
学习向导¶
本节给出AMCT(Ascend Model Compression Toolkit,简称AMCT)的概念以及优势、文档的使用对象,并给出不同框架下AMCT的差异,用户根据场景选择不同框架进行模型压缩。
AMCT是一个针对昇腾芯片亲和的深度学习模型压缩工具包,提供量化、张量分解等多种模型压缩特性,压缩后模型体积变小,部署到NPU IP加速器上后可使能低比特运算,提高计算效率,达到性能提升的目标。
AMCT基于开源框架运作,实现了神经网络模型中数据与权重低比特量化、张量分解、模型部署优化(主要为算子融合)的功能,该工具优点如下:
使用方便,基于用户原有的框架环境,安装工具包即可。
接口简单,在用户基于开源框架的推理脚本基础上,调用API即可完成模型压缩,压缩后的模型支持在CPU和GPU运行。
与硬件配套,生成的压缩模型经过ATC工具转换后可在NPU IP加速器上实现低比特推理。
量化可配置,用户可自行修改量化配置文件,调整压缩策略,获取较优的压缩结果。
AMCT当前使用的压缩方法主要包括量化和张量分解,量化过程中可以实现模型部署优化(主要为算子融合)。
各种压缩方式优缺点比较
表 1 压缩方式比较
压缩方式 |
优点 |
缺点 |
支持框架 |
支持产品型号 |
|
|---|---|---|---|---|---|
量化 |
训练后量化 |
|
依赖校准数据集分布情况,如果校准数据集与验证数据集分布差异较大,会导致量化结果差;没有对权重进行重训练,量化后模型精度掉点较大。 |
|
IPV350 |
量化感知训练 |
|
|
|
IPV350 |
|
稀疏 |
通道稀疏 |
|
|
|
不支持该特性 |
4选2结构化稀疏 |
稀疏的粒度较小,可以保留较多重要信息,具有细粒度稀疏的精度优势。 |
|
|
不支持该特性。 |
|
组合压缩 |
- |
可以同时对模型进行量化和稀疏,得到更高的压缩率。 |
涉及重训练,过程比较耗时;同步进行了量化和稀疏,对模型精度影响大。 |
|
不支持该特性 |
张量分解 |
- |
将卷积核分解为低秩张量,降低存储空间和计算量 |
- |
|
不支持该特性 |
自动混合精度搜索 |
- |
解决用户手动调优困难,自动对每一层计算精度配置给出较优解。 |
- |
|
不支持该特性 |
量化数据均衡预处理 |
- |
降低activation离群值对于量化后模型精度的影响。 |
- |
|
IPV350 |
逐层蒸馏 |
- |
在量化的基础上可以对权重进行微调,在保障较高精度的同时,对比重训练有更短的执行时长。 |
- |
PyTorch |
不支持该特性 |
AMCT各框架差异
手册 |
介绍 |
|---|---|
AMCT(PyTorch) |
针对PyTorch框架模型进行的压缩,需要搭建PyTorch环境,搭建完成后安装AMCT工具。 |
AMCT(ONNX) |
针对ONNX模型进行的压缩,需要搭建ONNX Runtime环境,搭建完成后安装AMCT工具。 |
AMCT(TensorFlow)(不支持) |
针对TensorFlow框架模型进行的压缩,需要搭建TensorFlow环境,搭建完成后安装AMCT工具。 如下产品型号不支持TensorFlow框架: IPV350 |
AMCT(Caffe)(不支持) |
针对Caffe框架模型进行的压缩,需要搭建Caffe环境,搭建完成后安装AMCT工具。 如下产品型号不支持Caffe框架: IPV350 |
使用对象
本文档用于指导开发者如何使用AMCT工具进行模型压缩,通过本文档您可以达成以下目标:
了解AMCT不同的压缩方法。
能够基于文档中提供的方法,完成不同模型的压缩。
掌握常用的压缩方法:量化。
熟悉Linux基本命令、具备Python语言程序开发能力,对机器学习、深度学习有一定了解的人员,可以更好地理解本文档。
概述¶
本节给出模型压缩过程中用到的概念,并介绍了不同压缩方法的原理。 本节介绍使用AMCT工具的具体流程,不同框架运行环境以及流程会有稍许差异。
基本概念¶
本节给出模型压缩过程中用到的概念,并介绍了不同压缩方法的原理。
量化
量化是指对模型的权重(weight)和数据(activation)进行低比特处理,让最终生成的网络模型更加轻量化,从而达到节省网络模型存储空间、降低传输时延、提高计算效率,达到性能提升与优化的目标。
AMCT将量化和模型转换分开,实现对模型中可量化算子的独立量化,并输出量化后的模型。其中量化后的仿真模型可以在CPU或者GPU上运行,完成精度仿真;量化后的部署模型可以部署在NPU IP加速器上运行,达到提升推理性能的目的。
当前该工具仅支持对float32/float16数据类型的网络模型进行量化(Caffe框架、MindSpore框架不支持float16类型),以量化到INT8数据类型为例,其运行原理如下图所示。
图 1 量化运行原理
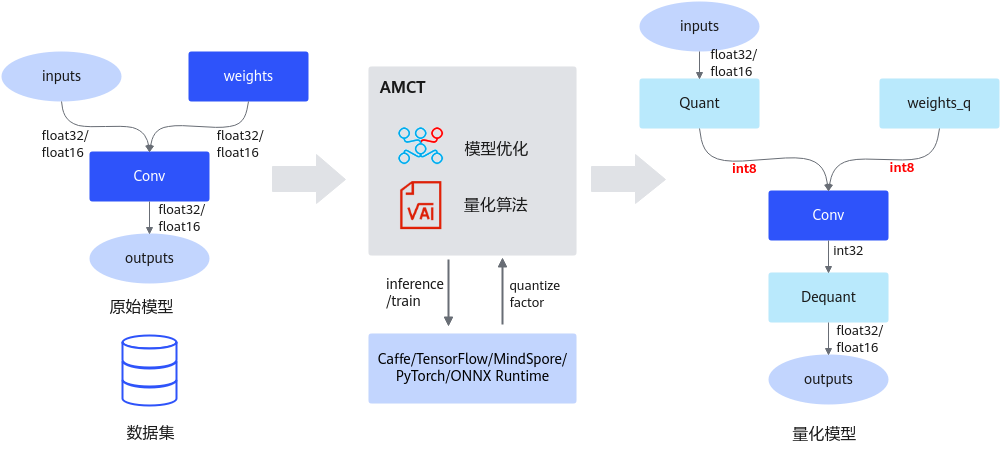
量化根据是否需要重训练,分为训练后量化(Post-Training Quantization,简称PTQ)和量化感知训练(Quantization-Aware Training,简称QAT),概念解释如下:
训练后量化
训练后量化是指在模型训练结束之后进行的量化,对训练后模型中的权重由浮点数量化到低比特整数,并通过少量校准数据基于推理过程对数据(activation)进行校准量化,从而尽可能减少量化过程中的精度损失。训练后量化简单易用,只需少量校准数据,适用于追求高易用性和缺乏训练资源的场景。
通常,训练后的模型权重已经确定,因此可以根据权重的数值离线计算得到权重的量化参数。而通常数据是在线输入的,因此无法准确获取数据的数值范围,通常需要一个较小的有代表性的数据集来模拟在线数据的分布,利用该数据集执行前向推理,得到对应的中间浮点结果,并根据这些浮点结果离线计算出数据的量化参数。其原理如下图所示。
图 2 训练后量化原理
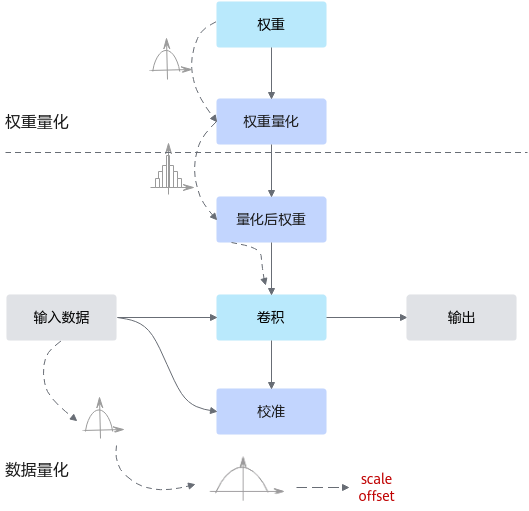
量化感知训练
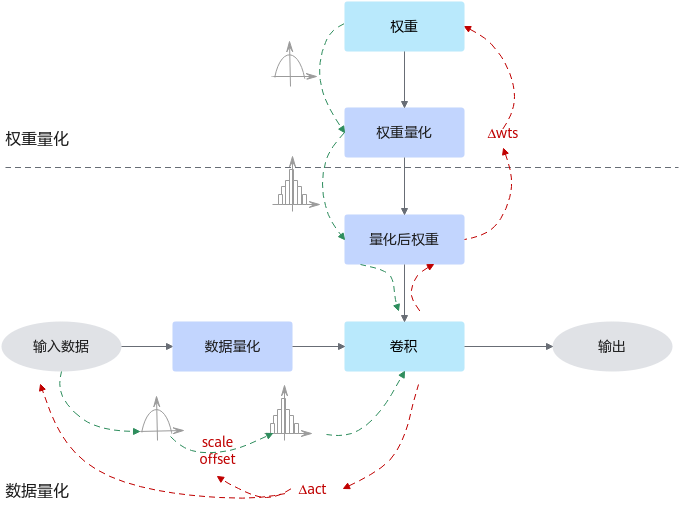
量化感知训练是指在重训练过程中引入量化,通过重训练提高模型对量化效应的能力,从而获得更高的量化模型精度的一种量化方式。量化感知训练借助用户完整训练数据集,在训练过程中引入伪量化的操作(从浮点量化到定点,再还原到浮点的操作),用来模拟前向推理时量化带来的误差,并借助训练让模型权重能更好地适应这种量化的信息损失,从而提升量化精度。
通常,量化感知训练相比训练后量化,精度损失会更小,但主要缺点是整体量化的耗时会更长;此外,量化过程需要的数据会更多,通常是完整训练数据集。
其运行原理如下图所示。
图 3 量化感知训练原理
张量分解(不支持该特性)****
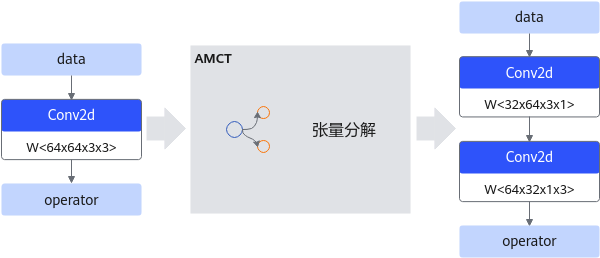
深度学习运算,尤其是CV(计算机视觉)类任务运算,包含大量的卷积运算,而张量分解通过分解卷积核的张量,可以将一个大卷积核分解为两个小卷积核的连乘,即将卷积核分解为低秩的张量,从而降低存储空间和计算量,降低推理开销。
以1个64*64*3*3的卷积分解为32*64*3*1和64*32*1*3的级联卷积为例,可以减少1 - (32*64*3*1 + 64*32*1*3) / 64*64*3*3 = 66.7%的计算量,在计算结果近似的情况下带来更具性价比的性能收益。张量分解运行原理如下图所示(以PyTorch框架为例)。
图 4 张量分解运行原理
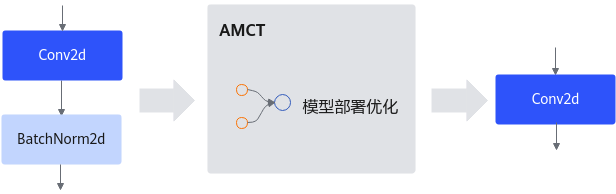
模型部署优化(不支持该特性)****
主要为算子融合,是指通过数学等价,将模型中的多个算子运算融合单算子运算,以减少实际前向过程中的运算量,如将卷积层和BN层融合为一个卷积层。
其运行原理如下图所示(以PyTorch框架为例)。
图 5 模型部署优化原理
稀疏(不支持该特性)****
稀疏是通过结构剪枝的方式,对模型中的部分算子实现权重的稀疏化,从而得到一个参数量更小、计算量更小的网络模型。AMCT目前有两种稀疏方式:通道稀疏和4选2结构化稀疏。每次只能使能其中一种稀疏方式,即对于同一层可压缩算子,通道稀疏和4选2结构化稀疏不能同时配置。
通道稀疏与4选2结构化稀疏相比,稀疏颗粒度更大,对模型的精度影响也越大,但是能够获取到的性能收益也越大,用户可以根据实际情况选择一种稀疏方式。
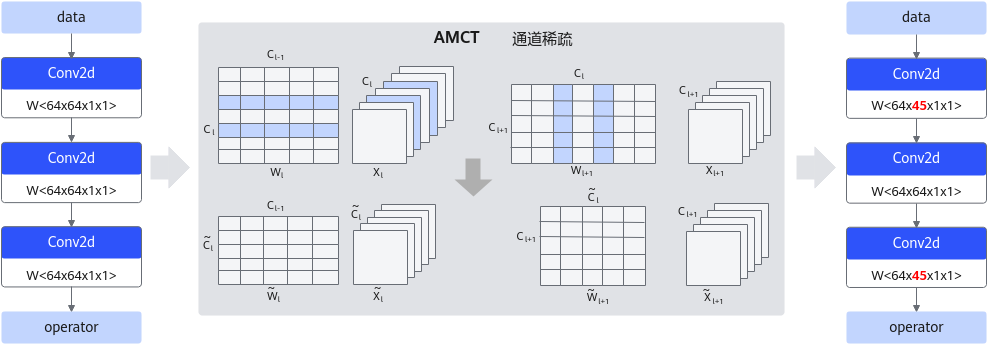
通道稀疏
通道稀疏基于重训练,通过裁剪网络通道数,在保持网络功能的前提下缩减模型参数量,从而降低整网的计算量。由于通道稀疏本身是依据通道的重要性进行裁剪,会裁剪掉重要性相对较低的通道,但是直接裁剪通道对网络精度影响较大,故裁剪后的模型需要进行重训练,以保证业务精度。通道稀疏的实现通常包括两个步骤:首先是通道选择,需要选择合适的通道组合以保留丰富的信息;然后是重建,需要使用选择的通道对下一层的输出进行重建。通道稀疏原理如下图所示。
图 6 通道稀疏示意图
4选2结构化稀疏
由于硬件约束,该芯片不支持4选2结构化稀疏特性:使能后获取不到性能收益。
4选2结构化稀疏基于重训练,在每4个连续的权重中保留2个重要性相对较高的权重,其余权重置0。因为稀疏的粒度较小,因此4选2结构化稀疏可以保留较多重要信息,具有细粒度稀疏的精度优势;同时4选2结构化稀疏在专门设计的硬件上可以降低运算量,具有结构化稀疏的性能优势。与通道稀疏不同的是,4选2稀疏并不改变权重的形状,因此不会影响上层或下层的算子。
原理如下图所示,在cin维度上相邻的4个元素为一组,在每组4个元素中保留绝对值最大的两个元素,如果cin不是4的倍数,填0补齐到4的倍数。
图 7 4选2稀疏示意图

组合压缩(不支持该特性)****
组合压缩是结合了稀疏和量化的特性,根据配置文件先进行稀疏,然后进行量化;在稀疏时根据相应算法插入稀疏算子,然后量化时,对稀疏后的模型插入数据和权重的量化层和SearchN的层,生成组合压缩模型,以期望得到更高的性能收益。生成组合压缩模型后,对模型进行重训练,保存为既可以进行精度仿真又可以部署的量化模型。
逐层蒸馏(不支持该特性)****
蒸馏量化是模型压缩的一种方法,利用原始模型的监督信息,对量化模型进行训练,以达到更好量化精度的目的。
将预训练好的原始模型作为教师网络,以教师网络层的输出做为目标,对学生网络进行监督训练,通过计算教师网络和学生网络输出预测值的损失,进行梯度更新,最终得到一个更高精度的量化模型。
相比训练后量化,知识蒸馏的量化可以取得更好的精度结果。
相比量化感知训练,知识蒸馏的量化不需要有标签的数据集,且可以在更短的量化时间内获得不错的量化结果。
图 8 逐层蒸馏示意图
工具运行流程¶
本节介绍使用AMCT工具的具体流程,不同框架运行环境以及流程会有稍许差异。
PyTorch/ONNX/TensorFlow/Caffe场景
如下产品型号不支持Caffe框架:
IPV350
如下产品型号不支持TensorFlow框架:
IPV350
具体运行流程如图1所示。
图 1 运行流程
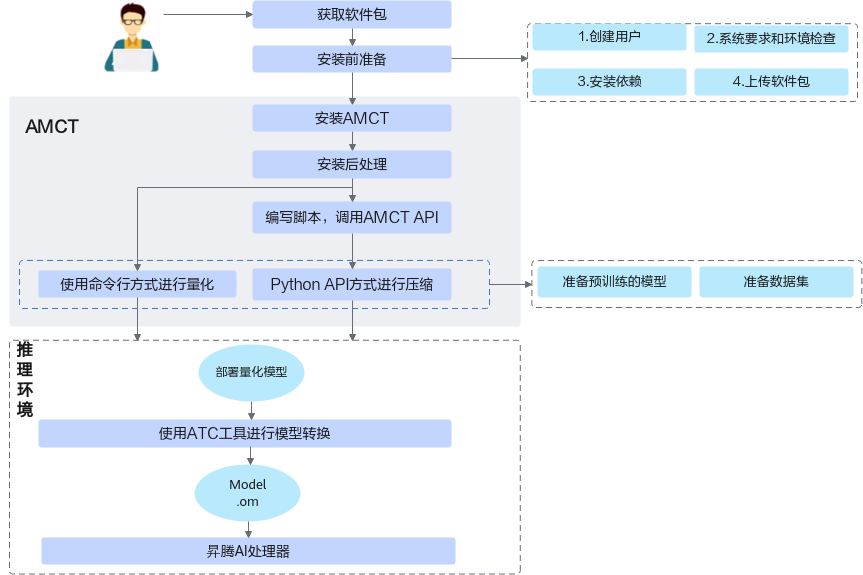
表 1 运行流程关键操作步骤说明
关键步骤 |
说明 |
|---|---|
获取软件包 |
安装前请先获取对应软件包,详情请参见获取软件包。 |
安装前准备 |
安装AMCT之前,需要创建AMCT的安装用户,检查系统环境是否满足要求,安装依赖以及上传软件包等一系列动作。详细操作请参见安装前准备。 不同框架环境配置不同,请参见对应框架进行操作。 |
安装 |
参见安装工具章节安装AMCT工具,不同框架安装命令不同,请参见对应框架安装步骤进行操作。 |
安装后处理 |
安装完AMCT后,需要参见安装后处理章节执行相关操作,没有该章节的框架,则忽略此步骤。 |
(可选)编写脚本,调用AMCT API |
如果使用AMCT提供的sample进行模型压缩,则可以直接调用本手册中的API; 如果用户需要压缩自己的网络模型,不使用本手册提供的sample链接进行压缩,则需要修改压缩脚本,进行适配,然后才能进行压缩。 |
压缩 |
执行压缩操作。 关于量化特性,AMCT提供了两种量化方法,命令行方式量化和调用Python API接口方式,两种方式详细区别请参见表1。
用户根据准备的原始网络模型以及数据集,采用本手册提供的量化脚本或者命令行,进行量化。 AMCT是基于深度学习框架进行开发的,在执行压缩过程中需要调用深度学习框架进行必要的推理或训练过程。 |
(后续处理)压缩后模型的推理 |
用户使用上述压缩后的部署模型,通过ATC工具转换成适配NPU IP加速器的离线模型,然后可以使用该模型进行推理。 |
准备环境¶
介绍安装前的准备动作,包括准备用户、检查环境、安装依赖、上传软件包等。 本节介绍AMCT工具具体的安装命令。
获取软件包¶
AMCT仅支持在Ubuntu 20.04 x86_64架构服务器安装;安装前,请先获取AMCT软件包:CANN-amct-{software version}-linux.x86_64.tar.gz
其中_{software version}_表示软件包具体版本号。
软件数字签名验证
为了防止软件包在传递过程或存储期间被恶意篡改,下载软件包时需下载对应的数字签名文件用于完整性验证。
在软件包下载之后,请参考《OpenPGP签名验证指南》,对从Support网站下载的软件包进行PGP数字签名校验。如果校验失败,请不要使用该软件包,先联系技术支持解决。
使用软件包安装/升级之前,也需要按上述过程先验证软件包的数字签名,确保软件包未被篡改。
安装前准备¶
介绍安装前的准备动作,包括准备用户、检查环境、安装依赖、上传软件包等。
用户准备¶
PyTorch/ONNX场景
支持任意用户(root或者非root)安装AMCT,本章节以非root用户为例进行操作。
若使用root用户安装,则不需要操作该章节,不需要对root用户做任何设置。
若使用已存在的非root用户安装,须保证该用户对$HOME目录具有读写以及可执行权限。
若使用新的非root用户安装,请参考如下步骤进行创建,如下操作请在root用户下执行。本手册以该种场景为例执行AMCT的安装。
执行以下命令创建AMCT安装用户并设置该用户的$HOME目录。
useradd -d /home/username -m username执行以下命令设置密码。
passwd username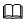 说明:
_username_为安装AMCT的用户名,该用户的umask值不能小于0027:
说明:
_username_为安装AMCT的用户名,该用户的umask值不能小于0027:若要查看umask的值,则执行命令**:umask**
若要修改umask的值,则执行命令:umask 新的取值
系统要求和环境检查¶
AMCT(PyTorch)¶
AMCT目前支持在Ubuntu 22.04 x86_64架构操作系统安装,版本配套信息如下:
表 1 配套版本信息
类别 |
版本限制 |
获取方式 |
注意事项 |
|---|---|---|---|
PyTorch |
2.1.0
|
用户根据实际情况选择安装CPU或GPU,请参见安装依赖。 |
|
CUDA toolkit/CUDA driver |
11.8
|
请用户自行获取相关软件包进行安装,例如可以参见如下链接获取相关toolkit包,该包中包括driver软件包。 |
如果使用GPU模式执行量化功能,则CUDA软件必须安装。 |
ONNX |
1.14.0 |
请参见安装依赖。 |
|
ONNX Runtime |
1.16.0 |
||
Python |
Python3.10.x、Python3.11.x 推荐使用3.10.0 |
Ubuntu操作系统请参见安装Python3.9.2(Ubuntu)。 |
|
numpy |
|
请参见安装依赖。 |
|
protobuf |
|
AMCT(ONNX)¶
AMCT目前支持在Ubuntu 22.04 x86_64架构操作系统安装,版本配套信息如下:
表 1 配套版本信息
类别 |
版本限制 |
获取方式 |
注意事项 |
|---|---|---|---|
操作系统及版本 |
Ubuntu 22.04 x86_64 |
请从Ubuntu官网下载对应版本软件进行安装,安装完成后查询命令为: cat /etc/*release && uname -m |
支持基于CPU,GPU的量化。 |
ONNX和Opset |
1.14.0
|
请参见安装依赖。 |
|
ONNX Runtime |
1.16.0 |
ONNX执行框架,请参见安装依赖。 |
|
CUDA、cuDNN |
|
请用户自行获取相关软件包进行安装。 CUDA获取路径:https://developer.nvidia.com/cuda-toolkit-archive cuDNN获取路径:https://developer.nvidia.com/zh-cn/cudnn |
如果使用ONNX Runtime GPU模式执行量化功能,则CUDA、cuDNN软件必须安装。 |
Python |
Python3.10.x、Python3.11.x 推荐使用Python 3.10.0 |
Ubuntu操作系统请参见安装Python3.9.2(Ubuntu)。 |
|
numpy |
|
请参见安装依赖。 |
|
protobuf |
|
AMCT(TensorFlow)¶
IPV350不支持
表 1 配套版本信息
类别 |
版本限制 |
获取方式 |
备注 |
|---|---|---|---|
CUDA toolkit/CUDA driver |
11.2或10.0 |
请用户自行获取相关软件包进行安装,例如可以参见如下链接获取相关toolkit包,该包中包括driver软件包。 |
如果使用GPU模式执行量化功能,则CUDA软件必须安装。
|
Python |
Python3.7.x、Python3.8.x、Python3.9.x 推荐使用Python3.9.2 |
Ubuntu操作系统请参见安装Python3.9.2(Ubuntu)。 |
|
TensorFlow |
2.6.5或1.15.0 |
请参见安装依赖。 |
TensorFlow版本与Python版本的对应关系:
|
numpy |
1.16.0~1.23.5或1.20.0~1.23.5 |
请参见安装依赖。 |
|
protobuf |
3.13.0+ |
请参见安装依赖。 |
- |
AMCT(Caffe)¶
IPV350不支持
表 1 配套版本信息
类别 |
版本限制 |
获取方式 |
备注 |
|---|---|---|---|
Caffe环境 |
caffe-master分支 当前仅支持commit id为9b891540183ddc834a02b2bd81b31afae71b2153的版本 |
请参考Caffe官方指导准备Caffe环境:https://github.com/BVLC/caffe/tree/master。 推荐使用源码方式安装Caffe环境,如果使用命令行方式安装,出现类似"/usr/bin/python3.7: can't open file '/usr/lib/python3.7/py_compile.py': [Error 2] No such file or directory"信息时,请参见使用命令行方式安装Caffe环境失败解决。 |
- |
CUDA toolkit/CUDA driver |
11.3或10.0 |
请用户自行获取相关软件包进行安装,例如可以参见如下链接获取相关toolkit包,该包中包括driver软件包。 |
如果使用GPU模式执行量化功能,则CUDA软件必须安装。 说明:
使用Ubuntu 20.04的情况下,推荐安装11.3版本CUDA软件。Ubuntu 20.04默认GCC版本为GCC9,如果使用10.0版本CUDA软件,因其配套GCC7版本,需要对默认的GCC版本进行降级,具体操作步骤请参见使用Ubuntu 20.04安装Caffe环境时,出现CUDA和GCC版本不匹配的编译报错。 |
Python |
Python3.7.x、Python3.8.x、Python3.9.x 推荐使用Python3.9.2 |
Ubuntu操作系统请参见安装Python3.9.2(Ubuntu)。 |
|
numpy |
1.20.0+ |
请参见安装依赖。 |
|
protobuf |
3.13.0+ |
安装依赖¶
AMCT(PyTorch)¶
请使用AMCT的安装用户安装依赖的软件,如果安装用户为非root,请确保该用户拥有sudo权限,请使用**su - username**命令切换到非root用户执行如下命令(如果安装用户为root,请将安装依赖命令中的--user删除)。
表 1 依赖列表
依赖名称 |
版本号 |
安装命令 |
|---|---|---|
PyTorch版本的CPU或GPU |
2.1.0 |
安装PyTorch时,请确保pip版本低于23.0.1,否则可能出现如下“ModuleNotFoundError:No module named 'torch' ”错误信息;如果用户pip版本高于23.0.1,且不想降低版本,则请优先安装wheel包(参考安装命令:pip3 install wheel --user),然后再执行后续操作。
|
ONNX |
1.14.0 |
|
ONNX Runtime |
1.16.0 |
|
Python |
以3.9.2版本为例 |
Ubuntu操作系统请参见安装Python3.9.2(Ubuntu)。 |
numpy |
|
|
protobuf |
|
|
AMCT(ONNX)¶
请使用AMCT的安装用户安装依赖的软件,如果安装用户为非root,请确保该用户拥有sudo权限,请使用**su - username**命令切换到非root用户执行如下命令(如果安装用户为root,请将安装依赖命令中的--user删除)。
表 1 依赖列表
依赖名称 |
版本号 |
安装命令 |
|---|---|---|
ONNX |
1.14.0 |
|
ONNX Runtime |
1.16.0 |
ONNX Runtime CPU安装命令请参见下面指导;1.9.0版本以下ONNX Runtime GPU版本需要用户自行安装。
|
Python |
以3.9.2版本为例 |
Ubuntu操作系统请参见安装Python3.9.2(Ubuntu)。 |
numpy |
|
|
protobuf |
|
|
AMCT(TensorFlow)¶
IPV350不支持
请使用AMCT的安装用户安装依赖的软件,如果安装用户为非root,请确保该用户拥有sudo权限,请使用**su - username**命令切换到非root用户执行如下命令(如果安装用户为root,请将安装依赖命令中的--user删除)。
表 1 依赖列表
依赖名称 |
版本号 |
安装命令 |
|---|---|---|
Python |
3.9.2或3.7.5 |
Ubuntu操作系统请参见安装Python3.9.2(Ubuntu)。 |
TensorFlow |
2.6.5或1.15.0 |
用户根据实际情况选择安装CPU或GPU。
须知:
|
numpy |
1.16.0~1.23.5或1.20.0~1.23.5 |
pip3 install numpy==1.16.0 --user 或pip3 install numpy==1.20.0 --user |
protobuf |
3.13.0+ |
pip3 install protobuf==3.13.0 --user |
AMCT(Caffe)¶
IPV350不支持
请使用AMCT的安装用户安装依赖的软件,如果安装用户为非root,请确保该用户拥有sudo权限,请使用**su - username**命令切换到非root用户执行如下命令(如果安装用户为root,请将安装依赖命令中的--user删除)。
表 1 依赖列表
依赖名称 |
版本号 |
安装命令 |
|---|---|---|
Python |
3.9.2 |
Ubuntu操作系统请参见安装Python3.9.2(Ubuntu)。 |
numpy |
1.20.0+ |
pip3 install numpy==1.20.0 --user |
protobuf |
3.13.0+ |
pip3 install protobuf==3.13.0 --user |
上传软件包¶
以AMCT的安装用户将CANN-amct-{software version}-linux.{arch}.tar.gz软件包上传到Linux服务器任意目录下,本示例为上传到$HOME/amct/目录。
执行如下命令解压AMCT软件包:
tar -zxvf CANN-amct-{software version}-linux.{arch}.tar.gz
获得如下内容:
表 1 AMCT软件包解压后内容
一级目录 |
二级目录 |
说明 |
使用场景及注意事项 |
|---|---|---|---|
amct_caffe/ |
Caffe框架AMCT目录。 |
|
|
amct_caffe-{version}-py3-none-linux_{arch}.whl |
Caffe框架AMCT安装包。 |
||
caffe_patch.tar.gz |
Caffe源代码增强包。 |
||
amct_tf/ |
TensorFlow框架AMCT目录。 |
||
amct_tensorflow-{version}-py3-none-linux_{arch}.tar.gz |
TensorFlow框架AMCT安装包,通过源码编译方式进行安装。 |
|
|
amct_tensorflow_ascend-{version}-py3-none-linux_{arch}.tar.gz |
基于TF_Adapter的AMCT安装包,通过源码编译方式进行安装。 |
|
|
amct_pytorch/ |
PyTorch框架AMCT目录。 |
|
|
amct_pytorch-{version}-py3-none-linux_{arch}.tar.gz |
PyTorch框架AMCT源码安装包。 |
||
amct_onnx/ |
ONNX模型AMCT目录。 |
|
|
amct_onnx-{version}-py3-none-linux_{arch}.whl |
ONNX模型AMCT安装包。 |
||
amct_onnx_op.tar.gz |
AMCT基于ONNX Runtime的自定义算子包。 |
||
conf/ |
- |
- |
记录包的安装信息,用户无需关注。 |
latest_manager/ |
- |
- |
安装升级使用的公共脚本,用户无需关注。 |
third_party/ |
Ascend-nca-{software version}-linux.{arch}.run |
NCA(Neural Compute Agent)软件包。 |
基于性能的自动量化场景下使用。该版本不支持third_party目录下的相关特性。 |
其中:_{version}表示AMCT具体版本号,{software version}为软件版本号,{arch}_表示具体操作系统架构。
安装工具¶
本节介绍AMCT工具具体的安装命令。
AMCT(PyTorch)
在AMCT软件包所在目录下,执行如下命令进行源码安装(如果安装用户为root,请将安装命令中的--user删除):
pip3 install amct_pytorch-{version}-py3-none-linux_{arch}.tar.gz --user其中:_{version}表示AMCT具体版本号,{arch}_表示软件包支持的安装服务器具体架构形态。如果使用root用户安装AMCT,并且使用了--target参数,请确保--target参数指定的路径为当前用户的路径,避免指定到其他非root用户。
若出现如下信息则说明工具安装成功。
Successfully build amct-pytorch ... Successfully installed amct-pytorch-{version}
用户可以在Python软件包所在路径下(例如:$HOME/.local/lib/python3.9/site-packages)查看已经安装的AMCT,例如:
drwxr-xr-x 5 amct amct 4096 Mar 17 11:50 amct_pytorch/ drwxr-xr-x 2 amct amct 4096 Mar 17 11:50 amct_pytorch-{version}.dist-info/
其中amct_pytorch即为AMCT所在安装目录。
说明:
amct_pytorch和amct_tensorflow不能在Python同一个进程中导入,两个包共用同一个basic_info.proto,同时导入会引发proto重复定义问题。
amct_tensorflow为TensorFlow框架AMCT的安装目录;basic_info.proto文件所在路径为:AMCT安装目录/proto。
AMCT(ONNX)
安装AMCT**。**
在AMCT软件包所在目录下,执行如下命令进行安装(如果安装用户为root,请将安装命令中的--user删除):
pip3 install amct_onnx-{version}-py3-none-linux_{arch}.whl --user其中:_{version}表示AMCT具体版本号,{arch}_表示软件包支持的安装服务器具体架构形态。如果使用root用户安装AMCT,并且使用了--target参数,请确保--target参数指定的路径为当前用户的路径,避免指定到其他非root用户。
若出现如下信息则说明工具安装成功。
Successfully installed amct-onnx-{version}用户可以在Python软件包所在路径下(例如:$HOME/.local/lib/python3.9/site-packages)查看已经安装的AMCT,例如:
drwxr-xr-x 5 amct amct 4096 Mar 17 11:50 amct_onnx/ drwxr-xr-x 2 amct amct 4096 Mar 17 11:50 amct_onnx-{version}.dist-info/
其中amct_onnx即为AMCT所在安装目录。
AMCT(TensorFlow)
IPV350不支持
在AMCT软件包所在目录,执行如下命令进行安装(如果安装用户为root,请将安装命令中的--user删除):
该格式软件包以源码方式安装,安装过程中执行编译并安装的操作:
pip3 install amct_tensorflow-{version}-py3-none-linux_{arch}.tar.gz --user其中:_{version}表示AMCT具体版本号,{arch}_表示软件包支持的安装服务器具体架构形态。如果使用root用户安装AMCT,并且使用了--target参数,请确保--target参数指定的路径为当前用户的路径,避免指定到其他非root用户。
如果用户的安装服务器缺少某些编译依赖,无法采用源码包的方式安装AMCT,则可以参见源码包编译为whl包,以whl包形式安装AMCT将源码包编译为whl包进行安装。
若出现如下信息则说明工具安装成功。
Successfully installed amct-tensorflow-{version}用户可以在Python软件包所在路径下(例如:$HOME/.local/lib/python3.9/site-packages)查看已经安装的AMCT,例如:
drwxr-xr-x 5 amct amct 4096 Mar 17 11:50 amct_tensorflow/ drwxr-xr-x 2 amct amct 4096 Mar 17 11:50 amct_tensorflow-{version}.dist-info/
其中amct_tensorflow即为AMCT所在安装目录。
说明:
amct_tensorflow和amct_pytorch不能在Python同一个进程中导入,两个包共用同一个basic_info.proto,同时导入会引发proto重复定义问题。
amct_pytorch为PyTorch框架AMCT的安装目录;basic_info.proto文件所在路径为:AMCT安装目录/proto。
AMCT(Caffe)
IPV350不支持
在AMCT软件包所在目录,执行如下命令进行安装(如果安装用户为root,请将安装命令中的--user删除):
pip3 install amct_caffe-{version}-py3-none-linux_{arch}.whl --user其中:_{version}表示AMCT具体版本号,{arch}_表示软件包支持的安装服务器具体架构形态。如果使用root用户安装AMCT,并且使用了--target参数,请确保--target参数指定的路径为当前用户的路径,避免指定到其他非root用户。
若出现如下信息则说明工具安装成功。
Successfully installed amct-caffe-{version}用户可以在Python3.9.2安装包所在路径下(例如:$HOME/.local/lib/python3.9/site-packages,该路径请以用户实际安装的为准)查看已经安装的AMCT,例如:
drwxr-xr-x 5 amct amct 4096 Mar 17 11:50 amct_caffe/ drwxr-xr-x 2 amct amct 4096 Mar 17 11:50 amct_caffe-{version}.dist-info/
其中amct_caffe即为AMCT所在安装目录。
安装后处理¶
AMCT量化过程中的日志信息以及日志级别,可以通过环境变量设置,本章节给出详细设置方法。
AMCT(PyTorch)¶
AMCT量化过程中的日志信息以及日志级别,可以通过环境变量设置,本章节给出详细设置方法。
日志包括打印在屏幕上的日志以及保存到amct_log/amct_pytorch.log文件中的日志,该部分环境变量为可选配置,如果不设置,则按照默认日志级别,默认级别为INFO。
变量取值
日志打印级别通过如下两个变量设置:
AMCT_LOG_FILE_LEVEL:控制amct_pytorch.log日志文件的信息级别以及生成精度仿真模型时,对应量化层生成的日志文件信息级别。
AMCT_LOG_LEVEL:控制屏幕输出的信息级别。
有效取值以及含义如表1所示。
表 1 变量取值范围
信息级别
含义
信息描述
DEBUG
输出DEBUG/INFO/WARNING/ERROR级别的运行信息。
详细的流程信息,包括量化层及对应的处理阶段(融合,参数量化或者数据量化等)。
INFO
输出INFO/WARNING/ERROR级别的运行信息。默认为INFO。
概要的量化处理信息,包含量化的阶段等信息。
WARNING
输出WARNING/ERROR级别的运行信息。
量化处理过程中的警告信息。
ERROR
输出ERROR级别的运行信息。
量化处理过程中的错误信息。
信息级别不区分大小写,即Info、info、INFO均为有效取值。
使用示例
如下命令只是样例,用户根据实际情况进行设置。
将量化日志amct_pytorch.log信息级别设置为INFO级别。
export AMCT_LOG_FILE_LEVEL=INFO将屏幕打印输出信息级别设置为INFO级别。
export AMCT_LOG_LEVEL=INFO
AMCT(ONNX)¶
由于AMCT存在基于ONNX Runtime的自定义算子包,而自定义算子包编译时依赖ONNX Runtime提供的头文件,该头文件需要用户自行下载后,然后编译并安装自定义算子包。 AMCT量化过程中的日志信息以及日志级别,可以通过环境变量设置,本章节给出详细设置方法。
编译并安装自定义算子包¶
由于AMCT存在基于ONNX Runtime的自定义算子包,而自定义算子包编译时依赖ONNX Runtime提供的头文件,该头文件需要用户自行下载后,然后编译并安装自定义算子包。
方法如下,该步骤为必选操作,否则可能会导致AMCT无法使用:
解压自定义算子包。
tar -zvxf amct_onnx_op.tar.gz解压后文件目录组织如下:
amct_onnx_op # 自定义算子根目录 ├── inc # 自定义算子编译头文件目录 ├── src # 自定义算子实现源文件,请参见ONNX Runtime官方API说明 └── setup.py # 编译脚本,编译自定义算子,并且拷贝生成动态库至AMCT软件包内
说明:
编译基于ONNX Runtime的自定义算子需要依赖ONNX Runtime提供的头文件,该文件需要在线从GitHub上下载。如果用户AMCT所在服务器能链接网络,并且能连通GitHub,则可以直接进行2;如果无法连接网络,则请自行下载如下文件,下载链接请单击Link,然后上传到AMCT所在服务器amct_onnx_op/inc目录:onnxruntime_cxx_api.h
onnxruntime_cxx_inline.h
onnxruntime_c_api.h
onnxruntime_session_options_config_keys.h
onnxruntime_float16.h 下载的头文件版本必须和ONNX Runtime版本一致,如果import amct_onnx时出现“segmentation fault”,建议删除头文件,卸载amct_onnx后下载正确版本的头文件后重新安装。
进入amct_onnx_op目录,编译并安装自定义算子包。
cd amct_onnx_op && python3 setup.py build出现以下信息表示编译并安装自定义算子包成功,若编译失败,请参见编译并安装自定义算子包时提示"AttributeError: module ‘onnxruntime’ has no attribute ‘SessionOption’"信息进行处理。
[INFO] Build amct_onnx_op success! [INFO] Install amct_onnx_op success!
设置环境变量¶
AMCT量化过程中的日志信息以及日志级别,可以通过环境变量设置,本章节给出详细设置方法。
日志包括打印在屏幕上的日志以及保存到amct_log/amct_onnx.log文件中的日志。该部分环境变量为可选配置,如果不设置,则按照默认日志级别,默认级别为INFO。
变量取值
日志打印级别通过如下两个变量设置:
AMCT_LOG_FILE_LEVEL:控制amct_onnx.log日志文件的信息级别以及生成精度仿真模型时,对应量化层生成的日志文件信息级别。
AMCT_LOG_LEVEL:控制屏幕输出的信息级别。
有效取值以及含义如表1所示。
表 1 变量取值范围
信息级别
含义
信息描述
DEBUG
输出DEBUG/INFO/WARNING/ERROR级别的运行信息。
详细的流程信息,包括量化层及对应的处理阶段(融合,参数量化或者数据量化等)。
INFO
输出INFO/WARNING/ERROR级别的运行信息。默认为INFO。
概要的量化处理信息,包含量化的阶段等信息。
WARNING
输出WARNING/ERROR级别的运行信息。
量化处理过程中的警告信息。
ERROR
输出ERROR级别的运行信息。
量化处理过程中的错误信息。
信息级别不区分大小写,即Info、info、INFO均为有效取值。
使用示例
如下命令只是样例,用户根据实际情况进行设置。
将量化日志amct_onnx.log信息级别设置为INFO级别。
export AMCT_LOG_FILE_LEVEL=INFO将屏幕打印输出信息级别设置为INFO级别。
export AMCT_LOG_LEVEL=INFO
AMCT(Caffe)¶
IPV350不支持
安装完AMCT后,量化模型前,用户需要获取并安装Caffe源代码增强包caffe_patch.tar.gz。 设置日志打印级别,其中日志包括打印在屏幕上的日志以及保存到amct_log/amct_caffe.log文件中的日志。该部分环境变量为可选配置,如果不设置,则按照默认日志级别,默认级别为INFO。
Caffe patch安装¶
安装完AMCT后,量化模型前,用户需要获取并安装Caffe源代码增强包caffe_patch.tar.gz。
该增强包用于完成如下内容:
如果AMCT所在服务器有用户自定义的custom.proto文件,则需要和AMCT软件包中提供的proto文件进行合并。该软件包提供了基于Caffe1.0版本的caffe.proto文件、AMCT自定义层以及caffe-master相较于caffe1.0更新层的amct_custom.proto文件。proto合并原理请参见proto合并原理。
拷贝新增源码和动态库文件到Caffe环境_caffe-master_工程目录下。
对Caffe环境_caffe-master_工程目录下部分文件安装patch,以实现对文件的自动修改。
proto合并前提条件
用户自行准备自定义的custom.proto,并上传到AMCT所在服务器任意目录。
样例如下,以下样例中的自定义层及参数仅作为参考,请用户根据实际场景对参数进行自定义。
message LayerParameter {
optional ReLU6Parameter relu6_param = 2060;
optional ROIPoolingParameter roi_pooling_param = 8266711;
}
message ReLU6Parameter {
optional float negative_slope = 1 [default = 0];
}
message ROIPoolingParameter {
// Pad, kernel size, and stride are all given as a single value for equal
// dimensions in height and width or as Y, X pairs.
optional uint32 pooled_h = 1 [default = 0]; // The pooled output height
optional uint32 pooled_w = 2 [default = 0]; // The pooled output width
// Multiplicative spatial scale factor to translate ROI coords from their
// input scale to the scale used when pooling
optional float spatial_scale = 3 [default = 1];
}
custom.proto主要分为两部分:
LayerParameter注册自定义层:
message LayerParameter { # user definition fields, each field takes one line. optional FieldType0 field_name0 = field_num0; optional FieldType1 field_name1 = field_num1; }
该字段用于在LayerParameter中声明用户自定义层,用户自定义层需要加入到LayerParameter中,从而可以在Caffe框架中写入Layer并从Layer中读取到;该声明分为四个部分:
optional:表示该定义在LayerParameter中是可选的,只能配置为optional。
FieldType:声明当前字段对应的自定义类型,需要有相应的message定义。
field_name:当前声明的id,需要唯一,如果提示冲突,需要用户修改自己的id名称,后续需要通过该id来访问相应的内容。
field_num:当前声明的编号,需要唯一,如果提示冲突,需要用户修改自己的编号值,建议区间段小于5000,并且不与ATC提供的caffe.proto中的编号冲突,在二进制caffemodel中需要通过该编号去解析对应字段。
示例如下:
message LayerParameter { optional ReLU6Parameter relu6_param = 2060; optional ROIPoolingParameter roi_pooling_param = 8266711; }
说明:custom.proto中用户自定义层编号建议区间段小于5000,并且不与ATC提供的caffe.proto中的内置编号冲突。
amct_custom.proto中的编号从200000开始(包括200000)。
caffe.proto中ATC自定义层的编号区间段为:[5000,200000)。
message定义自定义层参数:
message ReLU6Parameter { optional float negative_slope = 1 [default = 0]; }
用户自定义层参数定义,用于定义用户自定义层详细的参数内容,详细内容可以参考google protobuf。
该字段需要保证和AMCT自定义层amct_custom.proto不冲突,如果冲突,proto合并时会提示错误信息,用户根据提示信息进行修改;与ATC内置caffe.proto冲突则会优先使用用户的message定义覆盖。
当前AMCT自定义message包括:QuantParameter、DeQuantParameter、IFMRParameter、LSTMQuantParameter、SearchNParameter、 RetrainDataQuantParameter、RetrainWeightQuantParameter、SingleLayerRecord、 ScaleOffsetRecord,用户自定义层时不能同上述message名重复。
安装步骤
用户可以执行caffe_patch中的自动安装脚本install.py,如果脚本执行成功,则会自动将caffe_patch中的patch内容安装到Caffe环境_caffe-master_工程目录下,并完成proto合并、新增源码和动态库文件替换的功能。安装或手动修改完成后,需要重新编译Caffe环境。具体操作方法如下:
解压Caffe源代码增强包。
以AMCT的安装用户在软件包所在路径执行如下命令,解压caffe_patch.tar.gz软件包:
tar -zxvf caffe_patch.tar.gz获得如下内容:
caffe_patch ├── include //用于存放自定义层定义头文件以及公共函数 │ └── caffe │ ├── layers │ └── util ├── install.py //Caffe环境proto合并、patch安装以及源码和动态库文件执行脚本 ├── merge_proto //proto合并目录 │ ├── amct_custom.proto //AMCT自定义层以及caffe-master相较于Caffe1.0的更新层 │ ├── caffe.proto //ATC工具中内置的caffe.proto │ └── merge_proto.sh //proto合并脚本,实际合并时install.py会调用该脚本 ├── patch //LSTM层相关的patch文件 │ ├── lstm_calibration_layer.cpp.patch //用于在caffe-master/src/caffe/layers目录生成lstm_calibration_layer.cpp │ ├── lstm_calibration_layer.hpp.patch //用于在caffe-master/include/caffe/layers目录生成lstm_calibration_layer.hpp │ ├── lstm_quant_layer.cpp.patch //用于在caffe-master/src/caffe/layers/目录生成lstm_quant_layer.cpp │ └── lstm_quant_layer.hpp.patch //用于在caffe-master/include/caffe/layers/目录生成lstm_quant_layer.hpp ├── quant_lib //用于存放量化算法核心动态库 │ ├── libquant_gpu.so │ └── libquant.so └── src //用于存放自定义层实现源码文件以及公共函数 └── caffe ├── layers └── util
切换到caffe_patch/install.py脚本所在目录,执行如下命令。
python3 install.py --caffe_dir CAFFE_DIR [--custom_proto CUSTOM_PROTO_FILE]参数解释如下:
表 1 量化脚本所用参数说明
参数
说明
--h
可选。显示帮助信息。
--caffe_dir
必填。Caffe源代码路径,支持相对路径和绝对路径。
--custom_proto
可选。用户自定义custom.proto文件路径,支持相对路径和绝对路径。
使用样例如下:
python3 install.py --caffe_dir caffe-master --custom_proto custom.proto若提示如下信息,则说明执行成功。
# 拷贝新增源码和动态库文件到Caffe环境caffe-master工程目录下 [INFO]Begin to copy source files, header files and quant_lib to '$HOME/AMCT/AMCT_CAFFE/caffe-master' [INFO]Finish copy source files, header files and quant_lib to '$HOME/AMCT/AMCT_CAFFE/caffe-master' # 安装patch [INFO]Begin to install patch. [INFO]Install patch 'lstm_calibration_layer.cpp.patch' successfully. [INFO]Install patch 'lstm_quant_layer.hpp.patch' successfully. [INFO]Install patch 'lstm_quant_layer.cpp.patch' successfully. [INFO]Install patch 'lstm_quant_layer.hpp.patch' successfully. [INFO]Finish install patch. # proto合并 [INFO]Merge and replace "caffe.proto" success. # 修改Makefile [INFO]Merge and replace "Makefile" success.
执行脚本过程中(使用install.py脚本时,支持重复安装patch):
如果安装patch失败,则请用户自行将Caffe工程中caffe-master/src/caffe/layers/lstm_layer.cpp和caffe-master/include/caffe/layers/lstm_layer.hpp文件还原为caffe-master原生的。
proto合并阶段如果提示ERROR信息,则请参见执行proto合并时提示ERROR信息解决。
如果修改Makefile失败,则请根据提示信息进行修改;如果执行成功,则再次执行该脚本时,不会重复修改Makefile。
检查Python layer配置,如果没有配置,增加Python layer的实现。
修改Caffe工程中caffe-master/Makefile.config文件。
增加Python layer的实现。
# Uncomment to support layers written in Python (will link against Python libs) WITH_PYTHON_LAYER := 1
(可选)新增C++11标准代码的支持。
由于AMCT新增算子需要C++11支持,需要确保caffe-master/Makefile中增加了--std=c++11编译选项。2中执行install.py脚本时会自动修改该文件,请用户检查caffe-master/Makefile如下代码片段加粗部分是否增加--std=c++11编译选项,若已增加则该步骤请忽略,否则请手动修改。
# Complete build flags. COMMON_FLAGS += $(foreach includedir,$(INCLUDE_DIRS),-I$(includedir)) --std=c++11 CXXFLAGS += -pthread -fPIC $(COMMON_FLAGS) $(WARNINGS) NVCCFLAGS += -ccbin=$(CXX) -Xcompiler -fPIC $(COMMON_FLAGS)
返回caffe-master目录,执行如下命令重新编译Caffe以及pycaffe环境:
#如果用户环境安装patch之前已经编译过Caffe工程,安装patch之后,需要先执行make clean,然后再执行编译命令 make clean make all -j && make pycaffe -j
caffe.proto修改后需要重新编译为caffe_pb2.py:由于AMCT需要解析用户的Caffe模型,用户使用Caffe模型时可能会新增自定义层,此时需要修改caffe.proto文件,修改后,需要用户自行提供从修改后的caffe.proto文件编译出的caffe_pb2.py,给AMCT使用。
说明:
如果用户使用protoc方式来重新编译caffe.proto,例如protoc --python_out=./caffe.proto,此时,需要同步修改PYTHONPATH中caffe.proto所在路径。如下所示,${path}请替换为caffe.proto实际路径。export PYTHONPATH=$PYTHONPATH:${path}
环境变量设置¶
设置日志打印级别,其中日志包括打印在屏幕上的日志以及保存到amct_log/amct_caffe.log文件中的日志。该部分环境变量为可选配置,如果不设置,则按照默认日志级别,默认级别为INFO。
变量取值
日志打印级别通过如下两个变量设置:
AMCT_LOG_FILE_LEVEL:控制amct_caffe.log日志文件的信息级别以及生成精度仿真模型时,对应量化层生成的日志文件信息级别。
AMCT_LOG_LEVEL:控制屏幕输出的信息级别。
有效取值以及含义如表1所示。
表 1 变量取值范围
信息级别
含义
信息描述
DEBUG
输出DEBUG/INFO/WARNING/ERROR级别的运行信息。
详细的流程信息,包括量化层及对应的处理阶段(融合,参数量化或者数据量化等)。
INFO
输出INFO/WARNING/ERROR级别的运行信息。默认为INFO。
概要的量化处理信息,包含量化的阶段等信息。
WARNING
输出WARNING/ERROR级别的运行信息。
量化处理过程中的警告信息。
ERROR
输出ERROR级别的运行信息。
量化处理过程中的错误信息。
信息级别不区分大小写,即Info、info、INFO均为有效取值。
使用示例
如下命令只是样例,用户根据实际情况进行设置。
将量化日志amct_caffe.log信息级别设置为INFO级别。
export AMCT_LOG_FILE_LEVEL=INFO将屏幕打印输出信息级别设置为INFO级别。
export AMCT_LOG_LEVEL=INFO
常用操作¶
建议使用最新版本的AMCT,以便获得最新功能。 若用户不再使用AMCT时,可以参见该章节将其卸载。
工具更新¶
建议使用最新版本的AMCT,以便获得最新功能。
使用新版本之前请先参见工具卸载章节卸载之前版本的AMCT,然后参见安装工具章节安装最新版本。针对AMCT(Caffe),安装新版本的AMCT后,Caffe环境需要重新编译,详细方法请参见5。
工具卸载¶
若用户不再使用AMCT时,可以参见该章节将其卸载。
以AMCT的安装用户在Linux服务器任意目录执行如下命令进行卸载:
pip3 uninstall amct_xxx出现如下信息时,输入“y“:
Uninstalling amct-xxx-{version}: Would remove: ... ... Proceed (y/n)? y
若出现如下信息则说明卸载成功:
Successfully uninstalled amct-xxx-{version}卸载过程中不会卸载已经安装的框架,比如PyTorch,TensorFlow等,上述_xxx_请替换为具体的框架名称,比如pytorch,tensorflow等。
快速入门¶
本章节以压缩特性中的量化功能为例,并借助sample中的网络模型,为您介绍如何使用命令行方式压缩一个模型。
AMCT支持命令行方式和Python API接口方式量化原始网络模型,命令行方式压缩方式,目前仅支持ONNX框架:
其他未支持的框架和特性,只能使用Python API方式进行量化。命令行方式相比Python API接口方式有以下优点:
表 1 量化方式比较
命令行方式 |
Python API接口方式 |
|---|---|
量化准备动作简单,只需准备模型和模型匹配的数据集即可。 |
需要了解Python语法和量化流程。 |
量化过程简单,只涉及参数选择,无需对量化脚本进行适配。 |
需要适配修改量化脚本。 |
|
|
压缩ONNX网络模型
前提条件
已安装AMCT(ONNX)工具包,详情请参见准备环境。
获取sample包
单击Link获取sample软件包,并上传到AMCT所在服务器任意路径,例如上传到:_$HOME/software/AMCT_Pkg/_amct_sample。
解压sample软件包。
切换到_amct_sample_目录,执行如下命令解压sample包。
unzip samples-master.zip cd samples-master/python/level1_single_api/9_amct/amct_onnx/cmd
获得如下目录信息:
|-- README_CN.md |-- data # 数据集存放路径 |-- model # ONNX 模型文件所在目录 |-- scripts | |-- run_calibration.sh # 执行量化封装脚本 | |-- run_convert_qat.sh # QAT模型适配CANN模型命令行脚本 | |-- run_customized_calibration.sh # 用户自定义的训练后量化脚本 |-- src |-- process_data.py # 数据集预处理脚本,生成模型的输入数据;如果更换为其他数据集,需保证处理后数据shape与模型输入shape一致 |-- evaluator.py # 系统内置的,基于“Evaluator”基类并且包含evaluator评估器的Python脚本
量化模型
获取ONNX网络模型。
单击Link,获取resnet101_v11.onnx网络的模型文件(*.onnx),并以AMCT软件包运行用户将获取的文件上传至Linux服务器sample目录amct_onnx/cmd/model。
准备模型相匹配的二进制数据集。
切换到amct_onnx/cmd/data,依次执行如下命令,用于下载校准数据集。
wget https://obs-9be7.obs.cn-east-2.myhuaweicloud.com/models/amct_acl/classification/imagenet_calibration.tar.gz tar -zxvf imagenet_calibration.tar.gz
执行完成后,在images目录会生成*.jpg格式数据集。
在amct_onnx/cmd目录,执行如下命令将images目录下*.jpg格式数据集转换为bin格式数据集。
python3 ./src/process_data.py执行完成后,在data目录生成calibration目录,并在该目录中生成calibration.bin格式数据集。
在任意目录执行如下命令进行网络模型的量化操作。如下命令中使用的目录以及文件均为样例,请以实际为准。
amct_onnx calibration --model ./model/resnet101_v11.onnx --save_path ./results/resnet101_v11 --input_shape "input:16,3,224,224" --data_dir "./data/calibration" --data_types "float32"amct_onnx二进制所在路径为安装用户$HOME/.local/bin目录。用户可以通过amct_onnx calibration --help命令查看命令行涉及的所有参数,关于参数的详细解释以及使用方法请参见命令行参数说明。
说明:如果执行amct_onnx calibration --help命令后,查询不到AMCT工具,则可能是安装该工具时,使用的Python版本不对,参见安装Python3.9.2(Ubuntu)重新执行如下环境变量后再次尝试(路径请替换为实际安装的地址):
export PATH=/usr/local/python3.9.2/bin:$PATHAMCT的sample还提供了3量化命令以及2.b中数据集预处理脚本的封装脚本run_calibration.sh,用户准备完模型以及下载好数据集后,可以直接使用该脚本执行量化,切换到amct_onnx/cmd目录,执行如下命令:
bash ./scripts/run_calibration.sh若提示如下信息且无Error日志信息,则说明模型量化成功。
INFO - [AMCT]:[Utils]: The model file is saved in $HOME/xxx/results/resnet101_v11_fake_quant_model.onnx量化后生成文件说明如下:
amct_log/amct_onnx.log:记录了工具的日志信息,包括量化过程的日志信息。
上述日志文件重新执行量化时会被覆盖,请用户自行进行保存。此外,由于生成的日志文件大小和所要量化模型层数有关,请用户确保AMCT工具所在服务器有足够空间:
以量化resnet101模型为例,日志级别设置为INFO,日志文件大小为5KB左右,中间临时文件大小为170MB左右;日志级别设置为DEBUG,日志文件大小为2MB左右,中间临时文件大小为170MB左右。
results:量化结果文件。
resnet101_v11_deploy_model.onnx:量化后的可在NPU IP加速器部署的模型文件。
resnet101_v11_fake_quant_model.onnx:量化后的可在ONNX执行框架ONNX Runtime进行精度仿真的模型文件。
resnet101_v11_quant.json:量化信息文件(该文件名称和量化后模型名称保持统一),记录了量化模型同原始模型节点的映射关系,用于量化后模型同原始模型精度比对使用。
(可选)_随机数_时间戳,_该目录只有AMCT_LOG_LEVEL=DEBUG时才会生成,设置方法请参见设置环境变量。
quant_config.json:量化配置文件,描述了如何对模型中的每一层进行量化。如果当前目录已经存在量化配置文件,则再次进行量化时,如果新生成的量化配置文件与已有的文件同名,则会覆盖已有的量化配置文件,否则生成新的量化配置文件。
实际量化过程中,如果量化后的模型推理精度不满足要求,则用户可以根据量化后的quant_config.json,自行构造简易配置文件_config.cfg_,构造原则请参见调优流程。然后使用--calibration_config参数重新进行量化。通过该文件用户可以自行决定校准使用的数据量,以及控制哪些层进行量化等。
record.txt:记录量化因子的文件。关于该文件的原型定义请参见record记录文件。
modified_model.onnx、updated_model.onnx:量化过程中的中间文件。
压缩开源框架的TensorFlow网络模型
前提条件
已安装AMCT(TensorFlow)工具包,详情请参见准备环境。
IPV350不支持TensorFlow框架。
获取sample包
单击Link获取sample软件包,并上传到AMCT所在服务器任意路径,例如上传到:_$HOME/software/AMCT_Pkg/_amct_sample。
解压sample软件包。
切换到_amct_sample_目录,执行如下命令解压sample包。
unzip samples-master.zip cd samples-master/python/level1_single_api/9_amct/amct_tensorflow/cmd
获得如下目录信息:
|-- README_CN.md |-- data # 数据集存放路径 |-- model # TensorFlow模型文件所在目录 |-- scripts | |-- run_calibration.sh # 执行量化封装脚本 | |-- run_convert_qat.sh # QAT模型适配CANN模型命令行脚本 | |-- run_customized_calibration.sh # 用户自定义的训练后量化脚本 |-- src |-- evaluator.py # 系统内置的,基于“Evaluator”基类并且包含evaluator评估器的Python脚本 |-- process_data.py # 数据集预处理脚本,生成模型的输入数据;如果更换为其他数据集,需保证处理后数据shape与模型输入shape一致
量化模型
获取待量化的TensorFlow网络模型。
单击Link获取MobileNet V2网络模型,解压后将其中的(*.pb)文件,以AMCT软件包运行用户上传至Linux服务器sample目录amct_tensorflow/cmd/model。
准备模型相匹配的二进制数据集。
切换到amct_tensorflow/cmd/data,依次执行如下命令,用于下载校准数据集。
cd amct_tensorflow/cmd/data mkdir image && cd image wget https://obs-9be7.obs.cn-east-2.myhuaweicloud.com/models/amct_acl/classification/calibration.rar unrar e calibration.rar
上述命令执行完成后,在image/calibration目录会生成*.jpg格式数据集。
在amct_tensorflow/cmd目录,执行如下命令将calibration目录下*.jpg格式数据集转换为bin格式数据集。
python3 ./src/process_data.py执行完成后,在data目录会生成新的calibration目录,并在该目录生成calibration.bin格式数据集。
在任意目录执行如下命令进行网络模型的量化操作。如下命令中使用的目录以及文件均为样例,请以实际为准。
amct_tensorflow calibration --model=./model/mobilenet_v2_1.0_224_frozen.pb --save_path=./results/mobilenet_v2 --outputs="MobilenetV2/Predictions/Reshape_1:0" --input_shape="input:32,224,224,3" --data_dir="./data/calibration/" --data_types="float32"amct_tensorflow二进制所在路径为安装用户$HOME/.local/bin目录。用户可以通过amct_tensorflow calibration --help命令查看命令行涉及的所有参数,关于参数的详细解释以及使用方法请参见命令行参数说明。
说明:如果执行amct_tensorflow calibration --help命令后,查询不到AMCT工具,则可能是安装该工具时,使用的Python版本不对,参见安装Python3.9.2(Ubuntu)重新执行如下环境变量后再次尝试(路径请替换为实际安装的地址)。
export PATH=/usr/local/python3.9.2/bin:$PATHAMCT的sample还提供了3量化命令以及2.b中数据集预处理脚本的封装脚本run_calibration.sh,用户准备完模型以及下载好数据集后,可以直接使用该脚本执行量化,切换到amct_tensorflow/cmd目录,执行如下命令:
bash ./scripts/run_calibration.sh若提示如下信息且无Error日志信息,则说明模型量化成功。
INFO - [AMCT]:[save_model]: The model is saved in $HOME/xxx/results/mobilenet_v2_quantized.pb量化后生成文件说明如下:
amct_log/amct_tensorflow.log:记录了工具的日志信息,包括量化过程的日志信息。
上述日志文件重新执行量化时会被覆盖,请用户自行进行保存。此外,由于生成的日志文件大小和所要量化模型层数有关,请用户确保AMCT工具所在服务器有足够空间:
以量化resnet101模型为例,日志级别设置为INFO,日志文件大小为5KB左右,中间临时文件大小为170MB左右;日志级别设置为DEBUG,日志文件大小为2MB左右,中间临时文件大小为170MB左右。
results:量化结果文件。
mobilenet_v2_quantized.pb:量化后的可在TensorFlow环境进行精度仿真并可在NPU IP加速器部署的模型。
mobilenet_v2_quant.json:量化信息文件(该文件名称和量化后模型名称保持统一),记录了量化模型同原始模型节点的映射关系,用于量化后模型同原始模型精度比对使用。
(可选)随机数_时间戳:该目录只有set_logging_level接口打屏日志级别设置为debug才会生成。
quant_config.json:量化配置文件,描述了如何对模型中的每一层进行量化。如果当前目录已经存在量化配置文件,则再次进行量化时,如果新生成的量化配置文件与已有的文件同名,则会覆盖已有的量化配置文件,否则生成新的量化配置文件。
实际量化过程中,如果量化后的模型推理精度不满足要求,则用户可以根据量化后的quant_config.json,自行构造简易配置文件_config.cfg_,构造原则请参见调优流程。然后使用--calibration_config参数重新进行量化。通过该文件用户可以自行决定校准使用的数据量,以及控制哪些层进行量化等。
record.txt:记录量化因子的文件。关于该文件的原型定义请参见record记录文件。
压缩开源框架的Caffe网络模型
前提条件
已安装AMCT(Caffe)工具包,详情请参见准备环境。
IPV350不支持Caffe框架。
获取sample包
单击Link获取sample软件包,并上传到AMCT所在服务器任意路径,例如上传到:_$HOME/software/AMCT_Pkg/_amct_sample。
解压sample软件包。
切换到_amct_sample_目录,执行如下命令解压sample包。
unzip samples-master.zip cd samples-master/python/level1_single_api/9_amct/amct_caffe/cmd
获得如下目录信息:
|-- README_CN.md |-- data # 数据集存放目录 |-- model # Caffe模型文件所在目录 |-- scripts | |-- run_calibration.sh # 执行量化封装脚本 | |-- run_customized_calibration.sh # 用户自定义的训练后量化脚本 |-- src |-- download_models.py # 模型文件下载脚本 |-- evaluator.py # 系统内置的,基于“Evaluator”基类并且包含evaluator评估器的Python脚本 |-- process_data.py # 数据集预处理脚本,生成模型的输入数据;如果更换为其他数据集,需保证处理后数据shape与模型输入shape一致
量化模型
获取待量化的Caffe网络模型。
切换到amct_caffe/cmd目录,执行如下命令下载模型文件和权重文件。
python3 ./src/download_models.py --close_certificate_verify其中,--close_certificate_verify参数可选,用于关闭证书验证参数,确保模型正常下载。如果模型下载过程中提示认证失败相关信息,则可以增加该参数重新下载。
若提示如下信息,则说明模型文件下载成功:
[INFO]Download 'ResNet-50-deploy.prototxt' to 'xxx/amct_caffe/cmd/model/ResNet-50-deploy.prototxt' success. [INFO]Download file_name to 'xxx/amct_caffe/cmd/model/ResNet-50-model.caffemodel' success.
用户可以根据提示信息,在amct_caffe/cmd/model路径看到已经下载的模型文件。
准备模型相匹配的二进制数据集。
切换到amct_caffe/cmd目录,执行如下命令,用于下载校准数据集。
cd data mkdir image && cd image wget https://obs-9be7.obs.cn-east-2.myhuaweicloud.com/models/amct_acl/classification/calibration.rar unrar e calibration.rar
在amct_caffe/cmd目录,执行如下命令将calibration目录下*.jpg格式数据集转换为bin格式数据集。
python3 ./src/process_data.py执行完成后,在data目录会生成新的calibration目录,并在该目录生成calibration.bin格式数据集。
在任意路径执行如下命令进行网络模型的量化操作。如下命令中使用的目录以及文件均为样例,请以实际为准。
amct_caffe calibration --model=./model/ResNet-50-deploy.prototxt --weights=./model/ResNet-50-model.caffemodel --save_path=./results/ResNet-50 --input_shape="data:1,3,224,224" --data_dir="./data/calibration" --data_types="float32"amct_caffe二进制所在路径为安装用户$HOME/.local/bin目录。用户可以通过amct_caffe calibration --help命令查看命令行涉及的所有参数,关于参数的详细解释以及使用方法请参见命令行参数说明。
说明:如果执行amct_caffe calibration --help命令后,查询不到AMCT工具,则可能是安装该工具时,使用的Python版本不对,参见安装Python3.9.2(Ubuntu)重新执行如下环境变量后再次尝试(路径请替换为实际安装的地址):
export PATH=/usr/local/python3.9.2/bin:$PATHAMCT的sample还提供了3量化命令以及2.b中数据集预处理脚本的封装脚本run_calibration.sh,用户准备完模型以及下载好数据集后,可以直接使用该脚本执行量化,切换到amct_caffe/cmd目录,执行如下命令:
bash ./scripts/run_calibration.sh若提示如下信息且无Error日志信息,则说明模型量化成功。
INFO - [AMCT]:[Utils]: The weights_file is saved in $HOME/xxx/results/ResNet-50_fake_quant_weights.caffemodel INFO - [AMCT]:[Utils]: The model_file is saved in $HOME/xxx/results/ResNet-50_fake_quant_model.prototxt
量化后生成文件说明如下:
amct_log/amct_caffe.log:记录了工具的日志信息,包括量化过程的日志信息。
上述日志文件重新执行量化时会被覆盖,请用户自行进行保存。此外,由于生成的日志文件大小和所要量化模型层数有关,请用户确保AMCT工具所在服务器有足够空间:
以量化resnet101模型为例,日志级别设置为INFO,日志文件大小为5KB左右,中间临时文件大小为170MB左右;日志级别设置为DEBUG,日志文件大小为2MB左右,中间临时文件大小为170MB左右。
results:量化结果文件。
ResNet-50_deploy_model.prototxt:量化后的可在NPU IP加速器部署的模型文件。
ResNet-50_deploy_weights.caffemodel:量化后的可在NPU IP加速器部署的权重文件。
ResNet-50_fake_quant_model.prototxt:量化后的可在Caffe环境进行精度仿真模型文件。
ResNet-50_fake_quant_weights.caffemodel:量化后的可在Caffe环境进行精度仿真权重文件。
ResNet-50_quant.json:量化信息文件(该文件名称和量化后模型名称保持统一),记录了量化模型同原始模型节点的映射关系,用于量化后模型同原始模型精度比对使用。
(可选)_随机数_时间戳,_该目录只有AMCT_LOG_LEVEL=DEBUG时才会生成,设置方法请参见环境变量设置。
quant_config.json:量化配置文件,描述了如何对模型中的每一层进行量化。如果当前目录已经存在量化配置文件,则再次进行量化时,如果新生成的量化配置文件与已有的文件同名,则会覆盖已有的量化配置文件,否则生成新的量化配置文件。
实际量化过程中,如果量化后的模型推理精度不满足要求,则用户可以根据量化后的quant_config.json,自行构造简易配置文件_config.cfg_,构造原则请参见调优流程。然后使用--calibration_config参数重新进行量化。通过该文件用户可以自行决定校准使用的数据量,以及控制哪些层进行量化等。
modified_model.prototxt、modified_model.caffemodel:量化过程中生成的中间模型文件。
record.txt:记录量化因子的文件。关于该文件的原型定义请参见record记录文件。
AMCT(PyTorch)¶
量化¶
本章节详细介绍AMCT量化场景,以及每个场景下的功能。
简介¶
本章节详细介绍AMCT量化场景,以及每个场景下的功能。
量化分类
量化根据是否需要重训练,分为训练后量化(Post-Training Quantization,简称PTQ)和量化感知训练(Quantization-Aware Training,简称QAT),概念解释请参见量化。
训练后量化
根据量化后是否手动调优量化配置文件,分为手工量化和基于精度的自动量化。训练后量化使用的量化算法请参见训练后量化算法。
根据是否对权重数据进行压缩又分为均匀量化和非均匀量化(不支持)。如果量化后的精度不满足要求,则可以进行基于精度的自动量化或手工调优,推荐使用基于精度的自动量化。
量化感知训练
量化感知训练当前仅支持对float32数据类型的网络模型进行量化。量化感知训练使用的量化算法请参见量化感知训练算法。
当前仅支持手工量化,如果量化后的精度不满足要求,可以进行手工调优。
相关概念
量化过程中使用的相关术语解释如下:
表 1 量化过程中的相关概念
术语 |
解释 |
|---|---|
数据量化和权重量化 |
训练后量化和量化感知训练,根据量化对象不同,又分为数据(activation)量化和权重(weight)量化。 当前NPU IP加速器支持数据(activation)做对称/非对称量化,权重(weight)仅支持做对称量化(量化根据量化后数据中心点是否为0可以分为对称量化、非对称量化,详细的量化算法原理请参见量化算法原理)。
|
量化位宽 |
量化根据量化后低比特位宽大小分为常见的INT8、INT4、INT16,Binary量化等,当前版本仅支持INT8和INT16量化。
|
测试数据集 |
数据集的子集,用于最终测试模型的效果。 |
校准 |
训练后量化场景中,做前向推理获取数据量化因子的过程。 |
校准数据集 |
训练后量化场景中,做前向推理使用的数据集。该数据集的分布代表着所有数据集的分布,获取校准集时应该具有代表性,推荐使用测试集的子集作为校准数据集。如果数据集不是模型匹配的数据集或者代表性不够,则根据校准集计算得到的量化因子,在全数据集上表现较差,量化损失大,量化后精度低。 |
训练数据集 |
数据集的子集,基于用户训练网络中的数据集,用于对模型进行训练。 |
量化因子 |
将浮点数量化为整数的参数,包括缩放因子(scale),偏移量(offset)。 将浮点数量化为整数(以INT8为例)的公式如下:
|
scale |
量化因子,浮点数的缩放因子,该参数又分为:
|
offset |
量化因子,偏移量,该参数又分为:
|
量化敏感度 |
模型在不同数据精度下,计算结果是有差异的,正常情况下,数据精度越高计算越准确,网络模型的推理结果越准确,而使用量化方法降低网络模型或者某层的数据精度后,会影响模型推理的精度。为了评估这种影响,引入量化敏感度的概念。 量化敏感度用于评价网络模型或者可量化层受量化影响大小。通过比较网络的输出或者某层的输出在量化前后的差异来计算量化敏感度,常见的指标有MSE(Mean Square Error,均方误差),余弦相似度等。 |
比特复杂度 |
对模型中的某层来说,浮点计算量为Flops。而比特复杂度(bitops)则综合了浮点计算量和数据精度,描述在不同的数据精度下(比如,float32/float16/INT8/INT4),计算资源存在的差异。 具体计算方法如下,其中Flops为浮点计算量,act_bit为数据的数据精度,wts_bit为权重的数据精度。
|
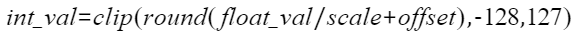
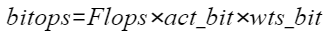
训练后量化¶
基于精度的自动量化是为了方便用户在对量化精度有一定要求时所使用的功能。该方法能够在保证用户所需的模型精度前提下,自动搜索模型的量化配置并执行训练后量化的流程,最终生成满足精度要求的量化模型。
基于精度的自动量化¶
基于精度的自动量化是为了方便用户在对量化精度有一定要求时所使用的功能。该方法能够在保证用户所需的模型精度前提下,自动搜索模型的量化配置并执行训练后量化的流程,最终生成满足精度要求的量化模型。
基于精度的自动量化基本原理与手工量化相同,但是用户无需手动调整量化配置文件,大大简化了优化流程,提高量化效率。量化支持的层以及约束请参见均匀量化,量化示例请参见样例列表。
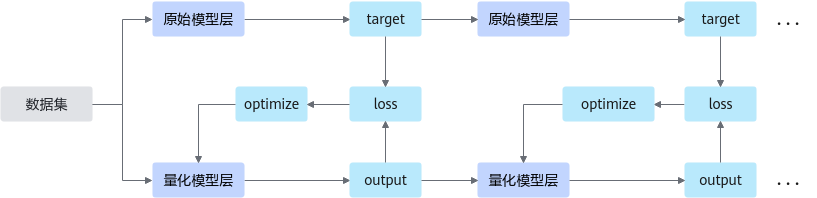
接口调用流程
接口调用流程如图1所示。
图 1 接口调用流程
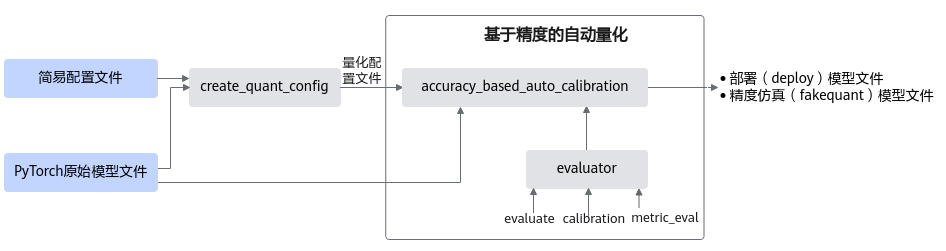
主要流程如下:
调用create_quant_config生成量化配置文件,然后调用accuracy_based_auto_calibration进行基于精度的自动量化。
调用accuracy_based_auto_calibration中由用户传入的evaluator实例进行精度测试,得到原始模型精度。
该过程还会调用accuracy_based_auto_calibration中的量化策略strategy模块,输出初始化的quant config量化配置文件,该文件记录所有层都可以进行量化。
使用用户传入的初始量化配置文件(1中调用create_quant_config生成的)对模型进行训练后量化,得到量化后fake quant模型的精度。
原始模型精度与量化后fake quant模型精度进行比较,如果精度达标,则输出量化后的部署模型和fake quant模型,如果不达标,则进行基于精度的自动量化流程:
进行原始PyTorch网络的推理, dump出每一层的输入activation数据,缓存起来;
利用训练后量化的量化因子构造量化层的单算子网络,利用缓存的activation数据计算量化后fake quant单算子网络的输出数据和原始PyTorch单算子网络输出的余弦相似度。
将余弦相似度的列表传给accuracy_based_auto_calibration中的量化策略strategy模块,strategy模块基于2中生成的初始化的量化配置文件,输出回退某些层后的新的quant config量化配置文件。
根据quant config量化配置文件重新进行训练后量化,得到回退后的fake quant模型。
调用accuracy_based_auto_calibration中的evaluator模块进行回退后的fake quant模型精度测试,查看精度是否达标:
如果达标,则输出回退后的fake quant模型以及部署模型。
如果不达标,则将余弦相似度排序最差的层回退,再次进行4.c,输出新的量化配置。
如果回退所有层后精度仍不达标,则不生成量化模型。
accuracy_based_auto_calibration接口内部基于精度的自动量化流程如图2所示。
图 2 自动量化流程
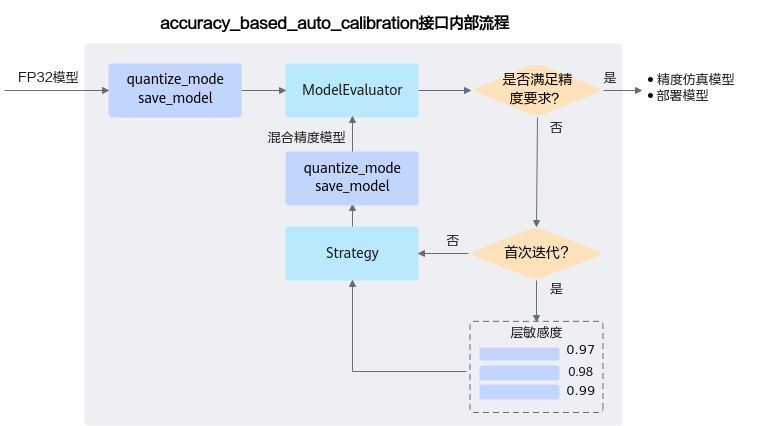
调用示例
本示例演示使用AMCT进行基于精度的自动量化流程。该过程需要用户实现一个模型推理得到精度的回调函数,由于AMCT需要基于回调函数返回的精度数据进行量化层的筛选,因此回调函数的返回数值应尽可能反映模型的精度。
如下示例标有“由用户补充处理”的步骤,需要用户根据自己的模型和数据集进行补充处理,示例中仅为示例代码。
如下示例调用AMCT的部分,函数入参请根据实际情况进行调整。
导入AMCT包。
import os import amct_pytorch as amct from amct_pytorch.common.auto_calibration import AutoCalibrationEvaluatorBase
(由用户补充处理)使用原始待量化的模型和测试集,实现回调函数calibration()、evaluate()、metric_eval()。
上述回调函数的入参要和基类AutoCalibrationEvaluatorBase保持一致。其中:
calibration()完成校准的推理。
evaluate()完成模型的精度测试过程。
metric_eval()完成原始模型和量化fake quant模型的精度损失评估,当精度损失小于预期值时返回True,否则返回False。
class ModelEvaluator(AutoCalibrationEvaluatorBase): # The evaluator for model def __init__(self, *args, **kwargs): # 成员变量初始化 # 设置预期精度损失,此处请替换为具体的数值 self.diff = expected_acc_loss pass def calibration(self, model_file, weights_file): # 进行模型的校准推理,推理的batch数要和量化配置的batch_num一致 pass def evaluate(self, model_file, weights_file): # evaluate the input models, get the eval metric of model pass def metric_eval(self, original_metric, new_metric): # 评估原始模型精度和量化模型精度的精度损失是否满足预期,满足返回True, 精度损失数据;否则返回False, 精度损失数据 loss = original_metric - new_metric if loss < self.diff: return True, loss return False, loss
(由用户补充处理)实例化pytorch模型,得到模型的对象。
model = MyNet()调用AMCT,进行基于精度的自动量化。
生成量化配置。
config_json_file = './config.json' skip_layers = [] batch_num = 1 amct.create_quant_config(config_json_file, model, input_data, skip_layers, batch_num) scale_offset_record_file = os.path.join(TMP, 'scale_offset_record.txt') result_path = os.path.join(RESULT, 'model')
初始化Evaluator。
evaluator = AutoCalibrationEvaluator()进行基于精度的量化配置自动搜索。
amct.accuracy_based_auto_calibration( model=model, model_evaluator=evaluator, config_file=config_json_file, record_file=record_file, save_dir=result_path, input_data=input_data, input_names=['input'], output_names=['output'], dynamic_axes={ 'input': {0: 'batch_size'}, 'output': {0: 'batch_size'} }, strategy='BinarySearch', sensitivity='CosineSimilarity' )
手工量化¶
均匀量化是指量化后的数据比较均匀地分布在某个数值空间中,例如INT8量化就是用只有8比特的INT8数据来表示32比特的float32数据或16比特的float16数据,将float32/float16的卷积运算过程(乘加运算)转换为INT8的卷积运算,加速运算和实现模型压缩;均匀的INT8量化则是量化后数据比较均匀地分布在INT8的数值空间[-128, 127]中。 非均匀量化是指量化后的数据在某个数值空间中的分布是不均匀的。非均匀量化过程中,会根据待量化数据的概率分布来对均匀量化后的数据分布进一步进行根据目标压缩率(保留数值量/原始量化数值量)的聚类操作。相较于均匀量化,非均匀量化在进一步压缩数据信息量的基础上尽可能的保留高概率分布的数据信息,从而减小压缩后的数据信息丢失。 执行训练后量化特性的精度如果不满足要求,可以尝试手动调整config.json文件中的参数,本节给出调整的原则,以及参数解释。
均匀量化¶
均匀量化是指量化后的数据比较均匀地分布在某个数值空间中,例如INT8量化就是用只有8比特的INT8数据来表示32比特的float32数据或16比特的float16数据,将float32/float16的卷积运算过程(乘加运算)转换为INT8的卷积运算,加速运算和实现模型压缩;均匀的INT8量化则是量化后数据比较均匀地分布在INT8的数值空间[-128, 127]中。
如果均匀量化后的模型精度无法满足要求,则需要进行基于精度的自动量化或量化感知训练或手工调优。均匀量化支持量化的层以及约束如下,量化示例请参见样例列表。
表 1 均匀量化支持的层以及约束
支持的层类型 |
约束 |
备注 |
|---|---|---|
torch.nn.Linear |
- |
复用层(共用weight和bias参数)不支持量化。 |
torch.nn.Conv2d |
|
|
torch.nn.ConvTranspose2d |
|
|
torch.nn.ConvTranspose1d |
padding_mode为zeros |
|
torch.nn.Conv1d |
|
接口调用流程
均匀量化接口调用流程如图1所示。
图 1 均匀量化接口调用流程
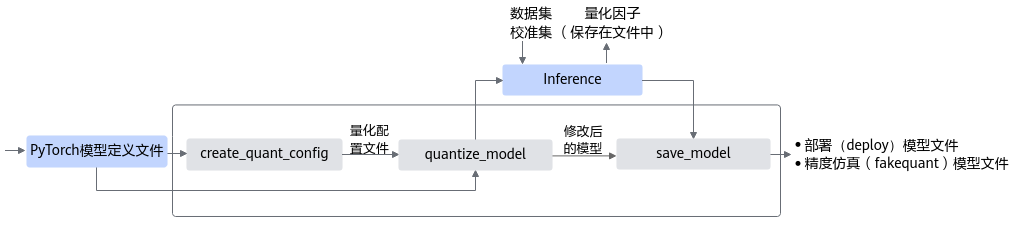
蓝色部分为用户实现,灰色部分为用户调用AMCT提供的API实现,工具使用分为如下场景:
用户首先构造PyTorch的原始模型,然后使用create_quant_config生成量化配置文件。
根据PyTorch模型和量化配置文件,即可调用quantize_model接口对原始PyTorch模型进行优化,优化后的PyTorch模型中包含了量化算法。
使用校准集在PyTorch环境下执行前向推理,产生量化因子,并将量化因子输出到文件中。
最后用户可以调用save_model接口保存量化后的模型,包括可在ONNX执行框架ONNX Runtime环境中进行精度仿真的模型文件和可部署在NPU IP加速器的模型文件。
精度仿真模型文件:ONNX格式的模型文件,模型名中包含fake_quant,可以在ONNX Runtime环境进行精度仿真。
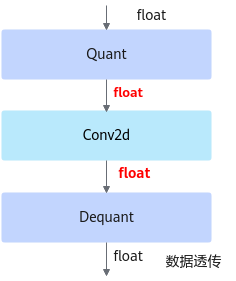
fake_quant模型主要用于验证量化后模型的精度,可以在ONNX Runtime环境下运行。进行前向推理的计算过程中,在fake_quant模型中对卷积层等的输入数据和权重进行了量化反量化的操作,来模拟量化后的计算结果,从而快速验证量化后模型的精度。如下图所示,以INT8量化为例,Quant层、Conv2d卷积层和DeQuant层之间的数据都是float32数据类型的,其中Quant层将数据量化到INT8又反量化为float32,权重也是量化到INT8又反量化为float32,实际卷积层的计算是基于float32数据类型的,该模型用于在ONNX Runtime环境验证量化后模型的精度,不能够用于ATC工具转换成om模型。
图 2 fake_quant模型
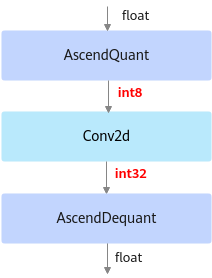
部署模型文件:ONNX格式的模型文件,模型名中包含deploy,经过ATC转换工具转换后可部署到NPU IP加速器。
以INT8量化为例,deploy模型由于已经将权重等转换为INT8,INT32类型,因此不能在ONNX Runtime环境上执行推理计算。如下图所示,deploy模型的AscendQuant层将float32的输入数据量化为INT8,作为卷积层的输入,权重也是使用INT8数据类型作为计算,在deploy模型中的卷积层的计算是基于INT8,INT32数据类型的,输出为INT32数据类型经过AscendDeQuant层转换成float32数据类型传输给下一个网络层。
图 3 deploy模型
调用示例
训练后量化主要包括如下几个步骤:
准备训练好的模型和数据集。
在原始PyTorch环境中验证模型精度以及环境是否正常。
编写训练后量化脚本调用AMCT API。
执行训练后量化脚本。
在ONNX Runtime环境中验证量化后仿真模型精度。
由于软件约束(动态shape场景下暂不支持输入数据为DT_INT8),量化后的部署模型使用ATC工具进行模型转换时,不能使用动态shape相关参数,例如--dynamic_batch_size和--dynamic_image_size等,否则模型转换会失败。
使用AMCT工具量化后的部署模型,使用ATC工具进行模型转换时,不能再使用高精度特性,比如不能再通过--precision_mode参数配置force_fp32或must_keep_origin_dtype(原图fp32输入);不能再通过--precision_mode_v2参数配置origin;不能通过--op_precision_mode配置high_precision参数等。在高精度模式下设置量化参数,既拿不到量化的性能收益,也拿不到高精度模式的精度收益。
如下示例标有“由用户补充处理”的步骤,需要用户根据自己的模型和数据集进行补充处理,示例中仅为示例代码。
如下示例调用AMCT的部分,函数入参请根据实际情况进行调整。
导入AMCT包,并通过安装后处理>AMCT(PyTorch)中的环境变量设置日志级别。
import amct_pytorch as amct(可选,由用户补充处理)在PyTorch原始环境中验证推理脚本及环境。
建议使用原始待量化的模型和测试集,在PyTorch环境下推理,验证环境、推理脚本是否正常。
推荐执行该步骤,请确保原始模型可以完成推理且精度正常;执行该步骤时,可以使用部分测试集,减少运行时间。
user_do_inference_torch(ori_model, test_data, test_iterations)调用AMCT,量化模型。
生成量化配置。
config_file = './tmp/config.json' skip_layers = [] batch_num = 1 amct.create_quant_config(config_file=config_file, model=ori_model, input_data=ori_model_input_data, skip_layers=skip_layers, batch_num=batch_num)
修改图,在图中插入数据量化,权重量化等相关的算子,用于计算量化相关参数。
record_file = './tmp/record.txt' modified_onnx_model = './tmp/modified_model.onnx' calibration_model = amct.quantize_model(config_file=config_file, modified_onnx_model=modified_onnx_model, record_file=record_file, model=ori_model, input_data=ori_model_input_data)
(由用户补充处理)基于PyTorch环境,使用修改后的模型(calibration_model)在校准集(calibration_data)上做模型推理,生成量化因子。
该步骤执行时,需要注意如下两点:
校准集及其预处理过程数据要与模型匹配,以保证量化的精度。
前向推理次数为batch_num,如果次数不足,由于校准算子没有将量化因子输出到record文件中,会导致后续读取record校验失败。
校准过程中如果提示[IFMR]: Do layer xxx data calibration failed!错误信息,则请参见校准执行过程中提示“[IFMR]: Do layer xxx data calibration failed!”解决。
user_do_inference_torch(calibration_model, calibration_data, batch_num)保存模型。
根据量化因子,调用save_model接口,插入AscendQuant、AscendDequant等算子,保存为量化模型。
quant_model_path = './results/user_model' amct.save_model(modified_onnx_file=modified_onnx_file, record_file=record_file, save_path=quant_model_path)
(可选,由用户补充处理)基于ONNX Runtime的环境,使用量化后模型(quant_model)在测试集(test_data)上做推理,测试量化后仿真模型的精度。
使用量化后仿真模型精度与2中的原始精度做对比,可以观察量化对精度的影响。
quant_model = './results/user_model_fake_quant_model.onnx' user_do_inference_onnx(quant_model, test_data, test_iterations)
非均匀量化(不支持)¶
非均匀量化是指量化后的数据在某个数值空间中的分布是不均匀的。非均匀量化过程中,会根据待量化数据的概率分布来对均匀量化后的数据分布进一步进行根据目标压缩率(保留数值量/原始量化数值量)的聚类操作。相较于均匀量化,非均匀量化在进一步压缩数据信息量的基础上尽可能的保留高概率分布的数据信息,从而减小压缩后的数据信息丢失。
模型在NPU IP加速器上推理时,可通过非均匀量化提高权重压缩率(需要与ATC工具配合,通过编译时使能权重压缩),降低权重传输开销,进一步提升推理性能。非均匀量化后,如果精度仿真模型在原始PyTorch环境中推理精度不满足要求,可通过调整非均匀量化配置文件config.json中的参数来恢复模型精度,调整方法请参见手工调优。量化示例请参见样例列表。
非均匀量化支持量化的层以及约束如下:
表 1 非均匀量化支持的层以及约束
支持的层类型 |
约束 |
|---|---|
torch.nn.Conv2d |
|
torch.nn.Linear |
仅支持带bias规格的非均匀量化,且Shape必须为两维 |
实现流程
静态非均匀量化实现原理同均匀量化,简要流程如图1所示。
图 1 非均匀量化流程图
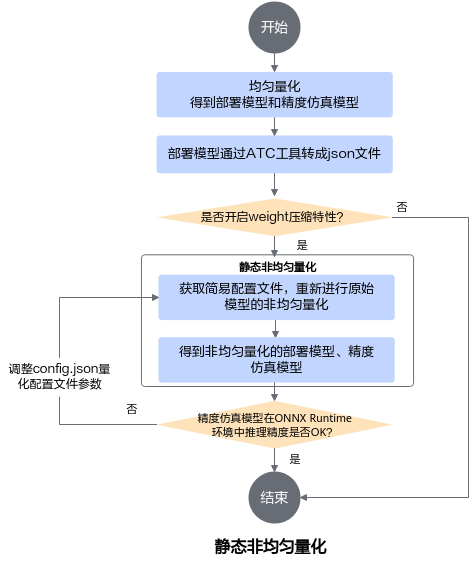
详细流程说明如下:
参见均匀量化章节获取均匀量化的部署模型和精度仿真模型。
参见《ATC离线模型编译工具用户指南》将1中生成的部署模型转换成JSON文件,该JSON文件记录了量化后模型的融合信息,同时也携带了支持weight压缩特性层的信息(通过fe_weight_compress字段识别)。
如果要进行weight压缩,则参见训练后量化简易配置文件章节获取非均匀量化简易配置文件,然后获取2生成的量化后模型的融合JSON文件进行非均匀量化。
非均匀量化过程中,会根据融合JSON文件,获取原始模型中哪些层支持weight压缩,然后重新生成非均匀量化的部署模型和量化配置文件。
查看非均匀量化后,精度仿真模型在原始ONNX Runtime环境中推理精度是否满足要求,如果不满足要求,则需要调整非均匀量化配置文件config.json中的参数,然后重新进行非均匀量化,直至满足精度要求。调整方法请参见手工调优。
手工调优¶
执行训练后量化特性的精度如果不满足要求,可以尝试手动调整config.json文件中的参数,本节给出调整的原则,以及参数解释。
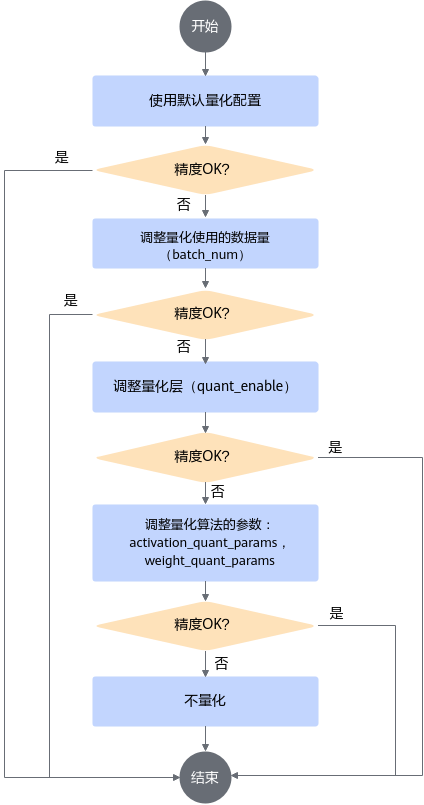
调优流程
通过create_quant_config接口生成的config.json文件中的默认配置进行量化,若量化后的推理精度不满足要求,则可调整量化配置重复量化,直至精度满足要求。本节详细介绍手动调优流程,调整对象是训练后量化配置文件config.json中的参数,主要涉及3个阶段:
调整校准使用的数据量。
跳过量化某些层。
调整量化算法及参数。
具体步骤如下:
根据create_quant_config接口生成的默认配置进行量化。若精度满足要求,则调参结束,否则进行2。
手动修改batch_num,调整校准使用的数据量。
batch_num控制量化使用数据的batch数目,可根据batch大小以及量化需要使用的图片数量调整。通常情况下:
batch_num越大,量化过程中使用的数据样本越多,量化后精度损失越小;但过多的数据并不会带来精度的提升,反而会占用较多的内存,降低量化的速度,并可能引起内存、显存、线程资源不足等情况;因此,建议batch_num*batch_size为16或32(batch_size表示每个batch使用的图片数量)。
手动修改quant_enable,跳过量化某些层。
quant_enable可以指定该层是否量化,取值为true时量化该层,取值为false时不量化该层,将该层的配置删除也可跳过该层量化。
在整网精度不达标的时候需要识别出网络中的量化敏感层(量化后误差显著增大),然后取消对量化敏感层的量化动作,识别量化敏感层有两种方法:
依据网络模型结构,一般网络中首层、尾层以及参数量偏少的层,量化后精度会有较大的下降。
通过精度比对工具,逐层比对原始模型和量化后模型输出误差(例如以余弦相似度作为标准,需要相似度达到0.99以上),找到误差较大的层,优先对其进行回退。
手动修改activation_quant_params和weight_quant_params,调整量化算法及参数:
算法参数意义请参见量化配置文件中的参数说明部分,算法说明请参见训练后量化算法。
若按照6中的量化配置进行量化后,精度满足要求,则调参结束,否则表明量化对精度影响很大,不能进行量化,去除量化配置。
图 1 调参流程
量化配置文件
如果通过create_quant_config接口生成的config.json量化配置文件,推理精度不满足要求,则需要参见该章节不断调整config.json文件中的内容(用户修改JSON文件时,请确保层名唯一),直至精度满足要求,json量化配置文件样例请参见接口中的调用示例部分。
配置文件中参数说明如下:
表 1 version参数说明
作用 |
控制量化配置文件版本号。 |
|---|---|
类型 |
int |
取值范围 |
1 |
参数说明 |
目前仅有一个版本号1。 |
推荐配置 |
1 |
可选或者必选 |
可选 |
表 2 batch_num参数说明
作用 |
控制量化使用多少个batch的数据。 |
|---|---|
类型 |
int |
取值范围 |
大于0 |
参数说明 |
如果不配置,则使用默认值1,建议校准集图片数量不超过50张,根据batch的大小batch_size计算相应的batch_num数值。 batch_num*batch_size为量化使用的校准集图片数量。 其中batch_size为每个batch所用的图片数量。 |
推荐配置 |
1 |
必选或可选 |
可选 |
表 3 activation_offset参数说明
作用 |
控制数据量化是对称量化还是非对称量化。全局配置参数。 若配置文件中同时存在activation_offset和asymmetric参数,asymmetric参数优先级>activation_offset参数。 |
|---|---|
类型 |
bool |
取值范围 |
true或false |
参数说明 |
|
推荐配置 |
true |
必选或可选 |
可选 |
表 4 do_fusion参数说明
作用 |
是否开启融合功能。 |
|---|---|
类型 |
bool |
取值范围 |
true或false |
参数说明 |
当前仅支持Conv+BN融合。 |
推荐配置 |
true |
可选或必选 |
可选 |
表 5 skip_fusion_layers参数说明
作用 |
跳过可融合的层。 |
|---|---|
类型 |
string |
取值范围 |
可融合层的层名。当前仅支持Conv+BN融合。 |
参数说明 |
不需要做融合的层。 |
推荐配置 |
- |
可选或必选 |
可选 |
表 6 layer_config参数说明
作用 |
指定某个网络层的量化配置。 |
|---|---|
类型 |
object |
取值范围 |
- |
参数说明 |
参数内部包含如下参数:
|
推荐配置 |
- |
必选或可选 |
可选 |
表 7 quant_enable参数说明
作用 |
该层是否做量化。 |
|---|---|
类型 |
bool |
取值范围 |
true或false |
参数说明 |
|
推荐配置 |
true |
必选或可选 |
可选 |
表 8 dmq_balancer_param参数说明
作用 |
DMQ均衡算法中的迁移强度。 |
|---|---|
类型 |
float |
取值范围 |
[0.2, 0.8] |
参数说明 |
代表将activation数据上的量化难度迁移至weight权重的程度,数据分布的离群值越大迁移强度应设置较小。 |
推荐配置 |
0.5 |
必选或可选 |
可选 |
表 9 activation_quant_params参数说明
作用 |
该层数据量化的参数。 |
|---|---|
类型 |
object |
取值范围 |
- |
参数说明 |
activation_quant_params内部包含如下参数,IFMR算法相关参数与HFMG算法相关参数在同一层中不能同时出现:
|
推荐配置 |
- |
必选或可选 |
可选 |
表 10 weight_quant_params参数说明
作用 |
该层权重量化的参数。 |
|---|---|
类型 |
object |
取值范围 |
- |
参数说明 |
|
推荐配置 |
- |
必选或可选 |
可选 |
表 11 num_bits参数说明
作用 |
量化位宽。 |
|---|---|
类型 |
int |
取值范围 |
8或16 |
参数说明 |
当前仅支持配置为8,表示采用INT8量化位宽。 |
推荐配置 |
- |
必选或可选 |
必选 |
表 12 act_algo参数说明
作用 |
数据量化算法。 |
|---|---|
类型 |
string |
取值范围 |
ifmr或者hfmg |
参数说明 |
IFMR数据量化算法:ifmr HFMG数据量化算法:hfmg |
推荐配置 |
- |
必选或可选 |
可选 |
表 13 asymmetric参数说明
作用 |
控制数据量化是对称量化还是非对称量化。用于控制逐层量化算法的选择。 若配置文件中同时存在activation_offset和asymmetric参数,asymmetric参数优先级>activation_offset参数。 |
|---|---|
类型 |
bool |
取值范围 |
true或false |
参数说明 |
|
推荐配置 |
true |
必选或可选 |
可选 |
表 14 max_percentile参数说明
作用 |
IFMR数据量化算法中,最大值搜索位置参数。 |
|---|---|
类型 |
float |
取值范围 |
(0.5,1] |
参数说明 |
在从大到小排序的一组数中,决定取第多少大的数,比如有100个数,1.0表示取第100-100*1.0=0,对应的就是第一个大的数。 对待量化的数据做截断处理时,该值越大,说明截断的上边界越接近待量化数据的最大值。 |
推荐配置 |
0.999999 |
必选或可选 |
可选 |
表 15 min_percentile参数说明
作用 |
IFMR数据量化算法中,最小值搜索位置参数。 |
|---|---|
类型 |
float |
取值范围 |
(0.5,1] |
参数说明 |
在从小到大排序的一组数中,决定取第多少小的数,比如有100个数,1.0表示取第100-100*1.0=0,对应的就是第一个小的数。 对待量化的数据做截断处理时,该值越大,说明截断的下边界越接近待量化数据的最小值。 |
推荐配置 |
0.999999 |
必选或可选 |
可选 |
表 16 search_range参数说明
作用 |
IFMR数据量化算法中,控制量化因子的搜索范围[search_range_start, search_range_end]。 |
|---|---|
类型 |
list,列表中两个元素类型为float。 |
取值范围 |
0<search_range_start<search_range_end |
参数说明 |
控制截断的上边界的浮动范围。
|
推荐配置 |
[0.7,1.3] |
必选或可选 |
可选 |
表 17 search_step参数说明
作用 |
IFMR数据量化算法中,控制量化因子的搜索步长。 |
|---|---|
类型 |
float |
取值范围 |
(0, (search_range_end-search_range_start)] |
参数说明 |
控制截断的上边界的浮动范围步长,值越小,浮动步长越小。 搜索次数search_iteration=(search_range_end-search_range_start)/search_step,如果搜索次数过大,搜索时间会很长,该场景下将会导致类似进程卡死的问题。 |
推荐配置 |
0.01 |
必选或可选 |
可选 |
表 18 num_of_bins参数说明
作用 |
HFMG数据量化算法用于调整直方图的bin(直方图中的一个最小单位直方图形)数目。 |
|---|---|
类型 |
unsigned int |
取值范围 |
{1024, 2048, 4096, 8192} |
参数说明 |
num_of_bins数值越大,直方图拟合原始数据分布的能力越强,可能获得更佳的量化效果,但训练后量化过程的耗时也会更长。 |
推荐配置 |
4096 |
必选或可选 |
HFMG算法量化场景下,该参数可选。 |
表 19 wts_algo参数说明
作用 |
权重量化算法 |
|---|---|
类型 |
string |
取值范围 |
arq_quantize |
参数说明 |
ARQ权重量化算法:arq_quantize |
推荐配置 |
- |
必选或可选 |
可选 |
表 20 channel_wise搜索相关参数说明
作用 |
ARQ权重量化算法中,是否对每个channel采用不同的量化因子。 |
|---|---|
类型 |
bool |
取值范围 |
true或false |
参数说明 |
|
推荐配置 |
true |
必选或可选 |
可选 |
量化感知训练¶
本节详细介绍量化感知训练支持的量化层,接口调用流程和示例。 执行量化感知训练特性后的精度如果不满足要求,可以尝试手动调整config.json文件中的参数,本节给出调整的原则,以及参数解释。
量化流程¶
本节详细介绍量化感知训练支持的量化层,接口调用流程和示例。
量化感知训练当前仅支持对float32数据类型的网络模型进行量化。量化感知训练支持量化的层以及约束如下,量化示例请参见样例列表。
表 1 量化感知训练支持的层以及约束
支持的层类型 |
约束 |
备注 |
|---|---|---|
torch.nn.Linear |
- |
|
torch.nn.Conv1d |
|
|
torch.nn.Conv2d |
|
|
torch.nn.ConvTranspose2d |
|
|
torch.nn.ConvTranspose1d |
|
|
torch.nn.LSTM |
|
|
torch.nn.GRU |
|
接口调用流程
量化感知训练接口调用流程如图1所示,如下流程中的训练环境借助PyTorch框架的CPU/GPU环境,在该开源框架的推理脚本基础上,调用AMCT API完成模型压缩,压缩后的部署模型需要使用ATC工具转换成适配NPU IP加速器的离线模型后,然后才能在NPU IP加速器上实现推理:
图 1 接口调用流程
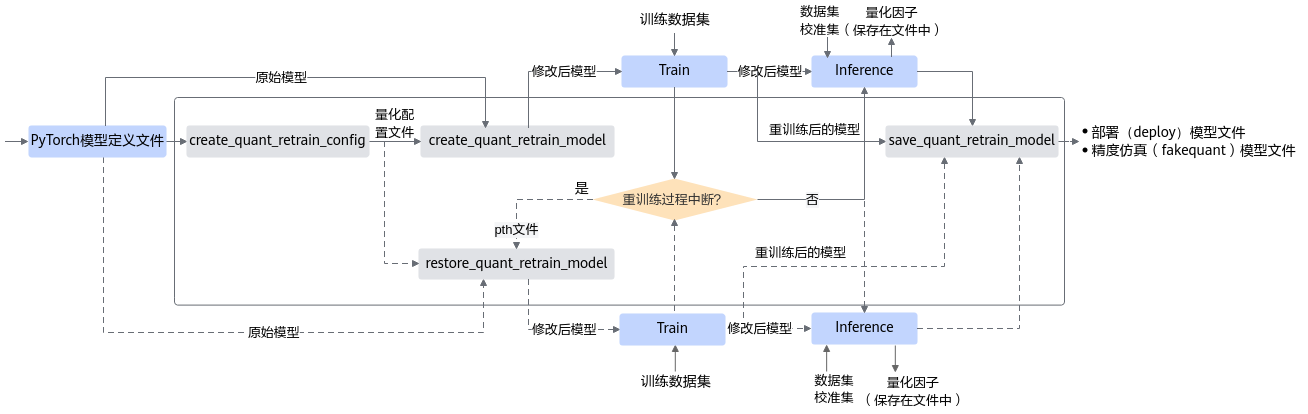
蓝色部分为用户实现,灰色部分为用户调用AMCT提供的API实现:
用户首先构造PyTorch的原始模型,调用create_quant_retrain_config接口生成量化配置文件。
调用create_quant_retrain_model接口对原始模型进行修改,修改后的模型中插入了数据量化、权重量化等相关算子,用于计算量化相关参数。
对修改后的模型进行训练,如果训练未中断,将训练后的模型进行推理,进行推理的过程中,会将量化因子写出到record文件中。
如果训练过程中断,则可基于保存的pth模型参数和量化配置文件,重新调用restore_quant_retrain_model接口,输出修改后的retrain network,继续进行量化感知的训练,然后进行推理。
调用save_quant_retrain_model接口,插入AscendQuant、AscendDequant等量化算子,保存量化模型。
调用示例
基于PyTorch环境进行训练,当前仅支持distributed模式(即DistributedDataParallel模式)的多卡训练,不支持DataParallel模式的多卡训练,使用DP模式训练会报错。
调用AMCT的部分,函数入参可以根据实际情况进行调整。量化感知训练基于用户的训练过程,请确保已经有基于PyTorch环境进行训练的脚本,并且训练后的精度正常。
使用AMCT的量化感知训练特性时,如果训练过程卡死,请检查当前服务器是否有其他ONNX Runtime程序在运行(可以用top命令查看服务器所有进程),如果有,请先暂停其他ONNX Runtime程序,重新执行量化感知训练。
参考本章节进行量化,模型中存在PyTorch自定义算子时,可能存在无法导出生成ONNX模型,从而导致量化失败的问题。具体报错信息如下:'Model cannot be quantized for it cannot be export to onnx!' 。此时,您可以参考单算子模式的量化感知训练章节,进行单算子模式的量化。
如下示例标有“由用户补充处理”的步骤,需要用户根据自己的模型和数据集进行补充处理,示例中仅为示例代码。
导入AMCT包,并通过安装后处理>AMCT(PyTorch)中的环境变量设置日志级别。
import amct_pytorch as amct(可选,由用户补充处理)建议使用原始待量化的模型和测试集,在PyTorch环境下推理,验证环境、推理脚本是否正常。
推荐执行该步骤,请确保原始模型可以完成推理且精度正常;执行该步骤时,可以使用部分测试集,减少运行时间。
ori_model.load() # 测试模型 user_test_model(ori_model, test_data, test_iterations)
调用AMCT,执行量化流程。
生成量化配置。
实现该步骤前,应先恢复训练好的参数,如2中的ori_model.load()。
config_file = './tmp/config.json' simple_cfg = './retrain.cfg' amct.create_quant_retrain_config(config_file=config_file, model=ori_model, input_data=ori_model_input_data, config_defination=simple_cfg)
修改模型。
在模型ori_model插入数据量化、权重量化等相关算子,用于计算量化相关参数,然后保存为新的训练模型retrain_model。
record_file = './tmp/record.txt' quant_retrain_model = amct.create_quant_retrain_model(config_file=config_file, model=ori_model, record_file=record_file, input_data=ori_model_input_data)
(由用户补充处理)使用修改后的图,创建反向梯度,在训练集上做训练,训练量化因子。
使用修改后的图,创建反向梯度。该步骤需要在3.b后执行。
optimizer = user_create_optimizer(quant_retrain_model)从训练好的checkpoint恢复模型,并训练模型。
注意:从训练好的checkpoint恢复模型参数后再训练;训练中保存的参数应该包括量化因子:前batch_num次训练后会生成量化因子,如果训练次数少于batch_num会导致失败。
quant_pth = './ckpt/user_model' user_train_model(optimizer, quant_retrain_model, train_data)
训练完成后,执行推理,计算量化因子并保存。
user_infer_graph(quant_retrain_model)
保存量化模型。
根据量化因子以及用户重训练好的模型,调用save_quant_retrain_model接口,插入AscendQuant、AscendDequant等算子,保存为量化模型。
quant_model_path = './result/user_model' amct.save_quant_retrain_model(config_file=config_file, model=quant_retrain_model, record_file=record_file, save_path=quant_model_path, input_data=ori_model_input_data)
说明:如果重训练过程每一轮都调用该接口保存模型,可能会导致重训异常,建议重训练完毕后调用该接口保存模型。
(可选,由用户补充处理)基于ONNX Runtime的环境,使用量化后模型(quant_model)在测试集(test_data)上做推理,测试量化后仿真模型的精度。
使用量化后仿真模型精度与2中的原始精度做对比,可以观察量化对精度的影响。
quant_model = './results/user_model_fake_quant_model.onnx' user_do_inference_onnx(quant_model, test_data, test_iterations)
如果训练过程中断,需要从ckpt中恢复数据,继续训练,则调用流程为:
导入AMCT包,并通过安装后处理>AMCT(PyTorch)中的环境变量设置日志级别。
import amct_pytorch as amct准备原始模型。
ori_model= user_create_model()调用AMCT,恢复量化训练流程。
修改模型,在模型ori_model插入量化相关的算子,保存为新的训练模型retrain_model。
config_file = './tmp/config.json' simple_cfg = './retrain.cfg' record_file = './tmp/record.txt' quant_pth_file = './ckpt/user_model_newest.ckpt' quant_retrain_model = amct.restore_quant_retrain_model(config_file=config_file, model=ori_model, record_file=record_file, input_data=ori_model_input_data, pth_file=quant_pth_file)
(由用户补充处理)使用修改后的图,创建反向梯度,在训练集上做训练,训练量化因子。
使用修改后的图,创建反向梯度。该步骤需要在3.a后执行。
optimizer = user_create_optimizer(retrain_model)从训练好的checkpoint恢复模型,并训练模型。
注意:从训练好的checkpoint恢复模型参数后再训练;训练中保存的参数应该包括量化因子:前batch_num次训练后会生成量化因子,如果训练次数少于batch_num会导致失败。
user_train_model(optimizer, retrain_model, train_data)训练完成后,执行推理,计算量化因子并保存。
user_infer_graph(train_graph, retrain_ops[-1].output_tensor)
保存模型。
quant_model_path = './result/user_model' amct.save_quant_retrain_model(config_file=config_file, model=ori_model, record_file=record_file, save_path=quant_model_path, input_data=ori_model_input_data)
(可选,由用户补充处理)基于ONNX Runtime的环境,使用量化后模型(quant_model)在测试集(test_data)上做推理,测试量化后仿真模型的精度。
使用量化后仿真模型精度与2中的原始精度做对比,可以观察量化对精度的影响。
quant_model = './results/user_model_fake_quant_model.onnx' user_do_inference_onnx(quant_model, test_data, test_iterations)
手工调优¶
执行量化感知训练特性后的精度如果不满足要求,可以尝试手动调整config.json文件中的参数,本节给出调整的原则,以及参数解释。
调优流程
通过create_quant_retrain_config接口生成的config.json文件中的默认配置进行量化,若量化后的推理精度不满足要求,则按照如下步骤调整量化配置文件中的参数。
根据create_quant_retrain_config接口生成的默认配置进行量化。若精度满足要求,则调参结束,否则进行下一步。
INT8量化场景下,可以将部分量化层取消量化,即将其"retrain_enable"参数修改为"false",通常模型首尾层对推理结果影响较大,故建议优先取消首尾层的量化;如果用户有推荐的clip_max和clip_min的参数取值,则可以按照如下方式修改量化配置文件:
{ "version":1, "batch_num":1, "layername1":{ "retrain_enable":true, "retrain_data_config":{ "algo":"ulq_quantize", "clip_max":3.0, "clip_min":-3.0 }, "retrain_weight_config":{ "algo":"arq_retrain", "channel_wise":true } }, "layername2":{ "retrain_enable":true, "retrain_data_config":{ "algo":"ulq_quantize", "clip_max":3.0, "clip_min":-3.0 }, "retrain_weight_config":{ "algo":"arq_retrain", "channel_wise":true } } }
完成配置后,精度满足要求则调参结束;否则表明量化感知训练对精度影响很大,不能进行量化感知训练,去除量化感知训练配置。
量化配置文件
如果通过create_quant_retrain_config接口生成的config.json量化感知训练配置文件,推理精度不满足要求,则需要参见该章节不断调整config.json文件中的内容,直至精度满足要求,该文件部分内容样例请参见接口中的调用示例部分(用户修改json文件时,请确保层名唯一)。
配置文件中参数说明如下,其中表8~表10的参数说明在手动调整量化配置文件时才会使用。
表 1 version参数说明
作用 |
控制量化配置文件版本号。 |
|---|---|
类型 |
int |
取值范围 |
1 |
参数说明 |
目前仅有一个版本号1。 |
推荐配置 |
1 |
必选或可选 |
可选 |
表 2 batch_num参数说明
作用 |
控制量化感知训练推理阶段使用多少个batch的数据。 |
|---|---|
类型 |
int |
取值范围 |
大于0 |
参数说明 |
如果不配置,则使用默认值1,建议校准集图片数量不超过50张,根据batch的大小batch_size计算相应的batch_num数值。 batch_num*batch_size为量化使用的校准集图片数量。 其中batch_size为每个batch所用的图片数量。 |
推荐配置 |
1 |
必选或可选 |
可选 |
表 3 retrain_enable参数说明
作用 |
该层是否进行量化感知训练。 |
|---|---|
类型 |
bool |
取值范围 |
true或false |
参数说明 |
|
推荐配置 |
true |
必选或可选 |
可选 |
表 4 retrain_data_config参数说明
作用 |
该层数据量化配置。 |
|---|---|
类型 |
object |
取值范围 |
- |
参数说明 |
包含如下参数:
|
推荐配置 |
- |
必选或可选 |
可选 |
表 5 retrain_weight_config参数说明
作用 |
该层权重量化配置。 |
|---|---|
类型 |
object |
取值范围 |
- |
参数说明 |
包含如下参数:
|
推荐配置 |
- |
必选或可选 |
可选 |
表 6 algo参数说明
作用 |
该层选择使用的量化算法。 |
|---|---|
类型 |
object |
取值范围 |
- |
参数说明 |
|
推荐配置 |
数据量化使用ulq_quantize,权重量化使用arq_retrain。 |
必选或可选 |
可选 |
表 7 channel_wise参数说明
作用 |
是否对每个channel采用不同的量化因子。 |
|---|---|
类型 |
bool |
取值范围 |
true或false |
参数说明 |
|
推荐配置 |
true |
必选或可选 |
可选 |
表 8 fixed_min参数说明
作用 |
设置数据量化算法下限的开关。 |
|---|---|
类型 |
bool |
取值范围 |
true或false |
参数说明 |
如果不选此项,AMCT根据图的结构自动设置。 如果选择此项,并且网络模型量化层的前一层是relu层,则该参数需要手动设置为true,如果为非relu层,则要手动设置为false。 |
推荐配置 |
不选此项 |
必选或可选 |
可选 |
表 9 clip_max参数说明
作用 |
数据量化算法上限。 |
|---|---|
类型 |
float |
取值范围 |
clip_max>0 根据不同层activation的数据分布找到最大值max,推荐取值范围为:0.3*max~1.7*max |
参数说明 |
截断上下限数据量化算法,如果选择此项则固定算法截断上限。如果不选此项,通过ifmr算法学习获取上限。 |
推荐配置 |
不选此项 |
必选或可选 |
可选 |
表 10 clip_min参数说明
作用 |
数据量化算法下限。 |
|---|---|
类型 |
float |
取值范围 |
clip_min<0 根据不同层activation的数据分布找到最小值min,推荐取值范围为:0.3*min~1.7*min |
参数说明 |
截断上下限数据量化算法,如果选择此项则固定算法截断下限。如果不选此项,通过ifmr算法学习获取下限。 |
推荐配置 |
不选此项 |
必选或可选 |
可选 |
表 11 dst_type参数说明
作用 |
量化位宽的类型。 |
|---|---|
类型 |
string |
取值范围 |
INT8或INT4,默认为INT8。当前版本仅支持INT8量化。 |
参数说明 |
量化时用于选择是INT8量化还是INT4量化。 |
推荐配置 |
- |
必选或可选 |
可选 |
稀疏(不支持)¶
通道稀疏¶
自动通道稀疏搜索¶
当前通道稀疏支持对不同的层做不同稀疏率的稀疏处理,但逐层设置稀疏率对用户的使用门槛较高,对于某一层,如何选择稀疏率(即配置中的prune_ratio)是比较困难的,手工尝试的配置需要进行重训练,耗费时间多。针对上述问题,引入自动通道稀疏搜索特性,根据用户模型来计算各通道的稀疏敏感度(影响精度)以及稀疏收益(影响性能),然后搜索策略依据稀疏敏感度和稀疏收益来搜索最优的逐层通道稀疏率,以平衡精度和性能。 介绍自动通道稀疏搜索特性的接口调用流程和调用示例。
简介¶
当前通道稀疏支持对不同的层做不同稀疏率的稀疏处理,但逐层设置稀疏率对用户的使用门槛较高,对于某一层,如何选择稀疏率(即配置中的prune_ratio)是比较困难的,手工尝试的配置需要进行重训练,耗费时间多。针对上述问题,引入自动通道稀疏搜索特性,根据用户模型来计算各通道的稀疏敏感度(影响精度)以及稀疏收益(影响性能),然后搜索策略依据稀疏敏感度和稀疏收益来搜索最优的逐层通道稀疏率,以平衡精度和性能。
稀疏敏感度:稀疏敏感度定义为当前通道稀疏后对整网精度的影响估计,稀疏敏感度越大代表当前通道稀疏后整网精度损失越大,默认算法根据loss(w - wi)的泰勒展开计算通道稀疏敏感度。支持用户自定义计算方式。裁剪第i个通道后,稀疏敏感度计算公式如下:
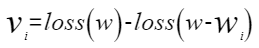
采用近似估计的方法对loss(w - wi)进行泰勒展开,目前考虑到计算量只算一阶。
稀疏收益:当前通道的稀疏收益用比特复杂度表示,为计算量化Flops与计算比特位宽之积:
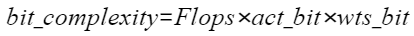
其中,Flops为浮点计算量,act_bit为数据的数据精度,wts_bit为权重的数据精度。
自动通道稀疏搜索流程如图1所示,支持稀疏的层以及规格请参见表1。
图 1 自动通道稀疏搜索流程
各流程简要说明如下:
初始化:初始化动作首先需要解析用户模型以及稀疏配置(可选),分析网络中可通道稀疏层及其对应的通道稀疏配置(是否有用户指定配置稀疏率),生成通道稀疏配置生成的搜索空间:解析用户目标压缩率配置。
搜索空间:为支持通道稀疏的层,但是没有通过override_layer_configs或者override_layer_types配置稀疏率。
压缩率:定义为原模型比特复杂度与稀疏后模型比特复杂度之比。
敏感度计算:计算每个通道的稀疏敏感度,内置基于损失估计的敏感度计算方法,使用泰勒展开的一次项估计裁剪该通道后网络loss的变化;支持用户自定义敏感度计算方法。
比特复杂度计算:计算每个通道的比特复杂度,视为通道的稀疏收益。
通道稀疏率配置搜索:默认采用自动通道稀疏搜索算法,搜索满足用户指定压缩率的最优通道稀疏率配置;支持用户自定义求解器。
说明:
自动通道稀疏搜索特性只是生成通道稀疏的简易配置文件,若想得到最终稀疏后模型,还需要进行手工稀疏,将上述生成的简易配置文件作为入参传入通道稀疏。
搜索流程¶
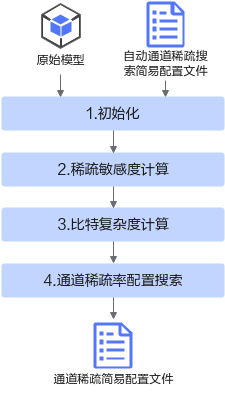
介绍自动通道稀疏搜索特性的接口调用流程和调用示例。
接口调用流程
接口调用流程如图1所示,蓝色部分为用户实现,灰色部分为用户调用AMCT提供的API实现。稀疏示例请参见样例列表。
用户准备好PyTorch的模型、自动通道稀疏搜索配置文件,调用auto_channel_prune_search,根据压缩率、各通道的稀疏敏感度以及稀疏收益,执行自动通道稀疏搜索,得到可用作通道稀疏的简易配置文件。其中,sensitivity模块与search_alg模块用户可以自定义或者使用接口内部默认方法。
sensitivity模块实现计算各通道的稀疏敏感度。
search_alg模块实现了基于通道敏感度与通道稀疏收益进行稀疏通道搜索的过程。
图 1 调用流程
调用示例
本示例演示了使用AMCT进行自动通道稀疏搜索的流程,该过程需要用户传入PyTorch模型与校准数据,用户可选择自定义实现sensitivity模块与search_alg模块。
如下示例标有“由用户补充处理”的步骤,需要用户根据自己的模型和数据集进行补充处理,示例中仅为示例代码。
如下示例调用AMCT的部分,函数入参请根据实际情况进行调整。
导入AMCT包,并通过安装后处理>AMCT(PyTorch)中的环境变量设置日志级别。
import amct_pytorch as amct(可选,由用户补充处理)实现sensitivity模块,获取各个layer各通道的敏感度,为后续的搜索算法提供数据。可参考系统默认sensitivity模块:AMCT安装目录
amct_pytorch/auto_channel_prune_search.py下的TaylorLossSensitivity方法,简要流程如下:
from amct.common.auto_channel_prune.sensitivity_base import SensitivityBase class Sensitivity(SensitivityBase) def __init__(self) pass def setup_initialization(self, graph_tuple, input_data, test_iteration): # 必要的初始化 # graph_tuple (graph, graph_info) pass def get_sensitivity(self, search_records): # 获取敏感度方法,计算后写到record中 pass
(可选,由用户补充处理)实现搜索算法search_alg模块,需要用户实现channel_prune_search回调接口,根据通道敏感度与通道稀疏收益进行稀疏通道搜索。可参考系统默认search_alg模块:AMCT安装目录/amct_pytorch/common/auto_prune/search_channel_base.py文件中GreedySearch方法。
from amct.common.auto_prune.search_channel_base import SearchChannelBase class Search(SearchChannelBase) def __init__(self) # 初始化 pass def channel_prune_search(self, graph_info, search_records, prune_config): """ 输入: graph_info: dict,包含图中各算子的通道数量与比特复杂度信息,可用于计算压缩率 search_records: protobuf对象,包含待搜索的可稀疏层 prune_config: 三元组-目标压缩率(float)、昇腾亲和优化开关(bool)、单层最大稀疏率(float) 输出: dict,key为待搜索的可稀疏层层名,value为01组成的list,对应该通道是否应稀疏 """ pass
(可选,由用户补充处理)获取PyTorch模型,在环境下推理,验证环境、推理脚本是否正常。执行该步骤时,可以使用部分测试集,减少运行时间。
ori_model.load() # 测试模型 user_test_model(ori_model, test_data, test_iterations)
(由用户补充处理)构造校准数据。
input_data = [] for _ in range(test_iteration): input_data.append(user_load_feed_dict())
调用AMCT,进行自动通道稀疏搜索。
output_prune_cfg = './prune.cfg' amct.auto_channel_prune_search( model=model, config=cfg_file, input_data=input_data, output_cfg=output_prune_cfg, sensitivity='TaylorLossSensitivity', search_alg='GreedySearch')
手工稀疏¶
本节介绍手工稀疏特性支持的稀疏层,接口调用流程和调用示例。 稀疏后,如果精度不满足要求,可以参见本节提供的方法进行调优。
稀疏流程¶
本节介绍手工稀疏特性支持的稀疏层,接口调用流程和调用示例。
AMCT目前主要支持基于重训练的通道稀疏模型压缩特性,稀疏示例请参见样例列表>通道稀疏,支持通道稀疏的层以及约束如下:
表 1 通道稀疏支持的层以及约束
优化方式 |
支持的层类型 |
约束 |
|---|---|---|
通道稀疏 |
torch.nn.Linear:全连接层 |
复用层(共用weight和bias参数)不支持稀疏。 |
torch.nn.Conv2d:卷积层 |
|
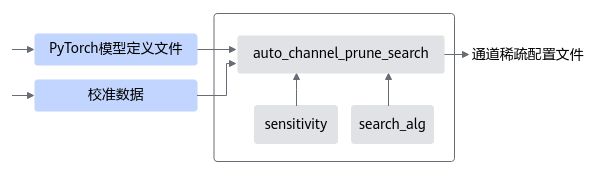
接口调用流程
通道稀疏功能接口调用流程如下图所示,如下流程中的训练环境借助PyTorch框架的CPU/GPU环境,在该开源框架的推理脚本基础上,调用AMCT API完成模型压缩,压缩后的部署模型需要使用ATC工具转换成适配NPU IP加速器的离线模型后,然后才能在NPU IP加速器上实现推理:
图 1 通道稀疏接口调用流程
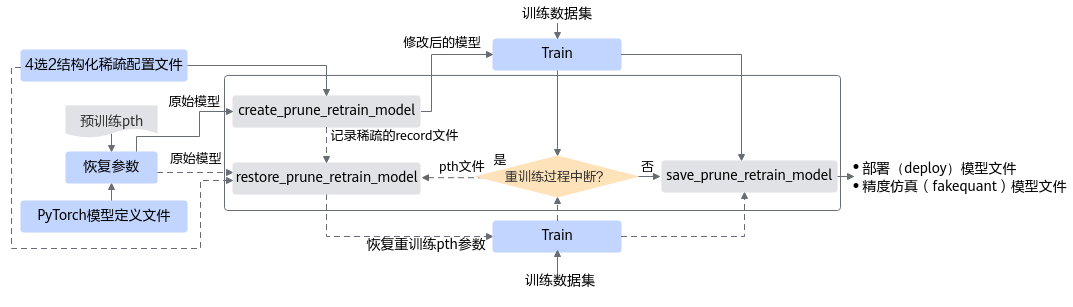
蓝色部分为用户实现,灰色部分为用户调用AMCT提供的API实现:
用户首先构造PyTorch的原始模型,调用create_prune_retrain_model接口对原始模型进行修改,在图结构中插入通道稀疏mask算子,修改后的模型参数量被裁剪。
对修改后的模型进行训练,直至精度满足要求;如果训练过程中断,则可基于原始模型和记录稀疏信息的文件,重新调用restore_prune_retrain_model接口稀疏模型,继续进行量化感知的训练,直至精度满足要求。
根据最终的重训练好的通道稀疏模型,生成满足精度要求的pth文件;或者调用save_prune_retrain_model接口,生成最终ONNX仿真模型以及部署模型。
调用示例
如下示例标有“由用户补充处理”的步骤,需要用户根据自己的模型和数据集进行补充处理,示例中仅为示例代码。
调用AMCT的部分,函数入参可以根据实际情况进行调整。稀疏基于用户的训练过程,请确保已经有基于PyTorch环境进行训练的脚本,并且训练后的精度正常。
导入AMCT包,并通过安装后处理>AMCT(PyTorch)中的环境变量设置日志级别。
import amct_pytorch as amct(可选,由用户补充处理)建议使用原始待稀疏的模型和测试集,在PyTorch环境下推理,验证环境、推理脚本是否正常。
推荐执行该步骤,请确保原始模型可以完成推理且精度正常;执行该步骤时,可以使用部分测试集,减少运行时间。
ori_model.load() # 测试模型 user_test_model(ori_model, test_data, test_iterations)
调用AMCT,执行带稀疏算子的训练流程。
对原始模型进行修改,在图结构中插入通道稀疏mask算子。
实现该步骤前,应先恢复训练好的参数,如2中的ori_model.load()。
simple_cfg = './retrain.cfg' record_file = './tmp/record.txt' prune_retrain_model = amct.create_prune_retrain_model(model=ori_model, input_data=ori_model_input_data, config_defination=simple_cfg, record_file=record_file)
(由用户补充处理)使用修改后的图,创建反向梯度,在训练集上做训练。
使用修改后的图,创建反向梯度。
该步骤需要在稀疏模型后执行。
optimizer = user_create_optimizer(prune_retrain_model)从训练好的checkpoint恢复模型,并训练模型。
注意:从训练好的checkpoint恢复模型参数后再训练。
quant_pth = './ckpt/user_model' user_train_model(optimizer, prune_retrain_model, train_data)
(可选)如果调用save_prune_retrain_model接口,则需要参考该步骤,如果保存为pth文件则不需要。
保存模型,实现通道稀疏。
prune_retrain_model = amct.save_prune_retrain_model( model=pruned_retrain_model, save_path=save_path, input_data=input_data)
(由用户补充处理)基于ONNX Runtime的环境,使用通道稀疏后模型(prune_retrain_model)在测试集(test_data)上做推理,测试量化后仿真模型的精度。
使用稀疏后仿真模型精度与2中的原始精度做对比,可以观察通道稀疏对精度的影响。
prune_retrain_model = './results/user_model_fake_prune_model.onnx' user_do_inference_onnx(prune_retrain_model, test_data, test_iterations)
如果训练过程中断,需要从ckpt中恢复数据,继续训练,则调用流程为:
导入AMCT包,并通过安装后处理>AMCT(PyTorch)中的环境变量设置日志级别。
import amct_pytorch as amct准备原始模型。
ori_model= user_create_model()调用AMCT,恢复量化训练流程。
修改模型,在图结构中插入通道稀疏mask算子,保存为新的prune_model。
model = ori_model input_data = ori_model_input_data record_file = './tmp/record.txt' config_defination = './prune_cfg.cfg' save_pth_path = /your/path/to/save/tmp.pth model.load_state_dict(torch.load(state_dict_path)) prune_retrain_model = amct.restore_prune_retrain_model(model=ori_model, input_data=ori_model_input_data, record_file=record_file, config_defination='./prune_cfg.cfg', save_pth_path=/your/path/to/save/tmp.pth, 'state_dict')
(由用户补充处理)使用修改后的模型,恢复断点,创建反向梯度,在训练集上做训练。
从稀疏后训练中断的checkpoint恢复模型参数。
quant_pth = './ckpt/user_prune_model' user_train_model(optimizer, prune_retrain_model, train_data)
使用修改后的图,创建反向梯度。
该步骤需要在恢复模型参数后执行。
optimizer = user_create_optimizer(prune_retrain_model)从训练好的checkpoint恢复模型,并训练模型。
注意:从训练好的checkpoint恢复模型参数后再训练。
user_train_model(optimizer, prune_retrain_model, train_data)
(可选)如果调用save_prune_retrain_model接口,则需要参考该步骤,如果保存为pth文件则不需要。
保存模型,实现通道稀疏。
prune_retrain_model = amct.save_prune_retrain_model( model=pruned_retrain_model, save_path=save_path, input_data=input_data)
(由用户补充处理)基于ONNX Runtime的环境,使用通道稀疏后模型(prune_retrain_model)在测试集(test_data)上做推理,测试量化后仿真模型的精度。
使用稀疏后仿真模型精度与2中的原始精度做对比,可以观察通道稀疏对精度的影响。
prune_retrain_model = './results/user_model_fake_prune_model.onnx' user_do_inference_onnx(prune_retrain_model, test_data, test_iterations)
后续处理
如果稀疏后输出的模型为pth格式,则需要参考该章节,如果调用save_prune_retrain_model接口,则不需要。
由于输出的pth模型无法直接用于推理,需要用户自行将pth模型转成ONNX网络模型,或者调用save_prune_retrain_model接口保存为最终ONNX仿真模型以及部署模型,然后才能使用ATC工具进行模型转换。调用save_prune_retrain_model接口的调用示例如下:
prune_retrain_model = amct.10.6.3-save_prune_retrain_model(
model=pruned_retrain_model,
save_path=save_path,
input_data=input_data)
手工调优¶
稀疏后,如果精度不满足要求,可以参见本节提供的方法进行调优。
如果按照某组配置稀疏模型后,经过重训练精度未满足要求,则可以修改简易配置文件(文件配置请参见量化感知训练简易配置文件)重新稀疏模型并重训练。常用的方法包括:
调整稀疏率,由简易配置文件中的prune_ratio参数控制,用户可尝试减小稀疏率并重新进行稀疏来进行调试。
某些层不做稀疏,由简易配置文件中的regular_prune_skip_layers参数控制,通过该参数配置不需要稀疏的层。
4选2结构化稀疏¶
本节介绍4选2结构化稀疏支持的层,接口调用流程和调用示例。 稀疏后,如果精度不满足要求,可以参见本节提供的方法进行调优。
稀疏流程¶
本节介绍4选2结构化稀疏支持的层,接口调用流程和调用示例。
由于硬件约束,该芯片不支持4选2结构化稀疏特性:使能后获取不到性能收益。
AMCT支持基于重训练的4选2结构化稀疏特性。该特性支持的层以及约束如下,稀疏示例请参见样例列表。
表 1 支持的层以及约束
优化方式 |
支持的层类型 |
约束 |
|---|---|---|
4选2结构化稀疏 |
torch.nn.Linear:全连接层 |
复用层(共用weight)不支持稀疏。 |
torch.nn.Conv2d:卷积层 |
|
|
torch.nn.ConvTranspose2d:反卷积层 |
|
接口调用流程
4选2结构化稀疏功能接口调用流程如下图所示,如下流程中的训练环境借助PyTorch框架的CPU/GPU环境,在该开源框架的推理脚本基础上,调用AMCT API完成模型压缩,压缩后的部署模型需要使用ATC工具转换成适配NPU IP加速器的离线模型后,然后才能在NPU IP加速器上实现推理:
图 1 4选2结构化稀疏接口调用流程
蓝色部分为用户实现,灰色部分为用户调用AMCT提供的API实现:
用户首先构造PyTorch的原始模型,调用create_prune_retrain_model接口对原始模型进行修改,把待稀疏的算子替换成插入了4选2结构化稀疏的算子。
对修改后的模型进行训练,直至精度满足要求;如果训练过程中断,则可基于原始模型和记录稀疏信息的文件,重新调用restore_prune_retrain_model接口稀疏模型,继续进行量化感知的训练,直至精度满足要求。
根据用户最终的重训练好的4选2结构化稀疏模型,调用save_prune_retrain_model接口,还原替换的算子并对weight进行稀疏,生成最终ONNX仿真模型以及部署模型。
调用示例
如下示例标有“由用户补充处理”的步骤,需要用户根据自己的模型和数据集进行补充处理,示例中仅为示例代码。
调用AMCT的部分,函数入参可以根据实际情况进行调整。稀疏基于用户的训练过程,请确保已经有基于PyTorch环境进行训练的脚本,并且训练后的精度正常。
(可选,由用户补充处理)建议使用原始待量化的模型和测试集,在PyTorch环境下推理,验证环境、推理脚本是否正常。
推荐执行该步骤,请确保原始模型可以完成推理且精度正常;执行该步骤时,可以使用部分测试集,减少运行时间。
ori_model.load() # 测试模型 user_test_model(ori_model, test_data, test_iterations)
调用AMCT,执行4选2结构化稀疏流程。
对原始模型进行修改,把待稀疏的算子替换成插入了4选2结构化稀疏的算子。
实现该步骤前,应先恢复训练好的参数,如1中的ori_model.load()。
simple_cfg = './retrain.cfg' record_file = './tmp/record.txt' prune_retrain_model = amct.create_prune_retrain_model(model=ori_model, input_data=ori_model_input_data, config_defination=simple_cfg, record_file=record_file)
(由用户补充处理)使用修改后的图,创建反向梯度,在训练集上做训练。
使用修改后的图,创建反向梯度。
该步骤需要在稀疏模型后执行。
optimizer = user_create_optimizer(prune_retrain_model)从训练好的checkpoint恢复模型,并训练模型。
注意:从训练好的checkpoint恢复模型参数后再训练。
quant_pth = './ckpt/user_model' user_train_model(optimizer, prune_retrain_model, train_data)
调用save_prune_retrain_model接口,保存模型,还原替换的算子并对weight进行结构化稀疏,生成最终ONNX仿真模型以及部署模型。
prune_retrain_model = amct.save_prune_retrain_model( model=pruned_retrain_model, save_path=save_path, input_data=input_data)
(可选,由用户补充处理)基于ONNX Runtime的环境,使用稀疏后模型(prune_retrain_model)在测试集(test_data)上做推理,测试量化后仿真模型的精度。
使用稀疏后仿真模型精度与1中的原始精度做对比,可以观察4选2结构化稀疏对精度的影响。
prune_retrain_model = './results/user_model_fake_prune_model.onnx' user_do_inference_onnx(prune_retrain_model, test_data, test_iterations)
如果训练过程中断,需要从ckpt中恢复数据,继续训练,则调用流程为:
准备原始模型。
ori_model= user_create_model()调用AMCT,恢复量化训练流程。
修改模型,把待稀疏的算子替换成插入了4选2结构化稀疏的算子,保存为新的prune_model。
model = ori_model input_data = ori_model_input_data record_file = './tmp/record.txt' config_defination = './prune_cfg.cfg' save_pth_path = /your/path/to/save/tmp.pth model.load_state_dict(torch.load(state_dict_path)) prune_retrain_model = amct.restore_prune_retrain_model(model=ori_model, input_data=ori_model_input_data, record_file=record_file, config_defination='./prune_cfg.cfg', save_pth_path=/your/path/to/save/tmp.pth, 'state_dict')
(由用户补充处理)使用修改后的模型,恢复断点,创建反向梯度,在训练集上做训练。
从稀疏后训练中断的checkpoint恢复模型参数。
quant_pth = './ckpt/user_prune_model' user_train_model(optimizer, prune_retrain_model, train_data)
使用修改后的图,创建反向梯度。
该步骤需要在恢复模型参数后执行。
optimizer = user_create_optimizer(prune_retrain_model)从训练好的checkpoint恢复模型,并训练模型。
注意:从训练好的checkpoint恢复模型参数后再训练。
user_train_model(optimizer, prune_retrain_model, train_data)
调用save_prune_retrain_model接口,保存模型,还原替换的算子并对weight进行结构化稀疏,生成最终ONNX仿真模型以及部署模型。
prune_retrain_model = amct.save_prune_retrain_model( model=pruned_retrain_model, save_path=save_path, input_data=input_data)
(可选,由用户补充处理)基于ONNX Runtime的环境,使用稀疏后模型(prune_retrain_model)在测试集(test_data)上做推理,测试量化后仿真模型的精度。
使用稀疏后仿真模型精度与1中的原始精度做对比,可以观察4选2结构化稀疏对精度的影响。
prune_retrain_model = './results/user_model_fake_prune_model.onnx' user_do_inference_onnx(prune_retrain_model, test_data, test_iterations)
手工调优¶
稀疏后,如果精度不满足要求,可以参见本节提供的方法进行调优。
如果按照某组配置稀疏模型后,经过重训练精度未满足要求,则可以修改简易配置文件(文件配置请参见量化感知训练简易配置文件)重新稀疏模型并重训练。常用的方法包括:
调整更新间隔(计算哪些元素被保留的间隔),由简易配置文件中的update_freq参数控制,用户可尝试将更新间隔改为正整数并重新进行稀疏来进行调试,一般来说更新间隔越小精度收益越大。
某些层不做稀疏,由简易配置文件中的regular_prune_skip_layers参数控制,通过该参数配置不需要稀疏的层。
组合压缩(不支持)¶
组合压缩是针对同一个网络模型,既进行量化又进行稀疏的操作,具体支持什么样的组合压缩方式,本章节给出详细介绍。
简介¶
组合压缩是针对同一个网络模型,既进行量化又进行稀疏的操作,具体支持什么样的组合压缩方式,本章节给出详细介绍。
组合压缩方式
目前组合压缩支持如下组合方式,使用AMCT进行压缩时,每层可压缩算子每次只能选择其中一种组合压缩方式,简要流程如图1所示。
手工稀疏+量化感知训练 INT8量化
4选2结构化稀疏+量化感知训练 INT8量化
当前组合压缩特性的压缩配置由用户手动处理(故又称之为静态组合压缩,压缩配置文件配置方法请参见量化感知训练简易配置文件),通过手动设置全局量化位宽和稀疏率(通道稀疏比例)或更新4选2稀疏的间隔,实现模型自动压缩;组合压缩示例请参见样例列表。
支持组合压缩的层以及约束请分别参见手工稀疏下的表1、4选2结构化稀疏下的表1或量化感知训练下的表1。
图 1 组合压缩简要流程
组合压缩场景介绍
当前组合压缩支持如下几种场景,实际使用时,可以通过简易配置文件中的参数进行控制。如下场景中的整网量化指量化感知训练,其中:
整网量化:
整网(全局)量化配置参数:retrain_data_quant_config/retrain_weight_quant_config
部分层差异化配置参数:override_layer_configs或override_layer_types
参数优先级:override_layer_configs>override_layer_types>retrain_data_quant_config/retrain_weight_quant_config
整网稀疏:包括通道稀疏和4选2结构化稀疏,使用时二选一。
整网(全局)稀疏配置参数:prune_config
部分层差异化稀疏参数:override_layer_configs或override_layer_types
参数优先级:override_layer_configs>override_layer_types>retrain_data_quant_config/retrain_weight_quant_config
关于上述参数的详细解释请参见量化感知训练简易配置文件。
表 1 组合压缩场景介绍
组合压缩场景 |
配置参数 |
说明 |
|---|---|---|
整网量化+整网稀疏 |
不配置override_layer_configs或override_layer_types |
- |
部分层差异化量化+整网稀疏 |
|
配置特性参数时,首先要指定全局配置,否则该特性不使能。 |
整网量化+部分层差异化稀疏 |
|
配置特性参数时,首先要指定全局配置,否则该特性不使能。 |
部分层量化+部分层差异化稀疏 |
|
配置特性参数时,首先要指定全局配置,否则该特性不使能。 |
整网量化 |
retrain_data_quant_config/retrain_weight_quant_config 不配置override_layer_configs或override_layer_types |
- |
部分层差异化量化 |
retrain_data_quant_config/retrain_weight_quant_config+override_layer_configs或override_layer_types |
配置特性参数时,首先要指定全局配置,否则该特性不使能。 |
整网稀疏 |
prune_config 不配置override_layer_configs或override_layer_types |
- |
部分层差异化稀疏 |
prune_config+override_layer_configs或override_layer_types |
配置特性参数时,首先要指定全局配置,否则该特性不使能。 |
压缩流程¶
本节介绍组合压缩特性的接口调用流程和调用示例。
接口调用流程
组合压缩接口调用流程如下图所示,如下流程中的训练环境借助PyTorch框架的CPU/GPU环境,在该开源框架的推理脚本基础上,调用AMCT API完成模型压缩,压缩后的部署模型需要使用ATC工具转换成适配NPU IP加速器的离线模型后,然后才能在NPU IP加速器上实现推理:
图 1 组合压缩接口调用流程
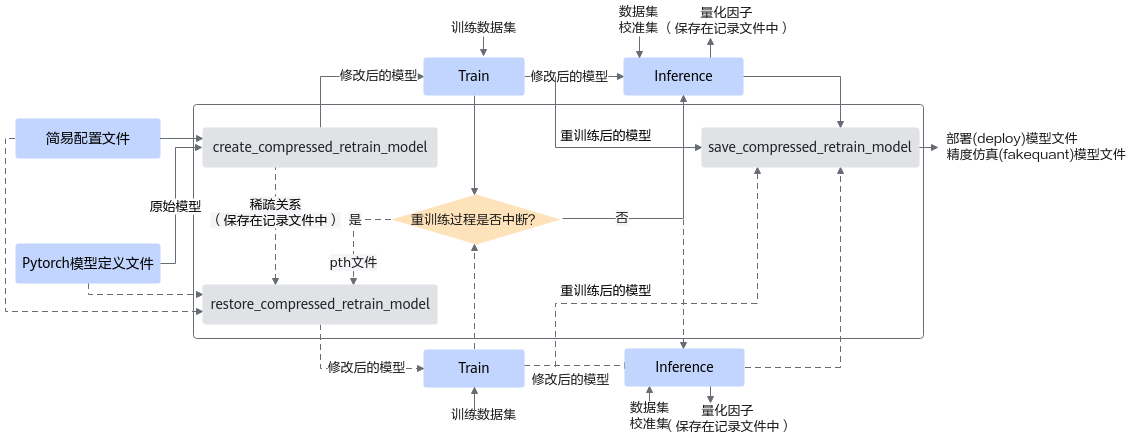
蓝色部分为用户实现,灰色部分为用户调用AMCT提供的API实现:
用户构造Pytorch的原始模型,调用create_compressed_retrain_model接口对原始模型进行修改,修改后的模型包含了稀疏和量化相关的算子。
对修改后的模型进行训练,如果训练未中断,将训练后的模型进行推理,在推理的过程中,会将量化因子写出到record文件中,然后调用save_compressed_retrain_model接口保存精度仿真模型以及部署模型;如果训练过程中断,则可基于保存的pth模型参数,重新调用restore_compressed_retrain_model接口,输出根据稀疏关系稀疏好并插入了量化算子的模型,并且重新加载中断前保存模型的权重,继续进行训练,然后进行推理,最后调用save_compressed_retrain_model接口保存量化后的模型。
调用示例
基于PyTorch环境进行训练,当前仅支持distributed模式(即DistributedDataParallel模式)的多卡训练,不支持DataParallel模式的多卡训练,使用DP模式训练会报错。
调用AMCT的部分,函数入参可以根据实际情况进行调整。组合压缩基于用户的训练过程,请确保已经有基于PyTorch环境进行训练的脚本,并且训练后的精度正常。
使用AMCT的量化感知训练特性时,如果训练过程卡死,请检查当前服务器是否有其他ONNX Runtime程序在运行(可以用top命令查看服务器所有进程),如果有,请先暂停其他ONNX Runtime程序,重新执行量化感知训练。
如下示例标有“由用户补充处理”的步骤,需要用户根据自己的模型和数据集进行补充处理,示例中仅为示例代码。
导入AMCT包,并通过安装后处理>AMCT(PyTorch)中的环境变量设置日志级别。
import amct_pytorch as amct(可选,由用户补充处理)建议使用原始待量化的模型和测试集,在PyTorch环境下推理,验证环境、推理脚本是否正常。
推荐执行该步骤,请确保原始模型可以完成推理且精度正常;执行该步骤时,可以使用部分测试集,减少运行时间。
ori_model.load() # 测试模型 user_test_model(ori_model, test_data, test_iterations)
调用AMCT,执行组合压缩流程。
修改模型,对模型ori_model进行稀疏并插入量化相关的算子,保存成新的训练模型retrain_model。
实现该步骤前,应先恢复训练好的参数,如2中的ori_model.load()。
simple_cfg = './compressed.cfg' record_file = './tmp/record.txt' compressed_retrain_model = amct.create_compressed_retrain_model( model=ori_model, input_data=ori_model_input_data, config_defination=simple_cfg, record_file=record_file)
(由用户补充处理)使用修改后的图,创建反向梯度,在训练集上做训练,训练量化因子。
使用修改后的图,创建反向梯度。
该步骤需要在3.a后执行。
optimizer = user_create_optimizer(compressed_retrain_model)从训练好的checkpoint恢复模型,并训练模型。
注意:从训练好的checkpoint恢复模型参数后再训练;训练中保存的参数应该包括量化因子:前batch_num次训练后会生成量化因子,如果训练次数少于batch_num会导致失败。
compressed_pth = './ckpt/user_model' user_train_model(optimizer, compressed_retrain_model, train_data)
训练完成后,执行推理,计算量化因子并保存。
user_infer_graph(compressed_retrain_model)
保存模型。
save_path = '/.result/user_model' amct.save_compressed_retrain_model( model=compressed_retrain_model, record_file=record_file, save_path=save_path, input_data=ori_model_input_data)
(可选,由用户补充处理)基于ONNX Runtime的环境,使用组合压缩后模型(compressed_model)在测试集(test_data)上做推理,测试组合压缩后仿真模型的精度。使用组合压缩后仿真模型精度与2中的原始精度做对比,可以观察组合压缩对精度的影响。
compressed_model = './results/user_model_fake_quant_model.onnx' user_do_inference_onnx(compressed_model, test_data, test_iterations)
如果训练过程中断,需要从ckpt中恢复数据,继续训练,则调用流程为:
导入AMCT包,并通过安装后处理>AMCT(PyTorch)中的环境变量设置日志级别。
import amct_pytorch as amct准备原始模型。
ori_model = user_create_model()调用AMCT,执行组合压缩流程。
修改模型,对模型ori_model进行稀疏并插入量化相关的算子,加载权重参数,保存成新的训练模型retrain_model。
simple_cfg = './compressed.cfg' record_file = './tmp/record.txt' compressed_pth_file = './ckpt/user_model_newest.ckpt' compressed_retrain_model = amct.restore_compressed_retrain_model( model=ori_model, input_data=ori_model_input_data, config_defination=simple_cfg, record_file=record_file, pth_file=compressed_pth_file)
(由用户补充处理)使用修改后的图,创建反向梯度,在训练集上做训练,训练量化因子。
使用修改后的图,创建反向梯度。
该步骤需要在3.a后执行。
optimizer = user_create_optimizer(compressed_retrain_model)从训练好的checkpoint恢复模型,并训练模型。
注意:从训练好的checkpoint恢复模型参数后再训练;训练中保存的参数应该包括量化因子:前batch_num次训练后会生成量化因子,如果训练次数少于batch_num会导致失败。
compressed_pth = './ckpt/user_model' user_train_model(optimizer, compressed_retrain_model, train_data)
训练完成后,执行推理,计算量化因子并保存。
user_infer_graph(compressed_retrain_model)
保存模型。
save_path = '/.result/user_model' amct.save_compressed_retrain_model( model=compressed_retrain_model, record_file=record_file, save_path=save_path, input_data=ori_model_input_data)
(可选,由用户补充处理)基于ONNX Runtime的环境,使用组合压缩后模型(compressed_model)在测试集(test_data)上做推理,测试组合压缩后仿真模型的精度。使用组合压缩后仿真模型精度与2中的原始精度做对比,可以观察组合压缩对精度的影响。
compressed_model = './results/user_model_fake_quant_model.onnx' user_do_inference_onnx(compressed_model, test_data, test_iterations)
手工调优¶
组合压缩后,模型精度不满足要求,则需要参见稀疏(不支持)下的手动调优章节和量化感知训练下的手工调优章节分别进行调优。
张量分解(不支持)¶
张量分解通过分解卷积核的张量,将一个卷积转化成两个小卷积的堆叠来降低推理开销,如用户模型中存在大量卷积,且卷积核shape普遍大于(64, 64, 3, 3)时推荐使用张量分解。 本节给出张量分解的接口调用流程和调用示例。
简介¶
张量分解通过分解卷积核的张量,将一个卷积转化成两个小卷积的堆叠来降低推理开销,如用户模型中存在大量卷积,且卷积核shape普遍大于(64, 64, 3, 3)时推荐使用张量分解。
目前仅支持满足如下条件的卷积进行分解:
group=1、dilation=(1,1)、stride<3
kernel_h>2、kernel_w>2
卷积是否分解由AMCT自动判断,即便满足上述条件,也不一定会分解;例如,用户使用的PyTorch原始模型中存在torch.nn.Conv2d层,且该层满足上述条件,才有可能将相应的Conv2d层分解成两个Conv2d层。
通常情况下,分解后模型的精度会比原始模型有所下降,因此在分解之后,需通过fine-tune(微调)来提高精度。最后使用AMCT将分解后的模型转换成可以在NPU IP加速器部署的量化模型,以便在模型推理时获得更好的性能。
该场景为可选操作,用户自行决定是否进行原始模型的分解。
分解约束
如果torch.nn.Conv2d层的权重shape过大,会造成分解时间过长或分解异常中止,为防止出现该情况,执行分解动作前,请先参见如下约束或参考数据:
分解工具性能参考数据:
CPU: Intel(R) Xeon(R) CPU E5-2699 v4 @ 2.20GHz
内存: 512G
分解单层卷积:
shape(512, 512, 5, 5),大约耗时7秒。
shape(1024, 1024, 3, 3),大约耗时12秒。
shape(1024, 1024, 5, 5),大约耗时52秒。
shape(2048, 2048, 3, 3),大约耗时89秒。
shape(2048, 2048, 5, 5),大约耗时374秒。
内存超限风险提醒:
分解大卷积核存在内存超限风险参考数值:分解shape为(2048, 2048, 5, 5)的卷积核约需9G内存。
分解方式
张量分解有两种使用方式,在线张量分解和离线张量分解,用户可以根据实际情况选择其中一个方式进行分解。详细说明如下:
在线张量分解
即直接分解原始网络模型并进行fine-tune:在训练代码中引入张量分解接口,对已包含预训练权重的模型进行分解,然后进行fine-tune。
该流程在张量分解时直接修改模型结构并更新权重,分解后的模型可直接使用,其优点是使用方便,仅需一步操作;而缺点是每次调用脚本都要重新进行分解计算,需要耗费一定时间。
离线张量分解
即先分解原始网络模型,然后再进行fine-tune:首先将含有预训练权重的模型调用张量分解接口进行分解,保存分解信息文件和分解后的权重;后续使用时,在训练脚本中引入张量分解接口,读取保存的分解信息文件对模型结构进行分解,然后加载保存的分解后的权重,再进行fine-tune。
该流程先将分解信息和分解后的权重保存下来,然后在fine-tune时快速加载使用,其优点是可以一次分解,多次使用,使用时加载几乎不耗费时间;而缺点是需要两步操作,且需保存分解后的权重并在使用时加载
分解流程¶
本节给出张量分解的接口调用流程和调用示例。
接口调用流程
接口调用流程如图1所示,具体分解示例请参见样例列表。
图 1 张量分解接口调用流程
在线分解流程
在训练脚本中,准备好含有预训练权重的torch.nn.Module模型对象,在将模型参数传递给优化器之前,将模型对象传递给auto_decomposition接口进行张量分解,得到分解后的模型对象,即可直接对其进行fine-tune。
离线分解流程
在任意脚本中,准备好含有预训练权重的torch.nn.Module模型对象,将模型对象和分解信息文件保存路径传递给auto_decomposition接口进行张量分解,得到分解后的模型对象和保存的分解信息文件,并对分解后的模型权重进行保存。
fine-tune时,在训练脚本中,在将模型参数传递给优化器之前,将模型对象和2.a中得到的分解信息文件路径传递给decompose_network接口,该接口会将模型结构修改为分解后的结构,然后加载2.a保存的分解后的模型权重,对模型进行fine-tune。
张量分解后会将1个卷积分解为2个串联的卷积,模型的其中一层卷积分解前后情况如图2所示。
图 2 卷积分解前后示意图
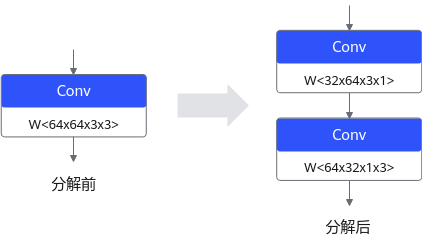
调用示例
在线张量分解
在训练脚本中,调用auto_decomposition分解含有预训练权重的PyTorch模型,然后直接fine-tune。
from amct_pytorch.tensor_decompose import auto_decomposition net = Net() # (*) 构建模型对象 net.load_state_dict(torch.load("src_path/net.pth")) # (*) 加载模型权重 net, changes = auto_decomposition(model=net) # 执行张量分解 optimizer = build_optimizer(net, ...) # (*) 构建优化器(将模型参数传递给优化器) train(net, optimizer, ...) # (*) fine-tune
离线张量分解
在任意脚本中,调用auto_decomposition分解含有预训练权重的PyTorch模型,保存分解信息文件和分解后的模型权重。
from amct_pytorch.tensor_decompose import auto_decomposition net = Net() # (*) 构建模型对象 net.load_state_dict(torch.load("src_path/weights.pth")) # (*) 加载模型权重 net, changes = auto_decomposition( # 执行张量分解,并保存分解信息文件 model=net, decompose_info_path="decomposed_path/decompose_info.json" # 分解信息文件保存路径 ) torch.save(net.state_dict(), "decomposed_path/decomposed_weights.pth") # 保存分解后的模型权重
在训练脚本中,调用decompose_network,根据2.a得到的分解信息文件将模型结构修改为分解后的结构,再加载2.a保存的分解后的模型权重,进行fine-tune。
from amct_pytorch.tensor_decompose import decompose_network net = Net() # (*) 构建用户模型对象 net, changes = decompose_network( # 加载分解信息文件,将模型结构修改为张量分解后的结构 model=net, decompose_info_path="decomposed_path/decompose_info.json" # 上一步保存的分解信息文件路径 ) net.load_state_dict(torch.load("decomposed_path/decomposed_weights.pth")) # 加载上一步保存的分解后模型权重 optimizer = build_optimizer(net, ...) # (*) 构建优化器(将模型参数传递给优化器) train(net, optimizer, ...) # (*) fine-tune
扩展更多特性¶
在一些数据分布不均匀的场景,由于离群值的影响,对数据进行per-tensor量化得到的结果误差较大,而per-channel量化可以获得更低的误差。但由于当前硬件不支持数据per-channel量化,仅支持权重per-channel量化;在该背景下AMCT设计出一套方法,本节将给出详细介绍。 本节详细介绍逐层蒸馏支持的层,接口调用流程和示例。
单算子模式的量化感知训练¶
功能介绍
参考量化感知训练章节进行基础量化时,量化的内部处理逻辑需要将原始模型转换成ONNX模型,并在ONNX模型基础上进行图的修改操作,此时若模型中存在Pytorch自定义算子时,可能存在无法导出生成ONNX模型,从而导致量化失败的问题。
单算子模式的量化感知训练功能,提供由Pytorch原生算子转换生成的自定义QAT算子,基于该算子进行量化因子的重训练,量化因子作为算子参数保存在QAT单算子中,无需导出ONNX模型,可以避免上述量化感知训练方案中的算子导出异常问题。训练完成后,通过torch.onnx.export机制,建立QAT算子与ONNX原生算子的映射关系,将Pytorch模型中QAT算子计算获得的参数传递给ONNX原生量化算子,完成模型导出。简易示意图如图1所示。
图 1 单算子模式量化感知训练
实现原理如下图所示(以torch.nn.Conv2d算子为例进行说明):
在torch原生算子torch.nn.Conv2d中插入ARQ权重量化,ULQ数据量化算子,进行量化因子的重训练,将量化因子作为算子参数保存在Conv2dQAT单算子中,最终调用torch.onnx.export接口,将QAT自定义算子通过映射关系导出成ONNX原生量化算子QuantizeLinear与DequantizeLinear,带有此两个量化算子的模型又称QDQ(Quantize and DeQuantize,简称QDQ)ONNX模型,QDQ格式模型具体介绍请参见Link。
QDQ ONNX模型不能直接通过ATC工具转成适配NPU IP加速器的离线模型,需要通过AMCT(ONNX)中的QAT模型适配CANN模型特性,将该模型适配成CANN模型后,然后才能使用ATC工具进行下一步的转换。
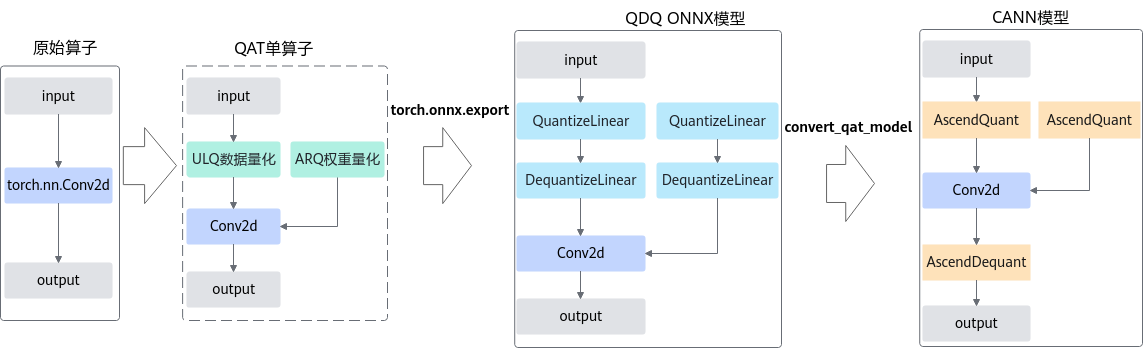 该功能支持Training from scratch和Fine-tune两种使用方法:
该功能支持Training from scratch和Fine-tune两种使用方法:
Training from scratch:使用QAT算子直接构图,从零开始训练。您可以在模型构建脚本中调用单算子模式提供的直接构造接口构造QAT算子,使用该算子进行模型构建。
Fine-tune:在已有网络基础上,对待量化算子进行替换,相比于Training from scratch更为常用。如果您已经完成模型构建,您可以调用单算子模式提供的基于原生算子构造接口,进行QAT算子构造;之后可以参考下文样例中的算子替换方案,对网络模型中的待量化算子进行替换。
QAT算子规格如下表所示,调用示例请参见样例列表。
表 1 QAT算子规格
待量化算子类型 |
替换后算子类型 |
限制 |
备注 |
|---|---|---|---|
torch.nn.Conv2d |
Conv2dQAT |
|
复用层(共用weight和bias参数)不支持量化。 |
torch.nn.ConvTranspose2d |
ConvTranspose2dQAT |
|
|
torch.nn.Linear |
LinearQAT |
不支持channel wise |
|
torch.nn.Conv1d |
Conv1dQAT |
padding_mode为zeros,数据类型为float32 |
- |
torch.nn.ConvTranspose1d |
ConvTranspose1dQAT |
|
- |
torch.nn.GRU |
GRUQAT |
|
- |
torch.nn.LSTM |
LSTMQAT |
|
- |
样例参考
Training from scratch方式代码样例:
import torch
import torch.nn as nn
import amct_pytorch as amct
from amct_onnx.convert_model import convert_qat_model
from amct_pytorch.nn.module.quantization.conv2d import Conv2dQAT
from amct_pytorch.nn.module.quantization.linear import LinearQAT
# QAT算子量化配置项
config = {
"retrain_data_config": {
"dst_type": "INT8",
"batch_num": 10,
"fixed_min": False,
"clip_min": None,
"clip_max": None
},
"retrain_weight_config": {
"dst_type": "INT8",
"weights_retrain_algo": "arq_retrain",
"channel_wise": False
}
}
# 使用QAT单算子构造Lenet网络
net = torch.nn.Sequential(
Conv2dQAT(1, 6, kernel_size=5, padding=2, config=config), nn.Sigmoid(),
nn.AvgPool2d(kernel_size=2, stride=2),
Conv2dQAT(6, 16, kernel_size=5, config=config), nn.Sigmoid(),
nn.AvgPool2d(kernel_size=2, stride=2),
nn.Flatten(),
LinearQAT(16 * 5 * 5, 120, config=config), nn.Sigmoid(),
LinearQAT(120, 84, config=config), nn.Sigmoid(),
LinearQAT(84, 10, config=config)
)
# 训练
train(net, train_data, test_data)
# 导出中间模型
torch.onnx.export(model, data, 'inter_model.onnx')
# 导出fake quant模型与deploy模型
# 生成lenet_fake_quant_model.onnx,可在 ONNX 执行框架 ONNX Runtime 进行精度仿真的模型。
# 生成lenet_deploy_model.onnx,可在AI 处理器部署的模型文件。
convert_qat_model('inter_model.onnx', './outputs/lenet')
# 使用fake quant模型进行精度仿真
validate_onnx('./outputs/lenet_fake_quant_model.onnx', val_data)
Fine-tune方式代码样例:
import torch
from torchvision.models.resnet import resnet101
import amct_pytorch as amct
from amct_onnx.convert_model import convert_qat_model
from amct_pytorch.nn.module.quantization.conv2d import Conv2dQAT
model = resnet101(pretrained=True)
# QAT算子量化配置项
config = {
"retrain_data_config": {
"dst_type": "INT8",
"batch_num": 10,
"fixed_min": False,
"clip_min": None,
"clip_max": None
},
"retrain_weight_config": {
"dst_type": "INT8",
"weights_retrain_algo": "arq_retrain",
"channel_wise": True
}
}
def _set_module(model, submodule_key, module):
# 将模型中原生算子替换为qat算子
tokens = submodule_key.split('.')
sub_tokens = tokens[:-1]
cur_mod = model
for s in sub_tokens:
cur_mod = getattr(cur_mod, s)
setattr(cur_mod, tokens[-1], module)
for name, module in model.named_modules():
# 遍历原图中各节点,将类型为Conv2d的torch原生算子替换为自定义QAT单算子
if isinstance(module, torch.nn.Conv2d):
qat_module = Conv2dQAT.from_float(
module, config=config)
_set_module(model, name, qat_module)
# 训练流程
train_and_val(model, train_data, test_data)
# 导出中间模型
torch.onnx.export(model, data, 'inter_model.onnx')
# 导出fake quant模型与deploy模型
# 生成resnet101_fake_quant_model.onnx,可在 ONNX 执行框架 ONNX Runtime 进行精度仿真的模型。
# 生成resnet101_deploy_model.onnx,可在AI 处理器部署的模型文件。
convert_qat_model('inter_model.onnx', './outputs/resnet101')
# 使用fake quant模型进行精度仿真
validate_onnx('./outputs/resnet101_fake_quant_model.onnx', val_data)
量化数据均衡预处理¶
在一些数据分布不均匀的场景,由于离群值的影响,对数据进行per-tensor量化得到的结果误差较大,而per-channel量化可以获得更低的误差。但由于当前硬件不支持数据per-channel量化,仅支持权重per-channel量化;在该背景下AMCT设计出一套方法,本节将给出详细介绍。
通过数据均衡预处理接口计算出均衡因子,将模型数据与权重进行数学等价换算,均衡模型数据与权重的分布,将数据的量化难度迁移一部分至权重,从而降低量化误差。该特性支持的层及约束如下:
表 1 支持的层以及约束
支持的层类型 |
约束 |
备注 |
|---|---|---|
torch.nn.Linear |
- |
复用层(共用weight和bias参数)不支持量化。 |
torch.nn.Conv2d |
padding_mode为zeros |
|
torch.nn.Conv3d |
dilation_d为1,dilation_h/dilation_w >= 1 padding_mode为zeros |
|
torch.nn.ConvTranspose2d |
padding_mode为zeros |
接口调用流程
均衡预处理接口调用流程如图1所示。
图 1 均衡预处理接口调用流程

