12226,aicpu_scheduler):2024-09-25-10:56:20.250.270 [aicpu_tf_kernel.cc:363][ProcessKernelRunOutput][tid:12236][TFAdapter]AICPUKernelAndDevice::Run failure, kernel_id=10000, op_name=BitwiseXor, op_type=BitwiseXor, error=UNIMPLEMENTED: Broadcast between [15,15,8,18,15,7,14] and [3,15,1,8,1,1,7,14] is not supported yet. [ERROR] CCECPU(12226,aicpu_scheduler):2024-09-25-10:56:20.250.315 [aicpu_tf_kernel_cache.cc:273][RunKernel][tid:12236][TFAdapter]Failed to Run kernel, kernel_id=10000. [ERROR] CCECPU(12226,aicpu_scheduler):2024-09-25-10:56:20.250.324 [tf_adpt_api.cc:86][APIInternalImpl][tid:12236][TFAdapter][sessionID:18446744073709551535] Invoke TFOperateAPI failed. [ERROR] CCECPU(12226,aicpu_scheduler):2024-09-25-10:56:20.250.334 [ae_kernel_lib_fwk.cc:352][TransformKernelErrorCode][tid:12236][AICPU_PROCESSER] Call tf api return failed:5, returncode:5, input param to tf api:0x12c100340004 [ERROR] CCECPU(12226,aicpu_scheduler):2024-09-25-10:56:20.250.346 [aicpusd_event_process.cpp:1690][PostProcessTsKernelTask][tid:12236] Aicpu engine process failed, result[5], opName[BitwiseXor].
样例3:RealDiv算子执行时间超时。
[ERROR] CCECPU(21711,aicpu_scheduler):2024-05-31-20:14:39.806.495 [aicpusd_monitor.cpp:437][HandleTaskTimeout][tid:21724] Send timeout to tsdaemon, tsdaemon will kill aicpu-sd process, thread index[2], op name[RealDiv], serialNo=279, stream_id=7, task_id=6812, nowTick:1846897065957, startTick:1845482875742, timeOut:1400000000, tickFreq:50000000.
处理步骤
根据报错信息检查算子代码是否正确,包括检查输入的数据维度/格式、是否越界、是否超时(参考处理步骤处理)等。
若仍无法解决请联系技术支持定位排查。
AI CPU算子维度超过8维报错¶
问题现象描述
GE执行报错,在应用程序运行日志中GE打印了ReportErrMessage的错误信息,且提示“shape dim num should be less than** **8”。
[ERROR] OP(1491846,main):2024-09-27-10:49:20.272.060 [aicpu_ext_info_handle.cpp:290][NNOP][UpdateShape][1491965] errno[561000] OpName:[aclnnGatherV2_0_GatherV2AiCPU] shape dim num should be less than 8, but got [9].
[INFO] GE(1491846,main):2024-09-27-10:49:20.272.133 [error_manager.cc:411]1491965 ReportErrMessage:report error_message, error_code:EZ9999, work_stream_id:149186091965, error_mode:0.
[ERROR] OP(1491846,main):2024-09-27-10:49:20.272.448 [aicpu_ext_info_handle.cpp:290][NNOP][UpdateShape][1491965] errno[561000] OpName:[aclnnGatherV2_0_GatherV2AiCPU] shape dim num should be less than 8, but got [9].
[INFO] GE(1491846,main):2024-09-27-10:49:20.272.473 [error_manager.cc:411]1491965 ReportErrMessage:report error_message, error_code:EZ9999, work_stream_id:149186091965, error_mode:0.
[ERROR] OP(1491846,main):2024-09-27-10:49:20.272.491 [aicpu_ext_info_handle.cpp:101][NNOP][AppendExtInfoShape][1491965] errno[561000] OpName:[aclnnGatherV2_0_GatherV2AiCPU] Assert ((UpdateShape(shape, &inputs[index])) == OK) failed
可能原因
AI CPU算子输入/输出参数的维度超过最大维度限制(8维)。
处理步骤
根据报错信息修改算子参数输入/输出维度,确保不超过8维。
若仍无法解决请联系技术支持定位排查。
AI CPU算子执行超时报错¶
问题现象描述
算子执行过程中,如果遇到下面任意一种报错,均属于算子执行超时报错。
现象1
当Runtime执行报错E39999,Host侧plog日志中Runtime打印了PrintAicpuErrorInfo错误信息,且提示“ErrCode=507018, desc=[aicpu exception]”.
