
前言¶
本文档详细描述了_图像分析引擎_2开发和_图像分析引擎_1的开发差异。
与本文档相对应的产品版本如下。
本文档主要适用于以下工程师:
技术支持工程师
软件开发工程师
修订记录累积了每次文档更新的说明。最新版本的文档包含以前所有文档版本的更新内容。
SDK接口差异¶
风格差异¶
图像分析引擎1为ACL接口,图像分析引擎2为SVP ACL接口。
为了避免编译时符号冲突,SVP ACL使用linux风格,宏定义和枚举采用SVP_ACL_前缀;ACL使用的驼峰风格,宏定义和枚举采用ACL_前缀。函数、宏定义、枚举以及结构体详细差异参见表1。
表 1 风格差异示例
使用差异¶
创建databuffer函数¶
由于_图像分析引擎_2逻辑在执行的时候,输入输出数据需要传入stride,用于逻辑读/写操作时快速跳到下一行,因此在创建和更新data buffer的时候会增加一个stride入参。
表 1 创建data buffer函数差异
由于引入stride,所以SVP ACL接口返回的输入输出size是按照stride对齐后的内存大小,为了方便获取stride,SVP_ACL接口新增了与stride操作相关的函数,增加函数见下表:
表 2 新增stride相关函数
模型加载函数¶
SVP_ACL模型加载函数为svp_acl_mdl_load_from_mem(),其实现与ACL对应接口的差异如下。
表 1 模型加载函数差异
获取模型输入个数函数¶
为了使模型独立于device,context以及stream,SVP ACL将task_buf和work_buf独立出来由用户管理,模型执行的时候作为输入传入,在保证task_buf和work_buf正确使用的情况下,使得模型可以同时被同步,异步,多线程或者多device执行,输入变化如图1所示。
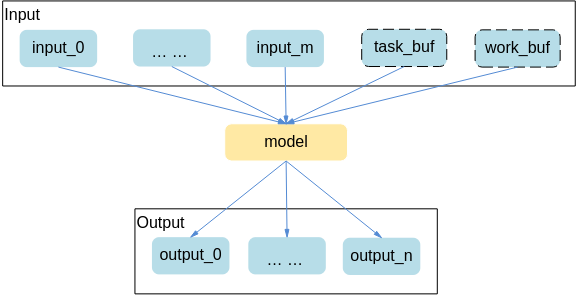
因此SVP ACL修改了模型输入接口的特性,差异说明如表1所示。
表 1 获取输入个数接口差异
size_t aclmdlGetNumInputs(aclmdlDesc *modelDesc); |
||
size_t svp_acl_mdl_get_num_inputs(const svp_acl_mdl_desc *model_desc) |
依据数据类型获取数据大小¶
SVP ACL为了支持紧密排布的RAW数据,如输入为12bit或14bit紧密排布。这样数据bit长度就不是8bit的整数倍,无法用Byte为单位表示,因此SVP ACL依据数据类型获取数据大小的时候返回值为bit数,而不是Byte数,差异如表1所示。
表 1 获取数据大小接口差异
size_t aclDataTypeSize(aclDataType dataType); |
||
size_t svp_acl_data_type_size(svp_acl_data_type data_type) |
板端环境安装差异¶
图像分析引擎1需要配置两个环境变量LD_LIBRARY_PATH以及ASCEND_AACPU_KERNEL_PATH,以SS928V100为例,相关库路径为/xxx(客户自定义)/smp/a55_linux/mpp/out/lib/nnn,其他解决方案类似,需要强调的是ASCEND_AACPU_KERNEL_PATH不支持路径拼接,因此在设定时需注意不能使用拼接路径。
图像分析引擎2只需要配置环境变量LD_LIBRARY_PATH,以SS928V100为例,相关库路径为/xxx(客户自定义)/smp/a55_linux/mpp/out/lib/svp_nnn,其他解决方案类似。
Recurrent网络执行¶
ACL不支持T可变,只支持N可变,也就是输入帧数一定是T的整数倍,SVP ACL支持Recurrent函数T可以变,N只能为1,因此增加接口用于用户配置每次执行中实际的总帧数的接口:
svp_acl_error svp_acl_mdl_set_total_t(uint32_t model_id, svp_acl_mdl_dataset *dataset, uint64_t total_t)
