
Nano AI应用界面¶
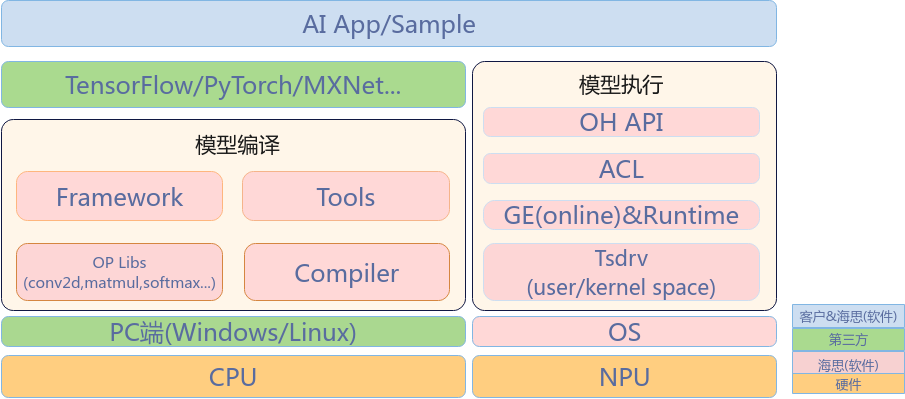
支持用户进行模型开发、部署、优化。
用户:
提供训练好的模型
开发AI App(模型执行,调用ACL接口层)
模型优化
海思:
模型编译工具链(包括算子库、编译器、量化工具等)
NPU驱动、执行态软件
NPU调用接口
NPU调用Sample
Nano 芯片支持数据类型和典型模型性能¶
使用场景:音频,感知,控制
支持算子:60+
模型类型:CNN/RNN/FIFO/Transformer
支持数据类型: cube s16*s8/s8*s8/s8*s4,vector fp16*fp16
算力:int8 16Gops@64MHz,int8 50Gops@200MHz
表 1 典型模型性能
Nano AI资料清单¶
表 1 Nano AI资料清单
Nano AI应用开发流程¶
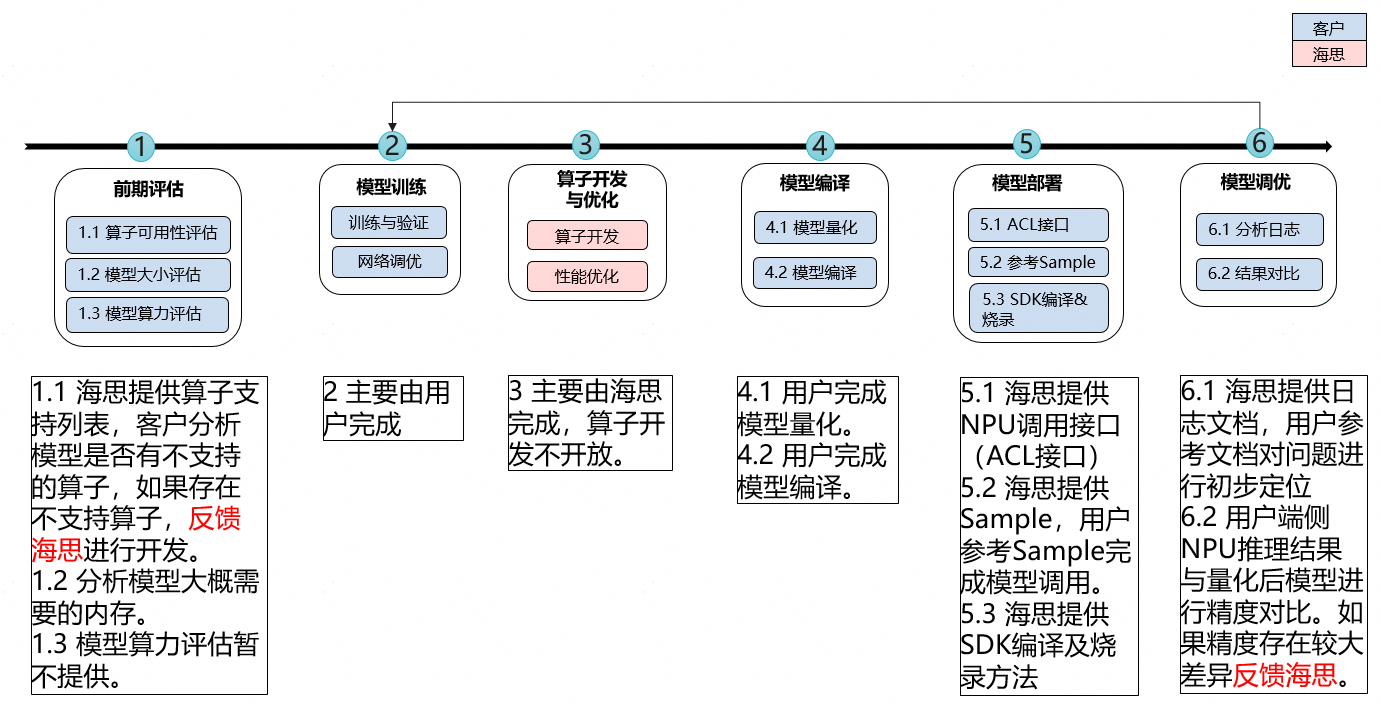
前期评估¶
算子可用性评估¶
背景&适用范围
Nano NPU使用全新芯片架构和全新指令集,相关算子目前处于持续演进开发的过程,用户可根据下述算子支持列表提前分析模型支持性
表 1 算子支持列表(onnx opset: V11-V18)
模型评估¶
表 1 模型评估项
脚本使用:
python3 onnx_estimate.py -m estimate_model_path -p
-m onnx模型路径
-p 添加该参数时打印各层信息
NPU模型与Onnx模型(由pytorch、TF框架模型转换)存在如下差异,评估出的数据与原始Onnx模型不一致:



模型编译¶

算法用户训练得到onnx模型,经过改图、量化、编译后得到可执行的exeom文件,将其部署于AI APP,调用执行框架实现加载和推理。
开发环境安装指南¶
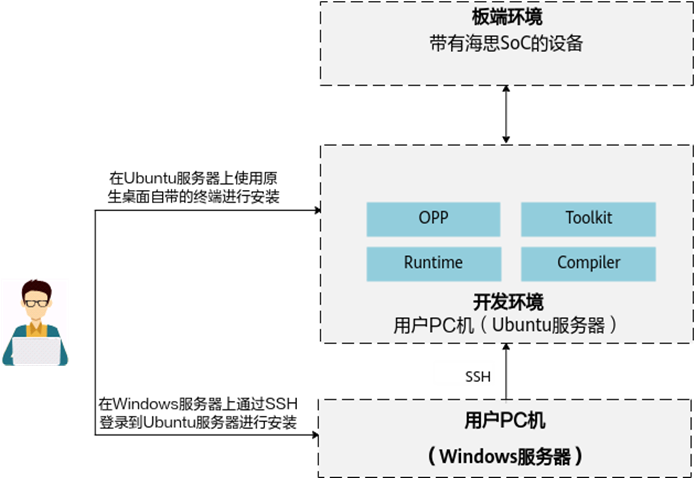
背景&适用范围
开发环境是指用户开发应用程序的环境,用户在开发环境上做开发、编译、模型转换。《开发环境安装指南》手册介绍了CANN支持的操作系统、GCC、Python等版本,并详细讲解CANN软件包的安装、升级、卸载方式。详细请参考《开发环境安装指南.pdf》文档。
文档主要内容
文档包括获取软件包、安装前准备、安装、常用操作(升级、解压、卸载等)、FAQ章节。
安装流程
准备CANN包:
CANN-runtime-xxx-linux.x86_64.run
CANN-compiler-xxx-linux.x86_64.run
CANN-opp-xxx-linux.x86_64.run
CANN-toolkit-xxx-linux.x86_64.run
解压安装
chmod +x CANN-*
./CANN-runtime-xxx-linux.x86_64.run --full –install-path=/home/xxxxx/local/Ascend/
./CANN-compiler-xxx-linux.x86_64.run --full –install-path=/home/xxxxx/local/Ascend/ --pylocal
./CANN-opp-xxx-linux.x86_64.run --full –install-path=/home/xxxxx/local/Ascend/
./CANN-toolkit-xxx-linux.x86_64.run --full –install-path=/home/xxxxx/local/Ascend/
