
学习向导¶
本文档用于指导开发者如何使用ATC(Ascend Tensor Compiler,简称ATC)工具进行模型转换,得到适配NPU IP加速器的离线模型。通过本文档您可以达成以下目标:
了解不同框架原始网络模型转成NPU IP加速器离线模型的方法。
能够基于本文档中的参数,转成满足不同定制要求的离线模型。
熟悉Linux基本命令,对机器学习、深度学习有一定了解的人员,可以更好地理解本文档。
介绍ATC工具的初级功能,比如将模型转成JSON文件查看参数信息,离线模型支持动态BatchSize、动态分辨率,以及如何组合各种ATC参数转换成满足要求的离线模型等。 |
ATC简介¶
介绍ATC工具的功能架构以及使用ATC工具过程中遇到的一些术语或者缩略语。 ATC工具运行前需要准备环境和模型,本节给出ATC工具的运行流程以及和各组件的交互流程。
ATC工具介绍¶
介绍ATC工具的功能架构以及使用ATC工具过程中遇到的一些术语或者缩略语。
昇腾张量编译器(Ascend Tensor Compiler,简称ATC)是异构计算架构CANN体系下的模型转换工具,它可以将开源框架的网络模型以及Ascend IR定义的单算子描述文件(JSON格式)转换为NPU IP加速器支持的.om/exeom(IPV350)格式离线模型。其功能架构如图1所示。
模型转换过程中,ATC会进行算子调度优化、权重数据重排、内存使用优化等具体操作,对原始的深度学习模型进行进一步的调优,从而满足部署场景下的高性能需求,使其能够高效执行在NPU IP加速器上。
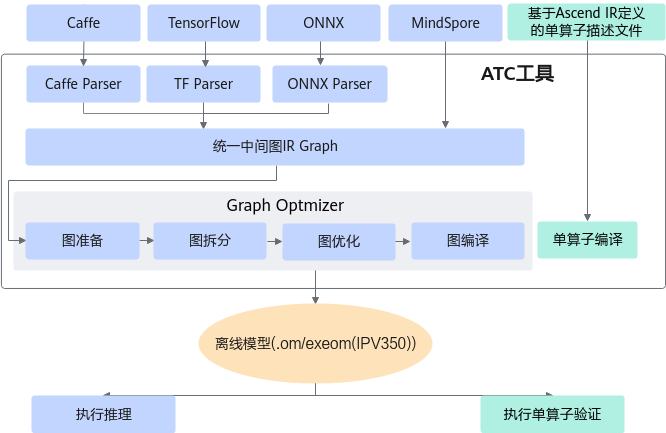
其中:
开源框架网络模型场景:
开源框架网络模型经过Parser解析后,转换为中间态IR Graph。
中间态IR经过图准备、图拆分、图优化、图编译等一系列操作后,转成适配NPU IP加速器的离线模型(此处图指网络模型拓扑图)。
转换后的离线模型上传到板端环境,通过AscendCL接口加载模型文件实现推理过程,详细流程请参见《AscendCL应用开发指南 (C&C++)》中的“模型管理”章节。
单算子描述文件场景:(该版本不支持单算子特性)
Ascend IR定义的单算子描述文件(JSON格式)通过ATC工具进行单算子编译后,转成适配NPU IP加速器的单算子离线模型,然后上传到板端环境,通过AscendCL接口加载单算子模型文件用于验证单算子功能,详细流程请参见《AscendCL应用开发指南 (C&C++)》中的“单算子调用 > 单算子模型执行”章节。
关于单算子描述文件的详细配置说明请参见单算子模型转换(该版本不支持单算子特性)章节。
表 1 概念介绍
Graph Engine,图引擎,是计算图编译和运行的控制中心,提供图优化、图编译管理以及图执行控制等功能。GE通过统一的图开发接口提供多种AI框架的支持,不同AI框架的计算图可以实现到Ascend图的转换。原图优化时,GE内部会进行整图优化。 |
|
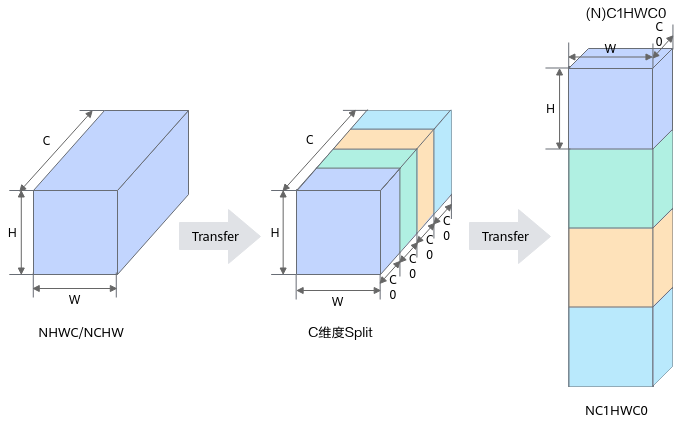
在深度学习框架中,多维数据通过多维数组存储,比如卷积神经网络的特征图(Feature Map)通常用四维数组保存,即4D,4D格式解释如下:
由于数据只能线性存储,因此这四个维度有对应的顺序。不同深度学习框架会按照不同的顺序存储特征图数据,比如TensorFlow中,排列顺序为[Batch, Height, Width, Channels],即NHWC。 如图2所示,以一张格式为RGB的图片为例,NCHW中,C排列在外层,每个通道内,像素紧挨在一起,实际存储的是“RRRRRRGGGGGGBBBBBB”,即同一通道的所有像素值顺序存储在一起;而NHWC中C排列在最内层,每个通道内,像素间隔挨在一起,实际存储的则是“RGBRGBRGBRGBRGBRGB”,即多个通道的同一位置的像素值顺序存储在一起。 |
|
NPU IP加速器中,为了提高通用矩阵乘法(GEMM)运算数据块的访问效率,所有张量数据统一采用NC1HWC0的五维数据格式。 其中C0与微架构强相关,是一个矩阵单元处理单边数据量,一个矩阵单元处理32B*32B的数据,单边是32B;例如数据类型为float16(2字节)时,C0=32/2=16,数据类型为float32(4字节)时,C0=32/4=8。 NHWC/NCHW -> NC1HWC0的转换过程为:将数据在C维度进行分割,变成C1份NHWC0/NC0HW,再将C1份NHWC0/NC0HW在内存中连续排列成NC1HWC0,其格式转换示意图如下图所示。 |
|
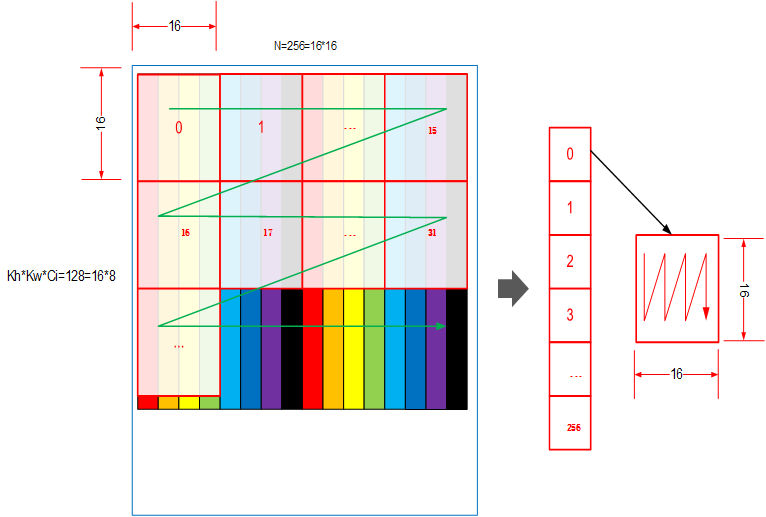
FRACTAL_Z是用于定义卷积权重的数据格式,由FT Matrix(FT:Filter,卷积核)变换得到。FRACTAL_Z是送往Cube的最终数据格式,采用“C1HW,N1,N0,C0”的4维数据排布。 第一层与Cube的Size相关,数据按照列的方向连续(小n);第二层与矩阵的Size相关,数据按照行的方向连续(大Z)。 例如:HWCN = (2, 2, 32, 32),将其变成FRACTAL_Z( C1HW, N1, N0, C0 ) = (8, 2, 16, 16)。 Tensor.padding([ [0,0], [0,0], [0,(C0–C%C0)%C0], [0,(N0–N%N0)%N0] ]).reshape( [H, W, C1, C0, N1, N0]).transpose( [2, 0, 1, 4, 5, 3] ).reshape( [C1*H*W, N1, N0, C0]) Tensor.padding([ [0,(N0–N%N0)%N0], [0,(C0–C%C0)%C0], [0,0], [0,0] ]).reshape( [N1, N0, C1, C0, H, W,]).transpose( [2, 4, 5, 0, 1, 3] ).reshape( [C1*H*W, N1, N0, C0]) |
|
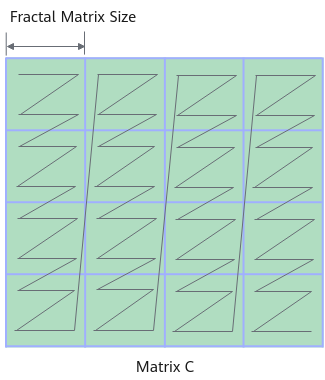
FRACTAL_NZ是分形格式,如Feature Map的数据存储,在cube单元计算时,输出矩阵的数据格式为NW1H1H0W0。整个矩阵被分为(H1*W1)个分形,按照column major排布,形状如N字形;每个分形内部有(H0*W0)个元素,按照row major排布,形状如z字形。考虑到数据排布格式,将NW1H1H0W0数据格式称为Nz(大N小z)格式。其中,H0,W0表示一个分形的大小,示意图如下所示: (..., N, H, W )->pad->(..., N, H1*H0, W1*W0)->reshape->(..., N, H1, H0, W1, W0)->transpose->(..., N, W1, H1, H0, W0) |
|

调用流程¶
ATC工具运行前需要准备环境和模型,本节给出ATC工具的运行流程以及和各组件的交互流程。
运行流程如图1所示。
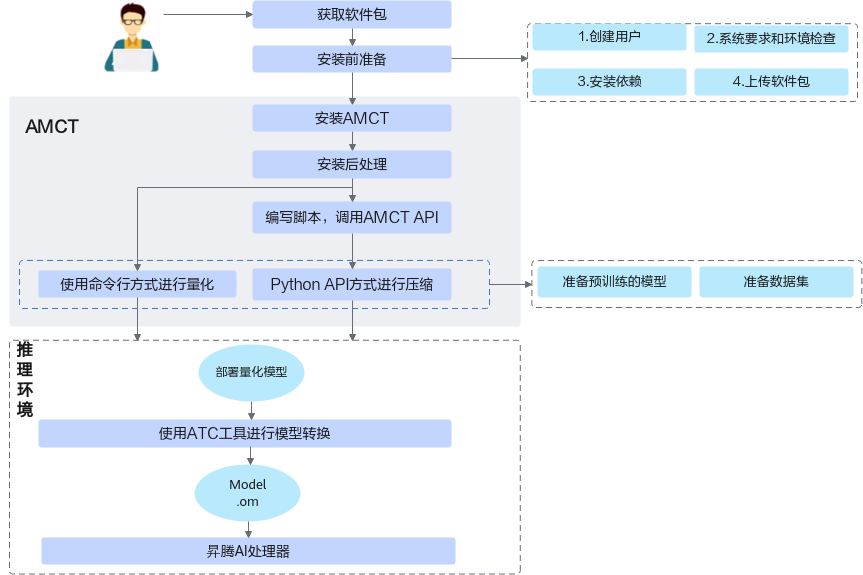
使用ATC工具之前,请先在开发环境安装CANN软件包,获取相关路径下的ATC工具,然后设置环境变量,详细说明请参见准备环境。
准备要进行转换的模型,并上传到开发环境。
使用ATC工具进行模型转换,模型转换过程中使用的参数请参见参数说明。
下面以开源框架网络模型转换为om离线模型为例,详细介绍模型转换过程中与周边模块的交互流程。
根据网络模型中算子计算单元的不同,分为AI Core算子和AI CPU算子:AI Core算子是指在NPU IP加速器的核心计算单元上执行的算子,而AI CPU算子则是在AI CPU计算单元上执行的算子。(该版本不支持AI CPU相关特性)
在AI Core算子、AI CPU算子的模型转换交互流程中,虽然都涉及图准备、图拆分、图优化、图编译等节点,但由于两者的计算单元不同,因此涉及交互的内部模块也有所不同,请参见下图。
关于算子类型、基本概念等详细介绍请参见《TBE&AI CPU算子开发指南》。如果用户使用的网络模型中有自定义算子,也请优先参见上述手册开发部署好自定义算子,模型转换时会优先去查找自定义算子库匹配模型文件中的算子;若匹配失败,则会去查找内置算子库。
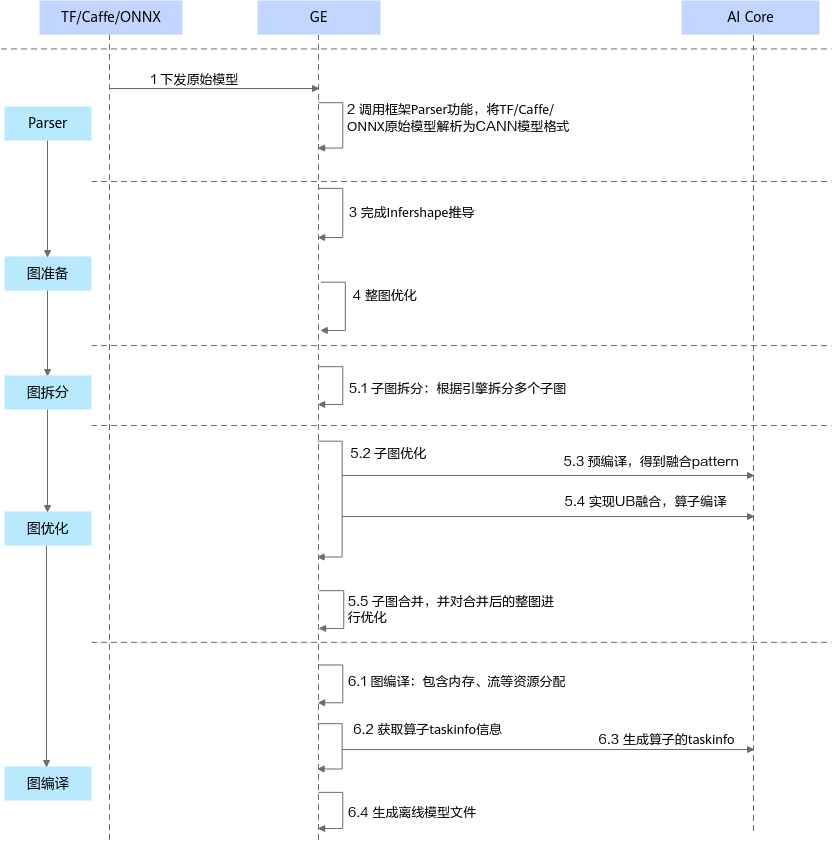
AI Core算子模型转换交互流程
调用框架Parser功能,将主流框架的模型格式转换成CANN模型格式。
图准备阶段:该阶段会完成原图优化以及Infershape推导(设置算子输出的shape和dtype)等功能。
图拆分阶段:GE(Graph Engine,图引擎)根据引擎拆分多个子图。
图优化阶段:GE将拆分后的子图进行优化,优化时按照当前子图流程对AI Core算子进行预编译和UB(Unified Buffer)融合,然后根据算子信息库中算子信息找到算子实现将其编译成算子kernel(算子的*.o与*.json),最后将优化后子图返回给GE。
优化后的子图合并为整图,再进行整图优化。
图编译阶段:GE进行图编译,包含内存分配、流资源分配等,图编译完成之后生成适配NPU IP加速器的离线模型文件(*.om/exeom(IPV350))。
准备环境¶
进行模型转换前,请先在开发环境安装CANN软件包,详情可参见《安装指南》,安装完成后,ATC工具安装在“${INSTALL_DIR}/bin”目录。其中,${INSTALL_DIR}请替换为CANN软件安装后文件存储路径。以root安装举例,安装后文件默认存储路径为:/usr/local/Ascend/latest。
须知:
使用export方式设置环境变量后,环境变量只在当前窗口有效。
使用ATC工具进行模型转换的过程中,会自动将ATC工具所在位置“../python/site-packages”目录下算子编译依赖的Python库写入PYTHONPATH环境变量。 若算子实现时用户引入了上述依赖外的其他Python依赖,请自行添加PYTHONPATH的环境变量,配置引入的Python依赖所在路径,如下所示: export PYTHONPATH=xxxx:$PYTHONPATH
必选环境变量
设置公共环境变量
安装CANN软件后,使用CANN运行用户进行编译、运行时,需要以CANN运行用户登录环境,执行如下环境变量:
source ${INSTALL_DIR}/bin/setenv.bash其中,${INSTALL_DIR}请替换为CANN软件安装后文件存储路径。以root安装举例,安装后文件默认存储路径为:/usr/local/Ascend/latest。
设置Python相关环境变量
模型编译依赖Python,以Python3.7.5为例,请以CANN软件包运行用户执行如下命令设置Python3.7.5相关环境变量。
#如果用户环境存在多个python3版本,则指定使用python3.7.5版本 export PATH=/usr/local/python3.7.5/bin:$PATH #设置python3.7.5库文件路径 export LD_LIBRARY_PATH=/usr/local/python3.7.5/lib:$LD_LIBRARY_PATH
上述环境变量只在当前窗口生效,用户可以将上述命令写入~/.bashrc文件,使其永久生效,方法如下:
以安装用户在任意目录下执行vi ~/.bashrc,在该文件最后添加上述内容。
保存文件中,执行source ~/.bashrc使环境变量生效。
可选环境变量
日志落盘、打屏与重定向。
日志重定向:
如果不想日志落盘,而是重定向到文件,则模型转换前需要设置上述的日志打屏环境变量,并且atc命令需要设置--log参数(不能设置为null),样例如下:
atc xxx --log=debug >log.txt
开启算子并行编译功能。
若网络模型较大,模型转换过程中,可设置如下环境变量,开启算子的并行编译功能。
export TE_PARALLEL_COMPILER=xxTE_PARALLEL_COMPILER的值代表算子编译进程数(配置为整数),取值范围为1~32,默认值为8,当取值大于1时开启算子的并行编译功能。建议不超过:CPU核数*80%/NPU IP加速器个数(IPV350无NPU加速器,加速器个数默认值为1)。其中NPU IP加速器个数查询方法如下(IPV350不支持):
在安装NPU IP加速器的环境中执行“npu-smi info -l”命令,回显信息中的Total Count即为对应的个数。
打印模型转换过程中各阶段的图描述信息。
export DUMP_GE_GRAPH=1上述环境变量控制dump图的内容多少,取值如下:
1:包含连边关系和数据信息的全量dump。
2:不含有权重等数据的基本版dump。
3:只显示节点关系的精简版dump。
设置上述环境变量后,还可以设置如下环境变量,控制dump图的个数。
export DUMP_GRAPH_LEVEL=2此环境变量只有在DUMP_GE_GRAPH开启时才生效,并且默认为2;支持如下两种配置方式,两种方式均是控制图落盘的个数,用户可以按需使用,注意两种配置方式不支持混合使用:
配置数值,取值如下:
1:dump所有图。
2:dump除子图外的所有图。
3:dump最后的生成图,即经过GE(Graph Engine,图引擎)优化、编译后的图。
4:dump最早的生成图,即经过GE解析映射算子后,给到软件栈的编译入口图,此时图结构尚未经过GE的编译优化。
配置按照|分隔的字符串,配置如下:
例如配置为"aa|bb",则表示dump出名称包含aa和bb的图,aa和bb需要指定为图编译流程中的合法字符串,合法字符串的获取可以从全量的dump图得到。
设置上述环境变量后,在执行atc命令的当前路径会生成如下文件:
ge_onnx*.pbtxt:基于ONNX的模型描述结构,可以使用Netron等可视化软件打开。
ge_proto*.txt:protobuf格式存储的文本文件,该文件可以转成JSON格式文件方便用户定位问题。该文件与ge_onnx*.pbtxt一般成对出现,但是ge_proto*.txt比ge_onnx*.pbtxt文件会多string类型的属性信息,因此ge_proto*.txt显示的更完整,用户选择其中一种文件打开即可。
由于ge_proto*.txt文件结构相比ge_onnx*.pbtxt已经做了文件大小的优化,因此DUMP_GE_GRAPH环境变量设置为2或3,对ge_proto*.txt文件效果相同,都显示为不含有权重等数据的基本版dump。
上述每个文件对应模型编译过程中的一个步骤,每个文件中包括完成该步骤所涉及的所有算子,关于dump图的详细信息请参见dump图详细信息。
更多可选环境变量请参见《环境变量参考》。
快速入门¶
本章节以各框架下模型转换为例,演示如何快速转换一个离线模型。
版本兼容性说明:
低版本的CANN软件包环境上转换出的离线模型,支持在高版本的CANN软件包环境上运行,兼容4个版本周期。
动态shape场景(IPV350不支持):若用户使用6.0.1之前的CANN版本进行的模型转换,无法在6.0.1及之后CANN版本进行推理,需要使用6.0.1及之后匹配的CANN版本重新进行模型转换。如果用户想查看已有离线模型使用的ATC工具等基础版本信息,则请参见借助离线模型查看软件基础版本号(IPV350不支持)。
如果模型转换时,用户使用了设置网络模型精度参数--precision_mode或--precision_mode_v2:
上述两个参数默认都为性能优先,后续推理时可能会导致精度溢出问题。如果推理时出现精度问题,可以参见《AscendCL应用开发指南 (C&C++)》手册的“精度/性能优化 > 模型推理精度提升建议”进行定位。
如果用户聚焦精度问题,可以修改为其他取值,比如--precision_mode设置为must_keep_origin_dtype或--precision_mode_v2设置为origin。
开源框架的TensorFlow网络模型转换成离线模型(IPV350不支持)
获取TensorFlow网络模型。
单击Link,根据页面提示获取ResNet50网络的模型文件(*.pb),并以CANN软件包运行用户将获取的文件上传至开发环境任意目录,例如上传到$HOME_/module__/_目录下。
执行如下命令生成离线模型。(如下命令中使用的目录以及文件均为样例,请以实际为准)
atc --model=$HOME/module/resnet50_tensorflow*.pb --framework=3 --output=$HOME/module/out/tf_resnet50 --soc_version=<soc_version>--model:ResNet50网络模型文件所在路径。
--framework:原始框架类型,3表示TensorFlow。
--output:生成的离线模型路径。
--soc_version:NPU IP加速器的型号。
关于参数的详细解释请参见参数说明,请使用与芯片名相对应的_<soc_version>_取值进行模型转换,然后再进行推理,具体使用芯片查询方法请参见--soc_version。
若提示如下信息,则说明模型转换成功。
ATC run success, welcome to the next use.成功执行命令后,在--output参数指定的路径下,可查看离线模型(如:tf_resnet50.om)。
获取ONNX网络模型。
单击Link进入ModelZoo页面,查看README.md中“快速上手>模型推理”章节获取*.onnx模型文件,再以CANN软件包运行用户将获取的文件上传至开发环境任意目录,例如上传到$HOME_/module__/_目录下。
执行如下命令生成离线模型。(如下命令中使用的目录以及文件均为样例,请以实际为准)
atc --model=$HOME/module/resnet50*.onnx --framework=5 --output=$HOME/module/out/onnx_resnet50 --soc_version=<soc_version>--model:Resnet50网络模型文件所在路径。
--framework:原始框架类型,5表示ONNX。
--output:生成的离线模型路径。
--soc_version:NPU IP加速器的型号。
关于参数的详细解释请参见参数说明,请使用与芯片名相对应的_<soc_version>_取值进行模型转换,然后再进行推理,具体使用芯片查询方法请参见--soc_version。
若提示如下信息,则说明模型转换成功。
ATC run success, welcome to the next use.成功执行命令后,在--output参数指定的路径下,可查看离线模型(如:onnx_resnet50.om)。
开源框架的Caffe网络模型转换成离线模型(IPV350不支持)
获取Caffe网络模型。
您可以从以下链接中获取ResNet-50网络的模型文件(*.prototxt)、权重文件(*.caffemodel),并以CANN软件包运行用户将获取的文件上传至开发环境任意目录,例如上传到$HOME_/module__/_目录下。
执行如下命令生成离线模型。(如下命令中使用的目录以及文件均为样例,请以实际为准)
atc --model=$HOME/module/resnet50.prototxt --weight=$HOME/module/resnet50.caffemodel --framework=0 --output=$HOME/module/out/caffe_resnet50 --soc_version=<soc_version>--model:ResNet-50网络模型文件所在路径。
--weight:ResNet-50网络权重文件所在路径。
--framework:原始框架类型,0表示Caffe。
--output:生成的离线模型路径。
--soc_version:NPU IP加速器的型号。
关于参数的详细解释请参见参数说明,请使用与芯片名相对应的_<soc_version>_取值进行模型转换,然后再进行推理,具体使用芯片查询方法请参见--soc_version。
若提示如下信息,则说明模型转换成功。
ATC run success, welcome to the next use.成功执行命令后,在--output参数指定的路径下,可查看离线模型(如:caffe_resnet50.om)。
初级功能¶
原始模型文件或离线模型转成JSON文件¶
如果用户不方便查看原始模型或离线模型的参数信息时,可以将原始模型或离线模型转成JSON文件进行查看。
本章节以TensorFlow框架ResNet50网络模型为例进行演示,单击Link,根据页面提示获取ResNet50网络模型文件(*.pb)。
原始模型文件转JSON文件
命令示例如下:
atc --mode=1 --om=$HOME/module/resnet50_tensorflow*.pb --json=$HOME/module/out/tf_resnet50.json --framework=3--mode:运行模式,1表示原始模型文件或离线模型转JSON,此处特指原始模型文件转JSON。
--om:指定ResNet50网络模型文件所在路径。
--json:转换为JSON格式的文件路径和文件名。
--framework:原始框架类型,3表示TensorFlow。
离线模型转JSON文件(IPV350不支持)
该场景的前提是用户根据开源框架的TensorFlow网络模型转换成离线模型(IPV350不支持)已经得到了om离线模型文件,命令示例如下:
atc --mode=1 --om=$HOME/module/out/tf_resnet50.om --json=$HOME/module/out/tf_resnet50.json--mode:运行模式,1表示原始模型文件或离线模型转JSON,此处特指离线模型文件转JSON。
--om:指定离线模型文件所在路径。
关于参数的详细解释请参见参数说明。若提示如下信息,则说明转换成功,。
ATC run success, welcome to the next use.