蓝色部分为用户实现,灰色部分为用户调用AMCT提供的API实现,工具使用分为如下场景:
用户首先构造PyTorch的原始模型,并在简易配置文件_dmp_quant.cfg_中设置dmq参数(简易配置文件配置参数请参见训练后量化简易配置文件),然后将配置文件传入create_quant_config。
根据PyTorch模型和量化配置文件,即可调用quantize_preprocess接口对原始PyTorch模型进行优化,优化后的PyTorch模型中包含了均衡量化算法。
使用校准集在PyTorch环境下执行一次前向推理,产生均衡量化因子,并将均衡量化因子输出到文件中。
根据PyTorch模型、量化配置文件和record文件,即可调用quantize_model接口对原始PyTorch模型再次进行优化,优化后的PyTorch模型中包含了量化算法。
使用校准集在PyTorch环境下执行前向推理,产生量化因子,并将量化因子输出到文件中。
最后用户可以调用save_model接口保存量化后的模型,包括可在ONNX执行框架ONNX Runtime环境中进行精度仿真的模型文件和可部署在NPU IP加速器的模型文件。
调用示例
如下示例标有“由用户补充处理”的步骤,需要用户根据自己的模型和数据集进行补充处理,示例中仅为示例代码。
如下示例调用AMCT的部分,函数入参请根据实际情况进行调整。
导入AMCT包,并通过安装后处理>AMCT(PyTorch)中的环境变量设置日志级别。
import amct_pytorch as amct(可选,由用户补充处理)在PyTorch原始环境中验证推理脚本及环境。
建议使用原始待量化的模型和测试集,在PyTorch环境下推理,验证环境、推理脚本是否正常。
推荐执行该步骤,请确保原始模型可以完成推理且精度正常;执行该步骤时,可以使用部分测试集,减少运行时间。
user_do_inference_torch(ori_model, test_data, test_iterations)调用AMCT,量化模型。
生成量化配置。
用户在简易配置文件_dmp_quant.cfg_中设置dmq参数,并将配置文件通过config_defination参数传入create_quant_config。
config_defination = os.path.join(PATH, 'dmp_quant.cfg') config_file = './tmp/config.json' skip_layers = [] batch_num = 1 amct.create_quant_config(config_file=config_file, model=ori_model, input_data=ori_model_input_data, skip_layers=skip_layers, batch_num=batch_num, config_defination=config_defination)
修改图,在图中插入均衡量化算子,用于计算均衡量化因子。
record_file = './tmp/record.txt' modified_onnx_model = './tmp/modified_model.onnx' calibration_model = amct.quantize_preprocess(config_file=config_file, record_file=record_file, model=ori_model, input_data=ori_model_input_data)
(由用户补充处理)基于PyTorch环境,使用修改后的模型(calibration_model)在校准集(calibration_data)上做模型推理,找到均衡量化因子。
该步骤执行时,需要注意如下两点:
校准集及其预处理过程数据要与模型匹配,以保证量化的精度。
前向推理的次数为1,如果次数超过1次,每执行一次推理,record中均衡量化因子会被记录一次,后续过程会失败。
user_do_inference_torch(calibration_model, calibration_data, test_iterations=1)修改图,在图中插入数据量化,权重量化等相关的算子,用于计算量化相关参数。
modified_onnx_model = './tmp/modified_model.onnx' calibration_model = amct.quantize_model(config_file=config_file, modified_onnx_model=modified_onnx_model, record_file=record_file, model=ori_model, input_data=ori_model_input_data)
(由用户补充处理)基于PyTorch环境,使用修改后的模型(calibration_model)在校准集(calibration_data)上做模型推理,生成量化因子。
该步骤执行时,需要注意如下两点:
校准集及其预处理过程数据要与模型匹配,以保证量化的精度。
前向推理的次数为batch_num,如果次数不够,后续过程会失败。
user_do_inference_torch(calibration_model, calibration_data, batch_num)保存模型。
根据量化因子,调用save_model接口,插入AscendQuant、AscendDequant等算子,保存为量化模型。
quant_model_path = './results/user_model' amct.save_model(modified_onnx_file=modified_onnx_file, record_file=record_file, save_path=quant_model_path)
(可选,由用户补充处理)基于ONNX Runtime的环境,使用量化后模型(quant_model)在测试集(test_data)上做推理,测试量化后仿真模型的精度。
使用量化后仿真模型精度与2中的原始精度做对比,可以观察量化对精度的影响。
quant_model = './results/user_model_fake_quant_model.onnx' user_do_inference_onnx(quant_model, test_data, test_iterations)
逐层蒸馏(不支持)¶
本节详细介绍逐层蒸馏支持的层,接口调用流程和示例。
如下产品型号不支持该特性:
IPV350
支持做蒸馏和量化的算子:
torch.nn.Linear:复用层(共用weight和bias参数)不支持量化。
torch.nn.Conv2d:padding_mode为zeros才支持量化,复用层(共用weight和bias参数)不支持量化。
支持做蒸馏的激活算子:
torch.nn.ReLU
torch.nn.LeakyReLU
torch.nn.Sigmoid
torch.nn.Tanh
torch.nn.Softmax
支持做蒸馏的归一化算子
torch.nn.BatchNorm2d:复用层(共用weight和bias参数)不支持蒸馏。
逐层蒸馏示例请参见样例列表。
接口调用流程
调用流程如图1所示。
图 1 蒸馏接口调用流程

