
简介¶
相比于业界标杆算子,昇腾自研算子在NPU IP加速器上的运算结果可能存在差异:
模型转换:ATC工具转换模型时,会对模型进行算子消除、算子融合、算子拆分等优化,这些操作可能会造成自研算子运算结果与业界标杆算子运算结果存在差异。
模型兼容:ATC工具转换的离线模型,由于CANN软件版本迭代、模型版本迭代、模型优化、硬件升级或ATC转换前开启或关闭了算子融合功能,可能会造成升级或优化后的离线模型存在精度下降问题。
为了帮助开发人员快速解决算子精度问题,精度调试工具提供了自有实现算子的运算结果与业界标杆算子运算结果之间比对的功能。
有关ATC的详细介绍请参见《ATC离线模型编译工具用户指南》。
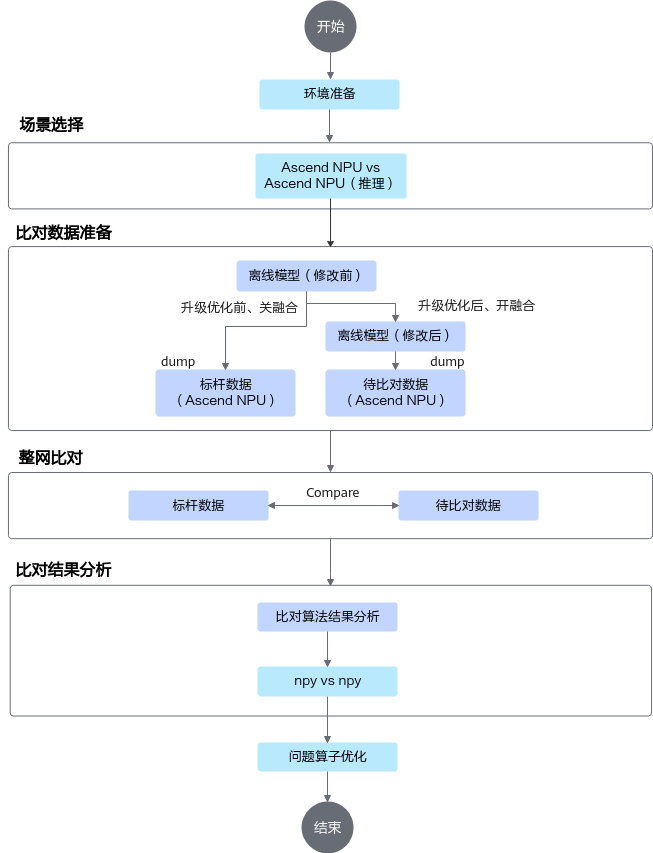
精度比对总体流程
精度比对总体流程如下:
使用前准备¶
使用前说明¶
总体说明
须知: 请在开发和调测场景下使用数据dump功能,生产上线后建议关掉数据dump开关,避免被攻击者利用,造成安全风险。
精度比对工具推荐环境配置:CPU 8核2.6GHz,内存16GB,低于该配置则工具执行迟缓。
本文中举例路径均需要确保运行用户具有读或读写权限。
建议使用普通用户,不建议使用高权限用户使用该工具,避免提权风险。
单算子网络不支持精度比对。
Python版本支持情况请参见《安装指南》。
精度比对支持的dump数据类型:
FLOAT
FLOAT16
DT_INT8
DT_UINT8
DT_INT16
DT_UINT16
DT_INT32
DT_INT64
DT_UINT32
DT_UINT64
DT_BOOL
DT_DOUBLE
DT_BFLOAT16
 说明:
若网络中存在DT_BFLOAT16数据类型,则需要使用pip3 install bfloat16ext安装依赖。
说明:
若网络中存在DT_BFLOAT16数据类型,则需要使用pip3 install bfloat16ext安装依赖。
环境准备¶
安装CANN软件后,使用CANN运行用户进行编译、运行时,需要以CANN运行用户登录环境,执行source ${INSTALL_DIR}/bin/setenv.bash命令设置环境变量。${INSTALL_DIR}请替换为CANN软件安装后文件存储路径。以root安装举例,安装后文件默认存储路径为:/usr/local/Ascend/latest。
GPU vs NPU(TensorFlow离线推理)-IPV350不支持¶
总体说明¶
TensorFlow场景仅支持非量化原始模型与非量化离线模型的精度比对。需准备输入数据如下表所示。
表 1 非量化原始模型 vs 非量化离线模型输入数据要求
文件 |
说明 |
获取方式 |
|---|---|---|
非量化原始模型的npy文件 |
标杆数据 |
准备TensorFlow模型npy数据文件 |
通过ATC转换离线模型文件生成的json文件 |
获取算子的映射关系 |
准备全网层信息文件 |
非量化离线模型在NPU IP加速器上运行生成的dump数据文件 |
待比对数据 |
离线推理场景各框架获取NPU环境的dump数据方法一致,请参考: 准备离线模型dump数据文件 |
准备TensorFlow模型npy数据文件¶
本版本不提供TensorFlow模型numpy(.npy)数据生成功能,请自行安装TensorFlow环境并提前准备numpy数据。本文仅提供生成numpy格式TensorFlow原始数据“*.npy“文件的样例参考。
在进行TensorFlow模型生成npy数据前,要求有一套完整的、可执行的、标准的TensorFlow模型应用工程。然后利用TensorFlow官方提供的debug工具tfdbg调试程序,从而生成npy文件。主要操作示例如下,请根据自己的应用工程适配操作。
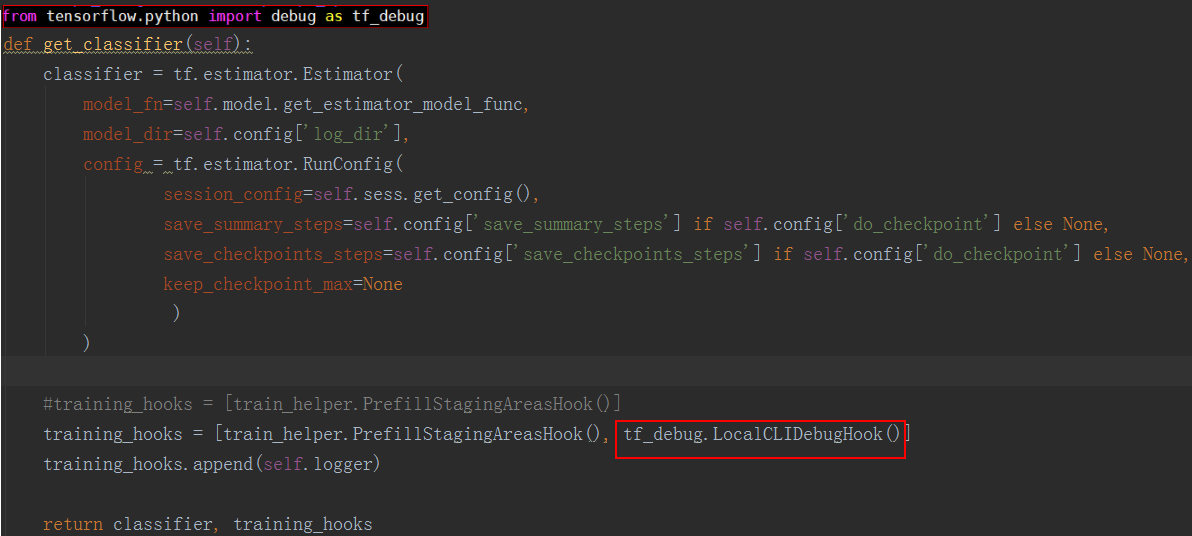
修改TensorFlow推理脚本,添加debug选项设置。代码中增加如下代码:
Estimator模式:
from tensorflow.python import debug as tf_debug training_hooks = [train_helper.PrefillStagingAreaHook(), tf_debug.LocalCLIDebugHook()]
如图1所示,添加tfdbg的hook。
图 1 Estimator模式
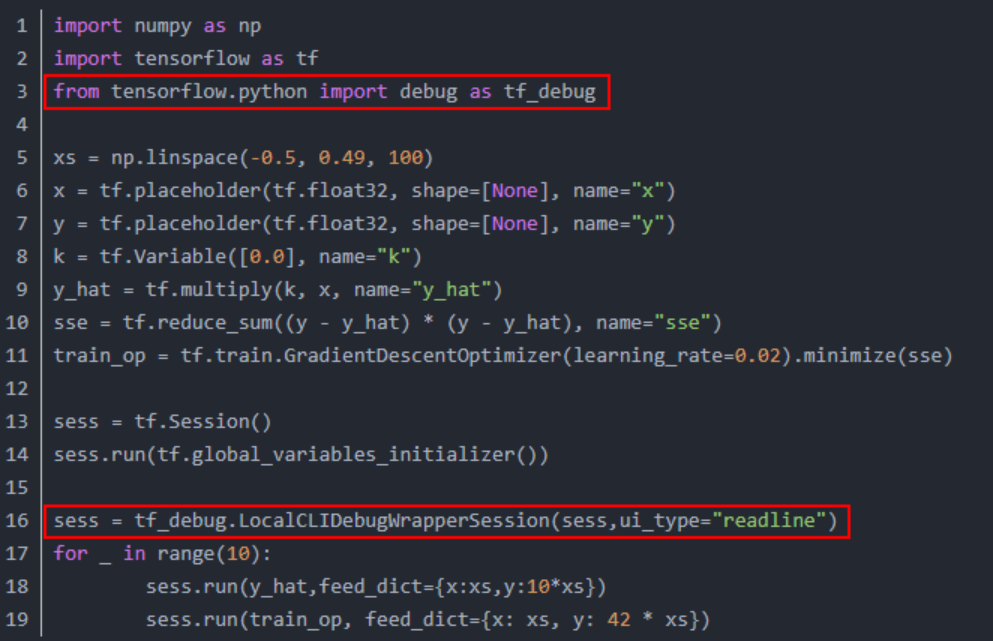
session.run模式:
from tensorflow.python import debug as tf_debug sess = tf_debug.LocalCLIDebugWrapperSession(sess, ui_type="readline")
如图2所示,在run之前设置tfdbg装饰器。
图 2 session.run模式
执行推理脚本。
推理完成后自动进入tfdbg调试命令行交互模式,执行run命令。
收集npy文件。
执行run命令完成后,可以在新的命令行窗口通过lt查询已存储的张量,通过pt可以查看已存储的张量内容,可以保存数据为numpy格式文件。
因为tfdbg一次命令只能dump一个tensor,为了自动生成收集所有数据,可以按以下几个步骤操作:
执行**lt > **_tensor_name_将所有tensor的名称暂存到文件里。
重新开启一个linux命令窗口,在新的窗口中执行下述命令,用以生成在tfdbg命令行执行的命令。
timestamp=$[$(date +%s%N)/1000] ; cat tensor_name | awk '{print "pt",$4,$4}' | awk '{gsub("/", "_", $3);gsub(":", ".", $3);print($1,$2,"-n 0 -w "$3".""'$timestamp'"".npy")}' > tensor_name_cmd.txt 说明:
该示例生成符合精度比对需要的npy文件名称格式,存储到tensor_name_cmd.txt文件。其中,tensor_name为自定义tensor列表对应的文件名,timestamp为16位的时间戳。回到tfdbg命令行窗口,输入run命令后,将上一步生成的所有tensor存储的命令粘贴执行,即可存储所有npy文件。
npy文件默认是以numpy.save()形式存储的,上述命令会将“/“用下划线_替换。
说明:
如果命令行界面无法粘贴文件内容,可以在tfdbg命令行中输入“mouse off“指令关闭鼠标模式后再进行粘贴。检查生成的npy文件命名是否符合_{op_name}.{output_index}.{timestamp}_.npy格式,如图3所示。
说明:如果因算子名较长,造成按命名规则生成的npy文件名超过255字符而产生文件名异常,这类算子不支持精度比对。
因tfdbg自身原因或运行环境原因,可能存在部分生成的npy文件名不符合精度比对要求,请按命名规则手工重命名。如果不符合要求的npy文件较多,请参见生成npy文件名异常情况批量处理重新生成npy文件。
图 3 查询.npy文件
准备全网层信息文件¶
以下介绍通过ATC模型转换工具获取离线模型的操作步骤,更多操作请参见《ATC离线模型编译工具用户指南》。
登录安装了Ascend-cann-toolkit开发套件包的昇腾AI环境。
获取原始模型文件并保存在任意目录下。
例如:$HOME/module/resnet50_tensorflow*.pb
执行ATC模型转换。
atc --model=$HOME/module/resnet50_tensorflow*.pb --framework=3 --output=$HOME/module/out/tf_resnet50 --soc_version=<soc_version>若提示如下信息,则说明模型转换成功。
ATC run success成功执行命令后,在--output参数指定的路径下可查看离线模型(如:tf_resnet50.om)。
生成json文件。
atc --mode=1 --om=$HOME/module/out/tf_resnet50.om --json=$HOME/module/out/tf_resnet50.json若提示如下信息,则说明转换json文件成功。
ATC run success成功执行命令后,在--json参数指定的路径下可查看转换后的json文件。
比对操作和分析¶
说明
本节涉及的.json文件、目录等名称均为举例,请根据实际环境替换。其中,-out指定的结果存放路径,需确保操作用户具有读写权限。
如果执行过程中报“MemoryError”,则表示数据量过大导致了内存溢出,请将NPU的dump数据文件拆分到多个目录后,再逐一进行比对。
当指定的比对数据文件大小超过1GB或.json文件大小超过100MB时,比对过程可能耗时较长,系统提示:'The size (%d) of %s more than the XX, it needs more time to run.'。
前提条件
请确保完成使用前准备。
根据总体说明中的场景准备比对文件。
操作步骤
登录CANN工具安装环境。
进入${INSTALL_DIR}/toolkit/tools/operator_cmp/compare,${INSTALL_DIR}请替换为CANN软件安装后文件存储路径。以root安装举例,安装后文件默认存储路径为:/usr/local/Ascend/latest。
执行比对命令。
说明:
由于dump和npy比对数据文件是由多个文件组成,故下文操作步骤中**-m和-g**参数须指定数据文件所在的父目录。如:_$HOME/MyApp/resnet50,_其中_resnet50_文件夹下直接保存比对数据文件。
目录结构示例如下:root@xxx:$HOME/MyApp/resnet50# tree . ├── BatchMatMul.bert_encoder_layer_0_attention_self_MatMul_1.24.1614717261785536 ├── BatchMatMul.bert_encoder_layer_0_attention_self_MatMul.21.1614717261768864 ├── BatchMatMul.bert_encoder_layer_10_attention_self_MatMul_1.235.1614717263664916 # 仅为示例,此处省略剩余文件名。
python3 msaccucmp.py compare -m $HOME/MyApp/tf_resnet50/20230815201822/0/resnet50_tensorflow_1_7/1/0/ -g $HOME/MyApp/resnet50_tensorflow_1_dump/ -f $HOME/module/out/tf_resnet50/tf_resnet50.json -out $HOME/result -advisor 说明:上述命令仅展示当前场景所需参数的示例,若需要配置更多参数,比如已知可能出现精度问题的范围或因大型网络模型输出结果文件数据量过大,通过配置参数来减少输出结果的数据量,请参见命令格式说明获取更多参数详细介绍。
需要安装pandas 1.3或更高版本依赖,否则无法执行-advisor参数输出专家建议。
表 1 整网比对命令行参数说明
参数名
参数说明
是否必选
-m
--my_dump_path
基于NPU IP加速器运行生成的数据文件所在目录。
是
-g
--golden_dump_path
基于GPU/CPU运行生成的原始网络数据文件所在目录。
是
-f
--fusion_rule_file
全网层信息文件。
通过ATC转换.om模型文件生成的.json文件,文件包含整网算子的映射关系,用于精度比对时算子匹配。
否
-out
--output
比对数据结果存放路径,默认为当前路径。
不建议配置与当前用户不一致的其它用户目录,避免提权风险。
否
-advisor
在Tensor比对结束后,针对比对结果进行数据分析,给出专家建议。详情请参见比对结果专家建议
否
比对结果如图1所示。
图 1 比对结果示例

以上比对结果字段解释请参见完整比对结果参数说明。
比对结果分析。
请参见比对结果分析。对于比对结果中可能存在部分无法比对或异常情况(比如结果中的NaN),请参见比对结果说明。
GPU vs NPU(ONNX离线推理)-IPV350不支持¶
总体说明¶
ONNX场景仅支持非量化的精度比对。需准备输入数据如下表所示。
表 1 非量化原始模型 vs 非量化离线模型输入数据要求
文件 |
说明 |
获取方式 |
|---|---|---|
非量化原始模型的npy文件 |
标杆数据 |
准备ONNX模型npy数据文件 |
通过ATC转换离线模型文件生成的json文件 |
获取算子的映射关系 |
准备全网层信息文件 |
非量化离线模型在NPU IP加速器上运行生成的dump数据文件 |
待比对数据 |
离线推理场景各框架获取NPU环境的dump数据方法一致,请参考: 准备离线模型dump数据文件 |
准备ONNX模型npy数据文件¶
前提条件
需要确保每个算子节点有名称,否则无法生成正确的文件名。没有名称的算子节点需要先生成名称。
本参考示例以每个节点只有一个输出为例,多个输出的需要在文件名生成处适配output_index的获取。
代码参考示例
本版本不提供ONNX模型npy数据生成功能,请自行安装ONNX环境并提前准备ONNX原始数据.npy文件。本文提供的样例代码仅作参考。
为输出符合精度比对要求的.npy数据文件,需在推理结束后的代码中增加dump操作,示例代码如下:
import os
import onnx
import onnxruntime
import numpy as np
import time
from skl2onnx.helpers.onnx_helper import enumerate_model_node_outputs