成功执行命令后,在--json参数指定的路径下,可查看转换后的JSON文件信息,如下为部分JSON片段:
{
"node": [
{
"attr": [
{
"key": "shape",
"value": {
"shape": {
"dim": [
{
"size": 1
},
{
"size": 224
},
{
"size": 224
},
{
"size": 3
}
]
}
}
},
{
"key": "dtype",
"value": {
"type": "DT_FLOAT"
}
}
],
"name": "Placeholder",
"op": "Placeholder"
},
离线模型支持动态BatchSize/动态分辨率¶
该版本不支持动态BatchSize和动态分辨率特性。
某些推理场景,如检测出目标后再执行目标识别网络,由于目标个数不固定导致目标识别网络输入BatchSize不固定。如果每次推理都按照最大的BatchSize或最大分辨率进行计算,会造成计算资源浪费。
为此,ATC工具提供了--dynamic_batch_size参数设置BatchSize档位;提供了--dynamic_image_size参数设置分辨率档位。
如下转换示例以TensorFlow框架ResNet50网络模型为例进行演示,单击Link,根据页面提示获取ResNet50网络的模型文件(*.pb)。
以CANN软件包运行用户登录开发环境,将模型文件(*.pb)上传到开发环境任意路径,例如上传到$HOME_/module__/_目录下。
执行如下命令生成离线模型。(如下命令中使用的目录以及文件均为样例,请以实际为准)
动态BatchSize
atc --model=$HOME/module/resnet50_tensorflow*.pb --framework=3 --output=$HOME/module/out/tf_resnet50 --soc_version=<soc_version> --input_shape="Placeholder:-1,224,224,3" --dynamic_batch_size="1,2,4,8"动态分辨率
atc --model=$HOME/module/resnet50_tensorflow*.pb --framework=3 --output=$HOME/module/out/tf_resnet50 --soc_version=<soc_version> --input_shape="Placeholder:1,-1,-1,3" --dynamic_image_size="224,224;448,448"
关键参数解释如下:
--dynamic_batch_size:设置动态BatchSize参数。
--dynamic_image_size:设置输入图片的动态分辨率参数。
--input_shape:指定模型输入数据的shape,配合--dynamic_batch_size或--dynamic_image_size参数使用。
--model:ResNet50网络模型文件所在路径。
--framework:原始框架类型,3表示TensorFlow。
关于参数的详细解释请参见参数说明。若提示如下信息,则说明模型转换成功,。
ATC run success, welcome to the next use.成功执行命令后,在--output参数指定的路径下,可查看离线模型(如:tf_resnet50.om)。
模型转换完成后,在生成的om/exeom(IPV350)离线模型中,会新增一个输入(如图1中红框中的Data输入),在模型推理时通过该新增的输入提供具体的Batch值(或分辨率值)。例如,a输入的BatchSize是动态的(或分辨率是动态的),在om离线模型中,会有与a对应的b输入来描述a的BatchSize(或分辨率取值)。
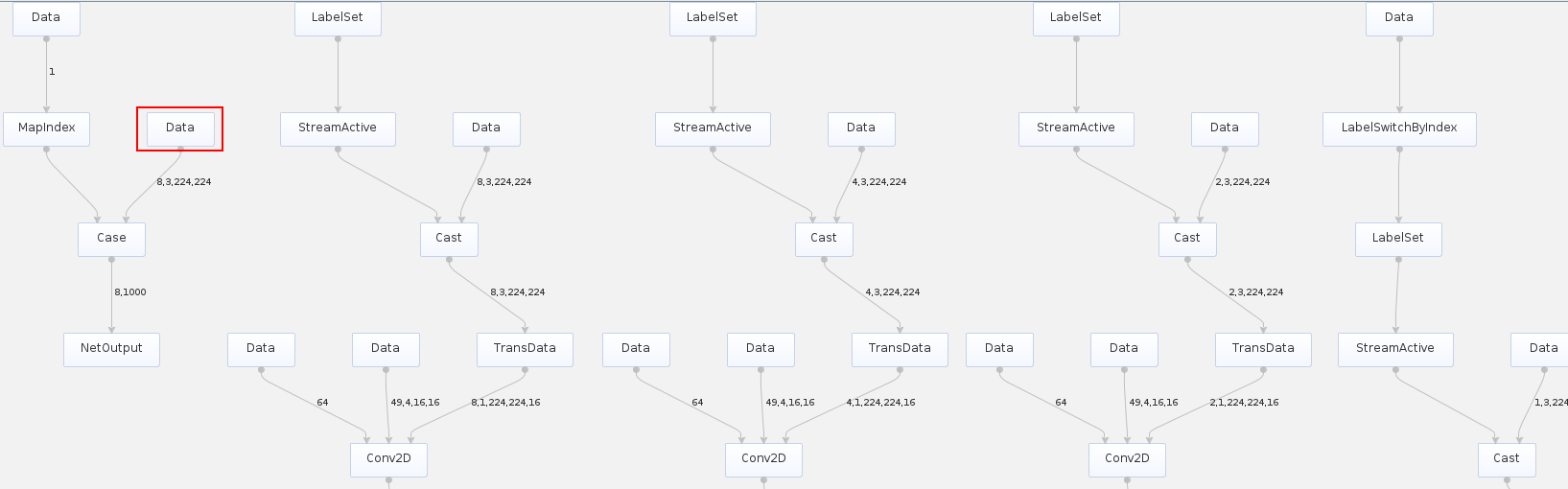
离线模型支持动态维度¶
该版本不支持动态维度特性。
为支持Transformer等网络模型在输入Tensor维度不确定的场景,ATC工具提供了--dynamic_dims参数实现ND格式下任意维度的档位设置。ND表示支持任意格式。
本章节以TensorFlow框架ResNet50网络模型为例进行演示,单击Link,根据页面提示获取ResNet50网络模型文件(*.pb)。
以CANN软件包运行用户登录开发环境,将模型文件上传到开发环境任意路径,例如上传到$HOME_/module__/_目录下。
执行如下命令生成离线模型。(如下命令中使用的目录以及文件均为样例,请以实际为准)
atc --model=$HOME/module/resnet50_tensorflow*.pb --framework=3 --output=$HOME/module/out/tf_resnet50 --soc_version=<soc_version> --input_shape="Placeholder:-1,-1,-1,3" --dynamic_dims="1,224,224;8,448,448" --input_format=ND关键参数解释如下:
--dynamic_dims:设置ND格式下动态维度档位。
--input_shape:指定模型输入数据的shape,配合--dynamic_dims参数使用。
--input_format:指定Format为ND格式。
--model:ResNet50网络模型文件所在路径。
--framework:原始框架类型,3表示TensorFlow。
关于参数的详细解释请参见参数说明。若提示如下信息,则说明模型转换成功,。
ATC run success, welcome to the next use.成功执行命令后,在--output参数指定的路径下,可查看离线模型。
模型转换完成后,在生成的om离线模型中,会新增一个输入(如图1中红框中的Data输入),在模型推理时通过该新增的输入提供具体的维度值。例如,a输入的维度为动态的,在om离线模型中,会有与a对应的b输入来描述a的维度值。
自定义离线模型的输入输出数据类型¶
模型转换时支持指定网络的输入节点、输出节点的DataType、Format、模型转换支持精度选择等关键参数。
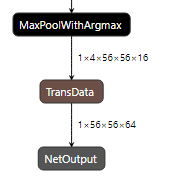
假如,针对TensorFlow框架ResNet-50网络模型,要求转换后离线模型的输入数据为Float16类型,指定_MaxPoolWithArgmax_算子作为输出算子(对应的节点名称为fp32_vars/MaxPoolWithArgmax),并且指定该输出节点的数据类型为FP16。该场景下就需要分别使用--input_fp16_nodes、--out_nodes、--output_type等参数来实现上述功能。
本章节以TensorFlow框架ResNet50网络模型为例进行演示,单击Link,根据页面提示获取ResNet50网络模型文件(*.pb)。
以CANN软件包运行用户登录开发环境,将模型文件(*.pb)上传到开发环境任意路径,例如上传到$HOME_/module__/_目录下。
执行如下命令生成离线模型。(如下命令中使用的目录以及文件均为样例,请以实际为准)
atc --model=$HOME/module/resnet50_tensorflow_1.7.pb --framework=3 --output=$HOME/module/out/tf_resnet50 --soc_version=<soc_version> --input_fp16_nodes="Placeholder" --out_nodes="fp32_vars/MaxPoolWithArgmax:0" --output_type="fp32_vars/MaxPoolWithArgmax:0:FP16"关键参数解释如下:
--input_fp16_nodes:指定输入数据类型为Float16。
--out_nodes:指定MaxPoolWithArgmax算子作为模型的输出。
--output_type:指定输出节点的数据类型为Float16。
--model:ResNet50网络模型文件所在路径。
--framework:原始框架类型,3表示TensorFlow。
关于参数的详细解释请参见参数说明。若提示如下信息,则说明模型转换成功,。
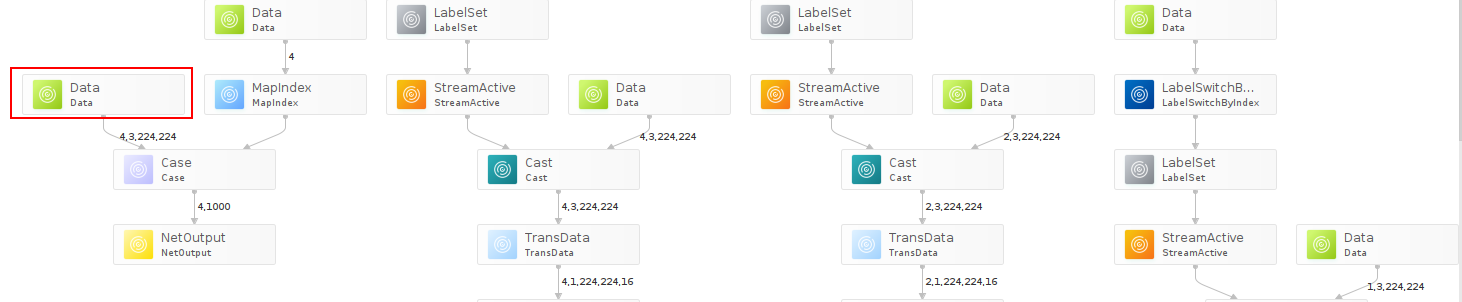
ATC run success, welcome to the next use.成功执行命令后,在output参数指定的路径下,可查看离线模型(如:tf_resnet50.om/exeom(IPV350))。图1为_MaxPoolWithArgmax_算子作为模型输出算子的示意图(下图使用Netron可视化软件打开)。
借助离线模型查看软件基础版本号(IPV350不支持)¶
不同CANN软件包版本,由于软件功能差异,所转换出的离线模型功能也有差异,该场景下建议用户使用匹配CANN软件版本的ATC工具重新进行模型转换。假如用户已有转换好的离线模型,想查看使用的CANN软件包基础版本号,则可以参见本章节完成。
获取已经转换好的离线模型,例如_tf_resnet50.om_,并以CANN软件包运行用户将其上传至开发环境任意目录,例如上传到$HOME_/module__/_目录下。
将离线模型转成JSON文件:
atc --mode=1 --om=$HOME/module/tf_resnet50.om --json=$HOME/module/out/tf_resnet50.json--om:指定离线模型文件_tf_resnet50.om_所在路径。
--json:转换为JSON格式的文件路径和文件名。
在转换后的JSON文件中,可以查看原始模型转换为离线模型时,使用的基础版本号,示例如下(如下为部分JSON片段),_<version>_即为展示的版本号信息:
{ "key": "opp_version", "value": { "s": "<version>" } }, ... ... { "key": "atc_version", "value": { "s": "<version>" } }, ... ... { "key": "atc_cmdline", "value": { "s": "xxx/atc.bin --model ./resnet50_tensorflow*.pb --framework 3 --output ./out/tf_resnet50 --soc_version <soc_version>" } }, ... ... { "key": "soc_version", "value": { "s": "<soc_version>" } },
高级功能¶
AIPP使能**(该版本不支持AIPP特性)**¶
本节介绍什么是AIPP,AIPP分类以及包括的特性。
通过在模型转换过程中开启AIPP功能,可以在推理之前就完成所有的数据处理;由于用的是专门的加速模块实现并保证性能,从而可以不让图像处理成为推理阶段的瓶颈,图像处理方式比较灵活。本章节给出如何在模型转换阶段开启AIPP功能。 AIPP提供了更为方便的图像格式转换方式:色域转换,用于将输入的图片格式,转换为模型需要的图片格式,一旦确认了AIPP处理前与AIPP处理后的图片格式,即可确定色域转换相关的参数值(matrix_r*c*配置项的值是固定的,不需要调整)。 归一化就是要把需要处理的数据经过处理后限制在一定范围内,方便后面数据的处理。AIPP支持的归一化设置,通过减均值和乘系数的操作完成,这样的能力不仅能用于常规的归一化,还能用于不同数据格式的转化。
如果有配置AIPP,无论静态AIPP还是动态AIPP,最终生成离线模型的输入大小(即input_size)均会被Crop、Padding等操作影响。本节给出对模型输入大小的约束说明。 AIPP配置文件通过本章节给出的模板进行配置,内容需要满足prototxt格式,用户根据场景决定配置哪些参数,修改为合适的取值另存后供模型转换使用;使用配置模板之前需要先查看相关约束。
什么是AIPP¶
本节介绍什么是AIPP,AIPP分类以及包括的特性。
该版本不支持AIPP特性。
AIPP(Artificial Intelligence Pre-Processing)人工智能预处理,用于在AI Core上完成数据预处理,包括改变图像尺寸、色域转换(转换图像格式)、减均值/乘系数(改变图像像素),数据预处理之后再进行真正的模型推理。
AIPP根据配置方式不同,分为静态AIPP和动态AIPP;如果要将原始图片输出为满足推理要求的图片格式,则需要使用色域转换功能;如果要输出固定大小的图片,则需要使用AIPP提供的Crop(抠图)、Padding(补边)功能。
在使能AIPP功能时,您只能选择静态AIPP或动态AIPP方式来处理图片,不能同时配置静态AIPP和动态AIPP两种方式,使能AIPP时可以通过aipp_mode参数控制。具体配置示例请参见AIPP配置示例,关于参数解释请参见配置文件模板。
静态AIPP:模型转换时设置AIPP模式为静态,同时设置AIPP参数,模型生成后,AIPP参数值被保存在离线模型中,每次模型推理过程采用固定的AIPP预处理参数进行处理,而且在之后的推理过程中无法通过业务代码进行直接的修改。
如果使用静态AIPP方式,多batch情况下共用同一份AIPP参数。
动态AIPP:模型转换时设置AIPP模式为动态,每次在执行推理前,根据需求动态修改AIPP参数值,然后在模型执行时可使用不同的AIPP参数。动态AIPP参数值会根据需求在不同的业务场景下选用合适的参数(如不同摄像头采用不同的归一化参数,输入图片格式需要兼容YUV420和RGB等)。
如果模型转换时设置了动态AIPP,则使用应用工程进行模型推理时,需要在AscendCL提供的aclmdlExecute接口之前,调用aclmdlSetInputAIPP接口,设置模型推理的动态AIPP数据。接口详细说明请参见《AscendCL应用开发指南 (C&C++)》手册中的“acl API参考 > 模型管理 > 模型执行”。
如果使用动态AIPP方式,多batch使用不同的参数,体现在动态参数结构体中,每个batch可以配置不同的crop等参数。关于动态参数结构体,请参见动态AIPP的参数输入结构。
色域转换,用于将输入的图片格式,转换为模型需要的图片格式,在使能AIPP功能时,通过csc_switch参数控制色域转换功能是否开启,参数解释请参见配置文件模板。
一旦确认了AIPP处理前与AIPP处理后的图片格式,即可确定色域转换其他相关的参数值,本文提供相关模板可以供用户使用,无需再次修改,配置示例请参见色域转换配置说明。
AIPP功能中的改变图像尺寸操作由Crop(抠图)、Padding(补边)完成,分别对应配置模板中的crop、padding参数。参数解释请参见配置文件模板。
关于该功能的详细说明以及AIPP参数配置示例请参见Crop/Padding配置说明。
AIPP配置示例¶
AIPP配置文件支持定义多组AIPP配置,对不同的模型输入进行不同的AIPP处理,配置多组AIPP参数时,将一组AIPP配置放到一个aipp_op配置项里;如果模型只有一个输入,则只需要配置第一组aipp_op即可。 AIPP配置文件支持定义多组AIPP配置,对不同的模型输入进行不同的AIPP处理,配置多组AIPP参数时,将一组AIPP配置放到一个aipp_op配置项里;如果模型只有一个输入,则只需要配置第一组aipp_op即可。
静态AIPP配置示例¶
AIPP配置文件支持定义多组AIPP配置,对不同的模型输入进行不同的AIPP处理,配置多组AIPP参数时,将一组AIPP配置放到一个aipp_op配置项里;如果模型只有一个输入,则只需要配置第一组aipp_op即可。
如下示例以网络模型为多输入时进行说明:
静态AIPP+动态shape场景:模型转换时,通过--insert_op_conf参数设置了静态AIPP,又通过--input_shape设置了动态shape,则: 如果模型只有一个输入,该场景不支持;如果模型有多个输入,则必须对不同的输入节点进行设置,比如一个输入节点设置静态AIPP,另外一个节点设置动态shape。
如果模型转换时,用户设置了--dynamic_image_size动态分辨率参数,即输入图片的宽和高不确定,同时又通过--insert_op_conf参数设置了静态AIPP功能:该场景下,AIPP配置文件中不能开启Crop和Padding功能,并且需要将配置文件中的src_image_size_w和src_image_size_h取值设置为0。
使用related_input_rank参数标识,对模型第几个输入进行AIPP处理,如下配置定义了两组AIPP参数,分别对模型第一个和第二个输入进行AIPP处理:
aipp_op { aipp_mode : static related_input_rank : 0 # 标识对第1个输入进行AIPP处理 src_image_size_w : 608 src_image_size_h : 608 crop : false input_format : YUV420SP_U8 csc_switch : true rbuv_swap_switch : false matrix_r0c0 : 298 matrix_r0c1 : 0 matrix_r0c2 : 409 matrix_r1c0 : 298 matrix_r1c1 : -100 matrix_r1c2 : -208 matrix_r2c0 : 298 matrix_r2c1 : 516 matrix_r2c2 : 0 input_bias_0 : 16 input_bias_1 : 128 input_bias_2 : 128 mean_chn_0 : 104 mean_chn_1 : 117 mean_chn_2 : 123 } aipp_op { aipp_mode : static related_input_rank : 1 # 标识对第2个输入进行AIPP处理 src_image_size_w : 608 src_image_size_h : 608 crop : false input_format : YUV420SP_U8 csc_switch : true rbuv_swap_switch : false matrix_r0c0 : 298 matrix_r0c1 : 0 matrix_r0c2 : 409 matrix_r1c0 : 298 matrix_r1c1 : -100 matrix_r1c2 : -208 matrix_r2c0 : 298 matrix_r2c1 : 516 matrix_r2c2 : 0 input_bias_0 : 16 input_bias_1 : 128 input_bias_2 : 128 mean_chn_0 : 104 mean_chn_1 : 117 mean_chn_2 : 123 }
动态AIPP配置示例¶
AIPP配置文件支持定义多组AIPP配置,对不同的模型输入进行不同的AIPP处理,配置多组AIPP参数时,将一组AIPP配置放到一个aipp_op配置项里;如果模型只有一个输入,则只需要配置第一组aipp_op即可。
如下示例以网络模型为多输入时进行说明。
如果模型转换时,用户设置了--dynamic_batch_size动态Batch档位参数,同时又通过--insert_op_conf参数配置了动态AIPP功能: 实际推理时,调用aclmdlSetInputAIPP接口,设置动态AIPP相关参数值时,需确保batchSize要设置为最大Batch数。接口详细说明请参见《AscendCL应用开发指南 (C&C++)》手册中的“acl API参考 > 模型管理 > 模型执行 > aclmdlSetInputAIPP”。
如果模型转换时,用户设置了--dynamic_image_size动态分辨率参数,同时又通过--insert_op_conf参数配置了动态AIPP功能: 实际推理时,调用aclmdlSetInputAIPP接口,设置动态AIPP相关参数值时,不能开启Crop和Padding功能。该场景下,还需要确保通过aclmdlSetInputAIPP接口设置的宽和高与aclmdlSetDynamicHWSize接口设置的宽、高相等,都必须设置成动态分辨率最大档位的宽、高。接口详细说明请参见《AscendCL应用开发指南 (C&C++)》手册中的“acl API参考 > 模型管理 > 模型执行”章节。
如果模型转换时,用户设置了--input_shape动态shape范围参数,同时又通过--insert_op_conf参数配置了AIPP功能,则AIPP输出的宽和高要在--input_shape所设置的范围内。
动态AIPP场景下,用户无需手动配置csc_switch、rbuv_swap_switch等参数,根据如下配置文件配置好相关参数后,模型转换时,ATC会为动态AIPP新增一个模型输入(以下简称AippData)。
实际推理时,需要调用aclmdlSetInputAIPP接口,设置动态AIPP相关参数值,然后传给上述新增的AippData,AippData根据传入的参数值构造的结构体为动态AIPP的参数输入结构,该结构体无需用户手动处理。接口详细说明请参见《AscendCL应用开发指南 (C&C++)》手册中的“acl API参考 > 模型管理 > 模型执行 > aclmdlSetInputAIPP”。
aipp_op
{
aipp_mode: dynamic
related_input_rank: 0 # 标识对第1个输入进行AIPP处理
max_src_image_size: 752640 # 输入图像最大的size,参数必填
}
aipp_op
{
aipp_mode: dynamic
related_input_rank: 1 # 标识对第2个输入进行AIPP处理
max_src_image_size: 752640 # 输入图像最大的size,参数必填
}
根据配置示例配置好动态AIPP文件后,模型推理时为动态AIPP新增模型输入(AippData)传入参数值后,自动形成的结构体如下,该结构体无需用户手动处理:
typedef struct tagAippDynamicBatchPara
{
int8_t cropSwitch; //crop switch
int8_t scfSwitch; //resize switch
int8_t paddingSwitch; // 0: unable padding,
// 1: padding config value,sfr_filling_hblank_ch0 ~ sfr_filling_hblank_ch2
// 2: padding source picture data, single row/collumn copy
// 3: padding source picture data, block copy
// 4: padding source picture data, mirror copy
int8_t rotateSwitch; //rotate switch,0: non-rotate,1: rotate 90°clockwise,2: rotate 180°clockwise,3: rotate 270° clockwise
int8_t reserve[4];
int32_t cropStartPosW; //the start horizontal position of cropping
int32_t cropStartPosH; //the start vertical position of cropping
int32_t cropSizeW; //crop width
int32_t cropSizeH; //crop height
int32_t scfInputSizeW; //input width of scf
int32_t scfInputSizeH; //input height of scf
int32_t scfOutputSizeW; //output width of scf
int32_t scfOutputSizeH; //output height of scf
int32_t paddingSizeTop; //top padding size
int32_t paddingSizeBottom; //bottom padding size
int32_t paddingSizeLeft; //left padding size
int32_t paddingSizeRight; //right padding size
int16_t dtcPixelMeanChn0; //mean value of channel 0
int16_t dtcPixelMeanChn1; //mean value of channel 1
int16_t dtcPixelMeanChn2; //mean value of channel 2
int16_t dtcPixelMeanChn3; //mean value of channel 3
uint16_t dtcPixelMinChn0; //min value of channel 0
uint16_t dtcPixelMinChn1; //min value of channel 1
uint16_t dtcPixelMinChn2; //min value of channel 2
uint16_t dtcPixelMinChn3; //min value of channel 3
uint16_t dtcPixelVarReciChn0; //sfr_dtc_pixel_variance_reci_ch0
uint16_t dtcPixelVarReciChn1; //sfr_dtc_pixel_variance_reci_ch1
uint16_t dtcPixelVarReciChn2; //sfr_dtc_pixel_variance_reci_ch2
uint16_t dtcPixelVarReciChn3; //sfr_dtc_pixel_variance_reci_ch3
int8_t reserve1[16]; //32B assign, for ub copy
}kAippDynamicBatchPara;
typedef struct tagAippDynamicPara
{
uint8_t inputFormat; //input format:YUV420SP_U8/XRGB8888_U8/RGB888_U8
//uint8_t outDataType; //output data type: CC_DATA_HALF,CC_DATA_INT8, CC_DATA_UINT8
int8_t cscSwitch; //csc switch
int8_t rbuvSwapSwitch; //rb/ub swap switch
int8_t axSwapSwitch; //RGBA->ARGB, YUVA->AYUV swap switch
int8_t batchNum; //batch parameter number
int8_t reserve1[3];
int32_t srcImageSizeW; //source image width
int32_t srcImageSizeH; //source image height
int16_t cscMatrixR0C0; //csc_matrix_r0_c0
int16_t cscMatrixR0C1; //csc_matrix_r0_c1
int16_t cscMatrixR0C2; //csc_matrix_r0_c2
int16_t cscMatrixR1C0; //csc_matrix_r1_c0
int16_t cscMatrixR1C1; //csc_matrix_r1_c1
int16_t cscMatrixR1C2; //csc_matrix_r1_c2
int16_t cscMatrixR2C0; //csc_matrix_r2_c0
int16_t cscMatrixR2C1; //csc_matrix_r2_c1
int16_t cscMatrixR2C2; //csc_matrix_r2_c2
int16_t reserve2[3];
uint8_t cscOutputBiasR0; //output bias for RGB to YUV, element of row 0, unsigned number
uint8_t cscOutputBiasR1; //output bias for RGB to YUV, element of row 1, unsigned number
uint8_t cscOutputBiasR2; //output bias for RGB to YUV, element of row 2, unsigned number
uint8_t cscInputBiasR0; //input bias for YUV to RGB, element of row 0, unsigned number
uint8_t cscInputBiasR1; //input bias for YUV to RGB, element of row 1, unsigned number
uint8_t cscInputBiasR2; //input bias for YUV to RGB, element of row 2, unsigned number
uint8_t reserve3[2];
int8_t reserve4[16]; //32B assign, for ub copy
kAippDynamicBatchPara aippBatchPara; //allow transfer several batch para.
} kAippDynamicPara;
如何使能AIPP¶
通过在模型转换过程中开启AIPP功能,可以在推理之前就完成所有的数据处理;由于用的是专门的加速模块实现并保证性能,从而可以不让图像处理成为推理阶段的瓶颈,图像处理方式比较灵活。本章节给出如何在模型转换阶段开启AIPP功能。
本章节以TensorFlow框架ResNet50网络模型为例,演示如何通过模型转换使能静态AIPP功能,使能AIPP功能后,若实际提供给模型推理的测试图片不满足要求(包括图片格式,图片尺寸等),经过模型转换后,会输出满足模型要求的图片,并将该信息固化到转换后的离线模型中(模型转换后AIPP功能会以Aipp算子形式插入离线模型中)。
ResNet50网络模型要求的图片格式为RGB,图片尺寸为224*224,另外,假设提供给模型推理的测试图片尺寸为250*250,图片格式为YUV420SP,有效数据区域从左上角(0, 0)像素开始,使能AIPP过程中所需操作如表1分析所示。
表 1 场景分析
该场景下需要开启AIPP的色域转换功能,将YUV420SP格式转成模型要求的RGB格式,关于色域转换功能详细说明请参见色域转换配置说明。 |
|||
提供的测试图片尺寸250*250大于224*224,该场景下需要开启AIPP抠图功能,并且抠图起始位置水平、垂直方向坐标load_start_pos_h、load_start_pos_w为0,执行推理时,将从(0, 0)点开始选取224*224区域的数据。 |
详细实现步骤如下:
获取TensorFlow网络模型。
单击Link,根据页面提示获取ResNet50网络的模型文件(*.pb),并以CANN软件包运行用户将获取的文件上传至开发环境任意目录,例如上传到$HOME_/module__/_目录下。
构造AIPP配置文件_insert_op.cfg_。
静态AIPP配置模板主要由如下几部分组成:AIPP配置模式(静态AIPP或者动态AIPP),原始图片信息(包括图片格式,以及图片尺寸),改变图片尺寸(抠图,补边)、色域转换功能等,如下分别介绍如何进行配置。
AIPP配置模式由aipp_mode参数决定,静态场景下的配置示例如下:
aipp_mode : static #static表示配置为静态AIPP配置原始图片信息。
input_format : YUV420SP_U8 #输入给AIPP的原始图片格式 src_image_size_w : 250 #输入给AIPP的原始图片宽高 src_image_size_h : 250
改变图片尺寸。
改变图片尺寸由抠图和补边等功能完成,本示例需要配置抠图起始位置,抠图后的图片大小等信息,若抠图后图片尺寸仍旧不满足模型要求,还需要配置补边功能。
而AIPP提供了更为方便的配置方式,就是若开启抠图功能,并且不配置补边功能,抠图大小可以取值为0或者不配置,此时抠图大小的宽和高来自模型--input_shape中的宽和高。本示例中我们不配置抠图大小,配置示例如下:
crop: true #抠图开关,用于改变图片尺寸 load_start_pos_h: 0 #抠图起始位置水平、垂直方向坐标 load_start_pos_w: 0
色域转换功能。
色域转换功能由csc_switch参数控制,并通过色域转换系数matrix_r*c*、通道交换rbuv_swap_switch等参数配合使用。AIPP提供了一个比较方便的功能,就是一旦确认了AIPP处理前与AIPP处理后的图片格式,即可确定色域转换相关的参数值,用户无需修改,即上述参数都可以直接从模板中进行复制,模板示例以及更多配置模板请参见色域转换配置说明。如下为该场景下的配置示例:
csc_switch : true #色域转换开关,true表示开启色域转换 rbuv_swap_switch : false #通道交换开关(R通道与B通道交换开关/U通道与V通道交换),本例中不涉及两个通道的交换,故设置为false,默认为false matrix_r0c0 : 256 #色域转换系数 matrix_r0c1 : 0 matrix_r0c2 : 359 matrix_r1c0 : 256 matrix_r1c1 : -88 matrix_r1c2 : -183 matrix_r2c0 : 256 matrix_r2c1 : 454 matrix_r2c2 : 0 input_bias_0 : 0 input_bias_1 : 128 input_bias_2 : 128
将上述所有的参数组合到_insert_op.cfg_文件中,即为我们需要构造的AIPP配置文件,完整示例如下:
aipp_op { aipp_mode : static #AIPP配置模式 input_format : YUV420SP_U8 #输入给AIPP的原始图片格式 src_image_size_w : 250 #输入给AIPP的原始图片宽高 src_image_size_h : 250 crop: true #抠图开关,用于改变图片尺寸 load_start_pos_h: 0 #抠图起始位置水平、垂直方向坐标 load_start_pos_w: 0 csc_switch : true #色域转换开关,true表示开启色域转换 rbuv_swap_switch : false #通道交换开关 matrix_r0c0 : 256 #色域转换系数,用户无需修改 matrix_r0c1 : 0 matrix_r0c2 : 359 matrix_r1c0 : 256 matrix_r1c1 : -88 matrix_r1c2 : -183 matrix_r2c0 : 256 matrix_r2c1 : 454 matrix_r2c2 : 0 input_bias_0 : 0 input_bias_1 : 128 input_bias_2 : 128 }
您可以根据AIPP配置示例或典型场景样例参考章节获取更多场景AIPP配置示例,如果上述示例仍旧无法满足要求,则需要参见配置文件模板自行构造配置文件。将上述_insert_op.cfg_文件上传到ATC工具所在Linux服务器。
atc命令中加入--insert_op_conf参数,用于插入aipp预处理算子,执行如下命令生成离线模型。(如下命令中使用的目录以及文件均为样例,请以实际为准)
atc --model=$HOME/module/resnet50_tensorflow*.pb --framework=3 --output=$HOME/module/out/tf_resnet50 --soc_version=<soc_version> --insert_op_conf=$HOME/module/insert_op.cfg关于参数的详细解释以及使用方法请参见参数说明。若提示如下信息,则说明模型转换成功。
ATC run success, welcome to the next use.成功执行命令后,在--output参数指定的路径下,可查看离线模型(如:tf_resnet50.om)。
(可选)如果用户想查看转换后离线模型中Aipp算子的相关信息,则可以将上述离线模型转成JSON文件查看,命令如下:
atc --mode=1 --om=$HOME/module/out/tf_resnet50.om --json=$HOME/module/out/tf_resnet50.json如下为JSON文件中带有aipp信息的样例(如下样例中所有aipp属性值都为样例,请以用户实际构造的配置文件为准):
{ "key": "aipp", "value": { "func": { "attr": [ { "key": "mean_chn_0", "value": { "i": 0 } }, { "key": "mean_chn_1", "value": { "i": 0 } }, { "key": "mean_chn_2", "value": { "i": 0 } }, { "key": "mean_chn_3", "value": { "i": 0 } }, { "key": "csc_switch", "value": { "b": true } }, { "key": "input_format", "value": { "i": 1 } }, { "key": "input_bias_0", "value": { "i": 0 } }, { "key": "input_bias_1", "value": { "i": 128 } }, { "key": "input_bias_2", "value": { "i": 128 } }, { "key": "aipp_mode", "value": { "i": 1 } }, { "key": "src_image_size_h", "value": { "i": 250 } }, { "key": "crop_size_h", "value": { "i": 0 } }, { "key": "matrix_r0c0", "value": { "i": 256 } }, { "key": "matrix_r0c1", "value": { "i": 0 } }, { "key": "matrix_r0c2", "value": { "i": 359 } }, { "key": "src_image_size_w", "value": { "i": 250 } }, { "key": "crop_size_w", "value": { "i": 0 } }, { "key": "rbuv_swap_switch", "value": { "b": false } }, { "key": "padding", "value": { "b": false } }, { "key": "ax_swap_switch", "value": { "b": false } }, { "key": "top_padding_size", "value": { "i": 0 } }, { "key": "matrix_r1c0", "value": { "i": 256 } }, { "key": "matrix_r1c1", "value": { "i": -88 } }, { "key": "matrix_r1c2", "value": { "i": -183 } }, { "key": "resize", "value": { "b": false } }, { "key": "resize_output_h", "value": { "i": 0 } }, { "key": "related_input_rank", "value": { "i": 0 } }, { "key": "load_start_pos_h", "value": { "i": 0 } }, { "key": "matrix_r2c0", "value": { "i": 256 } }, { "key": "matrix_r2c1", "value": { "i": 454 } }, { "key": "matrix_r2c2", "value": { "i": 0 } }, { "key": "resize_output_w", "value": { "i": 0 } }, { "key": "var_reci_chn_0", "value": { "f": "1" } }, { "key": "var_reci_chn_1", "value": { "f": "1" } }, { "key": "var_reci_chn_2", "value": { "f": "1" } }, { "key": "load_start_pos_w", "value": { "i": 0 } }, { "key": "var_reci_chn_3", "value": { "f": "1" } }, { "key": "single_line_mode", "value": { "b": false } }, { "key": "output_bias_0", "value": { "i": 16 } }, { "key": "output_bias_1", "value": { "i": 128 } }, { "key": "output_bias_2", "value": { "i": 128 } }, { "key": "right_padding_size", "value": { "i": 0 } }, { "key": "bottom_padding_size", "value": { "i": 0 } }, { "key": "min_chn_0", "value": { "f": "0" } }, { "key": "min_chn_1", "value": { "f": "0" } }, { "key": "min_chn_2", "value": { "f": "0" } }, { "key": "min_chn_3", "value": { "f": "0" } }, { "key": "crop", "value": { "b": false } }, { "key": "cpadding_value", "value": { "f": "0" } }, { "key": "left_padding_size", "value": { "i": 0 } } ] } } }
色域转换配置说明¶
AIPP提供了更为方便的图像格式转换方式:色域转换,用于将输入的图片格式,转换为模型需要的图片格式,一旦确认了AIPP处理前与AIPP处理后的图片格式,即可确定色域转换相关的参数值(matrix_r*c*配置项的值是固定的,不需要调整)。
例如:将视频解码后的YUV格式数据转为RGB格式。而根据不同的彩色视频数字化标准又可以将视频格式分为BT-601标准清晰度视频格式(定义于SDTV标准中)和BT-709高清晰度视频格式(定义于HDTV标准中)。两种视频格式又分为NARROW和WIDE,其中:
NARROW取值范围为: ,WIDE取值范围为:
,WIDE取值范围为: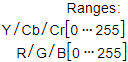
关于如何判断输入数据的标准,请参见使用AIPP色域转换模型时如何判断视频流的格式标准。
YUV格式的数据转为RGB格式可以视作如下公式展示的矩阵乘法,这其中的转换矩阵就是待配置的参数和偏移量。
# YUV转BGR:
| B | | matrix_r0c0 matrix_r0c1 matrix_r0c2 | | Y - input_bias_0 |
| G | = | matrix_r1c0 matrix_r1c1 matrix_r1c2 | | U - input_bias_1 | >> 8
| R | | matrix_r2c0 matrix_r2c1 matrix_r2c2 | | V - input_bias_2 |
在AIPP处理前,针对模型输入的图片或视频(各颜色编码方式,如YUV420SP_U8、RGB888_U8等),当前给出BT-601NARROW、BT-601WIDE、BT-709NARROW、BT-709WIDE几种典型场景下的色域转换配置。
支持的色域转换配置如表1所示。
表 1 色域转换概览表
aipp_op {
aipp_mode: static
input_format : YUV420SP_U8
csc_switch : false
rbuv_swap_switch : false
}
aipp_op {
aipp_mode: static
input_format : YUV420SP_U8
csc_switch : false
rbuv_swap_switch : true
}
输入数据为BT-601NARROW视频
输入数据为BT-601WIDE视频
输入数据为BT-709NARROW视频
输入数据为BT-709WIDE视频
输入数据为BT-601NARROW视频
输入数据为BT-601WIDE视频
输入数据为BT-709NARROW视频
输入数据为BT-709WIDE视频
aipp_op {
aipp_mode: static
input_format : YUV420SP_U8
csc_switch : true
rbuv_swap_switch : false
matrix_r0c0 : 256
matrix_r0c1 : 0
matrix_r0c2 : 0
matrix_r1c0 : 0
matrix_r1c1 : 0
matrix_r1c2 : 0
matrix_r2c0 : 0
matrix_r2c1 : 0
matrix_r2c2 : 0
input_bias_0 : 0
input_bias_1 : 0
input_bias_2 : 0
}
输入数据为BT-601NARROW视频
输入数据为BT-601WIDE视频
输入数据为BT-709NARROW视频
输入数据为BT-709WIDE视频
输入数据为BT-601NARROW视频
输入数据为BT-601WIDE视频
输入数据为BT-709NARROW视频
输入数据为BT-709WIDE视频
aipp_op {
aipp_mode: static
input_format : RGB888_U8
csc_switch : false
rbuv_swap_switch : false
}
aipp_op {
aipp_mode : static
input_format : RGB888_U8
csc_switch : false
rbuv_swap_switch : true
}
输入数据为BT-601NARROW视频
输入数据为BT-601WIDE视频
输入数据为BT-709NARROW视频
输入数据为BT-709WIDE视频
输入数据为BT-601NARROW视频
输入数据为BT-601WIDE视频
输入数据为BT-709NARROW视频
输入数据为BT-709WIDE视频
aipp_op {
aipp_mode: static
input_format : RGB888_U8
csc_switch : true
rbuv_swap_switch : false
matrix_r0c0 : 76
matrix_r0c1 : 150
matrix_r0c2 : 30
matrix_r1c0 : 0
matrix_r1c1 : 0
matrix_r1c2 : 0
matrix_r2c0 : 0
matrix_r2c1 : 0
matrix_r2c2 : 0
output_bias_0 : 0
output_bias_1 : 0
output_bias_2 : 0
}
aipp_op {
aipp_mode: static
input_format : RGB888_U8
csc_switch : true
rbuv_swap_switch : true
matrix_r0c0 : 76
matrix_r0c1 : 150
matrix_r0c2 : 30
matrix_r1c0 : 0
matrix_r1c1 : 0
matrix_r1c2 : 0
matrix_r2c0 : 0
matrix_r2c1 : 0
matrix_r2c2 : 0
output_bias_0 : 0
output_bias_1 : 0
output_bias_2 : 0
}
aipp_op {
aipp_mode: static
input_format : RGB888_U8
csc_switch : false
rbuv_swap_switch : true
}
aipp_op {
aipp_mode: static
input_format : RGB888_U8
csc_switch : false
rbuv_swap_switch : false
}
aipp_op {
aipp_mode: static
input_format : XRGB8888_U8
csc_switch : false
rbuv_swap_switch : false
ax_swap_switch : true
}
aipp_op {
aipp_mode : static
input_format : XRGB8888_U8
csc_switch : false
rbuv_swap_switch : true
ax_swap_switch : true
}
输入数据为BT-601NARROW视频
输入数据为BT-601WIDE视频
输入数据为BT-709NARROW视频
输入数据为BT-709WIDE视频
输入数据为BT-601NARROW视频
输入数据为BT-601WIDE视频
输入数据为BT-709NARROW视频
输入数据为BT-709WIDE视频
aipp_op {
aipp_mode: static
input_format : XRGB8888_U8
csc_switch : true
rbuv_swap_switch : false
ax_swap_switch : true
matrix_r0c0 : 76
matrix_r0c1 : 150
matrix_r0c2 : 30
matrix_r1c0 : 0
matrix_r1c1 : 0
matrix_r1c2 : 0
matrix_r2c0 : 0
matrix_r2c1 : 0
matrix_r2c2 : 0
output_bias_0 : 0
output_bias_1 : 0
output_bias_2 : 0
}
aipp_op {
aipp_mode: static
input_format : XRGB8888_U8