蓝色部分为用户实现,灰色部分为用户调用AMCT提供的API实现,逐层蒸馏特性主要分为4个部分,创建蒸馏配置、创建蒸馏模型、蒸馏量化模型和保存量化模型,详情如下:
创建蒸馏配置,用户首先构造PyTorch的原始模型,然后使用create_distill_config接口,将用户自定义的蒸馏配置与AMCT算法定义的蒸馏配置相结合,输出网络每一层的蒸馏配置信息。
创建蒸馏模型,调用create_distill_model接口对原始模型进行修改,根据蒸馏配置信息生成一个待蒸馏的量化模型。
蒸馏模型,调用distill接口,根据用户配置的模型推理和优化方法,结合蒸馏配置信息,对网络进行分块蒸馏,得到蒸馏后的性能优化的量化模型。
保存量化模型,最后调用save_distill_model接口保存已蒸馏优化的量化模型,包括可在ONNX执行框架ONNX Runtime环境中进行精度仿真的模型文件和可部署在NPU IP加速器的模型文件。
调用示例
如下示例标有“由用户补充处理”的步骤,需要用户根据自己的模型和数据集进行补充处理,示例中仅为示例代码。
如下示例调用AMCT的部分,函数入参请根据实际情况进行调整。
导入AMCT包,并通过安装后处理>AMCT(PyTorch)中的环境变量设置日志级别。
import amct_pytorch as amct(可选,由用户补充处理)在PyTorch原始环境中验证推理脚本及环境。
建议使用原始待量化的模型和测试集,在PyTorch环境下推理,验证环境、推理脚本是否正常。
推荐执行该步骤,请确保原始模型可以完成推理且精度正常;执行该步骤时,可以使用部分测试集,减少运行时间。
user_do_inference_torch(ori_model, test_data, test_iterations)调用AMCT,蒸馏模型。
调用create_distill_config接口生成蒸馏配置。输出的蒸馏配置中包含用户自定义的和自动查找到的蒸馏结构。
config_file = './tmp/config.json' simple_cfg = './distill.cfg' amct.create_distill_config(config_file=config_file, model=ori_model, input_data=ori_model_input_data, config_defination=simple_cfg)
调用create_distill_model接口创建蒸馏模型。
对待蒸馏的浮点模型进行量化,将浮点模型中的待压缩算子替换为CANN量化算子。
compress_model = amct.create_distill_model( config_file=config_file, model=ori_model, input_data=ori_model_input_data)
逐层蒸馏。
调用distill接口进行逐层蒸馏。针对配置中的蒸馏结构进行蒸馏。
distill_model = amct.distill( model=ori_model, compress_model, config_file=config_file, train_loader, epochs=1, lr=1e-3, sample_instance=None, loss=loss, optimizer=optimizer)
保存蒸馏模型。
调用save_distill_model接口,插入AscendQuant、AscendDequant等算子,保存为蒸馏模型。
amct.save_distill_model( model, "./model/distilled", input_data, record_file="./results/records.txt", input_names=['input'], output_names=['output'], dynamic_axes={'input':{0: 'batch_size'}, 'output':{0: 'batch_size'}})
(可选,由用户补充处理)基于ONNX Runtime的环境,使用蒸馏后模型(quant_model)在测试集(test_data)上做推理,测试蒸馏后仿真模型的精度。
使用量化后仿真模型精度与2中的原始精度做对比,可以观察量化对精度的影响。
quant_model = './results/user_model_fake_quant_model.onnx' user_do_inference_onnx(quant_model, test_data, test_iterations)
接口说明¶
整体约束和接口列表¶
整体约束
若接口中存在需要用户输入文件路径的参数,请确保输入路径正确,AMCT不会对路径做安全校验。
若接口中存在需要用户输入文件路径的参数,重新执行量化时,该参数相关取值将会被覆盖;量化打屏日志中也会有相关文件被覆盖的warning风险提示信息。
接口列表
分类 |
接口名称 |
功能描述 |
|---|---|---|
公共接口 |
ModelEvaluator |
针对某一个模型,根据模型的bin类型输入数据,提供一个Python实例,可对该模型执行校准和推理的评估器。 |
训练后量化接口 |
create_quant_config |
训练后量化接口,根据图的结构找到所有可量化的层,自动生成量化配置文件,并将可量化层的量化配置信息写入文件。 |
quantize_model |
训练后量化接口,将输入的待量化的图结构按照给定的量化配置文件进行量化处理,在传入的图结构中插入权重量化、数据量化相关的算子,生成量化因子记录文件record_file,返回修改后的torch.nn.Module校准模型。 |
|
save_model |
训练后量化接口,根据量化因子记录文件record_file以及修改后的模型,插入AscendQuant、AscendDequant等算子,然后保存为可以在ONNX Runtime环境进行精度仿真的fake_quant模型,和可以在NPU IP加速器做推理的部署模型。 |
|
accuracy_based_auto_calibration |
根据用户输入的模型、配置文件进行自动的校准过程,搜索得到一个满足目标精度的量化配置,输出可以在ONNX Runtime环境下做精度仿真的fake_quant模型,和可在NPU IP加速器上做推理的deploy模型。 |
|
quantize_preprocess |
量化数据均衡预处理接口,将输入的待量化的图结构按照给定的量化配置文件进行量化处理,在传入的图结构中插入均衡量化相关的算子,生成均衡量化因子记录文件record_file,返回修改后的torch.nn.Module校准模型。 |
|
量化感知训练接口 |
create_quant_retrain_config |
量化感知训练接口,根据图的结构找到所有可量化的层,自动生成量化配置文件,并将可量化层的量化配置信息写入配置文件。 |
create_quant_retrain_model |
量化感知训练接口,将输入的待量化的图结构按照给定的量化配置文件进行量化处理,在传入的图结构中插入量化相关的算子(数据和权重的量化感知训练层以及找N的层),生成量化因子记录文件record_file,返回修改后可用于量化感知训练的torch.nn.Module模型。 |
|
restore_quant_retrain_model |
量化感知训练接口,将输入的待量化的图结构按照给定的量化感知训练配置文件进行量化处理,在传入的图结构中插入量化感知训练相关的算子(数据和权重的量化感知训练层以及找N的层),生成量化因子记录文件record_file,加载训练过程中保存的checkpoint权重参数,返回修改后的torch.nn.Module量化感知训练模型。 |
|
save_quant_retrain_model |
量化感知训练接口,根据用户最终的重训练好的模型,插入AscendQuant、AscendDequant等算子,生成最终量化精度仿真模型以及量化部署模型。 |
|
量化感知训练接口(单算子模式) |
Conv2dQAT |
构造Conv2d的QAT算子。 |
ConvTranspose2dQAT |
构造ConvTranspose2d的QAT算子。 |
|
LinearQAT |
构造Linear的QAT算子。 |
|
同上 |
Conv1dQAT |
构造Conv1d的QAT算子。 |
ConvTranspose1dQAT |
构造ConvTranspose1d的QAT算子。 |
|
GRUQAT |
构造GRU的QAT算子。 |
|
LSTMQAT |
构造LSTM的QAT算子。 |
|
稀疏接口 |
create_prune_retrain_model |
通道稀疏或4选2结构化稀疏接口,两种稀疏特性每次只能使能一个:将输入的待稀疏的图结构按照给定的稀疏配置文件进行稀疏处理,在传入的图结构中插入或者替换相关的算子,生成记录稀疏信息的record_file,返回修改后可用于稀疏后训练的torch.nn.Module模型。 |
restore_prune_retrain_model |
通道稀疏或4选2结构化稀疏接口,两种稀疏特性每次只能使能一个:将输入的待稀疏的图结构按照给定的record_file中稀疏记录进行稀疏,返回修改后可用于稀疏后训练的torch.nn.Module模型。 |
|
save_prune_retrain_model |
稀疏接口,根据用户最终的重训练好的稀疏模型,生成最终ONNX仿真模型以及部署模型。 |
|
自动通道稀疏搜索接口 |
auto_channel_prune_search |
自动通道稀疏接口,根据用户模型来计算各通道的稀疏敏感度(影响精度)以及稀疏收益(影响性能),然后搜索策略依据该输入来搜索最优的逐层通道稀疏率,以平衡精度和性能。最终输出一个配置文件。 |
组合压缩接口 |
create_compressed_retrain_model |
静态组合压缩接口,将输入的待静态组合压缩的模型按照给定的组合压缩配置文件进行压缩处理,即将传入的模型先进行稀疏(通道稀疏或者4选2结构化稀疏,二选一),后对模型插入量化相关的算子(数据和权重的量化感知训练层以及searchN的层),生成稀疏和量化因子记录文件record_file(如果配置存在),返回修改后的torch.nn.Module模型。 |
restore_compressed_retrain_model |
静态组合压缩训练接口,将输入的待静态组合压缩的模型按照给定的组合压缩配置文件和record记录文件进行压缩处理(先稀疏后量化),加载保存的权重。将传入的模型按照给定record_file中稀疏记录进行稀疏,后对模型插入量化相关的算子(数据和权重的量化感知训练层以及searchN的层)。加载训练过程中保存的checkpoint权重参数,返回修改后的torch.nn.Module模型。 |
|
save_compressed_retrain_model |
静态组合压缩接口,根据用户最终的重训练好的模型,生成最终静态组合压缩精度仿真模型以及部署模型。 |
|
张量分解接口 |
auto_decomposition |
对用户输入的PyTorch模型对象进行张量分解,得到分解后的模型对象和分解前后层的对应名称,并保存分解信息文件(可选)。 |
decompose_network |
用户输入PyTorch模型对象和通过auto_decomposition保存的分解信息文件,根据分解信息文件将模型对象改变为张量分解后的结构,得到分解后的模型对象和分解前后层的对应名称。 |
|
蒸馏接口 |
create_distill_config |
蒸馏接口,根据图的结构找到所有可蒸馏量化的层和可蒸馏量化的结构,自动生成蒸馏量化配置文件,并将可蒸馏量化层的量化配置和蒸馏结构写入配置文件。 |
create_distill_model |
蒸馏接口,将输入的待量化压缩的图结构按照给定的蒸馏量化配置文件进行量化处理,在传入的图结构中插入量化相关的算子(数据和权重的蒸馏量化层以及找N的层),返回修改后可用于蒸馏的torch.nn.Module模型。 |
|
distill |
蒸馏接口,将输入的待蒸馏的图结构按照给定的蒸馏量化配置文件进行蒸馏处理,返回修改后的torch.nn.Module蒸馏模型。 |
|
save_distill_model |
蒸馏接口,根据用户最终的蒸馏好的模型,生成最终量化精度仿真模型以及量化部署模型。 |
公共接口¶
ModelEvaluator¶
产品支持情况
产品 |
是否支持 |
|---|---|
IPV350 |
√ |
功能说明
针对某一个模型,根据模型的bin类型输入数据,提供一个Python实例,可对该模型执行校准和推理的评估器。
函数原型
class ModelEvaluator(AutoCalibrationEvaluatorBase):
def __init__(self, data_dir, input_shape, data_types):
参数说明
参数名 |
输入/输出 |
说明 |
|---|---|---|
data_dir |
输入 |
含义:与模型匹配的bin格式数据集路径。 数据类型:string 参数值格式:"data/input1/;data/input2/" 使用约束:
|
input_shape |
输入 |
含义:模型输入的shape信息。 数据类型:string 参数值格式:"input_name1:n1,c1,h1,w1;input_name2:n2,c2,h2,w2"。 使用约束:指定的节点必须放在双引号中,节点中间使用英文分号分隔。 |
data_types |
输入 |
含义:输入数据的类型。 数据类型:string 参数值格式:"float32;float64" 使用约束:若模型有多个输入,且数据类型不同,则需要分别指定不同输入的数据类型,指定的输入数据类型必须按照输入节点顺序依次放在双引号中,所有的输入数据类型必须放在双引号中,中间使用英文分号分隔。 |
返回值说明
一个Python实例。
调用示例
import amct_pytorch as amct
evaluator = amct.ModelEvaluator(
data_dir="./data/input_bin/",
input_shape="input:32,3,224,224",
data_types="float32")
训练后量化接口¶
create_quant_config¶
产品支持情况
产品 |
是否支持 |
|---|---|
IPV350 |
√ |
功能说明
训练后量化接口,根据图的结构找到所有可量化的层,自动生成量化配置文件,并将可量化层的量化配置信息写入文件。
函数原型
create_quant_config(config_file, model, input_data, skip_layers=None, batch_num=1, activation_offset=True, config_defination=None)
参数说明
参数名 |
输入/输出 |
说明 |
|---|---|---|
config_file |
输入 |
含义:待生成的量化配置文件存放路径及名称。如果存放路径下已经存在该文件,则调用该接口时会覆盖已有文件。 数据类型:string |
model |
输入 |
含义:待量化的模型,已加载权重。 数据类型:torch.nn.Module |
input_data |
输入 |
含义:模型的输入数据。一个torch.tensor会被等价为tuple(torch.tensor)。 数据类型:tuple |
skip_layers |
输入 |
含义:可量化但不需要量化的层名。 默认值:None 数据类型:list,列表中元素类型为string 使用约束:如果使用简易配置文件作为入参,则该参数需要在简易配置文件中设置,此时输入参数中该参数配置不生效。 |
batch_num |
输入 |
含义:量化使用的batch数量,即使用多少个batch的数据生成量化因子。 数据类型:int 取值范围:大于0的整数,默认值为1。 使用约束:
|
activation_offset |
输入 |
含义:数据量化是否带offset。 默认值:True 数据类型:bool 使用约束:如果使用简易配置文件作为入参,则该参数需要在简易配置文件中设置,此时输入参数中该参数配置不生效。 |
config_defination |
输入 |
含义:基于calibration_config_pytorch.proto文件生成的简易量化配置文件quant.cfg,*.proto文件所在路径为:AMCT安装目录/amct_pytorch/proto/。 *.proto文件参数解释以及生成的quant.cfg简易量化配置文件样例请参见训练后量化简易配置文件。 默认值:None 数据类型:string 使用约束:当取值为None时,使用输入参数生成配置文件;否则,忽略输入的其他量化参数(skip_layers,batch_num,activation_offset),根据简易量化配置文件参数config_defination生成JSON格式的配置文件。 |
返回值说明
无
调用示例
import amct_pytorch as amct
# 建立待量化的网络图结构
model = build_model()
model.load_state_dict(torch.load(state_dict_path))
input_data = tuple([torch.randn(input_shape)])
model.eval()
# 生成量化配置文件
amct.create_quant_config(config_file="./configs/config.json",
model=model,
input_data=input_data,
skip_layers=None,
batch_num=1,
activation_offset=True)
落盘文件说明:生成JSON格式的量化配置文件,样例如下(重新执行量化时,该接口生成的量化配置文件将会被覆盖):
均匀量化配置文件(数据量化使用IFMR数据量化算法)
{ "version":1, "batch_num":2, "activation_offset":true, "do_fusion":true, "skip_fusion_layers":[], "conv1":{ "quant_enable":true, "dmq_balancer_param":0.5, "activation_quant_params":{ "num_bits":8, "max_percentile":0.999999, "min_percentile":0.999999, "search_range":[ 0.7, 1.3 ], "search_step":0.01, "act_algo":"ifmr", "asymmetric":false }, "weight_quant_params":{ "num_bits":8, "wts_algo":"arq_quantize", "channel_wise":true } }, "fc":{ "quant_enable":true, "dmq_balancer_param":0.5, "activation_quant_params":{ "num_bits":8, "max_percentile":0.999999, "min_percentile":0.999999, "search_range":[ 0.7, 1.3 ], "search_step":0.01, "act_algo":"ifmr", "asymmetric":false }, "weight_quant_params":{ "num_bits":8, "wts_algo":"arq_quantize", "channel_wise":false } } }
均匀量化配置文件(数据量化使用HFMG数据量化算法)
{ "version":1, "batch_num":2, "activation_offset":true, "do_fusion":true, "skip_fusion_layers":[], "conv1":{ "quant_enable":true, "dmq_balancer_param":0.5, "activation_quant_params":{ "num_bits":8, "act_algo":"hfmg", "num_of_bins":4096, "asymmetric":false }, "weight_quant_params":{ "num_bits":8, "wts_algo":"arq_quantize", "channel_wise":true } } }
自适应舍入量化简易配置文件(权重量化使用ADA权重量化算法)
"layer_name1":{ "quant_enable":true, "weight_quant_params":{ "wts_algo":"ada_quantize", "num_iteration":10000, "reg_param":0.1, "beta_range":[20,2], "warm_start":0.2, "num_bits":8, "channel_wise":true } }
quantize_model¶
产品支持情况
产品 |
是否支持 |
|---|---|
IPV350 |
√ |
功能说明
训练后量化接口,将输入的待量化的图结构按照给定的量化配置文件进行量化处理,在传入的图结构中插入权重量化、数据量化相关的算子,生成量化因子记录文件record_file,返回修改后的torch.nn.Module校准模型。
函数原型
calibration_model = quantize_model(config_file, modfied_onnx_file, record_file, model, input_data, input_names=None, output_names=None, dynamic_axes=None)
参数说明
参数名 |
输入/输出 |
说明 |
|---|---|---|
config_file |
输入 |
含义:用户生成的量化配置文件,用于指定模型network中量化层的配置情况。 数据类型:string |
modfied_onnx_file |
输入 |
含义:文件名,用于存储融合后模型的onnx格式。 数据类型:string |
record_file |
输入 |
含义:量化因子记录文件路径及名称。 数据类型:string |
model |
输入 |
含义:待量化的模型,已加载权重。 数据类型:torch.nn.Module |
input_data |
输入 |
含义:模型的输入数据。一个torch.tensor会被等价为tuple(torch.tensor)。 数据类型:tuple |
input_names |
输入 |
含义:模型的输入的名称,用于modfied_onnx_file中显示。 默认值:None 数据类型:list(string) |
output_names |
输入 |
含义:模型的输出的名称,用于modfied_onnx_file中显示。 默认值:None 数据类型:list(string) |
dynamic_axes |
输入 |
含义:对模型输入输出动态轴的指定,例如对于输入inputs(NCHW),N、H、W为不确定大小,输出outputs(NL),N为不确定大小,则dynamic_axes={"inputs": [0,2,3], "outputs": [0]}。 默认值:None 数据类型:dict<string, dict<python:int, string>> or dict<string, list(int)> |
返回值说明
返回修改后的torch.nn.Module校准模型。
调用示例
import amct_pytorch as amct
# 建立待量化的网络图结构
model = build_model()
model.load_state_dict(torch.load(state_dict_path))
input_data = tuple([torch.randn(input_shape)])
scale_offset_record_file = os.path.join(TMP, 'scale_offset_record.txt')
modfied_model = os.path.join(TMP, 'modfied_model.onnx')
# 插入量化API
calibration_model = amct.quantize_model(config_json_file,
modfied_model,
scale_offset_record_file,
model,
input_data,
input_names=['input'],
output_names=['output'],
dynamic_axes={'input':{0: 'batch_size'},
'output':{0: 'batch_size'}})
save_model¶
产品支持情况
产品 |
是否支持 |
|---|---|
IPV350 |
√ |
功能说明
训练后量化接口,根据量化因子记录文件record_file以及修改后的模型,插入AscendQuant、AscendDequant等算子,然后保存为可以在ONNX Runtime环境进行精度仿真的fake_quant模型,和可以在NPU IP加速器做推理的部署模型。
函数原型
save_model(modfied_onnx_file, record_file, save_path)
参数说明
参数名 |
输入/输出 |
说明 |
|---|---|---|
modfied_onnx_file |
输入 |
含义:文件名,存储融合后模型的onnx格式。 数据类型:string |
record_file |
输入 |
含义:量化因子记录文件路径及名称。 数据类型:string |
save_path |
输入 |
含义:模型存放路径。该路径需要包含模型名前缀,例如./quantized_model/*model。 数据类型:string |
返回值说明
无
约束说明
在网络推理的batch数目达到batch_num后,再调用该接口,否则量化因子不正确,量化结果不正确。
该接口只接收quantize_model接口产生的ONNX类型模型文件。
该接口需要输入量化因子记录文件,量化因子记录文件在quantize_model阶段生成,在模型推理阶段填充有效值。
调用示例
import amct_pytorch as amct
# 进行网络推理,期间完成量化
for i in batch_num:
output = calibration_model(input_batch)
# 插入API,将量化的模型存为ONNX文件
amct.save_model(modfied_onnx_file="./tmp/modfied_model.onnx",
record_file="./tmp/scale_offset_record.txt",
save_path="./results/model")
落盘文件说明:
精度仿真模型文件:ONNX格式的模型文件,模型名中包含fake_quant,可以在ONNX Runtime环境进行精度仿真。
部署模型文件:ONNX格式的模型文件,模型名中包含deploy,经过ATC转换工具转换后可部署到NPU IP加速器。
(可选)*.external文件,包括*deploy.external和*fakequant.external:
只有保存的精度仿真模型以及部署模型文件大小>=2GB才会生成该类文件,且与压缩后的*.onnx模型文件生成在同级目录,用于保存Tensor中的数据,每个Tensor数据单独保存一份*.external文件,文件名与Tensor相同,例如_conv1.weight__deploy.external和_conv1.weight__fakequant.external。
后续通过ATC工具加载压缩后的*.onnx部署模型文件进行模型转换时,会自动读取同级目录下*.external文件中的Tensor数据。
重新执行量化时,该接口输出的上述文件将会被覆盖。
accuracy_based_auto_calibration¶
产品支持情况
产品 |
是否支持 |
|---|---|
IPV350 |
√ |
功能说明
根据用户输入的模型、配置文件进行自动的校准过程,搜索得到一个满足目标精度的量化配置,输出可以在ONNX Runtime环境下做精度仿真的fake_quant模型,和可在NPU IP加速器上做推理的deploy模型。
函数原型
accuracy_based_auto_calibration(model,model_evaluator,config_file,record_file,save_dir,input_data,input_names,output_names,dynamic_axes,strategy='BinarySearch',sensitivity='CosineSimilarity')
参数说明
参数名 |
输入/输出 |
说明 |
|---|---|---|
model |
输入 |
含义:用户的torch model。 数据类型:torch.nn.Module |
model_evaluator |
输入 |
含义:自动量化进行校准和评估精度的Python实例。 数据类型:Python实例 |
config_file |
输入 |
含义:用户生成的量化配置文件。 数据类型:string |
record_file |
输入 |
含义:存储量化因子的路径,如果该路径下已存在文件,则会被重写。 数据类型:string |
save_dir |
输入 |
含义:模型存放路径。该路径需要包含模型名前缀,例如./quantized_model/*model。 数据类型:string |
input_data |
输入 |
含义:模型的输入数据。一个torch.tensor会被等价为tuple(torch.tensor)。 数据类型:tuple |
input_names |
输入 |
含义:模型的输入的名称,用于modfied_onnx_file中显示。 默认值:None 数据类型:list(string) |
output_names |
输入 |
含义:模型的输出的名称,用于modfied_onnx_file中显示。 默认值:None 数据类型:list(string) |
dynamic_axes |
输入 |
含义:对模型输入输出动态轴的指定,例如对于输入inputs(NCHW),N、H、W为不确定大小,输出outputs(NL),N为不确定大小,则{"inputs": [0,2,3], "outputs": [0]}。 默认值:None 数据类型:dict<string, dict<python:int, string>> or dict<string, list(int)> |
strategy |
输入 |
含义:搜索满足精度要求的量化配置的策略,默认是二分法策略。 数据类型:string或Python实例 默认值:BinarySearch |
sensitivity |
输入 |
含义:评价每一层量化层对于量化敏感度的指标,默认是余弦相似度。 数据类型:string或Python实例 默认值:CosineSimilarity |
返回值说明
无
调用示例
import amct_pytorch as amct
from amct_pytorch.common.auto_calibration import AutoCalibrationEvaluatorBase
# You need to implement the AutoCalibrationEvaluator's calibration(), evaluate() and metric_eval() funcs
class AutoCalibrationEvaluator(AutoCalibrationEvaluatorBase):
""" subclass of AutoCalibrationEvaluatorBase"""
def __init__(self, target_loss, batch_num):
super(AutoCalibrationEvaluator, self).__init__()
self.target_loss = target_loss
self.batch_num = batch_num
def calibration(self, model):
""" implement the calibration function of AutoCalibrationEvaluatorBase
calibration() need to finish the calibration inference procedure
so the inference batch num need to >= the batch_num pass to create_quant_config
"""
model_forward(model=model, batch_size=32, iterations=self.batch_num)
def evaluate(self, model):
""" implement the evaluate function of AutoCalibrationEvaluatorBase
params: model in torch.nn.module
return: the accuracy of input model on the eval dataset, or other metric which
can describe the 'accuracy' of model
"""
top1, _ = model_forward(model=model, batch_size=32, iterations=5)
if torch.cuda.is_available():
torch.cuda.empty_cache()
return top1
def metric_eval(self, original_metric, new_metric):
""" implement the metric_eval function of AutoCalibrationEvaluatorBase
params: original_metric: the returned accuracy of evaluate() on non quantized model
new_metric: the returned accuracy of evaluate() on fake quant model
return:
[0]: whether the accuracy loss between non quantized model and fake quant model
can satisfy the requirement
[1]: the accuracy loss between non quantized model and fake quant model
"""
loss = original_metric - new_metric
if loss * 100 < self.target_loss:
return True, loss
return False, loss
...
# 1. step1 create quant config json file
config_json_file = os.path.join(TMP, 'config.json')
skip_layers = []
batch_num = 2
amct.create_quant_config(
config_json_file,
model,
input_data,
skip_layers,
batch_num
)
# 2. step2 construct the instance of AutoCalibrationEvaluator
evaluator = AutoCalibrationEvaluator(target_loss=0.5, batch_num=batch_num)
# 3. step3 using the accuracy_based_auto_calibration to quantized the model
record_file = os.path.join(TMP, 'scale_offset_record.txt')
result_path = os.path.join(PATH, 'result/mobilenet_v2')
amct.accuracy_based_auto_calibration(
model=model,
model_evaluator=evaluator,
config_file=config_json_file,
record_file=record_file,
save_dir=result_path,
input_data=input_data,
input_names=['input'],
output_names=['output'],
dynamic_axes={
'input': {0: 'batch_size'},
'output': {0: 'batch_size'}
},
strategy='BinarySearch',
sensitivity='CosineSimilarity'
)
落盘文件说明:
精度仿真模型文件:ONNX格式的模型文件,模型名中包含fake_quant,可以在ONNX Runtime环境进行精度仿真。
部署模型文件:ONNX格式的模型文件,模型名中包含deploy,经过ATC转换工具转换后可部署到NPU IP加速器。
量化因子记录文件:在接口中的record_file中写入量化因子。
敏感度信息文件:该文件记录了待量化层对于量化的敏感度信息,根据该信息进行量化回退层的选择。
自动量化回退历史记录文件:记录的回退层的信息。
quantize_preprocess¶
产品支持情况
产品 |
是否支持 |
|---|---|
IPV350 |
√ |
功能说明
量化数据均衡预处理接口,将输入的待量化的图结构按照给定的量化配置文件进行量化处理,在传入的图结构中插入均衡量化相关的算子,生成均衡量化因子记录文件record_file,返回修改后的torch.nn.Module校准模型。
函数原型
calibration_model = quantize_preprocess(config_file, record_file, model, input_data)
参数说明
参数名 |
输入/输出 |
说明 |
|---|---|---|
config_file |
输入 |
含义:用户生成的量化配置文件,用于指定模型network中量化层的配置情况。 数据类型:string |
record_file |
输入 |
含义:均衡量化因子记录文件路径及名称。 数据类型:string |
model |
输入 |
含义:待量化的模型,已加载权重。 数据类型:torch.nn.Module |
input_data |
输入 |
含义:模型的输入数据。一个torch.tensor会被等价为tuple(torch.tensor)。 数据类型:tuple |
返回值说明
返回修改后的torch.nn.Module校准模型。
调用示例
import amct_pytorch as amct
# 建立待量化的网络图结构
model = build_model()
model.load_state_dict(torch.load(state_dict_path))
input_data = tuple([torch.randn(input_shape)])
tensor_balance_factor_record_file = os.path.join(TMP, 'tensor_balance_factor_record.txt')
modified_model = os.path.join(TMP, 'modified_model.onnx')
# 插入量化API
calibration_model = amct.quantize_preprocess(config_json_file,
tensor_balance_factor_record_file,
model,
input_data)
量化感知训练接口¶
create_quant_retrain_config¶
产品支持情况
产品 |
是否支持 |
|---|---|
IPV350 |
|
功能说明
量化感知训练接口,根据图的结构找到所有可量化的层,自动生成量化配置文件,并将可量化层的量化配置信息写入配置文件。
函数原型
create_quant_retrain_config(config_file, model, input_data, config_defination=None)
参数说明
参数名 |
输入/输出 |
说明 |
|---|---|---|
config_file |
输入 |
含义:待生成的量化感知训练配置文件存放路径及名称。如果存放路径下已经存在该文件,则调用该接口时会覆盖已有文件。 数据类型:string |
model |
输入 |
含义:待进行量化感知训练的模型,已加载权重。 数据类型:torch.nn.Module |
input_data |
输入 |
含义:模型的输入数据。一个torch.tensor会被等价为tuple(torch.tensor)。 数据类型:tuple |
config_defination |
输入 |
含义:简易配置文件。 基于retrain_config_pytorch.proto文件生成的简易配置文件quant.cfg,*.proto文件所在路径为:AMCT安装目录/amct_pytorch/proto/。*.proto文件参数解释以及生成的quant.cfg简易量化配置文件样例请参见量化感知训练简易配置文件。 默认值:None。 数据类型:string |
返回值说明
无
调用示例
import amct_pytorch as amct
# 建立待量化的网络图结构
model = build_model()
model.load_state_dict(torch.load(state_dict_path))
input_data = tuple([torch.randn(input_shape)])
# 生成量化配置文件
amct.create_quant_retrain_config(config_file="./configs/config.json",
model=model,
input_data=input_data)
落盘文件说明:生成JSON格式的量化感知训练配置文件,样例如下(重新执行量化感知训练时,该接口输出的配置文件将会被覆盖)。
{
"version":1,
"batch_num":1,
"conv1":{
"retrain_enable":true,
"retrain_data_config":{
"algo":"ulq_quantize",
"dst_type":"INT8"
},
"retrain_weight_config":{
"algo":"arq_retrain",
"channel_wise":true,
"dst_type":"INT8"
}
},
"layer1.0.conv1":{
"retrain_enable":true,
"retrain_data_config":{
"algo":"ulq_quantize",
"dst_type":"INT8"
},
"retrain_weight_config":{
"algo":"arq_retrain",
"channel_wise":true,
"dst_type":"INT8"
}
},
"fc":{
"retrain_enable":true,
"retrain_data_config":{
"algo":"ulq_quantize",
"dst_type":"INT8"
},
"retrain_weight_config":{
"algo":"arq_retrain",
"channel_wise":false,
"dst_type":"INT8"
}
}
}
create_quant_retrain_model¶
产品支持情况
产品 |
是否支持 |
|---|---|
IPV350 |
|
功能说明
量化感知训练接口,将输入的待量化的图结构按照给定的量化配置文件进行量化处理,在传入的图结构中插入量化相关的算子(数据和权重的量化感知训练层以及找N的层),生成量化因子记录文件record_file,返回修改后可用于量化感知训练的torch.nn.Module模型。
函数原型
quant_retrain_model = create_quant_retrain_model (config_file, model, record_file, input_data)
参数说明
参数名 |
输入/输出 |
说明 |
|---|---|---|
config_file |
输入 |
含义:用户生成的量化感知训练配置文件,用于指定模型network中量化层的配置情况。 数据类型:string |
model |
输入 |
含义:待进行量化感知训练的模型,已加载权重。 数据类型:torch.nn.Module |
record_file |
输入 |
含义:量化因子记录文件路径及名称。 数据类型:string |
input_data |
输入 |
含义:模型的输入数据。一个torch.tensor会被等价为tuple(torch.tensor)。 数据类型:tuple |
返回值说明
返回修改后可用于量化感知训练的torch.nn.Module模型。
调用示例
import amct_pytorch as amct
# 建立待进行量化感知训练的网络图结构
model = build_model()
model.load_state_dict(torch.load(state_dict_path))
input_data = tuple([torch.randn(input_shape)])
scale_offset_record_file = os.path.join(TMP, 'scale_offset_record.txt')
# 插入量化API
quant_retrain_model = amct.create_quant_retrain_model(
config_json_file,
model,
scale_offset_record_file,
input_data)
restore_quant_retrain_model¶
产品支持情况
产品 |
是否支持 |
|---|---|
IPV350 |
|
功能说明
量化感知训练接口,将输入的待量化的图结构按照给定的量化感知训练配置文件进行量化处理,在传入的图结构中插入量化感知训练相关的算子(数据和权重的量化感知训练层以及找N的层),生成量化因子记录文件record_file,加载训练过程中保存的checkpoint权重参数,返回修改后的torch.nn.Module量化感知训练模型。
函数原型
quant_retrain_model = restore_quant_retrain_model (config_file, model, record_file, input_data, pth_file, state_dict_name=None)
参数说明
参数名 |
输入/输出 |
说明 |
|---|---|---|
config_file |
输入 |
含义:用户生成的量化感知训练配置文件,用于指定模型network中量化层的配置情况。 数据类型:string 使用约束:该接口输入的config.json必须和create_quant_retrain_model接口输入的config.json一致。 |
model |
输入 |
含义:待进行量化感知训练的原始模型,未加载权重。 数据类型:torch.nn.Module |
record_file |
输入 |
含义:量化因子记录文件路径及名称。 数据类型:string |
input_data |
输入 |
含义:模型的输入数据。一个torch.tensor会被等价为tuple(torch.tensor)。 数据类型:tuple |
pth_file |
输入 |
含义:训练过程中保存的权重文件。 数据类型:string |
state_dict_name |
输入 |
含义:权重文件中的权重对应的键值。 默认值:None 数据类型:string |
返回值说明
返回修改后的torch.nn.Module量化感知训练模型。
调用示例
import amct_pytorch as amct
# 建立待量化的网络图结构
model = build_model()
input_data = tuple([torch.randn(input_shape)])
scale_offset_record_file = os.path.join(TMP, 'scale_offset_record.txt')
# 插入量化API
quant_retrain_model = amct.restore_quant_retrain_model(
config_json_file,
model,
scale_offset_record_file,
input_data,
pth_file)
save_quant_retrain_model¶
产品支持情况
产品 |
是否支持 |
|---|---|
IPV350 |
|
功能说明
量化感知训练接口,根据用户最终的重训练好的模型,插入AscendQuant、AscendDequant等算子,生成最终量化精度仿真模型以及量化部署模型。
函数原型
save_quant_retrain_model (config_file, model, record_file, save_path, input_data, input_names=None, output_names=None, dynamic_axes=None)
参数说明
参数名 |
输入/输出 |
说明 |
|---|---|---|
config_file |
输入 |
含义:用户生成的量化感知训练配置文件,用于指定模型network中量化层的配置情况。 数据类型:string |
model |
输入 |
含义:已进行量化感知训练后的量化模型。 数据类型:torch.nn.Module |
record_file |
输入 |
含义:量化因子记录文件路径及名称。 数据类型:string |
save_path |
输入 |
含义:量化模型存放路径。该路径需要包含模型名前缀,例如./quantized_model/*model。 数据类型:string |
input_data |
输入 |
含义:模型的输入数据。一个torch.tensor会被等价为tuple(torch.tensor)。 数据类型:tuple |
input_names |
输入 |
含义:模型的输入的名称,用于保存的量化onnx模型中显示。 默认值:None 数据类型:list(string) |
output_names |
输入 |
含义:模型的输出的名称,用于保存的量化onnx模型中显示。 默认值:None 数据类型:list(string) |
dynamic_axes |
输入 |
含义:对模型输入输出动态轴的指定,例如对于输入inputs(NCHW),N、H、W为不确定大小,输出outputs(NL),N为不确定大小,则指定形式为: {"inputs": [0,2,3], "outputs": [0]},其中0,2,3分别表示N,H,W所在位置的索引。 默认值:None 数据类型:dict<string, dict<python:int, string>> or dict<string, list(int)> 使用约束:int类型取值需要为非负数 |
返回值说明
无
调用示例
import amct_pytorch as amct
# 建立待量化的网络图结构
model = build_model()
model.load_state_dict(torch.load(state_dict_path))
input_data = tuple([torch.randn(input_shape)])
# 训练量化retrain模型,训练量化因子
train_model(quant_retrain_model, input_batch)
# 推理量化retrain模型,导出量化因子
infer_model(quant_retrain_model, input_batch)
# 插入量化API,将量化感知训练的模型存为ONNX文件
amct.save_quant_retrain_model(
config_json_file,
model,
record_file,
save_path="./results/model"
input_data,
input_names=['input'],
output_names=['output'],
dynamic_axes={'input':{0: 'batch_size'},
'output':{0: 'batch_size'}})
落盘文件说明:
精度仿真模型文件:ONNX格式的模型文件,模型名中包含fake_quant,可以在ONNX Runtime环境进行精度仿真。
部署模型文件:ONNX格式的模型文件,模型名中包含deploy,经过ATC转换工具转换后可部署到NPU IP加速器。
(可选)*.external文件,包括*deploy.external和*fakequant.external:
只有保存的精度仿真模型以及部署模型文件大小>=2GB才会生成该类文件,且与压缩后的*.onnx模型文件生成在同级目录,用于保存Tensor中的数据,每个Tensor数据单独保存一份*.external文件,文件名与Tensor相同,例如_conv1.weight__deploy.external和_conv1.weight__fakequant.external。
后续通过ATC工具加载压缩后的*.onnx部署模型文件进行模型转换时,会自动读取同级目录下*.external文件中的Tensor数据。
重新执行量化感知训练时,该接口输出的上述文件将会被覆盖。
单算子模式¶
Conv1dQAT¶
产品支持情况
产品 |
是否支持 |
|---|---|
IPV350 |
√ |
功能说明
构造Conv1d的QAT算子。
函数原型
直接构造接口:
qat = amct_pytorch.nn.module.quantization.conv1d.Conv1dQAT(in_channels,out_channels, kernel_size, stride, padding, dilation, groups, bias, padding_mode, device, dtype, config)基于原生算子构造接口:
qat = amct_pytorch.nn.module.quantization.conv1d.Conv1dQAT.from_float(mod, config)
参数说明
表 1 直接构造接口参数说明
参数名 |
输入/输出 |
说明 |
|---|---|---|
in_channels |
输入 |
含义:输入channel个数。 数据类型:int |
out_channels |
输入 |
含义:输出channel个数。 数据类型:int |
kernel_size |
输入 |
含义:卷积核大小。 数据类型:int/tuple |
stride |
输入 |
含义:卷积步长。 数据类型:int/tuple |
padding |
输入 |
含义:填充大小。 数据类型:int/tuple |
dilation |
输入 |
含义:kernel元素之间的间距。 数据类型:int/tuple |
groups |
输入 |
含义:输入和输出的链接关系。 数据类型:int |
bias |
输入 |
含义:是否开启偏置项参与学习。 数据类型:bool,其他数据类型(比如整数,字符串,列表等)按照Python真值判断规则转换。 默认值:True |
padding_mode |
输入 |
含义:填充方式。 数据类型:string |
device |
输入 |
含义:运行设备。 数据类型:string 默认值:None |
dtype |
输入 |
含义:数值类型。 torch数据类型, 仅支持torch.float32 |
config |
输入 |
含义:量化配置。配置参考样例如下,量化配置参数的具体说明请参见量化配置参数说明。 config = {
"retrain_enable":true,
"retrain_data_config": {
"dst_type": "INT8",
"batch_num": 10,
"fixed_min": False,
"clip_min": -1.0,
"clip_max": 1.0
},
"retrain_weight_config": {
"dst_type": "INT8",
"weights_retrain_algo": "arq_retrain",
"channel_wise": False
}
}
数据类型:dict 默认值:None |
表 2 基于原生算子构造接口
参数名 |
输入/输出 |
说明 |
|---|---|---|
mod |
输入 |
含义:待量化的原生Conv1d算子。 数据类型:torch.nn.Module |
config |
输入 |
含义:量化配置。配置参考样例如下,量化配置参数的具体说明请参见量化配置参数说明。 config = {
"retrain_enable":true,
"retrain_data_config": {
"dst_type": "INT8",
"batch_num": 10,
"fixed_min": False,
"clip_min": -1.0,
"clip_max": 1.0
},
"retrain_weight_config": {
"dst_type": "INT8",
"weights_retrain_algo": "arq_retrain",
"channel_wise": False
}
}
数据类型:dict 默认值:None |
返回值说明
直接构造:返回构造的QAT单算子实例。
基于原生算子构造:torch.nn.Module转化后的QAT单算子。
调用示例
直接构造:
from amct_pytorch.nn.module.quantization.conv1d import Conv1dQAT Conv1dQAT(in_channels=1, out_channels=1, kernel_size=1, stride=1, padding=0, dilation=1, groups=1, bias=True, padding_mode='zeros', device=None, dtype=None, config=None)
基于原生算子构造:
import torch from amct_pytorch.nn.module.quantization.conv1d import Conv1dQAT conv1d_op = torch.nn.Conv1d(in_channels=1, out_channels=1, kernel_size=1, stride=1, padding=0, dilation=1, groups=1, bias=True, padding_mode='zeros', device=None, dtype=None) Conv1dQAT.from_float(mod=conv1d_op, config=None)
Conv2dQAT¶
产品支持情况
产品 |
是否支持 |
|---|---|
IPV350 |
√ |
功能说明
构造Conv2d的QAT算子。
函数原型
直接构造接口:
qat = amct_pytorch.nn.module.quantization.conv2d.Conv2dQAT(in_channels, out_channels, kernel_size, stride, padding, dilation, groups, bias, padding_mode, device, dtype, config)基于原生算子构造接口:
qat = amct_pytorch.nn.module.quantization.conv2d.Conv2dQAT.from_float(mod, config)
参数说明
表 1 直接构造接口参数说明
参数名 |
输入/输出 |
说明 |
|---|---|---|
in_channels |
输入 |
含义:输入channel个数。 数据类型:int |
out_channels |
输入 |
含义:输出channel个数、 数据类型:int |
kernel_size |
输入 |
含义:卷积核大小。 数据类型:int/tuple |
stride |
输入 |
含义:卷积步长。 数据类型:int/tuple 默认值:1 |
padding |
输入 |
含义:填充大小。 数据类型:int/tuple 默认值:0 |
dilation |
输入 |
含义:kernel元素之间的间距。 数据类型:int/tuple 默认值:1 |
groups |
输入 |
含义:输入和输出的连接关系。 数据类型:int 默认值:1 |
bias |
输入 |
含义:是否开启偏置项参与学习。 数据类型:bool,其他数据类型(比如整数,字符串,列表等)按照Python真值判断规则转换。 默认值:True |
padding_mode |
输入 |
含义:填充方式。 使用约束:仅支持zeros |
device |
输入 |
含义:运行设备。 默认值:None |
dtype |
输入 |
含义:torch数值类型。 torch数据类型,仅支持torch.float32 |
config |
输入 |
含义:量化配置,配置参考样例如下,量化配置参数的具体说明请参见量化配置参数说明 config = {
"retrain_enable":true,
"retrain_data_config": {
"dst_type": "INT8",
"batch_num": 10,
"fixed_min": False,
"clip_min": -1.0,
"clip_max": 1.0
},
"retrain_weight_config": {
"dst_type": "INT8",
"weights_retrain_algo": "arq_retrain",
"channel_wise": False
}
}
数据类型:dict 默认值:None |
表 2 基于原生算子构造接口
参数名 |
输入/输出 |
说明 |
|---|---|---|
mod |
输入 |
含义:待量化的原生Conv2d算子 数据类型:torch.nn.Module |
config |
输入 |
含义:量化配置,配置参考样例如下,量化配置参数的具体说明请参见量化配置参数说明 config = {
"retrain_enable":true,
"retrain_data_config": {
"dst_type": "INT8",
"batch_num": 10,
"fixed_min": False,
"clip_min": -1.0,
"clip_max": 1.0
},
"retrain_weight_config": {
"dst_type": "INT8",
"weights_retrain_algo": "arq_retrain",
"channel_wise": False
}
}
数据类型:dict 默认值:None |
返回值说明
直接构造:返回构造的QAT单算子实例。
基于原生算子构造:torch.nn.Module转化后的QAT单算子。
调用示例
直接构造:
from amct_pytorch.nn.module.quantization.conv2d import Conv2dQAT Conv2dQAT(in_channels=1, out_channels=1, kernel_size=1, stride=1, padding=0, dilation=1, groups=1, bias=True, padding_mode='zeros', device=None, dtype=None, config=None)
基于原生算子构造:
import torch from amct_pytorch.nn.module.quantization.conv2d import Conv2dQAT conv2d_op = torch.nn.Conv2d(in_channels=1, out_channels=1, kernel_size=1, stride=1, padding=0, dilation=1, groups=1, bias=True, padding_mode='zeros', device=None, dtype=None) Conv2dQAT.from_float(mod=conv2d_op, config=None)
ConvTranspose1dQAT¶
产品支持情况
产品 |
是否支持 |
|---|---|
IPV350 |
√ |
功能说明
构造ConvTranspose1d的QAT算子。
函数原型
直接构造接口:
amct_pytorch.nn.module.quantization.conv_transpose_1d.ConvTranspose1dQAT(in_channels,out_channels, kernel_size, stride, padding, dilation, groups, bias, padding_mode, device, dtype, config)基于原生算子构造接口:
qat = amct_pytorch.nn.module.quantization.conv_transpose_1d.ConvTranspose1dQAT.from_float(mod, config)
参数说明
表 1 直接构造接口参数说明
参数名 |
输入/输出 |
说明 |
|---|---|---|
in_channels |
输入 |
含义:输入channel个数。 数据类型:int |
out_channels |
输入 |
含义:输出channel个数。 数据类型:int |
kernel_size |
输入 |
含义:卷积核大小。 数据类型:int/tuple |
stride |
输入 |
含义:卷积步长。 数据类型:int/tuple |
padding |
输入 |
含义:填充大小。 数据类型:int/tuple |
dilation |
输入 |
含义:kernel元素之间的间距。 数据类型:int/tuple |
groups |
输入 |
含义:输入和输出的链接关系。 数据类型:int |
bias |
输入 |
含义:是否开启偏置项参与学习。 数据类型:bool,其他数据类型(比如整数,字符串,列表等)按照Python真值判断规则转换。 默认值:True |
padding_mode |
输入 |
含义:填充方式。 数据类型:string |
device |
输入 |
含义:运行设备。 数据类型:string 默认值:None |
dtype |
输入 |
含义:数值类型。 torch数据类型, 仅支持torch.float32 |
config |
输入 |
含义:量化配置。配置参考样例如下,量化配置参数的具体说明请参见量化配置参数说明。 config = {
"retrain_enable":true,
"retrain_data_config": {
"dst_type": "INT8",
"batch_num": 10,
"fixed_min": False,
"clip_min": -1.0,
"clip_max": 1.0
},
"retrain_weight_config": {
"dst_type": "INT8",
"weights_retrain_algo": "arq_retrain",
"channel_wise": False
}
}
数据类型:dict 默认值:None |
表 2 基于原生算子构造接口
参数名 |
输入/输出 |
说明 |
|---|---|---|
mod |
输入 |
含义:待量化的原生ConvTranspose1d算子。 数据类型:torch.nn.Module |
config |
输入 |
含义:量化配置。配置参考样例如下,量化配置参数的具体说明请参见量化配置参数说明。 config = {
"retrain_enable":true,
"retrain_data_config": {
"dst_type": "INT8",
"batch_num": 10,
"fixed_min": False,
"clip_min": -1.0,
"clip_max": 1.0
},
"retrain_weight_config": {
"dst_type": "INT8",
"weights_retrain_algo": "arq_retrain",
"channel_wise": False
}
}
数据类型:dict 默认值:None |
返回值说明
无
调用示例
直接构造:
from amct_pytorch.nn.module.quantization.conv_transpose_1d import ConvTranspose1dQAT ConvTranspose1dQAT(in_channels=1, out_channels=1, kernel_size=1, stride=1, padding=0, dilation=1, groups=1, bias=True, padding_mode='zeros', device=None, dtype=None, config=None)
基于原生算子构造:
import torch from amct_pytorch.nn.module.quantization.conv_transpose_1d import ConvTranspose1dQAT conv_transpose1d_op = torch.nn.ConvTranspose1d(in_channels=1, out_channels=1, kernel_size=1, stride=1, padding=0, dilation=1, groups=1, bias=True, padding_mode='zeros', device=None, dtype=None) ConvTranspose1dQAT.from_float(mod=conv_transpose2d_op, config=None)
ConvTranspose2dQAT¶
产品支持情况
产品 |
是否支持 |
|---|---|
IPV350 |
√ |
功能说明
构造ConvTranspose2d的QAT算子。
函数原型
直接构造接口:
qat = amct_pytorch.nn.module.quantization.conv_transpose_2d.ConvTranspose2dQAT(in_channels, out_channels, kernel_size, stride, padding, dilation, groups, bias, padding_mode, device, dtype, config)基于原生算子构造接口:
qat = amct_pytorch.nn.module.quantization.conv_transpose_2d.ConvTranspose2dQAT.from_float(mod, config)
参数说明
表 1 直接构造接口参数说明
参数名 |
输入/输出 |
说明 |
|---|---|---|
in_channels |
输入 |
含义:输入channel个数。 数据类型:int |
out_channels |
输入 |
含义:输出channel个数、 数据类型:int |
kernel_size |
输入 |
含义:卷积核大小。 数据类型:int/tuple |
stride |
输入 |
含义:卷积步长。 数据类型:int/tuple 默认值:1 |
padding |
输入 |
含义:填充大小。 数据类型:int/tuple 默认值:0 |
dilation |
输入 |
含义:kernel元素之间的间距。 数据类型:int/tuple 默认值:1 |
groups |
输入 |
含义:输入和输出的连接关系。 数据类型:int 默认值:1 |
bias |
输入 |
含义:是否开启偏置项参与学习。 数据类型:bool,其他数据类型(比如整数,字符串,列表等)按照Python真值判断规则转换。 默认值:True |
padding_mode |
输入 |
含义:填充方式。 使用约束:仅支持zeros |
device |
输入 |
含义:运行设备。 默认值:None |
dtype |
输入 |
含义:torch数值类型。 torch数据类型,仅支持torch.float32 |
config |
输入 |
含义:量化配置,配置参考样例如下,量化配置参数的具体说明请参见量化配置参数说明 config = {
"retrain_enable":true,
"retrain_data_config": {
"dst_type": "INT8",
"batch_num": 10,
"fixed_min": False,
"clip_min": -1.0,
"clip_max": 1.0
},
"retrain_weight_config": {
"dst_type": "INT8",
"weights_retrain_algo": "arq_retrain",
"channel_wise": False
}
}
数据类型:dict 默认值:None |
表 2 基于原生算子构造接口
参数名 |
输入/输出 |
说明 |
|---|---|---|
mod |
输入 |
含义:待量化的原生ConvTranspose2d算子。 数据类型:torch.nn.Module |
config |
输入 |
含义:量化配置。配置参考样例如下,量化配置参数的具体说明请参见量化配置参数说明。 config = {
"retrain_enable":true,
"retrain_data_config": {
"dst_type": "INT8",
"batch_num": 10,
"fixed_min": False,
"clip_min": -1.0,
"clip_max": 1.0
},
"retrain_weight_config": {
"dst_type": "INT8",
"weights_retrain_algo": "arq_retrain",
"channel_wise": False
}
}
数据类型:dict 默认值:None |
返回值说明
直接构造:返回构造的QAT单算子实例。
基于原生算子构造:torch.nn.Module转化后的QAT单算子。
调用示例
直接构造:
from amct_pytorch.nn.module.quantization.conv_transpose_2d import ConvTranspose2dQAT ConvTranspose2dQAT(in_channels=1, out_channels=1, kernel_size=1, stride=1, padding=0, dilation=1, groups=1, bias=True, padding_mode='zeros', device=None, dtype=None, config=None)
基于原生算子构造:
import torch from amct_pytorch.nn.module.quantization.conv_transpose_2d import ConvTranspose2dQAT conv_transpose2d_op = torch.nn.ConvTranspose2d(in_channels=1, out_channels=1, kernel_size=1, stride=1, padding=0, dilation=1, groups=1, bias=True, padding_mode='zeros', device=None, dtype=None) ConvTranspose2dQAT.from_float(mod=conv_transpose2d_op, config=None)
GRUQAT¶
产品支持情况
产品 |
是否支持 |
|---|---|
IPV350 |
√ |
功能说明
构造GRU的QAT算子。
函数原型
直接构造接口:
qat = amct_pytorch.nn.module.quantization.gru.GRUQAT(input_size, hidden_size, num_layers=1, bias=True, batch_first=False, dropout=0.0, bidirectional=False, device=None, dtype=None, config=None)基于原生算子构造接口:
qat = amct_pytorch.nn.module.quantization.gru.GRUQAT.from_float(mod, config)
参数说明
表 1 直接构造接口参数说明
参数名 |
输入/输出 |
说明 |
|---|---|---|
input_size |
输入 |
含义:输入x中预期特征的数量。 数据类型:int |
hidden_size |
输入 |
含义:隐藏状态的特征数h。 数据类型:int |
num_layers |
输入 |
含义:循环层数,有几层LSTM算子,单算子中限制为1。 数据类型:int 默认值:1 |
bias |
输入 |
含义:是否开启偏置项参与学习。 数据类型:bool 默认值:True |
batch_first |
输入 |
含义:是否将batch_size放到第一维,如果为True,则输入和输出张量将为(batch,seq,feature),否则为(seq, batch, feature)。注意只对x输入生效,不对h和c生效。(gru中为h)。 数据类型:bool 默认值:False |
dropout |
输入 |
含义:是否在除最后一层之外的每个LSTM层的输出上引入一个Dropout层。如果非零,则引入,单算子中限制为0。 数据类型:int或者float 默认值:0 |
bidirectional |
输入 |
含义:是否为双向LSTM算子。如果为True,则成为双向LSTM,单算子中限制为False。 数据类型:bool 默认值:False |
device |
输入 |
含义:运行设备。 数据类型:string 默认值:None |
dtype |
输入 |
含义:torch数值类型。 数据类型:torch数据类型, 仅支持torch.float32 |
config |
输入 |
含义:量化配置,配置参考样例如下,量化配置参数的具体说明请参见量化配置参数说明。 DEFAULT_QAT_CONF = {
"retrain_enable": True,
"retrain_data_config": {
"dst_type": "INT8", # INT8
"batch_num": 1, # 大于0
"fixed_min": True,
"clip_max": 1.0,
"clip_min": -1.0
},
"retrain_weight_config": {
"dst_type": "INT8", # INT8
"weights_retrain_algo": "arq_retrain", # arq_retrain/ulq_retrain
"channel_wise": True
}
}
数据类型:dict 默认值:None |
表 2 基于原生算子构造接口
参数名 |
输入/输出 |
说明 |
|---|---|---|
mod |
输入 |
含义:待量化的原生GRU算子。 数据类型:torch.nn.Module |
config |
输入 |
含义:量化配置,配置参考样例如下,量化配置参数的具体说明请参见量化配置参数说明。 config = {
"retrain_enable":true,
"retrain_data_config": {
"dst_type": "INT8",
"batch_num": 10,
"fixed_min": False,
"clip_min": -1.0,
"clip_max": 1.0
},
"retrain_weight_config": {
"dst_type": "INT8",
"weights_retrain_algo": "arq_retrain",
"channel_wise": False
}
}
数据类型:dict 默认值:None |
返回值说明
直接构造:返回构造的QAT单算子实例。
基于原生算子构造:torch.nn.Module转化后的QAT单算子。
调用示例
直接构造:
from amct_pytorch.nn.module.quantization.gru import GRUQAT GRUQAT(input_size=3, hidden_size=3, num_layers=1, bias=True, batch_first=True, dropout=0, bidirectional=False, device=None, dtype=None, config=None)
基于原生算子构造:
import torch from amct_pytorch.nn.module.quantization.gru import GRUQAT gru_op = torch.nn.lstm(input_size=1, hidden_size=1, num_layers=1, bias=True, batch_first=True, dropout=0, bidirectional=False, device=None, dtype=None, config=None) GRUQAT.from_float(mod=lstm_op, config=None)
LinearQAT¶
产品支持情况
产品 |
是否支持 |
|---|---|
IPV350 |
√ |
功能说明
构造Linear的QAT算子。
函数原型
直接构造接口:
qat = amct_pytorch.nn.module.quantization.linear.LinearQAT(in_features, out_features, bias, device, dtype, config)基于原生算子构造接口:
qat = amct_pytorch.nn.module.quantization.linear.LinearQAT.from_float(mod, config)
参数说明
表 1 直接构造接口参数说明
参数名 |
输入/输出 |
说明 |
|---|---|---|
in_features |
输入 |
含义:输入特征数。 数据类型:int |
out_features |
输入 |
含义:输出特征数。 数据类型:int |
bias |
输入 |
含义:是否开启偏置项参与学习。 数据类型:bool,其他数据类型(比如整数,字符串,列表等)按照Python真值判断规则转换。 默认值为True |
device |
输入 |
含义:运行设备。 默认值:None |
dtype |
输入 |
含义:torch数值类型。 数据类型:torch数据类型,仅支持torch.float32 |
config |
输入 |
含义:量化配置,配置参考样例如下,量化配置参数的具体说明请参见量化配置参数说明。 config = {
"retrain_enable":true,
"retrain_data_config": {
"dst_type": "INT8",
"batch_num": 10,
"fixed_min": False,
"clip_min": -1.0,
"clip_max": 1.0
},
"retrain_weight_config": {
"dst_type": "INT8",
"weights_retrain_algo": "arq_retrain",
"channel_wise": False
}
}
数据类型:dict 默认值:None |
表 2 基于原生算子构造接口
参数名 |
输入/输出 |
说明 |
|---|---|---|
mod |
输入 |
含义:待量化的原生Linear算子。 数据类型:torch.nn.Module |
config |
输入 |
含义:量化配置。配置参考样例如下,量化配置参数的具体说明请参见量化配置参数说明。 config = {
"retrain_enable":true,
"retrain_data_config": {
"dst_type": "INT8",
"batch_num": 10,
"fixed_min": False,
"clip_min": -1.0,
"clip_max": 1.0
},
"retrain_weight_config": {
"dst_type": "INT8",
"weights_retrain_algo": "arq_retrain",
"channel_wise": False
}
}
数据类型:dict 默认值:None |
返回值说明
直接构造:返回构造的QAT单算子实例。
基于原生算子构造:torch.nn.Module转化后的QAT单算子。
调用示例
直接构造:
from amct_pytorch.nn.module.quantization.linear import LinearQAT LinearQAT(in_features=1, out_features=1, bias=True, device=None, dtype=None, config=None)
基于原生算子构造:
import torch from amct_pytorch.nn.module.quantization.linear import LinearQAT linear_op = torch.nn.Linear(in_features=1, out_features=1, bias=True, device=None, dtype=None) LinearQAT.from_float(mod=linear_op, config=None)
LSTMQAT¶
产品支持情况
产品 |
是否支持 |
|---|---|
IPV350 |
√ |
功能说明
构造LSTM的QAT算子。
函数原型
直接构造接口:
qat = amct_pytorch.nn.module.quantization.lstm.LSTMQAT(input_size, hidden_size, num_layers=1, bias=True, batch_first=False, dropout=0.0, bidirectional=False, proj_size=0, device=None, dtype=None, config=None)基于原生算子构造接口:
qat = amct_pytorch.nn.module.quantization.lstm.LSTMQAT.from_float(mod, config)
参数说明
表 1 直接构造接口参数说明
参数名 |
输入/输出 |
说明 |
|---|---|---|
input_size |
输入 |
含义:输入x中预期特征的数量。 数据类型:int |
hidden_size |
输入 |
含义:隐藏状态的特征数h。 数据类型:int |
num_layers |
输入 |
含义:循环层数,有几层LSTM算子,单算子中限制为1。 数据类型:int 默认值:1 |
bias |
输入 |
含义:是否开启偏置项参与学习。 数据类型:bool 默认值:True |
batch_first |
输入 |
含义:是否将batch_size放到第一维,如果为True,则输入和输出张量将为(batch,seq,feature),否则为(seq,batch,feature)。注意只对x输入生效,不对h和c生效。(gru中为h)。 数据类型:bool 默认值:False |
dropout |
输入 |
含义:是否在除最后一层之外的每个LSTM层的输出上引入一个Dropout层。如果非零,则引入,单算子中限制为0。 数据类型:int或者float 默认值:0 |
bidirectional |
输入 |
含义:是否为双向LSTM算子。如果为True,则成为双向LSTM,单算子中限制为False。 数据类型:bool 默认值:False |
proj_size |
输入 |
含义:如果>0,将使用具有相应投影大小的LSTM,单算子中限制为0。 数据类型:int 默认值:0 |
device |
输入 |
含义:运行设备。 数据类型:string 默认值:None |
dtype |
输入 |
含义:torch数值类型。 数据类型:torch数据类型, 仅支持torch.float32 |
config |
输入 |
含义:量化配置,配置参考样例如下,量化配置参数的具体说明请参见量化配置参数说明。 DEFAULT_QAT_CONF = {
"retrain_enable": True,
"retrain_data_config": {
"dst_type": "INT8", # INT8
"batch_num": 1, # 大于0
"fixed_min": True,
"clip_max": 1.0,
"clip_min": -1.0
},
"retrain_weight_config": {
"dst_type": "INT8", # INT8
"weights_retrain_algo": "arq_retrain", # arq_retrain/ulq_retrain
"channel_wise": True
}
}
数据类型:dict 默认值:None |
表 2 基于原生算子构造接口
参数名 |
输入/输出 |
说明 |
|---|---|---|
mod |
输入 |
含义:待量化的原生LSTM算子。 数据类型:torch.nn.Module |
config |
输入 |
含义:量化配置,配置参考样例如下,量化配置参数的具体说明请参见量化配置参数说明。 config = {
"retrain_enable":true,
"retrain_data_config": {
"dst_type": "INT8",
"batch_num": 10,
"fixed_min": True,
"clip_min": -1.0,
"clip_max": 1.0
},
"retrain_weight_config": {
"dst_type": "INT8",
"weights_retrain_algo": "arq_retrain",
"channel_wise": True
}
}
数据类型:dict 默认值:None |
返回值说明
直接构造:返回构造的QAT单算子实例。
基于原生算子构造:torch.nn.Module转化后的QAT单算子。
调用示例
直接构造:
from amct_pytorch.nn.module.quantization.lstm import LSTMQAT LSTMQAT(input_size=3, hidden_size=3, num_layers=1, bias=True, batch_first=True, dropout=0, bidirectional=False, proj_size=0, device=None, dtype=None, config=None)
基于原生算子构造:
import torch from amct_pytorch.nn.module.quantization.lstm import LSTMQAT lstm_op = torch.nn.lstm(input_size=3, hidden_size=3, num_layers=1, bias=True, batch_first=True, dropout=0, bidirectional=False, proj_size=0, device=None, dtype=None, config=None) LSTMQAT.from_float(mod=lstm_op, config=None)
量化配置参数说明¶
表 1 retrain_enable参数说明
作用 |
该层是否进行量化感知训练。 |
|---|---|
类型 |
bool |
取值范围 |
true或false |
参数说明 |
|
推荐配置 |
true |
必选或可选 |
可选 |
表 2 retrain_data_config参数说明
作用 |
该层数据量化配置。 |
|---|---|
类型 |
dict |
取值范围 |
- |
参数说明 |
包含如下参数:
|
推荐配置 |
- |
必选或可选 |
可选 |
表 3 retrain_weight_config参数说明
作用 |
该层权重量化配置。 |
|---|---|
类型 |
dict |
取值范围 |
- |
参数说明 |
包含如下参数:
|
推荐配置 |
- |
必选或可选 |
可选 |
表 4 weights_retrain_algo参数说明
作用 |
该层选择使用的权重量化算法。 |
|---|---|
类型 |
string |
取值范围 |
- |
参数说明 |
|
推荐配置 |
arq_retrain |
必选或可选 |
可选 |
表 5 channel_wise参数说明
作用 |
是否对每个channel采用不同的量化因子。 |
|---|---|
类型 |
bool |
取值范围 |
true或false |
参数说明 |
|
推荐配置 |
true |
必选或可选 |
可选 |
表 6 batch_num参数说明
作用 |
量化使用的batch数量。 |
|---|---|
类型 |
int |
取值范围 |
大于0 |
参数说明 |
如果不配置,则使用默认值1,建议校准集图片数量不超过50张,根据batch的大小batch_size计算相应的batch_num数值。 batch_num*batch_size为量化使用的校准集图片数量。 其中batch_size为每个batch所用的图片数量。 |
推荐配置 |
1 |
必选或可选 |
可选 |
表 7 fixed_min参数说明
作用 |
设置数据量化算法下限的开关。 |
|---|---|
类型 |
bool |
取值范围 |
true或false |
参数说明 |
|
推荐配置 |
不选此项 |
必选或可选 |
可选 |
表 8 clip_max参数说明
作用 |
数据量化算法上限。 |
|---|---|
类型 |
float |
取值范围 |
clip_max>0 根据不同层activation的数据分布找到最大值max,推荐取值范围为:0.3*max~1.7*max |
参数说明 |
截断上下限数据量化算法,如果选择此项则固定算法截断上限。如果不选此项,通过ifmr算法学习获取上限。 |
推荐配置 |
不选此项 |
必选或可选 |
可选 |
表 9 clip_min参数说明
作用 |
数据量化算法下限。 |
|---|---|
类型 |
float |
取值范围 |
clip_min<0 根据不同层activation的数据分布找到最小值min,推荐取值范围为:0.3*min~1.7*min |
参数说明 |
截断上下限数据量化算法,如果选择此项则固定算法截断下限。如果不选此项,通过ifmr算法学习获取下限。 |
推荐配置 |
不选此项 |
必选或可选 |
可选 |
表 10 dst_type参数说明
作用 |
量化位宽的类型。 |
|---|---|
类型 |
string |
取值范围 |
当前只支持INT8,默认为INT8。 |
参数说明 |
量化时用于选择量化位宽。 |
推荐配置 |
- |
必选或可选 |
可选 |
稀疏接口¶
create_prune_retrain_model¶
产品支持情况
产品 |
是否支持 |
|---|---|
IPV350 |
|
注:上述4选2结构化稀疏特性,标记“x”的产品,调用接口不会报错,但是获取不到性能收益。
功能说明
通道稀疏或4选2结构化稀疏接口,两种稀疏特性每次只能使能一个:将输入的待稀疏的图结构按照给定的稀疏配置文件进行稀疏处理,在传入的图结构中插入或者替换相关的算子,生成记录稀疏信息的record_file,返回修改后可用于稀疏后训练的torch.nn.Module模型。
函数原型
prune_retrain_model = create_prune_retrain_model (model, input_data, config_defination, record_file)
参数说明
参数名 |
输入/输出 |
说明 |
|---|---|---|
model |
输入 |
含义:待进行稀疏的模型,已加载权重。 数据类型:torch.nn.Module |
input_data |
输入 |
含义:模型的输入数据。一个torch.tensor会被等价为tuple(torch.tensor)。 数据类型:tuple |
config_defination |
输入 |
含义:简易配置文件。 基于retrain_config_pytorch.proto文件生成的简易配置文件prune.cfg,*.proto文件所在路径为:AMCT安装目录/amct_pytorch/proto/。*.proto文件参数解释以及生成的prune.cfg简易量化配置文件样例请参见量化感知训练简易配置文件。 数据类型:string |
record_file |
输入 |
含义:记录稀疏信息的文件路径及名称,记录通道稀疏结点间的级联关系或记录4选2稀疏的节点。 数据类型:string |
返回值说明
返回修改后可用于稀疏后训练的torch.nn.Module模型。
调用示例
import amct_pytorch as amct
# 建立待进行稀疏的网络图结构
model = build_model()
model.load_state_dict(torch.load(state_dict_path))
input_data = tuple([torch.randn(input_shape)])
# 调用稀疏模型API
record_file = os.path.join(TMP, 'scale_offset_record.txt')
cfg_file = './prune_config.cfg'
prune_retrain_model = amct.create_prune_retrain_model(
model,
input_data,
cfg_file,
record_file)
restore_prune_retrain_model¶
产品支持情况
产品 |
是否支持 |
|---|---|
IPV350 |
|
注:上述4选2结构化稀疏特性,标记“x”的产品,调用接口不会报错,但是获取不到性能收益。
功能说明
通道稀疏或4选2结构化稀疏接口,两种稀疏特性每次只能使能一个:将输入的待稀疏的图结构按照给定的record_file中稀疏记录进行稀疏,返回修改后可用于稀疏后训练的torch.nn.Module模型。
函数原型
prune_retrain_model = restore_prune_retrain_model (model, input_data, record_file, config_defination, pth_file, state_dict_name=None)
参数说明
参数名 |
输入/输出 |
说明 |
|---|---|---|
model |
输入 |
含义:待进行稀疏的模型,未加载权重。 数据类型:torch.nn.Module |
input_data |
输入 |
含义:模型的输入数据。一个torch.tensor会被等价为tuple(torch.tensor)。 数据类型:tuple |
record_file |
输入 |
含义:记录稀疏信息的文件路径及名称,由create_prune_retrain_model生成,确保两个接口生成的模型一致。 数据类型:string |
config_defination |
输入 |
含义:简易配置文件。基于retrain_config_pytorch.proto文件生成的简易配置文件prune.cfg,*.proto文件所在路径为:AMCT安装目录/amct_pytorch/proto/。*.proto文件参数解释以及生成的prune.cfg简易量化配置文件样例请参见量化感知训练简易配置文件。 数据类型:string |
pth_file |
输入 |
含义:训练过程中保存的权重文件。 数据类型:string |
state_dict_name |
输入 |
含义:权重文件中的权重对应的键值。 默认值:None 数据类型:string |
返回值说明
返回修改后可用于稀疏后训练的torch.nn.Module模型。
调用示例
import amct_pytorch as amct
# 建立待进行稀疏的网络图结构
config_defination = './prune_cfg.cfg'
model = build_model()
input_data = tuple([torch.randn(input_shape)])
save_pth_path = /your/path/to/save/tmp.pth
model.load_state_dict(torch.load(state_dict_path))
# 调用稀疏模型API
record_file = os.path.join(TMP, 'scale_offset_record.txt')
prune_retrain_model = amct.restore_prune_retrain_model(
model,
input_data,
record_file,
config_defination,
save_pth_path,
'state_dict')
save_prune_retrain_model¶
产品支持情况
产品 |
是否支持 |
|---|---|
IPV350 |
|
注:上述4选2结构化稀疏特性,标记“x”的产品,调用接口不会报错,但是获取不到性能收益。
功能说明
稀疏接口,根据用户最终的重训练好的稀疏模型,生成最终ONNX仿真模型以及部署模型。
约束说明
针对稀疏模型,通过该接口生成的两个文件为直接使用PyTorch导出的ONNX文件,文件内容一致,文件名称分别包括deploy和fake_quant关键字。
函数原型
save_prune_retrain_model(model, save_path, input_data, input_names=None, output_names=None, dynamic_axes=None)
参数说明
参数名 |
输入/输出 |
说明 |
|---|---|---|
model |
输入 |
含义:已经进行稀疏后的PyTorch模型。 数据类型:torch.nn.Module |
save_path |
输入 |
含义:保存压缩模型的路径。该路径需要包含模型名前缀,例如./prune_model/*model。 数据类型:string |
input_data |
输入 |
含义:模型的输入数据。一个torch.tensor会被等价为tuple(torch.tensor)。 数据类型:tuple |
input_names |
输入 |
含义:模型的输入名称,用于保存的稀疏ONNX模型中显示。 默认值:None 数据类型:list(string) |
output_names |
输入 |
含义:模型的输出名称,用于保存的稀疏ONNX模型中显示。 默认值:None 数据类型:list(string) |
dynamic_axes |
输入 |
含义:对模型输入输出动态轴的指定,例如对于输入inputs(NCHW),N、H、W为不确定大小,输出outputs(NL),N为不确定大小,则指定形式为: { "inputs": [0,2,3], "outputs": [0]},其中0,2,3分别表示N,H,W所在位置的索引。 默认值:None 数据类型:dict<string, dict<python:int, string>> or dict<string, list(int)> |
返回值说明
无
调用示例
import amct_pytorch as amct
# 建立待压缩的网络图结构
model = build_model()
# create selective prune model
#训练retrain模型,训练量化因子
train(pruned_retrain_model)
infer(pruned_retrain_model)
input_data = tuple([torch.randn(input_shape)])
save_path = os.path.join(OUTPUTS_DIR, 'custom_name')
#插入保存组合压缩模型的API,转换成ONNX文件
amct.save_prune_retrain_model(
pruned_retrain_model,
save_path,
input_data,
input_names=['input'],
output_names=['output'],
dynamic_axes={'input':{0:'batch_size'}, 'output':{0:'batch_size'}})
落盘文件说明:
精度仿真模型文件:ONNX格式的模型文件,模型名中包含fake_quant,可以在ONNX Runtime环境进行精度仿真。
部署模型文件:ONNX格式的模型文件,模型名中包含deploy,经过ATC转换工具转换后可部署到NPU IP加速器。
(可选)external data文件,稀疏特性不区分*deploy.external和*fakequant.external文件:
只有保存的精度仿真模型以及部署模型文件大小>=2GB才会生成该类文件,且与压缩后的*.onnx文件生成在同级目录,用于保存Tensor中的数据,每个Tensor数据单独保存一个文件,文件名与Tensor相同,例如conv_1.weight。
后续通过ATC工具加载压缩后的*.onnx部署模型文件进行模型转换时,会自动读取同级目录下external data文件中的Tensor数据。
重新执行稀疏特性时,该接口输出的上述文件将会被覆盖。
自动通道稀疏搜索接口¶
auto_channel_prune_search¶
产品支持情况
产品 |
是否支持 |
|---|---|
IPV350 |
x |
功能说明
自动通道稀疏接口,根据用户模型来计算各通道的稀疏敏感度(影响精度)以及稀疏收益(影响性能),然后搜索策略依据该输入来搜索最优的逐层通道稀疏率,以平衡精度和性能。最终输出一个配置文件。
函数原型
auto_channel_prune_search(model, config, input_data, output_cfg, sensitivity, search_alg)
参数说明
参数名 |
输入/输出 |
说明 |
|---|---|---|
model |
输入 |
含义:待稀疏的PyTorch模型。 数据类型:torch.nn.Module |
config |
输入 |
含义:自动通道稀疏配置文件路径。 基于basic_info.proto文件中的AutoChannelPruneConfig生成的简易配置文件,*.proto文件所在路径为:AMCT安装目录/amct_pytorch/proto/。 *.proto文件参数解释以及生成的自动通道稀疏搜索配置文件样例请参见自动通道稀疏搜索简易配置文件。 数据类型:string |
input_data |
输入 |
含义:用户提供获取输入数据(含label)。 数据类型:list[data,label],列表元素数据类型为torch.tensor。 |
output_cfg |
输入 |
含义:输出的最终的通道稀疏配置文件路径。 数据类型:string |
sensitivity |
输入 |
含义:敏感度计算方法。 数据类型:string或SensitivityBase的子类,string为AMCT已有的方法,目前可选为'TaylorLossSensitivity';SensitivityBase的子类实例化,可由用户来继承定义。 |
search_alg |
输入 |
含义:待稀疏的通道搜索方法。 数据类型:string或SearchChannelBase的子类,string为AMCT已有的方法,目前可选为'GreedySearch';SearchChannelBase的子类实例化,可由用户来继承定义。 |
返回值说明
无
调用示例
import amct_pytorch as amct
#构造输入数据input_data
input_data = torch.randn(input_shape)
model.eval()
output = model.forward(input_data)
labels = torch.randn(output.size())
data = [input_data,labels]
amct.auto_channel_prune_search(
model=model,
config='./tmp/sample.cfg',
input_data=data,
output_cfg='./tmp/output.cfg',
sensitivity='TaylorLossSensitivity',
search_alg='GreedySearch')
落盘文件说明:
保存的自动通道稀疏配置文件,需要传给通道稀疏接口完成后续的业务。
组合压缩接口¶
create_compressed_retrain_model¶
产品支持情况
产品 |
是否支持 |
|---|---|
IPV350 |
|
注:特性中标记“x”的产品,调用接口不会报错,但是获取不到性能收益。
功能说明
静态组合压缩接口,将输入的待静态组合压缩的模型按照给定的组合压缩配置文件进行压缩处理,即将传入的模型先进行稀疏(通道稀疏或者4选2结构化稀疏,二选一),后对模型插入量化相关的算子(数据和权重的量化感知训练层以及searchN的层),生成稀疏和量化因子记录文件record_file(如果配置存在),返回修改后的torch.nn.Module模型。
函数原型
compressed_retrain_model = create_compressed_retrain_model(model, input_data, config_defination, record_file)
参数说明
参数名 |
输入/输出 |
说明 |
|---|---|---|
model |
输入 |
含义:PyTorch的model。 数据类型:torch.nn.Module |
input_data |
输入 |
含义:模型的输入数据。 数据类型:tuple |
config_defination |
输入 |
含义:静态组合压缩简易配置文件。 基于retrain_config_pytorch.proto文件生成的简易配置文件compressed.cfg,*.proto文件所在路径为:AMCT安装目录/amct_pytorch/proto/。*.proto文件参数解释以及生成的compressed.cfg简易配置文件样例请参见量化感知训练简易配置文件。 数据类型:string |
record_file |
输入 |
含义:待记录稀疏和量化因子文件路径及名称。 数据类型:string |
返回值说明
根据配置文件进行稀疏后(如果配置稀疏),且插入量化相关层(如果配置量化)的torch.nn.Module静态组合压缩模型。
约束说明
组合压缩配置文件至少存在一个配置:稀疏配置或者量化配置。
调用示例
import amct_pytorch as amct
# 建立待进行静态组合压缩的网络
model = build_model()
input_data = tuple([torch.randn(input_shape)])
# 调用静态组合压缩API
record_file = os.path.join(TMP, 'compressed_record.txt')
config_defination = './compressed_cfg.cfg'
compressed_retrain_model = amct.create_compressed_retrain_model(
model,
input_data,
config_defination,
record_file)
落盘文件说明:
保存的静态组合压缩记录文件record_file,如果简易配置文件中含有稀疏配置,则在该函数完成后,record_file中含有稀疏记录信息。
restore_compressed_retrain_model¶
产品支持情况
产品 |
是否支持 |
|---|---|
IPV350 |
|
注:特性中标记“x”的产品,调用接口不会报错,但是获取不到性能收益。
功能说明
静态组合压缩训练接口,将输入的待静态组合压缩的模型按照给定的组合压缩配置文件和record记录文件进行压缩处理(先稀疏后量化),加载保存的权重。将传入的模型按照给定record_file中稀疏记录进行稀疏,后对模型插入量化相关的算子(数据和权重的量化感知训练层以及searchN的层)。加载训练过程中保存的checkpoint权重参数,返回修改后的torch.nn.Module模型。
函数原型
compressed_retrain_model = restore_compressed_retrain_model(model, input_data, config_defination, record_file, pth_file, state_dict_name=None)
参数说明
参数名 |
输入/输出 |
说明 |
|---|---|---|
model |
输入 |
含义:Torch的model。 数据类型:torch.nn.Module |
input_data |
输入 |
含义:模型的输入数据。一个torch.tensor会被等价为tuple(torch.tensor)。 数据类型:tuple |
config_defination |
输入 |
含义:静态组合压缩简易配置文件。 基于retrain_config_pytorch.proto文件生成的简易配置文件compressed.cfg,*.proto文件所在路径为:AMCT安装目录/amct_pytorch/proto/。*.proto文件参数解释以及生成的compressed.cfg简易量化配置文件样例请参见量化感知训练简易配置文件。 数据类型:string |
record_file |
输入 |
含义:已经记录稀疏和量化因子的文件。 数据类型:string |
pth_file |
输入 |
含义:训练过程中保存的权重文件。 数据类型:string |
state_dict_name |
输入 |
含义:权重文件中权重对应的键值。 默认值:None 数据类型:string |
返回值说明
根据record_file中稀疏关系进行稀疏后的,且插入量化相关层的,已加载权重文件的torch.nn.Module静态组合压缩训练模型。
约束说明
组合压缩配置文件至少存在一个配置:稀疏配置或者量化配置。
调用示例
import amct_pytorch as amct
# 建立待进行组合压缩的网络图结构
model = build_model()
input_data = tuple(torch.randn(input_shape))
save_pth_path = /your/path/to/save/tmp.pth
record_file = os.path.join(TMP, 'compressed_record.txt')
config_defination = './compressed_cfg.cfg'
torch.save({'state_dict': model.state_dict()}, save_pth_path)
compressed_retrain_model = amct.restore_compressed_retrain_model(
model,
input_data,
config_defination,
record_file,
save_pth_path,
'state_dict')
save_compressed_retrain_model¶
产品支持情况
产品 |
是否支持 |
|---|---|
IPV350 |
|
注:特性中标记“x”的产品,调用接口不会报错,但是获取不到性能收益。
功能说明
静态组合压缩接口,根据用户最终的重训练好的模型,生成最终静态组合压缩精度仿真模型以及部署模型。
函数原型
save_compressed_retrain_model(model, record_file, save_path, input_data, input_names=None, output_names=None, dynamic_axes=None)
参数说明
参数名 |
输入/输出 |
说明 |
|---|---|---|
model |
输入 |
含义:已经进行静态组合压缩后的PyTorch模型。 数据类型:torch.nn.Module |
record_file |
输入 |
含义:稀疏和量化因子记录文件路径及名称。 数据类型:string |
save_path |
输入 |
含义:保存压缩模型的路径。 数据类型:string |
input_data |
输入 |
含义:模型的输入数据。一个torch.tensor会被等价为tuple(torch.tensor)。 数据类型:tuple |
input_names |
输入 |
含义:模型的输入的名称,用于保存的量化onnx模型中显示。 默认值:None 数据类型:list(string) |
output_names |
输入 |
含义:模型的输出的名称,用于保存的量化onnx模型中显示。 默认值:None 数据类型:list(string) |
dynamic_axes |
输入 |
含义:对模型输入输出动态轴的指定,例如对于输入inputs(NCHW),N、H、W为不确定大小,输出outputs(NL),N为不确定大小,则指定形式为: { "inputs": [0,2,3], "outputs": [0]},其中0,2,3分别表示N,H,W所在位置的索引。 默认值:None 数据类型:dict<string, dict<python:int, string>> or dict<string, list(int)> |
返回值说明
无
约束说明
若模型只做了稀疏(没有做量化),则通过该接口生成的两个文件为直接使用PyTorch导出的onnx文件,文件内容一致,文件名称分别包括deploy和fake_quant关键字。
调用示例
import amct_pytorch as amct
# 建立待压缩的网络图结构
model = build_model()
# create compressed model
#训练retrain模型,训练量化因子
train(compressed_retrain_model)
infer(compressed_retrain_model)
input_data = tuple([torch.randn(input_shape)])
save_path = os.path.join(OUTPUTS_DIR, 'custom_name')
record_file = os.path.join(TMP, 'compressed_record.txt')
#插入保存组合压缩模型的API,转换成ONNX文件
amct.save_compressed_retrain_model(
compressed_retrain_model,
record_file,
save_path,
input_data,
input_names=['input'],
output_names=['output'],
dynamic_axes={'input':{0:'batch_size'}, 'output':{0:'batch_size'}})
落盘文件说明:
精度仿真模型文件:ONNX格式的模型文件,模型名中包含fake_quant,可以在ONNX Runtime环境进行精度仿真。
部署模型文件:ONNX格式的模型文件,模型名中包含deploy,经过ATC转换工具转换后可部署到NPU IP加速器。
(可选)*.external文件,包括*deploy.external和*fakequant.external:
只有保存的精度仿真模型以及部署模型文件大小>=2GB才会生成该类文件,且与压缩后的*.onnx模型文件生成在同级目录,用于保存Tensor中的数据,每个Tensor数据单独保存一份*.external文件,文件名与Tensor相同,例如_conv1.weight__deploy.external和_conv1.weight__fakequant.external。
后续通过ATC工具加载压缩后的*.onnx部署模型文件进行模型转换时,会自动读取同级目录下*.external文件中的Tensor数据。
重新执行静态组合压缩时,该接口输出的上述文件将会被覆盖。
张量分解接口¶
auto_decomposition¶
产品支持情况
产品 |
是否支持 |
|---|---|
IPV350 |
x |
功能说明
对用户输入的PyTorch模型对象进行张量分解,得到分解后的模型对象和分解前后层的对应名称,并保存分解信息文件(可选)。
函数原型
model, changes = auto_decomposition(model, decompose_info_path=None)
参数说明
参数名 |
输入/输出 |
使用限制 |
|---|---|---|
model |
输入 |
含义:待分解的含有预训练权重的PyTorch模型对象。在调用该接口时建议将模型放置于CPU而不是GPU上,以防分解时显存不足。 数据类型:torch.nn.Module |
decompose_info_path |
输入 |
含义:分解信息文件保存路径。将以JSON格式存储,因此建议使用.json扩展名。为None时不保存分解信息文件(默认)。 数据类型:string 默认值:None |
返回值说明
张量分解后的模型对象,类型为torch.nn.Module。
张量分解前后的对应层名构成的字典,类型为dict,形如{'conv1': ['conv1.0', 'conv1.1'], 'conv2': ['conv2.0', 'conv2.1'], ...}。
约束说明
用户输入的模型需为torch.nn.Module类型的对象。
本接口函数仅对通过torch.nn.Conv2d()构建的卷积进行分解。
用户调用本接口函数,接口函数对符合分解条件的卷积层进行自动分解,约束请参见分解约束。
调用示例
from amct_pytorch.tensor_decompose import auto_decomposition
net = Net() # 构建用户模型对象
net.load_state_dict(torch.load("src_path/weights.pth")) # 加载模型权重
net, changes = auto_decomposition( # 执行张量分解
model=net,
decompose_info_path="decomposed_path/decompose_info.json"
)
当涉及模型训练时,本接口的调用需在将模型参数传递给优化器之前;如使用了torch.nn.parallel.DistributedDataParallel (DDP),则本接口的调用也需在将模型传递给DDP之前。
本接口将原地修改传入的模型对象,即分解后会改变用户传入的模型对象本身(例外:传入的模型是一个torch.nn.Conv2d对象,该情况下本接口不会对其进行修改,如发生分解,则返回的模型是新构建的torch.nn.Module对象)。
decompose_network¶
产品支持情况
产品 |
是否支持 |
|---|---|
IPV350 |
x |
功能说明
用户输入PyTorch模型对象和通过auto_decomposition保存的分解信息文件,根据分解信息文件将模型对象改变为张量分解后的结构,得到分解后的模型对象和分解前后层的对应名称。
函数原型
model, changes = decompose_network(model, decompose_info_path)
参数说明
参数名 |
输入/输出 |
说明 |
|---|---|---|
model |
输入 |
含义:待分解的PyTorch模型对象。在调用该接口时建议将模型放置于CPU而不是GPU上,以防分解时显存不足。 数据类型:torch.nn.Module |
decompose_info_path |
输入 |
含义:分解信息文件路径,该文件通过auto_decomposition获得。 数据类型:string |
返回值说明
改变为张量分解后结构的模型对象,类型为torch.nn.Module。
张量分解前后的对应层名构成的字典,类型为dict,形如{'conv1': ['conv1.0', 'conv1.1'], 'conv2': ['conv2.0', 'conv2.1'], ...}。
约束说明
用户输入的模型需为torch.nn.Module类型的对象。
本接口函数仅支持对通过torch.nn.Conv2d()构建的卷积的结构修改。
用户输入的模型结构需与调用auto_decomposition获取分解信息文件时的模型结构一致,分解信息文件要与该模型结构配套使用。
调用示例
from amct_pytorch.tensor_decompose import decompose_network
net = Net() # 构建用户模型对象
net, changes = decompose_network( # 加载分解信息文件,将模型结构修改为张量分解后的结构
model=net,
decompose_info_path="decomposed_path/decompose_info.json" # 由auto_decomposition保存的分解信息文件路径
)
当涉及模型训练时,本接口的调用需在将模型参数传递给优化器之前;如使用了torch.nn.parallel.DistributedDataParallel (DDP),则本接口的调用也需在将模型传递给DDP之前。
本接口将原地修改传入的模型对象,即分解后会改变用户传入的模型对象本身(例外:传入的模型是一个torch.nn.Conv2d对象,该情况下本接口不会对其进行修改,返回的分解后模型是新构建的torch.nn.Module对象)。
本接口仅对模型结构进行修改,不会更新分解后的卷积权重,权重的值为torch.nn.Conv2d()构建的默认值。如需fine-tune,请在调用auto_decomposition后将分解后的模型权重保存下来,在调用本接口之后加载该权重,再进行fine-tune。
蒸馏接口¶
create_distill_config¶
产品支持情况
产品 |
是否支持 |
|---|---|
IPV350 |
x |
功能说明
蒸馏接口,根据图的结构找到所有可蒸馏量化的层和可蒸馏量化的结构,自动生成蒸馏量化配置文件,并将可蒸馏量化层的量化配置和蒸馏结构写入配置文件。
函数原型
create_distill_config(config_file, model, input_data, config_defination=None)
参数说明
参数名 |
输入/输出 |
说明 |
|---|---|---|
config_file |
输入 |
含义:待生成的蒸馏量化配置文件存放路径及名称。如果存放路径下已经存在该文件,则调用该接口时会覆盖已有文件。 数据类型:string |
model |
输入 |
含义:待进行蒸馏量化的原始浮点模型,已加载权重。 数据类型:torch.nn.Module |
input_data |
输入 |
含义:模型的输入数据。一个torch.tensor会被等价为tuple(torch.tensor)。 数据类型:tuple |
config_defination |
输入 |
含义:简易配置文件。基于distill_config_pytorch.proto文件生成的简易配置文件distill.cfg,*.proto文件所在路径为:AMCT安装目录/amct_pytorch/proto/。*.proto文件参数解释以及生成的distill.cfg简易量化配置文件样例请参见蒸馏简易配置文件。 默认值:None。 数据类型:string |
返回值说明
无
调用示例
import amct_pytorch as amct
# 建立待进行蒸馏量化的网络图结构
model = build_model()
model.load_state_dict(torch.load(state_dict_path))
input_data = tuple([torch.randn(input_shape)])
# 生成蒸馏配置文件
amct.create_distill_config(config_file="./configs/config.json",
model,
input_data,
config_defination="./configs/distill.cfg")
落盘文件说明:
生成JSON格式的蒸馏量化配置文件,样例如下(重新执行蒸馏时,该接口输出的配置文件将会被覆盖,如下为INT8量化场景下的配置文件):
{
"version":1,
"batch_num":1,
"group_size":1,
"data_dump":false,
"distill_group":[
[
"conv1",
"bn",
"relu"
],
[
"conv2",
"bn2",
"relu2"
]
],
"conv1":{
"quant_enable":true,
"distill_data_config":{
"algo":"ulq_quantize",
"dst_type":"INT8"
},
"distill_weight_config":{
"algo":"arq_distill",
"channel_wise":true,
"dst_type":"INT8"
}
},
"conv2":{
"quant_enable":true,
"distill_data_config":{
"algo":"ulq_quantize",
"dst_type":"INT8"
},
"distill_weight_config":{
"algo":"arq_distill",
"channel_wise":true,
"dst_type":"INT8"
}
}
}
create_distill_model¶
产品支持情况
产品 |
是否支持 |
|---|---|
IPV350 |
x |
功能说明
蒸馏接口,将输入的待量化压缩的图结构按照给定的蒸馏量化配置文件进行量化处理,在传入的图结构中插入量化相关的算子(数据和权重的蒸馏量化层以及找N的层),返回修改后可用于蒸馏的torch.nn.Module模型。
函数原型
compress_model = create_distill_model(config_file, model, input_data)
参数说明
参数名 |
输入/输出 |
说明 |
|---|---|---|
config_file |
输入 |
含义:用户生成的蒸馏量化配置文件,用于指定模型network中量化层的配置情况和蒸馏结构。 数据类型:string 使用约束:该接口输入的config.json必须和create_distill_config接口输入的config.json一致 |
model |
输入 |
含义:待进行蒸馏量化的原始浮点模型,已加载权重。 数据类型:torch.nn.Module |
input_data |
输入 |
含义:模型的输入数据。一个torch.tensor会被等价为tuple(torch.tensor)。 数据类型:tuple |
返回值说明
修改后可用于蒸馏的torch.nn.Module模型。
调用示例
import amct_pytorch as amct
# 建立待进行蒸馏量化的网络图结构
model = build_model()
model.load_state_dict(torch.load(state_dict_path))
input_data = tuple([torch.randn(input_shape)])
# 生成压缩模型
compress_model = amct.create_distill_model(
config_json_file,
model,
input_data)
distill¶
产品支持情况
产品 |
是否支持 |
|---|---|
IPV350 |
x |
功能说明
蒸馏接口,将输入的待蒸馏的图结构按照给定的蒸馏量化配置文件进行蒸馏处理,返回修改后的torch.nn.Module蒸馏模型。
函数原型
distill_model = distill(model, compress_model, config_file, train_loader, epochs=1, lr=1e-3, sample_instance=None, loss=None, optimizer=None)
参数说明
参数名 |
输入/输出 |
说明 |
|---|---|---|
model |
输入 |
含义:待进行蒸馏量化的原始浮点模型,已加载权重。 数据类型:torch.nn.Module |
compress_model |
输入 |
含义:修改后的可用于蒸馏的torch.nn.Module模型。 数据类型:torch.nn.Module 使用约束:该接口输入的模型必须是量化后的压缩模型。 |
config_file |
输入 |
含义:用户生成的蒸馏量化配置文件,用于指定模型network中量化层的配置情况和蒸馏结构。 数据类型:string 使用约束:该接口输入的config.json必须和create_distill_config接口输入的config.json一致。 |
train_loader |
输入 |
含义:训练数据集。 数据类型:torch.utils.data.DataLoader 使用约束:必须与模型输入大小匹配。 |
epochs |
输入 |
含义:最大迭代次数。 默认值:1 数据类型:int |
lr |
输入 |
含义:学习率。 默认值:1e-3 数据类型:float |
sample_instance |
输入 |
含义:用户提供的获取模型输入数据方法的实例化对象。 默认值:None 数据类型:DistillSampleBase 使用约束:必须继承自DistillSampleBase类,并且实现get_model_input_data方法。可参考AMCT安装目录/amct_pytorch/distill/distill_sample.py文件。 |
loss |
输入 |
含义:用于计算损失的实例化对象。 默认值:None 数据类型:torch.nn.Modules.loss._Loss |
optimizer |
输入 |
含义:优化器的实例化对象。 默认值:None 数据类型:torch.optim.Optimizer |
返回值说明
修改后的torch.nn.Module蒸馏模型。
调用示例
import amct_pytorch as amct
# 建立待进行蒸馏量化的网络图结构
model = build_model()
model.load_state_dict(torch.load(state_dict_path))
compress_model = compress(model)
input_data = tuple([torch.randn(input_shape)])
train_loader = torch.utils.data.DataLoader(input_data)
loss = torch.nn.MSELoss()
optimizer = torch.optim.AdamW(compress_model.parameters(), lr=0.1)
# 蒸馏
distill_model = amct.distill(
model,
compress_model
config_json_file,
train_loader,
epochs=1,
lr=1e-3,
sample_instance=None,
loss=loss,
optimizer=optimizer)
save_distill_model¶
产品支持情况
产品 |
是否支持 |
|---|---|
IPV350 |
x |
功能说明
蒸馏接口,根据用户最终的蒸馏好的模型,生成最终量化精度仿真模型以及量化部署模型。
函数原型
save_distill_model(model, save_path, input_data, record_file=None, input_names=None, output_names=None, dynamic_axes=None)
参数说明
参数名 |
输入/输出 |
说明 |
|---|---|---|
model |
输入 |
含义:已进行蒸馏后的量化模型。 数据类型:torch.nn.Module |
save_path |
输入 |
含义:蒸馏后的量化模型存放路径。该路径需要包含模型名前缀,例如./quantized_model/*model。 数据类型:string |
input_data |
输入 |
含义:模型的输入数据。一个torch.tensor会被等价为tuple(torch.tensor)。 数据类型:tuple |
record_file |
输入 |
含义:量化因子记录文件路径及名称。 默认值:None 数据类型:string 使用约束:传入值为None的情况下量化因子记录文件存放在amct_log文件夹中。 |
input_names |
输入 |
含义:模型输入节点的名称,用于在保存的量化onnx模型中显示。 默认值:None 数据类型:list(string) |
output_names |
输入 |
含义:模型输出节点的名称,用于在保存的量化onnx模型中显示。 默认值:None 数据类型:list(string) |
dynamic_axes |
输入 |
含义:对模型输入输出动态轴的指定,例如对于输入inputs(NCHW),N、H、W为不确定大小,输出outputs(NL),N为不确定大小,则指定形式为:{"inputs": [0,2,3], "outputs": [0]},其中0,2,3分别表示N,H,W所在位置的索引。 默认值:None 数据类型:dict<string, dict<python:int, string>> or dict<string, list(int)> |
返回值说明
无
调用示例
import amct_pytorch as amct
# 建立待进行蒸馏量化的网络图结构
model = build_model()
model.load_state_dict(torch.load(state_dict_path))
input_data = tuple([torch.randn(input_shape)])
# 插入蒸馏API,将蒸馏的模型存为onnx文件
amct.save_distill_model(
model,
"./model/distilled"
input_data,
record_file="./results/records.txt"
input_names=['input'],
output_names=['output'],
dynamic_axes={'input':{0: 'batch_size'},
'output':{0: 'batch_size'}})
落盘文件说明:
精度仿真模型文件:ONNX格式的模型文件,模型名中包含fake_quant,可以在ONNX Runtime环境进行精度仿真。
部署模型文件:ONNX格式的模型文件,模型名中包含deploy,经过ATC转换工具转换后可部署到NPU IP加速器。
重新执行蒸馏时,该接口输出的上述文件将会被覆盖。
参考信息¶
工具实现的融合功能¶
当前该工具主要实现的为Conv+BN融合:AMCT在量化前会对模型中的"torch.nn.Conv2d+torch.nn.BatchNorm2d"结构做Conv+BN融合,融合后的torch.nn.BatchNorm2d层会被删除。
训练后量化简易配置文件¶
calibration_config_pytorch.proto文件参数说明如表1所示,该文件所在目录为:AMCT安装目录/amct_pytorch/proto/calibration_config_pytorch.proto。
表 1 calibration_config_pytorch.proto参数说明
消息 |
是否必填 |
类型 |
字段 |
说明 |
|---|---|---|---|---|
AMCTConfig |
- |
- |
- |
AMCT训练后量化的简易量化配置。 |
optional |
uint32 |
batch_num |
量化使用的batch数量。 |
|
optional |
bool |
activation_offset |
数据量化是否带offset。全局配置参数。
|
|
repeated |
string |
skip_layers |
不需要量化层的层名。 |
|
repeated |
string |
skip_layer_types |
不需要量化的层类型。 |
|
optional |
NuqConfig |
nuq_config |
非均匀量化配置。 |
|
optional |
FakequantPrecisionMode |
fakequant_precision_mode |
fakequant模型中quant自定义算子的scale_d数值精度模式。
|
|
optional |
CalibrationConfig |
common_config |
通用的量化配置,全局量化配置参数。若某层未被override_layer_types或者override_layer_configs重写,则使用该配置。 参数优先级:override_layer_configs>override_layer_types>common_config |
|
repeated |
OverrideLayerType |
override_layer_types |
重写某一类型层的量化配置,即对哪些层进行差异化量化。 例如全局量化配置参数配置的量化因子搜索步长为0.01,可以通过该参数对部分层进行差异化量化,可以配置搜索步长为0.02。 参数优先级:override_layer_configs>override_layer_types>common_config |
|
repeated |
OverrideLayer |
override_layer_configs |
重写某一层的量化配置,即对哪些层进行差异化量化。 例如全局量化配置参数配置的量化因子搜索步长为0.01,可以通过该参数对部分层进行差异化量化,可以配置搜索步长为0.02。 参数优先级:override_layer_configs>override_layer_types>common_config |
|
optional |
bool |
do_fusion |
是否开启BN融合功能,默认为true,表示开启该功能。 |
|
repeated |
string |
skip_fusion_layers |
跳过BN融合的层,配置之后这些层不会进行BN融合。 |
|
NuqConfig |
- |
- |
- |
非均匀量化配置。 |
required |
string |
mapping_file |
均匀量化后的deploy模型通过ATC工具转换得到的om模型,然后通过ATC工具转换得到JSON文件,即量化后模型的融合JSON文件。 |
|
optional |
NUQuantize |
nuq_quantize |
非均匀量化的参数。 |
|
OverrideLayerType |
- |
- |
- |
重置某层类型的量化配置。 |
required |
string |
layer_type |
支持量化的层类型的名字。 |
|
required |
CalibrationConfig |
calibration_config |
重置的量化配置。 |
|
OverrideLayer |
- |
- |
- |
重置某层量化配置。 |
required |
string |
layer_name |
被重置层的层名。 |
|
required |
CalibrationConfig |
calibration_config |
重置的量化配置。 |
|
CalibrationConfig |
- |
- |
- |
Calibration量化的配置。 |
- |
ARQuantize |
arq_quantize |
权重量化算法配置。 arq_quantize:ARQ量化算法配置。 |
|
- |
NUQuantize |
nuq_quantize |
权重量化算法配置。 nuq_quantize:非均匀量化算法配置。 |
|
- |
ADAquantize |
ada_quantize |
权重量化算法配置。 ada_quantize:Adaptive rounding (AdaRound) ,自适应舍入量化算法配置。 |
|
- |
FMRQuantize |
ifmr_quantize |
数据量化算法配置。 ifmr_quantize:IFMR量化算法配置。 |
|
- |
HFMGQuantize |
hfmg_quantize |
数据量化算法配置。 hfmg_quantize:HFMG量化算法配置。 |
|
- |
DMQBalancer |
dmq_balancer |
均衡量化算法配置。 dmq_balancer:DMQBalancer均衡算法配置。 |
|
ARQuantize |
- |
- |
- |
ARQ量化算法配置。算法介绍请参见ARQ权重量化算法。 该算法与ADAquantize、NUQuantize算法不能同时配置,若同时配置,则以配置文件中最后配置的量化算法为准。 |
optional |
bool |
channel_wise |
是否对每个channel采用不同的量化因子。
|
|
optional |
uint32 |
quant_bits |
权重量化位宽。支持配置为INT6、INT7、INT8。 默认为INT8量化。 该字段配置为INT6、INT7仅支持Conv2d类型算子。 如果在common_config中配置quant_bits为INT6、INT7,则只对Conv2d算子生效,其他算子改为默认INT8。 |
|
ADAquantize |
- |
- |
- |
AdaRound自适应舍入量化算法,算法介绍请参见ADA权重量化算法。量化样例请参见ada round量化校准。 该算法与ARQuantize、NUQuantize算法不能同时配置,若同时配置,则以配置文件中最后配置的量化算法为准。 该量化算法支持的激活函数为:ReLU、RReLU、LeakyReLU、PReLU、GELU、ReLU6、Sigmoid、Tanh。 上述激活函数对应的ONNX算子为:Relu、LeakyRelu、LeakyRelu、PRelu、Gelu、Clip、Sigmoid、Tanh。 AMCT工具获取量化配置中的可量化层(该特性支持的量化层为torch.nn.Linear、torch.nn.Conv2d、torch.nn.ConvTranspose2d,约束请参见均匀量化),按照导出的ONNX模型中的拓扑顺序获取可量化模块,若量化模块后为上述激活函数,将量化模块和激活函数作为一个整体。 说明: 将上述激活函数导出为ONNX算子时,需要torch 2.1版本torch.onnx.export接口,且Gelu算子需要Opset版本为v20,其他算子Opset版本为v17。 |
optional |
uint32 |
num_iteration |
迭代次数,取值范围>=0,默认值为10000。 |
|
optional |
float |
reg_param |
正则化参数,取值范围为(0,1),默认值为0.01。 |
|
optional |
float |
beta_range_start |
beta起始参数,默认值为20,beta_range_start>beta_range_end>0。 |
|
optional |
float |
beta_range_end |
beta终止参数,默认值为2。 |
|
optional |
float |
warm_start |
预热因子,取值范围为(0,1),默认值为0.2。 |
|
optional |
bool |
channel_wise |
是否对每个channel采用不同的量化因子。
|
|
DMQBalancer |
- |
- |
- |
DMQ均衡算法配置。算法介绍请参见DMQ均衡算法。 |
optional |
float |
migration_strength |
迁移强度,代表将activation数据上的量化难度迁移至weight权重的程度。支持的范围为[0.2, 0.8],默认值0.5,数据分布的离群值越大迁移强度应设置较小。 |
|
FMRQuantize |
- |
- |
- |
FMR数据量化算法配置。算法介绍请参见IFMR数据量化算法。 该算法与HFMGQuantize算法不能同时配置,若同时配置,则以配置文件中最后配置的量化算法为准。 |
optional |
float |
search_range_start |
量化因子搜索范围左边界。 |
|
optional |
float |
search_range_end |
量化因子搜索范围右边界。 |
|
optional |
float |
search_step |
量化因子搜索步长。 |
|
optional |
float |
max_percentile |
最大值搜索位置。 |
|
optional |
float |
min_percentile |
最小值搜索位置。 |
|
optional |
bool |
asymmetric |
是否进行对称量化。用于控制逐层量化算法的选择。
如果override_layer_configs、override_layer_types、common_config配置项都配置该参数,或者配置了 activation_offset参数,则生效优先级为: override_layer_configs>override_layer_types>common_config>activation_offset |
|
optional |
CalibrationDataType |
dst_type |
量化位宽,数据量化是采用INT8量化还是INT16量化,默认为INT8量化。 |
|
HFMGQuantize |
- |
- |
- |
HFMG数据量化算法配置。算法介绍请参见HFMG数据量化算法。 该算法与FMRQuantize算法不能同时配置,若同时配置,则以配置文件中最后配置的量化算法为准。 |
optional |
uint32 |
num_of_bins |
直方图的bin(直方图中的一个最小单位直方图形)数目,支持的范围为{1024, 2048, 4096, 8192}。 默认值为4096。 |
|
optional |
bool |
asymmetric |
是否进行对称量化。用于控制逐层量化算法的选择。
如果override_layer_configs、override_layer_types、common_config配置项都配置该参数,或者配置了 activation_offset参数,则生效优先级为: override_layer_configs>override_layer_types>common_config>activation_offset |
|
optional |
CalibrationDataType |
dst_type |
数据量化位宽,数据量化是采用INT8量化还是INT16量化,默认为INT8量化。 |
|
NUQuantize |
- |
- |
- |
非均匀量化参数。算法介绍请参见NUQ权重量化算法。 该算法与ARQuantize、ADAquantize算法不能同时配置,若同时配置,则以配置文件中最后配置的量化算法为准。 |
optional |
uint32 |
num_steps |
非均匀量化的台阶数。 |
|
optional |
uint32 |
num_of_iteration |
非均匀量化优化的迭代次数。 |
基于该文件构造的均匀量化简易配置文件quant.cfg样例如下所示:
# global quantize parameter batch_num : 2 activation_offset : true skip_layers : "Opname" skip_layer_types:"Optype" do_fusion: true skip_fusion_layers : "Opname" common_config : { arq_quantize : { channel_wise : true quant_bits : 7 } ifmr_quantize : { search_range_start : 0.7 search_range_end : 1.3 search_step : 0.01 max_percentile : 0.999999 min_percentile : 0.999999 asymmetric : true } dmq_balancer : { migration_strength : 0.5 } } override_layer_types : { layer_type : "Conv2d" calibration_config : { arq_quantize : { channel_wise : false quant_bits : 6 } ifmr_quantize : { search_range_start : 0.8 search_range_end : 1.2 search_step : 0.02 max_percentile : 0.999999 min_percentile : 0.999999 asymmetric : false } dmq_balancer : { migration_strength : 0.5 } } } override_layer_configs : { layer_name : "Opname" calibration_config : { arq_quantize : { channel_wise : true } ifmr_quantize : { search_range_start : 0.8 search_range_end : 1.2 search_step : 0.02 max_percentile : 0.999999 min_percentile : 0.999999 asymmetric : false } dmq_balancer : { migration_strength : 0.5 } } }
如果数据量化算法使用HFMG,则上述配置文件中加粗部分可以替换成如下参考参数信息,举例如下(如下配置信息只是样例,请根据实际情况进行修改):
# global quantize parameter activation_offset : true batch_num : 2 ... common_config : { hfmg_quantize : { num_of_bins : 4096 asymmetric : false } ... }
基于该文件构造的自适应舍入简易配置文件_ada_round.cfg_样例如下所示:
common_config : { ada_quantize : { num_iteration : 10000 warm_start : 0.2 reg_param : 0.01 beta_range_start : 20 beta_range_end : 2 channel_wise : false } }
基于该文件构造的量化数据均衡预处理简易配置文件dmq_balancer.cfg样例如下所示:
# global quantize parameter batch_num : 2 activation_offset : true skip_layers : "Opname" skip_layer_types:"Optype" do_fusion: true skip_fusion_layers : "Opname" common_config : { arq_quantize : { channel_wise : true } ifmr_quantize : { search_range_start : 0.7 search_range_end : 1.3 search_step : 0.01 max_percentile : 0.999999 min_percentile : 0.999999 asymmetric : true } dmq_balancer : { migration_strength : 0.5 } } override_layer_types : { layer_type : "Optype" calibration_config : { arq_quantize : { channel_wise : false } ifmr_quantize : { search_range_start : 0.8 search_range_end : 1.2 search_step : 0.02 max_percentile : 0.999999 min_percentile : 0.999999 asymmetric : false } dmq_balancer : { migration_strength : 0.5 } } } override_layer_configs : { layer_name : "Opname" calibration_config : { arq_quantize : { channel_wise : true } ifmr_quantize : { search_range_start : 0.8 search_range_end : 1.2 search_step : 0.02 max_percentile : 0.999999 min_percentile : 0.999999 asymmetric : false } dmq_balancer : { migration_strength : 0.5 } } }
量化感知训练简易配置文件¶
retrain_config_pytorch.proto文件参数说明如表1所示,该文件所在目录为:AMCT安装目录/amct_pytorch/proto/retrain_config_pytorch.proto。
该文件可以配置出量化感知训练简易配置文件、稀疏简易配置文件,组合压缩简易配置文件,用户根据场景进行配置。
表 1 retrain_config_pytorch.proto参数说明
消息 |
是否必填 |
类型 |
字段 |
说明 |
|---|---|---|---|---|
AMCTRetrainConfig |
- |
- |
- |
AMCT量化感知训练的简易配置。 |
repeated |
string |
skip_layers |
按层名跳过哪些层不做压缩。全局参数,方便后续拓展其他特性场景下可同时跳过的层,比如下述拓展的quant_skip_layers参数、regular_prune_skip_layers参数,则通过skip_layers参数可以同时配置两个特性场景下需要跳过的层。而无需在quant_skip_layers和regular_prune_skip_layers参数中分别配置。 若同时配置了skip_layers和quant_skip_layers参数,或skip_layers和regular_prune_skip_layers参数,则取两者并集。 |
|
repeated |
string |
skip_layer_types |
按层类型跳过哪些层不做压缩。全局参数,方便后续拓展其他特性场景下可同时跳过的层,比如下述拓展的quant_skip_types参数、regular_prune_skip_types参数,则通过skip_layer_types参数可以同时配置两个特性场景下需要跳过的层。而无需在quant_skip_types和regular_prune_skip_types参数中分别配置。 若同时配置了skip_layer_types和quant_skip_types参数,或skip_layer_types和regular_prune_skip_types参数,则取两者并集。 |
|
repeated |
RetrainOverrideLayer |
override_layer_configs |
按层名重写哪些层,即对哪些层进行差异化压缩。 例如全局量化配置参数配置的量化位宽为INT8,可以通过该参数对部分层进行差异化量化,可以配置为INT4量化。当前版本仅支持INT8量化。 参数优先级为:
|
|
repeated |
RetrainOverrideLayerType |
override_layer_types |
按层类型重写哪些层,即对哪些层进行差异化压缩。 例如全局量化配置参数配置的量化位宽为INT8,可以通过该参数对部分层进行差异化量化,可以配置为INT4量化。当前版本仅支持INT8量化。 参数优先级为:
|
|
optional |
FakequantPrecisionMode |
fakequant_precision_mode |
fakequant模型中quant自定义算子的scale_d数值精度模式。
|
|
optional |
uint32 |
batch_num |
量化使用的batch数量。 |
|
required |
RetrainDataQuantConfig |
retrain_data_quant_config |
量化感知训练数据量化配置参数。全局量化配置参数。 参数优先级为:override_layer_configs>override_layer_types>retrain_data_quant_config/retrain_weight_quant_config |
|
required |
RetrainWeightQuantConfig |
retrain_weight_quant_config |
量化感知训练权重量化配置参数。全局量化配置参数。 参数优先级为:override_layer_configs>override_layer_types>retrain_data_quant_config/retrain_weight_quant_config |
|
repeated |
string |
quant_skip_layers |
按层名跳过不需要量化的层。量化场景下使用的参数。 若同时配置了skip_layers和quant_skip_layers参数,则取两者并集。 |
|
repeated |
string |
quant_skip_types |
按层类型跳过不需要量化的层。量化场景下使用的参数。 若同时配置了skip_layer_types和quant_skip_types参数,则取两者并集。 |
|
optional |
PruneConfig |
prune_config |
稀疏配置。全局稀疏配置参数。 参数优先级为:override_layer_configs>override_layer_types>prune_config |
|
repeated |
string |
regular_prune_skip_layers |
按层名跳过不需要结构化稀疏的层。稀疏场景下使用的参数。 若同时配置了skip_layers和regular_prune_skip_layers参数,则取两者并集。 |
|
repeated |
string |
regular_prune_skip_types |
按层类型跳过不需要结构化稀疏的层。稀疏场景下使用的参数。 若同时配置了skip_layer_types和regular_prune_skip_types参数,则取两者并集。 |
|
RetrainDataQuantConfig |
- |
- |
- |
量化感知训练数据量化配置。 |
- |
ActULQquantize |
ulq_quantize |
数据量化的算法,目前仅支持ULQ。 |
|
ActULQquantize |
- |
- |
- |
ULQ数据量化算法配置。算法介绍请参见ULQ数据量化算法。 |
optional |
DataType |
dst_type |
数据量化位宽,支持如下配置:当前版本仅支持INT8、INT16量化。
|
|
optional |
ClipMaxMin |
clip_max_min |
初始化的上下限值,如果不配置,默认用ifmr进行初始化。 |
|
optional |
bool |
fixed_min |
是否下限不学习且固定为0。默认ReLu后为true,其他为false。 |
|
ClipMaxMin |
- |
- |
- |
初始上下限。 |
required |
float |
clip_max |
初始上限值。 |
|
required |
float |
clip_min |
初始下限值。 |
|
RetrainWeightQuantConfig |
- |
- |
- |
量化感知训练权重量化配置。 |
- |
ARQRetrain |
arq_retrain |
ARQ权重量化算法。 |
|
- |
WtsULQRetrain |
ulq_retrain |
ULQ权重量化算法。 |
|
ARQRetrain |
- |
- |
- |
ARQ权重量化算法配置。算法介绍请参见ARQ权重量化算法。 |
optional |
DataType |
dst_type |
用以选择INT8或INT4量化位宽,默认为INT8。当前版本仅支持INT8量化。 |
|
optional |
bool |
channel_wise |
是否做channel wise的ARQ。 |
|
WtsULQRetrain |
- |
- |
- |
ULQ权重量化算法配置。算法介绍请参见ULQ数据量化算法。 |
optional |
DataType |
dst_type |
用以选择INT8或INT4量化位宽,默认为INT8。当前版本仅支持INT8量化。 |
|
optional |
bool |
channel_wise |
是否做channel wise的ULQ。 |
|
RetrainOverrideLayer |
- |
- |
- |
重写的层配置。 |
required |
string |
layer_name |
层名。 |
|
required |
RetrainDataQuantConfig |
retrain_data_quant_config |
重写的数据层量化参数。 |
|
required |
RetrainWeightQuantConfig |
retrain_weight_quant_config |
重写的权重层量化参数。 |
|
optional |
PruneConfig |
prune_config |
重写的稀疏配置参数。 |
|
RetrainOverrideLayerType |
- |
- |
- |
重写的层类型配置。 |
required |
string |
layer_type |
层类型。 |
|
required |
RetrainDataQuantConfig |
retrain_data_quant_config |
重写的数据层量化参数。 |
|
required |
RetrainWeightQuantConfig |
retrain_weight_quant_config |
重写的权重层量化参数。 |
|
optional |
PruneConfig |
prune_config |
重写的稀疏配置参数。 |
|
PruneConfig |
- |
- |
- |
稀疏的配置。 |
- |
FilterPruner |
filter_pruner |
filter(输出维度通道)稀疏的配置。 |
|
- |
NOutOfMPruner |
n_out_of_m_pruner |
4选2稀疏的配置。 由于硬件约束,该芯片不支持4选2结构化稀疏特性:使能后获取不到性能收益。 |
|
FilterPruner |
- |
- |
- |
filter稀疏的配置。 |
- |
BalancedL2NormFilterPruner |
balanced_l2_norm_filter_prune |
BalancedL2NormFilterPruner(简称BCP)算法,算法介绍请参见手工通道稀疏算法。 |
|
BalancedL2NormFilterPruner |
- |
- |
- |
BalancedL2NormFilterPruner算法的配置。 |
required |
float |
prune_ratio |
稀疏率,被稀疏的filter数量与filter总数量的比值。推荐配置为0.2,即20%的输出通道将被裁剪。 |
|
optional |
bool |
ascend_optimized |
是否做昇腾亲和优,如果稀疏后的模型要部署在NPU IP加速器上,建议此项配置为true。 |
|
NOutOfMPruner |
- |
- |
- |
4选2稀疏的配置。 |
- |
L1SelectivePruner |
l1_selective_prune |
L1SelectivePrune算法,算法介绍请参见4选2结构化稀疏算法。 |
|
L1SelectivePruner |
- |
- |
- |
L1SelectivePrune算法的配置 |
optional |
NOutOfMType |
n_out_of_m_type |
目前仅支持M4N2,即每4个连续权重中保留2个权重。 |
|
optional |
uint32 |
update_freq |
更新4选2稀疏的间隔。update_freq=0时仅在第一个batch更新4选2稀疏的选择,update_freq=2时每2个batch更新一次,以此类推。默认为0。 |
基于该文件构造的量化感知训练简易配置文件quant.cfg样例如下所示:
# global quantize parameter retrain_data_quant_config: { ulq_quantize: { clip_max_min: { clip_max: 6.0 clip_min: -6.0 } fixed_min: true dst_type: INT8 } } retrain_weight_quant_config: { arq_retrain: { channel_wise: true dst_type: INT8 } } skip_layers: "Opname" skip_layer_types: "Optype" override_layer_types : { layer_type: "Optype" retrain_weight_quant_config: { arq_retrain: { channel_wise: false dst_type: INT8 } } } override_layer_configs : { layer_name: "Opname" retrain_data_quant_config: { ulq_quantize: { clip_max_min: { clip_max: 3.0 clip_min: -3.0 } dst_type: INT8 } } }
基于该文件构造的通道稀疏简易配置文件prune.cfg样例如下所示:
# global prune parameter prune_config{ filter_pruner { balanced_l2_norm_filter_prune { prune_ratio: 0.3 ascend_optimized: True } } } # skip layers regular_prune_skip_layers: "Opname" regular_prune_skip_layers: "Opname" # overide specific layers override_layer_configs: { layer_name: "Opname" prune_config : { filter_pruner: { balanced_l2_norm_filter_prune: { prune_ratio: 0.5 ascend_optimized: True } } } }
基于该文件构造的4选2结构化稀疏简易配置文件selective_prune.cfg样例如下所示:
# global prune parameter prune_config{ n_out_of_m_pruner { l1_selective_prune { n_out_of_m_type: M4N2 update_freq: 0 } } } # skip layers regular_prune_skip_layers: "Opname" regular_prune_skip_layers: "Opname" # overide specific layers override_layer_configs: { layer_name: "Opname" prune_config : { n_out_of_m_pruner: { l1_selective_prune: { n_out_of_m_type: M4N2 update_freq: 1 } } } }
基于该文件构造的组合压缩(通道稀疏+INT8量化)简易配置文件compressed1.cfg样例如下所示:
prune_config : { filter_pruner : { balanced_l2_norm_filter_prune : { prune_ratio : 0.3 ascend_optimized: True } } } # skip_layers: "skip_layers_name_0" skip_layer_types: "Optype" quant_skip_layers: "Opname" quant_skip_types: "Optype" retrain_weight_quant_config: { arq_retrain: { channel_wise: true dst_type: INT8 } } override_layer_types : { layer_type: "Optype" retrain_weight_quant_config: { arq_retrain: { channel_wise: false dst_type: INT8 } } retrain_data_quant_config : { ulq_quantize : { clip_max_min : { clip_max : 6.0 clip_min : -6.0 } } } prune_config : { filter_pruner : { balanced_l2_norm_filter_prune : { prune_ratio : 0.5 ascend_optimized: True } } } }
基于该文件构造的组合压缩(4选2结构化稀疏+INT8量化)简易配置文件compressed2.cfg样例如下所示:
prune_config{ n_out_of_m_pruner { l1_selective_prune { n_out_of_m_type: M4N2 update_freq: 0 } } } # skip_layers: "skip_layers_name_0" skip_layer_types: "Optype" quant_skip_layers: "quant_skip_layers_name_0" quant_skip_types: "Optype" retrain_weight_quant_config: { arq_retrain: { channel_wise: true dst_type: INT8 } } override_layer_types : { layer_type: "Optype" retrain_weight_quant_config: { arq_retrain: { channel_wise: false dst_type: INT8 } } retrain_data_quant_config : { ulq_quantize : { clip_max_min : { clip_max : 6.0 clip_min : -6.0 } } } prune_config{ n_out_of_m_pruner { l1_selective_prune { n_out_of_m_type: M4N2 update_freq: 1 } } } }
自动通道稀疏搜索简易配置文件¶
自动通道稀疏搜索的相关配置说明存在于basic_info.proto文件中,该文件所在目录为:_AMCT_安装目录/amct_pytorch/proto/basic_info.proto。
消息 |
是否必填 |
类型 |
字段 |
说明 |
|---|---|---|---|---|
AutoMixedPrecisionConfig |
- |
- |
- |
AMCT自动混合精度搜索简易配置。当前版本暂不支持该特性。 |
optional |
float |
compress_ratio |
压缩率。以所有可量化层的计算量为基准压缩的倍数。 |
|
repeated |
QuantBitLimit |
quant_bit_limit |
指定某些层的量化位宽搜索范围。 |
|
optional |
string |
ptq_cfg |
用户配置的训练后量化简易配置文件,执行校准过程中用于获取INT4、INT8量化位宽下的量化因子。 若不配置,则采用训练后量化默认配置。 |
|
optional |
int64 |
test_iteration |
dump数据的batch数目,根据这些数据来衡量量化的影响以及计算量。数据量应该具有代表性。 |
|
optional |
string |
override_qat_cfg |
用户配置的量化感知训练简易配置文件,自动混合精度搜索输出会覆盖其层的位宽,其余参数保持不变。 若不配置,则采用量化感知训练简易配置文件说明(.proto格式) ,生成带有量化位宽信息的cfg格式配置文件。 |
|
AutoChannelPruneConfig |
- |
- |
- |
AMCT自动通道稀疏搜索简易配置。 |
required |
float |
compress_ratio |
压缩率。以所有可量化层的计算量为基准压缩的倍数。 |
|
optional |
bool |
ascend_optimized |
是否做昇腾亲和优化,如果稀疏后的模型要部署在NPU IP加速器上,建议此项配置为true。 |
|
optional |
float |
max_prune_ratio |
单层最大稀疏率,限定接口输出的稀疏配置中稀疏率的最大值,默认为1。 |
|
optional |
int64 |
test_iteration |
输入测试数据的batch数量。 |
|
optional |
string |
override_prune_cfg |
用户配置的指定通道稀疏简易配置文件,仅允许包含skip与override配置,配置的层将沿用指定的配置,不会被自动通道稀疏搜索接口重写。 |
|
QuantBitLimit |
- |
- |
- |
指定某些层的量化位宽搜索范围。 |
optional |
string |
layer_name |
层名。 |
|
repeated |
DataType |
data_range |
量化位宽范围。 |
|
DataType |
- |
- |
- |
量化位宽范围。枚举类型。当前版本仅支持INT8量化。 |
- |
- |
FLOAT |
浮点,不量化。 |
|
- |
- |
INT8 |
INT8量化。 |
|
- |
- |
INT4 |
INT4量化。 |
基于该文件构造的自动通道稀疏简易配置文件amc.cfg样例如下所示:
compress_ratio: 1.5
ascend_optimized: true
max_prune_ratio: 0.8
test_iteration: 1
override_prune_cfg: 'your/path/to/override_channel_prune.cfg'
record记录文件¶
record文件,为基于protobuf协议的序列化数据结构文件,记录量化场景量化因子scale/offset,稀疏场景各稀疏层间的级联关系等,通过该文件、压缩配置文件以及原始网络模型文件,生成压缩后的模型文件。
record原型定义
record文件对应的protobuf原型定义为(或查看_AMCT安装目录_/amct_pytorch/proto/scale_offset_record_pytorch.proto文件):
syntax = "proto2";
import "amct_pytorch/proto/basic_info.proto";
message SingleLayerRecord {
optional float scale_d = 1;
optional int32 offset_d = 2;
repeated float scale_w = 3;
repeated int32 offset_w = 4;
repeated uint32 shift_bit = 5;
repeated float tensor_balance_factor = 6;
optional bool skip_fusion = 9 [default = true];
optional string dst_type = 10 [default = 'INT8'];
optional string act_type = 11 [default = 'INT8'];
optional string wts_type = 12 [default = 'INT8'];
}
message SingleLayerKVCacheRecord {
repeated float scale = 1;
repeated int32 offset = 2;
}
message MapFiledEntry {
optional string key = 1;
optional SingleLayerRecord value = 2;
optional SingleLayerKVCacheRecord kv_cache_value = 3;
}
message ScaleOffsetRecord {
repeated MapFiledEntry record = 1;
repeated PruneRecord prune_record = 2;
}
message PruneRecord {
repeated PruneNode producer = 1;
repeated PruneNode consumer = 2;
optional PruneNode selective_prune = 3;
}
message PruneNode {
required string name = 1;
repeated AMCTProto.AttrProto attr = 2;
}
参数说明如下:
消息 |
是否必填 |
类型 |
字段 |
说明 |
|---|---|---|---|---|
SingleLayerRecord |
- |
- |
- |
包含了量化层所需要的所有量化因子记录信息。 |
optional |
float |
scale_d |
数据量化scale因子,仅支持对数据进行统一量化。 |
|
optional |
int32 |
offset_d |
数据量化offset因子,仅支持对数据进行统一量化。 |
|
repeated |
float |
scale_w |
权重量化scale因子,支持标量(对当前层的权重进行统一量化),向量(对当前层的权重按channel_wise方式进行量化)两种模式,仅支持Conv2d类型进行channel_wise量化模式。 |
|
repeated |
int32 |
offset_w |
权重量化offset因子,同scale_w一样支持标量和向量两种模式,且需要同scale_w维度一致,当前不支持权重带offset量化模式,offset_w仅支持0。 |
|
repeated |
uint32 |
shift_bit |
移位因子。保留参数,shift_bit参数不会写入record文件。 |
|
optional |
bool |
skip_fusion |
配置当前层是否要跳过Conv+BN融合,默认为false,即当前层要做上述融合。 |
|
optional |
string |
dst_type |
量化位宽,包括INT8和INT4两种量化类型。该字段仅量化感知训练场景使用。 |
|
repeated |
float |
tensor_balance_factor |
均衡量化因子。该字段仅量化数据均衡预处理场景使用。 |
|
optional |
string |
act_type |
数据量化位宽,包括INT8和INT16两种量化类型。 |
|
optional |
string |
wts_type |
权重量化位宽。 当前INT6、INT7量化后的量化因子仍保存为INT8类型。 |
|
SingleLayerKVCacheRecord |
- |
- |
- |
kv-cache量化因子配置。 |
repeated |
float32 |
scale |
scale量化因子。 |
|
repeated |
int32 |
offset |
offset量化因子。 |
|
ScaleOffsetRecord |
- |
- |
- |
map结构,为保证兼容性,采用离散的map结构。 |
repeated |
MapFiledEntry |
record |
每个record对应一个量化层的量化因子记录;record包括两个成员:
|
|
repeated |
PruneRecord |
prune_record |
稀疏信息的记录。 |
|
MapFiledEntry |
optional |
string |
key |
层名。 |
optional |
SingleLayerRecord |
value |
量化因子配置。 |
|
optional |
SingleLayerKVCacheRecord |
kv_cache_value |
kv-cache量化因子配置。 |
|
PruneRecord |
- |
- |
- |
稀疏信息的记录。 |
repeated |
PruneNode |
producer |
稀疏的producer,可稀疏结点间级联关系的根节点。 例如conv1>bn>relu>conv2都可以稀疏,且bn、relu、conv2都会受到conv1稀疏的影响,则bn、relu、conv2是conv1的consumer;conv1是bn、relu、conv2的producer。 |
|
repeated |
PruneNode |
consumer |
稀疏的consumer,可稀疏结点间级联关系的下游节点。 例如conv1>bn>relu>conv2都可以稀疏,且bn、relu、conv2都会受到conv1稀疏的影响,则bn、relu、conv2是conv1的consumer;conv1是bn、relu、conv2的producer。 |
|
optional |
PruneNode |
selective_prune |
4选2结构化稀疏节点。 由于硬件约束,该芯片不支持4选2结构化稀疏特性:使能后获取不到性能收益。 |
|
PruneNode |
- |
- |
- |
稀疏的节点。 |
required |
string |
name |
节点名称。 |
|
repeated |
AMCTProto.AttrProto |
attr |
节点属性。 |
对于optional字段,由于protobuf协议未对重复出现的值报错,而是采用覆盖处理,因此出现重复配置的optional字段内容时会默认保留最后一次配置的值,需要用户自己保证文件的正确性。
record记录文件
最终生成的record文件格式为_record.txt_,文件内容根据特性不同划分如下。
量化特性record文件
对于一般量化层配置需要包含scale_d、offset_d、scale_w、offset_w参数,文件内容示例如下:
record { key: "conv1" value { scale_d: 0.0798481479 offset_d: 1 scale_w: 0.00297622895 offset_w: 0 skip_fusion: true dst_type: "INT8" } } record { key: "layer1.0.conv1" value { scale_d: 0.00392156886 offset_d: -128 scale_w: 0.00106807391 scale_w: 0.00104224426 offset_w: 0 offset_w: 0 dst_type: "INT8" } }
量化数据均衡预处理特性record文件,内容示例如下:
record { key: "linear_1" value { scale_d: 0.00784554612 offset_d: -1 scale_w: 0.00778095098 offset_w: 0 tensor_balance_factor: 0.948409557 tensor_balance_factor: 0.984379828 } } record { key: "conv_1" value { scale_d: 0.00759239076 offset_d: -4 scale_w: 0.0075149606 offset_w: 0 tensor_balance_factor: 1.04744744 tensor_balance_factor: 1.44586647 } }
通道稀疏record文件记录各稀疏层间的级联关系,文件内容示例如下:
prune_record { producer { name: "conv1" attr { name: "type" type: STRING s: "Conv2d" } attr { name: "begin" type: INT i: 0 } attr { name: "end" type: INT i: 64 } } consumer { name: "BN_1" attr { name: "type" type: STRING s: "FusedBatchNormV3" } attr { name: "begin" type: INT i: 0 } attr { name: "end" type: INT i: 64 } } }
结构化稀疏record文件内容示例如下:
prune_record { selective_prune { name: "conv1" attr { name: "mask_shape" type: INTS ints: 3 ints: 3 ints: 3 ints: 32 } } }
蒸馏简易配置文件¶
distill_config_pytorch.proto文件参数说明如表1所示,该文件所在目录为:AMCT安装目录/amct_pytorch/proto/distill_config_pytorch.proto。
表 1 distill_config_pytorch.proto参数说明
消息 |
是否必填 |
类型 |
字段 |
说明 |
|---|---|---|---|---|
AMCTDistillConfig |
- |
- |
- |
AMCT蒸馏的简易配置。 |
optional |
uint32 |
batch_num |
蒸馏batch数量,用于ifmr积累数据计算量化因子。 |
|
optional |
uint32 |
group_size |
蒸馏block中最小蒸馏单元个数。 |
|
optional |
bool |
data_dump |
teacher网络block输入输出dump开关。 |
|
repeated |
DistillGroup |
distill_group |
用户自定义蒸馏结构。 |
|
optional |
DistillDataQuantConfig |
distill_data_quant_config |
蒸馏数据量化配置参数。 |
|
optional |
DistillWeightQuantConfig |
distill_weight_quant_config |
蒸馏权重量化配置参数。 |
|
repeated |
DistillOverrideLayer |
distill_override_layers |
重写某一层的量化配置。 |
|
repeated |
DistillOverrideLayerType |
distill_override_layer_types |
重写某一类型层的量化配置。 |
|
repeated |
string |
quant_skip_layers |
不需要量化的层,仍然做蒸馏。 |
|
repeated |
string |
quant_skip_layer_types |
不需要量化的算子类型,仍然需要做蒸馏。 |
|
DistillGroup |
- |
- |
- |
用户自定义蒸馏结构。蒸馏结构中仅支持torch.nn.Module类型的算子。 |
required |
string |
start_layer_name |
用户自定义蒸馏结构起始层。 |
|
required |
string |
end_layer_name |
用户自定义蒸馏结构结束层。 |
|
DistillDataQuantConfig |
- |
- |
- |
蒸馏数据量化配置。 |
- |
ActULQquantize |
ulq_quantize |
数据量化的算法,目前仅支持ulq。 |
|
ActULQquantize |
- |
- |
- |
ULQ数据量化算法配置。算法介绍请参见xx |
optional |
ClipMaxMin |
clip_max_min |
初始化的上下限值,如果不配置,默认用ifmr进行初始化。 |
|
optional |
bool |
fixed_min |
是否下限不学习且固定为0。默认ReLu后为true,其他为false。 |
|
optional |
DataType |
dst_type |
用以选择INT8或INT4量化位宽,默认为INT8。当前版本仅支持INT8量化。 |
|
ClipMaxMin |
- |
- |
- |
初始上下限。 |
required |
float |
clip_max |
初始上限值。 |
|
required |
float |
clip_min |
初始下限值。 |
|
DistillWeightQuantConfig |
- |
- |
- |
蒸馏权重量化配置。 |
- |
ARQDistill |
arq_distill |
ARQ权重量化算法。 |
|
- |
WtsULQDistill |
ulq_distill |
ULQ权重量化算法。 |
|
ARQDistill |
- |
- |
- |
ARQ权重量化算法配置。算法介绍请参见ARQ权重量化算法。 |
optional |
DataType |
dst_type |
用以选择INT8或INT4量化位宽,默认为INT8。 |
|
optional |
bool |
channel_wise |
是否做channel wise的arq。 |
|
WtsULQDistill |
- |
- |
- |
ULQ权重量化算法配置。算法介绍请参见ULQ数据量化算法。 |
optional |
DataType |
dst_type |
用以选择INT8或INT4量化位宽,默认为INT8。当前版本仅支持INT8量化。 |
|
optional |
bool |
channel_wise |
是否做channel wise的ulq。 |
|
DistillOverrideLayer |
- |
- |
- |
重写的层配置。 |
required |
string |
layer_name |
层名。 |
|
optional |
DistillDataQuantConfig |
distill_data_quant_config |
重写的数据层量化参数。 |
|
optional |
DistillWeightQuantConfig |
distill_weight_quant_config |
重写的权重层量化参数。 |
|
DistillOverrideLayerType |
- |
- |
- |
重写的层类型配置。 |
required |
string |
layer_type |
层类型。 |
|
optional |
DistillDataQuantConfig |
distill_data_quant_config |
重写的数据层量化参数。 |
|
optional |
DistillWeightQuantConfig |
distill_weight_quant_config |
重写的权重层量化参数。 |
基于该文件构造的蒸馏简易配置文件quant.cfg样例如下所示:
batch_num: 1
group_size: 1
data_dump: true
distill_group: {
start_layer_name: "layer1"
end_layer_name: "layer2"
}
distill_data_quant_config: {
ulq_quantize: {
clip_max_min: {
clip_max: 6.0
clip_min: -6.0
}
fixed_min: true
dst_type: INT8
}
}
distill_weight_quant_config: {
arq_distill: {
channel_wise: true
dst_type: INT8
}
}
quant_skip_layers: "layer3"
quant_skip_layer_types: "type1"
distill_override_layers : {
layer_name: "layer4"
distill_data_quant_config: {
ulq_quantize: {
clip_max_min: {
clip_max: 3.0
clip_min: -3.0
}
fixed_min: true
dst_type: INT8
}
}
distill_weight_quant_config: {
arq_distill: {
channel_wise: false
dst_type: INT8
}
}
}
distill_override_layer_types : {
layer_type: "type2"
distill_data_quant_config: {
ulq_quantize: {
clip_max_min: {
clip_max: 3.0
clip_min: -3.0
}
fixed_min: true
dst_type: INT8
}
}
distill_weight_quant_config: {
ulq_distill: {
channel_wise: false
dst_type: INT8
}
}
}
AMCT(ONNX)¶
量化¶
本章节详细介绍AMCT量化场景,以及每个场景下的功能。
简介¶
本章节详细介绍AMCT量化场景,以及每个场景下的功能。
量化分类
根据量化后是否手动调优量化配置文件,分为手工量化和自动量化。训练后量化使用的量化算法请参见训练后量化算法。
根据是否对权重数据进行压缩又分为均匀量化和非均匀量化(不支持该特性)。如果量化后的精度不满足要求,则可以进行自动量化或手工调优,推荐使用自动量化。
相关概念
表 1 量化过程中的相关概念
术语 |
解释 |
|---|---|
数据量化和权重量化 |
训练后量化根据量化对象不同,又分为数据(activation)量化和权重(weight)量化。 当前NPU IP加速器支持数据(activation)做对称/非对称量化,权重(weight)仅支持做对称量化(量化根据量化后数据中心点是否为0可以分为对称量化、非对称量化,详细的量化算法原理请参见量化算法原理)。
|
量化位宽 |
量化根据量化后低比特位宽大小分为常见的INT8、INT16量化:权重量化仅支持INT8量化,数据量化支持INT8和INT16两种量化方式。
|
测试数据集 |
数据集的子集,用于最终测试模型的效果。 |
校准 |
训练后量化场景中,做前向推理获取数据量化因子的过程。 |
校准数据集 |
训练后量化场景中,做前向推理使用的数据集。该数据集的分布代表着所有数据集的分布,获取校准集时应该具有代表性,推荐使用测试集的子集作为校准数据集。如果数据集不是模型匹配的数据集或者代表性不够,则根据校准集计算得到的量化因子,在全数据集上表现较差,量化损失大,量化后精度低。 |
量化因子 |
将浮点数量化为整数的参数,包括缩放因子(scale),偏移量(offset)。 将浮点数量化为整数(以INT8为例)的公式如下:
|
scale |
量化因子,浮点数的缩放因子,该参数又分为:
|
offset |
量化因子,偏移量,该参数又分为:
|
自动量化¶
基于精度的自动量化是为了方便用户在对量化精度有一定要求时所使用的功能。该方法能够在保证用户所需的模型精度前提下,自动搜索模型的量化配置并执行训练后量化的流程,最终生成满足精度要求的量化模型。
基于精度的自动量化¶
基于精度的自动量化是为了方便用户在对量化精度有一定要求时所使用的功能。该方法能够在保证用户所需的模型精度前提下,自动搜索模型的量化配置并执行训练后量化的流程,最终生成满足精度要求的量化模型。
基于精度的自动量化基本原理与手工量化相同,但是用户无需手动调整量化配置文件,大大简化了优化流程,提高量化效率。量化支持的层以及约束请参见均匀量化,量化示例请参见样例列表。
接口调用流程
接口调用流程如图1所示。
图 1 接口调用流程
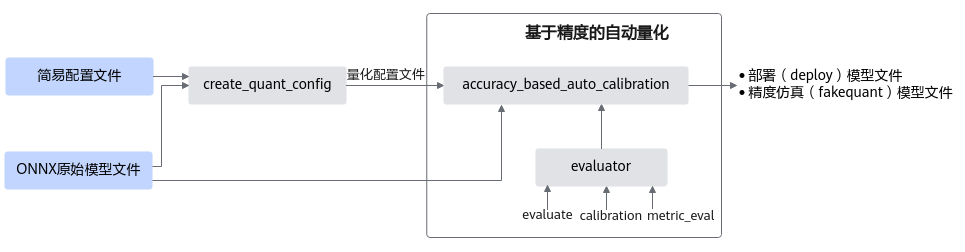
主要流程如下:
调用create_quant_config生成量化配置文件,然后调用accuracy_based_auto_calibration进行基于精度的自动量化。
调用accuracy_based_auto_calibration中由用户传入的evaluator实例进行精度测试,得到原始模型精度。
该过程还会调用accuracy_based_auto_calibration中的量化策略strategy模块,输出初始化的quant config量化配置文件,该文件记录所有层都可以进行量化。
使用用户传入的初始量化配置文件(1中调用create_quant_config生成的)对模型进行训练后量化,得到量化后fake quant模型的精度。
原始模型精度与量化后fake quant模型精度进行比较,如果精度达标,则输出量化后的部署模型和fake quant模型,如果不达标,则进行基于精度的自动量化流程:
进行原始ONNX网络的推理, dump出每一层的输入activation数据,缓存起来。
利用训练后量化的量化因子构造量化层的单算子网络,利用缓存的activation数据计算量化后fake quant单算子网络的输出数据和原始ONNX单算子网络输出的余弦相似度。
将余弦相似度的列表传给accuracy_based_auto_calibration中的量化策略strategy模块,strategy模块基于2中生成的初始化的量化配置文件,输出回退某些层后的新的quant config量化配置文件。
根据quant config量化配置文件重新进行训练后量化,得到回退后的fake quant模型。
调用accuracy_based_auto_calibration中的evaluator模块进行回退后的fake quant模型精度测试,查看精度是否达标:
如果达标,则输出回退后的fake quant模型以及部署模型。
如果不达标,则将余弦相似度排序最差的层回退,再次进行4.c,输出新的量化配置。
如果回退所有层后精度仍不达标,则不生成量化模型。
accuracy_based_auto_calibration接口内部基于精度的自动量化流程如图2所示。
图 2 自动量化流程
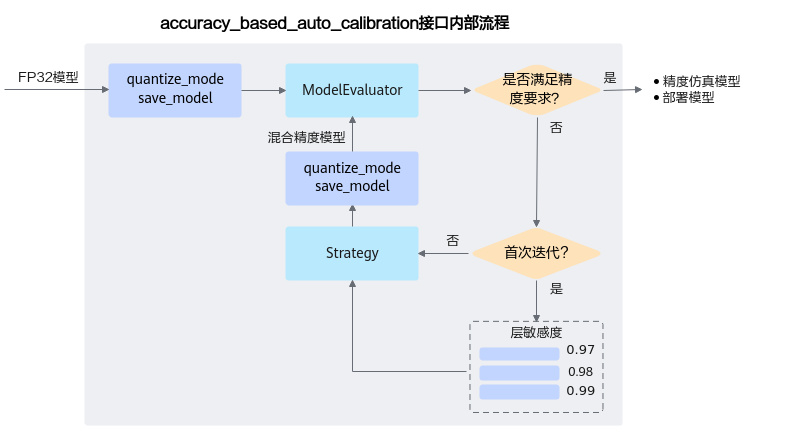
调用示例
本示例演示使用AMCT进行基于精度的自动量化流程。该过程需要用户实现一个模型推理得到精度的回调函数,由于AMCT需要基于回调函数返回的精度数据进行量化层的筛选,因此回调函数的返回数值应尽可能反映模型的精度。
如下示例标有“由用户补充处理”的步骤,需要用户根据自己的模型和数据集进行补充处理,示例中仅为示例代码。
如下示例调用AMCT的部分,函数入参请根据实际情况进行调整。
导入AMCT包。
import os import amct_onnx as amct from amct_onnx.common.auto_calibration import AutoCalibrationEvaluatorBase
(由用户补充处理)使用原始待量化的模型和测试集,实现回调函数calibration()、evaluate()、metric_eval()。
上述回调函数的入参要和基类AutoCalibrationEvaluatorBase保持一致。其中:
calibration()完成校准的推理。
evaluate()完成模型的精度测试过程。
metric_eval()完成原始模型和量化fake quant模型的精度损失评估,当精度损失小于预期值时返回True,否则返回False。
class ModelEvaluator(AutoCalibrationEvaluatorBase): # The evaluator for model def __init__(self, *args, **kwargs): # 成员变量初始化 # 设置预期精度损失,此处请替换为具体的数值 self.diff = expected_acc_loss pass def calibration(self, model_file): # 进行模型的校准推理,推理的batch数要和量化配置的batch_num一致 pass def evaluate(self, model_file): # evaluate the input models, get the eval metric of model pass def metric_eval(self, original_metric, new_metric): # 评估原始模型精度和量化模型精度的精度损失是否满足预期,满足返回True, 精度损失数据;否则返回False, 精度损失数据 loss = original_metric - new_metric if loss < self.diff: return True, loss return False, loss
(由用户补充处理)根据模型确定模型输入文件。
model_file = os.path.realpath(user_model_file)调用AMCT,进行基于精度的自动量化。
生成量化配置。
config_json_file = './config.json' skip_layers = [] batch_num = 1 activation_offset = True amct.create_quant_config(config_json_file, model_file, skip_layers, batch_num, activation_offset) scale_offset_record_file = os.path.join(TMP, 'scale_offset_record.txt') result_path = os.path.join(RESULT, 'model')
初始化Evaluator。
evaluator = AutoCalibrationEvaluator()进行基于精度的量化配置自动搜索。
amct.accuracy_based_auto_calibration( model_file=model_file, model_evaluator=evaluator, config_file=config_json_file, record_file=scale_offset_record_file, save_dir=result_path, strategy='BinarySearch', sensitivity='CosineSimilarity' )
手工量化¶
均匀量化是指量化后的数据比较均匀地分布在某个数值空间中,例如INT8量化就是用只有8比特的INT8数据来表示32比特的float32数据或16比特的float16数据,将float32/float16的卷积运算过程(乘加运算)转换为INT8的卷积运算,加速运算和实现模型压缩;均匀的INT8量化则是量化后数据比较均匀地分布在INT8的数值空间[-128, 127]中。 非均匀量化是指量化后的数据在某个数值空间中的分布是不均匀的。非均匀量化过程中,会根据待量化数据的概率分布来对均匀量化后的数据分布进一步进行根据目标压缩率(保留数值量/原始量化数值量)的聚类操作。相较于均匀量化,非均匀量化在进一步压缩数据信息量的基础上尽可能的保留高概率分布的数据信息,从而减小压缩后的数据信息丢失。 执行训练后量化特性的精度如果不满足要求,可以尝试手动调整config.json文件中的参数,本节给出调整的原则,以及参数解释。
均匀量化¶
均匀量化是指量化后的数据比较均匀地分布在某个数值空间中,例如INT8量化就是用只有8比特的INT8数据来表示32比特的float32数据或16比特的float16数据,将float32/float16的卷积运算过程(乘加运算)转换为INT8的卷积运算,加速运算和实现模型压缩;均匀的INT8量化则是量化后数据比较均匀地分布在INT8的数值空间[-128, 127]中。
均匀量化支持量化的层以及约束如下,量化示例请参见样例列表。
表 1 均匀量化支持的层以及约束
支持的层类型 |
约束 |
|---|---|
Conv |
支持3维或4维输入,且权重类型为constant或Initializer的量化。 |
ConvTranspose |
仅支持3维或4维输入,且权重类型为constant。 |
Gemm |
transpose_a=false、Alpha=Beta=1.0;权重类型为constant或Initializer。 |
GRU |
约束请参见表3。 如果执行基于精度的自动量化,该算子只能量化,不能进行回退; |
LSTM |
约束请参见表2。 如果执行基于精度的自动量化,该算子只能量化,不能进行回退; |
MatMul |
|
表 2 LSTM算子约束
类型 |
输入/参数名称 |
要求 |
|---|---|---|
输入约束 |
X |
X输入第一维长度必须为1(对应sequence_lens限制),否则在IFMR/HFMG算子中抛出异常。 |
initial_h |
必须有对应输入,且该输入不能连接Const节点或者Const子图。 |
|
initial_c |
必须有对应输入,且该输入不能连接Const节点或者Const子图。 |
|
sequence_lens |
必须无对应输入。 |
|
P |
必须无对应输入。 |
|
W |
类型为constant/initializer,且输入第一维为1(对应num_direction限制)。 |
|
R |
类型为constant/initializer,且输入第一维为1(对应num_direction限制)。 |
|
属性约束 |
activation_alpha |
必须不指定对应属性。 |
activation_beta |
必须不指定对应属性。 |
|
activations |
必须不指定对应属性。 |
|
clip |
必须不指定对应属性。 |
|
direction |
必须不指定对应属性,或者为forward(同默认值)。 |
|
input_forget |
必须不指定对应属性,或者为0(同默认值)。 |
|
layout |
必须不指定对应属性,或者为0(同默认值)。 |
|
输出约束 |
Y |
必须有对应输出。 |
Y_h |
必须有对应输出。 |
|
Y_c |
必须有对应输出。 |
表 3 GRU算子约束
类型 |
输入/参数名称 |
要求 |
|---|---|---|
输入约束 |
X |
X输入第一维长度必须为1(对应sequence_lens限制),否则在IFMR/HFMG算子中会抛出异常。 |
initial_h |
必须有对应输入,必须与外部输入关联(直接或间接)。 |
|
sequence_lens |
必须无对应输入。 |
|
W |
类型为constant/initializer,且输入第一维为1(对应num_directions限制)。 |
|
R |
类型为constant/initializer,且输入第一维为1(对应num_directions限制)。 |
|
属性约束 |
activation_alpha |
必须不指定对应属性。 |
activation_beta |
必须不指定对应属性。 |
|
activations |
必须不指定对应属性。 |
|
direction |
必须不指定对应属性,或者为forward(同默认值)。 |
|
layout |
必须不指定对应属性,或者为0(同默认值)。 |
|
linear_before_reset |
仅支持配置为非0值的场景,将所有非0值在部署图中设置为1。 |
|
输出约束 |
Y |
必须有对应输出。 |
Y_h |
必须有对应输出。 |
接口调用流程
均匀量化接口调用流程如图1所示:
图 1 均匀量化接口调用流程