from skl2onnx.helpers.onnx_helper import select_model_inputs_outputs
from skl2onnx.helpers.onnx_helper import save_onnx_model
# 修改模型,增加输出节点
model_onnx = onnx.load("./resnet50.onnx")
output = []
for out in enumerate_model_node_outputs(model_onnx):
output.append(out)
num_onnx = select_model_inputs_outputs(model_onnx,outputs=output)
save_onnx_model(num_onnx, "resnet50_dump.onnx")
# 推理得到输出,本示例中采用随机数作为输入
input_data = np.random.random((1,3,224,224)).astype(np.float32)
input_data.tofile("test_data.bin")
sess = onnxruntime.InferenceSession("resnet50_dump.onnx")
input_name = sess.get_inputs()[0].name
output_name = [node.name for node in sess.get_outputs()]
res = sess.run(output_name, {input_name: input_data})
# 获得输出名称,确保每个算子节点有对应名称
node_name = [node.name for node in model_onnx.graph.node]
# 保存数据
node_output_num = [len(node.output) for node in model_onnx.graph.node]
idx = 0
for num, name in zip(node_output_num, node_name):
for i in range(num):
data = res[idx]
file_name = name + "." + str(i) + "." + str(round(time.time() * 1000000)) + ".npy"
output_dump_path = os.path.join("./onnx_dump/", file_name)
np.save(output_dump_path, data.astype(np.float16))
idx += 1
需要根据代码中的output_dump_path参数在当前目录新建对应“onnx_dump”目录或自定义目录。
.npy数据文件命名格式为_{op_name}.{output_index}.{timestamp}.npy,其中需要确保文件名中的{output_index}_字段存在值为0,否则无比对结果,原因是精度比对时默认从第一个output_index为0的数据开始。
准备全网层信息文件¶
以下介绍通过ATC模型转换工具获取离线模型的操作步骤,更多操作请参见《ATC离线模型编译工具用户指南》。
登录安装了Ascend-cann-toolkit开发套件包的昇腾AI环境。
获取原始模型文件并保存在任意目录下。
例如:resnet50*.onnx
执行ATC模型转换。
atc --model=$HOME/module/resnet50*.onnx --framework=5 --output=$HOME/module/out/onnx_resnet50 --soc_version=<soc_version>若提示如下信息,则说明模型转换成功。
ATC run success成功执行命令后,在--output参数指定的路径下,可查看离线模型(如:onnx_resnet50.om)。
生成json文件。
atc --mode=1 --om=$HOME/module/out/onnx_resnet50.om --json=$HOME/module/out/onnx_resnet50.json若提示如下信息,则说明转换json文件成功。
ATC run success成功执行命令后,在--json参数指定的路径下可查看转换后的json文件。
比对操作和分析¶
说明
本节涉及的.json文件、目录等名称均为举例,请根据实际环境替换。其中,-out指定的结果存放路径,需确保操作用户具有读写权限。
如果执行过程中报“MemoryError”,则表示数据量过大导致了内存溢出,请将NPU的dump数据文件拆分到多个目录后,再逐一进行比对。
当指定的比对数据文件大小超过1GB或.json文件大小超过100MB时,比对过程可能耗时较长,系统提示:'The size (%d) of %s more than the XX, it needs more time to run.'。
前提条件
请确保完成使用前准备。
根据总体说明中的场景准备比对文件。
操作步骤
本节以非量化NPU IP加速器运行生成的dump数据与非量化ONNX模型npy数据比对为例进行介绍,下文中参数说明均以该示例介绍,请根据您的实际情况进行替换。
登录CANN工具安装环境。
进入${INSTALL_DIR}/toolkit/tools/operator_cmp/compare,${INSTALL_DIR}请替换为CANN软件安装后文件存储路径。以root安装举例,安装后文件默认存储路径为:/usr/local/Ascend/latest。
执行比对命令。
说明:
由于dump和npy比对数据文件是由多个文件组成,故下文操作步骤中**-m和-g**参数须指定数据文件所在的父目录。如:_$HOME/MyApp/resnet50,_其中_resnet50_文件夹下直接保存比对数据文件。
目录结构示例如下:root@xxx:$HOME/MyApp/resnet50# tree . ├── BatchMatMul.bert_encoder_layer_0_attention_self_MatMul_1.24.1614717261785536 ├── BatchMatMul.bert_encoder_layer_0_attention_self_MatMul.21.1614717261768864 ├── BatchMatMul.bert_encoder_layer_10_attention_self_MatMul_1.235.1614717263664916 # 仅为示例,此处省略剩余文件名。
python3 msaccucmp.py compare -m $HOME/MyApp/npu_dump/20230216155330/0/resnet50/1/0/ -g $HOME/MyApp/onnx_dump/ -f $HOME/module/out/onnx_resnet50.json -out $HOME/result -advisor 说明:上述命令仅展示当前场景所需参数的示例,若需要配置更多参数,比如已知可能出现精度问题的范围或因大型网络模型输出结果文件数据量过大,通过配置参数来减少输出结果的数据量,请参见命令格式说明获取更多参数详细介绍。
需要安装pandas 1.3或更高版本依赖,否则无法执行-advisor参数输出专家建议。
表 1 整网比对命令行参数说明
参数名
参数说明
是否必选
-m
--my_dump_path
基于NPU IP加速器运行生成的数据文件所在目录。
是
-g
--golden_dump_path
基于GPU/CPU运行生成的原始网络数据文件所在目录。
是
-f
--fusion_rule_file
全网层信息文件。
通过ATC转换.om模型文件生成的.json文件,文件包含整网算子的映射关系,用于精度比对时算子匹配。
否
-out
--output
比对数据结果存放路径,默认为当前路径。
不建议配置与当前用户不一致的其它用户目录,避免提权风险。
否
-advisor
在Tensor比对结束后,针对比对结果进行数据分析,给出专家建议。详情请参见比对结果专家建议
否
比对结果如图1所示。
图 1 比对结果示例

以上比对结果字段解释请参见完整比对结果参数说明。
比对结果分析。
请参见比对结果分析。对于比对结果中可能存在部分无法比对或异常情况(比如结果中的NaN),请参见比对结果说明。
NPU vs NPU(离线推理)¶
总体说明¶
对于该场景需要排查比对结果说明。
本场景仅针对相同芯片之间的比对。
NPU vs NPU场景仅支持非量化离线模型 vs 非量化离线模型和量化离线模型 vs 量化离线模型场景的精度比对。
本场景主要包括以下子场景:
版本迭代前后精度比对:用于判断CANN软件版本迭代、模型版本迭代或模型优化前后,模型是否存在精度问题,进行前后两份精度数据的比对。
开启和关闭算子融合功能模型转换的精度比对:一般情况下,通过ATC工具转换离线模型时,会默认开启算子融合功能。为了判断融合前后的算子精度差异,进行融合前后两份精度数据的比对。
版本迭代前后精度比对
对于进行ATC转换后的离线模型,由于CANN软件版本迭代、模型版本迭代或模型进行优化,需要判断迭代、优化后的模型在NPU IP加速器上运行是否存在精度下降问题。分为非量化 vs 非量化和量化 vs 量化,输入数据准备如下。
表 1 非量化 vs 非量化输入数据要求
文件 |
说明 |
获取方式 |
|---|---|---|
非量化离线模型在NPU IP加速器上运行生成的dump数据文件(版本迭代前) |
标杆数据 |
离线推理场景各框架获取NPU环境的dump数据方法一致,请参考: |
非量化离线模型在NPU IP加速器上运行生成的dump数据文件(版本迭代后) |
待比对数据 |
表 2 量化 vs 量化输入数据要求
文件 |
说明 |
获取方式 |
|---|---|---|
量化离线模型在NPU IP加速器上运行生成的dump数据文件(版本迭代前) |
标杆数据 |
离线推理场景各框架获取NPU环境的dump数据方法一致,请参考: |
量化离线模型在NPU IP加速器上运行生成的dump数据文件(版本迭代后) |
待比对数据 |
开启和关闭算子融合功能模型转换的精度比对
一般情况下,通过ATC工具转换离线模型时,会默认开启算子融合功能。那么需要判断融合前后的算子精度差异,就需要获取:
开启算子融合功能进行ATC转换离线模型,并以转换后的离线模型进行精度数据dump。
关闭算子融合功能进行ATC转换离线模型,并以转换后的离线模型进行精度数据dump。
最后将以上两份数据进行精度比对。
该场景分为非量化开融合 vs 非量化关融合和量化开融合 vs 量化关融合,输入数据准备如下。
表 3 非量化开融合 vs 非量化关融合输入数据要求
文件 |
说明 |
获取方式 |
|---|---|---|
非量化离线模型文件(*.exeom)(关闭算子融合) 非量化离线模型文件(*.exeom)(开启算子融合) |
模型文件 |
准备离线模型文件 |
非量化离线模型在NPU IP加速器上运行生成的dump数据文件(关闭算子融合) |
标杆数据 |
离线推理场景各框架获取NPU环境的dump数据方法一致,请参考: 准备离线模型dump数据文件 |
非量化离线模型在NPU IP加速器上运行生成的dump数据文件(开启算子融合) |
待比对数据 |
表 4 量化开融合 vs 量化关融合输入数据要求
文件 |
说明 |
获取方式 |
|---|---|---|
量化离线模型文件(*.exeom)(关闭算子融合) 量化离线模型文件(*.exeom)(开启算子融合) |
模型文件 |
准备离线模型文件 |
量化离线模型(关闭算子融合)在NPU IP加速器上运行生成的dump数据文件 |
标杆数据 |
离线推理场景各框架获取NPU环境的dump数据方法一致,请参考: 准备离线模型dump数据文件 |
量化离线模型(开启算子融合)在NPU IP加速器上运行生成的dump数据文件 |
待比对数据 |
准备离线模型文件¶
非量化离线模型文件
以下介绍通过ATC模型转换工具获取离线模型的操作步骤,更多操作请参见《ATC离线模型编译工具用户指南》。
登录安装了Ascend-cann-toolkit开发套件包的昇腾AI环境。
获取原始模型文件并保存在任意目录下。
例如:resnet50.prototxt和resnet50.caffemodel
开启算子融合执行ATC模型转换。
atc --model=$HOME/module/resnet50.prototxt --weight=$HOME/module/resnet50.caffemodel --framework=0 --output=$HOME/module/out/caffe_resnet50_on --soc_version=<soc_version> 说明:
模型转换时,算子融合功能默认开启,无需配置。若提示如下信息,则说明模型转换成功。
ATC run success成功执行命令后,在$HOME/module/out/目录下生成离线模型(如:caffe_resnet50_on.om,IPV350为.exeom格式)。
关闭算子融合执行ATC模型转换。
atc --model=$HOME/module/resnet50.prototxt --weight=$HOME/module/resnet50.caffemodel --framework=0 --output=$HOME/module/out/caffe_resnet50_off --soc_version=<soc_version> --fusion_switch_file=$HOME/module/fusion_switch.cfg 说明:
关闭算子融合功能需要通过--fusion_switch_file参数指定算子融合规则配置文件(如fusion_switch.cfg),并在配置文件中关闭算子融合。融合规则配置文件关闭配置如下:{ "Switch":{ "GraphFusion":{ "ALL":"off" }, "UBFusion":{ "ALL":"off" } } }
若提示如下信息,则说明模型转换成功。
ATC run success成功执行命令后,在$HOME/module/out/目录下生成离线模型(如:caffe_resnet50_off.om,IPV350为.exeom格式)。
量化离线模型文件
以下仅以Caffe模型为例介绍通过AMCT工具获取量化信息文件的操作步骤,更多操作请参见《AMCT模型压缩工具用户指南》。
参见《AMCT模型压缩工具用户指南》的“工具安装”章节完成工具安装。
获取原始模型文件并保存在任意目录下。
例如:resnet50.prototxt和resnet50.caffemodel
准备模型相匹配的二进制数据集。
切换到amct_caffe/cmd目录,执行如下命令,用于下载校准数据集。
cd data mkdir image && cd image wget https://obs-9be7.obs.cn-east-2.myhuaweicloud.com/models/amct_acl/classification/calibration.rar unrar e calibration.rar
在amct_caffe/cmd目录,执行如下命令将calibration目录下*.jpg格式数据集转换为bin格式数据集。
python3 ./src/process_data.py执行完成后,在data目录会生成新的calibration目录,并在该目录生成calibration.bin格式数据集。
执行如下命令进行网络模型的量化操作。
amct_caffe calibration --model=./model/resnet50.prototxt --weights=./model/resnet50.caffemodel --save_path=./results --input_shape="data:1,3,224,224" --data_dir="./data/calibration" --data_types="float32"若提示如下信息且无Error日志信息,则说明模型量化成功。
INFO - [AMCT]:[Utils]: The weights_file is saved in $HOME/xxx/results/resnet50_fake_quant_weights.caffemodel INFO - [AMCT]:[Utils]: The model_file is saved in $HOME/xxx/results/resnet50_fake_quant_model.prototxt
量化后生成文件说明如下:
resnet50_quant.json:量化信息文件,记录了量化模型同原始模型节点的映射关系,用于量化后模型同原始模型精度比对使用。
resnet50_deploy_model.prototxt:量化后的可在NPU IP加速器部署的模型文件。
resnet50_deploy_weights.caffemodel:量化后的可在NPU IP加速器部署的权重文件。
resnet50_fake_quant_model.prototxt:量化后的可在Caffe环境进行精度仿真模型文件。
resnet50_fake_quant_weights.caffemodel:量化后的可在Caffe环境进行精度仿真权重文件。
按照非量化离线模型文件中的ATC操作将量化原始模型文件resnet50_deploy_model.prototxt和resnet50_deploy_weights.caffemodel进行模型转换,即可获取到开启和关闭算子融合的量化离线模型文件。
准备离线模型dump数据文件¶
使用前须知
请在dump数据前,完成模型对应的应用工程的编译、运行,确保工程正常。
每次推理都会产生dump数据,在循环次数较多的情况下,每次推理的dump数据量随之增大,建议dump数据时仅执行一次推理。同时对于大模型场景,通常dump数据量太大并且耗时长,可以通过dump_data开启算子统计功能,根据统计数据识别可能异常的算子后,再dump可能异常的算子。
提供**aclInit()接口和aclmdlSetDump()**接口两种接口方式dump数据。
**aclInit()**接口的详细使用方法请参见《AscendCL应用开发指南 (C&C++)》中的“acl API参考 > 系统配置 > aclInit”。
**aclmdlSetDump()**接口的详细使用方法请参见《AscendCL应用开发指南 (C&C++)》中的“acl API参考 > 模型管理 > 模型执行 > aclmdlSetDump”。
dump数据
参考以下步骤进行离线模型dump操作:
打开**aclInit()函数所在的推理应用工程代码文件,查看调用的aclInit()或aclmdlSetDump()**函数,获取acl.json文件路径。
说明:
如果aclInit()或aclmdlSetDump()初始化为空,则需要修改该函数,补充步骤2创建的acl.json路径。这里的acl.json路径是相对工程编译生成的二进制文件的路径。在查到的目录下修改acl.json文件(如不存在,则需要新建,建议放在工程编译后的out目录下),添加dump配置,格式如下所示。
模型推理场景下,开启Dump数据采集:
{ "dump":{ "dump_list":[ { "model_name":"ResNet-101" }, { "model_name":"ResNet-50", "layer":[ "conv1conv1_relu", "res2a_branch2ares2a_branch2a_relu", "res2a_branch1", "pool1" ] } ], "dump_path":"/home/output", "dump_mode":"output", "dump_op_switch":"off", "dump_data":"tensor" } }
表 1 acl.json文件格式说明
配置项
参数说明
dump_list
(必选)待dump数据的整网模型列表。
创建模型dump配置信息,当存在多个模型需要dump时,需要每个模型之间用英文逗号隔开。
model_name
模型名称,各个模型的model_name值须唯一。
- 模型加载方式为文件加载时,填入模型文件的名称,不需要带后缀名;也可以配置为ATC模型文件转换后的json文件里的最外层"name"字段对应值。
- 模型加载方式为内存加载时,配置为ATC模型文件转换后的json文件里的最外层"name"字段对应值。IPV350不支持该方式。
layer
IO性能相对较差时,可能会出现由于数据量过大导致执行超时,所以不建议全量dump,请指定算子进行dump。通过该字段可以指定需要dump的算子名,支持指定为ATC模型转换后的算子名,也支持指定为转换前的原始算子名,配置时需注意:
- 需按格式配置,每行配置模型中的一个算子名,且每个算子之间用英文逗号隔开。
- 用户可以无需设置model_name,此时会默认dump所有model下的相应算子。如果配置了model_name,则dump对应model下的相应算子。
- 若指定的算子其输入涉及data算子,会同时将data算子信息dump出来;若需dump data算子,需要一并填写data节点算子的后继节点,才能dump出data节点算子数据。
- 当需要dump模型中所有算子时,不需要包含layer字段。
dump_path
(必选)dump数据文件存储到运行环境的目录,该目录需要提前创建且确保安装时配置的运行用户具有读写权限。IPV350需要提前将编译生成的dbg文件放在该目录。
支持配置绝对路径或相对路径:- 绝对路径配置以“/”开头,例如:/home/output。
- 相对路径配置直接以目录名开始,例如:output。
dump_mode
dump数据模式。
- input:dump算子的输入数据。
- output:dump算子的输出数据,默认取值output。
- all:dump算子的输入、输出数据。
注意,配置为all时,由于部分算子在执行过程中会修改输入数据,例如集合通信类算子HcomAllGather、HcomAllReduce等,因此系统在进行dump时,会在算子执行前dump算子输入,在算子执行后dump算子输出,这样,针对同一个算子,算子输入、输出的dump数据是分开落盘,会出现多个dump文件,在解析dump文件后,用户可通过文件内容判断是输入还是输出。
dump_level
dump数据级别,取值:
- op:按算子级别dump数据。
- kernel:按kernel级别dump数据。
- all:默认值,op和kernel级别的数据都dump。
默认配置下,dump数据文件会比较多,例如有一些aclnn开头的dump文件,若用户对dump性能有要求或内存资源有限时,则可以将该参数设置为op级别,以便提升dump性能、精简dump数据文件数量。
说明:算子是一个运算逻辑的表示(如加减乘除运算),kernel是运算逻辑真正进行计算处理的实现,需要分配具体的计算设备完成计算。
dump_step
指定采集哪些迭代的Dump数据。推理场景无需配置。
不配置该参数,默认所有迭代都会产生dump数据,数据量比较大,建议按需指定迭代。
多个迭代用“|”分割,例如:0|5|10;也可以用“-”指定迭代范围,例如:0|3-5|10。
配置示例:
{ "dump":{ "dump_list":[ ...... ], "dump_path":"/home/output", "dump_mode":"output", "dump_op_switch":"off", "dump_step": "0|3-5|10" } }dump_data
算子dump内容类型,取值:
- tensor: dump算子数据,默认为tensor。
- stats: dump算子统计数据,结果文件为csv格式,文件中包含算子名称、输入/输出的数据类型、最大值、最小值等。IPV350不支持该方式。
通常dump数据量太大并且耗时长,可以先dump算子统计数据,根据统计数据识别可能异常的算子,然后再dump算子数据。
运行应用程序,生成dump数据文件,生成的路径及格式说明如下。
dump数据文件路径为:{dump_path}/{time}/{device_id}/{model_name}/{model_id}/{data_index}/{dump文件}
单算子模型dump时为_{dump_path}/{time}/{device_id}/{dump文件}_
表 2 dump数据文件路径说明
路径key
说明
备注
dump_path
acl.json中配置的dump数据文件存储目录。
dump数据文件命名格式为:{op_type}.{op_name}.{task_id}.{stream_id}.{timestamp}
time
dump数据文件落盘的时间。
格式为:YYYYMMDDHHMMSS
device_id
设备ID。
-
model_name
模型名称。
如果model_name出现了“.”、“/”、“\”、空格时,转换为下划线表示。
model_id
模型ID号。
-
data_index
针对每个Task ID执行的次数维护一个序号,从0开始计数,该Task每dump一次数据,序号递增1。
-
说明:dump文件如果op_type、op_name出现了“.“、“/“、“\“、空格时,则会转换为下划线表示。
如果文件名称长度超过了OS文件名称长度限制(一般是255个字符),则会将该dump文件重命名为一串随机数字,映射关系可查看同目录下的mapping.csv。
图执行时,如下算子不会产生dump数据:
在图执行前,某些算子明确不会下发到Device侧执行,如条件类算子(if/while/for/case等)、数据类算子(Data/RefData/Const等)、数据流算子(StackPush/StackPop/Concat/Split等)。
在图优化过程中,GE会标识部分算子不下发到Device侧执行,这些算子的Dump图中attr的_no_task属性为true。
图中走不到最终执行分支的算子。
比对操作和分析¶
-IPV350不支持
说明
当指定的比对数据文件大小超过1GB或.json文件大小超过100MB时,比对过程可能耗时较长,系统提示:'The size (%d) of %s more than the XX, it needs more time to run.'。
前提条件
请确保完成使用前准备。
根据总体说明中的场景准备比对文件。
操作步骤
登录CANN工具安装环境。
生成json文件。
使用开启算子融合功能的离线模型生成resnet50_on.json文件。
atc --mode=1 --om=$HOME/module/out/caffe_resnet50_on.om --json=$HOME/module/out/caffe_resnet50/resnet50_on.json使用关闭算子融合功能的离线模型生成resnet50_off.json文件。
atc --mode=1 --om=$HOME/module/out/caffe_resnet50_off.om --json=$HOME/module/out/caffe_resnet50/resnet50_off.json
说明:
版本迭代前后精度比对场景跳过此步骤。进入${INSTALL_DIR}/toolkit/tools/operator_cmp/compare,${INSTALL_DIR}请替换为CANN软件安装后文件存储路径。以root安装举例,安装后文件默认存储路径为:/usr/local/Ascend/latest。
执行比对命令。