csc_switch : true
rbuv_swap_switch : true
ax_swap_switch : true
matrix_r0c0 : 76
matrix_r0c1 : 150
matrix_r0c2 : 30
matrix_r1c0 : 0
matrix_r1c1 : 0
matrix_r1c2 : 0
matrix_r2c0 : 0
matrix_r2c1 : 0
matrix_r2c2 : 0
output_bias_0 : 0
output_bias_1 : 0
output_bias_2 : 0
}
aipp_op {
aipp_mode: static
input_format : XRGB8888_U8
csc_switch : true
rbuv_swap_switch : false
ax_swap_switch : false
matrix_r0c0 : 76
matrix_r0c1 : 150
matrix_r0c2 : 30
matrix_r1c0 : 0
matrix_r1c1 : 0
matrix_r1c2 : 0
matrix_r2c0 : 0
matrix_r2c1 : 0
matrix_r2c2 : 0
output_bias_0 : 0
output_bias_1 : 0
output_bias_2 : 0
}
aipp_op {
aipp_mode: static
input_format : XRGB8888_U8
csc_switch : true
rbuv_swap_switch : true
ax_swap_switch : false
matrix_r0c0 : 76
matrix_r0c1 : 150
matrix_r0c2 : 30
matrix_r1c0 : 0
matrix_r1c1 : 0
matrix_r1c2 : 0
matrix_r2c0 : 0
matrix_r2c1 : 0
matrix_r2c2 : 0
output_bias_0 : 0
output_bias_1 : 0
output_bias_2 : 0
}
aipp_op {
aipp_mode: static
input_format : YUV400_U8
csc_switch : false
}
aipp_op {
aipp_mode: static
related_input_rank: 0
input_format : RGB888_U8
src_image_size_w : 640
src_image_size_h : 640
mean_chn_0 : 0
mean_chn_1 : 0
mean_chn_2 : 0
var_reci_chn_0 : 1.0
var_reci_chn_1 : 1.0
var_reci_chn_2 : 1.0
}
归一化配置说明¶
归一化就是要把需要处理的数据经过处理后限制在一定范围内,方便后面数据的处理。AIPP支持的归一化设置,通过减均值和乘系数的操作完成,这样的能力不仅能用于常规的归一化,还能用于不同数据格式的转化。
比如在由uint8转为fp16时,其转换可以视作如下公式。其中,mean_chn_i表示每个通道的均值,min_chn_i表示每个通道的最小值,var_reci_chn_i表示每个通道方差的倒数,各通道的这三个值都是需要进行配置的参数。
pixel_out_chx(i)=[pixel_in_chx(i)-mean_chn_i-min_chn_i]*var_reci_chn_i
Crop/Padding配置说明¶
原图大小为srcImageSizeW、srcImageSizeH的图像经过图像预处理后变为模型预期的dstImageSizeW、dstImageSizeH图像尺寸。
说明: 图中实线框表示当前图片size,虚线框表示经过右侧箭头上的AIPP操作处理后的图片size。
从执行角度看,我们需要在配置文件中指出裁剪的起始位置左上点坐标loadStartPosW、loadStartPosH以及裁剪后的图像大小crop_size_w、crop_size_h。在padding环节,我们需要指明在裁剪后的图像四周padding的尺寸,即left_padding_size、right_padding_size、top_padding_size和bottom_padding_size。而经过图像尺寸改变之后最终图片大小,需要跟模型文件输入的图像大小即**--input_shape**中的宽和高相等。
对于YUV420SP_U8图片类型,load_start_pos_w、load_start_pos_h参数必须配置为偶数。配置样例如下:
aipp_op {
aipp_mode: static
input_format: YUV420SP_U8
src_image_size_w: 320
src_image_size_h: 240
crop: true
load_start_pos_w: 10
load_start_pos_h: 20
crop_size_w: 50
crop_size_h: 60
padding: true
left_padding_size: 20
right_padding_size: 15
top_padding_size: 20
bottom_padding_size: 15
padding_value: 0
}
AIPP对模型输入大小的校验说明¶
如果有配置AIPP,无论静态AIPP还是动态AIPP,最终生成离线模型的输入大小(即input_size)均会被Crop、Padding等操作影响。本节给出对模型输入大小的约束说明。
假设模型的Batch数量为N(如果为动态batch场景,N为最大档位数的取值),模型输入图片的宽为src_image_size_w,高为src_image_size_h,最后模型输入的Size的计算公式如下所示。
不支持该特性。
不支持该特性。
如果为动态AIPP,模型转换时,ATC会为动态AIPP新增一个模型输入,用于接收模型推理阶段通过调用aclmdlSetInputAIPP接口后传入的AIPP参数,该场景下新增输入节点大小计算公式如下,接口详细说明请参见《AscendCL应用开发指南 (C&C++)》手册中的“acl API参考 > 模型管理 > 模型执行 > aclmdlSetInputAIPP”。
sizeof(kAippDynamicPara) - sizeof(kAippDynamicBatchPara) + batch_count * sizeof(kAippDynamicBatchPara)
kAippDynamicPara以及kAippDynamicBatchPara参数解释请参见动态AIPP的参数输入结构。
配置文件模板¶
AIPP配置文件通过本章节给出的模板进行配置,内容需要满足prototxt格式,用户根据场景决定配置哪些参数,修改为合适的取值另存后供模型转换使用;使用配置模板之前需要先查看相关约束。
使用配置文件模板时,请将需要配置的参数去注释,并改为合适的值。
模板中参数取值都为默认值,实际使用时,如果配置文件中某些参数未配置,则模型转换时自动设置成该模板中相应参数的默认值。
静态AIPP场景下,input_format属性为必选属性,其余属性均为可选配置,如果未配置,则模型转换时自动设置成该模板中相应参数的默认值。
由于硬件处理逻辑的限制,配置文件中的参数有如下处理顺序要求:通道交换(rbuv_swap_switch)>图像裁剪(crop )> 色域转换(通道交换) > 数据减均值/归一化 > 图像边缘填充(padding)。
AIPP当前支持色域转换、图像裁剪、减均值、乘系数、通道交换、单行模式的能力,输入图片的类型仅支持RAW和UINT8格式。
若输入图片为RGB(由R、G、B三个分量组成的图片),其对应的输入、输出通道顺序,从高地址到低地址依次为:{R,G,B}。
动态AIPP的参数每次推理需要计算,计算需要耗时,所以动态AIPP的性能比静态AIPP性能要差。
经过AIPP处理后的图片,统一采用NC1HWC0的五维数据格式进行存储:
以原始模型要求的图片为RGB(由R、G、B三个分量组成的图片)为例进行说明,配置了AIPP功能场景下:
ONNX框架数据格式只能设置为NCHW(数据存储格式为RRRRRRGGGGGGBBBBBB)
TensorFlow框架数据格式只能设置为NHWC(数据存储格式为RGBRGBRGBRGBRGBRGB)或NCHW(数据存储格式为RRRRRRGGGGGGBBBBBB)。
实际提供的图片经过AIPP色域转换功能处理后,输出的离线模型中图片为RGB,并以NC1HWC0五维数据格式进行存储(关于NC1HWC0详细介绍请参见关键概念):若AIPP输出数据类型为FP16,则C0=16,从高位到低位依次为R,G,B,其余位数补0;C1=1。
模型转换是否开启AIPP功能,执行推理业务时,对输入图片数据的要求:
模型转换时开启AIPP:在进行推理业务时,输入图片数据要求为NHWC排布,该场景下最终与AIPP连接的输入节点的格式被强制改成NHWC,可能与模型转换命令中--input_format参数指定的格式不一致。
模型转换时没有开启AIPP:在进行推理业务时,模型的Format需与输入图片的Format保持一致。例如,输入图片的Format为NHWC,但某模型默认的Format为NCHW,此时输入图片和模型的Format不一致,用户可在模型转换时指定--input_format调整模型的Format,也可以选择符合模型要求的输入图片。
对于输入图像格式YUV420SP,根据UV分量顺序不同,YUV420SP又分为YUV420SP_UV(NV12)和YUV420SP_VU(NV21),分别对应色域转换配置说明中的YUV420SP_U8、YVU420SP_U8,默认为YUV420SP_UV(NV12)。
对于AIPP配置文件中的input_format参数,需始终配置为NV12格式(YUV420SP_U8),通过rbuv_swap_switch参数控制实际提供给AIPP的图片格式:
若rbuv_swap_switch设置为false,则实际提供的图片格式为YUV420SP_U8。
若rbuv_swap_switch设置为true,则实际提供的图片格式为YVU420SP_U8。
AIPP不同图像格式对应C轴取值约束。
表 1 不同图像格式对应C轴取值
AIPP针对各种图像格式的典型参数配置如下表所示。
表 2 各种图像格式的典型参数配置
- XRGB package
- XBGR package
- RGBX package
- BGRX package
# AIPP的配置以aipp_op开始,标识这是一个AIPP算子的配置,aipp_op支持配置多个
aipp_op {
#========================= 全局设置(start) ===========================================================================================================================================================
# aipp_mode指定了AIPP的模式,必须配置
# 类型:enum
# 取值范围:dynamic/static,dynamic表示动态AIPP,static表示静态AIPP
aipp_mode:
# related_input_rank参数为可选,标识对模型的第几个输入做AIPP处理,从0开始,默认为0。例如模型有两个输入,需要对第2个输入做AIPP,则配置related_input_rank为1。
# 类型:整型
# 配置范围 >= 0
related_input_rank: 0
#========================= 全局设置(end) =============================================================================================================================================================
#========================= 动态AIPP需设置,静态AIPP无需设置(start) ===================================================================================================================================
# 输入图像最大的size,动态AIPP必须配置(如果为动态batch场景,N为最大档位数的取值)
# 类型:int
max_src_image_size: 0
# 若输入图像格式为YUV420SP_U8,则max_src_image_size>=N * src_image_size_w * src_image_size_h * 1.5。
# 若输入图像格式为,则max_src_image_size>=N * src_image_size_w * src_image_size_h * 4。
# 若输入图像格式为RGB888_U8,则max_src_image_size>=N * src_image_size_w * src_image_size_h * 3。
# 是否支持旋转,保留字段,暂不支持该功能
# 类型:bool
# 取值范围:true/false,true表示支持旋转,false表示不支持旋转
support_rotation: false
#========================= 动态AIPP需设置,静态AIPP无需设置(end) =======================================================================================================================================
#========================= 静态AIPP需设置,动态AIPP无需设置(start)======================================================================================================================================
# 输入图像格式,必选
# 类型: enum
input_format:
# 说明:模型转换完毕后,在对应的om离线模型文件中,上述参数分别以枚举值呈现。
# 原始图像的宽度、高度
# 类型:int32
# 取值范围&约束:宽度取值范围为[2,4096]或0;高度取值范围为[1,4096]或0,对于YUV420SP_U8类型的图像,要求原始图像的宽和高取值是偶数
src_image_size_w: 0
src_image_size_h: 0
# 说明:请根据实际图片的宽、高配置src_image_size_w和src_image_size_h;只有crop,padding功能都没有开启的场景,src_image_size_w和src_image_size_h才能取值为0或不配置,该场景下会取网络模型输入定义的w和h,并且网络模型输入定义的w取值范围为[2,4096],h取值范围为[1,4096]。
# C方向的填充值,保留字段,暂不支持该功能
# 类型: float16
# 取值范围:[-65504, 65504]
cpadding_value: 0.0
#========= crop参数设置(配置样例请参见AIPP配置 > Crop/Padding配置说明) =========
# AIPP处理图片时是否支持抠图
# 类型:bool
# 取值范围:true/false,true表示支持,false表示不支持
crop: false
# 抠图起始位置水平、垂直方向坐标,抠图大小为网络输入定义的w和h
# 类型:int32
# 取值范围&约束: [0,4095]
# 说明:load_start_pos_w<src_image_size_w,load_start_pos_h<src_image_size_h
load_start_pos_w: 0
load_start_pos_h: 0
# 抠图后的图像size
# 类型:int32
# 取值范围&约束: [0,4096]、load_start_pos_w + crop_size_w <= src_image_size_w、load_start_pos_h + crop_size_h <= src_image_size_h
crop_size_w: 0
crop_size_h: 0
说明:若开启抠图功能,并且没有配置padding,该场景下crop_size_w和crop_size_h才能取值为0或不配置,此时抠图大小(crop_size[W|H])的宽和高取值来自模型文件--input_shape中的宽和高,并且--input_shape中的宽和高取值范围为[1,4096]。
# 抠图约束如下:
# 若input_format取值为其他值,对load_start_pos_w、load_start_pos_h无约束。
# 若开启抠图功能,则src_image_size[W|H] >= crop_size[W|H]+load_start_pos[W|H]。
#================================== resize参数设置 ================================
# AIPP处理图片时是否支持缩放
# 类型:bool
# 取值范围:true/false,true表示支持,false表示不支持
resize: false
# 缩放后图像的宽度和高度
# 类型:int32
# 取值范围&约束:resize_output_h:[16,4096]或0;resize_output_w:[16,1920]或0;resize_output_w/resize_input_w∈[1/16,16]、resize_output_h/resize_input_h∈[1/16,16]
resize_output_w: 0
resize_output_h: 0
# 说明:若开启了缩放功能,并且没有配置padding,该场景下resize_output_w和resize_output_h才能取值为0或不配置,此时缩放后图像的宽和高取值来自模型文件--input_shape中的宽和高,并且--input_shape中的高取值范围为[16,4096],宽取值范围为[16,1920]。
#======== padding参数设置(配置样例请参见AIPP配置 > Crop/Padding配置说明) =========
# AIPP处理图片时padding使能开关
# 类型:bool
# 取值范围:true/false,true表示支持,false表示不支持
padding: false
# H和W的填充值,静态AIPP配置
# 类型: int32
# 取值范围:[0,32]
left_padding_size: 0
right_padding_size: 0
top_padding_size: 0
bottom_padding_size: 0
# 说明:AIPP经过padding后,输出的H和W要与模型需要的H和W保持一致
# 上下左右方向上padding的像素取值,静态AIPP配置
# 类型:uint8/int8/float16
# 取值范围分别为:[0,255]、[-128, 127]、[-65504, 65504]
padding_value: 0
# 说明:该参数取值需要与最终AIPP输出图片的数据类型保持一致。
#================================ rotation参数设置 ==================================
# AIPP处理图片时的旋转角度,保留字段,暂不支持该功能
# 类型:uint8
# 范围:{0, 1, 2, 3} 0不旋转,1顺时针90°,2顺时针180°,3顺时针270°
rotation_angle: 0
#========= 色域转换参数设置(配置样例请参见AIPP配置 > 色域转换配置说明) =============
# 色域转换开关,静态AIPP配置
# 类型:bool
# 取值范围:true/false,true表示开启色域转换,false表示关闭
csc_switch: false
# R通道与B通道交换开关/U通道与V通道交换开关
# 类型:bool
# 取值范围:true/false,true表示开启通道交换,false表示关闭
rbuv_swap_switch :false
# RGBA->ARGB, YUVA->AYUV交换开关
# 类型:bool
# 取值范围:true/false,true表示开启,false表示关闭
ax_swap_switch: false
# 单行处理模式(只处理抠图后的第一行)开关,保留字段,暂不支持该功能
# 类型:bool
# 取值范围:true/false,true表示开启单行处理模式,false表示关闭
single_line_mode: false
# 若色域转换开关为false,则本功能不起作用。
# 若输入图片通道数为4,则忽略A通道或X通道。
# YUV转BGR:
# | B | | matrix_r0c0 matrix_r0c1 matrix_r0c2 | | Y - input_bias_0 |
# | G | = | matrix_r1c0 matrix_r1c1 matrix_r1c2 | | U - input_bias_1 | >> 8
# | R | | matrix_r2c0 matrix_r2c1 matrix_r2c2 | | V - input_bias_2 |
# BGR转YUV:
# | Y | | matrix_r0c0 matrix_r0c1 matrix_r0c2 | | B | | output_bias_0 |
# | U | = | matrix_r1c0 matrix_r1c1 matrix_r1c2 | | G | >> 8 + | output_bias_1 |
# | V | | matrix_r2c0 matrix_r2c1 matrix_r2c2 | | R | | output_bias_2 |
# 3*3 CSC矩阵元素
# 类型:int16
# 取值范围:[-32677 ,32676]
matrix_r0c0: 298
matrix_r0c1: 516
matrix_r0c2: 0
matrix_r1c0: 298
matrix_r1c1: -100
matrix_r1c2: -208
matrix_r2c0: 298
matrix_r2c1: 0
matrix_r2c2: 409
# RGB转YUV时的输出偏移
# 类型:uint8
# 取值范围:[0, 255]
output_bias_0: 16
output_bias_1: 128
output_bias_2: 128
# YUV转RGB时的输入偏移
# 类型:uint8
# 取值范围:[0, 255]
input_bias_0: 16
input_bias_1: 128
input_bias_2: 128
#============================== 减均值、乘系数设置 =================================
# 计算规则如下:
# 当uint8->uint8时,本功能不起作用
# 当uint8->fp16时,pixel_out_chx(i) = [pixel_in_chx(i) – mean_chn_i – min_chn_i] * var_reci_chn_i
# 每个通道的均值
# 类型:uint8
# 取值范围:[0, 255]
mean_chn_0: 0
mean_chn_1: 0
mean_chn_2: 0
mean_chn_3: 0
# 每个通道的最小值
# 类型:float16
# 取值范围:[0, 255]
min_chn_0: 0.0
min_chn_1: 0.0
min_chn_2: 0.0
min_chn_3: 0.0
# 每个通道方差的倒数
# 类型:float16
# 取值范围:[-65504, 65504]
var_reci_chn_0: 1.0
var_reci_chn_1: 1.0
var_reci_chn_2: 1.0
var_reci_chn_3: 1.0
#========================= 静态AIPP需设置,动态AIPP无需设置(end)=====================================================================================================================================
}
典型场景样例参考¶
YUV400_U8转GRAY格式¶
场景说明:
AIPP输入图像格式为YUV400_U8、输出图像格式为GRAY,输入图像尺寸为224*224,有效数据区域从左上角(0, 0)像素开始;原始网络模型的C=1,H和W均为220。
该场景下涉及以下AIPP配置:
开启抠图功能参数crop;
抠图起始位置水平、垂直方向坐标load_start_pos_h、load_start_pos_w为0;
无需配置crop_size_w和crop_size_h参数,此时抠图大小(crop_size[W|H])的宽和高取值来自模型转换时**--input_shape**参数中的宽和高,将从(0, 0)点开始选取220*220区域的数据;
无需配置色域转换开关csc_switch,并且对于同一个原始网络模型,如果AIPP输入的是YUV420SP_U8图像,则可以使用同一套AIPP配置,即只取了Y通道的数据。
AIPP配置文件示例如下:
aipp_op{ aipp_mode: static csc_switch: false crop: true input_format: YUV400_U8 load_start_pos_h: 0 load_start_pos_w: 0 src_image_size_w: 224 src_image_size_h: 224 # 归一化系数需要根据用户模型实际需求配置,如下所列常见值仅作为示例 mean_chn_0: 128 min_chn_0: 0.0 var_reci_chn_0: 0.00390625 }
YUV420SP_U8转BGR格式¶
场景说明:
AIPP输入图像格式为YUV420SP_U8(NV12)、输出图像格式为BGR,输入图像尺寸为256*256;原始网络模型的C=3,H和W与AIPP输入图像尺寸相同。
该场景涉及以下AIPP配置:
无需配置抠图功能参数crop;
需要配置色域转换开关csc_switch和相应的CSC矩阵参数。
AIPP配置文件示例如下:
aipp_op { aipp_mode: static input_format: YUV420SP_U8 csc_switch: true # 如果输入的是YVU420SP_U8(NV21)图像,则需要将rbuv_swap_switch参数设置为true rbuv_swap_switch: false related_input_rank: 0 src_image_size_w: 256 src_image_size_h: 256 crop: false matrix_r0c0: 298 matrix_r0c1: 516 matrix_r0c2: 0 matrix_r1c0: 298 matrix_r1c1: -100 matrix_r1c2: -208 matrix_r2c0: 298 matrix_r2c1: 0 matrix_r2c2: 409 input_bias_0: 16 input_bias_1: 128 input_bias_2: 128 # 归一化系数需要根据用户模型实际需求配置,如下所列常见值仅作为示例 # 归一化系数应用于色域转换和通道交换之后的通道 mean_chn_0: 104 mean_chn_1: 117 mean_chn_2: 123 min_chn_0: 0.0 min_chn_1: 0.0 min_chn_2: 0.0 var_reci_chn_0: 1.0 var_reci_chn_1: 1.0 var_reci_chn_2: 1.0 }
RGB888_U8转RGB(或BGR)格式¶
场景说明:
AIPP输入图像格式为RGB888_U8、输出图像格式为RGB,输入图像尺寸为250*250,有效数据区域从左上角(0, 0)像素开始;原始网络模型的C=3,H和W均为240。
该场景下涉及以下AIPP配置:
开启抠图功能参数crop;
抠图起始位置水平、垂直方向坐标load_start_pos_h、load_start_pos_w为0;
无需配置crop_size_w和crop_size_h参数,此时抠图大小(crop_size[W|H])的宽和高取值来自模型转换时**--input_shape**参数中的宽和高,将从(0, 0)点开始选取240*240区域的数据;
无需配置通道交换开关参数rbuv_swap_switch、色域转换开关参数csc_switch和CSC矩阵参数。
AIPP配置文件示例如下:
aipp_op { aipp_mode: static input_format: RGB888_U8 csc_switch: false related_input_rank: 0 src_image_size_w: 250 src_image_size_h: 250 crop: true load_start_pos_w: 0 load_start_pos_h: 0 # 如果原始模型需要的是BGR格式,则需要将rbuv_swap_switch参数设置为true rbuv_swap_switch: false # 归一化系数需要根据用户模型实际需求配置,此处取默认值,即不改变像素的值 # 若配置归一化系数,将应用于通道交换之后的通道 }
单算子模型转换**(该版本不支持单算子特性)**¶
本节给出单算子描述文件转成离线模型的详细步骤。
什么是单算子描述文件¶
单算子描述文件是基于Ascend IR定义的单个算子的定义文件,包括算子的输入、输出及属性等信息,借助该文件转换成适配昇腾AI处理器的离线模型适配NPU IP加速器的离线模型后,可以验证单算子的功能。
单算子描述文件是由OpDesc数组构成的JSON文件,参数构成以及解释如下:
表 1 OpDesc参数说明
表 2 TensorDesc数组参数说明
可选。动态输入,取值必须和算子信息库中该算子定义的输入name相同。 该参数用于设置算子动态输入的分组与动态输入的个数,例如算子原型定义中某算子的动态输入为: 则表示动态输入有两组,分别为x,y。每一组的输入个数,根据dynamic_input的个数确定。具体设置原则可以参见TensorDesc数组中name参数的说明。
|
||
必填。Tensor计算过程中实际使用的格式,又称运行时格式,对应Device上计算使用的格式。
|
||
可选。Tensor的名称。算子的输入为动态输入时,需要设置该字段。 该参数用于设置每一组动态输入中,具体输入的名称,每一个输入名称为算子原型中定义的输入名称+编号,编号根据dynamic_input的个数确定,从0开始依次递增。
|
||
必填。Tensor计算过程中实际使用的Shape,例如[1, 224, 224, 3],实际Shape乘积不能超过int32最大值(2147483647)。
|
||
必填。Tensor的数据类型,支持的type以及对应的枚举如下:
|
||
可选。Shape为动态时(不包括-2场景),unknow shape的取值范围。 例如,若Shape取值为[16,-1,20,-1]:其中的-1表示unknow shape。 shape_range取值为[1,128],[1,-1]:[1,128]表示从1到128的取值范围,对应Shape参数中第一个-1;[1,-1]表示从1到无穷大的取值范围,对应Shape参数中第二个-1。 |
||
|
||
|
当前仅支持一维list配置,list中具体配置个数由Shape取值决定。例如,Shape取值为2,则const_value中列表个数为2。 取值类型由type决定,假设type取值为float16,则单算子编译时会自动将const_value中的取值转换为float16格式的取值。 |
表 3 Attr数组参数说明
配置文件样例¶
不同输入或者不同Format场景,单算子描述文件配置不同,本章节给出各场景的配置示例。 描述文件支持定义多组算子JSON文件配置,一组配置包括算子类型、算子输入和输出信息、视算子情况决定是否包括属性信息。 动态Shape场景,单算子描述文件根据场景不同,内容也有差异,本章节就给出不同场景下的配置样例。
单算子描述文件配置¶
不同输入或者不同Format场景,单算子描述文件配置不同,本章节给出各场景的配置示例。
本章节中的单算子是基于Ascend IR定义的,描述文件为JSON格式。关于JSON描述文件中各参数的解释请参见表1,关于单算子的Ascend IR定义请参见《AOL算子加速库接口参考》 >“CANN算子规格说明” 。
Format为ND:
该示例中的单算子转换后的离线模型为:add.om
[ { "op": "Add", "name": "add", "input_desc": [ { "format": "ND", "shape": [3,3], "type": "int32" }, { "format": "ND", "shape": [3,3], "type": "int32" } ], "output_desc": [ { "format": "ND", "shape": [3,3], "type": "int32" } ] } ]
Format为NCHW:
该示例中的单算子转换后的离线模型为:conv2d.om
[ { "op": "Conv2D", "name": "conv2d", "input_desc": [ { "format": "NCHW", "shape": [1, 3, 16, 16], "type": "float16" }, { "format": "NCHW", "shape": [3, 3, 3, 3], "type": "float16" } ], "output_desc": [ { "format": "NCHW", "shape": [1, 3, 16, 16], "type": "float16" } ], "attr": [ { "name": "strides", "type": "list_int", "value": [1, 1, 1, 1] }, { "name": "pads", "type": "list_int", "value": [1, 1, 1, 1] }, { "name": "dilations", "type": "list_int", "value": [1, 1, 1, 1] } ] } ]
Tensor计算过程中使用的Format与原始Format不同
ATC模型转换时,会将origin_format与origin_shape转成离线模型需要的format与shape。
该示例中的单算子转换后的离线模型为:add.om
[ { "op": "Add", "name": "add", "input_desc": [ { "format": "NC1HWC0", "origin_format": "NCHW", "shape": [8, 1, 16, 4, 16], "origin_shape": [8, 16, 16, 4], "type": "float16" }, { "format": "NC1HWC0", "origin_format": "NCHW", "shape": [8, 1, 16, 4, 16], "origin_shape": [8, 16, 16, 4], "type": "float16" } ], "output_desc": [ { "format": "NC1HWC0", "origin_format": "NCHW", "shape": [8, 1, 16, 4, 16], "origin_shape": [8, 16, 16, 4], "type": "float16" } ] } ]
输入指定为常量
该场景下,支持设置为常量的输入,新增is_const和const_value两个参数,分别表示是否为常量以及常量取值,const_value当前仅支持一维list配置,具体配置个数由shape取值决定,例如,如下样例中shape为2,则const_value中列表个数为2;const_value中取值类型由type决定,假设type取值为float16,则单算子编译时会自动将const_value中的取值转换为float16格式的取值。
该示例中的单算子转换后的离线模型为:resizeBilinearV2.om
[ { "op": "ResizeBilinearV2", "name": "resizeBilinearV2", "input_desc": [ { "format": "NHWC", "name": "x", "shape": [ 4, 16, 16, 16 ], "type": "float16" }, { "format": "NHWC", "is_const": true, "const_value": [49, 49], "name": "size", "shape": [ 2 ], "type": "int32" } ], "output_desc": [ { "format": "NHWC", "name": "y", "shape": [ 4, 48, 48, 16 ], "type": "float" } ], "attr": [ { "name": "align_corners", "type": "bool", "value": false }, { "name": "half_pixel_centers", "type": "bool", "value": false } ] } ]
可选输入(optional input):
当存在可选输入,且可选输入没有输入数据时,则必须将可选输入的format配置为RESERVED,同时将type配置为UNDEFINED;若可选输入有输入数据时,则按其输入数据的format、type配置即可。
该示例中的单算子转换后的离线模型为:matMulV2.om
[ { "op": "MatMulV2", "name": "matMulV2", "input_desc": [ { "format": "ND", "shape": [16, 16], "type": "float" }, { "format": "ND", "shape": [16, 16], "type": "float" }, { "format": "RESERVED", "shape": [], "type": "UNDEFINED" }, { "format": "RESERVED", "shape": [], "type": "UNDEFINED" } ], "attr": [ { "name": "transpose_x1", "type": "bool", "value": false }, { "name": "transpose_x2", "type": "bool", "value": false } ], "output_desc": [ { "format": "ND", "shape": [16, 16], "type": "float" } ] } ]
输入个数不确定(动态输入场景):
该场景下,单算子的输入个数不确定。此处以AddN单算子为例。该示例中的单算子转换后的离线模型为:addN.om
构造的单算子JSON文件使用动态输入dynamic_input参数,而不使用Tensor的名称name参数。
该场景下算子的dynamic_input取值必须和算子信息库中该算子定义的输入name的取值相同。具体设置几个输入,由AddN单算子描述文件属性参数中N的取值决定,用户可以自行修改输入的个数,但是必须和属性中N的取值匹配。(该说明仅针对AddN算子生效,其他动态输入算子的约束以具体算子为准。)
[ { "op": "AddN", "name": "addN", "input_desc": [ { "dynamic_input": "x", "format": "NCHW", "shape": [1,3,166,166], "type": "float32" }, { "dynamic_input": "x", "format": "NCHW", "shape": [1,3,166,166], "type": "int32" }, { "dynamic_input": "x", "format": "NCHW", "shape": [1,3,166,166], "type": "float32" } ], "output_desc": [ { "format": "NCHW", "shape": [1,3,166,166], "type": "float32" } ], "attr": [ { "name": "N", "type": "int", "value": 3 } ] } ]
构造的单算子JSON文件使用Tensor的名称name参数,而不使用动态输入dynamic_input参数。
该场景下算子的name取值必须和算子原型定义中算子的输入名称相同,根据输入的个数自动生成x0、x1、x2……。具体设置几个Tensor名称,由AddN单算子描述文件属性参数中N的取值决定,用户可以自行修改Tensor名称的个数,但是必须和属性中N的取值匹配,例如N取值为3,则name取值分别设置为x0、x1、x2。(该说明仅针对AddN算子生效,其他动态输入算子的约束以具体算子为准。)
[ { "op": "AddN", "name": "addN", "input_desc": [ { "name":"x0", "format": "NCHW", "shape": [1,3,166,166], "type": "float32" }, { "name":"x1", "format": "NCHW", "shape": [1,3,166,166], "type": "int32" }, { "name":"x2", "format": "NCHW", "shape": [1,3,166,166], "type": "float32", } ], "output_desc": [ { "format": "NCHW", "shape": [1,3,166,166], "type": "float32" } ], "attr": [ { "name": "N", "type": "int", "value": 3 } ] } ]
多组算子描述文件配置¶
描述文件支持定义多组算子JSON文件配置,一组配置包括算子类型、算子输入和输出信息、视算子情况决定是否包括属性信息。
如果JSON文件配置了多组算子,则模型转换完成后,会生成多组算子对应的om离线模型文件。如下配置文件只是样例,请根据实际情况进行修改。
[
{
"op": "MatMul",
"name": "matMul01",
"input_desc": [
{
"format": "ND",
"shape": [
16,
16
],
"type": "float16"
},
... ...
],
"output_desc": [
{
"format": "ND",
"shape": [
16,
16
],
"type": "float16"
}
],
"attr": [
{
"name": "alpha",
"type": "float",
"value": 1.0
},
... ...
]
},
{
"op": "MatMul",
"name": "matMul02",
"input_desc": [
{
"format": "ND",
"shape": [
256,
256
],
"type": "float16"
},
... ...
],
"output_desc": [
{
"format": "ND",
"shape": [
256,
256
],
"type": "float16"
}
],
"attr": [
{
"name": "alpha",
"type": "float",
"value": 1.0
},
... ...
]
}
]
动态Shape单算子描述文件配置¶
动态Shape场景,单算子描述文件根据场景不同,内容也有差异,本章节就给出不同场景下的配置样例。
模型编译时不指定Shape,模型执行时根据输入静态Shape,能推导出具体输出Shape:
[ { "op": "Add", "name": "add", "input_desc": [ { "format": "ND", "shape": [-1,16], "shape_range": [[0, 32]], "type": "int64" }, { "format": "ND", "shape": [-1,16], "shape_range": [[0, 32]], "type": "int64" } ], "output_desc": [ { "format": "ND", "shape": [-1,16], "shape_range": [[0,32]], "type": "int64" } ] } ]
模型编译时不指定Shape,模型执行时根据输入静态Shape和常量,能推导出具体输出Shape:
[ { "op": "TopK", "name": "topK", "input_desc": [ { "format": "ND", "shape": [-1], "shape_range": [[1,-1]], "type": "int32" }, { "format": "ND", "shape": [], #推理时会传入常量 "type": "int32" } ], "output_desc": [ { "format": "ND", "shape": [-1], "shape_range": [[1,-1]], "type": "int32" }, { "format": "ND", "shape": [-1], "shape_range": [[1,-1]], "type": "int32" }], "attr": [ { "name": "sorted", "type": "bool", "value": true } ] } ]
模型编译时不指定Shape,模型执行时根据输入静态Shape,无法得到算子的准确输出Shape,但可以得到输出Shape的范围。
该场景下在输出参数output_desc中将算子输出TensorDesc中Shape为动态维度的纬度值记为“-1”,并对其“-1”的维度给出shape_range取值范围:
[ { "op": "Where", "name": "where", "input_desc": [ { "format": "ND", "shape": [-1], "shape_range": [[1,-1]], "type": "int32" } ], "output_desc": [ { "format": "ND", "shape": [-1, 1], "shape_range": [[1,-1]], "type": "int64" } ] } ]
如何将算子描述文件转成离线模型¶
本节给出单算子描述文件转成离线模型的详细步骤。
参见什么是单算子描述文件中的参数解释以及配置文件样例构造单算子描述文件。本章节以构造format为ND的Add单算子add.json为例进行说明。
以CANN软件包运行用户,将步骤1构造的单算子描述文件上传到开发环境任意目录,例如_$HOME/singleop/_目录下。
执行如下命令生成离线模型。(如下命令中使用的目录以及文件均为样例,请以实际为准)
atc --singleop=$HOME/singleop/add.json --output=$HOME/singleop/out/op_model --soc_version=<soc_version>--singleop:用于指定_add.json_单算子描述文件。
--output:转换后的离线模型存放路径。
--soc_version:NPU IP加速器的型号。
关于参数的详细解释请参见参数说明。
若提示如下信息,则说明模型转换成功。若模型转换失败,请参见《故障处理》> “错误码参考”章节进行辅助定位。
ATC run success, welcome to the next use.成功执行命令后,在output参数指定的路径下,可查看离线模型文件*.om。
参数说明¶
使用ATC工具转换模型之前,首先查看使用工具过程中的一些限制,然后借助本章节提供的参数概览功能,可以快速预览相关参数。
参数概览¶
使用ATC工具转换模型之前,首先查看使用工具过程中的一些限制,然后借助本章节提供的参数概览功能,可以快速预览相关参数。
在进行模型转换前,请务必查看如下约束要求:
支持原始框架类型为TensorFlow(IPV035不支持)、MindSpore(IPV035不支持)、ONNX的模型转换:
当原始框架类型为MindSpore(IPV035不支持)、ONNX时,输入数据类型为FP32(IPV035不支持)、FP16、UINT8(通过配置数据预处理--insert_op_conf实现)。
当原始框架类型为TensorFlow(IPV035不支持)时,输入数据类型为FP16、FP32、UINT8、INT32、INT64、BOOL。
模型中的所有层算子除const算子外,输入和输出需要满足dim!=0。
只支持《AOL算子加速库接口参考》>“CANN算子规格说明”中的算子,并需满足算子限制条件。
由于软件约束(动态shape场景下暂不支持输入数据为DT_INT8),量化后的部署模型使用ATC工具进行模型转换时,不能使用动态shape相关参数,例如--dynamic_batch_size和--dynamic_image_size等,否则模型转换会失败。
使用AMCT工具量化后的部署模型,使用ATC工具进行模型转换时,不能再使用高精度特性,比如不能再通过--precision_mode参数配置force_fp32或must_keep_origin_dtype(原图fp32输入);不能再通过--precision_mode_v2参数配置origin;不能通过--op_precision_mode配置high_precision参数等。在高精度模式下设置量化参数,既拿不到量化的性能收益,也拿不到高精度模式的精度收益。
如果通过atc --help命令查询出的参数未解释在表1,则说明该参数预留或适用于其他产品,用户无需关注。
使用atc命令进行模型转换时,命令有两种方式,用户根据实际情况进行选择,本手册以选择第一种方式为例进行说明:
atc param1=value1 param2=value2 ...(value值前面不能有空格,否则会导致截断,param取的value值为空)
atc param1 value1 param2 value2 ...
