
前言¶
本文档详细的描述了Profiling工具的使用约束、环境准备及具体的操作指导,同时提供了常见的问题解答及故障处理方法。
与本文档相对应的产品版本如下。
本文档主要适用于开发人员。
在本文中可能出现下列标志,它们所代表的含义如下。





概述¶
功能介绍¶
Profiling性能分析工具用于采集和分析运行在SoC上的推理业务(应用或算子)各个运行阶段的关键性能指标,用户可根据输出的性能数据针对关键性能瓶颈做出优化以实现产品的极致性能。
Profiling性能分析工具针对APP工程运行过程中的硬件和软件性能数据进行采集、分析并汇总展示。
硬件的性能数据包括:AA Core、AA Vector Core等模块的PMU指标及系统硬件性能指标。
软件的性能数据包括:ACL等模块的性能指标数据。
方案介绍¶
当前推理业务主要支持以下场景进行推理任务的Profiling数据的采集和解析,如图1所示。
板端采集,开发环境侧解析。
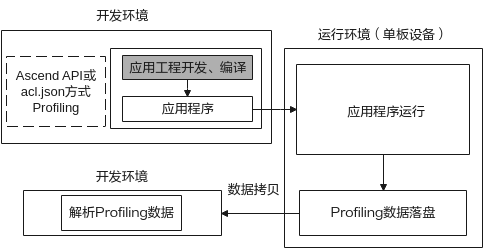
此场景下需要首先在开发环境(如ubutun18.04环境)中进行应用工程的开发,开发过程中应用工程可通过添加配置文件acl.json或调用ACL API接口使能Profiling,在板端执行应用程序时,会开启Profiling数据采集,采集完成后将其输出数据拷贝到开发环境进行数据解析。
场景介绍¶
当前用于推理的昇腾AA处理器进行Profiling时,主要通过CANN软件包来进行Profiling数据的获取与解析,具体如表1所示。
表 1 CANN软件包使能Profiling说明
应用场景说明:昇腾设备部署开发套件包Ascend-cann-toolkit,对应开发环境**,**但同时可以作为运行环境运行应用程序。
此场景下能通过acl.json、ACL API两种方式在板端采集Profiling数据,再将数据拷贝到CANN包所在环境,通过Profiling解析工具msprof.pyc进行Profiling数据的解析。用户在此场景下可实现Profiling全部操作,当用户需要进行代码开发、编译、运行、调测等开发活动,推荐使用此场景。
使用约束¶
使用Profiling功能具有以下约束:
使用Profiling功能前请确保执行用户的umask值大于等于0027,否则会导致获取的Profiling数据所在目录和文件权限过大。
若要查看umask的值,则执行命令**:umask**
若要修改umask的值,则执行命令:umask 新的取值
Profiling提供acl.json和ACL API两种方式,两种方式优先级为命令行 acl.json > ACL API。如果使用ACL API方式,需要确保acl.json文件中的Profiling开关设置为off。
Profiling不支持发起多个基于相同结果目录的Profiling,可能会导致采集的数据结果不准确。比如main程序中包含多个独立推理任务,通过Profiling调用时会出现该问题。
不支持在同一个Device侧同时拉起多个Profiling任务。
配置Profiling相关路径时,仅支持路径由字母、数字和下划线字符组成,不支持带有特殊字符的路径。
Profiling功能与Dump功能不支持同时使用,即启动Profiling前,请关闭数据Dump。原因:如果同时开启,由于Dump操作会影响系统性能,会造成Profiling采集的性能数据指标不准确。
采集Profiling数据过程中如果配置的落盘路径磁盘空间已满,会出现性能数据无法落盘情况,因此,需要用户保证磁盘空间够用。另外,落盘的性能原始数据需要用户自行老化,预防磁盘空间被占满。
解析Profiling数据过程中如果配置的落盘路径磁盘或用户目录空间已满,会出现解析失败的或文件无法落盘的情况,须自行清理磁盘或用户目录空间。
Profiling工具需要配套python3.7.5版本使用,推荐使用python3.7.5版本。
应用工程开发务必遵循《应用开发指南》手册,调用**svp_acl_init()接口完成ACL初始化和调用svp_acl_finalize()**接口完成ACL去初始化,才能获取到完整的Profiling性能数据。
说明: 如果应用程序已调用**svp_acl_init()接口而未调用svp_acl_finalize()**接口导致Profiling流程未正常结束,采集数据会不完整,最后1秒内Profiling已采集的数据可能因未及时同步而丢失,但丢失的数据不大于2M,不影响已同步的性能数据分析。
Profiling流程¶
推理Profiling总体流程如图1所示。请按流程提前准备环境,进行应用程序开发或算子开发并采集Profiling性能数据、解析Profiling性能数据。

表 1 Profiling流程说明
使能Profiling需要先进行环境搭建以进行Profiling数据采集和解析。详情请参见环境准备。 |
|