假设开启和关闭算子融合功能的离线模型在NPU IP加速器上运行生成dump数据。
数据分别保存在:
$HOME/MyApp_mind/resnet50_on
$HOME/MyApp_mind/resnet50_off
版本迭代前后精度比对场景同样是把两份比对数据保存在不同目录下。
说明:
由于dump和npy比对数据文件是由多个文件组成,故下文操作步骤中**-m和-g**参数须指定数据文件所在的父目录。如:_$HOME/MyApp/resnet50,_其中_resnet50_文件夹下直接保存比对数据文件。
目录结构示例如下:root@xxx:$HOME/MyApp/resnet50# tree . ├── BatchMatMul.bert_encoder_layer_0_attention_self_MatMul_1.24.1614717261785536 ├── BatchMatMul.bert_encoder_layer_0_attention_self_MatMul.21.1614717261768864 ├── BatchMatMul.bert_encoder_layer_10_attention_self_MatMul_1.235.1614717263664916 # 仅为示例,此处省略剩余文件名。
python3 msaccucmp.py compare -m $HOME/MyApp_mind/resnet50_on -g $HOME/MyApp_mind/resnet50_off -f $HOME/module/out/caffe_resnet50/resnet50_on.json -cf $HOME/module/out/caffe_resnet50/resnet50_off.json -out $HOME/MyApp_mind/out 说明:
上述命令仅展示当前场景所需参数的示例,若需要配置更多参数,比如已知可能出现精度问题的范围或因大型网络模型输出结果文件数据量过大,通过配置参数来减少输出结果的数据量,请参见命令格式说明获取更多参数详细介绍。表 1 整网比对命令行参数说明
参数名
参数说明
是否必选
-m
--my_dump_path
开启算子融合的离线模型基于NPU IP加速器运行生成的数据文件所在目录。
是
-g
--golden_dump_path
关闭算子融合的离线模型基于NPU IP加速器运行生成的数据文件所在目录。
是
-f
--fusion_rule_file
全网层信息文件。使用开启算子融合功能的离线模型通过ATC转换生成的.json文件。
版本迭代前后精度比对场景无需配置。
否
-cf
--close_fusion_rule_file
全网层信息文件。
使用关闭算子融合功能的离线模型通过ATC转换生成的.json文件。
版本迭代前后精度比对场景无需配置。
否
-out
--output
比对数据结果存放路径,默认为当前路径。
不建议配置与当前用户不一致的其它用户目录,避免提权风险。
否
比对结果如图1所示。
图 1 融合算子精度问题排查比对结果

以上比对结果字段解释请参见完整比对结果参数说明。
其中NPUDump表示开启算子融合功能的离线模型的算子名;GroundTruth表示关闭算子融合功能的离线模型的算子名。
比对结果分析。
请参见比对结果分析。对于比对结果中可能存在部分无法比对或异常情况(比如结果中的NaN),请参见比对结果说明。
比对结果说明¶
本节内容主要说明对于比对结果中可能存在部分无法比对或异常情况(比如结果中的NaN)。
对于TensorFlow模型,若不是相同模型的数据,但模型中有相同的算子名称,也可以进行比对,但结果数据只显示匹配到的相同算子的比对结果,该场景不进行分析。
如果在图编译过程中,原图的算子发生了融合,导致算子的output在编译后的模型中找不到对应的output时,该算子无法进行比对。
如果在图编译阶段对图做了结构性修改(如stride切分、L1 fusion、L2 fusion)的场景,会造成算子的input或output无法比对。
如果比对数据两边相同算子有dump数据,但算子的Shape不一致(离线模型算子Shape变小)或Format不支持转换,该算子无法进行比对。
量化模型里经过量化处理的算子无法比对,必须是反量化的输出才能比对。例如,量化模型里AscendQuant算子的output无法比对。
针对FastRCNN网络场景,ProposalD算子及之后的算子,算子精度不达标属于正常情况,最终结果以FSRDetectionOutput算子的比对结果精度为准。
当模型转换对输入数据做了额外的预处理,造成原始模型的输入与离线模型的data算子输入格式不同时(比如AIPP场景下data输入为YUV),data算子比对结果异常、不具备参考意义。
如果比对数据两边相同算子有多个input且input顺序不一致,会导致该算子的input的比对结果不可信。
如果没有关闭对应的融合规则,会使得量化算子与之前的算子进行融合,导致该算子的output的比对结果不可信。
比对结果分析¶
比对结果分析指导¶
显示“*“,表示在NPU侧新增独有的算子;无对应的标准算子,无法比对,显示为“NaN“。
余弦相似度和KL散度比对结果为NaN,其他算法有比对数据,则表明该算子的待比对或标杆数据为0;KL散度比对结果为Inf,则表明该算子的标杆数据中有一个为0。
针对常见精度问题,通过输出“Advisor”专家建议,快速定位问题算子。
针对专家建议无法覆盖的复杂场景,通过查看整网比对结果中不同的算法指标,根据计算精度评价指标,定位存在精度问题的算子。
在多次比对或存在模糊问题定界场景中,可以通过配置-r或-s参数,实现任意选定范围内的算子精度比对,尤其针对偏大型网络,可以实现快速定位精度问题,-r或-s参数详细介绍请参见命令格式说明。
针对存疑的比对结果可以先进行npy与npy文件之间的精度比对进行精度问题排查。
针对精度差异较大算子,可通过单算子比对功能进一步分析对应张量的详细精度差异。
针对问题算子,根据具体场景,通过算子本身的修改、算子替换、算子融合等方式进行详细优化。
比对结果专家建议¶
-IPV350不支持
概述¶
精度比对工具本身只提供自有实现算子在NPU IP加速器上的运算结果与业界标准算子的运算结果的差异比对功能,输出的比对结果需要用户自行分析并找出问题。对于用户来说,对结果的分析工作也是一大难点。本节提供专家系统工具为用户提供精度比对结果的分析功能,有效减少用户排查问题的时间。
当前支持的分析检测类型有:Float16溢出检测、输入不一致检测、整网一致性检测(整网一致性检测包括:问题节点检测、单点误差检测和一致性检测三个小点)。
使用前必读¶
环境准备
需要安装pandas 1.3或更高版本依赖。安装示例:pip3 install pandas==1.3.5。非root用户安装,需要在安装命令后加上**--user**,例如:pip3 install pandas==1.3.5 --user。
约束
本功能不支持以下场景:
单算子比对的结果文件分析。
指定了--select或--range参数生成的比对结果文件分析。
通过命令行方式分析比对结果¶
命令格式说明
通过命令行方式分析比对结果是基于Tensor比对的基础上执行-advisor参数功能,完成精度比对之后继续进行专家系统分析并输出结果。
命令行格式如下:
python3 msaccucmp.py compare -m my_dump_path -g golden_dump_path -advisor
表 1 整网比对命令行参数说明
参数名 |
参数说明 |
|---|---|
-advisor |
在Tensor比对结束后,针对比对结果进行数据分析,给出专家建议。 |
注:-overflow_detection参数为Float16溢出检测专家建议提供数据,配置-advisor参数后会自动打开该参数功能。 |
|
操作步骤
登录CANN工具安装环境。
生成json文件。
atc --mode=1 --om=$HOME/data/resnet50.om --json=$HOME/data/resnet50.json进入${INSTALL_DIR}/toolkit/tools/operator_cmp/compare,${INSTALL_DIR}请替换为CANN软件安装后文件存储路径。以root安装举例,安装后文件默认存储路径为:/usr/local/Ascend/latest。
执行比对命令。
python3 msaccucmp.py compare -m $HOME/MyApp_mind/resnet50 -g $HOME/Standard_caffe/resnet50 -f $HOME/data/resnet50.json -out $HOME/result -advisor执行命令后会进行精度比对,比对完成后将直接进行专家系统分析,并打印输出结果,结果文件命名为advisor_summary.txt,保存路径同样由-out参数确定。输出结果详细介绍请参见输出结果和优化建议。
通过脚本工具方式分析比对结果¶
脚本工具介绍
专家系统提供“mscmp_advisor.py“脚本工具。功能及安装路径如下:
表 1 脚本工具介绍
脚本名 |
功能 |
路径 |
|---|---|---|
“mscmp_advisor.py” |
对Tensor比对结果进行专家系统分析,并输出优化建议。 |
${INSTALL_DIR}/toolkit/tools/operator_cmp/compare,${INSTALL_DIR}请替换为CANN软件安装后文件存储路径。以root安装举例,安装后文件默认存储路径为:/usr/local/Ascend/latest。 |
命令格式说明
“mscmp_advisor.py“脚本是直接用比对结果.csv文件进行分析,所以在进行该操作前需要先完成精度比对获取.csv文件。
命令行格式如下:
python3 mscmp_advisor.py -i <input_file> [-input_nodes <node_name>] [-o <out_path>]
表 2 整网比对命令行参数说明
参数名 |
参数说明 |
是否必选 |
|---|---|---|
-i --input_file |
指定比对结果.csv文件。例如:$HOME/result/result_*.csv 本参数最大支持.csv文件的大小为100M。 |
是 |
-input_nodes |
指定网络模型的输入节点。多个节点用英文分号(;)隔开。例如:"node_name1;node_name2;node_name3" |
否 若不配置,则不进行输入检测。 |
-o --out_path |
分析结果输出路径。结果文件命名为advisor_summary.txt。 不建议配置与当前用户不一致的其它用户目录,避免提权风险。 |
否 若不配置,不落盘结果文件。 |
操作步骤
登录CANN工具安装环境。
生成json文件。
atc --mode=1 --om=$HOME/data/resnet50.om --json=$HOME/data/resnet50.json配置环境变量。
export PYTHONPATH=${INSTALL_DIR}/toolkit/tools/operator_cmp/compare:$PYTHONPATH执行精度比对命令。
python3 msaccucmp.py compare -m $HOME/MyApp_mind/resnet50 -g $HOME/Standard_caffe/resnet50 -f $HOME/data/resnet50.json -out $HOME/result -overflow_detection此处需要配置**-overflow_detection**参数识别溢出算子。执行比对后输出比对结果文件result_*.csv_。_
执行专家系统分析。
python3 mscmp_advisor.py -i $HOME/result/result_*.csv -input_nodes "node_name1;node_name2;node_name3" -o $HOME/result执行命令后进行专家系统分析并直接打印输出结果。输出结果详细介绍请参见输出结果和优化建议。
输出结果和优化建议¶
Float16溢出检测
针对比对数据中数据类型为Float16的数据,进行溢出检测。如果存在溢出数据,输出专家建议。
场景限制:量化原始模型的npy文件(Caffe)与非量化原始模型的npy文件(Caffe)的比对场景不支持溢出检测分析。
比对结果:
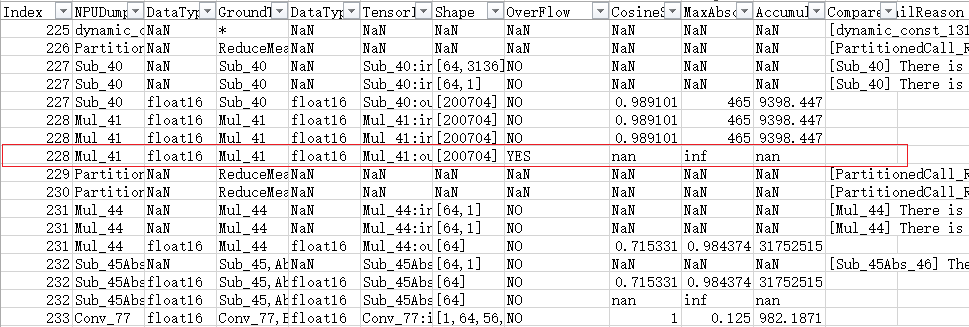
算子ID为228的数据,存在Float16数据溢出。
专家系统分析结果:
Detection Type: FP16 overflow
Operator Index: 228
Expert Advice: Float16 data overflow occurs. Rectify the fault and perform comparison again.
检测类型:Float16溢出检测
Operator Index:228
专家建议:存在Float16数据溢出,请修正溢出问题,再进行比对。
输入不一致检测
针对整网的输入数据进行检测,主要判断整网两批待比对数据的输入data是否一致。如果存在不一致问题(余弦相似度<0.99),输出专家建议。
比对结果:

算子ID为0的数据,输入数据为Input_1,其余弦相似度小于0.99,因此认为此次比对,输入或数据预处理存在问题。
专家系统分析结果:
Detection Type: Input inconsistent
Operator Index: 0
Expert Advice: The input data of NPUDump is inconsistent with that of GroundTruth. Use the same data or check the data preprocessing process.