使用ATC参数时,参数名支持以**--作为前缀(例如--help),也支持以-作为前缀(例如-help),当使用-作为前缀时,在执行atc命令时,会自动转换为--。本文的参数名均以--**前缀为例。
使用ATC参数时,参数名称支持以下划线连接两个字符串(例如soc_version),也支持以中划线连接两个字符串(例如soc-version)。本文的参数名称均以下划线连接两个字符串(例如soc_version)为例。
表1中的“是否必选”列,需要根据--mode取值具体区分。
表 1 ATC参数概览
|
|||
执行atc --help命令查看“--host_env_os”参数的默认值或查看${INSTALL_DIR}/opp/scene.info文件中的取值 |
|||
执行atc --help命令查看“--host_env_cpu”参数的默认值或查看${INSTALL_DIR}/opp/scene.info文件中的取值 |
|||
生成om离线模型时,是否将原始网络中的Const/Constant节点的权重保存在单独的文件中,同时将节点类型转换为FileConstant类型。 |
|||
扩展算子(非标准算子)映射配置文件路径和文件名,不同的网络中某扩展算子的功能不同,可以指定该扩展算子到具体网络中实际运行的扩展算子的映射。 |
|||
设置网络模型的精度模式。与--precision_mode不能同时使用,推荐使用--precision_mode_v2。 |
|||
设置optype列表中算子的实现模式,算子实现模式包括high_precision、high_performance两种。 |
|||
该参数功能已经不演进,后续版本会废弃,推荐使用--op_precision_mode参数。 |
|||
基础功能参数¶
总体选项¶
--help或--h¶
显示帮助信息。
无。
无。
无。
atc --help
返回的部分信息如下所示:
ATC start working now, please wait for a moment.
usage: atc <args>
generate offline model example:
atc --model=./alexnet.prototxt --weight=./alexnet.caffemodel --framework=0 --output=./domi --soc_version=<soc_version>
generate offline model for single op example:
atc --singleop=./op_list.json --output=./op_model --soc_version=<soc_version>
===== Basic Functionality =====
[General]
--h/help Show this help message
... ...
无。
--mode¶
运行模式。
若--mode取值为1或5,则需要与--om、--json参数配合使用。如果将原始模型文件转换成带shape信息的JSON文件,则还需要与--dump_mode参数配合使用。
若--mode取值为3,需要自行指定预检结果保存路径时,需要与--check_report参数配合使用。
若--soc_version取值为Ascend035,则该参数仅支持配置为30。
参数值:
0:(默认值)生成适配昇腾AI处理器的离线模型适配NPU IP加速器的离线模型,模型文件格式为*.om。
1:离线模型或原始模型文件转JSON文件,方便查看模型中的参数信息。
3:仅做预检,检查模型文件的内容是否合法。
5:dump图结构文件转JSON文件,用于解析图编译过程中产生的dump图结构(ge_proto*.txt格式文件,ge_onnx*.pbtxt暂不支持),然后将dump图结构转换成JSON文件,方便用户定位。
6:针对已有的离线模型,显示模型信息,包括模型占用的关键资源信息、编译与运行环境等信息。
30:生成适配昇腾AI处理器的离线模型适配NPU IP加速器的离线模型,模型文件格式为*.exeom,同时生成图调试信息文件*.dbg,用于dump、profiling的图调试。*.om模型和*.exeom模型的对比如下:
*.om文件不感知具体的硬件调度能力、包含中间态的抽象数据结构,在模型加载阶段,再根据具体执行平台的调度特性,生成运行时数据结构。
*.exeom文件感知具体的硬件调度能力、包含目标执行平台的运行时数据结构(这些数据以二进制的形式保存在*.exeom文件中),在模型加载阶段,加载恢复二进制内容,根据用户应用程序传递的数据区地址,或实际申请到的数据地址,刷新二进制中的地址指针值后,将二进制内容直接拷贝至Device,达到提升模型加载性能、降低模型加载内存峰值占用的效果。在一些资源受限的场景,建议使用*.exeom模型文件,增强产品的商用竞争力。
参数值约束:
若--mode取值为5,需要设置相关环境变量,先获取dump图结构文件,方法请参见2.c。设置完环境变量,模型转换完毕,在执行atc命令的当前路径会生成相应的图结构文件。
无。
参数值取值为0:
atc --mode=0 --framework=3 --model=$HOME/module/resnet50_tensorflow*.pb --output=$HOME/module/out/tf_resnet50 --soc_version=<soc_version>参数值取值为1:
离线模型转换为JSON文件
--mode=1 --om=$HOME/module/out/tf_resnet50.om --json=$HOME/module/out/tf_resnet50.json原始模型文件转换为JSON文件
--mode=1 --om=$HOME/module/resnet50_tensorflow*.pb --json=$HOME/module/out/tf_resnet50.json --framework=3
参数值取值为3:
atc --mode=3 --framework=3 --model=$HOME/module/resnet50_tensorflow*.pb --soc_version=<soc_version>执行完毕,在当前路径生成预检结果文件check_result.json。
参数值取值为5:
--mode=5 --om=$HOME/module/ge_proto_00000000_PreRunBegin.txt --json=$HOME/module/out/ge_proto.json参数值取值为6:
atc --mode=6 --om=$HOME/module/out/tf_resnet50.om命令执行完毕,屏幕会打印类似如下信息:
============ Display Model Info start ============ # 模型转换使用的atc命令 Original Atc command line: ${INSTALL_DIR}/bin/atc.bin --model=$HOME/module/resnet50_tensorflow*.pb --framework=3 --output=$HOME/module/out/tf_resnet50 --soc_version=<soc_version> --display_model_info=1 # ATC软件版本信息、soc_version版本信息、原始框架信息 system info: atc_version[xxx], soc_version[xxx], framework_type[xxx]. # 运行时的占用内存、权重大小、逻辑stream数目、event数目 resource info: memory_size[xxx B], weight_size[xxx B], stream_num[xxx], event_num[xxx]. # 离线模型文件中各分区大小、包括ModelDef、权重、tbe_kernels、task_info、so占用的大小等 om info: modeldef_size[xxx B], weight_data_size[xxx B], tbe_kernels_size[xxx B], cust_aicpu_kernel_store_size[xxx B], task_info_size[xxx B], so_store_size[xxx B]. ============ Display Model Info end ============
参数值取值为30:
atc --mode=30 --framework=3 --model=$HOME/module/resnet50_tensorflow*.pb --output=$HOME/module/out/tf_resnet50 --soc_version=<soc_version>
无。
输入选项¶
--framework¶
原始网络模型框架类型。
该版本仅支持ONNX框架。
无。
参数值:
1:MindSpore框架*.air格式的模型文件或TorchAir通过export导出的标准*.air格式文件
3:TensorFlow
5:ONNX
参数值约束:
当--mode为1时,该参数可选,可以指定TensorFlow、ONNX原始模型转成JSON文件,不指定时默认为离线模型转JSON文件,如果指定时需要保证--om模型和--framework类型对应一致,例如:
--mode=1 --framework=3 --om=$HOME/module/resnet50_tensorflow*.pb --mode=1 --framework=5 --om=$HOME/module/resnet50.onnx
当--mode为0或3时,该参数必选,可以指定TensorFlow、MindSpore或ONNX。
当取值为3时,即为TensorFlow框架网络模型,只支持FrozenGraphDef格式,即尾缀为pb的模型文件,pb文件采用protobuf格式存储,网络模型和权重数据都存储在同一个文件中。
当取值为5时,即为ONNX格式网络模型,支持ai.onnx算子域中opset v11~v15版本的算子;而PyTorch框架的pth模型,可以转化为ONNX格式的模型或者通过TorchAir export导出标准的*.air格式文件,然后才能进行模型转换。
当取值为1,且为MindSpore框架网络模型时,请务必查看如下限制:
模型转换时,仅支持后缀为*.air的模型文件;
--mode只支持配置为0;
--input_format只支持配置为NCHW,配置其它值无效,但模型转换成功;
MindSpore框架下,使用--input_shape、--out_nodes、--is_output_adjust_hw_layout、--input_fp16_nodes、--is_input_adjust_hw_layout、--op_name_map参数不生效,但模型转换成功;
当模型大小超过2G时,在MindSpore框架中保存模型时会同时生成*.air文件、weight文件夹及其中的权重文件,在模型转换时,需要将weight文件夹与*.air文件存放在同级目录下,否则模型转换报错。
无。
ONNX网络模型:
--mode=0 --framework=5 --model=$HOME/module/resnet50.onnx --output=$HOME/module/out/onnx_resnet50 --soc_version=<soc_version>TensorFlow框架:
--mode=0 --framework=3 --model=$HOME/module/resnet50_tensorflow*.pb --output=$HOME/module/out/tf_resnet50 --soc_version=<soc_version>*.air格式的模型文件:
--mode=0 --framework=1 --model=$HOME/module/ResNet50.air --output=$HOME/module/out/ResNet50_mindspore --soc_version=<soc_version>
针对TensorFlow框架原始网络模型,如果存在控制流算子(比如Switch/Merge/LoopCond/Case/While等),该类网络模型不能直接使用ATC工具进行模型转换,需要先将控制流算子的网络模型转成函数类算子的网络模型,然后利用ATC工具转换成适配昇腾AI处理器的离线模型适配NPU IP加速器的离线模型,详细转换方式请参见定制网络修改(TensorFlow)。
--model¶
原始网络模型文件路径与文件名。
当原始模型为Caffe框架时,需要和--weight参数配合使用。
**参数值:**模型文件路径与文件名。
**参数值格式:**路径和文件名:支持大小写字母(a-z,A-Z)、数字(0-9)、下划线(_)、短横线(-)、句点(.)、中文汉字。
无。
--model=$HOME/module/resnet50_tensorflow*.pb
无。
--weight¶
原始网络模型权重文件路径与文件名,当原始网络模型是Caffe时需要指定。
当原始模型为Caffe框架时,需要和--model参数配合使用。
**参数值:**权重文件路径与文件名。
**参数值格式:**路径和文件名:支持大小写字母(a-z,A-Z)、数字(0-9)、下划线(_)、短横线(-)、句点(.)、中文汉字。
无。
atc --mode=0 --model=$HOME/module/resnet50.prototxt --weight=$HOME/module/resnet50.caffemodel --framework=0 --soc_version=<soc_version> --output=$HOME/module/out/caffe_resnet50
无。
--input_format¶
指定模型输入数据的格式。
无。
参数值:
当原始框架为ONNX时,支持NCHW、NCDHW、ND(表示支持任意维度格式,N<=4)三种格式,默认为NCHW。
当原始框架是TensorFlow时,支持NCHW、NHWC、ND、NCDHW、NDHWC五种输入格式,默认为NHWC。
如果TensorFlow模型是通过ONNX模型转换工具输出的,则该参数必填,且值为NCHW。
如果原始模型中含有带data_format入参的算子,则该参数必填,推荐取值为ND,模型转换过程中会根据data_format属性的算子,推导出具体的format。若用户无法确定输入数据格式,则推荐指定为ND。
当原始框架为MindSpore时,只支持配置为NCHW,设置为其它值无效,但模型转换成功。
参数默认值:MindSpore、ONNX默认为NCHW;TensorFlow默认为NHWC。
参数值约束:
如果模型转换时开启AIPP,在进行推理业务时,输入图片数据要求为NHWC排布,该场景下最终与AIPP连接的输入节点的格式被强制改成NHWC,可能与atc模型转换命令中--input_format参数指定的格式不一致。
如果同时配置了--insert_op_conf参数,则--input_format参数只能配置为NCHW、NHWC。
若模型有多个输入,不同输入需要设置为相同的数据格式。
无。
--input_format=NCHW
无。
--input_shape¶
指定模型输入数据的shape。
动态分档场景,需要配合使用--dynamic_batch_size(设置BatchSize档位)或--dynamic_image_size(设置分辨率档位)或--dynamic_dims(设置指定维度档位)参数。
参数值:
原始模型为静态shape,--input_shape参数为可选配置
若模型为单个输入,则shape样例为"input_name:n,c,h,w"。
若模型有多个输入,shape之间使用英文分号分隔,样例为"input_name1:n1,c1,h1,w1**;**input_name2:n2,c2,h2,w2"。
原始模型为动态shape,--input_shape参数必须配置
若原始模型中输入数据的某个或某些维度值不固定,当前支持通过设置动态分档或设置shape范围两种方式转换模型:
设置动态分档,包括设置BatchSize档位、设置分辨率档位、设置指定维度档位。
设置--input_shape参数时,将对应维度值设置为-1,同时配合使用--dynamic_batch_size(设置BatchSize档位)或--dynamic_image_size(设置分辨率档位)或--dynamic_dims(设置指定维度档位)参数。
设置shape范围(动态shape)。IPV350不支持设置shape范围。
设置--input_shape参数时,可将对应维度的值设置为范围,例如1~10,设置的range值范围必须有效。
如果用户不想指定维度的范围或具体取值,则可以将其设置为-1,模型执行时该维度被解析为>=0的任意取值。
原始模型shape为标量
非动态分档场景:
shape为标量的输入,可选配置,例如模型有两个输入,input_name1为标量,即shape为"[]"形式,input_name2输入shape样例为[n2,c2,h2,w2],则shape信息为"**input_name1:;**input_name2:n2,c2,h2,w2";标量的输入如果配置,则配置为空。
动态分档场景:
如果模型输入中既有标量shape,又有支持动态分档的shape,则标量输入不能忽略,必须配置。例如模型有三个输入,分别为A:[-1,c1,h1,w1]、B:[]、C:[n2,c2,h2,w2],则shape信息为"A:-1,c1,h1,w1;**B:;**C:n2,c2,h2,w2",标量输入B必须配置。
参数值约束:
若模型有多个输入,则指定的节点必须放在双引号中,不同输入之间使用英文分号分隔,input_name必须是转换前的网络模型中的节点名称。
若原始模型中输入数据的某个维度值不固定(例如input_name1:?,h,w,c),通过Netron等可视化软件打开模型之后,输入信息样例如下:
该场景下--input_shape参数必填,并可以进行如下操作:
静态shape,将维度值设置为固定取值,例如,input_name1:1,h,w,c,用于将输入数据某个维度不固定的原始模型转换为固定维度的离线模型。
设置shape分档,例如设置为“-1”,与--dynamic_batch_size参数配合使用。
设置shape范围时,若设置为-1,表示此维度可以使用>=0的任意取值,该场景下取值上限为int64数据类型表示范围,但受限于host和device侧物理内存的大小,用户可以通过增大内存来支持。
若使用该参数时,同时通过--insert_op_conf设置了AIPP功能,则AIPP输出图片的宽和高要在本参数所设置的范围内。
无。
静态shape,--input_shape可选配置
例如某网络的输入shape信息,输入1**:**input_0_0 [16,32,208,208],输入2:input_1_0 [16,64,208,208],则--input_shape的配置信息为:
--input_shape="input_0_0:16,32,208,208;input_1_0:16,64,208,208"动态shape,--input_shape必须配置
设置BatchSize档位的示例,请参见--dynamic_batch_size。
设置分辨率档位的示例,请参见--dynamic_image_size。
设置指定维度档位的示例,请参见--dynamic_dims。
设置shape范围的示例:
--input_shape="input_0_0:1~10,32,208,208;input_1_0:16,64,100~208,100~208"
shape为标量
非动态分档场景
shape为标量的输入,可选配置。例如模型有两个输入,input_name1为标量,input_name2输入shape为[16,32,208,208],配置示例为:
--input_shape="input_name1:;input_name2:16,32,208,208"上述示例中的input_name1为可选配置**。**
动态分档场景
shape为标量的输入,必须配置。例如模型有三个输入,shape信息分别为A:[-1,32,208,208]、B:[]、C:[16,64,208,208],则配置示例为(A为动态分档输入,此处以设置BatchSize档位为例):
--input_shape="A:-1,32,208,208;B:;C:16,64,208,208" --dynamic_batch_size="1,2,4"
使用约束:
如果用户通过--input_shape设置了动态shape范围参数,同时又通过--insert_op_conf参数配置了动态AIPP功能,则AIPP输出的宽和高要在--input_shape所设置的范围内。
如果用户通过--input_shape设置了动态shape范围参数,同时又通过--insert_op_conf参数配置了静态AIPP功能,则:
如果模型只有一个输入,该场景不支持;如果模型有多个输入,则必须对不同的输入节点进行设置,比如一个输入节点设置静态AIPP,另外一个节点设置动态shape。
接口约束:
如果模型转换时通过该参数设置了shape的范围,使用应用工程进行模型推理时,需在aclmdlExecute接口之前,调用aclmdlSetDatasetTensorDesc接口,用于设置真实的输入Tensor描述信息(输入shape范围);模型执行之后,调用aclmdlGetDatasetTensorDesc接口获取模型动态输出的Tensor描述信息;再进一步调用aclTensorDesc下的操作接口获取输出Tensor数据占用的内存大小、Tensor的Format信息、Tensor的维度信息等。
关于aclmdlSetDatasetTensorDesc、aclmdlGetDatasetTensorDesc等接口的具体使用方法,请参见《AscendCL应用开发指南 (C&C++)》手册“acl API参考”章节。
--dynamic_batch_size¶
该版本不支持动态BatchSize特性。
设置动态BatchSize参数,适用于执行推理时,每次处理图片或者句子数量不固定的场景。
在某些推理场景,如检测出目标后再执行目标识别网络,由于目标个数不固定导致目标识别网络输入BatchSize不固定。如果每次推理都按照最大的BatchSize或最大分辨率进行计算,会造成计算资源浪费。因此,推理需要支持动态BatchSize和动态分辨率的场景,使用ATC工具时,通过该参数设置支持的BatchSize,通过--dynamic_image_size参数设置支持的分辨率档位。
模型转换完成后,在生成的om离线模型中,会新增一个输入,在模型推理时通过该新增的输入提供具体的BatchSize值。例如,a输入的BatchSize是动态的,在om离线模型中,会有与a对应的b输入来描述a的具体BatchSize。
该参数需要与--input_shape配合使用,不能与--dynamic_image_size、--dynamic_dims同时使用。且只支持N在shape首位的场景,即shape的第一位设置为"-1"。如果N在非首位场景下,请使用--dynamic_dims参数进行设置。
**参数值:**档位数,例如"1,2,4,8"。
**参数值格式:**指定的参数必须放在双引号中,档位之间使用英文逗号分隔。
参数值约束:
档位数取值范围为(1,100],即必须设置至少2个档位,最多支持100档配置;每个档位数值建议限制为:[1~2048]。
如果用户设置的档位数值过大或档位过多,在运行环境执行推理时,建议执行swapoff -a命令关闭swap交换区间作为内存的功能,防止出现由于内存不足,将swap交换空间作为内存继续调用,导致运行环境异常缓慢的情况。
如果用户设置的档位数值过大或档位过多,可能会导致模型转换失败,此时建议用户减少档位或调低档位数值。
CV(计算机视觉)类的网络,--dynamic_batch_size建议取值为8、16档位,该场景下的网络性能比单个BatchSize更优(8、16档位只是建议取值,实际使用时还请以实际测试结果为准)。
OCR/NLP(文字识别/自然语言处理)类网络,--dynamic_batch_size档位取值建议为16的整数倍(该档位值只是建议取值,实际使用时还请以实际测试结果为准)。
--input_shape="data:-1,3,416,416;img_info:-1,4" --dynamic_batch_size="1,2,4,8"
其中,“--input_shape“中的“-1“表示设置动态BatchSize。则ATC在模型编译时,支持的输入组合档数分别为:
第0档:data(1,3,416,416)+img_info(1,4)
第1档:data(2,3,416,416)+img_info(2,4)
第2档:data(4,3,416,416)+img_info(4,4)
第3档:data(8,3,416,416)+img_info(8,4)
使用约束:
不支持含有过程动态shape算子(网络中间层shape不固定)的网络。
如果用户设置了动态BatchSize,同时又通过--insert_op_conf参数设置了动态AIPP功能:
实际推理时,调用aclmdlSetInputAIPP接口设置动态AIPP相关参数值时,需确保batchSize要设置为最大Batch数。接口详细说明请参见《AscendCL应用开发指南 (C&C++)》手册中的“acl API参考 > 模型管理 > 模型执行 > aclmdlSetInputAIPP”。
通过该参数设置动态BatchSize特性后,生成的离线模型网络结构会与固定BatchSize场景下的不同,推理性能可能存在差异。
接口约束:
如果模型转换时通过该参数设置了动态BatchSize,则使用应用工程进行推理时,在模型执行接口之前:
使用aclmdlSetDynamicBatchSize接口,用于设置真实的BatchSize档位。
不使用aclmdlSetDynamicBatchSize接口,则模型执行时,默认按照BatchSize设置范围的最大值进行赋值。
接口详细说明请参见《AscendCL应用开发指南 (C&C++)》手册中的“acl API参考 > 模型管理 > 模型执行 > aclmdlSetDynamicBatchSize”。
--dynamic_image_size¶
该版本不支持动态分辨率特性。
设置输入图片的动态分辨率参数。适用于执行推理时,每次处理图片宽和高不固定的场景。
该参数需要与--input_shape配合使用,不能与--dynamic_batch_size、--dynamic_dims同时使用。
使用该参数设置动态分辨率时,--input_format参数只支持配置为NCHW、NHWC;其他format场景下,设置分辨率请使用--dynamic_dims参数。
**参数值:**动态分辨率参数,例如"imagesize1_height,imagesize1_width;imagesize2_height,imagesize2_width"。
参数值格式:指定的参数必须放在双引号中,档位之间英文分号分隔,每档内参数使用英文逗号分隔。
参数值约束:
档位数取值范围为(1,100],即必须设置至少2个档位,最多支持100档配置。
如果用户设置的分辨率数值过大或档位过多,在运行环境执行推理时,建议执行swapoff -a命令关闭swap交换区间作为内存的功能,防止出现由于内存不足,将swap交换空间作为内存继续调用,导致运行环境异常缓慢的情况。
如果用户设置的分辨率数值过大或档位过多,可能会导致模型转换失败,此时建议用户减少档位或调低档位数值。
--input_shape="data:8,3,-1,-1;img_info:8,4,-1,-1" --dynamic_image_size="416,416;832,832"
其中,“--input_shape“中的“-1“表示设置动态分辨率。则ATC在编译模型时,支持的输入组合档数分别为:
第0档:data(8,3,416,416)+img_info(8,4,416,416)
第1档:data(8,3,832,832)+img_info(8,4,832,832)
使用约束:
不支持含有过程动态shape算子(网络中间层shape不固定)的网络。
如果用户设置了动态分辨率,则请确保不同档位的分辨率能在原生框架下正常推理。
如果用户设置了动态分辨率,实际推理时,使用的数据集图片大小需要与具体使用的分辨率相匹配。
如果用户设置了动态分辨率,即输入图片的宽和高不确定,同时又通过--insert_op_conf参数设置了静态AIPP功能:该场景下,AIPP配置文件中不能开启Crop和Padding功能,并且需要将配置文件中的src_image_size_w和src_image_size_h取值设置为0。
如果用户设置了动态分辨率,同时又通过--insert_op_conf参数设置了动态AIPP功能:
实际推理时,调用aclmdlSetInputAIPP接口,设置动态AIPP相关参数值时,不能开启Crop和Padding功能。该场景下,还需要确保通过aclmdlSetInputAIPP接口设置的宽和高与aclmdlSetDynamicHWSize接口设置的宽、高相等,都必须设置成动态分辨率最大档位的宽、高。
接口详细说明请参见《AscendCL应用开发指南 (C&C++)》手册中的“acl API参考 > 模型管理 > 模型执行”章节。
通过该参数设置动态分辨率特性后,生成的离线模型网络结构会与固定分辨率场景下的不同,推理性能可能存在差异。
接口约束:
如果模型转换时通过该参数设置了动态分辨率,则使用应用工程进行模型推理时,在模型执行接口之前:
使用aclmdlSetDynamicHWSize接口,用于设置真实的分辨率,且实际推理时,使用的数据集图片大小需要与具体使用的分辨率相匹配。
不使用aclmdlSetDynamicHWSize接口,则模型执行时,默认按照动态分辨率设置范围的最大档位宽、高进行赋值。
接口详细说明请参见《AscendCL应用开发指南 (C&C++)》手册中的“acl API参考 > 模型管理 > 模型执行 > aclmdlSetDynamicHWSize”。
--dynamic_dims¶
设置ND格式下动态维度的档位。适用于执行推理时,每次处理任意维度的场景。
为支持Transformer等网络在输入格式的维度不确定的场景,通过该参数实现ND格式下任意维度的档位设置。ND表示支持任意格式。
该参数需要与--input_shape、--input_format配合使用,不能与--dynamic_batch_size、--dynamic_image_size、--insert_op_conf同时使用。
**参数值:**通过"dim1,dim2,dim3;dim4,dim5,dim6;dim7,dim8,dim9"的形式设置。
参数值格式:所有档位必须放在双引号中,档位之间使用英文分号分隔,每档内参数使用英文逗号分隔;每档内的dim值与--input_shape参数中的-1标识的参数依次对应,--input_shape参数中有几个-1,则每档必须设置几个维度。
参数值约束:
档位数取值范围为(1,100],即必须设置至少2个档位,最多支持100档配置,建议配置为3~4档。
无。
若网络模型只有一个输入:
每档中的dim值与--input_shape参数中的-1标识的参数依次对应,--input_shape参数中有几个-1,则每档必须设置几个维度。例如:
ATC参数取值为:
--input_shape="data:1,-1" --dynamic_dims="4;8;16;64" --input_format=ND则ATC在编译模型时,支持的data算子的shape为1,4; 1,8; 1,16; 1,64。
ATC参数取值为:
--input_shape="data:1,-1,-1" --dynamic_dims="1,2;3,4;5,6;7,8" --input_format=ND则ATC在编译模型时,支持的data算子的shape为1,1,2; 1,3,4; 1,5,6; 1,7,8。
若网络模型有多个输入:
每档中的dim值与网络模型输入参数中的-1标识的参数依次对应,网络模型输入参数中有几个-1,则每档必须设置几个维度。例如网络模型有三个输入,分别为data(1,1,40,T),label(1,T),mask(T,T) ,其中T为动态可变。则配置示例为:
--input_shape="data:1,1,40,-1;label:1,-1;mask:-1,-1" --dynamic_dims="20,20,1,1;40,40,2,2;80,60,4,4" --input_format=ND在ATC编译模型时,支持的输入dims组合档数分别为:
第0档:data(1,1,40,20)+label(1,20)+mask(1,1)
第1档:data(1,1,40,40)+label(1,40)+mask(2,2)
第2档:data(1,1,40,80)+label(1,60)+mask(4,4)
使用约束:
不支持含有过程动态shape算子(网络中间层shape不固定)的网络。
接口约束:
如果模型转换时通过该参数设置了动态维度,则使用应用工程进行模型推理时,在模型执行接口之前:
使用aclmdlSetInputDynamicDims接口,用于设置真实的维度。
不使用aclmdlSetInputDynamicDims接口,则模型执行时,默认按照动态维度设置范围的最大值进行赋值。
接口详细说明请参见《AscendCL应用开发指南 (C&C++)》手册中的“acl API参考 > 模型管理 > 模型执行 > aclmdlSetInputDynamicDims”章节。
--om¶
离线模型(.om)、原始模型文件(例如Caffe框架的.prototxt,TensorFlow框架的.pb等)、GE dump图结构文件(.txt)的路径和文件名。
若--mode取值为1:
离线模型转换为JSON文件
原始模型文件转换为JSON文件
--om需要与--mode=1、--json、--framework参数配合使用。
若--mode取值为5:
若--mode取值为6:
针对已有的离线模型,显示模型信息等信息,则--om只需要与--mode参数配合使用。
**参数值:**离线模型(.om)、原始模型文件(例如Caffe框架的.prototxt,TensorFlow框架的.pb)或GE dump图结构文件(.txt)的路径。
**参数值格式:**路径和文件名:支持大小写字母(a-z,A-Z)、数字(0-9)、下划线(_)、短横线(-)、句点(.)、中文汉字。
无。
若--mode取值为1
离线模型转换为JSON文件
--mode=1 --om=$HOME/module/out/tf_resnet50.om --json=$HOME/module/out/tf_resnet50.json原始模型文件转换为JSON文件
--mode=1 --om=$HOME/module/resnet50_tensorflow*.pb --json=$HOME/module/out/tf_resnet50.json --framework=3
若--mode取值为5
--mode=5 --om=$HOME/module/ge_proto_00000000_PreRunBegin.txt --json=$HOME/module/out/ge_proto.json若--mode取值为6
atc --mode=6 --om=$HOME/module/out/tf_resnet50.om
无。
--singleop¶
该版本不支持单算子特性。
单算子描述文件,将单个算子描述文件(JSON格式)转换成适配NPU IP加速器的离线模型,以便进行后续的单算子功能验证。
兼容性说明:
动态shape算子场景,om离线模型转换环境的CANN软件包版本,必须与产品运行环境的CANN软件包版本相同。
使用该参数时,只有如下参数可以配合使用,其中--output、--soc_version为必填。
**参数值:**单算子描述文件(JSON格式)格式以及参数配置请参见单算子模型转换(该版本不支持单算子特性)。
**参数值约束:**该参数指定的单算子都是基于Ascend IR定义的,关于单算子的详细定义请参见《AOL算子加速库接口参考》 中的“CANN算子规格说明”章节。
无。
下面以Add单算子为例进行说明,该单算子对应的描述文件为_add.json_ ,将该文件上传到ATC工具所在服务器任意目录,例如上传到_$HOME/singleop_,使用示例如下:
--singleop=$HOME/singleop/add.json --output=$HOME/singleop/out/op_model --soc_version=<soc_version>
使用约束
单算子JSON文件转换成离线模型场景,如果希望模型转换时只使用TBE算子(不查找AI CPU算子,找不到TBE算子则报错),还需设置如下环境变量:
export ASCEND_ENGINE_PATH=${INSTALL_DIR}/lib64/plugin/opskernel/libfe.so:${INSTALL_DIR}/lib64/plugin/opskernel/libge_local_engine.so:${INSTALL_DIR}/lib64/plugin/opskernel/librts_engine.so执行上述命令后,如果用户想要执行其他操作,需要删除上述环境变量:执行unset ASCEND_ENGINE_PATH命令,使其失效。
接口约束
单算子描述文件转换后的om离线模型文件,使用应用工程进行模型推理时,需调用AscendCL接口加载算子模型(例如aclopSetModelDir接口),最后调用AscendCL接口执行算子(例如aclopExecuteV2接口)。
接口详细说明请参见《AscendCL应用开发指南 (C&C++)》手册中的“acl API参考 > 单算子调用 > 单算子模型执行”章节。
输出选项¶
--output¶
如果是开源框架的网络模型:
存放转换后的离线模型的路径以及文件名,例如:$HOME/module__/out/tf_resnet50,转换后的模型文件名以指定的为准,自动以.om后缀结尾,例如:tf_resnet50.om或_tf_resnet50_<os>_<arch>_.om,若.om文件名中包含操作系统及架构,则该文件只能在该操作系统及架构的运行环境中使用。
如果是单算子描述文件(JSON格式):
存放转换后的单算子模型的路径,例如:_$HOME/_singleop/out/op_model。转换后的模型文件命名规则默认为:序号_算子类型_输入的描述(dataType_format_shape)_输出的描述(dataType_format_shape),如果不采用默认命名规则,可以通过单算子描述文件中的name属性指定模型文件名。
若使用atc命令转换出来的om离线模型文件名中含操作系统及架构,但操作系统及其架构与模型运行环境不一致时,则需要与--host_env_os、--host_env_cpu参数配合使用,设置模型运行环境的操作系统类型及架构。
参数值:
如果是开源框架的网络模型:存放转换后的离线模型的路径以及文件名。
如果是单算子描述文件(JSON格式):存放转换后的单算子模型的路径。
**参数值格式:**路径和文件名:支持大小写字母(a-z,A-Z)、数字(0-9)、下划线(_)、短横线(-)、句点(.)、中文汉字。
无。
TF框架网络模型:
--output=$HOME/module/out/tf_resnet50ONNX网络模型:
--output=$HOME/module/out/onnx_resnet50单算子描述文件:
--output=$HOME/singleop/out/op_model
无。
--output_type¶
指定网络输出数据类型或指定某个输出节点的输出类型。
若指定某个输出节点的输出类型,则需要和--out_nodes参数配合使用。
参数值:
FP32(IPV350不支持):推荐分类网络、检测网络使用。
UINT8:图像超分辨率网络,推荐使用,推理性能更好。
FP16:推荐分类网络、检测网络使用。通常用于一个网络输出作为另一个网络输入场景。
INT8
参数值约束:
模型转换完毕,在对应的om离线模型文件中,数据类型以DT_FLOAT或DT_UINT8或DT_FLOAT16或DT_INT8值呈现。
若在模型转换时不指定网络具体输出数据类型,则以原始网络模型最后一层输出的算子数据类型为准;若指定了类型,则以该参数指定的类型为准,此时--is_output_adjust_hw_layout参数指定的类型不生效。
无。
指定网络输出数据类型
--output_type=FP32指定某个输出节点的输出数据类型
例如:--output_type="node1:0:FP16;node2:0:FP32",表示node1节点第一个输出设置为FP16,node2第一个节点输出设置为FP32。指定的节点必须放在双引号中,节点中间使用英文分号分隔。
该场景下,该参数需要与--out_nodes参数配合使用。
--model=$HOME/module/resnet50_tensorflow*.pb --framework=3 --output=$HOME/module/out/tf_resnet50 --soc_version=<soc_version> --output_type="conv1:0:FP16" --out_nodes="conv1:0"
无。
--check_report¶
用于配置预检结果保存文件路径和文件名。