蓝色部分为用户实现,灰色部分为用户调用AMCT提供的API实现,使用流程如下:
用户准备ONNX原始模型,然后使用create_quant_config生成量化配置文件。
根据ONNX模型和量化配置文件,即可调用quantize_model接口对原始ONNX模型进行量化前优化,包括Conv+BN融合等,插入权重量化算子,进行权重量化;插入数据量化算子,得到校准模型。
用户基于ONNX Runtime以及校准集,执行校准模型推理完成数据量化,并将量化因子输出到文件中。
最后用户可以调用save_model接口保存量化后的模型,包括可在ONNX执行框架ONNX Runtime环境中进行精度仿真的模型文件和可部署在NPU IP加速器的模型文件。
精度仿真模型文件:模型名中包含fake_quant,可以在ONNX执行框架ONNX Runtime进行精度仿真。
fake_quant模型主要用于验证量化后模型的精度,可以在ONNX Runtime环境下运行。进行前向推理的计算过程中,在fake_quant模型中对卷积层等的输入数据和权重进行了量化反量化的操作,来模拟量化后的计算结果,从而快速验证量化后模型的精度。如下图所示,以INT8量化为例,Quant层、Conv卷积层和DeQuant层之间的数据都是float32数据类型的,其中Quant层将数据量化到INT8又反量化为float32,权重也是量化到INT8又反量化为float32,实际卷积层的计算是基于float32数据类型的,该模型用于ONNX Runtime环境验证量化后模型的精度,不能够用于ATC工具转换成om模型。
图 2 fake_quant模型
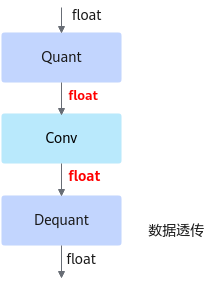
部署模型文件:模型名中包含deploy,经过ATC转换工具转换后可部署到NPU IP加速器。
以INT8量化为例,deploy模型由于已经将权重等转换成为了INT8、INT32类型,因此不能在ONNX Runtime环境上执行推理计算。如下图所示,deploy模型的AscendQuant层将float32的输入数据量化为INT8,作为卷积层的输入,权重也是使用INT8数据类型作为计算,在deploy模型中的卷积层的计算是基于INT8、INT32数据类型的,输出为INT32数据类型经过AscendDeQuant层转换成float32数据类型传输给下一个网络层。
图 3 deploy模型
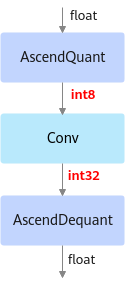
调用示例
本章节详细给出训练后量化的模板代码解析说明,通过解读该代码,用户可以详细了解AMCT的工作流程以及原理,方便用户基于已有模板代码进行修改,以便适配其他网络模型的量化。训练后量化主要包括如下几个步骤:
准备训练好的模型和数据集。
在原始ONNX Runtime环境中验证模型精度以及环境是否正常。
编写训练后量化脚本调用AMCT API。
执行训练后量化脚本。
在原始ONNX Runtime环境中验证量化后仿真模型精度。
如下流程详细演示如何编写脚本调用AMCT API进行模型量化。
如下示例标有“由用户补充处理”的步骤,需要用户根据自己的模型和数据集进行补充处理,示例中仅为示例代码。
如下示例调用AMCT的部分,函数入参请根据实际情况进行调整。
导入AMCT包,并通过设置环境变量日志级别。
import amct_onnx as amct(可选,由用户补充处理)在ONNX Runtime环境中验证推理脚本及环境。
建议使用原始待量化的模型和测试集,在ONNX Runtime环境下推理,验证环境、推理脚本是否正常。
推荐执行该步骤,请确保原始模型可以完成推理且精度正常;执行该步骤时,可以使用部分测试集,减少运行时间。
user_do_inference(ori_model, test_data, test_iterations)调用AMCT,量化模型。
生成量化配置。
config_file = './tmp/config.json' skip_layers = [] batch_num = 1 amct.create_quant_config(config_file=config_file, model_file=ori_model, skip_layers=skip_layers, batch_num=batch_num)
修改图,在图中插入数据量化,权重量化等相关的算子,用于计算量化相关参数。
record_file = './tmp/record.txt' modified_model = './tmp/modified_model.onnx' amct.quantize_model(config_file=config_file, model_file=ori_model, modified_onnx_file=modified_model, record_file=record_file)
(由用户补充处理)使用修改后的图在校准集上做模型推理,找到量化因子。
该步骤执行时,需要注意如下两点:
校准集及其预处理过程数据要与模型匹配,以保证量化的精度。
前向推理次数为batch_num,如果次数不足,由于校准算子没有将量化因子输出到record文件中,会导致后续读取record校验失败。
若校准过程中有错误信息,则可以尝试参见校准过程中提示"IFMR node. Name:'layer_ifmr_op' Status Message: std::bad_alloc"信息或校准过程中出现"killed"信息进行处理。
若校准执行过程中提示"IfmrQuantWithOffset scale is illegal",则请参见校准执行过程中提示“[IfmrQuantWithoutOffset]scale is illegal”处理。
user_do_inference(modified_onnx_file, calibration_data, batch_num)保存模型。
根据量化因子以及修改后的模型,调用save_model接口,插入AscendQuant、AscendDequant等算子,保存为量化模型。
quant_model_path = './results/user_model' amct.save_model(modified_onnx_file=modified_model, record_file=record_file, save_path=quant_model_path)
(可选,由用户补充处理)基于ONNX Runtime的环境,使用量化后模型(quant_model)在测试集(test_data)上做推理,测试量化后仿真模型的精度。
使用量化后仿真模型精度与2中的原始精度做对比,可以观察量化对精度的影响。
quant_model = './results/user_model_fake_quant_model.onnx' user_do_inference(quant_model, test_data, test_iterations)
如果量化后仿真模型在CPU推理速度,相较于原始模型推理速度变慢,则可以尝试通过设置如下环境变量解决:
#设置执行期间使用的线程数 export OMP_NUM_THREADS=8
环境变量的取值,跟模型数据量大小,运行环境的CPU数量相关,比如Resnet101模型,数据量大小为10W量级,线程数可以设置为8。
非均匀量化**(不支持该特性)**¶
非均匀量化是指量化后的数据在某个数值空间中的分布是不均匀的。非均匀量化过程中,会根据待量化数据的概率分布来对均匀量化后的数据分布进一步进行根据目标压缩率(保留数值量/原始量化数值量)的聚类操作。相较于均匀量化,非均匀量化在进一步压缩数据信息量的基础上尽可能的保留高概率分布的数据信息,从而减小压缩后的数据信息丢失。
模型在NPU IP加速器上推理时,可通过非均匀量化提高权重压缩率(需要与ATC工具配合,通过编译时使能权重压缩),降低权重传输开销,进一步提升推理性能。非均匀量化后,如果精度仿真模型在原始ONNX Runtime环境中推理精度不满足要求,可通过调整非均匀量化配置文件config.json中的参数来恢复模型精度,调整方法请参见手工调优。
非均匀量化支持量化的层以及约束如下,量化示例请参见样例列表。
表 1 非均匀量化支持量化的层以及约束
支持的层类型 |
约束 |
|---|---|
Conv:卷积层 |
dilation为1、group为1、filter维度为4 |
Gemm:广义矩阵乘 |
transpose_a=false、Alpha=Beta=1.0 |
实现流程
静态非均匀量化实现原理同均匀量化,简要流程如图1所示。
图 1 非均匀量化流程图
详细流程说明如下:
参见均匀量化章节获取均匀量化的部署模型和精度仿真模型。
参见《ATC离线模型编译工具用户指南》将1中生成的部署模型转换成JSON文件,该JSON文件记录了量化后模型的融合信息,同时也携带了支持weight压缩特性层的信息(通过fe_weight_compress字段识别)。
如果要进行weight压缩,则参见训练后量化简易配置文件章节获取非均匀量化简易配置文件,然后获取2生成的量化后模型的融合json文件进行非均匀量化。
非均匀量化过程中,会根据融合JSON文件,获取原始模型中哪些层支持weight压缩,然后重新生成非均匀量化的部署模型和量化配置文件。
查看非均匀量化后,精度仿真模型在ONNX Runtime环境中推理精度是否满足要求,如果不满足要求,则需要调整非均匀量化配置文件config.json中的参数,然后重新进行非均匀量化,直至满足精度要求。调整方法请参见手工调优。
手工调优¶
执行训练后量化特性的精度如果不满足要求,可以尝试手动调整config.json文件中的参数,本节给出调整的原则,以及参数解释。
调优流程
通过create_quant_config接口生成的config.json文件中的默认配置进行量化,若量化后的推理精度不满足要求,则可调整量化配置重复量化,直至精度满足要求。本节详细介绍手动调优流程,调整对象是训练后量化配置文件config.json中的参数,主要涉及3个阶段:
调整校准使用的数据量。
跳过量化某些层。
调整量化算法及参数。
具体步骤如下:
根据create_quant_config接口生成的默认配置进行量化。若精度满足要求,则调参结束,否则进行2。
手动修改batch_num,调整校准使用的数据量。
batch_num控制量化使用数据的batch数目,可根据batch大小以及量化需要使用的图片数量调整。通常情况下:
batch_num越大,量化过程中使用的数据样本越多,量化后精度损失越小;但过多的数据并不会带来精度的提升,反而会占用较多的内存,降低量化的速度,并可能引起内存、显存、线程资源不足等情况;因此,建议batch_num*batch_size为16或32(batch_size表示每个batch使用的图片数量)。
若按照2中的量化配置进行量化后,精度满足要求,则调参结束,否则进行#ZH-CN_TOPIC_0000002473904536/li718684715113。
手动修改activation_quant_params和weight_quant_params,调整量化算法及参数:
算法参数意义请参见量化配置文件中的参数说明部分,算法说明请参见训练后量化算法。
若按照4中的量化配置进行量化后,精度满足要求,则调参结束,否则表明量化对精度影响很大。
图 1 调参流程
量化配置文件
如果通过create_quant_config接口生成的config.json量化配置文件,推理精度不满足要求,则需要参见该章节不断调整config.json文件中的内容(用户修改JSON文件时,请确保层名唯一),直至精度满足要求,json量化配置文件样例请参见接口中的调用示例部分。
配置文件中参数说明如下:
表 1 version参数说明
作用 |
控制量化配置文件版本号 |
|---|---|
类型 |
int |
取值范围 |
1 |
参数说明 |
目前仅有一个版本号1。 |
推荐配置 |
1 |
可选或者必选 |
可选 |
表 2 batch_num参数说明
作用 |
控制量化使用多少个batch的数据。 |
|---|---|
类型 |
int |
取值范围 |
大于0 |
参数说明 |
如果不配置,则使用默认值1,建议校准集图片数量不超过50张,根据batch的大小batch_size计算相应的batch_num数值。 batch_num*batch_size为量化使用的校准集图片数量。 其中batch_size为每个batch所用的图片数量。 |
推荐配置 |
1 |
必选或可选 |
可选 |
表 3 activation_offset参数说明
作用 |
控制数据量化是对称量化还是非对称量化。全局配置参数。 若配置文件中同时存在activation_offset和asymmetric参数,asymmetric参数优先级>activation_offset参数。 |
|---|---|
类型 |
bool |
取值范围 |
true或false |
参数说明 |
|
推荐配置 |
true |
必选或可选 |
可选 |
表 4 joint_quant参数说明
作用 |
是否进行Eltwise联合量化。 |
|---|---|
类型 |
bool |
取值范围 |
true或false |
参数说明 |
|
推荐配置 |
false |
必选或可选 |
可选 |
表 5 do_fusion参数说明
作用 |
是否开启融合功能。 |
|---|---|
类型 |
bool |
取值范围 |
true或false |
参数说明 |
当前仅支持Conv+BN融合。 |
推荐配置 |
true |
可选或必选 |
可选 |
表 6 skip_fusion_layers参数说明
作用 |
跳过可融合的层。 |
|---|---|
类型 |
string |
取值范围 |
可融合层的层名。当前仅支持Conv+BN融合。 |
参数说明 |
不需要做融合的层。 |
推荐配置 |
- |
可选或必选 |
可选 |
表 7 layer_config参数说明
作用 |
指定某个网络层的量化配置。 |
|---|---|
类型 |
object |
取值范围 |
- |
参数说明 |
参数内部包含如下参数:
|
推荐配置 |
- |
必选或可选 |
可选 |
表 8 quant_enable参数说明
作用 |
该层是否做量化。 |
|---|---|
类型 |
bool |
取值范围 |
true或false |
参数说明 |
|
推荐配置 |
true |
必选或可选 |
可选 |
表 9 dmq_balancer_param参数说明
作用 |
DMQ均衡算法中的迁移强度。 |
|---|---|
类型 |
float |
取值范围 |
[0.2, 0.8] |
参数说明 |
代表将activation数据上的量化难度迁移至weight权重的程度,数据分布的离群值越大迁移强度应设置较小。 |
推荐配置 |
0.5 |
必选或可选 |
可选 |
表 10 activation_quant_params参数说明
作用 |
该层数据量化的参数。 |
|---|---|
类型 |
object |
取值范围 |
- |
参数说明 |
activation_quant_params内部包含如下参数,IFMR算法相关参数与HFMG算法相关参数在同一层中不能同时出现:
|
推荐配置 |
- |
必选或可选 |
可选 |
表 11 weight_quant_params参数说明
作用 |
该层权重量化的参数。 |
|---|---|
类型 |
object |
取值范围 |
- |
参数说明 |
|
推荐配置 |
- |
必选或可选 |
可选 |
表 12 num_bits参数说明
作用 |
量化位宽。 |
|---|---|
类型 |
int |
取值范围 |
8或16 |
参数说明 |
当前支持配置为8/16,表示采用INT8/INT16量化位宽。 |
推荐配置 |
- |
必选或可选 |
必选 |
表 13 act_algo参数说明
作用 |
数据量化算法。 |
|---|---|
类型 |
string |
取值范围 |
ifmr或者hfmg |
参数说明 |
IFMR数据量化算法:ifmr HFMG数据量化算法:hfmg |
推荐配置 |
- |
必选或可选 |
可选 |
表 14 asymmetric参数说明
作用 |
控制数据量化是对称量化还是非对称量化。用于控制逐层量化算法的选择。 若配置文件中同时存在activation_offset和asymmetric参数,asymmetric参数优先级>activation_offset参数。 |
|---|---|
类型 |
bool |
取值范围 |
true或false |
参数说明 |
|
推荐配置 |
true |
必选或可选 |
可选 |
表 15 max_percentile参数说明
作用 |
IFMR数据量化算法中,最大值搜索位置参数。 |
|---|---|
类型 |
float |
取值范围 |
(0.5,1] |
参数说明 |
在从大到小排序的一组数中,决定取第多少大的数,比如有100个数,1.0表示取第100-100*1.0=0,对应的就是第一个大的数。 对待量化的数据做截断处理时,该值越大,说明截断的上边界越接近待量化数据的最大值。 |
推荐配置 |
0.999999 |
必选或可选 |
可选 |
表 16 min_percentile参数说明
作用 |
IFMR数据量化算法中,最小值搜索位置参数。 |
|---|---|
类型 |
float |
取值范围 |
(0.5,1] |
参数说明 |
在从小到大排序的一组数中,决定取第多少小的数,比如有100个数,1.0表示取第100-100*1.0=0,对应的就是第一个小的数。 对待量化的数据做截断处理时,该值越大,说明截断的下边界越接近待量化数据的最小值。 |
推荐配置 |
0.999999 |
必选或可选 |
可选 |
表 17 search_range参数说明
作用 |
IFMR数据量化算法中,控制量化因子的搜索范围[search_range_start, search_range_end]。 |
|---|---|
类型 |
list,列表中两个元素类型为float。 |
取值范围 |
0<search_range_start<search_range_end |
参数说明 |
控制截断的上边界的浮动范围。
|
推荐配置 |
[0.7,1.3] |
必选或可选 |
可选 |
表 18 search_step参数说明
作用 |
IFMR数据量化算法中,控制量化因子的搜索步长。 |
|---|---|
类型 |
float |
取值范围 |
(0, (search_range_end-search_range_start)] |
参数说明 |
控制截断的上边界的浮动范围步长,值越小,浮动步长越小。 |
推荐配置 |
0.01 |
必选或可选 |
可选 |
表 19 num_of_bins参数说明
作用 |
HFMG数据量化算法用于调整直方图的bin(直方图中的一个最小单位直方图形)数目。 |
|---|---|
类型 |
unsigned int |
取值范围 |
{1024, 2048, 4096, 8192} |
参数说明 |
num_of_bins数值越大,直方图拟合原始数据分布的能力越强,可能获得更佳的量化效果,但训练后量化过程的耗时也会更长。 |
推荐配置 |
4096 |
必选或可选 |
HFMG算法量化场景下,该参数可选。 |
表 20 wts_algo参数说明
作用 |
权重量化算法 |
|---|---|
类型 |
string |
取值范围 |
arq_quantize |
参数说明 |
ARQ权重量化算法:arq_quantize |
推荐配置 |
- |
必选或可选 |
可选 |
表 21 channel_wise搜索相关参数说明
作用 |
ARQ权重量化算法中,是否对每个channel采用不同的量化因子。 |
|---|---|
类型 |
bool |
取值范围 |
true或false |
参数说明 |
|
推荐配置 |
true |
必选或可选 |
可选 |
表 22 tensor_quantize参数说明
作用 |
指定某个网络层的量化配置。 |
|---|---|
类型 |
object |
取值范围 |
- |
参数说明 |
参数内部包含如下参数:
|
推荐配置 |
- |
必选或可选 |
可选 |
表 23 layer_name参数说明
作用 |
需要对节点输入Tensor进行训练后量化的节点名称。 |
|---|---|
类型 |
string |
取值范围 |
- |
参数说明 |
当前仅支持对MaxPool算子的输入Tensor进行量化。 |
推荐配置 |
- |
必选或可选 |
必选 |
表 24 input_index参数说明
作用 |
需要对节点输入Tensor进行训练后量化的节点的输入索引。 |
|---|---|
类型 |
uint32 |
取值范围 |
- |
参数说明 |
节点的输入索引。 |
推荐配置 |
- |
必选或可选 |
必选 |
扩展更多特性¶
如果用户已经使用ONNX原生的QuanitzeLinear、DequantizeLinear算子实现量化功能(以下简称QAT模型),但是该模型无法使用ATC工具转成适配NPU IP加速器的离线模型,则需要借助本节提供的功能,将该QAT模型适配成CANN量化模型格式。然后才能使用ATC工具,将CANN量化模型转成适配NPU IP加速器的离线模型。 在一些数据分布不均匀的场景,由于离群值的影响,对数据进行per-tensor量化得到的结果误差较大,而per-channel量化可以获得更低的误差。但由于当前硬件不支持数据per-channel量化,仅支持权重per-channel量化;在该背景下AMCT设计出一套方法,本节将给出详细介绍。
QAT模型适配CANN模型¶
如果用户已经使用ONNX原生的QuanitzeLinear、DequantizeLinear算子实现量化功能(以下简称QAT模型),但是该模型无法使用ATC工具转成适配NPU IP加速器的离线模型,则需要借助本节提供的功能,将该QAT模型适配成CANN量化模型格式。然后才能使用ATC工具,将CANN量化模型转成适配NPU IP加速器的离线模型。
表 1 支持的场景及约束
场景 |
支持的层类型 |
约束 |
|---|---|---|
QuanitzeLinear-DequantizeLinear图结构对被量化算子的输入和权重同时进行量化,输入侧量化算子替换成AscendQuant,对常量类型权重侧根据目标数据类型离线进行量化,输出侧插入AscendDequant算子进行反量化 |
|
|
QuanitzeLinear-DequantizeLinear图结构对算子的其中一路或两路输入进行量化,在算子输入侧将量化算子替换为AscendQuant-AscendAntiquant |
Add |
Add:仅支持per-tensor量化 |
QuanitzeLinear算子为非中间层output算子,且为单输出:模型适配时,不需要和DequantizeLinear配对,适配过程中会将QuantizeLinear算子替换成AscendQuant,对模型输出进行量化(单输出) |
- |
- |
注意:
若QuantizeLinear不为output算子:仅支持对QAT模型中包含QuantizeLinear和DequantizeLinear两类FakeQuant层结构的模型进行适配,且仅权重支持per-channel量化,成对的QuantizeLinear、DequantizeLinear层需要存在相同的量化因子。
针对QAT模型中的QuantizeLinear算子,有如下约束:
执行per-channel量化时,属性axis只支持1。
根据y_zero_point类型不同,执行不同的量化方式,其他数据类型不支持:
若为INT8/UINT8,则执行INT8量化。
若为INT16/UINT16,则执行INT16量化。
说明:
由于AMCT_ONNX目前支持的最高Opset版本为v16,该版本QuantizeLinear算子的y_zero_point输入类型不支持INT16/UINT16,可以通过如下两种方式执行数据INT16量化:生成Opset版本为v21的原始模型后,将Opset版本修改为v16,并将ir_version修改为当前环境中ONNX Runtime版本支持的ir_version。
生成Opset版本v16的原始模型,手动修改QuantizeLinear算子的y_zero_point数据类型,将数据类型修改为INT16/UINT16。
适配原理
适配原理如图1所示。蓝色部分为用户实现,灰色部分为用户调用AMCT提供的convert_qat_model实现,用户在ONNX QAT网络推理的代码中导入库,并在特定的位置调用相应API,即可实现适配功能。具体适配示例请参见样例列表。
图 1 QAT模型适配CANN模型

调用示例
本示例演示了如何将ONNX的QAT量化模型通过AMCT适配为CANN量化模型格式。
如下示例标有“由用户补充处理”的步骤,需要用户根据自己的模型和数据集进行补充处理,示例中仅为示例代码。
如下示例调用AMCT的部分,函数入参请根据实际情况进行调整。
导入AMCT包,并通过设置环境变量日志级别。
import amct_onnx as amct(可选,由用户补充处理)在ONNX Runtime环境中验证推理脚本及环境。
建议使用原始待量化的模型和测试集,在ONNX Runtime环境下推理,验证环境、推理脚本是否正常。
推荐执行该步骤,请确保原始模型可以完成推理且精度正常;执行该步骤时,可以使用部分测试集,减少运行时间。
user_do_inference(ori_model, test_data, test_iterations)调用AMCT中的convert_qat_model接口,执行模型适配。
该接口内部会将待适配的模型解析为graph形式,完成图的预处理操作>修改解析后的图结构,插入AscendQuant、AscendDequant等算子,保存为量化模型。
model_file = "./pre_model/mobilenet_v2_qat.onnx" save_path="./results/model" amct.convert_qat_model(model_file, save_path)
(可选,由用户补充处理)使用量化后模型和测试集,在ONNX Runtime环境下推理,测试量化后的仿真模型精度。
使用量化后仿真模型精度与2中的原始精度做对比,可以观察量化对精度的影响。
quant_model = './results/user_model_fake_quant_model.onnx' user_do_inference(quant_model, test_data, test_iterations)
如果模式适配后,deploy部署模型和fakequant精度仿真模型推理精度和原始模型推理精度相比差异较大,原因是deploy模型上板推理需要对bias做量化,fakequant模型推理会对bias做量化反量化,可能与原始模型中的bias存在差异,从而导致了上述精度的差异;该场景下,建议用户先对原始模型的bias进行量化反量化操作,然后再进行模型适配,进行量化反量化的公式如下:
round(bias/(scale_d*scale_w))*(scale_d*scale_w)
量化数据均衡预处理¶
在一些数据分布不均匀的场景,由于离群值的影响,对数据进行per-tensor量化得到的结果误差较大,而per-channel量化可以获得更低的误差。但由于当前硬件不支持数据per-channel量化,仅支持权重per-channel量化;在该背景下AMCT设计出一套方法,本节将给出详细介绍。
通过数据均衡预处理接口计算出均衡因子,将模型数据与权重进行数学等价换算,均衡模型数据与权重的分布,将数据的量化难度迁移一部分至权重,从而降低量化误差。
表 1 支持的层以及约束
支持的层类型 |
约束 |
备注 |
|---|---|---|
Conv:卷积层 |
支持4维或5维输入场景下的量化 |
复用层(共用weight)不支持预处理均衡量化。 |
Gemm:广义矩阵乘 |
transpose_a=false、Alpha=Beta=1.0 |
|
MatMul:全连接层 |
当权重维度为2时,才支持量化 |
|
ConvTranspose:转置卷积层 |
仅支持4维输入场景下的量化 |
接口调用流程
均衡预处理接口调用流程如图1所示:
图 1 均衡预处理接口调用流程