动态batch¶
SVP ACL支持配置任意batch值,只要不超过目前SDK的约束范围,图像最大batch为256,非图像最大batch是5000。在执行前模型前通过svp_acl_mdl_set_dynamic_batch_size()函数配置本次执行要处理的实际batch数。可以通过svp_acl_mdl_get_dynamic_batch()接口获取模型中配置的batch数(只支持一个档位),注意获取的不是svp_acl_mdl_set_dynamic_batch_size()函数配置的batch数。
获取模型中模式识别cpu任务个数¶
如果模型中含有_模式识别_CPU算子,模型执行异步推理的时候需要起一个线程调用_模式识别_CPU任务处理函数,为了对外能感知模型中是否函数_模式识别_CPU算子,从而决定是否要起_模式识别_CPU任务处理线程,SVP ACL增加函数来获取模型中_模式识别_CPU任务个数,如果为0,则不需要起线程,反之则要起_模式识别_CPU任务处理线程,新增接口如下。
svp_acl_error svp_acl_ext_get_mdl_aacpu_task_num(uint32_t model_id, uint32_t *num);
数据排布¶
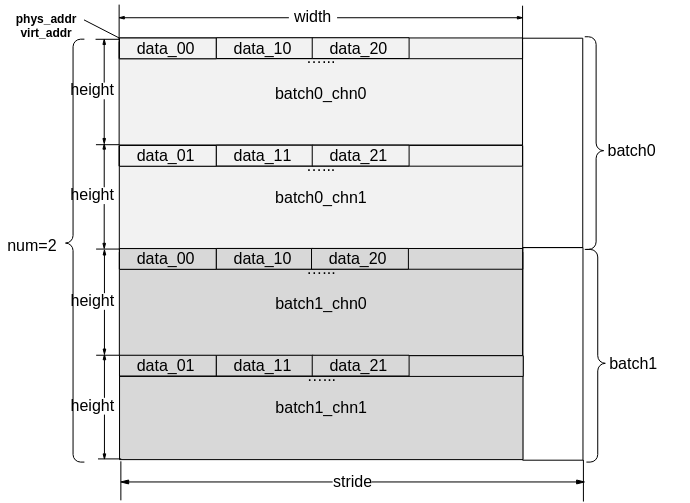
SVP_ACL统一输入输出数据格式如图1所示(YVU420SP/YUV420SP除外)。
如果是RGB_PACKAGE格式,data_xx数据类型为U24,通道数为1。
如果是XRGB_PACKAGE格式,data_xx数据类型为U32,通道数为1。
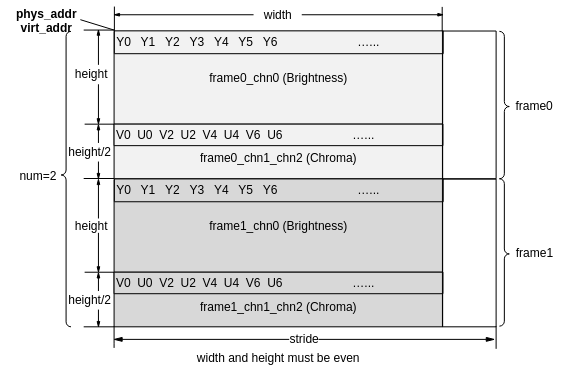
YVU420SP/YUV420SP数据排布如图2所示。
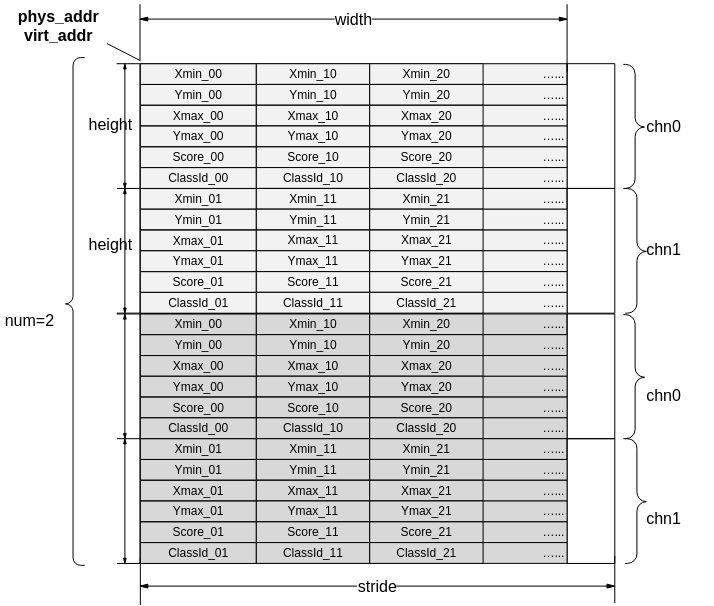
在SVP ACL为了让使用者软件开发人员不用感知检测网网络类型,将检测网输出框结果排布统一成如图3格式。
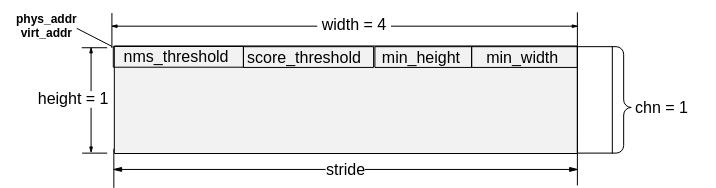
SVP ACL支持检测网阈值通过data层传入,阈值输入固定长度为4,分别nms_threshold,score_threshold,min_height,min_width,排布格式如图4所示。
支持的接口¶
表 1 支持的接口差异
小型化工具使用差异¶
Caffe小型化工具差异¶
支持量化的算子不同¶
为了实现更低的带宽成本,_图像分析引擎_2小型化工具除了支持带权重层的量化,还支持对不带权重的层做激活量化。
当前支持的带权重量化层为:全连接层(InnerProduct)、卷积层(Convolution和DepthwiseConv)、反卷积层(Deconvolution)。
当前支持的不带权重的量化层为:PassThrough, Pooling, PSROIPooling, ROIPooling, SPP, Upsample, Eltwise, Slice, Concat, Softmax, ROIAlign, AbsVal, BNLL, CReLU, ELU, Exp, Interp, Log, LRN, Mvm, Nms, Normalize, Power, PReLU, Reduction, ReLU, Sigmoid, Sort, Threshold, Scale, BatchNorm, Bias, Reshape, ShuffleChannel, Crop, Axpy, Flatten, Permute, Tile, Split, ArgMax, Clip, Hswish, MVN, Reorg, TanH, MatMul, RReLU, ReLU6
支持量化的位宽不同¶
_图像分析引擎_2小型化工具支持更灵活的量化位宽控制。
激活量化在Calibration和Retrain时可以配置8~16之间任意位宽,配置8时最终使用8bit部署,配置大于8时为高精度模式,最终使用16bit部署(一般推荐8或者12)
权重量化在Calibration时可以配置4和8两种位宽量化,在Retrain时可以配置8一种量化位宽