--mode:当--mode=0时解析图失败时或--mode=3仅做预检时,通过该参数指定预检结果文件的保存路径。
**参数值:**预检结果文件路径和文件名。
**参数值格式:**路径和文件名:支持大小写字母(a-z,A-Z)、数字(0-9)、下划线(_)、短横线(-)、句点(.)、中文汉字。
**参数默认值:**执行atc命令当前路径生成check_result.json
无。
--check_report=$HOME/module/out/check_result.json
预检结果文件存储路径,除--check_report参数设置的方式外,还可以配置环境变量ASCEND_WORK_PATH,几种方式优先级为
配置参数“--check_report”>环境变量ASCEND_WORK_PATH>默认存储路径(执行atc命令当前路径)。
关于环境变量ASCEND_WORK_PATH的详细说明请参见《环境变量参考》。
--json¶
离线模型、原始模型文件、GE dump图结构文件转换为JSON文件的路径和文件名。
如果是已有的离线模型转换为JSON文件,在转换后的文件中还可以查看原始模型转换为该离线模型时,使用的基础版本号(比如ATC软件版本信息,OPP算子包版本信息等)以及当时模型转换使用的atc命令。
离线模型转换为JSON文件
原始模型文件转换为JSON文件
该参数需要与--mode=1、--om参数、--framework配合使用。
原始模型为MindSpore框架时,即--framework=1时,不支持转换为JSON文件。
GE dump图结构文件转JSON文件
仅支持dump出的ge_proto*.txt格式文件转成JSON文件。
**参数值:**JSON文件的路径和文件名。
**参数值格式:**路径和文件名:支持大小写字母(a-z,A-Z)、数字(0-9)、下划线(_)、短横线(-)、句点(.)、中文汉字。
无。
离线模型转换为JSON文件
--mode=1 --om=$HOME/module/out/tf_resnet50.om --json=$HOME/module/out/tf_resnet50.json原始模型文件转换为JSON文件
--mode=1 --om=$HOME/module/resnet50_tensorflow*.pb --json=$HOME/module/out/tf_resnet50.json --framework=3GE dump图结构文件转JSON文件
--mode=5 --om=$HOME/module/ge_proto_00000000_PreRunBegin.txt --json=$HOME/module/out/ge_proto.json
无。
--host_env_os¶
若模型编译环境的操作系统及其架构与模型运行环境不一致时,则需使用本参数设置模型运行环境的操作系统类型。
如果不设置,则默认取模型编译环境的操作系统类型,即ATC工具所在环境的操作系统类型。
如果模型编译环境的操作系统及其架构与模型运行环境不一致,需要与--host_env_cpu参数配合使用,通过--host_env_os参数设置操作系统类型、通过--host_env_cpu参数设置操作系统架构。
参数值:执行atc --help命令查看“--host_env_os“参数支持的所有取值。
参数默认值:执行atc --help命令查看“--host_env_os“参数的默认值或查看${INSTALL_DIR}/opp/scene.info文件中的取值。
${INSTALL_DIR}请替换为CANN软件安装后文件存储路径。以root安装举例,安装后文件默认存储路径为:/usr/local/Ascend/latest。
无。
--host_env_os=linux --host_env_cpu=x86_64
若转换后的离线模型包含操作系统类型、架构,例如:xxx_linux_x86_64.om,则说明该模型运行的环境只能是_x86_64_架构的_Linux_操作系统。
若转换后的离线模型不包含操作系统类型、架构,例如:xxx.om,则说明CANN软件包所支持的操作系统,都支持该模型运行。
无。
--host_env_cpu¶
若模型编译环境的操作系统及其架构与模型运行环境不一致时,则需使用本参数设置模型运行环境的操作系统架构。
如果不设置,则默认取模型编译环境的操作系统架构,即ATC工具所在环境的操作系统架构。
如果模型编译环境的操作系统及其架构与模型运行环境不一致,需要与--host_env_os参数配合使用,通过--host_env_os参数设置操作系统类型、通过--host_env_cpu参数设置操作系统架构。
参数值:执行atc --help命令查看“--host_env_cpu“参数支持的所有取值。
参数默认值:执行atc --help命令查看“--host_env_cpu“参数的默认值或查看${INSTALL_DIR}/opp/scene.info文件中的取值。
${INSTALL_DIR}请替换为CANN软件安装后文件存储路径。以root安装举例,安装后文件默认存储路径为:/usr/local/Ascend/latest。
无。
--host_env_os=linux --host_env_cpu=x86_64
若转换后的离线模型包含操作系统类型、架构,例如:xxx_linux_x86_64.om,则说明该模型运行的环境只能是_x86_64_架构的_Linux_操作系统。
若转换后的离线模型不包含操作系统类型、架构,例如:xxx.om,则说明CANN软件包所支持的操作系统,都支持该模型运行。
无。
目标芯片选项¶
--soc_version¶
配置模型在推理运行阶段所使用的NPU IP加速器型号。
模型转换阶段不依赖NPU IP加速器,但是转换时使用的--soc_version取值,必须为转换后模型运行阶段所使用的NPU IP加速器型号。
兼容性说明:
不同产品,只要--soc_version取值相同,则只需转换一次模型,即可分别在这些产品上进行部署运行。
部署运行环境要求:请确保产品运行环境的CANN软件包版本不低于转换om离线模型时转换环境的CANN软件包版本。
低版本的CANN软件包环境上转换出的om离线模型,支持在高版本的CANN软件包环境上运行,兼容4个版本周期。
无。
Ascend035
无。
IPV350使用示例:
--soc_version=Ascend035
无。
--aicore_num¶
用于配置模型编译时使用的AI Core核数。
无。
参数值:"整数1|整数2",中间使用“|”分割:
场景2:针对如下产品,仅需配置整数1,配置格式为:"整数1|",配置整数2不会生效,表示算子编译时使用的AI Core核数:
IPV350
参数值约束:
针对参数值中的场景2:
不同产品型号NPU IP加速器包含的最大AI Core数量可从"${INSTALL_DIR}/<arch>-linux/data/platform_config/xxx.ini"文件查看,如下所示,说明NPU IP加速器上存在10个AI Core。
[SoCInfo] # AI Core默认值,默认值即为最大值 ai_core_cnt=10 vector_core_cnt=8
如果配置该参数的同时启用了算子编译缓存功能(--op_compiler_cache_mode参数配置为“enable”或者“force”),此参数仅在首次编译时生效。若您想在非首次编译时生效该参数,需要清理编译磁盘的缓存。
其中,${INSTALL_DIR}请替换为CANN软件安装后文件存储路径。以root安装举例,安装后文件默认存储路径为:/usr/local/Ascend/latest。_<arch>_表示具体操作系统架构,_xxx_请根据实际产品型号进行选择。
无。
场景2配置示例
--aicore_num="10|"
无。
高级功能参数¶
功能配置选项¶
--out_nodes¶
指定某层输出节点(算子)作为网络模型的输出或指定网络模型输出的名称。
如果不指定输出节点,则模型的输出默认为最后一层的算子信息,如果指定,则以指定的为准。某些情况下,用户想要查看中间层算子输出,即可以在模型转换时通过该参数指定输出某层算子,模型转换后,在相应om离线模型文件最后即可以看到指定输出算子的参数信息,如果通过om离线模型文件无法查看,则可以将其转换成JSON格式后查看。
当--framework取值为1,且为MindSpore框架网络模型时,设置本参数无效,但模型转换成功。
参数值:
指定网络模型中的节点(node_name)名称
若指定多个输出节点,则多个输出节点的名称必须放在双引号中,中间使用英文分号分隔。node_name必须是模型转换前的网络模型中的节点名称,冒号后的数字表示第几个输出,例如node_name1:0,表示节点名称为node_name1的第1个输出。
指定网络模型输出的名称(output的name)(该场景仅支持ONNX网络模型)
若指定多个输出,则多个输出的name必须放在双引号中,中间使用英文分号分隔。output必须是网络模型的输出。
参数值约束:
参数值中的三种方式,使用时只能取其一,不能同时存在。
若参数值取值为网络模型输出的名称(output的name),该种方式仅限于ONNX网络模型。
无。
参数值取网络模型中节点(node_name)的名称
--out_nodes="node_name1:0;node_name1:1;node_name2:0"参数值取网络模型输出的名称(output的name)
--out_nodes="output1;output2;output3"
无。
--input_fp16_nodes¶
指定输入数据类型为float16的输入节点名称。
若配置了该参数,则不能对同一个输入节点同时使用--insert_op_conf参数。
当--framework取值为1,且为MindSpore框架网络模型时,设置本参数无效,但模型转换成功。
**参数值:**数据类型为float16的输入节点名称。
参数值约束:指定的节点有多个时,必须放在双引号中,节点中间使用英文分号分隔。
无。
--input_fp16_nodes="node_name1;node_name2"
无。
--insert_op_conf¶
插入算子的配置文件路径与文件名,例如AIPP预处理算子。该版本不支持AIPP特性。
若使用该参数后,输入数据类型为UINT8。
若配置了该参数,则不能对同一个输入节点同时使用--input_fp16_nodes参数。
**参数值:**插入算子的配置文件路径与文件名。
**参数值格式:**路径和文件名:支持大小写字母(a-z,A-Z)、数字(0-9)、下划线(_)、短横线(-)、句点(.)、中文汉字。
**参数值约束:**文件后缀不局限于.cfg格式,但是配置文件中的内容需要满足prototxt格式。
无。
下面以插入AIPP预处理算子为例进行说明,配置文件内容示例如下(文件名为举例为:insert_op.cfg)。
aipp_op {
aipp_mode:static
input_format:YUV420SP_U8
csc_switch:true
var_reci_chn_0:0.00392157
var_reci_chn_1:0.00392157
var_reci_chn_2:0.00392157
}
将配置好的_insert_op.cfg_文件上传到ATC工具所在服务器任意目录,例如上传到_$HOME/module_,使用示例如下:
--insert_op_conf=$HOME/module/insert_op.cfg
如果用户设置了静态AIPP功能,同时又通过--input_shape设置了动态shape范围参数,则:
如果模型只有一个输入,该场景不支持;如果模型有多个输入,则必须对不同的输入节点进行设置,比如一个输入节点设置静态AIPP,另外一个节点设置动态shape。
如果用户设置了静态AIPP功能,同时又通过--dynamic_image_size设置了动态分辨率(输入图片的宽和高不确定):
该场景下,AIPP配置文件中不能开启Crop和Padding功能,并且需要将配置文件中的src_image_size_w和src_image_size_h取值设置为0。
如果用户设置了动态AIPP功能,同时又通过--input_shape设置了动态shape范围参数,则AIPP输出的宽和高要在--input_shape所设置的范围内。
如果用户设置了动态AIPP功能,同时又通过--dynamic_batch_size设置了动态BatchSize:
实际推理时,调用aclmdlSetInputAIPP接口设置动态AIPP相关参数值时,需确保batchSize要设置为最大Batch数。接口详细说明请参见《AscendCL应用开发指南 (C&C++)》手册中的“acl API参考 > 模型管理 > 模型执行 > aclmdlSetInputAIPP”。
如果用户设置了动态AIPP功能,同时又通过--dynamic_image_size设置了动态分辨率(输入图片的宽和高不确定):
实际推理时,调用aclmdlSetInputAIPP接口,设置动态AIPP相关参数值时,不能开启Crop和Padding功能。该场景下,还需要确保通过aclmdlSetInputAIPP接口设置的宽和高与aclmdlSetDynamicHWSize接口设置的宽、高相等,都必须设置成动态分辨率最大档位的宽、高。接口详细说明请参见《AscendCL应用开发指南 (C&C++)》手册中的“acl API参考 > 模型管理 > 模型执行”。
--external_weight¶
生成om离线模型文件时,是否将原始网络中的Const/Constant节点的权重外置,同时将节点类型转换为FileConstant类型。
离线场景,如果模型权重较大且环境对om离线模型大小有限制,建议开启外置权重将权重单独保存,来减小om大小。
需要和--output参数配合使用,生成的权重文件保存在与om离线模型文件同层级的weight目录下,权重文件以weight_+hash值命名。
0:(默认值)权重不外置,直接保存在om离线模型文件中。
1:权重外置,将网络中所有的Const/Constant节点的权重文件落盘,并将节点类型转换为FileConstant类型;权重文件以weight_+hash值命名。
无。
以ONNX网络模型为例:
atc --framework=5 --model=$HOME/module/resnet50.onnx --output=$HOME/module/out/onnx_resnet50 --soc_version=<soc_version> --external_weight=1
权重外置场景,在使用AscendCL接口开发推理应用、加载模型时:
若使用aclmdlLoadFromFile接口加载模型,需将权重文件保存在与om离线模型文件同层级的weight目录下。
若使用aclmdlSetConfigOpt和aclmdlLoadWithConfig接口加载模型,对权重外置目录没有要求,后续加载模型时,通过aclmdlLoadWithConfig接口指定权重外置目录。
接口详细说明请参见《AscendCL应用开发指南 (C&C++)》手册中的“acl API参考 >模型管理 > 模型加载和卸载”章节。
--op_name_map¶
扩展算子(非标准算子)映射配置文件路径和文件名,不同的网络中某扩展算子的功能不同,可以指定该扩展算子到具体网络中实际运行的扩展算子的映射。
当--framework取值为1,且为MindSpore框架网络模型时,设置本参数无效,但模型转换成功。
**参数值:**扩展算子映射配置文件路径和文件名。
**参数值格式:**路径和文件名:支持大小写字母(a-z,A-Z)、数字(0-9)、下划线(_)、短横线(-)、句点(.)、中文汉字。
无。
扩展算子映射配置文件内容示例如下(文件名举例为:opname_map.cfg):
OpA:Network1OpA
将配置好的_opname_map.cfg_上传到ATC工具所在服务器任意目录,例如上传到_$HOME/module_,使用示例如下:
--op_name_map=$HOME/module/opname_map.cfg
无。
--is_input_adjust_hw_layout¶
与--input_fp16_nodes参数配合使用,指定网络模型输入数据类型为float16、数据格式为NC1HWC0。单独配置本参数无效,但模型转换成功。
--is_input_adjust_hw_layout参数设置为true,需要与--input_fp16_nodes参数配合使用,通过--input_fp16_nodes参数指定的节点输入数据类型为float16、输入数据格式为NC1HWC0。
--is_input_adjust_hw_layout参数取值个数必须和--input_fp16_nodes参数指定节点个数匹配,多个参数取值使用英文逗号分割。
当--framework取值为1,且为MindSpore框架网络模型时,设置本参数无效,但模型转换成功。
true:指定网络模型输入数据类型为float16、数据格式为NC1HWC0。
false:(默认值)不指定。
无。
若--input_fp16_nodes配置了一个节点:
atc --model=$HOME/module/resnet50_tensorflow*.pb --framework=3 --output=$HOME/module/out/tf_resnet50 --is_input_adjust_hw_layout=true --input_fp16_nodes="data" --soc_version=<soc_version>若--input_fp16_nodes配置了多个节点:
atc --model=$HOME/module/resnet50_tensorflow*.pb --framework=3 --output=$HOME/module/out/tf_resnet50 --is_input_adjust_hw_layout="true,true" --input_fp16_nodes="data1;data2" --soc_version=<soc_version>
无。
--is_output_adjust_hw_layout¶
与--out_nodes参数配合使用,指定网络模型输出数据类型为float16、数据格式为NC1HWC0。单独配置本参数无效,但模型转换成功。
--is_output_adjust_hw_layout参数设置为true,需要与--out_nodes参数配合使用,通过--out_nodes参数指定的节点输出数据类型为float16、输出数据格式为NC1HWC0。
--is_output_adjust_hw_layout参数取值个数必须和--out_nodes参数指定节点个数匹配,多个参数取值使用英文逗号分割。
当--framework取值为1,且为MindSpore框架网络模型时,设置本参数无效,但模型转换成功。
true:指定网络模型输出数据类型为float16、数据格式为NC1HWC0。
false:(默认值)不指定。
无。
若--out_nodes配置了一个节点
atc --model=$HOME/module/resnet50_tensorflow*.pb --framework=3 --output=$HOME/module/out/tf_resnet50 --is_output_adjust_hw_layout=true --out_nodes="prob:0" --soc_version=<soc_version>若--out_nodes配置了多个节点
atc --model=$HOME/module/resnet50_tensorflow*.pb --framework=3 --output=$HOME/module/out/tf_resnet50 --is_output_adjust_hw_layout="true,true" --out_nodes="prob:0;prob:1" --soc_version=<soc_version>
无。
模型调优选项¶
--buffer_optimize¶
数据缓存优化开关。
无。
参数值:
l1_optimize:表示开启l1优化。当前版本该参数无效,等同于off_optimize。
l2_optimize:(默认值)表示开启l2优化。
off_optimize:表示关闭数据缓存优化。
其中,l1表示L1 Buffer,通用内部存储,是AI Core内比较大的一块数据中转区,可暂存AI Core中需要反复使用的一些数据从而减少从总线读写的次数;l2表示L2 Buffer,表示外部存储;AI Core需要把外部存储中的数据加载到内部存储中,才能完成相应的计算。
建议打开数据缓存优化功能:开启数据缓存优化可提高计算效率、提升性能,但由于部分算子在实现上可能存在未考虑的场景,导致影响精度,因此在出现精度问题时可以尝试关闭数据缓存优化。如果关闭数据缓存优化功能后,精度达标,则需要识别出问题算子,反馈给技术支持进一步分析、解决算子问题;解决算子问题后,建议仍旧保持开启数据缓存优化功能。
--buffer_optimize=l2_optimize
无。
--disable_reuse_memory¶
内存复用开关。
内存复用是指按照生命周期和内存大小,把不冲突的内存重复使用,来降低网络内存占用。
无。
0:(默认值)开启内存复用。
1:关闭内存复用。如果网络模型较大,关闭内存复用开关,会造成后续推理时Device侧内存不复用,从而导致内存不足。
无。
--disable_reuse_memory=0
在内存复用场景下(默认开启内存复用),支持基于指定算子(节点名称/算子类型)单独分配内存。通过OP_NO_REUSE_MEM环境变量指定要单独分配的一个或多个节点,支持混合配置。配置多个节点时,中间通过英文逗号(“,”)隔开。详细说明请参见《环境变量参考》。
基于节点名称配置
节点名称需要配置为转换为CANN平台网络后的节点名称,节点名称可以通过设置DUMP_GE_GRAPH环境变量,在导出的ge_onnx_xxx_Build.pbtxt最终图中查看“name”字段获取。
export OP_NO_REUSE_MEM=gradients/logits/semantic/kernel/Regularizer/l2_regularizer_grad/Mul_1,resnet_v1_50/conv1_1/BatchNorm/AssignMovingAvg2基于算子类型配置
export OP_NO_REUSE_MEM=FusedMulAddN,BatchNorm混合配置
export OP_NO_REUSE_MEM=FusedMulAddN,resnet_v1_50/conv1_1/BatchNorm/AssignMovingAvg
--enable_scope_fusion_passes¶
指定编译时需要生效的Scope融合规则列表。
无论是内置还是用户自定义的Scope融合规则,都分为如下两类:
通用融合规则(General):各网络通用的Scope融合规则;默认生效,不支持用户更改。
定制化融合规则(Non-General):特定网络适用的Scope融合规则;默认不生效,用户可以通过--enable_scope_fusion_passes指定生效的融合规则列表。
当前支持的融合规则请参见《TensorFlow Parser Scope融合规则参考》。
无。
**参数值:**注册的融合规则名称。
**参数值格式:**允许传入多个规则列表,中间使用英文逗号分隔,例如ScopePass1,ScopePass2,...。
无。
--enable_scope_fusion_passes=ScopePass1,ScopePass2
该参数只适用于TensorFlow网络模型。如果要查看模型转换过程中融合规则相关的日志信息,则--log至少要设置为warning级别。
--fusion_switch_file¶
融合规则(包括图融合和UB融合)开关配置文件路径以及文件名,通过该参数关闭配置文件中指定的融合规则。
图融合:是FE根据融合规则进行改图的过程。图融合用融合后算子替换图中融合前算子,提升计算效率。图融合的场景如下:
在某一些算子的数学计算量可以进行优化的情况下,可以进行图融合,融合后可以节省计算时间。例如:conv+biasAdd,可以融合成一个算子,直接在L0C中完成累加,从而省去add的计算过程。
在融合后的计算过程可以通过硬件指令加速的情况下,可以进行图融合,融合后能够加速。例如:conv+biasAdd的累加过程,就是通过L0C中的累加功能进行加速的,可以通过图融合完成。
UB融合:UB即NPU IP加速器上的Unified Buffer,UB融合指A算子的计算结果在Unified Buffer上,需要搬移到Global Memory。B算子再执行时,需要将A算子的输出由Global Memory再搬移到Unified Buffer,进行B的计算逻辑,计算完之后,又从Unified Buffer搬移回Global Memory。
从这个过程会发现A的结果从Unified Buffer->Global Memory->Unified Buffer->Global Memory。这个经过Global Memory进行数据搬移的过程是浪费的,因此将A和B算子合并成一个算子,省去了数据搬移的过程叫UB融合。UB融合可以减少整网中数据搬移的时间(Global Memory>Unified Buffer,Unified Buffer->Global Memory),提高运算效率,有效降低带宽。
无。
**参数值:**配置文件路径以及文件名。
**参数值格式:**路径和文件名:支持大小写字母(a-z,A-Z)、数字(0-9)、下划线(_)、短横线(-)、句点(.)、中文汉字。
参数值约束:
系统内置的图融合和UB融合规则,均为默认开启,用户可以根据需要通过该参数关闭指定的融合规则。当前可以关闭的融合规则请参见《图融合和UB融合规则参考》,由于系统机制,其他融合规则无法关闭。
无。
场景1:逐条配置待关闭融合规则
配置文件样例如下,冒号前面为融合规则名,后面字段表示融合规则是否开启(融合规则开关配置文件名举例为_fusion_switch.cfg_):
xxxFusionPass:off yyyFusionPass:off ....
场景2:一键式关闭融合规则
该参数支持用户一键式关闭融合规则,配置文件样例如下:
{ "Switch":{ "GraphFusion":{ "ALL":"off" }, "UBFusion":{ "ALL":"off" } } }
说明:
关闭某些融合规则可能会导致功能问题,因此此处的一键式关闭仅关闭系统部分融合规则,而不是全部融合规则。
一键式关闭融合规则时,可以同时开启部分融合规则,样例如下:
{ "Switch":{ "GraphFusion":{ "ALL":"off", "SoftmaxFusionPass":"on" }, "UBFusion":{ "ALL":"off", "TbePool2dQuantFusionPass":"on" } } }
将上述配置好的_fusion_switch.cfg_文件上传到ATC工具所在服务器任意目录,例如上传到_$HOME/module_,使用示例如下:
--fusion_switch_file=$HOME/module/fusion_switch.cfg
模型转换完毕,根据--export_compile_stat参数的取值,决定是否生成算子融合信息结果文件"fusion_result.json"。
该文件用于记录图编译过程中除去fusion_switch.cfg文件中关闭的融合规则外,仍旧使用的融合规则,其中,"match_times"字段表示模型转换过程中匹配到的融合规则次数,"effect_times"字段表示实际生效的次数。如果未配置--fusion_switch_file参数,则生成的"fusion_result.json"文件中记录模型转换过程中匹配到的所有融合规则。
若网络模型中Convolution算子的“group“属性取值==模型文件prototxt中“num_output“属性的取值,则上述配置文件中**_Vxxx_RequantFusionPass**必须打开。
AMCT对原始框架模型进行量化时,会插入量化和反量化算子,而使用ATC工具进行模型转换过程中,会对插入的量化和反量化算子进行融合,此情况下再进行量化后模型dump结果与原始模型dump结果的比对可能不准确,因此如果用户想使用AMCT量化后的模型进行精度比对,则需要通过--fusion_switch_file参数关闭部分融合功能,该场景下需要关闭的融合规则如下:
融合规则简述如下,详细描述请参见《图融合和UB融合规则参考》。
ConvConcatFusionPass
图融合规则,支持conv2d*N+concat算子的图融合规则,conv2d后面可以连接dequant和Relu类算子。
SplitConvConcatFusionPass
图融合规则,支持split+conv2d*N+concat算子的融合规则,conv2d后面可以连接dequant和Relu类算子。
TbeEltwiseQuantFusionPass
UB融合规则,支持elemwise+quant算子的UB融合,quant算子为可选节点。
TbeConvDequantVaddReluQuantFusionPass
UB融合规则,量化场景下,对Conv-dequant-vadd-relu-quant连续的节点,标记UB融合,提升推理性能。
TbeConvDequantVaddReluFusionPass
UB融合规则,支持conv2d+dequant+vadd+relu/conv2d+dequant+(leakyrelu)+vadd算子的融合节点。
TbeConvDequantQuantFusionPass
UB融合规则,量化场景下,对Conv-dequant-quant连续的节点,标记UB融合,提升推理性能。
TbeDepthwiseConvDequantFusionPass
UB融合规则,支持depthwiseConv2d+dequant+(relu/mul)+quant/depthwiseConv2d+dequant+(sigmoid)+mul/depthwiseConv2d+requant/depthwiseConv2d+(power+relu6+power)+elemwise+(quant)算子的融合节点。
TbeFullyconnectionElemwiseDequantFusionPass
UB融合规则,支持如下两种形式的融合:
静态shape场景BatchMatMul/BatchMatMulV2 + elemwise的融合。
静态shape场景MatMul/MatMulV2/BatchMatMul/BatchMatMulV2 + AscendDequant + elemwise1(+ elemwise2)的融合。
TbeConv2DAddMulQuantPass
UB融合规则,支持conv+dequant+add+quant融合,add算子除quant外还必须有另两路任意输出才可以进行融合。
TbePool2dQuantFusionPass
UB融合规则,量化场景下,对Pool2d-quant连续的节点,标记UB融合,提升推理性能。
TbeCommonRules0FusionPass
UB融合规则,支持StridedRead+Conv2D+dequant+elemwise+quant+StridedWrite算子的UB融合,除Conv2D外,其他节点都是可选节点。
TbeCommonRules2FusionPass
UB融合规则,支持StridedRead+Conv2D+dequant+elemwise+quant+StridedWrite算子的UB融合,除Conv2D外,其他节点都是可选节点;elemwise支持多输出场景下的融合。
--enable_small_channel¶
是否使能small channel的优化,使能后在channel<=4的卷积层会有性能收益。建议用户在推理场景下打开此开关。
该参数使能后,建议与--insert_op_conf参数(AIPP功能)配合使用,可以获得更优的性能。
在配合使用时,由于软件约束,只能和静态AIPP配合使用,不能和动态AIPP配合使用。
参数值:
0:(默认值)关闭,模型推理时关闭small channel优化。
1:使能,模型推理时使能small channel优化。
**参数值约束:**如果模型Input的channel<=4,建议开启该参数,并配合静态AIPP(--insert_op_conf)使用,可获得更优的性能;如果开启之后出现性能下降,建议进行Tiling调优。
无。
--enable_small_channel=1
该参数使能后,建议与AIPP功能--insert_op_conf同时使用,否则可能没有收益。
--quant_dumpable¶
是否采集量化算子的dump数据。
参考《AscendCL应用开发指南 (C&C++)》手册中的“精度/性能优化 > 模型推理精度提升建议”章节进行精度定位时,如果存在AMCT量化后的模型,该模型转成om离线模型时,图编译过程中可能优化量化算子的输入输出,从而影响量化算子dump数据的导出,例如:两个被量化的卷积计算,中间输出被优化为int8的量化后输出。
为此引入--quant_dumpable参数,使能该参数后,量化算子的输入输出不做融合,并且会插入transdata算子,还原原始模型的格式,从而能采集到量化算子的dump数据。
无。
0:(默认值)图编译过程中可能优化量化算子的输入输出,此时无法获取量化算子的dump数据。
1:开启此配置后,可确保能够采集量化算子的dump数据。
开启Data Dump的场景下,建议该参数设置为1,确保可以采集量化算子的dump数据。
--quant_dumpable=1
--compression_optimize_conf¶
压缩优化功能配置文件路径以及文件名,通过该参数使能配置文件中指定的压缩优化特性,从而提升网络性能。IPV350不支持该特性。
若通过该参数配置了calibration量化特性,则不能再使用高精度特性,比如不能再通过--precision_mode参数配置force_fp32或must_keep_origin_dtype(原图fp32输入);不能再通过--precision_mode_v2参数配置origin;不能通过--op_precision_mode配置high_precision参数等。在高精度模式下设置量化参数,既拿不到量化的性能收益,也拿不到高精度模式的精度收益。
**参数值:**配置文件路径以及文件名。
**参数值格式:**路径和文件名:支持大小写字母(a-z,A-Z)、数字(0-9)、下划线(_)、短横线(-)、句点(.)、中文汉字。
参数值约束:
当前仅支持配置如下两种压缩方式,用户根据实际情况决定配置哪种压缩方式:
calibration:
{
input_data_dir: ./data.bin,d2.bin
input_shape: in:16,16;in1:16,16
config_file: simple_config.cfg
infer_soc: xxxxxx
infer_aicore_num: 10
log: info
}
其中:
calibration:训练后量化,是指在模型训练结束之后进行的量化,对训练后模型中的权重由浮点数(当前支持float32/float16)量化到低比特整数(比如int8),并通过少量校准数据基于推理过程对数据(activation)进行校准量化,进而加速模型推理速度。训练后量化简单易用,只需少量校准数据,适用于追求高易用性和缺乏训练资源的场景。训练后量化的样例请单击Link获取。
各参数说明如下,
input_data_dir:必选配置,模型输入校准数据的bin文件路径。若模型有多个输入,则多个输入的bin数据文件以英文逗号分隔。校准数据集用来计算量化参数,获取校准集时应该具有代表性,推荐使用测试集的子集作为校准数据集。校准数据的bin文件的生成方式可以参考链接。
input_shape:必选配置,模型输入校准数据的shape信息,例如:input_name1:n1,c1,h1,w1;input_name2:n2,c2,h2,w2,节点中间使用英文分号分隔。
config_file:可选配置,训练后量化简易配置文件,该文件配置示例以及参数解释请参见简易配置文件。
infer_soc:必选配置,进行训练后量化校准推理时,所使用的芯片名称,
log:可选配置,设置训练后量化时的日志等级,该参数只控制训练后量化过程中显示的日志级别,默认显示info级别:
debug:输出debug/info/warning/error/event级别的日志信息。
info:输出info/warning/error/event级别的日志信息。
warning:输出warning/error/event级别的日志信息。
error:输出error/event级别的日志信息。
此外,训练后量化过程中的日志打屏以及日志落盘信息由AMCT_LOG_DUMP环境变量进行控制:
export AMCT_LOG_DUMP=1:日志打印到屏幕,并落盘到当前路径的amct_log_时间戳/amct_acl.log文件中,不保存量化因子record文件和graph文件。
export AMCT_LOG_DUMP=2:将日志落盘到当前路径的amct_log_时间戳/amct_acl.log文件中,并保存量化因子record文件_。_
export AMCT_LOG_DUMP=3:将日志落盘到当前路径的amct_log_时间戳/amct_acl.log文件中,并保存量化因子record文件和graph文件_。_
为防止日志文件、record文件、graph文件持续落盘导致磁盘被写满,请及时清理这些文件。
如果用户配置了ASCEND_WORK_PATH环境变量,则上述日志、量化因子record文件和graph文件存储到该环境变量指定的路径下,例如ASCEND_WORK_PATH=/home/test,则存储路径为:/home/test/amct_acl/amct_log_{pid}_时间戳。其中,amct_acl模型转换过程中会自动创建,_{pid}_为进程号。
说明:
上述日志文件、record文件、graph文件重新执行量化时会被覆盖,请用户自行进行保存。此外,由于生成的日志文件大小和所要量化模型层数有关,请用户确保ATC工具所在服务器有足够空间:
以量化resnet101模型为例,日志级别设置为INFO,日志文件大小为12KB左右,中间临时文件大小为260MB左右;日志级别设置为DEBUG,日志文件大小为390KB左右,中间临时文件大小为430MB左右。
**参数默认值:**无。
无
假设压缩优化功能配置文件名称为_compression_optimize.cfg_,文件内容配置示例如下:
calibration:
{
input_data_dir: ./data.bin,d2.bin
input_shape: in:16,16;in1:16,16
config_file: simple_config.cfg
infer_soc: xxxxxx
infer_aicore_num: 10
log: info
}
将该文件上传到ATC工具所在服务器,例如上传到_$HOME/module_,使用示例如下:
--compression_optimize_conf=$HOME/module/compression_optimize.cfg
开启量化功能后,模型转换时提示“build_main build graph[infer_graph_info] failed”,请参见开启量化功能,模型转换时提示“build_main build graph[infer_graph_info] failed”。
--mdl_bank_path¶
该版本不支持子图调优特性。
加载子图调优后自定义知识库的路径。
子图调优详情请参见《AOE调优工具用户指南》。
该参数需要与--buffer_optimize参数配合使用,仅在数据缓存优化开关打开的情况下生效,通过利用高速缓存--buffer_optimize暂存数据的方式,达到提升性能的目的。
**参数值:**子图调优后自定义知识库路径。
**参数值格式:**支持大小写字母(a-z,A-Z)、数字(0-9)、下划线(_)、中划线(-)、句点(.)。
参数默认值:$HOME/Ascend/latest/data/aoe/custom/graph/<soc_version>
无。
例如子图调优后自定义知识库的路径为$HOME/custom_module_bank,则使用示例为:
加载子图调优后自定义知识库路径优先级:--mdl_bank_path参数加载路径>TUNE_BANK_PATH环境变量设置路径>默认子图调优后自定义知识库路径。
如果模型转换前,通过TUNE_BANK_PATH环境变量指定了子图调优自定义知识库路径,模型转换时又通过--mdl_bank_path参数加载了自定义知识库路径,该场景下以--mdl_bank_path参数加载的路径为准,TUNE_BANK_PATH环境变量设置的路径不生效。
--mdl_bank_path参数和环境变量指定路径都不生效或无可用自定义知识库,则使用默认自定义知识库路径。
如果上述路径下都无可用的自定义知识库,则atc工具会查找子图调优内置知识库,该路径为:${INSTALL_DIR}/compiler/data/fusion_strategy/built-in
--oo_level¶
调试功能扩展参数,当前不支持应用于商用产品中。
图编译多级优化选项,包括子图优化、整图优化、静态Shape模型下沉等。
