前言¶
本文介绍如何使用MindCmd工具,以及如何通过工具进行一键推理、数据预处理、开源框架推理、模型压缩、模型转换、仿真推理、上板推理、精度比对、性能分析等功能。
与本文档相对应的产品版本如下。
须知: MindCmd仅作为开发调试工具,不建议在实际产品中集成。 本文未有特殊说明,SS928与SS927内容完全一致。
本文档(本指南)主要适用于以下工程师:
算法工程师
技术支持工程师
软件开发工程师
在本文中可能出现下列标志,它们所代表的含义如下。





简介¶
MindCmd命令行工具主要关注一键化、自动化,聚焦部署侧的全流程开发效率的大幅提升。
针对网络模型的开发,MindCmd集成了离线模型转换工具、模型量化工具、模型精度比对工具、模型性能分析工具,提升了网络模型移植、分析和优化的效率。
功能框架图¶
如图1所示,工具目前包含数据预处理、开源框架推理、模型压缩、模型转换、功能仿真、指令仿真、上板推理、性能分析、精度比对以及Oneclick一键推理。

工具功能¶
MindCmd中主要几个功能特性如下。
一键推理:提供一键推理功能,一键式端到端执行数据预处理、开源框架推理、模型压缩、模型转换、功能仿真、指令仿真、上板推理、Dump、精度比对、性能分析等功能。参见一键推理。
数据预处理:提供数据预处理功能,在进行模型压缩、模型转换等功能之前通过数据预处理将数据处理成与模型匹配的数据。参见数据预处理。
开源框架推理:提供开源框架推理功能。获取Ground Truth数据。参见开源框架推理。
模型压缩:提供模型压缩功能,对模型的权重(weight)和数据(activation)进行低比特处理,让最终生成的网络模型更加轻量化,从而达到节省网络模型存储空间、降低传输时延、提高计算效率,达到性能提升与优化的目标,参见模型压缩。
模型转换:提供模型转换功能,将训练好的模型转换为离线模型,参见模型转换。
功能仿真:提供功能仿真推理功能,参见应用工程。
指令仿真:提供指令仿真推理功能,参见应用工程。
上板推理:提供上板推理功能,参见应用工程。
精度比对:提供精度比对功能,可以用来比对模型转换后SoC支持的算子运行结果与标准算子的运行结果,以便用来确认运算误差发生的原因,参见精度比对。
性能分析:提供性能分析功能,用于采集和分析SoC推理业务各个运行阶段的关键性能指标,参见性能分析。
工具模块:提供可单独调用的工具,包括原始Caffe模型子网导出、数据格式转换、模型Uninplace、ATC命令行转cfg文件,参见Tools。
安装¶
MindCmd软件包可以安装在Linux服务器上,可以使用Linux服务器上原生桌面自带的终端gnome-terminal进行安装,也可以在Windows服务器上通过SSH登录到Linux服务器进行安装。


MindCmd安装流程如图3所示。

软件包获取¶
MindCmd工具只支持在18.04 x86_64架构服务器安装。安装前,请先获取MindCmd工具软件包。
当前MindCmd工具的模型转换、模型推理依赖CANN软件包。模型压缩依赖AMCT软件包。具体说明请参见表1。
表 1 软件包说明
MindCmd工具主要用于端到端一键执行数据预处理、模型量化、模型转换、仿真推理、模型推理、精度比对和性能分析。各子模块支持单独调用,参见MindCmd子命令。 |
||
模型压缩工具(AMCT)为MindCmd工具提供网络模型量化的支持,让最终生成的网络模型更加轻量化,从而达到节省网络模型存储空间、降低传输时延、提高计算效率,达到性能提升与优化的目标。 |
||
hotwheels_amct_pytorch-<version>-py3-none-linux_x86_64.tar.gz |
其中_<version>_表示软件版本号。
安装前准备¶
Ubuntu18.04-x86_64系统¶
安装MindCmd的环境,所要求的硬件以及操作系统要满足以下条件。
表 1 Ubuntu系统配套版本信息
|
||
|
||
如果已安装Ascend-cann-toolkit开发套件包,请使用Ascend-cann-toolkit开发套件包的安装用户安装MindCmd。
如果未安装Ascend-cann-toolkit开发套件包,请参考如下示例准备安装用户。
您可以使用任意用户(含root或非root用户)进行安装。
若使用root用户安装,则不需要操作该章节,不需要对root用户做任何设置。
若使用已存在的非root用户安装,须保证该用户对$HOME目录具有读写以及可执行权限。
若使用新的非root用户安装,请参考如下步骤进行创建,如下操作请在root用户下执行。本手册以该种场景为例执行MindCmd的安装。
执行以下命令创建用户组和MindCmd安装用户并设置该用户的$HOME目录。
groupadd usergroup useradd -g usergroup -d /home/username -m username -s /bin/bash
例如以MindCmdUser群组为例,可执行如下命令创建MindCmd安装用户并加入到群组中。
groupadd MindCmdUser useradd -g MindCmdUser -d /home/username -m username -s /bin/bash
 说明:
用户所属的属组必须和Driver运行用户所属组相同;如果不同,请用户自行添加到Driver运行用户属组。
说明:
用户所属的属组必须和Driver运行用户所属组相同;如果不同,请用户自行添加到Driver运行用户属组。执行以下命令设置密码。
passwd username_username_为安装MindCmd的用户名,该用户的umask值为0027:
若要查看umask的值,则执行命令:umask
若要修改umask的值,则执行命令:umask 新的取值
如果用户通过上述方式修改了umask取值,则修改后的取值只在当前窗口有效,用户也可以通过修改~/.bashrc文件方式设置永久umask取值:
在任意目录下执行如下命令,打开.bashrc文件:
vi ~/.bashrc在文件最后一行后面添加**umask 新的取值**内容。
执行:wq!命令保存文件并退出。
执行source ~/.bashrc命令使其立即生效。
安装过程需要下载相关依赖,请确保服务器能够连接网络。
请在root用户下执行如下命令检查源是否可用。
apt-get update
使用MindCmd工具前,需要完成相关环境搭建。开发人员可根据不同组件的使用需求进行环境搭建,使用一键推理,需要完整搭建各组件依赖的环境。
支持在Docker中使用MindCmd,解决方案提供了Dockerfile文件,构建镜像请参考《驱动和开发环境安装指南》“容器镜像构建”章节,启动容器请参考Docker容器中使用MindCmd。
表 2 各组件依赖
安装python依赖:skl2onnx>=1.13.0, packaging>=18.0。 Caffe模型推理需参见《AMCT使用指南(Caffe)》"安装AMCT"。 |
|
安装MindCmd¶
在MindCmd工具软件包所在目录下,执行如下命令安装。
pip3.7.5 install mindcmd-<version>-py3-none-linux_x86_64.tar.gz --user若出现如下信息则说明工具安装成功。
Successfully installed mindcmd-<version>用户可以在python3.7.5软件包所在路径下(例如:$HOME/.local/lib/python3.7.5/site-packages)查看已经安装的MindCmd工具,例如
drwxr-xr-x 9 mindcmd mindcmd 4096 Oct 13 23:16 mindcmd/ drwxr-xr-x 2 mindcmd mindcmd 4096 Oct 13 23:16 mindcmd-<version>.dist-info/
其中,mindcmd即为MindCmd工具所在安装路径,下文中均用{MINDCMD_INSTALL_PATH}表示MindCmd安装路径。
说明:
卸载
用户通过如上方式成功安装MindCmd工具后,可执行如下命令卸载MindCmd工具。pip3.7.5 uninstall mindcmd若出现如下信息则说明卸载成功。
Successfully uninstalled mindcmd-<version>MindCmd工具升级时可以先卸载再重新安装:
pip3.7.5 uninstall mindcmd pip3.7.5 install mindcmd-<version>-py3-none-linux_x86_64.tar.gz
如果安装过程中出现下载依赖连接超时的情况,请用户检查pip环境是否正常可用,如需网络代理或更换镜像源,请用户自行配置。
安装MindCmd后,请使用如下命令配置到生态开源版本默认配置:
mindcmd config --global base_config.target_version=SS928V100 mindcmd config --global base_config.cross_compiler=musl_clang
全局配置¶
MindCmd提供子命令查看和修改全局配置。
查看全局配置列表,结果如图1所示。
mindcmd config --list

查看某一个配置项的值(以查看“base_config.cann_install_path”为例),结果如图2所示。
mindcmd config --global base_config.cann_install_path

修改某一个配置项的值(以修改“base_config.cann_install_path”为例),结果如图3所示。
mindcmd config --global base_config.cann_install_path=~/Ascend/ascend-toolkit/svp_latest

MindCmd命令行工具为用户提供全局配置文件,配置文件路径为:{MINDCMD_INSTALL_PATH}/mindcmd.ini,或通过运行命令 mindcmd config --list , 控制台会打印配置文件路径,如图4中高亮部分所示。

工具安装完毕后,需要在MindCmd全局配置文件中指定CANN软件包安装路径,如表1。
表 1 MindCmd配置
CANN软件包的安装路径,如:CANN_INSTALL_PATH=/home/user/Ascend/ascend-toolkit/<version>/ |
||||
默认工作空间,如:DEFAULT_WORKSPACE=/home/user/mindcmd_workspace 若DEFAULT_WORKSPACE=NA,则会在用户主目录下创建MindCmd-WorkSpace文件夹作为默认工作路径。 |
||||
上板推理默认配置文件,若需要执行上板推理,则需要配置此参数。详细配置项参考ssh.cfg文件配置。 |
||||
运行前先删除工作路径下一键推理的历史输出目录,默认值为1。 |
||||
模型压缩开关,默认值为1。 |
||||
开源框架推理开关,默认值为1。 |
||||
上板推理开关,默认值为0。 |
||||
功能仿真运行开关,默认值为1。 |
||||
指令仿真运行开关,默认值为0。 |
||||
Dump数据精度比对开关,默认值为1。 |
||||
在一键推理流程执行到ATC组件时,追加ATC支持的命令参数,每个命令按行隔开,具体命令参见《ATC工具使用指南》。需要满足key=value格式,工具会转换为--key=value。例如配置:log_level=0 |
mindcmd.ini中的所有配置项前不可加空格。
参数值格式:支持大小写字母(a-z,A-Z)、数字(0-9)、下划线(_)、中划线(-)、句点(.)。
Sample介绍¶
工具内置一个PyTorch 模型pooling算子快速上手的用例,位于{MINDCMD_INSTALL_PATH}/testcase。请参考安装MindCmd完成安装,再参考全局配置完成MindCmd工具配置。
参考以下命令。
mindcmd oneclick pytorch -m mindcmd.testcase.pooling.Model --input_shape 1,3,224,224
一键推理¶
功能介绍¶
