
前言¶
本文档详细的描述了精度比对工具的使用约束、比对数据准备以及具体的比对操作指导,同时提供了dump数据格式转换、查看等方法。
与本文档相对应的产品版本如下。
本文档主要适用于开发人员。
技术支持工程师
软件开发工程师
在本文中可能出现下列标志,它们所代表的含义如下。





功能与约束¶
简介¶
ATC在模型转换过程中对模型进行了优化,包括算子消除、算子融合、算子拆分,可能会造成自有实现的算子运算结果与用业界标准算子(如Caffe)的运算结果存在偏差,此时需要提供工具比对两者之间的差距,帮助开发人员快速解决算子精度问题。
精度比对工具的定位是解决模型的精度问题,提供比对自有模型算子的运算结果与Caffe等标准算子的运算结果,以便确认误差发生的算子,目前提供以下比对方法。
Vector比对,包含余弦相似度、最大绝对误差、累积相对误差、欧氏相对距离、KLD散度、标准差的算法比对。
功能¶
当前版本,Vector比对支持通过SoC运行生成的dump数据与Ground Truth(基于GPU/CPU运行生成的npy数据)进行比对,同时还支持量化、非量化的数据比对。请在比对操作前确保已按您的比对场景准备好数据,如表1。
表 1 精度比对场景
约束与说明¶
使用精度比对工具前,请参考《驱动和开发环境安装指南》手册完成开发环境搭建。本文以HLAAUser 普通用户安装,且默认安装路径/home/HLAAUser /Ascend为例,介绍精度比对的操作方法,请实际操作时根据您自己的环境进行替换。本文中举例路径均需要确保HLAAUser 具有读或读写权限。
本文多处举例或说明提到运行环境,请根据实际情况替换。标准形态:Ascend EP(Endpoint)环境,表示Host侧;Ascend RC(Root Complex)环境,表示板端环境;开放形态:表示Device侧。
使用精度比对工具,请确保硬件环境满足要求:CPU 8核 2.6Ghz,内存16GB,否则有可能会造成比对缓慢。
精度比对工具需要配套python3.7.5版本使用。
精度比对支持的dump数据的类型:
FLOAT
FLOAT16
DT_INT8
DT_UINT8
DT_INT16
DT_UINT16
DT_INT32
DT_INT64
DT_UINT32
DT_UINT64
DT_BOOL
DT_DOUBLE
比对数据准备¶
数据格式要求¶
当前版本支持多种比对方式,因此dump、npy数据文件命名需满足以下要求。
表 1 数据文件命名规则
命名格式说明:op_type、op_name对应的名称需满足“A-Za-z0-9_-”正则表达式规则,SoC的dump结果timestamp为12位时间戳,其余为16位。output_index、task_id、stream_id为0~9数字组成。 |
||
准备离线模型dump数据文件(ACL接口方式)¶
前提条件¶
在准备dump数据前,请参考《ATC工具使用指南》模型转换,准备好离线模型文件;如果涉及模型量化,请参考《AMCT使用指南(Caffe)》和《AMCT使用指南(PyTorch)》完成量化操作后再进行模型转换,生成量化的离线模型文件。并请使用配套生成的模型文件完成应用工程的编译、运行,确保工程正常。
说明:
执行模型压缩工具时,同步会生成量化融合规则文件,该文件在精度比对时会使用。
提供2种接口方式dump数据:svp_acl_init()接口和svp_acl_mdl_set_dump()接口。 svp_acl_init()接口和svp_acl_mdl_set_dump()接口的详细使用方法请参考《应用开发指南》。
dump数据¶
参考下面步骤进行离线模型dump操作:
打开工程文件,查看调用的svp_acl_init()或svp_acl_mdl_set_dump()函数,获取acl.json文件路径。
说明:
如果svp_acl_init()或svp_acl_mdl_set_dump()初始化为空,则需要修改该函数,补充步骤2创建的acl.json路径。这里的acl.json路径是相对工程编译生成的二进制文件的路径。在查出的目录下修改acl.json文件(如不存在,则需要新建,建议放在工程编译后的out目录下),添加dump配置,格式如下所示,参数说明参见表1。
{ "dump":{ "dump_list":[ { "model_name":"ResNet-101" }, { "model_name":"ResNet-50", "layer":[ "conv1conv1_relu", "res2a_branch2ares2a_branch2a_relu", "res2a_branch1", "pool1" ] } ], "dump_path":"/home/HLAAUser /output", "dump_mode":"output" } }
表 1 acl.json文件格式说明
- 不具有输出的AA CPU算子不会生成dump数据。