蓝色部分为用户实现,灰色部分为用户调用AMCT提供的API实现,使用流程如下:
用户准备ONNX原始模型,并在简易配置文件_dmp_quant.cfg_中设置dmq参数(简易配置文件配置参数请参见训练后量化简易配置文件),然后将配置文件传入create_quant_config。
根据ONNX模型和量化配置文件,即可调用quantize_preprocess接口对原始ONNX模型进行量化前优化:均衡量化,将数据的量化难度迁移到权重量化。
用户基于ONNX Runtime以及校准集,执行一次校准模型推理完成均衡量化,并将均衡因子输出到record文件中。
根据ONNX模型、量化配置文件和record,即可调用quantize_model接口对原始ONNX模型进行量化前优化,包括Conv+BN融合等,插入权重量化算子,进行权重量化;插入数据量化算子,得到校准模型。
用户基于ONNX Runtime以及校准集,执行校准模型推理完成数据量化,并将量化因子输出到文件中。
最后用户可以调用save_model接口保存量化后的模型,包括可在ONNX执行框架ONNX Runtime环境中进行精度仿真的模型文件和可部署在NPU IP加速器的模型文件。
调用示例
如下示例标有“由用户补充处理”的步骤,需要用户根据自己的模型和数据集进行补充处理,示例中仅为示例代码。
如下示例调用AMCT的部分,函数入参请根据实际情况进行调整。
导入AMCT包,并通过设置环境变量日志级别。
import amct_onnx as amct(可选,由用户补充处理)在ONNX Runtime环境中验证推理脚本及环境。
建议使用原始待量化的模型和测试集,在ONNX Runtime环境下推理,验证环境、推理脚本是否正常。
推荐执行该步骤,请确保原始模型可以完成推理且精度正常;执行该步骤时,可以使用部分测试集,减少运行时间。
user_do_inference(ori_model, test_data, test_iterations)调用AMCT,量化模型。
生成量化配置。
用户在简易配置文件_dmp_quant.cfg_中设置dmq参数,并将配置文件通过config_defination参数传入create_quant_config。
config_defination = os.path.join(PATH, 'dmp_quant.cfg') config_file = './tmp/config.json' skip_layers = [] batch_num = 1 amct.create_quant_config(config_file=config_file, model=ori_model, input_data=ori_model_input_data, skip_layers=skip_layers, batch_num=batch_num, config_defination=config_defination)
修改图,在图中插入均衡量化算子,用于计算均衡量化因子。
record_file = './tmp/record.txt' modified_model = './tmp/modified_model.onnx' amct.quantize_preprocess(config_file=config_file, record_file=record_file, model_file=ori_model, modified_onnx_file=modified_model)
(由用户补充处理)使用修改后的图在校准集上做模型推理,找到均衡量化因子。
该步骤执行时,需要注意如下两点:
校准集及其预处理过程数据要与模型匹配,以保证量化的精度。
前向推理的次数为1,如果次数超过1次,每执行一次推理,record中均衡量化因子会被记录一次,后续过程会失败。
user_do_inference(modified_onnx_file, calibration_data, test_iterations=1)修改图,在图中插入数据量化,权重量化等相关的算子,用于计算量化相关参数。
modified_model = './tmp/modified_model.onnx' amct.quantize_model(config_file=config_file, model_file=ori_model, modified_onnx_file=modified_model, record_file=record_file)
(由用户补充处理)使用修改后的图在校准集上做模型推理,找到量化因子。
该步骤执行时,需要注意如下两点:
校准集及其预处理过程数据要与模型匹配,以保证量化的精度。
前向推理的次数为batch_num,如果次数不够,后续过程会失败。
若校准过程中有错误信息,则可以尝试参见校准过程中提示"IFMR node. Name:'layer_ifmr_op' Status Message: std::bad_alloc"信息或校准过程中出现"killed"信息进行处理。
user_do_inference(modified_onnx_file, calibration_data, batch_num)保存模型。
根据量化因子以及修改后的模型,调用save_model接口,插入AscendQuant、AscendDequant等算子,保存为量化模型。
quant_model_path = './results/user_model' amct.save_model(modified_onnx_file=modified_model, record_file=record_file, save_path=quant_model_path)
(可选,由用户补充处理)基于ONNX Runtime的环境,使用量化后模型(quant_model)在测试集(test_data)上做推理,测试量化后仿真模型的精度。
使用量化后仿真模型精度与2中的原始精度做对比,可以观察量化对精度的影响。
quant_model = './results/user_model_fake_quant_model.onnx' user_do_inference(quant_model, test_data, test_iterations)
接口说明¶
整体约束和接口列表¶
整体约束
若接口中存在需要用户输入文件路径的参数,请确保输入路径正确,AMCT不会对路径做安全校验。
若接口中存在需要用户输入文件路径的参数,重新执行量化时,该参数相关取值将会被覆盖;量化打屏日志中也会有相关文件被覆盖的warning风险提示信息。
接口列表
分类 |
接口名称 |
功能描述 |
|---|---|---|
训练后量化接口 |
create_quant_config |
根据图的结构找到所有可量化的层,自动生成量化配置文件,并将可量化层的量化配置信息写入文件。 |
quantize_model |
将输入的待量化的图结构按照给定的量化配置文件进行量化处理,在传入的图结构中插入权重量化,以及数据量化等相关的算子,生成量化因子记录文件record_file,返回修改后的ONNX校准模型。 |
|
save_model |
根据量化因子记录文件record_file以及修改后的模型,调用该接口,插入AscendQuant、AscendDequant等算子,然后保存为可以在ONNX Runtime环境进行精度仿真的fake_quant模型,和可以在NPU IP加速器做推理的deploy模型。 |
|
accuracy_based_auto_calibration |
根据用户输入的模型、配置文件进行自动的校准过程,搜索得到一个满足目标精度的量化配置,输出可以在ONNX Runtime环境下做精度仿真的fake_quant模型,和可在NPU IP加速器上做推理的deploy模型。 |
|
quantize_preprocess |
量化数据均衡预处理接口,将输入的待量化的图结构按照给定的量化配置文件进行训练后量化预处理,在传入的图结构中插入均衡量化算子,生成均衡量化因子记录文件record_file,返回修改后的ONNX校准模型。 |
|
模型适配接口 |
convert_qat_model |
将ONNX量化模型适配为CANN支持的量化模型。 |
训练后量化接口¶
create_quant_config¶
产品支持情况
产品 |
是否支持 |
|---|---|
IPV350 |
√ |
功能说明
根据图的结构找到所有可量化的层,自动生成量化配置文件,并将可量化层的量化配置信息写入文件。
函数原型
create_quant_config(config_file, model_file, skip_layers=None, batch_num=1, activation_offset=True, config_defination=None, updated_model=None)
参数说明
参数名 |
输入/输出 |
说明 |
|---|---|---|
config_file |
输入 |
含义:待生成的量化配置文件存放路径及名称。如果存放路径下已经存在该文件,则调用该接口时会覆盖已有文件。 数据类型:string |
model_file |
输入 |
含义:待量化的ONNX模型文件。该模型必须是基于ONNX opset11生成的模型,并且能够在ONNX Runtime 1.5.2上完成推理。 数据类型:string |
skip_layers |
输入 |
含义:可量化但不需要量化的层名。 默认值:None 数据类型:list,列表中元素类型为string 使用约束:如果使用简易配置文件作为入参,则该参数需要在简易配置文件中设置,此时输入参数中该参数配置不生效。 |
batch_num |
输入 |
含义:量化使用的batch数量,即使用多少个batch的数据生成量化因子。 数据类型:int 取值范围:大于0的整数 默认值:1 使用约束:
|
activation_offset |
输入 |
含义:数据量化是否带offset。 默认值:True 数据类型:bool 使用约束:如果使用简易配置文件作为入参,则该参数需要在简易配置文件中设置,此时输入参数中该参数配置不生效。 |
config_defination |
输入 |
含义:基于calibration_config_onnx.proto文件生成的简易量化配置文件quant.cfg,*.proto文件所在路径为:AMCT安装目录/amct_onnx/proto/。*.proto文件参数解释以及生成的quant.cfg简易量化配置文件样例请参见训练后量化简易配置文件。 默认值:None 数据类型:string 使用约束:当取值为None时,使用输入参数生成配置文件;否则,忽略输入的其他量化参数(skip_layers,batch_num,activation_offset),根据简易量化配置文件参数config_defination生成JSON格式的配置文件。 |
updated_model |
输入 |
含义:如果配置,会去更新模型里节点name,没有name的会按{op_type}_{index}格式生成唯一的name,对于已有的name重复的节点会通过增加数字后缀保证name唯一,然后按配置的文件路径保存更新后的ONNX模型。 默认值:None 数据类型:string |
返回值说明
无
调用示例
import amct_onnx as amct
model_file = "resnet101.onnx"
# 生成量化配置文件
amct.create_quant_config(config_file="./configs/config.json",
model_file=model_file,
skip_layers=None,
batch_num=1,
activation_offset=True)
落盘文件说明:生成JSON格式的量化配置文件,样例如下(重新执行量化时,该接口输出的量化配置文件将会被覆盖):
均匀量化配置文件(数据量化使用IFMR数据量化算法)
{ "version":1, "batch_num":2, "activation_offset":true, "joint_quant":false, "do_fusion":true, "skip_fusion_layers":[], "tensor_quantize":[ { "layer_name": "maxpool_ld_default", "input_index":0, "activation_quant_params":{ "num_bits":16, "max_percentile":0.999999, "min_percentile":0.999999, "search_range":[ 0.7, 1.3 ], "search_step":0.01, "act_algo":"ifmr", "asymmetric":false } } ], "layer_name1":{ "quant_enable":true, "dmq_balancer_param":0.5, "activation_quant_params":{ "num_bits":16, "max_percentile":0.999999, "min_percentile":0.999999, "search_range":[ 0.7, 1.3 ], "search_step":0.01, "act_algo":"ifmr", "asymmetric":false }, "weight_quant_params":{ "num_bits":8, "wts_algo":"arq_quantize", "channel_wise":true } }, "layer_name2":{ "quant_enable":true, "dmq_balancer_param":0.5, "activation_quant_params":{ "num_bits":16, "max_percentile":0.999999, "min_percentile":0.999999, "search_range":[ 0.7, 1.3 ], "search_step":0.01, "act_algo":"ifmr", "asymmetric":false }, "weight_quant_params":{ "num_bits":8, "wts_algo":"arq_quantize", "channel_wise":false } } }
均匀量化配置文件(数据量化使用HFMG数据量化算法)
{ "version":1, "batch_num":2, "activation_offset":true, "do_fusion":true, "skip_fusion_layers":[], "tensor_quantize":[ { "layer_name": "maxpool_ld_default", "input_index":0, "activation_quant_params":{ "num_bits":16, "max_percentile":0.999999, "min_percentile":0.999999, "search_range":[ 0.7, 1.3 ], "search_step":0.01 "act_algo":"hfmg" "asymmetric":false } } ], "layer_name1":{ "quant_enable":true, "dmq_balancer_param":0.5, "activation_quant_params":{ "num_bits":16, "act_algo":"hfmg", "num_of_bins":4096 "asymmetric":false }, "weight_quant_params":{ "num_bits":8, "wts_algo":"arq_quantize", "channel_wise":true } } }
quantize_model¶
产品支持情况
产品 |
是否支持 |
|---|---|
IPV350 |
√ |
功能说明
将输入的待量化的图结构按照给定的量化配置文件进行量化处理,在传入的图结构中插入权重量化,以及数据量化等相关的算子,生成量化因子记录文件record_file,返回修改后的ONNX校准模型。
函数原型
quantize_model(config_file, model_file, modified_onnx_file, record_file)
参数说明
参数名 |
输入/输出 |
说明 |
|---|---|---|
config_file |
输入 |
含义:用户生成的量化配置文件,用于指定模型network中量化层的配置情况。 数据类型:string |
model_file |
输入 |
含义:用户原始ONNX模型文件或者通过create_quant_config生成的updated模型。 数据类型:string |
modified_onnx_file |
输入 |
含义:文件名,用于存储待执行数据量化的ONNX校准模型。 数据类型:string |
record_file |
输入 |
含义:量化因子记录文件路径及名称。 数据类型:string |
返回值说明
无
调用示例
import amct_onnx as amct
model_file = "resnet101.onnx"
scale_offset_record_file = os.path.join(TMP, 'scale_offset_record.txt')
modified_model = os.path.join(TMP, 'modified_model.onnx')
config_file="./configs/config.json"
# 插入量化API
amct.quantize_model(config_file,
model_file,
modified_model,
scale_offset_record_file)
save_model¶
产品支持情况
产品 |
是否支持 |
|---|---|
IPV350 |
√ |
功能说明
根据量化因子记录文件record_file以及修改后的模型,调用该接口,插入AscendQuant、AscendDequant等算子,然后保存为可以在ONNX Runtime环境进行精度仿真的fake_quant模型,和可以在NPU IP加速器做推理的deploy模型。
约束说明
在网络推理的batch数目达到batch_num后,再调用该接口,否则量化因子不正确,量化结果不正确。
该接口只接收quantize_model接口产生的ONNX类型模型文件。
该接口需要输入量化因子记录文件,量化因子记录文件在quantize_model阶段生成,在模型推理阶段填充有效值。
函数原型
save_model(modified_onnx_file, record_file, save_path)
参数说明
参数名 |
输入/输出 |
说明 |
|---|---|---|
modified_onnx_file |
输入 |
含义:文件名,修改后的ONNX模型文件,由quantize_model接口输出。 数据类型:string |
record_file |
输入 |
含义:量化因子记录文件路径及名称。 数据类型:string |
save_path |
输入 |
含义:模型存放路径。该路径需要包含模型名前缀,例如./quantized_model/*model。 数据类型:string |
返回值说明
无
调用示例
import amct_onnx as amct
# 进行网络推理,期间完成量化
# 由于quantize_model接口生成的校准模型中包含了AMCT新增的自定义算子,所以在执行校准集的推理时创建的onnxruntime的InferenceSession需要包含AMCT提供的SessionOptions
for i in batch_num:
onnxruntime.InferenceSession(onnx_model, amct.AMCT_SO).run(None, {'input':input_batch})
# 插入API,将量化的模型存为onnx文件
amct.save_model(modified_onnx_file="./tmp/modified_model.onnx",
record_file="./scale_offset_record_file.txt",
save_path="./results/model")
落盘文件说明:
精度仿真模型文件:模型名中包含fake_quant,可以在ONNX执行框架ONNX Runtime进行精度仿真。
部署模型文件:模型名中包含deploy,经过ATC转换工具转换后可部署到NPU IP加速器。
(可选)*.external文件,包括*deploy.external和*fakequant.external:
如果原始模型为非分离模式网络(不包含external data),只有保存的精度仿真模型以及部署模型文件大小>=2GB才会生成该类文件,且与压缩后的*.onnx模型文件生成在同级目录,用于保存Tensor中的数据,每个Tensor数据单独保存一份*.external文件,文件名与Tensor相同,例如_conv1.weight__deploy.external和_conv1.weight__fakequant.external。
如果原始模型为数据模型分离模式网络(包含external data),不论压缩后的模型文件是否>=2GB,Tensor数据都会单独保存,即始终会生成*.external文件(constant节点不支持转存为external_data)。
后续通过ATC工具加载压缩后的*.onnx部署模型文件进行模型转换时,会自动读取同级目录下*.external文件中的Tensor数据。
重新执行量化时,该接口输出的上述文件将会被覆盖。
accuracy_based_auto_calibration¶
产品支持情况
产品 |
是否支持 |
|---|---|
IPV350 |
√ |
功能说明
根据用户输入的模型、配置文件进行自动的校准过程,搜索得到一个满足目标精度的量化配置,输出可以在ONNX Runtime环境下做精度仿真的fake_quant模型,和可在NPU IP加速器上做推理的deploy模型。
约束说明
无。
函数原型
accuracy_based_auto_calibration(model_file,model_evaluator,config_file,record_file,save_dir,strategy='BinarySearch',sensitivity='CosineSimilarity')
参数说明
参数名 |
输入/输出 |
说明 |
|---|---|---|
model_file |
输入 |
含义:用户onnx模型文件,格式为.onnx。 数据类型:string |
model_evaluator |
输入 |
含义:自动量化进行校准和评估精度的Python实例。 数据类型:Python实例 |
config_file |
输入 |
含义:用户生成的量化配置文件。 数据类型:string |
record_file |
输入 |
含义:存储量化因子的路径,如果该路径下已存在文件,则会被重写。 数据类型:string |
save_dir |
输入 |
含义:模型存放路径。该路径需要包含模型名前缀,例如./quantized_model/*model。 数据类型:string |
strategy |
输入 |
含义:搜索满足精度要求的量化配置的策略,默认是二分法策略。 数据类型:string或Python实例 默认值:BinarySearch |
sensitivity |
输入 |
含义:评价每一层量化层对于量化敏感度的指标,默认是余弦相似度。 数据类型:string或Python实例 默认值:CosineSimilarity |
返回值说明
无
调用示例
import amct_onnx as amct
from amct_onnx.common.auto_calibration import AutoCalibrationEvaluatorBase
# You need to implement the AutoCalibrationEvaluator's calibration(), evaluate() and metric_eval() funcs
class AutoCalibrationEvaluator(AutoCalibrationEvaluatorBase):
""" subclass of AutoCalibrationEvaluatorBase"""
def __init__(self, target_loss, batch_num):
super(AutoCalibrationEvaluator, self).__init__()
self.target_loss = target_loss
self.batch_num = batch_num
def calibration(self, model_file):
""" implement the calibration function of AutoCalibrationEvaluatorBase
calibration() need to finish the calibration inference procedure
so the inference batch num need to >= the batch_num pass to create_quant_config
"""
onnx_forward(onnx_model=model_file, batch_size=32, iterations=self.batch_num)
def evaluate(self, model_file):
""" implement the evaluate function of AutoCalibrationEvaluatorBase
params: model_file in .onnx
return: the accuracy of input model on the eval dataset, or other metric which
can describe the 'accuracy' of model
"""
top1, top5 = onnx_forward(onnx_model=model_file, batch_size=32, iterations=5)
return top1
def metric_eval(self, original_metric, new_metric):
""" implement the metric_eval function of AutoCalibrationEvaluatorBase
params: original_metric: the returned accuracy of evaluate() on non quantized model
new_metric: the returned accuracy of evaluate() on fake quant model
return:
[0]: whether the accuracy loss between non quantized model and fake quant model
can satisfy the requirement
[1]: the accuracy loss between non quantized model and fake quant model
"""
loss = original_metric - new_metric
if loss * 100 < self.target_loss:
return True, loss
return False, loss
...
config_json_file = os.path.join(TMP, 'config.json')
skip_layers = []
batch_num = 1
model_file = "mobilenet_v2.onnx"
amct.create_quant_config(
config_file=config_json_file, model_file=model_file, skip_layers=skip_layers, batch_num=batch_num,
activation_offset=True, config_defination=None)
# 1. step1 create quant config json file
scale_offset_record_file = os.path.join(TMP, 'scale_offset_record.txt')
result_path = os.path.join(PATH, 'results/mobilenet_v2')
# 2. step2 construct the instance of AutoCalibrationEvaluator
evaluator = AutoCalibrationEvaluator(target_loss=0.5, batch_num=batch_num)
# 3. step3 using the accuracy_based_auto_calibration to quantized the model
amct.accuracy_based_auto_calibration(
model_file=model_file,
model_evaluator=evaluator,
config_file=config_json_file,
record_file=scale_offset_record_file,
save_dir=result_path,
strategy='BinarySearch',
sensitivity='CosineSimilarity'
)
落盘文件说明:
精度仿真模型文件:模型名中包含fake_quant,可以在ONNX执行框架ONNX Runtime进行精度仿真。
部署模型文件:模型名中包含deploy,经过ATC工具转换后可部署到NPU IP加速器。
量化因子记录文件:在接口中的record_file中写入量化因子。
敏感度信息文件:该文件记录了待量化层对于量化的敏感度信息,根据该信息进行量化回退层的选择。
自动量化回退历史记录文件:记录的回退层的信息。
quantize_preprocess¶
产品支持情况
产品 |
是否支持 |
|---|---|
IPV350 |
√ |
功能说明
量化数据均衡预处理接口,将输入的待量化的图结构按照给定的量化配置文件进行训练后量化预处理,在传入的图结构中插入均衡量化算子,生成均衡量化因子记录文件record_file,返回修改后的ONNX校准模型。
函数原型
quantize_preprocess(config_file, record_file, model_file, modified_onnx_file)
参数说明
参数名 |
输入/输出 |
说明 |
|---|---|---|
config_file |
输入 |
含义:用户生成的量化配置文件,用于指定模型network中量化层的配置情况。 数据类型:string |
record_file |
输入 |
含义:均衡量化因子记录文件路径及名称。 数据类型:string |
model_file |
输入 |
含义:用户原始onnx模型文件或者通过create_quant_config生成的updated模型。 数据类型:string |
modified_onnx_file |
输入 |
含义:文件名,用于存储待执行数据量化的ONNX校准模型。 数据类型:string |
返回值说明
无
调用示例
import amct_onnx as amct
model_file = "resnet101.onnx"
tensor_balance_factor_record_file = os.path.join(TMP, 'tensor_balance_factor_record.txt')
modified_model = os.path.join(TMP, 'modified_model.onnx')
config_file="./configs/config.json"
# 插入量化API
amct.quantize_preprocess(config_file,
tensor_balance_factor_record_file,
model_file,
modified_model)
模型适配接口¶
convert_qat_model¶
产品支持情况
产品 |
是否支持 |
|---|---|
IPV350 |
√ |
功能说明
将ONNX量化模型适配为CANN支持的量化模型。
约束说明
若QuantizeLinear不为output算子:仅支持对QAT模型中包含QuantizeLinear和DequantizeLinear两类FakeQuant层结构的模型进行适配,且仅权重支持per-channel量化,成对的QuantizeLinear、DequantizeLinear层需要存在相同的量化因子。
若QuantizeLinear为非中间层的output算子,且为单输出:则模型适配时,不需要和DequantizeLinear配对,适配过程中会将QuantizeLinear算子替换成AscendQuant算子。
说明:
由于ONNX原始模型中的offset值以INT32类型存储,进行算子替换时,可能会出现offset值超过INT8表示范围的情况;但是实际计算过程中,ONNX Runtime以及AMCT都会对offset做合法化处理,不会影响适配流程及结果。
函数原型
convert_qat_model(model_file, save_path, record_file=None)
参数说明
参数名 |
输入/输出 |
说明 |
|---|---|---|
model_file |
输入 |
含义:待适配的.onnx格式模型文件路径。 数据类型:string |
save_path |
输入 |
含义:模型存放路径。该路径需要包含模型名前缀,例如./quantized_model/*model。 数据类型:string |
record_file |
输入 |
含义:用户计算得到的量化因子记录文件路径,量化因子记录文件格式为.txt。 数据类型:string 默认值为:None |
返回值说明
无
调用示例
import amct_onnx as amct
model_file = "./pre_model/mobilenet_v2_qat.onnx"
save_path="./results/model"
amct.convert_qat_model(model_file, save_path)
落盘文件说明:
可用于CPU/GPU测试的fakequant模型以及用于ATC转换的deploy模型。
(可选)生成一个量化参数的txt格式记录文件,内部记录了完整量化层的量化参数。
参考信息¶
工具实现的融合功能¶
当前该工具主要实现的融合功能如下:
Conv+BN融合:AMCT在量化前会对模型中的"Conv+BatchNormalization"结构做Conv+BN融合,融合后的"BatchNormalization"层会被删除。
BatchNormalization+Mul:AMCT在量化前会对模型中的"BatchNormalization+Mul"结构做"BN+Mul"融合,融合后的"Mul"层会被删除。
BatchNormalization+Add:AMCT在量化前会对模型中的"BatchNormalization+Add"结构做"BN+Add"融合,融合后的"Add"层会被删除。
训练后量化简易配置文件¶
calibration_config_onnx.proto文件参数说明如表1所示,该文件所在目录为:AMCT安装目录/amct_onnx/proto/calibration_config_onnx.proto。
表 1 calibration_config_onnx.proto参数说明
消息 |
是否必填 |
类型 |
字段 |
说明 |
|---|---|---|---|---|
AMCTConfig |
- |
- |
- |
AMCT训练后量化的简易配置。 |
optional |
uint32 |
batch_num |
量化使用的batch数量。 |
|
optional |
bool |
activation_offset |
数据量化是否带offset。全局配置参数。
|
|
repeated |
string |
skip_layers |
不需要量化层的层名。 |
|
repeated |
string |
skip_layer_types |
不需要量化的层类型。 |
|
optional |
NuqConfig |
nuq_config |
非均匀量化配置。 |
|
optional |
bool |
joint_quant |
是否进行Eltwise联合量化,默认为false,表示关闭联合量化功能。 |
|
optional |
FakequantPrecisionMode |
fakequant_precision_mode |
fakequant模型中quant自定义算子的scale_d数值精度模式。
|
|
optional |
CalibrationConfig |
common_config |
通用的量化配置,全局量化配置参数。若某层未被override_layer_types或者override_layer_configs重写,则使用该配置。 参数优先级:override_layer_configs>override_layer_types>common_config |
|
repeated |
OverrideLayerType |
override_layer_types |
重写某一类型层的量化配置,即对哪些层进行差异化量化。 例如全局量化配置参数配置的量化因子搜索步长为0.01,可以通过该参数对部分层进行差异化量化,可以配置搜索步长为0.02。 参数优先级:override_layer_configs>override_layer_types>common_config |
|
repeated |
OverrideLayer |
override_layer_configs |
重写某一层的量化配置,即对哪些层进行差异化量化。 例如全局量化配置参数配置的量化因子搜索步长为0.01,可以通过该参数对部分层进行差异化量化,可以配置搜索步长为0.02。 参数优先级:override_layer_configs>override_layer_types>common_config |
|
optional |
bool |
do_fusion |
是否开启BN融合功能,默认为true,表示开启该功能。 |
|
repeated |
string |
skip_fusion_layers |
跳过BN融合的层,配置之后这些层不会进行BN融合。 |
|
repeated |
TensorQuantize |
tensor_quantize |
对网络模型中指定节点的输入Tensor进行训练后量化,来提高数据搬运时的推理性能。 当前仅支持对MaxPool/Add算子做tensor量化。 |
|
NuqConfig |
- |
- |
- |
非均匀量化配置。 |
required |
string |
mapping_file |
均匀量化后的deploy模型通过ATC工具转换得到om模型,然后通过ATC工具转换得到JSON文件,即量化后模型的融合JSON文件。 |
|
optional |
NUQuantize |
nuq_quantize |
非均匀量化的参数。 |
|
OverrideLayerType |
- |
- |
- |
重置某层类型的量化配置。 |
required |
string |
layer_type |
支持量化的层类型的名字。 |
|
required |
CalibrationConfig |
calibration_config |
重置的量化配置。 |
|
OverrideLayer |
- |
- |
- |
重置某层量化配置。 |
required |
string |
layer_name |
被重置层的层名。 |
|
required |
CalibrationConfig |
calibration_config |
重置的量化配置。 |
|
TensorQuantize |
- |
- |
- |
需要进行训练后量化的输入Tensor配置。 |
required |
string |
layer_name |
需要对节点输入Tensor进行训练后量化的节点名称,当前仅支持对MaxPool/Add算子的输入Tensor进行量化。 |
|
required |
uint32 |
input_index |
需要对节点输入Tensor进行训练后量化的节点的输入索引。 |
|
- |
FMRQuantize |
ifmr_quantize |
数据量化算法配置。 ifmr_quantize:IFMR量化算法配置。默认为IFMR量化算法。 |
|
- |
HFMGQuantize |
hfmg_quantize |
数据量化算法配置。 hfmg_quantize:HFMG量化算法配置。 |
|
CalibrationConfig |
- |
- |
- |
Calibration量化的配置。 |
- |
ARQuantize |
arq_quantize |
权重量化算法配置。 arq_quantize:ARQ量化算法配置。 |
|
- |
NUQuantize |
nuq_quantize |
权重量化算法配置。 nuq_quantize:非均匀量化算法配置。 |
|
- |
FMRQuantize |
ifmr_quantize |
数据量化算法配置。 ifmr_quantize:IFMR量化算法配置。 |
|
- |
HFMGQuantize |
hfmg_quantize |
数据量化算法配置。 hfmg_quantize:HFMG量化算法配置。 |
|
- |
DMQBalancer |
dmq_balancer |
均衡量化算法配置。 dmq_balancer:DMQBalancer均衡算法配置。 |
|
ARQuantize |
- |
- |
- |
ARQ量化算法配置。算法介绍请参见ARQ权重量化算法。 该算法与NUQuantize算法不能同时配置,若同时配置,则以配置文件中最后配置的量化算法为准。 |
optional |
bool |
channel_wise |
是否对每个channel采用不同的量化因子。
|
|
optional |
uint32 |
quant_bits |
权重量化位宽。支持配置为INT6、INT7、INT8。 默认为INT8量化。 该字段配置为INT6、INT7仅支持Conv2d(Kernel shape为4的Conv算子)类型算子。 如果在common_config中配置quant_bits为INT6、INT7,则只对Conv2d算子生效,其他算子改为默认INT8;如果在override_layer_types中指定Conv类算子quant_bits为INT6、INT7,则只对weight dim为4场景生效。 |
|
FMRQuantize |
- |
- |
- |
FMR量化算法配置。算法介绍请参见IFMR数据量化算法。 该算法与HFMGQuantize算法不能同时配置,若同时配置,则以配置文件中最后配置的量化算法为准。 |
optional |
float |
search_range_start |
量化因子搜索范围左边界。 |
|
optional |
float |
search_range_end |
量化因子搜索范围右边界。 |
|
optional |
float |
search_step |
量化因子搜索步长。 |
|
optional |
float |
max_percentile |
最大值搜索位置。 |
|
optional |
float |
min_percentile |
最小值搜索位置。 |
|
optional |
bool |
asymmetric |
是否进行对称量化。用于控制逐层量化算法的选择。
如果override_layer_configs、override_layer_types、common_config配置项都配置该参数,或者配置了 activation_offset参数,则生效优先级为: override_layer_configs>override_layer_types>common_config>activation_offset |
|
optional |
CalibrationDataType |
dst_type |
量化位宽,数据量化是采用INT8量化还是INT16量化,默认为INT8量化。 |
|
HFMGQuantize |
- |
- |
- |
HFMG数据量化算法配置。算法介绍请参见HFMG数据量化算法。 该算法与FMRQuantize算法不能同时配置,若同时配置,则以配置文件中最后配置的量化算法为准。 |
optional |
uint32 |
num_of_bins |
直方图的bin(直方图中的一个最小单位直方图形)数目,支持的范围为{1024, 2048, 4096, 8192}。 默认值为4096。 |
|
optional |
bool |
asymmetric |
是否进行对称量化。用于控制逐层量化算法的选择。
如果override_layer_configs、override_layer_types、common_config配置项都配置该参数,或者配置了 activation_offset参数,则生效优先级为: override_layer_configs>override_layer_types>common_config>activation_offset |
|
optional |
CalibrationDataType |
dst_type |
量化位宽,数据量化是采用INT8量化还是INT16量化,默认为INT8量化。 |
|
NUQuantize |
- |
- |
- |
非均匀量化算法配置。算法介绍请参见NUQ权重量化算法。 该算法与ARQuantize算法不能同时配置,若同时配置,则以配置文件中最后配置的量化算法为准。 |
optional |
uint32 |
num_steps |
非均匀量化的台阶数。 |
|
optional |
uint32 |
num_of_iteration |
非均匀量化优化的迭代次数。 |
|
DMQBalancer |
- |
- |
- |
DMQ均衡算法配置。算法介绍请参见DMQ均衡算法。 |
optional |
float |
migration_strength |
迁移强度,代表将activation数据上的量化难度迁移至weight权重的程度。支持的范围为[0.2, 0.8],默认值0.5,数据分布的离群值越大迁移强度应设置较小。 |
基于该文件构造的均匀量化简易配置文件quant.cfg样例如下所示:
# global quantize parameter batch_num : 2 activation_offset : true joint_quant : false skip_layers : "Opname" skip_layer_types:"Optype" do_fusion: true skip_fusion_layers : "Optype" common_config : { arq_quantize : { channel_wise : true quant_bits : 7 } ifmr_quantize : { search_range_start : 0.7 search_range_end : 1.3 search_step : 0.01 max_percentile : 0.999999 min_percentile : 0.999999 asymmetric : true dst_type : INT16 } } override_layer_types : { layer_type : "Conv2d" calibration_config : { arq_quantize : { channel_wise : false quant_bits : 6 } ifmr_quantize : { search_range_start : 0.8 search_range_end : 1.2 search_step : 0.02 max_percentile : 0.999999 min_percentile : 0.999999 asymmetric : false dst_type : INT16 } } } override_layer_configs : { layer_name : "Opname" calibration_config : { arq_quantize : { channel_wise : true } ifmr_quantize : { search_range_start : 0.8 search_range_end : 1.2 search_step : 0.02 max_percentile : 0.999999 min_percentile : 0.999999 asymmetric : false dst_type : INT16 } } } tensor_quantize { layer_name: "Opname" input_index: 0 ifmr_quantize: { search_range_start : 0.7 search_range_end : 1.3 search_step : 0.01 min_percentile : 0.999999 asymmetric : false dst_type : INT16 } } tensor_quantize { layer_name: "Opname" input_index: 0 }
如果数据量化算法使用HFMG,则上述配置文件中加粗部分可以替换成如下参考参数信息,举例如下(如下配置信息只是样例,请根据实际情况进行修改):
# global quantize parameter activation_offset : true batch_num : 1 ... common_config : { hfmg_quantize : { num_of_bins : 4096 asymmetric : false dst_type : INT16 } ... }
基于该文件生成的非均匀量化简易配置文件quant.cfg样例如下所示:
# global quantize parameter activation_offset : true joint_quant : false batch_num : 2 nuq_config { mapping_file : "./nuq_files/resnet101_quantized.json" nuq_quantize : { num_steps : 32 num_of_iteration : 0 } } common_config : { arq_quantize : { channel_wise : true } ifmr_quantize : { search_range_start : 0.7 search_range_end : 1.3 search_step : 0.01 max_percentile : 0.999999 min_percentile : 0.999999 asymmetric : true } } override_layer_types : { layer_type : "Optype" calibration_config : { arq_quantize : { channel_wise : false } ifmr_quantize : { search_range_start : 0.7 search_range_end : 1.3 search_step : 0.01 max_percentile : 0.999999 min_percentile : 0.999999 asymmetric : false } } } tensor_quantize { layer_name: "Opname" input_index: 0 ifmr_quantize: { search_range_start : 0.7 search_range_end : 1.3 search_step : 0.01 min_percentile : 0.999999 asymmetric : false } } tensor_quantize { layer_name: "Opname" input_index: 0 }
如果数据量化算法使用HFMG,则上述配置文件中加粗斜体部分可以替换成如下参考参数信息,举例如下(如下配置信息只是样例,请根据实际情况进行修改):
# global quantize parameter activation_offset : true batch_num : 1 ... common_config : { hfmg_quantize : { num_of_bins : 4096 asymmetric : false } ... }
基于该文件构造的量化数据均衡预处理简易配置文件dmq_balancer.cfg样例如下所示:
# global quantize parameter batch_num : 2 activation_offset : true joint_quant : false skip_layers : "Opname" skip_layer_types:"Optype" do_fusion: true skip_fusion_layers : "Opname" common_config : { arq_quantize : { channel_wise : true } ifmr_quantize : { search_range_start : 0.7 search_range_end : 1.3 search_step : 0.01 max_percentile : 0.999999 min_percentile : 0.999999 asymmetric : true } dmq_balancer : { migration_strength : 0.5 } } override_layer_types : { layer_type : "Optype" calibration_config : { arq_quantize : { channel_wise : false } ifmr_quantize : { search_range_start : 0.8 search_range_end : 1.2 search_step : 0.02 max_percentile : 0.999999 min_percentile : 0.999999 asymmetric : false } dmq_balancer : { migration_strength : 0.5 } } } override_layer_configs : { layer_name : "Opname" calibration_config : { arq_quantize : { channel_wise : true } ifmr_quantize : { search_range_start : 0.8 search_range_end : 1.2 search_step : 0.02 max_percentile : 0.999999 min_percentile : 0.999999 asymmetric : false } dmq_balancer : { migration_strength : 0.5 } } }
record记录文件¶
record文件,为基于protobuf协议的序列化数据结构文件,记录量化因子scale/offset等,通过该文件、压缩配置文件以及原始网络模型文件,生成压缩后的模型文件。
record原型定义
record文件对应的protobuf原型定义为(或查看_AMCT安装目录_/amct_onnx/proto/scale_offset_record_onnx.proto文件):
syntax = "proto2";
message SingleLayerRecord {
optional float scale_d = 1;
optional int32 offset_d = 2;
repeated float scale_w = 3;
repeated int32 offset_w = 4;
repeated uint32 shift_bit = 5;
optional bool skip_fusion = 6 [default = true];
optional bool is_tensor_quantize = 10 [default = false];
repeated float tensor_balance_factor = 13;
optional string op_data_type = 15;
optional string act_type = 20 [default = 'INT8'];
optional string wts_type = 21 [default = 'INT8'];
}
message MapFiledEntry {
optional string key = 1;
optional SingleLayerRecord value = 2;
}
message ScaleOffsetRecord {
repeated MapFiledEntry record = 1;
}
参数说明如下:
消息 |
是否必填 |
类型 |
字段 |
说明 |
|---|---|---|---|---|
SingleLayerRecord |
- |
- |
- |
包含了量化层所需要的所有量化因子记录信息。 |
optional |
float |
scale_d |
数据量化scale因子,仅支持对数据进行统一量化。 |
|
optional |
int32 |
offset_d |
数据量化offset因子,仅支持对数据进行统一量化。 |
|
repeated |
float |
scale_w |
权重量化scale因子,支持标量(对当前层的权重进行统一量化),向量(对当前层的权重按channel_wise方式进行量化)两种模式,仅支持Conv2d类型进行channel_wise量化模式。 |
|
repeated |
int32 |
offset_w |
权重量化offset因子,同scale_w一样支持标量和向量两种模式,且需要同scale_w维度一致,当前不支持权重带offset量化模式,offset_w仅支持0。 |
|
repeated |
uint32 |
shift_bit |
移位因子。只有训练后量化简易配置文件配置了joint_quant参数,shift_bit参数才会写入record文件。 |
|
optional |
bool |
skip_fusion |
配置当前层是否要跳过Conv+BN融合,默认为false,即当前层要做上述融合。 |
|
optional |
bool |
is_tensor_quantize |
标识当前record文件中Tensor的量化记录,默认为false,表示该条record记录为非Tensor量化记录。 |
|
repeated |
float |
tensor_balance_factor |
均衡量化因子。该字段仅量化数据均衡预处理场景使用。 |
|
optional |
string |
op_data_type |
算子的输入数据类型。包括FLOAT16和FLOAT32两种类型。 |
|
optional |
string |
act_type |
数据量化位宽,包括INT8和INT16两种量化类型。 |
|
optional |
string |
wts_type |
权重量化位宽。 当前INT6、INT7量化后的量化因子仍保存为INT8类型。 |
|
ScaleOffsetRecord |
- |
- |
- |
map结构,为保证兼容性,采用离散的map结构。 |
repeated |
MapFiledEntry |
record |
每个record对应一个量化层的量化因子记录;record包括两个成员:
|
|
MapFiledEntry |
optional |
string |
key |
层名。 |
optional |
SingleLayerRecord |
value |
量化因子配置。 |
对于optional字段,由于protobuf协议未对重复出现的值报错,而是采用覆盖处理,因此出现重复配置的optional字段内容时会默认保留最后一次配置的值,需要用户自己保证文件的正确性。
record记录文件
最终生成的record文件格式为_record.txt_,文件内容根据特性不同划分如下。
量化特性record文件
对于一般量化层配置需要包含scale_d、offset_d、scale_w、offset_w、shift_bit参数,文件内容示例如下:
record { key: "conv" value { shift_bit: 1 //只有训练后量化简易配置文件配置了joint_quant参数,record文件中才会记录shift_bit信息 scale_d: 0.0798481479 offset_d: 1 op_data_type: 'FLOAT32' scale_w: 0.007364662 scale_w: 0.0069018262 offset_w: 0 offset_w: 0 skip_fusion: true act_type: "INT16" wts_type: "INT8" } } record { key: "maxpool_ld_default:0" value { scale_d: 0.00392156886 offset_d: -128 op_data_type: 'FLOAT32' is_tensor_quantize: true } }
量化数据均衡预处理特性record文件,内容示例如下:
record { key: "matmul_1" value { scale_d: 0.00784554612 offset_d: -1 op_data_type: 'FLOAT32' scale_w: 0.00778095098 offset_w: 0 shift_bit: 2 //只有训练后量化简易配置文件配置了joint_quant参数,record文件中才会记录shift_bit信息 tensor_balance_factor: 0.948409557 tensor_balance_factor: 0.984379828 } } record { key: "conv_1" value { scale_d: 0.00759239076 offset_d: -4 op_data_type: 'FLOAT32' scale_w: 0.0075149606 offset_w: 0 shift_bit: 1 tensor_balance_factor: 1.04744744 tensor_balance_factor: 1.44586647 } }
AMCT(TensorFlow)(不支持)¶
张量分解通过分解卷积核的张量,将一个卷积转化成两个小卷积的堆叠来降低推理开销,如用户模型中存在大量卷积,且卷积核shape普遍大于(64, 64, 3, 3)时推荐使用张量分解。
量化¶
本章节详细介绍AMCT量化场景,以及每个场景下的功能。
简介¶
本章节详细介绍AMCT量化场景,以及每个场景下的功能。
量化分类
量化根据是否需要重训练,分为训练后量化(Post-Training Quantization,简称PTQ)和量化感知训练(Quantization-Aware Training,简称QAT),概念解释请参见量化。
训练后量化
根据量化后是否手动调优量化配置文件,分为手工量化和自动量化。训练后量化使用的量化算法请参见训练后量化算法。
根据是否对权重数据进行压缩又分为均匀量化和非均匀量化。如果量化后的精度不满足要求,则可以进行自动量化或手工调优,推荐使用自动量化。
量化感知训练
量化感知训练当前仅支持对float32数据类型的网络模型进行量化。量化感知训练使用的量化算法请参见量化感知训练算法。
当前仅支持手工量化,如果量化后的精度不满足要求,可以进行手工调优。
相关概念
量化过程中使用的相关术语解释如下:
表 1 量化过程中的相关概念
术语 |
解释 |
|---|---|
数据量化和权重量化 |
训练后量化和量化感知训练,根据量化对象不同,又分为数据(activation)量化和权重(weight)量化。 当前NPU IP加速器支持数据(activation)做对称/非对称量化,权重(weight)仅支持做对称量化(量化根据量化后数据中心点是否为0可以分为对称量化、非对称量化,详细的量化算法原理请参见量化算法原理)。
|
量化位宽 |
量化根据量化后低比特位宽大小分为常见的INT8、INT4、INT16、Binary量化等,当前版本仅支持INT8、INT16量化。
|
测试数据集 |
数据集的子集,用于最终测试模型的效果。 |
校准 |
训练后量化场景中,做前向推理获取数据量化因子的过程。 |
校准数据集 |
训练后量化场景中,做前向推理使用的数据集。该数据集的分布代表着所有数据集的分布,获取校准集时应该具有代表性,推荐使用测试集的子集作为校准数据集。如果数据集不是模型匹配的数据集或者代表性不够,则根据校准集计算得到的量化因子,在全数据集上表现较差,量化损失大,量化后精度低。 |
训练数据集 |
数据集的子集,基于用户训练网络中的数据集,用于对模型进行训练。 |
量化因子 |
将浮点数量化为整数的参数,包括缩放因子(scale),偏移量(offset)。 将浮点数量化为整数(以INT8为例)的公式如下:
|
scale |
量化因子,浮点数的缩放因子,该参数又分为:
|
offset |
量化因子,偏移量,该参数又分为:
|
量化敏感度 |
模型在不同数据精度下,计算结果是有差异的,正常情况下,数据精度越高计算越准确,网络模型的推理结果越准确,而使用量化方法降低网络模型或者某层的数据精度后,会影响模型推理的精度。为了评估这种影响,引入量化敏感度的概念。 量化敏感度用于评价网络模型或者可量化层受量化影响大小。通过比较网络的输出或者某层的输出在量化前后的差异来计算量化敏感度,常见的指标有MSE(Mean Square Error,均方误差),余弦相似度等。 |
比特复杂度 |
对模型中的某层来说,浮点计算量为Flops。而比特复杂度(bitops)则综合了浮点计算量和数据精度,描述在不同的数据精度下(比如,float32/float16/INT8/INT4),计算资源存在的差异。 具体计算方法如下,其中Flops为浮点计算量,act_bit为数据的数据精度,wts_bit为权重的数据精度。
|
训练后量化¶
自动量化¶
基于精度的自动量化是为了方便用户在对量化精度有一定要求时所采用的方法。该功能能够在保证用户所需的模型精度前提下,自动搜索模型的量化配置并执行训练后量化的流程,最终生成满足精度要求的量化模型。
基于精度的自动量化¶
基于精度的自动量化是为了方便用户在对量化精度有一定要求时所采用的方法。该功能能够在保证用户所需的模型精度前提下,自动搜索模型的量化配置并执行训练后量化的流程,最终生成满足精度要求的量化模型。
基于精度的自动量化基本原理与手工量化相同,但是用户无需手动调整量化配置文件,大大简化了优化流程,提高了量化效率。量化支持的层以及约束请参见均匀量化,量化示例请参见样例列表。
接口调用流程
接口调用流程如图1所示。
图 1 自动量化接口调用流程
主要流程如下:
调用create_quant_config生成量化配置文件,然后调用accuracy_based_auto_calibration进行基于精度的自动量化。
调用accuracy_based_auto_calibration中由用户传入的evaluator实例进行精度测试,得到原始模型精度。
该过程还会调用accuracy_based_auto_calibration中的量化策略strategy模块,输出初始化的quant config量化配置文件,该文件记录所有层都可以进行量化。
使用用户传入的初始量化配置文件(1中调用create_quant_config生成的)对模型进行量化,得到量化后fake quant模型的精度。
原始模型精度与量化后fake quant模型精度进行比较,如果精度达标,则输出量化后的部署模型和fake quant模型,如果不达标,则进行基于精度的量化流程:
进行原始TensorFlow网络的推理, dump出每一层的输入activation数据,缓存起来。
利用calibration量化后的量化因子构造量化层的单算子网络,利用缓存的activation计算量化后fake quant单算子网络的输出数据和原始TensorFlow单算子网络输出的余弦相似度。
将余弦相似度的列表传给accuracy_based_auto_calibration中的量化策略strategy模块,strategy模块基于2中生成的初始化的量化配置文件,输出回退某些层后的新的quant config量化配置文件。
根据quant config量化配置文件重新进行训练后量化,得到回退后的fake quant模型。
调用accuracy_based_auto_calibration中的evaluator模块进行回退后的fake quant模型精度测试,查看精度是否达标:
如果达标,则输出回退后的fake quant模型以及部署模型。
如果不达标,则将余弦相似度排序最差的层回退,则再次进行4.c,输出新的量化配置。
如果回退所有层后精度仍不达标,则不生成量化模型。
accuracy_based_auto_calibration接口内部基于精度的自动量化流程如图2所示。
图 2 基于精度的自动量化流程
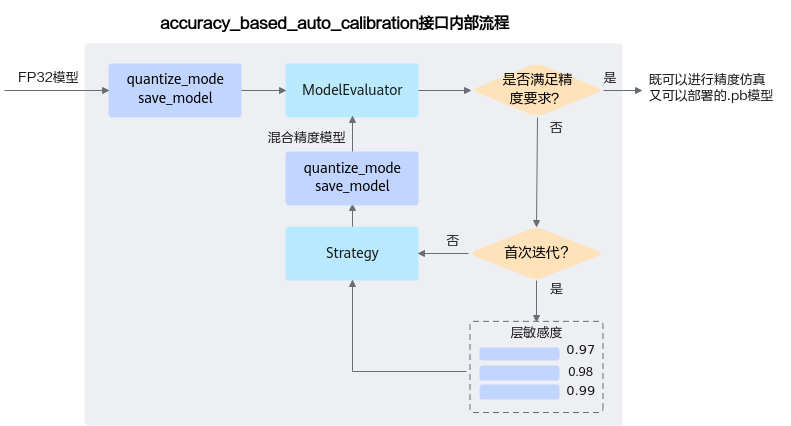
调用示例
本示例演示了使用AMCT进行基于精度的自动量化流程。该过程需要用户实现一个模型推理得到精度的回调函数。由于AMCT需要基于回调函数返回的精度数据进行量化层的筛选,因此回调函数的返回数值应尽可能反映模型的精度。
如下示例标有“由用户补充处理”的步骤,需要用户根据自己的模型和数据集进行补充处理,示例中仅为示例代码。
如下示例调用AMCT的部分,函数入参请根据实际情况进行调整。
导入AMCT包,设置日志级别。
import amct_tensorflow as amct from amct_tensorflow.common.auto_calibration import AutoCalibrationEvaluatorBase amct.set_logging_level(print_level="info", save_level="info")
(由用户补充处理)使用原始待量化的模型和测试集,实现回调函数calibration()、evaluate()、metric_eval()。
上述回调函数的入参要和基类AutoCalibrationEvaluatorBase保持一致。其中:
calibration()完成校准的推理。
evaluate()完成模型的精度测试过程。
metric_eval()完成原始模型和量化fake quant模型的精度损失评估,当精度损失小于预期值时返回True,否则返回False。
class ModelEvaluator(AutoCalibrationEvaluatorBase): # The evaluator for model def __init__(self, *args, **kwargs): # 做成员变量初始化 # 设置预期精度损失,此处请替换为具体的数值 self.diff = expected_acc_loss pass def calibration(self, graph, outputs): # 进行模型的校准推理,推理的batch数要和量化配置的batch_num一致 pass def evaluate(self, graph, outputs): # pylint: disable=R0914 # evaluate the input models, get the eval metric of model pass def metric_eval(self, original_metric, new_metric): # 评估原始模型精度和量化模型精度的精度损失是否满足预期,满足返回True,精度损失数据;否则返回False,精度损失数据 loss = original_metric - new_metric if loss < self.diff: return True, loss return False, loss
(由用户补充处理)根据模型user_model.pb,准备好图结构tf.Graph。
ori_graph = user_load_graph()调用AMCT工具,进行基于精度的自动量化。
生成量化配置。
config_file = './tmp/config.json' skip_layers = [] batch_num = 1 amct.create_quant_config(config_file=config_file, graph=ori_graph, skip_layers=skip_layers, batch_num=batch_num)
初始化evaluator。
evaluator = ModelEvaluator()进行基于精度的量化配置自动搜索。
amct.accuracy_based_auto_calibration(ori_pb_model, outputs, record_file, config_file, save_dir, evaluator)
手工量化¶
均匀量化是指量化后的数据比较均匀地分布在某个数值空间中,例如INT8量化就是用只有8比特的INT8数据来表示32比特的float32数据或16比特的float16数据,将float32/float16的卷积运算过程(乘加运算)转换为INT8的卷积运算,加速运算和实现模型压缩;均匀的INT8量化则是量化后数据比较均匀地分布在INT8的数值空间[-128, 127]中。 非均匀量化是指量化后的数据在某个数值空间中的分布是不均匀的。非均匀量化过程中,会根据待量化数据的概率分布来对均匀量化后的数据分布进一步进行根据目标压缩率(保留数值量/原始量化数值量)的聚类操作。相较于均匀量化,非均匀量化在进一步压缩数据信息量的基础上尽可能的保留高概率分布的数据信息,从而减小压缩后的数据信息丢失。 执行训练后量化特性的精度如果不满足要求,可以尝试手动调整config.json文件中的参数,本节给出调整的原则,以及参数解释。
均匀量化¶
均匀量化是指量化后的数据比较均匀地分布在某个数值空间中,例如INT8量化就是用只有8比特的INT8数据来表示32比特的float32数据或16比特的float16数据,将float32/float16的卷积运算过程(乘加运算)转换为INT8的卷积运算,加速运算和实现模型压缩;均匀的INT8量化则是量化后数据比较均匀地分布在INT8的数值空间[-128, 127]中。
如果均匀量化后的模型精度无法满足要求,则需要进行基于精度的自动量化或量化感知训练或手工调优。
均匀量化支持量化的层以及约束如下,量化示例请参见样例列表。
表 1 均匀量化支持的层以及约束
支持的层类型 |
约束 |
|---|---|
MatMul |
transpose_a=False、transpose_b=False、adjoint_a=False、adjoint_b=False。 |
Conv2D |
weight的输入来源不含有placeholder等可动态变化的节点,且weight的节点类型只能是const。 |
Conv2DBackpropInput |
|
DepthwiseConv2dNative |
|
Conv1D |
TensorFlow支持tf.nn.Conv1D构图,在pb模型中转换为extend_dims算子+Conv2D算子+Unsqueeze算子的组合。 |
接口调用流程
均匀量化接口调用流程如图1所示。
图 1 均匀量化接口调用流程
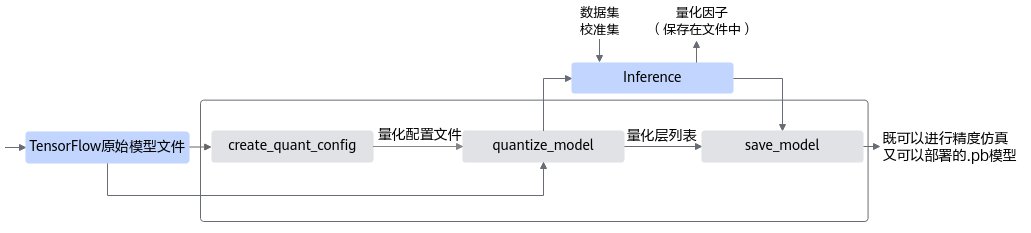
蓝色部分为用户实现,灰色部分为用户调用AMCT提供的API实现,用户在TensorFlow原始网络推理的代码中导入库,并在特定的位置调用相应API,即可实现量化功能。工具运行流程如下:
用户首先构造TensorFlow的原始模型,然后使用create_quant_config接口生成量化配置文件。
根据TensorFlow模型和量化配置文件,即可调用quantize_model接口对原始TensorFlow模型进行优化,修改后的模型中插入数据量化、权重量化等相关算子,用于计算量化相关参数。
用户使用2输出的修改后的模型,借助AMCT提供的数据集和校准集,在TensorFlow环境中进行inference,可以得到量化因子。
其中数据集用于在TensorFlow环境中对模型进行推理时,测试量化数据的精度;校准集用来产生量化因子,保证精度。
最后用户可以调用save_model接口,插入AscendQuant、AscendDequant等算子,保存为量化模型,该模型既可在TensorFlow环境中进行精度仿真又可以在NPU IP加速器部署。
调用示例
本章节详细给出训练后量化的模板代码解析说明,通过解读该代码,用户可以详细了解AMCT的工作流程以及原理,方便用户基于已有模板代码进行修改,以便适配其他网络模型的量化。训练后量化主要包括如下几个步骤:
准备训练好的模型和数据集。
在原始TensorFlow环境中验证模型精度以及环境是否正常。
编写训练后量化脚本调用AMCT API。
执行训练后量化脚本。
在原始TensorFlow环境中验证量化后仿真模型精度。
如下流程详细演示如何编写脚本调用AMCT API进行模型量化。
如下示例标有“由用户补充处理”的步骤,需要用户根据自己的模型和数据集进行补充处理,示例中仅为示例代码。
如下示例调用AMCT的部分,函数入参请根据实际情况进行调整。
导入AMCT包,设置日志级别。
import amct_tensorflow as amct amct.set_logging_level(print_level='info', save_level='info')
(可选,由用户补充处理)在TensorFlow原始环境中验证推理脚本及环境。
建议使用原始待量化的模型和测试集,在TensorFlow环境下推理,验证环境、推理脚本是否正常。
推荐执行该步骤,请确保原始模型可以完成推理且精度正常;执行该步骤时,可以使用部分测试集,减少运行时间。
user_do_inference(ori_model, test_data, test_iterations)(由用户补充处理)根据模型user_model.pb,准备好图结构tf.Graph。
ori_graph = user_load_graph()调用AMCT,量化模型。
生成量化配置。
config_file = './tmp/config.json' skip_layers = [] batch_num = 1 amct.create_quant_config(config_file=config_file, graph=ori_graph, skip_layers=skip_layers, batch_num=batch_num)
修改图,在图中插入数据量化,权重量化等相关的算子,用于计算量化相关参数。
record_file = './tmp/record.txt' amct.quantize_model(graph=ori_graph, config_file=config_file, record_file=record_file)
使用AMCT调用quantize_model接口对用户的原始TensorFlow模型进行图修改时,由于插入了searchN层导致尾层输出节点发生改变的场景,可以参见TensorFlow网络模型由于AMCT导致输出节点改变,如何通过修改量化脚本进行后续的量化动作进行处理。如果量化过程存在空tensor输入报错信息,请参见使用训练后量化进行量化时,量化过程存在空tensor输入报错信息进行处理。
(由用户补充处理)使用修改后的图在校准集上做模型推理,找到量化因子。
该步骤执行时,需要注意如下两点:
校准集及其预处理过程数据要与模型匹配,以保证量化的精度。
前向推理次数为batch_num,如果次数不足,由于校准算子没有将量化因子输出到record文件中,会导致后续读取record校验失败。
user_do_inference(ori_graph, calibration_data, batch_num)若校准时提示“Invalid argument: You must feed a value for placeholder tensor **”,请参见校准时提示“Invalid argument: You must feed a value for placeholder tensor **”进行处理。
若校准过程中如果提示“xxx calculate scale failed”错误信息,请参见IFMR数据量化时,存在"inf或NaN值"或"xxx calculate scale failed",量化过程报错。
保存模型。
根据量化因子,调用save_model接口,插入AscendQuant、AscendDequant等算子,保存为量化模型。
quant_model_path = './results/user_model' amct.save_model(pb_model='user_model.pb', outputs=['user_model_outputs0', 'user_model_outputs1'], record_file=record_file, save_path=quant_model_path)
保存模型时提示“RuntimeError: cannot find shift_bit of layer ** in record_file”,则请参见保存模型时提示“RuntimeError: record_file is empty, no layers to be quantized”进行处理。
(可选,由用户补充处理)使用量化后模型user_model_quantized.pb和测试集(test_data),在TensorFlow环境下推理,测试量化后的仿真模型精度。
使用量化后仿真模型精度与2中的原始精度做对比,可以观察量化对精度的影响。
quant_model = './results/user_model_quantized.pb' user_do_inference(quant_model, test_data, test_iterations)
非均匀量化¶
非均匀量化是指量化后的数据在某个数值空间中的分布是不均匀的。非均匀量化过程中,会根据待量化数据的概率分布来对均匀量化后的数据分布进一步进行根据目标压缩率(保留数值量/原始量化数值量)的聚类操作。相较于均匀量化,非均匀量化在进一步压缩数据信息量的基础上尽可能的保留高概率分布的数据信息,从而减小压缩后的数据信息丢失。
模型在NPU IP加速器上推理时,可通过非均匀量化提高权重压缩率(需要与ATC工具配合,通过编译时使能权重压缩),降低权重传输开销,进一步提升推理性能。非均匀量化后,如果精度仿真模型在原始TensorFlow环境中推理精度不满足要求,可通过调整非均匀量化配置文件config.json中的参数来恢复模型精度,调整方法请参见手工调优。
非均匀量化支持量化的层以及约束如下,量化示例请参见样例列表。
表 1 非均匀量化支持的层以及约束
支持的层类型 |
约束 |
备注 |
|---|---|---|
MatMul |
transpose属性为false |
weight的输入来源不含有placeholder等可动态变化的节点,且weight的节点类型只能是const。 |
Conv2D |
- |
weight的输入来源不含有placeholder等可动态变化的节点,且weight的节点类型只能是const。 |
实现流程
静态非均匀量化实现原理同均匀量化,简要流程如图1所示。
图 1 非均匀量化流程图
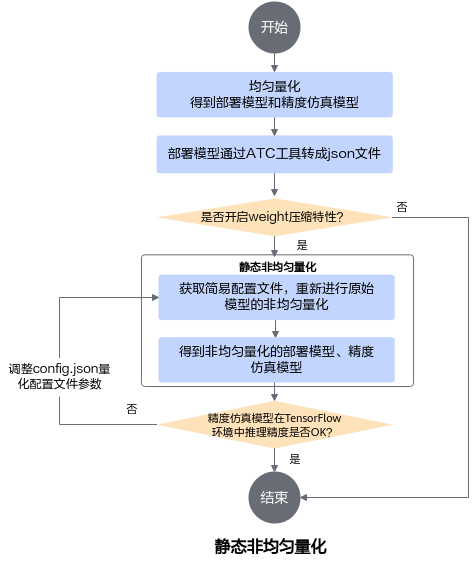
详细流程说明如下:
参见均匀量化章节获取均匀量化的部署模型和精度仿真模型。
参见《ATC离线模型编译工具用户指南》将1中生成的部署模型转换成JSON文件,该JSON文件记录了量化后模型的融合信息,同时也携带了支持weight压缩特性层的信息(通过fe_weight_compress字段识别)。
如果要进行weight压缩,则参见训练后量化简易配置文件章节获取非均匀量化简易配置文件,然后获取2生成的量化后模型的融合JSON文件进行非均匀量化。
非均匀量化过程中,会根据融合JSON文件,获取原始模型中哪些层支持weight压缩,然后重新生成非均匀量化的部署模型和量化配置文件。
查看非均匀量化后,精度仿真模型在原始TensorFlow环境中推理精度是否满足要求,如果不满足要求,则需要手动调整非均匀量化配置文件config.json中的参数,然后重新进行非均匀量化,直至满足精度要求。调整方法请参见手工调优。
手工调优¶
执行训练后量化特性的精度如果不满足要求,可以尝试手动调整config.json文件中的参数,本节给出调整的原则,以及参数解释。
调优流程
通过create_quant_config接口生成的config.json文件中的默认配置(示例请参见量化配置文件)进行量化,若量化后的推理精度不满足要求,则可调整量化配置重复量化,直至精度满足要求。本节详细介绍手动调优流程,调整对象是训练后量化配置文件config.json中的参数,主要涉及3个阶段:
调整校准使用的数据量。
跳过量化某些层。
调整量化算法及参数。
具体步骤如下:
根据create_quant_config接口生成的默认配置进行量化。若精度满足要求,则调参结束,否则进行2。
手动修改batch_num,调整校准使用的数据量。
batch_num控制量化使用数据的batch数目,可根据batch大小以及量化需要使用的图片数量调整。通常情况下:
batch_num越大,量化过程中使用的数据样本越多,量化后精度损失越小;但过多的数据并不会带来精度的提升,反而会占用较多的内存,降低量化的速度,并可能引起内存、显存、线程资源不足等情况;因此,建议batch_num*batch_size为16或32(batch_size表示每个batch使用的图片数量)。
手动修改quant_enable,跳过量化某些层。
quant_enable可以指定该层是否量化,取值为true时量化该层,取值为false时不量化该层,将该层的配置删除也可跳过该层量化。
在整网精度不达标的时候需要识别出网络中的量化敏感层(量化后误差显著增大),然后取消对量化敏感层的量化动作,识别量化敏感层有两种方法:
依据网络模型结构,一般网络中首层、尾层以及参数量偏少的层,量化后精度会有较大的下降。
通过精度比对工具,逐层比对原始模型和量化后模型输出误差(例如以余弦相似度作为标准,需要相似度达到0.99以上),找到误差较大的层,优先对其进行回退。
手动修改activation_quant_params和weight_quant_params,调整量化算法及参数:
算法参数意义请参见量化配置文件中的参数说明部分,算法说明请参见训练后量化算法。
若按照6中的量化配置进行量化后,精度满足要求,则调参结束,否则表明量化对精度影响很大,不能进行量化,去除量化配置。
图 1 调参流程
量化配置文件
如果通过create_quant_config接口生成的config.json量化配置文件,推理精度不满足要求,则需要参见该章节不断调整config.json文件中的内容(用户修改JSON文件时,请确保层名唯一),直至精度满足要求,JSON量化配置文件样例请参见接口中的调用示例部分。
配置文件中参数说明如下:
表 1 version参数说明
作用 |
控制量化配置文件版本号。 |
|---|---|
类型 |
int |
取值范围 |
1 |
参数说明 |
目前仅有一个版本号1。 |
推荐配置 |
1 |
可选或者必选 |
可选 |
表 2 batch_num参数说明
作用 |
控制量化使用多少个batch的数据。 |
|---|---|
类型 |
int |
取值范围 |
大于0 |
参数说明 |
如果不配置,则使用默认值1,建议校准集图片数量不超过50张,根据batch的大小batch_size计算相应的batch_num数值。 batch_num*batch_size为量化使用的校准集图片数量。 其中batch_size为每个batch所用的图片数量。 |
推荐配置 |
1 |
必选或可选 |
可选 |
表 3 activation_offset参数说明
作用 |
控制数据量化是对称量化还是非对称量化。全局配置参数。 若配置文件中同时存在activation_offset和asymmetric参数,asymmetric参数优先级>activation_offset参数。 |
|---|---|
类型 |
bool |
取值范围 |
true或false |
参数说明 |
|
推荐配置 |
true |
必选或可选 |
可选 |
表 4 joint_quant参数说明
作用 |
是否进行Eltwise联合量化。 |
|---|---|
类型 |
bool |
取值范围 |
true或false |
参数说明 |
|
推荐配置 |
false |
必选或可选 |
可选 |
表 5 do_fusion参数说明
作用 |
是否开启融合功能。 |
|---|---|
类型 |
bool |
取值范围 |
true或false |
参数说明 |
当前支持融合的层以及融合规则请参见工具实现的融合功能。 |
推荐配置 |
true |
可选或必选 |
可选 |
表 6 skip_fusion_layers参数说明
作用 |
跳过可融合的层。 |
|---|---|
类型 |
string |
取值范围 |
可融合层的层名。 当前支持融合的层以及融合规则请参见工具实现的融合功能。 |
参数说明 |
不需要做融合的层。 |
推荐配置 |
- |
可选或必选 |
可选 |
表 7 layer_config参数说明
作用 |
指定某个网络层的量化配置。 |
|---|---|
类型 |
object |
取值范围 |
- |
参数说明 |
参数内部包含如下参数:
|
推荐配置 |
- |
必选或可选 |
可选 |
表 8 quant_enable参数说明
作用 |
该层是否做量化。 |
|---|---|
类型 |
bool |
取值范围 |
true或false |
参数说明 |
|
推荐配置 |
true |
必选或可选 |
可选 |
表 9 dmq_balancer_param参数说明
作用 |
DMQ均衡算法中的迁移强度。 |
|---|---|
类型 |
float |
取值范围 |
[0.2, 0.8] |
参数说明 |
代表将activation数据上的量化难度迁移至weight权重的程度,数据分布的离群值越大迁移强度应设置较小。 |
推荐配置 |
0.5 |
必选或可选 |
可选 |
表 10 activation_quant_params参数说明
作用 |
该层数据量化的参数。 |
|---|---|
类型 |
object |
取值范围 |
- |
参数说明 |
activation_quant_params内部包含如下参数,IFMR算法相关参数与HFMG算法相关参数在同一层中不能同时出现:
|
推荐配置 |
- |
必选或可选 |
可选 |
表 11 weight_quant_params参数说明
作用 |
该层权重量化的参数。 |
|---|---|
类型 |
object |
取值范围 |
- |
参数说明 |
|
推荐配置 |
- |
必选或可选 |
可选 |
表 12 num_bits参数说明
作用 |
量化位宽。 |
|---|---|
类型 |
int |
取值范围 |
8或16 |
参数说明 |
INT8量化精度无法满足要求的场景,建议尝试使用INT16量化。 |
推荐配置 |
- |
必选或可选 |
必选 |
表 13 act_algo参数说明
作用 |
数据量化算法。 |
|---|---|
类型 |
string |
取值范围 |
ifmr或者hfmg |
参数说明 |
IFMR数据量化算法:ifmr HFMG数据量化算法:hfmg |
推荐配置 |
- |
必选或可选 |
可选 |
表 14 asymmetric参数说明
作用 |
控制数据量化是对称量化还是非对称量化。用于控制逐层量化算法的选择。 若配置文件中同时存在activation_offset和asymmetric参数,asymmetric参数优先级>activation_offset参数。 |
|---|---|
类型 |
bool |
取值范围 |
true或false |
参数说明 |
|
推荐配置 |
true |
必选或可选 |
可选 |
表 15 max_percentile参数说明
作用 |
IFMR数据量化算法中,最大值搜索位置参数。 |
|---|---|
类型 |
float |
取值范围 |
(0.5,1] |
参数说明 |
在从大到小排序的一组数中,决定取第多少大的数,比如有100个数,1.0表示取第100-100*1.0=0,对应的就是第一个大的数。 对待量化的数据做截断处理时,该值越大,说明截断的上边界越接近待量化数据的最大值。 |
推荐配置 |
0.999999 |
必选或可选 |
可选 |
表 16 min_percentile参数说明
作用 |
IFMR数据量化算法中,最小值搜索位置参数。 |
|---|---|
类型 |
float |
取值范围 |
(0.5,1] |
参数说明 |
在从小到大排序的一组数中,决定取第多少小的数,比如有100个数,1.0表示取第100-100*1.0=0,对应的就是第一个小的数。 对待量化的数据做截断处理时,该值越大,说明截断的下边界越接近待量化数据的最小值。 |
推荐配置 |
0.999999 |
必选或可选 |
可选 |
表 17 search_range参数说明
作用 |
IFMR数据量化算法中,控制量化因子的搜索范围[search_range_start, search_range_end]。 |
|---|---|
类型 |
list,列表中两个元素类型为float。 |
取值范围 |
0<search_range_start<search_range_end |
参数说明 |
控制截断的上边界的浮动范围。
|
推荐配置 |
[0.7,1.3] |
必选或可选 |
可选 |
表 18 search_step参数说明
作用 |
IFMR数据量化算法中,控制量化因子的搜索步长。 |
|---|---|
类型 |
float |
取值范围 |
(0, (search_range_end-search_range_start)] |
参数说明 |
控制截断的上边界的浮动范围步长,值越小,浮动步长越小。 |
推荐配置 |
0.01 |
必选或可选 |
可选 |
表 19 num_of_bins参数说明
作用 |
HFMG数据量化算法用于调整直方图的bin(直方图中的一个最小单位直方图形)数目。 |
|---|---|
类型 |
unsigned int |
取值范围 |
{1024, 2048, 4096, 8192} |
参数说明 |
num_of_bins数值越大,直方图拟合原始数据分布的能力越强,可能获得更佳的量化效果,但训练后量化过程的耗时也会更长。 |
推荐配置 |
4096 |
必选或可选 |
HFMG算法量化场景下,该参数可选。 |
表 20 wts_algo参数说明
作用 |
权重量化算法。 |
|---|---|
类型 |
string |
取值范围 |
arq_quantize |
参数说明 |
均匀量化取值:arq_quantize |
推荐配置 |
- |
必选或可选 |
可选 |
表 21 channel_wise搜索相关参数说明
作用 |
ARQ权重量化算法中,是否对每个channel采用不同的量化因子。 |
|---|---|
类型 |
bool |
取值范围 |
true或false |
参数说明 |
|
推荐配置 |
true |
必选或可选 |
可选 |
量化感知训练¶
本节详细介绍量化感知训练支持的量化层,接口调用流程和示例。 执行量化感知训练特性后的精度如果不满足要求,可以尝试手动调整config.json文件中的参数,本节给出调整的原则,以及参数解释。
量化流程¶
本节详细介绍量化感知训练支持的量化层,接口调用流程和示例。
量化感知训练当前仅支持对float32数据类型的网络模型进行量化。量化感知训练支持量化的层以及约束如下,量化示例请参见样例列表。
表 1 量化感知训练支持的层以及约束
支持的层类型 |
约束 |
|---|---|
MatMul |
transpose_a=False、transpose_b=False、adjoint_a=False、adjoint_b=False。 |
Conv2D |
由于硬件约束,原始模型中输入通道数Cin<=16时不建议进行量化感知训练,否则可能会导致量化后的部署模型推理时精度下降。 |
DepthwiseConv2dNative |
|
Conv2DBackpropInput |
|
AvgPool |
- |
Conv1D |
TensorFlow支持tf.nn.Conv1D构图,在pb模型中转换为extend_dims算子+Conv2D算子+Unsqueeze算子的组合。 |
接口调用流程
量化感知训练接口调用流程如图1所示,如下流程中的训练环境借助TensorFlow框架的CPU/GPU环境,在该开源框架的推理脚本基础上,调用AMCT API完成模型压缩,压缩后的部署模型需要使用ATC工具转换成适配NPU IP加速器的离线模型后,然后才能在NPU IP加速器上实现推理:
图 1 接口调用流程
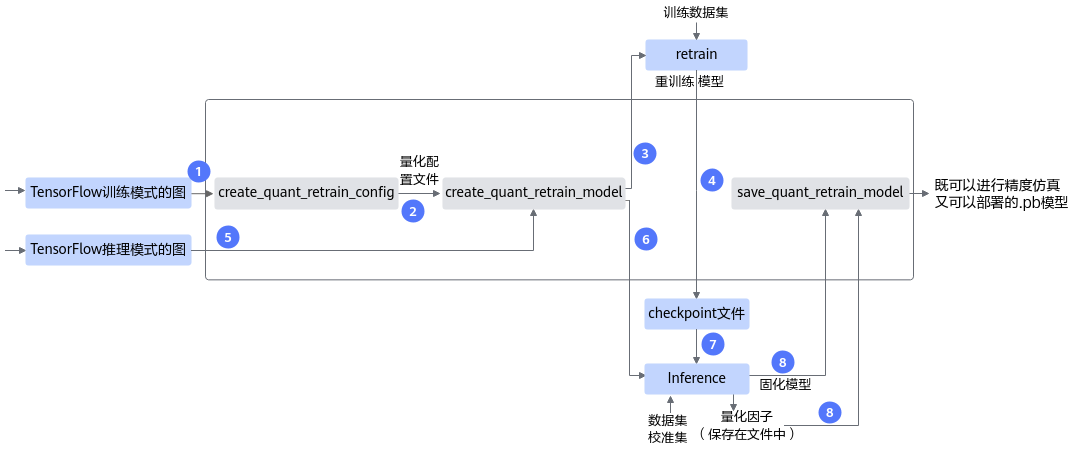
蓝色部分为用户实现,灰色部分为用户调用AMCT提供的API实现,用户在TensorFlow原始网络推理的代码中导入库,并在特定的位置调用相应API,即可实现量化功能。
简要流程如下:
用户构造训练模式的图结构,然后调用create_quant_retrain_config接口生成量化配置文件。
调用create_quant_retrain_model图修改接口,根据量化配置文件对训练的图进行量化前的图结构修改:插入数据量化,权重量化相关算子等。
训练模型,将参数保存为checkpoint文件。
调用create_quant_retrain_model接口,对推理模式的图进行修改:插入数据量化,权重量化相关算子等。
恢复训练参数,加载ckpt文件,推理量化的输出节点,将量化因子写入record文件,并将推理图固化为pb模型。
调用save_quant_retrain_model接口,插入AscendQuant/AscendDequant等量化算子,保存量化模型。
调用示例
如下示例标有“由用户补充处理”的步骤,需要用户根据自己的模型和数据集进行补充处理,示例中仅为示例代码。
调用AMCT的部分,函数入参可以根据实际情况进行调整。量化感知训练基于用户的训练过程,请确保已经有基于TensorFlow环境进行训练的脚本,并且训练后的精度正常。
导入AMCT包,设置日志级别。
import amct_tensorflow as amct amct.set_logging_level(print_level='info', save_level='info')
(可选,由用户补充处理)创建图并读取训练好的参数,在TensorFlow环境下推理,验证环境、推理脚本是否正常。
推荐执行该步骤,以确保原始模型可以完成推理且精度正常;执行该步骤时,可以使用部分测试集,减少运行时间。
user_test_evaluate_model(evaluate_model, test_data)(由用户补充处理)创建训练图。
train_graph = user_load_train_graph()调用AMCT,执行带量化参数的训练流程。
生成量化配置。
用户基于构造的训练模式的图结构(BN的is_training参数为True),调用create_quant_retrain_config接口生成量化配置文件(对应图1中的序号1)。
config_file = './tmp/config.json' simple_cfg = './retrain.cfg' amct.create_quant_retrain_config(config_file=config_file, graph=train_graph, config_defination=simple_cfg)
修改训练模式的图。
调用量化图修改接口create_quant_retrain_model,根据量化配置文件对训练的图进行量化前的图结构修改:在图中插入数据量化、权重量化等相关算子,用于计算量化相关参数(对应图1中的序号2)。
record_file = './tmp/record.txt' retrain_ops = amct.create_quant_retrain_model(graph=train_graph, config_file=config_file, record_file=record_file)
(由用户补充处理)使用修改后的图,创建反向梯度,在训练集上做训练,训练量化因子。
使用修改后的图,调用自适应学习率优化器(RMSPropOptimizer)建立反向梯度图。该步骤需要在4.b后执行。
optimizer = tf.compat.v1.train.RMSPropOptimizer( ARGS.learning_rate, momentum=ARGS.momentum) train_op = optimizer.minimize(loss)
创建会话,进行模型的训练,并将训练后的参数保存为checkpoint文件(对应图1中的序号3,4)。
注意:从训练好的checkpoint恢复模型参数后再训练;训练中保存的参数应该包括量化因子:前batch_num次训练后会生成量化因子,如果训练次数少于batch_num会导致失败。
with tf.Session() as sess: sess.run(tf.compat.v1.global_variables_initializer()) sess.run(outputs) #将训练后的参数保存为checkpoint文件 saver_save.save(sess, retrain_ckpt, global_step=0)
(由用户补充处理)创建推理图。
test_graph = user_load_test_graph()调用AMCT,实现量化感知训练。
修改推理模式的图。
用户基于构造的推理模式的图结构(BN的is_training参数为False),调用量化图修改接口create_quant_retrain_model,根据量化配置文件对推理的图进行量化前的图结构修改:在图中插入数据量化、权重量化等相关算子(对应图1中的序号5)。
record_file = './tmp/record.txt' retrain_ops = amct.create_quant_retrain_model(graph=train_graph, config_file=config_file, record_file=record_file)
(由用户补充处理)创建会话,恢复训练参数,推理量化的输出节点(retrain_ops[-1]),将量化因子写入record文件,并将推理图固化为pb模型(对应图1中的序号6,7)。
说明:推理和恢复的参数要在同一session中,推理执行的是retrain_ops[-1]的输出tensor;推理图固化为pb模型时,包含训练好的参数。
variables_to_restore = tf.compat.v1.global_variables() saver_restore = tf.compat.v1.train.Saver(variables_to_restore) with tf.Session() as sess: sess.run(tf.compat.v1.global_variables_initializer()) #恢复训练参数 saver_restore.restore(sess, retrain_ckpt) #推理量化的输出节点(retrain_ops[-1]),将量化因子写入record文件 sess.run(retrain_ops[-1]) #固化pb模型 constant_graph = tf.compat.v1.graph_util.convert_variables_to_constants( sess, eval_graph.as_graph_def(), [output.name[:-2] for output in outputs]) with tf.io.gfile.GFile(frozen_quant_eval_pb, 'wb') as f: f.write(constant_graph.SerializeToString())
保存量化模型。
根据量化因子以及pb文件,调用save_quant_retrain_model接口,插入AscendQuant、AscendDequant等算子,保存为量化模型(对应图1中的序号8)。
quant_model_path = './result/user_model' amct.save_quant_retrain_model(pb_model=trained_pb, outputs=user_model_outputs, record_file=record_file, save_path=quant_model_path)
(可选,由用户补充处理)使用量化后模型user_model_quantized.pb和测试集,在TensorFlow环境下推理,测试量化后的仿真模型精度。
使用量化后仿真模型精度与2中的原始精度做对比,可以观察量化对精度的影响。
quant_model = './results/user_model_quantized.pb' user_do_inference(quant_model, test_data)
手工调优¶
执行量化感知训练特性后的精度如果不满足要求,可以尝试手动调整config.json文件中的参数,本节给出调整的原则,以及参数解释。
调优流程
通过create_quant_retrain_config接口生成的config.json文件中的默认配置进行量化,若量化后的推理精度不满足要求,则按照如下步骤调整量化配置文件中的参数。
根据create_quant_retrain_config接口生成的默认配置进行量化。若精度满足要求,则调参结束,否则进行2。
INT8量化场景下,可以将部分量化层取消量化,即将其"retrain_enable"参数修改为"false",通常模型首尾层对推理结果影响较大,故建议优先取消首尾层的量化;如果用户有推荐的clip_max和clip_min的参数取值,则可以按照如下方式修改量化配置文件:
{ "version":1, "batch_num":1, "inference/Conv2D":{ "retrain_enable":true, "retrain_data_config":{ "algo":"ulq_quantize", "clip_max":3.0, "clip_min":-3.0 }, "retrain_weight_config":{ "algo":"arq_retrain", "channel_wise":true } }, "inference/Conv2D_1":{ "retrain_enable":true, "retrain_data_config":{ "algo":"ulq_quantize", "clip_max":3.0, "clip_min":-3.0 }, "retrain_weight_config":{ "algo":"arq_retrain", "channel_wise":true } } }
完成配置后,精度满足要求则调参结束;否则表明量化感知训练对精度影响很大,不能进行量化感知训练,去除量化感知训练配置。
量化配置文件
如果通过create_quant_retrain_config接口生成的config.json量化感知训练配置文件,推理精度不满足要求,则需要参见该章节不断调整config.json文件中的内容,直至精度满足要求,该文件部分内容样例请参见接口中的调用示例部分(用户修改JSON文件时,请确保层名唯一)。配置文件中参数说明如下:
表 1 version参数说明
作用 |
控制量化配置文件版本号。 |
|---|---|
类型 |
int |
取值范围 |
1 |
参数说明 |
目前仅有一个版本号1。 |
推荐配置 |
1 |
必选或可选 |
可选 |
表 2 batch_num参数说明
作用 |
控制量化感知训练推理阶段使用多少个batch的数据。 |
|---|---|
类型 |
int |
取值范围 |
大于0 |
参数说明 |
如果不配置,则使用默认值1,建议校准集图片数量不超过50张,根据batch的大小,batch_size计算相应的batch_num数值。 batch_num*batch_size为量化使用的校准集图片数量。 其中batch_size为每个batch所用的图片数量。 |
推荐配置 |
1 |
必选或可选 |
可选 |
表 3 retrain_enable参数说明
作用 |
该层是否进行量化感知训练。 |
|---|---|
类型 |
bool |
取值范围 |
true或false |
参数说明 |
|
推荐配置 |
true |
必选或可选 |
可选 |
表 4 retrain_data_config参数说明
作用 |
该层数据量化配置。 |
|---|---|
类型 |
object |
取值范围 |
- |
参数说明 |
包含如下参数:
|
推荐配置 |
- |
必选或可选 |
可选 |
表 5 retrain_weight_config参数说明
作用 |
该层权重量化配置。 |
|---|---|
类型 |
object |
取值范围 |
- |
参数说明 |
包含如下参数:
|
推荐配置 |
- |
必选或可选 |
可选 |
表 6 algo参数说明
作用 |
该层选择使用的量化算法。 |
|---|---|
类型 |
object |
取值范围 |
- |
参数说明 |
|
推荐配置 |
数据量化使用ulq_quantize,权重量化使用arq_retrain。 |
必选或可选 |
可选 |
表 7 channel_wise参数说明
作用 |
是否对每个channel采用不同的量化因子。 |
|---|---|
类型 |
bool |
取值范围 |
true或false |
参数说明 |
|
推荐配置 |
true |
必选或可选 |
可选 |
表 8 fixed_min参数说明
作用 |
设置数据量化算法下限的开关。 |
|---|---|
类型 |
bool |
取值范围 |
true或false |
参数说明 |
如果不选此项,amct根据图的结构自动设置。 如果选择此项,并且网络模型量化层的前一层是relu层,则该参数需要手动设置为true,如果为非relu层,则要手动设置为false。 |
推荐配置 |
不选此项 |
必选或可选 |
可选 |
表 9 clip_max参数说明
作用 |
数据量化算法上限。 |
|---|---|
类型 |
float |
取值范围 |
clip_max>0 根据不同层activation的数据分布找到最大值max,推荐取值范围为: 0.3*max~1.7*max |
参数说明 |
截断上下限数据量化算法,如果选择此项则固定算法截断上限。如果不选此项,通过ifmr算法学习获取上限。 |
推荐配置 |
不选此项 |
必选或可选 |
可选 |
表 10 clip_min参数说明
作用 |
数据量化算法下限。 |
|---|---|
类型 |
float |
取值范围 |
clip_min<0 根据不同层activation的数据分布找到最小值min,推荐取值范围为: 0.3*min~1.7*min |
参数说明 |
截断上下限数据量化算法,如果选择此项则固定算法截断下限。如果不选此项,通过ifmr算法学习获取下限。 |
推荐配置 |
不选此项 |
必选或可选 |
可选 |
表 11 dst_type参数说明
作用 |
量化位宽的类型。 |
|---|---|
类型 |
string |
取值范围 |
INT8或INT4,默认为INT8,当前版本仅支持INT8量化。 |
参数说明 |
量化时用于选择是INT8量化还是INT4量化。 |
推荐配置 |
- |
必选或可选 |
可选 |
稀疏¶
通道稀疏¶
自动通道稀疏搜索¶
当前通道稀疏支持对不同的层做不同稀疏率的稀疏处理,但逐层设置稀疏率对用户的使用门槛较高,对于某一层,如何选择稀疏率(即配置中的prune_ratio)是比较困难的,手工尝试的配置需要进行重训练,耗费时间多。针对上述问题,引入自动通道稀疏搜索特性,根据用户模型来计算各通道的稀疏敏感度(影响精度)以及稀疏收益(影响性能),然后搜索策略依据稀疏敏感度和稀疏收益来搜索最优的逐层通道稀疏率,以平衡精度和性能。 介绍自动通道稀疏搜索特性的接口调用流程和调用示例。
简介¶
当前通道稀疏支持对不同的层做不同稀疏率的稀疏处理,但逐层设置稀疏率对用户的使用门槛较高,对于某一层,如何选择稀疏率(即配置中的prune_ratio)是比较困难的,手工尝试的配置需要进行重训练,耗费时间多。针对上述问题,引入自动通道稀疏搜索特性,根据用户模型来计算各通道的稀疏敏感度(影响精度)以及稀疏收益(影响性能),然后搜索策略依据稀疏敏感度和稀疏收益来搜索最优的逐层通道稀疏率,以平衡精度和性能。
稀疏敏感度:稀疏敏感度定义为当前通道稀疏后对整网精度的影响估计,稀疏敏感度越大代表当前通道稀疏后整网精度损失越大,默认算法根据loss(w - wi)的泰勒展开计算通道稀疏敏感度。支持用户自定义计算方式。裁剪第i个通道后,稀疏敏感度计算公式如下:
采用近似估计的方法对loss(w - wi)进行泰勒展开,目前考虑到计算量只算一阶。
稀疏收益:当前通道的稀疏收益用比特复杂度表示,为计算量化Flops与计算比特位宽之积:
其中,Flops为浮点计算量,act_bit为数据的数据精度,wts_bit为权重的数据精度。
自动通道稀疏搜索流程如图1所示,支持稀疏的层以及规格请参见表1。
图 1 自动通道稀疏搜索流程
各流程简要说明如下:
初始化:初始化动作首先需要解析用户模型以及稀疏配置(可选),分析网络中可通道稀疏层及其对应的通道稀疏配置(是否有用户指定配置稀疏率),生成通道稀疏配置生成的搜索空间:解析用户目标压缩率配置。
搜索空间:为支持通道稀疏的层,但是没有通过override_layer_configs或者override_layer_types配置稀疏率。
压缩率:定义为原模型比特复杂度与稀疏后模型比特复杂度之比。
敏感度计算:计算每个通道的稀疏敏感度,内置基于损失估计的敏感度计算方法,使用泰勒展开的一次项估计裁剪该通道后网络loss的变化;支持用户自定义敏感度计算方法。
比特复杂度计算:计算每个通道的比特复杂度,视为通道的稀疏收益。
通道稀疏率配置搜索:默认采用自动通道稀疏搜索算法,搜索满足用户指定压缩率的最优通道稀疏率配置;支持用户自定义求解器。
说明:
自动通道稀疏搜索特性只是生成通道稀疏的简易配置文件,若想得到最终稀疏后模型,还需要进行手工稀疏,将上述生成的简易配置文件作为入参传入通道稀疏。
搜索流程¶
介绍自动通道稀疏搜索特性的接口调用流程和调用示例。
接口调用流程
接口调用流程如图1所示,蓝色部分为用户实现,灰色部分为用户调用AMCT提供的API实现。稀疏示例请参见样例列表。
用户准备好TensorFlow的训练模型、自动通道稀疏搜索配置文件和校准数据,调用auto_channel_prune_search,根据压缩率、各通道的稀疏敏感度以及稀疏收益,执行自动通道稀疏搜索,得到可用作通道稀疏的简易配置文件。其中,sensitivity模块与search_alg模块用户可以自定义或者使用接口内部默认方法。
sensitivity模块实现计算各通道的稀疏敏感度。
search_alg模块实现了基于通道敏感度与通道稀疏收益进行稀疏通道搜索的过程。
图 1 调用流程
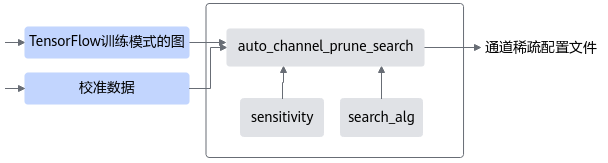
调用示例
本示例演示了使用AMCT进行自动通道稀疏搜索的流程,该过程需要用户传入tensorflow训练模式的图与校准数据,用户可选择自定义实现sensitivity模块与search_alg模块。
如下示例标有“由用户补充处理”的步骤,需要用户根据自己的模型和数据集进行补充处理,示例中仅为示例代码。
如下示例调用AMCT的部分,函数入参请根据实际情况进行调整。
导入AMCT包,设置日志级别。
import amct_tensorflow as amct amct.set_logging_level(print_level="info", save_level="info")
(可选,由用户补充处理)实现sensitivity模块,获取各个layer各通道的敏感度,为后续的搜索算法提供数据。可参考系统默认sensitivity模块:AMCT安装目录
amct_tensorflow/interface/auto_channel_prune_search.py下的TaylorLossSensitivity方法,简要流程如下:
from amct.common.auto_prune.sensitivity_base import SensitivityBase class Sensitivity(SensitivityBase) def __init__(self) pass def setup_initialization(self, graph_tuple, input_data, test_iteration, output_nodes=None): # 必要的初始化 # graph_tuple (graph, graph_info) pass def get_sensitivity(self, search_records): # 获取敏感度方法,计算后写到record中 pass
(可选,由用户补充处理)实现搜索算法search_alg模块,需要用户实现channel_prune_search内部回调接口,根据通道敏感度与通道稀疏收益进行稀疏通道搜索。可参考系统默认search_alg模块:AMCT安装目录/amct_tensorflow/common/auto_prune/search_channel_base.py文件中GreedySearch方法。
from amct.common.auto_prune.search_channel_base import SearchChannelBase class Search(SearchChannelBase) def __init__(self) # 初始化 pass def channel_prune_search(self, graph_info, search_records, prune_config): """ 输入: graph_info: dict,包含图中各算子的通道数量与比特复杂度信息,可用于计算压缩率 search_records: protobuf对象,包含待搜索的可稀疏层 prune_config: 三元组-目标压缩率(float)、昇腾亲和优化开关(bool)、单层最大稀疏率(float) 输出: dict,key为待搜索的可稀疏层层名,value为01组成的list,对应该通道是否应稀疏 """ pass
(可选,由用户补充处理)创建图并读取训练好的参数,在TensorFlow环境下推理,验证环境、推理脚本是否正常。
推荐执行该步骤,以确保原始模型可以完成推理且精度正常;执行该步骤时,可以使用部分测试集,减少运行时间。
user_test_evaluate_model(evaluate_model, test_data)(由用户补充处理)创建训练图,构造校准数据。
train_graph = user_load_train_graph() input_data = [] for _ in range(test_iteration): input_data.append(user_load_feed_dict())
调用AMCT,进行自动通道稀疏搜索。
output_prune_cfg = './prune.cfg' amct.auto_channel_prune_search( graph=train_graph, output_nodes=user_model_outputs, config=cfg_file, input_data=input_data, output_cfg=output_prune_cfg, sensitivity='TaylorLossSensitivity', search_alg='GreedySearch')
手工稀疏¶
本节介绍手工稀疏特性支持的稀疏层,接口调用流程和调用示例。 稀疏后,如果精度不满足要求,可以参见本节提供的方法进行调优。
稀疏流程¶
本节介绍手工稀疏特性支持的稀疏层,接口调用流程和调用示例。
AMCT目前主要支持基于重训练的通道稀疏模型压缩特性,稀疏示例请参见样例列表>TensorFlow>通道稀疏(手工稀疏)。支持通道稀疏的层以及约束如下:
表 1 通道稀疏支持的层以及约束
支持的层类型 |
约束 |
|---|---|
MatMul |
transpose_a=False、transpose_b=True/False、adjoint_a=False、adjoint_b=True/False 权重数据类型为float32,float64 |
Conv2D |
|
接口调用流程
通道稀疏功能接口调用流程如下图所示,如下流程中的训练环境借助TensorFlow框架的CPU/GPU环境,在该开源框架的推理脚本基础上,调用AMCT API完成模型压缩,压缩后的部署模型需要使用ATC工具转换成适配NPU IP加速器的离线模型后,然后才能在NPU IP加速器上实现推理:
图 1 通道稀疏接口调用流程
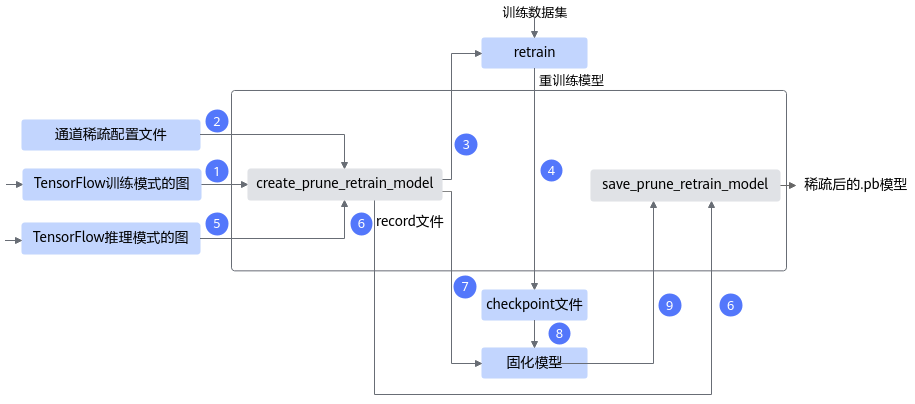
蓝色部分为用户实现,灰色部分为用户调用AMCT提供的API实现,用户在TensorFlow原始网络推理的代码中导入库,并在特定的位置调用相应API,即可实现稀疏功能。
简要流程如下:
用户构造训练模式的图结构,调用create_prune_retrain_model接口,根据稀疏配置文件对训练的图进行稀疏前的图结构修改:在图结构中插入mask稀疏算子。
训练模型,将训练后的参数保存为checkpoint文件。
用户构造推理模式的图结构,调用稀疏图修改接口create_prune_retrain_model,同时根据配置文件对推理的图进行稀疏前的图结构修改:在图结构中插入mask稀疏算子;同时生成记录稀疏信息的record文件。
创建会话,恢复训练参数,并将推理图固化为pb模型。
调用稀疏图保存接口save_prune_retrain_model,根据record文件以及固化模型,导出通道裁剪后的pb推理模型,同时删除插入的mask稀疏算子。
调用示例
如下示例标有“由用户补充处理”的步骤,需要用户根据自己的模型和数据集进行补充处理,示例中仅为示例代码。
调用AMCT的部分,函数入参可以根据实际情况进行调整。量化感知训练基于用户的训练过程,请确保已经有基于TensorFlow环境进行训练的脚本,并且训练后的精度正常。
导入AMCT包,设置日志级别。
import amct_tensorflow as amct amct.set_logging_level(print_level='info', save_level='info')
(可选,由用户补充处理)创建图并读取训练好的参数,在TensorFlow环境下推理,验证环境、推理脚本是否正常。
推荐执行该步骤,以确保原始模型可以完成推理且精度正常;执行该步骤时,可以使用部分测试集,减少运行时间。
user_test_evaluate_model(evaluate_model, test_data)(由用户补充处理)创建训练图。
train_graph = user_load_train_graph()调用AMCT,执行带稀疏算子的训练流程。
在训练图中插入稀疏算子。
用户基于构造的训练模式的图结构(BN的is_training参数为True) ,调用create_prune_retrain_model接口(对应图1中的序号1),根据稀疏配置文件(对应图1中的序号2)对训练的图进行稀疏前的图结构修改。create_prune_retrain_model接口会在图结构中插入mask算子,达到推理时伪稀疏的效果。稀疏配置文件需要参见量化感知训练简易配置文件自行构造。
record_file = './tmp/record.txt' simple_cfg = './retrain.cfg' amct.create_prune_retrain_model(graph=train_graph, outputs=user_model_outputs, record_file=record_file, config_defination=simple_cfg)
说明:
由于tf.graph不具有直接删减通道的能力,修改网络中某一个算子的规格,TensorFlow会校验图结构的正确性,导致无法删减通道。因此TensorFlow通过增加mask算子,训练时通过mask算子来屏蔽掉被稀疏通道对整网训练的影响。(由用户补充处理)使用修改后的图,创建反向梯度,在训练集上做训练。
使用修改后的图,创建反向梯度。
调用自适应学习率优化器(比如RMSPropOptimizer)建立反向梯度图(该步骤需要在1后执行)。
optimizer = tf.compat.v1.train.RMSPropOptimizer( ARGS.learning_rate, momentum=ARGS.momentum) train_op = optimizer.minimize(loss)
训练模型。
创建会话,进行模型的训练,将训练后的参数保存为checkpoint文件,并得到稀疏算子的结果(对应图1中的序号3,4)。
with tf.Session() as sess: sess.run(tf.compat.v1.global_variables_initializer()) sess.run(outputs) #将训练后的参数保存为checkpoint文件 saver_save.save(sess, retrain_ckpt, global_step=0)
(由用户补充处理)创建推理图。
test_graph = user_load_test_graph()调用AMCT,实现通道稀疏。
先在推理图中插入稀疏算子。
用户基于构建的推理模式的图结构(BN的is_training参数为False),调用稀疏图修改接口create_prune_retrain_model,同时根据配置文件对推理的图进行稀疏前的图结构修改(对应图1中的序号5),同时生成记录稀疏信息的record文件(对应图1中的序号6)。
record_file = './tmp/record.txt' simple_cfg = './retrain.cfg' amct.create_prune_retrain_model(graph=test_graph, outputs=user_model_outputs, record_file=record_file, config_defination=simple_cfg)
恢复4中训练得到的checkpoint权重并固化为pb模型。
创建会话,恢复训练参数,并将推理图固化为pb模型(对应图1中的序号7, 8)。
variables_to_restore = tf.compat.v1.global_variables() saver_restore = tf.compat.v1.train.Saver(variables_to_restore) with tf.Session() as sess: sess.run(tf.compat.v1.global_variables_initializer()) #恢复训练参数 saver_restore.restore(sess, retrain_ckpt) #固化pb模型 constant_graph = tf.compat.v1.graph_util.convert_variables_to_constants( sess, eval_graph.as_graph_def(), [output.name[:-2] for output in outputs]) with tf.io.gfile.GFile(masked_pb_path, 'wb') as f: f.write(constant_graph.SerializeToString())
保存模型,删除插入的mask稀疏算子,并实现通道稀疏。
根据record文件以及固化模型,导出通道裁剪后的pb推理模型(对应图1中的序号6,9)。
pruned_model_path = './result/user_model' amct.save_prune_retrain_model(pb_model=masked_pb_path, outputs=user_model_outputs, record_file=record_file, save_path=pruned_model_path)
(可选,由用户补充处理)使用稀疏后模型user_model_pruned.pb和测试集,在TensorFlow的环境下推理,测试稀疏后的仿真模型精度。
使用稀疏后仿真模型精度与2中的原始精度做对比,可以观察稀疏对精度的影响。
pruned_model = './results/user_model_pruned.pb' user_do_inference(pruned_model, test_data)
手工调优¶
稀疏后,如果精度不满足要求,可以参见本节提供的方法进行调优。
如果按照某组配置稀疏模型后,经过重训练精度未满足要求,则可以修改简易配置文件(文件配置请参见量化感知训练简易配置文件)重新稀疏模型并重训练。常用的方法包括:
调整稀疏率,由简易配置文件中的prune_ratio参数控制,用户可尝试减小稀疏率并重新进行稀疏来进行调试。
某些层不做稀疏,由简易配置文件中的regular_prune_skip_layers参数控制,通过该参数配置不需要稀疏的层。
4选2结构化稀疏¶
本节介绍4选2结构化稀疏支持的层,接口调用流程和调用示例。 稀疏后,如果精度不满足要求,可以参见本节提供的方法进行调优。
稀疏流程¶
本节介绍4选2结构化稀疏支持的层,接口调用流程和调用示例。
由于硬件约束,该芯片不支持4选2结构化稀疏特性:使能后获取不到性能收益。
AMCT支持基于重训练的4选2结构化稀疏特性,稀疏示例请参见样例列表。该特性支持的层以及约束如下:
表 1 4选2结构化稀疏支持的层以及约束
支持的层类型 |
约束 |
备注 |
|---|---|---|
MatMul |
transpose_a=False 权重数据类型为float32、float64 |
- |
Conv2D |
权重数据类型为float32、float64 |
weight的输入来源不含有placeholder等可动态变化的节点,且weight的节点类型只能是const。 |
Conv2DBackpropInput |
- |
接口调用流程
4选2结构化稀疏功能接口调用流程如下图所示,如下流程中的训练环境借助TensorFlow框架的CPU/GPU环境,在该开源框架的推理脚本基础上,调用AMCT API完成模型压缩,压缩后的部署模型需要使用ATC工具转换成适配NPU IP加速器的离线模型后,然后才能在NPU IP加速器上实现推理:
图 1 4选2结构化稀疏接口调用流程
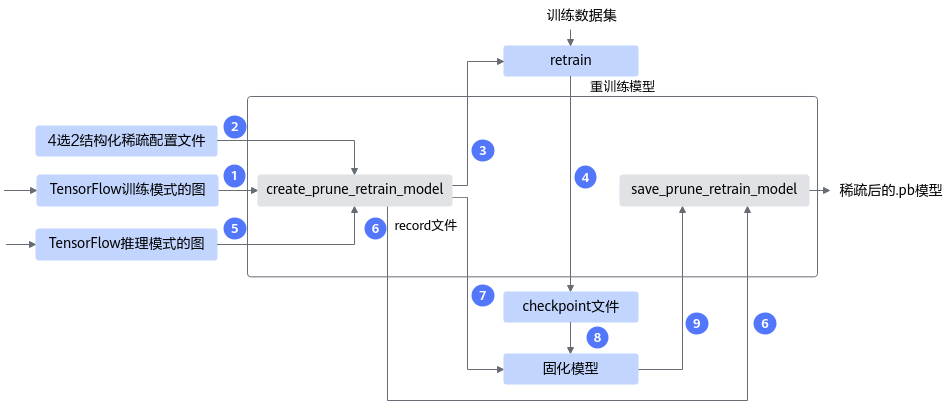
蓝色部分为用户实现,灰色部分为用户调用AMCT提供的API实现,用户在TensorFlow原始网络推理的代码中导入库,并在特定的位置调用相应API,即可实现稀疏功能。
简要流程如下:
用户构造训练模式的图结构,调用create_prune_retrain_model接口,根据稀疏配置文件对训练的图进行稀疏前的图结构修改:在图结构中插入4选2结构化稀疏算子。
训练模型,将训练后的参数保存为checkpoint文件。
用户构造推理模式的图结构,调用稀疏图修改接口create_prune_retrain_model,同时根据配置文件对推理的图进行稀疏前的图结构修改:在图结构中插入4选2结构化稀疏算子;同时生成记录稀疏信息的record文件。
创建会话,恢复训练参数,并将推理图固化为pb模型。
调用稀疏图保存接口save_prune_retrain_model,根据record文件以及固化模型,导出通道裁剪后的pb推理模型,同时删除插入的4选2结构化稀疏算子。
调用示例
如下示例标有“由用户补充处理”的步骤,需要用户根据自己的模型和数据集进行补充处理,示例中仅为示例代码。
调用AMCT的部分,函数入参可以根据实际情况进行调整。量化感知训练基于用户的训练过程,请确保已经有基于TensorFlow环境进行训练的脚本,并且训练后的精度正常。
导入AMCT包,设置日志级别。
import amct_tensorflow as amct amct.set_logging_level(print_level='info', save_level='info')
(可选,由用户补充处理)创建图并读取训练好的参数,在TensorFlow环境下推理,验证环境、推理脚本是否正常。
推荐执行该步骤,以确保原始模型可以完成推理且精度正常;执行该步骤时,可以使用部分测试集,减少运行时间。
user_test_evaluate_model(evaluate_model, test_data)(由用户补充处理)创建训练图。
train_graph = user_load_train_graph()调用AMCT,执行带稀疏算子的训练流程。
在训练图中插入稀疏算子。
用户基于构造的训练模式的图结构(BN的is_training参数为True),调用create_prune_retrain_model接口(对应图1中的序号1),根据稀疏配置文件(对应图1中的序号2)对训练的图进行稀疏前的图结构修改。create_prune_retrain_model接口会在图结构中插入4选2结构化稀疏算子,达到推理时伪稀疏的效果。稀疏配置文件需要参见量化感知训练简易配置文件自行构造。
record_file = './tmp/record.txt' simple_cfg = './retrain.cfg' amct.create_prune_retrain_model(graph=train_graph, outputs=user_model_outputs, record_file=record_file, config_defination=simple_cfg)
(由用户补充处理)使用修改后的图,创建反向梯度,在训练集上做训练。
使用修改后的图,创建反向梯度。
调用自适应学习率优化器(比如RMSPropOptimizer)建立反向梯度图(该步骤需要在1后执行)。
optimizer = tf.compat.v1.train.RMSPropOptimizer( ARGS.learning_rate, momentum=ARGS.momentum) train_op = optimizer.minimize(loss)
训练模型。
创建会话,进行模型的训练,将训练后的参数保存为checkpoint文件,并得到稀疏算子的结果(对应图1中的序号3,4)。
with tf.Session() as sess: sess.run(tf.compat.v1.global_variables_initializer()) sess.run(outputs) #将训练后的参数保存为checkpoint文件 saver_save.save(sess, retrain_ckpt, global_step=0)
(由用户补充处理)创建推理图。
test_graph = user_load_test_graph()调用AMCT,实现4选2稀疏。
先在推理图中插入稀疏算子。
用户基于构建的推理模式的图结构(BN的is_training参数为False),调用稀疏图修改接口create_prune_retrain_model,同时根据配置文件对推理的图进行稀疏前的图结构修改(对应图1中的序号5),同时生成记录稀疏信息的record文件(对应图1中的序号6)。
record_file = './tmp/record.txt' simple_cfg = './retrain.cfg' amct.create_prune_retrain_model(graph=test_graph, outputs=user_model_outputs, record_file=record_file, config_defination=simple_cfg)
恢复4中训练得到的checkpoint权重并固化为pb模型。
创建会话,恢复训练参数,并将推理图固化为pb模型(对应图1中的序号7, 8)。
variables_to_restore = tf.compat.v1.global_variables() saver_restore = tf.compat.v1.train.Saver(variables_to_restore) with tf.Session() as sess: sess.run(tf.compat.v1.global_variables_initializer()) #恢复训练参数 saver_restore.restore(sess, retrain_ckpt) #固化pb模型 constant_graph = tf.compat.v1.graph_util.convert_variables_to_constants( sess, eval_graph.as_graph_def(), [output.name[:-2] for output in outputs]) with tf.io.gfile.GFile(masked_pb_path, 'wb') as f: f.write(constant_graph.SerializeToString())
保存模型,删除插入的结构化稀疏算子,实现稀疏。
根据record文件以及固化模型,导出4选2结构化稀疏后的pb推理模型(对应图1中的序号6,9)。
pruned_model_path = './result/user_model' amct.save_prune_retrain_model(pb_model=masked_pb_path, outputs=user_model_outputs, record_file=record_file, save_path=pruned_model_path)
(可选,由用户补充处理)使用稀疏后模型user_model_pruned.pb和测试集,在TensorFlow的环境下推理,测试稀疏后的仿真模型精度。
使用稀疏后仿真模型精度与2中的原始精度做对比,可以观察稀疏对精度的影响。
pruned_model = './results/user_model_pruned.pb' user_do_inference(pruned_model, test_data)
手工调优¶
稀疏后,如果精度不满足要求,可以参见本节提供的方法进行调优。
如果按照某组配置稀疏模型后,经过重训练精度未满足要求,则可以修改简易配置文件(文件配置请参见量化感知训练简易配置文件)重新稀疏模型并重训练。常用的方法包括:
调整更新间隔(计算哪些元素被保留的间隔),由简易配置文件中的update_freq参数控制,用户可尝试将更新间隔改为正整数并重新进行稀疏来进行调试,一般来说更新间隔越小精度收益越大。
某些层不做稀疏,由简易配置文件中的regular_prune_skip_layers参数控制,通过该参数配置不需要稀疏的层。
组合压缩¶
组合压缩是针对同一个网络模型,既进行量化又进行稀疏的操作,具体支持什么样的组合压缩方式,本章节给出详细介绍。 本节介绍组合压缩特性的接口调用流程和调用示例。
简介¶
组合压缩是针对同一个网络模型,既进行量化又进行稀疏的操作,具体支持什么样的组合压缩方式,本章节给出详细介绍。
组合压缩方式
目前组合压缩支持如下组合方式,使用AMCT进行压缩时,每层可压缩算子每次只能选择其中一种组合压缩方式,简要流程如图1所示。
通道稀疏+量化感知训练 INT8量化
4选2结构化稀疏+量化感知训练 INT8量化
当前组合压缩特性的压缩配置由用户手动处理(故又称之为静态组合压缩,压缩配置文件配置方法请参见量化感知训练简易配置文件),通过手动设置全局量化位宽和稀疏率(通道稀疏比例)或更新4选2稀疏的间隔,实现模型自动压缩。组合压缩示例请参见样例列表。
支持组合压缩的层以及约束请分别参见通道稀疏下的表1、4选2结构化稀疏下的表1或量化感知训练下的表1。
图 1 组合压缩简要流程
组合压缩场景介绍
当前组合压缩支持如下几种场景,实际使用时,可以通过简易配置文件中的参数进行控制。如下场景中的整网量化指量化感知训练,其中:
整网量化:
整网(全局)量化配置参数:retrain_data_quant_config/retrain_weight_quant_config
部分层差异化配置参数:override_layer_configs或override_layer_types
参数优先级:override_layer_configs>override_layer_types>retrain_data_quant_config/retrain_weight_quant_config
整网稀疏:包括通道稀疏和4选2结构化稀疏,使用时二选一。
整网(全局)稀疏配置参数:prune_config
部分层差异化稀疏参数:override_layer_configs或override_layer_types
参数优先级:override_layer_configs>override_layer_types>retrain_data_quant_config/retrain_weight_quant_config
关于上述参数的详细解释请参见量化感知训练简易配置文件。
表 1 组合压缩场景介绍
组合压缩场景 |
配置参数 |
说明 |
|---|---|---|
整网量化+整网稀疏 |
不配置override_layer_configs或override_layer_types |
- |
部分层差异化量化+整网稀疏 |
|
配置特性参数时,首先要指定全局配置,否则该特性不使能。 |
整网量化+部分层差异化稀疏 |
|
配置特性参数时,首先要指定全局配置,否则该特性不使能。 |
部分层量化+部分层差异化稀疏 |
|
配置特性参数时,首先要指定全局配置,否则该特性不使能。 |
整网量化 |
retrain_data_quant_config/retrain_weight_quant_config 不配置override_layer_configs或override_layer_types |
- |
部分层差异化量化 |
retrain_data_quant_config/retrain_weight_quant_config+override_layer_configs或override_layer_types |
配置特性参数时,首先要指定全局配置,否则该特性不使能。 |
整网稀疏 |
prune_config 不配置override_layer_configs或override_layer_types |
- |
部分层差异化稀疏 |
prune_config+override_layer_configs或override_layer_types |
配置特性参数时,首先要指定全局配置,否则该特性不使能。 |
压缩流程¶
本节介绍组合压缩特性的接口调用流程和调用示例。
接口调用流程
组合压缩接口调用流程如下图所示,如下流程中的训练环境借助TensorFlow框架的CPU/GPU环境,在该开源框架的推理脚本基础上,调用AMCT API完成模型压缩,压缩后的部署模型需要使用ATC工具转换成适配NPU IP加速器的离线模型后,然后才能在NPU IP加速器上实现推理:
图 1 组合压缩接口调用流程
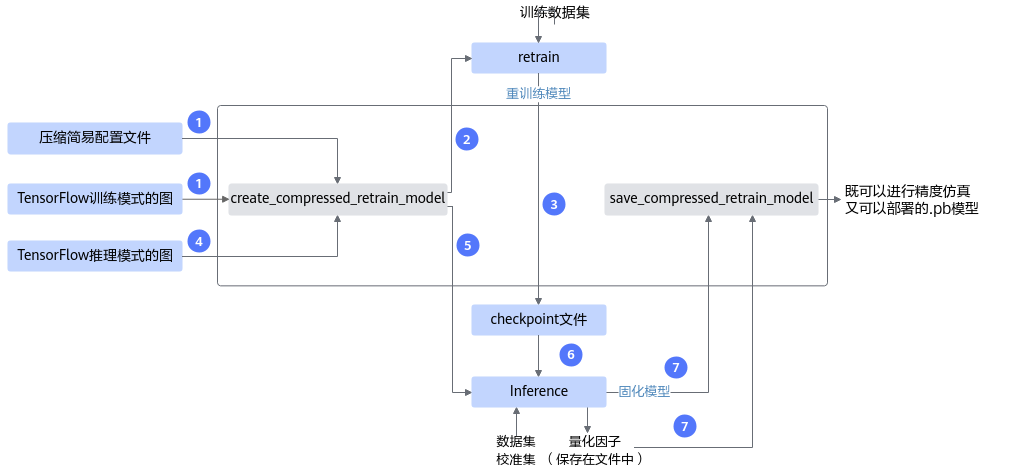
蓝色部分为用户实现,灰色部分为用户调用AMCT提供的API实现,用户在TensorFlow原始网络推理的代码中导入库,并在特定的位置调用相应API,即可实现压缩功能。
简要流程如下:
用户构造训练模式的图结构,调用压缩图修改接口create_compressed_retrain_model,根据简易配置文件对训练的图进行压缩前的图结构修改:插入通道稀疏或4选2结构化稀疏(稀疏方式二选一)以及量化感知训练的算子。
训练模型,将训练后的参数保存为checkpoint文件。
用户构建推理模式的图结构,调用压缩图修改接口create_compressed_retrain_model,根据量化配置文件对推理的图进行压缩前的图结构修改,插入通道稀疏或4选2结构化稀疏(稀疏方式二选一)以及量化感知训练的算子。
恢复训练参数,推理量化的输出节点,将量化因子写入record文件,并将推理图固化为pb模型。
调用压缩图保存接口save_compressed_retrain_model,根据稀疏和量化因子记录文件以及固化模型,保存为组合压缩的模型。
调用示例
如下示例标有“由用户补充处理”的步骤,需要用户根据自己的模型和数据集进行补充处理,示例中仅为示例代码。
调用AMCT的部分,函数入参可以根据实际情况进行调整。量化感知训练基于用户的训练过程,请确保已经有基于TensorFlow环境进行训练的脚本,并且训练后的精度正常。
导入AMCT包,设置日志级别。
import amct_tensorflow as amct amct.set_logging_level(print_level='info', save_level='info')
(可选,由用户补充处理)创建图并读取训练好的参数,在TensorFlow环境下推理,验证环境、推理脚本是否正常。
推荐执行该步骤,以确保原始模型可以完成推理且精度正常;执行该步骤时,可以使用部分测试集,减少运行时间。
user_test_evaluate_model(evaluate_model, test_data)(由用户补充处理)创建训练图。
train_graph = user_load_train_graph()调用AMCT,执行带稀疏算子和量化参数的训练流程。
修改图,在图中插入稀疏和量化相关的算子。
调用压缩图修改接口create_compressed_retrain_model,根据简易配置文件与用户原始模型对训练的图进行压缩前的图结构修改,插入通道稀疏或4选2结构化稀疏(稀疏方式二选一)以及量化感知训练的算子,生成用于组合压缩训练的图结构(对应图1中的序号1)。
record_file = './tmp/record.txt' retrain_ops = amct.create_compressed_retrain_model(graph=train_graph, config_defination=simple_cfg, outputs=user_model_outputs, record_file=record_file)
(由用户补充处理)使用修改后的图,创建反向梯度,在训练集上做训练,训练模型参数与量化因子。
使用修改后的图,创建反向梯度。该步骤需要在4.a后执行。
调用自适应学习率优化器(RMSPropOptimizer)建立反向梯度图。
optimizer = tf.compat.v1.train.RMSPropOptimizer( ARGS.learning_rate, momentum=ARGS.momentum) train_op = optimizer.minimize(loss)
创建会话,进行模型的训练,并将训练后的参数保存为checkpoint文件(对应图1中的序号2,3)。
注意:从训练好的checkpoint恢复模型参数后再训练;训练中保存的参数应该包括量化因子:前batch_num次训练后会生成量化因子,如果训练次数少于batch_num会导致失败。
with tf.Session() as sess: sess.run(tf.compat.v1.global_variables_initializer()) sess.run(outputs) #将训练后的参数保存为checkpoint文件 saver_save.save(sess, retrain_ckpt, global_step=0)
(由用户补充处理)创建推理图。
test_graph = user_load_test_graph()调用AMCT,执行组合压缩流程。
修改推理模式的图。
用户构建推理模式的图结构(BN的is_training参数为False),调用组合压缩图修改接口create_compressed_retrain_model,根据量化配置文件对推理的图进行压缩前的图结构修改,插入通道稀疏或4选2结构化稀疏(稀疏方式二选一)与量化感知训练的算子,用于后续模型固化与精度推理,同时生成记录稀疏信息和量化因子的record文件(对应图1中的序号4,5)。
(由用户补充处理)创建会话,恢复训练参数,推理量化的输出节点(retrain_ops[-1]),将量化因子写入record文件,并将推理图固化为pb模型(对应图1中的序号6,7)。
说明:推理和恢复的参数要在同一session中,推理执行的是retrain_ops[-1]的输出tensor;推理图固化为pb模型时,包含训练好的参数。
variables_to_restore = tf.compat.v1.global_variables() saver_restore = tf.compat.v1.train.Saver(variables_to_restore) with tf.Session() as sess: sess.run(tf.compat.v1.global_variables_initializer()) #恢复训练参数 saver_restore.restore(sess, retrain_ckpt) #将量化因子写入record文件,说明:如用户未使能任何量化功能则无需执行此步骤,直接执行下一步 sess.run(retrain_ops[-1]) #固化pb模型 constant_graph = tf.compat.v1.graph_util.convert_variables_to_constants( sess, eval_graph.as_graph_def(), [output.name[:-2] for output in outputs]) with tf.io.gfile.GFile(frozen_quant_eval_pb, 'wb') as f: f.write(constant_graph.SerializeToString())
保存组合压缩模型。
根据稀疏和量化因子记录文件以及固化模型,删除插入的稀疏算子,插入AscendQuant、AscendDequant等量化算子,保存组合压缩模型。
compressed_model_path = './result/user_model' amct.save_compressed_retrain_model(pb_model=trained_pb, outputs=user_model_outputs, record_file=record_file, save_path=compressed_model_path)
(可选,由用户补充处理)使用组合压缩后的模型user_model_compressed.pb和测试集,在TensorFlow的环境下推理,测试组合压缩后的仿真模型精度。
使用组合压缩后的仿真模型精度与2中的原始精度做对比,可以观察组合压缩对精度的影响。
compressed_model = './results/user_model_compressed.pb' user_do_inference(compressed_model, test_data)
手工调优¶
组合压缩后,如果模型精度不满足要求,需要参见稀疏下的手工调优章节和量化感知训练下的手工调优章节分别进行调优。
张量分解¶
张量分解通过分解卷积核的张量,将一个卷积转化成两个小卷积的堆叠来降低推理开销,如用户模型中存在大量卷积,且卷积核shape普遍大于(64, 64, 3, 3)时推荐使用张量分解。
目前仅支持满足如下条件的卷积进行分解:
group=1、dilation=(1,1)、stride<3
kernel_h>2、kernel_w>2
卷积是否分解由AMCT自动判断,即便满足上述条件,也不一定会分解。
例如,用户使用的TensorFlow原始模型中存在Conv2D层,并且该层满足上述条件,才有可能将相应的Conv2D层分解成两个Conv2D层;然后使用AMCT转换成可以在NPU IP加速器部署的量化模型,以便在模型推理时获得更好的性能。
该场景为可选操作,用户自行决定是否进行原始模型的分解。
分解约束
如果Conv2D层的shape过大,会造成分解时间过长或分解异常中止,为防止出现该情况,执行分解动作前,请先参见如下约束或参考数据:
分解工具性能参考数据:
CPU: Intel(R) Xeon(R) CPU E5-2699 v4 @ 2.20GHz
内存: 512G
分解单层卷积:
shape(512, 512, 5, 5),大约耗时25秒。
shape(1024, 1024, 3, 3),大约耗时16秒。
shape(1024, 1024, 5, 5),大约耗时78秒。
shape(2048, 2048, 3, 3),大约耗时63秒。
shape(2048, 2048, 5, 5),大约耗时430秒。
内存超限风险提醒:
分解大卷积核存在内存超限风险参考数值:shape为(2048, 2048, 5, 5)的卷积核约占用32G内存。
接口调用流程
接口调用流程如图1所示,具体分解示例请参见样例列表。
图 1 接口调用流程
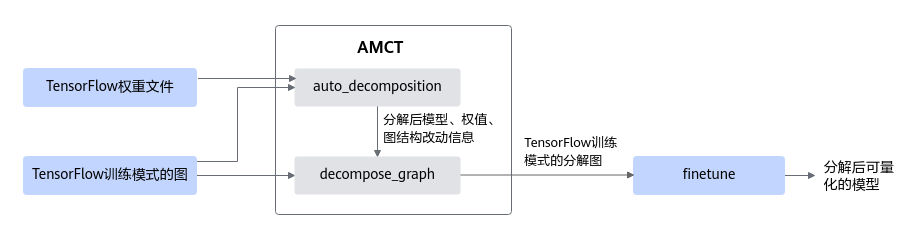
具体流程如下:
根据用户提供的TensorFlow模型文件,调用auto_decomposition生成张量分解后的模型文件。
在TensorFlow训练模式的图的基础上,调用decompose_graph加载1输出的图结构改动信息(*.pkl)分解训练代码中的图,并加载1输出的分解后的模型权重文件,输出训练模式的分解图。
对分解后的模型进行fine-tune,输出可以进行量化的模型。后续可以进行训练后量化或者量化感知训练。
图2为resnet_v2_50网络模型分解前后的示意图。
图 2 模型分解前后示意图
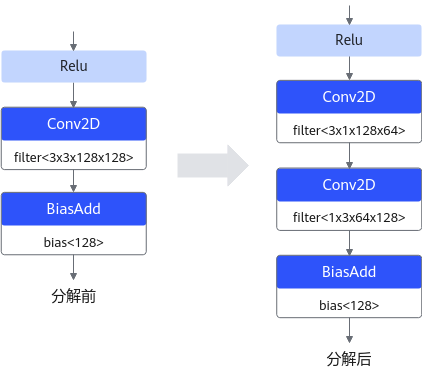
调用示例
调用auto_decomposition分解已有TensorFlow模型。
from amct_tensorflow.tensor_decompose import auto_decomposition meta_path = "src_path/xxx.meta" # meta文件路径 ckpt_path = "src_path/xxx" # ckpt文件路径,例如,原始模型文件为src_path下的xxx.data-XXXXX-of-XXXXX和xxx.index,则设该路径为src_path/xxx save_path = "decomposed_path/xxx" # 保存分解后模型的路径,如设为decomposed_path/xxx,则会在decomposed_path下生成xxx.data-XXXXX-of-XXXXX等文件 auto_decomposition(meta_path, ckpt_path, save_path) # 执行张量分解
修改已有训练代码,调用decompose_graph分解代码中的图,加载分解后的权重进行fine-tune。
根据实际训练代码从如下Session方式和Estimator方式中选择一种。
说明:
(*)表示用户已有的代码;...表示用户已有代码的省略,如下所列代码仅做示例,实际用户代码可能不同,请根据实际情况进行调整。Session方式
from amct_tensorflow.tensor_decompose import decompose_graph save_path = "decom_path/xxx" # 保存分解后模型的路径。即第1步中的save_path。 # ... net_output = build_net(net_input, ...) # (*)构建网络的图 decompose_graph(save_path) # 对构建出的图进行分解,请注意该步骤必须插入在构建网络图之后、应用优化器之前 variables_to_restore = tf.global_variables() # 网络图中的所有变量 restorer = tf.train.Saver(variables_to_restore) # 设置网络图中的变量为要加载的变量 loss = build_loss(net_output, ...) # (*)构造loss optimizer = build_optimizer(...) # (*)构造优化器 train_op = optimizer.minimize(loss, ...) # (*)应用优化器优化loss # ... variables_to_init = [v for v in tf.global_variables() if v not in variables_to_restore] # 不会加载的变量 init = tf.variables_initializer(variables_to_init) # 为不会加载的变量准备初始化 with tf.Session() as sess: # (*)训练用Session sess.run(init) # 初始化不会加载的变量 restorer.restore(sess, save_path) # 从分解后的模型权重中加载要加载的变量 # ...
Estimator方式
from amct_tensorflow.tensor_decompose import decompose_graph save_path = "decom_path/xxx" # 保存分解后模型的路径,即[1](#li127685227562)中的save_path # ... def model_fn(features, labels, ...): # (*)Estimator的模型函数 net_output = build_net(net_input, ...) # (*)构建网络的图 decompose_graph(save_path) # 对构建出的图进行分解,请注意该步骤必须插入在构建网络图之后、应用优化器之前 loss = build_loss(net_output, ...) # (*)构造loss optimizer = build_optimizer(...) # (*)构造优化器 train_op = optimizer.minimize(loss, ...) # (*)应用优化器优化loss # ... estimator = tf.estimator.Estimator(model_fn, warm_start_from=save_path, ...) # (*)构造Estimator,通过warm_start_from参数加载分解后的模型权重 # ...
扩展更多特性¶
在一些数据分布不均匀的场景,由于离群值的影响,对数据进行per-tensor量化得到的结果误差较大,而per-channel量化可以获得更低的误差。但由于当前硬件不支持数据per-channel量化,仅支持权重per-channel量化;在该背景下AMCT设计出一套方法,本节将给出详细介绍。
模型适配¶
如果用户有自己计算得到的量化因子以及TensorFlow原始模型,该模型无法直接使用ATC工具转成适配NPU IP加速器的离线模型,需要借助该章节提供的功能,将其转成CANN量化模型格式,然后才能使用ATC工具,将CANN量化模型转成适配NPU IP加速器的离线模型。 如果用户使用TensorFlow框架的原始模型已经做了量化功能(以下简称QAT模型),但是该模型无法使用ATC工具转成适配NPU IP加速器的离线模型,需要借助本节提供的功能,将该QAT模型适配成CANN量化模型格式。然后才能使用ATC工具,将CANN量化模型转成适配NPU IP加速器的离线模型。
convert_model接口模型适配¶
如果用户有自己计算得到的量化因子以及TensorFlow原始模型,该模型无法直接使用ATC工具转成适配NPU IP加速器的离线模型,需要借助该章节提供的功能,将其转成CANN量化模型格式,然后才能使用ATC工具,将CANN量化模型转成适配NPU IP加速器的离线模型。
适配原理
适配原理如下图所示,蓝色部分为用户实现,灰色部分为用户调用AMCT提供的convert_model接口实现,用户在TensorFlow原始网络推理的代码中导入库,并在特定的位置调用相应API,即可实现模型适配功能。该场景下的适配样例请参见样例列表。
图 1 模型适配原理
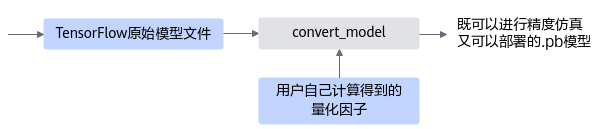
调用示例
本示例演示如何使用convert_model接口对原始模型进行适配。
如下示例标有“由用户补充处理”的步骤,需要用户根据自己的模型和数据集进行补充处理,示例中仅为示例代码。
如果用户需要基于如下代码,对其他模型进行量化,需要准备原始未量化的模型,将用户自己准备的量化因子转换为量化因子记录文件。
导入AMCT包,设置日志级别。
import amct_tensorflow as amct amct.set_logging_level(print_level='info', save_level='info')
(可选,由用户补充处理)建议使用原始待量化的模型和测试集,在TensorFlow环境下推理,验证环境、推理脚本是否正常。
推荐执行该步骤,以确保原始模型可以完成推理且精度正常;执行该步骤时,可以使用部分测试集,减少运行时间。
user_do_inference(ori_model, test_data)调用AMCT中的convert_model接口,进行模型适配。
该接口内部会将pb格式的模型解析为graph形式,完成图的预处理操作>解析用户传入的量化因子文件>然后根据量化因子和修改后的图结构,插入AscendQuant、AscendDequant等算子,保存为量化模型。
quant_model_path = './results/user_model' record_file = './results/record.txt' amct.convert_model(pb_model=ori_model, outputs=ori_model_outputs, record_file=record_file, save_path=quant_model_path)
(可选,由用户补充处理)使用量化后模型user_model_quantized.pb和测试集,在TensorFlow环境下推理,测试量化后的仿真模型精度。
使用量化后仿真模型精度与2中的原始精度做对比,可以观察量化对精度的影响。
quant_model = './results/user_model_quantized.pb' user_do_inference(quant_model, test_data)
QAT模型适配CANN模型¶
如果用户使用TensorFlow框架的原始模型已经做了量化功能(以下简称QAT模型),但是该模型无法使用ATC工具转成适配NPU IP加速器的离线模型,需要借助本节提供的功能,将该QAT模型适配成CANN量化模型格式。然后才能使用ATC工具,将CANN量化模型转成适配NPU IP加速器的离线模型。
转换约束如下:
当前仅支持对QAT模型中包含FakeQuantWithMinMaxVars、FakeQuantWithMinMaxVarsPerChannel(仅权重支持)两类FakeQuant层结构的模型进行适配。
当前仅支持Conv2D、MatMul、DepthwiseConv2dNative、Conv2dBackpropInput、AvgPool类型层匹配fake_quant节点并进行适配,层约束请参见均匀量化。
适配原理
适配原理如下图所示,蓝色部分为用户实现,灰色部分为用户调用AMCT提供的convert_qat_model接口实现,用户在TensorFlow QAT网络推理的代码中导入库,并在特定的位置调用相应API,即可实现适配功能。QAT模型当前不支持自动量化功能。详细适配样例请参见样例列表,您也可以获取命令行方式的示例,快速体验其功能。
图 1 QAT模型适配CANN模型

调用示例
本示例演示了如何将TensorFlow的QAT量化模型通过AMCT适配为CANN量化模型格式。
如下示例标有“由用户补充处理”的步骤,需要用户根据自己的模型和数据集进行补充处理,示例中仅为示例代码。
如下示例调用AMCT的部分,函数入参请根据实际情况进行调整。
导入AMCT包,设置日志级别。
import amct_tensorflow as amct amct.set_logging_level(print_level='info', save_level='info')
(可选,由用户补充处理)建议使用原始待量化的模型和测试集,在TensorFlow环境下推理,验证环境、推理脚本是否正常。
推荐执行该步骤,以确保原始模型可以完成推理且精度正常;执行该步骤时,可以使用部分测试集,减少运行时间。
user_do_inference(ori_qat_model, test_data)调用AMCT中的convert_qat_model接口,执行模型适配。
该接口内部会将pb格式的模型解析为graph形式,完成图的预处理操作>修改解析后的图结构,插入AscendQuant、AscendDequant等算子,保存为量化模型。
quant_model_path = './results/user_model' record_file = './results/record.txt' amct.convert_qat_model(pb_model=ori_qat_model, outputs=ori_qat_model_outputs, save_path=quant_model_path, record_file=record_file)
(可选,由用户补充处理)使用量化后模型user_model_quantized.pb和测试集,在TensorFlow的环境下推理,测试量化后的仿真模型精度。
使用量化后仿真模型精度与2中的原始精度做对比,可以观察量化对精度的影响。
quant_model = './results/user_model_quantized.pb' user_do_inference(quant_model, test_data)
量化数据均衡预处理¶
在一些数据分布不均匀的场景,由于离群值的影响,对数据进行per-tensor量化得到的结果误差较大,而per-channel量化可以获得更低的误差。但由于当前硬件不支持数据per-channel量化,仅支持权重per-channel量化;在该背景下AMCT设计出一套方法,本节将给出详细介绍。
通过数据均衡预处理接口计算出均衡因子,将模型数据与权重进行数学等价换算,均衡模型数据与权重的分布,将数据的量化难度迁移一部分至权重,从而降低量化误差。该特性支持的层及约束如下:
表 1 支持的层以及约束
支持的层类型 |
约束 |
备注 |
|---|---|---|
MatMul |
transpose_a=False、transpose_b=False、adjoint_a=False、adjoint_b=False |
weight的输入来源不含有placeholder等可动态变化的节点,且weight的节点类型只能是const。 |
Conv2D |
- |
|
Conv3D |
dilation_d为1,dilation_h/dilation_w >= 1 |
|
DepthwiseConv2dNative |
dilation为1 |
|
Conv2DBackpropInput |
dilation为1 |
接口调用流程
均衡预处理接口调用流程如图1所示。
图 1 均衡预处理接口调用流程

