
前言¶
本文用于指导开发人员基于现有模型、使用SVP ACL(Smart Vision Processing Advanced Computing Language)提供的C语言API库开发图像分析工具应用,用于实现目标识别、图像分类等功能。
与本文档相对应的产品版本如下。
本文档适用于基于SVP ACL接口进行应用开发的人员,通过本文档您可以达成:
了解SVP ACL的功能架构、基本概念以及接口的典型调用流程。
使用SVP ACL接口进行应用开发的基本流程和实现方法。
能够基于本文档中的样例,扩展进行其它应用的开发。
掌握以下经验和技能可以更好地理解本文档:
具备C++/C语言程序开发能力。
对机器学习、_图像分析方法_有一定的了解。
使用约束¶
不支持使用fork函数创建多个进程,且在进程中调用SVP ACL接口的场景,否则进程运行时会报错或者卡死。
对于创建类接口(例如:svp_acl_rt_create_context 、svp_acl_rt_create_stream、svp_acl_create_data_buffer等),用户调用该类接口创建对应的资源后,资源使用完成后,建议及时调用对应的销毁类接口(例如:svp_acl_rt_destroy_context、svp_acl_rt_destroy_stream、svp_acl_destroy_data_buffer等),否则,程序可能会异常。
对于销毁类接口(例如:svp_acl_rt_destroy_context、svp_acl_rt_destroy_stream、svp_acl_rt_free、svp_acl_destroy_data_buffer等),用户调用该类接口后,不能继续使用已释放或销毁的资源,建议用户调用销毁类接口后,将相关资源设置为无效值(例如,置为NULL)。
一个Device上默认最多只能支持64个用户进程。
新手指引¶
文档结构总览¶
本文档分为以下几章:
前言:介绍文档概述和读者对象。
使用约束:介绍SVP ACL的总体使用约束。
新手指引:介绍文档结构、接口命名规则。
简介:介绍SVP(Smart Vision Platform)ACL(Advanced Computing Language)的基础知识,包括功能、基本概念、各概念之间的关系、如何查看日志等。
接口调用流程介绍:介绍各场景下的SVP ACL接口调用流程。
开发流程:介绍使用SVP ACL提供的接口开发应用的基本步骤。
准备环境:介绍准备开发环境和板端环境时需要参考的文档。
开发首个应用:以开发图片分类应用(不包含抠图、缩放、解码等数据预处理的开发)为例,按照开发流程,结合示例代码,介绍各步骤的基本原理。
开发典型功能点的介绍:SVP ACL各功能点的详细介绍。
SVP ACL API参考:介绍API的功能、原型、参数等。
SVP ACL样例使用指导:介绍如何使用SVP ACL提供的样例。
表达约定¶
接口命名规则¶
接口命名同时满足如下规则:
规则1:svp_acl+接口类别缩写+操作动词+对象
规则2:操作动词和对象均采用小写
接口类别¶
注:
缩写原则上不超过4个字母
在接口命名中,如果类别与操作对象重叠时,操作动词后的对象将省略。
如:svp_acl_mdl_load_from_mem,表示model类接口,这个接口表示含义是load model from mem,因此在接口命名中Load后面 mdl将被省略。
简介¶
本文用于指导开发人员基于现有模型、使用SVP ACL(Smart Vision Processing Advanced Computing Language)提供的C语言API库开发图像分析工具应用,用于实现目标识别、图像分类等功能。
什么是SVP ACL¶
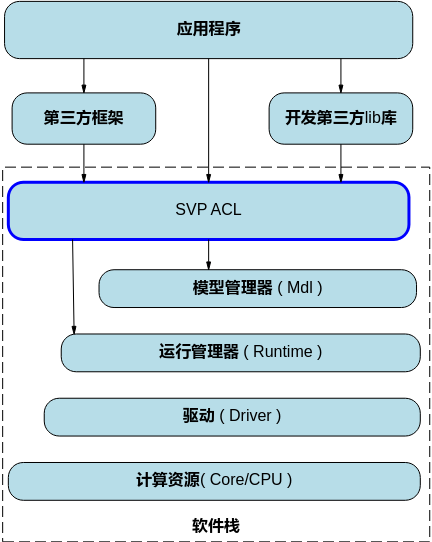
SVP ACL(Smart Vision Processing Advanced Computing Language)提供Device管理、Context管理、Stream管理、内存管理、模型加载与执行等C语言API库供用户开发图像分析工具应用,用于实现目标识别、图像分类等功能。用户可以通过第三方框架调用SVP ACL接口,以便使用SoC的计算能力;用户还可以使用SVP ACL封装实现第三方lib库,以便提供SoC的运行管理、资源管理能力。
在运行应用时,SVP ACL调用mdl管理器提供的接口实现模型的加载与执行、调用运行管理器的接口实现Device管理/Context管理/Stream管理/内存管理等。
计算资源层是SoC的硬件算力基础,主要完成图像分析工具的矩阵相关计算、完成控制算子/标量/向量等通用计算和执行控制功能、完成图像和视频数据的预处理,为图像分析工具计算提供了执行上的保障。
基本概念¶
表 1 概念介绍
本文中提及的同步、异步是站在调用者和执行者的角度,在当前场景下,若在板端环境调用接口后不等待Device执行完成再返回,则表示板端环境的调度是异步的;若在板端环境调用接口后需等待Device执行完成再返回,则表示板端环境的调度是同步的。 |
|
Context作为一个容器,管理了所有对象(包括Stream、设备内存等)的生命周期。不同Context的Stream之间、不同的Context之间是完全隔离的,无法建立同步等待关系。
|
|
Stream用于维护一些异步操作的执行顺序,确保按照应用程序中的代码调用顺序在Device上执行。
|
|
在某些场景下,模型每次输入的Batch数或分辨率是不固定的,如检测出目标后再执行目标识别网络,由于目标个数不固定导致目标识别网络输入BatchSize不固定。
|
|
在RGB色彩模式下,图像通道就是指单独的红色R、绿色G、蓝色B部分。也就是说,一幅完整的图像,是由红色绿色蓝色三个通道组成的,它们共同作用产生了完整的图像。 |
进程、线程、Device、Context、Stream之间的关系¶
各基本概念的介绍请参见基本概念。
Device、Context、Stream之间的关系¶
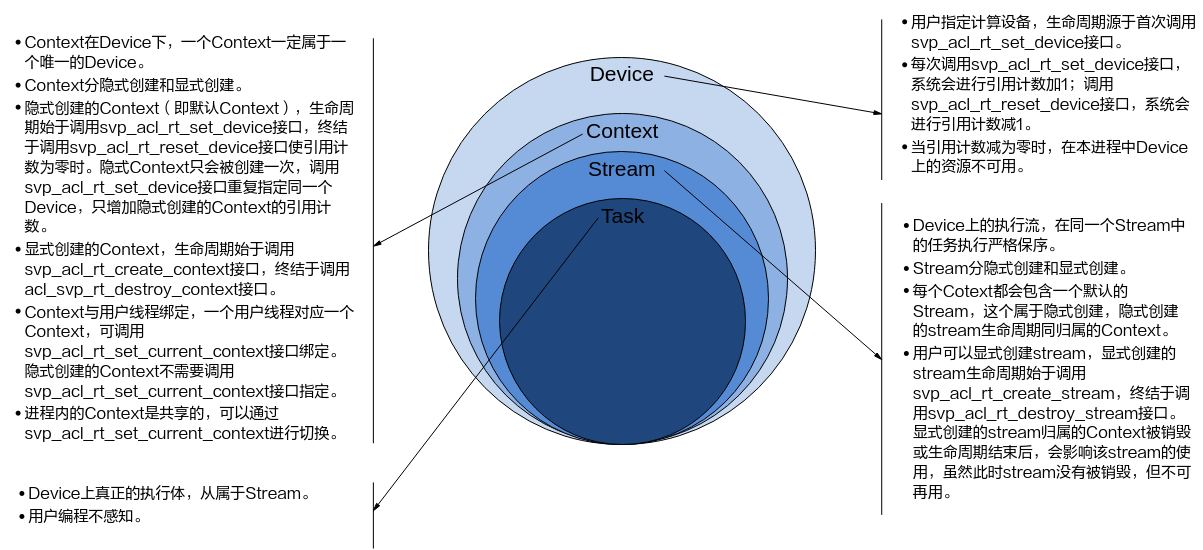
线程、Context、Stream之间的关系¶
一个用户线程一定会绑定一个Context,所有Device的资源使用或调度,都必须基于Context。
一个线程中当前会有一个唯一的Context在用,Context中已经关联了本线程要使用的Device。
可以通过svp_acl_rt_set_current_context进行Device的快速切换。示例代码如下,仅供参考,不可以直接拷贝编译运行:
… svp_acl_rt_create_context(&ctx1, 0); svp_acl_mdl_execute(mdl1, input1, output1); svp_acl_rt_create_context(&ctx2,1); /*在当前线程中,创建ctx2后,当前线程对应的Context切换为ctx2,对应在Device 1进行后续的计算任务,本例中将在Device 1上进行mdl2的执行调用 */ svp_acl_mdl_execute(mdl2, input2, output2); svp_acl_rt_set_current_context(ctx1); /*在当前线程中,通过Context切换,使后续模型计算任务在对应的Device 0上进行*/ svp_acl_mdl_execute(mdl3, input3, output3); …
一个线程中可以创建多个Stream,不同的Stream上计算任务是可以并行执行;多线程场景下,也可以每个线程创建一个Stream,线程之间的Stream在Device上相互独立,每个Stream内部的任务是按照Stream下发的顺序执行。
多线程的调度依赖于运行应用的操作系统调度,Device侧多Stream调度,由Device上调度组件进行调度。
一个进程内多个线程间的Context迁移¶
一个进程中可以创建多个Context,但一个线程同一时刻只能使用一个Context。
线程中创建的多个Context,线程缺省使用最后一次创建的Context。
进程内创建的多个Context,可以通过svp_acl_rt_set_current_context设置当前需要使用的Context。
默认Context和默认Stream的使用场景¶
Device上执行操作下发前,必须有Context和Stream,这个Context、Stream可以显式创建,也可以隐式创建。隐式创建的Context、Stream就是默认Context、默认Stream。
默认Stream作为接口入参时,直接传NULL。
默认Context不允许用户执行svp_acl_rt_get_current_context或svp_acl_rt_set_current_context操作,也不允许执行svp_acl_rt_destroy_context操作。
默认Context、默认Stream一般适用于简单应用,用户仅仅需要一个Device的计算场景下。多线程应用程序建议全部使用显式创建的Context和Stream。
示例代码如下,仅供参考,不可以直接拷贝编译运行:
…
svp_acl_init(...);
svp_acl_rt_set_device(0);
/*已经创建了一个default ctx,在default ctx中创建了一个default stream,并且在当前线程可用*/
…
svp_acl_mdl_execute_async(mdl1,input1,output1,NULL); //最后一个NULL表示在default stream上执行模型mdl1
svp_acl_mdl_execute_async(mdl2,input2,output2,NULL); //最后一个NULL表示在default stream上执行模型mdl2
svp_acl_rt_synchronize_stream(NULL);
/*等待计算任务全部完成(mdl1、mdl2执行结束),用户根据需要获取计算任务的输出结果*/
…
svp_acl_rt_reset_device(0); //释放计算设备0,对应的default ctx及default stream生命周期也终止
多线程、多stream的性能说明¶
线程调度依赖运行的操作系统,Stream上下发了任务后,Stream的调度由Device的调度单元调度,但如果一个进程内的多Stream上的任务在Device存在资源争抢的时候,性能可能会比单Stream低。
当前芯片有不同的执行部件,如模式识别Core、模式识别CPU等,对应使用不同执行部件的任务,建议多Stream的创建按照算子执行引擎划分。
单线程多Stream与多线程多Stream(进程属于多线程,每个线程中一个Stream)性能上哪个更优,具体取决于应用本身的逻辑实现,一般来说前者性能略好,原因是相对后者,应用层少了线程调度开销。
SVP ACL内存申请使用说明¶
用户内存管理有两种管理方式:
独立内存管理,根据需要单独申请所需的内存,内存不做拆分或者二次分配。
内存池管理内存,用户一次性申请一块较大内存,并在使用时从这块较大内存中二次分配所需内存。
在内存二次分配时,使用如下接口从内存池申请对应内存,由于接口对申请的内存地址、大小有约束,在内存池管理时,需要关注,否则容易出现内存越界。
- 使用svp_acl_rt_malloc接口申请的内存,需要通过svp_acl_rt_free接口释放内存。
- 频繁调用svp_acl_rt_malloc接口申请内存、调用svp_acl_rt_free接口释放内存,会损耗性能,建议用户提前做内存预先分配或二次管理,避免频繁申请/释放内存。
- 使用svp_acl_rt_malloc_host接口申请的内存,需要通过svp_acl_rt_free_host接口释放内存。
- 如果没有Host端,调用该接口会获取Device侧内存,也可调用svp_acl_rt_free释放。
- 频繁调用svp_acl_rt_malloc_host接口申请内存、调用svp_acl_rt_free_host接口释放内存,会损耗性能,建议用户提前做内存预先分配或二次管理,避免频繁申请/释放内存。
如何获取Sample¶
当前SVP ACL提供的样例如表1所示。
表 1 Sample列表
切至发布包Sample目录,解压samples.tar.gz
tar -zxvf samples.tar.gz
如何查看日志¶
在控制台上可以使用cat命令查看信息,cat /dev/logmpp查看错误日志。
如何查看Proc信息¶
概述¶
调试信息采用了Linux下的proc文件系统,可实时反映当前系统的运行状态,所记录的信息可供问题定位及分析时使用。
【文件目录】
/proc/umap
【信息查看方法】
在控制台上可以使用cat命令查看信息,cat /proc/umap/svp_nnn;也可以使用其他常用的文件操作命令,例如 cp /proc/umap/svp_nnn ./,将文件拷贝到当前目录。
在应用程序中可以将上述文件当作普通只读文件进行读操作,例如fopen、fread等。
说明: 参数在描述时有以下2种情况需要注意:
取值为{0, 1}的参数,如未列出具体取值和含义的对应关系,则参数为1时表示肯定,为0时表示否定。
取值为{aaa, bbb, ccc}的参数,未列出具体取值和含义的对应关系,但可直接根据取值aaa、bbb或ccc判断参数含义。
Proc信息说明¶
【调试信息】
# cat /proc/umap/svp_nnn
[SVP_NNN] Version: [xxxxVx.x.x.x B0xx Release], Build Time[mm dd yyyy, hh:mm:ss]
---------------------------svp_nnn module param--------------------------