支持一键式端到端完成模型的数据预处理、AMCT(模型压缩)、GT(Ground Truth)、ATC、仿真、上板推理、Dump、精度比对和Profiling功能。目前支持的开源框架模型包括:Caffe、PyTorch和ONNX。
Caffe模型一键推理¶
Caffe模型一键推理流程如图1所示。

命令行格式说明¶
Caffe模型一键推理的命令行格式如下。
mindcmd oneclick caffe -m MODEL -w WEIGHT
Caffe模型一键推理的命令行参数说明如表1所示。
表 1 Caffe模型一键推理命令行参数说明
指定权重文件(*.caffemodel)。未指定此参数时,工具将根据模型定义文件生成随机权重文件,位于模型定义文件所在路径下。 |
||
指定推理数据。支持图片列表(.txt)和feature map(.txt/.bin/.npy)格式。 工具根据传入路径参数后缀和文件内容区分图片列表或者feature map,具体规则如下。
多输入模型按照输入顺序指定,使用英文双引号""包含,并用英文分号;作为分割,如 --image_list="/home/MindCmdUser/image_list1.txt;/home/MindCmdUser/image_list2.txt"。 |
||
指定数据预处理配置文件,参见数据预处理配置文件样例。 |
||
指定推理数据的数据类型,只用于Feature map输入,不能用于图片输入。支持数据类型FP16, FP32, INT16, INT8, S16, S8, U16, U8, UINT16, UINT8。模型多路输入时,使用英文分号隔开,用英文双引号括住。eg.:--input_type="INT8;FP16"。 |
||
指定AMCT的简易量化配置文件(*.cfg)或量化配置文件(*.json)。配置方式请参考《AMCT使用指南(Caffe)》。 |
||
指定rpn文件(.txt),当模型包含rpn硬化层时,此参数要求必传,且AMCT和GT不执行。 指定多个rpn文件时使用英文双引号""包含,并用英文分号;作为分割,如 --rpndata="/home/MindCmdUser/rpn1.txt;/home/MindCmdUser/rpn2.txt"。 |
||
指定多batch模型的batch数量。多输入多batch模型只需指定较大的那个batch值。如双路输入的模型,其中一路支持32batch,一路不支持多batch,则输入 --batch_num=32。 |
||
指定工作目录,否则使用默认工作路径 $HOME/MindCmd-WorkSpace/XXX,XXX根据运行的模型动态生成。 如果开启了上板推理开关(IS_NNN_RUN=1),则工作目录不能超出ssh.cfg文件配置小节中“HOST_MOUNT_PATH”配置的路径。 |
||
指定板端ssh挂载配置文件。ssh挂载需先进行NFS环境搭建,可参考NFS环境搭建。 ssh挂载配置文件的模板,可参考ssh.cfg文件配置。 |
||
输入一个前缀${prefix},用于删除${work_dir}/output/目录下所有名为“${prefix}_xxxxx”的文件夹。删除oneclick模块的历史输出目录。 例如:输入 --clean project 将会删除${work_dir}/output/目录下所有名为“project_xxxxx”的文件夹。 |
||
输入各参数的位置要求位于其所属子命令之后,例如:
mindcmd oneclick -k {WORK_DIR} caffe -m xxx.prototxt
参数值格式:支持大小写字母(a-z,A-Z)、数字(0-9)、下划线(_)、中划线(-)、句点(.)。
当-i/--image_list指定图片列表的时候,图片列表的内容支持UTF-8编码的中文路径。
多输入场景支持feature map和图片列表混输,eg. -i="${图片列表};${feature_map}"。
执行样例¶
模型和数据准备。
将推理所需的Caffe模型文件(.prototxt)、权重文件(.caffemodel)以及所需的数据等上传到开发环境任意路径,参考目录结构如下。
├── test_case │ ├── ssh.cfg # 可选,否则需要关闭上板推理 │ ├── caffe_resnet50 │ │ ├── resnet50.prototxt # 必选 │ │ └── resnet50.caffemodel # 可选,否则工具自动创建随机权重 │ ├── data # 可选,否则工具自动使用随机数推理 │ │ ├── dog1_1024_683.jpg │ │ ├── dog2_1024_683.jpg │ │ ├── insert_op.cfg # 数据预处理配置文件 │ │ └── image_ref_list.txt # 图片列表
说明:推理数据的shape应该与模型所需输入数据的shape相同,如:模型resnet50的shape为(3,224,224),图片的shape也应为(3,224,224)。否则需要自定义数据预处理方式,通过--aapp参数指定数据预处理配置文件样例,数据预处理完整配置方式请参考《ATC工具使用指南》“--insert_op_conf ”章节。
当推理数据为图片且未指定数据预处理配置文件时,工具会自动将所有图片Resize成模型所需输入数据的shape。
选择一键推理场景
执行一键推理前在全局配置中配置一键推理场景开关
[oneclick_switch] # 是否清理当前工作目录下的历史输出结果 IS_CLEAN_PREVIOUS_OUTPUT=1 # 是否开启模型压缩 IS_AMCT_RUN=1 # 是否开启GT推理,支持Caffe、ONNX IS_GT_RUN=1 # 是否开启上板推理,开启需要配置ssh IS_NNN_RUN=0 # 是否开启功能仿真 IS_FUNC_RUN=1 # 是否开启指令仿真 IS_INST_RUN=0 # 是否在模型推理时开启Dump网络中间结果,作用于功能仿真、指令仿真、上板推理 IS_DUMP_OPEN=1 # 是否开启Dump数据精度比对 IS_COMPARE_OPEN=1 # 是否开启上板性能数据采集 IS_BOARD_PROFILING_OPEN=1 # 是否在控制台展示性能数据报告 IS_PROFILE_DISPLAY_OPEN=0 # 是否在控制台打印详细的执行日志 IS_PRINT_PROCESS_DETAIL=0
执行一键推理
执行以下命令进行一键推理:
cd test_case mindcmd oneclick caffe -m ./caffe_resnet50/resnet50.prototxt -w ./caffe_resnet50/resnet50.caffemodel -i ./data/image_ref_list.txt
执行结果
Caffe模型一键推理执行结束后会在工作路径下生成相应的文件,主要的目录结构如下。
├── work_space │ ├── bin # 可执行文件路径 │ ├── data │ │ ├── inference_data_XXX.txt # 图片数据/推理数据 │ │ ├── insert_op.cfg # aapp配置 │ ├── model # om离线模型保存路径 │ ├── output │ │ ├── project_XXX │ │ │ ├── amct # 模型压缩输出路径 │ │ │ ├── atc # 模型转换输出路径 │ │ │ ├── cmp # 精度比对结果保存路径 │ │ │ ├── dump # dump结果保存路径 │ │ │ │ ├── float # 原始模型浮点dump数据,用于精度比对 │ │ │ │ ├── fake_quant # 量化后模型dump数据,用于精度比对 │ │ │ │ ├── funcsim # 离线模型功能仿真dump数据,用于精度比对 │ │ │ │ │ └── trap │ │ │ │ ├── instsim # 离线模型指令仿真dump数据,用于精度比对 │ │ │ │ │ └── trap │ │ │ │ └── nnn # 离线模型上板推理dump数据,用于精度比对 │ │ │ │ │ └── trap │ │ │ ├── log # 一键推理执行日志所在文件夹 │ │ │ ├── profiling # 性能分析结果保存路径 │ │ │ └── preprocess # 数据预处理结果保存路径 │ │ └── latest_result # 最后一次执行的oneclick输出路径 │ ├── acl_dump_XXX.json # acl配置文件(下发dump配置) │ ├── acl_XXX.json # acl配置文件(下发release配置) │ ├── acl_profiling_XXX.json # acl配置文件(下发profiling配置) │ └── project.cfg # 工程参数配置文件
说明:
当IS_DUMP_OPEN值为0时,trap目录中只会保存模型尾层输出。
PyTorch模型一键推理¶
PyTorch模型一键推理流程如图1所示。
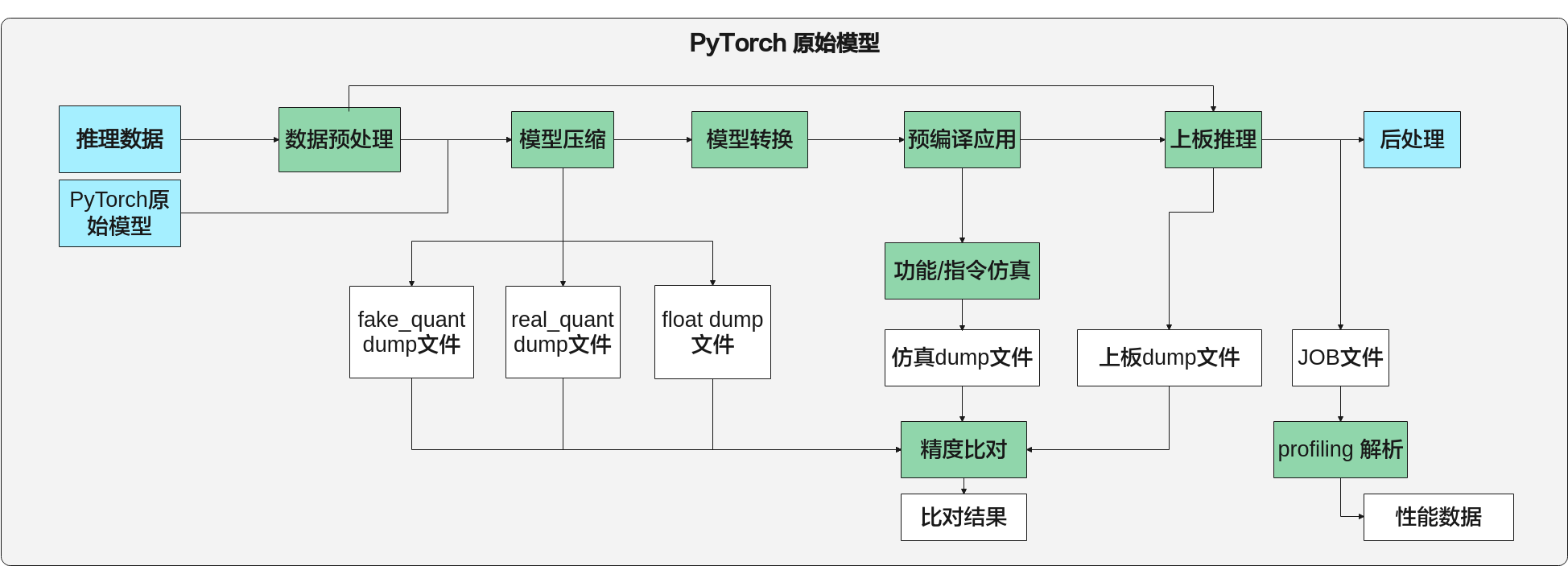
命令行格式说明¶
PyTorch模型一键推理的命令行格式如下。
mindcmd oneclick pytorch -m MODEL -i IMAGE_LIST --input_shape INPUT_SHAPE
PyTorch模型一键推理的命令行参数说明如表1所示。
表 1 PyTorch模型一键推理命令行参数说明
指定模型输入的shape。多输入模型按照输入顺序指定,用英文分号作为分割,用英文双引号括住,如 --input_shape="1,3,224,224;1,3,224,224"。 |
||
指定推理数据。支持图片列表(.txt)和feature map(.txt/.bin/.npy)格式。 工具按照传入路径参数后缀和文件内容区分图片列表或者feature map,具体规则如下。
多输入模型按照输入顺序指定,使用英文双引号包含,并用英文分号作为分割,如 --image_list="/home/MindCmdUser/image_list1.txt;/home/MindCmdUser/image_list2.txt"。 当未指定此参数时,工具将根据--input_shape参数所指定的shape信息,生成随机数feature map作为输入数据并用于推理。 |
||
指定数据预处理配置文件,参考数据预处理配置文件样例。 |
||
指定待处理数据的数据类型,只用于Feature map输入,不能用于图片输入。支持数据类型FP16, FP32, INT16, INT8, S16, S8, U16, U8, UINT16, UINT8。指定多个输入数据类型时,使用英文分号隔开,用英文双引号括住。eg.:--input_type="INT8;FP16" |
||
指定AMCT的简易量化配置文件(*.yml,*.yaml)或量化配置文件(*.json)。配置方式请参考《AMCT使用指南(PyTorch)》“静态图简易量化配置功能说明”章节。 |
||
rpn文件(.txt),当模型包含rpn硬化层时,此参数要求必传,且不执行AMCT和GT。 指定多个rpn文件时使用英文双引号包含,并用英文分号作为分割,如 --rpndata="/home/MindCmdUser/rpn1.txt;/home/MindCmdUser/rpn2.txt"。 |
||
指定多batch模型的batch数量。多输入多batch模型只需指定较大的那个batch值。如双路输入的模型,其中一路支持32batch,一路不支持多batch,则输入 --batch_num=32。 |
||
指定工作目录,否则使用默认工作路径 $HOME/MindCmd-WorkSpace/XXX,XXX根据运行的模型动态生成。 如果开启了上板推理开关(IS_NNN_RUN=1),则工作目录不能超出ssh.cfg文件配置小节中HOST_MOUNT_PATH配置的路径。 |
||
指定板端ssh挂载配置文件。ssh挂载需先进行NFS环境搭建,可参考NFS环境搭建。 ssh挂载配置文件的模板,可参考ssh.cfg文件配置。 |
||