对外接口和功能差异¶
_图像分析引擎_2小型化工具的接口和功能都和_图像分析引擎_1存在差异:
_图像分析引擎_2的Calibration把权重量化和激活量化分离为weights_quantize_model和activation_quantize_model两个接口;
_图像分析引擎_2的Calibration支持权重压缩成4bit,并且支持在权重量化后对BN层的参数进行更新;
新增了对推理图的uninplace功能,在Sample中新增中间结果打印脚本,方便中间结果导出和精度比对;
_图像分析引擎_2小型化工具不支持auto_nuq和accuracy_based_auto_calibration功能。
量化生成件差异¶
_图像分析引擎_2小型化工具生成的量化参数单独储存在名为quant_param_record.txt或者quant_param_record.bin的文件中,deploy模型中仅储存不含量化层的INT定点模型。
Pytorch小型化工具差异¶
支持量化的算子不同¶
为了实现更低的带宽成本,_图像分析引擎_2小型化工具除了支持带权重层的量化,还支持对不带权重的层做激活量化。
支持量化的位宽不同¶
_图像分析引擎_2小型化工具支持更灵活的量化位宽控制。
激活量化在Calibration和Retrain时可以配置8~16之间任意位宽,配置8时最终使用8bit部署,配置大于8时为高精度模式,最终使用16bit部署(一般推荐8或者12)。
权重量化在Calibration时可以配置4和8两种位宽量化,在Retrain时可以配置4和8两种量化位宽。
对外接口和功能差异¶
_图像分析引擎_2小型化工具的接口和功能都和_图像分析引擎_1存在差异:
_图像分析引擎_2的Calibration支持权重压缩成4bit,并且支持在权重量化后对BN层的参数进行更新;
4bit量化需要用到更新BN的接口:
update_bn_status(calibration_model, training=True)
_图像分析引擎_2在Calibration场景save_model接口函数原型为:
save_model(modfied_onnx_file, record_file, save_path, calibration_torch_model)
_图像分析引擎_1在Calibration场景save_model接口函数原型为:
save_model(modfied_onnx_file, record_file, save_path)
_图像分析引擎_2小型化工具不支持nuq算法和accuracy_based_auto_calibration功能
量化生成件差异¶
_图像分析引擎_2小型化工具生成的量化参数单独储存在名为quant_param_record.txt的文件中,deploy模型中仅储存不含量化层的INT定点模型。
ATC使用差异¶
SVP ATC特性差异¶
表 1 SVP ATC特性差异
不支持改变图像尺寸(Crop、Resize、Padding),支持色域转换(转换图像格式)、减均值/乘系数(改变图像像素值) |
||
SVP ATC 命令行差异¶
SVP ATC支持的算子规格差异¶
表 1 Caffe扩展算子差异
详细见《ATC工具使用指南》的“5 算子规格说明”。
仿真器差异¶
SVP ACL仿真器说明¶
在图像分析引擎2 SVP ACL中,提供仿真器Simulator,供用户在非上板的PC/服务器环境执行仿真任务。
仿真器与SVP ACL的SDK共用一套头文件定义,即一套相同的SVP ACL调用实现代码,通过链接仿真库的方法,可在仿真环境中使用编译器编译可执行程序或库,在仿真环境中执行_图像分析引擎_2仿真。
Simulator(Function)表示功能仿真,从功能一致性的角度去模拟硬件,速度较快;
Simulator(Instruction)表示指令仿真,从指令一致性的角度去模拟硬件,速度较慢。
功能仿真、指令仿真、板端环境三者的推理输出buffer内容保持完全一致。
仿真器的使用,请参考《MindCmd使用指南》“应用工程”章节。