设置环境变量
source /home/xxxxx/local/Ascend/latest/bin/setenv.bash
模型量化¶
背景
由于Nano平台Cube指令仅支持int16/int8类型输入,故包含如MatMul、Conv等算子的网络必须经过量化才能在Nano上执行。详细请参考《AMCT模型压缩工具用户指南.pdf》文档。
量化算法原理
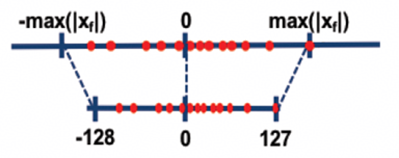
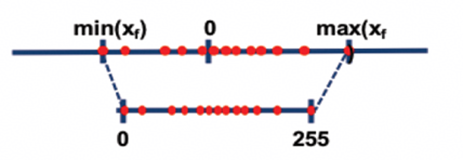
对称量化:

非对称量化:
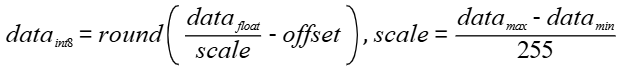
其中,scale是float32浮点数,确定了scale之后,INT8数据对应的表示范围对称为[- 128 * scale, 127 * scale],非对称为[scale * offset, scale * (255 + offset)] ,量化操作即为对量化数据以[-128*scale, 127*scale]进行饱和,即超过范围饱和到边界值。
量化工具安装
安装昇腾模型压缩工具
tar –zxvf CANN-amct-7.8.t5.0.b028-linux.x86_64.tar.gz
cd amct/amct_onnx
pip3 install amct_onnx-{version}-py3-none-linux_{arch}.whl –user
编译并安装自定义算子包
tar –zxvf amct_onnx_op.tar.gz
cd amct_onnx_op && python3 setup.py build
若服务器不能链接网络,则需手动下载头文件放置在amct_onnx_op/inc下,再执行setup.py,下载链接https://github.com/microsoft/onnxruntime/tree/v1.16.0/include/onnxruntime/core/session,链接版本需与onnx Runtime版本一致,包括以下头文件:
onnxruntime_cxx_api.h
onnxruntime_cxx_inline.h
onnxruntime_c_api.h
onnxruntime_session_options_config_keys.h
onnxruntime_float16.h
onnx 训练后量化
表 1 常见命令参数
量化命令示例:
amct_onnxcalibration --model before_quant.onnx --save_path quant _out --input_shape“x1:1,1;x2:1,2;x3:1,3" --data_dir“path_x1/x1; path_x2/x2; path_x3/x3" --data_types"float32;float32;float32" --calibration_config config.cfg
配置文件示例:
batch_num : 2 fakequant_precision_mode: FORCE_FP16_QUANT activation_offset : true common_config : { ifmr_quantize : { dst_type: INT8 search_range_start : 0.7 search_range_end : 1.3 search_step : 0.01 max_percentile : 0.999999 min_percentile : 0.999999 } } override_layer_types : { layer_type : "Gemm" calibration_config : { ifmr_quantize : { search_range_start : 0.8 search_range_end : 1.2 search_step : 0.02 max_percentile : 0.999999 min_percentile : 0.999999 } } }
pytorch量化感知训练
表 2 内容项说明
配置文件示例:
{ "version":1, "batch_num":1, "layername1":{ "retrain_enable":true, "retrain_data_config":{ "algo":"ulq_quantize", "clip_max":3.0, "clip_min":-3.0 }, "retrain_weight_config":{ "algo":"arq_retrain", "channel_wise":true } }, "layername2":{ "retrain_enable":true, "retrain_data_config":{ "algo":"ulq_quantize", "clip_max":3.0, "clip_min":-3.0 }, "retrain_weight_config":{ "algo":"arq_retrain", "channel_wise":true } } }
模型编译¶
背景
昇腾张量编译器 ATC(Ascend Tensor Compiler) 是异构计算架构CANN体系下的模型转换工具,将开源框架下的网络模型转换为昇腾AI处理器支持的exeom格式。详细请参考《ATC离线模型编译工具用户指南.pdf》文档。
编译命令示例
atc --mode=30 --framework=5 --soc_version=Ascend035A --model=matmul_sample.onnx --output=matmul --input_fp16_nodes="x" --output_type=FP16(Nano系列 mode需配置为30, onnx时 framework需配置为5 )
表 1 常见命令参数
格式:“input_name1:n1,c1,h1,w1;input_name2:n2,c2,h2,w2”,input_name为转换前网络模型中的节点名 |
模型部署¶
ACL接口¶
背景&适用范围
《应用开发指南》介绍了AscendCL的主要功能、基本概念,用户通过《应用开发指南》可以快速了解AscendCL整体框架,以及提供的接口。同时,还可以通过文档中的指导,在第三方框架中调用AscendCL接口,来开发自己的APP或封装第三方库

acl API参考包含以下内容:
描述了所有接口和数据类型,包括个别废弃的接口和错误码,接口描述中包含了原型描述和参数说明
头文件和库文件说明中介绍了对应接口所在的头文件和库文件,便于编译
根据流程来介绍接口,对应流程相关接口可以在前面的流程概述中找到使用方法
数据类型及其操作接口中介绍了自定义数据类型和枚举值,以及对应的接口使用方法
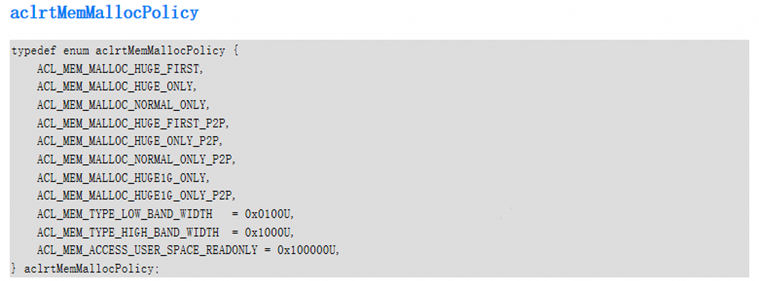