输入一个前缀${prefix}用于删除${work_dir}/output/目录下所有名为“${prefix}_xxxxx”的文件夹,删除oneclick模块的历史输出目录。 例如:输入 --clean project 将会删除${work_dir}/output/目录下所有名为“project_xxxxx”的文件夹。 |
||
输入各参数的位置要求位于其所属子命令之后,例如:
mindcmd oneclick -k {WORK_DIR} pytorch -m {package.model.class} --input_shape {INPUT_SHAPE}
参数值格式:支持大小写字母(a-z,A-Z)、数字(0-9)、下划线(_)、中划线(-)、句点(.)。
当-i/--image_list指定图片列表的时候,图片列表的内容支持UTF-8编码的中文路径。
多输入场景支持featuremap和图片列表混输,eg. -i="${图片列表};${feature_map}"。
执行样例¶
模型和数据准备。
将推理所需的PyTorch模型文件以及所需的数据等上传到开发环境任意路径, 如/home/MindCmdUser/test_case,参考目录结构如下。
├── test_case │ ├── ssh.cfg # 可选,否则需要关闭上板推理 │ ├── pytorch_resnet50 │ │ ├── __init__.py │ │ ├── resnet.py # 必选 │ │ └── resnet50-19c8e357.pth │ ├── data # 可选,否则工具自动使用随机数推理 │ │ ├── dog1_1024_683.jpg │ │ ├── dog2_1024_683.jpg │ │ ├── insert_op.cfg │ │ └── image_ref_list.txt
配置PYTHONPATH环境变量:
export PYTHONPATH=/home/MindCmdUser/test_case:$PYTHONPATH 说明:推理数据的shape应该与模型所需输入数据的shape相同,如:模型resnet50的shape为(3, 224, 224),图片的shape也应为(3, 224, 224)。否则需要自定义数据预处理方式,通过--aapp参数指定数据预处理配置文件样例,数据预处理完整配置方式请参考《ATC工具使用指南》“--insert_op_conf ”章节。
当推理数据为图片且未指定数据预处理配置文件时,工具会根据--input_shape参数值,将所有图片Resize成模型所需输入数据的shape。
选择一键推理场景
执行一键推理前可以在mindcmd.ini文件中配置一键推理开关[oneclick_switch]
[oneclick_switch] # 是否清理当前工作目录下的历史输出结果 IS_CLEAN_PREVIOUS_OUTPUT=1 # 是否开启模型压缩 IS_AMCT_RUN=1 # 是否开启GT推理,支持Caffe、ONNX IS_GT_RUN=1 # 是否开启上板推理,开启需要配置ssh IS_NNN_RUN=0 # 是否开启功能仿真 IS_FUNC_RUN=1 # 是否开启指令仿真 IS_INST_RUN=0 # 是否在模型推理时开启Dump网络中间结果,作用于功能仿真、指令仿真、上板推理 IS_DUMP_OPEN=1 # 是否开启Dump数据精度比对 IS_COMPARE_OPEN=1 # 是否开启上板性能数据采集 IS_BOARD_PROFILING_OPEN=1 # 是否在控制台展示性能数据报告 IS_PROFILE_DISPLAY_OPEN=0 # 是否在控制台打印详细的执行日志 IS_PRINT_PROCESS_DETAIL=0
执行一键推理
执行以下命令进行一键推理:
cd test_case mindcmd oneclick pytorch -m pytorch_resnet50.resnet.resnet50 -i ./data/image_ref_list.txt --input_shape 1,3,224,224 --realquant
执行结果
PyTorch模型一键推理执行结束后会在工作路径下生成相应的文件,主要的目录结构如下。
├── work_space │ ├── bin # 可执行文件路径 │ ├── data │ │ ├── inference_data_XXX.txt # 推理数据 │ │ ├── insert_op.cfg # aapp配置 │ ├── model # om离线模型保存路径 │ ├── output │ │ ├── project_XXX │ │ │ ├── amct # 模型压缩输出路径 │ │ │ ├── atc # 模型转换输出路径 │ │ │ ├── cmp # 精度比对结果保存路径 │ │ │ ├── dump # dump结果保存路径 │ │ │ │ ├── float # 原始模型浮点dump数据,用于精度比对 │ │ │ │ ├── fake_quant # 量化后模型假量化dump数据,用于精度比对 │ │ │ │ ├── real_quant # 量化后模型真量化dump数据,用于精度比对 │ │ │ │ ├── funcsim # 离线模型功能仿真dump数据,用于精度比对 │ │ │ │ │ └── trap │ │ │ │ ├── instsim # 离线模型指令仿真dump数据,用于精度比对 │ │ │ │ │ └── trap │ │ │ │ └── nnn # 离线模型上板推理dump数据,用于精度比对 │ │ │ │ │ └── trap │ │ │ ├── log # 一键推理执行日志所在文件夹 │ │ │ ├── profiling # 性能分析结果保存路径 │ │ │ └── preprocess # 数据预处理结果保存路径 │ │ └── latest_result # 最后一次执行的oneclick输出路径 │ ├── acl_XXX.json # acl配置文件(下发release配置) │ ├── acl_dump_XXX.json # acl配置文件(下发dump配置) │ ├── acl_profiling_XXX.json # acl配置文件(下发profiling配置) │ └── project.cfg # 工程参数配置文件
说明:当IS_DUMP_OPEN值为0时,trap目录中只会保存尾层输出。
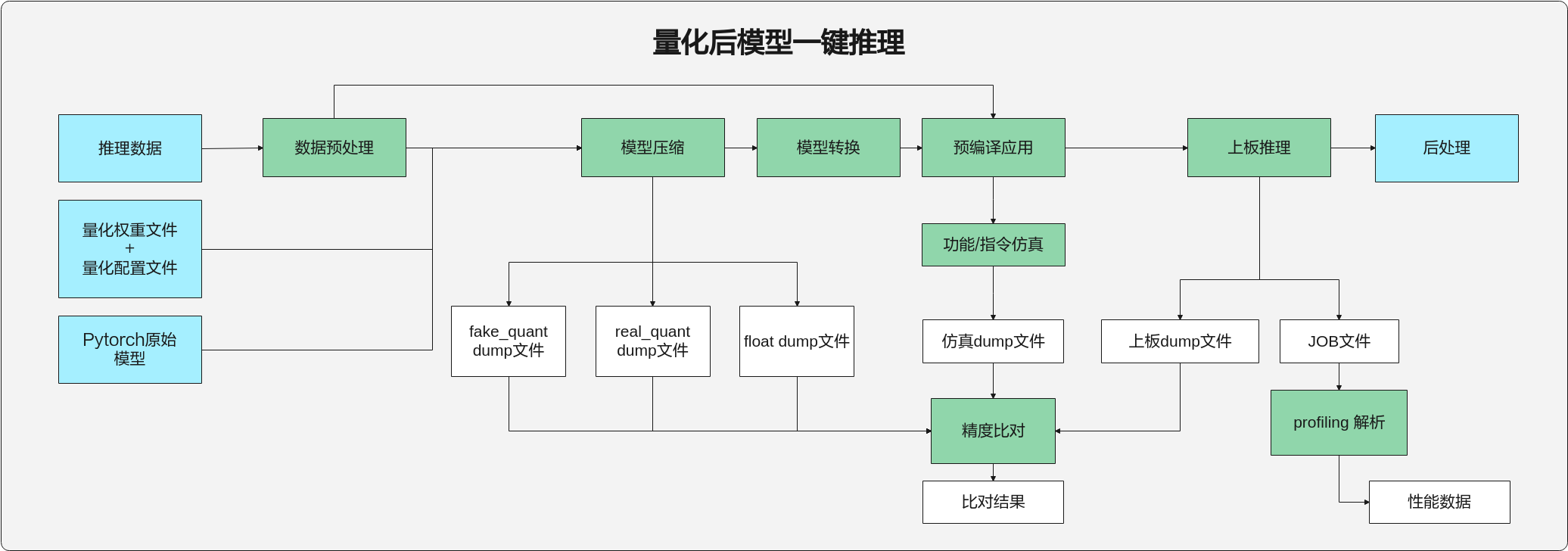
量化后模型一键推理¶
工具支持传入量化后的权重文件和量化配置文件执行量化后模型一键推理,流程如图1所示。命令行格式如下。
mindcmd oneclick pytorch -m MODEL -w WEIGHT -i IMAGE_LIST --input_shape INPUT_SHAPE --quant_config QUANT_CONFIG
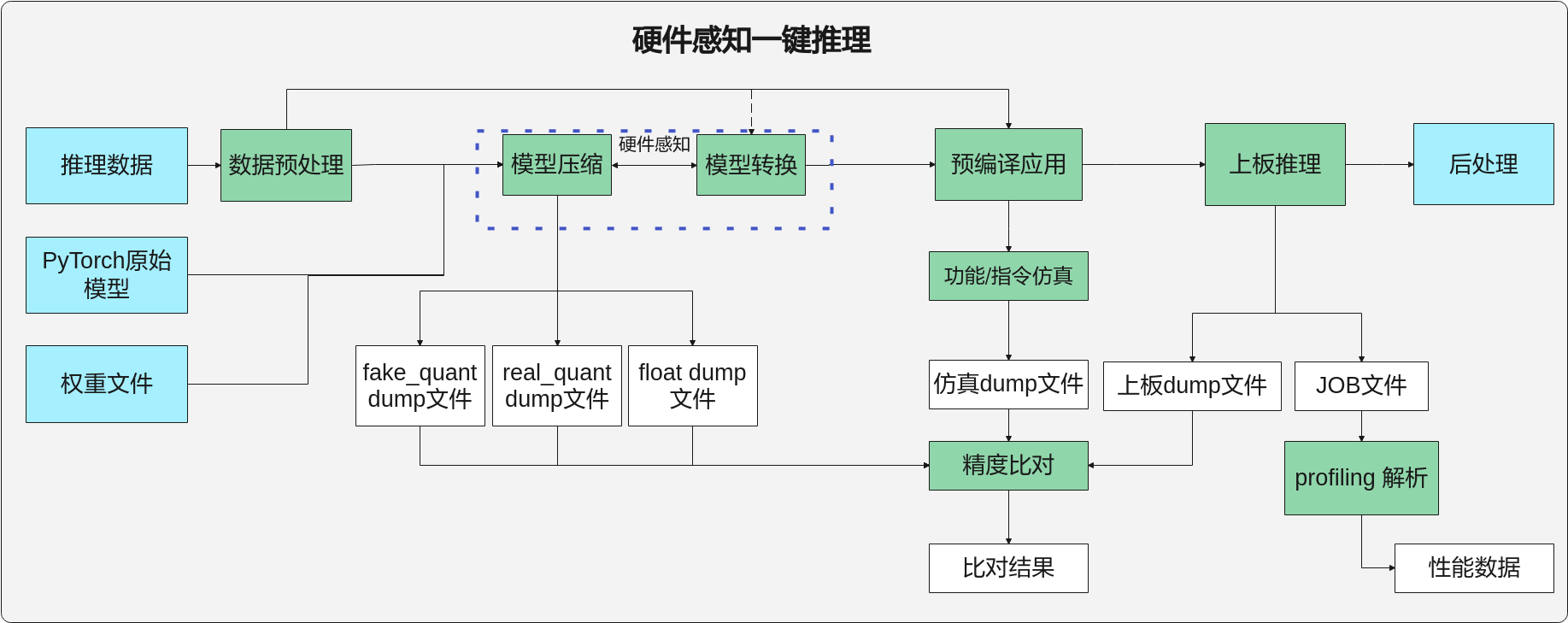
硬件感知一键推理¶
工具支持硬件感知一键推理流程,流程如图1所示。命令行格式如下。
mindcmd oneclick pytorch -m MODEL -i IMAGE_LIST --realquant
ONNX模型一键推理¶
ONNX模型一键推理流程如图1所示。
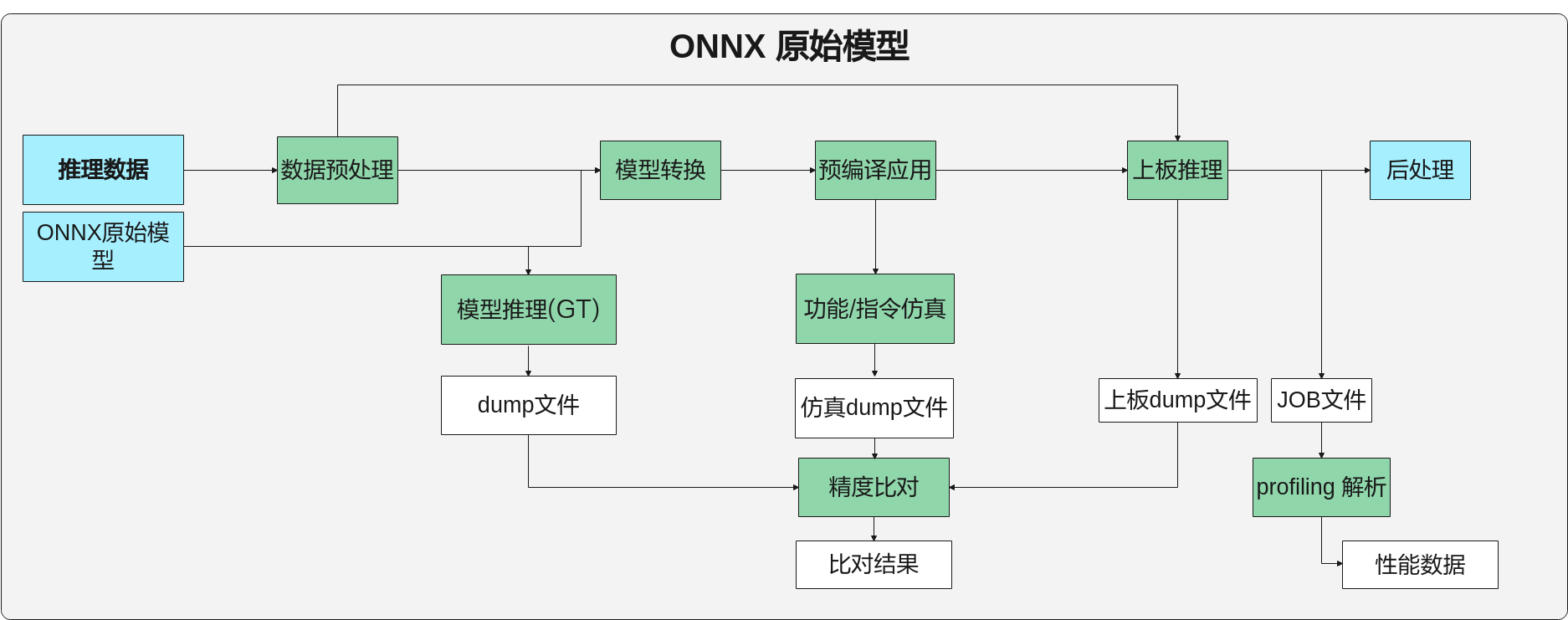
命令行格式说明¶
ONNX模型一键推理的命令行格式如下。
mindcmd oneclick onnx -m MODEL -i IMAGE_LIST
ONNX模型一键推理的命令行参数说明如表1所示。
表 1 ONNX模型一键推理命令行参数说明
指定推理数据。支持图片列表(.txt)和feature map(.txt/.bin/.npy)格式。 工具按照传入路径参数后缀和文件内容区分图片列表或者feature map,具体规则如下。
多输入模型按照输入顺序指定,使用双引号""包含,并用英文分号;作为分割,如 --image_list="/home/MindCmdUser/image_list1.txt;/home/MindCmdUser/image_list2.txt"。 |
||
指定数据预处理配置文件,参考数据预处理配置文件样例。 |
||
指定待处理数据的数据类型,只用于Feature map输入,不能用于图片输入。支持数据类型FP16, FP32, INT16, INT8, S16, S8, U16, U8, UINT16, UINT8。指定多个输入数据类型时,使用英文分号隔开,用双引号括住。eg.:--input_type="INT8;FP16" |
||
rpn文件(.txt),当模型包含rpn硬化层时,此参数要求必传,且不执行AMCT和GT。指定多个rpn文件时使用英文双引号""包含,并用英文分号;作为分割,如 --rpndata="/home/MindCmdUser/rpn1.txt;/home/MindCmdUser/rpn2.txt"。 |
||
指定多batch模型的batch数量。多输入多batch模型只需指定较大的那个batch值。如双路输入的模型,其中一路支持32batch,一路不支持多batch,则输入 --batch_num=32。 |
||
指定工作目录,否则使用默认工作路径 $HOME/MindCmd-WorkSpace/XXX,XXX根据运行的模型动态生成。 如果开启了上板推理开关(IS_NNN_RUN=1),则工作目录不能超出ssh.cfg文件配置小节中HOST_MOUNT_PATH配置的路径。 |
||
指定板端ssh挂载配置文件。ssh挂载需先进行NFS环境搭建,可参考NFS环境搭建。 ssh挂载配置文件的模板,可参考ssh.cfg文件配置。 |
||
输入一个前缀${prefix}用于删除${work_dir}/output/目录下所有名为“${prefix}_xxxxx”的文件夹,删除oneclick模块的历史输出目录。 例如:输入 --clean project 将会删除${work_dir}/output/目录下所有名为“project_xxxxx”的文件夹。 |
||
输入各参数的位置要求位于其所属子命令之后,例如:
mindcmd oneclick -k {WORK_DIR} onnx -m *.onnx
参数值格式:支持大小写字母(a-z,A-Z)、数字(0-9)、下划线(_)、中划线(-)、句点(.)。
当-i/--image_list指定图片列表的时候,图片列表的内容支持UTF-8编码的中文路径。
多输入场景支持feature map和图片列表混输,eg. -i="${图片列表};${feature_map}"。
执行样例¶
模型和数据准备。
将推理所需的ONNX模型文件以及所需的数据等上传到开发环境任意路径,参考目录如下。
├── test_case │ ├── ssh.cfg # 可选,否则需要关闭上板推理 │ ├── onnx_resnet50 │ │ └── resnet50.onnx # 必选 │ ├── data # 可选,否则工具自动使用随机数推理 │ │ ├── dog1_1024_683.jpg │ │ ├── dog2_1024_683.jpg │ │ ├── insert_op.cfg │ │ └── image_ref_list.txt
说明:推理数据的shape应该与模型所需输入数据的shape相同,如:模型resnet50的shape为(3, 224, 224),图片的shape也应为(3, 224, 224)。否则需要自定义数据预处理方式,通过--aapp参数指定数据预处理配置文件样例,数据预处理完整配置方式请参考《ATC工具使用指南》“--insert_op_conf ”章节。
当推理数据为图片且未指定数据预处理配置文件时,工具会将所有图片Resize成模型所需输入数据的shape大小。
选择一键推理场景
执行一键推理前可以在mindcmd.ini文件中配置一键推理开关[oneclick_switch]