nnn_save_power max_task_node_num
0 512
---------------------------svp_nnn resource info------------------------
free_model_num
63
device_id free_stream_num free_report_num free_task_node_num
0 127 128 511
---------------------------svp_nnn busy stream info----------------------
device_id stream_id report_id block_type send_task_num
0 0 -1 1 0
timeout_err_cnt hw_err_cnt aacpu_err_cnt
0 0 0
model_task_handle model_task_handle_wrap model_task_finish
1 0 0
model_task_finish_wrap
0
callback_task_handle callback_task_handle_wrap callback_task_finish
0 0 0
callback_task_finish_wrap
0
----------------------svp_nnn sync model task info-----------------
device_id task_send_num task_send_num_wrap task_finish_num task_finish_num_wrap
0 1 0 1 0
---------------------------svp_nnn irq info------------------------------
device_id irq_cnt_last_sec max_irq_cnt_per_sec total_irq_cnt
0 17 17 181
cur_irq_time max_irq_time irq_time_last_sec max_irq_time_per_sec
8 24 180 180
total_irq_time
2445
---------------------------svp_nnn runtime info--------------------------
device_id hw_status last_stream_id last_task_node_id net_seg_idx
0 0 0 0 446
net_seg_num
610
timeout_err_cnt hw_err_cnt aacpu_err_cnt
0 0 0
last_hw_task_time hw_utilization total_running_time
13 0% 897
【调试信息分析】
记录当前SVP图像分析引擎模块参数信息,资源信息,被调用stream信息,中断信息和运行时状态信息。
【参数说明】
最大任务节点个数,范围[1, 4096],默认为512个,用户可通过模块参数svp_nnn_max_task_node_num配置。配置方式是在加载svp_nnn的ko时,使用"svp_nnn_max_task_node_num=512"参数并修改"512"的值,将其配置成需要设置的数值。 |
||
备注:loadSS928V100脚本位置在版本包目录/mpp/out/ko/路径下。其中loadSS928V100脚本默认加载PQP的ko,PQP与svp__nnn_是互斥的,不能同时加载,需要手动修改loadSS928V100脚本加载svp__nnn_的ko。
接口调用流程介绍¶
主要接口调用流程¶
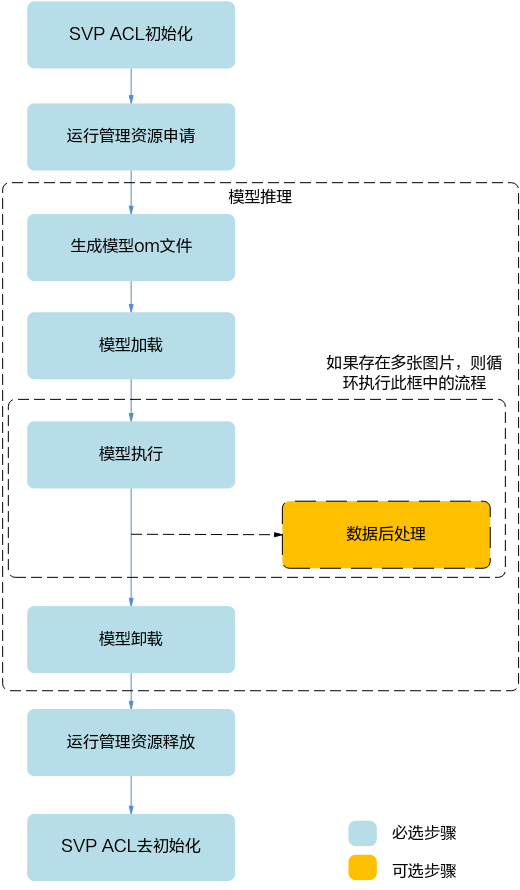
上图根据应用开发中的典型功能抽象出主要的接口调用流程,例如,如果需要实现模型推理的功能,则需要先加载模型,模型推理结束后,则需要卸载模型;如果模型推理后,需要从推理结果中查找最大置信度的类别标识对图片分类,则需要数据后处理。
SVP ACL初始化:调用svp_acl_init接口实现初始化SVP ACL。
运行管理资源申请:依次申请运行管理资源:Device、Context、Stream。具体流程,请参见“运行管理资源申请”。
模型推理。
生成模型om文件:需使用ATC工具将第三方网络(例如,Caffe ResNet-50网络)转换为适配SoC的离线模型(*.om文件),请参见《ATC工具使用指南》。
模型加载:模型推理前,需要先将对应的模型加载到系统中。具体流程,请参见“模型加载”。
模型执行:使用模型实现图片分类、目标识别等功能,目前SVP ACL提供同步推理接口和异步推理接口,支持动态Batch、动态分辨率等场景。具体流程,请参见“模型执行”。
(可选)数据后处理:处理模型推理的结果,此处根据用户的实际需求来处理推理结果,例如用户可以将获取到的推理结果写入文件、从推理结果中找到每张图片最大置信度的类别标识等。
模型卸载:调用svp_acl_mdl_unload接口卸载模型。
运行管理资源释放:所有数据处理都结束后,需要依次释放运行管理资源:Stream、Context、Device。具体流程,请参见“运行管理资源释放”。
SVP ACL去初始化:调用svp_acl_finalize接口实现SVP ACL去初始化。
说明:
在应用开发过程中,各环节都涉及内存的申请与释放、数据传输(通过内存复制实现)、数据类型的创建与销毁,因此未在图中一一标识,关于内存申请与释放、内存复制的接口请参见“内存管理”,数据类型的创建与销毁的接口请参见“数据类型及其操作接口”。
运行管理资源申请¶
您需要依次申请运行管理资源,包括:Device、Context、Stream。其中创建Context、Stream的方式分为隐式创建和显式创建。
隐式创建Context和Stream:适合简单、无复杂交互逻辑的应用,但缺点在于,在多线程编程中,每个线程都使用默认Context或默认Stream,默认Stream中任务的执行顺序取决于操作系统线程调度的顺序。
显式创建Context和Stream:推荐显式,适合大型、复杂交互逻辑的应用,且便于提高程序的可读性、可维护性。
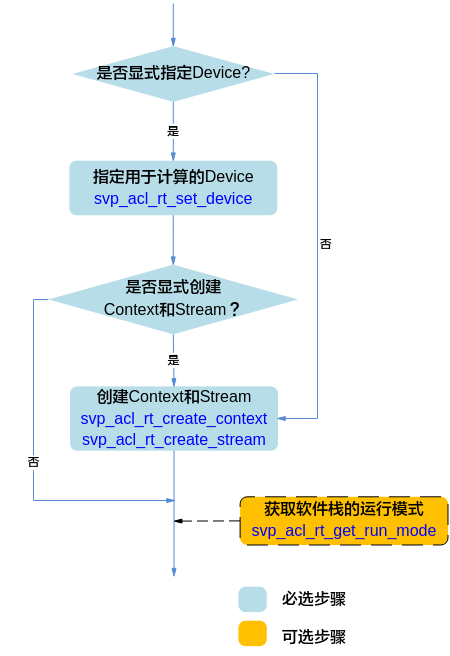
申请运行管理资源时,需按顺序依次申请:Device、Context、Stream。
调用svp_acl_rt_set_device接口显式指定用于运算的Device。
调用svp_acl_rt_create_context接口显式创建Context,调用svp_acl_rt_create_stream接口显式创建Stream。
不显式创建Context和Stream,系统会使用默认Context、默认Stream,该默认Context、默认Stream是在调用svp_acl_rt_set_device接口时隐式创建的。
默认Stream作为接口入参时,直接传NULL。
不显式指定用于运算的Device。
调用svp_acl_rt_create_context接口显式创建Context,调用svp_acl_rt_create_stream接口显式创建Stream。系统在显式创建Context时,系统内部会调用svp_acl_rt_set_device接口指定运行的Device,Device ID通过svp_acl_rt_create_context接口传入。
(可选)调用svp_acl_rt_get_run_mode接口获取软件栈的运行模式,根据运行模式来判断后续的内存申请接口调用逻辑,如果查询结果为SVP_ACL_HOST,则数据传输时涉及申请Host上的内存;如果查询结果为SVP_ACL_DEVICE,则数据传输时不涉及申请Host上的内存,仅需申请Device上的内存。
模型加载¶
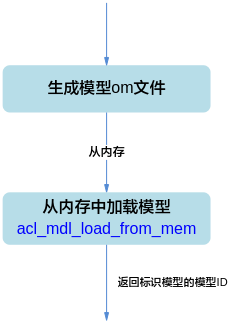
在模型加载前,需使用ATC工具将第三方网络(例如,Caffe ResNet-50网络)转换为适配SoC的离线模型(*.om文件),请参见《ATC工具使用指南》。
支持以下方式加载模型,模型加载成功后,返回标识模型的模型ID:
svp_acl_mdl_load_from_mem:从内存加载离线模型数据,由系统内部管理内存。
模型执行¶
基本的模型执行流程¶
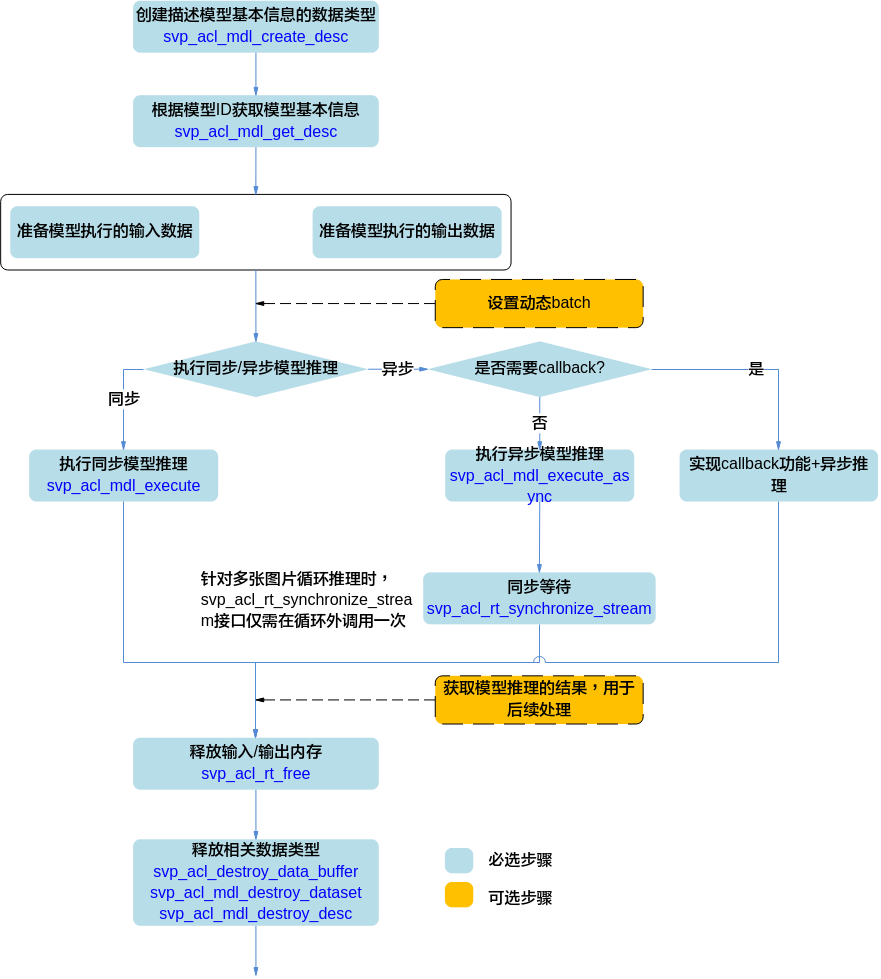
模型执行的关键流程说明如下:
调用svp_acl_mdl_create_desc接口创建描述模型基本信息的数据类型。
调用svp_acl_mdl_get_desc接口根据“模型加载”中返回的模型ID获取模型基本信息。
准备模型执行的输入、输出数据,具体流程,请参见“准备模型执行的输入/输出数据”。
设置动态Batch的具体流程,请参见“设置动态Batch和Total_t”。
执行模型推理。
当前系统支持模型的同步推理和异步推理:
同步推理时调用svp_acl_mdl_execute接口
异步推理时调用svp_acl_mdl_execute_async接口
对于异步接口,还需调用svp_acl_rt_synchronize_stream接口阻塞Host运行,直到指定Stream中的所有任务都完成。
如果同时需要实现Callback功能,请参见“Callback场景”。
获取模型推理的结果,用于后续处理。
对于同步推理,直接获取模型推理的输出数据即可。
对于异步推理,在实现Callback功能时,在回调函数内获取模型推理的结果,供后续使用。
释放内存。
调用svp_acl_rt_free接口释放Device上的内存。
释放相关数据类型的数据。
在模型推理结束后,需及时调用svp_acl_destroy_data_buffer接口和svp_acl_mdl_destroy_dataset接口释放描述模型输入的数据,且先调用svp_acl_destroy_data_buffer接口,再调用svp_acl_mdl_destroy_dataset接口。如果存在多个输入、输出,需调用多次svp_acl_destroy_data_buffer接口。
设置动态Batch和Total_t¶
须知:
Recurrent网络只支持设置动态batch为1,支持设置Total_t(要处理的总帧数);非Recurrent网络只支持设置动态batch,不支持设置Total_t。
图片输入时最大batch数为256。非图片输入时,最大batch数为5000。
准备模型推理的动态Batch输入的数据,详细流程请参见“准备模型执行的输入/输出数据”。
设置动态batch之前需要先调用svp_acl_mdl_get_input_index_by_name接口根据输入名称获取模型中标识动态Batch输入的index,动态Batch输入的名称固定为SVP_ACL_DYNAMIC_TENSOR_NAME,然后再调用svp_acl_mdl_set_dynamic_batch_size接口根据index设置动态batch。
申请动态Batch输入对应的内存前,需要先调用svp_acl_mdl_get_num_inputs获取输入个数,然后调用svp_acl_mdl_get_input_size_by_index接口根据index获取单batch所需内存大小,乘以用户要设置的动态batch值得到需要的内存大小(task_buf和work_buf不需要乘以动态batch值,详细请参见“准备模型执行的输入/输出数据”)。
说明:
SVP_ACL_DYNAMIC_TENSOR_NAME是一个宏,宏的定义如下:#define SVP_ACL_DYNAMIC_TENSOR_NAME "svp_acl_mbatch_shape_data"在成功加载模型之后,执行模型之前,设置动态Batch数或者设置Total_t。
设置动态Batch数
调用svp_acl_mdl_set_dynamic_batch_size接口设置动态Batch数。
设置Total_t
调用svp_acl_mdl_set_total_t接口设置Recurrent网络推理的帧数。
设置动态分辨率¶
准备模型推理的动态分辨率输入的数据,详细流程请参见“准备模型执行的输入/输出数据”。
设置动态分辨率之前需要先调用svp_acl_mdl_get_input_index_by_name接口根据输入名称获取模型中标识动态分辨率输入的index,动态分辨率输入的名称固定为SVP_ACL_DYNAMIC_TENSOR_NAME。
设置动态分辨率之前,调用svp_acl_mdl_get_input_size_by_index或者svp_acl_mdl_get_output_size_by_index接口根据index获取的是默认分辨率(最大分辨率)的size。
设置动态分辨率之前,调用svp_acl_mdl_get_input_default_stride或者svp_acl_mdl_get_output_default_stride接口根据index获取的是默认分辨率(最大分辨率)的stride。
设置动态分辨率之前,调用svp_acl_mdl_get_input_dims或者svp_acl_mdl_get_output_dims接口根据index获取的是默认分辨率(最大分辨率)的dims。
设置动态分辨率之后,以上接口获取的size/stride/dims是当前设置的分辨率的size/stride/dims;workbuf/taskbuf获取的(最大分辨率)size/stride/dims。
说明:
SVP_ACL_DYNAMIC_TENSOR_NAME是一个宏,宏的定义如下:#define SVP_ACL_DYNAMIC_TENSOR_NAME "svp_acl_mbatch_shape_data"当前动态分辨率的设置是跟随模型的,所以不支持多个线程同时对加载的一个模型进行同时设置不同的分辨率;当前支持的场景是设置一个分辨率,跑推理,当前推理完成;切换分辨率,继续推理。