采集Profiling数据前需参见《应用开发指南》进行应用开发,将应用软件可执行文件拷贝到运行环境运行并采集Profiling数据。通过acl.json方式采集请参见通过调用acl.json文件方式采集Profiling数据;通过ACL API方式采集请参见通过调用ACL API方式采集Profiling数据。 |
|
通过脚本工具msprof.pyc进行Profiling数据的解析并导出相应数据。详情请参见解析Profiling数据。 |
环境准备¶
在您使用Profiling功能前,需要根据场景介绍完成相关环境搭建。具体如下。
请参见《驱动和开发环境安装指南》“2.1板端环境安装”,完成板端和开发环境的搭建。
开发环境和运行环境分设场景安装:参见《驱动和开发环境安装指南》“2.3 命令行方式开发环境安装”,完成依赖环境、工具链、CANN包安装。
快速入门¶
msprof.pyc脚本工具介绍¶
msprof.pyc脚本工具是由Python编写的Profiling命令行工具,功能及安装路径如下。
功能:采集解析Profiling性能原始数据。
路径:${INSTALL_DIR}/toolkit/tools/profiler/profiler_tool/analysis/msprof
本节以Profiling工具安装目录"${INSTALL_DIR}"为例。
${INSTALL_DIR}请替换为CANN软件安装后文件存储路径。例如,$HOME/Ascend/ascend-toolkit/svp_latest/x86_64-linux。
Profiling工具使用安装时创建的普通用户(例如HwHi_Aa_User)运行,因此本文中无特殊说明的地方,均使用该用户执行。
如果原有的解析文件模型只进行加载或卸载,不执行相关execute推理接口,Profiling工具默认不生成相关数据。
一键Profiling¶
此功能为通过运行应用工程可执行文件、调用acl.json文件,读取Profiling相关配置,从而自动采集性能原始数据,采集性能原始数据成功后,可将采集的原始数据复制到装有CANN软件包的开发环境上进行性能数据解析,并生成解析数据的相关csv和json文件。
参考以下步骤完成acl.json文件配置,并完成应用工程编译和运行:
调用ATC模型转换时,需要配置如下参数,用于配置当前模型为支持Profiling的debug类型模型。
--online_model_type=2打开工程文件,查看调用的**svp_acl_init()**函数,获取acl.json文件路径,具体可以参考2
修改svp_acl_init方法指定的acl.json文件内容,添加Profiling相关配置,格式如下所示。
具体参数配置可以参考3
{ "profiler":{ "output":"/root/AscendProjects/MyAppTest/profiling", "aacpu":"on", "aac_metrics":"ArithmeticUtilization", "interval":"0", "acl_api":"on", "switch":"on" } }
说明:关于应用工程编译、运行的详细方法,请参考《应用开发指南》。
使用该方法,务必调用svp_acl_init()接口完成ACL初始化和调用svp_acl_finalize()完成ACL去初始化。
acl.json可不配置,Profiling采集时候会生成一个默认的acl.json配置。
建立SSH连接需要用户提供对应的配置文件,配置文件后缀为ini,请按照xxx.ini格式配置文件,具体参数配置如下,参数说明参见表1。
[ssh_config] ip = XXXX username = XXXX pwd = XXX port = XX
表 1 ini配置文件参数说明
 注意:
注意:用户请注意对配置文件使用完后进行清除,或者对配置文件自行加密,防止板端用户名和密码泄漏。
执行采集会自动挂载Profiling目录到服务器地址,防止板端空间不足,无法采集数据,请确保服务器挂载路径空间充足。
执行如下命令,进行上板操作:
python3.7.5 msprof.pyc collect -m <main> --config <config> --all执行上板采集命令后,会使用SSH将对应项目上传到板端并执行可执行文件main,板端生成的JOB数据会回传到对应本地output 路径上。
msprof.pyc工具详细介绍请参见msprof.pyc脚本工具介绍。
命令行参数详细介绍请参见采集Profiling数据。
对应output目录上生成并解析JOB,对应生成summary和timeline目录,如图1所示。

采集Profiling数据¶
通过调用acl.json文件方式采集Profiling数据¶
通过运行应用工程可执行文件,调用acl.json文件,读取Profiling相关配置,从而自动采集性能原始数据。采集性能原始数据成功后,可将采集的原始数据复制到装有CANN软件包的开发环境上进行性能数据解析,展示性能数据解析结果。