蓝色部分为用户实现,灰色部分为用户调用AMCT提供的API实现,用户在TensorFlow原始网络推理的代码中导入库,并在特定的位置调用相应API,即可实现量化功能。工具运行流程如下:
用户首先构造TensorFlow的原始模型,并在简易配置文件_dmp_quant.cfg_中设置dmq参数(简易配置文件配置参数请参见训练后量化简易配置文件),然后将配置文件传入create_quant_config。
根据TensorFlow模型和量化配置文件,调用quantize_preprocess接口,对原始TensorFlow模型插入均衡量化相关算子,用于计算均衡量化相关参数。
用户使用2输出的修改后的模型,借助AMCT提供的数据集和校准集,在TensorFlow环境中进行inference,可以得到均衡因子。
其中数据集用于在TensorFlow环境中对模型进行推理时,测试量化数据的精度;校准集用来产生均衡因子,保证精度。
根据TensorFlow模型和量化配置文件,调用quantize_model接口对原始TensorFlow模型进行优化,修改后的模型中插入数据量化、权重量化等相关算子,用于计算量化相关参数。
用户使用4输出的修改后的模型,借助AMCT提供的数据集和校准集,在TensorFlow环境中进行inference,可以得到量化因子。
最后用户可以调用save_model接口,插入AscendQuant、AscendDequant等算子,保存为量化模型,该模型既可在TensorFlow环境中进行精度仿真又可以在NPU IP加速器部署。
调用示例
本章节详细给出量化数据均衡预处理的模板代码解析说明,通过解读该代码,用户可以详细了解AMCT的工作流程以及原理,方便用户基于已有模板代码进行修改,以便适配其他网络模型。
如下示例标有“由用户补充处理”的步骤,需要用户根据自己的模型和数据集进行补充处理,示例中仅为示例代码。
如下示例调用AMCT的部分,函数入参请根据实际情况进行调整。
导入AMCT包,设置日志级别。
import amct_tensorflow as amct amct.set_logging_level(print_level='info', save_level='info')
(可选,由用户补充处理)在TensorFlow原始环境中验证推理脚本及环境。
建议使用原始待量化的模型和测试集,在TensorFlow环境下推理,验证环境、推理脚本是否正常。
推荐执行该步骤,请确保原始模型可以完成推理且精度正常;执行该步骤时,可以使用部分测试集,减少运行时间。
user_do_inference(ori_model, test_data, test_iterations)(由用户补充处理)根据模型user_model.pb,准备好图结构tf.Graph。
ori_graph = user_load_graph()调用AMCT,量化模型。
生成量化配置。
用户在简易配置文件_dmp_quant.cfg_中设置dmq参数,并将配置文件通过config_defination参数传入create_quant_config。
config_defination = os.path.join(PATH, 'dmp_quant.cfg') config_file = './tmp/config.json' skip_layers = [] batch_num = 1 amct.create_quant_config(config_file=config_file, graph=ori_graph, skip_layers=skip_layers, batch_num=batch_num, config_defination=config_defination)
修改图,在图中插入均衡量化相关的算子,用于计算均衡量化相关参数。
record_file = './tmp/record.txt' amct.quantize_preprocess(graph=ori_graph, config_file=config_file, record_file=record_file)
使用AMCT调用quantize_model接口对用户的原始TensorFlow模型进行图修改时,由于插入了searchN层导致尾层输出节点发生改变的场景,可以参见TensorFlow网络模型由于AMCT导致输出节点改变,如何通过修改量化脚本进行后续的量化动作进行处理。如果量化过程存在空tensor输入报错信息,请参见使用训练后量化进行量化时,量化过程存在空tensor输入报错信息进行处理。
(由用户补充处理)使用修改后的图在校准集上做模型推理,计算均衡量化因子。
该步骤执行时,需要注意如下两点:
校准集及其预处理过程数据要与模型匹配,以保证量化的精度。
前向推理的次数为1,如果次数超出1,后续过程会失败。
user_do_inference(ori_graph, calibration_data, batch_num)校准时提示“Invalid argument: You must feed a value for placeholder tensor **”,则请参见校准时提示“Invalid argument: You must feed a value for placeholder tensor **”进行处理。
重新载入原始模型,基于原始模型进行修改,在图中插入数据量化,权重量化等相关的算子,用于计算量化相关参数。
ori_graph = user_load_graph() amct.quantize_model(graph=ori_graph, config_file=config_file, record_file=record_file)
使用AMCT调用quantize_model接口对用户的原始TensorFlow模型进行图修改时,由于插入了searchN层导致尾层输出节点发生改变的场景,可以参见TensorFlow网络模型由于AMCT导致输出节点改变,如何通过修改量化脚本进行后续的量化动作进行处理。如果量化过程存在空tensor输入报错信息,请参见使用训练后量化进行量化时,量化过程存在空tensor输入报错信息进行处理。
(由用户补充处理)使用修改后的图在校准集上做模型推理,找到量化因子。
该步骤执行时,需要注意如下两点:
校准集及其预处理过程数据要与模型匹配,以保证量化的精度。
前向推理的次数为batch_num,如果次数不够,后续过程会失败。
user_do_inference(ori_graph, calibration_data, batch_num)校准时提示“Invalid argument: You must feed a value for placeholder tensor **”,则请参见校准时提示“Invalid argument: You must feed a value for placeholder tensor **”进行处理。
保存模型。
根据量化因子,调用save_model接口,插入AscendQuant、AscendDequant等算子,保存为量化模型。
quant_model_path = './results/user_model' amct.save_model(pb_model='user_model.pb', outputs=['user_model_outputs0', 'user_model_outputs1'], record_file=record_file, save_path=quant_model_path)
保存模型时提示“RuntimeError: cannot find shift_bit of layer ** in record_file”,则请参见保存模型时提示“RuntimeError: record_file is empty, no layers to be quantized”进行处理。
(可选,由用户补充处理)使用量化后模型user_model_quantized.pb和测试集(test_data),在TensorFlow环境下推理,测试量化后的仿真模型精度。
使用量化后仿真模型精度与2中的原始精度做对比,可以观察量化对精度的影响。
quant_model = './results/user_model_quantized.pb' user_do_inference(quant_model, test_data, test_iterations)
接口说明¶
整体约束和接口列表¶
整体约束
若接口中存在需要用户输入文件路径的参数,请确保输入路径正确,AMCT不会对路径做安全校验。
若接口中存在需要用户输入文件路径的参数,重新执行量化时,该参数相关取值将会被覆盖;量化打屏日志中也会有相关文件被覆盖的warning风险提示信息。
接口列表
分类 |
接口名称 |
功能描述 |
|---|---|---|
公共接口 |
set_logging_level |
设置信息输出的级别,其中信息包括打印在屏幕上的信息以及保存到amct_log/amct_tensorflow.log文件中的信息。 |
GraphEvaluator |
针对某一个模型,根据模型的bin类型输入数据,提供一个Python实例,可对该模型执行校准和推理的评估器。 |
|
训练后量化接口 |
create_quant_config |
训练后量化接口,根据图的结构找到所有可量化的层,自动生成量化配置文件,并将可量化层的量化配置信息写入文件。 |
quantize_model |
训练后量化接口,将输入的待量化的图结构按照给定的量化配置文件进行量化处理,在传入的图结构中插入量化相关的算子,生成量化因子记录文件record_file,并返回量化处理新增的算子列表。 |
|
save_model |
训练后量化接口,根据量化因子记录文件record_file和用户待量化的原始pb模型,插入AscendQuant、AscendDequant等算子,然后保存为既可以在TensorFlow环境进行精度仿真又可以在NPU IP加速器做离线推理的pb模型文件。 |
|
accuracy_based_auto_calibration |
根据用户输入的模型、配置文件进行自动的校准过程,搜索得到一个满足目标精度的量化配置,输出既可以在TensorFlow环境下做精度仿真的fake_quant模型又可在NPU IP加速器上做推理的deploy模型。 |
|
quantize_preprocess |
量化数据均衡预处理接口,将输入的待量化的图结构按照给定的量化配置文件进行量化预处理(当前仅支持均衡量化),在传入的图结构中插入均衡量化相关的算子,生成均衡因子记录文件record_file,供后续quantize_model阶段读取。 |
|
量化感知训练接口 |
create_quant_retrain_config |
量化感知训练接口,根据图的结构找到所有可量化的层,自动生成量化配置文件,并将可量化层的量化配置信息写入配置文件。 |
create_quant_retrain_model |
量化感知训练接口,根据用户设置的量化配置文件对图结构进行量化处理,该函数在config_file指定的层插入数据和weights伪量化层,将修改后的网络存为新的模型文件。 |
|
save_quant_retrain_model |
量化感知训练接口,根据用户最终的重训练好的模型,插入AscendQuant、AscendDequant等算子,生成最终既可以进行精度仿真又可以进行部署的模型。 |
|
稀疏接口 |
create_prune_retrain_model |
通道稀疏或4选2结构化稀疏接口,两种稀疏特性每次只能使能一个。 |
save_prune_retrain_model |
通道稀疏或4选2结构化稀疏接口,两种稀疏特性每次只能使能一个。 |
|
自动通道稀疏搜索接口 |
auto_channel_prune_search |
自动通道稀疏搜索接口,根据用户模型来计算各通道的稀疏敏感度(影响精度)以及稀疏收益(影响性能),然后搜索策略依据该输入来搜索最优的逐层通道稀疏率,以平衡精度和性能。最终输出一个配置文件。 |
组合压缩接口 |
create_compressed_retrain_model |
静态组合压缩接口,根据用户设置的压缩配置文件对图结构先进行稀疏(通道稀疏或者4选2结构化稀疏,二选一),后插入量化相关的算子,并返回修改后的图。 |
save_compressed_retrain_model |
静态组合压缩接口,根据用户最终重训练好的模型,生成最终静态组合压缩模型。 |
|
张量分解接口 |
auto_decomposition |
根据用户提供的TensorFlow模型文件,生成张量分解后的模型文件。 |
decompose_graph |
分解训练代码中的图,用于对分解后的模型进行fine-tune(微调)。 |
|
模型适配接口 |
convert_model |
根据用户自己计算得到的量化因子以及TensorFlow模型,适配成既可以在NPU IP加速器上部署的模型又可以在TensorFlow环境下进行精度仿真的量化模型。 |
convert_qat_model |
根据TensorFlow的QAT量化模型,适配成分别可以在CPU、GPU上进行精度仿真和NPU IP加速器上部署的量化模型。 |
公共接口¶
set_logging_level¶
产品支持情况
产品 |
是否支持 |
|---|---|
IPV350 |
√ |
功能说明
设置信息输出的级别,其中信息包括打印在屏幕上的信息以及保存到amct_log/amct_tensorflow.log文件中的信息。
函数原型
set_logging_level(print_level='info', save_level='info')
参数说明
参数名 |
输入/输出 |
说明 |
|---|---|---|
print_level |
输入 |
含义:控制打印信息的级别。
默认值为:info 数据类型:string |
save_level |
输入 |
含义:控制quant_info.log中保存信息的级别。
默认值为:info 数据类型:string |
信息级别 |
信息描述 |
|---|---|
DEBUG |
详细的量化处理信息,包含量化因子(scale/offset)以及相关调试信息。 |
INFO |
概要的量化处理信息,包含量化的层名、bn融合等信息。 |
WARNING |
量化处理过程中的警告信息。 |
ERROR |
量化处理过程中的错误信息。 |
信息级别不区分大小写,即Info、info、INFO均为有效取值。
返回值说明
无
调用示例
import amct_tensorflow as amct
amct.set_logging_level(print_level="info", save_level="info")
amct.quantize_model(
graph=tf.get_default_graph(),
config_file="./configs/config.json",
record_file="./record_scale_offset.txt")
...
amct.save_model(pb_model="./user_model.pb",
outputs=["model/outputs"],
record_file="./record_scale_offset.txt",
save_path="./inference/model")
GraphEvaluator¶
产品支持情况
产品 |
是否支持 |
|---|---|
IPV350 |
√ |
功能说明
针对某一个模型,根据模型的bin类型输入数据,提供一个Python实例,可对该模型执行校准和推理的评估器。
函数原型
class GraphEvaluator(AutoCalibrationEvaluatorBase):
def __init__(self, data_dir, input_shape, data_types):
参数说明
参数名 |
输入/输出 |
说明 |
|---|---|---|
data_dir |
输入 |
含义:与模型匹配的bin格式数据集路径。 数据类型:string 参数值格式:"data/input1/;data/input2/" 使用约束:
|
input_shape |
输入 |
含义:模型输入的shape信息。 数据类型:string 参数值格式:"input_name1:n1,c1,h1,w1;input_name2:n2,c2,h2,w2"。 使用约束:指定的节点必须放在双引号中,节点中间使用英文分号分隔。 |
data_types |
输入 |
含义:输入数据的类型。 数据类型:string 参数值格式:"float32;float64" 使用约束:若模型有多个输入,且数据类型不同,则需要分别指定不同输入的数据类型,指定的输入数据类型必须按照输入节点顺序依次放在双引号中,所有的输入数据类型必须放在双引号中,中间使用英文分号分隔。 |
返回值说明
一个Python实例。
调用示例
import amct_tensorflow as amct
evaluator = amct.GraphEvaluator(
data_dir="./data/input_bin/",
input_shape="input:32,3,224,224",
data_types="float32")
训练后量化接口¶
create_quant_config¶
产品支持情况
产品 |
是否支持 |
|---|---|
IPV350 |
√ |
功能说明
训练后量化接口,根据图的结构找到所有可量化的层,自动生成量化配置文件,并将可量化层的量化配置信息写入文件。
函数原型
create_quant_config(config_file, graph, skip_layers=None, batch_num=1, activation_offset=True, config_defination=None)
参数说明
参数名 |
输入/输出 |
说明 |
|---|---|---|
config_file |
输入 |
含义:待生成的量化配置文件存放路径及名称。 如果存放路径下已经存在该文件,则调用该接口时会覆盖已有文件。 数据类型:string |
graph |
输入 |
含义:用户传入的待量化模型的tf.Graph图。 数据类型:tf.Graph |
skip_layers |
输入 |
含义:tf.Graph图中不需要量化层的层名。 默认值:None 数据类型:list,列表中元素类型为string,比如['op1','op2','op3'] 使用约束:如果使用简易配置文件作为入参,则该参数需要在简易配置文件中设置,此时输入参数中该参数配置不生效。 |
batch_num |
输入 |
含义:量化使用的batch数量,即使用多少个batch的数据生成量化因子。 数据类型:int 取值范围:大于0的整数 默认值:1 使用约束:
|
activation_offset |
输入 |
含义:数据量化是否带offset。 默认值:True 数据类型:bool 使用约束:如果使用简易配置文件作为入参,则该参数需要在简易配置文件中设置,此时输入参数中该参数配置不生效。 |
config_defination |
输入 |
含义:训练后量化简易配置文件。 基于calibration_config_tf.proto文件生成的简易量化配置文件quant.cfg,*.proto文件所在路径为:AMCT安装目录/amct_tensorflow/proto/。*.proto文件参数解释以及生成的quant.cfg简易量化配置文件样例请参见训练后量化简易配置文件。 默认值:None 数据类型:string 使用约束:当取值为None时,使用输入参数生成配置文件;否则,忽略输入的其他量化参数(skip_layers,batch_num,activation_offset),根据简易量化配置文件参数config_defination生成JSON格式的配置文件。 |
返回值说明
无
调用示例
import amct_tensorflow as amct
# 建立待量化的网络图结构
network = build_network()
# 生成量化配置文件
amct.create_quant_config(config_file="./configs/config.json",
graph=tf.get_default_graph(),
skip_layers=None,
batch_num=1,
activation_offset=True)
生成的JSON格式的量化配置文件样例如下(重新执行量化时,该接口输出的量化配置文件将会被覆盖):
均匀量化配置文件(数据量化使用IFMR数据量化算法)
{ "version":1, "batch_num":1, "activation_offset":true, "joint_quant":false, "do_fusion":true, "skip_fusion_layers":[], "tensor_quantize":[ { "layer_name": "MaxPool", "input_index": 0, "activation_quant_params":{ "num_bits":16, "act_algo":"hfmg", "num_of_bins":4096, "asymmetric":false } } ] "MobilenetV2/Conv/Conv2D":{ "quant_enable":true, "dmq_balancer_param":0.5, "activation_quant_params":{ "num_bits":16, "max_percentile":0.999999, "min_percentile":0.999999, "search_range":[ 0.7, 1.3 ], "search_step":0.01, "act_algo":"ifmr", "asymmetric":false }, "weight_quant_params":{ "num_bits":8, "wts_algo":"arq_quantize", "channel_wise":true } }, "MobilenetV2/Logits/AvgPool":{ "quant_enable":true, "dmq_balancer_param":0.5, "activation_quant_params":{ "num_bits":16, "max_percentile":0.999999, "min_percentile":0.999999, "search_range":[ 0.7, 1.3 ], "search_step":0.01, "act_algo":"ifmr", "asymmetric":false }, "weight_quant_params":{ "num_bits":8, "wts_algo":"arq_quantize", "channel_wise":false } } }
均匀量化配置文件(数据量化使用HFMG数据量化算法)
{ "version":1, "batch_num":2, "activation_offset":true, "joint_quant":false, "do_fusion":true, "skip_fusion_layers":[], "MobilenetV2/Conv_1/Conv2D":{ "quant_enable":true, "dmq_balancer_param":0.5, "activation_quant_params":{ "num_bits":16, "act_algo":"hfmg", "num_of_bins":4096 "asymmetric":false }, "weight_quant_params":{ "num_bits":8, "wts_algo":"arq_quantize", "channel_wise":true } } }
quantize_model¶
产品支持情况
产品 |
是否支持 |
|---|---|
IPV350 |
√ |
功能说明
训练后量化接口,将输入的待量化的图结构按照给定的量化配置文件进行量化处理,在传入的图结构中插入量化相关的算子,生成量化因子记录文件record_file,并返回量化处理新增的算子列表。
函数原型
quant_add_ops = quantize_model(graph, config_file, record_file, calib_outputs=None)
参数说明
参数名 |
输入/输出 |
说明 |
|---|---|---|
graph |
输入 |
含义:用户传入的待量化模型的tf.Graph图。 数据类型:tf.Graph |
config_file |
输入 |
含义:用户生成的量化配置文件,用于指定模型tf.Graph图中量化层的配置情况。 数据类型:string |
record_file |
输入 |
含义:量化因子记录文件路径及名称。 数据类型:string |
calib_outputs |
输入 |
含义:graph输出算子列表。 当改图导致尾层输出节点变化,则输出列表也随之更新。 数据类型:list 默认值:None |
quant_add_ops |
返回值 |
含义:量化插入的算子变量列表。 数据类型:list,列表中元素类型为tf.Variable 说明:
该列表中的变量值无法在模型训练参数文件中找到,故模型训练参数直接恢复会出现变量无法找到的错误,因此需要在模型训练参数恢复之前,将 quant_add_ops列表中的变量值从恢复列表中剔除,具体的剔除方法请参见插入量化算子后,如何恢复模型训练参数。 |
返回值说明
网络中量化的层名信息列表。
quantize_model对图做了融合,则网络的输出节点会发生变化。例如,Conv+BN(或Conv+BiasAdd+BN)融合后为Conv+BiasAdd,BN等价的输出节点为BiasAdd节点。
调用示例
import amct_tensorflow as amct
# 建立待量化的网络结构
network = build_network()
# 插入量化API
amct.quantize_model(
graph=tf.get_default_graph(),
config_file="./configs/config.json",
record_file="./record_scale_offset.txt")
save_model¶
产品支持情况
产品 |
是否支持 |
|---|---|
IPV350 |
√ |
功能说明
训练后量化接口,根据量化因子记录文件record_file和用户待量化的原始pb模型,插入AscendQuant、AscendDequant等算子,然后保存为既可以在TensorFlow环境进行精度仿真又可以在NPU IP加速器做离线推理的pb模型文件。
函数原型
save_model(pb_model, outputs, record_file, save_path)
参数说明
参数名 |
输入/输出 |
说明 |
|---|---|---|
pb_model |
输入 |
含义:用户待量化的原始pb模型文件。 数据类型:string |
outputs |
输入 |
含义:graph中输出算子的列表。 数据类型:list,列表中元素类型为string |
record_file |
输入 |
含义:量化因子记录文件路径及名称。通过该文件、量化配置文件以及原始pb模型文件,生成量化后的模型文件。 数据类型:string |
save_path |
输入 |
含义:模型存放路径。 该路径需要包含模型名前缀,例如./quantized_model/*model。 数据类型:string |
返回值说明
无
约束说明
在网络推理的batch数目达到batch_num后,再调用该接口,否则量化因子不正确,量化结果不正确。
该接口只接收pb类型的模型文件,用户需要将待量化模型提前转换为pb类型。
该接口需要输入量化因子记录文件,量化因子记录文件在quantize_model阶段生成,在模型推理阶段填充有效值。
调用示例
import amct_tensorflow as amct
# 进行网络推理,期间完成量化
for i in batch_num:
sess.run(outputs, feed_dict={inputs: inputs_data})
# 插入API,将量化的模型存为PB文件
amct.save_model(pb_model="./user_model.pb",
outputs=["model/outputs"],
record_file="./record_scale_offset.txt",
save_path="./inference/model")
落盘的量化后的模型:既可以在TensorFlow环境进行精度仿真又可以在NPU IP加速器做离线推理的pb模型文件。重新执行量化时,该接口输出的上述文件将会被覆盖。
accuracy_based_auto_calibration¶
产品支持情况
产品 |
是否支持 |
|---|---|
IPV350 |
√ |
功能说明
根据用户输入的模型、配置文件进行自动的校准过程,搜索得到一个满足目标精度的量化配置,输出既可以在TensorFlow环境下做精度仿真的fake_quant模型又可在NPU IP加速器上做推理的deploy模型。
函数原型
accuracy_based_auto_calibration(model_file,outputs,record_file,config_file,save_dir,evaluator,strategy='BinarySearch',sensitivity='CosineSimilarity')
参数说明
参数名 |
输入/输出 |
说明 |
|---|---|---|
model_file |
输入 |
含义:用户未量化的TensorFlow模型的定义文件,格式为.pb。 数据类型:string |
outputs |
输入 |
含义:输出节点的字符串列表。 数据类型:string |
config_file |
输入 |
含义:用户生成的量化配置文件。 数据类型:string |
record_file |
输入 |
含义:存储量化因子的路径,如果该路径下已存在文件,则会被重写。 数据类型:string |
save_dir |
输入 |
含义:模型存放路径。 该路径需要包含模型名前缀,例如./quantized_model/*model。 数据类型:string |
evaluator |
输入 |
含义:自动量化进行校准和评估精度的Python实例。 数据类型:Python实例 |
strategy |
输入 |
含义:搜索满足精度要求的量化配置的策略,默认是二分法策略。 数据类型:string或Python实例 默认值:BinarySearch |
sensitivity |
输入 |
含义:评价每一层量化层对于量化敏感度的指标,默认是余弦相似度。 数据类型:string或Python实例 默认值:CosineSimilarity |
返回值说明
无
调用示例
import amct_tensorflow as amct
from amct_tensorflow.accuracy_based_auto_calibration import accuracy_based_auto_calibration
def main():
args_check(args)
outputs = [PREDICTIONS]
record_file = os.path.join(RESULT_DIR, 'record.txt')
config_file = os.path.join(RESULT_DIR, 'config.json')
with tf.io.gfile.GFile(args.model, mode='rb') as model:
graph_def = tf.compat.v1.GraphDef()
graph_def.ParseFromString(model.read())
tf.import_graph_def(graph_def, name='')
graph = tf.compat.v1.get_default_graph()
amct.create_quant_config(config_file, graph)
save_dir = os.path.join(RESULT_DIR, 'MobileNetV2')
evaluator = MobileNetV2Evaluator(args.dataset, args.keyword, args.num_parallel_reads, args.batch_size)
accuracy_based_auto_calibration(args.model, outputs, record_file, config_file, save_dir, evaluator)
落盘文件说明:
既可以在TensorFlow环境进行精度仿真又可以在NPU IP加速器做推理的pb模型文件。
量化因子记录文件、量化配置文件、层相似度文件以及自动量化回退历史记录文件。
quantize_preprocess¶
产品支持情况
产品 |
是否支持 |
|---|---|
IPV350 |
√ |
功能说明
量化数据均衡预处理接口,将输入的待量化的图结构按照给定的量化配置文件进行量化预处理(当前仅支持均衡量化),在传入的图结构中插入均衡量化相关的算子,生成均衡因子记录文件record_file,供后续quantize_model阶段读取。
函数原型
quantized_preprocess(graph, config_file, record_file, outputs=None)
参数说明
参数名 |
输入/输出 |
说明 |
|---|---|---|
graph |
输入 |
含义:用户传入的待量化模型的tf.Graph图。 数据类型:tf.Graph |
config_file |
输入 |
含义:用户生成的量化配置文件,用于指定模型tf.Graph图中量化层的配置情况。 数据类型:string |
record_file |
输入 |
含义:均衡因子记录文件路径及名称。 数据类型:string |
outputs |
输入 |
含义:graph输出算子列表。 当改图导致尾层输出节点变化,则输出列表也随之更新。 数据类型:list 默认值:None |
调用示例
import amct_tensorflow as amct
# 建立待量化的网络结构
network = build_network()
# 插入量化API
amct.quantized_preprocess(
graph=tf.get_default_graph(),
config_file="./configs/config.json",
record_file="./record_scale_offset.txt")
量化感知训练接口¶
create_quant_retrain_config¶
产品支持情况
产品 |
是否支持 |
|---|---|
IPV350 |
|
功能说明
量化感知训练接口,根据图的结构找到所有可量化的层,自动生成量化配置文件,并将可量化层的量化配置信息写入配置文件。
函数原型
create_quant_retrain_config(config_file, graph, config_defination=None)
参数说明
参数名 |
输入/输出 |
说明 |
|---|---|---|
config_file |
输入 |
含义:待生成的量化感知训练配置文件存放路径及名称。 如果存放路径下已经存在该文件,则调用该接口时会覆盖已有文件。 数据类型:string |
graph |
输入 |
含义:用户传入的待量化模型的tf.Graph图。 数据类型:tf.Graph |
config_defination |
输入 |
含义:量化感知训练简易配置文件。 基于retrain_config_tf.proto文件生成的简易配置文件quant.cfg,*.proto文件所在路径为:AMCT安装目录/amct_tensorflow/proto/。*.proto文件参数解释以及生成的quant.cfg简易量化配置文件样例请参见量化感知训练简易配置文件。 数据类型:string 默认值:None |
返回值说明
无
调用示例
PATH, _ = os.path.split(os.path.realpath(__file__))
config_path = os.path.join(PATH, 'resnet50_config.json')
simple_config = './retrain/retrain.cfg'
graph = tf.compat.v1.get_default_graph()
amct.create_quant_retrain_config(config_path, graph, simple_config)
生成的JSON格式的量化感知训练配置文件样例如下(重新执行量化感知训练时,该接口输出的配置文件将会被覆盖):
{
"version":1,
"batch_num":1,
"conv1":{
"retrain_enable":true,
"retrain_data_config":{
"algo":"ulq_quantize",
"dst_type":"INT8"
},
"retrain_weight_config":{
"algo":"arq_retrain",
"channel_wise":true,
"dst_type":"INT8"
}
},
"conv2_1/expand":{
"retrain_enable":true,
"retrain_data_config":{
"algo":"ulq_quantize",
"dst_type":"INT8"
},
"retrain_weight_config":{
"algo":"arq_retrain",
"channel_wise":true,
"dst_type":"INT8"
}
}
}
create_quant_retrain_model¶
产品支持情况
产品 |
是否支持 |
|---|---|
IPV350 |
|
功能说明
量化感知训练接口,根据用户设置的量化配置文件对图结构进行量化处理,该函数在config_file指定的层插入数据和weights伪量化层,将修改后的网络存为新的模型文件。
函数原型
retrain_ops = create_quant_retrain_model(graph, config_file, record_file)
参数说明
参数名 |
输入/输出 |
说明 |
|---|---|---|
graph |
输入 |
含义:用户传入的待量化模型的tf.Graph图。 数据类型:tf.Graph |
config_file |
输入 |
含义:用户生成的量化感知训练配置文件,用于指定模型tf.Graph图中量化感知训练层的配置情况。 数据类型:string |
record_file |
输入 |
含义:量化因子记录文件路径。 数据类型:string |
返回值说明
量化感知训练新增的层名变量列表,类型为list,列表中元素类型为tf.Variable。
调用示例
retrain_ops = amct.create_quant_retrain_model(graph, config_file, record_file)
save_quant_retrain_model¶
产品支持情况
产品 |
是否支持 |
|---|---|
IPV350 |
|
功能说明
量化感知训练接口,根据用户最终的重训练好的模型,插入AscendQuant、AscendDequant等算子,生成最终既可以进行精度仿真又可以进行部署的模型。
函数原型
save_quant_retrain_model(pb_model, outputs, record_file, save_path)
参数说明
参数名 |
输入/输出 |
说明 |
|---|---|---|
pb_model |
输入 |
含义:重训练后保存的pb模型。 数据类型:string |
outputs |
输入 |
含义:用户模型的输出。 数据类型:list,列表中元素类型为string,例如[output1,output2,...]。 |
record_file |
输入 |
含义:存储量化因子的文件。通过该文件以及原始pb模型文件,生成量化后的模型文件。 数据类型:string |
save_path |
输入 |
含义:模型存放路径。 该路径需要包含模型名前缀,例如./quantized_model/*model。 数据类型:string |
返回值说明
无
调用示例
amct.save_quant_retrain_model(FLAGS.checkpoint_path+'/output_graph.pb',output_node_names, record_file, FLAGS.checkpoint_path+'/resnet50')
保存的量化后的文件,既可以在TensorFlow环境进行精度仿真又可以在NPU IP加速器做推理的pb模型文件。
重新执行量化感知训练功能时,该接口输出的上述文件将会被覆盖。
稀疏接口¶
create_prune_retrain_model¶
产品支持情况
产品 |
是否支持 |
|---|---|
IPV350 |
|
注:上述4选2结构化稀疏特性,标记“x”的产品,调用接口不会报错,但是获取不到性能收益。
功能说明
通道稀疏或4选2结构化稀疏接口,两种稀疏特性每次只能使能一个。
通道稀疏场景:根据用户设置的稀疏配置文件对图结构进行稀疏处理,该函数在图结构中插入通道稀疏mask算子,达到推理时伪稀疏的效果。
4选2结构化稀疏:根据用户设置的稀疏配置文件对图结构进行稀疏处理,该函数在图结构中插入4选2结构化稀疏算子,达到推理时伪稀疏的效果。
函数原型
create_prune_retrain_model(graph, outputs, record_file, config_defination)
参数说明
参数名 |
输入/输出 |
说明 |
|---|---|---|
graph |
输入 |
含义:用户传入的待稀疏模型的tf.Graph图。 数据类型:tf.Graph |
outputs |
输入 |
含义:用户模型的输出。 数据类型:list,列表中元素类型为string,例如[output1,output2,...]。 |
record_file |
输入 |
含义:记录稀疏信息的文件路径及名称,记录通道稀疏结点间的级联关系或记录4选2稀疏的节点。 数据类型:string |
config_defination |
输入 |
含义:用户提供的稀疏配置文件,用于指定模型tf.Graph图中各层稀疏配置情况。 基于retrain_config_tf.proto文件生成的简易配置文件prune.cfg,*.proto文件所在路径为:AMCT安装目录/amct_tensorflow/proto/。 *.proto文件参数解释以及生成的prune.cfg稀疏配置文件样例请参见量化感知训练简易配置文件。 数据类型:string |
返回值说明
无
调用示例
amct.create_prune_retrain_model(graph, [operation_name_1, operation_name_2], './tmp/record.txt', './tmp/sample_prune.cfg')
save_prune_retrain_model¶
产品支持情况
产品 |
是否支持 |
|---|---|
IPV350 |
|
注:上述4选2结构化稀疏特性,标记“x”的产品,调用接口不会报错,但是获取不到性能收益。
功能说明
通道稀疏或4选2结构化稀疏接口,两种稀疏特性每次只能使能一个。
通道稀疏场景:根据用户最终的重训练好的带mask算子的模型,生成最终实现通道裁剪的稀疏模型,并删除mask算子。
4选2结构化稀疏场景:根据用户最终的重训练好的带4选2结构化稀疏算子的模型,生成最终的稀疏模型,并删除结构化稀疏算子。
函数原型
save_prune_retrain_model(pb_model, outputs, record_file, save_path)
参数说明
参数名 |
输入/输出 |
说明 |
|---|---|---|
pb_model |
输入 |
含义:带有稀疏算子的推理pb模型,其参数由重训练checkpoint恢复。 数据类型:string |
outputs |
输入 |
含义:用户模型的输出。 数据类型:list,列表中元素类型为string,例如[output1,output2,...]。 |
record_file |
输入 |
含义:记录稀疏信息的文件路径及名称。 数据类型:string |
save_path |
输入 |
含义:模型存放路径。 该路径需要包含模型名前缀,例如./prune_model/*model。 数据类型:string |
返回值说明
无
调用示例
amct.save_prune_retrain_model(masked_pb_path, [operation_name_1, operation_name_2], './tmp/record.txt', './pb_model/final_model')
落盘文件为:实现稀疏的pb模型。
自动通道稀疏搜索接口¶
auto_channel_prune_search¶
产品支持情况
产品 |
是否支持 |
|---|---|
IPV350 |
√ |
功能说明
自动通道稀疏搜索接口,根据用户模型来计算各通道的稀疏敏感度(影响精度)以及稀疏收益(影响性能),然后搜索策略依据该输入来搜索最优的逐层通道稀疏率,以平衡精度和性能。最终输出一个配置文件。
函数原型
auto_channel_prune_search(graph, output_nodes, config, input_data, output_cfg, sensitivity, search_alg)
参数说明
参数名 |
输入/输出 |
说明 |
|---|---|---|
graph |
输入 |
含义:待稀疏的、包含自动微分的tf.Graph训练图。 数据类型:tf.Graph |
output_nodes |
输入 |
含义:模型输出节点的名称。 数据类型:list,列表中元素类型为string |
config |
输入 |
含义:自动通道稀疏搜索配置文件路径。 基于basic_info.proto文件中的AutoChannelPruneConfig生成的简易配置文件,*.proto文件所在路径为:AMCT安装目录/amct_tensorflow/proto/。 *.proto文件参数解释以及生成的自动通道稀疏搜索配置文件样例请参见自动通道稀疏搜索简易配置文件说明。 数据类型:string |
input_data |
输入 |
含义:用户提供的校准数据。 数据类型:list,内容为对应的feed_dict数据 |
output_cfg |
输入 |
含义:输出的最终的通道稀疏配置文件路径。 数据类型:string |
sensitivity |
输入 |
含义:敏感度计算方法。 数据类型:string或 SensitivityBase的子类,string为AMCT已有的方法,目前可选为'TaylorLossSensitivity';子类为SensitivityBase的子类的实例化,可由用户来继承定义。默认为'TaylorLossSensitivity'。 |
search_alg |
输入 |
含义:待稀疏的通道搜索方法。 数据类型:string或 SearchChannelBase的子类,string为AMCT已有的方法,目前可选为'GreedySearch';子类为SearchChannelBase的子类的实例化,可由用户来继承定义。默认为'GreedySearch'。 |
返回值说明
无
调用示例
import amct_tensorflow as amct
#构造feed_dict数据
input_data = np.random.uniform(-10, 10, (2, 14, 14, 64)).astype(np.str_)
feed_dict = [{'input:0': input_data}]
amct.auto_channel_prune_search(
graph=graph,
output_nodes=[operation_name_1, operation_name_2],
config='./tmp/sample.cfg',
input_data=feed_dict,
output_cfg='./tmp/output.cfg',
sensitivity='TaylorLossSensitivity',
search_alg='GreedySearch')
落盘文件:自动通道稀疏配置文件,该文件需要传给通道稀疏接口完成后续的业务。
组合压缩接口¶
create_compressed_retrain_model¶
产品支持情况
产品 |
是否支持 |
|---|---|
IPV350 |
|
注:特性中标记“x”的产品,调用接口不会报错,但是获取不到性能收益。
功能说明
静态组合压缩接口,根据用户设置的压缩配置文件对图结构先进行稀疏(通道稀疏或者4选2结构化稀疏,二选一),后插入量化相关的算子,并返回修改后的图。
函数原型
quant_add_ops = create_compressed_retrain_model(graph, config_defination, outputs, record_file)
参数说明
参数名 |
输入/输出 |
说明 |
|---|---|---|
graph |
输入 |
含义:待稀疏的tf.Graph图。 数据类型:tf.Graph |
config_defination |
输入 |
含义:静态组合压缩简易配置文件路径。 用户提供的组合压缩配置文件,用于指定模型tf.Graph图中各层压缩配置情况。 基于retrain_config_tf.proto文件生成的简易配置文件compressed.cfg,*.proto文件所在路径为:AMCT安装目录/amct_tensorflow/proto/。 *.proto文件参数解释以及生成的compressed.cfg简易配置文件样例请参见量化感知训练简易配置文件。 数据类型:string |
outputs |
输入 |
含义:模型输出节点的名称。 数据类型:list,列表中元素类型为string |
record_file |
输入 |
含义:待记录稀疏和量化因子文件路径及名称。 数据类型:string |
返回值说明
组合压缩插入的算子变量列表,类型为list,列表中元素类型为tf.Variable。
约束说明
组合压缩配置文件至少存在一个配置:稀疏配置或者量化配置。
调用示例
import amct_tensorflow as amct
amct.create_compressed_retrain_model(graph, './tmp/sample.cfg', [operation_name_1, operation_name_2], './tmp/record.txt')
落盘文件:
插入稀疏和量化算子的图。
记录稀疏信息和量化因子的record文件
save_compressed_retrain_model¶
产品支持情况
产品 |
是否支持 |
|---|---|
IPV350 |
|
注:特性中标记“x”的产品,调用接口不会报错,但是获取不到性能收益。
功能说明
静态组合压缩接口,根据用户最终重训练好的模型,生成最终静态组合压缩模型。
函数原型
save_compressed_retrain_model(pb_model, outputs, record_file, save_path)
参数说明
参数名 |
输入/输出 |
说明 |
|---|---|---|
pb_model |
输入 |
含义:带稀疏与量化算子的推理模式pb模型。 数据类型:string |
outputs |
输入 |
含义:graph中输出算子的列表。 数据类型:list,列表中元素类型为string |
record_file |
输入 |
含义:稀疏和量化因子记录文件路径及名称。 数据类型:string |
save_path |
输入 |
含义:保存压缩模型的路径。 该路径需要包含模型名前缀,例如./compressed_model/*model。 数据类型:string |
返回值说明
无
调用示例
import amct_tensorflow as amct
amct.save_compressed_retrain_model(masked_pb_path, [operation_name_1, operation_name_2], './tmp/record.txt', './pb_model/final_model')
落盘文件:压缩后的模型,该模型既可以在TensorFlow环境进行精度仿真又可以在NPU IP加速器做推理。
张量分解接口¶
auto_decomposition¶
产品支持情况
产品 |
是否支持 |
|---|---|
IPV350 |
√ |
功能说明
根据用户提供的TensorFlow模型文件,生成张量分解后的模型文件。
函数原型
add_ops = auto_decomposition(meta_path, ckpt_path, save_path)
参数说明
参数名 |
输入/输出 |
说明 |
|---|---|---|
meta_path |
输入 |
含义:待分解的TensorFlow模型定义文件路径,格式为.meta。 数据类型:string 说明:
请确保.meta能被tf.compat.v1.train.import_meta_graph正常加载。 例如:对于使用horovod训练得到的meta文件,必须执行import horovod.tensorflow才能被auto_decomposition接口调用。 |
ckpt_path |
输入 |
含义:待分解的TensorFlow模型权重文件路径,该参数为.data-XXXXX-of-XXXXX文件与.index文件的共同前缀路径。 例如上述两个文件分别为path/model-200.data-00000-of-00001和path/model-200.index, 则ckpt_path取值为path/model-200。 数据类型:string |
save_path |
输入 |
含义:张量分解后所得文件的保存路径,将生成以该路径为前缀的.data-XXXXX-of-XXXXX等文件。 例如该参数设置为path/model,则生成的.data-XXXXX-of-XXXXX文件与.index等文件为: path/model.data-XXXXX-of-XXXXX和path/model.index。 数据类型:string |
返回值说明
张量分解后新添加卷积层的名字的列表,类型为list。
约束说明
用户提供用于分解的原始TensorFlow模型,需要保证各模型文件配套使用,即模型定义(.meta)、模型权重(.data-X__XXXX-of-X__XXXX)及权重索引文件(.index)需配套。
用户调用张量分解接口函数,输入原始模型路径以及模型分解后的保存路径,接口函数对符合分解条件的卷积层进行自动分解,约束请参见分解约束。
调用示例
from amct_tensorflow.tensor_decompose import auto_decomposition
auto_decomposition(meta_path='src_path/model.meta',
ckpt_path='src_path/model',
save_path='decomposed_path/model'
)
落盘文件:
checkpoint:checkpoint列表文件。
.meta:张量分解后的模型定义文件。
.data-00000-of-00001:张量分解后的权重文件。
.index:张量分解后的权重文件索引。
.pkl:分解时图结构的改动信息文件,用于decompose_graph接口修改原训练代码中的图。
decompose_graph¶
产品支持情况
产品 |
是否支持 |
|---|---|
IPV350 |
√ |
功能说明
分解训练代码中的图,用于对分解后的模型进行fine-tune(微调)。
函数原型
add_ops = decompose_graph(save_path, graph=None)
参数说明
参数名 |
输入/输出 |
说明 |
|---|---|---|
save_path |
输入 |
含义:auto_decomposition张量分解后所得文件的保存路径。 数据类型:string |
graph |
输入 |
含义:待分解的图,可选。如果不输入或为None,则会对当前图进行分解。 数据类型:tf.Graph 默认值:None |
add_ops |
返回值 |
含义:张量分解后新添加卷积层的名字的列表。 数据类型:list |
返回值说明
张量分解后新添加卷积层的名字的列表。
约束说明
用户已经使用auto_decomposition接口成功分解模型。
需基于训练代码使用该接口,且必须保证auto_decomposition接口分解的模型文件是基于该训练代码得到的。
该接口只会修改图,但不会修改已经引用卷积的变量,假如一个卷积在被分解前已经被某个变量引用,则不应再使用该变量。
调用示例
用户训练代码中:
from amct_tensorflow.tensor_decompose import decompose_graph
# 构造网络的图的用户代码...
decompose_graph(save_path='decomposed_path/model')
# 构造并应用优化器的用户代码...
# ...
# 在训练前加载分解后模型权重的代码(由用户补充处理)...
模型适配接口¶
convert_model¶
产品支持情况
产品 |
是否支持 |
|---|---|
IPV350 |
√ |
功能说明
根据用户自己计算得到的量化因子以及TensorFlow模型,适配成既可以在NPU IP加速器上部署的模型又可以在TensorFlow环境下进行精度仿真的量化模型。
函数原型
convert_model(pb_model, outputs, record_file, save_path)
参数说明
参数名 |
输入/输出 |
说明 |
|---|---|---|
pb_model |
输入 |
含义:用户待适配的原始pb模型文件。 数据类型:string |
outputs |
输入 |
含义:graph中输出算子的列表。 数据类型:list |
record_file |
输入 |
含义:用户计算得到的量化因子记录文件路径,量化因子记录文件格式为.txt。 数据类型:string |
save_path |
输入 |
含义:模型存放路径。该路径需要包含模型名前缀,例如./quantized_model/*model。 数据类型:string |
返回值说明
无
约束说明
用户模型需要保证和量化因子记录文件配套,例如用户对Conv+BN结构先进行融合再计算得到融合Conv的量化因子,则所提供用于转换的原始TensorFlow模型中Conv+BN结构也需要预先进行融合。
量化因子记录文件格式及记录内容需要严格符合AMCT定义要求,详细信息请参见record记录文件。
仅支持对AMCT支持量化的层:卷积层(Conv2D)、全连接层(MatMul)、深度可分离卷积层(DepthwiseConv2dNative,dilation为1)、反卷积层(Conv2DBackpropInput,dilation为1)、平均下采样层AvgPool。
该接口支持对用户模型中的Conv+BN、Depthwise_Conv+BN、Group_Conv+BN融合结构进行融合,且可逐层配置是否做融合。
仅支持输入原始浮点数模型进行适配,不支持用户对包含量化工具插入自定义层(QuantIfmr层、QuantArq层、SearchN层、AscendQuant层、AscendDequant层、AscendAntiQuant层、AscendWeightQuant层)的模型进行适配。
调用示例
import amct_tensorflow as amct
convert_model(pb_model='./user_model.pb',
outputs=["model/outputs"],
record_file='./record_quantized.txt',
save_path='./quantized_model/model')
落盘文件:既可以在TensorFlow环境进行精度仿真又可以在NPU IP加速器做离线推理的pb模型文件。
重新执行适配时,该接口输出的上述文件将会被覆盖。
convert_qat_model¶
产品支持情况
产品 |
是否支持 |
|---|---|
IPV350 |
√ |
功能说明
根据TensorFlow的QAT量化模型,适配成分别可以在CPU、GPU上进行精度仿真和NPU IP加速器上部署的量化模型。
函数原型
convert_qat_model(pb_model, outputs, save_path, record_file=None)
参数说明
参数名 |
输入/输出 |
说明 |
|---|---|---|
pb_model |
输入 |
含义:待适配的QAT模型路径。 数据类型:string |
outputs |
输入 |
含义:graph中输出算子的列表。 数据类型:list |
record_file |
输入 |
含义:用户计算得到的量化因子记录文件路径,量化因子记录文件格式为.txt。 数据类型:string 默认值为:None |
save_path |
输入 |
含义:模型存放路径。该路径需要包含模型名前缀,例如./quantized_model/*model。 数据类型:string |
返回值说明
graph中输出算子的列表。
约束说明
仅支持适配含有FakeQuantWithMinMaxVars和FakeQuantWithMinMaxVarsPerchannel算子的TensorFlow模型,格式为.pb。
调用示例
import amct_tensorflow as amct
convert_qat_model(pb_model, outputs, save_path)
落盘文件:既可以在TensorFlow环境进行精度仿真又可以在NPU IP加速器做离线推理的pb模型文件。
重新执行适配时,该接口输出的上述文件将会被覆盖。
参考信息¶
工具实现的融合功能¶
当前该工具主要实现的融合功能,分为如下几类(如下融合场景中涉及的单个算子,需要先满足各个压缩场景比如量化、组合压缩等的约束条件):
Conv+BN融合:
AMCT在量化前会对模型中的"Conv2D/Conv3D+BatchNorm"结构做Conv+BN融合,融合后的"BatchNorm"层会被删除。
AMCT在量化前会识别模型中的"Conv2D+BatchToSpace+BN"结构,检测到Channel一致时会调整为"Conv2D+BN+BatchToSpace"结构,然后进行Conv+BN融合,融合后的"BatchNorm"层会被删除。
Depthwise_Conv+BN融合:AMCT在量化前会对模型中的"DepthwiseConv2dNative+BatchNorm"结构做Depthwise_Conv+BN融合,融合后的"BatchNorm"层会被删除。
OP+(BiasAdd)+Mul融合:AMCT在量化前会对模型中的“Conv2D/Conv3D/MatMul/DepthwiseConv2dNative/Conv2DBackpropInput+Mul”和“Conv2D/MatMul/DepthwiseConv2d/Conv2DBackpropInput+BiasAdd+Mul”结构做OP+(BiasAdd)+Mul融合,融合后的“Mul”层会被删除。
该场景下,要求Mul的另外一路输入为Const类型,且Shape为空。
Group_conv+BN融合:如果模型中使用"Split+多路Conv2D/Conv3D+ ConcatV2(或Concat,且Concat在C轴)"表示Group_conv,AMCT在量化前会对模型中"Group_conv+BatchNorm"结构做融合,融合后的"BatchNorm"层会被删除。
BN支持融合的算子类型为FusedBatchNorm、FusedBatchNormV2和FusedBatchNormV3。
requant融合(Relu6无法做Requant融合,需替换为Relu):由于Relu6算子在Relu的基础上增加了对6以上数值的截断,同时量化过程中也会对输入浮点数进行截断,故Relu6+Ascendquant与Relu+Ascendquant存在等价的场景可以进行替换。基于该背景AMCT对量化部署模型中的Relu6+Ascendquant算子等价替换为Relu+Ascendquant。
OP+Add融合(算子替换):当Add/AddV2算子的一路为常量,且不能与placeholder节点的关联,另一路为如下类型的算子,Add/AddV2会替换成BiasAdd算子,以便进行后续的Bias量化:
Conv2d/Conv3d:Add是标量,或者多维数组,或者最后一个轴和cout轴长度对齐的一维数组。
DepthwiseConv2dNative:Add是标量,或者多维数组,或者最后一个轴和cout轴长度对齐的一维数组。
Conv2DBackpropInput:Add是标量,或者多维数组,或者最后一个轴和cout轴长度对齐的一维数组。
MatMul:Add与Matmul的cout轴长度对齐,Add算子其他轴均是1。
BatchMatMul:Add是常量、一维或者其他轴长度均为1,最后一个轴长度与cout对齐。
MatMul+BN融合:
MatMul算子要满足如下条件,并且第二个Reshape算子输出的shape和MatMul输出Tensor shape要一致,示例如图1所示。
不带biasadd,format为NHWC,shape不固定
不带biasadd,format为NCHW,shape不固定
不带biasadd,format为NHWC,shape固定
不带biasadd,format为NCHW,shape固定
带biasadd,format为NHWC,shape不固定
带biasadd,format为NCHW,shape不固定
带biasadd,format为NHWC,shape固定
带biasadd,format为NCHW,shape固定
图 1 MatMul+BN融合场景
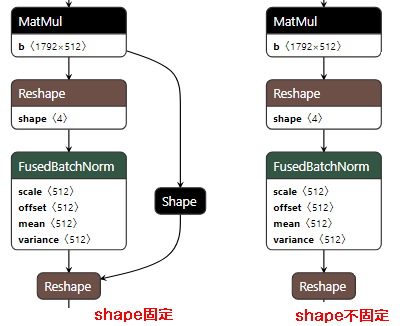
BN支持融合的算子类型为FusedBatchNorm、FusedBatchNormV2和FusedBatchNormV3。
BN小算子融合为FusedBatchNormV3大算子:仅训练后量化支持,并且只有Conv+BN或者Conv+BiasAdd+BN结构才会触发BN小算子融合为大算子,若TensorFlow版本为1.15.0,则只支持BN小算子输入为4维的场景;若TensorFlow版本为2.6.3,则支持BN小算子输入为4维、5维的场景,并且5维场景下上述结构中的Conv算子必须为Conv3D。
AMCT对tf.keras.layers.BatchNormalization产生的小算子结构的BN进行匹配,并且将匹配到的小算子BN结构替换为大算子的BN结构,具体支持的小算子BN结构的场景如下所示:
tf.keras.layers.BatchNormalization接口满足:入参fused=False,调用参数inputs,training=False,融合前后网络结构图为:
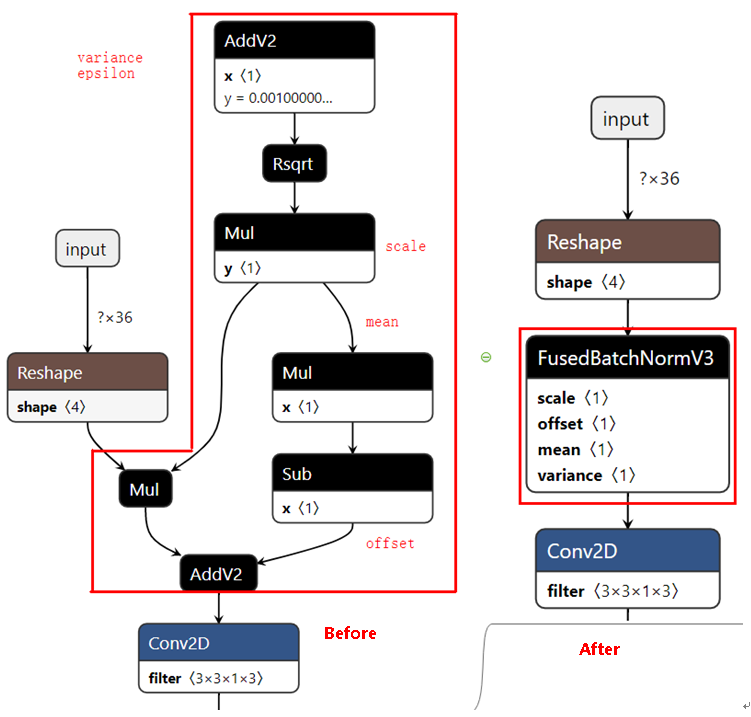
tf.keras.layers.BatchNormalization接口满足:入参fused=False、center=False,调用参数inputs,training=False,融合前后网络结构图为:
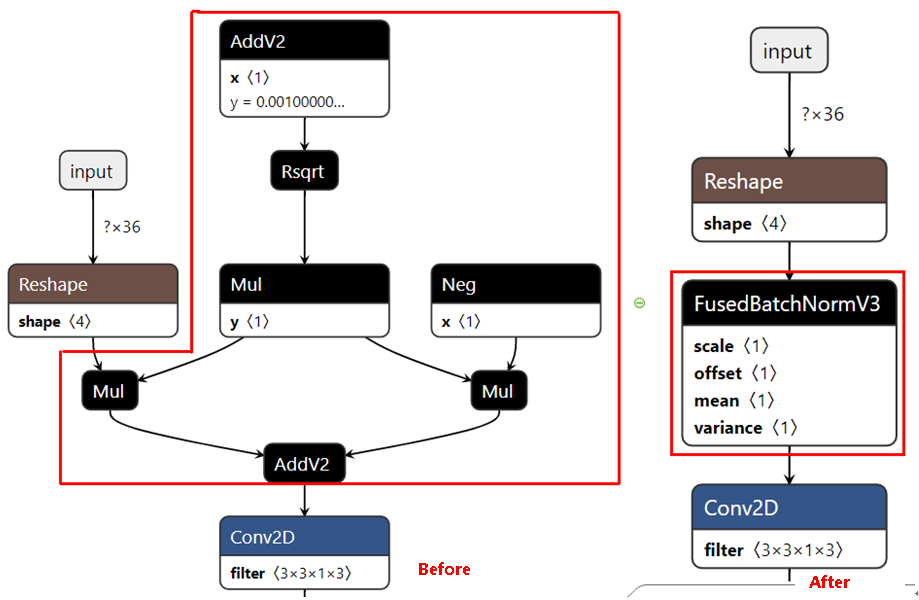
tf.keras.layers.BatchNormalization接口满足:入参fused=False,scale=False,调用参数inputs,training=False,融合前后网络结构图为:
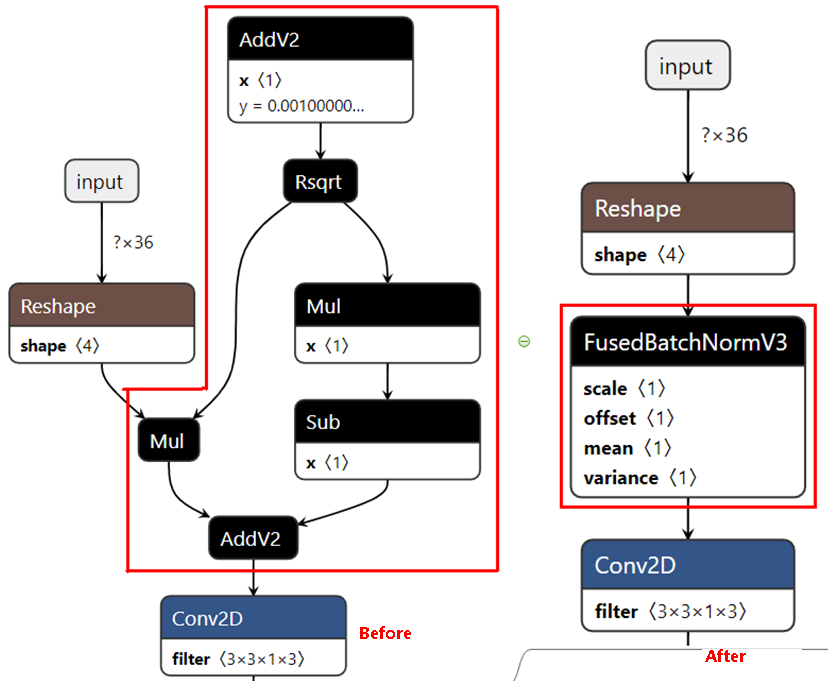
tf.keras.layers.BatchNormalization接口满足:入参fused=False,scale=False,center=False,调用参数inputs,training=False,融合前后网络结构图为:
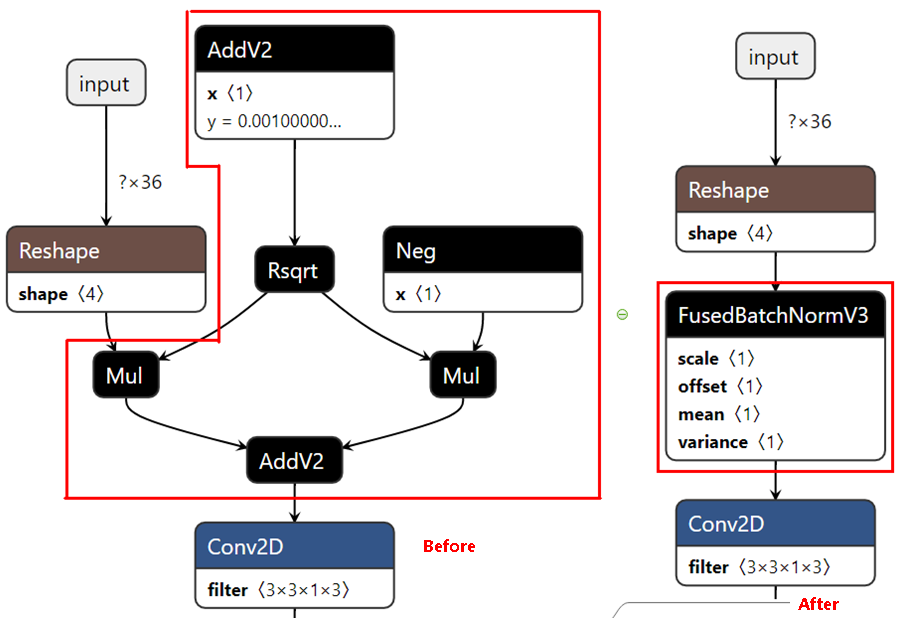
训练后量化简易配置文件¶
calibration_config_tf.proto文件参数说明如表1所示,该文件所在目录为:AMCT安装目录/amct_tensorflow/proto/calibration_config_tf.proto。
表 1 calibration_config_tf.proto参数说明
消息 |
是否必填 |
类型 |
字段 |
说明 |
|---|---|---|---|---|
AMCTConfig |
- |
- |
- |
AMCT训练后量化的简易配置。 |
optional |
uint32 |
batch_num |
量化使用的batch数量。 |
|
optional |
bool |
activation_offset |
数据量化是否带offset。全局配置参数。
|
|
optional |
bool |
joint_quant |
是否进行Eltwise联合量化,默认为false,表示关闭联合量化功能。 开启后对部分网络可能会存在性能提升但是精度下降的问题。 |
|
repeated |
string |
skip_layers |
不需要量化层的层名。 |
|
repeated |
string |
skip_layer_types |
不需要量化的层类型。 |
|
repeated |
string |
skip_approximation_layers |
不需要近似校准的层名。 该版本不支持近似校准特性。 |
|
optional |
FakequantPrecisionMode |
fakequant_precision_mode |
fakequant模型中quant自定义算子的scale_d数值精度模式。
|
|
optional |
NuqConfig |
nuq_config |
非均匀量化配置。 |
|
optional |
CalibrationConfig |
common_config |
通用的量化配置,全局量化配置参数。若某层未被override_layer_types或者override_layer_configs重写,则使用该配置。 参数优先级:override_layer_configs>override_layer_types>common_config |
|
repeated |
OverrideLayerType |
override_layer_types |
重写某一类型层的量化配置,即对哪些层进行差异化量化。 例如全局量化配置参数配置的量化因子搜索步长为0.01,可以通过该参数对部分层进行差异化量化,可以配置搜索步长为0.02。 参数优先级:override_layer_configs>override_layer_types>common_config |
|
repeated |
OverrideLayer |
override_layer_configs |
重写某一层的量化配置,即对哪些层进行差异化量化。 例如全局量化配置参数配置的量化因子搜索步长为0.01,可以通过该参数对部分层进行差异化量化,可以配置搜索步长为0.02。 参数优先级:override_layer_configs>override_layer_types>common_config |
|
optional |
bool |
do_fusion |
是否开启BN融合功能,默认为true,表示开启该功能。 |
|
repeated |
string |
skip_fusion_layers |
跳过BN融合的层,配置之后这些层不会进行BN融合。 |
|
repeated |
TensorQuantize |
tensor_quantize |
对网络模型中指定节点的输入Tensor进行训练后量化,来提高数据搬运时的推理性能。 当前仅支持对MaxPool/Add算子做tensor量化。 |
|
NuqConfig |
- |
- |
- |
非均匀量化配置。 |
required |
string |
mapping_file |
均匀量化后的deploy模型通过ATC工具转换得到的OM模型,通过ATC工具转换得到的JSON文件,即量化后模型的融合JSON文件。 |
|
optional |
NUQuantize |
nuq_quantize |
非均匀量化的参数。 |
|
OverrideLayerType |
- |
- |
- |
重置某层类型的量化配置。 |
required |
string |
layer_type |
支持量化的层类型的名字。 |
|
required |
CalibrationConfig |
calibration_config |
重置的量化配置。 |
|
OverrideLayer |
- |
- |
- |
重置某层量化配置。 |
required |
string |
layer_name |
被重置层的层名。 |
|
required |
CalibrationConfig |
calibration_config |
重置的量化配置。 |
|
TensorQuantize |
- |
- |
- |
需要进行训练后量化的输入Tensor配置。 |
required |
string |
layer_name |
需要对节点输入Tensor进行训练后量化的节点名称,当前仅支持对MaxPool/Add算子的输入Tensor进行量化。 |
|
required |
uint32 |
input_index |
需要对节点输入Tensor进行训练后量化的节点的输入索引。 |
|
- |
FMRQuantize |
ifmr_quantize |
数据量化算法配置。 ifmr_quantize:IFMR量化算法配置。默认为IFMR量化算法。 |
|
- |
HFMGQuantize |
hfmg_quantize |
数据量化算法配置。 hfmg_quantize:HFMG量化算法配置。 |
|
CalibrationConfig |
- |
- |
- |
Calibration量化的配置。 |
- |
ARQuantize |
arq_quantize |
权重量化算法配置。 arq_quantize:ARQ量化算法配置。 |
|
- |
NUQuantize |
nuq_quantize |
权重量化算法配置。 nuq_quantize:非均匀量化算法配置。 |
|
- |
FMRQuantize |
ifmr_quantize |
数据量化算法配置。 ifmr_quantize:IFMR量化算法配置。 |
|
- |
HFMGQuantize |
hfmg_quantize |
数据量化算法配置。 hfmg_quantize:HFMG量化算法配置。 |
|
- |
DMQBalancer |
dmq_balancer |
均衡算法配置。 dmq_balancer:DMQBalancer均衡算法配置。 |
|
ARQuantize |
- |
- |
- |
ARQ权重量化算法配置。算法介绍请参见ARQ权重量化算法。 该算法与NUQuantize算法不能同时配置,若同时配置,则以配置文件中最后配置的量化算法为准。 |
optional |
bool |
channel_wise |
是否对每个channel采用不同的量化因子。
|
|
optional |
uint32 |
quant_bits |
权重量化位宽。支持配置为INT6、INT7、INT8。 默认为INT8量化。 该字段配置为INT6、INT7仅支持Conv2d类型算子。 如果在common_config中配置quant_bits为INT6、INT7,则只对Conv2d算子生效,其他算子改为默认INT8。 |
|
FMRQuantize |
- |
- |
- |
FMR数据量化算法配置。算法介绍请参见IFMR数据量化算法。 该算法与HFMGQuantize算法不能同时配置,若同时配置,则以配置文件中最后配置的量化算法为准。 |
optional |
float |
search_range_start |
量化因子搜索范围左边界。 |
|
optional |
float |
search_range_end |
量化因子搜索范围右边界。 |
|
optional |
float |
search_step |
量化因子搜索步长。 |
|
optional |
float |
max_percentile |
最大值搜索位置。 |
|
optional |
float |
min_percentile |
最小值搜索位置。 |
|
optional |
bool |
asymmetric |
是否进行非对称量化。用于控制逐层量化算法的选择。
如果override_layer_configs、override_layer_types、common_config配置项都配置该参数,或者配置了 activation_offset参数,则生效优先级为: override_layer_configs>override_layer_types>common_config>activation_offset |
|
optional |
CalibrationDataType |
dst_type |
量化位宽,数据量化是采用INT8量化还是INT16量化,默认为INT8量化。 |
|
HFMGQuantize |
- |
- |
- |
HFMG数据量化算法配置。算法介绍请参见HFMG数据量化算法。 该算法与FMRQuantize算法不能同时配置,若同时配置,则以配置文件中最后配置的量化算法为准。 |
optional |
uint32 |
num_of_bins |
直方图的bin(直方图中的一个最小单位直方图形)数目,支持的范围为{1024, 2048, 4096, 8192}。 默认值为4096。 |
|
optional |
bool |
asymmetric |
是否进行非对称量化。用于控制逐层量化算法的选择。
如果override_layer_configs、override_layer_types、common_config配置项都配置该参数,或者配置了 activation_offset参数,则生效优先级为: override_layer_configs>override_layer_types>common_config>activation_offset |
|
optional |
CalibrationDataType |
dst_type |
量化位宽,数据量化是采用INT8量化还是INT16量化,默认为INT8量化。 |
|
NUQuantize |
- |
- |
- |
非均匀权重量化算法配置。算法介绍请参见NUQ权重量化算法。 该算法与ARQuantize算法不能同时配置,若同时配置,则以配置文件中最后配置的量化算法为准。 |
optional |
uint32 |
num_steps |
非均匀量化的台阶数。当前仅支持设置为16和32。 |
|
optional |
uint32 |
num_of_iteration |
非均匀量化优化的迭代次数。当前仅支持设置为{0,1,2,3,4,5},0表示没有迭代。 |
|
DMQBalancer |
- |
- |
- |
DMQ均衡算法配置。算法介绍请参见DMQ均衡算法。 |
optional |
float |
migration_strength |
迁移强度,代表将activation数据上的量化难度迁移至weight权重的程度。支持的范围为[0.2, 0.8],默认值0.5,数据分布的离群值越大迁移强度应设置较小。 |
基于该文件构造的均匀量化简易配置文件quant.cfg样例如下所示:
# global quantize parameter batch_num : 2 activation_offset : true joint_quant : false skip_layers : "Opname" skip_layer_types:"Optype" do_fusion: true skip_fusion_layers : "Opname" common_config : { arq_quantize : { channel_wise : true quant_bits : 7 } ifmr_quantize : { search_range_start : 0.7 search_range_end : 1.3 search_step : 0.01 max_percentile : 0.999999 min_percentile : 0.999999 asymmetric : true dst_type : INT16 } } override_layer_types : { layer_type : "Conv2D" calibration_config : { arq_quantize : { channel_wise : false quant_bits : 6 } ifmr_quantize : { search_range_start : 0.8 search_range_end : 1.2 search_step : 0.02 max_percentile : 0.999999 min_percentile : 0.999999 asymmetric : false dst_type : INT16 } } } override_layer_configs : { layer_name : "Opname" calibration_config : { arq_quantize : { channel_wise : true } ifmr_quantize : { search_range_start : 0.8 search_range_end : 1.2 search_step : 0.02 max_percentile : 0.999999 min_percentile : 0.999999 asymmetric : false dst_type : INT16 } } } tensor_quantize { layer_name: "Opname" input_index: 0 ifmr_quantize: { search_range_start : 0.7 search_range_end : 1.3 search_step : 0.01 min_percentile : 0.999999 asymmetric : false dst_type : INT16 } } tensor_quantize { layer_name: "Opname" input_index: 0 }
如果数据量化算法使用HFMG,则上述配置文件中加粗部分可以替换成如下参考参数信息,举例如下(如下配置信息只是样例,请根据实际情况进行修改):
# global quantize parameter activation_offset : true batch_num : 1 ... common_config : { hfmg_quantize : { num_of_bins : 4096 asymmetric : false dst_type : INT16 } ... }
基于该文件构造的非均匀量化简易配置文件quant.cfg样例如下所示:
# global quantize parameter activation_offset : true joint_quant : false batch_num : 2 nuq_config { mapping_file : "nuq_files/resnet50_quantized.json" nuq_quantize : { num_steps : 32 num_of_iteration : 0 } } common_config : { arq_quantize : { channel_wise : true } ifmr_quantize : { search_range_start : 0.7 search_range_end : 1.3 search_step : 0.01 max_percentile : 0.999999 min_percentile : 0.999999 asymmetric : true } } override_layer_types : { layer_type : "Optype" calibration_config : { arq_quantize : { channel_wise : false } ifmr_quantize : { search_range_start : 0.7 search_range_end : 1.3 search_step : 0.01 max_percentile : 0.999999 min_percentile : 0.999999 asymmetric : false } } } tensor_quantize { layer_name: "Opname" input_index: 0 ifmr_quantize: { search_range_start : 0.7 search_range_end : 1.3 search_step : 0.01 min_percentile : 0.999999 asymmetric : false } } tensor_quantize { layer_name: "Opname" input_index: 0 }
如果数据量化算法使用HFMG,则上述配置文件中加粗部分可以替换成如下参考参数信息,举例如下(如下配置信息只是样例,请根据实际情况进行修改):
# global quantize parameter activation_offset : true batch_num : 1 ... common_config : { hfmg_quantize : { num_of_bins : 4096 asymmetric : false } ... }
基于该文件构造的量化数据均衡预处理简易配置文件dmq_balancer.cfg配置文件样例如下:
# global quantize parameter activation_offset : true batch_num : 1 ... common_config : { dmq_balancer : { migration_strength : 0.5 } ... }
量化感知训练简易配置文件¶
retrain_config_tf.proto文件参数说明如表1所示,该文件所在目录为:AMCT安装目录/amct_tensorflow/proto/retrain_config_tf.proto。
该文件可以配置出量化感知训练简易配置文件、稀疏简易配置文件,组合压缩简易配置文件,用户根据场景进行配置。
表 1 retrain_config_tf.proto参数说明
消息 |
是否必填 |
类型 |
字段 |
说明 |
|---|---|---|---|---|
AMCTRetrainConfig |
- |
- |
- |
AMCT量化感知训练的简易配置。 |
repeated |
string |
skip_layers |
按层名跳过哪些层不进行压缩。全局参数,方便后续拓展其他特性场景下可同时跳过的层,比如下述拓展的quant_skip_layers参数、regular_prune_skip_layers参数,则通过skip_layers参数可以同时配置两个特性场景下需要跳过的层。而无需在quant_skip_layers和regular_prune_skip_layers参数中分别配置。 若同时配置了skip_layers和quant_skip_layers参数,或skip_layers和regular_prune_skip_layers参数,则取两者并集。 |
|
repeated |
string |
skip_layer_types |
按层类型跳过哪些层不进行压缩。全局参数,方便后续拓展其他特性场景下可同时跳过的层,比如下述拓展的quant_skip_types参数、regular_prune_skip_types参数,则通过skip_layer_types参数可以同时配置两个特性场景下需要跳过的层。而无需在quant_skip_types和regular_prune_skip_types参数中分别配置。 若同时配置了skip_layer_types和quant_skip_types参数,或skip_layer_types和regular_prune_skip_types参数,则取两者并集。 |
|
repeated |
RetrainOverrideLayer |
override_layer_configs |
按层名重写哪些层,即对哪些层进行差异化压缩。 例如全局量化配置参数配置的量化位宽为INT8,可以通过该参数对部分层进行差异化量化,可以配置为INT4量化。当前版本仅支持INT8量化。 参数优先级为:
|
|
repeated |
RetrainOverrideLayerType |
override_layer_types |
按层类型重写哪些层,即对哪些层进行差异化压缩。 例如全局量化配置参数配置的量化位宽为INT8,可以通过该参数对部分层进行差异化量化,可以配置为INT4量化。当前版本仅支持INT8量化。 参数优先级为:
|
|
optional |
FakequantPrecisionMode |
fakequant_precision_mode |
fakequant模型中quant自定义算子的scale_d数值精度模式。
|
|
optional |
uint32 |
batch_num |
量化使用的batch数量。 |
|
required |
RetrainDataQuantConfig |
retrain_data_quant_config |
量化感知训练数据量化配置参数。全局量化配置参数。 参数优先级为:override_layer_configs>override_layer_types>retrain_data_quant_config/retrain_weight_quant_config |
|
required |
RetrainWeightQuantConfig |
retrain_weight_quant_config |
量化感知训练权重量化配置参数。全局量化配置参数。 参数优先级为:override_layer_configs>override_layer_types>retrain_data_quant_config/retrain_weight_quant_config |
|
repeated |
string |
quant_skip_layers |
按层名跳过不需要量化的层。量化场景下使用的参数。 若同时配置了skip_layers和quant_skip_layers参数,则取两者并集。 |
|
repeated |
string |
quant_skip_types |
按层类型跳过不需要量化的层。量化场景下使用的参数。 若同时配置了skip_layer_types和quant_skip_types参数,则取两者并集。 |
|
optional |
PruneConfig |
prune_config |
稀疏配置。全局稀疏配置参数。 参数优先级为:override_layer_configs>override_layer_types>prune_config |
|
repeated |
string |
regular_prune_skip_layers |
按层名跳过不需要稀疏的层。稀疏场景下使用的参数。 若同时配置了skip_layer和regular_prune_skip_layers参数,则取两者并集。 |
|
repeated |
string |
regular_prune_skip_types |
按层类型跳过不需要稀疏的层。稀疏场景下使用的参数。 若同时配置了skip_layer_types和regular_prune_skip_types参数,则取两者并集。 |
|
RetrainDataQuantConfig |
- |
- |
- |
量化感知训练数据量化配置。 |
- |
ActULQquantize |
ulq_quantize |
数据量化的算法,目前仅支持ULQ。 |
|
ActULQquantize |
- |
- |
- |
ULQ数据量化算法参数。算法介绍请参见ULQ数据量化算法。 |
optional |
DataType |
dst_type |
用以选择INT8或INT4量化位宽,默认为INT8。当前版本仅支持INT8量化。 |
|
optional |
ClipMaxMin |
clip_max_min |
初始化的上下限值,如果不配置,默认用ifmr进行初始化。 |
|
optional |
bool |
fixed_min |
是否下限不学习且固定为0。默认ReLu后为true,其他为false。 |
|
ClipMaxMin |
- |
- |
- |
初始上下限。 |
required |
float |
clip_max |
初始上限值。 |
|
required |
float |
clip_min |
初始下限值。 |
|
RetrainWeightQuantConfig |
- |
- |
- |
量化感知训练权重量化配置。 |
- |
ARQRetrain |
arq_retrain |
ARQ权重量化算法。 |
|
- |
WtsULQRetrain |
ulq_retrain |
ULQ权重量化算法。 |
|
ARQRetrain |
- |
- |
- |
ARQ权重量化算法参数。算法介绍请参见ARQ权重量化算法。 |
optional |
DataType |
dst_type |
量化位宽,用以选择INT8量化还是INT4量化,默认为INT8量化。当前版本仅支持INT8量化。 |
|
optional |
bool |
channel_wise |
是否做channel wise的arq。 |
|
WtsULQRetrain |
- |
- |
- |
ULQ权重量化算法参数。算法介绍请参见ULQ数据量化算法。 |
optional |
DataType |
dst_type |
量化位宽,用以选择INT8量化还是INT4量化,默认为INT8量化。当前版本仅支持INT8量化。 |
|
optional |
bool |
channel_wise |
是否做channel wise的ulq。 |
|
RetrainOverrideLayer |
- |
- |
- |
重写的层配置。 |
required |
string |
layer_name |
层名。 |
|
required |
RetrainDataQuantConfig |
retrain_data_quant_config |
重写的数据层量化参数。 |
|
required |
RetrainWeightQuantConfig |
retrain_weight_quant_config |
重写的权重层量化参数。 |
|
optional |
PruneConfig |
prune_config |
重写的稀疏配置参数。 |
|
RetrainOverrideLayerType |
- |
- |
- |
重写的层类型配置。 |
required |
string |
layer_type |
层类型。 |
|
required |
RetrainDataQuantConfig |
retrain_data_quant_config |
重写的数据层量化参数。 |
|
required |
RetrainWeightQuantConfig |
retrain_weight_quant_config |
重写的权重层量化参数。 |
|
optional |
PruneConfig |
prune_config |
重写的稀疏配置参数。 |
|
PruneConfig |
- |
- |
- |
稀疏的配置。 |
- |
FilterPruner |
filter_pruner |
filter(输出维度通道)稀疏的配置。 |
|
- |
NOutOfMPruner |
n_out_of_m_pruner |
4选2稀疏的配置。 由于硬件约束,该芯片不支持4选2结构化稀疏特性:使能后获取不到性能收益。 |
|
FilterPruner |
- |
- |
- |
filter稀疏的配置。 |
- |
BalancedL2NormFilterPruner |
balanced_l2_norm_filter_prune |
BalancedL2Norm算法,算法介绍请参见手工通道稀疏算法。 |
|
BalancedL2NormFilterPruner |
- |
- |
- |
BalancedL2Norm算法的配置。 |
required |
float |
prune_ratio |
稀疏率,被稀疏的filter数量与filter总数量的比值。推荐配置为0.2,即20%的输出通道将被裁剪。 |
|
optional |
bool |
ascend_optimized |
是否做昇腾亲和优化,如果稀疏后的模型要部署在NPU IP加速器上,建议此项配置为true。 |
|
NOutOfMPruner |
- |
- |
- |
4选2稀疏的配置。 |
- |
L1SelectivePruner |
l1_selective_prune |
L1SelectivePrune算法,算法介绍请参见4选2结构化稀疏算法。 |
|
L1SelectivePruner |
- |
- |
- |
L1SelectivePrune算法的配置。 |
optional |
NOutOfMType |
n_out_of_m_type |
目前仅支持M4N2,即每4个连续权重中保留2个权重。 |
|
optional |
uint32 |
update_freq |
更新4选2稀疏的间隔。update_freq=0时仅在第一个batch更新4选2稀疏的选择,update_freq=2时每2个batch更新一次,以此类推。默认为0。 |
基于该文件构造的量化感知训练简易配置文件quant.cfg样例如下所示:
# global quantize parameter retrain_data_quant_config: { ulq_quantize: { clip_max_min: { clip_max: 6.0 clip_min: -6.0 } dst_type: INT8 } } retrain_weight_quant_config: { arq_retrain: { channel_wise: true dst_type: INT8 } } skip_layers: "conv_1" override_layer_types : { layer_type: "Optype" retrain_weight_quant_config: { arq_retrain: { channel_wise: false dst_type: INT8 } } } override_layer_configs : { layer_name: "Opname" retrain_weight_quant_config: { arq_retrain: { channel_wise: false dst_type: INT8 } } }
基于该文件构造的通道稀疏简易配置文件prune.cfg样例如下所示:
# global prune parameter prune_config{ filter_pruner { balanced_l2_norm_filter_prune { prune_ratio: 0.3 ascend_optimized: True } } } # skip layers regular_prune_skip_layers: "Opname" regular_prune_skip_layers: "Opname" # overide specific layers override_layer_configs: { layer_name: "Opname" prune_config : { filter_pruner: { balanced_l2_norm_filter_prune: { prune_ratio: 0.5 ascend_optimized: True } } } }
基于该文件构造的4选2结构化稀疏简易配置文件selective_prune.cfg样例如下所示:
# global prune parameter prune_config{ n_out_of_m_pruner { l1_selective_prune { n_out_of_m_type: M4N2 update_freq: 0 } } } # skip layers regular_prune_skip_layers: "Opname" regular_prune_skip_layers: "Opname" # overide specific layers override_layer_configs: { layer_name: "Opname" prune_config : { n_out_of_m_pruner: { l1_selective_prune: { n_out_of_m_type: M4N2 update_freq: 1 } } } }
基于该文件构造的组合压缩(通道稀疏+INT8量化)简易配置文件compressed1.cfg样例如下所示:
prune_config : { filter_pruner : { balanced_l2_norm_filter_prune : { prune_ratio : 0.3 ascend_optimized: True } } } # skip_layers: "skip_layers_name_0" skip_layer_types: "Optype" quant_skip_layers: "Opname" quant_skip_types: "Optype" retrain_weight_quant_config: { arq_retrain: { channel_wise: true dst_type: INT8 } } override_layer_types : { layer_type: "Optype" retrain_weight_quant_config: { arq_retrain: { channel_wise: false dst_type: INT8 } } retrain_data_quant_config : { ulq_quantize : { clip_max_min : { clip_max : 6.0 clip_min : -6.0 } } } prune_config : { filter_pruner : { balanced_l2_norm_filter_prune : { prune_ratio : 0.5 ascend_optimized: True } } } }
基于该文件构造的组合压缩(4选2结构化稀疏+INT8量化)简易配置文件compressed2.cfg样例如下所示:
prune_config{ n_out_of_m_pruner { l1_selective_prune { n_out_of_m_type: M4N2 update_freq: 0 } } } # skip_layers: "skip_layers_name_0" skip_layer_types: "Optype" quant_skip_layers: "Opname" quant_skip_types: "Optype" retrain_weight_quant_config: { arq_retrain: { channel_wise: true dst_type: INT8 } } override_layer_types : { layer_type: "Optype" retrain_weight_quant_config: { arq_retrain: { channel_wise: false dst_type: INT8 } } retrain_data_quant_config : { ulq_quantize : { clip_max_min : { clip_max : 6.0 clip_min : -6.0 } } } prune_config{ n_out_of_m_pruner { l1_selective_prune { n_out_of_m_type: M4N2 update_freq: 1 } } } }
自动通道稀疏搜索简易配置文件说明¶
自动通道稀疏搜索的相关配置说明存在于basic_info.proto文件中,该文件所在目录为:AMCT__安装目录/amct_tensorflow/proto/basic_info.proto。文件内容如下所示:
消息 |
是否必填 |
类型 |
字段 |
说明 |
|---|---|---|---|---|
AutoMixedPrecisionConfig |
- |
- |
- |
AMCT自动混合精度搜索简易配置。当前版本暂不支持该特性。 |
optional |
float |
compress_ratio |
压缩率。以所有可量化层的计算量为基准压缩的倍数。 |
|
repeated |
QuantBitLimit |
quant_bit_limit |
指定某些层的量化位宽搜索范围。 |
|
optional |
string |
ptq_cfg |
用户配置的训练后量化简易配置文件,执行校准过程中用于获取INT4、INT8量化位宽下的量化因子。 若不配置,则采用训练后量化默认配置。 |
|
optional |
int64 |
test_iteration |
dump数据的batch数目,根据这些数据来衡量量化的影响以及计算量。数据量应该具有代表性。 |
|
optional |
string |
override_qat_cfg |
用户配置的量化感知训练简易配置文件,自动混合精度搜索输出会覆盖其层的位宽,其余参数保持不变。 若不配置,则采用量化感知训练简易配置文件说明(.proto格式) ,生成带有量化位宽信息的cfg格式配置文件。 |
|
AutoChannelPruneConfig |
- |
- |
- |
AMCT自动通道稀疏搜索简易配置。 |
required |
float |
compress_ratio |
压缩率。以所有可量化层的计算量为基准压缩的倍数。 |
|
optional |
bool |
ascend_optimized |
是否做昇腾亲和优化,如果稀疏后的模型要部署在NPU IP加速器上,建议此项配置为true。 |
|
optional |
float |
max_prune_ratio |
单层最大稀疏率,限定接口输出的稀疏配置中稀疏率的最大值,默认为1。 |
|
optional |
int64 |
test_iteration |
输入测试数据的batch数量。 |
|
optional |
string |
override_prune_cfg |
用户配置的指定通道稀疏简易配置文件,仅允许包含skip与override配置,配置的层将沿用指定的配置,不会被自动通道稀疏搜索接口重写。 |
|
QuantBitLimit |
- |
- |
- |
指定某些层的量化位宽搜索范围。 |
optional |
string |
layer_name |
层名。 |
|
repeated |
DataType |
data_range |
量化位宽范围。 |
|
DataType |
- |
- |
- |
量化位宽范围。枚举类型。当前版本仅支持INT8量化。 |
- |
- |
FLOAT |
浮点,不量化。 |
|
- |
- |
INT8 |
INT8量化。 |
|
- |
- |
INT4 |
INT4量化。 |
基于该文件构造的自动通道稀疏搜索简易配置文件amc.cfg样例如下所示:
compress_ratio: 1.5
ascend_optimized: true
max_prune_ratio: 0.8
test_iteration: 1
override_prune_cfg: 'your/path/to/override_channel_prune.cfg'
record记录文件¶
record文件,为基于protobuf协议的序列化数据结构文件,记录量化场景量化因子scale/offset,稀疏场景各稀疏层间的级联关系等,通过该文件、压缩配置文件以及原始网络模型文件,生成压缩后的模型文件。
convert_model接口record原型定义
convert_model接口场景record文件对应的protobuf原型定义为(或查看_AMCT安装目录_/amct_tensorflow/proto/scale_offset_record_tf.proto文件):
syntax = "proto2";
package AMCTTensorflow;
// this proto is designed for convert_model API
message SingleLayerRecord {
optional float scale_d = 1;
optional int32 offset_d = 2;
repeated float scale_w = 3;
repeated int32 offset_w = 4;
// convert_model does not support this field [shift_bit] yet
repeated uint32 shift_bit = 5;
optional bool skip_fusion = 9 [default = false];
optional string act_type = 14 [default = 'INT8'];
optional string wts_type = 15 [default = 'INT8'];
}
message MapFiledEntry {
optional string key = 1;
optional SingleLayerRecord value = 2;
}
message ScaleOffsetRecord {
repeated MapFiledEntry record = 1;
}
该场景下对应参数说明如下:
消息 |
是否必填 |
类型 |
字段 |
说明 |
|---|---|---|---|---|
SingleLayerRecord |
- |
- |
- |
包含了量化层所需要的所有量化因子记录信息。 |
optional |
float |
scale_d |
数据量化scale因子,仅支持对数据进行统一量化。 |
|
optional |
int32 |
offset_d |
数据量化offset因子,仅支持对数据进行统一量化。 |
|
repeated |
float |
scale_w |
权重量化scale因子,支持标量(对当前层的权重进行统一量化),向量(对当前层的权重按channel_wise方式进行量化)两种模式,仅支持卷积层(Conv2D)、Depthwise卷积层(DepthwiseConv2dNative)、反卷积层(Conv2DBackpropInput)类型进行channel_wise量化模式。 |
|
repeated |
int32 |
offset_w |
权重量化offset因子,同scale_w一样支持标量和向量两种模式,且需要同scale_w维度一致,当前不支持权重带offset量化模式,offset_w仅支持0。 |
|
repeated |
uint32 |
shift_bit |
移位因子。convert_model接口场景下预留字段,当前不支持,不需要配置。 |
|
optional |
bool |
skip_fusion |
配置当前层是否要跳过Conv+BN融合、Depthwise_Conv+BN融合、Group_conv+BN融合、BatchNorm融合,默认为false,即当前层要做上述融合。 |
|
optional |
string |
act_type |
数据量化位宽,当前仅支持配置为INT8。 |
|
optional |
string |
wts_type |
权重量化位宽。当前仅支持配置为INT8。 |
|
ScaleOffsetRecord |
- |
- |
- |
map结构,为保证兼容性,采用离散的map结构。 |
repeated |
MapFiledEntry |
record |
每个record对应一个量化层的量化因子记录;record包括两个成员:
|
|
MapFiledEntry |
optional |
string |
key |
层名。 |
optional |
SingleLayerRecord |
value |
量化因子配置。 |
对于optional字段,由于protobuf协议未对重复出现的值报错,而是采用覆盖处理,因此出现重复配置的optional字段内容时会默认保留最后一次配置的值,需要用户自己保证文件的正确性。
量化、稀疏场景record原型定义
量化或稀疏场景record文件对应的protobuf原型定义为(或查看_AMCT安装目录_/amct_tensorflow/proto/inner_scale_offset_record_tf.proto文件):
syntax = "proto2";
import "amct_tensorflow/proto/basic_info.proto";
package AMCTTensorflow;
// this proto is designed for amct tools
message InnerSingleLayerRecord {
optional float scale_d = 1;
optional int32 offset_d = 2;
repeated float scale_w = 3;
repeated int32 offset_w = 4;
repeated uint32 shift_bit = 5;
// the cluster of nuq, only nuq layer has this field;
repeated int32 cluster = 6;
optional bool skip_fusion = 9 [default = false];
optional string dst_type = 10 [default = 'INT8'];
repeated string prune_producer = 11;
repeated string prune_consumer = 12;
repeated float tensor_balance_factor = 13;
optional string act_type = 14 [default = 'INT8'];
optional string wts_type = 15 [default = 'INT8'];
}
message InnerMapFiledEntry {
optional string key = 1;
optional InnerSingleLayerRecord value = 2;
}
message InnerScaleOffsetRecord {
repeated InnerMapFiledEntry record = 1;
repeated PruneRecord prune_record = 2;
}
message PruneRecord {
repeated PruneNode producer = 1;
repeated PruneNode consumer = 2;
optional PruneNode selective_prune = 3;
}
message PruneNode {
required string name = 1;
repeated AMCTProto.AttrProto attr = 2;
}
该场景下对应参数说明如下:
消息 |
是否必填 |
类型 |
字段 |
说明 |
|---|---|---|---|---|
InnerSingleLayerRecord |
- |
- |
- |
包含了量化层所需要的所有量化因子记录信息。 |
optional |
float |
scale_d |
数据量化scale因子,仅支持对数据进行统一量化。 |
|
optional |
int32 |
offset_d |
数据量化offset因子,仅支持对数据进行统一量化。 |
|
repeated |
float |
scale_w |
权重量化scale因子,支持标量(对当前层的权重进行统一量化),向量(对当前层的权重按channel_wise方式进行量化)两种模式,仅支持卷积层(Conv2D)、Depthwise卷积层(DepthwiseConv2dNative)、反卷积层(Conv2DBackpropInput)类型进行channel_wise量化模式。 |
|
repeated |
int32 |
offset_w |
权重量化offset因子,同scale_w一样支持标量和向量两种模式,且需要同scale_w维度一致,当前不支持权重带offset量化模式,offset_w仅支持0。 |
|
repeated |
uint32 |
shift_bit |
移位因子。只有训练后量化简易配置文件配置了joint_quant参数,shift_bit参数才会写入record文件。 |
|
repeated |
int32 |
cluster |
聚类中心。只有非均匀量化场景下需要使能该字段,不支持该字段。 |
|
optional |
bool |
skip_fusion |
配置当前层是否要跳过Conv+BN融合、Depthwise_Conv+BN融合、Group_conv+BN融合、BatchNorm融合,默认为false,即当前层要做上述融合。 |
|
optional |
string |
dst_type |
量化位宽,包括INT8和INT4两种量化类型。该字段仅量化感知训练场景使用。当前版本仅支持INT8量化。 |
|
repeated |
string |
prune_producer |
稀疏的producer,可稀疏节点间级联关系的根节点。该字段仅稀疏场景下使用。 |
|
repeated |
string |
prune_consumer |
稀疏的consumer,可稀疏节点间级联关系的下游节点。该字段仅稀疏场景下使用。 |
|
repeated |
float |
tensor_balance_factor |
均衡量化因子。该字段仅量化数据均衡预处理场景使用。 |
|
optional |
string |
act_type |
数据量化位宽,包括INT8和INT16两种量化类型。该字段仅训练后量化场景使用。 |
|
optional |
string |
wts_type |
权重量化位宽。该字段仅训练后量化场景使用。 当前INT6、INT7量化后的量化因子仍保存为INT8类型。 |
|
InnerScaleOffsetRecord |
- |
- |
- |
map结构,为保证兼容性,采用离散的map结构。 |
repeated |
InnerMapFiledEntry |
record |
每个record对应一个量化层的量化因子记录;record包括两个成员:
|
|
repeated |
PruneRecord |
prune_record |
稀疏信息的记录。 |
|
InnerMapFiledEntry |
optional |
string |
key |
层名。 |
optional |
InnerSingleLayerRecord |
value |
量化因子配置。 |
|
PruneRecord |
- |
- |
- |
稀疏信息的记录。 |
repeated |
PruneNode |
producer |
稀疏的producer,可稀疏结点间级联关系的根节点。 例如conv1>bn>relu>conv2都可以稀疏,且bn、relu、conv2都会受到conv1稀疏的影响,则bn、relu、conv2是conv1的consumer;conv1是bn、relu、conv2的producer。 |
|
repeated |
PruneNode |
consumer |
稀疏的consumer,可稀疏结点间级联关系的下游节点。 例如conv1>bn>relu>conv2都可以稀疏,且bn、relu、conv2都会受到conv1稀疏的影响,则bn、relu、conv2是conv1的consumer;conv1是bn、relu、conv2的producer。 |
|
optional |
PruneNode |
selective_prune |
4选2结构化稀疏节点。 由于硬件约束,该芯片不支持4选2结构化稀疏特性:使能后获取不到性能收益。 |
|
PruneNode |
- |
- |
- |
稀疏的节点。 |
required |
string |
name |
节点名称。 |
|
repeated |
AMCTProto.AttrProto |
attr |
节点属性。 |
对于optional字段,由于protobuf协议未对重复出现的值报错,而是采用覆盖处理,因此出现重复配置的optional字段内容时会默认保留最后一次配置的值,需要用户自己保证文件的正确性。
record记录文件
最终生成的record文件格式为_record.txt_,文件内容根据特性不同划分如下。
训练后量化特性record文件
record { key: "conv2d/Conv2D" value { scale_d: 1.541161146e-05 offset_d: -32768 scale_w: 0.007854792 scale_w: 0.0077705383 offset_w: 0 offset_w: 0 shift_bit: 12 //只有训练后量化简易配置文件配置了joint_quant参数,record文件中才会记录shift_bit信息 shift_bit: 13 act_type: "INT16" wts_type: "INT8" } }
量化感知训练特性record文件
对于一般量化层配置需要包含scale_d、offset_d、scale_w、offset_w、shift_bit参数,对于AvgPool因为没有权重,因此不能配置scale_w、offset_w参数。文件内容示例如下(如下示例以inner_scale_offset_record.proto原型文件对应的量化因子为例进行说明):
record { key: "fc4/Tensordot/MatMul" value { scale_d: 0.0798481479 offset_d: 1 scale_w: 0.00297622895 offset_w: 0 shift_bit: 1 dst_type: "INT8" } } record { key: "conv2d/Conv2D" value { scale_d: 0.00392156886 offset_d: -128 scale_w: 0.00106807391 scale_w: 0.00104224426 offset_w: 0 offset_w: 0 shift_bit: 1 shift_bit: 1 dst_type: "INT8" } }
量化数据均衡预处理特性record文件,内容示例如下:
record { key: "matmul_1" value { scale_d: 0.00784554612 offset_d: -1 scale_w: 0.00778095098 offset_w: 0 shift_bit: 2 tensor_balance_factor: 0.948409557 tensor_balance_factor: 0.984379828 } } record { key: "conv_1" value { scale_d: 0.00759239076 offset_d: -4 scale_w: 0.0075149606 offset_w: 0 shift_bit: 1 tensor_balance_factor: 1.04744744 tensor_balance_factor: 1.44586647 } }
通道稀疏特性record文件记录各稀疏层间的级联关系,文件内容示例如下:
prune_record { producer { name: "conv_1" attr { name: "type" type: STRING s: "Conv2D" } attr { name: "begin" type: INT i: 0 } attr { name: "end" type: INT i: 64 } } consumer { name: "BN_1" attr { name: "type" type: STRING s: "FusedBatchNormV3" } attr { name: "begin" type: INT i: 0 } attr { name: "end" type: INT i: 64 } } }
结构化稀疏特性record文件内容示例如下:
prune_record { selective_prune { name: "conv2d/Conv2D" attr { name: "mask_shape" type: INTS ints: 3 ints: 3 ints: 3 ints: 32 } } }
开源网络模型分解数据参考¶
精度指标:分类:top1 ACC(%),检测: mAP(%),分割: DSC(%)。fine-tune学习率从原始学习率的0.1倍开始降低。
模型 |
任务类型 |
数据集 |
基线精度 |
分解后精度 |
分解后fine-tune精度 |
|---|---|---|---|---|---|
ResNet18 |
分类 |
ImageNet |
70.66 |
44.02 |
70.34 |
ResNet34 |
分类 |
ImageNet |
74.2 |
54.92 |
74.15 |
ResNet50 |
分类 |
ImageNet |
75.6 |
73.64 |
75.91 |
ResNet101 |
分类 |
ImageNet |
78.52 |
76.97 |
78.24 |
InceptionV3 |
分类 |
ImageNet |
77.98 |
76.95 |
77.78 |
SSD |
检测 |
coco2017 |
27.2 |
24.2 |
27.9 |
faster-rcnn |
检测 |
coco2017 |
32.5 |
31 |
32.2 |
mask-rcnn |
检测 |
coco2017 |
37.9 |
36.8 |
38 |
UNet |
分割 |
SSTEM |
87.63 |
85.05 |
87.57 |
源码包编译为whl包,以whl包形式安装AMCT¶
如果用户AMCT安装服务器缺少源码编译安装时的某些依赖,则用户可以将源码包编译为whl包,然后进行安装,方法如下:
安装编译所需wheel依赖。
执行pip3 list命令检查所列软件中是否包括wheel,若有请忽略该步骤,否则执行如下命令进行安装:
pip3 install wheel --user解压TensorFlow框架安装包。
tar -zxvf amct_tensorflow-{version}-py3-none-linux_{arch}.tar.gz编译whl包。
进入解压后的目录,执行如下命令进行编译:
cd amct_tensorflow-{version} && python3 setup.py bdist_wheel编译完成后,在dist目录下生成所需的whl包。
以whl包形式安装AMCT。
pip3 install amct_tensorflow-{version}-py3-none-any.whl --user若出现如下信息则说明工具安装成功。
Successfully installed amct-tensorflow-{version}
AMCT(Caffe)(不支持)¶
张量分解通过分解卷积核的张量,将一个卷积转化成两个小卷积的堆叠来降低推理开销,如用户模型中存在大量卷积,且卷积核shape普遍大于(64, 64, 3, 3)时推荐使用张量分解。 如果用户有自己计算得到的量化因子以及Caffe原始模型,该模型无法直接使用ATC工具转成适配NPU IP加速器的离线模型,需要借助该章节提供的功能,将其转成CANN量化模型格式,然后才能使用ATC工具,将CANN量化模型转成适配NPU IP加速器的离线模型。
量化¶
本章节详细介绍AMCT量化场景,以及每个场景下的功能。
简介¶
本章节详细介绍AMCT量化场景,以及每个场景下的功能。
量化分类
量化根据是否需要重训练,分为训练后量化(Post-Training Quantization,简称PTQ)和量化感知训练(Quantization-Aware Training,简称QAT),概念解释请参见量化。
训练后量化
根据量化后是否手动调优量化配置文件,分为手工量化和自动量化。训练后量化支持的量化算法请参见训练后量化算法。
根据是否对权重数据进行压缩又分为均匀量化和非均匀量化。如果量化后的精度不满足要求,则可以进行自动量化或手工调优,推荐使用自动量化。
量化感知训练
当前仅支持手工量化,如果量化后的精度不满足要求,则可以进行手工调优。量化感知训练支持的量化算法请参见量化感知训练算法。
相关概念
量化过程中使用的相关术语解释如下:
表 1 量化过程中的相关概念
术语 |
解释 |
|---|---|
数据量化和权重量化 |
训练后量化和量化感知训练,根据量化对象不同,又分为数据(activation)量化和权重(weight)量化。 当前NPU IP加速器支持数据(activation)做对称/非对称量化,权重(weight)仅支持做对称量化(量化根据量化后数据中心点是否为0可以分为对称量化、非对称量化,详细的量化算法原理请参见量化算法原理)。
|
测试数据集 |
数据集的子集,用于最终测试模型的效果。 |
校准 |
训练后量化场景中,做前向推理获取数据量化因子的过程。 |
校准数据集 |
训练后量化场景中,做前向推理使用的数据集。该数据集的分布代表着所有数据集的分布,获取校准集时应该具有代表性,推荐使用测试集的子集作为校准数据集。如果数据集不是模型匹配的数据集或者代表性不够,则根据校准集计算得到的量化因子,在全数据集上表现较差,量化损失大,量化后精度低。 |
训练数据集 |
数据集的子集,基于用户训练网络中的数据集,用于对模型进行训练。 |
量化因子 |
将浮点数量化为整数的参数,包括缩放因子(scale),偏移量(offset)。 将浮点数量化为整数(以INT8为例)的公式如下:
|
scale |
量化因子,浮点数的缩放因子,该参数又分为:
|
offset |
量化因子,偏移量,该参数又分为:
|
训练后量化¶
基于精度的自动量化是为了方便用户在对量化精度有一定要求时所使用的功能。该方法能够在保证用户所需的模型精度前提下,自动搜索模型的量化配置并执行训练后量化的流程,最终生成满足精度要求的量化模型。
基于精度的自动量化¶
基于精度的自动量化是为了方便用户在对量化精度有一定要求时所使用的功能。该方法能够在保证用户所需的模型精度前提下,自动搜索模型的量化配置并执行训练后量化的流程,最终生成满足精度要求的量化模型。
基于精度的自动量化基本原理与手工量化相同,但是用户无需手动调整量化配置文件,大大简化了优化流程,提高量化效率。量化示例请参见样例列表。
接口调用流程
接口调用流程如下图所示。
图 1 自动量化接口调用流程
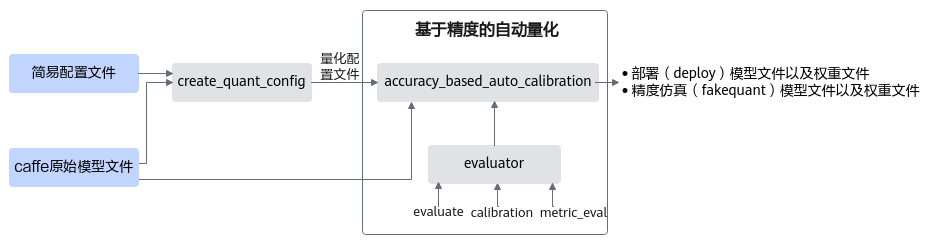
主要流程如下:
调用create_quant_config生成量化配置文件,然后调用accuracy_based_auto_calibration进行基于精度的自动量化。
调用accuracy_based_auto_calibration中由用户传入的evaluator实例进行精度测试,得到原始模型精度。
该过程还会调用accuracy_based_auto_calibration中的量化策略strategy模块,输出初始化的quant config量化配置文件,该文件记录所有层都可以进行量化。
使用用户传入的初始量化配置文件(1中调用create_quant_config生成的)对模型进行训练后量化,得到量化后fake quant模型的精度。
原始模型精度与量化后fake quant模型精度进行比较,如果精度达标,则输出量化后的部署模型和fake quant模型,如果不达标,则进行基于精度的自动量化流程:
进行原始Caffe网络的推理, dump出每一层的输入activation数据,缓存起来;
利用训练后量化的量化因子构造量化层的单算子网络,利用缓存的activation数据计算量化后fake quant单算子网络的输出数据和原始Caffe单算子网络输出的余弦相似度。
将余弦相似度的列表传给accuracy_based_auto_calibration中的量化策略strategy模块,strategy模块基于2中生成的初始化的量化配置文件,输出回退某些层后的新的quant config量化配置文件。
根据quant config量化配置文件重新进行训练后量化,得到回退后的fake quant模型。
调用accuracy_based_auto_calibration中的evaluator模块进行回退后的fake quant模型精度测试,查看精度是否达标:
如果达标,则输出回退后的fake quant模型以及部署模型。
如果不达标,则将余弦相似度排序最差的层回退,再次进行4.c,输出新的量化配置。
如果回退所有层后精度仍不达标,则不生成量化模型。
accuracy_based_auto_calibration接口内部基于精度的自动量化流程如图2所示。
图 2 自动量化流程
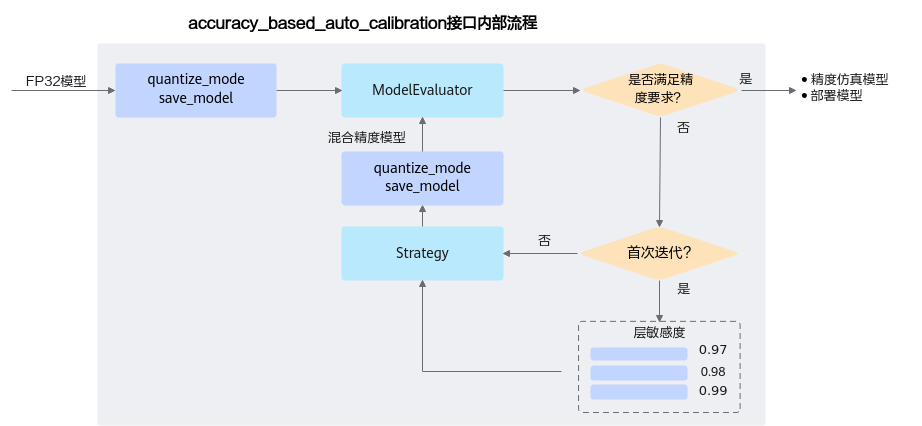
调用示例
本示例演示使用AMCT进行基于精度的自动量化流程。该过程需要用户实现一个模型推理得到精度的回调函数,由于AMCT需要基于回调函数返回的精度数据进行量化层的筛选,因此回调函数的返回数值应尽可能反映模型的精度。
如下示例标有“由用户补充处理”的步骤,需要用户根据自己的模型和数据集进行补充处理,示例中仅为示例代码。
如下示例调用AMCT的部分,函数入参请根据实际情况进行调整。
导入AMCT包。
import os import amct_caffe as amct from amct_caffe.common.auto_calibration import AutoCalibrationEvaluatorBase
(由用户补充处理)使用原始待量化的模型和测试集,实现回调函数calibration()、evaluate()、metric_eval()。
上述回调函数的入参要和基类AutoCalibrationEvaluatorBase保持一致。其中:
calibration()完成校准的推理。
evaluate()完成模型的精度测试过程。
metric_eval()完成原始模型和量化fake quant模型的精度损失评估,当精度损失小于预期值时返回True,否则返回False。
class ModelEvaluator(AutoCalibrationEvaluatorBase): # The evaluator for model def __init__(self, *args, **kwargs): # 成员变量初始化 # 设置预期精度损失,此处请替换为具体的数值 self.diff = expected_acc_loss pass def calibration(self, model_file, weights_file): # 进行模型的校准推理,推理的batch数要和量化配置的batch_num一致 pass def evaluate(self, model_file, weights_file): # evaluate the input models, get the eval metric of model pass def metric_eval(self, original_metric, new_metric): # 评估原始模型精度和量化模型精度的精度损失是否满足预期,满足返回True, 精度损失数据;否则返回False, 精度损失数据 loss = original_metric - new_metric if loss < self.diff: return True, loss return False, loss
(由用户补充处理)根据模型确定模型输入文件。
model_file = os.path.realpath(user_model_file) weights_file = os.path.realpath(user_weights_file)
调用AMCT,进行基于精度的自动量化。
生成量化配置。
config_json_file = './config.json' skip_layers = [] batch_num = 1 activation_offset = True amct.create_quant_config(config_json_file, model_file, weights_file, skip_layers, batch_num, activation_offset) scale_offset_record_file = os.path.join(TMP, 'scale_offset_record.txt') result_path = os.path.join(RESULT, 'model')
初始化Evaluator。
evaluator = AutoCalibrationEvaluator()进行基于精度的量化配置自动搜索。
amct.accuracy_based_auto_calibration( model_file, weights_file, evaluator, config_json_file, scale_offset_record_file, result_path)
手工量化¶
均匀量化是指量化后的数据比较均匀地分布在某个数值空间中,例如INT8量化就是用只有8比特的INT8数据来表示32比特的float32数据,将float32的卷积运算过程(乘加运算)转换为INT8的卷积运算,加速运算和实现模型压缩;均匀的INT8量化则是量化后数据比较均匀地分布在INT8的数值空间[-128, 127]中。 非均匀量化是指量化后的数据在某个数值空间中的分布是不均匀的。非均匀量化过程中,会根据待量化数据的概率分布来对均匀量化后的数据分布进一步进行根据目标压缩率(保留数值量/原始量化数值量)的聚类操作。相较于均匀量化,非均匀量化在进一步压缩数据信息量的基础上尽可能的保留高概率分布的数据信息,从而减小压缩后的数据信息丢失。 执行训练后量化特性的精度如果不满足要求,可以尝试手动调整config.json文件中的参数,本节给出调整的原则,以及参数解释。
均匀量化¶
均匀量化是指量化后的数据比较均匀地分布在某个数值空间中,例如INT8量化就是用只有8比特的INT8数据来表示32比特的float32数据,将float32的卷积运算过程(乘加运算)转换为INT8的卷积运算,加速运算和实现模型压缩;均匀的INT8量化则是量化后数据比较均匀地分布在INT8的数值空间[-128, 127]中。
如果均匀量化后的模型精度无法满足要求,则需要进行量化感知训练或基于精度的自动量化或手工调优。
均匀量化支持量化的层以及约束如下,量化示例请参见样例列表。
表 1 均匀量化支持的层以及约束
量化方式 |
支持的层类型 |
约束 |
|---|---|---|
均匀量化 |
InnerProduct:全连接层 |
transpose属性为false,axis为1 |
Convolution:卷积层 |
filter维度为4 |
|
Deconvolution:反卷积层 |
dilation为1、filter维度为4 |
|
Pooling:平均下采样层 |
下采样方式为AVE,且非global pooling |
接口调用流程
均匀量化接口调用流程如图1所示,均匀量化不支持多个GPU同时运行。
图 1 均匀量化接口调用流程
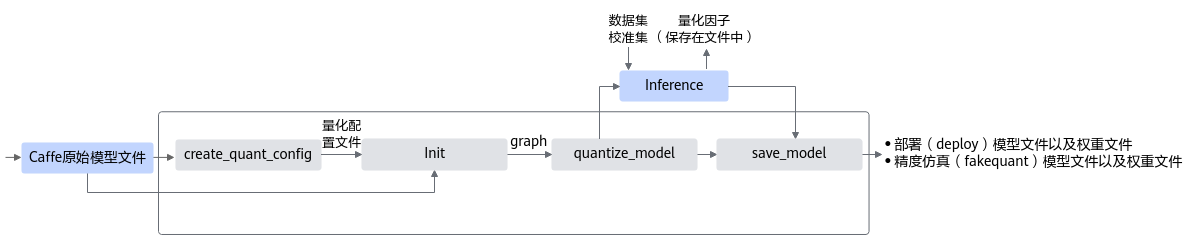
蓝色部分为用户实现,灰色部分为用户调用AMCT提供的API实现,用户在Caffe原始网络推理的代码中导入库,并在特定的位置调用相应API,即可实现量化功能。工具运行流程如下:
用户首先构造Caffe的原始模型,然后使用create_quant_config生成量化配置文件。
根据Caffe模型和量化配置文件,调用init接口,初始化工具,配置量化因子存储文件,将模型解析为图结构graph。
调用quantize_model接口对原始Caffe模型的图结构graph进行优化,修改后的图中插入数据量化、权重量化等相关算子,用于计算量化相关参数。
用户使用3输出的修改后的模型,借助AMCT提供的数据集和校准集,在Caffe环境中进行inference,可以得到量化因子。
其中数据集用于在Caffe环境中对模型进行推理时,测试量化数据的精度;校准集用来产生量化因子,保证精度。
最后用户可以调用save_model接口,插入AscendQuant、AscendDequant等量化算子,保存量化模型:包括可在Caffe环境中进行精度仿真的模型文件和权重文件,以及可部署在NPU IP加速器的模型文件和权重文件。
精度仿真模型文件:文件名中包含fake_quant,模型可在Caffe环境下做推理实现量化精度仿真。
fake_quant模型主要用于验证量化后模型的精度,可以在Caffe框架下运行。进行前向推理的计算过程中,在fake_quant模型中对卷积层等的输入数据和权重进行了量化反量化的操作,来模拟量化后的计算结果,从而快速验证量化后模型的精度。如下图所示,Quant层、Convolution卷积层和DeQuant层之间的数据都是float32数据类型的,其中Quant层将数据量化到INT8又反量化为float32,权重也是量化到INT8又反量化为float32,实际卷积层的计算是基于float32数据类型的,该模型用于在Caffe框架验证量化后模型的精度,不能够用于ATC工具转换成om模型。
图 2 fake_quant模型
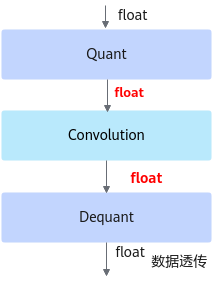
部署模型文件:文件名中包含deploy,模型经过ATC工具转换后可部署到NPU IP加速器上。
deploy模型由于已经将权重等转换成为了INT8、INT32类型,因此不能在Caffe框架上执行推理计算。如下图所示,deploy模型的AscendQuant层将float32的输入数据量化为INT8,作为卷积层的输入,权重也是使用INT8数据类型作为计算,在deploy模型中的卷积层的计算是基于INT8、INT32数据类型的,输出为INT32数据类型经过AscendDequant层转换成float32数据类型传输给下一个网络层。
图 3 deploy模型
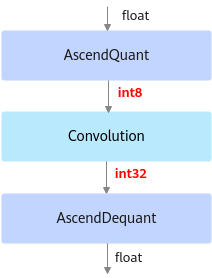
调用示例
本章节详细给出训练后量化的模板代码解析说明,通过解读该代码,用户可以详细了解AMCT的工作流程以及原理,方便用户基于已有模板代码进行修改,以便适配其他网络模型的量化。训练后量化主要包括如下几个步骤:
准备训练好的模型和数据集。
在原始Caffe环境中验证模型精度以及环境是否正常。
编写训练后量化脚本调用AMCT API。
执行训练后量化脚本。
在原始Caffe环境中验证量化后仿真模型精度。
如下流程详细演示如何编写脚本调用AMCT API进行模型量化。
如下示例标有“由用户补充处理”的步骤,需要用户根据自己的模型和数据集进行补充处理,示例中仅为示例代码。
如下示例调用AMCT的部分,函数入参请根据实际情况进行调整。
导入AMCT包,并通过环境变量设置日志级别。
import amct_caffe as amct设置运行设备模式。
AMCT支持CPU或GPU运行模式,所使用的API分别是set_cpu_mode和set_gpu_mode,其中GPU模式与Caffe框架相关,在此模式下,多GPU device的选择是通过Caffe的API caffe.set_mode_gpu()和caffe.set_device(args.gpu_id)来实现的,因此需要先配置Caffe的运行设备模式,再配置AMCT的设备模式。另外因为此处已经指定了运行设备,模型推理函数中无需再次配置运行设备,代码样例如下:
if args.gpu_id is not None and not args.cpu_mode: caffe.set_mode_gpu() caffe.set_device(args.gpu_id) amct.set_gpu_mode() else: caffe.set_mode_cpu()
(可选,由用户补充处理)在Caffe原始环境中验证推理脚本及环境。
建议首先运行下Caffe框架下原始模型推理,验证推理脚本及环境是否正常:
# Run original model without quantize test if args.pre_test: run_caffe_model(args.model_file, args.weights_file, args.iterations) print('[INFO]Run %s without quantize success!' %(args.model_name)) return
调用AMCT,量化模型。
解析用户模型,生成全量量化配置文件。
有两种方法生成量化配置文件:
通过简易配置文件生成,则需要指定config_defination参数的输入,其余入参将无效,可以不用输入。
使用API入参指定量化参数skip_layers、batch_num、activation_offset来生成量化配置文件,默认为API方式。代码样例如下:
# Generate quantize configurations config_json_file = 'tmp/config.json' batch_num = 2 if args.cfg_define is not None: amct.create_quant_config(config_json_file, args.model_file, args.weights_file, config_defination=args.cfg_define) else: skip_layers = [] amct.create_quant_config(config_json_file, args.model_file, args.weights_file, skip_layers, batch_num)
初始化AMCT,读取用户全量量化配置文件、解析用户模型文件、生成用户内部修改模型的Graph IR。
# Phase0: Init amct task scale_offset_record_file = 'tmp/scale_offset_record.txt' graph = amct.init(config_json_file, args.model_file, args.weights_file, scale_offset_record_file)
执行图融合、执行权重离线量化以及插入数据量化层得到校准模型,从而在后续calibration推理过程中执行数据量化动作。
# Phase1: Do conv+bn+scale fusion, weights calibration and fake # quantize, insert data-quantize layer modified_model_file = 'tmp/modified_model.prototxt' modified_weights_file = 'tmp/modified_model.caffemodel' amct.quantize_model(graph, modified_model_file, modified_weights_file)
(由用户补充处理)执行校准模型推理,完成数据量化。
该步骤所需要的推理iterations数量需要大于等于设置用于数据量化的batch_num参数。
# Phase2: run caffe model to do activation calibration run_caffe_model(modified_model_file, modified_weights_file, batch_num)
校准执行过程中提示"IfmrQuantWithOffset scale is illegal",则请参见校准执行过程中提示"IfmrQuantCalibration with offset scale is illegal"或"IfmrQuantCalibration without offset scale is illegal"处理。
保存量化模型。
根据量化因子以及修改后的图结构,调用save_model接口,插入AscendQuant、AscendDequant等算子,并保存得到最终的量化部署模型(deploy)和量化仿真模型(fake_quant)。
# Phase3: save final model, one for caffe do fake quant test, one # deploy model for ATC result_path = 'results/%s' %(args.model_name) amct.save_model(graph, 'Both', result_path)
如果保存模型时,提示Error: Cannot find scale_d of layer '**' in record file信息,则请参见量化执行过程中提示“Check scale and offset record file record.txt failed”处理。
(可选,由用户补充处理)执行量化仿真模型(fake_quant)推理,测试量化后模型精度。
# Phase4: if need test quantized model, uncomment to do final fake quant # model test. fake_quant_model = 'results/{0}_fake_quant_model.prototxt'.format(args.model_name) fake_quant_weights = 'results/{0}_fake_quant_weights.caffemodel'.format(args.model_name) run_caffe_model(fake_quant_model, fake_quant_weights, args.iterations)
如果用户想借助上述sample代码,量化自己的模型,则需要参见如下步骤修改部分代码:
修改执行入参代码。
用于传入AMCT所使用的执行入参(该步骤非必须,用户可使用任意方式实现类似功能,也可以直接将参数写到sample样例代码里面)。代码样例如下:
class Args(object): """struct for Args""" def __init__(self): self.model_name = '' # Caffe model name as prefix to save model self.model_file = '' # user caffe model txt define file self.weights_file = '' # user caffe model binary weights file self.cpu = True # If True, force to CPU mode, else set to False self.gpu_id = 0 # Set the gpu id to use self.pre_test = False # Set true to run original model test, set # False to run quantize with amct_caffe tool self.iterations = 5 # Iteration to run caffe model self.cfg_define = None # If None use args = Args() #############################user modified start######################### """User set basic info to use amct_caffe tool """ # e.g. args.model_name = 'ResNet50' args.model_file = 'pre_model/ResNet-50-deploy.prototxt' args.weights_file = 'pre_model/ResNet-50-model.caffemodel' args.cpu = True args.gpu_id = None args.pre_test = False args.iterations = 5 args.cfg_define = None #############################user modified end###########################
修改执行Caffe模型推理的代码:
代码样例如下:
def run_caffe_model(model_file, weights_file, iterations): """run caffe model forward""" net = caffe.Net(model_file, weights_file, caffe.TEST) #############################user modified start######################### """User modified to execute caffe model forward """ # # e.g. # for iter_num in range(iterations): # data = get_data() # forward_kwargs = {'data': data} # blobs_out = net.forward(**forward_kwargs) # # if have label and need check network forward result # post_process(blobs_out) # return #############################user modified end###########################
代码解析如下,需要用户根据具体业务网络实现对传入模型的推理工作:
加载传入模型文件,得到Caffe Net示例(推理时设置phase为caffe.TEST):
net = caffe.Net(model_file, weights_file, caffe.TEST)根据入参的iterations来循环执行指定次数推理。
获取每次推理所需要的网络数据,需要根据具体业务网络完成数据预处理操作(例如ResNet50,一般需要将YUV图片转换为RGB,然后缩放到224尺寸,再减去各通道均值);然后通过字典的形式,根据网络输入的blob名称来构建相应的输入,如果有多个输入,则分别按照key(blob名称):value(numpy数组)的格式构建相应输入:
data = get_data() forward_kwargs = {'data': data}
执行一次网络的前向推理,并获取网络的输出:
blobs_out = net.forward(**forward_kwargs)Caffe执行Net的输出blobs_out也是以字典格式存储的输出结果,例如{'prob1': blob1, 'prob2':blob2},如果要获取输出,可直接按照指定的blob名称获取对应的blob数据结构。
(可选)如果用户需要测试网络的输出,可按上述形式获取对应的数据,然后计算分类或者检测结果等;该步骤非AMCT需要,AMCT仅需执行网络推理拿到所有网络中间层数据即可,对于网络的最终计算结果用户可自行选择是否需要进行后处理。
post_process(blobs_out)
非均匀量化¶
非均匀量化是指量化后的数据在某个数值空间中的分布是不均匀的。非均匀量化过程中,会根据待量化数据的概率分布来对均匀量化后的数据分布进一步进行根据目标压缩率(保留数值量/原始量化数值量)的聚类操作。相较于均匀量化,非均匀量化在进一步压缩数据信息量的基础上尽可能的保留高概率分布的数据信息,从而减小压缩后的数据信息丢失。
模型在NPU IP加速器上推理时,可通过非均匀量化提高权重压缩率(需要与ATC工具配合,通过编译时使能权重压缩),降低权重传输开销,进一步提升推理性能。非均匀量化后,如果精度仿真模型在原始Caffe环境中推理精度不满足要求,可通过调整非均匀量化配置文件config.json中的参数来恢复模型精度,根据是否自动调整量化配置文件,非均匀量化又分为静态非均匀量化和自动非均匀量化。
静态非均匀量化:需要用户参见手工调优章节手动调整相应参数。详细量化过程请参见样例列表>非均匀量化>静态非均匀量化。
自动非均匀量化:由AMCT自动搜索出一个量化配置,在满足给出的精度损失要求前提下使得量化后的模型压缩率更高。该场景下用户需要基于给出的自动非均匀量化基类(AutoNuqEvaluatorBase)实现一个子类,需要实现eval_model(self, model_file, weights_file, batch_num)和is_satisfied(self, original_metric, new_metric)两个方法:
eval_model根据输入的模型和batch_num进行数据前处理、模型推理、数据后处理,得到模型的评估结果,要求返回的评估结果唯一,如分类网络的top1,检测网络的mAP等,同时也可以是指标的加权结果。
is_satisfied用于判断量化后的模型是否达到了精度损失的要求,如果达到了则返回True,否则返回False;如分类网络的top1用小数表示,则判断条件可以写作if (original_metric - new_metric) * 100 < 1,表示精度的损失要小于1个百分点。
详细量化示例请参见样例列表>非均匀量化>自动非均匀量化。
非均匀量化支持量化的层以及约束如下:
表 1 非均匀量化支持的层以及约束
量化方式 |
支持的层类型 |
约束 |
|---|---|---|
非均匀量化 |
Convolution:卷积层 |
dilation为1、group为1、filter维度为4 |
InnerProduct:全连接层 |
transpose属性为false,axis为1 |
接口调用流程
非均匀量化接口调用流程如图1所示。非均匀量化不支持多个GPU同时运行。
图 1 非均匀量化接口调用流程
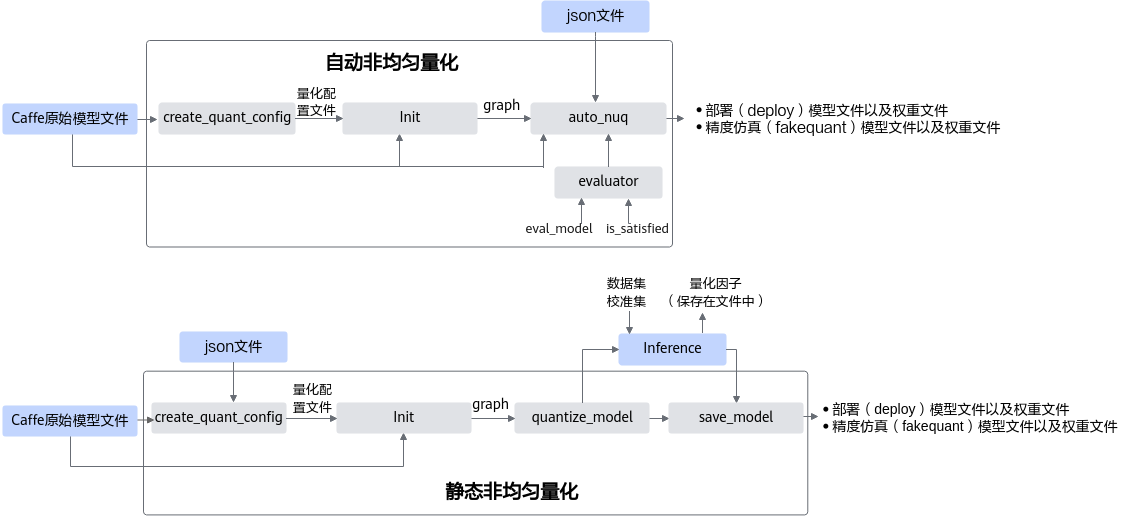
下面以自动非均匀量化为例介绍主要流程,静态非均匀量化流程请参见均匀量化。
用户首先构造Caffe的原始模型,然后使用create_quant_config生成量化配置文件。
根据Caffe模型和量化配置文件,调用init接口,初始化工具,配置量化因子存储文件,将模型解析为图结构graph。
根据原始模型文件、通过ATC工具转换的JSON文件(该文件携带了支持weight压缩特性层的信息,通过fe_weight_compress字段识别)调用auto_nuq进行自动非均匀量化,该过程中会调用由用户传入的evaluator实例进行精度测试,得到原始模型精度。
简要流程如图2所示。
图 2 非均匀量化流程图
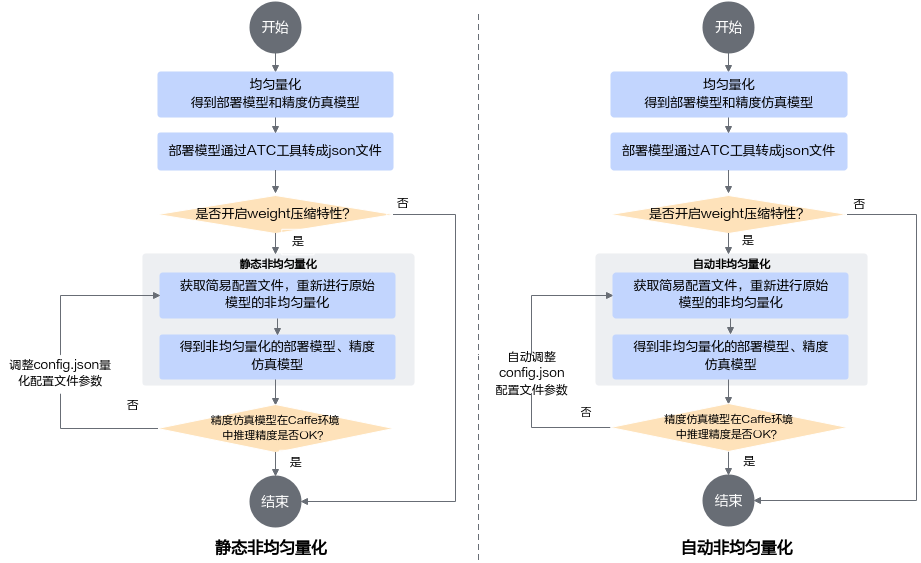
调用示例
导入AMCT包。
import amct_caffe as amct from amct_caffe.auto_nuq import AutoNuqEvaluatorBase
根据给定的AutoNuqEvaluatorBase基类实现一个子类,需要实现能够得到模型精度的评估方法eval_model和判断当前的量化后模型是否精度达标的is_satisfied方法。
class AutoNuqEvaluator(AutoNuqEvaluatorBase): # Auto Nuq Evaluator def __init__(self, evaluate_batch_num): super().__init__(self) self.evaluate_batch_num = evaluate_batch_num
实现模型精度评估方法eval_model。
eval_model根据输入的模型和batch_num进行数据前处理、模型推理、数据后处理,得到模型的评估结果,要求返回的评估结果唯一,如分类网络的top1,检测网络的mAP等,同时也可以是指标的加权结果。
def eval_model(self, model_file, weights_file, batch_num): return do_benchmark_test(QUANT_ARGS, model_file, weights_file, batch_num)
实现精度损失的评估方法is_satisfied。
is_satisfied用于判断量化后的模型是否达到了精度损失的要求,如果达到了则返回True,否则返回False;如分类网络的top1用小数表示,则判断条件可以写作if (original_metric - new_metric) *100 < 1,表示精度的损失要小于1个百分点。
original_metric代表原始未量化模型精度。
new_metric代表量化后fake quant模型精度,根据精度损失是否满足阈值返回True或False。
def is_satisfied(self, original_metric, new_metric): # the loss of top1 acc need to be less than 1% if (original_metric - new_metric) * 100 < 1: return True return False
生成量化配置文件。
config_json_file = os.path.join(TMP, 'config.json') skip_layers = [] batch_num = 2 activation_offset = True # do weights calibration with non uniform quantize configure amct.create_quant_config( config_json_file, args.model_file, args.weights_file, skip_layers, batch_num, activation_offset, args.cfg_define) scale_offset_record_file = os.path.join(TMP, 'scale_offset_record.txt') result_path = os.path.join(RESULT, 'ResNet50')
开始自动非均匀量化流程。
evaluator = AutoNuqEvaluator(args.iterations) amct.auto_nuq( args.model_file, args.weights_file, evaluator, config_json_file, scale_offset_record_file, result_path)
手工调优¶
执行训练后量化特性的精度如果不满足要求,可以尝试手动调整config.json文件中的参数,本节给出调整的原则,以及参数解释。
调优流程
通过create_quant_config接口生成的config.json文件中的默认配置进行量化,若量化后的推理精度不满足要求,则可调整量化配置重复量化,直至精度满足要求。本节详细介绍手动调优流程,调整对象是训练后量化配置文件config.json中的参数,主要涉及3个阶段:
调整校准使用的数据量。
跳过量化某些层。
调整量化算法及参数。
具体步骤如下:
根据create_quant_config接口生成的默认配置进行量化。若精度满足要求,则调参结束,否则进行2。
手动修改batch_num,调整校准使用的数据量。
batch_num控制量化使用数据的batch数目,可根据batch大小以及量化需要使用的图片数量调整。通常情况下:
batch_num越大,量化过程中使用的数据样本越多,量化后精度损失越小;但过多的数据并不会带来精度的提升,反而会占用较多的内存,降低量化的速度,并可能引起内存、显存、线程资源不足等情况;因此,建议batch_num*batch_size为16或32(batch_size表示每个batch使用的图片数量)。
手动修改quant_enable,跳过量化某些层。
quant_enable可以指定该层是否量化,取值为true时量化该层,取值为false时不量化该层,将该层的配置删除也可跳过该层量化。
在整网精度不达标的时候需要识别出网络中的量化敏感层(量化后误差显著增大),然后取消对量化敏感层的量化动作,识别量化敏感层有两种方法:
依据网络模型结构,一般网络中首层、尾层以及参数量偏少的层,量化后精度会有较大的下降。
通过精度比对工具,逐层比对原始模型和量化后模型输出误差(例如以余弦相似度作为标准,需要相似度达到0.99以上),找到误差较大的层,优先对其进行回退。
手动修改activation_quant_params和weight_quant_params,调整量化算法及参数:
算法参数意义请参见量化配置文件中的参数说明部分,算法说明请参见训练后量化算法。
若按照6中的量化配置进行量化后,精度满足要求,则调参结束,否则表明量化对精度影响很大,不能进行量化,去除量化配置。
图 1 调参流程
量化配置文件
如果通过create_quant_config接口生成的config.json量化配置文件,推理精度不满足要求,则需要参见该章节不断调整config.json文件中的内容(用户修改JSON文件时,请确保层名唯一),直至精度满足要求,JSON量化配置文件样例请参见接口中的调用示例部分。配置文件中参数说明如下:
表 1 version参数说明
作用 |
控制量化配置文件版本号。 |
|---|---|
类型 |
int |
取值范围 |
1 |
参数说明 |
目前仅有一个版本号1。 |
推荐配置 |
1 |
可选或者必选 |
可选 |
表 2 batch_num参数说明
作用 |
控制量化使用多少个batch的数据。 |
|---|---|
类型 |
int |
取值范围 |
大于0 |
参数说明 |
如果不配置,则使用默认值1,建议校准集图片数量不超过50张,根据batch的大小batch_size计算相应的batch_num数值。 batch_num*batch_size为量化使用的校准集图片数量。 其中batch_size为每个batch所用的图片数量。 |
推荐配置 |
1 |
必选或可选 |
可选 |
表 3 activation_offset参数说明
作用 |
控制数据量化是对称量化还是非对称量化。全局配置参数。 若配置文件中同时存在activation_offset和asymmetric参数,asymmetric参数优先级>activation_offset参数。 |
|---|---|
类型 |
bool |
取值范围 |
true或false |
参数说明 |
|
推荐配置 |
true |
必选或可选 |
可选 |
表 4 joint_quant参数说明
作用 |
是否进行Eltwise联合量化。 |
|---|---|
类型 |
bool |
取值范围 |
true或false |
参数说明 |
|
推荐配置 |
false |
必选或可选 |
可选 |
表 5 do_fusion参数说明
作用 |
是否开启融合功能。 |
|---|---|
类型 |
bool |
取值范围 |
true或false |
参数说明 |
当前支持融合的层以及融合规则请参见工具实现的融合功能。 |
推荐配置 |
true |
可选或必选 |
可选 |
表 6 skip_fusion_layers参数说明
作用 |
跳过可融合的层。 |
|---|---|
类型 |
string |
取值范围 |
可融合层的层名。 当前支持融合的层以及融合规则请参见工具实现的融合功能。 |
参数说明 |
不需要做融合的层。 |
推荐配置 |
- |
可选或必选 |
可选 |
表 7 layer_config参数说明
作用 |
指定某个网络层的量化配置。 |
|---|---|
类型 |
object |
取值范围 |
- |
参数说明 |
参数内部包含如下参数:
|
推荐配置 |
- |
必选或可选 |
可选 |
表 8 quant_enable参数说明
作用 |
该层是否做量化。 |
|---|---|
类型 |
bool |
取值范围 |
true或false |
参数说明 |
|
推荐配置 |
true |
必选或可选 |
可选 |
表 9 activation_quant_params参数说明
作用 |
该层数据量化的参数。 |
|---|---|
类型 |
object |
取值范围 |
- |
参数说明 |
activation_quant_params内部包含如下参数,IFMR算法相关参数与HFMG算法相关参数在同一层中不能同时出现:
|
推荐配置 |
- |
必选或可选 |
可选 |
表 10 weight_quant_params参数说明
作用 |
该层权重量化的参数。 |
|---|---|
类型 |
object |
取值范围 |
- |
参数说明 |
|
推荐配置 |
- |
必选或可选 |
可选 |
表 11 act_algo参数说明
作用 |
数据量化算法。 |
|---|---|
类型 |
string |
取值范围 |
ifmr或者hfmg |
参数说明 |
IFMR数据量化算法:ifmr HFMG数据量化算法:hfmg |
推荐配置 |
- |
必选或可选 |
可选 |
表 12 asymmetric参数说明
作用 |
控制数据量化是对称量化还是非对称量化。用于控制逐层量化算法的选择。 若配置文件中同时存在activation_offset和asymmetric参数,asymmetric参数优先级>activation_offset参数。 |
|---|---|
类型 |
bool |
取值范围 |
true或false |
参数说明 |
|
推荐配置 |
true |
必选或可选 |
可选 |
表 13 max_percentile参数说明
作用 |
IFMR数据量化算法中,最大值搜索位置参数。 |
|---|---|
类型 |
float |
取值范围 |
(0.5,1] |
参数说明 |
在从大到小排序的一组数中,决定取第多少大的数,比如有100个数,1.0表示取第100-100*1.0=0,对应的就是第一个大的数。 对待量化的数据做截断处理时,该值越大,说明截断的上边界越接近待量化数据的最大值。 |
推荐配置 |
0.999999 |
必选或可选 |
可选 |
表 14 min_percentile参数说明
作用 |
IFMR数据量化算法中,最小值搜索位置参数。 |
|---|---|
类型 |
float |
取值范围 |
(0.5,1] |
参数说明 |
在从小到大排序的一组数中,决定取第多少小的数,比如有100个数,1.0表示取第100-100*1.0=0,对应的就是第一个小的数。 对待量化的数据做截断处理时,该值越大,说明截断的下边界越接近待量化数据的最小值。 |
推荐配置 |
0.999999 |
必选或可选 |
可选 |
表 15 search_range参数说明
作用 |
IFMR数据量化算法中,控制量化因子的搜索范围[search_range_start, search_range_end]。 |
|---|---|
类型 |
list,列表中两个元素类型为float |
取值范围 |
0<search_range_start<search_range_end |
参数说明 |
控制截断的上边界的浮动范围。
|
推荐配置 |
[0.7,1.3] |
必选或可选 |
可选 |
表 16 search_step参数说明
作用 |
IFMR数据量化算法中,控制量化因子的搜索步长。 |
|---|---|
类型 |
float |
取值范围 |
(0, (search_range_end-search_range_start)] |
参数说明 |
控制截断的上边界的浮动范围步长,值越小,浮动步长越小。 搜索次数search_iteration=(search_range_end-search_range_start)/search_step,如果搜索次数过大,搜索时间会很长,该场景下将会导致类似进程卡死的问题。 |
推荐配置 |
0.01 |
必选或可选 |
可选 |
表 17 num_of_bins参数说明
作用 |
HFMG数据量化算法用于调整直方图的bin(直方图中的一个最小单位直方图形)数目。 |
|---|---|
类型 |
unsigned int |
取值范围 |
{1024, 2048, 4096, 8192} |
参数说明 |
num_of_bins数值越大,直方图拟合原始数据分布的能力越强,可能获得更佳的量化效果,但训练后量化过程的耗时也会更长。 |
推荐配置 |
4096 |
必选或可选 |
HFMG算法量化场景下,该参数可选。 |
表 18 wts_algo参数说明
作用 |
权重量化算法。 |
|---|---|
类型 |
string |
取值范围 |
arq_quantize |
参数说明 |
ARQ权重量化算法:arq_quantize |
推荐配置 |
- |
必选或可选 |
可选 |
表 19 channel_wise参数说明
作用 |
ARQ权重量化算法中,是否对每个channel采用不同的量化因子。 |
|---|---|
类型 |
bool |
取值范围 |
true或false |
参数说明 |
|
推荐配置 |
true |
必选或可选 |
可选 |
量化感知训练¶
本节详细介绍量化感知训练支持的量化层,接口调用流程和示例。 执行量化感知训练特性后的精度如果不满足要求,可以尝试手动调整config.json文件中的参数,本节给出调整的原则,以及参数解释。
量化流程¶
本节详细介绍量化感知训练支持的量化层,接口调用流程和示例。
量化示例请参见样例列表。量化感知训练支持量化的层以及约束如下:
表 1 量化感知训练支持的层以及约束
支持的层类型 |
约束 |
|---|---|
InnerProduct:全连接层 |
transpose属性为false,axis为1 |
Convolution:卷积层 |
filter维度为4 |
Deconvolution:反卷积层 |
group为1、dilation为1、filter维度为4 |
Pooling:平均下采样层 |
下采样方式为AVE,且非global pooling |
接口调用流程
量化感知训练接口调用流程如图1所示,如下流程中的训练环境借助Caffe框架的CPU/GPU环境,在该开源框架的推理脚本基础上,调用AMCT API完成模型压缩,压缩后的部署模型需要使用ATC工具转换成适配NPU IP加速器的离线模型后,然后才能在NPU IP加速器上实现推理:
图 1 量化感知训练接口调用流程
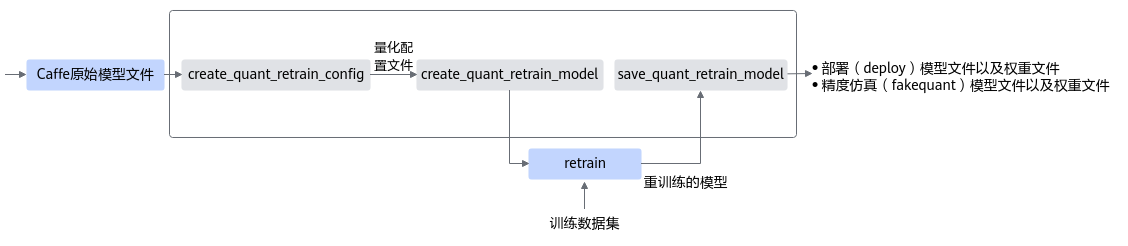
蓝色部分为用户实现,灰色部分为用户调用AMCT提供的API实现,用户在Caffe原始网络推理的代码中导入库,并在特定的位置调用相应API,即可实现量化功能:
用户首先构造Caffe的原始模型,然后使用create_quant_retrain_config生成量化配置文件。
调用create_quant_retrain_model接口对原始Caffe模型进行优化,修改后的模型中插入数据量化、权重量化等相关算子,用于计算量化相关参数;用户使用该模型借助AMCT提供的数据集和校准集,在Caffe环境中进行重训练,可以得到量化因子。
执行Caffe train流程,并配置solver,在训练过程中增加TEST过程,并配置TEST iteration数目大于量化配置文件中batch_num数目。
最后用户调用save_quant_retrain_model接口,插入AscendQuant、AscendDequant等量化算子,保存量化模型:包括可在Caffe环境中进行精度仿真的模型文件和权重文件,以及可部署在NPU IP加速器的模型文件和权重文件。
调用示例
量化感知训练场景下对训练过程的建议: 量化后的训练过程,设置需要与原始训练过程的配置基本保持一致,主要调整如下两点:
epoch数:需调整为原始epoch数的1/4~原始epoch数的1/3。
学习率:需调整为初始学习率的1/100左右。
如下示例标有“由用户补充处理”的步骤,需要用户根据自己的模型和数据集进行补充处理,示例中仅为示例代码。
调用AMCT的部分,函数入参可以根据实际情况进行调整。量化感知训练基于用户的训练过程,请确保已经有基于Caffe环境进行训练的脚本,并且训练后的精度正常。
导入AMCT包,并通过环境变量设置日志级别。
import amct_caffe as amct设置设备运行模式。
AMCT支持CPU或GPU运行模式,若选择GPU模式,需要先设置Caffe的GPU运行设备模式,再设置AMCT的设备模式;另外因为此处已经指定了运行设备,模型推理函数中无需再次配置运行设备:
if 'gpu': caffe.set_mod_gpu() caffe.set_device(gpu_id) amct.set_gpu_mode() else: caffe.set_mode_cpu()
(可选,由用户补充处理)使用原始待量化的模型和测试集,在Caffe环境下推理,验证环境、推理脚本是否正常。
推荐执行该步骤,请确保原始模型可以完成推理且精度正常;执行该步骤时,可以使用部分测试集,减少运行时间。
user_test_model(ori_model_file, ori_weights_file, test_data, test_iterations)调用AMCT,量化模型。
生成量化配置文件。
config_file = './tmp/config.json' amct_caffe.create_quant_retrain_config(config_file=config_file, model_file=ori_model_file, weights_file=ori_weights_file)
修改模型,插入伪量化层并存为新的模型文件。
根据量化配置文件对模型进行修改,插入数据量化、权重量化等相关算子,用于计算量化相关参数。
modified_model_file = './tmp/modified_model.prototxt' modified_weights_file = './tmp/modified_model.caffemodel' scale_offset_record_file = './tmp/record.txt' amct_caffe.create_quant_retrain_model(model_file=ori_model_file, weights_file=ori_weights_file, config_file=config_file, modified_model_file=modified_model_file, modified_weights_file=modified_weights_file, scale_offset_record_file=scale_offset_record_file)
(由用户补充处理)使用修改后的模型,创建反向梯度,在训练集上做训练,训练量化因子。
在solver.prototxt中增加TEST phase(test_interval > 0,test_iter > 0),以触发在TEST phase中执行移位因子N的搜索动作,并且关闭预测test_initialization=false,避免误触发移位因子N的搜索计算。
solver.prototxt文件需要包含参数示例如下:
test_iter: 1 test_interval: 4 base_lr: 9.999999747378752e-05 max_iter: 4 lr_policy: "step" gamma: 0.10000000149011612 momentum: 0.8999999761581421 weight_decay: 9.999999747378752e-05 stepsize: 10 snapshot: 4 net: "$HOME/amct_path/sample/resnet50/tmp/modified_model.prototxt" test_initialization: false
test_iter:repeated参数,指定每次TEST执行的测试的迭代次数,由于移位因子N需要在该过程中执行,因此该数目需要大于等于移位因子N的参数batch_num,否则会由于数据不足,移位因子N计算失败。test_iter*batch_size为每次测试的图片数。
test_interval:两次测试之间TEST的训练次数,每执行test_interval次训练迭代后会执行TEST过程,该参数默认为0,建议配置为max_iter的因子,sample中配置test_interval==max_iter,即仅完成训练后执行一次TEST。
max_iter:训练最大迭代次数。
net:训练使用的模型,Caffe支持配置一个net分别用于TRAIN,TEST(通过算子内phase来区分不同模式需要执行的算子),也可以通过分别指定train_net,test_net来指定不同phase执行的模型;AMCT仅产生了一个模型,通过算子内部phase来区分不同模式,因子仅支持net,不支持配置train_net,test_net。
test_initialization:是否要在训练之前执行原始模型的TEST,数据类型为bool型,默认为True,即执行一次预测试;若设置为True,初始化参数为0,计算出的移位因子N错误,因此需要关掉预测试,即需要配置test_initialization = False。
base_lr、lr_policy、gamma几个参数用于控制学习策略,即learning_rate如何变化。
momentum:上一次梯度更新的权重。
weight_decay:权重衰减项,防止过拟合的一个参数。
snapshot:快照,将训练出来的model和solver状态进行保存,snapshot用于设置训练多少次后进行保存。
训练模型。
user_train_model(modified_model_file, modified_weights_file, train_data)训练过程中数据量化算子训练得到量化上下限clip_max、clip_min,保存到算子blob中,权重量化算子执行量化参数学习,并保存更新后的参数至模型中:前batch_num次训练后会生成量化因子,如果训练次数少于batch_num会导致失败。
保存模型。
根据量化因子以及用户重训练好的模型,调用save_quant_retrain_model接口,插入AscendQuant、AscendDequant等算子,保存为deploy和fake-quant量化模型。
quant_model_path = './result/user_model' amct.save_quant_retrain_model(retrained_model_file=modified_model_file, retrained_weights_file=modified_weights_file, save_type='Both', save_path=quant_model_path, scale_offset_record_file=scale_offset_record_file, config_file=config_file)
(可选,由用户补充处理)使用量化后模型fake_quant_model、fake_quant_weights和测试集,在Caffe环境下推理,测试量化后的仿真模型精度。
使用量化后仿真模型精度与3中的原始精度做对比,可以观察量化对精度的影响。
fake_quant_model = './result/user_model_fake_quant_model.prototxt' fake_quant_weights = './result/user_model_fake_quant_weights.caffemodel' user_test_model(fake_quant_model, fake_quant_weights, test_data, test_iterations)
手工调优¶
执行量化感知训练特性后的精度如果不满足要求,可以尝试手动调整config.json文件中的参数,本节给出调整的原则,以及参数解释。
调优流程
通过create_quant_retrain_config接口生成的config.json文件中的默认配置进行量化,若量化后的推理精度不满足要求,则需要按照如下步骤不断调整训练后量化配置文件config.json中的参数,直至精度满足要求。
根据create_quant_retrain_config接口生成的默认配置进行量化。若精度满足要求,则调参结束,否则进行2。
将部分量化层取消量化,即将其"retrain_enable"参数修改为"false"。通常模型首尾层对推理结果影响较大,故建议优先取消首尾层的量化。
如果用户有推荐的clip_max和clip_min的参数取值,则可以按照如下方式修改量化配置文件:
{ "version":1, "layername1":{ "retrain_enable":true, "retrain_data_config":{ "algo":"ulq_quantize", "clip_max":3.0, "clip_min":-3.0 }, "retrain_weight_config":{ "algo":"arq_retrain", "channel_wise":true } }, "layername2":{ "retrain_enable":true, "retrain_data_config":{ "algo":"ulq_quantize", "clip_max":3.0, "clip_min":-3.0 }, "retrain_weight_config":{ "algo":"arq_retrain", "channel_wise":true } } }
完成配置后,精度满足要求则调参结束;否则表明量化感知训练对精度影响很大,不能进行量化感知训练,去除量化感知训练配置。
量化配置文件
通过create_quant_retrain_config接口生成的config.json量化感知训练配置文件,部分内容样例请参见调用示例(用户修改JSON文件时,请确保层名唯一)。配置文件中参数说明如下,其中表7~表9的参数说明在手动调整量化配置文件时才会使用。
表 1 version参数说明
作用 |
控制量化配置文件版本号。 |
|---|---|
类型 |
int |
取值范围 |
1 |
参数说明 |
目前仅有一个版本号1。 |
推荐配置 |
1 |
必选或可选 |
可选 |
表 2 retrain_enable参数说明
作用 |
该层是否进行量化感知训练。 |
|---|---|
类型 |
bool |
取值范围 |
true或false |
参数说明 |
|
推荐配置 |
true |
必选或可选 |
可选 |
表 3 retrain_data_config参数说明
作用 |
该层数据量化配置。 |
|---|---|
类型 |
object |
取值范围 |
- |
参数说明 |
包含如下参数:
|
推荐配置 |
- |
必选或可选 |
可选 |
表 4 retrain_weight_config参数说明
作用 |
该层权重量化配置。 |
|---|---|
类型 |
object |
取值范围 |
- |
参数说明 |
包含如下参数:
|
推荐配置 |
- |
必选或可选 |
可选 |
表 5 algo参数说明
作用 |
该层选择使用的量化算法。 |
|---|---|
类型 |
object |
取值范围 |
- |
参数说明 |
|
推荐配置 |
数据量化使用ulq_quantize,权重量化使用arq_retrain。 |
必选或可选 |
可选 |
表 6 channel_wise参数说明
作用 |
是否对每个channel采用不同的量化因子。 |
|---|---|
类型 |
bool |
取值范围 |
true或false |
参数说明 |
|
推荐配置 |
true |
必选或可选 |
可选 |
表 7 fixed_min参数说明
作用 |
设置数据量化算法下限的开关。 |
|---|---|
类型 |
bool |
取值范围 |
true或false |
参数说明 |
如果不选此项,amct根据图的结构自动设置。 如果选择此项,并且网络模型量化层的前一层是relu层,则该参数需要手动设置为true,如果为非relu层,则要手动设置为false。 |
推荐配置 |
不选此项 |
必选或可选 |
可选 |
表 8 clip_max参数说明
作用 |
数据量化算法上限。 |
|---|---|
类型 |
float |
取值范围 |
clip_max>0 根据不同层activation的数据分布找到最大值max,推荐取值范围为: 0.3*max~1.7*max |
参数说明 |
截断上下限数据量化算法,如果选择此项则固定算法截断上限。如果不选此项,通过ifmr算法学习获取上限。 |
推荐配置 |
不选此项 |
必选或可选 |
可选 |
表 9 clip_min参数说明
作用 |
数据量化算法下限。 |
|---|---|
类型 |
float |
取值范围 |
clip_min<0 根据不同层activation的数据分布找到最小值min,推荐取值范围为: 0.3*min~1.7*min |
参数说明 |
截断上下限数据量化算法,如果选择此项则固定算法截断下限。如果不选此项,通过ifmr算法学习获取下限。 |
推荐配置 |
不选此项 |
必选或可选 |
可选 |
张量分解¶
张量分解通过分解卷积核的张量,将一个卷积转化成两个小卷积的堆叠来降低推理开销,如用户模型中存在大量卷积,且卷积核shape普遍大于(64, 64, 3, 3)时推荐使用张量分解。
目前仅支持满足如下条件的卷积进行分解:
group=1、dilation=(1,1)、stride<3
kernel_h>2、kernel_w>2
例如,用户使用的Caffe原始模型中存在Convolution层,并且该层满足上述条件,才有可能将相应的Convolution层分解成两个Convolution层,然后使用AMCT转换成可以在NPU IP加速器部署的量化模型,以便在模型推理时获得更好的性能。
该场景为可选操作,用户自行决定是否进行原始模型的分解。
分解约束
如果Convolution层的shape过大,会造成分解时间过长或分解异常中止,为防止出现该情况,执行分解动作前,请先参见如下约束或参考数据:
分解工具性能参考数据:
CPU: Intel(R) Xeon(R) CPU E5-2699 v4 @ 2.20GHz
内存: 512G
分解单层卷积:
shape(512, 512, 5, 5),大约耗时25秒。
shape(1024, 1024, 3, 3),大约耗时16秒。
shape(1024, 1024, 5, 5),大约耗时78秒。
shape(2048, 2048, 3, 3),大约耗时63秒。
shape(2048, 2048, 5, 5),大约耗时430秒。
内存超限风险提醒:
分解大卷积核存在内存超限风险参考数值:shape为(2048, 2048, 5, 5)的卷积核约占用32G内存。
接口调用流程
接口调用流程如图1所示,分解示例请参见样例列表。
图 1 张量分解接口调用流程