注意
文档中会附带代码示例,所有代码示例均为关键步骤的示例,不可直接拷贝编译运行,仅供参考,详细例子可以参考Sample
此文档中仅包含AscendCL的错误码和定位流程,对于部分特殊场景下的报错,需要结合驱动日志来定位问题
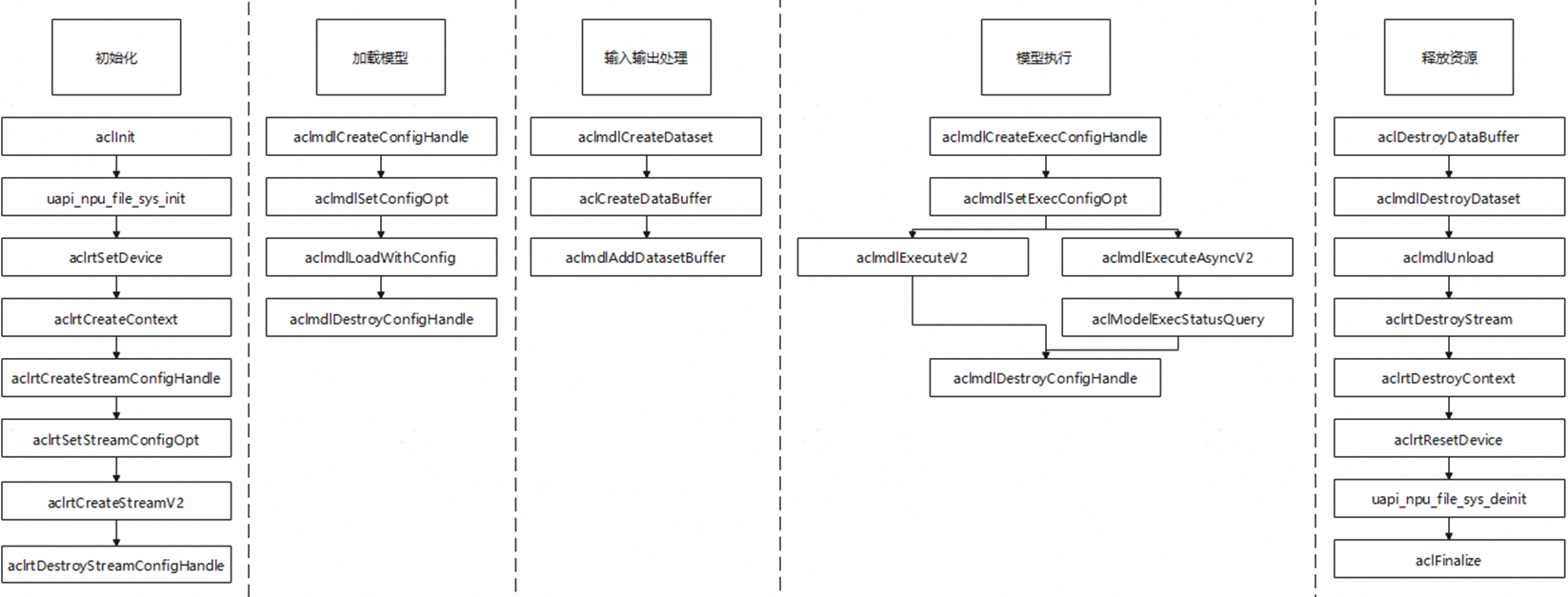
参考Sample¶
背景
对于一次完整的模型推理,需要调用多个acl接口进行实现,为方便用户快速上手开发,现提供sample供用户学习。详细示例可参考“SDK application/samples/ai_samples”以及“SDK application/3322/3322_ai_engine/ai_sample”。
示例路径
application ├── 3322 │ └── 3322_ai_engine │ └── ai_sample // 行业sample │ └── public // 开源目录 │ ├── fuzzy_command_word // 模糊命令词sample │ │ ├── files // 必需的二进制文件 │ │ ├── inc // 头文件 │ │ ├── readme.md // 帮助文档 │ │ └── src // 源文件 │ └── tts // TTS │ ├── files // 必需的二进制文件 │ ├── inc // 头文件 │ ├── readme.md // 帮助文档 │ └── src // 源文件 └── samples └── ai_samples └── acl // 教学sample └── matmul // 级联matmul ├── build_npu.sh // sample编译脚本 ├── files // 必需的二进制文件 ├── readme.md // 帮助文档 └── src // 源文件
行业sample
模糊命令词:根据音频内容来识别语音意图,最后根据不同的语音意图输出对应的字符串,例如输入为"查看心率",输出openheartrate
TTS:接收长度为100的音素数据,将其转换为pcm数据并保存
教学sample
级联matmul:一个简易的矩阵乘计算模型,对输入与固定值进行矩阵乘运输,得到输出。主要向用户呈现acl接口的使用方法

SDK编译&烧录¶
背景
用户需要使用自己编写的代码,提供编译与烧录方法将代码运行在板端环境中
流程
调用根目录下的编译脚本进行编译,执行命令./build.py 3322 –c,选择版本进行编译。编译完成后,在output/3322/fwpkg目录下获取镜像文件,使用burntool工具将镜像文件烧录到板子中
示例
若用户需要将自己的代码添加到版本中,需要进行以下操作
假设用户将代码编写在根目录下的mycode目录下
编写mycode目录下的CMakeLists.txt文件,添加代码set(COMPONENT_NAME "MyCode")
修改mycode目录同级的CMakeLists.txt文件,添加代码add_subdirectory_if_exist(mycode)
修改编译配置文件,在对应版本中添加自定义代码仓