参考以下步骤完成acl.json文件配置,并完成应用工程编译和运行。
调用ATC模型转换时,需要配置如下参数,用于配置当前模型为支持Profiling的debug类型模型。
--online_model_type=2打开工程文件,查看调用的**svp_acl_init()**函数,获取acl.json文件路径。例如图1所示。
说明:
如果svp_acl_init()初始化为空,则需要修改该函数,补充2创建的acl.json路径。修改svp_acl_init方法指定的acl.json文件内容,添加Profiling相关配置,格式如下所示。
{ "profiler":{ "output":"/root/AscendProjects/MyAppTest/profiling", "aacpu":"on", "aac_metrics":"ArithmeticUtilization", "interval":"0", "acl_api":"on", "switch":"on" } }
profiler参数配置说明:
switch:Profiling开关,取值on或off。可选参数。
on表示开启Profiling,off表示关闭Profiling;如果缺失该参数或参数值不为on,则表示关闭Profiling。
output:Profiling性能数据在本地运行服务器输出的路径。可选参数。
Profiling采集结束后,在该目录下生成JOB开头目录,存放Profiling采集的性能原始数据,每个目录对应一个Device的数据。支持配置绝对路径或相对路径(相对执行命令行时的当前路径):
绝对路径配置以“/“开头,例如:/home/HwHi_Aa_User/mdc/output, 建议使用项目路径/profiling作为output路径。
如果该处设置的目录不存在,默认存放采集结果数据到应用工程可执行文件所在目录(确保安装时配置的运行用户具有该目录的读写权限)。
注意:
该参数指定的目录需要提前创建且确保安装时配置的运行用户具有读写权限。
aa cpu:是否采集_aa_ cpu数据的开关,可选on或off,默认为on。可选参数。
aac_metrics:AA Core采集事件,当前只支持ArithmeticUtilization,配置为ArithmeticUtilization代表采集_模式识别_ Core性能数据,否则为不采集。
acl_api:是否采集acl api数据的开关,可选on或off,默认为on,可选参数。
interval:按照推理间隔作为采样的间隔,默认为0。
例如,执行1000张图片推理,batch_num设置为100,循环推理10次,将Inference Interval设置为2时,就是每隔200张图片采集一次性能数据。
配置acl.json完成后,参考《应用开发指南》重新编译应用工程、并运行应用工程。
output指定路径下生成Profiling性能原始数据路径,如图2所示。
说明:当interval配置不为0时,对于推理执行很快的情况,存盘速度可能会跟不上推理完成的速度,可能会出现报告份数缺少的情况,建议此种情况下,在每轮推理时添加sleep,保证落盘时间充足。
采集的Profiling性能原始数据有可能将磁盘存满,请确保预留足够的磁盘空间。
使用命令行工具进行SSH方式将编译好的工程同步到板端进行采集。
说明:
使用SSH请先安装 paramiko组件,可使用 pip3.7.5 install paramiko方式安装第三方依赖。进行采集时候会在板端目录上创建profiling文件夹,建议将profiling目录挂载在本地,命令示例如下,其中,profiling表示板端环境上的目录,没有可以先创建该目录。
mount -t nfs -o nolock,tcp NFS服务器IP地址:服务器绝对路径 用户根目录/profiling 说明:
挂载profiling目录到服务器地址是防止板端空间不足,无法采集数据,请确保服务器挂载路径空间充足。执行如下命令,进行上板操作,参数说明参见表1。
python3.7.5 msprof.pyc collect -m <main> --config <config> [--all]执行上板采集命令后,会使用SSH将对应项目上传到板端并执行可执行文件main,板端生成的JOB数据会回传到对应本地target 路径上。
表 1 采集数据命令参数说明
SSH相关配置的文件路径,使用可参考表1


通过调用ACL API方式采集Profiling数据¶
请参见《应用开发指南》手册“8.6 Profiling性能数据采集”章节。
解析Profiling数据¶
解析Profiling数据¶
在解析任意目录的Profiling数据前,需参见采集Profiling数据采集相应的数据。
以Toolkit组件包Ascend-cann-toolkit开发套件包的运行用户登录开发环境。以HwHi_Aa_User用户为例。