静态Shape模型下沉:静态Shape模型在编译时即可确定所有算子的输入输出Shape,完成模型级内存编排、算子的Tiling计算等Host侧计算,在模型加载时整体下发到Device流上,但不立即执行,通过下发模型执行Task触发模型中所有Task的执行。
无。
O1:会关闭所有图融合和UB融合PASS,只做促成静态下沉的相关优化,如InferShape(进行输出Tensor的shape推导)、常量折叠、死边消除等。
O3:(默认值)开启所有优化。
无。
--oo_level=O1
取值为O1时,会关闭所有图融合和UB融合PASS,只开启静态下沉的相关PASS,但是如下路径文件中的图融合PASS,由于关闭后会有功能问题,会默认开启:
“${INSTALL_DIR}/x86_64-linux/lib64/plugin/opskernel/fusion_pass/config/fusion_config.json”文件中"ExceptionalPassOfO1Level"字段下的所有图融合PASS。
其中${INSTALL_DIR}请替换为CANN软件安装后文件存储路径。以root安装举例,安装后文件默认存储路径为:/usr/local/Ascend/latest。
--oo_constant_folding¶
调试功能扩展参数,当前不支持应用于商用产品中。
是否开启常量折叠优化。
常量折叠是将计算图中可以预先确定输出值的节点替换成常量,并对计算图进行一些结构简化的操作。
无。
参数值:
true:(默认值)开启常量折叠优化。
false:关闭常量折叠优化。
无。
--oo_constant_folding=true
无
--oo_dead_code_elimination¶
调试功能扩展参数,当前不支持应用于商用产品中。
是否开启死边消除优化。
死边消除:switch死边消除,switch的pred输入(1号输入)为const节点时,根据const的值消除其中一条分支:const为true时,消除false分支;const为false时,消除true分支。
无。
true:(默认值)开启死边消除优化。
false:关闭死边消除优化。
无。
--oo_dead_code_elimination=true
无。
--topo_sorting_mode¶
对算子进行图模式编译时,可选择的不同图遍历模式。
无
0:BFS,Breadth First Search,广度优先遍历策略。搜索算法的一种,与DFS类似,从某个状态出发,搜索所有可以到达的状态;与DFS的区别是,BFS是一层层进行遍历。
1:(默认值)DFS,Depth First Search,深度优先遍历策略。搜索算法的一种,从某个状态开始,不断转移状态直到无法转移,然后回退到前一步的状态,继续转移到其他状态,按此重复,直到找到最终解。
2:RDFS,Reverse DFS,反向深度优先遍历策略。
3:StableRDFS,稳定拓扑序策略,针对图里已有的算子,不会改变其计算顺序;针对图里新增的算子,使用RDFS遍历策略。
无。
--topo_sorting_mode=3
模型转换过程中如果加载了自定义知识库路径,上述图遍历模式的改变可能会影响调优结果,建议重新进行调优,详情请参见《AOE调优工具用户指南》。
算子调优选项¶
--precision_mode¶
设置网络模型的精度模式。
该参数不能与--precision_mode_v2参数同时使用,建议使用--precision_mode_v2参数,--precision_mode_v2是新版本中新增的,选项值语义更清晰,便于理解。
当取值为allow_mix_precision时,如果用户想要在内置优化策略基础上进行调整,自行指定哪些算子允许降精度,哪些算子不允许降精度,则需要参见--modify_mixlist参数设置。
推理场景下,使用--precision_mode参数设置整个网络模型的精度模式,可能会有个别算子存在性能或精度问题,该场景下可以使用--keep_dtype参数,使原始网络模型编译时保持个别算子的计算精度不变,但--precision_mode参数取值为must_keep_origin_dtype时,--keep_dtype不生效。
参数值:
force_fp32/cube_fp16in_fp32out:
配置为force_fp32或cube_fp16in_fp32out,效果等同,系统内部都会根据矩阵类算子或矢量类算子,来选择不同的处理方式。cube_fp16in_fp32out为新版本中新增的,对于矩阵计算类算子,该选项语义更清晰。
对于矩阵计算类算子,系统内部会按算子实现的支持情况处理:
优先选择输入数据类型为float16且输出数据类型为float32;
如果1中的场景不支持,则选择输入数据类型为float32且输出数据类型为float32;
如果2中的场景不支持,则选择输入数据类型为float16且输出数据类型为float16;
如果3中的场景不支持,则报错。
对于矢量计算类算子,表示网络模型中算子支持float16和float32时,强制选择float32,若原图精度为float16,也会强制转为float32。
如果网络模型中存在部分算子实现不支持float32,比如某算子仅支持float16类型,则该参数不生效,仍然使用支持的float16;如果该算子不支持float32,且又配置了黑名单(precision_reduce = false),则会使用float32的AI CPU算子;如果AI CPU算子也不支持,则执行报错。
force_fp16(默认值):
表示网络模型中算子支持float16和float32时,强制选择float16。
allow_fp32_to_fp16:
对于矩阵类算子,使用float16。
对于矢量类算子,优先保持原图精度,如果网络模型中算子支持float32,则保留原始精度float32,如果网络模型中算子不支持float32,则直接降低精度到float16。
must_keep_origin_dtype:
保持原图精度。该版本不支持bfloat16类型。
如果原图中某算子精度为float16,AI Core中该算子的实现不支持float16、仅支持float32和bfloat16,则系统内部会自动采用高精度float32。
如果原图中某算子精度为float16,AI Core中该算子的实现不支持float16、仅支持bfloat16,则会使用float16的AI CPU算子;如果AI CPU算子也不支持,则执行报错。
如果原图中某算子精度为float32,AI Core中该算子的实现不支持float32类型、仅支持float16类型,则会使用float32的AI CPU算子;如果AI CPU算子也不支持,则执行报错。
allow_mix_precision/allow_mix_precision_fp16:
配置为allow_mix_precision或allow_mix_precision_fp16,效果等同,均表示使用混合精度float16和float32数据类型来处理神经网络的过程。allow_mix_precision_fp16为新版本中新增的,语义更清晰,便于理解。
针对网络模型中float32数据类型的算子,按照内置的优化策略,自动将部分float32的算子降低精度到float16,从而在精度损失很小的情况下提升系统性能并减少内存使用。
若配置了该种模式,则可以在${INSTALL_DIR}/opp/built-in/op_impl/ai_core/tbe/config/xxx/aic-xxx-ops-info.json内置优化策略文件中查看“precision_reduce“参数的取值:
若取值为true(白名单),则表示允许将当前float32类型的算子,降低精度到float16。
若取值为false(黑名单),则不允许将当前float32类型的算子降低精度到float16,相应算子仍旧使用float32精度。
若网络模型中算子没有配置该参数(灰名单),当前算子的混合精度处理机制和前一个算子保持一致,即如果前一个算子支持降精度处理,当前算子也支持降精度;如果前一个算子不允许降精度,当前算子也不支持降精度。
上述路径中的${INSTALL_DIR}请替换为CANN软件安装后文件存储路径。以root安装举例,安装后文件默认存储路径为:/usr/local/Ascend/latest。_xxx_请根据实际产品型号进行选择。
参数值约束:
该参数默认为性能优先,后续推理时可能会导致精度溢出问题。如果推理时出现精度问题,可以参见《AscendCL应用开发指南 (C&C++)》章节的“精度/性能优化 > 模型推理精度提升建议”进行定位。
如果用户聚焦精度问题,可以修改为其他取值,比如must_keep_origin_dtype。
所配置的精度模式不同,网络模型精度以及性能有所不同,具体为:
精度高低排序:force_fp32>must_keep_origin_dtype>allow_fp32_to_fp16>allow_mix_precision>force_fp16
性能优劣排序:force_fp16>=allow_mix_precision>allow_fp32_to_fp16>must_keep_origin_dtype>force_fp32
--precision_mode=force_fp16
--precision_mode_v2¶
设置网络模型的精度模式。
该参数不能与--precision_mode参数同时使用,建议使用--precision_mode_v2参数,--precision_mode_v2是新版本中新增的,选项值语义更清晰,便于理解。
当取值为mixed_float16时,如果用户想要在内置优化策略基础上进行调整,自行指定哪些算子允许降精度,哪些算子不允许降精度,则需要参见--modify_mixlist参数设置。
推理场景下,使用--precision_mode_v2参数设置整个网络模型的精度模式,可能会有个别算子存在性能或精度问题,该场景下可以使用--keep_dtype参数,使原始网络模型编译时保持个别算子的计算精度不变,但--precision_mode_v2参数取值为origin时,--keep_dtype不生效。
fp16(默认值):
算子支持float16和float32数据类型时,强制选择float16。
origin:
保持原图精度。该版本不支持bfloat16类型。
如果原图中某算子精度为float16,AI Core中该算子的实现不支持float16、仅支持float32和bfloat16,则系统内部会自动采用高精度float32。
如果原图中某算子精度为float16,AI Core中该算子的实现不支持float16、仅支持bfloat16,则会使用float16的AI CPU算子;如果AI CPU算子也不支持,则执行报错。
如果原图中某算子精度为float32,AI Core中该算子的实现不支持float32类型、仅支持float16类型,则会使用float32的AI CPU算子;如果AI CPU算子也不支持,则执行报错。
cube_fp16in_fp32out:
算子既支持float32又支持float16数据类型时,系统内部根据算子类型不同,选择不同的处理方式。
对于矩阵计算类算子,系统内部会按算子实现的支持情况处理:
优先选择输入数据类型为float16且输出数据类型为float32;
如果1中的场景不支持,则选择输入数据类型为float32且输出数据类型为float32;
如果2中的场景不支持,则选择输入数据类型为float16且输出数据类型为float16;
如果3中的场景不支持,则报错。
对于矢量计算类算子,表示网络模型中算子支持float16和float32时,强制选择float32,若原图精度为float16,也会强制转为float32。
如果网络模型中存在部分算子实现不支持float32,比如某算子仅支持float16类型,则该参数不生效,仍然使用支持的float16;如果该算子不支持float32,且又配置了黑名单(precision_reduce = false),则会使用float32的AI CPU算子;如果AI CPU算子也不支持,则执行报错。
mixed_float16:
表示使用混合精度float16和float32数据类型来处理神经网络。针对网络模型中float32数据类型的算子,按照内置的优化策略,自动将部分float32的算子降低精度到float16,从而在精度损失很小的情况下提升系统性能并减少内存使用。
若配置了该种模式,则可以在${INSTALL_DIR}/opp/built-in/op_impl/ai_core/tbe/config/xxx/aic-xxx-ops-info.json内置优化策略文件中查看“precision_reduce“参数的取值:
若取值为true(白名单),则表示允许将当前float32类型的算子,降低精度到float16。
若取值为false(黑名单),则不允许将当前float32类型的算子降低精度到float16,相应算子仍旧使用float32精度。
若网络模型中算子没有配置该参数(灰名单),当前算子的混合精度处理机制和前一个算子保持一致,即如果前一个算子支持降精度处理,当前算子也支持降精度;如果前一个算子不允许降精度,当前算子也不支持降精度。
**mixed_hif8:**开启自动混合精度功能,表示混合使用hifloat8(此数据类型介绍可参见Link)、float16和float32数据类型来处理神经网络。针对网络模型中float16和float32数据类型的算子,按照内置的优化策略,自动将部分float16和float32的算子降低精度到hifloat8,从而在精度损失很小的情况下提升系统性能并减少内存使用。当前版本不支持该选项。
若配置了该种模式,则可以在${INSTALL_DIR}/opp/built-in/op_impl/ai_core/tbe/config/xxx/aic-xxx-ops-info.json内置优化策略文件中查看“precision_reduce”参数的取值:
若取值为true(白名单),则表示允许将当前float16和float32类型的算子,降低精度到hifloat8。
若取值为false(黑名单),则不允许将当前float16和float32类型的算子降低精度到hifloat8,相应算子仍旧使用float16和float32精度。
若网络模型中算子没有配置该参数(灰名单),当前算子的混合精度处理机制和前一个算子保持一致,即如果前一个算子支持降精度处理,当前算子也支持降精度;如果前一个算子不允许降精度,当前算子也不支持降精度。
cube_hif8:表示若网络模型中的cube算子既支持hifloat8,又支持float16或float32数据类型时,强制选择hifloat8数据类型。当前版本不支持该选项。
上述路径中的${INSTALL_DIR}请替换为CANN软件安装后文件存储路径。以root安装举例,安装后文件默认存储路径为:/usr/local/Ascend/latest。_xxx_请根据实际产品型号进行选择。
参数值约束:
该参数默认为性能优先,后续推理时可能会导致精度溢出问题。如果推理时出现精度问题,可以参见《AscendCL应用开发指南 (C&C++)》章节的“精度/性能优化 > 模型推理精度提升建议”进行定位。
如果用户聚焦精度问题,可以修改为其他取值,比如origin。
所配置的精度模式不同,网络模型精度以及性能有所不同,具体为:
精度高低排序:origin>mixed_float16>fp16;性能优劣排序:fp16>=mixed_float16>origin
--precision_mode_v2=fp16
--op_precision_mode¶
设置指定算子内部处理时的精度模式,支持指定一个算子或多个算子。
该参数不能与--op_select_implmode、--optypelist_for_implmode参数同时使用,若三个参数同时配置,则只有--op_precision_mode参数指定的模式生效。
关联参数示意图如图1所示。
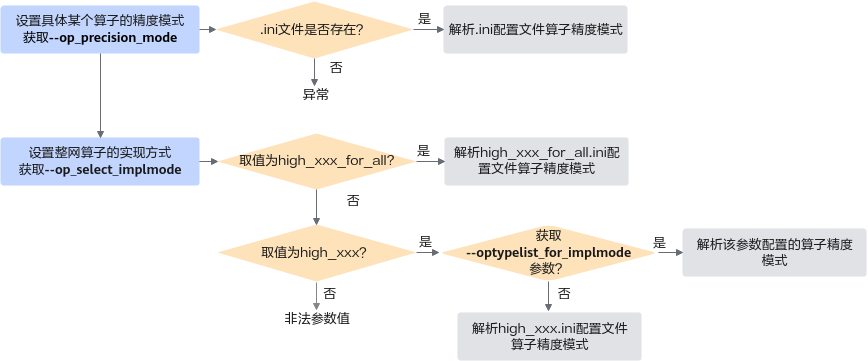
设置具体算子精度模式场景下:
首先读取--op_precision_mode参数,校验该参数的ini配置文件是否存在,若存在则解析文件并读取算子的精度模式,否则上报异常。
--op_precision_mode不存在则读取--op_select_implmode参数:
首先检测是否配置为high_xxx_for_all参数,若是则解析high_xxx_for_all.ini文件并读取算子的精度模式。
若配置为high_xxx参数,则检测是否配置--optypelist_for_implmode参数,若是,则读取该参数配置的算子精度模式;否则解析high_xxx.ini文件并读取算子的精度模式。
**参数值:**设置算子精度模式的配置文件(.ini格式)路径以及文件名,配置文件中支持设置如下精度模式:
high_precision:表示高精度。
high_performance:表示高性能。
support_out_of_bound_index:表示对gather、scatter和segment类算子的indices输入进行越界校验,校验会降低算子的执行性能。
keep_fp16:算子内部处理时使用FP16数据类型功能,该场景下FP16数据类型不会自动转换为FP32数据类型;若使用FP32计算时性能不满足预期,同时精度要求不高情况下,可以选择keep_fp16模式,牺牲精度提升性能,不建议使用该低精度模式。
super_performance:表示超高性能,和高性能相比,在算法计算公式上进行了优化。
具体某个算子支持配置的精度/性能模式取值,可以通过CANN软件安装后文件存储路径的opp/built-in/op_impl/ai_core/tbe/impl_mode/all_ops_impl_mode.ini文件查看。
**参数值格式:**路径和文件名:支持大小写字母(a-z,A-Z)、数字(0-9)、下划线(_)、短横线(-)、句点(.)、中文汉字。
参数值约束:
当前仅支持通过.ini配置文件方式设置算子精度,配置文件中的内容以key-value(算子类型=精度模式)形式呈现,每一行设置一个算子的精度模式。
算子类型必须为基于Ascend IR定义的算子的OpType,算子类型查看方法请参见如何确定原始框架网络模型中的算子与NPU IP加速器支持的算子的对应关系。
该参数不建议配置,若使用高性能或者高精度模式,网络性能或者精度不是最优,则可以使用该参数,通过配置ini文件调整具体某个算子的精度模式。
通过该参数加载的ini配置文件,建议使用--op_select_implmode参数用户另存后的ini配置文件,详情请参见推荐配置及收益。
构造算子精度模式配置文件_op_precision.ini_,并在该文件中按照算子类型、节点名称设置精度模式,每一行设置一个算子类型或节点名称的精度模式**,按节点名称设置精度模式的优先级高于按算子类型**。
配置样例如下:
[ByOpType]
optype1=high_precision
optype2=high_performance
optype4=support_out_of_bound_index
[ByNodeName]
nodename1=high_precision
nodename2=high_performance
nodename4=support_out_of_bound_index
将配置好的_op_precision.ini_文件上传到ATC工具所在服务器任意目录,例如上传到_$HOME/conf_,使用示例如下:
--op_precision_mode=$HOME/conf/op_precision.ini
无。
--modify_mixlist¶
混合精度场景下,修改算子使用的混合精度黑白灰名单,自行指定哪些算子允许降精度,哪些算子不允许降精度。
黑白灰名单,可从“${INSTALL_DIR}/opp/built-in/op_impl/ai_core/tbe/config/xxx/aic-xxx-ops-info.json”内置优化策略文件中查看“precision_reduce“参数下的flag参数值:(其中,${INSTALL_DIR}请替换为CANN软件安装后文件存储路径。以root安装举例,安装后文件默认存储路径为:/usr/local/Ascend/latest。_xxx_请根据实际产品型号进行选择。)
若取值为true(白名单),表示混合精度模式下,允许降低精度。
若取值为false(黑名单),表示混合精度模式下,不允许降低精度。
不配置该参数(灰名单),表示混合精度模式下,当前算子的混合精度处理机制和前一个算子保持一致,即如果前一个算子支持降精度处理,当前算子也支持降精度;如果前一个算子不允许降精度,当前算子也不支持降精度。
开启混合精度方式:
--precision_mode参数设置为allow_mix_precision、allow_mix_precision_fp16。
--precision_mode_v2参数设置为mixed_float16。
与--precision_mode参数不能同时配置,建议使用--precision_mode_v2。
**参数值:**混合精度名单路径以及文件名。
**参数值格式:**路径和文件名:支持大小写字母(a-z,A-Z)、数字(0-9)、下划线(_)、短横线(-)、句点(.)、中文汉字。
参数值约束:
名单格式为*.json格式,文件中的算子列表由用户指定,多个算子使用英文逗号分隔。
配置的算子类型必须为基于Ascend IR定义的算子的OpType,算子类型查看方法请参见如何确定原始框架网络模型中的算子与NPU IP加速器支持的算子的对应关系。
无。
黑白灰名单查询示例如下,flag参数值为true表示白名单,为false表示黑名单,不配置flag参数表示灰名单:
"Conv2D":{
......
"precision_reduce":{
"flag":"true"
},
......
}
混合精度名单样例如下,ops_info.json为文件名示例,OpTypeA、OpTypeB、OpTypeC、OpTypeD为算子示例。
{
"black-list": { // 黑名单
"to-remove": [ // 黑名单算子转换为灰名单算子,配置该参数时,请确保被转换的算子已经存在于黑名单中
"OpTypeA"
],
"to-add": [ // 白名单或灰名单算子转换为黑名单算子
"OpTypeB"
]
},
"white-list": { // 白名单
"to-remove": [ // 白名单算子转换为灰名单算子,配置该参数时,请确保被转换的算子已经存在于白名单中
"OpTypeC"
],
"to-add": [ // 黑名单或灰名单算子转换为白名单算子
"OpTypeD"
]
}
}
假设算子A默认在白名单中,如果您希望将该算子配置为黑名单算子,则配置示例和系统处理逻辑为:
将该算子添加到黑名单中:
{ "black-list": { "to-add": ["A"] } }
则系统会将该算子从白名单中删除,并添加到黑名单中,最终该算子在黑名单中。
将该算子从白名单中删除,同时添加到黑名单中:
{ "black-list": { "to-add": ["A"] } "white-list": { "to-remove": ["A"] } }
则系统会将该算子从白名单中删除,并添加到黑名单中,最终该算子在黑名单中。
对于只从黑/白名单中删除,而不添加到白/黑名单的场景,系统会将该算子添加到灰名单中,配置示例如下(例如,从白名单删除某个算子):
{ "white-list": { "to-remove": ["A"] } }
则系统会将该算子从白名单中删除,然后添加到灰名单中,最终该算子在灰名单中。
将配置好的_ops_info.json_文件上传到ATC工具所在服务器任意目录,例如上传到_$HOME/module_,使用示例如下:
--precision_mode=allow_mix_precision --modify_mixlist=$HOME/module/ops_info.json
无。
--optypelist_for_implmode¶
设置optype列表中算子的实现模式,算子实现模式包括high_precision、high_performance两种。
该参数需要与--op_select_implmode参数配合使用,通过--optypelist_for_implmode参数设置的算子,统一使用--op_select_implmode参数指定的实现模式,不能为列表中的每个算子设置不同的实现模式。
该参数配合--op_select_implmode参数使用时,不能与--op_precision_mode参数同时使用,若同时配置,则只有--op_precision_mode参数指定的模式生效。上述参数配合运行流程请参见图1。
**参数值:**算子列表。
参数值约束:
该列表中的算子OpType必须为基于Ascend IR定义的算子的OpType,算子类型查看方法请参见如何确定原始框架网络模型中的算子与NPU IP加速器支持的算子的对应关系。
该列表中的算子使用--op_select_implmode参数指定的实现模式,且仅支持指定为high_precision、high_performance两种模式,多个算子使用英文逗号进行分隔。
该参数仅对指定的算子生效,不指定的算子按照默认实现方式选择。
无。
--op_select_implmode=high_precision --optypelist_for_implmode=Pooling,SoftmaxV2
上述配置示例表示对Pooling、SoftmaxV2算子使用统一的高精度模式,未指定算子使用算子的默认实现方式。
无。
--keep_dtype¶
通过配置文件指定原始模型中特定算子的数据类型在模型编译过程中保持不变。
推理场景下,使用--precision_mode或--precision_mode_v2参数设置整个网络模型的精度模式,可能会有个别算子存在性能或精度问题,为此引入--keep_dtype参数,保持原始网络模型编译时个别算子的计算精度不变,若原始网络模型中算子的计算精度,在NPU IP加速器上不支持,则系统内部会自动采用算子支持的高精度来计算。
该参数需要与--precision_mode或--precision_mode_v2参数配合使用,但当--precision_mode取值为must_keep_origin_dtype或--precision_mode_v2取值为origin时,--keep_dtype参数不生效。
--customize_dtypes参数与--keep_dtype参数都用于设置算子的计算精度,若涉及需提升模型推理精度的场景,建议先使用--keep_dtype参数保持原图精度,若精度依然得不到提升,可以尝试使用--customize_dtypes参数自定义某个或某些算子的计算精度。
但需注意,使用--customize_dtypes参数且通过配置算子名称的方式,可能会由于内部模型优化过程中的融合、拆分等操作导致算子名称发生变化,进而导致配置不生效,未达到提升精度的目的,可进一步获取日志定位问题,关于日志的详细说明请参见《日志参考》。
若同时使用了--customize_dtypes参数与--keep_dtype参数,则以--customize_dtypes参数设置的精度为准。
**参数值:**算子配置文件路径以及文件名,配置文件中列举需保持计算精度的算子名称或算子类型,每个算子单独一行。
参数值约束:若为算子类型,则以OpType::typeName格式进行配置,每个OpType单独一行,且算子OpType必须为基于Ascend IR定义的算子的OpType,算子类型查看方法请参见如何确定原始框架网络模型中的算子与NPU IP加速器支持的算子的对应关系。
**参数值格式:**路径和文件名:支持大小写字母(a-z,A-Z)、数字(0-9)、下划线(_)、短横线(-)、句点(.)、中文汉字。
无。
若配置文件中为算子名称,则配置样例如下(文件名举例为_exceptionlist.cfg_):
Opname1 Opname2 …
若配置文件中为算子类型,则配置样例为(文件名举例为_exceptionlist.cfg_):
OpType::TypeName1 OpType::TypeName2 …
以TensorFlow ResNet50网络模型中的Relu算子为例,其对应的Ascend IR定义的算子类型为Relu,配置样例如下:
#算子名称配置样例:
fp32_vars/Relu
#算子类型配置样例:
OpType::Relu
将配置好的_exceptionlist.cfg_文件上传到ATC工具所在服务器任意目录,例如上传到$HOME,使用示例如下:
--keep_dtype=$HOME/exceptionlist.cfg --precision_mode=force_fp16
模型编译时,_exceptionlist.cfg_文件中的算子,保持原始网络模型精度,即精度不会改变,其余网络模型中的算子以--precision_mode或--precision_mode_v2参数指定的精度模式进行编译。
无。
--customize_dtypes¶
模型编译时自定义某个或某些算子的计算精度。
若本参数与--precision_mode或--precision_mode_v2配合使用时,除本参数指定的算子,模型中其它算子按--precision_mode或--precision_mode_v2参数配置的精度模式来编译。
--customize_dtypes参数与--keep_dtype参数都用于设置算子的计算精度,若涉及需提升模型推理精度的场景,建议先使用--keep_dtype参数保持原图精度,若精度依然得不到提升,可以尝试使用--customize_dtypes参数自定义某个或某些算子的计算精度。
但需注意,使用--customize_dtypes参数且通过配置算子名称的方式,可能会由于内部模型优化过程中的融合、拆分等操作导致算子名称发生变化,进而导致配置不生效,未达到提升精度的目的,可进一步获取日志定位问题,关于日志的详细说明请参见《日志参考》。
若同时使用了--customize_dtypes参数与--keep_dtype参数,则以--customize_dtypes参数设置的精度为准。
**参数值:**算子配置文件路径以及文件名,配置文件中列举需要自定义计算精度的算子名称或算子类型,每个算子单独一行。
参数值约束:
若为算子名称,以Opname::InputDtype:dtype1,...,OutputDtype:dtype1,...格式进行配置,每个Opname单独一行,dtype1,dtype2...需要与可设置计算精度的算子输入,算子输出的个数一一对应。
若为算子类型,以**OpType::TypeName:InputDtype:dtype1,...,OutputDtype:dtype1,...**格式进行配置,每个OpType单独一行,dtype1,dtype2...需要与可设置计算精度的算子输入,算子输出的个数一一对应,且算子OpType必须为基于Ascend IR定义的算子的OpType,算子类型查看方法请参见如何确定原始框架网络模型中的算子与NPU IP加速器支持的算子的对应关系。
对于同一个算子,如果同时配置了Opname和OpType的配置项,编译时以Opname的配置项为准。
使用该参数指定某个算子的计算精度时,如果模型转换过程中该算子被融合掉,则该算子指定的计算精度不生效。
**参数值格式:**路径和文件名:支持大小写字母(a-z,A-Z)、数字(0-9)、下划线(_)、短横线(-)、句点(.)、英文冒号(:)、中文汉字。
无。
若配置文件中为算子名称,则配置样例为(文件名举例为_customize_dtypes.cfg_):
Opname1::InputDtype:dtype1,dtype2,...,OutputDtype:dtype1,... Opname2::InputDtype:dtype1,dtype2,...,OutputDtype:dtype1,...
若配置文件中为算子类型,则配置样例为(文件名举例为_customize_dtypes.cfg_):
OpType::TypeName1:InputDtype:dtype1,dtype2,...,OutputDtype:dtype1,... OpType::TypeName2:InputDtype:dtype1,dtype2,...,OutputDtype:dtype1,...
算子具体支持的计算精度可以从《AOL算子加速库接口参考》 > “CANN算子规格说明”中查看。
以TensorFlow ResNet50网络模型中的Relu算子为例,其对应的Ascend IR定义的算子类型为Relu,该算子输入和输出只有一个,该配置样例如下:
算子名称配置样例:
fp32_vars/Relu::InputDtype:float16,OutputDtype:int8算子类型配置样例:
OpType::Relu:InputDtype:float16,OutputDtype:int8
将配置好的_customize_dtypes.cfg_文件上传到ATC工具所在服务器任意目录,例如上传到$HOME,使用示例如下:
--customize_dtypes=$HOME/customize_dtypes.cfg --precision_mode=force_fp16
模型编译时,_customize_dtypes.cfg_文件中的算子,使用指定的计算精度,其余网络模型中的算子以--precision_mode或--precision_mode_v2参数指定的精度模式进行编译。
使用该参数指定算子的计算精度,由于其优先级高于--precision_mode或--precision_mode_v2、--keep_dtype参数,可能会导致后续推理精度或者性能的下降。
使用该参数指定算子的计算精度,如果指定的精度算子本身不支持,则会导致模型编译失败。
--op_bank_path¶
该版本不支持算子调优特性。
加载算子调优后自定义知识库的路径。
算子调优详情请参见《AOE调优工具用户指南》。
**参数值:**算子调优后自定义知识库路径。
**参数值格式:**支持大小写字母(a-z,A-Z)、数字(0-9)、下划线(_)、中划线(-)、句点(.)。
**参数默认值:**默认自定义知识库路径$HOME/Ascend/latest/data/aoe/custom/op
无。
例如算子调优后自定义知识库的路径为$HOME/custom_tune_bank,则使用示例为:
--op_bank_path=$HOME/custom_tune_bank
加载算子调优后自定义知识库路径优先级:TUNE_BANK_PATH环境变量设置路径>--op_bank_path参数加载路径>默认算子调优后自定义知识库路径。
如果模型转换前,通过TUNE_BANK_PATH环境变量指定了算子调优自定义知识库路径,模型转换时又通过--op_bank_path参数加载了自定义知识库路径,该场景下以TUNE_BANK_PATH环境变量设置的路径为准,--op_bank_path参数加载的路径不生效。
--op_bank_path参数和环境变量指定路径都不生效前提下,使用默认自定义知识库路径。
如果上述路径下都无可用的自定义知识库,则ATC工具会查找算子调优内置知识库。
--is_weight_clip¶
浮点类型权重数据高位转低位时,是否对数据进行裁剪。
若原始模型权重数据类型为高位(比如float32),模型转换过程中会插入Cast算子进行数据类型转换,将高位(比如float32)类型转换为低位(比如float16)类型,该场景下可能会存在数据溢出,而通过使能--is_weight_clip参数,在Cast算子前对高位(比如float32)类型数据进行裁剪,可以保证数据不溢出。
无。
0:不裁剪。
1:(默认值)裁剪。
无。
--is_weight_clip=1
无。
调试选项¶
--dump_mode¶
是否生成带shape信息的JSON文件。
该参数需要与--json、--mode=1、--framework、--om参数(需要为原始模型文件,如果为Caffe框架模型文件,还需要增加--weight参数)配合使用。
0:(默认值)生成不带shape信息的JSON文件。
1:生成带shape信息的JSON文件。
无。
atc --mode=1 --om=$HOME/module/resnet50_tensorflow*.pb --json=$HOME/module/out/tf_resnet50.json --framework=3 --dump_mode=1
无。
--log¶
设置ATC模型转换过程中日志的级别。
无。
调试日志,支持设置如下级别:
debug:输出debug/info/warning/error级别的调试日志信息。
info:输出info/warning/error级别的调试日志信息。
warning:输出warning/error级别的调试日志信息。
error:输出/error级别的调试日志信息。
null:(默认值)不输出调试日志。
运行日志默认会输出info/warning/error/event级别日志,不支持级别调整。安全日志默认输出debug/info/warning/error级别日志,不支持级别调整。
无。
--log=debug
如果模型转换失败,则可以通过分析日志定位问题。日志格式如下,更多日志信息请参见《日志参考》(IPV350不支持该手册中的特性)。
[Level] ModuleName(PID,PName):DateTimeMS [FileName:LineNumber]LogContent
各字段解释如下:
表 1 日志字段说明
样例如下:
[INFO] FE(30741,atc.bin):2021-12-09-16:10:22.539.141 [fe_type_utils.cc:52]30741 GetRealPath:"path /usr/local/Ascend/opp/built-in/op_impl/ai_core/tbe/config/ascendxxx is not exist."
[WARNING] FE(30741,atc.bin):2021-12-09-16:10:22.539.146 [sub_op_info_store.cc:52]30741 Initialize:"The config file[/usr/local/Ascend/opp/built-in/op_impl/ai_core/tbe/config/ascendxxx] of op information library[tbe-builtin] is not existed. "
[ERROR] GE(30741,atc.bin):2021-12-09-16:10:22.539.201 [error_manager.cc:263]30741 ReportErrMessage: [INIT][OPS_KER][Report][Error]error_code: W21000, arg path is not existed in map
问题定位思路:
表 2 问题定位思路
|
||
日志重定向:
如果不想日志落盘,而是重定向到文件,则模型转换前需要设置上述的日志打屏环境变量,并且atc命令需要设置--log参数(不能设置为null),样例如下:
atc xxx --log=debug >log.txt
--display_model_info¶
编译原始框架网络模型时,查询模型占用的关键资源信息、编译与运行环境等信息,查询出的信息直接在屏幕打印显示。
无。
参数值:
0:(默认值)关闭查询功能。
1:打开查询功能。
**参数值约束:**该参数不支持单算子描述文件转离线模型时信息的查看。
无。
下面示例以TensorFlow框架网络模型为例进行说明:
atc --model=$HOME/module/resnet50_tensorflow*.pb --framework=3 --output=$HOME/module/out/tf_resnet50 --soc_version=<soc_version> --display_model_info=1
命令执行完毕,屏幕会打印类似如下信息:
============ Display Model Info start ============
# 模型转换使用的atc命令
Original Atc command line: ${INSTALL_DIR}/bin/atc.bin --model=$HOME/module/resnet50_tensorflow*.pb --framework=3 --output=$HOME/module/out/tf_resnet50 --soc_version=<soc_version> --display_model_info=1
# ATC软件版本信息、soc_version版本信息、原始框架信息
system info: atc_version[xxx], soc_version[xxx], framework_type[xxx].
# 运行时的占用内存、权重大小、逻辑stream数目、event数目
resource info: memory_size[xxx B], weight_size[xxx B], stream_num[xxx], event_num[xxx].
# 离线模型文件中各分区大小、包括ModelDef、权重、tbe_kernels、task_info、so占用的大小等
om info: modeldef_size[xxx B], weight_data_size[xxx B], tbe_kernels_size[xxx B], cust_aicpu_kernel_store_size[xxx B], task_info_size[xxx B], so_store_size[xxx B].