检测类型:输入不一致检测
Operator Index:0
专家建议:NPUDump和GroundTruth的输入数据不一致,请使用相同数据或者检查数据预处理流程。
整网一致性检测(问题节点检测)
判断整网比对结果中,是否某层小于阈值,该层后续数据均小于阈值或最后一层小于阈值(余弦相似度<0.99),输出量化误差修正建议。
比对结果:
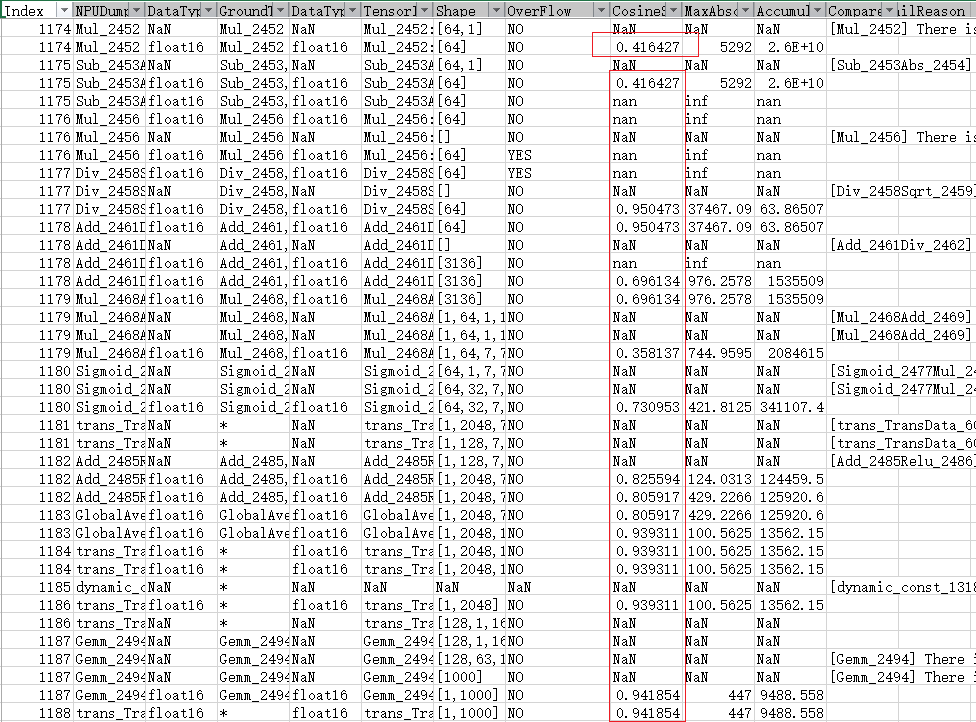
算子ID为1174的数据,余弦相似度小于0.99,且后续余弦相似度均小于0.99,判断问题节点存在精度问题。
专家系统分析结果:
检测类型:整网一致性检测
Operator Index:1174
专家建议:部分张量精度较低,且导致最终结果精度不达标;很可能由量化造成,请进行数据校准或者您可以获取日志后单击Link联系技术支持。
整网一致性检测(单点误差检测)
判断整网比对结果中,是否某层小于阈值(余弦相似度<0.99),但最终结果符合精度要求,输出专家建议。
比对结果:

算子ID为195的数据,余弦相似度小于0.99,但最后一层数据符合精度要求,判断为单点误差。
专家系统分析结果:
检测类型:整网一致性检测
Operator Index:195
专家建议:部分张量精度较低,但最终结果精度达标,可能由内部优化导致,请忽略或您可以获取日志后单击Link联系技术支持。
整网一致性检测(一致性检测)
比对结果中的所有数据均符合精度要求,输出专家建议。
比对结果:

所有数据均符合精度要求,判断模型符合精度要求。
专家系统分析结果:
Detection Type: global consistency
Operator Index: NA
Expert Advice: All data in the comparison result meets the accuracy requirements.
If data accuracy of the model is still not up to standard in practical application, please check the post-processing process of model outputs.
检测类型:整网一致性检测
Operator Index:NA
专家建议:比对结果中的所有数据均符合精度要求。
如果模型实际应用中,精度依旧不达标,请排查输出数据的后处理流程。
计算精度评价指标¶
精度比对是以GPU的计算结果为标杆,以不同算法维度,比对算子精度差异,根据每个算法维度的结果判断算子在运行时是否存在精度问题。
计算精度评价指标:
CosineSimilarity:通过计算两个向量的余弦值来判断其相似度,数值越接近于1,说明计算出的两个张量越相似,实际可接受阈值为大于0.99。在计算中可能会存在nan,主要由于可能会出现其中一个向量为0。
RelativeEuclideanDistance:欧氏相对距离越接近于0,表明越相近,实际可接受阈值为小于0.05。
KullbackLeiblerDivergence:KL散度越小,真实分布与近似分布之间的匹配越好,实际可接受阈值为小于0.005。
MeanAbsoluteError和RootMeanSquareError:平均绝对误差和均方根误差相关联,MeanAbsoluteError越大,RootMeanSquareError等于或近似MeanAbsoluteError,说明整体偏差越集中,实际可接受阈值为等于1。
npy与npy文件之间的精度比对¶
概述
精度比对工具支持单个npy与npy文件之间的精度比对。基本要求如下:
对于dump数据文件需要先完成执行dump数据文件Format转换。
需要确保两个比对文件内的Shape一致。
仅支持CosineSimilarity(余弦相似度)、MaxAbsoluteError(最大绝对误差)、AccumulatedRelativeError(累积相对误差)、RelativeEuclideanDistance(欧氏相对距离)、MeanAbsoluteError(平均绝对误差)、RootMeanSquareError(均方根误差)、MaxRelativeError(最大相对误差)、MeanRelativeError(平均相对误差)比对算法。
命令格式说明
python3 msaccucmp.py file_compare -m my_dump_path -g golden_dump_path -out output
命令行参数说明如表1所示。
该功能通过msaccucmp.py脚本实现,脚本存放在${INSTALL_DIR}/toolkit/tools/operator_cmp/compare,${INSTALL_DIR}请替换为CANN软件安装后文件存储路径。以root安装举例,安装后文件默认存储路径为:/usr/local/Ascend/latest。
表 1 命令行参数说明
参数名 |
参数说明 |
是否必选 |
|---|---|---|
-m --my_dump_path |
待比对的npy文件。 |
是 |
-g --golden_dump_path |
待比对的npy标杆数据文件。 |
是 |
-out --output |
比对数据结果存放目录。 结果文件名格式为:file_result_{timestamp}.txt 不建议配置与当前用户不一致的其它用户目录,避免提权风险。 |
是 |
操作步骤
登录CANN工具安装环境。
进入${INSTALL_DIR}/toolkit/tools/operator_cmp/compare,${INSTALL_DIR}请替换为CANN软件安装后文件存储路径。以root安装举例,安装后文件默认存储路径为:/usr/local/Ascend/latest。
执行file_compare比对命令。
python3 msaccucmp.py file_compare -m my_dump_path/a.npy -g golden_dump_path/b.npy -out output命令执行完成后输出比对结果。如图1所示。
图 1 比对结果

比对结果可根据计算精度评价指标判断是否符合精度要求。
单算子比对¶
-IPV350不支持
概述¶
单算子比对功能由compare命令的具体参数决定,主要包括配置输入文件和输出路径、选择具体比对算子、设置比对算子的输入或输出数据和输出文件的形式等。可以根据参数具体的功能描述,判断输入文件的实际情况,来决定使用具体的参数功能。
比对操作¶
说明
本节涉及的.json文件、目录等名称均为举例,请根据实际环境替换。其中,-out指定的结果存放路径,需确保操作用户具有读写权限。
基于相同模型(开/关融合)、NPU IP加速器运行生成的dump数据进行单算子精度比对时,需同时指定-f和-cf参数或同时不指定这两个参数。
操作步骤
本节以非量化NPU IP加速器运行生成的dump数据与非量化Caffe模型npy数据比对为例进行介绍,下文中参数说明均以该示例介绍,请根据您的实际情况进行替换。
登录CANN工具安装环境。
生成json文件。
atc --mode=1 --om=$HOME/data/resnet50.om --json=$HOME/data/resnet50.json进入${INSTALL_DIR}/toolkit/tools/operator_cmp/compare,${INSTALL_DIR}请替换为CANN软件安装后文件存储路径。以root安装举例,安装后文件默认存储路径为:/usr/local/Ascend/latest。
执行单算子比对默认配置比对。
说明:
由于dump和npy比对数据文件是由多个文件组成,故下文操作步骤中**-m和-g**参数须指定数据文件所在的父目录。如:_$HOME/MyApp/resnet50,_其中_resnet50_文件夹下直接保存比对数据文件。
目录结构示例如下:root@xxx:$HOME/MyApp/resnet50# tree . ├── BatchMatMul.bert_encoder_layer_0_attention_self_MatMul_1.24.1614717261785536 ├── BatchMatMul.bert_encoder_layer_0_attention_self_MatMul.21.1614717261768864 ├── BatchMatMul.bert_encoder_layer_10_attention_self_MatMul_1.235.1614717263664916 # 仅为示例,此处省略剩余文件名。
python3 msaccucmp.py compare -m $HOME/MyApp_mind/resnet50 -g $HOME/Standard_caffe/resnet50 -f $HOME/data/resnet50.json -out $HOME/result -op pool5 -i 0各参数详细介绍请参见命令格式说明。
图 1 单算子比对概要结果
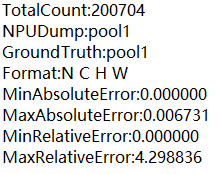
单算子比对概要结果存放在_{op_name}_input_{index}_summary.txt或{op_name}_output_{index}__summary.txt文件中,各参数说明如下:
表 1 单算子比对概要结果的参数说明
参数
说明
TotalCount
该算子的dump数据的data个数。
NPUDump
表示My Output模型算子名。
GroundTruth
表示Ground Truth模型的算子名。
Format
数据格式。
MinAbsoluteError
绝对误差的最小值。
MaxAbsoluteError
绝对误差的最大值。
MinRelativeError
相对误差的最小值。
MaxRelativeError
相对误差的最大值。
图 2 单算子完整比对结果
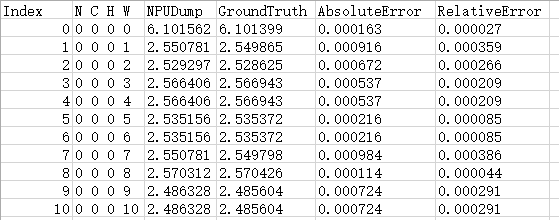
单算子比对完整结果存放在_{op_name}_input_{index}_{file_index}.csv或{op_name}_output_{index}_{file_index}_.csv文件中,每个文件最多记录100万条数据。配置--ignore_single_op_result参数时不生成此结果。比对结果各列参数说明如表2。
表 2 单算子完整比对结果参数说明
参数
说明
N C H W
数据的坐标点。
NPUDump
My Output模型的算子dump值。
GroundTruth
Ground Truth模型的算子dump值。
RelativeError
相对误差,AbsoluteError值除以Ground Truth模型算子的dump值比对出来的结果。当Ground Truth算子的dump值为0时,该处显示为“-”。
AbsoluteError
绝对误差,My Output模型算子的dump值减Ground Truth模型算子的dump值取绝对值比对出来的结果。
若已知输出结果文件数据量较大,可以通过配置参数来减少输出结果的数据量。根据结果文件说明选择合适的比对场景,执行6,以便快速识别算子存在精度问题的位置(输入、输出、坐标点)。
(可选)执行单算子比对仅比对TopN条数据。
python3 msaccucmp.py compare -m $HOME/MyApp_mind/resnet50 -g $HOME/Standard_caffe/resnet50 -f $HOME/data/resnet50.json -out $HOME/result -op pool1 -o 0 -n 20各参数详细介绍请参见命令格式说明。
比对完成后的打印结果如图3所示。
图 3 前20条数据比对结果
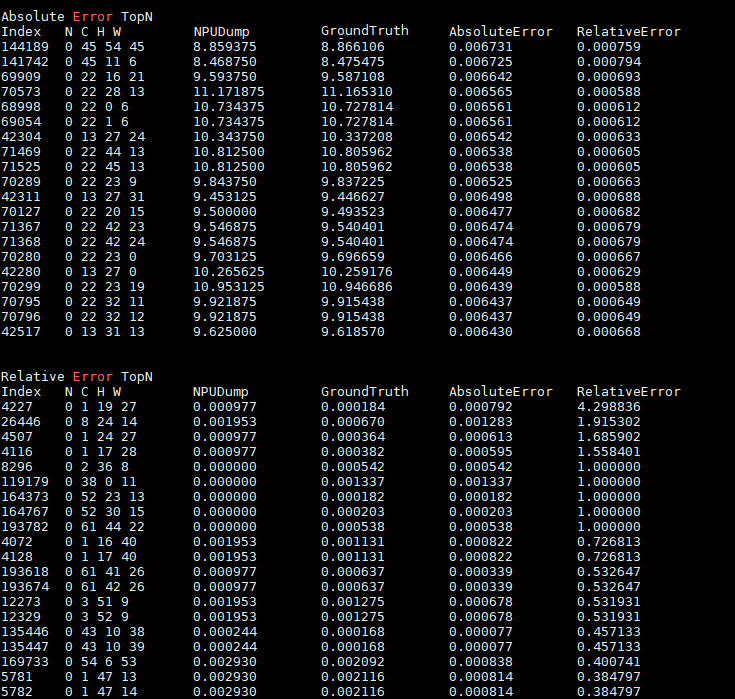
图 4 绝对误差(Top20)
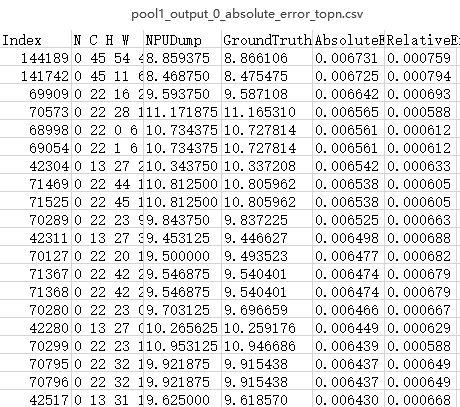
图 5 相对误差(Top20)
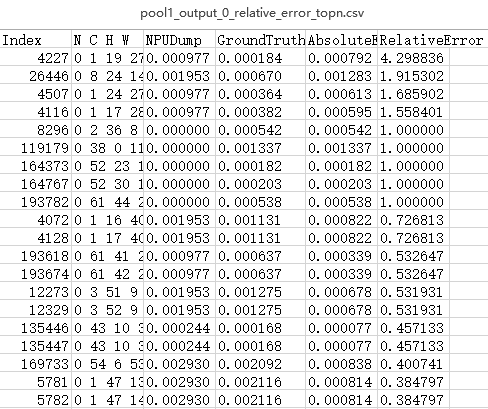
比对结果分析。
输出比对结果文件后,首先将绝对误差或相对误差由大到小排序,找出TopN条数据,用户可以基于自己的评估指标判断该算子精度是否达标。如果不满足精度要求,可以将当前测评数据交由算子开发人员进行算子内部逻辑分析。
说明:
绝对误差或相对误差的值越趋近于0表示精度越高,但实际算子需要满足的精度根据用户实际需求判断。
结果文件说明¶
单算子比对执行比对操作,默认比对指定算子数据的绝对误差和相对误差,根据指定比对算子的输入或输出数据以及设置的输出文件形式生成比对结果文件如表1。
表 1 结果文件形式
结果文件输出条件 |
结果文件 |
|---|---|
比对输入数据、默认生成前20条数据 --input_tensor |
单算子比对概要结果:{op_name}_input_{index}_summary.txt 单算子比对完整结果:{op_name}_input_{index}_{file_index}.csv 单算子比对Top20结果:
|
比对输出数据、默认生成前20条数据 --output_tensor |
单算子比对概要结果:{op_name}_output_{index}_summary.txt 单算子比对完整结果:{op_name}_output_{index}_{file_index}.csv 单算子比对Top20结果:
|
比对输入数据、生成前n条数据 --input_tensor、--topn |
单算子比对概要结果:{op_name}_input_{index}_summary.txt 单算子比对完整结果:{op_name}_input_{index}_{file_index}.csv 单算子比对TopN结果:
|
比对输出数据、生成前n条数据 --output_tensor、--topn |
单算子比对概要结果:{op_name}_output_{index}_summary.txt 单算子比对完整结果:{op_name}_output_{index}_{file_index}.csv 单算子比对TopN结果:
|
比对输入数据、不生成完整比对数据、默认生成前20条数据 --input_tensor、--ignore_single_op_result |
单算子比对概要结果:{op_name}_input_{index}_summary.txt 单算子比对Top20结果:
|
比对输出数据、不生成完整比对数据、默认生成前20条数据 --output_tensor、--ignore_single_op_result |
单算子比对概要结果:{op_name}_output_{index}_summary.txt 单算子比对Top20结果:
|
比对输入数据、配置单个csv文件包含最大文件条数、默认生成前20条数据 --input_tensor、--max_line |
单算子比对概要结果:{op_name}_input_{index}_summary.txt 单算子比对拆分结果:{op_name}_input_{index}_{file_index}.csv 单算子比对Top20结果:
|
比对输出数据、配置单个csv文件包含最大文件条数、默认生成前20条数据 --output_tensor、--max_line |
单算子比对概要结果:{op_name}_output_{index}_summary.txt 单算子比对拆分结果:{op_name}_output_{index}_{file_index}.csv 单算子比对Top20结果:
|
注1:当算子名称{op_name}过长时,将自动转换为比对算子所在的dump文件名,增加输出转换后的结果文件与实际结果文件(超长算子名未转换)的映射关系文件“simple_op_mapping.csv”。 注2:file_index为输出结果csv文件的编号,默认情况下为0,当配置--max_line时,则取值为(n-1)*max_line,n为从1开始的正整数。 注3:以上各参数详细介绍请参见命令格式说明。 |