切换至msprof.pyc脚本所在目录,如${INSTALL_DIR}/toolkit/tools/profiler/profiler_tool/analysis/msprof。
说明:
小技巧:为方便执行msprof.pyc脚本,您可以使用HwHi_Aa_User用户执行命令alias msprof='python3.7.5 ${INSTALL_DIR}/toolkit/tools/profiler/profiler_tool/analysis/msprof/msprof.pyc'设置别名,后续就可以不用进入${INSTALL_DIR}/toolkit/tools/profiler/profiler_tool/analysis/msprof目录,在任意目录输入msprof即可执行Profiling命令。
${INSTALL_DIR}请替换为CANN软件安装后文件存储路径。例如,$HOME/Ascend/ascend-toolkit/svp_latest/x86_64-linux。执行如下命令,解析任意目录的Profiling数据。支持以下解析方式,说明如下。
解析任意目录的Profiling数据,参数说明参见表1。
python3.7.5 msprof.pyc import [-h] -dir <dir>例如:
**python3.7.5 msprof.pyc import -dir **_/home/HwHi_Aa_User/_JOBXXXX
说明:
使用import方式解析Profiling数据时,即使原始Profiling数据目录中已经生成.db文件,该方式也会重新生成.db文件。表 1 解析任意目录命令参数说明
执行完上述命令,解析完成后对应的JOBXXX目录下会生成sqlite目录,sqlite目录下会有.db文件生成。
timeline数据说明¶
导出timeline数据¶
在导出timeline数据前,需参见解析Profiling数据。参见如下步骤导出timeline数据。
以Toolkit组件包Ascend-cann-toolkit开发套件包的运行用户登录开发环境。以HwHi_Aa_User用户为例。
切换至“msprof.pyc“脚本所在目录,如${INSTALL_DIR}/toolkit/tools/profiler/profiler_tool/analysis/msprof。
说明:
小技巧:为方便执行msprof.pyc脚本,您可以使用HwHi_Aa_User用户执行命令alias msprof='python3.7.5 ${INSTALL_DIR}/toolkit/tools/profiler/profiler_tool/analysis/msprof/msprof.pyc'设置别名,后续就可以不用进入${INSTALL_DIR}/toolkit/tools/profiler/profiler_tool/analysis/msprof目录,在任意目录输入msprof即可执行Profiling命令。
${INSTALL_DIR}请替换为CANN软件安装后文件存储路径。例如,$HOME/Ascend/ascend-toolkit/svp_latest/x86_64-linux。执行如下命令,导出timeline数据。
命令行格式如下,参数说明参见表1。
python3.7.5 msprof.pyc export timeline [-h] -dir <dir>例如导出推理或系统的Profiling的timeline数据命令如下。
**python3.7.5 msprof.pyc export timeline -dir **/home/HwHi_Aa_User/JOBXXX
表 1 导出timeline数据命令参数说明
收集到的Profiling数据目录。须指定为JOB_XXX目录,里面存在data文件夹和对应info.json.0文件。
执行完上述命令后,会在collection-dir目录下生成timeline目录,不同的数据生成对应的json文件,具体内容参见表2。
表 2 timeline文件介绍
task_time_{deviceid}.{model_file_name}.{model_id}.{batch_num}.json
Task Scheduler任务调度信息。文件详情请参见Task Scheduler任务调度信息数据说明。
acl_{device_id}.{model_file_name}.{model_id}.{batch_num}.json
ACL接口耗时数据,生成该文件需要采集的Profiling数据中包含AclModule.开头的文件。文件详情请参见ACL接口耗时数据说明。
表3展示了通过acl.json或ACL API两种方式,采集解析导出后包含的timeline数据文件对比。
表 3 生成数据文件对比
task_time_{deviceid}.{model_file_name}.{model_id}.{batch_num}.json