在成功加载模型之后,执行模型之前,设置动态分辨率大小。
调用svp_acl_mdl_get_dynamic_hw接口获取支持的动态分辨率个数和大小。
调用svp_acl_mdl_set_dynamic_hw_size接口根据index设置动态分辨率大小。
准备模型执行的输入/输出数据¶
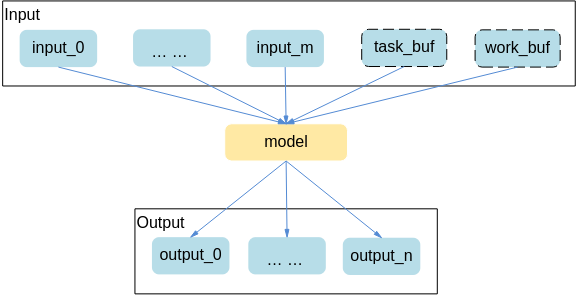
准备输入内存时需要额外输入两块内存,分别为task_buf,work_buf,对应的输入索引为M-2和M-1(M是通过svp_acl_mdl_get_num_inputs接口获取的输入个数)。在申请动态batch内存时,这两块内存不需要乘以batch值。
task_buf用于填充模型推理的任务信息,当前模型推理完之前不能被修改或被其他模型推理任务使用,task_buf的大小不为0。
work_buf用于任务执行时存储中间结果,一个stream上如果会执行不同的模型,开辟一个最大的work_buf即可,这些模型在该stream上推理时可以共用,不同stream间不能共用,work_buf大小不为0。
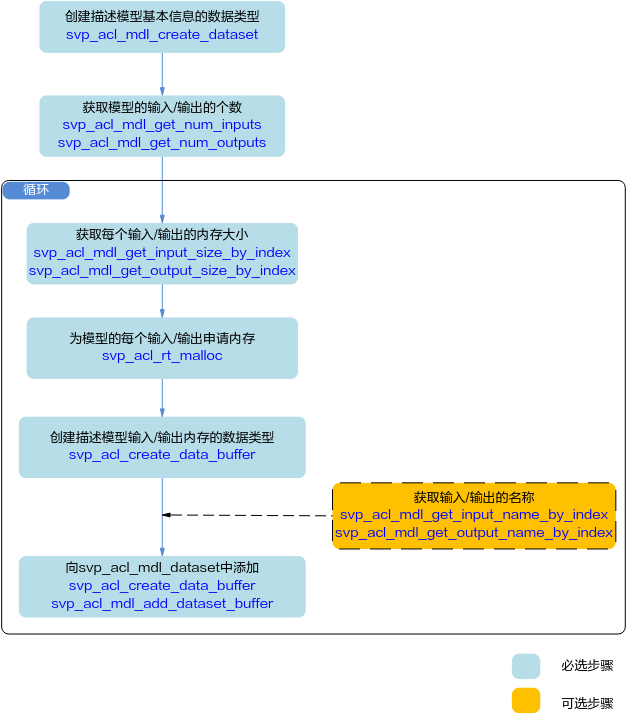
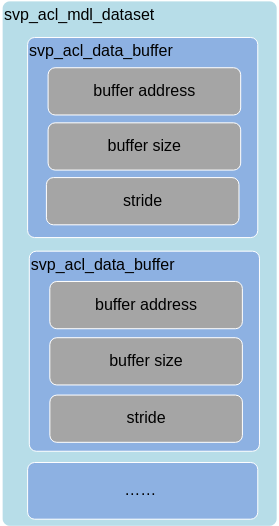
使用svp_acl_mdl_desc类型的数据描述模型基本信息(例如输入/输出的个数、名称、数据类型、Format、维度信息等),使用svp_acl_mdl_dataset类型的数据描述模型的输入/输出数据,模型可能存在多个输入、多个输出,每个输入/输出的内存地址、内存大小用svp_acl_data_buffer类型的数据来描述。
图 3 svp_acl_mdl_dataset类型与svp_acl_data_buffer类型的关系
模型存在多个输入、输出时,用户在向svp_acl_mdl_dataset中添加svp_acl_create_data_buffer时,为避免顺序出错,可以先获取输入、输出的名称,根据输入、输出名称所对应的index的顺序添加。
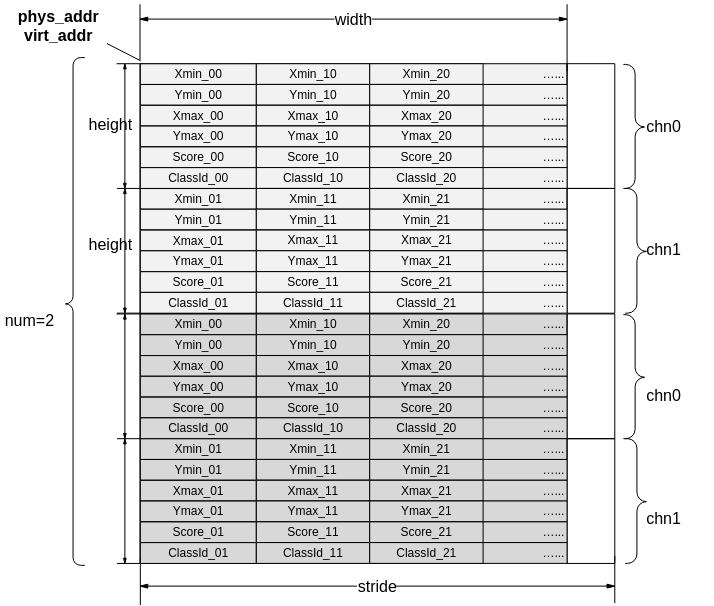
图 4 模型输入/输出数据排布(通道为2,batch为2示意图)
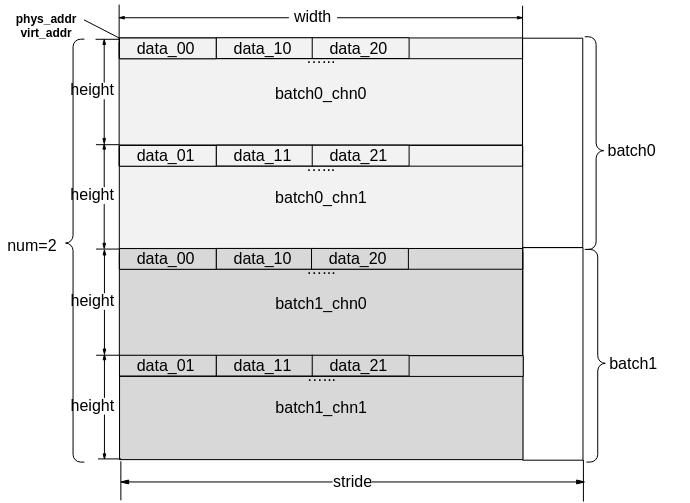
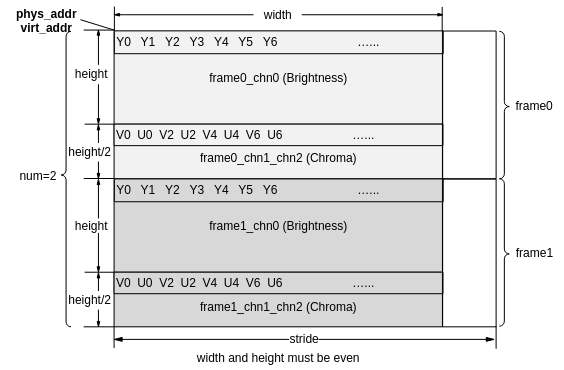
SVP_ACL输入输出数据stride都是按照最后一维对齐,除YVU420SP与YUV420SP输入格式外,数据排布都如图4所示。
如果是RGB_PACKAGE格式,data_xx数据类型为U24,通道数为1。
如果是XRGB_PACKAGE格式,data_xx数据类型为U32,通道数为1。
如果是XBGR_PACKAGE格式,data_xx数据类型为U32,通道数为1。
如果是RGBX_PACKAGE格式,data_xx数据类型为U32,通道数为1。
如果是BGRX_PACKAGE格式,data_xx数据类型为U32,通道数为1。
如果是BGR_PACKAGE格式,data_xx数据类型为U24,通道数为1。
如果是BGR_PLANAR格式,data_xx数据类型为U8,通道数为3。
如果是RGB_PLANAR格式,data_xx数据类型为U8,通道数为3。
如果是XRGB_PLANAR格式,data_xx数据类型为U8,通道数为3。
如果是XBGR_PLANAR格式,data_xx数据类型为U8,通道数为3。
如果是RGBX_PLANAR格式,data_xx数据类型为U8,通道数为3。
如果是BGRX_PLANAR格式,data_xx数据类型为U8,通道数为3。
如果是RAW_RGGB格式,data_xx数据类型为U8/U12/U14/U16,通道数为1。
如果是RAW_GRBG格式,data_xx数据类型为U8/U12/U14/U16,通道数为1。
如果是RAW_GBRG格式,data_xx数据类型为U8/U12/U14/U16,通道数为1。
如果是RAW_BGGR格式,data_xx数据类型为U8/U12/U14/U16,通道数为1。
图 5 YVU420SP/YUV420SP数据排布(通道为2,frame为2示意图)
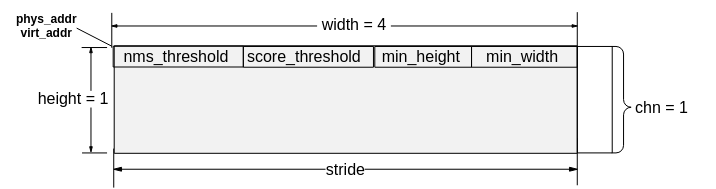
SVP_ACL支持检测网阈值通过data层传入,阈值输入固定长度为4,分别是nms_threshold,score_threshold,min_height,min_width,同时将检测网络输出的检测框结果数据排布进行了统一,检测网阈值和检测框结果排布格式如图7所示。
同步等待¶
多Device场景¶
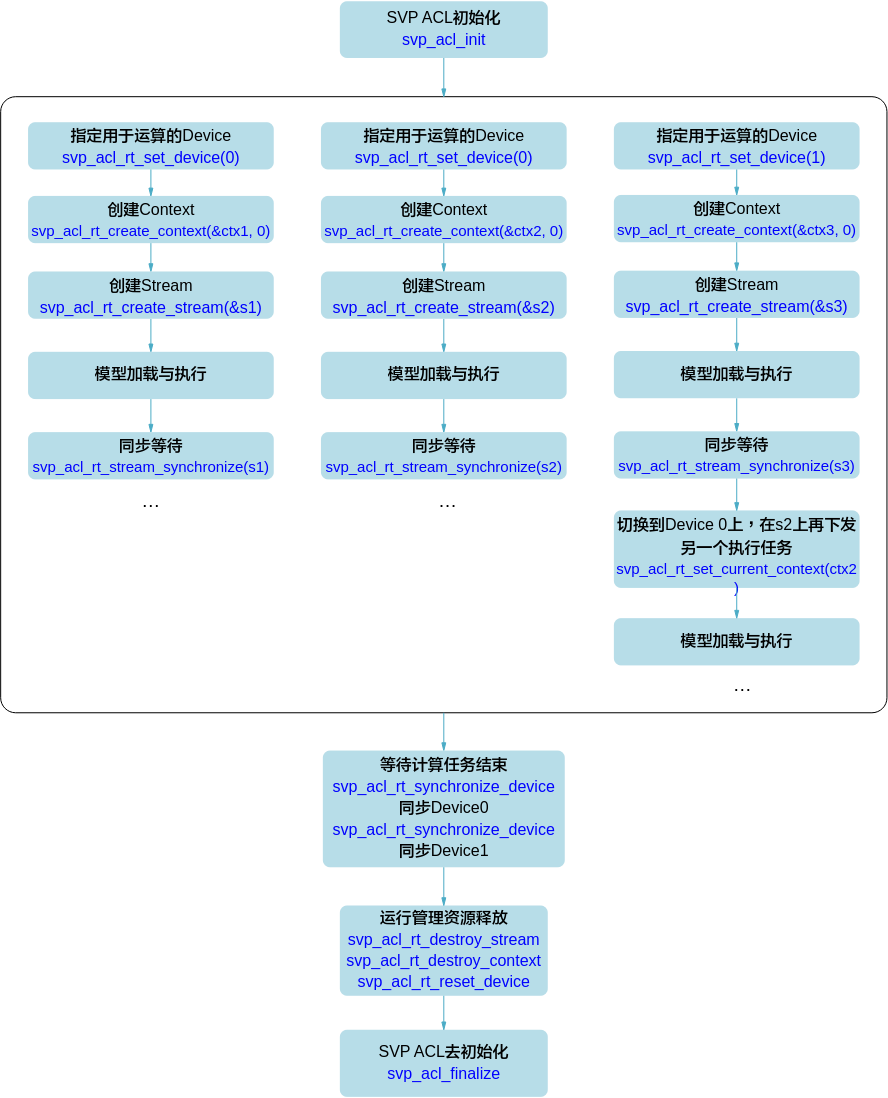
在多Device时,利用Context切换(调用svp_acl_rt_set_current_context接口)来切换Device,比使用svp_acl_rt_set_device接口效率高。
调用svp_acl_rt_synchronize_device接口等待Device上的计算任务结束。
多Stream场景¶
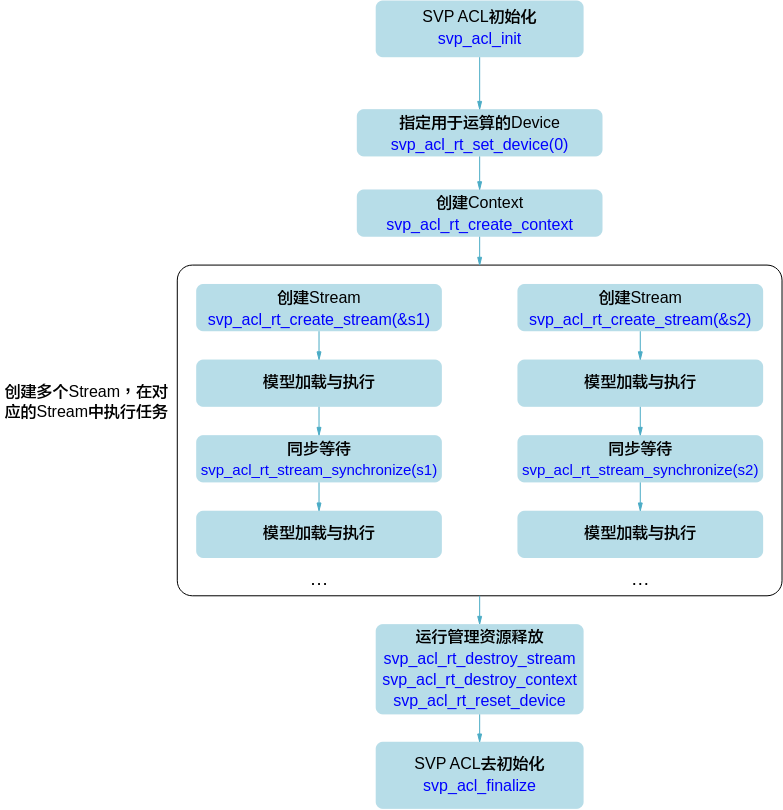
Callback场景¶
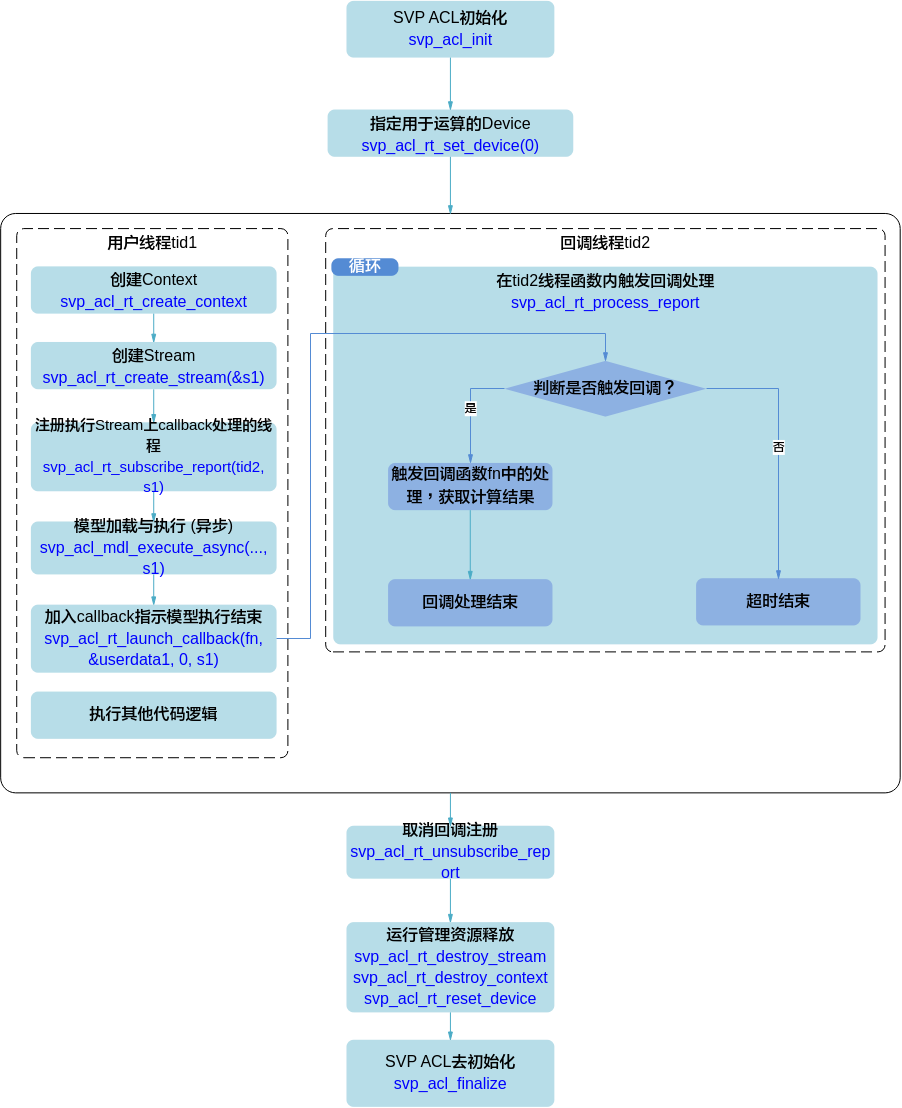
Callback流程中关键流程说明如下:
回调函数fn需由用户提前创建,用于获取并处理模型推理或算子执行的结果。
线程tid2需由用户提前创建,并自定义线程函数,在线程函数内调用svp_acl_rt_process_report接口,等待指定时间后,触发回调函数。
调用svp_acl_rt_subscribe_report接口:指定处理Stream上回调函数的线程,线程与tid2保持一致。
调用svp_acl_rt_launch_callback接口:在Stream的任务队列中增加一个需要在板端环境上执行的回调函数,回调函数与fn保持一致。
调用svp_acl_rt_unsubscribe_report接口:取消线程注册(Stream上的回调函数不再由指定线程处理)。
如果是异步推理Callback场景,为确保Stream中所有任务都完成、模型推理的结果数据都经过Callback函数处理,在Stream销毁前,需要调用一次svp_acl_rt_synchronize_device接口。
运行管理资源释放¶
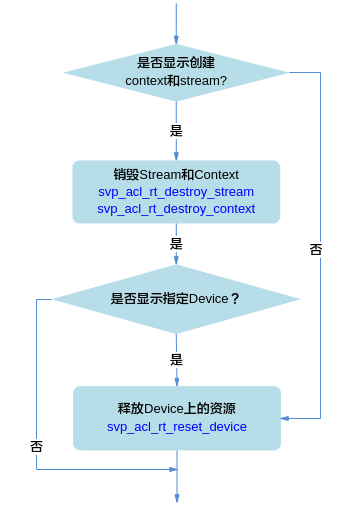
释放运行管理资源时,需按顺序依次释放:Stream、Context、Device。
显式创建Context和Stream时,需调用svp_acl_rt_destroy_stream接口释放Stream,再调用svp_acl_rt_destroy_context接口释放Context。若显式调用svp_acl_rt_set_device接口指定运算的Device时,还需调用svp_acl_rt_reset_device接口释放Device上的资源。
不显式创建Context和Stream时,仅需调用svp_acl_rt_reset_device接口释放Device上的资源。
开发流程¶
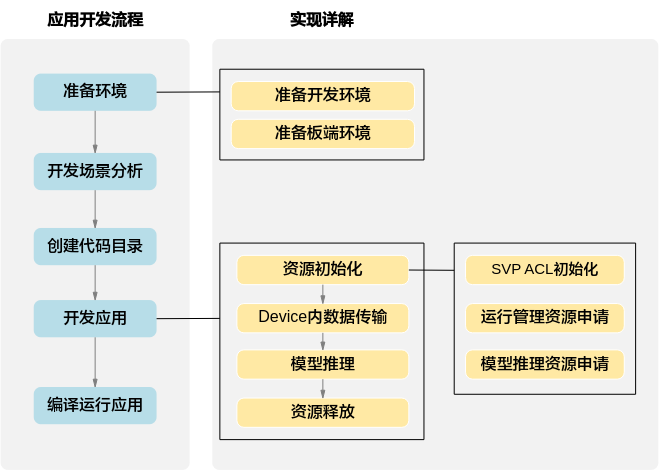
准备环境,包括开发环境和板端环境。
开发场景分析。
根据开发场景分析涉及哪些功能(例如,数据传输、模型推理等)的开发,确定功能后,再明确涉及的命令或接口,请参见“开发场景分析”。
创建代码目录。
在开发应用前,您需要先创建目录,存放代码文件、编译脚本、测试图片数据、模型文件等,请参见“创建代码目录”。
开发应用。
资源初始化,包括SVP ACL初始化、运行管理资源申请、模型推理资源申请等,请参见“资源初始化”。
使用SVP ACL接口开发应用时,必须先调用svp_acl_init接口进行SVP ACL初始化,否则可能会导致后续系统内部资源初始化出错,进而导致其它业务异常。
数据传输,请参见“读入图片数据”。
执行模型推理。请参见“模型推理”。
模型推理结束后,需及时释放相关资源。
若需要处理模型推理的结果,还需要进行数据后处理,例如对于图片分类应用,通过数据后处理从推理结果中查找最大置信度的类别标识。
所有数据处理结束后,需及时释放运行管理资源。
编译运行应用,包括模型转换、编译代码、运行应用,请参见“编译及运行应用”。
准备环境¶
准备开发环境¶
您需要参见《驱动和开发环境安装指南》安装开发环境,获取以下文件:
从“SVP ACLlib组件的安装目录/acllib/include/acl”目录下获取调用SVP ACL接口所需的头文件。
从“SVP ACLlib组件的安装目录/acllib/lib64/stub”目录下获取编译SVP ACL接口所需的库文件。
在安装开发环境后,您需要参见《驱动和开发环境安装指南》中的“安装后处理 ”章节安装交叉编译器,并配置对应环境变量。
须知:本文以如下安装路径示例来说明操作步骤,实际编译、运行应用前,请务必获取这些组件的实际安装路径,以便后续操作时使用,其中,$HOME表示安装用户的家目录: 以非root用户安装ACLlib组件安装包,安装路径示例为$HOME/acl,在该路径下,包括“acllib”目录。
本文中的操作步骤(包括模型转换、编译代码等)需以运行用户登录开发环境后再执行,请务必获取各组件的运行用户,以便后续操作时使用。
用户使用export命令在当前终端窗口下声明环境变量,关闭Shell终端或切换用户时环境变量失效。
准备运行环境¶
如果您需要运行应用,需完成板端环境的配置、软件包的部署等,请参见《驱动和开发环境安装指南》。
板端环境的操作系统为Linux时,在部署与调试后,使用过程中,若板端环境上的空间不足时,您可以使用mount命令将NFS服务器上的目录挂载到板端环境的指定目录。
以root用户登录Linux服务器(Ubuntu操作系统),安装NFS服务并配置共享目录。
确保环境连网且源可用的前提下,安装NFS服务,可参考如下命令安装,如果安装过程中提示已安装NFS服务,则无需重复安装:
apt-get install nfs-kernel-server在“/etc/exports”文件中配置共享目录,配置完成后,执行/etc/init.d/nfs-kernel-server restart命令重启NFS服务使配置生效。可参考如下配置段(添加在文件的末尾),斜体部分请根据实际情况替换,服务器绝对路径表示Linux服务器的共享目录,如不存在,请提前创建。
服务器绝对路径 *(rw,sync,root_squash,anonuid=id*,anongid=gid*)命令示例如下,其中,path表示板端环境上的目录,需根据实际情况修改,例如:/root。
mount -t nfs -o nolock,tcp NFS服务器IP地址:服务器绝对路径 path
开发首个应用¶
开发场景分析¶
开发场景¶
开发图片分类应用,对2张分辨率为1024*683的*.jpg图片分类。
场景分析¶
您可从以下几方面入手分析该应用需包含哪些功能,这些功能点对应哪些SVP ACL接口。
本文介绍的场景是图片分类,因此需要选取开源的分类网络,此处选择的是Caffe resnet-50网络,将开源的resnet-50网络转换为适配图像分析引擎的离线模型(*.om文件),使用该离线模型推理图片所属的类别。 resnet-50网络对输入图片宽高的要求为224*224,且要求输入图片格式为RGB。但当前输入图片是*.jpg格式,因此下文的样例中提供了一个Python脚本先转换图片。 |
创建代码目录¶
在开发应用前,您需要先创建目录,存放代码文件、编译脚本、测试图片数据、模型文件等。
以开发环境的安装用户,在开发环境的任意目录下创建存放应用代码的目录,如下仅是示例,可参考:
├App名称
├── caffe_model //该目录下存放模型转换相关的文件
│ ├── xxx.caffemodel
├── model //该目录下存放转化后的om模型
│ ├── xxx.om
├── data
│ ├── xxx.jpg //原始测试数据
├── inc //该目录下存放声明函数的头文件
│ ├── xxx.h
├── out //该目录下存放输出结果
├── src //该目录下存放系统初始化的配置文件、编译脚本、函数的实现文件
│ ├── xxx.json //系统初始化的配置文件
│ ├── CMakeLists.txt //编译脚本
│ ├── xxx.cpp //实现文件
开发应用¶
资源初始化¶
SVP ACL初始化¶
基本原理:必须调用svp_acl_init接口初始化SVP ACL,配置文件内容为json格式,当前支持以下配置。
dump信息配置,示例、配置说明及约束请参见《ATC工具使用指南》“online_model_type”章节。默认不启动dump配置。
示例代码:可以从acl_resnet50样例中查看完整样例代码。
调用接口后,增加了异常处理的分支,同时通过ERROR_LOG记录报错日志、通过INFO_LOG记录各动作的提示日志,示例代码中不一一列举。以下是关键步骤的代码示例,不可以直接拷贝编译运行,仅供参考。
#include "acl/svp_acl.h"
//......
//初始化基本配置。
//此处的..表示相对路径,相对可执行文件所在的目录
//例如,编译出来的可执行文件存放在out目录下,此处的..就表示out目录的上一级目录
const char * acl_config_path = "../src/acl.json";
svp_acl_error ret = svp_acl_init(acl_config_path);
//......