- 采用dump部分算子场景下,因data算子不会在AA CPU或AA Core上执行。只有用户填写dump data节点算子时一并填写data节点算子的后继节点,才能dump出data节点算子数据。
通过ATC命令生成模型的json文件,在json文件中查找"name"字段对应值,查找模型名称和算子名称,模型名称在"graph"字段外、算子名称在"graph"字段内。生成json文件的方法请参考比对步骤中2的方法。
- 当需要dump指定的部分算子时,按格式配置layer字段,每行配置模型中的一个算子名,且每个算子之间用英文逗号隔开。
- 当需要dump模型的所有算子时,不需要包含layer字段。
在IO性能相对较差的开发者板上,可能会出现由于数据量过大导致执行超时的情况,所以不建议全量dump,请指定算子进行dump。
- 绝对路径配置以“/”开头,例如:/home/HLAAUser /output。
- 相对路径配置直接以目录名开始,例如:output。
例如:dump_path配置为/home/HLAAUser /output,则dump数据文件存储到运行环境的/home/HLAAUser /output目录下。
- input:dump算子的输入数据。
- output:dump算子的输出数据。
- all:dump算子的输入、输出数据。
运行应用工程,生成dump数据文件。
工程运行完毕后,可以在运行环境查看到生成的dump数据文件。生成的路径及格式说明:
{dump_path}/{time}/{deviceid}/{model_name}/{model_id}/{data_index}/{dump文件} 单算子模型dump时为{dump_path}/{time}/{deviceid}/{dump文件}
表 2 Simulator生成dump数据文件路径说明
表 3 SoC生成dump数据文件路径说明
命名规则格式为{op_type}.{op_name}.{output_index}.{timestamp}。如果按命名规则定义的文件名称长度超过了OS文件名称长度限制(一般是255个字符),则会将该dump文件重命名为一串随机数字,映射关系可查看同目录下的mapping.csv
准备Caffe模型npy数据文件¶
本版本不提供Caffe模型npy数据生成功能,请自行安装Caffe环境并提前准备Caffe原始数据“*.npy”文件。我们仅提供生成符合精度比对要求的numpy格式Caffe原始数据“*.npy”文件的样例参考。
Caffe原始npy数据文件准备要求:
文件内容以 numpy格式保存。
文件命名以op_name.output_index.timestamp.npy形式命名。设置numpy数据文件名包括output_index字段且值为0,确保转换生成的dump数据的output_index为0。因为精度比对时,默认从第一个output_index为0的数据开始,否则无比对结果。
为确保生成符合命名要求的.npy文件,需要对原始的Caffe模型文件去除in-place,生成新的.prototxt模型文件用于生成.npy文件(例如:如果有未去除in-place的A、B、C、D四个融合算子,进行dump数据,输出的结果为D算子的结果,但命名却是A算子开头,就会导致比对时找不到文件)。针对量化场景,需要先在环境上安装模型压缩工具再执行去除in-place命令,安装方法请参考《AMCT使用指南(Caffe)》。
进入/home/HLAAUser /Ascend/ascend-toolkit/svp_latest/toolkit/tools/operator_cmp/compare目录,执行命令去除in-place,命令行举例如下。
python3.7.5 inplace_layer_process.pyc -i /home/user/resnet50.prototxt
执行命令后,在/home/user目录下生成去除in-place的new_resnet50.prototxt文件。
针对量化场景:为确保精度误差,需要执行Caffe模型推理时预处理数据与Caffe模型压缩时预处理数据一致。
为输出符合精度比对要求的“*.npy”数据文件,需在推理结束后的代码中增加以下类似代码。
#read prototxt file
net_param = caffe_pb2.NetParameter()
with open(self.model_file_path, 'rb') as model_file:
google.protobuf.text_format.Parse(model_file.read(), net_param)
# save data to numpy file
for layer in net_param.layer:
name = layer.name.replace("/", "_").replace(".", "_")
index = 0
for top in layer.top:
data = net.blobs[top].data[...]