acl_{deviceid}.{model_file_name}.{model_id}.{batch_num}.json
说明:timeline目录中的文件是根据采集的实际Profiling数据进行生成,如果实际的Profiling数据没有相关的数据文件,就不会导出对应的timeline数据。
使用export命令能直接从已解析的Profiling数据中导出数据文件。当Profiling数据未解析时,单独执行export命令也能进行解析Profiling数据并导出数据文件。
生成的json(chrome trace)文件可以通过以下方式打开查看:在Chrome浏览器中输入“chrome://tracing“地址,然后将落盘文件拖到空白处即可打开文件内容。下文中文件介绍均使用此种形式。关于chrome trace的格式,可参考chrome trace介绍。
导出的数据中涉及到的时间节点(非Timestamp)为系统单调时间,只与系统有关,非真实时间。
Task Scheduler任务调度信息数据说明¶
请参见导出timeline数据获取Task Scheduler任务调度信息数据文件
task_time_{deviceid}.{model_file_name}.{model_id}.{batch_num}.json,其中{device_id}表示设备ID,{model_file_name}表示模型名称,{model_id}表示模型ID,{batch_num}表示batch的数量。
task_time_{deviceid}.{model_file_name}.{model_id}.{batch_num}.json在Chrome浏览器中展示如图1所示。
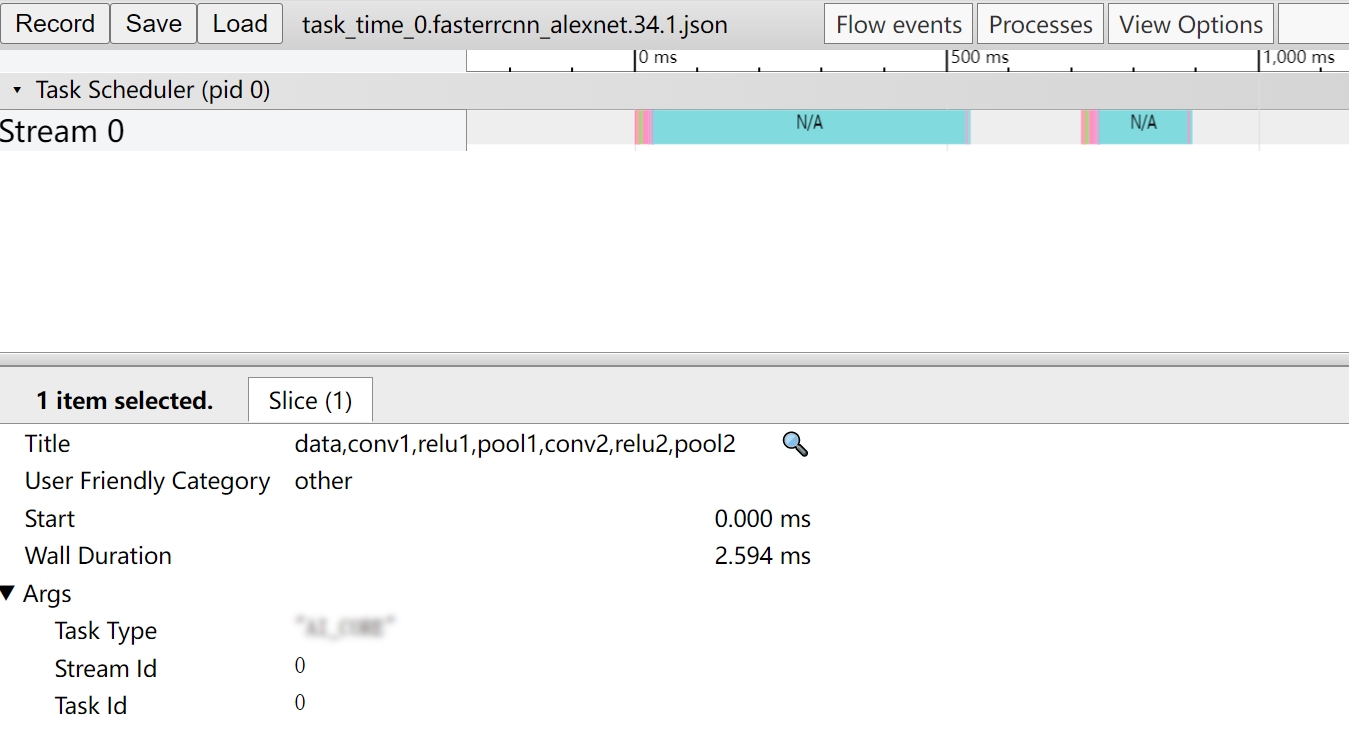
关键字段说明如表1所示。
表 1 字段说明
ACL接口耗时数据说明¶
请参见导出timeline数据获取ACL接口耗时数据文件acl_{deviceid}.{model_file_name}.{model_id}.{batch_num}.json,其中{device_id}表示设备ID,{model_file_name}表示模型名称,{model_id}表示模型ID,{batch_num}表示batch的数量。
acl_{deviceid}.{model_file_name}.{model_id}.{batch_num}.json在Chrome浏览器中展示如图1所示。
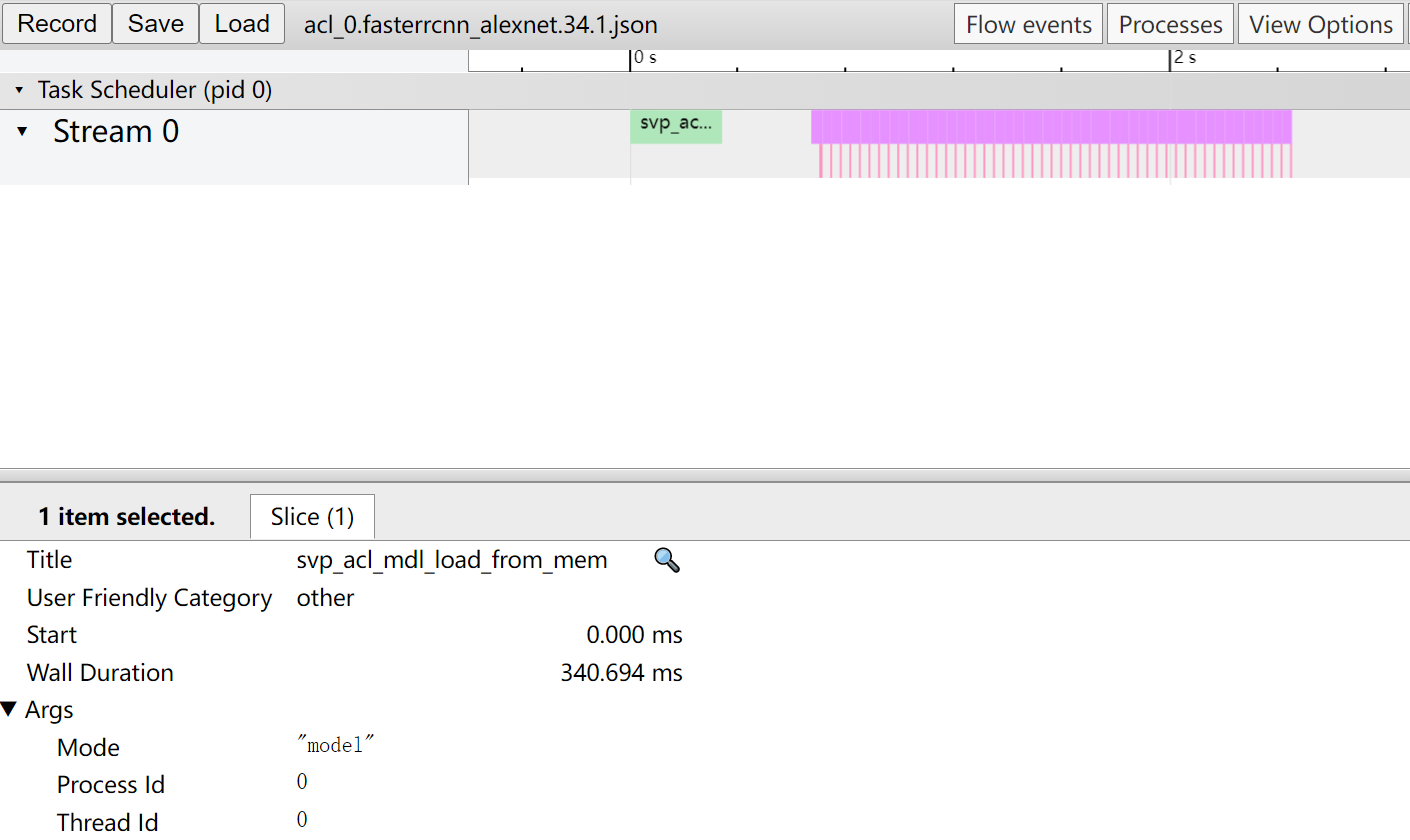
关键字段说明如表1所示。
表 1 字段说明
summary数据说明¶
导出summary数据¶
在导出summary数据前,需要参见解析Profiling数据解析Profiling数据。参见如下步骤导出summary数据。
以Toolkit组件包Ascend-cann-toolkit开发套件包的运行用户登录开发环境。以HwHi_Aa_User用户为例。
切换至msprof.pyc脚本所在目录,如${INSTALL_DIR}/toolkit/tools/profiler/profiler_tool/analysis/msprof。
说明:
小技巧:为方便执行msprof.pyc脚本,您可以使用HwHi_Aa_User用户执行命令alias msprof='python3.7.5 ${INSTALL_DIR}/toolkit/tools/profiler/profiler_tool/analysis/msprof/msprof.pyc'设置别名,后续就可以不用进入${INSTALL_DIR}/toolkit/tools/profiler/profiler_tool/analysis/msprof目录,在任意目录输入msprof即可执行Profiling命令。
${INSTALL_DIR}请替换为CANN软件安装后文件存储路径。例如,$HOME/Ascend/ascend-toolkit/svp_latest/x86_64-linux。执行如下命令,导出summary数据。
命令行格式如下,参数说明参见表1。
python3.7.5 msprof.pyc export summary [-h] -dir <dir> [--format <export_format>]例如导出推理或系统的Profiling的summary数据命令如下。
python3.7.5 msprof.pyc export summary -dir_ /home/HwHiAaUser/JOBXXX _--format csv
表 1 导出summary数据命令参数说明
收集到的Profiling数据目录。须指定为JOB_XXX目录,里面存在data文件夹和对应info.json.0文件。
说明:
下文中summary文件介绍均以csv文件为例。执行完上述命令后,会在collection-dir目录下生成summary目录,不同的数据(推理,系统)生成对应的csv文件,具体内容参见表2。