|
扩展功能¶
AI业务运行过程中出现浮点异常情况时,可通过溢出算子数据采集和解析进行问题定界定位。
溢出算子数据采集与解析¶
AI业务运行过程中出现浮点异常情况时,可通过溢出算子数据采集和解析进行问题定界定位。
采集溢出算子数据
离线推理场景,请参见《AscendCL应用开发指南 (C&C++)》中的“更多特性 > 溢出算子数据采集及分析”章节采集溢出数据。
查看溢出算子数据
生成的溢出算子数据文件默认存储在{dump_path}/{time}/{device_id}/{model_name}/{model_id}/{data_index}目录下,例如:“/home/HwHiAiUser/output/20200808163566/0/npu_cluster_0/11/0”。如果没有采集到溢出数据,即不存在溢出情况,则不会生成上述目录。
存放路径及文件命名规则:
dump_path:用户配置的溢出数据存放路径,例如/home/HwHiAiUser/output。
time:时间戳,例如20200808163566。
device_id:设备ID。
model_name:子图名称。model_name层可能存在多个文件夹,如果model_name出现了“.“、“/“、“\“、空格时,转换为下划线表示。
model_id:子图ID。
data_index:迭代数,用于保存对应迭代的溢出数据。
上述目录下会生成两类溢出数据文件:
溢出算子的dump文件:命名规则如{op_type}.{op_name}.{task_id}.{stream_id}.{timestamp},如果op_type、op_name出现了“.”、“/”、“\”、空格时,会转换为下划线表示。
用户可通过该信息知道具体出现溢出错误的算子,并通过解析溢出算子dump文件知道该算子的输入和输出。
算子溢出数据文件:命名规则如Opdebug.Node_OpDebug.{task_id}.{stream_id}.{timestamp}。
用户可通过解析算子溢出数据文件得知溢出相关信息。
说明:文件名中的task_id不是溢出算子的task_id,用户不需要关注task_id的实际含义。
在docker内执行时,生成的数据存在docker里。
解析溢出算子dump文件
将采集到的数据文件上传到安装有Toolkit软件包的环境。
进入${INSTALL_DIR}/toolkit/tools/operator_cmp/compare,${INSTALL_DIR}请替换为CANN软件安装后文件存储路径。以root安装举例,安装后文件默认存储路径为:/usr/local/Ascend/latest。
执行msaccucmp.py脚本,转换dump文件为numpy文件。举例:
python3 msaccucmp.py convert -d /home/HwHiAiUser/dump -out /home/HwHiAiUser/dumptonumpy -v 2 说明:
-d参数支持传入单个文件,对单个dump文件进行转换,也支持传入目录,对整个path下所有的dump文件进行转换。调用Python,转换numpy文件为txt文件。举例:
$ python3 >>> import numpy as np >>> a = np.load("/home/HwHiAiUser/dumptonumpy/Pooling.pool1.1.5.1732082705016774.output.0.npy") >>> b = a.flatten() >>> np.savetxt("/home/HwHiAiUser/dumptonumpy/Pooling.pool1.1.5.1732082705016774.output.0.txt", b)
转换为.txt格式文件后,维度信息、dtype均不存在。详细的使用方法请参考NumPy官网介绍。
解析算子溢出数据文件
由于生成的溢出数据是二进制格式,可读性较差,需要通过工具将bin文件解析为用户可读性好的json文件。
请根据实际情况,将算子溢出数据文件上传到安装有Toolkit软件包的环境。
说明:
建议用户将data_index最小的目录下时间戳最小的dump文件作为待解析文件。进入${INSTALL_DIR}/toolkit/tools/operator_cmp/compare,${INSTALL_DIR}请替换为CANN软件安装后文件存储路径。以root安装举例,安装后文件默认存储路径为:/usr/local/Ascend/latest。
执行解析命令,例如:
python3 msaccucmp.py convert -d /home/HwHiAiUser/opdebug/Opdebug.Node_OpDebug.1.5.1732082705016774 -out /home/HwHiAiUser/result关键参数:
-d:溢出数据文件所在目录,包括文件名。
-out:解析结果待存储目录,如果不指定,默认生成在当前目录下。
解析结果文件内容如下示例。
说明:如果同时开启AI Core算子溢出检测和Atomic Add溢出检测,则仅显示最先出现的溢出信息。
如下示例中,先出现AI Core算子溢出信息,因此Atomic Add即便是有溢出信息也不会显示出来。
{ "DHA Atomic Add": { "model_id": 0, "stream_id": 0, "task_id": 0, "task_type": 0, "pc_start": "0x0", "para_base": "0x0", "status": 0 }, "L2 Atomic Add": { "model_id": 0, "stream_id": 0, "task_id": 0, "task_type": 0, "pc_start": "0x0", "para_base": "0x0", "status": 0 }, "AI Core": { "model_id": 514, "stream_id": 563, "task_id": 57, "task_type": 0, "pc_start": "0x1008005b0000", "para_base": "0x100800297000", "kernel_code": "0x1008005ae000", "block_id": 1, "status": 32 } }
完整字段说明:
说明:
下列字段包含当前可解析的所有字段,各产品所包含字段请以实际产品解析结果为准。model_id:标识溢出算子所在的模型ID。
stream_id:标识溢出算子所在的Stream ID。
task_id:标识溢出算子的Task ID。
task_type:标识溢出算子的Task类型。
pc_start:标识溢出算子的代码程序的起始位置。
para_base:标识溢出算子的参数起始地址。
block_id:标识溢出算子的Block ID参数。
status:AICore的status寄存器状态,包含了溢出的信息。用户可以从status值分析得到具体溢出错误,具体请参见下文“通过status分析错误原因”。
通过status分析错误原因
AI Core算子溢出检测状态字段status为十进制表示,需要转换成十六进制,然后定位到具体错误。
例如:status为272,转换成十六进制为0x00000110,则可以判定出可能原因为0x00000010+0x00000100。
0x00000008:带符号的整数最小负数NEG符号位取反溢出。
0x00000010:整数加法、减法、乘法或乘加操作计算有溢出。
0x00000020:浮点计算有溢出。
0x00000080:浮点数转无符号数的输入是负数。
0x00000100:Float32转Float16或32位待符号的整数转Float16中出现溢出。
0x00000400:CUBE累加出现溢出。
注:上述浮点异常信息为对应十六进制bit位的异常表示,可能会出现多种浮点异常组合的情况。
DHA Atomic Add溢出检测状态字段status的值为十进制,大于0即表示出现DHA Atomic Add溢出。
L2 Atomic Add溢出检测状态字段status的值为十进制,大于0即表示出现L2 Atomic Add溢出。
Top溢出算子解析¶
AI业务运行过程中可能存在算子溢出的情况,此时若直接进行精度比对操作则会造成比对结果不准确。通过执行查看溢出算子数据,可以检测并收集溢出的算子信息,生成算子溢出数据文件和溢出算子的dump文件。
当生成的算子溢出数据文件和溢出算子的dump文件的落盘时间与算子溢出的时间不一致时,在这两个文件中则无法第一时间定位到第一个溢出的算子。
为了帮助用户快速定位溢出算子,本章节介绍的Top溢出算子解析,可以对生成的Debug file和溢出算子的dump文件进行分析,并展示TopN溢出算子的关键信息。
命令格式说明
算子溢出检测命令行格式如下:
python3 msaccucmp.py overflow -d <dump_path> -out <output_path> [-n <topn>]
命令行参数说明如表1所示。
该功能通过msaccucmp.py脚本实现,脚本存放在${INSTALL_DIR}/toolkit/tools/operator_cmp/compare,${INSTALL_DIR}请替换为CANN软件安装后文件存储路径。以root安装举例,安装后文件默认存储路径为:/usr/local/Ascend/latest。
表 1 算子溢出检测命令行参数说明
参数名 |
参数说明 |
是否必选 |
|---|---|---|
-d --dump_path |
Debug file和溢出算子的dump文件所在目录。 请参见查看溢出算子数据获取文件目录。 目录下如果缺少dump文件,则会导致-out输出时缺少npy文件;如果目录下没有Debug file,则表示无溢出。 |
是 |
-out --output_path |
算子溢出分析结果文件输出目录。 输出文件包括:
缺少npy文件,会导致结果文件解析不到溢出算子的输入输出信息。 不建议配置与当前用户不一致的其它用户目录,避免提权风险。 |
是 |
-n --topn |
解析溢出的前N个算子,取值范围为1~5,默认值为1。 |
否 |
执行步骤
使用以下步骤进行算子溢出分析之前请参见查看溢出算子数据,对dump文件进行算子溢出检测,并生成Debug file和溢出算子的dump文件。
算子溢出检测命令行方式操作步骤:
登录CANN工具安装环境。
进入${INSTALL_DIR}/toolkit/tools/operator_cmp/compare,${INSTALL_DIR}请替换为CANN软件安装后文件存储路径。以root安装举例,安装后文件默认存储路径为:/usr/local/Ascend/latest。
执行算子溢出检测命令。
python3 msaccucmp.py overflow -d /MyApp20/dump -out /MyApp20/out -n 3执行算子溢出检测结果overflow_summary_{timestamp}.txt文件内容如图1所示。
图 1 溢出算子结果信息

结果文件信息中,根据展示数据从上到下顺序,展示信息如下:
从1到n表示解析出第一个溢出的算子到第n个溢出的算子。
每个溢出算子的类型和名称。
算子的溢出信息,包括:溢出类型,溢出的任务ID,流ID和溢出错误码。
timestamp为算子溢出的时间戳。
*.input.*.npy为溢出算子的输入数据的npy文件。
*.input.*.npy文件名下方展示的是文件中算子溢出的输入关键信息,包括数据格式,数据维度,数据类型,最大值,最小值和均值。
*.output.*.npy为溢出算子的输出数据的npy文件。
*.output.*.npy文件名下方展示的是文件中算子溢出的输出关键信息,包括数据格式,数据维度,数据类型,最大值,最小值和均值。
dump数据文件Format转换¶
执行dump数据文件Format转换
本版本提供dump数据文件Format转换能力,用于用户根据自身需求将NPU IP加速器生成的dump数据文件转换成numpy数据文件,方便查看。
该功能通过msaccucmp.py脚本实现,脚本存放在${INSTALL_DIR}/toolkit/tools/operator_cmp/compare,${INSTALL_DIR}请替换为CANN软件安装后文件存储路径。以root安装举例,安装后文件默认存储路径为:/usr/local/Ascend/latest。
命令格式如下:
python3 msaccucmp.py convert -d <dump_file> [-out <output>] [-f <format>] [-s <shape>] [-o <output_tensor>] [-i <input_tensor>] [-c <custom_script_path>] [-v <version>] [-t <type>]
命令格式参数项说明如表1所示。
表 1 Format转换参数项说明
参数名 |
描述 |
是否必选 |
|---|---|---|
-d --dump_file |
NPU IP加速器生成的dump文件。 支持指定单个文件;单个路径(不支持递归嵌套,只支持文件的父目录);同时指定多个文件,文件名用逗号隔开,例如-d /{PATH}/dump_file1,/{PATH}/dump_file2。 |
是 |
-out --output |
转换后的数据存放目录,默认为当前路径。 不建议配置与当前用户不一致的其它用户目录,避免提权风险。 |
否 |
-f --format |
|
否 |
-s --shape |
Format转换需要的Shape,当前仅FRACTAL_NZ转换需要配置该参数,格式为([0-9]+,)+[0-9]+,每个数字必须大于0。配置-f时有效。 |
否 |
-o --output_tensor |
转换指定index的output数据,与-i互斥。配置-f时有效。 当-o与-i均未配置时,默认转换所有的input与output。 |
否 |
-i --input_tensor |
转换指定index的input数据,与-o互斥。配置-f时有效。 |
否 |
-c --custom_script_path |
用户自定义Format转换.py文件存放路径,需指定到“format_convert”目录的上一层目录。.py文件相关要求参见准备自定义Format转换.py文件。配置-f时有效。 不建议调用与当前用户不一致的其它用户目录下的自定义脚本文件,避免提权风险。 |
否 |
-v --version |
dump文件类型,1代表protobuf序列化后的数据文件,2代表自定义格式的数据文件。默认值为2。 |
否 |
-t --type |
输出文件的类型。取值为:
默认值为npy。 |
否 |
支持的Format转换类型
结果保存为“原始文件名.output.{index}.{shape}.npy“或“原始文件名.input.{index}.{shape}.npy“,Shape的格式如:1x3x224x224。
当前内置的Format转换支持如下类型:
FRACTAL_NZ转换NCHW
FRACTAL_NZ转换成NHWC
FRACTAL_NZ转换ND
HWCN转换FRACTAL_Z
HWCN转换成NCHW
HWCN转换成NHWC
NC1HWC0转换成HWCN
NC1HWC0转换成NCHW
NC1HWC0转换成NHWC
NCHW转换成FRACTAL_Z
NCHW转换成NHWC
NHWC转换成FRACTAL_Z
NHWC转换成HWCN
NHWC转换成NCHW
NDC1HWC0转换成NCDHW
准备自定义Format转换.py文件