进一步查看AI CPU的Device日志发现提示HandleTaskTimeout错误信息。
该现象与AI CPU算子Kernel执行报错中“可能原因 > 样例3”日志报错信息一样。
现象2
当Runtime执行报错,在应用程序日志中Runtime打印了PrintAicpuErrorInfo的错误信息,且提示“ErrCode=507017, desc=[aicpu timeout]”。
[ERROR] RUNTIME(16243,msame):2022-09-22-11:27:01.794.510 [api_c.cc:661]16243 rtStreamSynchronize:[EXEC][DEFAULT]ErrCode=507017, desc=[aicpu timeout], InnerCode=0x715002a
可能原因
算子的输入/输出Shape太大导致算子执行缓慢。
硬件性能较差,不足以支撑算子大量的复杂计算。
处理步骤
该类型的错误,可尝试使用aclrtSetOpExecuteTimeOut接口,适当调大算子执行的超时时间。
接口原型定义如下:
aclError aclrtSetOpExecuteTimeOut(uint32_t timeout) // timeout单位为秒若步骤1仍未能解决问题,可联系技术支持定位排查。
单算子匹配失败¶
问题现象描述
单算子执行过程中,出现匹配失败,日志显示如下类似信息。
离线加载执行场景:
EH9999 [Match][OpModel]failed to match model, opName = xxx Has not been compiled or loaded, Please make sure the op executed and the op compiled is matched, you can check the op type, op inputs number, outputs number, input format, origin format, datatype, memtype, attr, dim range, and so on.
在线加载执行场景:
EH9999 [Match][OpModel]MatchOpModel fail from static map or dynamic map. Please make sure the op executed and the op compiled is matched, you can check the op type, op inputs number, outputs number, input format, origin format, datatype, memtype, attr, dim range, and so on.
可能原因
离线场景:算子om文件未出现在aclSetModelDir中指定的路径下。
在线场景:一些特殊的匹配规则未适配,导致算子匹配失败。
处理步骤
离线场景:重新编译缺少的算子,并复制到aclSetModelDir中指定的路径下,余下步骤按离线单算子推理步骤进行。
在线场景:根据报错信息检查前后两次编译的算子的opType、dataType、format等信息是否一致。
执行单算子产生coredump的定位处理¶
问题现象描述
单算子执行结束,出现重复释放内存,导致coredump,屏幕显示关键日志信息:
double free or corruption(!prev)
可能原因
分析屏显日志信息,可能存在以下故障原因:代码中出现重复释放内存的操作。
处理步骤
通过gdb挂载可执行文件,通过查看栈信息做排查:
重复释放内存代码是否是用户自身代码bug,如果是则需修复代码bug。
提供栈信息。
具体步骤如下:
gdb挂载可执行文件。
执行gdb调试。
查看调用栈。
如果该问题非用户代码问题,需要联系技术支持定位排查。
算子库包版本问题导致加载单算子失败¶
问题现象描述
加载单算子报错失败,日志显示如下类似信息:
E19999: Inner Error
E19999 The opp version of the model does not match the current opp run package, Model is [6.4.T11.0.B300], opp run package is [7.0.T3.0.B107], try to convert the om again!
原因分析
动态Shape算子场景下,单算子模型数据加载环境中的算子库包安装版本(包名为CANN-opp-*-linux.*.run,命名中的*为版本号或架构类型)与om模型文件编译环境的算子库包安装版本不一致,导致加载算子时会报错。
解决措施
动态Shape算子场景下,单算子模型数据加载环境中的算子库包安装版本需与om模型文件编译环境的算子库包安装版本保持一致,出现该报错后,需排查安装版本,选择更换算子加载环境的opp包版本或更换编译算子om文件环境的opp包版本,若选择更换后者,则需要重新转换模型。
编译/执行AI应用问题¶
acl接口执行无输出无报错¶
问题现象描述
调用acl时,无接口报错,但是没得到预期结果。
可能原因
执行acl接口过程中链接到了stub中的so。
异步场景下,在拷贝输出数据时没有做流同步。
处理步骤
针对第一种情况:使用ldd命令查看执行文件链接的so是否正确,保证链接了有效的so。
针对第二种情况:对于异步接口,主机线程调用异步接口后仅代表下发任务,在任务未完成前,异步接口已向主机线程返回成功。用户需要调用显式同步接口(例如aclrtSynchronizeStream)阻塞主机线程,等待任务完成,否则可能会导致训练或推理等业务异常、Device断链掉卡等未知情况。
附录¶
使用约束¶
表 1 总体约束列表
分类 |
约束项 |
|---|---|
关于低功耗 |
进入系统休眠前,需要确保不下发AI推理、媒体数据处理等相关业务,或者退出业务进程。等待系统唤醒成功后,再继续下发业务或重启业务进程。 |
关于进程 |
|
关于创建类和销毁类接口 |
|
关于内存 |
|