例如:需要将代码编入3322-wstp-app版本中,参考/build/config/target_config/3322/config.py,可知该版本的base_target_name为target_standard_3322_application_template,在/build/config/target_config/3322/ target_config.py中,修改target_standard_3322_application_template的ram_component字段,添加MyCode自定义代码仓
注意:如果用户需要将自己的代码编译为.a文件,需要使用miniSDK,参考相关指导文档进行编译
模型调优¶
分析日志¶
背景&适用范围
在部分场景下,仅AscendCL错误码不能定位到根本原因,需要通过驱动日志来辅助定位
《日志分析用户指南》中介绍了驱动日志格式,可以通过关键字来快速搜索对应的错误日志,然后通过文档中对日志的介绍,来定位问题
详细文档可参考《驱动日志说明文档.pdf》
目录结构
日志分类中介绍了驱动日志的打印等级以及模块分类,同时提供了设置打印等级的接口使用方式,可以通过设置打印等级来减少日志数量;通过模块分类来快速定位异常模块
异常场景中列举了驱动中几个主要的异常场景,以及异常场景时的日志关键字,通过关键字匹配可以定位到当前异常的场景
典型案例中介绍了几种异常场景下的定位过程,以及解决方法和注意事项
示例
日志打印等级设置接口使用示例
// 只打印error日志
uapi_npu_dlog_setlevel(0x10, 3, 0);
// 屏蔽所有日志
uapi_npu_dlog_setlevel(0x10, 4, 0);
日志关键字匹配
在驱动初始化、模型加载、创建流、模型执行等过程中,都有资源的申请和释放,驱动内部的资源申请失败时有以下打印
// 申请内存资源失败
[NDRV]***** malloc fail
// 申请其他资源失败,如从模型池中申请模型id失败
[NDRV]***** alloc fail
案例分析和解决方法
在调用查询接口查询模型信息过程中,报以下错误
[NFS]region not init
[NFS]file open fail
[ERROR][model_segment_load.c:24]7:ErrorNo:545000(GE_ERRORNO_STR)[GE][MODULE] [open][file]
failed, file 11111.exeom
[ERROR][ge_executor.c:107]7:ErrorNo:545000(GE_ERRORNO_STR)[GE][MODULE] Load file[11111.exeom]
failed, ret = [145002]
[model.c:205]7:REPORT_CALL_ERROR query partition size failed, ge ret[145002]
acl层接口返回的错误码是145002,对应错误是模型路径无效,实际上对应模型文件路径正确。从驱动错误日志可以看出,文件系统未初始化导致找不到对应的模型文件,在加载模型之前执行uapi_npu_file_sys_init即可
精度对比分析¶
背景&适用范围
网络遇到精度问题时可以通过dump工具导出指定层输入/输出数据,并转换为指定格式,快速定位至异常层。
可对比融合规则关闭前后数据、标杆数据结果。
详细文档可参考《精度调试工具用户指南.pdf》。
使用步骤
注:dbg为编译时同步生成的文件,需放入json中dump_path的路径下
解析命令
Dump文件生成指定类型文件:
python3 msaccucmp.py convert -d <dump_file> [-t <npy/bin等>]