[oneclick_switch] # 是否清理当前工作目录下的历史输出结果 IS_CLEAN_PREVIOUS_OUTPUT=1 # 是否开启模型压缩 IS_AMCT_RUN=1 # 是否开启GT推理,支持Caffe、ONNX IS_GT_RUN=1 # 是否开启上板推理,开启需要配置ssh IS_NNN_RUN=0 # 是否开启功能仿真 IS_FUNC_RUN=1 # 是否开启指令仿真 IS_INST_RUN=0 # 是否在模型推理时开启Dump网络中间结果,作用于功能仿真、指令仿真、上板推理 IS_DUMP_OPEN=1 # 是否开启Dump数据精度比对 IS_COMPARE_OPEN=1 # 是否开启上板性能数据采集 IS_BOARD_PROFILING_OPEN=1 # 是否在控制台展示性能数据报告 IS_PROFILE_DISPLAY_OPEN=0 # 是否在控制台打印详细的执行日志 IS_PRINT_PROCESS_DETAIL=0
执行一键推理
执行以下命令进行一键推理:
cd test_case mindcmd oneclick onnx -m ./onnx_resnet50/resnet50.onnx -i ./data/image_ref_list.txt
执行结果
ONNX模型一键推理执行结束后会在工作路径下生成相应的文件,主要的目录结构如下。
├── work_space │ ├── bin # 可执行文件路径 │ ├── data │ │ ├── inference_data_XXX.txt # 推理数据 │ │ ├── insert_op.cfg # aapp配置 │ ├── model # om离线模型保存路径 │ ├── output │ │ ├── project_XXX │ │ │ ├── atc # 模型转换输出路径 │ │ │ ├── cmp # 精度比对结果保存路径 │ │ │ ├── dump # dump结果保存路径 │ │ │ │ ├── float # 原始模型浮点dump数据,用于精度比对 │ │ │ │ ├── funcsim # 离线模型功能仿真dump数据,用于精度比对 │ │ │ │ │ └── trap │ │ │ │ ├── instsim # 离线模型指令仿真dump数据,用于精度比对 │ │ │ │ │ └── trap │ │ │ │ ├── atc_fake_quant # ATC量化dump数据,用于精度比对 │ │ │ │ └── nnn # 离线模型上板推理dump数据,用于精度比对 │ │ │ │ │ └── trap │ │ │ ├── log # 一键推理执行日志所在文件夹 │ │ │ ├── profiling # 性能分析结果保存路径 │ │ │ └── preprocess # 数据预处理结果保存路径 │ │ └── latest_result # 最后一次执行的oneclick输出路径 │ ├── acl_dump_XXX.json # acl配置文件(下发dump配置) │ ├── acl_XXX.json # acl配置文件(下发release配置) │ ├── acl_profiling_XXX.json # acl配置文件(下发profiling配置) │ └── project.cfg # 工程参数配置文件
说明:当IS_DUMP_OPEN值为0时,trap目录中只会保存尾层输出。
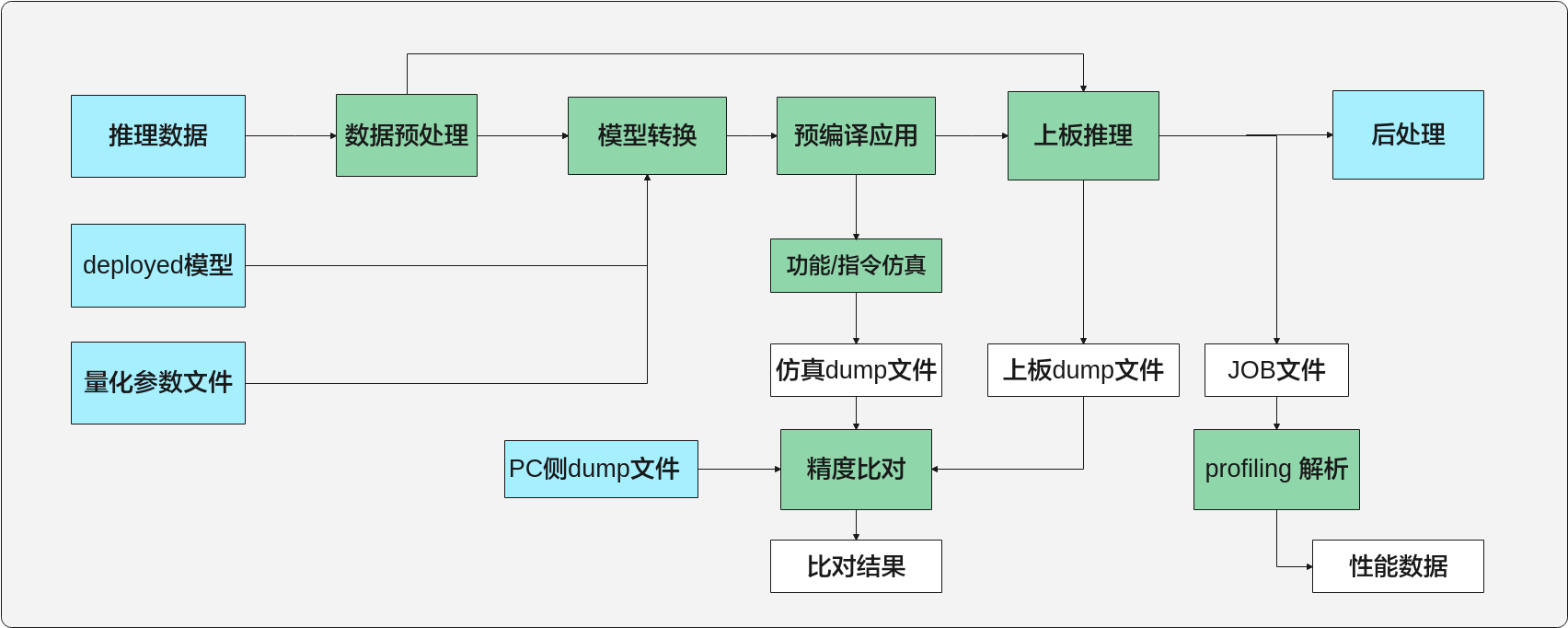
Deployed模型一键推理¶
针对单独调用AMCT PTQ或QAT生成的定点模型流程如图1所示。
数据预处理¶
功能介绍¶
此功能对数据进行预处理,生成AMCT/ATC/仿真/上板的推理数据(.npy 和 .bin格式)。
当前支持图像裁剪(crop)、图像边缘填充(padding)、图像缩放(resize)、色域转换、通道数据交换、减均值、乘系数。
命令行格式说明¶
数据预处理命令行格式如下。
mindcmd preprocess --model_input_shape MODEL_INPUT_SHAPE -i IMAGE_LIST
命令行参数说明如表1 所示
表 1 数据预处理命令行参数说明
参数值格式:支持大小写字母(a-z,A-Z)、数字(0-9)、下划线(_)、中划线(-)、句点(.)。
当-i/--image_list指定图片列表的时候,图片列表的内容支持UTF-8编码的中文路径。
多输入场景支持feature map和图片列表混输,eg. -i="${图片列表};${feature_map}"。
执行样例¶
模型和数据准备。
需要进行预处理的数据可进行如下准备:
├── data │ ├── dog1.jpg │ ├── dog2.jpg │ ├── insert_op.cfg │ └── image_ref_list.txt
执行数据预处理
执行以下命令进行数据预处理:
cd data mindcmd preprocess --model_input_shape 1,3,224,224 --aapp ./insert_op.cfg -i ./image_ref_list.txt -o ./preprocess_output/
-
数据预处理执行结束后会在指定输出路径下生成数据,主要目录结构如下。
├── preprocess_output │ ├── calibration_dataset # 校准数据集 │ │ ├── bin # bin格式数据 │ │ │ └── input_0_dog1_shape_1_3_224_224_FP32.bin │ │ ├── npy # npy格式数据 │ │ │ └── input_0_dog1_shape_1_3_224_224_FP32.npy │ │ └── original # 原始输入数据 │ │ │ └── dog1.jpg │ ├── validation_dataset # 验证数据集 │ │ ├── bin # bin格式数据 │ │ │ └── input_0_dog2_bgr_planar_shape_1_3_224_224_U8.bin │ │ ├── npy # npy格式数据 │ │ │ └── input_0_dog2_shape_1_3_224_224_FP32.npy │ │ └── original # 原始输入数据 │ │ │ └── dog2.jpg │ ├── input_format # 按input_format解析的原始输入数据 │ ├── input0_calibration_npy_FP32.txt # 保存了npy格式校准数据的路径 │ ├── input0_validation_bin_FP32.txt # 保存了bin格式验证数据的路径 │ ├── input0_validation_npy_FP32.txt # 保存了npy格式验证数据的路径 │ └── insert_op.cfg # 数据预处理配置文件
说明:当用户传入的-i/--image_list有多组数据且每组的数据个数不等时,MindCmd将采用最小的数据个数作为预处理操作的图片个数。示例:
mindcmd preprocess --model_input_shape "1,3,2,2;1,3,4,4" --image_list "./pic1.txt;./pic2.txt"如果pic1.txt中有4张图片,pic2.txt中有2张图片,那么MindCmd执行预处理时pic1.txt中的最后两张图片不会被处理,以保证每路输入的数据个数是相同的。
关于校准数据集和验证数据集的说明: 如果输入为N张图片,那么MindCmd将使用前N-1张数据作为校准集数据,第N张图片作为验证集数据(当只有一张图片时,该图片既作为校准集数据,也作为验证集数据)。
预处理的输出生成件命名与实际配置的insert_op相关,上述执行结果中的示例仅供参考,生成件文件名描述的shape、input_format等以实际配置为准。
开源框架推理¶
功能介绍¶
该功能支持开源框架(Caffe/ONNX)推理,生成的dump数据可用于精度比对。
Caffe模型推理¶
命令行格式说明¶
Caffe模型推理的命令行格式如下。
mindcmd gt caffe -w WEIGHT -m MODEL -i IMAGE_LIST
命令行参数说明如表1所示
表 1 Caffe模型推理命令行参数说明
指定Caffe模型的权重文件(.caffemodel)路径,未指定将根据-m/--model参数指定的模型定义文件生成随机权重文件,位于-o/--output指定的数据输出路径下。 |
||
执行推理模型所需的数据集(.txt)。txt文件内要求为.npy、.bin或者.txt格式的feature map推理数据,每行定义一条推理数据的路径。 |
||
参数值格式:支持大小写字母(a-z,A-Z)、数字(0-9)、下划线(_)、中划线(-)、句点(.)。
当-i/--image_list指定图片列表的时候,图片列表的内容支持UTF-8编码的中文路径。
执行样例¶
数据准备
执行开源框架前需要提前准备推理数据(参考数据预处理),参考文件结构如下。
├── test_case │ ├── caffe_resnet50 │ │ ├── resnet50.caffemodel │ │ └── resnet50.prototxt │ ├── data │ │ ├── data_dog1_shape_1_3_224_224_float32.npy │ │ ├── data_dog2_shape_1_3_224_224_float32.npy │ │ └── image_ref_list.txt
执行模型推理
执行以下命令进行模型推理:
cd test_case mindcmd gt caffe -m ./caffe_resnet50/resnet50.prototxt -w ./caffe_resnet50/resnet50.caffemodel -i ./data/image_ref_list.txt -o ./gt_output/
执行结果
执行结束后会在指定输出路径中生成Ground Truth dump数据,主要文件结构示例如下。
├── gt_output │ ├── ${时间戳}_ops │ │ ├── 0 # 第0个推理过程中每一层的dump文件(.npy) │ │ └── 1 # 第1个推理过程中每一层的dump文件(.npy)
ONNX模型推理¶
命令行格式说明¶
ONNX模型推理的命令行格式如下。
mindcmd gt onnx -m MODEL -i IMAGE_LIST
命令行参数说明如表1所示
表 1 ONNX模型推理命令行参数说明
参数值格式:支持大小写字母(a-z,A-Z)、数字(0-9)、下划线(_)、中划线(-)、句点(.)。
当-i/--image_list指定图片列表的时候,图片列表的内容支持UTF-8编码的中文路径。
执行样例¶
数据准备
执行开源框架前需要提前准备推理数据(处理方法参考数据预处理),参考文件结构如下。
├── test_case │ ├── onnx_resnet50 │ │ └── resnet50.onnx │ ├── data │ │ ├── npy_data │ │ ├── data_dog1_shape_1_3_224_224_float32.npy │ │ ├── data_dog2_shape_1_3_224_224_float32.npy │ │ └── image_ref_list.txt
执行模型推理
执行以下命令进行模型Ground Truth推理:
cd test_case mindcmd gt onnx -m ./onnx_resnet50/resnet50.onnx -i ./data/image_ref_list.txt -o ./gt_output/
执行结果
执行结束后会在指定输出路径中生成Ground Truth dump数据,主要文件结构示例如下。
├── gt_output │ ├── ${时间戳}_ops │ │ ├── 0 # 第0个推理过程中每一层的dump文件(.npy) │ │ └── 1 # 第1个推理过程中每一层的dump文件(.npy)
模型压缩¶
功能介绍¶
该功能支持对开源框架(Caffe/PyTorch)的模型压缩,从而达到节省网络模型存储空间、降低传输时延、提高计算效率,达到性能提升与优化的目标。
Caffe模型压缩¶
命令行格式说明¶
Caffe模型压缩的命令行格式如下。
mindcmd amct caffe -w WEIGHT -m MODEL -i IMAGE_LIST -o OUTPUT
Caffe模型压缩的命令行参数说明如表1所示。
表 1 Caffe模型压缩命令行参数说明