file_name = name + "." + str(index) + "." + str(
round(time.time() * 1000000)) + ".npy"
output_dump_path = os.path.join(self.output_path, file_name)
np.save(output_dump_path, data)
os.chmod(output_dump_path, FILE_PERMISSION_FLAG)
print('The dump data of "' + layer.name
+ '" has been saved to "' + output_dump_path + '".')
index += 1
增加上述代码后,运行Caffe模型的应用工程,即可生成符合要求的“*.npy”数据文件。
Vector比对¶
约束¶
Vector命令行比对提供了按模型比对和按单算子比对两种方式,请根据比对场景选择比对方式。
Vector比对使用约束:
需要确保离线模型的dump文件与Caffe模型的npy文件为相同模型的数据。如果不是相同模型的数据,但模型中有相同的算子名称,也可以进行比较,但结果数据只显示匹配到的相同算子的比对结果。
针对FastRcnn网络场景,Proposal算子及之后的算子,算子精度不达标属于正常情况,以最终画框结果为准。
如果在图编译过程中,原图的算子发生了融合,导致算子的output在编译后的模型中找不到对应的output时,该算子无法进行比对。
如果在图编译阶段对图做了结构性修改(如stride切分、L1 fusion、L2 fusion)的场景,会造成算子的input或output无法比对。
如果比对数据两边相同算子有dump数据,但算子的shape不一致(离线模型算子shape变小)或format不支持转换,该算子无法进行比对。
当模型转换对输入数据做了额外的预处理,造成原始模型的输入与离线模型的data算子输入格式不同时(比如AAPP场景下data输入为YUV),data算子比对结果异常,不具备参考意义。
如果比对数据两边相同算子有多个input且input顺序不一致,会导致该算子的input的比对结果不可信。
如果没有关闭对应的融合规则,会使得量化算子与之前的算子进行融合,导致该算子的output的比对结果不可信。
量化模型里做了量化处理的算子无法比对,必须是反量化的输出才能比对,量化模型里未做量化处理的算子不受影响。例如,量化模型里AscendQuant算子的output无法比对。
比对数据说明¶
执行Vector比对前,请根据您将要进行Vector比对的场景参考表1要求准备好比对数据。
离线模型文件:使用SoC运行生成的dump数据与Ground Truth比对,选择该模型文件。
量化融合规则文件:只要涉及量化与非量化数据比对,则必须选择该文件。
表 1 Vector比对前数据准备
|
|||
|
|||
|
|||
|
|||
|
|||
|
|||
整网比对¶
命令格式说明¶
msaccucmp.pyc脚本工具是由Python编写的精度比对命令行工具。功能及安装路径如下:
功能:整网比对和单算子比对功能。
路径:${INSTALL_DIR}/toolkit/tools/operator_cmp/compare
Vector比对命令行格式如下:
python3.7.5 msaccucmp.pyc compare -m my_dump_path -g golden_dump_path [-f fusion_rule_file] [-q quant_fusion_rule_file] [-out output] [-c custom_script_path] [-v version]
命令行参数说明如表1所示。
msaccucmp.pyc工具保存在开发工具包CANN安装路径/{version}/x86_64-linux/toolkit/tools/operator_cmp/compare目录下。
表 1 整网比对命令行参数说明
用户自定义Format转换.py文件存放路径,需指定到"format_convert"目录的上一层目录。.py文件相关要求参见准备自定义Format转换.py文件。 |
||
请根据比对数据说明中准备的数据类型,正确选择-f或-q参数项。
比对步骤¶
Vector比对命令行方式操作步骤。