Dump文件之间比较:
python3 msaccucmp.py file_compare -m my_dump_path –g golden_dump_path –out output
json配置示例
{ “dump”: { “dump_list”: [ { “model_name”: “matmul_sample”, “layer”:[ “matmul_2” ] } ], "dump_path": "/home/output", "dump_mode": "output", "dump_op_switch": "off", "dump_data": "tensor" } }

精度优化建议¶
量化精度
合适的QAT算法量化精度相比PTQ更高,因此尽量选择QAT算法
Fm仅支持per_tensor量化,weight支持per_channel或per_tensor量化,需尽可能保证fm和输入的数据分布较均匀,否则会出现较大的量化误差
产品端实际的输入数据需跟量化过程使用的校准数据分布范围保持一致,否则实际数据在NPU上执行时会计算溢出,产生较大的误差
LSTM、GRU这类RNN算子使用历史数据用于当前帧计算,量化误差会随帧数累积,可降低隐藏层维度,或减少该类算子使用
算子计算精度
FAQ¶
Q:模型编译工具(ATC)中input_fp16_nodes、output_type参数怎么理解,什么时候需要配置?
A:这两个参数用于指定输入是fp16类型的节点和输出节点的数据类型;Nano NPU的Vector只支持fp16类型,当输入节点为浮点类型,应配置为fp16类型,输出节点中只要有一个节点为浮点就需要把output_type配置为fp16。
Q:模型中哪些层需要做量化,如果某些层数据精度对量化敏感,能否不做量化?
A:网络中涉及矩阵运算的层,如Matmul、Conv、ConvTranspose、LSTM、GRU、Gemm等均需量化,只涉及向量运算的层不量化;是否量化由算子是否涉及矩阵运算决定,即使是精度对量化敏感的层,涉及矩阵运算也需要量化。
Q:量化训练过程中如何判断是否收敛,结果不收敛时如何判断是哪个算子导致?
A:量化训练和pytorch训练一样,可以输出训练过程中的Loss值,从而判断是否收敛;如果不收敛,则可通过量化配置文件使某些层不量化,从而判断是否是这些层的量化导致的问题。
Q:LSTM、GRU算子序列长度大于1的情况是否需要将其复制成多个算子,这两类算子如果拆成小算子和一整个算子是否有差别?
A:当前只支持序列长度为1的LSTM、GRU算子,需要将单个算子拆成多个,但权重数据共用一份;拆成小算子后会造成数据频繁搬入搬出NPU,影响性能。
Q:权重1M的模型,模型总的占用内存大概是多少
A:模型占用内存由权重、算子指令、输入输出、中间层数据构成,不同的模型在算子指令和中间层数据方面可能有较大差异,可通过1.2节中的模型评估脚本进行初步评估。
Q:om文件有没有说明文档,能否可视化?
A:Nano NPU使用exeom格式,该格式暂无说明文档,内部算子类型和网络结构已通过编译的方式进行隐藏,因此无法可视化,同时这种方式在一定程度上也对模型进行了一次加密。
Q:调用NPU时最多能创建多少个device、context,是建议使用1个context对应多个流还是多个context对应多个流?
A:通常1个NPU就只创建1个device,按照模型优先级的数量创建context,同一个优先级的网络对应1个context和1条流。