用户自定义的Format转换.py文件只能用来进行Format转换,文件安全性由用户自行保证。
为满足用户自定义Format转换,需要按以下要求准备:
.py文件命名需满足规则:“convert_{format_from}_to_{format_to}.py“,其中,format_from和format_to支持的类型如下:
NCHW
NHWC
ND
NC1HWC0
FRACTAL_Z
NC1C0HWPAD
NHWC1C0
FSR_NCHW
FRACTAL_DECONV
C1HWNC0
FRACTAL_DECONV_TRANSPOSE
FRACTAL_DECONV_SP_STRIDE_TRANS
NC1HWC0_C04
FRACTAL_Z_C04
CHWN
DECONV_SP_STRIDE8_TRANS
NC1KHKWHWC0
BN_WEIGHT
FILTER_HWCK
HWCN
LOOKUP_LOOKUPS
LOOKUP_KEYS
LOOKUP_VALUE
LOOKUP_OUTPUT
LOOKUP_HITS
MD
NDHWC
C1HWNCoC0
FRACTAL_NZ
NCHDW
.py文件内容需满足以下规则:
def convert(shape_from, shape_to, array): return numpy_array
表 2 参数说明
参数
说明
shape_from
array数据的转换前的Shape,一维数组。
shape_to
array数据的转换后的Shape,一维数组,可选。
array
一维原始数据。
return
返回值,返回转换后的numpy数组。
.py文件存放目录需满足:
.py文件必须存放在“format_convert“目录下,如果该目录不存在,需要新建。
查看dump数据文件¶
dump文件无法通过文本工具直接查看其内容,为了查看dump文件内容,本文提供以下脚本将dump文件转换为numpy格式文件后,再通过numpy官方提供的能力转为txt文档进行查看。
该功能通过msaccucmp.py脚本实现,脚本存放在${INSTALL_DIR}/toolkit/tools/operator_cmp/compare,${INSTALL_DIR}请替换为CANN软件安装后文件存储路径。以root安装举例,安装后文件默认存储路径为:/usr/local/Ascend/latest。
python3 msaccucmp.py convert -d <dump_file> [-out <output>] [-v <version>] [-t <type>]
命令格式参数项说明如表1所示。
表 1 参数说明
参数名 |
描述 |
是否必选 |
|---|---|---|
-d --dump_file |
NPU IP加速器生成的dump文件。 支持指定单个文件;单个路径(不支持递归嵌套,只支持文件的父目录);同时指定多个文件,文件名用逗号隔开,例如-d /{PATH}/dump_file1,/{PATH}/dump_file2。 |
是 |
-out --output |
转换后的数据存放目录,默认为当前路径。 不建议配置与当前用户不一致的其它用户目录,避免提权风险。 |
否 |
-v --version |
dump文件类型,1代表protobuf序列化后的数据文件,2代表自定义格式的数据文件。默认取值为2。 |
否 |
-t --type |
输出文件的类型。取值为:
默认值为npy。 |
否 |
操作步骤
使用安装用户登录开发环境。
进入${INSTALL_DIR}/toolkit/tools/operator_cmp/compare,${INSTALL_DIR}请替换为CANN软件安装后文件存储路径。以root安装举例,安装后文件默认存储路径为:/usr/local/Ascend/latest。
执行msaccucmp.py脚本,转换dump文件为numpy文件。
python3 msaccucmp.py convert -d $HOME/dump -out $HOME/dumptonumpy -v 2 说明:msaccucmp.py脚本的各个输入参数使用方法,请参见dump数据文件Format转换。
-d参数支持传入单个文件,对单个dump文件进行转换,也支持传入目录(不支持递归嵌套,只支持文件的父目录),对整个path下所有的dump文件进行转换。
调用Python,转换numpy文件为txt文件。举例:
$ python3 Python 3 (default, Mar 5 2020, 16:07:54)[GCC 5.4.0 20160609] on linuxType "help", "copyright", "credits" or "license" for more information. >>> import numpy as np >>> a = np.load("$HOME/dumptonumpy/Pooling.pool1.1.1147.1589195081588018.output.0.npy") >>> b = a.flatten() >>> np.savetxt("$HOME/dumptonumpy/Pooling.pool1.1.1147.1589195081588018.output.0.txt", b)
转换为.txt格式文件后,维度信息、dtype均不存在。详细的使用方法请参见NumPy官网介绍。
GPU/NPU映射表获取¶
-IPV350不支持
说明
本节涉及的.json文件、目录等名称均为举例,请根据实际环境替换。其中,-out指定的结果存放路径,需确保操作用户具有读写权限。
操作步骤
以HwHiAiUser用户登录开发环境。
生成json文件。
atc --mode=1 --om=$HOME/data/resnet50.om --json=$HOME/data/resnet50.json进入${INSTALL_DIR}/toolkit/tools/operator_cmp/compare,${INSTALL_DIR}请替换为CANN软件安装后文件存储路径。以root安装举例,安装后文件默认存储路径为:/usr/local/Ascend/latest。
执行获取GPU/NPU的映射表命令。
说明:
由于dump和npy比对数据文件是由多个文件组成,故下文操作步骤中**-m和-g**参数须指定数据文件所在的父目录。如:_$HOME/MyApp/resnet50,_其中_resnet50_文件夹下直接保存比对数据文件。
目录结构示例如下:root@xxx:$HOME/MyApp/resnet50# tree . ├── BatchMatMul.bert_encoder_layer_0_attention_self_MatMul_1.24.1614717261785536 ├── BatchMatMul.bert_encoder_layer_0_attention_self_MatMul.21.1614717261768864 ├── BatchMatMul.bert_encoder_layer_10_attention_self_MatMul_1.235.1614717263664916 # 仅为示例,此处省略剩余文件名。
python3 msaccucmp.py compare -m $HOME/MyApp_mind/resnet50 -g $HOME/Standard_caffe/resnet50 -f $HOME/data/resnet50.json -out $HOME/result -map输出结果为mapping_*.csv文件内容如图1所示。
图 1 GPU/NPU的映射表

表 1 输出参数说明
参数
说明
Index
算子的ID。
OpType
算子类型。指定-f,-cf或-q参数时获取算子类型。
NPUDump
表示基于NPU IP加速器运行生成的dump数据的算子名。
GroundTruth
表示基于GPU/CPU运行生成的npy或dump数据的算子名。
TensorIndex
表示基于NPU IP加速器运行生成的dump数据的算子的input ID和output ID。
NPUDumpPath
表示基于NPU IP加速器运行生成的dump文件路径。
GroundTruthPath
表示基于GPU/CPU运行生成的npy或dump文件路径。
自定义算法.py文件准备¶
用户自定义的比对算法Python文件只能用来进行精度比对,文件安全性和传入参数的安全性由用户保证。
用户自定义算法,需要在.py格式文件内写好自定义算法脚本,按以下要求准备:
.py文件命名需满足规则:“ alg_{algorithm_name}.py“,其中,algorithm_name为算法名。
.py文件内容需满足以下规则:
def compare(my_output_dump_data, ground_truth_dump_data, args): #算法固定头格式 #以下为算法示例 """ Function Description: compare the my output dump data and the ground truth dump data by algorithm Parameter: my_output_dump_data: the my output dump data ground_truth_dump_data: the ground truth dump data args: the algorithm arguments Return Value: the compare algorithm value, string; error_msg, string """
表 1 参数说明
参数
说明
my_output_dump_data
my output dump数据,一维数组。
ground_truth_dump_data
ground truth dump数据,一维数组。
args
算法参数,用户自行解析。
Return Value
返回值,包括:
- 算法比对的结果,String格式。
- 错误信息,String格式。
需要在当前用户的目录下创建“algorithm“目录用于保存.py文件,请确保用户对目录和文件具有读写权限。
AICPU自定义算子日志解析¶
-IPV350不支持
概述
dump数据文件解析功能通过解析dump数据文件,获取dump数据文件中的信息。
当前该功能支持从dump数据文件中解析AICPU自定义算子的日志,并将其保存到日志文件内。
命令格式说明
python3 dump_parser.py save_log -d <dump_file> [-out <output>]
命令行参数说明如表1所示。
该功能通过dump_parser.py脚本实现,脚本存放在${INSTALL_DIR}/toolkit/tools/operator_cmp/compare,${INSTALL_DIR}请替换为CANN软件安装后文件存储路径。以root安装举例,安装后文件默认存储路径为:/usr/local/Ascend/latest。
表 1 命令行参数说明
参数名 |
参数说明 |
是否必选 |
|---|---|---|
-d --dump_file |
待解析的dump数据文件。 |
是 |
-out --output |
AICPU自定义算子的日志存放目录。默认为当前目录。 结果文件名格式为:dump_file_name.{index}.log 不建议配置与当前用户不一致的其它用户目录,避免提权风险。 |
否 |
操作步骤
登录CANN工具安装环境。
进入${INSTALL_DIR}/toolkit/tools/operator_cmp/compare,${INSTALL_DIR}请替换为CANN软件安装后文件存储路径。以root安装举例,安装后文件默认存储路径为:/usr/local/Ascend/latest。
执行save_log解析命令。
python3 dump_parser.py save_log -d my_dump_path/dump_file -out /MyApp20/out命令执行完成后在**-out**指定目录下生成日志文件。
Windows dump文件转换为Linux dump文件¶
在Linux上准备转换脚本windows_to_linux.py,内容如下。
import argparse import os import sys class WindowsToLinux: """ The class for format windows to linux """ def __init__(self): parse = argparse.ArgumentParser() parse.add_argument("-i", dest="windows_dump_path", default="", help="<Required> the dump file path", required=True) parse.add_argument("-o", dest="output_path", default="", help="<Required> the output path", required=True) args, _ = parse.parse_known_args(sys.argv[1:]) self.windows_dump_path = os.path.realpath(args.windows_dump_path) self.output_path = os.path.realpath(args.output_path) def windows_to_linux(self, dump_path): try: with open(dump_path, "rb") as dump_file: content = dump_file.read() new_content = content.replace(b"\r\n", b"\n") output_file_path = os.path.join(self.output_path, os.path.basename(dump_path)) with open(output_file_path, "wb") as new_dump_file: new_dump_file.write(new_content) print('Info: convert dump to linux for "%s" successfully.' % dump_path) except (OSError, IOError, MemoryError, SystemError) as error: print('Error: convert windows dump file "%s" to linux dump file failed. %s' % (dump_path, error)) def convert(self): try: if not os.path.exists(self.windows_dump_path) and \ not os.access(self.windows_dump_path, os.R_OK): print('Error: the path "%s" does not exist or can not readable.') sys.exit() if not os.path.exists(self.output_path): os.makedirs(self.output_path) if not os.path.exists(self.output_path) and \ not os.access(self.output_path, os.W_OK): print('Error: the path "%s" does not exist or can not writable.') sys.exit() if os.path.isfile(self.windows_dump_path): self.windows_to_linux(self.windows_dump_path) else: for file_name in os.listdir(self.windows_dump_path): self.windows_to_linux(os.path.join(self.windows_dump_path, file_name)) except (OSError, IOError, MemoryError, SystemError) as error: print('Error: convert windows dump file to linux dump file failed. %s' % error) sys.exit() if __name__ == "__main__": main = WindowsToLinux() main.convert()