具体流程如下:
根据用户提供的Caffe原始模型,调用auto_decomposition生成张量分解后的模型文件以及权重文件。
对分解后的模型进行fine-tune,输出分解后的模型,如果要对该模型进行量化,则请参见训练后量化或者量化感知训练。
图2为resnet50网络模型分解前后的示意图。
图 2 模型分解前后示意图
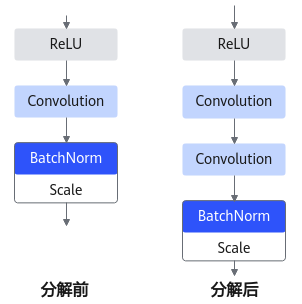
调用示例
# 导入相关模块
from amct_caffe.tensor_decompose import auto_decomposition
# 待分解模型文件
model_file = 'src_path/xxx.prototxt'
# 待分解权值文件
weights_file = 'src_path/xxx.caffemodel'
# 分解后保存的模型文件
new_model_file = 'decomposed_path/xxx.prototxt'
# 分解后保存的权值文件
new_weights_file = 'decomposed_path/xxx.caffemodel'
# 执行张量分解
auto_decomposition(model_file=model_file, weights_file=weights_file,
new_model_file=new_model_file, new_weights_file=new_weights_file)
扩展更多特性(模型适配)¶
如果用户有自己计算得到的量化因子以及Caffe原始模型,该模型无法直接使用ATC工具转成适配NPU IP加速器的离线模型,需要借助该章节提供的功能,将其转成CANN量化模型格式,然后才能使用ATC工具,将CANN量化模型转成适配NPU IP加速器的离线模型。
适配原理
适配原理如下图所示,蓝色部分为用户实现,灰色部分为用户调用AMCT提供的convert_model实现,用户在Caffe原始网络推理的代码中导入库,并在特定的位置调用相应API,即可实现模型适配功能。该场景下的适配示例请参见样例列表>模型适配。
图 1 模型适配原理

调用示例
如下示例标有“由用户补充处理”的步骤,需要用户根据自己的模型和数据集进行补充处理,示例中仅为示例代码。
如果用户需要基于如下代码,对其他模型进行量化,需要准备原始未量化的模型,将用户自己准备的量化因子转换为量化因子记录文件。
导入AMCT包,并通过环境变量设置日志级别。
import amct_caffe as amct设置设备运行模式。
AMCT支持CPU或GPU运行模式,若选择GPU模式,需要先设置Caffe的GPU运行设备模式,再设置AMCT的设备模式;另外因为此处已经指定了运行设备,模型推理函数中无需再次配置运行设备:
if 'gpu': caffe.set_mod_gpu() caffe.set_device(gpu_id) amct.set_gpu_mode() else: caffe.set_mode_cpu()
(可选,由用户补充处理)使用原始待量化的模型和测试集,在Caffe环境下推理,验证环境、推理脚本是否正常。
推荐执行该步骤,请确保原始模型可以完成推理且精度正常;执行该步骤时,可以使用部分测试集,减少运行时间。
user_test_model(ori_model_file, ori_weights_file, test_data, test_iterations)调用convert_model接口,进行模型适配。
该接口内部会将原始模型解析为graph形式,完成图的预处理操作>解析用户传入的量化因子文件>然后根据量化因子和修改后的图结构,插入AscendQuant、AscendDequant等算子,保存为量化模型。
quant_model_path = './result/user_model' record_file = './result/record.txt' amct.convert_model(model_file=ori_model_file, weights_file=ori_weights_file, scale_offset_record_file=record_file, save_path=quant_model_path)
(可选,由用户补充处理)使用量化后模型fake_quant_model、fake_quant_weights和测试集,在Caffe环境下推理,测试量化后的仿真模型精度。
使用量化后仿真模型精度与3中的原始精度做对比,可以观察量化对精度的影响。
fake_quant_model = './result/user_model_fake_quant_model.prototxt' fake_quant_weights = './result/user_model_fake_quant_weights.caffemodel' user_test_model(fake_quant_model, fake_quant_weights, test_data, test_iterations)
接口说明¶
整体约束和接口列表¶
整体约束
若接口中存在需要用户输入文件路径的参数,请确保输入路径正确,AMCT不会对路径做安全校验。
若接口中存在需要用户输入文件路径的参数,重新执行量化时,该参数相关取值将会被覆盖;量化打屏日志中也会有相关文件被覆盖的warning风险提示信息。
接口列表
分类 |
接口名称 |
功能描述 |
|---|---|---|
公共接口 |
set_gpu_mode |
调用该接口之后,AMCT执行权重量化的时候,会使用GPU进行加速。 |
set_cpu_mode |
调用该接口之后,AMCT执行权重量化的时候,使用CPU进行计算。 |
|
训练后量化接口 |
create_quant_config |
训练后量化接口,根据图的结构找到所有可量化的层,自动生成量化配置文件,并将可量化层的量化配置信息写入配置文件。 |
init |
训练后量化接口,用于初始化AMCT,记录存储量化因子的文件,解析用户模型为图结构graph,供quantize_model和save_model使用。 |
|
quantize_model |
训练后量化接口,根据用户设置的量化配置文件对图结构进行量化处理,该函数在config_file指定的层插入权重量化层,完成权重量化,并插入数据量化层,将修改后的网络存为新的模型文件。 |
|
save_model |
训练后量化接口,根据修改后的图结构,插入AscendQuant、AscendDequant等算子,将模型保存为可以做推理的文件,支持保存为可在Caffe环境下做精度仿真的fake_quant模型,和可在NPU IP加速器上做推理的deploy模型。 |
|
auto_nuq |
训练后量化接口,根据用户输入的模型、配置文件进行自动非均匀量化,搜索得到一个满足目标精度的非均匀量化配置,输出可以在Caffe环境下做精度仿真的fake_quant模型,和可在NPU IP加速器上做在线推理的deploy模型。 |
|
accuracy_based_auto_calibration |
根据用户输入的模型、配置文件进行自动的校准过程,搜索得到一个满足目标精度的量化配置,输出可以在Caffe环境下做精度仿真的fake_quant模型,和可在NPU IP加速器上做推理的deploy模型。 |
|
量化感知训练接口 |
create_quant_retrain_config |
量化感知训练接口,根据图的结构找到所有可量化的层,自动生成量化配置文件,并将可量化层的量化配置信息写入配置文件。 |
create_quant_retrain_model |
量化感知训练接口,根据用户设置的量化配置文件对图结构进行量化处理,该函数在config_file指定的层插入数据和weights伪量化层,将修改后的网络存为新的模型文件。 |
|
save_quant_retrain_model |
量化感知训练接口,根据用户最终的重训练好的模型,插入AscendQuant、AscendDequant等算子,生成最终fake quant仿真模型和deploy部署模型。 |
|
模型适配接口 |
convert_model |
根据用户自己计算得到的量化因子以及Caffe模型,适配成可以在NPU IP加速器上做在线推理的Deploy量化部署模型和可以在Caffe环境下进行精度仿真的Fakequant量化模型。 |
张量分解接口 |
auto_decomposition |
根据用户提供的Caffe原始模型(.prototxt和.caffemodel),生成张量分解后的模型文件以及权重文件。 |
公共接口¶
set_gpu_mode¶
产品支持情况
产品 |
是否支持 |
|---|---|
IPV350 |
x |
功能说明
调用该接口之后,AMCT执行权重量化的时候,会使用GPU进行加速。
函数原型
set_gpu_mode()
参数说明
无
返回值说明
无
约束说明
用户有GPU环境,且支持CUDA10.0。该接口不支持选择GPU卡,用户可以通过CUDA环境变量(CUDA_VISIBLE_DEVICES)来选择GPU卡,或者使用pycaffe的set_device()接口来选择GPU卡。
如果既不调用set_gpu_mode接口也不调用set_cpu_mode接口。AMCT默认使用CPU进行权重的量化。
调用示例
import amct_caffe as amct
amct.set_gpu_mode()
set_cpu_mode¶
产品支持情况
产品 |
是否支持 |
|---|---|
IPV350 |
x |
功能说明
调用该接口之后,AMCT执行权重量化的时候,使用CPU进行计算。
函数原型
set_cpu_mode()
参数说明
无
返回值说明
无
约束说明
如果既不调用set_gpu_mode接口也不调用set_cpu_mode接口。AMCT默认使用CPU进行权重的量化。
调用示例
import amct_caffe as amct
amct.set_cpu_mode()
训练后量化接口¶
create_quant_config¶
产品支持情况
产品 |
是否支持 |
|---|---|
IPV350 |
x |
功能说明
训练后量化接口,根据图的结构找到所有可量化的层,自动生成量化配置文件,并将可量化层的量化配置信息写入配置文件。
函数原型
create_quant_config(config_file, model_file, weights_file, skip_layers=None, batch_num=1, activation_offset=True, config_defination=None)
参数说明
参数名 |
输入/输出 |
说明 |
|---|---|---|
config_file |
输入 |
含义:待生成的量化配置文件存放路径及名称。如果存放路径下已经存在该文件,则调用该接口时会覆盖已有文件。 数据类型:string |
model_file |
输入 |
含义:用户Caffe模型的定义文件,格式为.prototxt。 数据类型:string |
weights_file |
输入 |
含义:用户训练好的Caffe模型权重文件,格式为.caffemodel。 数据类型:string |
skip_layers |
输入 |
含义:可量化但不需要量化层的层名。 默认值:None 数据类型:list,列表中元素类型为string 使用约束:如果使用简易配置文件作为入参,则该参数需要在简易配置文件中设置,此时输入参数中该参数配置不生效。 |
batch_num |
输入 |
含义:量化使用的batch数量,即使用多少个batch的数据生成量化因子。 数据类型:int 取值范围:大于0的整数 默认值:1 使用约束:
|
activation_offset |
输入 |
含义:数据量化是否带offset。 默认值:True 数据类型:bool 使用约束:如果使用简易配置文件作为入参,则该参数需要在简易配置文件中设置,此时输入参数中该参数配置不生效。 |
config_defination |
输入 |
含义:基于calibration_config_caffe.proto文件生成的简易量化配置文件quant.cfg,*.proto文件所在路径为:AMCT安装目录/amct_caffe/proto/。*.proto文件参数解释以及生成的quant.cfg简易量化配置文件样例请参见训练后量化简易配置文件。 默认值:None 数据类型:字符串 使用约束:当取值为None时,使用输入参数生成配置文件;否则,忽略输入的其他量化参数(skip_layers,batch_num,activation_offset),根据简易配置文件参数config_defination生成JSON格式的配置文件。 |
返回值说明
无
约束说明
由于数据格式转换,生成的量化配置文件中与简易配置文件中的量化参数,数值上不完全一致,但不影响精度。
调用示例
from amct_caffe import create_quant_config
# 通过参数来生成量化配置文件
create_quant_config(config_file="./configs/config.json",
model_file="./pretrained_model/model.prototxt",
weights_file="./pretrained_model/model.caffemodel",
skip_layers=None,
batch_num=1,
activation_offset=True)
# 通过简易配置文件来生成量化配置文件
create_quant_config(config_file="./configs/config.json",
model_file="./pretrained_model/model.prototxt",
weights_file="./pretrained_model/model.caffemodel",
config_defination="./configs/quant.cfg")
落盘文件说明:
生成一个JSON格式的量化配置文件,样例如下(重新执行量化时,该接口输出的量化配置文件将会被覆盖)。
均匀量化配置文件(数据量化使用IFMR数据量化算法)
{ "version":1, "batch_num":2, "activation_offset":true, "joint_quant":false, "do_fusion":true, "skip_fusion_layers":[], "conv1":{ "quant_enable":true, "activation_quant_params":{ "max_percentile":0.999999, "min_percentile":0.999999, "search_range":[ 0.7, 1.3 ], "search_step":0.01, "act_algo":"ifmr", "asymmetric":false }, "weight_quant_params":{ "wts_algo":"arq_quantize", "channel_wise":true } }, "conv2":{ "quant_enable":true, "activation_quant_params":{ "max_percentile":0.999999, "min_percentile":0.999999, "search_range":[ 0.7, 1.3 ], "search_step":0.01, "act_algo":"ifmr", "asymmetric":false }, "weight_quant_params":{ "wts_algo":"arq_quantize", "channel_wise":false } } }
均匀量化配置文件(数据量化使用HFMG数据量化算法)
{ "version":1, "batch_num":2, "activation_offset":true, "joint_quant":false, "do_fusion":true, "skip_fusion_layers":[], "conv1":{ "quant_enable":true, "activation_quant_params":{ "act_algo":"hfmg", "num_of_bins":4096 "asymmetric":false }, "weight_quant_params":{ "wts_algo":"arq_quantize", "channel_wise":true } } }
init¶
产品支持情况
产品 |
是否支持 |
|---|---|
IPV350 |
x |
功能说明
训练后量化接口,用于初始化AMCT,记录存储量化因子的文件,解析用户模型为图结构graph,供quantize_model和save_model使用。
函数原型
graph = init(config_file, model_file, weights_file, scale_offset_record_file)
参数说明
参数名 |
输入/输出 |
说明 |
|---|---|---|
config_file |
输入 |
含义:用户生成的量化配置文件。 数据类型:string |
model_file |
输入 |
含义:用户Caffe模型的定义文件,格式为.prototxt,与create_quant_config中的model_file保持一致 数据类型:string 使用约束:model_file中包含的用于推理的层,LayerParameter设置满足推理要求,比如BatchNorm层的use_global_stats必须设置为1。 |
weights_file |
输入 |
含义:用户训练好的Caffe模型文件,格式为.caffemodel,与create_quant_config中的weights_file保持一致。 数据类型:string |
scale_offset_record_file |
输入 |
含义:存储量化因子的文件,文件如果不存在,则会被创建,否则会被清空。 数据类型:string |
返回值说明
graph:用户模型解析出来的图结构。
调用示例
from amct_caffe import init
# 初始化工具
graph = init(config_file="./configs/config.json",
model_file="./pretrained_model/model.prototxt",
weights_file="./pretrained_model/model.caffemodel",
scale_offset_record_file="./recording.txt")
落盘文件说明:量化因子文件,重新执行量化时,该接口输出的存储量化因子文件将会被覆盖。
quantize_model¶
产品支持情况
产品 |
是否支持 |
|---|---|
IPV350 |
x |
功能说明
训练后量化接口,根据用户设置的量化配置文件对图结构进行量化处理,该函数在config_file指定的层插入权重量化层,完成权重量化,并插入数据量化层,将修改后的网络存为新的模型文件。
函数原型
quantize_model(graph, modified_model_file, modified_weights_file)
参数说明
参数名 |
输入/输出 |
使用限制 |
|---|---|---|
graph |
输入 |
含义:用户模型经过init接口解析出来的图结构。 数据类型:工具自定义的数据结构Graph |
modified_model_file |
输入 |
含义:文件名,用于存储插入量化层的Caffe模型定义文件(格式为.prototxt)。 数据类型:string |
modified_weights_file |
输入 |
含义:文件名,用于存储插入量化层的Caffe模型权重文件(格式为.caffemodel)。 数据类型:string |
返回值说明
无
调用示例
from amct_caffe import quantize_model
# 插入量化API
quantize_model(graph=graph,
modified_model_file="./quantized_model/modified_model.prototxt",
modified_weights_file="./quantized_model/modified_model.caffemodel")
落盘文件说明:
量化因子:在init接口中的scale_offset_record_file中写入量化层的权重量化因子(scale_w,offset_w)。
modified_model_file:修改后模型的定义文件,在原始模型上插入了量化层。
modified_weights_file:修改后模型的权重文件,在原始模型上插入了量化层。
重新执行量化时,该接口输出的文件将会被覆盖。
save_model¶
产品支持情况
产品 |
是否支持 |
|---|---|
IPV350 |
x |
功能说明
训练后量化接口,根据修改后的图结构,插入AscendQuant、AscendDequant等算子,将模型保存为可以做推理的文件,支持保存为可在Caffe环境下做精度仿真的fake_quant模型,和可在NPU IP加速器上做推理的deploy模型。
函数原型
save_model(graph, save_type, save_path)
参数说明
参数名 |
输入/输出 |
说明 |
|---|---|---|
graph |
输入 |
含义:经过quantize_model接口修改后的图结构。 数据类型:工具自定义的数据结构Graph |
save_type |
输入 |
含义:保存模型的类型:
数据类型:string |
save_path |
输入 |
含义:模型存放路径。该路径需要包含模型名前缀,例如./quantized_model/*model。 数据类型:string |
返回值说明
无
约束说明
在网络推理的batch数目达到batch_num后,再调用save_model接口,否则量化因子不正确,量化结果不正确。
由于数据格式转换,生成的部署模型中存储的量化因子(scale/offset)与计算出来的量化因子,数值上不完全一致,但不影响精度。
scale_offset_record_file中必须有所有量化层的量化因子,否则会报错,即quantize_model中的modified_model_file与modified_weights_file必须在Caffe环境中完成batch_num次推理。
调用示例
from amct_caffe import save_model
# 在Caffe环境中对修改后的模型做batch_num次推理,以完成量化
run_caffe_model(modified_model_file, modified_weights_file, batch_num)
# 插入API,将量化的模型存为prototxt模型文件以及caffemodel权重文件,在./quantized_model中生成五个文件:model_fake_quant_model.prototxt,model_fake_quant_weights.caffemodel,model_deploy_model.prototxt,model_deploy_weights.caffemodel,model_quant.json。
save_model(graph=graph,
save_type="Both",
save_path="./quantized_model/model")
落盘文件说明:
精度仿真模型文件:一个模型定义文件,一个模型权重文件,文件名中包含fake_quant;模型可在Caffe环境下做推理实现量化精度仿真。
部署模型文件:一个模型定义文件,一个模型权重文件,文件名中包含deploy;模型经过ATC工具转换后可部署到NPU IP加速器上。
量化信息文件:该文件记录了AMCT插入的量化算子位置以及算子融合信息,用于量化后的模型进行精度比对使用。
重新执行量化时,该接口输出的上述文件将会被覆盖。
auto_nuq¶
产品支持情况
产品 |
是否支持 |
|---|---|
IPV350 |
x |
注:标记“x”的产品,调用接口不会报错,但是获取不到性能收益。
功能说明
训练后量化接口,根据用户输入的模型、配置文件进行自动非均匀量化,搜索得到一个满足目标精度的非均匀量化配置,输出可以在Caffe环境下做精度仿真的fake_quant模型,和可在NPU IP加速器上做在线推理的deploy模型。
函数原型
auto_nuq(model_file, weights_file, nuq_evaluator, config_file, scale_offset_record_file, save_dir)
参数说明
参数名 |
输入/输出 |
说明 |
|---|---|---|
model_file |
输入 |
含义:用户Caffe模型的定义文件,格式为.prototxt。 数据类型:string |
weights_file |
输入 |
含义:用户训练好的Caffe模型权重文件,格式为.caffemodel。 数据类型:string |
nuq_evaluator |
输入 |
含义:自动非均匀量化评估的Python实例。 数据类型:Python实例 |
config_file |
输入 |
含义:用户生成的量化配置文件。 数据类型:string |
scale_offset_record_file |
输入 |
含义:存储量化因子的文件,如果该文件存在,会被重写。 数据类型:string |
save_dir |
输入 |
含义:模型存放路径。该路径需要包含模型名前缀,例如./quantized_model/*model。 数据类型:string |
返回值说明
无
调用示例
import amct_caffe as amct
from amct_caffe.auto_nuq import AutoNuqEvaluatorBase
class AutoNuqEvaluator(AutoNuqEvaluatorBase):
def __init__(self, evaluate_batch_num):
self.evaluate_batch_num = evaluate_batch_num
def eval_model(self, model_file, weights_file, batch_num):
return do_benchmark_test(args, model_file, weights_file, batch_num)
def is_satisfied(self, original_metric, new_metric):
# the loss of top1 acc need to be less than 1%
if (original_metric - new_metric) *100<1:
return True
return False
evaluator = AutoNuqEvaluator(1000)
amct.auto_nuq(
model_file,
weights_file,
evaluator,
config_json_file,
scale_offset_record_file,
'./results/Resnet50')
落盘文件说明:
精度仿真模型文件:一个模型定义文件,一个模型权重文件,文件名中包含fake_quant;模型可在Caffe环境下做推理实现量化精度仿真。
部署模型文件:一个模型定义文件,一个模型权重文件,文件名中包含deploy;模型经过ATC工具转换后可部署到NPU IP加速器上。
量化因子记录文件:在接口中的scale_offset_record_file中写入量化层的权重量化因子(scale_w,offset_w)。
非均匀量化信息记录文件:该文件记录了哪些层做了非均匀量化。
量化信息文件:该文件记录了AMCT插入的量化算子位置以及算子融合信息,用于量化后的模型进行精度比对使用。
重新执行量化时,该接口输出的上述文件将会被覆盖。
accuracy_based_auto_calibration¶
产品支持情况
产品 |
是否支持 |
|---|---|
IPV350 |
x |
功能说明
根据用户输入的模型、配置文件进行自动的校准过程,搜索得到一个满足目标精度的量化配置,输出可以在Caffe环境下做精度仿真的fake_quant模型,和可在NPU IP加速器上做推理的deploy模型。
约束说明
无。
函数原型
accuracy_based_auto_calibration(model_file,weights_file,model_evaluator,config_file,record_file,save_dir,strategy='BinarySearch',sensitivity='CosineSimilarity')
参数说明
参数名 |
输入/输出 |
说明 |
|---|---|---|
model_file |
输入 |
含义:用户Caffe模型的定义文件,格式为.prototxt。 数据类型:string |
weights_file |
输入 |
含义:用户训练好的Caffe模型权重文件,格式为.caffemodel。 数据类型:string |
model_evaluator |
输入 |
含义:自动量化进行校准和评估精度的Python实例。 数据类型:Python实例 |
config_file |
输入 |
含义:用户生成的量化配置文件。 数据类型:string |
record_file |
输入 |
含义:存储量化因子的路径,如果该路径下已存在文件,则会被重写。 数据类型:string |
save_dir |
输入 |
含义:模型存放路径。该路径需要包含模型名前缀,例如./quantized_model/*model。 数据类型:string |
strategy |
输入 |
含义:搜索满足精度要求的量化配置的策略,默认是二分法策略。 数据类型:string或Python实例 默认值:BinarySearch |
sensitivity |
输入 |
含义:评价每一层量化层对于量化敏感度的指标,默认是余弦相似度。 数据类型:string或Python实例 默认值:CosineSimilarity |
返回值说明
无
调用示例
import amct_caffe as amct
from amct_caffe.common.auto_calibration import AutoCalibrationEvaluatorBase
from amct_caffe.common.auto_calibration import BinarySearchStrategy
from amct_caffe.common.auto_calibration import CosineSimilaritySensitivity
class AutoCalibrationEvaluator(AutoCalibrationEvaluatorBase):
def __init__(self):
"""
evaluate_batch_num is the needed batch num for evaluating
the model. Larger evaluate_batch_num is recommended, because
the evaluation metric of input model can be more precise
with larger eval dataset.
"""
super().__init__()
def calibration(self, model_file, weights_file):
""""
Function:
do the calibration with model
Parameter:
model_file: the prototxt model define file of caffe model
weights_file: the binary caffemodel file of caffe model
"""
run_caffe_model(args, model_file, weights_file, CALIBRATION_BATCH_NUM)
def evaluate(self, model_file, weights_file):
""""
Function:
evaluate the model with batch_num of data, return the eval
metric of the input model, such as top1 for classification
model, mAP for detection model and so on.
Parameter:
model_file: the prototxt model define file of caffe model
weights_file: the binary caffemodel file of caffe model
"""
return do_benchmark_test(args, model_file, weights_file, args.iterations)
def metric_eval(self, original_metric, new_metric):
"""
Function:
whether the metric of new fake quant model can satisfy the
requirement
Parameter:
original_metric: the metric of non quantized model
new_metric: the metric of new quantized model
"""
# the loss of top1 acc need to be less than 0.2%
loss = original_metric - new_metric
if loss * 100 < 0.2:
return True, loss
return False, loss
# step 1: create the quant config file
config_json_file = './config.json'
skip_layers = []
batch_num = CALIBRATION_BATCH_NUM
activation_offset = True
amct.create_quant_config(config_json_file, model_file, weights_file,
skip_layers, batch_num, activation_offset)
scale_offset_record_file = os.path.join(TMP, 'scale_offset_record.txt')
result_path = os.path.join(RESULT, 'MobileNetV2')
evaluator = AutoCalibrationEvaluator()
# step 2: start the accuracy_based_auto_calibration process
amct.accuracy_based_auto_calibration(
args.model_file,
args.weights_file,
evaluator,
config_json_file,
scale_offset_record_file,
result_path)
落盘文件说明:
精度仿真模型文件:一个模型定义文件,一个模型权重文件,文件名中包含fake_quant;模型可在Caffe环境下做推理实现量化精度仿真。
部署模型文件:一个模型定义文件,一个模型权重文件,文件名中包含deploy;模型经过ATC工具转换后可部署到NPU IP加速器上。
量化因子记录文件:在接口中的record_file中写入量化层的权重量化因子(scale_w,offset_w)。
量化信息文件:该文件记录了AMCT插入的量化算子位置以及算子融合信息,用于量化后的模型进行精度比对使用。
敏感度信息文件:该文件记录了待量化层对于量化的敏感度信息,根据该信息进行量化回退层的选择。
自动量化回退历史记录文件:记录的回退层的信息。
量化感知训练接口¶
create_quant_retrain_config¶
产品支持情况
产品 |
是否支持 |
|---|---|
IPV350 |
x |
功能说明
量化感知训练接口,根据图的结构找到所有可量化的层,自动生成量化配置文件,并将可量化层的量化配置信息写入配置文件。
约束说明
无。
函数原型
create_quant_retrain_config(config_file, model_file, weights_file, config_defination=None)
参数说明
参数名 |
输入/输出 |
说明 |
|---|---|---|
config_file |
输入 |
含义:待生成的量化感知训练配置文件存放路径及名称。 如果存放路径下已经存在该文件,则调用该接口时会覆盖已有文件。 数据类型:string |
model_file |
输入 |
含义:Caffe原始模型的定义文件,格式为.prototxt。 数据类型:string |
weights_file |
输入 |
含义:Caffe原始模型权重文件,格式为.caffemodel。 数据类型:string |
config_defination |
输入 |
含义:基于retrain_config_caffe.proto文件生成的简易配置文件quant.cfg,*.proto文件所在路径为:AMCT安装目录/amct_caffe/proto/。*.proto文件参数解释以及生成的quant.cfg简易量化配置文件样例请参见量化感知训练简易配置文件。 默认值:None。 数据类型:string 使用约束:当取值为None时,使用输入参数生成配置文件;否则根据量化感知训练简易配置文件参数config_defination生成JSON格式的配置文件。 |
返回值说明
无
调用示例
from amct_caffe import amct
retrain_simple = 'retrain/retrain.cfg'
model_file = 'resnet50_train.prototxt'
weights_file = 'ResNet-50-model.caffemodel'
config_json_file = './config.json'
amct.create_quant_retrain_config(config_json_file, model_file, weights_file, retrain_simple)
落盘文件说明:
生成一个JSON格式的量化感知训练配置文件(重新执行量化感知训练时,该接口输出的配置文件将会被覆盖)。样例如下:
{
"version":1,
"conv1":{
"retrain_enable":true,
"retrain_data_config":{
"algo":"ulq_quantize"
},
"retrain_weight_config":{
"algo":"arq_retrain",
"channel_wise":true
}
},
"conv2_1/expand":{
"retrain_enable":true,
"retrain_data_config":{
"algo":"ulq_quantize"
},
"retrain_weight_config":{
"algo":"arq_retrain",
"channel_wise":true
}
},
"conv2_1/dwise":{
"retrain_enable":true,
"retrain_data_config":{
"algo":"ulq_quantize"
},
"retrain_weight_config":{
"algo":"arq_retrain",
"channel_wise":true
}
},
}
create_quant_retrain_model¶
产品支持情况
产品 |
是否支持 |
|---|---|
IPV350 |
x |
功能说明
量化感知训练接口,根据用户设置的量化配置文件对图结构进行量化处理,该函数在config_file指定的层插入数据和weights伪量化层,将修改后的网络存为新的模型文件。
函数原型
create_quant_retrain_model(model_file, weights_file, config_file, modified_model_file, modified_weights_file, scale_offset_record_file)
参数说明
参数名 |
输入/输出 |
说明 |
|---|---|---|
model_file |
输入 |
含义:用户Caffe模型的定义文件,格式为.prototxt。 数据类型:string |
weights_file |
输入 |
含义:用户训练好的Caffe模型权重文件,格式为.caffemodel。 数据类型:string |
config_file |
输入 |
含义:量化配置文件。 数据类型:string |
modified_model_file |
输入 |
含义:文件名,用于存储插入量化感知训练层的Caffe模型定义文件(格式为.prototxt)。 数据类型:string |
modified_weights_file |
输入 |
含义:文件名,用于存储插入量化感知训练层的Caffe模型权重文件(格式为.caffemodel)。 数据类型:string |
scale_offset_record_file |
输入 |
含义:存储量化因子的文件。 数据类型:string |
返回值说明
无
调用示例
from amct_caffe import amct
model_file = 'resnet50_train.prototxt'
weights_file = 'ResNet-50-model.caffemodel'
modified_model_file = './tmp/modified_model.prototxt'
modified_weights_file = './tmp/modified_model.caffemodel'
config_json_file = './config.json'
scale_offset_record_file = './record.txt'
amct.create_quant_retrain_model( model_file, weights_file, config_json_file, modified_model_file, modified_weights_file, scale_offset_record_file)
落盘文件说明:
modified_model_file:修改后模型的定义文件,在原始模型上插入了量化感知训练层。
modified_weights_file:修改后模型的权重文件,在原始模型上插入了量化感知训练层。
save_quant_retrain_model¶
产品支持情况
产品 |
是否支持 |
|---|---|
IPV350 |
x |
功能说明
量化感知训练接口,根据用户最终的重训练好的模型,插入AscendQuant、AscendDequant等算子,生成最终fake quant仿真模型和deploy部署模型。
约束说明
无。
函数原型
save_quant_retrain_model(retrained_model_file, retrained_weights_file, save_type, save_path, scale_offset_record_file = None, config_file = None)
参数说明
参数名 |
输入/输出 |
说明 |
|---|---|---|
retrained_model_file |
输入 |
含义:用户重训练好的Caffe模型的定义文件,格式为.prototxt。 数据类型:string 使用约束:retrained_model_file中包含的用于推理的层,LayerParameter设置满足推理要求,比如BatchNorm层的use_global_stats必须设置为1。 |
retrained_weights_file |
输入 |
含义:用户重训练好的Caffe模型的权重文件,格式为.caffemodel。 数据类型:string |
save_type |
输入 |
含义:保存模型的类型:
数据类型:string |
save_path |
输入 |
含义:模型存放路径。 该路径需要包含模型名前缀,例如./quantized_model/*model。 数据类型:string |
scale_offset_record_file |
输入 |
含义:存储量化因子的文件。 数据类型:string。默认已初始化,传None |
config_file |
输入 |
含义:量化配置文件。 数据类型:string。默认已初始化,传None |
返回值说明
无
调用示例
from amct_caffe import amct
retrained_model_file = './pre_model/retrained_resnet50.prototxt'
retrained_weights_file = './pre_model/resnet50_solver_iter_35000.caffemodel'
scale_offset_record_file = './record.txt'
# 插入API,将重训练的模型保存为prototxt模型文件以及caffemodel权重文件,在./result中生成四个文件:model_fake_quant_model.prototxt,model_fake_quant_weights.caffemodel,model_deploy_model.prototxt,model_deploy_weights.prototxt
amct.save_quant_retrain_model(retrained_model_file, retrained_weights_file, 'Both', './result/model', scale_offset_record_file, config_json_file)
落盘文件说明:
精度仿真模型文件:一个模型定义文件,一个模型权重文件,文件名中包含fake_quant;模型可在Caffe环境下做推理实现量化精度仿真。
部署模型文件:一个模型定义文件,一个模型权重文件,文件名中包含deploy;模型经过ATC工具转换后可部署到NPU IP加速器上。
模型适配接口¶
convert_model¶
产品支持情况
产品 |
是否支持 |
|---|---|
IPV350 |
x |
功能说明
根据用户自己计算得到的量化因子以及Caffe模型,适配成可以在NPU IP加速器上做在线推理的Deploy量化部署模型和可以在Caffe环境下进行精度仿真的Fakequant量化模型。
函数原型
convert_model(model_file,weights_file,scale_offset_record_file,save_path)
参数说明
参数名 |
输入/输出 |
说明 |
|---|---|---|
model_file |
输入 |
含义:用户Caffe模型的定义文件,格式为.prototxt。 数据类型:string 使用约束:model_file中包含的用于推理的层,LayerParameter设置满足推理要求,比如BatchNorm层的use_global_stats必须设置为1。 |
weights_file |
输入 |
含义:用户训练好的Caffe模型权重文件,格式为.caffemodel。 数据类型:string |
scale_offset_record_file |
输入 |
含义:用户计算得到的量化因子记录文件,格式为.txt。 数据类型:string |
save_path |
输入 |
含义:模型存放路径。该路径需要包含模型名前缀,例如./quantized_model/*model。 数据类型:string |
返回值说明
无
约束说明
用户模型需要保证和量化因子记录文件配套,例如用户对Conv+BN+Scale结构先进行融合再计算得到融合Conv的量化因子,则所提供用于转换的原始caffe模型中Conv+BN+Scale结构也需要预先进行融合。
量化因子记录文件格式及记录内容需要严格符合AMCT定义要求,详细信息请参见record记录文件。
仅支持对AMCT支持量化的层:全连接层(InnerProduct:transpose属性为true或axis!=1都不进行量化)、卷积层(Convolution:filter维度为4)、反卷积层(Deconvolution:group为1、dilation为1、filter维度为4)、平均下采样层(Pooling:下采样方式为AVE,且非global pooling)。
该接口支持对用户模型中的Conv+BN+Scale结构进行融合,且可逐层配置是否做融合。
仅支持输入原始浮点数模型进行适配,不支持用户对已量化模型(包含量化工具插入的Quant、DeQuant、AntiQuant层,或参数已量化为INT8,INT32类型)进行二次量化。
调用示例
from amct_caffe import convert_model
convert_model(model_file='ResNet-50-deploy.prototxt',
weights_file='ResNet-50-weights.caffemodel',
scale_offset_record_file='record.txt',
save_path='./quantized_model/model')
落盘文件说明:
精度仿真模型文件:一个模型定义文件,一个模型权重文件,文件名中包含fake_quant;模型可在Caffe环境下做推理实现量化精度仿真。
部署模型文件:一个模型定义文件,一个模型权重文件,文件名中包含deploy;模型经过ATC工具转换后可部署到NPU IP加速器上。
量化信息文件:该文件记录了AMCT插入的量化算子位置以及算子融合信息,用于量化后的模型进行精度比对使用。
重新执行适配时,该接口输出的上述文件将会被覆盖。
张量分解接口¶
auto_decomposition¶
产品支持情况
产品 |
是否支持 |
|---|---|
IPV350 |
x |
功能说明
根据用户提供的Caffe原始模型(.prototxt和.caffemodel),生成张量分解后的模型文件以及权重文件。
函数原型
auto_decomposition(model_file,weights_file,new_model_file,new_weights_file)
参数说明
参数名 |
输入/输出 |
说明 |
|---|---|---|
model_file |
输入 |
含义:用户Caffe模型的定义文件,格式为.prototxt。 数据类型:string |
weights_file |
输入 |
含义:用户训练好的Caffe模型权重文件,格式为.caffemodel。 数据类型:string |
new_model_file |
输入 |
含义:张量分解后的Caffe模型定义文件,格式为.prototxt,例如xx_tensor_decomposition.prototxt。 数据类型:string |
new_weights_file |
输入 |
含义:张量分解后的Caffe模型权重文件,格式为.caffemodel,例如xx_tensor_decomposition.caffemodel。 数据类型:string |
返回值说明
无
约束说明
用户提供用于转换的原始Caffe模型,需要保证prototxt文件和caffemodel配套。
用户调用张量分解接口函数,输入原始模型路径以及模型分解后的保存路径,接口函数对符合分解条件的卷积层进行自动分解,约束请参见分解约束。
调用示例
from amct_caffe.tensor_decompose import auto_decomposition
auto_decomposition(model_file='ResNet-50-deploy.prototxt',
weights_file='ResNet-50-weights.caffemodel',
new_model_file='ResNet-50-deploy_tensor_decomposition.prototxt',
new_weights_file='ResNet-50-deploy_tensor_decomposition.caffemodel')
落盘文件说明:
张量分解后的模型定义文件,格式为.prototxt。
张量分解后的模型权重文件,格式为.caffemodel。
参考信息¶
proto合并原理¶
合并原理如图1所示,其中:
AMCT(Ascend Model Compression Toolkit):昇腾模型压缩工具,简称AMCT。
ATC(Ascend Tensor Compiler):昇腾张量编译器,即模型转换工具。
各proto文件说明:
custom.proto:用户自行准备的自定义文件。
amct_custom.proto:AMCT提供的文件,包括AMCT自定义层以及caffe-master相较于Caffe1.0的更新层。
caffe.proto:ATC软件包中内置的文件,该文件相较于Caffe1.0版本的caffe.proto,增加了ATC自定义层及调整了编号顺序。该文件同步合入AMCT软件包。
图 1 proto合并原理
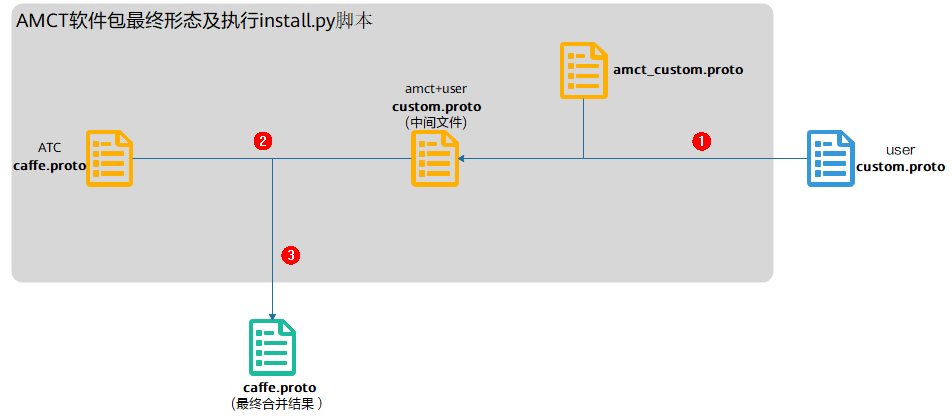
合并流程以及原则:
用户准备自定义的custom.proto,执行AMCT提供的install.py脚本,该脚本会将用户的custom.proto与AMCT提供的amct_custom.proto进行合并,生成中间文件custom.proto。
如果custom.proto和amct_custom.proto存在算子编号冲突的场景,则报错,提示用户修改custom.proto的算子编号。
如果custom.proto和amct_custom.proto存在算子名相同的场景,则报错,提示用户修改custom.proto的算子名。
将生成的中间文件custom.proto与ATC软件包中的caffe.proto进行合并,生成最终的caffe.proto。
如果custom.proto和caffe.proto存在算子编号冲突的场景,则报错,提示用户修改custom.proto的算子编号。
如果custom.proto和caffe.proto存在算子名相同的场景,做去重处理,以custom.proto为准。
最后会根据用户指定的caffe_dir路径,找到用户Caffe工程下的caffe.proto文件,对其进行备份后替换。
amct_custom.proto中的编号从200000开始(包括200000)。
caffe.proto中ATC自定义层的编号区间段为:\5000,200000)。
custom.proto中用户自定义层编号建议区间段小于5000,并且不与ATC提供的caffe.proto中的内置编号冲突。
工具实现的融合功能¶
当前该工具主要实现的是BN融合功能,分为如下几类(如下融合场景中涉及的单个算子,需要先满足[量化场景下的约束条件):
Conv+BN+Scale融合:AMCT在量化前会对模型中的"Convolution+BatchNorm+Scale"结构做Conv+BN+Scale融合,融合后的"BatchNorm"、"Scale"层会被删除。
Deconv+BN+Scale融合:AMCT在量化前会对模型中的"Deconvolution+BatchNorm+Scale"结构做Deconv+BN+Scale融合,融合后的"BatchNorm"、"Scale"层会被删除。
BN+Scale+Conv融合:仅训练后量化支持,AMCT在量化前会对模型中的"BatchNorm+Scale+Convolution"结构做BN+Scale+Conv融合,融合后的"BatchNorm"、"Scale"层会被删除。
FC+BN+Scale融合:仅训练后量化支持,AMCT在量化前会对模型中的"InnerProduct+BatchNorm+Scale"结构做FC+BN+Scale融合,融合后的"BatchNorm"、"Scale"层会被删除。
训练后量化简易配置文件¶
calibration_config_caffe.proto文件参数说明如表1所示,该文件所在目录为:AMCT安装目录/amct_caffe/proto/calibration_config_caffe.proto。
表 1 calibration_config_caffe.proto参数说明
消息 |
是否必填 |
类型 |
字段 |
说明 |
|---|---|---|---|---|
AMCTConfig |
- |
- |
- |
AMCT训练后量化的简易配置。 |
optional |
uint32 |
batch_num |
量化使用的batch数量。 |
|
optional |
bool |
activation_offset |
数据量化是否带offset。全局配置参数。
|
|
optional |
bool |
joint_quant |
是否进行Eltwise联合量化,默认为false,表示关闭联合量化功能。 |
|
repeated |
string |
skip_layers |
不需要量化层的层名。 |
|
repeated |
string |
skip_layer_types |
不需要量化的层类型。 |
|
optional |
NuqConfig |
nuq_config |
非均匀量化配置。 |
|
optional |
CalibrationConfig |
common_config |
通用的量化配置,全局量化配置参数。若某层未被override_layer_types或者override_layer_configs重写,则使用该配置。 参数优先级:override_layer_configs>override_layer_types>common_config |
|
repeated |
OverrideLayerType |
override_layer_types |
重写某一类型层的量化配置,即对哪些层进行差异化量化。 例如全局量化配置参数配置的量化因子搜索步长为0.01,可以通过该参数对部分层进行差异化量化,可以配置搜索步长为0.02。 参数优先级:override_layer_configs>override_layer_types>common_config |
|
repeated |
OverrideLayer |
override_layer_configs |
重写某一层的量化配置,即对哪些层进行差异化量化。 例如全局量化配置参数配置的量化因子搜索步长为0.01,可以通过该参数对部分层进行差异化量化,可以配置搜索步长为0.02。 参数优先级:override_layer_configs>override_layer_types>common_config |
|
optional |
bool |
do_fusion |
是否开启BN融合功能,默认为true,表示开启该功能。 |
|
repeated |
string |
skip_fusion_layers |
跳过BN融合的层,配置之后这些层不会进行BN融合。 |
|
optional |
CalibrationConfig |
conv_calibration_config |
卷积层的量化配置,适用于所有未被重新配置的卷积层和反卷积层。Deprecated,不推荐用户使用。 |
|
optional |
CalibrationConfig |
fc_calibration_config |
全连接层和平均下采样pooling层的量化配置,适用于所有未被重新配置的全连接层和平均下采样pooling层。Deprecated,不推荐用户使用。 |
|
NuqConfig |
- |
- |
- |
非均匀量化配置。 |
required |
string |
mapping_file |
均匀量化后的deploy模型通过ATC工具转换得到的om模型,然后通过ATC工具转换得到JSON文件,即量化后模型的融合JSON文件。 |
|
optional |
NUQuantize |
nuq_quantize |
非均匀量化的参数。 |
|
OverrideLayerType |
- |
- |
- |
重置某层类型的量化配置。 |
required |
string |
layer_type |
支持量化的层类型的名字。 |
|
required |
CalibrationConfig |
calibration_config |
重置的量化配置。 |
|
OverrideLayer |
- |
- |
- |
重置某层量化配置。 |
required |
string |
layer_name |
被重置层的层名。 |
|
required |
CalibrationConfig |
calibration_config |
重置的量化配置。 |
|
CalibrationConfig |
- |
- |
- |
Calibration量化的配置。 |
- |
ARQuantize |
arq_quantize |
权重量化算法配置。 arq_quantize:ARQ量化算法配置。 |
|
- |
NUQuantize |
nuq_quantize |
权重量化算法配置。 nuq_quantize:非均匀量化算法配置。 |
|
- |
FMRQuantize |
ifmr_quantize |
数据量化算法配置。 ifmr_quantize:IFMR量化算法配置。 |
|
- |
HFMGQuantize |
hfmg_quantize |
数据量化算法配置。 hfmg_quantize:HFMG量化算法配置。 |
|
ARQuantize |
- |
- |
- |
ARQ量化算法配置。算法介绍请参见ARQ权重量化算法。 |
optional |
bool |
channel_wise |
是否对每个channel采用不同的量化因子。 |
|
FMRQuantize |
- |
- |
- |
FMR数据量化算法配置。算法介绍请参见IFMR数据量化算法。 该算法与HFMGQuantize算法不能同时配置,若同时配置,则以配置文件中最后配置的量化算法为准。 |
optional |
float |
search_range_start |
量化因子搜索范围左边界。 |
|
optional |
float |
search_range_end |
量化因子搜索范围右边界。 |
|
optional |
float |
search_step |
量化因子搜索步长。 |
|
optional |
float |
max_percentile |
最大值搜索位置。 |
|
optional |
float |
min_percentile |
最小值搜索位置。 |
|
optional |
bool |
asymmetric |
是否进行对称量化。用于控制逐层量化算法的选择。
如果override_layer_configs、override_layer_types、common_config配置项都配置该参数,或者配置了 activation_offset参数,则生效优先级为: override_layer_configs>override_layer_types>common_config>activation_offset |
|
HFMGQuantize |
- |
- |
- |
HFMG数据量化算法配置。算法介绍请参见HFMG数据量化算法。 该算法与FMRQuantize算法不能同时配置,若同时配置,则以配置文件中最后配置的量化算法为准。 |
optional |
uint32 |
num_of_bins |
直方图的bin(直方图中的一个最小单位直方图形)数目,支持的范围为{1024, 2048, 4096, 8192}。 默认值为4096。 |
|
optional |
bool |
symmetric |
是否进行对称量化。用于控制逐层量化算法的选择。
如果override_layer_configs、override_layer_types、common_config配置项都配置该参数,或者配置了 activation_offset参数,则生效优先级为: override_layer_configs>override_layer_types>common_config>activation_offset |
|
NUQuantize |
- |
- |
- |
非均匀量化算法配置。算法介绍请参见NUQ权重量化算法。 |
optional |
uint32 |
num_steps |
非均匀量化的台阶数。 |
|
optional |
uint32 |
num_of_iteration |
非均匀量化优化的迭代次数。 |
基于该文件构造的均匀量化简易配置文件quant.cfg样例如下所示:
# global quantize parameter batch_num : 2 activation_offset : true joint_quant : false skip_layers : "Opname" skip_layer_types:"Optype" do_fusion: true skip_fusion_layers : "Opname" common_config : { arq_quantize : { channel_wise : true } ifmr_quantize : { search_range_start : 0.7 search_range_end : 1.3 search_step : 0.01 max_percentile : 0.999999 min_percentile : 0.999999 asymmetric : true } } override_layer_types : { layer_type : "Optype" calibration_config : { arq_quantize : { channel_wise : false } ifmr_quantize : { search_range_start : 0.8 search_range_end : 1.2 search_step : 0.02 max_percentile : 0.999999 min_percentile : 0.999999 asymmetric : false } } } override_layer_configs : { layer_name : "Opname" calibration_config : { arq_quantize : { channel_wise : true } ifmr_quantize : { search_range_start : 0.8 search_range_end : 1.2 search_step : 0.02 max_percentile : 0.999999 min_percentile : 0.999999 asymmetric : false } } }
如果数据量化算法使用HFMG,则上述配置文件中加粗部分可以替换成如下参考参数信息,举例如下(如下配置信息只是样例,请根据实际情况进行修改):
# global quantize parameter activation_offset : true batch_num : 1 ... common_config : { hfmg_quantize : { num_of_bins : 4096 asymmetric : false } ... }
量化感知训练简易配置文件¶
retrain_config_caffe.proto文件参数说明如表1所示,该文件所在目录为:AMCT安装目录/amct_caffe/proto/retrain_config_caffe.proto。
表 1 retrain_config_caffe.proto参数说明
消息 |
是否必填 |
类型 |
字段 |
说明 |
|---|---|---|---|---|
AMCTRetrainConfig |
- |
- |
- |
AMCT量化感知训练的简易配置。 |
repeated |
string |
skip_layers |
按层名跳过哪些层。全局参数,方便后续拓展其他特性场景下可同时跳过的层,比如下述拓展的quant_skip_layers参数,若后续又拓展了xxx_skip_layers参数,则通过skip_layers参数可以同时配置两个特性场景下需要跳过的层。而无需在quant_skip_layers和xxx_skip_layers参数中分别配置。 若同时配置了skip_layers和quant_skip_layers参数,则取两者并集。 |
|
repeated |
string |
skip_layer_types |
按层类型跳过哪些层(当前版本不支持)。全局参数,方便后续拓展其他特性场景下可同时跳过的层,比如下述拓展的quant_skip_types参数,若后续又拓展了xxx_skip_types参数,则通过skip_layer_types参数可以同时配置两个特性场景下需要跳过的层。而无需在quant_skip_types和xxx_skip_types参数中分别配置。 若同时配置了skip_layer_types和quant_skip_types参数,则取两者并集。 |
|
repeated |
RetrainOverrideLayer |
override_layer_configs |
按层名重写哪些层,即对哪些层进行差异化压缩。 例如全局量化配置参数配置的初始上下限值为[-0.6,0.6],可以通过该参数对部分层进行差异化量化,可以配置为[-0.3,0.3]。 参数优先级为:
|
|
repeated |
RetrainOverrideLayerType |
override_layer_types |
按层类型重写哪些层,即对哪些层进行差异化压缩。 例如全局量化配置参数配置的初始上下限值为[-0.6,0.6],可以通过该参数对部分层进行差异化量化,可以配置为[-0.3,0.3]。 参数优先级为:
|
|
optional |
uint32 |
batch_num |
量化使用的batch数量。 |
|
required |
RetrainDataQuantConfig |
retrain_data_quant_config |
量化感知训练数据量化配置参数。全局量化配置参数。 参数优先级为:override_layer_configs>override_layer_types>retrain_data_quant_config/retrain_weight_quant_config |
|
required |
RetrainWeightQuantConfig |
retrain_weight_quant_config |
量化感知训练权重量化配置参数。全局量化配置参数。 参数优先级为:override_layer_configs>override_layer_types>retrain_data_quant_config/retrain_weight_quant_config |
|
repeated |
string |
quant_skip_layers |
按层名跳过不需要量化的层。量化场景下使用的参数。 若同时配置了skip_layers和quant_skip_layers参数,则取两者并集。 |
|
repeated |
string |
quant_skip_types |
按层类型跳过不需要量化的层(当前版本不支持)。量化场景下使用的参数。 若同时配置了skip_layer_types和quant_skip_types参数,则取两者并集。 |
|
RetrainDataQuantConfig |
- |
- |
- |
量化感知训练数据量化参数配置。 |
- |
ULQuantize |
ulq_quantize |
数据量化算法,目前仅支持ulq。 |
|
ULQuantize |
- |
- |
- |
ULQ量化算法配置。算法介绍请参见ULQ数据量化算法。 |
optional |
ClipMaxMin |
clip_max_min |
初始化的上下限值,如果不配置,默认用ifmr进行初始化。 |
|
optional |
bool |
fixed_min |
是否下限不学习且固定为0。默认ReLu后为true,其他为false。 |
|
ClipMaxMin |
- |
- |
- |
初始上下限。 |
required |
float |
clip_max |
初始上限值。 |
|
required |
float |
clip_min |
初始下限值。 |
|
RetrainWeightQuantConfig |
- |
- |
- |
量化感知训练权重量化参数配置。 |
- |
ARQRetrain |
arq_retrain |
权重量化算法,目前仅支持arq。 |
|
ARQRetrain |
- |
- |
- |
ARQ量化算法配置。算法介绍请参见ARQ权重量化算法。 |
required |
bool |
channel_wise |
是否做channel wise的arq。 |
|
RetrainOverrideLayer |
- |
- |
- |
重写的层配置。 |
required |
string |
layer_name |
层名。 |
|
required |
RetrainDataQuantConfig |
retrain_data_quant_config |
重写的数据层量化参数。 |
|
required |
RetrainWeightQuantConfig |
retrain_weight_quant_config |
重写的权重层量化参数。 |
|
RetrainOverrideLayerType |
- |
- |
- |
重写的层类型配置。 |
required |
string |
layer_type |
层类型。 |
|
required |
RetrainDataQuantConfig |
retrain_data_quant_config |
重写的数据层量化参数。 |
|
required |
RetrainWeightQuantConfig |
retrain_weight_quant_config |
重写的权重层量化参数。 |
基于该文件构造的量化感知训练简易配置文件quant.cfg样例如下所示:
# global quantize parameter
retrain_data_quant_config: {
ulq_quantize: {
clip_max_min: {
clip_max: 6.0
clip_min: -6.0
}
}
}
retrain_weight_quant_config: {
arq_retrain: {
channel_wise: true
}
}
skip_layers: "conv_1"
override_layer_types : {
layer_type: "InnerProduct"
retrain_weight_quant_config: {
arq_retrain: {
channel_wise: false
}
}
}
override_layer_configs : {
layer_name: "fc_5"
retrain_weight_quant_config: {
arq_retrain: {
channel_wise: false
}
}
}
record记录文件¶
record文件,为基于protobuf协议的序列化数据结构文件,记录量化因子scale/offset等,通过该文件、压缩配置文件以及原始网络模型文件,生成压缩后的模型文件。
record原型定义
record文件对应的protobuf原型定义为:
message SingleLayerRecord {
optional float scale_d = 1;
optional int32 offset_d = 2;
repeated float scale_w = 3;
repeated int32 offset_w = 4;
repeated uint32 shift_bit = 5;
optional uint32 channels = 6;
optional uint32 height = 7;
optional uint32 width = 8;
optional bool skip_fusion = 9 [default = false];
}
message ScaleOffsetRecord {
message MapFiledEntry {
optional string key = 1;
optional SingleLayerRecord value = 2;
}
repeated MapFiledEntry record = 1;
}
参数说明如下:
消息 |
是否必填 |
类型 |
字段 |
说明 |
|---|---|---|---|---|
ScaleOffsetRecord |
- |
- |
- |
map结构,为保证兼容性,采用离散的map结构。 |
repeated |
MapFiledEntry |
record |
每个record对应一个量化层的量化因子记录;record包括两个成员:
|
|
SingleLayerRecord |
- |
- |
- |
包含了量化层所需要的所有量化因子记录信息。 |
optional |
float |
scale_d |
数据量化scale因子,仅支持对数据进行统一量化。 |
|
optional |
int32 |
offset_d |
数据量化offset因子,仅支持对数据进行统一量化。 |
|
repeated |
float |
scale_w |
权重量化scale因子,支持标量(对当前层的权重进行统一量化),向量(对当前层的权重按channel_wise方式进行量化)两种模式,仅支持卷积层(Convolution),反卷积层(Deconvolution)类型进行channel_wise量化模式。 |
|
repeated |
int32 |
offset_w |
权重量化offset因子,同scale_w一样支持标量和向量两种模式,且需要同scale_w维度一致,当前不支持权重带offset量化模式,offset_w仅支持0。 |
|
repeated |
uint32 |
shift_bit |
移位因子。convert_model接口场景下预留字段,当前不支持,不需要配置。 |
|
optional |
uint32 |
channels |
由于AMCT不支持整网infer_shape,需要配置当前层的输入shape信息,该字段用于配置输入的channel大小; |
|
optional |
uint32 |
height |
由于AMCT不支持整网infer_shape,需要配置当前层的输入shape信息,该字段用于配置输入的height大小。 |
|
optional |
uint32 |
width |
由于AMCT不支持整网infer_shape,需要配置当前层的输入shape信息,该字段用于配置输入的width大小。 |
|
optional |
bool |
skip_fusion |
配置当前层是否要跳过Conv+BN+Scale、Deconv+BN+Scale、BN+Scale+Conv、FC+BN+Scale融合操作,默认为false,即当前层要做上述融合。 |
对于optional字段,由于protobuf协议未对重复出现的值报错,而是采用覆盖处理,因此出现重复配置的optional字段内容时会默认保留最后一次配置的值,需要用户自己保证文件的正确性。
record记录文件
最终生成的record文件格式为_record.txt_。对于一般量化层配置需要包含scale_d、offset_d、scale_w、offset_w、channels、height、width、shift_bit参数,对于AVE Pooling因为没有权重,因此不能配置scale_w、offset_w参数。量化因子record文件内容示例如下:
record {
key: "conv1"
value: {
scale_d: 0.01424
offset_d: -128
scale_w: 0.43213
scale_w: 0.78163
scale_w: 1.03213
offset_w: 0
offset_w: 0
offset_w: 0
shift_bit: 1
shift_bit: 1
shift_bit: 1
channels:3
height: 144
width: 144
skip_fusion: true
}
}
record {
key: "pool1"
value: {
scale_d: 0.532532
offset_d: 13
channels:256
height: 32
width: 32
}
}
record {
key: "fc1"
value: {
scale_d: 0.37532
offset_d: -67
scale_w: 0.876221
offset_w: 0
shift_bit: 1
channels:1024
height: 1
width: 1
}
}
命令行参数说明¶
以下涉及TensorFlow、Caffe的参数IPV350不支持
本节给出命令行场景所使用的参数概览。
概览¶
本节给出命令行场景所使用的参数概览。
须知:
如果通过amct_xxx calibration --help命令查询出的参数未解释在表1,则说明该参数预留或适用于其他芯片版本,用户无需关注。
使用amct__xxx_命令行进行量化时,命令有两种方式,用户根据实际情况进行选择:
amct_xxx calibration param1=value1 param2=value2 ...(value值前面不能有空格,否则会导致截断,param取的value值为空)
amct_xxx calibration param1 value1 param2 value2 ... _xxx_请替换为具体框架名称:caffe、tensorflow、onnx。
表 1 参数概览
参数项 |
参数说明 |
使用框架/网络 |
使用场景 |
|---|---|---|---|
--help或--h |
打印帮助信息。 |
|
|
--model |
待量化网络的模型文件路径与文件名:
|
|
|
--weights |
待量化网络的权重文件路径与文件名,格式为.caffemodel。该参数仅适用于Caffe框架模型。 |
|
|
--outputs |
指定原始模型输出Tensor的名称。 |
|
|
--save_path |
量化后模型的存放路径。 |
|
|
--input_shape |
指定模型输入的shape,该shape需要与数据集处理后输入数据shape一致。 若未使用--evaluator参数,则该参数必填。 |
|
|
--batch_num |
训练后量化推理阶段的batch数。 |
|
|
--calibration_config |
训练后量化简易配置文件路径与文件名。 |
|
|
--data_dir |
与模型匹配的bin格式数据集路径。 若未使用--evaluator参数,则该参数必填。 |
|
|
--data_types |
输入数据的类型。 若未使用--evaluator参数,则该参数必填。 |
|
|
--evaluator |
基于"Evaluator"基类并且包含evaluator评估器的Python脚本。 该参数与--input_shape、--data_dir、--data_types不能同时使用。 |
|
|
--gpu_id |
指定使用GPU进行量化。 |
|
|
总体选项¶
--help或--h¶
功能说明
显示帮助信息。
关联参数
无。
参数取值
无。
推荐配置及收益
无。
示例
Caffe框架
amct_caffe calibration --helpTensorFlow框架
训练后量化场景:
amct_tensorflow calibration --helpQAT模型适配CANN模型场景:
amct_tensorflow convert --help
ONNX网络
训练后量化场景:
amct_onnx calibration --helpQAT模型适配CANN模型场景:
amct_onnx convert --help
依赖约束
无。
必选参数¶
--model¶
功能说明
待量化网络模型文件路径与文件名。
关联参数
针对Caffe框架网络模型,需要和--weights参数配合使用。
参数取值
**参数值:**模型文件路径与文件名。
**参数值格式:**路径和文件名:支持大小写字母(a-z,A-Z)、数字(0-9)、下划线(_)、中划线(-)、句点(.)、中文字符。
推荐配置及收益
无。
示例
Caffe框架网络模型
--model=$HOME/test/ResNet-50-deploy.prototxt --weights=$HOME/test/ResNet-50-model.caffemodelTensorFlow框架网络模型
--model=$HOME/test/resnet_v1_50.pbONNX网络模型
--model=$HOME/test/resnet101_v11.onnx
使用约束
该参数训练后量化场景和QAT模型适配CANN模型场景都必填。
--weights¶
功能说明
待量化网络权重文件路径与文件名。
关联参数
需要和--model参数配合使用,该参数仅适用于Caffe框架模型。
参数取值
**参数值:**权重文件路径与文件名。
**参数值格式:**路径和文件名:支持大小写字母(a-z,A-Z)、数字(0-9)、下划线(_)、中划线(-)、句点(.)、中文字符。
推荐配置及收益
无。
示例
--model=$HOME/test/ResNet-50-deploy.prototxt --weights=$HOME/test/ResNet-50-model.caffemodel
依赖约束
无。
--outputs¶
功能说明
该参数仅适用于TensorFlow框架网络模型。
指定原始模型输出Tensor的名称。
关联参数
无。
参数取值
**参数值:**原始模型输出Tensor的名称。
**参数值格式:**Tensor名称必须符合"<op_name>:<output_index>"格式,其中op_name表示算子名,output_index表示输出索引,即第几个输出。
推荐配置及收益
无。
示例
--outputs="Reshape_1:0"
使用约束
该参数训练后量化场景和QAT模型适配CANN模型场景都必填。
--save_path¶
功能说明
量化后模型的存放路径。
关联参数
无。
参数取值
**参数值:**量化后模型的存放路径。
参数值约束:
路径无需用户提前创建,量化过程中会自动创建;该路径需要包含模型名前缀,例如:"./results/model_prefix"。
路径和文件名:支持大小写字母(a-z,A-Z)、数字(0-9)、下划线(_)、中划线(-)、句点(.)、中文字符。
推荐配置及收益
无。
示例
--save_path=./results/ResNet-50
使用约束
该参数训练后量化场景和QAT模型适配CANN模型场景都必填。
可选参数¶
--input_shape¶
功能说明
指定模型输入的shape,该shape需要与数据集处理后输入数据shape一致。
关联参数
若未使用--evaluator参数,则该参数必填。
参数取值
**参数值:**模型输入的shape信息。
参数值格式:"input_name1:n1,c1,h1,w1;input_name2:n2,c2,h2,w2"。
**参数值约束:**指定的节点必须放在双引号中,节点中间使用英文分号分隔。input_name必须是转换前的网络模型中的节点名称。
推荐配置及收益
无。
示例
--input_shape="input_name1:n1,c1,h1,w1;input_name2:n2,c2,h2,w2"
使用约束
如果模型的shape不固定,例如"input_name1:?,h,w,c",其中“?“为每个batch使用的图片数量,该场景下图片数量要等于处理成bin格式数据集的图片数量。
该参数只在训练后量化场景使用。
--batch_num¶
功能说明
训练后量化推理阶段的batch数。
关联参数
该参数与--calibration_config不能同时使用。
参数取值
**参数值:**推理阶段的batch数。
**参数值约束:**无。
参数默认值:1
推荐配置及收益
无。
示例
--batch_num=1
使用约束
该参数只在训练后量化场景使用。
--calibration_config¶
功能说明
训练后量化简易配置文件路径与文件名。
如果用户自己构造了训练后量化简易配置文件:即用户自行决定哪些层进行量化,哪些层不量化,则需要使用该参数。
关联参数
该参数不能与--batch_num参数同时使用。
参数取值
**参数值:**量化简易配置文件路径与文件名。
**参数值约束:**路径和文件名:支持大小写字母(a-z,A-Z)、数字(0-9)、下划线(_)、中划线(-)、句点(.)、中文字符。
参数默认值:None
推荐配置及收益
无。
示例
--calibration_config=./config.cfg
文件样例如下所示,以Caffe框架为例,参数说明请参见表1。(如下文件中的所有参数取值都为示例,请根据实际情况进行修改)
# global quantize parameter
batch_num : 2
activation_offset : true
joint_quant : false
skip_layers : "conv_1"
skip_layer_types:"Convolution"
do_fusion: true
skip_fusion_layers : "conv_1"
common_config : {
arq_quantize : {
channel_wise : true
}
ifmr_quantize : {
search_range_start : 0.7
search_range_end : 1.3
search_step : 0.01
max_percentile : 0.999999
min_percentile : 0.999999
}
}
override_layer_types : {
layer_type : "InnerProduct"
calibration_config : {
arq_quantize : {
channel_wise : false
}
ifmr_quantize : {
search_range_start : 0.8
search_range_end : 1.2
search_step : 0.02
max_percentile : 0.999999
min_percentile : 0.999999
}
}
}
使用约束
该参数只在训练后量化场景使用。
--data_dir¶
功能说明
与模型匹配的bin格式数据集路径。
关联参数
若未使用--evaluator参数,则该参数必填。
参数取值
**参数值:**bin格式数据集路径。
参数值约束:
路径支持大小写字母(a-z,A-Z)、数字(0-9)、下划线(_)、中划线(-)、句点(.)、中文字符。
若模型有多个输入,且每个输入有多个batch数据,则不同的输入数据必须存储在不同的目录中,目录中文件的名称必须按照升序排序。所有的输入数据路径必须放在双引号中,节点中间使用英文分号分隔。
推荐配置及收益
无。
示例
--data_dir="data/input1/;data/input2/"
input1和input2目录中,数据文件名举例为input1batch1.bin、input1batch2.bin;input2batch1.bin、input2batch2.bin,文件名称按照升序进行排列。
使用约束
该参数只在训练后量化场景使用。
--data_types¶
功能说明
输入数据的类型。
关联参数
若未使用--evaluator参数,则该参数必填。
参数取值
**参数值:**模型输入数据的类型。
参数值格式:"float32;float64"。
**参数值约束:**若模型有多个输入,且数据类型不同,则需要分别指定不同输入的数据类型,指定的输入数据类型必须按照输入节点顺序依次放在双引号中,所有的输入数据类型必须放在双引号中,中间使用英文分号分隔。
推荐配置及收益
无。
示例
--data_types="float32"
使用约束
该参数只在训练后量化场景使用。
--evaluator¶
功能说明
基于"Evaluator"基类并且包含evaluator评估器的Python脚本。
如果用户没有获取到模型匹配的bin格式数据集,或者用户想使用自己的脚本进行训练后量化,则需要使用该参数。
关联参数
该参数与--input_shape、--data_dir、--data_types不能同时使用。
参数取值
**参数值:**包含evaluator评估器的Python脚本。
**参数值约束:**无
推荐配置及收益
无。
示例
--evaluator=EVALUATOR.py
脚本样例如下,用户需要使用原始待量化的模型和测试集,实现回调函数**calibration()。**其中,calibration()用于完成校准的推理。
class ModelEvaluator(AutoCalibrationEvaluatorBase):
# The evaluator for model
def calibration(self, model_file, weights_file):
# 进行模型的校准推理,推理的batch数要和量化配置的batch_num一致
使用约束
该参数只在训练后量化场景使用。
--gpu_id¶
功能说明
该参数仅适用于Caffe框架网络模型。
指定使用GPU进行量化,不使用该参数,则默认使用CPU进行量化。
关联参数
无。
参数取值
参数值:可用的GPU ID,用户可以通过nvidia-smi命令查询可用的GPU。
**参数值约束:**使用该参数时,请确保根据安装前准备已经安装CUDA软件包。
参数默认值:无
推荐配置及收益
无。
示例
--gpu_id=1
依赖约束
无。
样例列表¶
表 1 Sample列表
框架 |
特性 |
获取链接 |
|---|---|---|
PyTorch |
基于精度的自动量化 |
单击auto_calibration获取样例,参见README执行相关操作。 |
均匀量化 |
单击calibration获取样例,参见README执行相关操作。 |
|
非均匀量化 |
单击calibration_nuq获取样例,参见README执行相关操作。 |
|
量化感知训练 |
单击retrain获取样例,参见README执行相关操作。 |
|
自动通道稀疏搜索 |
单击auto_channel_prune获取样例,参见README执行相关操作。 |
|
通道稀疏 |
单击channel_prune获取样例,参见README执行相关操作。 |
|
4选2结构化稀疏 |
单击selective_prune获取样例,参见README执行相关操作。 |
|
组合压缩 |
单击mix_compression获取样例,参见README执行相关操作。 |
|
张量分解 |
单击tensor_decompose获取样例,参见README执行相关操作。 |
|
单算子模式的量化感知训练 |
单击retrain_qat_op获取样例,参见README执行相关操作。 |
|
逐层蒸馏 |
单击distillation获取样例,参见README执行相关操作。 |
|
ADA自适应舍入量化 |
单击ada_round_calibration获取样例,参见README执行相关操作。 |
|
ONNX |
命令行方式量化
|
单击cmd获取样例,参见README执行命令行方式量化。 |
基于精度的自动量化 |
单击accuracy_based_auto_calibration获取样例,参见README执行基于精度的自动量化。 |
|
均匀量化 |
单击calibration获取样例,参见README执行均匀量化。 |
|
非均匀量化 |
单击calibration_nuq获取样例,参见README执行非均匀量化。 |
|
QAT模型适配CANN模型 |
单击convert_qat2ascend获取样例,参见README将QAT模型转成CANN模型。 |
|
TensorFlow |
命令行方式量化
|
单击cmd获取样例,参见README执行相关操作。 |
基于精度的自动量化 |
单击auto_calibration获取样例,参见README执行相关操作。 |
|
均匀量化 |
单击calibration获取样例,参见README执行相关操作。 |
|
非均匀量化 |
单击calibration_nuq获取样例,参见README执行相关操作。 |
|
量化感知训练 |
单击retrain获取样例,参见README执行相关操作。 |
|
自动通道稀疏搜索 |
单击auto_channel_prune获取样例,参见README执行相关操作。 |
|
通道稀疏(手工稀疏) |
单击channel_prune获取样例,参见README执行相关操作。 |
|
4选2结构化稀疏 |
单击selective_prune获取样例,参见README执行相关操作。 |
|
组合压缩 |
单击mix_compression获取样例,参见README执行相关操作。 |
|
张量分解 |
单击tensor_decompose获取样例,参见README执行相关操作。 |
|
convert_model接口模型适配 |
单击convert_model获取样例,参见README执行相关操作。 |
|
QAT模型适配CANN模型 |
单击convert_qat2ascend获取样例,参见README执行相关操作。 |
|
Caffe |
命令行方式量化 |
单击cmd获取样例,参见README执行相关操作。 |
基于精度的自动量化 |
单击auto_calibration获取样例,参见README执行相关操作。 |
|
均匀量化 |
单击calibration获取样例,参见README执行相关操作。 |
|
非均匀量化 |
|
|
量化感知训练 |
单击retrain获取样例,参见README执行相关操作。 |
|
张量分解 |
单击tensor_decompose获取样例,参见README执行相关操作。 |
|
模型适配 |
单击convert_model获取样例,参见README执行相关操作。 |
FAQ¶
安装python3-tk时提示错误信息¶
问题现象描述
安装python3-tk依赖时,提示如下错误提示信息:
原因分析
从上述报错信息看“[Errno 2] No such file or directory dpkg ...”可能是缺少py_compile.py文件导致的。
解决措施
将缺失的文件py_compile.py复制到/usr/lib/python3.7路径,然后重新安装。
cp /usr/local/python3.7.5/lib/python3.7/py_compile.py /usr/lib/python3.7
/usr/local/python3.7.5/lib/python3.7/py_compile.py请以该文件所在实际路径进行替换。
校准执行过程中提示“[IFMR]: Do layer xxx data calibration failed!”¶
问题现象描述
在调用PyTorch框架执行中间校准模型推理过程中,由于输入数据范围不合法,导致量化算法计算得到的scale不合理,从而校准过程失败,终止校准流程。
原因分析
原始数据不在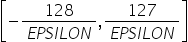 范围:(其中_EPSILON_包括DBL_EPSILON double类型,FLT_EPSILON float类型,当前使用的是FLT_EPSILON类型)
范围:(其中_EPSILON_包括DBL_EPSILON double类型,FLT_EPSILON float类型,当前使用的是FLT_EPSILON类型)
AMCT量化支持计算得到的最大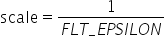 ,因为在NPU IP加速器量化动作做的是乘法计算:
,因为在NPU IP加速器量化动作做的是乘法计算: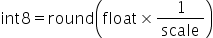 ,如果scale大于
,如果scale大于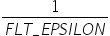 ,
,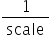 会小于_FLT_EPSILON_,此时量化后结果就不可信。因此AMCT量化算法仅支持原始数据范围在
会小于_FLT_EPSILON_,此时量化后结果就不可信。因此AMCT量化算法仅支持原始数据范围在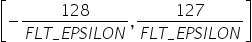 内进行量化,否则会提示不支持并提示错误信息。
内进行量化,否则会提示不支持并提示错误信息。
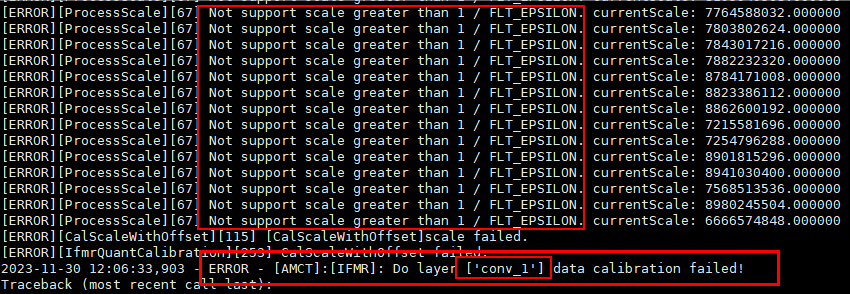
解决措施
根据提示信息,跳过日志中的量化层,例如上述提示信息中的conv_1层。
编译并安装自定义算子包时提示"AttributeError: module ‘onnxruntime’ has no attribute ‘SessionOption’"信息¶
问题现象描述
安装AMCT过程中,编译并安装自定义算子包时,出现"AttributeError: module 'onnxruntime' has no attribute 'SessionOption' "错误,编译过程中止,AMCT无法使用。
原因分析
Python环境中的ONNX Runtime库异常或者版本不满足要求,没有SessionOption属性。
解决措施
首先确认ONNX Runtime的版本是否为环境所要求的(详情请参见系统要求和环境检查),若不是,则请安装正确版本。
在Python环境中import onnxruntime查看其版本(version)和路径(path),若仍旧提示AttributeError,则说明ONNX Runtime未正确安装,请参见如下命令强制重新安装ONNX Runtime。
pip3 install --force-reinstall onnxruntime==1.x.x --user造成ONNX Runtime未正确安装的原因可能是用户同时安装了onnxruntime和onnxruntime_gpu,卸载其中一个版本,导致另一个也无法正常使用。
校准过程中提示"IFMR node. Name:'layer_ifmr_op' Status Message: std::bad_alloc"信息¶
问题现象描述
训练后量化校准过程中,对某层进行量化,提示内存错误"IFMR node. Name:'layer_ifmr_op' Status Message: std::bad_alloc "。
原因分析
相较于环境中的CPU或者GPU存储,量化时使用的数据量过大,导致内存错误。
解决措施
减少校准所用的数据量,即降低batch_size或者batch_num,可直接使用batch_size * batch_num的最小值尝试量化。
如果网络中仅个别层的feature map很大,出现内存错误,则可以跳过该层,不对其进行量化。
校准过程中出现"killed"信息¶
问题现象描述
校准过程中,出现“killed”信息。
原因分析
相较于环境中的CPU或者GPU存储,量化时使用的数据量过大,导致内存错误。
解决措施
减少校准所用的数据量,即降低batch_size或者batch_num,可直接使用batch_size * batch_num的最小值尝试量化。
如果网络中仅个别层的featuremap很大,出现内存错误,则可以跳过该层,不对其进行量化。
QDQ格式模型推理过程中出现ONNXRuntimeError报错¶
问题现象描述
QDQ(Quantize and DeQuantize)格式模型,比如从TensorFlow转换或从PyTorch导出的量化感知训练(QAT)模型,在ONNX Runtime1.8.0及以上的CPU版本环境下推理,出现类似下图的ONNXRuntimeError报错。(QDQ格式模型具体介绍请参见Link)
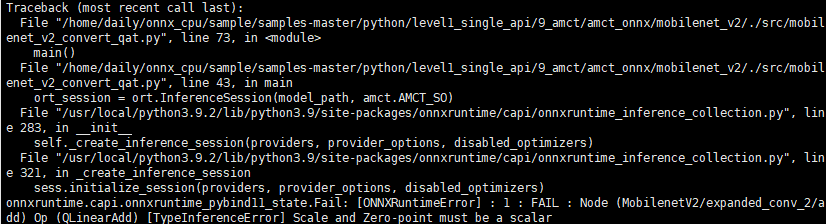
原因分析
ONNX Runtime为了提高性能,提供了多种图优化方式,默认情况下,启用所有优化。在执行优化过程中,模型和ONNX Runtime版本间存在不兼容问题,导致上述报错。
解决措施
调用InferenceSession函数执行推理时,配置入参SessionOptions的图优化级别属性值为ORT_DISABLE_ALL,禁用所有优化。
import onnxruntime as ort
import amct_onnx as amct
amct.AMCT_SO.graph_optimization_level = ort.GraphOptimizationLevel.ORT_DISABLE_ALL
ort_session = ort.InferenceSession('model.onnx', amct.AMCT_SO)
...
校准执行过程中提示“[IfmrQuantWithoutOffset]scale is illegal”¶
问题现象描述
在调用ONNX Runtime框架执行中间校准模型推理过程中,由于输入数据范围不合法,导致量化算法计算得到的scale不合理,从而校准过程失败,终止校准流程。
原因分析
原始数据不在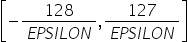 范围:(其中_EPSILON_包括DBL_EPSILON double类型,FLT_EPSILON float类型,当前使用的是FLT_EPSILON类型)
范围:(其中_EPSILON_包括DBL_EPSILON double类型,FLT_EPSILON float类型,当前使用的是FLT_EPSILON类型)
AMCT量化支持计算得到的最大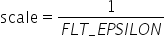 ,因为在NPU IP加速器量化动作做的是乘法计算:
,因为在NPU IP加速器量化动作做的是乘法计算: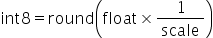 ,如果scale大于
,如果scale大于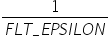 ,
,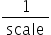 会小于_FLT_EPSILON_,此时量化后结果就不可信。因此AMCT量化算法仅支持原始数据范围在
会小于_FLT_EPSILON_,此时量化后结果就不可信。因此AMCT量化算法仅支持原始数据范围在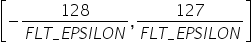 内进行量化,否则会提示不支持并提示错误信息。
内进行量化,否则会提示不支持并提示错误信息。
[ERROR][IfmrQuantWithoutOffset][183] [IfmrQuantWithoutOffset]scale is illegal.
[ERROR][ProcessScale][64] Not support scale greater than 1 / FLT_EPSILON. currentScale: 1513411575808.000000
[ERROR][IfmrQuantWithoutOffset][183] [IfmrQuantWithoutOffset]scale is illegal.
[ERROR][ProcessScale][64] Not support scale greater than 1 / FLT_EPSILON. currentScale: 1492095991808.000000
[ERROR][CalScaleWithoutOffset][146] [CalScaleWithoutOffset]scale failed.
[ERROR][IfmrQuantCalibration][264] CalScaleWithoutOffset failed.
[ERROR][DoCalibration][126] Do IFMR calibration failed, error code: -65519.
Traceback (most recent call last):
File "/g/daily/xxx/bin/amct_onnx", line 8, in <module>
sys.exit(main())
File "/g/daily/xxx/lib/python3.9/site-packages/amct_onnx/cmd_line_tools/command.py", line 159, in main
calibration_function(args_var)
File "/g/daily/xxx/lib/python3.9/site-packages/amct_onnx/cmd_line_tools/command.py", line 113, in calibration_function
amct.save_model(
File "/g/daily/xxx/lib/python3.9/site-packages/amct_onnx/common/utils/check_params.py", line 43, in wrapper
return func(*args, **kwargs)
File "/g/daily/xxx/lib/python3.9/site-packages/amct_onnx/quantize_tool.py", line 277, in save_model
RecordFileParser.cmp_config(records)
File "/g/daily/xxx/lib/python3.9/site-packages/amct_onnx/parser/parse_record_file.py", line 96, in cmp_config
raise RuntimeError(
RuntimeError: batchmatmul_7 is quantizable in config but has no record in record_file
解决措施
根据提示信息,跳过日志中的量化层,例如上述提示信息中的batchmatmul_7层。
量化校准过程中因数据量过大导致报错¶
问题现象描述
场景1:积攒数据的size过大溢出
失败信息显示如下:
tensorflow.python.framework.errors_impl.InvalidArgumentError: Check failed: size <= tensorflow::kint32max (2684354560 vs. 2147483647)场景2:内存/显存溢出
AMCT在使用过程中会额外申请内存/显存的部分资源,在内存/显存资源紧张的情况下,会出现资源申请失败的情况,导致系统抛出资源申请失败的信息。
常见的系统资源申请失败的信息如下所示:
CPU运行环境下,内存申请失败的部分信息显示如下:
MemoryError: Unable to allocate array with shape (1048576, 102400) and data type float32GPU运行环境下,显存申请失败的部分信息显示如下:
ResourceExhaustedError (see above for traceback): OOM when allocating tensor with shape[1,1073741824] and type int32 on /job:localhost/replica:0/task:0/device:GPU:0 by allocator G [[node TopKV2_1 (defined at test_input_big_tensor.py:30) = TopKV2[T=DT_FLOAT, sorted=true, _device="/job:localhost/replica:0/task:0/device:GPU:0"](Reshape, Cast_1/_5)]] Hint: If you want to see a list of allocated tensors when OOM happens, add report_tensor_allocations_upon_oom to RunOptions for current allocation info. [[{{node QuantIfmr/_17}} = _Recv[client_terminated=false, recv_device="/job:localhost/replica:0/task:0/device:CPU:0", send_device="/job:localhost/replica:0/task:0/device:arnation=1, tensor_name="edge_55_QuantIfmr", tensor_type=DT_FLOAT, _device="/job:localhost/replica:0/task:0/device:CPU:0"]()]] Hint: If you want to see a list of allocated tensors when OOM happens, add report_tensor_allocations_upon_oom to RunOptions for current allocation info.
场景3:因量化进程占用内存过大,导致系统内存不足,出现Out of memory问题,进程被系统终止,出现类似下图的“killed”报错信息。