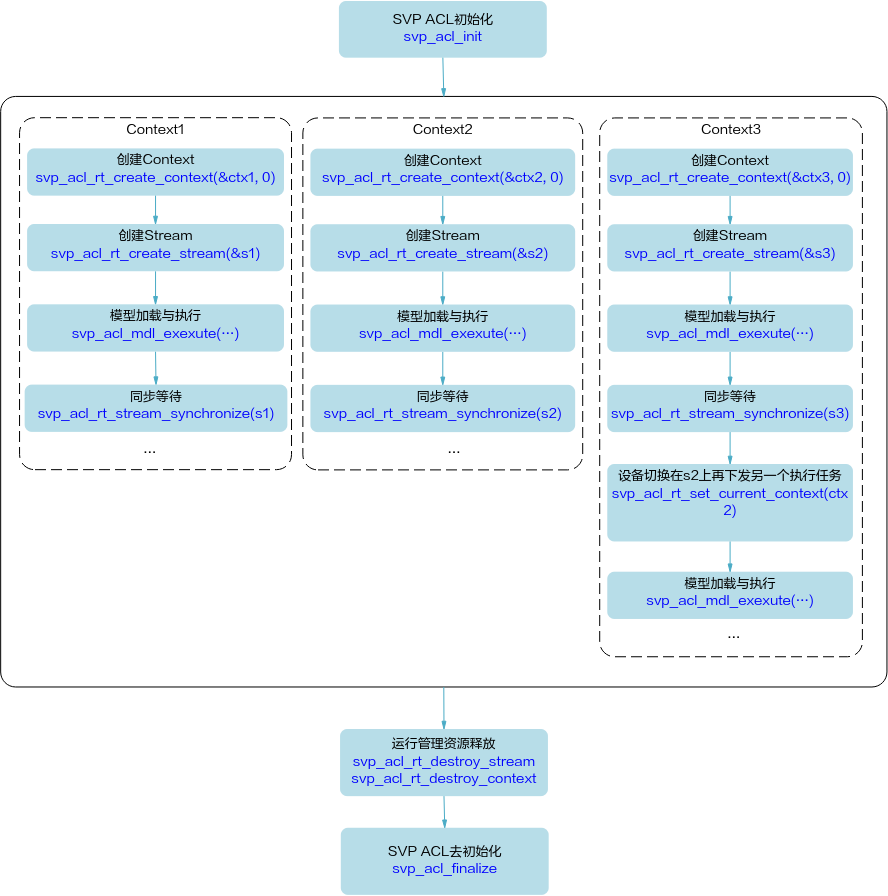
运行管理资源申请(单进程+单线程+单Stream)¶
多线程、多Stream的场景请参见Stream管理。
基本原理:需要按顺序依次申请如下资源:Device、Context、Stream,确保可以使用这些资源执行运算、管理任务。
关于Context和Stream
显式创建Context时,调用svp_acl_rt_create_context接口,此时需显式调用svp_acl_rt_destroy_context接口释放。
显式创建Stream时,调用svp_acl_rt_create_stream接口,此时需显式调用svp_acl_rt_destroy_stream接口释放。
如果不显式创建Context和Stream,您可以使用svp_acl_rt_set_device接口隐式创建的默认Context和默认Stream,但默认Context和默认Stream存在如下限制:
一个Device对应一个默认Context,默认Context不能通过svp_acl_rt_destroy_context接口来释放。
一个Device对应一个默认Stream,默认Stream不能通过svp_acl_rt_destroy_stream接口来释放。默认Stream作为接口入参时,直接传NULL。
关于单进程、单线程、单Stream场景
单进程:一个应用程序对应一个进程。
单线程:不显式创建多个线程时,默认只有一个线程。
单Stream:整个开发的过程中使用同一个Stream。
对于同一个Stream中的异步任务,SVP ACL会按照应用程序中任务的顺序执行任务,确保异步任务执行的顺序。
示例代码:可以从acl_resnet50样例中查看完整样例代码。
调用接口后,增加了异常处理的分支,同时通过ERROR_LOG记录报错日志、通过INFO_LOG记录各动作的提示日志,示例代码中不一一列举。以下是关键步骤的代码示例,不可以直接拷贝编译运行,仅供参考。
#include "acl/svp_acl.h"
//......
//1.初始化变量
extern bool g_is_device;
//......
//2.指定运算的Device,SoC场景下,当前只有一个Device
ret = svp_acl_rt_set_device(device_id);
//3.显式创建一个Context,用于管理Stream对象
ret = svp_acl_rt_create_context(&context, device_id);
//4.显式创建一个Stream
//用于维护一些异步操作的执行顺序,确保按照应用程序中的代码调用顺序执行任务
ret = svp_acl_rt_create_stream(&stream);
//5.获取当前svp_acl软件栈的运行模式,根据不同的运行模式,后续的接口调用方式不同
//SoC场景下,该接口的查询结果为SVP_ACL_DEVICE,表示svp_acl软件栈运行在SoC的CPU上,只需申请SoC上的内存
svp_acl_rt_run_mode run_mode;
ret = svp_acl_rt_get_run_mode(&run_mode);
g_is_device = (run_mode == SVP_ACL_DEVICE);
//......
模型推理资源申请¶
基本原理:在模型推理前,需要从离线模型文件(适配SoC的离线模型)中加载模型数据到内存中。
关于模型转换
在模型加载前,需要将第三方网络(例如,Caffe ResNet-50网络)转换为适配SoC的离线模型,请参见《ATC工具使用指南》。
关于模型加载
加载模型数据方式如下:
svp_acl_mdl_load_from_mem:从内存加载离线模型数据,由系统内部管理内存。
关于模型的输入、输出数据
svp_acl_mdl_dataset主要用于描述模型推理时的输入数据/输出数据,模型可能存在多个输入/多个输出,每个输入/输出的内存地址、内存大小用svp_acl_data_buffer类型的数据来描述。
示例代码:可以从acl_resnet50样例中查看完整样例代码。
以下是关键步骤的代码示例,不可以直接拷贝编译运行,仅供参考。
#include "acl/svp_acl.h"
//......
//1.初始化变量。
//此处的..表示相对路径,相对可执行文件所在的目录
//例如,编译出来的可执行文件存放在out目录下,此处的..就表示out目录的上一级目录
const char* om_model_path = "../model/resnet50.om"
//......
//2.申请用于存储.om文件内存,model_mem_size为.om文件大小。
ret = svp_acl_rt_malloc(&model_mem_ptr, model_mem_size, SVP_ACL_MEM_MALLOC_HUGE_FIRST);
//......
//3.加载离线模型文件(适配SoC的离线模型)。
//模型加载成功,返回标识模型的ID。
ret = svp_acl_mdl_load_from_mem(model_mem_ptr, model_mem_size, &model_id);
//4.根据5中加载成功的模型的ID,获取该模型的描述信息。
// model_desc为svp_acl_mdl_desc类型。
model_desc = svp_acl_mdl_create_desc();
ret = svp_acl_mdl_get_desc(model_desc, model_id);
//5.创建svp_acl_model_dataset类型的数据,描述模型推理的输出。
//output为svp_acl_mdl_dataset类型
output = svp_acl_mdl_create_dataset();
//6.1 获取模型的输出个数.
size_t output_size = svp_acl_mdl_get_num_outputs(model_desc);
//6.2 循环为每个输出申请内存,并将每个输出添加到svp_acl_model_dataset类型的数据中.
for (size_t i = 0; i < output_size; ++i) {
size_t buffer_size = svp_acl_mdl_get_output_size_by_index(model_desc, i);
void *output_buffer = nullptr;
svp_acl_error ret = svp_acl_rt_malloc(&output_buffer, buffer_size, SVP_ACL_MEM_MALLOC_NORMAL_ONLY);
svp_acl_data_buffer* output_data = svp_acl_create_data_buffer(output_buffer, buffer_size);
ret = svp_acl_mdl_add_dataset_buffer(output, output_data);
}
//......
读入图片数据¶
基本原理:
根据“运行管理资源申请(单进程+单线程+单Stream)”中svp_acl_rt_get_run_mode接口的查询结果(SVP_ACL_DEVICE,表示软件栈运行在SoC的图像分析引擎上),在自定义函数ReadBinFile内部,直接调用svp_acl_rt_malloc申请Device上的内存,再调用C++标准库的read函数将图片数据读入Device的内存中。
读入图片数据(即将输入图片数据传输到Device上,用于推理)。
示例代码:可以从acl_resnet50样例中查看完整样例代码。
以下是关键步骤的代码示例,不可以直接拷贝编译运行,仅供参考。
#include <iostream>
#include <fstream>
#include <cstring>
#include "acl/svp_acl.h"
//......
//以下数据用于描述图片的路径及图片名称picName。
string testFile[] = {
"../data/dog1_1024_683.bin",
"../data/dog2_1024_683.bin"
};
//循环处理每张图片
for (size_t index = 0; index < sizeof(testFile) / sizeof(testFile[0]); ++index) {
//自定义函数,调用C++标准库std::ifstream中的函数读取图片文件。
//并输出图片文件占用的内存大小fileSize,返回值为图片文件的内存地址inputBuff。
void *inputBuff = nullptr;
uint32_t fileSize = 0;
auto ret = Utils::ReadBinFile(fileName, inputBuff, fileSize);
//TODO:模型推理
}
//......
模型推理¶
基本原理:同步执行模型推理。模型推理结束后,需及时释放相关资源。
关于模型推理
调用svp_acl_mdl_execute接口实现同步模型推理,该接口的入参之一是模型ID,在模型推理资源申请阶段,如果加载模型成功,则会返回标识模型的ID。
关于模型输出数据的处理
示例代码中的代码逻辑是:获取模型推理的输出数据,将输出数据转换为float类型后,再输出其中top5置信度的类别编号。
关于资源释放
svp_acl_mdl_dataset主要用于描述模型推理时的输入数据、输出数据,模型可能存在多个输入、多个输出,每个输入/输出的内存地址、内存大小用svp_acl_data_buffer类型的数据来描述。在模型推理结束后,需及时调用svp_acl_destroy_data_buffer接口和svp_acl_mdl_destroy_dataset接口释放描述模型输入的数据,且先调用svp_acl_destroy_data_buffer接口,再调用svp_acl_mdl_destroy_dataset接口。如果存在多个输入,需调用多次svp_acl_destroy_data_buffer接口。
在模型推理结束后,还需要通过svp_acl_mdl_unload接口卸载模型。
示例代码¶
您可以从acl_resnet50样例中查看完整样例代码。
调用接口后,增加了异常处理的分支,同时通过ERROR_LOG记录报错日志、通过INFO_LOG记录各动作的提示日志,示例代码中不一一列举。以下是关键步骤的代码示例,不可以直接拷贝编译运行,仅供参考。
#include <iostream>
#include <map>
#include <sstream>
#include <algorithm>
#include "acl/svp_acl.h"
//......
//以下数据用于描述图片的路径及图片名称picName。
string testFile[] = {
"../data/dog1_1024_683.bin",
"../data/dog2_1024_683.bin"
};
//循环处理每张图片
for (size_t index = 0; index < sizeof(testFile) / sizeof(testFile[0]); ++index) {
//1. 创建模型推理的输入数据
//创建svp_acl_mdl_dataset类型的数据input_,用于描述模型推理时的输入数据(图片数据集)
//输入的内存地址、内存大小用svp_acl_data_buffer类型的数据来描述
input_ = svp_acl_mdl_create_dataset();
//示例中的模型只有1个输入,将“读入图片数据”阶段的图片数据作为模型推理的输入
//inputDataBuffer表示图片数据在Device中的内存,bufferSize表示内存大小
svp_acl_data_buffer* inputData = svp_acl_create_data_buffer(inputDataBuffer, bufferSize);
svp_acl_error ret = svp_acl_mdl_add_dataset_buffer(input_, inputData);
//2. 执行模型推理
//modelId_表示模型ID,在“模型推理资源初始化”时成功加载模型后,会返回标识模型的ID
//output_表示模型推理的输出数据,在“模型推理资源初始化”时已定义
svp_acl_error ret = svp_acl_mdl_execute(modelId_, input_, output_);
//获取模型推理的输出,做数据后处理,输出top5置信度的类别编号
for (size_t i = 0; i < svp_acl_mdl_get_dataset_num_buffers (output_); ++i) {
//获取每个输出的内存地址和内存大小
svp_acl_data_buffer* dataBuffer = svp_acl_mdl_get_dataset_buffer(output_, i);
void* data = svp_acl_get_data_buffer_addr(dataBuffer);
size_t len = svp_acl_get_data_buffer_size(dataBuffer);
//将内存中的数据转换为float类型
float *outData = NULL;
outData = reinterpret_cast<float*>(data);
//屏显每张图片的top5置信度的类别编号
map<float, int, greater<float> > resultMap;
for (int j = 0; j < len / sizeof(float); ++j) {
resultMap[*outData] = j;
outData++;
}
int cnt = 0;
for (auto it = resultMap.begin(); it != resultMap.end(); ++it) {
// print top 5
if (++cnt > 5) {
break;
}
INFO_LOG("top %d: index[%d] value[%lf]", cnt, it->second, it->first);
}
//3. 模型推理结束后,释放模型推理的输入内存picDevBuffer
svp_acl_rt_free(picDevBuffer);
//4. 释放资源
//如果模型存在多个输入,则需要多次调用svp_acl_destroy_data_buffer释放描述每个输入的svp_acl_mdl_dataset类型数据
for (size_t i = 0; i < svp_acl_mdl_get_dataset_num_buffers(input_); ++i) {
svp_acl_data_buffer* dataBuffer = svp_acl_mdl_get_dataset_buffer(input_, i);
void* data = svp_acl_get_data_buffer_addr(dataBuffer);
(void)svp_acl_rt_free(data);
svp_acl_destroy_data_buffer(dataBuffer);
}
svp_acl_mdl_destroy_dataset(input_);
//......
}
//TODO:释放运行管理资源
运行管理资源释放与SVP ACL去初始化¶
基本原理:
所有数据处理都结束后,需要释放运行管理资源,包括Stream、Context、Device。释放资源时,需要按顺序释放,先释放Stream,再释放Context,最后再释放Device。
如果使用默认Stream,则不能通过svp_acl_rt_destroy_stream接口来释放。
如果使用默认Context,则不能通过svp_acl_rt_destroy_context接口来释放。
默认Context、默认Stream,是在调用svp_acl_rt_reset_device接口后自动释放。
调用svp_acl_finalize接口实现SVP ACL去初始化。
示例代码:可以从acl_resnet50样例中查看完整样例代码。
以下是关键步骤的代码示例,不可以直接拷贝编译运行,仅供参考。
#include "acl/svp_acl.h"
//......
svp_acl_error ret = svp_acl_rt_destroy_stream(stream);
ret = svp_acl_rt_destroy_context(context);
ret = svp_acl_rt_reset_device(device_id);
ret = svp_acl_finalize();
//......
编译及运行应用¶
编译运行应用的步骤,请参见基于Caffe ResNet-50网络实现图片分类(同步推理)。
相关注意点:
模型转换,详细说明请参见《ATC工具使用指南》。
编译代码时,编译脚本的修改点如下。
您可以从acl_resnet50样例中获取编译脚本CMakeLists.txt,在该编译脚本的基础上修改如下参数。
include_directories:添加头文件所在的目录。
示例如下:
include_directories( directoryPath1 directoryPath2 )
link_directories:添加库文件所在的目录。
示例如下:
link_directories( directoryPath3 directoryPath4 )
add_executable:修改可执行文件的名称(例如:main)、添加*.cpp文件所在的目录。
示例如下:
add_executable(main directoryPath5 directoryPath6)
target_link_libraries:修改可执行文件的名称(与 add_executable中保持一致)、添加可执行文件依赖的库文件。
示例如下:
target_link_libraries(main svp_acl libName1 libName2)
依赖的库文件与接口所在的头文件有关,具体对应关系如下:
表 1 头文件与库文件的对应关系
编译通过后,运行应用时,通过配置环境变量,应用会链接到运行环境上“Acllib组件的安装目录/acllib/lib64”目录下的*.so库,运行时会自动链接到依赖其它组件的*.so库。
编译基于SVP ACL接口的代码逻辑时,请按照引用的头文件,依赖对应的so文件,引用多余的so文件可能导致后续版本升级时存在兼容性问题。 编译选项修改可执行文件的名称(与 add_executable保持一致),以及可执行文件的安装目录。 示例如下,表示main安装在${CMAKE_INSTALL_PREFIX}/out目录下,${CMAKE_INSTALL_PREFIX}变量定义的路径是相对路径,相对cmake命令执行的路径:
set(CMAKE_RUNTIME_OUTPUT_DIRECTORY "../../../out") install(TARGETS main DESTINATION ${CMAKE_RUNTIME_OUTPUT_DIRECTORY})
关于cmake参数的详细介绍,请参见https://cmake.org/cmake/help/latest/guide/tutorial/index.html,选择对应的版本后查看参数。
运行可执行文件时,需将SVP ACL初始化配置文件(acl.json)所在的目录、可执行文件所在的目录、测试图片所在的目录、*.om文件所在的目录都上传到板端环境的同一个目录下。
如果在SVP ACL初始化阶段,在svp_acl_init接口中传入空指针,则无需将SVP ACL初始化配置文件(acl.json)所在的目录上传到板端环境。
开发典型功能点的介绍¶
Stream管理¶
原理介绍¶
在SVP ACL中,Stream是一个任务队列,应用程序通过Stream来管理任务的并行,一个Stream内部的任务保序执行,即Stream根据发送过来的任务依次执行;不同Stream中的任务并行执行。一个默认Context下会挂一个默认Stream,如果不显式创建Stream,可使用默认Stream。默认Stream作为接口入参时,直接传NULL。
单线程单Stream¶
调用接口后,需增加异常处理的分支,示例代码中不一一列举。以下是关键步骤的代码示例,不可以直接拷贝编译运行,仅供参考。
#include "acl/svp_acl.h"
//......
//显式创建一个Stream
svp_acl_rt_stream stream;
svp_acl_rt_create_stream(&stream);
uint32_t model_id = 0;
//调用触发任务的接口,例如异步模型推理,任务下发在stream1
svp_acl_mdl_dataset *input;
svp_acl_mdl_dataset *output;
svp_acl_mdl_execute_async(model_id, input, output, stream);
//调用svp_acl_rt_synchronize_stream接口,阻塞应用程序运行,直到指定Stream中的所有任务都完成。
svp_acl_rt_synchronize_stream(stream);
//Stream使用结束后,显式销毁Stream
svp_acl_rt_destroy_stream(stream);
//......
单线程多Stream¶
调用接口后,需增加异常处理的分支,示例代码中不一一列举。以下是关键步骤的代码示例,不可以直接拷贝编译运行,仅供参考。
#include "acl/svp_acl.h"
//......
int32_t device_id = 0 ;
uint32_t model_id1 = 0;
uint32_t model_id2 = 1;
svp_acl_rt_context context;
svp_acl_rt_stream stream1;
svp_acl_rt_stream stream2;
//如果只创建了一个Context,线程默认将这个Context作为线程当前的Context;
//如果是多个Context,则需要调用svp_acl_rt_set_current_context接口设置当前线程的Context
svp_acl_rt_create_context(&context, device_id);
svp_acl_rt_create_stream(&stream1);
//调用触发任务的接口,例如异步模型推理,任务下发在stream1
svp_acl_mdl_dataset *input1;
svp_acl_mdl_dataset *output1;
svp_acl_mdl_execute_async(model_id1, input1, output1, stream1);
svp_acl_rt_create_stream(&stream2);
//调用触发任务的接口,例如异步模型推理, 任务下发在stream2
svp_acl_mdl_dataset *input2;
svp_acl_mdl_dataset *output2;
svp_acl_mdl_execute_async(model_id2, input2, output2, stream2);
// 流同步
svp_acl_rt_synchronize_stream(stream1);
svp_acl_rt_synchronize_stream(stream2);
//释放资源
svp_acl_rt_destroy_stream(stream1);
svp_acl_rt_destroy_stream(stream2);
svp_acl_rt_destroy_context(context);
//....