表 2 summary文件介绍
表3展示了通过acl.json和ACL API两种方式,采集解析导出后包含的summary数据文件对比。
表 3 生成数据文件对比
说明:summary目录中的文件是根据采集的实际Profiling数据进行生成,如果实际的Profiling数据没有相关的数据文件,就不会导出对应的summary的数据。
使用export命令能直接从已解析的Profiling数据中导出数据文件。当Profiling数据未解析时,单独执行export命令也能进行解析Profiling数据并导出数据文件。
小技巧:生成的summary数据文件使用excel打开时,会出现字段值为科学计数的情况,例如“1.00159E+12“。此时可选中该单元格,然后“右键>设置单元格格式“,在弹出的对话框中“数字“标签下选择“数值“,单击“确定“就能正常显示。
生成的summary数据文件中某些字段值为“N/A“时,表示此时该值不存在。
导出的数据中涉及到的时间节点(非Timestamp)为系统单调时间,只与系统有关,非真实时间。
ACL接口耗时数据说明¶
ACL接口调用次数及耗时数据说明¶
请参见导出summary数据获取ACL接口调用次数及耗时数据acl_statistic_{device_id}_{model_id}_{iter_id}.csv,其中{device_id}表示设备ID,{model_id}表示模型ID,{iter_id}表示某轮迭代的ID号。
acl_statistic_{device_id}_{model_id}_{iter_id}.csv文件内容格式示例如图1所示。

导出的ACL接口耗时数据表文件列说明如下。
表 1 字段说明
AA Core数据说明¶
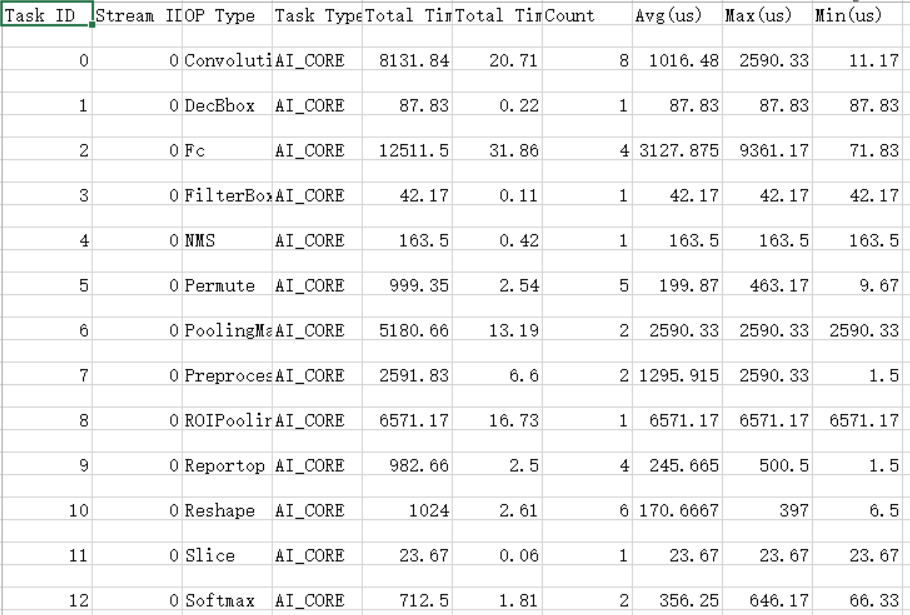
请参见导出summary数据获取_AA_ Core数据op_summary_{device_id}.{model_file_name}.{model_id}.{batch_num}.{input_pic_num}.{current_pic_count}.{icache_miss_rate}.{frequency}.csv,其中{device_id}表示设备ID,{model_file_name}表示模型名称,{model_id}表示模型ID,{batch_num}表示batch次数,{input_pic_num}表示输入图片总数,{current_pic_count}表示当前图片数,{icache_miss_rate}表示icache的损失率,{frequency}表示频率,{iter_id}表示某轮迭代的ID号。
整网场景op_summary_{device_id}.{model_file_name}.{model_id}.{batch_num}.{input_pic_num}.{current_pic_count}.{icache_miss_rate}.{frequency}.csv文件内容格式示例(示例仅展示部分参数,详情请参见表1)如图1。
导出的_AA_ Core数据表文件列说明如表1所示。
表 1 字段说明
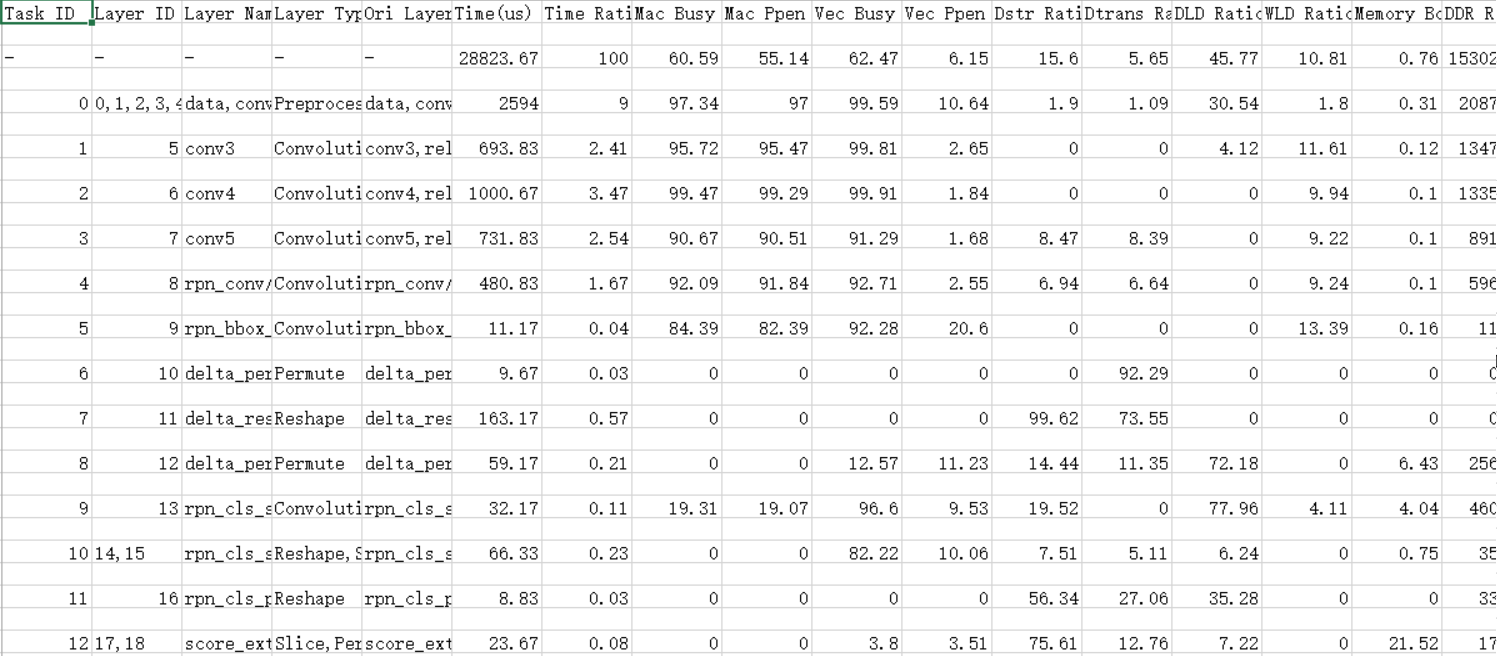
算子的输入维度Input Shapes取值为空,即表示为“; ; ; ;“格式时,表示当前输入的为标量,其中“;”为每个维度的分隔符。算子的输出维度同理。
性能数据中"-"代表的是total层的数据信息
AA Core算子调用次数及耗时数据说明¶
请参见导出summary数据获取_AA_ Core算子调用次数及耗时数据op_statistic_{device_id}_{model_id}_{current_pic_count}_{iter_id}.csv,其中{device_id}表示设备ID,{model_id}表示模型ID,{current_pic_count}表示当前图片数,{iter_id}表示某轮迭代的ID号。
展示Profiling数据¶
msprof.pyc工具是由Python编写的Profiling命令行工具。功能及安装路径如表1。
表 1 msprof.pyc脚本说明
|
${INSTALL_DIR}/toolkit/tools/profiler/profiler_tool/analysis/msprof |
展示数据操作及说明¶
以Toolkit组件包Ascend-cann-toolkit开发套件包的运行用户登录开发环境。以HwHi_Aa_User用户为例。
切换至“msprof.pyc“脚本所在目录,如${INSTALL_DIR}/toolkit/tools/profiler/profiler_tool/analysis/msprof。
说明:
小技巧:为方便执行msprof.pyc脚本,您可以使用HwHi_Aa_User用户执行命令alias msprof='python3.7.5 ${INSTALL_DIR}/toolkit/tools/profiler/profiler_tool/analysis/msprof/msprof.pyc'设置别名,后续就可以不用进入${INSTALL_DIR}/toolkit/tools/profiler/profiler_tool/analysis/msprof目录,在任意目录输入msprof即可执行Profiling命令。
${INSTALL_DIR}请替换为CANN软件安装后文件存储路径。例如,$HOME/Ascend/ascend-toolkit/svp_latest/x86_64-linux。执行如下命令,展示解析生成的数据,参数说明参见表1。
python3.7.5 msprof.pyc show [-h] -dir <dir>表 1 打屏命令参数说明
收集到的Profiling数据目录。须指定为JOB_XXX目录,里面存在data文件夹和对应info.json.0文件。
说明:
使用展示打屏功能请先安装 tabulate组件,可使用 pip3.7.5 install tabulate方式安装第三方依赖。执行命令后,命令行上会展示Profiling解析的数据,各数据展示属性分别如图1、图2、图3和图4所示。
说明:
执行完show展示功能后,JOBXXXX目录上会生成对应sqlite文件夹、log文件夹以及timeline文件夹。




Profiling性能分析样例参考¶
网络应用中的函数计算性能优化分析样例¶
使用PyTorch网络应用在昇腾模式识别处理器SoC执行推理过程中,发现整体执行时间较长。为了找出原因,使用Profiling性能分析工具对该网络应用执行推理耗时分析,分析结果显示运行的接口svp_acl_mdl_execute执行耗时数值较高,进一步分析结果发现Conv算子执行时间最长。因此我们打开PyTorch网络转换成的om模型查询Conv算子,发现该算子是多个计算单元组成,这样会造成极大的推理开销。由于Conv算子所在函数为Mish激活函数,而当前昇腾模式识别处理器SoC支持的激活函数只有:Relu、Leakyrelu、PRelu、Elu。Mish函数暂时不在支持范围内,因此造成模型转换后的Mish函数被分解成了多个计算单元。
问题解决:我们通过将om模型中的Mish函数替换昇腾模式识别处理器SoC的激活函数,尝试降低推理耗时,以Leakyrelu替换Mish函数为例,重新执行Profiling性能分析,结果发现推理耗时明显降低。
通过以下操作方法执行Profiling:
采集Profiling数据。
参考采集Profiling数据,得到JOB开头的即为保存的原始Profiling数据。
解析Profiling数据。
以Toolkit组件包Ascend-cann-toolkit开发套件包的运行用户登录开发环境。以HwHi_Aa_User用户为例。
切换至msprof.pyc脚本所在目录,如${INSTALL_DIR}/toolkit/tools/profiler/profiler_tool/analysis/msprof。
说明:
小技巧:为方便执行msprof.pyc脚本,您可以使用HwHi_Aa_User用户执行命令alias msprof='python3.7.5 ${INSTALL_DIR}/toolkit/tools/profiler/profiler_tool/analysis/msprof/msprof.pyc'设置别名,后续就可以不用进入${INSTALL_DIR}/toolkit/tools/profiler/profiler_tool/analysis/msprof目录,在任意目录输入msprof即可执行Profiling命令。
${INSTALL_DIR}请替换为CANN软件安装后文件存储路径。例如,$HOME/Ascend/ascend-toolkit/svp_latest/x86_64-linux。执行如下命令,解析JOBXXX目录下的Profiling数据。
python3.7.5 msprof.pyc import -dir /home/HwHiAaUser/JOBXXX此处以通过import命令行方式解析Profiling数据为例,解析Profiling数据详细介绍请参见解析Profiling数据。
在msprof.pyc脚本所在目录继续执行如下命令,导出timeline数据。
python3.7.5 msprof.pyc export timeline -dir home/HwHiAaUser/JOBXXX执行完上述命令后,会在collection-dir目录下的JOBXXX目录下生成timeline目录,不同的数据生成对应的json文件,如图1所示,具体内容参见表2。
在msprof.pyc脚本所在目录继续执行如下命令,导出summary数据。