============ Display Model Info end ============
无。
--op_compiler_cache_mode¶
用于配置算子编译磁盘缓存模式。
如果要自行指定算子编译磁盘缓存的路径,则需要通过--op_compiler_cache_dir参数指定。
参数值:
enable:表示启用算子编译缓存。启用后可以避免针对相同编译参数及算子参数的算子重复编译,从而提升编译速度。
force:启用算子编译缓存功能,区别于enable模式,force模式下会强制刷新缓存,即先删除已有缓存,再重新编译并加入缓存。比如当用户的python变更、依赖库变更、算子调优后知识库变更等,需要先指定为force用于先清理已有的缓存,后续再修改为enable模式,以避免每次编译时都强制刷新缓存。
disable:(默认值)表示禁用算子编译缓存,算子重新编译。
参数值约束:
由于force选项会先删除已有缓存,所以不建议在程序并行编译时设置,否则可能会导致其他模型使用的缓存内容被清除而导致失败。
建议模型最终发布时设置编译缓存选项为disable或者force。
如果算子调优后知识库变更,则需要通过设置为force来刷新缓存,否则无法应用新的调优知识库,从而导致调优应用执行失败。
调试开关打开的场景下:
--op_debug_level配置非0值:会忽略--op_compiler_cache_mode参数的配置,不启用算子编译缓存功能,算子全部重新编译。
--op_debug_config配置非空,且未配置op_debug_list字段,会忽略--op_compiler_cache_mode参数的配置,不启用算子编译缓存功能,算子全部重新编译。
--op_debug_config配置非空,且配置文件中配置了op_debug_list字段:
列表中的算子,忽略--op_compiler_cache_mode参数的配置继续重新编译。
列表外的算子,如果--op_compiler_cache_mode参数配置为enable或force,则启用缓存功能;若配置为disable,则不启用缓存功能,仍旧重新编译。
推荐配置为enable:启用后可以避免针对相同编译参数及算子参数的算子重复编译,从而提升编译速度。
--op_compiler_cache_mode=enable --op_compiler_cache_dir=$HOME/atc_data/kernel_cache --op_debug_level=0
启用算子编译缓存功能时,可以通过配置文件(ATC工具运行后,会在--op_compiler_cache_dir参数指定的路径下自动生成op_cache.ini配置文件)、环境变量两种方式来设置缓存文件夹的磁盘空间大小:
通过配置文件op_cache.ini设置
若op_cache.ini文件不存在,则需要手动创建。打开该文件,增加如下信息:
#配置文件格式,必须包含,自动生成的文件中默认包括如下信息,手动创建时,需要输入 [op_compiler_cache] #限制某个芯片下缓存文件夹的磁盘空间的大小,默认值为500,取值需为整数,单位为MB max_op_cache_size=500 #设置需要保留缓存的空间大小比例,取值范围:[1,100],默认值为50,单位为百分比;例如取值为80表示缓存空间不足时,删除缓存文件,保留80%缓存空间 remain_cache_size_ratio=50
上述文件中的max_op_cache_size和remain_cache_size_ratio参数取值都有效时,op_cache.ini文件才会生效。
当编译缓存文件大小超过“max_op_cache_size”的设置值,且超过半小时缓存文件未被访问时,缓存文件就会老化(算子编译时,不会因为编译缓存文件大小超过设置值而中断,所以当“max_op_cache_size”设置过小时,会出现实际编译缓存文件大小超过此设置值的情况)。
若需要关闭编译缓存老化功能,可将“max_op_cache_size”设置为“-1”,此时访问算子缓存时不会更新访问时间,算子编译缓存不会老化,磁盘空间使用默认大小500MB。
若多个使用者使用相同的缓存路径,建议使用配置文件的方式进行设置,该场景下op_cache.ini文件会影响所有使用者。
通过环境变量设置
该场景下,开发者可以通过环境变量ASCEND_MAX_OP_CACHE_SIZE来限制某个芯片下缓存文件夹的磁盘空间的大小,当编译缓存空间大小达到ASCEND_MAX_OP_CACHE_SIZE设置的取值,且超过半个小时缓存文件未被访问时,缓存文件就会老化。可通过环境变量ASCEND_REMAIN_CACHE_SIZE_RATIO设置需要保留缓存的空间大小比例。
配置示例如下:
# ASCEND_MAX_OP_CACHE_SIZE环境变量默认值为500,取值需为整数,单位为MB export ASCEND_MAX_OP_CACHE_SIZE=500 # ASCEND_REMAIN_CACHE_SIZE_RATIO环境变量取值范围:[1,100],默认值为50,单位为百分比;例如取值为80表示缓存空间不足时,删除缓存文件,保留80%缓存空间 export ASCEND_REMAIN_CACHE_SIZE_RATIO=50
通过环境变量配置,只对当前用户生效。
若需要关闭编译缓存老化功能,可将环境变量“ASCEND_MAX_OP_CACHE_SIZE”设置为“-1”,此时访问算子缓存时不会更新访问时间,算子编译缓存不会老化,磁盘空间使用默认大小500MB。
若同时配置了op_cache.ini文件和环境变量,则优先读取op_cache.ini文件中的配置项,若op_cache.ini文件和环境变量都未设置,则读取系统默认值:默认磁盘空间大小500MB,默认保留缓存的空间50%。
--op_compiler_cache_dir¶
用于配置算子编译磁盘缓存的路径。
如果要自行指定算子编译磁盘缓存的路径,需--op_compiler_cache_dir与--op_compiler_cache_mode参数配合使用。
**参数值:**存放算子编译磁盘缓存的路径。
**参数值格式:**路径支持大小写字母(a-z,A-Z)、数字(0-9)、下划线(_)、短横线(-)、句点(.)、中文汉字。
参数值约束:
如果--op_compiler_cache_dir参数指定的路径存在且有效,则在指定的路径下自动创建子目录kernel_cache;如果指定的路径不存在但路径有效,则先自动创建目录,然后在该路径下自动创建子目录kernel_cache。
用户请不要在默认缓存目录下存放其他自有内容,自有内容在软件包安装或升级时会同默认缓存目录一并被删除。
通过该参数指定的非默认缓存目录无法删除(软件包安装或升级时不会被删除)。
参数默认值:$HOME/atc_data
无。
--op_compiler_cache_dir=$HOME/atc_data --op_compiler_cache_mode=enable
算子编译磁盘缓存路径,除--op_compiler_cache_dir参数设置的方式外,还可以配置环境变量ASCEND_CACHE_PATH,几种方式优先级为
配置参数“--op_compiler_cache_dir”>环境变量ASCEND_CACHE_PATH>默认存储路径。
关于环境变量ASCEND_CACHE_PATH的详细说明请参见《环境变量参考》。
--op_debug_level¶
算子debug功能开关。
如果要自行指定算子编译的过程文件存放路径,需--op_debug_level(取值为非0)与--debug_dir配合使用。
参数值:
0:(默认值)不开启算子debug功能,在当前执行路径不生成算子编译目录kernel_meta。
1:开启算子debug功能,在当前执行路径生成kernel_meta文件夹,并在该文件夹下生成*.o(算子二进制文件)、*.json文件(算子描述文件)和TBE指令映射文件(算子cce文件*.cce和python-cce映射文件*_loc.json),用于后续分析AICore Error问题。
2:开启算子debug功能,在当前执行路径生成kernel_meta文件夹,并在该文件夹下生成*.o(算子二进制文件)、*.json文件(算子描述文件)和TBE指令映射文件(算子cce文件*.cce和python-cce映射文件*_loc.json),用于后续分析AICore Error问题,同时设置为2,还会关闭编译优化开关、开启ccec调试功能(ccec编译器选项设置为-O0-g)。
3:不开启算子debug功能,在当前执行路径生成kernel_meta文件夹,并在该文件夹中生成*.o(算子二进制文件)和*.json文件(算子描述文件),分析算子问题时可参考。
4:不开启算子debug功能,在当前执行路径生成kernel_meta文件夹,并在该文件夹下生成*.o(算子二进制文件)、*.json文件(算子描述文件)、TBE指令映射文件(算子cce文件*.cce)和UB融合计算描述文件({$kernel_name}_compute.json),可在分析算子问题时进行问题复现、精度比对时使用。
参数值约束:
进行模型转换时,建议配置为0、3或4。如果需要定位AICore Error问题,则需要将参数值设置为1或2。设置为1或2后,由于加入了调试功能,会导致网络性能下降。
若--op_debug_level配置为0,同时配置了--op_debug_config参数,该场景下在执行atc命令当前路径会保留算子编译目录kernel_meta。
若--op_debug_level配置为0,同时设置了NPU_COLLECT_PATH环境变量,则会始终保留编译目录kernel_meta;若设置了ASCEND_WORK_PATH环境变量,则保留在该环境变量指定路径下,若无ASCEND_WORK_PATH环境变量,则保留在当前执行路径。
配置为2(即开启ccec编译选项)时,会导致算子Kernel(*.o文件)大小增大。动态Shape场景下,由于算子编译时会遍历可能的Shape场景,因此可能会导致算子Kernel文件过大而无法进行编译,此种场景下,建议不要配置ccec编译选项。
由于算子Kernel文件过大而无法编译的报错日志示例如下:
message:link error ld.lld: error: InputSection too large for range extension thunk ./kernel_meta_xxxxx.odebug功能开关打开场景下,若模型中含有如下通算融合算子,算子编译目录kernel_meta中,不会生成下述算子的*.o、*.json、*.cce文件。
MatMulAllReduce
MatMulAllReduceAddRmsNorm
AllGatherMatMul
MatMulReduceScatter
AlltoAllAllGatherBatchMatMul
BatchMatMulReduceScatterAlltoAll
无。
--op_debug_level=1
算子编译生成的调试文件存储路径,除--debug_dir参数设置的方式外,还可以配置环境变量ASCEND_WORK_PATH,几种方式优先级为:配置参数“--debug_dir”>环境变量ASCEND_WORK_PATH >默认存储路径。
关于ASCEND_WORK_PATH的详细说明请参见《环境变量参考》。
该参数优先级高于算子编译接口(TBE DSL的build接口或者TBE TIK的BuildCCE接口)中的tbe_debug_level的值。
--op_debug_config¶
使能Global Memory(DDR)内存检测功能的配置文件路径及文件名。
无。
**参数值:**配置文件路径及文件名。
**参数值格式:**路径和文件名:支持大小写字母(a-z,A-Z)、数字(0-9)、下划线(_)、短横线(-)、句点(.)、中文汉字。
参数值约束:
配置文件中支持配置如下选项,多个选项使用英文逗号分隔。
oom:算子执行过程中,检测Global Memory是否内存越界。
配置该选项,算子编译时,在当前执行路径算子编译生成的kernel_meta文件夹中保留.o(算子二进制文件)和.json文件(算子描述文件)。
使用该选项后,在算子编译过程中会加入如下的检测逻辑,用户可以通过再使用dump_cce参数,在生成的.cce文件中查看如下的代码。
inline __aicore__ void CheckInvalidAccessOfDDR(xxx) { if (access_offset < 0 || access_offset + access_extent > ddr_size) { if (read_or_write == 1) { trap(0X5A5A0001); } else { trap(0X5A5A0002); } } }
dump_cce:算子编译时,在当前执行路径算子编译生成的kernel_meta文件夹中保留算子cce文件*.cce,以及.o(算子二进制文件)和.json文件(算子描述文件)。
dump_loc:算子编译时,在当前执行路径算子编译生成的kernel_meta文件夹中保留python-cce映射文件*_loc.json,以及.o(算子二进制文件)和.json文件(算子描述文件)。
ccec_O0:算子编译时,开启ccec编译器选项-O0,配置该选项不会对调试信息执行优化操作,用于后续分析AI Core Error问题。
ccec_g:算子编译时,开启ccec编译器选项-g,配置该选项会对调试信息执行优化操作,用于后续分析AI Core Error问题。
check_flag:算子执行时,检测算子内部流水线同步信号是否匹配。
配置该选项,算子编译时,在当前执行路径算子编译生成的kernel_meta文件夹中保留.o(算子二进制文件)和.json文件(算子描述文件)。
使用该选项后,在算子编译过程中会加入如下的检测逻辑,用户可以通过再使用dump_cce参数,在生成的.cce文件中查看如下的代码。
set_flag(PIPE_MTE3, PIPE_MTE2, EVENT_ID0); set_flag(PIPE_MTE3, PIPE_MTE2, EVENT_ID1); set_flag(PIPE_MTE3, PIPE_MTE2, EVENT_ID2); set_flag(PIPE_MTE3, PIPE_MTE2, EVENT_ID3); .... pipe_barrier(PIPE_MTE3); pipe_barrier(PIPE_MTE2); pipe_barrier(PIPE_M); pipe_barrier(PIPE_V); pipe_barrier(PIPE_MTE1); pipe_barrier(PIPE_ALL); wait_flag(PIPE_MTE3, PIPE_MTE2, EVENT_ID0); wait_flag(PIPE_MTE3, PIPE_MTE2, EVENT_ID1); wait_flag(PIPE_MTE3, PIPE_MTE2, EVENT_ID2); wait_flag(PIPE_MTE3, PIPE_MTE2, EVENT_ID3); ...
实际执行推理过程中,如果确实存在算子内部流水线同步信号不匹配,则最终会在有问题的算子处超时报错,并终止程序,报错信息示例为:
Aicore kernel execute failed, ..., fault kernel_name=算子名,... rtStreamSynchronizeWithTimeout execute failed....
配置ccec编译选项(即ccec_O0、ccec_g选项)时,会导致算子Kernel(*.o文件)大小增大。动态Shape场景下,由于算子编译时会遍历可能的Shape场景,因此可能会导致算子Kernel文件过大而无法进行编译,此种场景下,建议不要配置ccec编译选项。 由于算子Kernel文件过大而无法编译的报错日志示例如下:
message:link error ld.lld: error: InputSection too large for range extension thunk ./kernel_meta_xxxxx.o:
ccec编译器选项ccec_O0和oom不能同时开启,可能会导致AICore Error报错,报错信息示例如下:
...there is an aivec error exception, core id is 49, error code = 0x4 ...
若配置NPU_COLLECT_PATH环境变量,不支持打开“检测Global Memory是否内存越界”的开关(--op_debug_config配置为oom),否则编译出来的模型文件或算子kernel包在使用时会报错。
配置编译选项oom、dump_cce、dump_loc时,若模型中含有如下通算融合算子,算子编译目录kernel_meta中,不会生成下述算子的*.o、*.json、*.cce文件。 MatMulAllReduce MatMulAllReduceAddRmsNorm AllGatherMatMul MatMulReduceScatter AlltoAllAllGatherBatchMatMul BatchMatMulReduceScatterAlltoAll
无。
假设使能Global Memory内存检测功能的配置文件名称为_gm_debug.cfg_,文件内容配置示例如下:
op_debug_config=ccec_g,oom
将该文件上传到ATC工具所在服务器,例如上传到_$HOME/module_,使用示例如下:
--op_debug_config=$HOME/module/gm_debug.cfg
算子编译时,如果用户不想编译所有AI Core算子,而是指定某些AI Core算子进行编译,则需要在上述_gm_debug.cfg_配置文件中新增op_debug_list字段,算子编译时,只编译该列表指定的算子,并按照op_debug_config配置的选项进行编译。op_debug_list字段要求如下:
支持指定算子名称或者算子类型。
算子之间使用英文逗号分隔,若为算子类型,则以OpType::typeName格式进行配置,支持算子类型和算子名称混合配置。
要编译的算子,必须放在--op_debug_config参数指定的配置文件中。算子类型必须为基于Ascend IR定义的算子的类型,算子类型查看方法请参见如何确定原始框架网络模型中的算子与NPU IP加速器支持的算子的对应关系。
配置示例如下:
在--op_debug_config参数指定的配置文件(例如_gm_debug.cfg_)中增加如下信息:
op_debug_config=ccec_g,oom
op_debug_list=GatherV2,OpType::ReduceSum
将该文件上传到ATC工具所在服务器,例如上传到_$HOME/module_,使用示例如下:
--op_debug_config=$HOME/module/gm_debug.cfg
实际模型转换时,_GatherV2,ReduceSum_算子按照ccec_g,oom选项进行编译。
--debug_dir¶
用于配置模型转换过程中算子编译生成的调试相关过程文件的路径。
过程文件包括但不限于算子.o(算子二进制文件)、.json(算子描述文件)、.cce等文件,具体生成的文件以--op_debug_level参数设置的取值为准。
如果要自行指定算子编译的过程文件存放路径,需--debug_dir参数与--op_debug_level(取值为非0)参数配合使用。
**参数值:**算子编译生成的调试相关文件的路径。
**参数值格式:**路径支持大小写字母(a-z,A-Z)、数字(0-9)、下划线(_)、短横线(-)、句点(.)、中文汉字。
参数值约束:如果使用该参数,则在执行atc命令之前,请先创建该参数要指定的目录。
参数默认值:在执行atc命令的当前路径./kernel_meta文件夹中生成算子编译的过程文件。
无。
例如创建的目录名为debug_info,则执行命令为:
--debug_dir=$HOME/module/out/debug_info --op_debug_level=1
算子编译生成的调试文件存储路径,除--debug_dir参数设置的方式外,还可以配置环境变量ASCEND_WORK_PATH,几种方式优先级为:配置参数“--debug_dir”>环境变量ASCEND_WORK_PATH >默认存储路径。
关于环境变量ASCEND_WORK_PATH的详细说明请参见《环境变量参考》。
--atomic_clean_policy¶
是否集中清理网络中所有memset算子(含有memset属性的算子都是memset算子)占用的内存。
无。
0:(默认值)集中清理。
1:单独清理,对网络中每一个memset算子进行单独清理。当网络中memset算子内存过大时建议使用此种清理方式,对降低使用内存有明显效果,但可能会导致一定的性能损耗。
无。
设置memset算子清理策略为单独清理,使用示例如下:
--atomic_clean_policy=1
无。
--status_check¶
控制编译算子时是否添加溢出检测逻辑。
当模型计算精度有问题,并且怀疑是模型中算子有计算溢出时,模型编译时可以通过使能该参数,添加编译算子时的溢出检测逻辑,然后重新编译模型。
使用该参数时,建议与--op_debug_level参数配合使用,这样在生成的算子*.cce文件中,可以查看是否加入了溢出检测逻辑,加入了溢出检测逻辑的代码样例如下:
if (status_overflow[0]) {
xxxxxx
}
0:(默认值)不使能,算子编译时不添加溢出检测逻辑。
1:使能,算子编译时添加溢出检测逻辑。
--status_check=1
使用--status_check参数只是在模型编译后生成的算子*.cce文件中加入了溢出检测逻辑,如果想查看具体哪些算子有溢出,则需要配合模型推理过程中提供的aclInit接口,在该接口入参的JSON配置文件中打开“dump_debug”开关,接口详细说明请参见《AscendCL应用开发指南 (C&C++)》中的“acl API参考 > 系统配置 > aclInit”章节。
--export_compile_stat¶
配置图编译过程中是否生成算子融合信息(包括图融合和UB融合)的结果文件fusion_result.json。
该文件用于记录图编译过程中使用的融合规则,文件中:
session_and_graph_id_xx_xx:表示融合结果所属线程和图编号。
graph_fusion:表示图融合。
ub_fusion:表示UB融合。
match_times:表示图编译过程中匹配到的融合规则次数。
effect_times:表示实际生效的次数。
repository_hit_times:优化UB融合知识库命中的次数。
该参数用于生成算子融合信息,而--fusion_switch_file参数可以关闭指定的融合规则,关闭的融合规则,不会在fusion_result.json文件中呈现。
0:不生成算子融合信息结果文件。
1:(默认值)程序运行正常退出时,生成算子融合信息结果文件。
2:图编译完成时,生成算子融合信息结果文件。即如果图编译已完成,后续程序提前中断,也会生成算子融合信息结果文件。
若未设置ASCEND_WORK_PATH环境变量,结果文件默认生成在执行atc命令的当前路径;若设置了ASCEND_WORK_PATH环境变量,则保存路径为:$ASCEND_WORK_PATH/FE/${进程号}/fusion_result.json。环境变量详细说明请参见《环境变量参考》。
--export_compile_stat=1
无。
后续版本废弃参数¶
--op_select_implmode¶
该参数功能已经不演进,后续版本会废弃,推荐使用--op_precision_mode参数。
NPU IP加速器部分内置算子有高精度和高性能实现方式,用户可以通过该参数配置模型编译时算子选择哪种实现方式。
高精度是指在float16输入场景,通过泰勒展开/牛顿迭代等手段进一步提升算子的精度;高性能是指在float16输入的情况下,不影响网络精度前提的最优性能实现。
无。
high_precision:表示算子采用高精度实现模式。
该选项采用系统内置的配置文件设置算子实现模式,内置配置文件路径为${INSTALL_DIR}/opp/built-in/op_impl/ai_core/tbe/impl_mode/high_precision.ini。
为保持兼容,该参数仅对high_precision.ini文件中算子列表生效,通过该列表可以控制算子生效的范围并保证之前版本的网络模型不受影响。
high_performance:(默认值)表示算子采用高性能实现模式。
该选项采用系统内置的配置文件设置算子实现模式,内置配置文件路径为${INSTALL_DIR}/opp/built-in/op_impl/ai_core/tbe/impl_mode/high_performance.ini。
为保持兼容,该参数仅对high_performance.ini文件中算子列表生效,通过该列表可以控制算子生效的范围并保证之前版本的网络模型不受影响。
high_precision_for_all:表示算子采用高精度实现模式。
该选项采用系统内置的配置文件设置算子实现模式,内置配置文件路径为${INSTALL_DIR}/opp/built-in/op_impl/ai_core/tbe/impl_mode/high_precision_for_all.ini,该文件中列表后续可能会跟随版本更新。
该实现模式不保证兼容,如果后续新的软件包中有算子新增了实现模式(即配置文件中新增了某个算子的实现模式),之前版本使用high_precision_for_all的网络模型,在新版本上性能可能会下降。
上述实现模式,根据算子的dtype进行区分。${INSTALL_DIR}请替换为CANN软件安装后文件存储路径。以root安装举例,安装后文件默认存储路径为:/usr/local/Ascend/latest。
不建议用户使用--op_select_implmode参数设置算子的实现模式,该参数仅作为调测使用,推荐通过--op_precision_mode参数加载ini配置文件方式设置算子精度模式:
如果用户对性能有更高要求,则建议优先使用high_performance_for_all参数,若经过验证性能满足要求,则建议用户复制一份high_performance_for_all.ini文件,并且重命名为“网络模型.ini”文件,跟随网络使用,不同网络模型使用不同的ini文件,后续模型转换时,可以直接使用--op_precision_mode参数加载保存的“网络模型.ini”配置文件。
如果用户对精度有更高要求,则建议优先使用high_precision_for_all参数,若经过验证精度满足要求,则建议用户复制一份high_precision_for_all.ini文件,并且重命名为“网络模型.ini”文件,跟随网络使用,不同网络模型使用不同的ini文件,后续模型转换时,可以直接使用--op_precision_mode参数加载保存的“网络模型.ini”配置文件。
如果用户在使用high_performance_for_all时,虽然性能得到很大的提升,但是发现精度不满足要求,发现是由于xxx算子使用了高性能模式引起的,则需要复制一份high_performance_for_all.ini文件,重命名为"网络模型.ini"文件,并将文件中该xxx算子的实现模式调整为高精度模式,后续模型转换时,直接使用--op_precision_mode参数加载“网络模型.ini”配置文件。
如果用户在使用high_precision_for_all时,虽然精度得到很大的提升,但是发现性能下降较厉害,发现是由于xxx算子使用了高精度模式引起的,则需要复制一份high_precision_for_all.ini文件,重命名为"网络模型.ini"文件,并将文件中该xxx算子的实现模式调整为高性能模式,后续模型转换时,直接使用--op_precision_mode参数加载“网络模型.ini”配置文件。
high_*.ini文件中算子的实现模式以all_ops_impl_mode.ini文件(路径为${INSTALL_DIR}/opp/built-in/op_impl/ai_core/tbe/impl_mode)所列出的为准,不在该文件中的实现模式不支持配置。
上述路径中的${INSTALL_DIR}请替换为CANN软件安装后文件存储路径。以root安装举例,安装后文件默认存储路径为:/usr/local/Ascend/latest。
--op_select_implmode=high_precision
如果有新支持精度模式的算子也选择高性能或者高精度模式,又不想破坏已有网络的精度或性能,则可以通过如下两种方式进行配置:
通过--optypelist_for_implmode参数指定新增的具体算子
--op_select_implmode=high_precision --optypelist_for_implmode=算子optype通过--op_precision_mode参数设置算子的精度模式
构造算子精度模式配置文件_op_precision.ini_,并在该文件中设置算子的精度模式,每一行设置一个算子的精度模式,样例如下:
optype1=high_precision optype2=high_performance
将配置好的_op_precision.ini_文件上传到ATC工具所在服务器任意目录,例如上传到_$HOME/conf_,使用示例如下:
--op_precision_mode=$HOME/conf/op_precision.ini
--op_select_implmode参数表示设置网络模型中所有算子的高精度或高性能模式,如果算子实现了高精度和高性能,则运行时选择--op_select_implmode参数指定的模式;如果算子只实现了一种,则按照算子实现的方式运行,例如:
某个算子当前只支持高精度,而--op_select_implmode设置为高性能,则--op_select_implmode参数对于该算子不生效,使用该算子当前实现的高精度方式运行。
--shape_generalized_build_mode¶
该参数后续版本会废弃,请勿使用。
图编译时Shape的编译方式。
该参数不能与--dynamic_batch_size、--dynamic_image_size、--dynamic_dims同时使用。
参数值:
shape_generalized:模糊编译,在编译时系统内部对可变维度做了泛化后再进行编译。如果算子Shape是固定,则可变维度会修改为-1(维度不变,例如原来Shape为4维,模糊编译后仍为4维)进行编译。
该参数使用场景为:用户想编译一次达到多次执行推理的目的时,可以使用模糊编译特性。
shape_precise:(默认值)精确编译,是指按照用户指定的维度信息、在编译时系统内部不做任何转义直接编译。
**参数值约束:**如果算子本身不支持动态Shape、只支持静态Shape(无可变维度),此时按照静态Shape编译算子,不按模糊编译做泛化。
图1为编译的两种方式。
无。
--shape_generalized_build_mode=shape_generalized
如果模型转换时通过该参数设置了模糊编译,则使用应用工程进行模型推理时,需要在aclmdlExecute接口之前,增加aclmdlSetDatasetTensorDesc接口,用于设置真实的shape取值。
接口详细说明请参见《AscendCL应用开发指南 (C&C++)》手册“AscendCL API参考”章节。
专题¶
定制网络修改(TensorFlow)¶
该版本不支持TensorFlow
概述¶
本章节介绍如何使用TensorFlow的xlacompile工具,将有控制流算子的网络模型(如图1所示)转成函数类算子的网络模型(如图2所示),然后利用ATC工具转换成适配昇腾AI处理器的离线模型适配NPU IP加速器的离线模型。
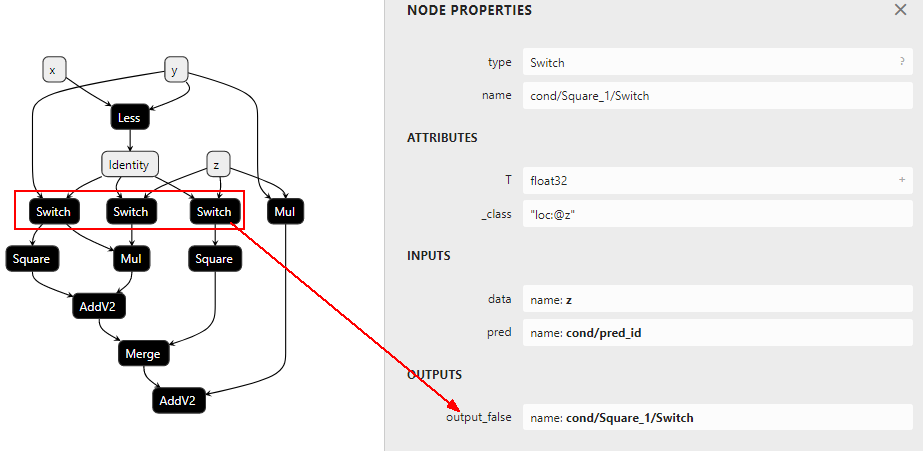
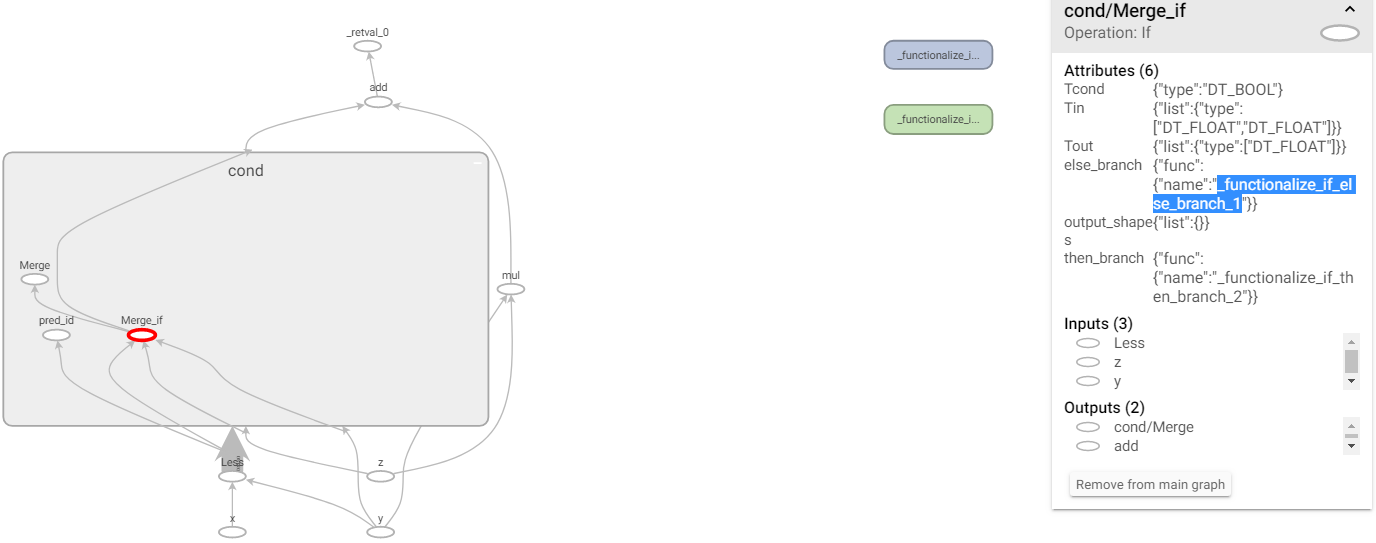
确保ATC工具所在服务器能连接网络。
安装bazel编译工具。
请参见https://docs.bazel.build/versions/master/install-ubuntu.html官方地址安装bazel编译工具。
安装TensorFlow以及依赖future。
ATC安装路径下的func2graph.py脚本依赖TensorFlow,使用pip3.7.5 list查看列表中是否有TensorFlow依赖,若有则不用安装,否则执行如下命令安装:
pip3.7.5 install tensorflow==1.15 --userbazel编译工具依赖python,请使用pip3.7.5 list命令查看是否安装future、patch,若有则不用安装,否则执行如下命令安装:
pip3.7.5 install future --user pip3.7.5 install patch --user pip3.7.5 install numpy --user
如果执行上述命令时无法连接网络,且提示“Could not find a version that satisfies the requirement xxx”,请参见使用pip3.7.5 install软件时提示" Could not find a version that satisfies the requirement xxx"解决。
编译可执行文件¶
请以ATC软件包安装用户进行如下操作:
从https://github.com/tensorflow/tensorflow/archive/v1.15.0.tar.gz链接下载Tensorflow源码,然后将下载的源码上传到ATC工具所在Linux服务器任意目录。
登录Linux服务器,切换到Tensorflow源码所在路径,执行如下命令解压源码包:
tar -zxvf tensorflow-1.15.0.tar.gz进入解压后的tensorflow-1.15.0,安装补丁。
参见获取xlacompile.patch补丁文件获取xlacompile.patch补丁,然后上传到Linux服务器tensorflow-1.15.0路径下,执行如下命令安装补丁:
patch -p1 < xlacompile.patch切换到tensorflow-1.15.0目录,执行如下命令编译xlacompile工具:
bazel build --config=monolithic //tensorflow/compiler/aot:xlacompile若出现类似如下信息,则说明编译成功,编译大约需要10分钟左右;若编译失败,请参见使用bazel编译工具编译时提示“An error occurred during the fetch of repository 'io_bazel_rules_docker'”,编译失败解决。
Target //tensorflow/compiler/aot:xlacompile up-to-date: bazel-bin/tensorflow/compiler/aot/xlacompile INFO: Elapsed time: 214.550s, Critical Path: 73.38s INFO: 1511 processes: 1511 local. INFO: Build completed successfully, 1513 total actions
编译成功后,会在$HOME/.cache/bazel/_bazel_test/abd37aaac8a380ca5a3f13938322fcb2/external/org_tensorflow/bazel-out/k8-opt/bin/tensorflow/compiler/aot路径生成xlacompile可执行文件(该路径只是样例,请以用户实际编译后的为准)。
xlacompile可执行文件用于将控制流算子的网络模型转成函数类算子的网络模型。
切换到tensorflow-1.15.0目录,执行如下命令编译summarize_graph工具:
bazel build --config=monolithic -c opt //tensorflow/tools/graph_transforms:summarize_graph若出现类似如下信息,则说明编译成功:
Target //tensorflow/tools/graph_transforms:summarize_graph up-to-date: bazel-bin/tensorflow/tools/graph_transforms/summarize_graph INFO: Elapsed time: 70.474s, Critical Path: 53.16s INFO: 1028 processes: 1028 local. INFO: Build completed successfully, 1053 total actions
编译成功后,会在$HOME/.cache/bazel/_bazel_test/abd37aaac8a380ca5a3f13938322fcb2/execroot/org_tensorflow/bazel-out/k8-opt/bin/tensorflow/tools/graph_transforms路径生成summarize_graph可执行文件(该路径只是样例,请以用户实际编译后的为准)。
summarize_graph可执行文件用来查看有控制流算子网络模型的输入输出节点,方便用户构造config.pbtxt输入输出配置文件。
转换模型¶
下面以Switch_v1.pb网络模型为例进行说明,演示如何将有控制流算子网络模型转换成函数类算子网络模型,然后通过ATC工具转换成适配昇腾AI处理器的离线模型适配NPU IP加速器的离线模型。请先参见获取Switch_v1.pb网络模型获取Switch_v1.pb网络模型。
-
切换到summarize_graph可执行文件所在路径,执行如下命令:
./summarize_graph --in_graph=/home/test/module/Switch_v1.pb若返回如下信息,则说明执行成功:
Found 3 possible inputs: (name=x, type=float(1), shape=<unknown>) (name=y, type=float(1), shape=<unknown>) (name=z, type=float(1), shape=<unknown>) No variables spotted. Found 1 possible outputs: (name=add, op=AddV2) Found 0 (0) const parameters, 0 (0) variable parameters, and 0 control_edges Op types used: 3 Placeholder, 3 Switch, 2 AddV2, 2 Mul, 2 Square, 1 Identity, 1 Less, 1 Merge To use with tensorflow/tools/benchmark:benchmark_model try these arguments: bazel run tensorflow/tools/benchmark:benchmark_model -- --graph=/home/test/module/Switch_v1.pb --show_flops --input_layer=x,y,z --input_layer_type=float,float,float --input_layer_shape=:: --output_layer=add
构造config.pbtxt输出配置文件。
在任意路径执行vim config.pbtxt命令创建config.pbtxt文件,本示例以在$HOME/module路径创建为例进行说明。
根据1所示,该网络模型有一个输出,构造的config.pbtxt配置文件样例如下(如下配置文件只是样例,需要用户根据实际情况修改输出算子的name,其中fetch表示输出):
fetch { id { node_name: "add" } }
配置完成后,保存文件并退出。
生成函数类算子网络模型的配置文件。
在任意路径执行如下命令设置xlacompile命令执行过程中的打屏日志信息:
export TF_CPP_MIN_LOG_LEVEL=0 export TF_CPP_MIN_VLOG_LEVEL=1
切换到xlacompile可执行文件所在路径,执行如下命令:
./xlacompile --graph=/home/test/module/Switch_v1.pb --config=/home/test/module/config.pbtxt --output=/home/test/module/Switch_v1_v2如果提示“Successfully convert ...“信息,则说明转换成功。切换到**--output**参数指定的路径,可以看到如下输出文件:
-rw-rw-r-- 1 test test 1236 Jun 20 17:13 Switch_v1_v2.pb -rw-rw-r-- 1 test test 4803 Jun 20 17:13 Switch_v1_v2.pbtxt
函数类算子网络模型生成graph子图。后续使用ATC工具进行模型转换时,需要使用该文件生成子图。
在任意路径执行如下命令,将函数类算子网络模型生成子图:
python3.7.5 ${INSTALL_DIR}/compiler/python/func2graph/func2graph.py -m /home/test/module/Switch_v1_v2.pb若提示如下信息,则说明生成成功。
graph_def_file: /home/test/module/graph_def_library.pbtxt INFO: Convert to subgraphs successfully.
函数类算子网络模型转换成适配昇腾AI处理器的离线模型。
参见设置环境变量设置ATC工具执行时需设置的环境变量,然后执行如下命令进行模型转换:
atc --model=/home/test/module/Switch_v1_v2.pb --framework=3 --output=/home/test/module/out/Switch_v1_v2_to_om --soc_version=<soc_version>若提示如下信息,则说明模型转换成功:
ATC run success, welcome to the next use.成功执行命令后,在**--output**参数指定的路径下,可查看模型文件。
FAQ¶
使用bazel编译工具编译时提示“An error occurred during the fetch of repository 'io_bazel_rules_docker'”,编译失败¶
使用bazel build --config=monolithic //tensorflow/compiler/aot:xlacompilebazel build命令编译过程中,提示“ERROR: An error occurred during the fetch of repository 'io_bazel_rules_docker'”,检查服务器,能够连接网络,但仍旧提示如下错误信息:
ERROR: An error occurred during the fetch of repository 'io_bazel_rules_docker':
java.io.IOException: Error downloading [https://github.com/bazelbuild/rules_docker/releases/download/v0.14.3/rules_docker-v0.14.3.tar.gz] to /home/test/.cache/bazel/_bazel_test/abd37aaac8a380ca5a3f13938322fcb2/external/io_bazel_rules_docker/rules_docker-v0.14.3.tar.gz: PKIX path building failed: sun.security.provider.certpath.SunCertPathBuilderException: unable to find valid certification path to requested target
ERROR: no such package '@io_bazel_rules_docker//repositories': java.io.IOException: Error downloading [https://github.com/bazelbuild/rules_docker/releases/download/v0.14.3/rules_docker-v0.14.3.tar.gz] to /home/test/.cache/bazel/_bazel_test/abd37aaac8a380ca5a3f13938322fcb2/external/io_bazel_rules_docker/rules_docker-v0.14.3.tar.gz: PKIX path building failed: sun.security.provider.certpath.SunCertPathBuilderException: unable to find valid certification path to requested target
INFO: Elapsed time: 24.586s
INFO: 0 processes.