Caffe模型的权重文件( .caffemodel)路径。未指定将根据-m/--model参数指定的模型定义文件生成随机权重文件,位于模型定义文件所在路径下。 |
||
指定AMCT的简易量化配置文件(*.cfg)或量化配置文件(*.json)。配置方式请参考《AMCT使用指南(Caffe)》。 说明:
通过--quant_config可以先对模型进行调试,符合预期后将量化的deployed模型使用Caffe模型一键推理部署。 |
||
参数值格式:支持大小写字母(a-z,A-Z)、数字(0-9)、下划线(_)、中划线(-)、句点(.)。
当-i/--image_list指定图片列表的时候,图片列表的内容支持UTF-8编码的中文路径。
执行样例¶
模型和数据准备。
将需要进行模型压缩的Caffe模型文件(.prototxt)、权重文件(.caffemodel)以及所需的数据(feature_map)等上传到服务器工作路径,参考目录结构如下。
├── test_case │ ├── caffe_resnet50 │ │ ├── resnet50.caffemodel │ │ └── resnet50.prototxt │ ├── data │ │ ├── data_dog1_shape_1_3_224_224_float32.npy │ │ ├── data_dog2_shape_1_3_224_224_float32.npy │ │ └── image_ref_list.txt
执行模型压缩
执行以下命令进行模型压缩:
cd test_case mindcmd amct caffe -m ./caffe_resnet50/resnet50.prototxt -w ./caffe_resnet50/resnet50.caffemodel -i ./data/image_ref_list.txt -o ./amct_output
执行结果
Caffe模型压缩执行结束后会在输出路径下生成相应的文件,主要文件结构示例如下。
├── amct_output │ ├── resnet50_tmp │ ├── amct_log │ │ └── amct_caffe.log │ ├── resnet50_config.json │ ├── resnet50_deploy_model.prototxt │ ├── resnet50_deploy_weights.caffemodel │ ├── resnet50_fake_quant_model.prototxt │ ├── resnet50_fake_quant_weights.caffemodel │ ├── resnet50_quant.json │ ├── resnet50_quant_param_record.bin │ ├── resnet50_quant_param_record.txt │ └── resnet50_uninplace.prototxt
对应文件的描述如表1所示。
表 1 Caffe模型压缩结果文件描述
PyTorch模型压缩¶
命令行格式说明¶
PyTorch模型压缩的命令行格式如下。
mindcmd amct pytorch -m MODEL -i IMAGE_LIST -o OUTPUT
PyTorch模型压缩的命令行参数说明如表1所示。
表 1 PyTorch模型压缩命令行参数说明
指定模型的shape。多输入模型按照输入顺序指定,用分号;作为分割,用双引号括住,如 --input_shape="1,3,224,224;1,3,224,224"。 当未指定-i, --image_list参数时,此参数要求必传,工具将根据输入的shape信息生成随机数feature map,位于-o, --output指定的数据输出路径下。 |
||
指定AMCT的简易量化配置文件(*.yml, *.yaml)或量化配置文件(*.json)。配置方式请参考《AMCT使用指南(PyTorch)》“静态图简易量化配置功能说明”章节。 说明:
通过--quant_config可以先对模型进行调试,符合预期后将量化的deployed模型使用oneclick部署。 |
||
参数值格式:支持大小写字母(a-z,A-Z)、数字(0-9)、下划线(_)、中划线(-)、句点(.)。
当-i/--image_list指定图片列表的时候,图片列表的内容支持UTF-8编码的中文路径。
执行样例¶
模型和数据准备。
将需要进行模型压缩的PyTorch模型文件以及所需的数据(.npy)等上传到服务器工作路径,如/home/MindCmdUser/test_case,参考目录结构如下。
├── test_case │ ├── pytorch_resnet50 │ │ ├── __pycache__ │ │ ├── __init__.py │ │ ├── resnet.py │ │ └── resnet50-19c8e357.pth │ ├── data │ │ ├── data_dog1_shape_1_3_224_224_float32.npy │ │ ├── data_dog2_shape_1_3_224_224_float32.npy │ │ └── image_ref_list.txt
配置PYTHONPATH环境变量:
export PYTHONPATH=/home/MindCmdUser/test_case:$PYTHONPATH执行模型压缩
执行以下命令进行模型压缩:
cd test_case mindcmd amct pytorch -m pytorch_resnet50.resnet.resnet50 -i ./data/image_ref_list.txt -o ./amct_output
执行结果
PyTorch模型压缩执行结束后会在指定输出路径下生成相应的文件,主要文件结构示例如下。
├── amct_output │ ├── tmp │ ├── amct_log │ │ └── hotwheels.amct_pytorch.log │ ├── resnet50_deploy_model.onnx │ ├── resnet50_calibration.pt │ └── resnet50_quant_param_record.txt
对应文件的描述如表1所示。
表 1 模型压缩结果文件描述
模型转换¶
功能介绍¶
该功能将开源框架模型(Caffe/ONNX)转换成图像分析引擎支持的离线模型,模型转换过程中可以实现算子调度的优化、权值数据重排、内存使用优化等,可以脱离设备完成模型的预处理。
命令行格式说明¶
模型转换功能的命令行格式如下。
mindcmd atc [-c | -a [[...]]]
命令行参数说明如表1所示。
表 1 模型转换命令行参数说明
执行样例¶
数据准备
执行模型转换前需准备相应的模型和数据(以Caffe模型为例),其文件结构如下。
├── atc_resoure │ ├── data │ │ └── dog1_1024_683.bin │ ├── caffe_resnet50 │ │ ├── resnet50.prototxt │ │ └── resnet50.caffemodel
执行模型转换
执行以下命令进行模型转换:
cd atc_resoure mindcmd atc -a --model=./caffe_resnet50/resnet50.prototxt --weight=./caffe_resnet50/resnet50.caffemodel --image_list="data:./data/dog1_1024_683.bin" --output=./atc_output/resnet50 --input_type="data:U8"
说明:
以上执行示例中--image_list参数和--input_type的参数值开头的“data”为网络首层节点名称,请根据网络实际情况进行替换。执行结果
模型转换执行结束后会在指定输出路径中生成数据,主要文件结构示例如下。
├── atc_output │ ├── atc_perf.csv # 预估模型在板端运算时实际计算量 │ ├── calibration_param.txt # 模型使用的量化参数 │ ├── cnn_net_tree.dot # 网络优化后的算子信息 │ ├── cnn_net_tree_adapt.dot # 网络适配后的算子信息 │ ├── cnn_net_tree_after_tiling_seg_0.dot # 网络深度融合后的算子信息 │ ├── cnn_net_tree_org.dot │ ├── cnn_net_tree_parser.dot # 原始模型解析后的算子信息 │ ├── cnn_net_tree_shape5d_seg_0.dot │ ├── resnet50.om # 转换后的模型文件 │ └── mapper_debug.log # 转换模型的调试日志
应用工程¶
功能介绍¶
提供应用工程功能仿真、指令仿真、上板推理、Dump中间结果和Profiling功能。
功能仿真¶
命令行格式说明¶
功能仿真的命令行格式如下。
mindcmd app funcsim -m OM -i IMAGE_LIST {dump} ...
命令行参数说明如表1所示。
命令行中的app、funcsim、dump子命令存在父子关系,因此输入需满足先后顺序。
功能仿真要求输入的om模型在经过ATC模型转换时已经设置了--save_original_model=true。
表 1 功能仿真命令行参数说明
指定工作路径,否则使用表1中配置的默认工作路径。 |
||
指定Recurrent网络(包含LSTM/RNN/GRU层)每一句话的最大帧数,用于板端运行时分配输入内存。与-b互斥。 |
||
指定rpn文件(.txt),当模型包含rpn硬化层时,此参数要求必传,且不执行AMCT和GT。 指定多个rpn文件时使用双引号""包含,并用分号;作为分割,如 --rpndata="/home/MindCmdUser/rpn1.txt;/home/MindCmdUser/rpn2.txt"。 |
||
指定推理结果存放路径,默认为 ${work_dir}/dump。当同时指定dump子命令中的--output命令时,以dump子命令的--output为准。 |
||
dump开关,如果指定此子命令表示开启dump,将根据-m/--om指定的离线模型文件生成包含dump配置的acl.json文件。默认关闭dump功能。 |
||
指定想要dump的层。如果指定多层,请使用空格作为分割 eg. --dump_list conv1 pool1。不指定--dump_list时,默认dump所有层。 |
||
参数值格式:支持大小写字母(a-z,A-Z)、数字(0-9)、下划线(_)、中划线(-)、句点(.)。
当-i/--image_list指定图片列表的时候,图片列表的内容支持UTF-8编码的中文路径。
执行样例¶
模型和数据准备
参考目录结构如下。
├── test_case │ ├── resnet50 │ │ └── resnet50.om │ ├── data │ │ ├── dog1_shape_1_3_224_224_uint8.bin │ │ ├── dog2_shape_1_3_224_224_uint8.bin │ │ └── image_ref_list.txt
配置默认工作路径(可选)
使用mindcmd.ini文件[base_config] section 下配置的默认工作路径,或通过命令行参数-k/--work_dir指定工作路径
[base_config] DEFAULT_WORKSPACE=/home/MindCmdUser/workspace/
执行功能仿真
执行以下命令完成功能仿真:
cd test_case mindcmd app funcsim -m ./resnet50/resnet50.om -i ./data/image_ref_list.txt dump
执行结果
功能仿真执行结果保存在工作路径下,主要目录结构示例如下。
├── workspace │ ├── bin │ ├── data │ ├── dump │ ├── model │ └── acl_xxxxxxxx.json
指令仿真¶
命令行格式说明¶
指令仿真的命令行格式如下。
mindcmd app instsim -m OM -i IMAGE_LIST {dump} ...