将Windows的dump文件拷贝到Linux某个目录下。
在Linux上执行转换脚本。
# windows_dump_path是步骤2中Windows的dump文件拷贝到Linux的目录 # linux_dump_path是生成的Linux的dump文件存放路径 python3 windows_to_linux.py -i {windows_dump_path} -o {linux_dump_path}
附录¶
数据格式要求¶
msaccucmp.py脚本精度比对工具支持多种比对方式,因此dump、npy数据文件命名需满足以下要求:
表 1 数据文件命名规则
数据类型 |
数据命名格式 |
备注 |
|---|---|---|
非量化离线模型在NPU IP加速器上运行生成的dump数据文件 |
命名格式说明:
如果op_type、op_name出现了“.”、“/”、“\”、空格时,转换为下划线表示。 |
|
量化离线模型在NPU IP加速器上运行生成的dump数据文件 |
||
npy数据文件() |
{op_name}.{output_index}.{timestamp}.npy |
命令格式说明¶
通用参数
精度比对命令行格式如下:
python3 msaccucmp.py compare -m <my_dump_path> -g <golden_dump_path> [-f <fusion_rule_file>] [-cf <close_fusion_rule_file>] [-q <quant_fusion_rule_file>] [-out <output>] [-map] [-c <custom_script_path>] [-alg <algorithm>] [-v <version>] [-r <range>] [-overflow_detection] [-max] [-advisor]
命令行参数说明如表1所示。
表 1 精度比对命令行参数说明
参数名 |
参数说明 |
是否必选 |
|---|---|---|
-m --my_dump_path |
基于NPU IP加速器运行生成的数据文件所在目录。 由于dump数据文件是多个二进制文件,故须指定dump数据文件所在的父目录。如:$HOME/MyApp_mind/resnet50,其中resnet50文件夹下直接保存dump数据文件。 |
是 |
-g --golden_dump_path |
基于GPU/CPU运行生成的原始网络数据文件所在目录。 由于npy数据文件是多个npy文件,故须指定npy数据文件所在的父目录。如:$HOME/Standard_caffe/resnet50 ,其中resnet50文件夹下直接保存npy数据文件。 当指定-cf参数时,该参数指定的就是模型转换关闭算子融合下dump数据文件的目录。 |
是 |
-f --fusion_rule_file |
全网层信息文件。 推理场景下:
|
否 |
-cf --close_fusion_rule_file |
全网层信息文件(通过使用ATC转换.om模型文件生成的json文件,文件包含关闭算子融合功能情况下整网算子的映射关系)。 本参数详细使用指导请参见比对操作和分析。 仅推理场景支持本参数。 |
否 |
-q --quant_fusion_rule_file |
量化信息文件(昇腾模型压缩输出的json文件)。 通过AMCT量化生成的量化信息文件(*.json),文件包含整网量化算子映射关系,用于精度比对时算子匹配。 Caffe非量化原始模型 vs 量化离线模型场景时,与-f参数二选一;Caffe非量化原始模型 vs 量化原始模型场景时,仅使用本参数。 仅推理场景支持本参数。 |
否 |
-out --output |
比对数据结果存放路径,默认为当前路径。 不建议配置与当前用户不一致的其它用户目录,避免提权风险。 |
否 |
-map --mapping |
输出GPU/NPU的映射表。 一般情况下GPU/NPU的映射表需要在完成精度比对之后,才能从csv中获取。本参数实现在精度比对前,直接提取GPU/NPU的映射表。建议在比对数据量太大,需要提前获取GPU/NPU的映射表的场景下使用。详细操作请参见GPU/NPU映射表获取。 |
否 |
-c --custom_script_path |
用户自定义脚本文件存放路径,包括自定义算法.py文件和自定义Format转换.py文件,需指定到脚本目录的上一层目录。指定本参数时判断是否存在以下文件目录:
不建议调用与当前用户不一致的其它用户目录下的自定义脚本文件,避免提权风险。 |
否 |
-alg --algorithm |
比对算法维度,取值为:
可多选,配置格式为各取值间用逗号分隔,可配置为数字或算法名,例如0,1,2,RelativeError。 若只选择比对部分维度,则比对结果同样只展示对应维度。 |
否 |
-a --algorithm_options |
比对算法的高级选项,可为指定的算法设置参数,指定的算法必须是-alg参数的内置算法或者-c参数的自定义算法,被本参数设置后的算法以本参数设置的值执行运算。 输入格式为:算法名:参数名=值,参数名=值;算法名:参数名=值,参数名=值。参数之间是逗号分隔,不同算法是分号分隔,例如:"CosineSimilarity:max=1,min=0;aa:max=1,min=0"。其中算法名与-c参数自定义算法.py文件的algorithm_name(参见自定义算法.py文件准备)一致。 |
否 |
-v --version |
dump文件类型,1代表protobuf序列化后的数据文件,2代表自定义格式的数据文件。默认取2。 |
否 |
-r --range |
设定算子比对范围。配置方式如下:
配置格式为:“start,end,step”。比如:-r 1,101,20,表示算子1,21,41,61,81,101的Tensor参与比对。 不配置本参数时,比对网络模型中的所有参与计算的算子。 Caffe非量化原始模型 vs 量化原始模型和NPU vs NPU精度比对场景不支持配置本参数。 须先配置-f或-cf参数指定离线模型全网层信息文件。 -s参数与-r参数二者只能选择一个配置。 |
否 |
-s --select |
设定算子比对范围。通过指定算子的索引(网络模型中算子的ID)来选择需要比对的算子,格式为:-s 1,2,3(数值之间以逗号隔开,取值与网络模型中算子的ID有关)。 须先配置-f或-cf参数指定离线模型全网层信息文件。 -s参数与-r参数二者只能选择一个配置。 |
否 |
-max --max_cmp_size |
设置每个dump数据比对的最大字节数,用于精度比对过程提速,默认0(表示全量比对),单位Byte。当模型中算子的输出存在较大Shape时、比对过于耗时,可以尝试配置。 |
否 |
-overflow_detection |
整网算子溢出检测。进行整网比对时可检测溢出算子。 默认未开启算子溢出检测。 当算子的Tensor数据类型是FP16时,tensor中的任意一个数值的绝对值 >= 65504,认为算子溢出。 Caffe非量化原始模型 vs 量化原始模型场景配置本参数不生效。 |
否 |
-advisor |
在Tensor比对结束后,针对比对结果进行数据分析,给出专家建议。 |
否 |
单算子比对
单算子比对命令行格式如下:
python3 msaccucmp.py compare -m <my_dump_path> -g <golden_dump_path> [-f <fusion_rule_file>] [-cf <close_fusion_rule_file>] [-q <quant_fusion_rule_file>] [-out <output>] [-op <op_name>] [-o <output_tensor>] [-i <input_tensor>] [-c <custom_script_path>] [-v <version>] [-n <topn>] [--ignore_single_op_result] [-ml <max_line>] [-overflow_detection]
命令行参数说明如表2所示。
表 2 单算子比对命令行参数说明
参数名 |
参数说明 |
是否必选 |
|---|---|---|
-op --op_name |
单算子比对的算子名。输入待比对算子名,算子名获取方式有:
|
是 |
-o --output_tensor |
比对指定Index的output数据。 配置格式:-o Index,其中Index可以从整网比对结果文件中的TensorIndex字段的output取值获取,例如TensorIndex为trans_Cast_0:input:0,则Index为0。 当-o与-i均未配置时,默认比对output数据的Index为0的数据。 配置-op时有效,与-i参数互斥。 |
否 |
-i --input_tensor |
比对指定Index的input数据。 配置格式:-i Index,其中Index可以从整网比对结果文件中的TensorIndex字段的input取值获取,例如TensorIndex为trans_Cast_0:input:0,则Index为0。 配置-op时有效,与-o参数互斥。 |
否 |
-n --topn |
仅展示绝对误差和相对误差的前n条数据,比对完成后打印并生成csv结果文件,取值范围为[1,10000],默认值为20。配置-op时有效。 生成的csv结果文件名分别为:
|
否 |
--ignore_single_op_result |
csv结果文件中不生成单算子比对的完整比对数据,即不生成完整比对结果的csv文件。配置-op时有效。 不配置本参数时,生成完整比对结果。 |
否 |
-ml --max_line |
单算子比对时生成的单个csv文件所包含最大的文件条数,取值范围为[10000,1000000],默认值为1000000。 文件中单算子的比对结果数据条数较大时,配置本参数可以将csv文件拆分为多个文件。比如数据条数为100000条,配置本参数为10000,那么比对结果则输出10个csv文件。 配置-op时有效,但配置--ignore_single_op_result时,本参数不生效。 |
否 |
完整比对结果参数说明¶
表 1 字段说明
字段 |
说明 |
|---|---|
Index |
网络模型中算子的ID。 |
OpSequence |
部分算子比对时算子运行的序列。即-f参数指定的全网层信息文件中算子的ID。仅配置-r或-s参数时展示。 |
OpType |
算子类型。指定-f参数时获取算子类型。 |
NPUDump |
表示My Output模型的算子名。 |
DataType |
表示NPU Dump侧数据算子的数据类型。 |
Address |
dump tensor的内存地址。用于判断算子的内存问题。仅基于NPU IP加速器运行生成的dump数据文件在整网比对时可提取该数据。 |
GroundTruth |
表示Ground Truth模型的算子名。 |
DataType |
表示Ground Truth侧数据算子的数据类型。 |
TensorIndex |
表示基于NPU IP加速器运行生成的dump数据的算子的input ID和output ID。 |
Shape |
比对的Tensor的Shape。 |
OverFlow |
溢出算子。显示YES表示该算子存在溢出;显示NO表示算子无溢出;显示NaN表示不做溢出检测。配置-overflow_detection参数时展示。 |
CosineSimilarity |
进行余弦相似度算法比对出来的结果,取值范围为[-1,1],比对的结果如果越接近1,表示两者的值越相近,越接近-1意味着两者的值越相反。 |
MaxAbsoluteError |
进行最大绝对误差算法比对出来的结果,取值范围为0到无穷大,值越接近于0,表明越相近,值越大,表明差距越大。 |
AccumulatedRelativeError |
进行累积相对误差算法比对出来的结果,取值范围为0到无穷大,值越接近于0,表明越相近,值越大,表明差距越大。 |
RelativeEuclideanDistance |
进行欧氏相对距离算法比对出来的结果,取值范围为0到无穷大,值越接近于0,表明越相近,值越大,表明差距越大。 |
KullbackLeiblerDivergence |
进行KL散度算法比对出来的结果,取值范围为0到无穷大。KL散度越小,真实分布与近似分布之间的匹配越好。 |
StandardDeviation |
进行标准差算法比对出来的结果,取值范围为0到无穷大。标准差越小,离散度越小,表明越接近平均值。 |
MeanAbsoluteError |
表示平均绝对误差。取值范围为0到无穷大,MeanAbsoluteError趋于0,RootMeanSquareError趋于0,说明测量值与真实值越近似;MeanAbsoluteError趋于0,RootMeanSquareError越大,说明存在局部过大的异常值;MeanAbsoluteError越大,RootMeanSquareError等于或近似MeanAbsoluteError,说明整体偏差越集中;MeanAbsoluteError越大,RootMeanSquareError越大于MeanAbsoluteError,说明存在整体偏差,且整体偏差分布分散;不存在以上情况的例外情况,因为RootMeanSquareError ≥ MeanAbsoluteError恒成立。 |
RootMeanSquareError |
表示均方根误差。取值范围为0到无穷大,MeanAbsoluteError趋于0,RootMeanSquareError趋于0,说明测量值与真实值越近似;MeanAbsoluteError趋于0,RootMeanSquareError越大,说明存在局部过大的异常值;MeanAbsoluteError越大,RootMeanSquareError等于或近似MeanAbsoluteError,说明整体偏差越集中;MeanAbsoluteError越大,RootMeanSquareError越大于MeanAbsoluteError,说明存在整体偏差,且整体偏差分布分散;不存在以上情况的例外情况,因为RootMeanSquareError ≥ MeanAbsoluteError恒成立。 |
MaxRelativeError |
表示最大相对误差。取值范围为0到无穷大,值越接近于0,表明越相近,值越大,表明差距越大。 |
MeanRelativeError |
表示平均相对误差。取值范围为0到无穷大,值越接近于0,表明越相近,值越大,表明差距越大。 |
CompareFailReason |
算子无法比对的原因。 若余弦相似度为1,则查看该算子的输入或输出Shape是否为空或全部为1,若为空或全部为1则算子的输入或输出为标量,提示:this tensor is scalar。 |