FAILED: Build did NOT complete successfully (0 packages loaded)
如果连网情况下,仍旧提示上述无法下载压缩包的问题,则请参见如下方法解决:
将如下链接中的附件下载到本地,然后上传到linux服务器任意路径,例如上传到$HOME/bazel_tools路径。
https://github.com/bazelbuild/rules_docker/releases/download/v0.14.3/rules_docker-v0.14.3.tar.gz https://github.com/bazelbuild/bazel-skylib/releases/download/0.8.0/bazel-skylib.0.8.0.tar.gz https://github.com/bazelbuild/rules_swift/releases/download/0.11.1/rules_swift.0.11.1.tar.gz https://github.com/llvm-mirror/llvm/archive/7a7e03f906aada0cf4b749b51213fe5784eeff84.tar.gz
则上述文件在linux服务器绝对路径为:
/home/test/bazel_tools/rules_docker-v0.14.3.tar.gz /home/test/bazel_tools/bazel-skylib.0.8.0.tar.gz /home/test/bazel_tools/rules_swift.0.11.1.tar.gz /home/test/bazel_tools/llvm-7a7e03f906aada0cf4b749b51213fe5784eeff84.tar.gz
修改bazel编译工具相关文件中的下载链接:
切换到tensorflow-1.15.0目录,使用vi WORKSPACE命令打开WORKSPACE,修改该文件中的下载链接,将下载链接修改为linux服务器绝对路径地址:
bazel_toolchains_repositories() http_archive( name = "io_bazel_rules_docker", sha256 = "6287241e033d247e9da5ff705dd6ef526bac39ae82f3d17de1b69f8cb313f9cd", strip_prefix = "rules_docker-0.14.3", urls = ["file:///home/test/bazel_tools/rules_docker-v0.14.3.tar.gz"], ) load( "@io_bazel_rules_docker//repositories:repositories.bzl", container_repositories = "repositories", ) container_repositories() load("//third_party/toolchains/preconfig/generate:workspace.bzl", "remote_config_workspace") remote_config_workspace() # Apple and Swift rules. http_archive( name = "build_bazel_rules_apple", sha256 = "6efdde60c91724a2be7f89b0c0a64f01138a45e63ba5add2dca2645d981d23a1", urls = ["https://github.com/bazelbuild/rules_apple/releases/download/0.17.2/rules_apple.0.17.2.tar.gz"], ) # https://github.com/bazelbuild/rules_apple/releases http_archive( name = "build_bazel_rules_swift", sha256 = "96a86afcbdab215f8363e65a10cf023b752e90b23abf02272c4fc668fcb70311", urls = ["file:///home/test/bazel_tools/rules_swift.0.11.1.tar.gz"], ) # https://github.com/bazelbuild/rules_swift/releases
保存文件并退出。
修改tensorflow-1.15.0/tensorflow路径下workspace.bzl文件中llvm对应的链接:
# TODO(phawkins): currently, this rule uses an unofficial LLVM mirror. # Switch to an official source of snapshots if/when possible. tf_http_archive( name = "llvm", build_file = clean_dep("//third_party/llvm:llvm.autogenerated.BUILD"), sha256 = "599b89411df88b9e2be40b019e7ab0f7c9c10dd5ab1c948cd22e678cc8f8f352", strip_prefix = "llvm-7a7e03f906aada0cf4b749b51213fe5784eeff84", urls = [ "https://mirror.bazel.build/github.com/llvm-mirror/llvm/archive/7a7e03f906aada0cf4b749b51213fe5784eeff84.tar.gz", "file:///home/test/bazel_tools/llvm-7a7e03f906aada0cf4b749b51213fe5784eeff84.tar.gz", ], )
修改完成后,重新切换到tensorflow-1.15.0目录,执行如下命令编译xlacompile工具:
bazel build --config=monolithic //tensorflow/compiler/aot:xlacompile若提示“ERROR: An error occurred during the fetch of repository 'bazel_skylib':“,则进入下一步继续修改bazel_skylib相关的文件。
修改**.cache目录**中的相关链接:
切换到$HOME目录,使用grep -r bazel-skylib.0.8.0 .cache/命令查看.cache目录哪个文件引用bazel-skylib.0.8.0.tar.gz的url,根据返回信息,进入引用该url文件所在的目录,例如.cache/bazel/_bazel_test/abd37aaac8a380ca5a3f13938322fcb2/external/io_bazel_rules_closure/closure/repositories.bzl(该路径只是样例,请以用户实际编译后的为准)
打开该文件,将其中的url改为:
file:///home/test/bazel_tools/bazel-skylib.0.8.0.tar.gz保存文件并退出。
使用pip3.7.5 install软件时提示" Could not find a version that satisfies the requirement xxx"¶
安装依赖时,使用pip3.7.5 install xxx命令安装相关软件时提示无法连接网络,且提示"Could not find a version that satisfies the requirement xxx",使用apt-get update命令检查源可用。提示信息如下图所示。

没有配置pip源。
配置pip源,配置方法如下:
使用ATC软件包安装用户,执行如下命令:
cd ~/.pip如果提示目录不存在,则执行如下命令创建:
mkdir ~/.pip cd ~/.pip
在.pip目录下创建pip.conf文件,命令为:
touch pip.conf编辑pip.conf文件。
使用vi pip.conf命令打开pip.conf文件,写入如下内容后,保存文件并退出:
[global] #可用的源,请根据实际情况进行替换。 index-url=http://xxx [install] #可信主机,请根据实际情况进行替换。 trusted-host=xxx
获取Switch_v1.pb网络模型¶
将如下文件中的脚本复制到.py文件中,例如复制到_Switch_v1.py_文件中。
import os import numpy as np import tensorflow as tf x = tf.compat.v1.placeholder(tf.float32, name='x') y = tf.compat.v1.placeholder(tf.float32, name='y') z = tf.compat.v1.placeholder(tf.float32, name='z') def then_branch(x, y, z): m = tf.square(x) return m + tf.multiply(y, z) def else_branch(x, y, z): m = tf.pow(x, y) return m - tf.div(y, z) # 控制流算子使用入口,执行脚本之后,在图中生成对应的V1控制流算子 def testDefun(x, y, z): return tf.cond(pred=x < y, true_fn=lambda: then_branch(x, y, z), false_fn=lambda: else_branch(x, y, z)), y def testCase(x, y, z): a, b = testDefun(x, y, z) return a + b * z with tf.compat.v1.Session() as sess: result = sess.run(testCase(x, y, z), feed_dict={x: 1., y: .6, z: .2}) with tf.io.gfile.GFile('./Switch_v1.pb', 'wb') as f: f.write(sess.graph_def.SerializeToString())
切换到_Switch_v1.py_脚本所在目录,执行如下命令生成Switch_v1.pb网络模型:
python3.7.5 Switch_v1.py命令执行完毕,在当前目录会生成Switch_v1.pb网络模型。
获取xlacompile.patch补丁文件¶
用户安装完xlacompile.patch补丁,编译成xlacompile工具后,该工具可以将有控制流的V1网络模型转成函数类的V2网络模型。
将如下代码复制到文件中,并另存为xlacompile.patch,然后上传到Linux服务器tensorflow-1.15.0路径下:
---
WORKSPACE | 7 +
tensorflow/compiler/aot/BUILD | 27 ++++
tensorflow/compiler/aot/xlacompile_main.cc | 170 +++++++++++++++++++++
tensorflow/compiler/tf2xla/tf2xla.cc | 6 +
tensorflow/compiler/tf2xla/tf2xla.h | 4 +
5 files changed, 195 insertions(+)
create mode 100644 tensorflow/compiler/aot/xlacompile_main.cc
diff --git a/WORKSPACE b/WORKSPACE
index 74ea14d..d2265f9 100644
--- a/WORKSPACE
+++ b/WORKSPACE
@@ -34,6 +34,13 @@ load(
bazel_toolchains_repositories()
+http_archive(
+ name = "io_bazel_rules_docker",
+ sha256 = "6287241e033d247e9da5ff705dd6ef526bac39ae82f3d17de1b69f8cb313f9cd",
+ strip_prefix = "rules_docker-0.14.3",
+ urls = ["https://github.com/bazelbuild/rules_docker/releases/download/v0.14.3/rules_docker-v0.14.3.tar.gz"],
+)
+
load(
"@io_bazel_rules_docker//repositories:repositories.bzl",
container_repositories = "repositories",
diff --git a/tensorflow/compiler/aot/BUILD b/tensorflow/compiler/aot/BUILD
index f871115..b2620db 100644
--- a/tensorflow/compiler/aot/BUILD
+++ b/tensorflow/compiler/aot/BUILD
@@ -106,6 +106,33 @@ cc_library(
],
)
+tf_cc_binary(
+ name = "xlacompile",
+ visibility = ["//visibility:public"],
+ deps = [":xlacompile_main"],
+)
+
+cc_library(
+ name = "xlacompile_main",
+ srcs = ["xlacompile_main.cc"],
+ visibility = ["//visibility:public"],
+ deps = [
+ ":tfcompile_lib",
+ "//tensorflow/compiler/tf2xla:tf2xla_proto",
+ "//tensorflow/compiler/tf2xla:tf2xla_util",
+ "//tensorflow/compiler/xla:debug_options_flags",
+ "//tensorflow/compiler/xla/service:compiler",
+ "//tensorflow/core:core_cpu",
+ "//tensorflow/core:core_cpu_internal",
+ "//tensorflow/core:framework",
+ "//tensorflow/core:framework_internal",
+ "//tensorflow/core:graph",
+ "//tensorflow/core:lib",
+ "//tensorflow/core:protos_all_cc",
+ "@com_google_absl//absl/strings",
+ ],
+)
+
# NOTE: Most end-to-end tests are in the "tests" subdirectory, to ensure that
# tfcompile.bzl correctly handles usage from outside of the package that it is
# defined in.
diff --git a/tensorflow/compiler/aot/xlacompile_main.cc b/tensorflow/compiler/aot/xlacompile_main.cc
new file mode 100644
index 0000000..bc795ef
--- /dev/null
+++ b/tensorflow/compiler/aot/xlacompile_main.cc
@@ -0,0 +1,170 @@
+/* Copyright 2017 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include <memory>
+#include <string>
+#include <utility>
+#include <vector>
+#include <map>
+
+#include "tensorflow/compiler/aot/flags.h"
+#include "tensorflow/compiler/tf2xla/tf2xla.h"
+#include "tensorflow/compiler/tf2xla/tf2xla_util.h"
+#include "tensorflow/core/platform/init_main.h"
+
+namespace tensorflow {
+namespace xlacompile {
+
+const char kUsageHeader[] =
+ "xlacompile performs ahead-of-time compilation of a TensorFlow graph,\n"
+ "resulting in an object file compiled for your target architecture, and a\n"
+ "header file that gives access to the functionality in the object file.\n"
+ "A typical invocation looks like this:\n"
+ "\n"
+ " $ xlacompile --graph=mygraph.pb --config=config.pbtxt --output=output.pbtxt\n"
+ "\n";
+
+void AppendMainFlags(std::vector<Flag>* flag_list, tfcompile::MainFlags* flags) {
+ const std::vector<Flag> tmp = {
+ {"graph", &flags->graph,
+ "Input GraphDef file. If the file ends in '.pbtxt' it is expected to "
+ "be in the human-readable proto text format, otherwise it is expected "
+ "to be in the proto binary format."},
+ {"config", &flags->config,
+ "Input file containing Config proto. If the file ends in '.pbtxt' it "
+ "is expected to be in the human-readable proto text format, otherwise "
+ "it is expected to be in the proto binary format."},
+ {"output", &flags->out_session_module,
+ "Output session module proto. Will generate '.pb' and '.pbtxt' file."},
+ };
+ flag_list->insert(flag_list->end(), tmp.begin(), tmp.end());
+}
+
+Status ReadProtoFile(const string& fname, protobuf::Message* proto) {
+ if (absl::EndsWith(fname, ".pbtxt")) {
+ return ReadTextProto(Env::Default(), fname, proto);
+ } else {
+ return ReadBinaryProto(Env::Default(), fname, proto);
+ }
+}
+
+Status Main(tfcompile::MainFlags& flags) {
+ // Process config.
+ tf2xla::Config config;
+ if (flags.config.empty()) {
+ return errors::InvalidArgument("Must specify --config");
+ }
+ TF_RETURN_IF_ERROR(ReadProtoFile(flags.config, &config));
+ TF_RETURN_IF_ERROR(ValidateConfig(config));
+ if (flags.dump_fetch_nodes) {
+ std::set<string> nodes;
+ for (const tf2xla::Fetch& fetch : config.fetch()) {
+ nodes.insert(fetch.id().node_name());
+ }
+ std::cout << absl::StrJoin(nodes, ",");
+ return Status::OK();
+ }
+
+ // Read and initialize the graph.
+ if (flags.graph.empty()) {
+ return errors::InvalidArgument("Must specify --graph");
+ }
+ if (flags.out_session_module.empty()) {
+ return errors::InvalidArgument("Must specify --output");
+ }
+
+ string output_pb_bin = flags.out_session_module + ".pb";
+ string output_pb_txt = flags.out_session_module + ".pbtxt";
+ if (output_pb_bin == flags.config || output_pb_bin == flags.graph ||
+ output_pb_txt == flags.config || output_pb_txt == flags.graph) {
+ return errors::InvalidArgument("Must different --config --graph --output");
+ }
+
+ GraphDef graph_def;
+ TF_RETURN_IF_ERROR(ReadProtoFile(flags.graph, &graph_def));
+ std::unique_ptr<Graph> graph;
+ TF_RETURN_IF_ERROR(ConvertGraphDefToXla(graph_def, config, graph));
+
+ std::map<string, string> arg_name_maps;
+ GraphDef new_graph_def;
+ graph->ToGraphDef(&new_graph_def);
+ // Delete _class attribute for: expects to be colocated with unknown node
+ for (int i = 0; i < new_graph_def.node_size(); ++i) {
+ NodeDef *node = new_graph_def.mutable_node(i);
+ node->mutable_attr()->erase("_class");
+ if (node->op() == "_Retval") {
+ node->set_name(absl::StrCat(node->attr().at("index").i(), "_Retval"));
+ }
+ if (node->op() == "_Arg") {
+ const string name = node->name();
+ node->set_name(absl::StrCat(node->attr().at("index").i(), "_Arg"));
+ arg_name_maps[name] = node->name();
+ }
+ }
+
+ for (int i = 0; i < new_graph_def.node_size() && !arg_name_maps.empty(); ++i) {
+ NodeDef *node = new_graph_def.mutable_node(i);
+ for (int j = 0; j < node->input_size(); ++j) {
+ auto it = arg_name_maps.find(node->input(j));
+ if (it != arg_name_maps.end()) {
+ *node->mutable_input(j) = it->second;
+ }
+ }
+ }
+
+ TF_RETURN_IF_ERROR(WriteBinaryProto(Env::Default(), output_pb_bin, new_graph_def));
+ std::cerr << "Successfully convert: " << output_pb_bin << "\n";
+ TF_RETURN_IF_ERROR(WriteTextProto(Env::Default(), output_pb_txt, new_graph_def));
+ std::cerr << "Successfully convert: " << output_pb_txt << "\n";
+ return Status::OK();
+}
+
+} // end namespace xlacompile
+} // end namespace tensorflow
+
+int main(int argc, char** argv) {
+ tensorflow::tfcompile::MainFlags flags;
+ flags.target_triple = "x86_64-pc-linux";
+ flags.out_function_object = "out_model.o";
+ flags.out_metadata_object = "out_helper.o";
+ flags.out_header = "out.h";
+ flags.entry_point = "entry";
+
+ std::vector<tensorflow::Flag> flag_list;
+ tensorflow::xlacompile::AppendMainFlags(&flag_list, &flags);
+
+ tensorflow::string usage = tensorflow::xlacompile::kUsageHeader;
+ usage += tensorflow::Flags::Usage(argv[0], flag_list);
+ if (argc > 1 && absl::string_view(argv[1]) == "--help") {
+ std::cerr << usage << "\n";
+ return 0;
+ }
+ bool parsed_flags_ok = tensorflow::Flags::Parse(&argc, argv, flag_list);
+ QCHECK(parsed_flags_ok) << "\n" << usage;
+
+ tensorflow::port::InitMain(usage.c_str(), &argc, &argv);
+ QCHECK(argc == 1) << "\nERROR: This command does not take any arguments "
+ "other than flags\n\n"
+ << usage;
+ tensorflow::Status status = tensorflow::xlacompile::Main(flags);
+ if (status.code() == tensorflow::error::INVALID_ARGUMENT) {
+ std::cerr << "INVALID ARGUMENTS: " << status.error_message() << "\n\n"
+ << usage;
+ return 1;
+ } else {
+ TF_QCHECK_OK(status);
+ }
+ return 0;
+}
diff --git a/tensorflow/compiler/tf2xla/tf2xla.cc b/tensorflow/compiler/tf2xla/tf2xla.cc
index 3c2b256..3872776 100644
--- a/tensorflow/compiler/tf2xla/tf2xla.cc
+++ b/tensorflow/compiler/tf2xla/tf2xla.cc
@@ -410,4 +410,10 @@ Status ConvertGraphDefToXla(const GraphDef& graph_def,
return Status::OK();
}
+Status ConvertGraphDefToXla(const GraphDef &graph_def,
+ const tf2xla::Config &config,
+ std::unique_ptr<Graph> &graph) {
+ return InitGraph(graph_def, config, &graph);
+}
+
} // namespace tensorflow
diff --git a/tensorflow/compiler/tf2xla/tf2xla.h b/tensorflow/compiler/tf2xla/tf2xla.h
index 432a12a..969500c 100644
--- a/tensorflow/compiler/tf2xla/tf2xla.h
+++ b/tensorflow/compiler/tf2xla/tf2xla.h
@@ -20,6 +20,7 @@ limitations under the License.
#include "tensorflow/compiler/xla/client/client.h"
#include "tensorflow/compiler/xla/client/xla_computation.h"
#include "tensorflow/core/framework/graph.pb.h"
+#include "tensorflow/core/graph/graph.h"
namespace tensorflow {
@@ -34,6 +35,9 @@ Status ConvertGraphDefToXla(const GraphDef& graph_def,
const tf2xla::Config& config, xla::Client* client,
xla::XlaComputation* computation);
+Status ConvertGraphDefToXla(const GraphDef &graph_def,
+ const tf2xla::Config &config,
+ std::unique_ptr<Graph> &graph);
} // namespace tensorflow
#endif // TENSORFLOW_COMPILER_TF2XLA_TF2XLA_H_
--
1.8.3.1
参考¶
本章节给出不同框架可量化的层以及相关约束。 如果要自动控制量化过程,比如控制哪些层是否量化、控制使用什么量化算法,则可以通过本章节构造的cfg配置文件实现。
dump图详细信息¶
模型转换前,通过设置如下环境变量,dump出编译过程中的模型图,用户可以通过查看dump图观察模型的变化:
export DUMP_GE_GRAPH=1 #控制dump图的内容多少
export DUMP_GRAPH_LEVEL=1 #控制dump图的个数
在执行atc命令的当前路径会生成如下文件,关于环境变量的详细介绍请参见2。
ge_onnx*.pbtxt:基于ONNX的模型描述结构,可以使用Netron等可视化软件打开。
ge_proto*.txt:protobuf格式存储的文本文件,该文件可以转成JSON格式文件方便用户定位问题。该文件与ge_onnx*.pbtxt一般成对出现,但是ge_proto*.txt比ge_onnx*.pbtxt文件会多string类型的属性信息,因此ge_proto*.txt显示的更完整,用户选择其中一种文件打开即可。
由于ge_proto*.txt文件结构相比ge_onnx*.pbtxt已经做了文件大小的优化,因此DUMP_GE_GRAPH环境变量设置为2或3,对ge_proto*.txt文件效果相同,都显示为不含有权重等数据的基本版dump。
上述每个文件对应模型编译过程中的一个步骤,比如以ge_onnx_00000001_graph_0_PreRunBegin.pbtxt开始,以ge_onnx_00000078_graph_0_PreRunAfterBuild.pbtxt结尾。每个文件中包括完成该步骤所涉及的所有算子,关于dump图每个阶段的子图详细作用请参见表1(每个模型生成的dump子图可能不一致,但是主流程基本一致)。
表 1 dump图详细信息说明
支持量化的层及约束¶
本章节给出不同框架可量化的层以及相关约束。
若网络模型输入数据类型或权重数据类型为Float16或混合精度类型(Float32/Float16共存),会关闭如下算子的量化功能: AvgPool、Pooling、AvgPoolV2、MaxPool、MaxPoolV3、Pooling、Add、Eltwise、BatchMatMulV2(两路输入都为变量tensor)。
INT16数据量化过程中,发现整网精度下降,可以通过精度比对工具,逐层比对原始模型和量化后模型输出误差(例如以余弦相似度作为标准,需要相似度达到0.99以上),找到误差较大的层,然后通过简易配置文件中的dst_type参数将该层修改为INT8量化,重新进行量化。
由于硬件约束,该版本不建议使用非均匀量化的功能,获取不到性能收益。
表 1 均匀量化支持的层及约束
|
|||
|
表 2 非均匀量化支持的层及约束
该版本不支持仅权重量化特性。
表 3 仅权重量化场景支持的层及约束
|
其中:
√表示支持,×表示该场景量化会异常。
权重ARQ中channel_wise=true:表示每个channel独立量化,量化因子不同。
权重ARQ中asymmetric
true:表示权重量化使用非对称量化
false:表示权重量化使用对称量化。
true和false表示权重量化支持对称量化和非对称量化。
量化简易配置文件¶
如果要自动控制量化过程,比如控制哪些层是否量化、控制使用什么量化算法,则可以通过本章节构造的cfg配置文件实现。
表 1 calibration_config.proto参数说明
基于该文件构造的均匀量化简易配置文件quant.cfg样例如下所示:_Optype_需要配置为基于Ascend IR定义的算子类型,详细对应关系请参见支持量化的层及约束。
# global quantize parameter activation_offset : true joint_quant : false enable_auto_nuq : false version : 1 skip_layers : "Optype" skip_layer_types:"Optype" do_fusion: true skip_fusion_layers : "Optype" common_config : { arq_quantize : { channel_wise : true quant_bits : 7 } ifmr_quantize : { search_range_start : 0.7 search_range_end : 1.3 search_step : 0.01 max_percentile : 0.999999 min_percentile : 0.999999 asymmetric : true dst_type : INT16 } } override_layer_types : { layer_type : "Optype" calibration_config : { arq_quantize : { channel_wise : false } ifmr_quantize : { search_range_start : 0.8 search_range_end : 1.2 search_step : 0.02 max_percentile : 0.999999 min_percentile : 0.999999 asymmetric : false dst_type : INT16 } } } override_layer_configs : { layer_name : "Opname" calibration_config : { arq_quantize : { channel_wise : true } ifmr_quantize : { search_range_start : 0.8 search_range_end : 1.2 search_step : 0.02 max_percentile : 0.999999 min_percentile : 0.999999 asymmetric : false dst_type : INT16 } } } tensor_quantize { layer_name: "Opname" input_index: 0 ifmr_quantize: { search_range_start : 0.7 search_range_end : 1.3 search_step : 0.01 min_percentile : 0.999999 asymmetric : false dst_type : INT16 } } tensor_quantize { layer_name: "Opname" input_index: 0 }
基于该文件构造的仅权重量化简易配置文件quant.cfg配置示例:
activation_offset : true joint_quant : false version : 1 do_fusion: true common_config : { weight_compress_only : true arq_quantize : { channel_wise : true asymmetric : false } } override_layer_types : { layer_type : "Optype" calibration_config : { weight_compress_only : true arq_quantize : { channel_wise : true asymmetric : true quant_bits : 6 } } } override_layer_configs : { layer_name : "Opname" calibration_config : { weight_compress_only : true arq_quantize : { channel_wise : true asymmetric : true } } }
基于该文件构造的非均匀量化简易配置文件quant.cfg配置示例:
# global quantize parameter activation_offset : true joint_quant : false enable_auto_nuq : false common_config : { arq_quantize : { channel_wise : true } ifmr_quantize : { search_range_start : 0.7 search_range_end : 1.3 search_step : 0.01 max_percentile : 0.999999 min_percentile : 0.999999 asymmetric : true } } override_layer_types : { layer_type : "Optype" calibration_config : { arq_quantize : { channel_wise : false } ifmr_quantize : { search_range_start : 0.7 search_range_end : 1.3 search_step : 0.01 max_percentile : 0.999999 min_percentile : 0.999999 asymmetric : false } } } override_layer_configs : { layer_name : "Opname" calibration_config : { nuq_quantize : { num_steps : 32 num_of_iteration : 1 } ifmr_quantize : { search_range_start : 0.8 search_range_end : 1.2 search_step : 0.02 max_percentile : 0.999999 min_percentile : 0.999999 asymmetric : false } } } tensor_quantize { layer_name: "Opname" input_index: 0 ifmr_quantize: { search_range_start : 0.7 search_range_end : 1.3 search_step : 0.01 min_percentile : 0.999999 asymmetric : false } } tensor_quantize { layer_name: "Opname" input_index: 0 }
FAQ¶
如何确定原始框架网络模型中的算子与NPU IP加速器支持的算子的对应关系¶
用户使用精度比对工具或者性能比对工具进行算子精度或者性能分析时,若发现某些算子精度或者性能有问题,可能会考虑使用ATC工具中的某些参数调整算子的计算精度后,重新进行模型转换然后推理,比如通过--modify_mixlist参数将有问题的算子配置为黑名单等,该场景下,ATC中的参数要求配置的必须为基于Ascend IR定义的算子的OpType。
那如何获取此类算子的OpType?或者如何通过原始框架网络模型中的算子,来获取我们NPU IP加速器对应支持的算子的OpType呢?
发现某些算子精度或者性能有问题,需要对此类算子进行精度调整时,不清楚该类算子对应的Ascend IR算子是什么。
下面就给出如何获取Ascend IR算子OpType的方法:
如果用户正在使用Profiling工具进行算子性能分析,该场景下直接获取NPU IP加速器支持的算子类型即可,参见《性能调优工具用户指南》手册:
导出summary数据中的“AI Core和AI CPU算子数据”,文件名为“op_summary_*.csv”格式。
该文件中的“OP Type”列即为NPU IP加速器支持的算子的OpType,从该列中找到有问题的算子即可。
如果用户正在使用精度比对工具进行算子精度分析:
参见《精度调试工具用户指南》手册获取精度比对结果文件result_*.csv。
根据该文件中的“NPUDump”列找到有问题的算子名,然后到对应dump数据文件中检索对应的OpType。
dump数据的第一段即为NPU IP加速器支持的算子的OpType,例如下图dump数据中标红部分的算子信息:
模型中存在不支持量化的层,量化模型失败¶
执行ATC模型转换命令时,通过--compression_optimize_conf参数配置模型量化(将模型中的权重由浮点数float32量化到低比特整数int8)相关的选项,结果报错提示如下:
ATC start working now, please wait for a moment.
[ERROR][ProcessScale][52] Not support scale greater than 1 / FLT_EPSILON.
[ERROR][WtsArqCalibrationCpuKernel][188] ArqQuantCPU scale is illegal.
[ERROR][ArqQuant][301] WtsArqCalibrationCpuKernel of format CO_CI_KH_KW failed.
[ERROR] AMCT(14815,atc.bin):2023-04-14-12:23:19[weight_algorithm.cpp:137]Default/network-DeepLabV3/resnet-Resnet/layer4-SequentialCell/0-Bottleneck/downsample-SequentialCell/0-Conv2d/Conv2D-op311 arq weight fake quant failed!
[ERROR] AMCT(14815,atc.bin):2023-04-14-12:23:19[weight_calibration_pass.cpp:90]Fail to execute WeightFakeQuant without trans!
[ERROR] AMCT(14815,atc.bin):2023-04-14-12:23:19[weight_calibration_pass.cpp:185]layer Default/network-DeepLabV3/resnet-Resnet/layer4-SequentialCell/0-Bottleneck/downsample-SequentialCell/0-Conv2d/Conv2D-op311 run WeightFakeQuantArq failed
[ERROR] AMCT(14815,atc.bin):2023-04-14-12:23:19[graph_optimizer.cpp:43]pass run failed
[ERROR] AMCT(14815,atc.bin):2023-04-14-12:23:19[quantize_api.cpp:227]Do GenerateCalibrationGraph optimizer pass failed.
[ERROR] AMCT(14815,atc.bin):2023-04-14-12:23:19[quantize_api.cpp:363]Generate calibration Graph failed.
[ERROR] AMCT(14815,atc.bin):2023-04-14-12:23:22[inner_graph_calibration.cpp:78]Failed to execute InnerQuantizeGraph failed.
通过报错提示layer xxxxxx run WeightFakeQuantArq failed可知,当前模型中有权重相关的层不支持量化,需要跳过这些不支持量化的层。
跳过不支持量化的层,配置方法如下:
增加配置,跳过不支持量化的层。
新增一个配置文件,文件名后缀为.cfg,例如_simple_config.cfg_,文件内容如下,加粗部分为报错提示中不支持量化的层:
skip_layers:"Default/network-DeepLabV3/resnet-Resnet/layer4-SequentialCell/0-Bottleneck/downsample-SequentialCell/0-Conv2d/Conv2D-op311"同时,在--compression_optimize_conf参数指定的量化配置文件中,增加config_file参数:
calibration: { input_data_dir: xxxxxx config_file: simple_config.cfg input_shape: xxxxxx infer_soc: xxxxxx }
重新执行模型转换。
重新执行推理。
如果跳过不支持量化的层影响模型推理的结果数据,则需要用户自行调整模型,再重新量化模型。
量化模型时模型输入大小过大,AI Core执行任务失败,量化模型失败¶
模型转换命令示例如下,模型输入大小与input_shape参数指定的shape有关:
atc --model=xxxxxx.pb --framework=3 --output=xxxxxx --soc_version=xxxxxx --input_shape="input:64,224,224,3" --input_format=NHWC --compression_optimize_conf=config/quant.cfg
模型转换时,报错示例如下:
[ERROR] AMCT(757013,atc.bin):2023-03-14-14:15:54[model_process.cpp:299]execute model failed, modelId is 1, errorCode is 507011
[ERROR] AMCT(757013,atc.bin):2023-03-14-14:15:54[sample_process.cpp:320]execute inference failed
[ERROR] AMCT(757013,atc.bin):2023-03-14-14:15:55[sample_process.cpp:275]ACL model infer failed.
[ERROR] AMCT(757013,atc.bin):2023-03-14-14:15:55[quantize_api.cpp:242]sample process failed
[ERROR] AMCT(757013,atc.bin):2023-03-14-14:15:55[quantize_api.cpp:378]Do Calibration failed.
[ERROR] AMCT(757013,atc.bin):2023-03-14-14:15:56[inner_graph_calibration.cpp:77]Failed to execute InnerQuantizeGraph failed.
ATC run failed, Please check the detail log, Try 'atc --help' for more information
EZ9999: Inner Error!
EZ9999 Aicore kernel execute failed, device_id=0, stream_id=11, report_stream_id=2, task_id=209, flip_num=0, fault kernel_name=17786444594805609729-1_0_1_vgg_16/conv1/conv1_2/Conv2D_histo, program id=206, hash=1846532111878224358.[FUNC:GetError][FILE:stream.cc][LINE:1131]
TraceBack (most recent call last):
Model synchronize execute failed, model_id=1![FUNC:GetStreamToSyncExecute][FILE:model.cc][LINE:630]
rtModelExecute execute failed, reason=[the model stream execute failed][FUNC:FuncErrorReason][FILE:error_message_manage.cc][LINE:49]
[Exec][Model]Execute model failed, ge result[507011], modelId[1][FUNC:ReportCallError][FILE:log_inner.cpp][LINE:161]
[Exec][Model]modelId[1] execute failed, result[507011][FUNC:ReportInnerError][FILE:log_inner.cpp][LINE:145]
An unknown error occurred. Please check the log.
AI Core执行任务失败,猜测可能是因为input_shape参数处的Batch size值过大,导致AI Core上的算子执行失败。
可将input_shape参数处的Batch size值调小,例如:--input_shape="input:8,224,224,3",调整参数值之后,再重新转换模型。
量化模型时校准集数据大小与模型输入大小不匹配,量化模型失败¶
执行ATC模型转换命令时,通过--compression_optimize_conf参数配置模型量化(将模型中的权重由浮点数float32量化到低比特整数int8)相关的选项,结果报错提示如下:
[ERROR] AMCT(21177,atc.bin):2023-04-14-14:43:17[utils_acl.cpp:133]input image size[1579014] is not equal to model input size[3158028]
[ERROR] AMCT(21177,atc.bin):2023-04-14-14:43:17[sample_process.cpp:234]memcpy device buffer failed
[ERROR] AMCT(21177,atc.bin):2023-04-14-14:43:17[sample_process.cpp:298]execute PreProcess failed
[ERROR] AMCT(21177,atc.bin):2023-04-14-14:43:17[sample_process.cpp:275]ACL model infer failed.
[ERROR] AMCT(21177,atc.bin):2023-04-14-14:43:17[quantize_api.cpp:240]sample process failed
[ERROR] AMCT(21177,atc.bin):2023-04-14-14:43:17[quantize_api.cpp:376]Do Calibration failed.
[ERROR] AMCT(21177,atc.bin):2023-04-14-14:43:20[inner_graph_calibration.cpp:78]Failed to execute InnerQuantizeGraph failed.
...
ATC run failed, Please check the detail log, Try 'atc --help' for more information
通过报错提示**input image size[xxxxxx] is not equal to model input size[xxxxxx]**可知,量化模型时校准集数据大小与模型输入大小不匹配,不匹配可能是校准集数据的shape与模型输入shape不一致,也有可能是校准集数据的数据类型与模型输入数据类型不一致。
需要逐一排查校准集数据shape、数据类型与模型输入shape、数据类型是否一致。
量化时,模型输入shape通过量化配置文件中的input_shape参数配置,模型输入数据类型需由用户从获取模型的网站获取或通过第三方软件打开模型文件查看。
开启量化功能,模型转换时提示“build_main build graph[infer_graph_info] failed”¶
模型转换时,通过--compression_optimize_conf参数配置了量化功能,结果模型转换失败,提示信息如下:

该问题可能是原始模型编译失败。
可以尝试将量化功能关闭,重新进行模型转换,检查出错原因;待原始模型不开启量化功能模型转换成功后,再尝试启用量化功能。
算子库包版本问题导致加载单算子失败¶
加载单算子报错失败,日志显示如下类似信息:
E19999: Inner Error
E19999 The opp version of the model does not match the current opp run package, Model is [6.4.T11.0.B300], opp run package is [7.0.T3.0.B107], try to convert the om again!
动态Shape算子场景下,单算子模型数据加载环境中的算子库包安装版本(包名为CANN-opp-*-linux.*.run,命名中的*为版本号或架构类型)与om模型文件编译环境的算子库包安装版本不一致,导致加载算子时会报错。
动态Shape算子场景下,单算子模型数据加载环境中的算子库包安装版本需与om模型文件编译环境的算子库包安装版本保持一致,出现该报错后,需排查安装版本,选择更换算子加载环境的opp包版本或更换编译算子om文件环境的opp包版本,若选择更换后者,则需要重新转换模型。