命令行参数说明如表1所示。
表 1 指令仿真命令行参数说明
指定工作路径,否则使用表1中配置的默认工作路径。 |
||
指定Recurrent网络(包含LSTM/RNN/GRU层)每一句话的最大帧数,用于板端运行时分配输入内存。与-b互斥。 |
||
指定rpn文件(.txt),当模型包含rpn硬化层时,此参数要求必传,且不执行AMCT和GT。 指定多个rpn文件时使用双引号""包含,并用分号;作为分割,如 --rpndata="/home/MindCmdUser/rpn1.txt;/home/MindCmdUser/rpn2.txt"。 |
||
指定推理结果存放路径,默认为 ${work_dir}/dump。当同时指定dump子命令中的--output命令时,以dump子命令的--output为准。/ |
||
dump开关,如果指定此子命令表示开启dump,将根据-m/--om指定的离线模型文件生成包含dump配置的acl.json文件。默认关闭dump功能。 |
||
指定想要dump的层。如果指定多层,请使用空格作为分割 eg. --dump_list conv1 pool1。不指定--dump_list时,默认dump所有层。 |
||
参数值格式:支持大小写字母(a-z,A-Z)、数字(0-9)、下划线(_)、中划线(-)、句点(.)。
当-i/--image_list指定图片列表的时候,图片列表的内容支持UTF-8编码的中文路径。
执行样例¶
模型和数据准备
参考目录结构如下。
├── test_case │ ├── resnet50 │ │ └── resnet50.om │ ├── data │ │ ├── dog1_shape_1_3_224_224_uint8.bin │ │ ├── dog2_shape_1_3_224_224_uint8.bin │ │ └── image_ref_list.txt
配置默认工作路径(可选)
使用mindcmd.ini文件[base_config] section 下配置的默认工作路径,或通过命令行参数-k/--work_dir指定工作路径。
[base_config] DEFAULT_WORKSPACE=/home/MindCmdUser/workspace/
执行指令仿真
执行以下命令进行指令仿真:
cd test_case mindcmd app instsim -m ./resnet50/resnet50.om -i ./data/image_ref_list.txt dump
执行结果
指令仿真执行结果保存在工作路径下,主要目录结构示例如下。
├── workspace │ ├── bin │ ├── data │ ├── dump │ ├── model │ └── acl_xxxxxxxx.json
上板推理¶
命令行格式说明¶
上板推理的命令行格式如下。
mindcmd app nnn -s SSH_CONFIG -m OM -i IMAGE_LIST {dump,profile} …
命令行参数说明如表1所示。
表 1 上板推理命令行参数说明
指定工作路径,否则使用表1中配置的默认工作路径。上板推理要求工作路径必须在HOST_MOUNT_PATH下。 |
||
指定Recurrent网络(包含LSTM/RNN/GRU层)每一句话的最大帧数,用于板端运行时分配输入内存。与-b互斥。 |
||
指定rpn文件(.txt),当模型包含rpn硬化层时,此参数要求必传,且不执行AMCT和GT。 指定多个rpn文件时使用双引号""包含,并用分号;作为分割,如 --rpndata="/home/MindCmdUser/rpn1.txt;/home/MindCmdUser/rpn2.txt"。 |
||
指定板端ssh挂载配置文件。ssh挂载需先进行NFS环境搭建,可参考NFS环境搭建。 ssh挂载配置文件的模板,可参考ssh.cfg文件配置。 |
||
指定推理结果存放路径,默认为 ${work_dir}/dump。当同时指定子命令中的--output命令时,以子命令的--output为准。 |
||
上板dump模型中间结果开关,与profile互斥。如果指定此子命令表示开启dump,将根据-m/--om指定的离线模型文件生成包含dump配置的acl.json文件。默认关闭dump功能。 |
||
上板Profiling数据采集开关,与dump互斥。如果指定此子命令表示开启Profiling,将根据-m/--om指定的离线模型文件生成包含Profiling配置的acl.json文件。默认关闭Profiling功能。 |
||
指定想要dump的层。如果指定多层,请使用空格作为分割 eg. --dump_list conv1 pool1。不指定--dump_list时,默认dump所有层。 |
||
参数值格式:支持大小写字母(a-z,A-Z)、数字(0-9)、下划线(_)、中划线(-)、句点(.)。
当-i/--image_list指定图片列表的时候,图片列表的内容支持UTF-8编码的中文路径。
执行样例¶
模型和数据准备
参考目录结构如下。
├── test_case │ ├── ssh.cfg │ ├── resnet50 │ │ └── resnet50.om │ ├── data │ │ ├── dog1_shape_1_3_224_224_uint8.bin │ │ ├── dog2_shape_1_3_224_224_uint8.bin │ │ └── image_ref_list.txt
配置默认工作路径(可选)
使用全局配置文件[base_config] section 下配置的默认工作路径,或通过命令行参数-k/--work_dir指定工作路径。
[base_config] DEFAULT_WORKSPACE=/home/MindCmdUser/workspace/
准备ssh.cfg文件,参考ssh.cfg文件配置
ssh.cfg文件配置优先级如下:-s/--ssh_config参数配置 > mindcmd.ini中的全局配置(SSH_CFG_PATH)。
执行上板推理(以开启dump为例)
执行以下命令进行上板推理:
cd test_case mindcmd app nnn -m ./resnet50/resnet50.om -i ./image_ref_list.txt dump
执行结果
上板推理结果保存在工作路径下,主要目录结构示例如下。
├── workspace │ ├── bin │ ├── data │ ├── dump │ ├── model │ ├── project.cfg │ └── acl_xxxxxxxx.json
精度比对¶
功能介绍¶
该功能将自有模型算子的运算结果与标准算子的运算结果进行比对,以便确认误差发生的算子,目前提供的比对指标有:余弦相似度、最大绝对误差、累计相对误差、相对欧几里德距离、KL散度、标准偏差等。
命令行格式说明¶
精度比对的命令行格式如下。
mindcmd compare -l MY_DUMP_PATH -r GOLDEN_DUMP_PATH
命令行参数说明如表1所示。
表 1 精度比对命令行参数说明
执行样例¶
dump数据准备
参考目录结构如下。
├── compare_resoure │ ├── func_dump # 功能仿真dump文件所在目录 │ └── nnn_dump # 上板推理dump文件所在目录
执行精度比对
执行以下命令进行精度比对:
cd compare_resoure mindcmd compare -l ./nnn_dump/ -r ./func_dump -out ./compare_output/
执行结果
精度比对执行结束后会在指定输出路径中生成对应csv文件,主要文件结构示例如下。
├── compare_output │ └── result_20221008101324.csv # result_{时间戳}.csv
文件内容如图1所示数据,参数说明请参考《精度比对工具使用指南》。
控制台会展示精度比对简易的执行结果,如图2。


性能分析¶
功能介绍¶
该功能用于分析SOC上的推理业务各个运行阶段的关键性能指标,用户可根据输出的性能数据针对关键性能瓶颈做出优化以实现产品的极致性能。
该功能对硬件和软件性能数据的采集和展示包括以下内容。
硬件:AA Core、AA Vector Core等模块的PMU指标及系统硬件性能指标。
软件:ACL等模块的性能指标数据。
命令行格式说明¶
Profile包含merge、show、collect三种操作。
merge操作将板端收集到的数据进行解析,导出timeline数据、summary数据、event view数据。
merge的命令行格式如下。
mindcmd profile merge -d COLLECTION_PATH
命令行参数说明如表1所示。
表 1 性能数据解析命令行参数说明
show操作将解析结果进行展示。
show的命令行格式如下。
mindcmd profile show -d COLLECTION_PATH
命令行参数说明如表2所示。
表 2 性能数据展示命令行参数说明
collect操作自动采集性能原始数据,并解析。
collect的命令行格式如下。
mindcmd profile collect -m MAIN -s SSH_CONFIG命令行参数说明如表3所示。
表 3 性能数据采集命令行参数说明
ssh配置文件的路径,具体配置内容见ssh.cfg文件配置。
执行样例¶
执行性能分析
模型和数据准备
性能分析前需要准备相应的性能文件,所准备的文件结构可参考如下。
├── profile_resoure │ ├── JOBXXXXXXXX │ │ ├── data │ │ └── info.json.0
执行以下命令进行性能分析:
cd profile_resoure mindcmd profile merge -d ./JOBXXXXXXXX
执行结果
性能分析执行结束后会在默认工作路径/home/MindCmdUser/profile_resoure/JOBXXXXXXXX中生成数据,主要文件结构示例如下。
├── profile_resoure │ ├── JOBXXXXXXXX │ │ ├── data │ │ ├── eventview │ │ ├── log │ │ ├── sqlite │ │ ├── summary │ │ ├── timeline │ │ └── info.json.0
执行性能分析展示
执行以下命令进行性能分析展示:
cd profile_resoure mindcmd profile show -d ./JOBXXXXXXXX
执行结果
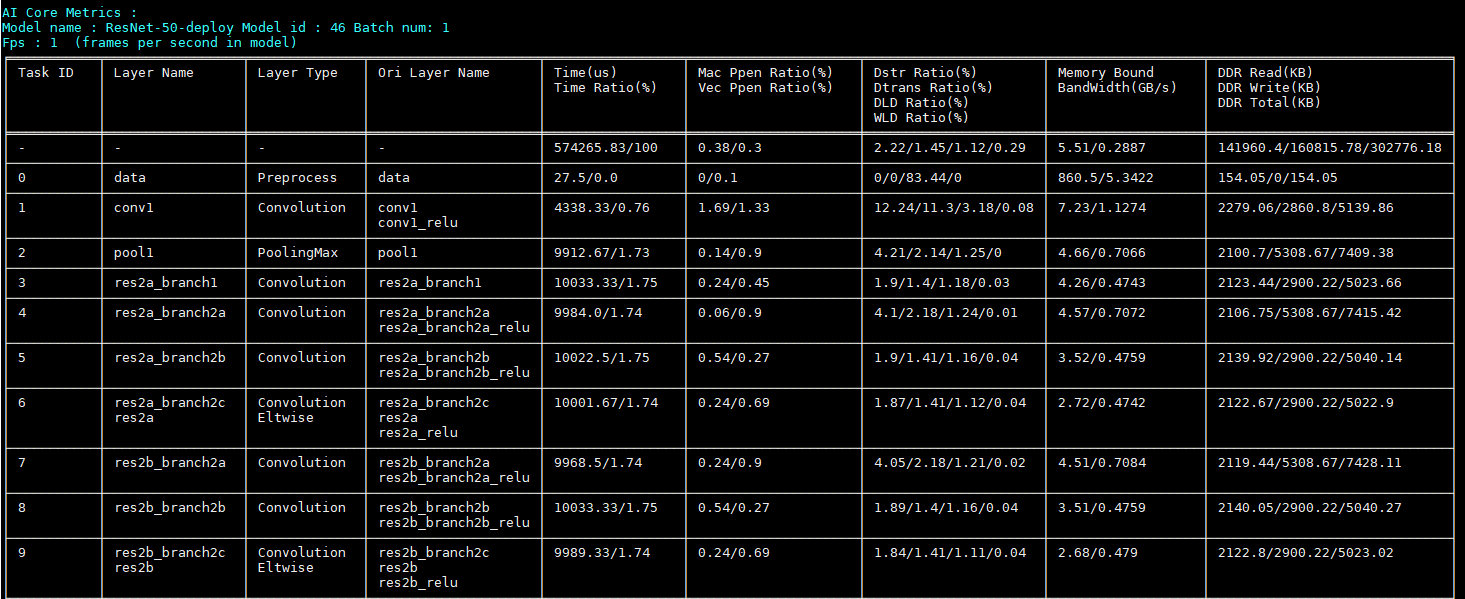
性能分析结果展示在控制台上,如图1,具体结果可参考《Profiling工具使用指南》“展示Profiling数据”章节。
执行性能数据采集
文件准备
请预先准备工程,主要工程目录及文件如下(以新建ACL ResNet50为例)。
├── 工程名 │ ├── .idea //IntelliJ IDEA自动创建的,用于存放项目的配置信息。 │ ├── build │ │ ├──cmake //存放cmake依赖文件 │ ├── data //存放data示例 │ ├── inc │ │ ├── model_process.h //声明模型处理相关函数的头文件 │ │ ├── sample_process.h //声明资源初始化/销毁相关函数的头文件 │ │ ├── utils.h //声明公共函数(例如:文件读取函数)的头文件 │ ├── out //存放编译出的可执行文件 │ │ ├── main │ ├── src │ │ ├── acl.json //系统初始化的配置文件 │ │ ├── CMakeLists.txt //编译脚本 │ │ ├── main.cpp //主函数,图片分类功能的实现文件 │ │ ├── model_process.cpp //模型处理相关函数的实现文件 │ │ ├── sample_process.cpp //资源初始化/销毁相关函数的实现文件 │ │ ├── utils.cpp //公共函数(例如:文件读取函数)的实现文件 │ ├── .project //工程信息文件,包含工程类型、工程描述、运行目标设备类型、CANN版本号等 │ ├── CMakeLists.txt //编译脚本,调用src目录下的CMakeLists文件
其中,main文件是根据工程编译的板端可执行文件,同时性能数据采集需要配置acl.json,内容如下。
{ "profiler":{ "output":"/home/MindCmdUser/profiling", "aacpu":"on", "aac_metrics":"ArithmeticUtilization", "interval":"0", "acl_api":"on", "switch":"on" } }
执行以下命令进行性能数据采集:
mindcmd profile collect -m MAIN 注意:
命令中MAIN表示工程中main文件的路径。
注意:
命令中MAIN表示工程中main文件的路径。执行结果
性能数据采集执行结束后会在上板项目目录下的profiling文件夹生成数据,主要文件结构示例如下。
├── project │ ├──profiling │ │ ├── JOBXXXXXXXX │ │ │ ├── data │ │ │ ├── log │ │ │ ├── sqlite │ │ │ ├── summary │ │ │ ├── timeline │ │ │ └── info.json.0
Tools¶
Caffe模型子网导出¶
该功能用于原始Caffe网络的剪切。
命令行格式说明¶
Caffe模型子网导出命令行格式如下。
mindcmd subnet -m MODEL_FILE -w WEIGHT_FILE -s START_LAYER -e END_LAYER
命令行参数说明如表1所示。
表 1 Caffe模型子网导出命令参数说明
执行样例¶
模型和数据准备
性能分析前需要准备相应的Caffe模型,所准备的文件结构可参考如下。
├── caffe_model_split │ ├── resnet50 │ │ ├── resnet50.caffemodel │ │ └── resnet50.prototxt
执行模型分割
进入MindCmd工程路径下,执行以下命令。
cd caffe_model_split mindcmd subnet -m ./resnet50/resnet50.prototxt -w ./resnet50/resnet50.caffemodel -s conv1 -e pool1 -o ./split_output
执行结果
性能分析执行结束后会在默认工作路径中生成数据,主要文件结构示例如下。
├── split_output │ ├── dump.caffemodel # 子模型权重 │ └── dump.prototxt # 子模型 └── shape_1665740903824.json # 原始模型.json
cmd命令转换为cfg文件¶
该功能用于将cmd命令转换为cfg文件保存。
命令行格式说明¶
cmd命令转换为cfg文件的命令行格式如下。
mindcmd cmdtrans -s CFG_SAVED_PATH -a [ARGS [ARGS ...]]