通过如下命令查看系统日志,有“oom-kill”报错信息。
vi /var/log/messages系统日志报错如下:
169 kernel: 0 678327 python3 170 Feb 27 03:30:38 kernel: [2599806.621086] oom-kill:constraint=CONSTRAINT_NONE,nodemask=(null) ,cpuset=/,mems_allowed=0-1,global_oom,task_memcg=/user.slice/user-0.slice/session-7474.scope,task=amct_tensorflow,pid=678157,uid=0 171 Feb 27 03:30:38 kernel: [2599809.519800] oom_reaper: reaped process 678157 (amct_tensorflow), now anon-rss:0kB, file-rss:0kB, shmem-rss:0kB
解决措施
建议用户适当减小量化使用的batch_num,由于硬件资源的不同,减小batch_num之后仍可能发生资源申请失败情况,建议用户将量化选择的batch_num以及每batch的size继续调低,或者选用硬件资源更加充足的平台进行量化处理。
如果上述方案仍旧无法解决问题,则可以尝试使用HFMG算法解决,即参见训练后量化简易配置文件构造包含HFMG算法的简易配置文件,重新进行量化。
IFMR数据量化时,存在"inf或NaN值"或"xxx calculate scale failed",量化过程报错¶
问题现象描述
在调用TensorFlow框架执行中间校准模型推理过程中,由于输入数据范围不合法,导致量化算法计算得到的scale不合理,从而校准过程失败,终止校准流程。
IFMR数据量化时,存在inf或NaN值,量化报错如下:
tensorflow.python.framework.errors_impl.InvalidArgumentError: 2 root error(s) found. (0) Invalid argument: Error: Exit Infinite value before data quantization! : Tensor had NaN values [[{{node CheckNumerics_33}}]] [[detector/yolo-v3-tiny/Conv_2/act_quant/act_quant_IFMR/cond/StringFormat/Switch/_69]] (1) Invalid argument: Error: Exit Infinite value before data quantization! : Tensor had NaN values [[{{node CheckNumerics_33}}]] 0 successful operations. 0 derived errors ignored. During handling of the above exception, another exception occurred:
calculate scale failed量化报错:
原因分析
针对“calculate scale failed”原因分析如下:
原始数据不在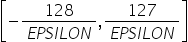 范围:(其中_EPSILON_包括DBL_EPSILON double类型,FLT_EPSILON float类型,当前使用的是FLT_EPSILON类型)
范围:(其中_EPSILON_包括DBL_EPSILON double类型,FLT_EPSILON float类型,当前使用的是FLT_EPSILON类型)
AMCT量化支持计算得到的最大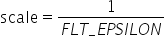 ,因为在NPU IP加速器量化动作做的是乘法计算:
,因为在NPU IP加速器量化动作做的是乘法计算: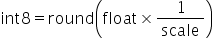 ,如果scale大于
,如果scale大于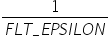 ,
,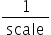 会小于_FLT_EPSILON_,此时量化后结果就不可信。因此AMCT量化算法仅支持原始数据范围在
会小于_FLT_EPSILON_,此时量化后结果就不可信。因此AMCT量化算法仅支持原始数据范围在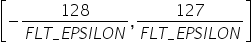 内进行量化,否则会提示不支持并提示错误信息。
内进行量化,否则会提示不支持并提示错误信息。
解决措施
根据提示信息,跳过日志中的量化层,例如上述提示信息中的Conv_2层。
量化过程中提示某层bias量化超出int32范围¶
问题现象描述
量化过程中提示某层bias量化超出int32范围,提示信息如下:
tensorflow.python.framework.errors_impl.InvalidArgumentError: 2 root error(s) found.
(0) Invalid argument: assertion failed: [Quantized bias of layer \"FlowNetS/decoding/deconv5_0/conv2d_transpose\" exceed int32 range: [-2147483648.0, 2147483647.0], please add it to skip layer.] [Condition x <= y did not hold element-wise:] [x (FlowNetS/decoding/deconv5_0/bias_quant/Round:0) = ] [3.35433197e+12 3.35244296e+12 3.352325e+12...] [y (FlowNetS/decoding/deconv5_0/bias_quant/assert_less_equal/y:0) = ] [2.14748365e+09]
[[{{node FlowNetS/decoding/deconv5_0/bias_quant/assert_less_equal/Assert/AssertGuard/Assert}}]]
[[FlowNetS/decoding/deconv5_0/bias_quant/Cast/_61]]
(1) Invalid argument: assertion failed: [Quantized bias of layer \"FlowNetS/decoding/deconv5_0/conv2d_transpose\" exceed int32 range: [-2147483648.0, 2147483647.0], please add it to skip layer.] [Condition x <= y did not hold element-wise:] [x (FlowNetS/decoding/deconv5_0/bias_quant/Round:0) = ] [3.35433197e+12 3.35244296e+12 3.352325e+12...] [y (FlowNetS/decoding/deconv5_0/bias_quant/assert_less_equal/y:0) = ] [2.14748365e+09]
[[{{node FlowNetS/decoding/deconv5_0/bias_quant/assert_less_equal/Assert/AssertGuard/Assert}}]]
0 successful operations.
0 derived errors ignored.
原因分析
scale_w、scale_d取值都较小、bias过大,导致bias量化超出int32的范围。
解决措施
根据提示信息,跳过日志中的量化层,例如上述提示信息中的conv2d_transpose层。
校准时提示“Invalid argument: You must feed a value for placeholder tensor **”¶
问题现象描述
训练后量化场景,修改模型后执行校准过程时,使用原始模型的输入输出做推理,报错提示必须给一个占位符输入数据,校准过程中断。提示信息如下:
Traceback (most recent call last):
File "xxx/site-packages/tensorflow_core/python/client/session.py", line 1365, in _do_call
return fn(*args)
File "xxx/site-packages/tensorflow_core/python/client/session.py", line 1350, in _run_fn
target_list, run_metadata
File "xxx/site-packages/tensorflow_core/python/client/session.py", line 1443, in _call_tf_sessionrun
run_metadata
tensorflow.python.framework.errors_impl.InvalidArgumentError: 2 root error(s) found.
(0) Invalid argument: You must feed a value for placeholder tensor 'input' with dtype float and shape [1,32,32,10]
[[{{node input}}]]
[[ConstantFoldingCtrl/conv1/search_n_quant/search_n_quant_SEARCHN/cond/Switch_0/_22]]
(1) Invalid argument: You must feed a value for placeholder tensor 'input' with dtype float and shape [1,32,32,10]
[[{{node input}}]]
原因分析
调用quantize_model处理用户的图结构时,会进行融合、替换等图操作,可能改变用户模型的输出,将原有的输出节点与placeholder连接。
解决措施
该场景下调用quantize_model时,会有warning信息提示输出节点发生变化,在执行校准的过程中,根据提示信息,修改输出节点即可。
保存模型时提示“RuntimeError: record_file is empty, no layers to be quantized”¶
问题现象描述
训练后量化场景,量化因子记录文件中无法找到某层的shift_bit字段,无法进行后续量化模型保存动作,量化流程终止。提示信息如下:
Traceback (most recent call last):
File "./GenAIModel/amt/tools/tmp_amct_tools.py", line 457, in wrapper
func(*args, **kwargs)
File "/raid/AMCT/demo/new_project/test/test_tf_iter37_d16w8.py", line 1806, in test_xxx
run_case(config, acc=True)
File "/raid/AMCT/demo/new_project/test/test_tf_iter37_d16w8.py", line 130, in run_case
res = tf_api_compress(model, input_data, quant_cfg=quant_cfg,data_config=data_config, nuq=nuq, per_channel=per_channel)
File "./GenAIModel/amt/model_process/infer_quant.py", line 754, in tf_api_compress
save_model(model, out_puts, record_file, f'{save_path}/{case_name}' )
File "/raid/AMCT/daily/daily_env/lib/python3.9/site-packages/amct_tensorflow/common/utils/check_params.py", line 43, in wrapper
return func(*args, **kwargs)
File "/raid/AMCT/daily/daily_env/lib/python3.9/site-packages/amct_tensorflow/interface/save_model.py", line 68, in save_model
save_model_inner(pb_model, outputs, record_file, save_path)
File "/raid/AMCT/daily/daily_env/lib/python3.9/site-packages/amct_tensorflow/interface/save_model.py", line 102, in save_model_inner
raise RuntimeError(
RuntimeError: record_file is empty, no layers to be quantized. please ensure calibration is finished by checking information!
原因分析
网络的尾层节点为量化节点时,如果量化推理时不修改推理的输出节点,则会导致该问题。此场景下,调用quantize_model时,会有warning信息提示输出节点发生变化。
解决措施
该场景下调用quantize_model时,会有warning信息提示输出节点发生变化,在执行校准的过程中,根据提示信息,修改输出节点即可。
使用训练后量化进行量化时,量化过程存在空tensor输入报错信息¶
问题现象描述
执行训练后量化时,存在空tensor输入报错信息,详细报错信息如下:
[ERROR][QuantIfmrInternelGpu][114] Empty pointer, all input tensor is empty
[ERROR][QuantIfmrInternelGpu][114] Empty pointer, all input tensor is empty
[ERROR][QuantIfmrInternelGpu][114] Empty pointer, all input tensor is empty
[ERROR][QuantIfmrInternelGpu][114] Empty pointer, all input tensor is empty
[ERROR][QuantIfmrInternelGpu][114] Empty pointer, all input tensor is empty
[ERROR][QuantIfmrInternelGpu][114] Empty pointer, all input tensor is empty
2022-07-02 22:11:36.232362: I tensorflow/core/kernels/logging_ops.cc:166 Do layer multilevel_roi_align/roi_level5/roi_align/AvgPool activation calibration with ifmr success!
原因分析
输入数据不是真实数据集。
解决措施
请使用真实数据集进行训练后量化。
导入amct_tensorflow时,提示“ModuleNotFoundError: No module named npu_bridge”¶
问题现象描述
导入amct_tensorflow时,在Python环境中找不到npu_bridge模块,导致导入失败,无法使用AMCT。
原因分析
amct_tensorflow依赖在线推理环境中的软件包,出现该问题是因为环境中CANN软件包安装不全。
解决措施
参见《安装指南》重新安装CANN软件包。
使用命令行方式安装Caffe环境失败¶
问题现象描述
使用命令行方式安装Caffe环境时,提示类似"/usr/bin/python3.7: can't open file '/usr/lib/python3.7/py_compile.py': [Error 2] No such file or directory"信息,导致Caffe环境安装失败。
原因分析
AMCT安装时,要求先安装Python3.7.5,但是Caffe1.0使用命令行方式安装时,会去寻找py_compile.py,该文件只在Python低级别版本3.6或者2.7上存在,在3.7.5版本上不存在。
解决措施
安装Python3.7.5时,增加如下软链接或将/usr/local/python3.7.5/lib/python3.7路径下的py_compile.py文件复制到/usr/lib/python3.7路径下,然后重新使用命令行方式安装Caffe环境。
执行如下命令设置软链接:
sudo ln -s /usr/local/python3.7.5/lib/python3.7 /usr/lib/python3.7
执行上述软链接时如果提示链接已经存在,则可以先执行如下命令删除原有链接然后重新执行。
sudo rm -rf /usr/lib/python3.7
执行proto合并时提示ERROR信息¶
问题现象描述1:用户message定义和AMCT自定义层冲突
用户自定义custom.proto内容如下,其中定义的QuantParameter层信息与amct_custom.proto中定义的重复:
message LayerParameter {
optional QuantParameter quant_param = 208;
optional ReLU6Parameter relu6_param = 1000000;
optional ROIPoolingParameter roi_pooling_param = 8266711;
}
message ReLU6Parameter {
optional float negative_slope = 1 [default = 0];
}
message ROIPoolingParameter {
// Pad, kernel size, and stride are all given as a single value for equal
// dimensions in height and width or as Y, X pairs.
optional uint32 pooled_h = 1 [default = 0]; // The pooled output height
optional uint32 pooled_w = 2 [default = 0]; // The pooled output width
// Multiplicative spatial scale factor to translate ROI coords from their
// input scale to the scale used when pooling
optional float spatial_scale = 3 [default = 1];
}
message QuantParameter {
optional bool with_offset = 1;
optional float scale = 2;
optional bytes offset = 3;
optional string object_layer = 4;
}
执行proto合并时报错信息如下:

解决措施1
根据提示信息,用户自行修改自定义的message信息。
问题现象描述2:用户自定义在LayerParameter中编号和AMCT编号冲突
用户自定义custom.proto内容如下,其中定义的LayerParameter编号与amct_custom.proto中编号重复:
message LayerParameter {
optional QuantParameter quant_param = 208;
optional ReLU6Parameter relu6_param = 1000000;
optional ROIPoolingParameter roi_pooling_param = 8266711;
}
message ReLU6Parameter {
optional float negative_slope = 1 [default = 0];
}
message ROIPoolingParameter {
// Pad, kernel size, and stride are all given as a single value for equal
// dimensions in height and width or as Y, X pairs.
optional uint32 pooled_h = 1 [default = 0]; // The pooled output height
optional uint32 pooled_w = 2 [default = 0]; // The pooled output width
// Multiplicative spatial scale factor to translate ROI coords from their
// input scale to the scale used when pooling
optional float spatial_scale = 3 [default = 1];
}
执行proto合并时报错信息如下:
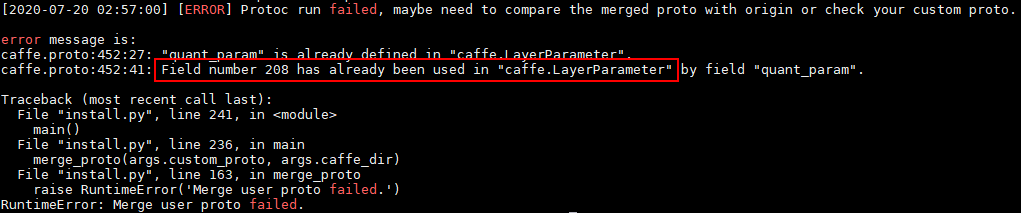
解决措施2
用户根据提示信息修改custom.proto中自定义的算子编号。
问题现象描述3:用户自定义在LayerParameter中编号和ATC编号冲突
用户自定义custom.proto内容如下,其中定义的LayerParameter编号与ATC中的caffe.proto中编号重复:
message LayerParameter {
optional ReLU6Parameter relu6_param = 206;
optional ROIPoolingParameter roi_pooling_param = 8266711;
}
message ReLU6Parameter {
optional float negative_slope = 1 [default = 0];
}
message ROIPoolingParameter {
// Pad, kernel size, and stride are all given as a single value for equal
// dimensions in height and width or as Y, X pairs.
optional uint32 pooled_h = 1 [default = 0]; // The pooled output height
optional uint32 pooled_w = 2 [default = 0]; // The pooled output width
// Multiplicative spatial scale factor to translate ROI coords from their
// input scale to the scale used when pooling
optional float spatial_scale = 3 [default = 1];
}
执行proto合并时报错信息如下:
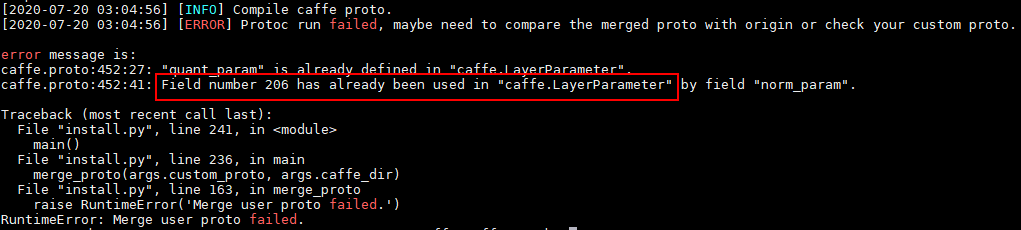
解决措施3
用户根据提示信息修改custom.proto中自定义的算子编号。
问题现象描述4:用户message定义和ATC自定义层冲突
用户自定义custom.proto内容如下,其中定义的NormalizeParameter层信息与caffe.proto中定义的重复:
message LayerParameter {
optional ReLU6Parameter relu6_param = 1000000;
optional ROIPoolingParameter roi_pooling_param = 8266711;
optional NormalizeParameter norm_param = 206;
}
message ReLU6Parameter {
optional float negative_slope = 1 [default = 0];
}
message ROIPoolingParameter {
// Pad, kernel size, and stride are all given as a single value for equal
// dimensions in height and width or as Y, X pairs.
optional uint32 pooled_h = 1 [default = 0]; // The pooled output height
optional uint32 pooled_w = 2 [default = 0]; // The pooled output width
// Multiplicative spatial scale factor to translate ROI coords from their
// input scale to the scale used when pooling
optional float spatial_scale = 3 [default = 1];
}
message NormalizeParameter {
optional bool across_spatial = 1 [default = true];
// Initial value of scale. Default is 1.0 for all
optional FillerParameter scale_filler = 2;
// Whether or not scale parameters are shared across channels.
optional bool channel_shared = 3 [default = true];
// Epsilon for not dividing by zero while normalizing variance
optional float eps = 4 [default = 1e-10];
}
执行proto合并时无错误提示信息,默认会覆盖ATC内置message定义,以custom.proto为准,提示信息如下:

解决措施4
无。
校准执行过程中提示"IfmrQuantCalibration with offset scale is illegal"或"IfmrQuantCalibration without offset scale is illegal"¶
问题现象描述
在调用Caffe框架执行中间校准模型推理过程中,由于输入数据范围不合法,导致量化算法计算得到的scale不合理,从而校准过程失败,终止Caffe校准流程。
原因分析
数据范围 [-inf , +inf]:
因为AMCT的量化算法需要强制过零点,所以计算出的scale也就是inf/255=inf,该情况下量化因子后续无法承载,因此量化算法会提示错误信息,不支持该数据范围。
场景1
I0513 16:12:37.508546 80719 ifmr_layer.cu:58] Doing layer: "Convolution1" calibration, already store 1/1 data. I0513 16:12:37.508558 80719 ifmr_layer.cu:65] Start to do ifmr quant. [ERROR][ProcessScale][48] Not support scale is +inf. [ERROR][IfmrQuantCalibration][338] IfmrQuantCalibration with offset scale is illegal. [ERROR][IfmrQuantInternel][462] IfmrQuantInternel calibration failed. F0513 16:12:37.535028 80719 ifmr_layer.cu:70] Check failed: ret == 0 (-65519 vs. 0) Do IFMR calibration failed *** Check failure stack trace: *** Aborted
场景2
I0513 16:14:48.173506 81053 ifmr_layer.cu:58] Doing layer: "Convolution1" calibration, already store 1/1 data. I0513 16:14:48.173519 81053 ifmr_layer.cu:65] Start to do ifmr quant. [ERROR][ProcessScale][48] Not support scale is +inf. [ERROR][IfmrQuantCalibration][359] IfmrQuantCalibration without offset scale is illegal. [ERROR][IfmrQuantInternel][462] IfmrQuantInternel calibration failed. F0513 16:14:48.199769 81053 ifmr_layer.cu:70] Check failed: ret == 0 (-65519 vs. 0) Do IFMR calibration failed *** Check failure stack trace: *** Aborted
数据范围
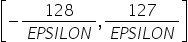 :(其中_EPSILON_包括DBL_EPSILON double类型,FLT_EPSILON float类型,当前使用的是FLT_EPSILON类型)
:(其中_EPSILON_包括DBL_EPSILON double类型,FLT_EPSILON float类型,当前使用的是FLT_EPSILON类型)AMCT量化支持计算得到的最大
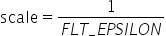 ,因为在NPU IP加速器量化动作做的是乘法计算:
,因为在NPU IP加速器量化动作做的是乘法计算: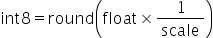 ,如果scale大于
,如果scale大于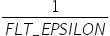 ,
,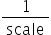 会小于_FLT_EPSILON_,此时量化后结果就不可信。因此AMCT量化算法仅支持原始数据范围在
会小于_FLT_EPSILON_,此时量化后结果就不可信。因此AMCT量化算法仅支持原始数据范围在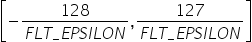 内进行量化,否则会提示不支持并提示错误信息。
内进行量化,否则会提示不支持并提示错误信息。2021-05-11 09:25:42,222 - INFO - [AMCT]:[WeightsCalibrationPass]: Do layer 'Convolution1[arq_quantize]' weights calibration success! 2021-05-11 09:25:42,222 - INFO - [AMCT]:[Optimizer]: Do <class 'amct_caffe.optimizer.insert_ifmr_layer.InsertIFMRLayerPass'> 2021-05-11 09:25:42,223 - INFO - [AMCT]:[Optimizer]: Do <class 'amct_caffe.optimizer.lstm_calibration_replace.LSTMCalibrationReplacePass'> 2021-05-11 09:25:42,223 - INFO - [AMCT]:[Optimizer]: Do <class 'amct_caffe.optimizer.insert_searchn_layer.InsertSearchNLayerPass'> 2021-05-11 09:25:42,223 - INFO - [AMCT]:[Graph]: Doing whole model dump... 2021-05-11 09:25:42,225 - INFO - [AMCT]:[Utils]: The weights_file is saved in xx/data/AMCT15_CAFFE_GPU_GPU_FAQ_LEVEL1_TC_001/AMCT15_CAFFE_GPU_GPU_FAQ_LEVEL1_TC_001_tmp.caffemodel 2021-05-11 09:25:42,226 - INFO - [AMCT]:[Utils]: The model_file is saved in xx/data/AMCT15_CAFFE_GPU_GPU_FAQ_LEVEL1_TC_001/AMCT15_CAFFE_GPU_GPU_FAQ_LEVEL1_TC_001_tmp.prototxt [ERROR][ProcessScale][52] Not support scale greater than 1 / FLT_EPSILON. [ERROR][IfmrQuantCalibration][338] IfmrQuantCalibration with offset scale is illegal. [ERROR][IfmrQuantInternel][462] IfmrQuantInternel calibration failed. WARNING: Logging before InitGoogleLogging() is written to STDERR F0511 09:25:42.292863 80432 ifmr_layer.cu:70] Check failed: ret == 0 (-65519 vs. 0) Do IFMR calibration failed *** Check failure stack trace: *** Aborted
解决措施
根据提示信息,跳过日志中的量化层,例如上述提示信息中的Convolution1层。
量化执行过程中提示“Check scale and offset record file _record.txt _failed”¶
问题现象描述
量化过程中调用save_model接口保存量化模型时,需要读取calibration阶段计算得到的数据量化参数scale_d,offset_d,如果未能在相应的记录文件中找到对应参数,则无法进行后续量化模型保存动作。因此AMCT会抛出上述错误,并终止流程。现象如下:
2021-05-11 09:29:18,138 - INFO - [AMCT]:[Optimizer]: Do <class 'amct_caffe.optimizer.check_record_scale_offset.CheckRecordScaleOffsetPass'>
2021-05-11 09:29:18,138 - ERROR - [AMCT]:[AMCT]: Cannot find scale_d,offset_d,channels,height,width of layer:Convolution1
2021-05-11 09:29:18,138 - ERROR - [AMCT]:[AMCT]: Check scale and offset record file xx/data/AMCT_CAFFE_GPU_GPU_FAQ/AMCT_CAFFE_GPU_GPU_FAQ_record.txt failed
2021-05-11 09:29:18,138 - ERROR - [AMCT]:[AMCT]: There may be something wrong while doing calibration
2021-05-11 09:29:18,138 - ERROR - [AMCT]:[AMCT]: Please check caffe log
Traceback (most recent call last):
File "test_caffe_faq.py", line 32, in <module>
main()
File "test_caffe_faq.py", line 28, in main
gen_amct_model(case,json_flag = True)
File "../caffe_lib/calibration_test/code/gen_amct_model.py", line 102, in gen_amct_model
save_model(graph, mode, AMCT_PATH+case_name)
File "xx/amct/lib/python3.7/site-packages/amct_caffe/common/utils/check_params.py", line 43, in wrapper
return func(*args, **kwargs)
File "xx/amct/lib/python3.7/site-packages/amct_caffe/quantize_tool.py", line 190, in save_model
optimizer.do_optimizer(graph)
File "xx/amct/lib/python3.7/site-packages/amct_caffe/optimizer/graph_optimizer.py", line 60, in do_optimizer
graph_pass.run(graph)
File "xx/amct/lib/python3.7/site-packages/amct_caffe/optimizer/check_record_scale_offset.py", line 103, in run
raise RuntimeError('Check file {} failed.'.format(record_file))
RuntimeError: Check file xx/data/AMCT15_CAFFE_GPU_GPU_FAQ/AMCT15_CAFFE_GPU_GPU_FAQ_record.txt failed.
原因分析
保存scale_d和offset_d参数是在用户执行calibration动作时(调用Caffe框架执行calibration模型做前向计算时),AMCT在calibration模型中插入的IFMR层做的动作,而IFMR层需要先攒够用户指定batch_num数据后再进行一次量化计算得到scale_d和offset_d。导致RuntimeError: _Check file record.txt _failed错误的原因主要分为两类:
执行Caffe做inference错误:该问题可能原因有很多种,例如用户编译的Caffe本身有问题,calibration模型存在问题,未能找到相应数据集等等。用户可以通过查看Caffe框架本身抛出的异常信息来查看。
用户提供的校准集数据量不满足设置的batch_num所需要的数据量:例如用户仅提供了一个batch的数据用作校准集,但设置了batch_num=2,这样在做calibration过程中,IFMR层未攒满足够的数据,不能执行量化操作,也就未能计算得到scale_d和offset_d,也会触发上述错误。用户可以通过查看IFMR在量化过程中打印的进程信息来排查,IFMR层会显示已经攒的数据量:
当攒够指定数据量后,会触发量化操作:

直至出现**Do layer:"conv1" activation calibration success!**信息才表示完成了当前层的量化动作。
解决措施
根据Caffe框架抛出的具体错误来相应进行修复。
适当增加校准集数据量或者降低量化算法batch_num配置(但降低batch_num可能会导致量化后模型精度下降,需要慎重考虑)直至满足校准集数据量大于等于_`_batch_num设置。
使用Ubuntu 20.04安装Caffe环境时,出现CUDA和GCC版本不匹配的编译报错¶
问题现象描述
使用Ubuntu 20.04安装Caffe环境时,出现类似如下信息的编译报错:
/usr/local/cuda-10.0/include/crt/host_config.h:129:2: error: #error --unsupported GNU version! Gcc versions later than7 are not supported!
原因分析
Ubuntu 20.04默认GCC版本为GCC9,如果使用10.0版本CUDA软件,因其配套GCC7版本,会报不支持GCC7以上的版本,需要对默认的GCC版本进行降级。
解决措施
安装低版本GCC(以GCC7为例),并将其链接到CUDA bin文件安装目录下,保证环境同时安装GCC7和GCC9时,CUDA编译可以找到正确的GCC版本。下文中的_/usr/local/cuda-10.0_仅作为示例,请以CUDA实际安装路径为准。
sudo apt-get install g++-7 -y
sudo ln -s /usr/bin/gcc-7 /usr/local/cuda-10.0/bin/gcc
sudo ln -s /usr/bin/g++-7 /usr/local/cuda-10.0/bin/g++
附录¶
安装Python3.9.2(Ubuntu)¶
检查系统是否安装满足版本要求的Python开发环境(具体要求请参见系统要求和环境检查,该章节以环境上需要使用Python 3.9.2为例进行说明)。
执行命令python3 --version,如果返回信息满足Python版本要求(3.9.0~ 3.9.2),则该章节请忽略,否则参见如下步骤安装对应的Python版本。
安装Python依赖的包。
sudo apt-get install -y make zlib1g zlib1g-dev build-essential libbz2-dev libsqlite3-dev libssl-dev libxslt1-dev libffi-dev openssl python3-tklibsqlite3-dev需要在Python安装之前安装,如果用户操作系统已经安装Python环境,在此之后再安装libsqlite3-dev,则需要重新编译Python环境。如果安装python3-tk失败,请参见安装python3-tk时提示错误信息解决。
安装Python3.9.2。
使用wget下载Python3.9.2源码包,可以下载到AMCT所在服务器任意目录,命令为:
wget https://www.python.org/ftp/python/3.9.2/Python-3.9.2.tgz进入下载后的目录,解压源码包,命令为:
tar -zxvf Python-3.9.2.tgz进入解压后的文件夹,执行配置、编译和安装命令:
cd Python-3.9.2 ./configure --prefix=/usr/local/python3.9.2 --with-ssl-default-suites=openssl --enable-shared CFLAGS=-fPIC make sudo make install
其中“--prefix“参数用于指定Python安装路径,用户根据实际情况进行修改,“--enable-shared“参数用于编译出动态库。
本手册以--prefix=/usr/local/python3.9.2路径为例进行说明。执行配置、编译和安装命令后,安装包在/usr/local/python3.9.2路径。
设置Python3.9.2环境变量。
如果Python安装用户为root:
该场景下AMCT使用root用户进行安装,请在当前终端窗口直接执行如下命令设置环境变量。
#用于设置Python3.9.2库文件路径 export LD_LIBRARY_PATH=/usr/local/python3.9.2/lib:$LD_LIBRARY_PATH #如果用户环境存在多个Python3版本,则指定使用Python3.9.2版本 export PATH=/usr/local/python3.9.2/bin:$PATH
须知:
运行用户是root,不建议修改.bashrc,否则可能会影响其它系统提供的Python工具的使用,如果仍想使用系统默认工具,则请重新开启终端窗口。如果Python安装用户为非root:
该场景下AMCT使用非root用户进行安装,请以非root用户在任意目录下执行vi ~/.bashrc命令,打开**.bashrc**文件,在文件最后一行后面添加如下内容。
#用于设置Python3.9.2库文件路径 export LD_LIBRARY_PATH=/usr/local/python3.9.2/lib:$LD_LIBRARY_PATH #如果用户环境存在多个Python3版本,则指定使用Python3.9.2版本 export PATH=/usr/local/python3.9.2/bin:$PATH
保存文件后,执行source ~/.bashrc命令使其立即生效。
安装完成之后,执行如下命令查看安装版本,如果返回相关版本信息,则说明安装成功。
python3 --version pip3 --version
压缩算法¶
量化算法原理¶
量化常用的算法有二值化、线性量化、对数量化,线性量化又可根据是否有offset细分为对称(Symmetric),非对称(Asymmetric)两种。AMCT与昇腾芯片配套的是采用线性量化方式,并将对称和非对称量化方式进行了归一,以INT8量化为例,其应用表达式为:
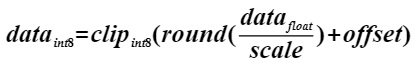
对于量化层数据和权重分别需要提供量化因子scale(浮点数的缩放因子),offset(偏移量)两项,支持的取值范围为:
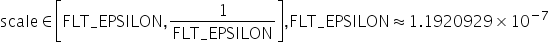
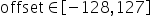
下面介绍上述表达式的由来。
对称量化算法原理
原始高精度数据和量化后INT8数据的转换为: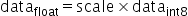 ,其中scale是float32的浮点数,为了能够表示正负数,
,其中scale是float32的浮点数,为了能够表示正负数,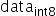 采用signed INT8的数据类型,通过原始高精度数据转换到INT8数据的操作如下,其中round为取整函数,量化算法需要确定的数值即为常数scale:
采用signed INT8的数据类型,通过原始高精度数据转换到INT8数据的操作如下,其中round为取整函数,量化算法需要确定的数值即为常数scale:
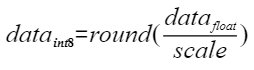
对权值和数据的量化可以归结为寻找scale的过程,由于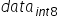 为有符号数,要保证正负数值表示范围的对称性,因此对所有数据首先进行取绝对值的操作,使待量化数据的范围变换为
为有符号数,要保证正负数值表示范围的对称性,因此对所有数据首先进行取绝对值的操作,使待量化数据的范围变换为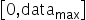 ,再来确定scale。由于INT8在正数范围内能表示的数值范围为[0,127],因此scale可以通过如下方式计算得到:
,再来确定scale。由于INT8在正数范围内能表示的数值范围为[0,127],因此scale可以通过如下方式计算得到:
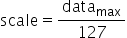
确定了scale之后,INT8数据对应的表示范围为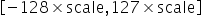 ,量化操作即为对量化数据以
,量化操作即为对量化数据以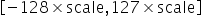 进行饱和,即超过范围的数据饱和到边界值,然后进行公式所示量化操作即可。
进行饱和,即超过范围的数据饱和到边界值,然后进行公式所示量化操作即可。
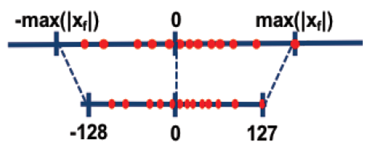
非对称量化算法原理
与对称量化算法主要区别在于数据转换的方式不同,如下,同样需要确定scale与offset这两个常数。
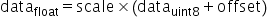
确定后通过原始高精度数据计算得到UINT8数据的转换,即为如下公式所示:
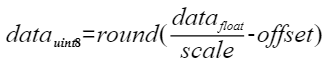
其中,scale是float32浮点数, 为unsigned INT8定点数,offset是INT8定点数,其表示的数据范围为
为unsigned INT8定点数,offset是INT8定点数,其表示的数据范围为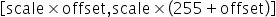 。若待量化数据的取值范围为
。若待量化数据的取值范围为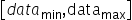 ,则scale和offset的计算方式如下:
,则scale和offset的计算方式如下:
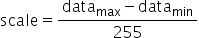 、
、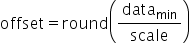
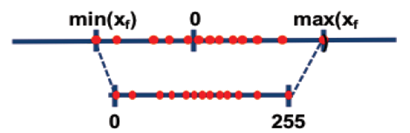
量化数据格式归一
AMCT采用的是归一的量化数据格式,即量化数据格式归一:
通过将非对称量化公式通过简单的数据变换,可以使得量化后的数据与对称量化算法在数据格式上保持一致,均为int格式。具体变换过程如下:
以INT8量化为例进行说明,公式符号与之前保持一致,输入原始高精度浮点数据为 ,原始量化后的定点数为
,原始量化后的定点数为 ,量化scale,原始量化
,量化scale,原始量化 (算法要求强制过零点,否则可能会出现精度问题),原始量化的计算原理公式如下:
(算法要求强制过零点,否则可能会出现精度问题),原始量化的计算原理公式如下:

其中 。通过上述变换,可以将量化数据也转成INT8格式。确定scale和变换后的offset'后,通过原始高精度浮点数据计算得到INT8数据的转换,即为如下公式所示:
。通过上述变换,可以将量化数据也转成INT8格式。确定scale和变换后的offset'后,通过原始高精度浮点数据计算得到INT8数据的转换,即为如下公式所示:
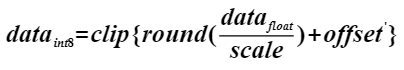
训练后量化算法¶
ARQ权重量化算法¶
ARQ (Adaptive Range Quantization)算法是对权重直接量化的算法。该算法提供了两种方式,channel_wise(是否对每个channel采用不同的量化因子,以PyTorch框架为例,参数解释请参见表20)量化和非channel_wise量化,量化原理图如下所示:
图 1 非channel_wise量化
图 2 channel_wise量化
量化配置中ARQuantize(以PyTorch框架为例,参数解释请参见表1)提供的参数channel_wise用来选择量化方式:
channel_wise为False时,选择图1量化方式,所有filter一起分析数据分布,进行量化,某一层的所有不同channel共用一个量化因子。
channel_wise为True时,选择图2的量化方式,每个filter独立做数据分析,进行量化,同一层的每个channel有独立的量化因子。
一般来说,每一个filter独立进行量化,即进行图2的量化,量化精度较高;如果每个filter的数据量比较少,量化效果会比较差,此时推荐使用图1的量化。
注意:全连接层、平均下采样层Pooling(下采样方式为AVE,且非global pooling)没有channel,设置channel_wise为True时,会提示错误信息。
ADA权重量化算法¶
在对神经网络进行量化时,主要方法是将每个浮点权重分配给其最接近的定点值。但这不是最佳的量化策略。本文引入的AdaRound(Adaptive Rounding),**一种用于训练后量化的更好的权重舍入机制,它可以适应数据和任务损失,**并且仅需要少量未标记的数据。
ADA权重量化算法用于PTQ流程,由于量化后的权重舍入模式会影响模型精度,ADA主要是对舍入模式进行微调,针对每个量化数据自适应向上或向下舍入模式,需要未标记的数据进行训练调优以确定不同的舍入模式。整体流程如下图所示,先将权重用KL散度算法计算weight初始量化因子scale和offset,然后使用无标签的数据进行训练,调整weight的舍入模式。
图 1 ADA权重量化算法
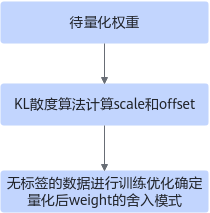
量化后的weight计算公式如下:
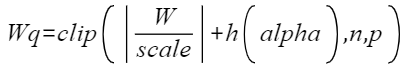 ,其中n和p分别是量化后的上下界。
,其中n和p分别是量化后的上下界。
训练过程主要是对alpha参数进行优化,目标是使得h(alpha)等于0或1:
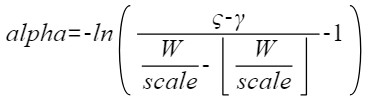 ,其中
,其中 和
和 是伸缩参数,分别取值为1.1和-0.1。
是伸缩参数,分别取值为1.1和-0.1。
将原始weight量化,量化完成后加上h(alpha)将其反量化,将反量化的weight引入最后的算子计算中,最终输出带量化误差的结果:
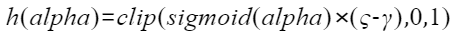
损失函数计算如下:
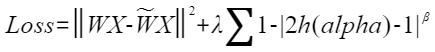
正则项(Loss函数的后半部分),用以约束h(alpha)向0和1两个值收敛,在迭代初期 较大值可以使得正则项对整体损失的影响比重变大,就会促使优化过程快速调整h(alpha),接近最优解的区域。迭代后期,此时h(alpha)已经处于最优解区域,使用较小
较大值可以使得正则项对整体损失的影响比重变大,就会促使优化过程快速调整h(alpha),接近最优解的区域。迭代后期,此时h(alpha)已经处于最优解区域,使用较小 ,不会因为微小的参数变动导致正则项剧烈变化,从而让模型在微调参数时更加稳健,避免因过度调整而错过最优解,使h(alpha)逼近最优解。
,不会因为微小的参数变动导致正则项剧烈变化,从而让模型在微调参数时更加稳健,避免因过度调整而错过最优解,使h(alpha)逼近最优解。
NUQ权重量化算法¶
该算法用于训练后量化下的非均匀量化场景。
NUQ(Non Uniform Quantization)是对权重非等间距量化的一种方法,均匀量化将权重数据从32比特量化到8比特,NUQ在此基础上挑选部分量化台阶。权重压缩后会带来精度损失,为了在指定的压缩目标下获得最小的精度损失,算法使用了搜索的方式来查找最小损失的压缩方式。量化配置中通过NUQuantize(以PyTorch框架为例,参数解释请参见表1)来控制NUQ算法。
num_steps用于指定压缩目标,值越小,压缩率越高,但精度损失会更大,反之则相反。
num_of_iteration代表搜索过程迭代次数,一般来说值越大,精度越高,但计算时间会指数级上升,建议使用默认值。
IFMR数据量化算法¶
IFMR(Input Feature Map Reconstruction)算法在某个数据分布下,通过搜索的方式确定最佳量化方式。该算法用于训练后量化场景,量化原理图如下所示:
图 1 IFMR数据量化算法
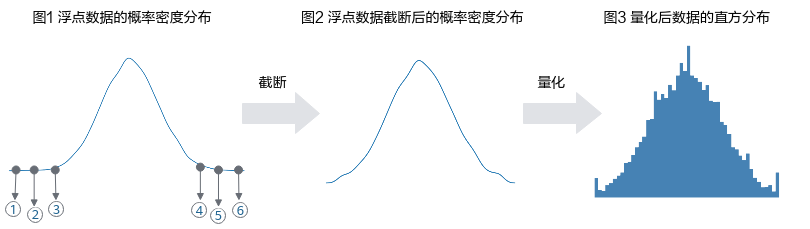
上图中序号[1,3]代表[clip_min_start, clip_min_end]、2代表clip_min、 [4,6]代表[clip_max_start, clip_max_end]、5代表clip_max。
该算法中量化过程分为两步,如图1所示,第一步,将浮点数截断到[clip_min, clip_max]范围,即图1中的[2,5]点;第二步,将浮点数据量化到int范围。通常情况下,数据分布处于边界附近的数值比较稀疏,均可做截断处理,以提高量化精度。
为获得最佳量化效果,可以不断改变截断范围[clip_min, clip_max],选择量化效果最好的一组范围作为最终的量化结果。IFMR算法中,clip_min和clip_max用来设置搜索范围和搜索步长,遍历查询得到最优的量化效果。量化配置中FMRQuantize(以PyTorch框架为例,参数解释请参见表1)提供的参数则用来调整截断范围。
clip_min(即图1中的序号2)的遍历取值范围为[clip_min_start, clip_min_end] (即图1中的[1,3]),步长为search_step。
clip_max(即图1中的序号5)的遍历取值范围为[clip_max_start, clip_max_end] (即图1中的[4,6]),步长为search_step。
在数据降序序列中,根据min_percentile参数获得clip_min_init,从而得到clip_min_start、clip_min_end参数,其中:
clip_min_start =clip_min_init*search_range_start
clip_min_end= clip_min_init* search_range_end
在数据升序序列中,根据max_percentile参数获得clip_max_init,从而得到clip_max_start、clip_max_end参数,其中:
clip_max_start =clip_max_init*search_range_start
clip_max_end=clip_max_init* search_range_end
通常情况下,搜索范围[clip_min_start, clip_min_end]越大、搜索步长search_step越小,可能获得更高的量化精度,但量化耗时更多。
HFMG数据量化算法¶
该算法用于训练后量化场景。
HFMG(Histogram Feature Map Glutton)算法通过直方图的方式来记录激活数据的数据分布,通过搜索的方式确定最佳的量化截断位置。量化原理如下所示:
第一步根据输入激活数据创建直方图。
若有更多batch的数据则对每个batch的数据创建一个直方图,然后进行直方图合并的操作,如图1所示。
基于激活数据的直方图根据搜索的方式确定数据的截断点,如图2所示。
该量化算法的数据放在内存中,和IFMR数据量化算法相比,更节省内存。该算法与IFMR数据量化算法同一层不能同时配置。
create_quant_config接口量化默认使用的为IFMR数据量化算法,如果想使用HFMG数据量化算法,则只能通过create_quant_config接口config_defination参数配置简易配置文件方式实现。
图 1 直方图合并过程
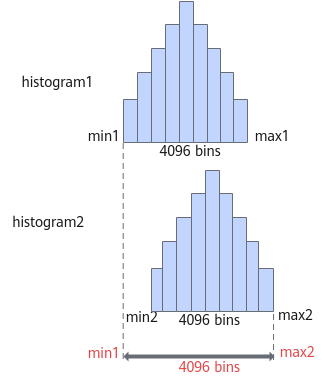
图 2 搜索得到最优的左右截断位置
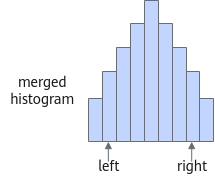
如果未获得最优的量化效果,则可以改变直方图的bin个数(直方图中的一个最小单位直方图形),选择量化误差更小的一组参数作为最终的量化结果。HFMG算法中,num_of_bins配置参数用来调整直方图的bin的数目,参数说明请参见训练后量化简易配置文件>HFMGQuantize的配置参数。通常情况下,num_of_bins数值越大,直方图拟合原始数据分布的能力越强,可能获得更佳的量化效果,但训练后量化过程的耗时也会更长。
DMQ均衡算法¶
该算法用于训练后量化场景。
DMQ(Diagonal Matrix Quantization Balancer)在计算量化因子之前对数据进行均衡处理,将数据的量化难度转移一部分至权重。如下图所示,X为数据,W为权重。
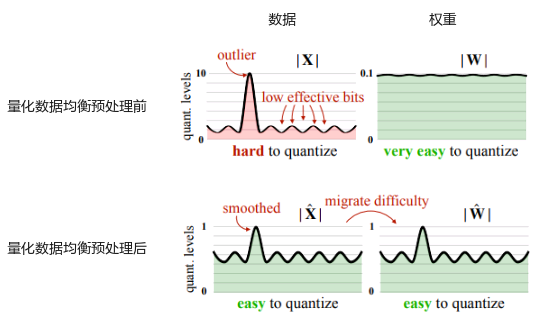
均衡原理为:
针对待量化算子的输入数据的每个通道,计算出均衡因子。
将数据除以均衡因子,同时权重乘以均衡因子,使得待量化算子的计算结果在均衡前后是数学等价的。
量化感知训练算法¶
ARQ权重量化算法¶
该场景下的原理同训练后量化算法中的ARQ权重量化算法,量化配置中ARQRetrain参数解释请参见表1(以PyTorch框架为例)。
ULQ数据量化算法¶
该算法用于量化感知训练场景。
ULQ(Universal Linear Quantization)算法在训练过程中不断训练量化因子,以减少量化损失。该算法初始化时会对数值做量化(包含截断),对初始化敏感。量化配置中ULQuantize(以PyTorch框架为例,参数解释请参见表1)来控制ULQ算法。
clip_max_min为初始化的截断范围,clip_min为截断下限,clip_max为截断上限,可根据数据的范围来设置,不设置则使用AMCT自带的默认方式初始化。
fixed_min表示在训练过程中,是否将截断下限设置为0。例如,当量化层的前一层是ReLU层,则数据范围为[0, +inf],此场景下数据量化可以设置fixed_min为true,表示截断下限始终为0。
稀疏算法¶
自动通道稀疏搜索算法¶
自动通道稀疏搜索默认采用的搜索算法为贪婪搜索算法,在给定模型计算量约束下,自动选择每一层可删除的、较为合适的通道(价值排序靠后的通道),降低通道稀疏对模型经过Fine-tune精度损失的影响。
该问题为组合优化问题,建模为背包问题,已知所有物品各自的价值vi和重量Fi,求背包容量C下能够装下总价值最多的物品,可以用公式表示为:
最大化: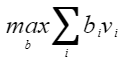
受限于: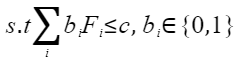
其中,vi相当于稀疏敏感度;Fi为比特复杂度;b为通道稀疏方案,即该通道是否保留;C为用户设置的压缩率。
对于通道稀疏任务,重量Fi为第i个通道的计算量,vi为裁剪第i个通道后网络w的损失函数变化:
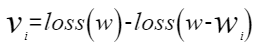
其中,loss(w - wi)可以通过一阶或者二阶泰勒展开式来做近似估计。
根据用户给定的目标稀疏率,计算每一层每一通道的价值密度(稀疏敏感度/比特复杂度),全局排序后挑选出价值密度最低的一批通道进行裁剪,通过上述的组合优化方法完成求解,达成搜索任务。
手工通道稀疏算法¶
AMCT使用的通道稀疏算法为BalancedL2Norm,该算法通过计算权重各个filter(输出维度通道)的L2范数(各元素的平方和然后求平方根),对输出通道进行重要性排序并裁剪重要性较低的通道,即重要性低的通道优先被稀疏,原理下图所示:
图 1 通道稀疏算法原理
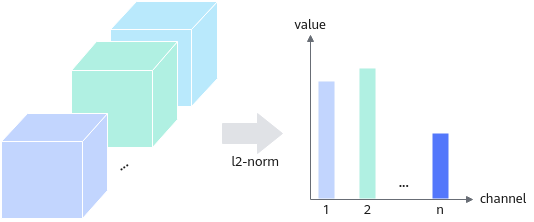
稀疏配置文件中通过BalancedL2NormFilterPruner字段(以PyTorch框架为例,参数解释请参见量化感知训练简易配置文件)来控制BalancedL2Norm算法。
prune_ratio:稀疏率,是被稀疏的filter数量与filter总数量的比值,稀疏化的程度由稀疏率控制,例如0.3的稀疏率表示30%的输出通道将被裁剪。
ascend_optimized:昇腾亲和优化,当前使用的为16对齐的优化方案,开启16对齐后,稀疏后保留的通道数将向16的倍数对齐。例如原始通道有20个,配置稀疏率为0.25并不开启16对齐时,稀疏后保留通道数为15;若相同稀疏率但开启16对齐,则稀疏后保留通道数为16;该配置可以提高稀疏后的模型在NPU IP加速器上的推理性能。
4选2结构化稀疏算法¶
AMCT使用的4选2结构化稀疏算法为L1SelectivePrune,通过比较权重的l1值即绝对值来决定保留哪些权重,每4个连续的权重中保留l1值最大的2个权重。
稀疏配置文件中通过L1SelectivePruner字段(以PyTorch框架为例,参数解释请参见量化感知训练简易配置文件)来控制L1SelectivePrune算法。
update_freq:更新4选2稀疏的间隔,计算哪些元素被保留的间隔。在重训练的过程中,权重会随着每个训练batch发生改变,对应的l1值排序可能会变化,比如本来保留的是4个元素中的前两个元素,更新之后可能变成第1,第3个元素保留。
update_freq=0时表示训练时仅在第一个batch计算哪些元素被保留,update_freq=2时,表示训练时每2个batch计算哪些元素被保留,以此类推。默认为0。
n_out_of_m_type:目前仅支持M4N2,即每4个连续权重中保留2个权重。
蒸馏算法¶
蒸馏量化的思想是将量化模型作为学生模型,原始模型作为教师模型,通过引导量化模型“模仿”浮点模型从而获得更好的精度结果。蒸馏量化,仅需要少量无标签数据集,即可以在较短的量化时间内达到较好的精度结果。
量化蒸馏的步骤:
量化原始模型,得到结构与浮点模型相同的量化模型。
将若干级联的量化层划分为一个蒸馏单元。
以浮点蒸馏模块的输出作为soft label,对量化蒸馏模块进行fine-tune。
完成所有的模块蒸馏,得到精度更优的量化模型。
图 1 蒸馏示意图
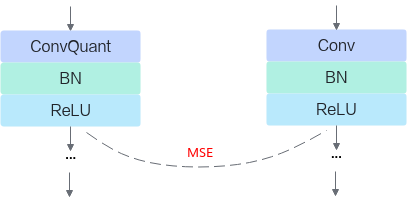
源码包编译为whl包,以whl包形式安装AMCT¶
如果用户AMCT安装服务器缺少源码编译安装时的某些依赖,则用户可以将源码包编译为whl包,然后进行安装,方法如下,如下步骤以编译并安装AMCT(TensorFlow)为例进行说明。
安装编译所需wheel依赖。
执行pip3 list命令检查所列软件中是否包括wheel,若有请忽略该步骤,否则执行如下命令进行安装:
pip3 install wheel --user解压TensorFlow框架安装包。
tar -zxvf amct_tensorflow-{version}-py3-none-linux_{arch}.tar.gz编译whl包。
进入解压后的目录,执行如下命令进行编译:
cd amct_tensorflow-{version} && python3 setup.py bdist_wheel编译完成后,在dist目录下生成所需的whl包。
以whl包形式安装AMCT。
pip3 install amct_tensorflow-{version}-py3-none-any.whl --user若出现如下信息则说明工具安装成功。
Successfully installed amct-tensorflow-{version}
TensorFlow网络模型由于AMCT导致输出节点改变,如何通过修改量化脚本进行后续的量化动作¶
背景信息
使用AMCT调用quantize_model接口对用户的原始TensorFlow模型进行图修改时,由于插入了searchN层导致尾层输出节点发生改变。该场景下,需要用户根据提示信息,将推理时的输出节点替换为新的输出节点的名称;AMCT量化过程中的日志信息给出了网络输出节点变化前后的节点名称,需要用户根据提示信息,自行修改量化脚本。
进行图修改时,导致尾层输出节点发生改变的场景有如下几种情况:
场景1:网络模型的尾层为Add/AddV2,且Add加数的维度为一维,满足BiasAdd的功能
图 1 尾层为Add/AddV2
尾层为Add时,图修改时的提示信息为:
2020-09-01 09:31:04,896 - WARNING - [AMCT]:[replace_add_pass]: Replace ADD at the end of the network! You need to replace the old output node by the new output node in inference process! >>>>>>>>>>>>>>>>>>>>>>>>>>>>>>The name of the old output node is 'Add:0' <<<<<<<<<<<<<<<<<<<<<<<<<<<<<<The name of the new output node is 'bias_add/BiasAdd:0' 2020-09-01 09:31:04,979 - WARNING - [AMCT]:[quantize_model]: Insert searchN operator at the end of the network! You need to replace the old output node by the new output node in inference process! >>>>>>>>>>>>>>>>>>>>>>>>>>>>>>The name of the old output node is 'bias_add/BiasAdd:0' //网络输出节点变化前的节点名称 <<<<<<<<<<<<<<<<<<<<<<<<<<<<<<The name of the new output node is 'search_n_quant/search_n_quant_SEARCHN/Identity:0' //网络输出节点变化后的节点名称
尾层为AddV2时,图修改时的提示信息为:
2020-09-01 09:32:42,281 - WARNING - [AMCT]:[replace_add_pass]: Replace ADD at the end of the network! You need to replace the old output node by the new output node in inference process! >>>>>>>>>>>>>>>>>>>>>>>>>>>>>>The name of the old output node is 'add:0' <<<<<<<<<<<<<<<<<<<<<<<<<<<<<<The name of the new output node is 'bias_add/BiasAdd:0' 2020-09-01 09:32:42,362 - WARNING - [AMCT]:[quantize_model]: Insert searchN operator at the end of the network! You need to replace the old output node by the new output node in inference process! >>>>>>>>>>>>>>>>>>>>>>>>>>>>>>The name of the old output node is 'bias_add/BiasAdd:0' //网络输出节点变化前的节点名称 <<<<<<<<<<<<<<<<<<<<<<<<<<<<<<The name of the new output node is 'search_n_quant/search_n_quant_SEARCHN/Identity:0' //网络输出节点变化后的节点名称
场景2:网络的尾层为BiasAdd,且其前面为Conv2D、DepthwiseConv2dNative、Conv2DBackpropInput、MatMul中的一种
图 2 网络的尾层为BiasAdd,且其前面为Conv2D
该场景下,图修改时的提示信息为:
2020-09-01 09:39:26,130 - WARNING - [AMCT]:[quantize_model]: Insert searchN operator at the end of the network! You need to replace the old output node by the new output node in inference process! >>>>>>>>>>>>>>>>>>>>>>>>>>>>>>The name of the old output node is 'BiasAdd:0' //网络输出节点变化前的节点名称 <<<<<<<<<<<<<<<<<<<<<<<<<<<<<<The name of the new output node is 'search_n_quant/search_n_quant_SEARCHN/Identity:0' //网络输出节点变化后的节点名称
场景3:网络的尾层为Conv2D、DepthwiseConv2dNative、Conv2DBackpropInput、MatMul、AvgPool中的一种
图 3 网络的尾层为Conv2D
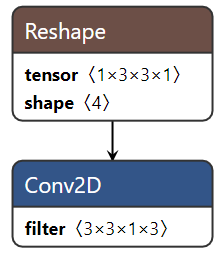
该场景下,图修改时的提示信息为:
2020-09-01 09:40:28,717 - WARNING - [AMCT]:[quantize_model]: Insert searchN operator at the end of the network! You need to replace the old output node by the new output node in inference process! >>>>>>>>>>>>>>>>>>>>>>>>>>>>>>The name of the old output node is 'Conv2D:0' //网络输出节点变化前的节点名称 <<<<<<<<<<<<<<<<<<<<<<<<<<<<<<The name of the new output node is 'search_n_quant/search_n_quant_SEARCHN/Identity:0' //网络输出节点变化后的节点名称
场景4:网络的尾层为FusedBatchNorm\FusedBatchNormV2\FusedBatchNormV3中的一种,且其前面为Conv2D+(BiasAdd)或DepthwiseConv2dNative+(BiasAdd)
图 4 尾层为FusedBatchNormV3
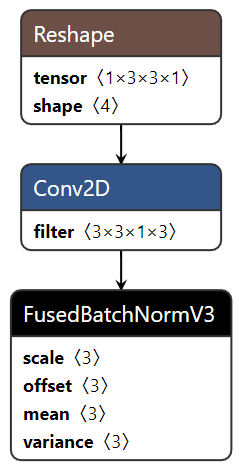
该场景下,图修改时的提示信息为:
2020-09-01 09:44:08,637 - WARNING - [AMCT]:[conv_bn_fusion_pass]: Fused BN at the end of the network! You need to replace the old output node by the new output node in inference process! >>>>>>>>>>>>>>>>>>>>>>>>>>>>>>The name of the old output node is 'batch_normalization/FusedBatchNormV3:0' <<<<<<<<<<<<<<<<<<<<<<<<<<<<<<The name of the new output node is 'bias_add:0' 2020-09-01 09:44:08,717 - WARNING - [AMCT]:[quantize_model]: Insert searchN operator at the end of the network! You need to replace the old output node by the new output node in inference process! >>>>>>>>>>>>>>>>>>>>>>>>>>>>>>The name of the old output node is 'bias_add:0' //网络输出节点变化前的节点名称 <<<<<<<<<<<<<<<<<<<<<<<<<<<<<<The name of the new output node is 'search_n_quant/search_n_quant_SEARCHN/Identity:0' //网络输出节点变化后的节点名称
场景5:网络的尾层为BN小算子结构,且其输入的为4维数据
图 5 尾层为BN小算子结构
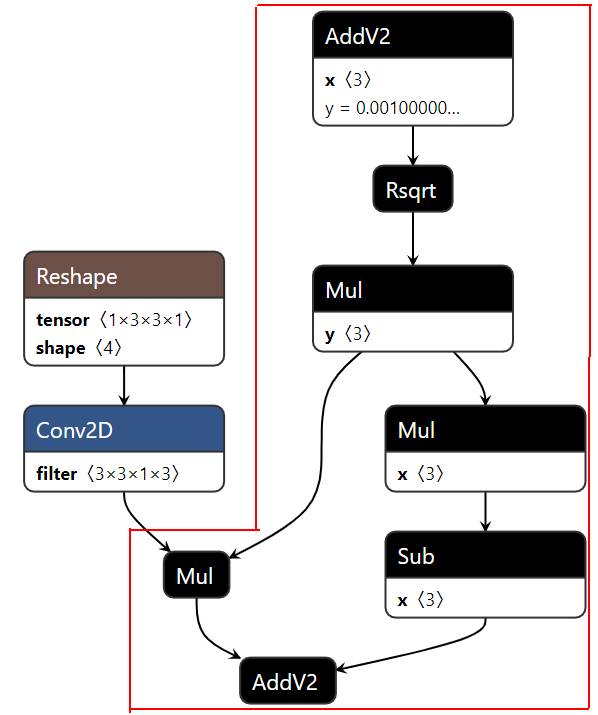
该场景下,图修改时的提示信息为:
2020-09-01 09:46:46,426 - WARNING - [AMCT]:[replace_bn_pass]: Replace BN at the end of the network! You need to replace the old output node by the new output node in inference process! >>>>>>>>>>>>>>>>>>>>>>>>>>>>>>The name of the old output node is 'batch_normalization/batchnorm/add_1:0' <<<<<<<<<<<<<<<<<<<<<<<<<<<<<<The name of the new output node is 'batch_normalization/batchnorm/bn_replace/batch_normalization/FusedBatchNormV3:0' 2020-09-01 09:46:46,439 - WARNING - [AMCT]:[conv_bn_fusion_pass]: Fused BN at the end of the network! You need to replace the old output node by the new output node in inference process! >>>>>>>>>>>>>>>>>>>>>>>>>>>>>>The name of the old output node is 'batch_normalization/batchnorm/bn_replace/batch_normalization/FusedBatchNormV3:0' <<<<<<<<<<<<<<<<<<<<<<<<<<<<<<The name of the new output node is 'bias_add:0' 2020-09-01 09:46:46,518 - WARNING - [AMCT]:[quantize_model]: Insert searchN operator at the end of the network! You need to replace the old output node by the new output node in inference process! >>>>>>>>>>>>>>>>>>>>>>>>>>>>>>The name of the old output node is 'bias_add:0' //网络输出节点变化前的节点名称 <<<<<<<<<<<<<<<<<<<<<<<<<<<<<<The name of the new output node is 'search_n_quant/search_n_quant_SEARCHN/Identity:0' //网络输出节点变化后的节点名称
脚本修改
如果调用quantize_model接口对用户的原始TensorFlow模型进行图修改时,由于在网络最后插入了searchN层导致尾层输出节点发生改变,需要用户根据日志信息,修改量化脚本,将网络推理过程中的输出节点替换为新的节点名称,修改方法如下:
修改前的量化脚本(如下脚本只是样例,请以实际量化的模型为准):
import tensorflow as tf
import amct_tensorflow as amct
def load_pb(model_name):
with tf.gfile.GFile(model_name, "rb") as f:
graph_def = tf.GraphDef()
graph_def.ParseFromString(f.read())
tf.import_graph_def(graph_def, name='')
def main():
# 网络pb文件的名字
model_name = './pb_model/case_1_1.pb'
# 网络量化推理输出节点的名字
infer_output_name = 'Add:0'
# 网络保存量化模型的输出节点的名字
save_output_name = 'Add:0'
# 载入网络的pb文件
load_pb(model_name)
# 获取网络的图结构
graph = tf.get_default_graph()
# 生成量化配置文件
amct.create_quant_config(
config_file='./configs/config.json',
graph=graph)
# 插入量化相关算子
amct.quantize_model(
graph=graph,
config_file='./configs/config.json',
record_file='./configs/record_scale_offset.txt')
# 执行网络的推理过程
with tf.Session() as sess:
output_tensor = graph.get_tensor_by_name(infer_output_name)
sess.run(tf.global_variables_initializer())
sess.run(output_tensor)
# 保存量化后的pb模型文件
amct.save_model(
pb_model=model_name,
outputs=[save_output_name[:-2]],
record_file='./configs/record_scale_offset.txt',
save_path='./pb_model/case_1_1')
if __name__ == '__main__':
main()
修改后的量化脚本:
import tensorflow as tf
import amct_tensorflow as amct
def load_pb(model_name):
with tf.gfile.GFile(model_name, "rb") as f:
graph_def = tf.GraphDef()
graph_def.ParseFromString(f.read())
tf.import_graph_def(graph_def, name='')
def main():
# 网络pb文件的名字
model_name = './pb_model/case_1_1.pb'
# 网络量化推理输出节点的名字,需要替换为日志打印的网络输出节点变化后的节点名称
infer_output_name = 'search_n_quant/search_n_quant_SEARCHN/Identity:0'
# 网络保存量化模型的输出节点的名字
save_output_name = 'Add:0'
# 载入网络的pb文件
load_pb(model_name)
# 获取网络的图结构
graph = tf.get_default_graph()
# 生成量化配置文件
amct.create_quant_config(
config_file='./configs/config.json',
graph=graph)
# 插入量化相关算子
amct.quantize_model(
graph=graph,
config_file='./configs/config.json',
record_file='./configs/record_scale_offset.txt')
# 执行网络的推理过程
with tf.Session() as sess:
output_tensor = graph.get_tensor_by_name(infer_output_name)
sess.run(tf.global_variables_initializer())
sess.run(output_tensor)
# 保存量化后的pb模型文件
amct.save_model(
pb_model=model_name,
outputs=[save_output_name[:-2]],
record_file='./configs/record_scale_offset.txt',
save_path='./pb_model/case_1_1')
if __name__ == '__main__':
main()
插入量化算子后,如何恢复模型训练参数¶
用户调用quantize_model接口在传入的图中插入量化相关的变量op列表(quant_add_ops),该列表中的变量值无法在模型训练参数文件中找到,故模型训练参数直接恢复会出现变量无法找到的错误,因此需要在模型参数恢复之前,将quant_add_ops列表中的变量值从恢复列表中剔除,具体的剔除方法如下:
影子变量恢复情况
# 1.获取所有变量的{变量名:变量值}对应字典variables_dict variables_ema = tf.train.ExponentialMovingAverage(moving_average_decay) variables_dict = variables_ema.variables_to_restore() # 2.定义需要恢复的变量的{变量名:变量值}对应字典params_need_load params_need_load = dict() # 3.基于quant_add_ops从variables_dict中找寻需要恢复的变量 for key, value in variables_dict.items(): if value not in quant_add_ops: params_need_load[key] = value # 4.恢复变量 loader = tf.train.Saver(params_need_load) loader.restore(sess, FLAGS.checkpoint)
非影子变量恢复的情况
# 1.获取所有变量的{变量名:变量值}对应字典variables_dict variables_global = tf.global_variables() variables_dict = dict() for var in variables_global: variables_dict[var.name[:-2]] = var # 2.定义需要恢复的变量的{变量名:变量值}对应字典params_need_load params_need_load = dict() # 3.基于quant_add_ops从variables_dict中找寻需要恢复的变量 for key, value in variables_dict.items(): if value not in quant_add_ops: params_need_load[key] = value # 4.恢复变量 loader = tf.train.Saver(params_need_load) loader.restore(sess, FLAGS.checkpoint)