多线程多Stream¶
调用接口后,需增加异常处理的分支,示例代码中不一一列举。以下是关键步骤的代码示例,不可以直接拷贝编译运行,仅供参考。
#include "acl/svp_acl.h"
//......
void run_thread(svp_acl_rt_stream stream) {
int32_t device_id =0 ;
svp_acl_rt_context context;
//如果只创建了一个Context,线程默认将这个Context作为线程当前的Context;
//如果是多个Context,则需要调用svp_acl_rt_set_current_context接口设置当前线程的Context
svp_acl_rt_create_context(&context, device_id);
svp_acl_rt_create_stream(&stream);
//调用触发任务的接口
//....
//释放资源
svp_acl_rt_destroy_stream(stream);
svp_acl_rt_destroy_context(context);
}
svp_acl_rt_stream stream1;
svp_acl_rt_stream stream2;
//创建2个线程,每个线程对应一个Stream
std::thread t1(runThread, stream1);
std::thread t2(runThread, stream2);
//显式调用join函数确保结束线程
t1.join();
t2.join();
同步等待¶
原理介绍¶
SVP ACL提供以下几种同步机制:
Stream内任务的同步等待:调用svp_acl_rt_synchronize_stream接口,阻塞应用程序运行,直到指定Stream中的所有任务都完成。
Device的同步等待:调用svp_acl_rt_synchronize_device接口,阻塞应用程序运行,直到正在运算中的Device完成运算。多Device场景下,调用该接口等待的是当前Context对应的Device。
关于Stream内任务的同步等待¶
调用接口后,需增加异常处理的分支,示例代码中不一一列举。以下是关键步骤的代码示例,不可以直接拷贝编译运行,仅供参考。
#include "acl/svp_acl.h"
//......
//显式创建一个Stream
svp_acl_rt_stream stream;
svp_acl_rt_create_stream(&stream);
uint32_t model_id = 0;
//调用触发任务的接口,例如异步模型推理,任务下发在stream1
svp_acl_mdl_dataset *input;
svp_acl_mdl_dataset *output;
svp_acl_mdl_execute_async(model_id, input, output, stream);
//调用svp_acl_rt_synchronize_stream接口,阻塞应用程序运行,直到指定Stream中的所有任务都完成。
svp_acl_rt_synchronize_stream(stream);
//Stream使用结束后,显式销毁Stream
svp_acl_rt_destroy_stream(stream);
//......
关于Device的同步等待¶
调用接口后,需增加异常处理的分支,示例代码中不一一列举。以下是关键步骤的代码示例,不可以直接拷贝编译运行,仅供参考。
#include "acl/svp_acl.h"
//......
//指定device
svp_acl_rt_set_device(0);
//创建context
svp_acl_rt_context ctx;
svp_acl_rt_create_context(&ctx, 0);
//创建stream
svp_acl_rt_stream stream;
svp_acl_rt_create_stream(&stream);
//阻塞应用程序运行,直到正在运算中的Device完成运算
svp_acl_rt_synchronize_device();
//资源销毁
svp_acl_rt_destroy_stream(stream);
svp_acl_rt_destroy_context(ctx);
svp_acl_rt_reset_device(0);
模型推理¶
单Batch+固定shape+单模型同步推理¶
若涉及色域转换(转换图像格式)、图像归一化(减均值/乘系数)等,在模型加载前,需要先参见《ATC工具使用指南》转换模型。
在模型推理前,需要从离线模型文件(适配SoC的离线模型)中加载模型数据到内存中,并创建svp_acl_mdl_dataset类型的数据描述模型的输出。请参见模型推理资源申请。
加载模型后,再同步执行模型推理。请参见模型推理。
异步推理+callback回调处理¶
基本原理:
异步推理场景下,关键接口的调用流程如下:
调用svp_acl_init接口初始化SVP ACL。
按顺序调用svp_acl_rt_set_device、svp_acl_rt_create_context、svp_acl_rt_create_stream接口依次申请运行管理资源:Device、Context、Stream,确保可以使用这些资源执行运算、管理任务。
如果不显式创建Context和Stream,您可以使用svp_acl_rt_set_device接口隐式创建的默认Context和默认Stream,但默认Context和默认Stream存在如下限制:
一个Device对应一个默认Context,默认Context不能通过svp_acl_rt_destroy_context接口来释放。
一个Device对应一个默认Stream,默认Stream不能通过svp_acl_rt_destroy_stream接口来释放。默认Stream作为接口入参时,直接传NULL。
申请模型推理资源。
加载模型。
svp_acl_mdl_load_from_mem:从内存加载离线模型数据。
调用svp_acl_mdl_get_desc接口获取成功加载的模型的描述信息。
初始化内存,用于存放模型推理的输入数据、输出数据。
此处需要用户可自行定义函数实现以下关键点:
调用svp_acl_mdl_create_dataset接口创建svp_acl_mdl_dataset类型的数据(描述模型的输入/输出)。
模型可能存在多个输入/输出,调用svp_acl_create_data_buffer接口创建svp_acl_data_buffer类型的数据(描述每个输入/输出数据的内存地址、内存大小)。
模型输入数据的内存大小,根据实际读入的图片数据的大小来确定。
模型输出数据的内存大小,可调用svp_acl_mdl_get_output_size_by_index接口根据3.b中模型描述信息获取每个输出需占用的内存大小。
调用svp_acl_mdl_add_dataset_buffer接口向svp_acl_mdl_dataset中增加svp_acl_data_buffer。
执行模型异步推理和callback(用于处理模型推理的结果)。
此处需要用户可自行定义函数实现以下关键点:
创建新线程(例如t1),在线程函数内调用svp_acl_rt_process_report接口,等待指定时间后,触发回调函数(例如CallBackFunc,用于处理模型推理结果)。
调用svp_acl_rt_subscribe_report接口,指定处理Stream上回调函数(CallBackFunc)的线程(t1),回调函数需要提前创建,用于处理模型推理的结果(例如,将推理结果写入文件、从推理结果中获取topn置信度的类别标识等)。
调用svp_acl_mdl_execute_async接口执行异步模型推理。
调用svp_acl_rt_launch_callback接口,在Stream的任务队列中增加一个需要在板端环境上执行的回调函数(CallBackFunc)。
调用svp_acl_rt_synchronize_stream接口,阻塞应用程序运行,直到指定Stream中的所有任务都完成。
调用svp_acl_rt_unsubscribe_report接口,取消线程注册,Stream上的回调函数(CallBackFunc)不再由指定线程(t1)处理。
模型推理结束后,调用svp_acl_mdl_unload接口卸载模型。
所有数据处理结束后,按顺序调用svp_acl_rt_destroy_stream、svp_acl_rt_destroy_context、svp_acl_rt_reset_device接口依次释放运行管理资源,包括Stream、Context、Device。
调用svp_acl_finalize接口实现SVP ACL去初始化。
示例代码:
您可以从acl_resnet50_async样例中查看完整样例代码,以下是关键步骤的代码示例,不可以直接拷贝编译运行,仅供参考。
在acl_resnet50_async样例中:
运行可执行文件,不带参数时:
执行模型异步推理的次数默认为10次,对应代码中的g_executeTimes变量;
callback间隔默认为1,表示1次异步推理后,下发一次callback任务,对应代码中的g_callbackInterval变量;
内存池中的内存块的个数默认为10个,对应代码中的g_memoryPoolSize。
运行可执行文件,带参数时:
第一个参数表示执行模型异步推理的次数;
第二个参数表示下发callback间隔,参数值为0时表示不下发callback任务,参数值为非0值(例如m)时表示m次异步推理后下发一次callback任务;
第三个参数表示内存池中内存块的个数,内存块个数需大于等于模型异步推理的次数。用户可根据输入图片数量,来调整内存块的个数,例如有2张输入图片、内存块个数为2时,则1张图片1个内存块;例如有3张输入图片、内存块个数为10时,则执行10次循环,每(10/3取整)个内存块对应同一张图片,剩下1个内存块随机对应1张图片。内存块中存放是模型推理的输入数据、输出数据,若多个内存块对应的是同一张图片,则多个内存块中存放的是相同的输入数据、输出数据,用于输入图片少但又想模拟大量图片数据的场景。
#include "acl/svp_acl.h" //...... //1. SVP ACL初始化 //此处的..表示相对路径,相对可执行文件所在的目录 //例如,编译出来的可执行文件存放在out目录下,此处的..就表示out目录的上一级目录 const char *aclConfigPath = "../src/acl.json"; svp_acl_error ret = svp_acl_init(aclConfigPath); //2. 申请运行管理资源 extern bool g_isDevice; ret = svp_acl_rt_set_device(deviceId_); ret = svp_acl_rt_create_context(&context_, deviceId_); ret = svp_acl_rt_create_stream(&stream_); //获取当前svp_acl软件栈的运行模式,根据不同的运行模式,后续的内存申请、内存复制等接口调用方式不同 svp_acl_rt_run_mode run_mode; ret = svp_acl_rt_get_run_mode(&runMode); g_isDevice = (runMode == ACL_DEVICE); //3. 申请模型推理资源 //此处的..表示相对路径,相对可执行文件所在的目录 //例如,编译出来的可执行文件存放在out目录下,此处的..就表示out目录的上一级目录 const char* omModelPath = "../model/resnet50.om" //3.1 加载模型 //根据模型文件获取模型执行时所需的权值内存大小、工作内存大小,并申请权值内存、工作内存 ret = svp_acl_rt_malloc(&modelMemPtr_, modelMemSize_, SVP_ACL_MEM_MALLOC_NORMAL_ONLY); //加载离线模型文件,模型加载成功,返回标识模型的ID。 ret = svp_acl_mdl_load_from_mem(modelPath, &modelId_, modelMemPtr_, modelMemSize_); //3.2 根据模型的ID,获取该模型的描述信息 modelDesc_ = svp_acl_mdl_create_desc(); ret = svp_acl_mdl_get_desc(modelDesc_, modelId_); //3.3 自定义函数InitMemPool,初始化内存池,存放模型推理的输入数据、输出数据 //-----自定义函数InitMemPool内部的关键实现----- string testFile[] = { "../data/dog1_1024_683.bin", "../data/dog2_1024_683.bin" }; size_t fileNum = sizeof(testFile) / sizeof(testFile[0]); for (size_t i = 0; i < g_memoryPoolSize; ++i) { size_t index = i % (sizeof(testFile) / sizeof(testFile[0])); // model process uint32_t devBufferSize; //自定义函数GetDeviceBufferOfFile,完成以下功能: //获取Host上存放输入图片数据的内存及内存大小、将图片数据从Host传输到Device、获取Device上存放输入图片数据的内存及内存大小 void *picDevBuffer = Utils::GetDeviceBufferOfFile(testFile[index], devBufferSize); aclmdlDataset *input = nullptr; //自定义函数CreateInput,创建aclmdlDataset类型的数据input,用于存放模型推理的输入数据 Result ret = CreateInput(picDevBuffer, devBufferSize, input); svp_acl_mdl_dataset *output = nullptr; //自定义函数CreateOutput,创建svp_acl_mdl_dataset类型的数据output,用于存放模型推理的输出数据,modelDesc表示模型的描述信息 CreateOutput(output, modelDesc); { std::lock_guard<std::recursive_mutex> lk(freePoolMutex_); freeMemoryPool_[input] = output; } } //-----自定义函数InitMemPool内部的关键实现----- //4 模型推理 //4.1 创建线程tid,并将该tid线程指定为处理Stream上回调函数的线程 //其中ProcessCallback为线程函数,在该函数内调用svp_acl_rt_process_report接口,等待指定时间后,触发回调函数处理 pthread_t tid; (void)pthread_create(&tid, nullptr, ProcessCallback, &s_isExit); //4.2 指定处理Stream上回调函数的线程 svp_acl_error aclRt = svp_acl_rt_subscribe_report(tid, stream_); //4.2 创建回调函数,用户处理模型推理的结果,由用户自行定义 void ModelProcess::CallBackFunc(void *arg) { std::map<svp_acl_mdl_dataset *, svp_acl_mdl_dataset *> *dataMap = (std::map<svp_acl_mdl_dataset *, svp_acl_mdl_dataset *> *)arg; svp_acl_mdl_dataset *input = nullptr; svp_acl_mdl_dataset *output = nullptr; MemoryPool *memPool = MemoryPool::Instance(); for (auto& data : *dataMap) { ModelProcess::OutputModelResult(data.second); memPool->FreeMemory(data.first, data.second); } delete dataMap; } //4.3 自定义函数ExecuteAsync,执行模型推理 //-----自定义函数ExecuteAsync内部的关键实现----- bool isCallback = (g_callbackInterval != 0); size_t callbackCnt = 0; std::map<svp_acl_mdl_dataset *, svp_acl_mdl_dataset *> *dataMap = nullptr; svp_acl_mdl_dataset *input = nullptr; svp_acl_mdl_dataset *output = nullptr; MemoryPool *memPool = MemoryPool::Instance(); for (uint32_t cnt = 0; cnt < g_executeTimes; ++cnt) { if (memPool->mallocMemory(input, output) != SUCCESS) { ERROR_LOG("get free memory failed"); return FAILED; } //执行异步推理 svp_acl_error ret = svp_acl_mdl_execute_async(modelId_, input, output, stream_); if (isCallback) { if (dataMap == nullptr) { dataMap = new std::map<svp_acl_mdl_dataset *, svp_acl_mdl_dataset *>; if (dataMap == nullptr) { ERROR_LOG("malloc list failed, modelId is %u", modelId_); memPool->FreeMemory(input, output); return FAILED; } } (*dataMap)[input] = output; callbackCnt++; if ((callbackCnt % g_callbackInterval) == 0) { //在Stream的任务队列中增加一个需要在Host上执行的回调函数 ret = svp_acl_rt_launch_callback(CallBackFunc, (void *)dataMap, SVP_ACL_CALLBACK_BLOCK, stream_); if (ret != ACL_SUCCESS) { ERROR_LOG("launch callback failed, index=%zu", callbackCnt); memPool->FreeMemory(input, output); delete dataMap; return FAILED; } dataMap = nullptr; } } } //-----自定义函数ExecuteAsync内部的关键实现----- //4.4 对于异步推理,需阻塞应用程序运行,直到指定Stream中的所有任务都完成 svp_acl_rt_synchronize_stream(stream_); //4.5 取消线程注册,Stream上的回调函数不再由指定线程处理 aclRt = svp_acl_rt_unsubscribe_report(static_cast<uint64_t>(tid), stream_); s_isExit = true; (void)pthread_join(tid, nullptr); //5 释放运行管理资源 svp_acl_error ret = svp_acl_rt_destroy_stream(stream_); ret = svp_acl_rt_destroy_context(context_); ret = svp_acl_rt_reset_device(deviceId_); //6 SVP ACL去初始化 ret = svp_acl_finalize(); //......
多模型推理¶
多模型推理的基本流程与单模型类似,请参见单Batch+固定shape+单模型同步推理。
多模型推理与单模型推理的不同点如下:
关于模型加载,如果涉及多个模型,需调用多次模型加载接口。
svp_acl_mdl_load_from_mem:从内存加载离线模型数据。
关于模型推理,如果涉及多个模型,需调用多次模型推理接口。
调用svp_acl_mdl_execute接口实现同步模型推理。
带cache属性的内存管理¶
基本原理:
通过svp_acl_rt_malloc_cached接口申请的内存支持cache缓存,对于频繁使用的内存,建议使用本接口分配内存,这样可以提高cpu的读写效率,提升系统性能,但需要用户处理cpu与硬件设备(如图像分析引擎)之间的数据一致性问题,SVP ACL提供了svp_acl_rt_mem_flush接口将cache中的数据刷新到ddr中,从而确保硬件设备(如图像分析引擎)可以从ddr中获取最新数据进行处理,SVP ACL还提供了svp_acl_rt_mem_invalidate接口将cache中的数据置为无效(如果cache被CPU写操作,调用该接口功能会将数据刷到ddr),从而确保cpu可以获取到ddr中的经图像分析引擎处理后的结果数据。
如果任务(例如,模型加载)不涉及cpu与硬件设备(如图像分析引擎)之间的数据交互,则不涉及两者之间的数据一致性问题,因此就不需要调用svp_acl_rt_mem_flush接口和svp_acl_rt_mem_invalidate接口。
示例代码:
调用接口后,需增加异常处理的分支,示例代码中不一一列举。以下是关键步骤的代码示例,不可以直接拷贝编译运行,仅供参考。
示例中,运行管理资源申请与释放请参见运行管理资源申请和运行管理资源释放,模型加载的接口调用流程请参见模型加载,模型推理的接口调用流程、准备模型推理的输入/输出数据的接口调用流程请参见模型执行。
//1.申请运行管理资源,包括设置用于计算的Device、创建Context、创建Stream
//......
//2.模型加载,加载成功后,返回标识模型的model_id
//......
//3.创建svp_acl_mdl_dataset类型的数据,用于描述模型的输入数据input、输出数据output
void *input_dev_buffer = null;
void *output_dev_buffer = null;
size_t input_size;
size_t output_size;
//3.1 申请支持cache缓存的内存:input_dev_buffer用于存放模型推理的输入数据
svp_acl_error ret = svp_acl_rt_malloc_cached(&input_dev_buffer, input_size, SVP_ACL_MEM_MALLOC_NORMAL_ONLY);
svp_acl_mdl_dataset *input = svp_acl_mdl_create_dataset();
svp_acl_data_buffer* input_data = svp_acl_create_data_buffer(input_dev_buffer, input_size);
ret = svp_acl_mdl_add_dataset_buffer(input, input_data);
//将输入数据读入内存中,该自定义函数ReadFile由用户实现
read_file(file_name, input_dev_buffer, input_size);
//3.2 申请支持cache缓存的内存:output_dev_buffer用于存放模型推理的输出数据
ret = svp_acl_rt_malloc_cached(&output_dev_buffer, output_size, SVP_ACL_MEM_MALLOC_NORMAL_ONLY);
svp_acl_mdl_dataset *output = svp_acl_mdl_create_dataset();
svp_acl_data_buffer* output_data = svp_acl_create_data_buffer(output_dev_buffer, output_size);
ret = svp_acl_mdl_add_dataset_buffer(output, output_data);
//4.把对应cache中的数据刷新到ddr
//示例以获取第一个输入为例,如果有多个输入,可调用svp_acl_mdl_get_dataset_num_buffers接口获取输入个数
svp_acl_data_buffer *input_data_buffer = svp_acl_mdl_get_dataset_buffer(input, 0);
void *input_data_buffer_addr = svp_acl_get_data_buffer_addr(input_data_buffer);
size_t input_data_buffer_size = svp_acl_get_data_buffer_size(input_data_buffer);
ret = svp_acl_rt_mem_flush(input_data_buffer_addr, input_data_buffer_size);
//5.执行模型
ret = svp_acl_mdl_execute(model_id, input, output);
//6.执行svp_acl_rt_mem_invalidate接口,把对应cache中的数据置为无效,确保cpu获取到的是ddr中的数据
//示例以获取第一个输出为例,如果有多个输出,可调用svp_acl_mdl_get_dataset_num_buffers接口获取输出个数
svp_acl_data_buffer *out_data_buffer = svp_acl_mdl_get_dataset_buffer(output, 0);
void *output_data_buffer_addr = svp_acl_get_data_buffer_addr(out_data_buffer);
size_t output_data_buffer_size = svp_acl_get_data_buffer_size(out_data_buffer);
ret = svp_acl_rt_mem_invalidate(output_data_buffer_addr, output_data_buffer_size);
//7.处理模型推理结果
//TODO
//8.释放内存
svp_acl_rt_free(input_dev_buffer);
svp_acl_rt_free(output_dev_buffer);
//9.释放描述模型输入/输出信息、内存等资源,卸载模型
//......