命令行参数说明如表1所示
表 1 cmd命令转cfg文件参数说明
执行样例¶
创建cfg文件保存路径,如/home/MindCmdUser/cfg_output
执行cmd命令转换
进入MindCmd工程路径下,执行以下命令。
mindcmd cmdtrans -s /home/MindCmdUser/cfg_output/resnet50.cfg -a --model="/home/MindCmdUser/atc_resoure/caffe_resnet50/caffe/resnet50.prototxt" --weight="/home/MindCmdUser/atc_resoure/caffe_resnet50/caffe/resnet50.caffemodel" --image_list="/home/MindCmdUser/atc_resoure/data/nnn_dog1_1024_683_uint8.bin" --output="/home/MindCmdUser/atc_output/resnet50"执行结果
cmd命令转换执行结束后会在默认工作路径/home/MindCmdUser/cfg_output/中生成resnet50.cfg文件,文件结构示例如下。
[model] /home/MindCmdUser/atc_resoure/caffe_resnet50/caffe/resnet50.prototxt [weight] /home/MindCmdUser/atc_resoure/caffe_resnet50/caffe/resnet50.caffemodel [image_list] /home/MindCmdUser/atc_resoure/data/nnn_dog1_1024_683_uint8.bin [output] /home/MindCmdUser/atc_output/resnet50
文件格式转换¶
该功能可以将.bin,.float,.npy,.dump和.{时间戳}文件转换为.bin,.float,.hex和.npy文件。
命令行格式说明¶
文件格式转换的命令行格式如下。
mindcmd datatrans -i INPUT -f file_format
命令行参数说明如表1所示
表 1 文件格式转换参数说明
执行样例¶
数据准备
性能分析前需要准备相应的caffe模型,所准备的文件结构可参考如下。
├── transform_resoure │ └── data.npy
执行文件格式转换
进入MindCmd工程路径下,执行以下命令。
cd transform_resoure mindcmd datatrans -i ./data.npy -f bin -o ./transform_output
执行结果
文件格式转换执行结束后会在默认工作路径中生成data.bin文件。
UnInplace¶
该功能对模型进行uninplace处理,uninplace后仅保存不带phase或者phase为TEST的层。
命令行格式说明¶
uninplace处理的命令行格式如下。
mindcmd uninplace -i INPUT_FILE_PATH
命令行参数说明如表1所示。
表 1 Uninplace命令参数说明
执行样例¶
模型和数据准备
性能分析前需要准备相应的caffe模型,所准备的文件结构可参考如下。
├── uninplace_resoure │ ├── resnet50 │ │ └── resnet50_deploy.prototxt
执行uninplace
进入MindCmd工程路径下,执行以下命令。
cd uninplace_resoure mindcmd uninplace -i ./resnet50/resnet50_deploy.prototxt -o=./uninplace_output/resnet50_uninplace.prototxt
执行结果
执行结束后会在指定路径中生成resnet50_uninplace.prototxt文件。
附录¶
MindCmd子命令¶
MindCmd工具可以在任意路径下通过mindcmd命令使用,命令行如下。
mindcmd {config,oneclick,preprocess,atc,amct,gt,app,compare,profile} ...
命令参数说明如表1所示。
表 1 MindCmd子命令参数说明
NFS环境搭建¶
在Host侧安装NFS软件包
执行以下命令安装NFS服务器和NFS客户端
sudo apt-get install nfs-kernel-server sudo apt-get install nfs-common
在Host侧新建共享目录${SHARE_DIR},并为该目录设置权限,参考:
sudo mkdir ${SHARE_DIR} # 若使用已有目录作为共享目录,此命令不执行 sudo chmod -R 777 ${SHARE_DIR} sudo chown user:group ${SHARE_DIR} -R # user用户,group为用户组,-R 表示递归更改该目录下所有文件
在Host侧添加NFS共享目录
sudo vim /etc/exports在该文件末尾添加下面一行内容,用于把 ${SHARE_DIR} 添加到NFS共享目录。请将其中的${SHARE_DIR}替换为实际需要共享的目录:
${SHARE_DIR} *(rw,sync,no_root_squash,no_subtree_check) # * 表示允许任何网段 IP 的系统访问该 NFS 目录 说明:
请设置安全权限范围的目录作为SHARE_DIR,避免mount提权风险。在Host侧启动NFS服务
可参考以下两条命令
sudo /etc/init.d/nfs-kernel-server start sudo /etc/init.d/nfs-kernel-server restart
测试NFS环境是否成功搭建
在板端上参考以下命令进行挂载
mount -t nfs x.x.x.x:${SHARE_DIR} /home/MindCmdUser/board_workspace -o nolock在板端上执行以下命令进行卸载
umount /home/MindCmdUser/board_workspace
ssh.cfg文件配置¶
工具运行上板推理需要指定此文件,用于描述板端IP、板端挂载路径、服务器挂载路径等信息,文件格式和详细内容如下。
[ssh_config]
# board ip
BOARD_IP=x.x.x.x
# board work directory, automatically mount to $HOST_MOUNT_PATH
BOARD_MOUNT_PATH=/home/MindCmdUser/board_workspace/
# board work directory
# to avoid bottlenecks caused by copying test resources, store test resources in this path as much as possible.
HOST_MOUNT_PATH=${SHARE_DIR}/host_workspace
# board user name
USER=${username}
# board user's password
PASSWORD=${password}
# default port is 22
PORT=22
ssh.cfg配置文件路径可写入MindCmd全局配置文件的SSH_CFG_PATH配置项,或作为工具命令行参数--ssh_config的值。
MindCmd工具上板推理时会根据以上配置文件提供的信息,自动执行mount、umount操作。
HOST_MOUNT_PATH配置的路径不能超出2所配置的NFS共享目录范围,否则可能会导致mount失败。
示例中的${SHARE_DIR}、${username}、${password}请根据实际情况替换。
板端ssh环境搭建请参考《驱动和开发环境安装指南》“OpenSSH服务搭建”章节。
数据预处理配置文件样例¶
自定义输入数据的预处理方式需要指定此文件,创建inset_op.cfg配置文件,文件格式和内容参考如下。
aapp_op {
related_input_rank : 0
aapp_mode : static
input_format : BGR_PLANAR
model_format : BGR
mean_chn_0 : 0
mean_chn_1 : 0
mean_chn_2 : 0
var_reci_chn_0 : 1.0
var_reci_chn_1 : 1.0
var_reci_chn_2 : 1.0
}
以上配置内容仅供参考,实际使用请根据输入数据以及预处理方式进行调整。
数据预处理完整配置方式请参考《ATC工具使用指南》“--insert_op_conf” 章节。
Docker容器中使用MindCmd¶
如果采用默认方式启动 Docker 容器,会产生一块虚拟网卡,可以理解为这块网卡连接着一个虚拟交换机。每个Docker容器拥有自己单独的网卡和IP,并且所有Docker容器也连接在这个虚拟交换机之下。当在 Docker 容器内运行 MindCmd 挂载板端时,容器内分配的是一个不对外网暴露的虚拟IP(如172.17.0.2),因此会导致在 Docker 内无法执行上板操作。为解决该问题,本章节提供在Docker容器中使用MindCmd的方法供用户参考。
使用挂载数据卷和共享主机ip的方式启动容器,相关命令参数说明如表1所示。
docker run -itd --gpus all -v /tmp/.X11-unix:/tmp/.X11-unix -v ${host_mount_dir}:${host_mount_dir} --net=host --name ${container_name} ${image_name:tag}表 1 启动容器参数说明
说明:- ${host_mount_dir}路径要求为服务器侧已存在路径,且前后${host_mount_dir}填写的路径应该保持一致,且不能超出ssh.cfg文件配置中配置的“HOST_MOUNT_PATH”。
说明:上下文参数中以变量符"${ }"形式描述的参数需要用户根据自己的环境进行填写,其他参数直接添加到执行命令中即可。 示例:如果用户挂载的数据卷为“/home/xxx”,那么对应填写的参数 -v ${host_mount_dir}:${host_mount_dir}为“-v /home/xxx:/home/xxx”。 类似--gpus all、--net=host等参数则直接拼接到命令当中,无需进行修改。
当在容器上板执行过程中出现挂载失败或报错提示“Permission denied”,请参考NFS环境搭建 检查宿主机的数据卷路径是否在宿主机NFS共享目录下。
构建解决方案镜像,请参考《驱动和开发环境安装指南》“容器镜像构建”章节。
进入容器