python3.7.5 msprof.pyc export summary -dir /home/HwHiAaUser/JOBXXX --format csv执行完上述命令后,会在collection-dir目录下生成summary目录,不同的数据(推理,系统)生成对应的csv文件,如图2所示,具体内容参见表2。


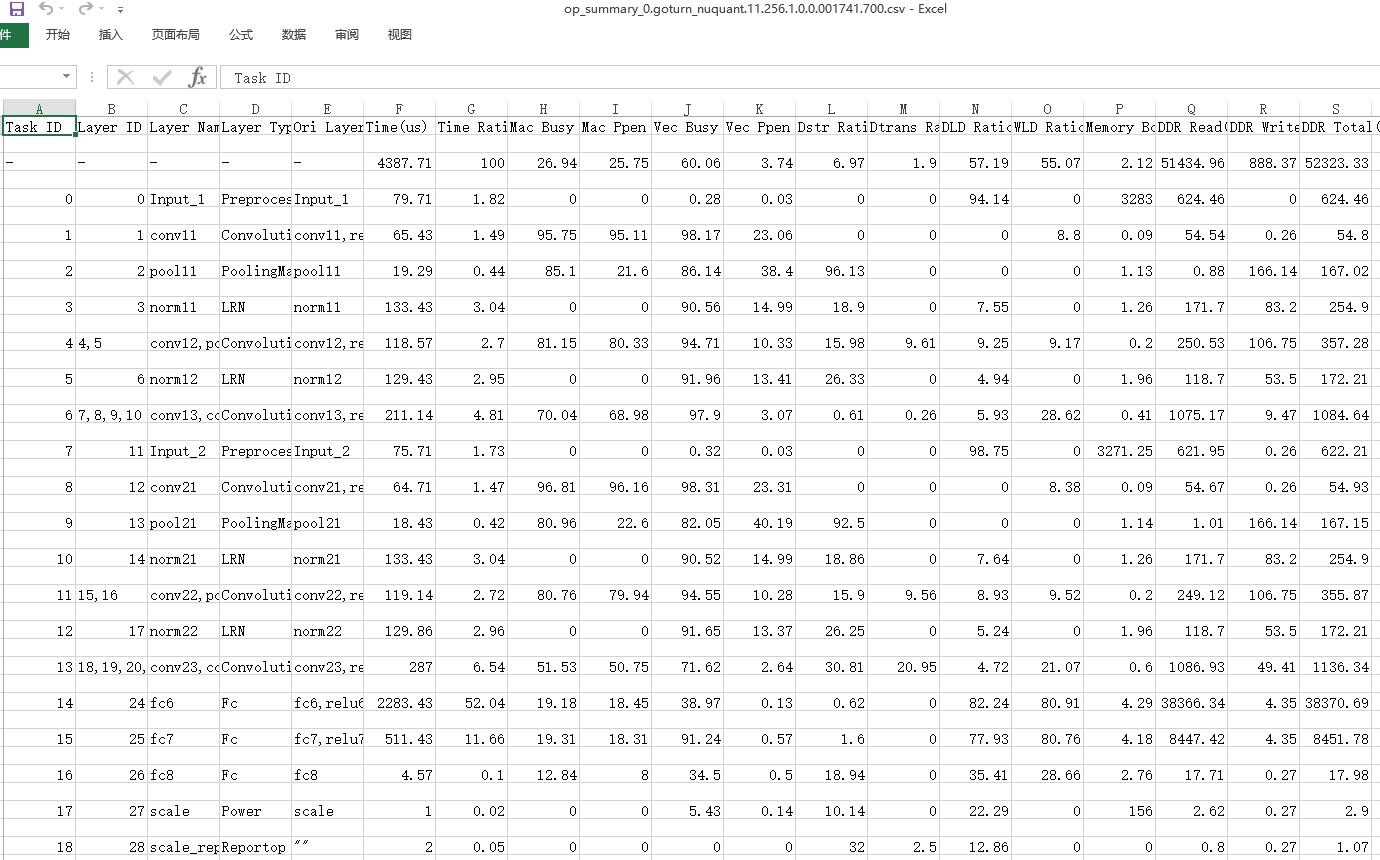
我们打开acl_{device_id}_{model_id}_{iter_id}.json文件查看ACL接口耗时数据。如图3所示。
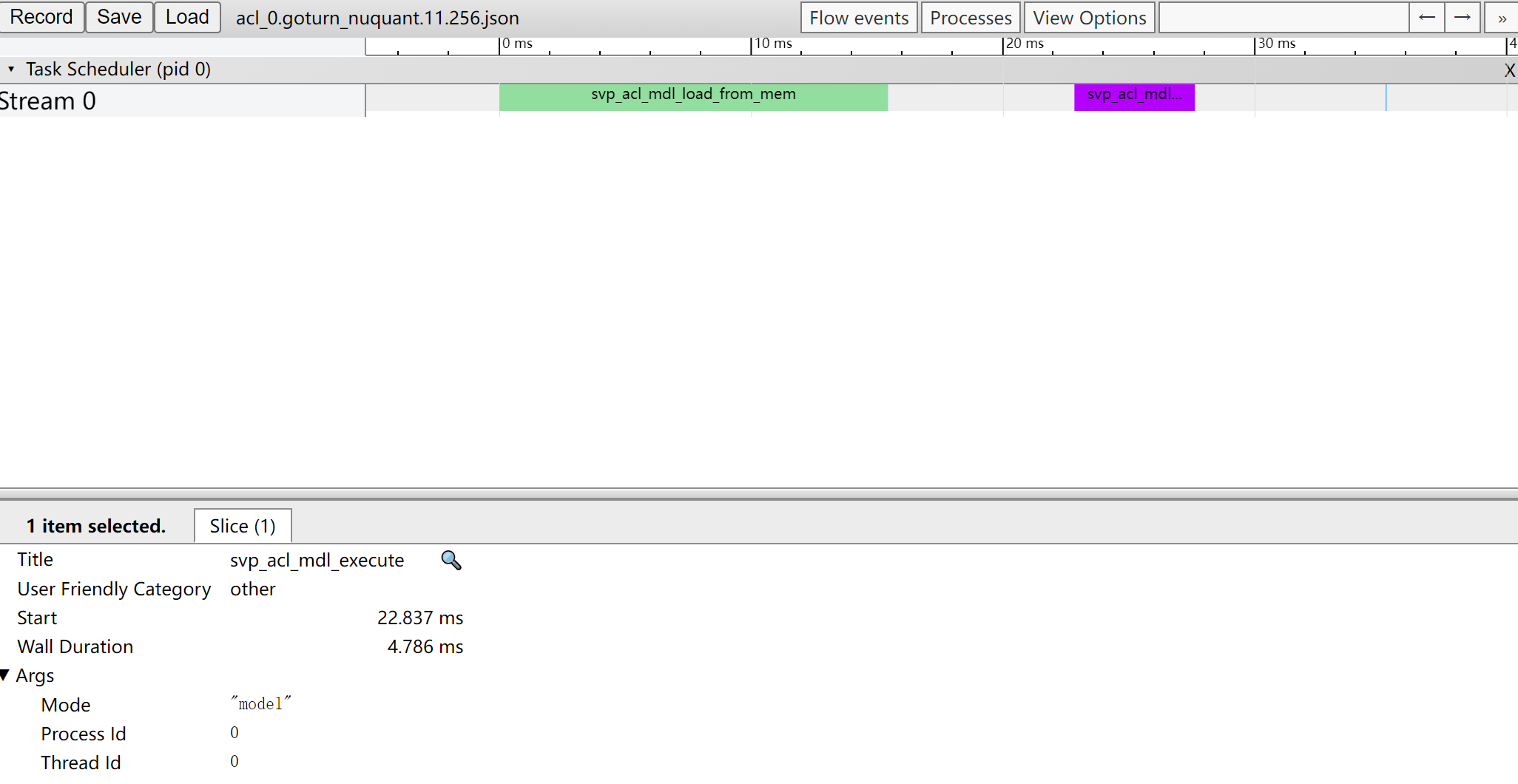
此时我们可以看到ACL接口中耗时最长的时间线有两段,分别为svp_acl_mdl_load_from_mem和svp_acl_mdl_execute接口。也就是说虽然svp_acl_mdl_execute接口是在执行接口中耗时最长,但是在ACL接口中,svp_acl_mdl_execute接口耗时仅排第二。
参见《应用开发指南》中的“ACL API参考”章节查找svp_acl_mdl_load_from_mem接口的作用为“从文件加载离线模型数据”,可以分析该接口耗时取决于加载离线模型的时间,加载时间我们暂时无法进行调优。那么还需要继续从svp_acl_mdl_execute接口深入分析。
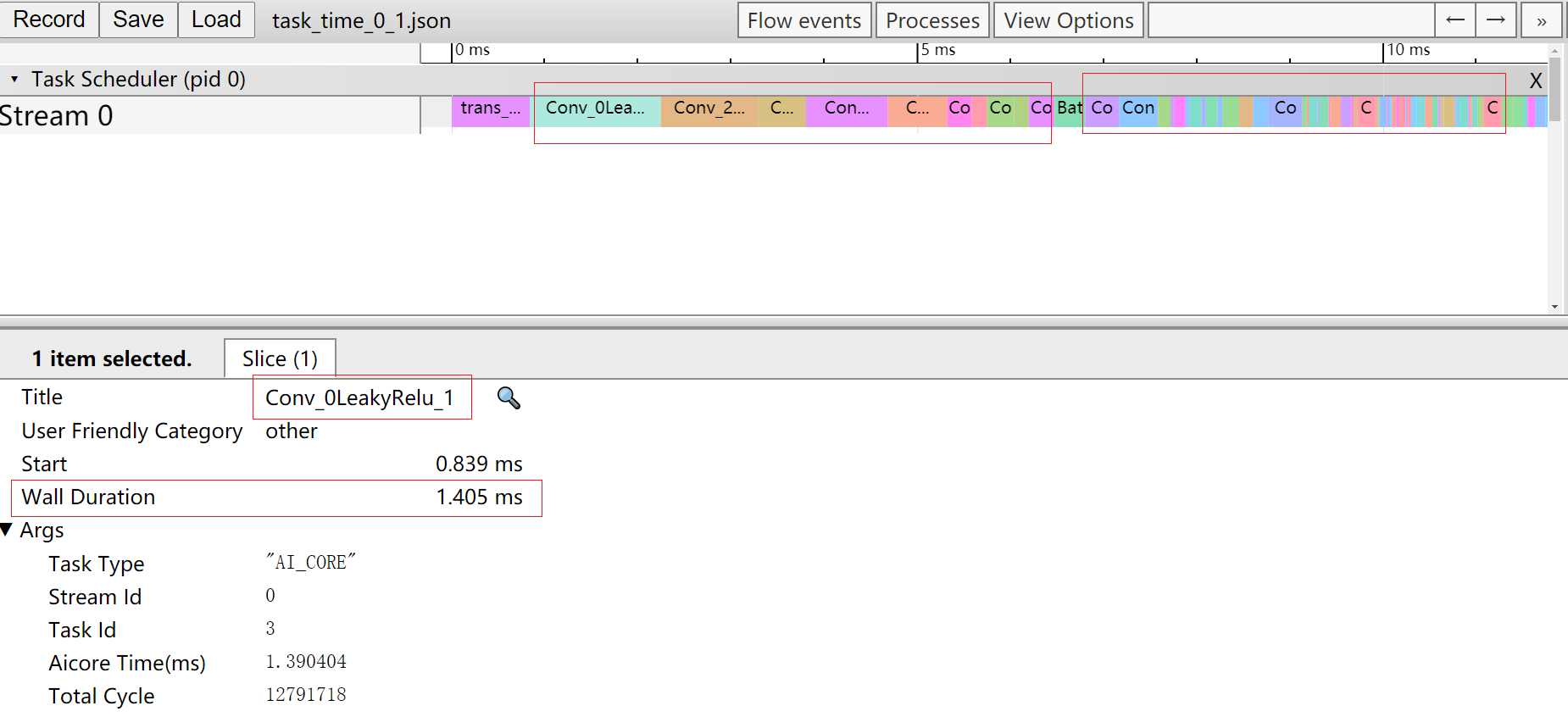
由于svp_acl_mdl_execute接口是执行接口,而模型中所有算子执行的时间总和就是执行耗时。那么我们通过打开task_time_{device_id}_{model_id}_{iter_id}.json文件查看Task Scheduler任务调度信息数据,分析执行推理过程中具体耗时较长的任务。如图4所示。
从Task Scheduler任务调度信息数据中我们可以看到,时间线中执行了大量的Conv算子(时间线过长图片无法完全展示),且每个Conv算子的执行时间都比其他算子长。
至此我们基本可以判断拖慢应用推理过程中执行效率的因素中,Conv算子的占比较大。
为了进一步验证这个结论我们可以打开summary数据中的acl_{device_id}_{model_id}_{iter_id}.csv文件如图5所示和task_time_{device_id}_{model_id}_{iter_id}.csv文件如图6所示。可以通过表格中的自定义排序,选择Total Time(us)为主要关键字,进行降序重排表格。
根据以上三张表中数据可以判断:各个组件耗时信息数据中ACL接口的svp_acl_mdl_load_from_mem接口耗时最长;ACL接口中耗时最长的时间线有两段,svp_acl_mdl_execute接口耗时排第二;Task Scheduler任务调度信息数据中存在大量的Conv算子,且每个Conv算子的执行时间都较长。
到此,Profiling性能分析工具的任务已经完成。
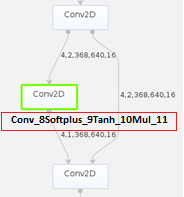
接下来我们可以参见《ATC工具使用指南》中的“基础功能”的章节,打开PyTorch网络转换成的om模型查询Conv算子,发现该算子是多个计算单元组成,如图7所示,这样会造成极大的推理开销。
我们通过查询代码发现计算单元中的Softplus、Tanh和Mul是属于Mish激活函数的计算公式,如图8所示。而当前昇腾模式识别处理器SoC支持的激活函数只有:Relu、Leakyrelu、Prelu、Elu和Srelu。Mish函数不在支持范围内,因此造成模型转换后的Mish函数被分解成了多个计算单元。
解决该问题最简单的办法就是找到效率更高的替代函数。




尝试以官方提供的Leaky Relu激活函数作为替换函数。函数替换操作请用户自行处理,此处不作阐述。完成函数替换后重新执行Profiling性能分析操作得到新的结果,我们查看图9已经从原先的23.299ms降低到现在的14.190ms,查看图10发现大多数Conv算子的时间线已经得到缩短。同时Leaky Relu函数的精度比Mish函数要小1%,Leaky Relu函数精度更高。
通过Profiling性能分析工具前后两次对网络应用推理的运行时间进行分析,并对比两次执行时间可以得出结论,替换Leaky Relu激活函数后,降低了Conv算子在应用推理的运行时间,提升了推理效率。
附录¶
FAQ¶
挂载命令中的ip与服务器ip不符¶
执行采集profileing数据上板操作时挂载失败,且挂载命令中的ip地址与服务器的ip不符
如:服务器ip为xxx.xxx.xxx.xxx,挂载ip为127.0.1.1
出现报错如图1所示。

/etc/hosts 文件中配置了回环地址如下。
127.0.0.1 localhost
127.0.1.1 hostname
将/etc/hosts 文件修改如下。
127.0.0.1 localhost
# 127.0.1.1 hostname