本节涉及的.json文件、目录等名称均为举例,请根据实际环境替换。其中,--out指定的结果存放路径,需确保HLAAUser 用户具有读写权限。
本节以非量化SoC运行生成的dump数据与非量化Caffe模型npy数据比对为例进行介绍,下文中参数说明均以该示例介绍,请根据您的实际情况进行替换。
如果是两份基于相同模型、SoC运行生成的dump数据进行精度比对,需确保input个数、output个数、format、shape必须完全一致,否则无法比对;另外,此场景下命令行只需要带-m、-g、-out参数,不需要输入-f、-q参数。
如果执行过程中报“MemoryError”,则表示数据量过大导致了内存溢出,请将板端的dump数据文件拆分到多个目录后,再逐一进行比对。
以HLAAUser 用户登录开发环境。
执行export命令设置环境变量并生成json文件。
设置环境变量:
export LD_LIBRARY_PATH=/home/HLAAUser /Ascend/ascend-toolkit/svp_latest/atc/third_party_lib:${LD_LIBRARY_PATH}生成json文件:
/home/HLAAUser /Ascend/ascend-toolkit/svp_latest/atc/bin/atc --mode=1 --om=/home/HLAAUser /data/resnet50.om --json=/home/HLAAUser /data/resnet50.json进入/home/HLAAUser /Ascend/ascend-toolkit/svp_latest/toolkit/tools/operator_cmp/compare目录。
执行Vector比对命令,样例命令如下。
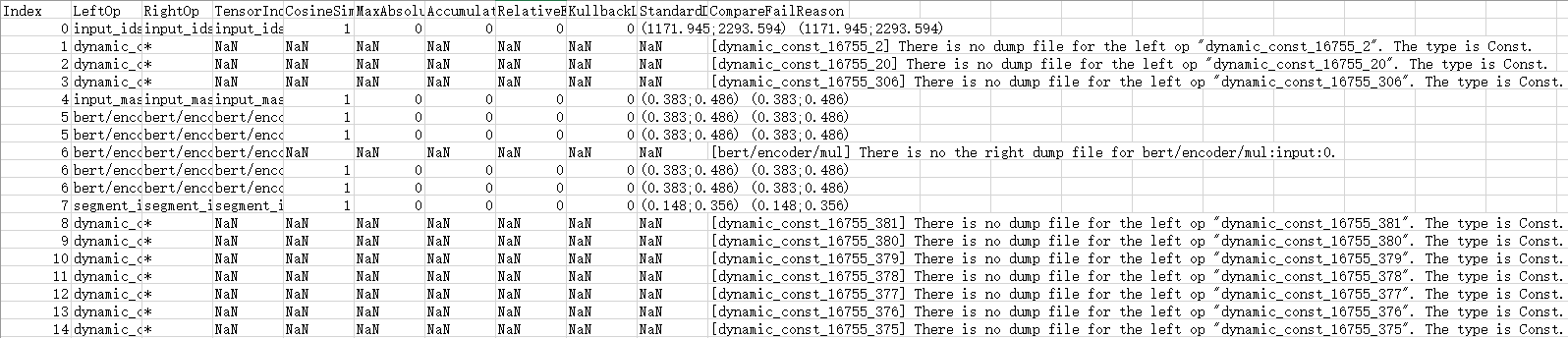
python3.7.5 msaccucmp.pyc compare -m /home/HLAAUser /MyApp_mind/resnet50 -g /home/HLAAUser /Standard_caffe/resnet50 -f /home/HLAAUser /data/resnet50.json -out /home/HLAAUser /resultVector比对结果result_*.csv文件内容如图1所示。
表 1 输出参数说明
单算子比对¶
命令格式说明¶
Vector比对命令行格式如下:
python3.7.5 msaccucmp.pyc compare -m my_dump_path -g golden_dump_path [-f fusion_rule_file] [-q quant_fusion_rule_file] [-out output] [-op op_name] [-o output_tensor] [-i input_tensor] [-c custom_script_path] [-v version]
msaccucmp.pyc工具保存在**开发工具包CANN安装路径_/{version}_**/x86_64-linux/toolkit/tools/operator_cmp/compare目录下。
命令行参数说明如表1所示。
表 1 单算子比对命令行参数说明
用户自定义Format转换.py文件存放路径,需指定到"format_convert"目录的上一层目录。.py文件相关要求参见准备自定义Format转换.py文件。 |
||
请根据比对数据说明中准备的数据类型,正确选择-f或-q参数项。
比对步骤¶
Vector比对命令行方式操作步骤。
本节涉及的.json文件、目录等名称均为举例,请根据实际环境替换。其中,--out指定的结果存放路径,需确保HLAAUser 用户具有读写权限。
本节以非量化SoC运行生成的dump数据与非量化Caffe模型npy数据比对为例进行介绍,下文中参数说明均以该示例介绍,请根据您的实际情况进行替换。
不支持两份基于相同模型、SoC运行生成的dump数据进行单算子精度比对。
以HLAAUser 用户登录开发环境。
执行export命令设置环境变量并生成json文件。
设置环境变量:
export LD_LIBRARY_PATH=/home/HLAAUser /Ascend/ascend-toolkit/svp_latest/atc/third_party_lib:${LD_LIBRARY_PATH}生成json文件:
/home/HLAAUser /Ascend/ascend-toolkit/svp_latest/atc/bin/atc --mode=1 --om=/home/HLAAUser /data/resnet50.om --json=/home/HLAAUser /data/resnet50.json进入/home/HLAAUser/Ascend/toolkit/tools/operator_cmp/compare目录。
执行Vector比对命令,样例命令如下:
python3.7.5 msaccucmp.pyc compare -m /home/HLAAUser /MyApp_mind/resnet50 -g /home/HLAAUser /Standard_caffe/resnet50 -f /home/HLAAUser /data/resnet50.json -out /home/HLAAUser /result -op pool5 -i 0单算子比对概要结果存放在“{op_name}_input_{index}_summary.txt”或“{op_name}_output_{index}_summary.txt”文件中,各参数说明如下。
表 1 单算子比对概要结果的参数说明
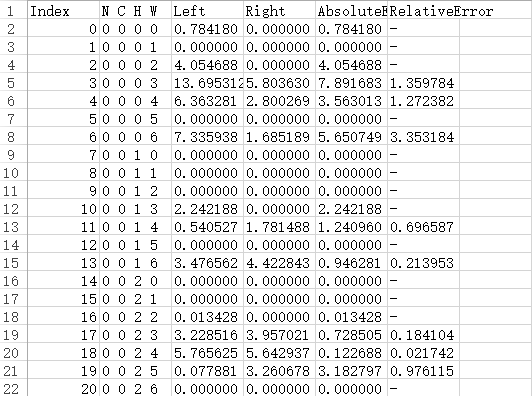
单算子比对详细结果存放在“{op_name}_input_{index}_{file_index}.csv”或“{op_name}_output_{index}_{file_index}.csv”文件中,每个文件最多记录100万条数据。图2中各列参数说明如下。
表 2 单算子详细比对结果参数说明
相对误差,AbsoluteError值除以Ground Truth模型算子的dump值比对出来的结果。当Ground Truth算子的dump值为0时,该处显示为“-”。

附录¶
如何进行dump数据文件Format转换¶
执行Dump数据文件format转换¶
本版本提供dump数据文件format转换能力,用于用户根据自身需求将SoC生成的dump数据文件转换成numpy数据文件,方便查看。
该功能通过msaccucmp.pyc脚本实现,该脚本存放在/home/HLAAUser /Ascend/ascend-toolkit/svp_latest/toolkit/tools/operator_cmp/compare路径下,命令格式如下。
python3.7.5 msaccucmp.pyc convert -d dump_file [-out output] [-f format -s shape] [-o output_tensor] [-i input_tensor] [-c custom_script_path] [-v version] [-t type]
命令格式参数项说明如表1所示。
表 1 Format转换参数项说明
|
||
format转换需要的shape,当前仅FRACTAL_NZ转换需要配置该参数,格式为([0-9]+,)+[0-9]+,每个数字必须大于0。配置-f时有效。 |
||
用户自定义Format转换.py文件存放路径,需指定到"format_convert"目录的上一层目录。.py文件相关要求参见准备自定义Format转换.py文件。配置-f时有效。 |
||
FRACTAL_NZ转换NCHW
FRACTAL_NZ转换成NHWC
FRACTAL_NZ转换ND
HWCN转换FRACTAL_Z
HWCN转换成NCHW
HWCN转换成NHWC
NC1HWC0转换成HWCN
NC1HWC0转换成NCHW
NC1HWC0转换成NHWC
NCHW转换成FRACTAL_Z
NCHW转换成NHWC
NHWC转换成FRACTAL_Z
NHWC转换成HWCN
NHWC转换成NCHW
准备自定义Format转换.py文件¶
为满足用户自定义Format转换,需要按以下要求准备。
.py文件命名需满足规则:“convert_{format_from}_to_{format_to}.py”,其中,format _from和format _to支持的类型如下。
NCHW
NHWC
ND
NC1HWC0
FRACTAL_Z
NC1C0HWPAD
NHWC1C0
FSR_NCHW
FRACTAL_DECONV
C1HWNC0
FRACTAL_DECONV_TRANSPOSE