docker exec -it ${container_name} /bin/bash-
查询分配的端口是否被占用,其中${port}为自定义端口
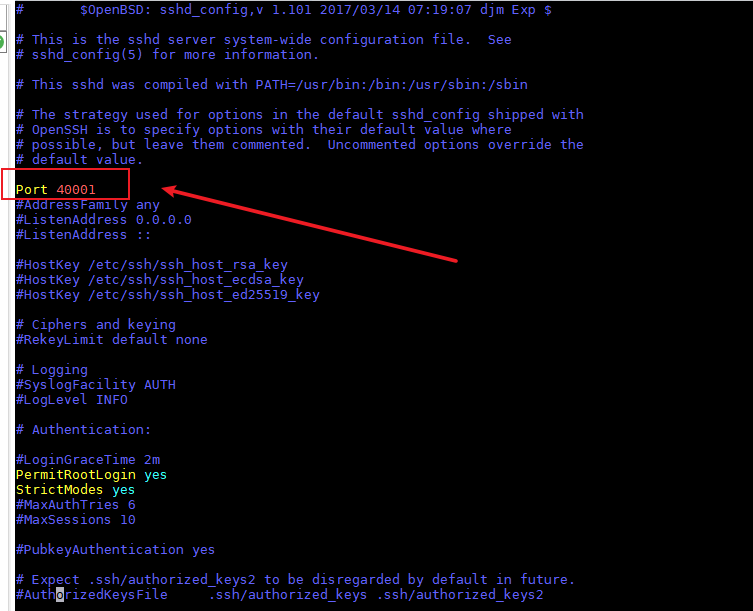
netstat -anp |grep ${port}2.将ssh默认端口22修改为自定义端口(如图1所示,端口被修改为40001)
vim /etc/ssh/sshd_config 设置容器的密码并重启容器SSH服务
passwd ${user_name} service ssh start
在容器中使用工具。
使用Xserver新建ssh连接,ip填写docker宿主机的ip,端口选择3中配置的端口号。(可选)
安装Python3.7.5(Ubuntu)¶
检查系统是否安装python3.7.5开发环境。
分别使用命令python3.7.5 --version、python3.7 --version、pip3.7.5 --version、pip3.7 --version检查是否已经安装,如果返回如下信息则说明已经安装,否则请参见下一步。
Python 3.7.5 pip 19.2.3 from /usr/local/python3.7.5/lib/python3.7/site-packages/pip (python 3.7)
安装python3.7.5依赖的包。
sudo apt-get install -y make zlib1g zlib1g-dev build-essential libbz2-dev libsqlite3-dev libssl-dev libxslt1-dev libffi-dev openssl python3-tklibsqlite3-dev需要在python安装之前安装,如果用户操作系统已经安装python3.7.5环境,在此之后再安装libsqlite3-dev,则需要重新编译python环境。如果安装python3-tk失败,请参见《AMCT使用指南(PyTorch)》中”安装python3-tk时提示错误信息”小节。
安装python3.7.5。
使用wget下载python3.7.5源码包,可以下载到模型压缩工具所在服务器任意目录,命令为:
wget https://www.python.org/ftp/python/3.7.5/Python-3.7.5.tgz进入下载后的目录,解压源码包,命令为:
tar -zxvf Python-3.7.5.tgz进入解压后的文件夹,执行配置、编译和安装命令:
cd Python-3.7.5 ./configure --prefix=/usr/local/python3.7.5 --enable-loadable-sqlite-extensions --enable-shared make sudo make install
其中“--prefix”参数用于指定python安装路径,用户根据实际情况进行修改,“--enable-shared”参数用于编译出libpython3.7m.so.1.0动态库,“--enable-loadable-sqlite-extensions”参数用于加载sqlite-devel依赖。
本手册以--prefix=/usr/local/python3.7.5路径为例进行说明。执行配置、编译和安装命令后,安装包在/usr/local/python3.7.5路径,libpython3.7m.so.1.0动态库在/usr/local/python3.7.5/lib/libpython3.7m.so.1.0路径。
执行如下命令设置软链接:
sudo ln -s /usr/local/python3.7.5/bin/python3 /usr/local/python3.7.5/bin/python3.7.5 sudo ln -s /usr/local/python3.7.5/bin/pip3 /usr/local/python3.7.5/bin/pip3.7.5
设置python3.7.5环境变量。
如果python安装用户为root:
该场景下模型压缩工具使用root用户进行安装,请在当前终端窗口直接执行如下命令设置环境变量。
#用于设置python3.7.5库文件路径 export LD_LIBRARY_PATH=/usr/local/python3.7.5/lib:$LD_LIBRARY_PATH #如果用户环境存在多个python3版本,则指定使用python3.7.5版本 export PATH=/usr/local/python3.7.5/bin:$PATH
须知:
运行用户是root,不建议修改.bashrc,否则可能会影响其它系统提供的python工具的使用,如果仍想使用系统默认工具,则请重新开启终端窗口。
如果python安装用户为非root:
该场景下模型压缩工具使用非root用户进行安装,请以非root用户在任意目录下执行vi ~/.bashrc命令,打开**.bashrc**文件,在文件最后一行后面添加如下内容。
#用于设置python3.7.5库文件路径 export LD_LIBRARY_PATH=/usr/local/python3.7.5/lib:$LD_LIBRARY_PATH #如果用户环境存在多个python3版本,则指定使用python3.7.5版本 export PATH=/usr/local/python3.7.5/bin:$PATH
执行**:wq!命令保存文件并退出,执行source ~/.bashrc**命令使其立即生效。
安装完成之后,执行如下命令查看安装版本,如果返回相关版本信息,则说明安装成功。
python3.7.5 --version pip3.7.5 --version python3.7 --version pip3.7 --version
公网URL¶
表 1 公网URL 说明
使用alias别名简化输入命令¶
常用命令可通过配置alias别名进行简化,示例如下。
alias mind_caffe="mindcmd oneclick caffe"
alias mind_torch="mindcmd oneclick pytorch"
alias mind_onnx="mindcmd oneclick onnx"
配置别名后,一键推理的简化命令为。
mind_caffe -m MODEL -w WEIGHT
mind_torch -m MODEL -i IMAGE_LIST --input_shape INPUT_SHAPE
mind_onnx -m MODEL -i IMAGE_LIST
FAQ¶
挂载命令中的ip与服务器ip不符¶
执行一键推理或上板推理时挂载失败,且挂载命令中的ip地址与服务器的ip不符。
如:服务器ip为xxx.xxx.xxx.xxx,挂载ip为127.0.1.1
出现如下报错:
RuntimeError: [Mount] Mount failed: mount: mounting 127.0.1.1:${MOUNT_PATH} on ${BOARD_PATH} failed: Connection timed out
/etc/hosts 文件中配置了回环地址如:
127.0.0.1 localhost
127.0.1.1 ${hostname}
方法一:
将服务器侧的/etc/hosts 文件参考修改如下。
127.0.0.1 localhost
# 127.0.1.1 ${hostname}
方法二:
将hostname对应的ip修改为正确的ip。
127.0.0.1 localhost
xxx.xxx.xxx.xxx ${hostname}
hostname方法二,查看/etc/hostname文件。
vi /etc/hostname
找不到mindcmd命令¶
执行mindcmd命令出现以下信息。
bash: mindcmd: command not found
python路径未配置到环境变量PATH中。mindcmd安装完成后会出现如下信息。
WARNING:The script mindcmd is installed in $HOME/.local/bin which is not on PATH.
用户可通过以下命令进行配置环境变量。
export PATH=$PATH:$HOME/.local/bin
关于工作路径、挂载路径、数据卷路径和NFS共享路径¶
对于工作路径、挂载路径、数据卷路径、NFS共享路径的描述如下。
工作路径确定MindCmd执行的工作空间,MindCmd生成的output文件等都会保存在该路径下。
挂载路径是由于板端硬件存储资源有限,因此需要将板端的某个目录挂载到服务器侧达到板端存储扩容的作用。在MindCmd上板执行过程中,此路径还用于服务器与板端的资源同步,上板执行所需要的输入和输出文件会被同步到该路径下。
数据卷路径标识宿主机(服务器)和Docker容器文件资源共享的范围,在此范围内,容器和宿主机都能访问该路径下的内容。
NFS共享路径是宿主机(服务器)配置的允许通过NFS服务共享宿主机资源的范围。
为了保证上板成功并能在容器中读取到上板生成的dump、profile等数据,要求配置上述路径的包含关系如下。
NFS共享路径 >= 数据卷路径 >= 挂载路径 >= 工作路径
MindCmd安装失败,找不到Rust编译器¶
执行如下命令安装MindCmd。
pip install mindcmd-<version>-py3-none-linux_x86_64.tar.gz --user
提示以下错误,具体图1所示。
error: can't find Rust compiler
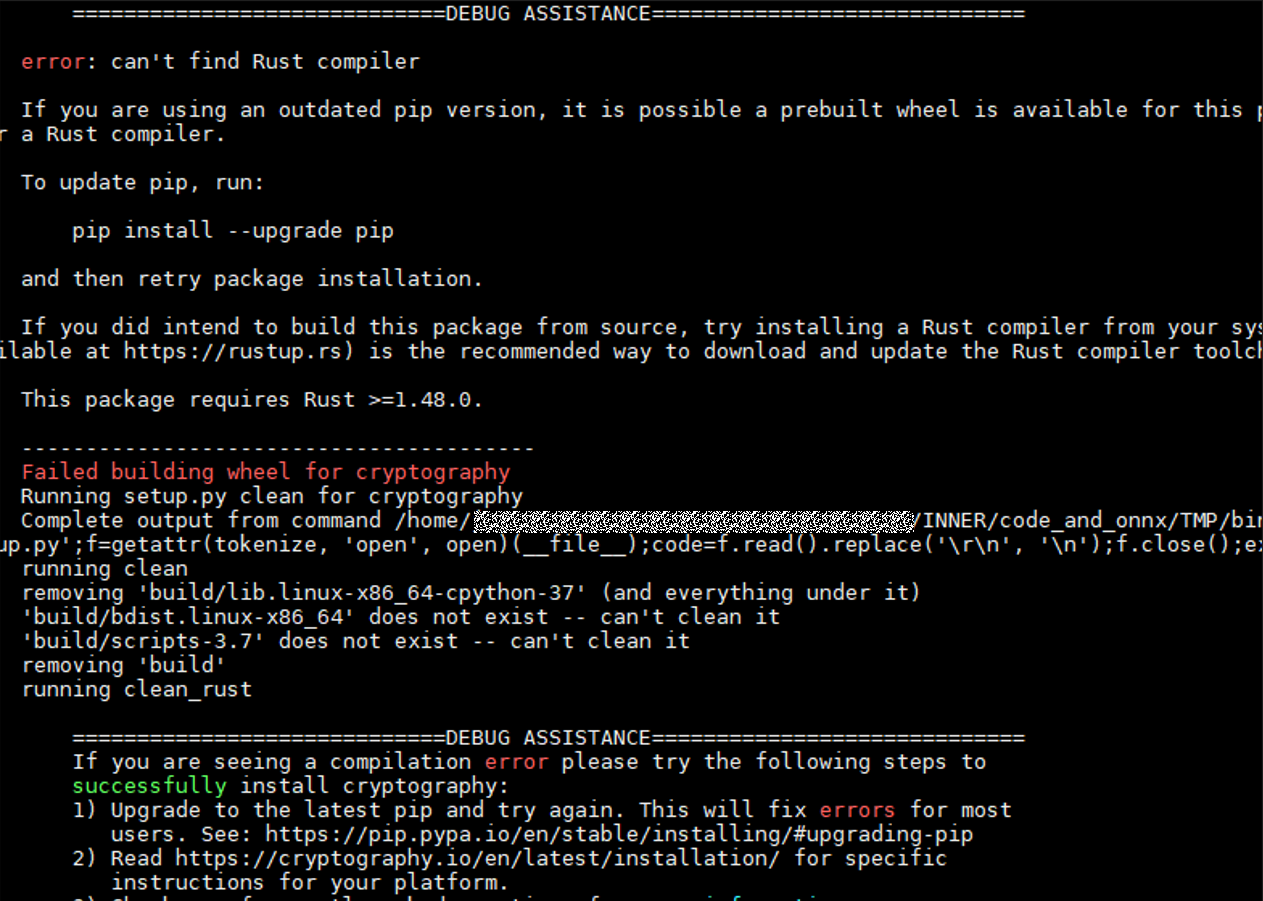
MindCmd安装需要依赖Rust编译器。
通过升级pip解决,命令如下。
pip install --upgrade pip
重新安装MindCmd
pip install mindcmd-<version>-py3-none-linux_x86_64.tar.gz --user
PyTorch模型推理失败¶
PyTorch模型执行模型压缩的过程中模型推理失败,如图1所示。

可能是因为输入数据与模型的输入不符。
使用原始模型进行推理,保证模型的正确性。
调整输入数据,保证传入的数据与模型的输入相符。
Pytorch模型推理报错¶
用户在Python脚本使用了argparse解析参数,调用MindCmd一键推理Pytorch模型时报错。
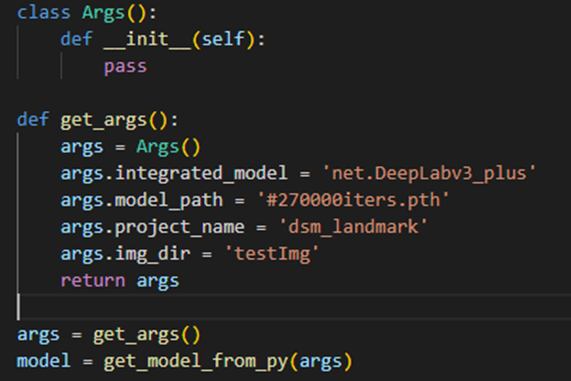
用户使用自己的Python脚本,main方法中调用了argparse解析,与MindCmd的命令行参数产生冲突,导致MindCmd解析参数产生异常。如图1所示。
图 1 Python脚本中使用了argparse进行参数解析
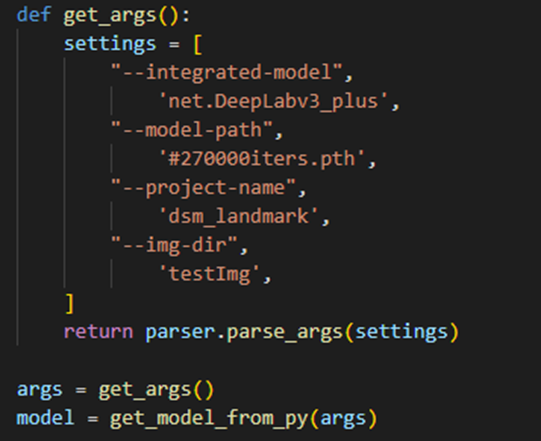
用户如果在Python脚本中有特定的参数传入需求,可以通过构造参数类传入,代替原有通过argparese解析的方式。如图2所示。