FRACTAL_DECONV_SP_STRIDE_TRANS
NC1HWC0_C04
FRACTAL_Z_C04
CHWN
DECONV_SP_STRIDE8_TRANS
NC1KHKWHWC0
BN_WEIGHT
FILTER_HWCK
HWCN
LOOKUP_LOOKUPS
LOOKUP_KEYS
LOOKUP_VALUE
LOOKUP_OUTPUT
LOOKUP_HITS
MD
NDHWC
C1HWNCoC0
FRACTAL_NZ
.py文件内容需满足以下规则:
def convert(shape_from, shape_to, array): return numpy_array
参数说明:
shape_from:array数据的转换前的shape,一维数组。
shape_to:array数据的转换后的shape,一维数组。(可选)。
array:一维原始数据。
返回值:转换后的numpy数组。
.py文件存放目录需满足:
.py文件必须存放在“format_convert”目录下,如果该目录不存在,需要新建。
如何查看dump数据文件¶
dump文件无法通过文本工具直接查看其内容,为了查看dump文件内容,我们提供以下脚本将dump文件转换为numpy格式文件后,再通过numpy官方提供的能力转为txt文档进行查看。
该功能通过msaccucmp.pyc脚本实现,该脚本存放在/home/HLAAUser/Ascend/toolkit/tools/operator_cmp/compare路径下,命令格式如下。
python3.7.5 msaccucmp.pyc convert -d dump_file [-out output] [-v version] [-t type]
命令格式参数项说明如表1所示。
表 1 参数说明
查看dump数据文件步骤¶
使用安装用户登录开发环境。
进入/home/HLAAUser /Ascend/toolkit/tools/operator_cmp/compare目录。
执行msaccucmp.pyc脚本,转换dump文件为numpy文件。举例:
python3.7.5 msaccucmp.pyc convert -d /home/HLAAUser /dump -out /home/HLAAUser /dumptonumpy -v 2
说明:msaccucmp.pyc脚本的各个输入参数使用方法,请参考如何进行dump数据文件Format转换。
参数支持传入单个文件,对单个dump文件进行转换,也支持传入目录,对整个path下所有的dump文件进行转换。
转换dump文件为numpy文件,不含有L1 Buffer数据时,转换成{op_type}.{op_name}.{task_id}.{timestamp}.input.{index}.npy和{op_type}.{op_name}.{task_id}.{timestamp}.output.{index}.npy文件;含有L1 Buffer时,会多生成{op_type}.{op_name}.{task_id}.{timestamp}.l1buffer.{index}.bin文件。
调用Python,转换numpy文件为txt文件。举例:
$ python3.7.5 Python 3.7.5 (default, Mar 5 2020, 16:07:54)[GCC 5.4.0 20160609] on linuxType "help", "copyright", "credits" or "license" for more information. >>> import numpy as np >>> a = np.load("/home/HLAAUser /dumptonumpy/Pooling.pool1.1147.1589195081588018.output.0.npy") >>> b = a.flatten() >>> np.savetxt("/home/HLAAUser /dumptonumpy/Pooling.pool1.1147.1589195081588018.output.0.txt", b)
转换为.txt格式文件后,维度信息、Dtype均不存在。详细的使用方法请参考numpy官网介绍。
安装依赖¶
请用户安装以下Python3依赖软件,如果安装用户为非root,则需要使用**su - username**命令切换到非root用户执行如表1中命令。
表 1 依赖列表