//10.释放运行管理资源
//......
推理使用模式识别CPU算子¶
基本原理:
SoC推理场景下,如果模型中有模式识别 Core不支持的算子,需要通过模式识别CPU算子来实现,这时,异步推理场景下可以调用svp_acl_ext_process_aacpu_task接口来接收模式识别CPU算子并在CPU上执行,同步推理场景下无需用户做特殊处理。下面就异步推理关于该接口的使用方式进行进一步介绍。
模式识别CPU算子在CPU侧执行时可能会引入一些问题,因此用户需要关注以下几点:
为了不影响整个推理业务,需要创建模式识别CPU工作线程对模式识别CPU算子进行处理,确保模式识别CPU算子处理和推理业务同时在CPU侧运行,且可保证各自的执行效率。
需要用户在模式识别CPU工作线程内,调用svp_acl_ext_process_aacpu_task接口来接收模式识别CPU算子并执行。
用户场景差异比较大,需要根据自己业务需求来部署模式识别CPU工作线程,例如线程数量,是否绑核。
示例代码:
调用接口后,需增加异常处理的分支,示例代码中不一一列举。以下是关键步骤的代码示例,不可以直接拷贝编译运行,仅供参考。
示例中,异步推理流程请参见异步推理+callback回调处理 。
//1.实现模式识别CPU工作线程处理函数 static bool thread_exit_flag = false; void *cpu_func_async_test(void *param) { while (thread_exit_flag == false) { svp_acl_ext_process_aacpu_task(1000); } return NULL; } //2.主线程创建模式识别CPU工作线程 static pthread_t g_tid; pthread_create(&g_tid, NULL, cpu_func_async_test, NULL); //3.异步推理流程 //...... //4.释放线程 thread_exit_flag = true; pthread_join(g_tid, NULL);
须知:
编译代码的时候,需要匹配对应的头文件svp_acl_ext.h,目前文件(分别在板端SDK版本的smp/a55_linux/mpp/out路径的include/svp_nnn和lib/svp_nnn目录下,其他解决方案类似参考)。
Profiling性能数据采集¶
基本原理:
该章节下的接口用于Profiling采集性能数据,实现方式支持以下两种:
方式一:将采集到的Profiling数据写入文件,再使用Profiling工具解析该文件。
方式二:将采集到的Profiling数据解析后写入管道,由用户读入内存,再由用户调用ACL的接口获取性能数据。
实现方式详细说明请参考“功能及约束说明”。
示例代码1:
调用接口后,需增加异常处理的分支,并记录报错日志、提示日志,此处不一一列举。以下是关键步骤的代码示例,不可以直接拷贝编译运行,仅供参考。
示例中,运行管理资源申请与释放、模型加载的接口调用流程、模型推理的接口调用流程、准备模型推理的输入/输出数据的接口调用流程请参见异步推理+callback回调处理。
//1.SVP ACL资源初始化、模型加载、数据创建
//2.创建管道(UNIX操作系统下需要引用C++标准库头文件unistd.h),用于读取以及写入模型订阅的数据
int sub_fd[2];
// 读管道指针指向sub_fd[0],写管道指针指向sub_fd[1]
pipe(sub_fd);
//3.创建模型订阅的配置并且进行模型订阅
svp_acl_prof_subscribe_config *config = svp_acl_prof_create_subscribe_config(1, 0, &sub_fd[1]);
//模型订阅需要传入模型的model_id
svp_acl_prof_model_subscribe(model_id, config);
//4.实现管道读取订阅数据的函数
//4.1 自定义函数,实现从用户内存中读取订阅数据的函数
void get_model_info(void *data, uint32_t len) {
uint32_t op_number = 0;
uint32_t data_len = 0;
//通过SVP ACL接口读取算子信息个数
svp_acl_prof_get_op_num(data, len, &op_number);
//遍历用户内存的算子信息
for (int32_t i = 0; i < op_number; i++){
//获取算子的模型id
uint32_t model_id = svp_acl_prof_get_model_id(data,len, i);
//获取算子的类型名称长度
size_t op_type_len = 0;
svp_acl_prof_get_op_type_len(data, len, i, &op_type_len);
//获取算子的类型名称
char op_type[op_type_len];
svp_acl_prof_get_op_type(data, len, i, op_type, op_type_len);
//获取算子的详细名称长度
size_t op_name_len = 0;
svp_acl_prof_get_op_name_len(data, len, i, &op_name_len);
//获取算子的详细名称
char op_name[op_name_len];
svp_acl_prof_get_op_name(data, len, i, op_name, op_name_len);
//获取算子的执行开始时间
uint64_t op_start = svp_acl_prof_get_op_start(data, len, i);
//获取算子的执行结束时间
uint64_t op_end = svp_acl_prof_get_op_end(data, len, i);
uint64_t op_duration = svp_acl_prof_get_op_duration(data, len, i);
}
}
//4.2 自定义函数,实现从管道中读取数据到用户内存的函数
void *prof_data_read(void *fd) {
//设置每次从管道中读取的算子信息个数
uint64_t N = 10;
//获取单位算子信息的大小(Byte)
uint64_t buffer_size = 0;
svp_acl_prof_get_op_desc_size(&buffer_size);
//计算存储算子信息的内存的大小,并且申请内存
uint64_t read_buf_len = buffer_size * N;
char *read_buf = (char *)malloc(sizeof(char) * read_buf_len);
//从管道中读取数据到申请的内存中,读取到的实际数据大小data_len可能小于buffer_size * N,如果管道中没有数据,默认会阻塞直到读取到数据为止
uint32_t data_len = read(*(int*)fd, read_buf, read_buf_len);
//读取数据到read_buf成功
while (data_len > 0) {
//调用4.1实现的函数解析内存中的数据
get_model_info(read_buf, data_len);
memset(read_buf, 0, buffer_size);
data_len = read(*(int*)fd, read_buf, read_buf_len);
}
free(read_buf);
}
//5. 启动线程读取管道数据并解析
pthread_t sub_tid = 0;
pthread_create(&sub_tid, NULL, prof_data_read, &sub_fd[0]);
//6.执行模型
ret = svp_acl_mdl_execute(model_id, input, output);
//7.处理模型推理结果、释放资源、卸载模型、等待线程数据获取完毕
//8.取消订阅,释放订阅相关资源
svp_acl_prof_model_unsubscribe(model_id);
close(sub_fd[1]);
pthread_join(sub_tid, NULL);
close(sub_fd[0]);
//释放config指针
svp_acl_prof_destroy_subscribe_config(config);
//9. 释放运行管理资源,SVP ACL去初始化
//......
示例代码2:
调用接口后,需增加异常处理的分支,示例代码中不一一列举。以下是关键步骤的代码示例,不可以直接拷贝编译运行,仅供参考。
示例中,运行管理资源申请与释放、模型加载的接口调用流程、模型推理的接口调用流程、准备模型推理的输入/输出数据的接口调用流程请参见异步推理+callback回调处理。
//1.SVP ACL资源初始化、模型加载、数据创建
//2.profiling初始化
//设置数据落盘路径
const char *prof_path = "./";
svp_acl_prof_init(prof_path, strlen(prof_path));
//3.进行profiling配置
uint32_t device_id_list[1] = {0};
//创建配置结构体
svp_acl_prof_config *config = svp_acl_prof_create_config(device_id_list, 1, 0, NULL, SVP_ACL_PROF_AACORE_METRICS | SVP_ACL_PROF_AACPU);
svp_acl_prof_start(config);
//4.执行模型
ret = svp_acl_mdl_execute(model_id, input, output);
//5.处理模型推理结果、释放资源、卸载模型
//6.关闭profiling配置, 释放配置资源, 释放profiling组件资源
svp_acl_prof_stop(config);
svp_acl_prof_destroy_config(config);
svp_acl_prof_finalize();
//7.释放运行管理资源,SVP ACL去初始化.
//......
JSON文件格式:
通过svp_acl_init指定带有Profiling配置的json文件也可以实现将采集到的Profiling数据写入文件的功能,文件格式如下:
{
"profiler": {
"switch": "on",
"output": "output",
"interval": "20",
"aac_metrics": "ArithmeticUtilization",
"aacpu": "on",
"acl_api": "on"
}
}
profiler参数配置说明:
switch:Profiling开关,取值on或off。可选参数。
on表示开启Profiling,off表示关闭Profiling;如果缺失该参数或参数值不为on,则表示关闭Profiling。
output:Profiling性能数据在板端环境上的落盘路径。可选参数。
Profiling采集结束后,在该目录下生成JOB开头目录,存放Profiling采集的性能原始数据。支持配置绝对路径或相对路径(相对执行命令行时的当前路径):
绝对路径配置以“/”开头,例如:/home/output。
相对路径配置直接以目录名开始,例如:output。
如果该处设置的目录不存在,默认存放采集结果数据到应用工程可执行文件所在目录(确保安装时配置的运行用户具有该目录的读写权限)。
 注意:
该参数指定的目录需要提前创建且确保安装时配置的运行用户具有读写权限。
注意:
该参数指定的目录需要提前创建且确保安装时配置的运行用户具有读写权限。interval:Profiling采集间隔,代表每interval次推理保存一次Profiling数据,此配置建议不要设置太小,否则可能由于落盘数据太慢而引起数据丢失。
_aa_c_metrics:模式识别Core采集事件,配置为ArithmeticUtilization代表采集模式识别Core性能数据,否则为不采集。
_aa_cpu:模式识别CPU采集事件,配置为on代表采集模式识别CPU性能数据,否则为不开启。
acl_api:ACL API采集事件,配置为on代表采集主要ACL API接口性能数据,否则为不开启。
不带aacpu算子的网络,建议采集数据时,一次采集不要超过510(512 - 2)份;
带aacpu算子的网络,建议采集数据时,一次采集不要超过255((512 - 2) / 2)份。
SVP ACL API参考¶
接口列表¶
系统配置¶
svp_acl_init¶
函数功能:SVP ACL初始化函数,同步接口。
约束说明:
一个进程内只能调用一次svp_acl_init接口。
使用SVP ACL接口开发应用时,必须先调用svp_acl_init接口,进行内部资源初始化,否则可能会导致业务异常。
进程退出时需要调用svp_acl_finalize接口释放内部资源。
函数原型:
svp_acl_error svp_acl_init(const char *config_path)
参数说明:
配置文件所在的路径,包含文件名,配置文件内容为json格式(json文件内的“{”的层级最多为10,“[”的层级最多为10)。如果以下的默认配置已满足需求,无需修改,可向svp_acl_init接口中传入NULL,或者可将配置文件配置为空json串(即配置文件中只有{})。
|
返回值说明:返回0表示成功,返回其它值表示失败。
svp_acl_finalize¶
函数功能:SVP ACL去初始化函数,用于释放进程内的SVP ACL内部管理的相关资源,同步接口。
约束说明:
用户申请的资源需要在调用svp_acl_finalize接口前通过调用对应的释放接口释放,防止未释放的资源造成内存泄露或者后续被误用而导致业务异常。
应用的进程退出前,应显式调用该接口实现SVP ACL去初始化,否则可能会导致异常,例如应用进程退出时有异常报错。
不建议在析构函数中调用svp_acl_finalize接口,否则在进程退出时可能由于单例析构顺序未知而导致进程异常退出的问题。
函数原型:
svp_acl_error svp_acl_finalize()
参数说明:无
返回值说明:返回0表示成功,返回其它值表示失败。
Device管理¶
svp_acl_rt_set_device¶
函数功能:
指定用于运算的Device,同时隐式创建默认Context,该默认Context中包含1个默认Stream,同步接口。
如果多次调用svp_acl_rt_set_device接口而不调用svp_acl_rt_reset_device接口释放本进程使用的Device资源,功能上不会有问题,因为在进程退出时也会释放本进程使用的Device资源。建议svp_acl_rt_set_device接口和svp_acl_rt_reset_device接口配对使用,在不使用Device上资源时,通过调用svp_acl_rt_reset_device接口及时释放本进程使用的Device资源。
支持以下使用场景:
在不同进程或线程中可指定同一个Device用于运算。
在某一进程中指定Device,该进程内的多个线程可共用此Device显式创建Context(svp_acl_rt_create_context接口)。
多Device场景下,可在进程中通过svp_acl_rt_set_device接口切换到其它Device。但利用Context切换(调用svp_acl_rt_set_current_context接口)来切换Device,比使用svp_acl_rt_set_device接口效率高。
函数原型:
svp_acl_error svp_acl_rt_set_device(int32_t device_id)
参数说明:
|
用户调用svp_acl_rt_get_device_count接口获取可用的Device数量后,这个Device ID的取值范围:[0, (可用的Device数量-1)] |
返回值说明:返回0表示成功,返回其它值表示失败。
svp_acl_rt_reset_device¶
函数功能:复位当前运算的Device,释放Device上的资源,包括默认Context、默认Stream以及默认Context下创建的所有Stream,同步接口。若默认Context或默认Stream下的任务还未完成,会删除任务,不再执行。
约束说明:
若要复位的Device上存在显式创建的Context、Stream,在复位前,建议遵循如下接口调用顺序,否则可能会导致业务异常。
接口调用顺序:调用svp_acl_rt_destroy_stream接口释放显式创建的Stream-->调用svp_acl_rt_destroy_context释放显式创建的Context-->调用svp_acl_rt_reset_device接口
函数原型:
svp_acl_error svp_acl_rt_reset_device(int32_t device_id)
参数说明:
返回值说明:返回0表示成功,返回其它值表示失败。
svp_acl_rt_get_device¶
函数功能:获取当前正在使用的Device的ID,同步接口。
约束说明:如果没有调用svp_acl_rt_set_device接口显式指定Device或没有调用svp_acl_rt_create_context接口隐式指定Device,则调用本接口时,返回错误。
函数原型:
svp_acl_error svp_acl_rt_get_device(int32_t *device_id)
参数说明:
返回值说明:返回0表示成功,返回其它值表示失败。
svp_acl_rt_get_run_mode¶
函数功能:获取当前svp_acl软件栈的运行模式,同步接口。
函数原型:
svp_acl_error svp_acl_rt_get_run_mode(svp_acl_rt_run_mode *run_mode)
参数说明:
typedef enum svp_acl_rt_run_mode { //软件栈运行在SoC的CPU上 SVP_ACL_DEVICE, //SoC不支持 SVP_ACL_HOST, } svp_acl_rt_run_mode; |
返回值说明:返回0表示成功,返回其它值表示失败。
svp_acl_rt_get_device_count¶
函数功能:获取可用Device的数量,同步接口。
函数原型:
svp_acl_error svp_acl_rt_get_device_count(uint32_t *count)
参数说明:
返回值说明:返回0表示成功,返回其它值表示失败。
Context管理¶
svp_acl_rt_create_context¶
函数功能:显式创建一个Context,该Context中包含1个默认Stream,同步接口。
支持以下使用场景:
若不调用svp_acl_rt_create_context接口显式创建Context,那系统会使用默认Context,该默认Context是在调用svp_acl_rt_set_device接口时隐式创建的。
隐式创建Context:适合简单、无复杂交互逻辑的应用,但缺点在于,在多线程编程中,执行结果取决于线程调度的顺序。
显式创建Context:推荐显式,适合大型、复杂交互逻辑的应用,且便于提高程序的可读性、可维护性。
若在某一进程内创建多个Context(Context的数量与Stream相关,Stream数量有限制,请参见svp_acl_rt_create_stream),当前线程在同一时刻内只能使用其中一个Context,建议通过svp_acl_rt_set_current_context接口明确指定当前线程的Context,增加程序的可维护性。
函数原型:
svp_acl_error svp_acl_rt_create_context(svp_acl_rt_context *context, int32_t device_id)
参数说明:
返回值说明:返回0表示成功,返回其它值表示失败。
svp_acl_rt_destroy_context¶
函数功能:销毁一个Context,释放Context的资源,同步接口。只能销毁通过svp_acl_rt_create_context接口创建的Context。
函数原型:
svp_acl_error svp_acl_rt_destroy_context(svp_acl_rt_context context)
参数说明:
返回值说明:返回0表示成功,返回其它值表示失败。
svp_acl_rt_set_current_context¶
函数功能:设置线程的Context,同步接口。
支持以下场景:
如果在某线程(例如:thread1)中调用svp_acl_rt_create_context接口显式创建一个Context(例如:ctx1),则可以不调用svp_acl_rt_set_current_context接口指定该线程的Context,系统默认将ctx1作为thread1的Context。
如果没有调用svp_acl_rt_create_context接口显式创建Context,则系统将默认Context作为线程的Context,此时,不能通过svp_acl_rt_destroy_context接口来释放默认Context。
如果多次调用svp_acl_rt_set_current_context接口设置线程的Context,以最后一次为准。
约束说明:
若给线程设置的Context所对应的Device已经被复位,则不能将该Context设置为线程的Context,否则会导致业务异常。
推荐在某一线程中创建的Context,在该线程中使用。若在线程A中调用svp_acl_rt_create_context接口创建Context,在线程B中使用该Context,则需由用户自行保证两个线程中同一个Context下同一个Stream中任务执行的顺序。
函数原型:
svp_acl_error svp_acl_rt_set_current_context(svp_acl_rt_context context)
参数说明:
返回值说明:返回0表示成功,返回其它值表示失败。
svp_acl_rt_get_current_context¶
函数功能:
获取线程的Context,同步接口。
如果用户多次调用svp_acl_rt_set_current_context接口设置当前线程的Context,则获取的是最后一次设置的Context。
函数原型:
svp_acl_error svp_acl_rt_get_current_context(svp_acl_rt_context *context)
参数说明:
返回值说明:返回0表示成功,返回其它值表示失败。
Stream管理¶
svp_acl_rt_create_stream¶
函数功能:创建一个Stream,同步接口。
约束说明:
SoC-cs形态,硬件资源最多支持128个Stream,如果已存在多个默认Stream,只能显式创建N个Stream(N=128-默认Stream个数),例如,若已存在一个默认Stream,则只能显式创建127个Stream。
每个Context对应一个默认Stream,该默认Stream是调用svp_acl_rt_set_device接口或svp_acl_rt_create_context接口隐式创建的。推荐调用svp_acl_rt_create_stream接口显式创建Stream。
隐式创建Stream:适合简单、无复杂交互逻辑的应用,但缺点在于,在多线程编程中,执行结果取决于线程调度的顺序。
显式创建Stream:推荐显式,适合大型、复杂交互逻辑的应用,且便于提高程序的可读性、可维护性。
函数原型:
svp_acl_error svp_acl_rt_create_stream(svp_acl_rt_stream *stream)
参数说明:
返回值说明:返回0表示成功,返回其它值表示失败。
svp_acl_rt_destroy_stream¶
函数功能:销毁指定Stream,只能销毁通过svp_acl_rt_create_stream接口创建的Stream,同步接口。
约束说明:
在调用svp_acl_rt_destroy_stream接口销毁指定Stream前,需要先调用svp_acl_rt_synchronize_stream接口确保Stream中的任务都已完成。
调用svp_acl_rt_destroy_stream接口销毁指定Stream时,需确保该Stream在当前Context下。
在调用svp_acl_rt_destroy_stream接口销毁指定Stream时,需确保其它接口没有正在使用该Stream。
函数原型:
svp_acl_error svp_acl_rt_destroy_stream(svp_acl_rt_stream stream)
参数说明:
返回值说明:返回0表示成功,返回其它值表示失败。
同步等待¶
svp_acl_rt_synchronize_device¶
函数功能:
阻塞应用程序运行,直到正在运算中的Device完成运算,同步接口。
多Device场景下,调用该接口等待的是当前Context对应的Device。
约束说明:一个进程内多线程场景下,不支持多线程并发调用本接口。
函数原型:
svp_acl_error svp_acl_rt_synchronize_device(void)
参数说明:无
返回值说明:返回0表示成功,返回其它值表示失败。
svp_acl_rt_synchronize_stream¶
函数功能:阻塞应用程序运行,直到指定Stream中的所有任务都完成,同步接口。
函数原型:
svp_acl_error svp_acl_rt_synchronize_stream(svp_acl_rt_stream stream)
参数说明:
返回值说明:返回0表示成功,返回其它值表示失败。
svp_acl_rt_subscribe_report¶
函数功能:注册处理Stream上回调函数的线程。同步接口。
约束说明:
支持多次调用本接口给多个Stream(仅支持同一Device内的多个Stream)注册同一个处理回调函数的线程;
为确保Stream内的任务按调用顺序执行,不支持调用本接口给同一个Stream注册多个处理回调函数的线程;
单进程内调用本接口注册的线程数量如果超过128个,则接口返回失败;
考虑操作系统的线程切换性能开销,建议调用本接口注册的线程数量控制在32个以下(包括32);
同一个进程内,在不同的Device上注册回调函数的线程时,不能指定同一个线程ID。
函数原型:
svp_acl_error svp_acl_rt_subscribe_report(uint64_t thread_id, svp_acl_rt_stream stream)
参数说明:
返回值说明:返回0表示成功,返回其它值表示失败。
svp_acl_rt_launch_callback¶
函数功能:在Stream的任务队列中增加一个需要在板端环境上执行的回调函数。异步接口。
函数原型:
svp_acl_error svp_acl_rt_launch_callback(svp_acl_rt_callback fn, void *user_data, svp_acl_rt_callback_block_type blockType, svp_acl_rt_stream stream)
参数说明:
typedef void (*svp_acl_rt_callback)(void *user_data) |
||
typedef enum svp_acl_rt_callback_block_type { SVP_ACL_CALLBACK_NO_BLOCK, //非阻塞 SVP_ACL_CALLBACK_BLOCK, //阻塞 } svp_acl_rt_callback_block_type; |
||
约束说明:用户需要保证传入的fn和user_data的正确性,以及user_data所指向内存空间大小是否足够,否则处理回调函数时会导致程序异常。
返回值说明:返回0表示成功,返回其它值表示失败。
svp_acl_rt_process_report¶
函数功能:
在timeout时间内,触发回调处理,由svp_acl_rt_subscribe_report接口指定的线程处理回调。同步接口。
用户需新建一个线程,在线程函数内调用本接口。
函数原型:
svp_acl_error svp_acl_rt_process_report(int32_t timeout)
参数说明:
|
返回值说明:返回0表示成功,返回其它值表示失败。
svp_acl_rt_unsubscribe_report¶
函数功能:取消线程注册,Stream上的回调函数不再由指定线程处理。同步接口。
函数原型:
svp_acl_error svp_acl_rt_unsubscribe_report(uint64_t thread_id, svp_acl_rt_stream stream)
参数说明:
返回值说明:返回0表示成功,返回其它值表示失败。
svp_acl_rt_set_op_wait_timeout¶
函数功能:
设置等待超时时间。同步接口。
对于需要等待Stream、Device上任务完成的场景,可以调用本接口设置等待超时时间。设置超时时间后,如果等待任务完成的时间超过所设置的时间,则SVP ACL会返回报错。不调用本接口设置等待超时时间,则默认超时时间是120秒。
函数原型:
svp_acl_error svp_acl_rt_set_op_wait_timeout(uint32_t timeout)
参数说明:
返回值说明:返回0表示成功,返回其它值表示失败。
内存管理¶
svp_acl_rt_malloc¶
函数功能:
申请Device上的内存,同步接口。
在Device上申请size大小的线性内存,通过*dev_ptr返回已分配内存的虚拟地址指针。
通过该接口申请的Device内存不支持cache缓存,如果用户需要申请支持cache缓存的内存,请参见svp_acl_rt_malloc_cached。
约束说明:
使用svp_acl_rt_malloc接口申请的内存,需要通过svp_acl_rt_free接口释放内存。
频繁调用svp_acl_rt_malloc接口申请内存、调用svp_acl_rt_free接口释放内存,会损耗性能,建议用户提前做内存预先分配或二次管理,避免频繁申请/释放内存。
函数原型:
svp_acl_error svp_acl_rt_malloc(void **dev_ptr, size_t size, svp_acl_rt_mem_malloc_policy policy)
参数说明:
返回值说明:返回0表示成功,返回其它值表示失败。
svp_acl_rt_malloc_cached¶
函数功能:
申请Device上的内存,同步接口,该接口在任何场景下申请的内存都是支持cache缓存。
在Device上申请size大小的线性内存,通过*dev_ptr返回已分配内存的虚拟地址指针。
通过本接口分配的内存支持cache缓存,对于频繁使用的内存,建议使用本接口分配内存,这样可以提高cpu的读写效率,提升系统性能。当cpu访问此接口申请的内存时,会将内存中的数据放在cache中,而硬件设备(如图像分析引擎)只能访问物理内存,不能访问cache中内容,对于这种cpu和硬件会共同操作的内存,需要调用svp_acl_rt_mem_flush接口做好数据同步。
约束说明:其它约束与svp_acl_rt_malloc接口相同,但使用本接口申请的支持cache缓存的内存,需要用户显式处理cpu与图像分析引擎之间cache的一致性。
函数原型:
svp_acl_error svp_acl_rt_malloc_cached(void **dev_ptr, size_t size, svp_acl_rt_mem_malloc_policy policy)
参数说明:
返回值说明:返回0表示成功,返回其它值表示失败。
svp_acl_rt_mem_flush¶
函数功能:
将cache中的数据刷新到ddr中,并将cache中的内容设置成无效。
当cache里的数据为最新数据时,为了保证不能直接访问cache的硬件(如图像分析引擎)在访问内存时能够得到正确的数据,此时需要先调用本接口将cache里的内容更新到内存,这样,当硬件访问内存时,保证了数据的一致性和正确性。
此接口应与svp_acl_rt_malloc_cached接口配套使用。
函数原型:
svp_acl_error svp_acl_rt_mem_flush(const void *dev_ptr, size_t size)
参数说明:
返回值说明:返回0表示成功,返回其它值表示失败。
svp_acl_rt_mem_invalidate¶
函数功能:
将cache中的数据设置成无效。
针对硬件输出的内存,如果此时cache中有预读引起的脏数据,硬件计算完成后,为了保证CPU后处理能获取到正确的数据,此时需要将cache中预读数据置无效。如果CPU对该内存执行过写操作,调用该接口会将cache中的数据同步到ddr。
此接口应与svp_acl_rt_malloc_cached接口配套使用。
函数原型:
svp_acl_error svp_acl_rt_mem_invalidate(const void *dev_ptr, size_t size)
参数说明:
返回值说明:返回0表示成功,返回其它值表示失败。
svp_acl_rt_free¶
函数功能:
释放Device上的内存,同步接口。
本接口只能释放通过svp_acl_rt_malloc接口或svp_acl_rt_malloc_cached接口申请的内存。如果应用在Device侧使用svp_acl_rt_malloc_host接口申请内存,也可以通过本接口释放。
函数原型:
svp_acl_error svp_acl_rt_free(const void *dev_ptr)
参数说明:
返回值说明:返回0表示成功,返回其它值表示失败。
svp_acl_rt_malloc_host¶
函数功能:申请Host或Device上的内存,Device上的内存按普通页申请。同步接口。
约束说明:
使用svp_acl_rt_malloc_host接口申请的内存,需要通过svp_acl_rt_free_host接口释放内存。
应用在Host上运行时,调用该接口申请的是Host内存,由系统保证内存首地址64字节对齐。应用在Device上运行时,调用该接口申请的是Device内存,由系统保证内存首地址64字节对齐。
频繁调用svp_acl_rt_malloc_host接口申请内存、调用svp_acl_rt_free_host接口释放内存,会损耗性能,建议用户提前做内存预先分配或二次管理,避免频繁申请/释放内存。
函数原型:
svp_acl_error svp_acl_rt_malloc_host(void **host_ptr, size_t size)
参数说明:
返回值说明:返回0表示成功,返回其它值表示失败。
svp_acl_rt_free_host¶
函数功能:
释放Host或Device上的内存,同步接口。
应用在Host侧,svp_acl_rt_free_host接口只能释放通过svp_acl_rt_malloc_host接口申请的内存。应用在Device侧,svp_acl_rt_free_host接口既可以释放svp_acl_rt_malloc_host接口申请的内存,也可以释放svp_acl_rt_malloc接口申请的内存。
函数原型:
svp_acl_error svp_acl_rt_free_host(const void *host_ptr)
参数说明:
返回值说明:返回0表示成功,返回其它值表示失败。
模型加载与执行¶
svp_acl_mdl_load_from_mem¶
函数功能:
从内存加载离线模型数据,加载的模型是独立的,不依赖于device,contxt等资源,可以被下发到不同的stream上执行,同步接口。
系统完成模型加载后,返回的模型ID,作为后续操作时用于识别模型的标志。
约束说明:
最多可加载128个模型。
输入/输出所有维度乘积值不能超过0xFFFFFFFF。
生成.om文件时配置的[internal_stride]项(详细参见《ATC工具使用指南》)必须大于0且为16的倍数(倍数须为2的非负整数次幂),最大不能超过256。
Recurrent网络生成.om文件时配置的[recurrent_max_total_t]项(详细参见《ATC工具使用指南》)必须大于0,最大不能超过1024。
输入/输出默认stride按照生成.om文件时配置的[internal_stride]的值对齐后不能超过0xFFFFFFFF(详细输入/输出默认stride计算方法请参见svp_acl_mdl_get_input_default_stride和svp_acl_mdl_get_output_default_stride)。
输入/输出按照默认stride计算得到的单batch内存大小不能超过0xFFFFFFFF(详细输入/输出内存计算方法请参见svp_acl_mdl_get_input_size_by_index和svp_acl_mdl_get_output_size_by_index)。
Recurrent网络data层个数范围:[2, 5]。
Recurrent网络不支持前后接模式识别CPU算子。
模型每个执行段data层和report层个数总和不能超过32。
函数原型:
svp_acl_error svp_acl_mdl_load_from_mem(const void* model,size_t model_size, uint32_t* model_id)
参数说明:
模型数据的内存地址。用户要保证内存中存储的模型数据的完整性和正确性,在调用svp_acl_mdl_unload接口卸载模型之前内存不能被释放且内存中的模型数据不能被修改。 |
||
返回值说明:返回0表示成功,返回其它值表示失败。
svp_acl_mdl_execute¶
函数功能:执行模型推理,直到返回推理结果,同步接口。
约束说明:
input中的task_buf(见准备模型执行的输入/输出数据)在任务模型推理完成前不能被改写也不能被其他任务使用。
input中的work_buf(见准备模型执行的输入/输出数据)不能被其他stream上的任务使用。
在模型推理完成之前,不能调用svp_acl_mdl_destroy_dataset接口释放input或output,不能调用svp_acl_update_data_buffer接口更新input或者output。
函数原型:
svp_acl_error svp_acl_mdl_execute(uint32_t model_id, const svp_acl_mdl_dataset *input, const svp_acl_mdl_dataset *output)
参数说明:
|
调用svp_acl_mdl_load_from_mem接口加载模型成功后,会返回模型ID。 |
||
|
若用户使用svp_acl_rt_malloc或svp_acl_rt_malloc_host接口申请大块内存并自行划分、管理内存时,用户在管理内存时,模型输入数据的内存有对齐和补齐要求,首地址和stride需要16字节对齐。 |
||
|
若用户使用svp_acl_rt_malloc接口申请大块内存并自行划分、管理内存时,用户在管理内存时,模型输出数据的内存有对齐和补齐要求,首地址和stride需要16字节对齐。 |
返回值说明:返回0表示成功,返回其它值表示失败。
svp_acl_mdl_execute_async¶
函数功能:执行模型推理,异步接口。
约束说明:
input中的task_buf(见准备模型执行的输入/输出数据)在任务模型推理完成前不能被改写也不能被其他任务使用。
input中的work_buf(见准备模型执行的输入/输出数据)不能被其他stream上的任务使用。
在模型推理完成之前,不能调用svp_acl_mdl_destroy_dataset接口释放input或output,不能调用svp_acl_update_data_buffer接口更新input或者output。
函数原型:
svp_acl_error svp_acl_mdl_execute_async(uint32_t model_id, const svp_acl_mdl_dataset *input, const svp_acl_mdl_dataset *output, svp_acl_rt_stream stream)
参数说明:
|
调用svp_acl_mdl_load_from_mem接口加载模型成功后,会返回模型ID。 |
||
|
若用户使用svp_acl_rt_malloc或svp_acl_rt_malloc_host接口申请大块内存并自行划分、管理内存时,用户在管理内存时,模型输入数据的内存有对齐和补齐要求,首地址和stride需要16字节对齐。 |
||
|
若用户使用svp_acl_rt_malloc接口申请大块内存并自行划分、管理内存时,用户在管理内存时,模型输出数据的内存有对齐和补齐要求,首地址和stride需要16字节对齐。 |
||
返回值说明:返回0表示成功,返回其它值表示失败。
svp_acl_mdl_unload¶
函数功能:系统完成模型推理后,可调用该接口卸载模型,释放资源,同步接口。
约束说明:
在调用svp_acl_mdl_unload接口卸载指定模型时,需确保其它接口没有正在使用该模型。
不建议在析构函数中调用svp_acl_mdl_unload接口,否则在进程退出时可能由于单例析构顺序未知而导致进程异常退出的问题。
函数原型:
svp_acl_error svp_acl_mdl_unload(uint32_t model_id)
参数说明:
返回值说明:返回0表示成功,返回其它值表示失败。
svp_acl_mdl_set_dynamic_batch_size¶
函数功能:用于设置模型推理时的批量大小Batch(每次处理图片的数量)。
约束说明:
配置batch_size时,batch_size需大于0,若输入为图片类型,不能超过256;若输入为非图片数据,不能超过5000。如果执行模型前没有调用该接口配置batch_size到dataset,则将按照dataset中默认的batch值(默认值为1)执行。
batch_size值约束请查看《ATC工具使用指南》中batch_num参数说明。
函数原型:
svp_acl_error svp_acl_mdl_set_dynamic_batch_size(uint32_t model_id, svp_acl_mdl_dataset *dataset, size_t index, uint64_t batch_size)
参数说明:
|
调用svp_acl_mdl_load_from_mem接口加载模型成功后,会返回模型ID。 |
||
|
使用svp_acl_mdl_dataset类型的数据描述模型推理时的输入数据,输入的内存地址、内存大小用svp_acl_data_buffer类型的数据来描述。 |
||
标识动态Batch输入的输入index,需调用svp_acl_mdl_get_input_index_by_name接口获取,输入名称固定为SVP_ACL_DYNAMIC_TENSOR_NAME。 |
||
返回值说明:返回0表示成功,返回其它值表示失败。
svp_acl_mdl_set_total_t¶
函数功能:用于设置Recurrent模型推理时要处理的总帧数。
约束说明:配置的total_t不能为0,也不能超过编译om时[recurrent_max_total_t]项配置的值(详细参见《ATC工具使用指南》)。执行Recurrent网络前可以调用该接口将total_t配置到dataset中,如果没有配置,将把编译om时[recurrent_max_total_t]项配置的值作为T维度长度进行内存校验和网络执行。
函数原型:
svp_acl_error svp_acl_mdl_set_total_t(uint32_t model_id, svp_acl_mdl_dataset *dataset, uint64_t total_t)
参数说明:
|
调用svp_acl_mdl_load_from_mem接口加载模型成功后,会返回模型ID。 |
||
|
使用svp_acl_mdl_dataset类型的数据描述模型推理时的输入数据,输入的内存地址、内存大小用svp_acl_data_buffer类型的数据来描述。 |
||
返回值说明:返回0表示成功,返回其它值表示失败。
svp_acl_mdl_init_dump¶
函数功能:
Dump初始化。
svp_acl_mdl_init_dump接口需要与svp_acl_mdl_set_dump接口、svp_acl_mdl_finalize_dump接口配合使用,用于配置Dump信息。
接口的调用顺序如下,以配置两个模型的Dump信息为例:svp_acl_init接口-->svp_acl_mdl_init_dump接口-->svp_acl_mdl_set_dump接口-->模型1加载-->svp_acl_mdl_finalize_dump接口-->svp_acl_mdl_init_dump接口-->svp_acl_mdl_set_dump接口-->模型2加载-->svp_acl_mdl_finalize_dump接口-->执行其它任务-->模型卸载-->svp_acl_finalize接口
约束说明:
如果已经通过svp_acl_init接口配置了dump信息,则调用svp_acl_mdl_init_dump接口时会返回失败。
必须在调用svp_acl_init接口之后、模型加载接口之前调用svp_acl_mdl_init_dump接口。
函数原型:
svp_acl_error svp_acl_mdl_init_dump()
参数说明:无
返回值说明:返回0表示成功,返回其它值表示失败。
svp_acl_mdl_set_dump¶
函数功能:
设置dump参数。
svp_acl_mdl_set_dump接口需要与svp_acl_mdl_init_dump接口、svp_acl_mdl_finalize_dump接口配合使用,用于配置Dump信息。
接口的调用顺序如下,以配置两个模型的Dump信息为例:svp_acl_init接口-->svp_acl_mdl_init_dump接口-->svp_acl_mdl_set_dump接口-->模型1加载-->svp_acl_mdl_finalize_dump接口-->svp_acl_mdl_init_dump接口-->svp_acl_mdl_set_dump接口-->模型2加载-->svp_acl_mdl_finalize_dump接口-->执行其它任务-->模型卸载-->svp_acl_finalize接口
约束说明:
只有在调用本接口之后加载模型,配置的Dump信息有效。在调用本接口之前已经加载的模型不受影响,除非用户在调用本接口后重新加载该模型。
例如以下接口调用顺序中,加载的模型1不受影响,配置的Dump信息仅对加载的模型2有效:
svp_acl_mdl_init_dump接口-->模型1加载-->svp_acl_mdl_set_dump接口-->模型2加载-->svp_acl_mdl_finalize_dump接口
多次调用本接口对同一个模型配置了Dump信息,系统内处理时会采用覆盖策略。
例如以下接口调用顺序中,第二次调用本接口配置的Dump信息会覆盖第一次配置的Dump信息:
svp_acl_mdl_init_dump接口-->svp_acl_mdl_set_dump接口-->svp_acl_mdl_set_dump接口-->模型1加载-->svp_acl_mdl_finalize_dump接口
Dump功能开启除了配置json文件,OM需要选择开启Dump模式的OM,开启Dump模式请参考《ATC工具使用指南》“online_model_type”的相关描述。
函数原型:
svp_acl_error svp_acl_mdl_set_dump(const char *dump_cfg_path)
参数说明:
|
配置文件格式为json格式,当前可配置dump数据的相关信息,示例请参见配置文件示例,详细配置说明请参见《精度比对工具使用指导》中的比对数据准备>准备离线模型Dump数据;如果不涉及配置信息,需向svp_acl_mdl_set_dump接口中传入NULL。 |
配置文件示例:
以Caffe ResNet-50网络为例,若需要比对Caffe ResNet-50网络与基于Caffe ResNet-50转换成的适配SoC的离线模型中某些层算子的输出结果,可以在配置文件中配置如下内容:
{
"dump":{
"dump_list":[
{
"model_name":"ResNet-50",
"layer":[
"conv1conv1_relu",
"res2a_branch2ares2a_branch2a_relu",
"res2a_branch1",
"pool1"
]
}
],
"dump_path":"/MyApp20/dump",
"dump_mode":"output"
}
}
返回值说明:返回0表示成功,返回其它值表示失败。
svp_acl_mdl_finalize_dump¶
函数功能:
Dump去初始化。
svp_acl_mdl_finalize_dump接口需要与svp_acl_mdl_init_dump接口、svp_acl_mdl_set_dump接口配合使用,用于配置Dump信息。
接口的调用顺序如下,以配置两个模型的Dump信息为例:svp_acl_init接口-->svp_acl_mdl_init_dump接口-->svp_acl_mdl_set_dump接口-->模型1加载-->svp_acl_mdl_finalize_dump接口-->svp_acl_mdl_init_dump接口-->svp_acl_mdl_set_dump接口-->模型2加载-->svp_acl_mdl_finalize_dump接口-->执行其它任务-->模型卸载-->svp_acl_finalize接口
函数原型:
svp_acl_error svp_acl_mdl_finalize_dump()
参数说明:无
返回值说明:返回0表示成功,返回其它值表示失败。
svp_acl_mdl_set_config_opt¶
函数功能:
设置模型加载的配置对象中的各属性的取值,包括模型执行的优先级、模型的内存地址、内存大小等。
约束说明:
按如下接口调用顺序可实现模型加载的功能:
调用svp_acl_mdl_create_config_handle接口创建模型加载的配置对象。
多次调用svp_acl_mdl_set_config_opt接口设置配置对象中每个属性的值。
调用svp_acl_mdl_load_with_config接口指定模型加载时需要的配置信息,并进行模型加载。
模型加载成功后,调用svp_acl_mdl_destroy_config_handle接口销毁。
值得注意的是通过svp_acl_mdl_load_with_config接口加载的模型同样需要调用svp_acl_mdl_unload接口进行模型卸载。
函数原型:
svp_acl_error svp_acl_mdl_set_config_opt(svp_acl_mdl_config_handle *handle, svp_acl_mdl_config_attr attr, const void *attr_value, size_t value_size)
参数说明:
指定模型加载的配置对象。需提前调用svp_acl_mdl_create_config_handle接口创建该对象。 |
||
返回值说明:返回0表示成功,返回其它值表示失败。
svp_acl_mdl_load_with_config¶
函数功能:
指定模型加载时需要的配置信息,并进行模型加载。
约束说明:
调用svp_acl_mdl_create_config_handle接口创建模型加载的配置对象。
多次调用svp_acl_mdl_set_config_opt接口设置配置对象中每个属性的值。
调用svp_acl_mdl_load_with_config接口指定模型加载时需要的配置信息,并进行模型加载。
模型加载成功后,调用svp_acl_mdl_destroy_config_handle接口销毁。
函数原型:
svp_acl_error svp_acl_mdl_load_with_config(const svp_acl_mdl_config_handle *handle, uint32_t *model_id)
参数说明:
指定模型加载的配置对象。需提前调用svp_acl_mdl_create_config_handle接口创建该对象,与svp_acl_mdl_set_config_opt中的handle保持一致。 |
||
返回值说明:返回0表示成功,返回其它值表示失败。
svp_acl_mdl_get_first__aa_pp_info¶
函数功能:
获取模型_AA_PP的配置信息。
约束说明:
使用本接口获取模型中_AA_PP的信息,只能获取svp_acl_aapp_info结构体中inputFormat的值,其他的值无法获取。
函数原型:
svp_acl_error svp_acl_mdl_get_first_aapp_info(uint32_t model_id, size_t index, svp_acl_aapp_info *aapp_info)
参数说明:
返回值说明:返回0表示成功,返回其它值表示失败。
svp_acl_mdl_get_dynamic_batch¶
函数功能:
根据模型描述信息获取模型生成时配置的Batch信息。同步接口。
函数原型:
svp_acl_error svp_acl_mdl_get_dynamic_batch(const svp_acl_mdl_desc *model_desc, svp_acl_mdl_batch *batch);
参数说明:
svp_acl_mdl_desc类型数据的指针。 |
||
#define SVP_ACL_MAX_BATCH_NUM 1 typedef struct svp_acl_mdl_batch { size_t batch_count; /* batch array count, only support 1 */ uint64_t batch[SVP_ACL_MAX_BATCH_NUM]; /* batch data array */ } svp_acl_mdl_batch; 当前只支持获取生成模型时配置的Batch信息。Batch值约束请查看《ATC工具使用指南》中batch_num参数说明。 |
返回值说明:返回0表示成功,返回其它值表示失败。
svp_acl_mdl_set_dynamic_hw_size¶
函数功能:
动态分辨率场景下,在模型执行前调用本接口设置模型推理时输入图片的高和宽。
函数原型:
svp_acl_error svp_acl_mdl_set_dynamic_hw_size(uint32_t model_id, svp_acl_mdl_dataset *dataset, size_t index, uint64_t height, uint64_t width);
参数说明:
|
使用svp_acl_mdl_dataset类型的数据描述模型推理时的输入数据,输入的内存地址、内存大小用svp_acl_data_buffer类型的数据来描述。 |
||
标识动态HW输入的输入index,需调用svp_acl_mdl_get_input_index_by_name接口获取,输入名称固定为SVP_ACL_DYNAMIC_TENSOR_NAME。 |
||
|
此处设置的分辨率只能是模型构建时设置的分辨率档位中的某一档,模型构建的详细说明请参见《ATC工具使用指南》--dynamic_image_size参数。 可以调用svp_acl_mdl_get_dynamic_hw接口获取指定模型支持的分辨率档位数以及每一档中的宽、高。 |
||
|
此处设置的分辨率只能是模型构建时设置的分辨率档位中的某一档,模型构建的详细说明请参见《ATC工具使用指南》--dynamic_image_size参数。 可以调用svp_acl_mdl_get_dynamic_hw接口获取指定模型支持的分辨率档位数以及每一档中的宽、高。 |
返回值说明:返回0表示成功,返回其它值表示失败。
Profiling配置¶
功能及约束说明¶
功能:
该章节下的接口用于Profiling采集性能数据,实现方式支持以下两种:
方式一:将采集到的Profiling数据写入文件,再使用Profiling工具解析该文件,并展示性能分析数据
包括以下两种接口调用方式:
svp_acl_prof_init接口、svp_acl_prof_start接口、svp_acl_prof_stop接口、svp_acl_prof_finalize接口配合使用,实现该方式的性能数据采集。该方式可获取SVP ACL的接口性能数据、_模式识别_Core上算子的执行时间、模式识别CPU算子的执行时间等。目前这些接口为进程级控制,表示在进程内任意线程调用该接口,其它线程都会生效。
一个进程内,可以根据需求多次调用这些接口,基于不同的Profiling采集配置,采集数据。
调用svp_acl_init接口,在SVP ACL初始化阶段,通过*.json文件传入要采集的Profiling数据。该方式可获取SVP ACL的接口性能数据、模式识别Core上算子的执行时间、模式识别CPU算子的执行时间等。
一个进程内,只能调用一次svp_acl_init接口,如果要修改Profiling采集配置,需修改*.json文件中的配置。详细使用说明请参见接口处的说明,不在本章节描述。
方式二:将采集到的Profiling数据解析后写入管道,由用户读入内存,再由用户调用SVP ACL的接口获取性能数据
svp_acl_prof_model_subscribe接口、svp_acl_prof_get*接口、svp_acl_prof_model_unsubscribe接口配合使用,实现该方式的性能数据采集,当前支持获取网络模型中模式识别Core算子的性能数据,包括算子名称、算子类型名称、算子执行时间等。
总体约束:两种方式的Profiling性能数据采集接口不能交叉调用。
svp_acl_prof_init接口和svp_acl_prof_finalize接口之间不能调用svp_acl_prof_model_subscribe接口、svp_acl_prof_get*接口、svp_acl_prof_model_unsubscribe接口;
svp_acl_prof_model_subscribe接口和svp_acl_prof_model_unsubscribe接口之间不能调用svp_acl_prof_init接口、svp_acl_prof_start接口、svp_acl_prof_stop接口、svp_acl_prof_finalize接口。
通过方式二实现的Profiling采集暂不能很好的支持Recurrent、RPN、ROI、CPU Loop的网络,这些网络建议通过MindStduio工具采集并解析Profiling数据。
开启profling进行数据采集时,由于第一帧推理需要配置profling的使能/内存,并且第一帧推理时硬件会额外处理页表等动作,所以第一帧推理采集的数据会偏高。
方式一的接口约束说明
调用接口要求:
svp_acl_prof_init接口必须在svp_acl_init接口之后、模型加载之前调用。
如果已经通过svp_acl_init接口配置了Profiling信息,则调用svp_acl_prof_init接口、svp_acl_prof_start接口、svp_acl_prof_stop接口、svp_acl_prof_finalize时,会返回报错。
如果没有调用svp_acl_prof_init接口,调用svp_acl_prof_start接口、svp_acl_prof_stop接口、svp_acl_prof_finalize时,会返回报错。
svp_acl_prof_start接口在模型执行之前调用,若在模型执行过程中调用svp_acl_prof_start接口,Profling采集到的数据为调用svp_acl_prof_start接口之后的数据,可能导致数据不完整。
调用svp_acl_prof_start接口时,可以指定从一个Device上采集性能数据,也可以指定从多个Device上采集性能数据。
一个用户APP进程内,如果连续调用多次svp_acl_prof_start接口,指定重复的Profiling配置,或指定的Device重复,会返回报错。
在用户APP的进程生命周期内,svp_acl_prof_init接口与svp_acl_prof_finalize接口配对使用,建议只调用一次,如该组合多次调用可以改变保存性能数据的文件的路径。
svp_acl_prof_start接口与svp_acl_prof_stop接口需配对使用。
接口调用顺序:
建议的接口调用顺序如下,以“一个用户APP进程内采集多个模型推理时的性能数据”为例:
svp_acl_init接口-->svp_acl_prof_init接口-->svp_acl_prof_start接口-->模型1加载-->模型1执行-->模型2加载-->模型2执行-->模型卸载-->svp_acl_prof_stop接口(与svp_acl_prof_start接口的svp_acl_prof_config数据保持一致)-->svp_acl_prof_finalize接口-->执行其它任务-->svp_acl_finalize接口
错误的接口调用顺序示例如下,以“一个用户APP进程内,如果连续调用多次svp_acl_prof_start接口,指定的Device重复”为例:
svp_acl_init接口-->svp_acl_prof_init接口-->svp_acl_prof_start接口(指定Device 0)-->svp_acl_prof_start接口(指定Device 0)-->模型1加载-->模型1执行-->模型2加载-->模型2执行-->svp_acl_prof_stop接口-->svp_acl_prof_stop接口-->svp_acl_prof_finalize-->执行其它任务-->模型卸载-->svp_acl_finalize接口
方式二的接口约束说明
接口调用要求:
svp_acl_prof_model_subscribe接口在模型执行之前调用,若在模型执行过程中调用svp_acl_prof_model_subscribe接口,Profling采集到的数据为调用svp_acl_prof_model_subscribe接口之后的数据,可能导致数据不完整。
svp_acl_prof_model_subscribe接口需与svp_acl_prof_model_unsubscribe接口配对使用,不能在调用接口前,多次调用
svp_acl_prof_model_subscribe接口重复订阅相同的模型。
不能调用svp_acl_prof_model_subscribe接口订阅不存在的模型ID。
不能调用svp_acl_prof_model_unsubscribe接口取消订阅不存在的模型ID或未订阅过的模型ID。
如果在同一个Device上加载了多个模型,只能对多个模型下发同样的订阅配置。
接口调用顺序:
建议的接口调用顺序如下:
模型加载-->svp_acl_prof_model_subscribe接口-->svp_acl_prof_get_op_desc_size接口-->svp_acl_prof_get_op_num接口-->svp_acl_prof_get_op_type/svp_acl_prof_get_op_name/svp_acl_prof_get_op_start/svp_acl_prof_get_op_end/svp_acl_prof_get_op_duration/svp_acl_prof_get_model_id接口-->svp_acl_prof_model_unsubscribe接口
错误的接口调用顺序示例如下,以重复定义同一个模型为例:
模型1加载-->svp_acl_prof_model_subscribe接口(指定模型1)-->svp_acl_prof_model_subscribe接口(指定模型1)-->svp_acl_prof_model_unsubscribe接口
svp_acl_prof_init¶
函数功能:初始化Profiling,目前用于设置保存性能数据的文件的路径。同步接口。
函数原型:
svp_acl_error svp_acl_prof_init(const char *result_path, size_t length)
参数说明:
返回值说明:返回0表示成功,返回其它值表示失败。
参考资源:接口调用示例,参见Profiling性能数据采集。
svp_acl_prof_start¶
函数功能:
下发Profiling请求,使能对应数据的采集。同步接口。
用户可根据需要,在模型执行过程中按需调用svp_acl_prof_start接口,Profiling采集到的数据为调用该接口之后的数据,且只会获取一次模型Profiling数据。
函数原型:
svp_acl_error svp_acl_prof_start (const svp_acl_prof_config *profiler_config)
参数说明:
|
需提前调用svp_acl_prof_create_config接口创建svp_acl_prof_config类型的数据。 |
返回值说明:返回0表示成功,返回其它值表示失败。
参考资源:接口调用示例,参见Profiling性能数据采集。
svp_acl_prof_stop¶
函数功能:停止Profiling数据采集,同步接口。
函数原型:
svp_acl_error svp_acl_prof_stop(const svp_acl_prof_config *profiler_config)
参数说明:
|
与svp_acl_prof_start接口中的svp_acl_prof_config类型数据保持一致。 |
返回值说明:返回0表示成功,返回其它值表示失败。
参考资源:接口调用示例,参见Profiling性能数据采集。
svp_acl_prof_finalize¶
函数功能:结束Profiling。同步接口。
函数原型:
svp_acl_error svp_acl_prof_finalize()
参数说明:无
返回值说明:返回0表示成功,返回其它值表示失败。
参考资源:接口调用示例,参见Profiling性能数据采集。
svp_acl_prof_model_subscribe¶
函数功能:网络场景下,订阅算子的基本信息,包括算子名称、算子类型、算子执行耗时等。同步接口。需要与svp_acl_prof_model_unsubscribe接口配对使用。
函数原型:
svp_acl_error svp_acl_prof_model_subscribe(uint32_t model_id, const svp_acl_prof_subscribe_config *prof_subscribe_config)
参数说明:
|
调用svp_acl_mdl_load_from_mem接口加载模型成功后,会返回模型ID。 |
||
|
需提前调用svp_acl_prof_create_subscribe_config接口创建svp_acl_prof_subscribe_config类型的数据。 |
返回值说明:返回0表示成功,返回其它值表示失败。
参考资源:接口调用示例,参见Profiling性能数据采集。
svp_acl_prof_model_unsubscribe¶
函数功能:网络场景下,取消订阅算子的基本信息,包括算子名称、算子类型、算子执行耗时等。同步接口。需要与svp_acl_prof_model_subscribe接口配对使用。
函数原型:
svp_acl_error svp_acl_prof_model_unsubscribe(uint32_t model_id)
参数说明:
返回值说明:返回0表示成功,返回其它值表示失败。
参考资源:接口调用示例,参见Profiling性能数据采集。
svp_acl_prof_get_op_desc_size¶
函数功能:
获取单个算子数据结构的大小,单位为Byte。当前版本中约定每个算子数据结构的大小是一样的。同步接口。
建议用户新建一个线程,在新线程内调用该接口,否则可能阻塞主线程中的其它任务调度。
函数原型:
svp_acl_error svp_acl_prof_get_op_desc_size(size_t *op_desc_size)
参数说明:
返回值说明:返回0表示成功,返回其它值表示失败。
参考资源:接口调用示例,参见Profiling性能数据采集。
svp_acl_prof_get_op_num¶
函数功能:
获取指定内存中算子的数量。同步接口。
建议用户新建一个线程,在新线程内调用该接口,否则可能阻塞主线程中的其它任务调度。
函数原型:
svp_acl_error svp_acl_prof_get_op_num(const void *op_info, size_t op_info_len, uint32_t *op_number)
参数说明:
|
调用svp_acl_prof_get_op_desc_size接口获取到单个算子数据结构的大小后,用户需按照“单个算子数据结构的大小*整数系数”得到的数值申请内存,用于存放Profiling采集到的算子信息数据,作为本接口的输入。 |
||
返回值说明:返回0表示成功,返回其它值表示失败。
参考资源:接口调用示例,参见Profiling性能数据采集。
svp_acl_prof_get_op_type_len¶
函数功能:
获取算子类型的字符串长度,用于内存申请。同步接口。
建议用户新建一个线程,在新线程内调用该接口,否则可能阻塞主线程中的其它任务调度。
函数原型:
svp_acl_error svp_acl_prof_get_op_type_len(const void *op_info, size_t op_info_len, uint32_t index, size_t *op_type_len)
参数说明:
|
用户调用svp_acl_prof_get_op_num接口获取算子数量后,这个index的取值范围:[0, (算子数量-1)] |
||
返回值说明:返回0表示成功,返回其它值表示失败。
参考资源:接口调用示例,参见Profiling性能数据采集。
svp_acl_prof_get_op_type¶
函数功能:
获取指定算子的算子类型名称,同步接口。
建议用户新建一个线程,在新线程内调用该接口,否则可能阻塞主线程中的其它任务调度。
函数原型:
svp_acl_error svp_acl_prof_get_op_type(const void *op_info, size_t op_info_len, uint32_t index, char *op_type, size_t op_type_len)
参数说明:
|
用户调用svp_acl_prof_get_op_num接口获取算子数量后,这个index的取值范围:[0, (算子数量-1)] |
||
op_type的实际内存申请长度。取值范围建议不小于svp_acl_prof_get_op_type_len,否则内容会有截断。 |
返回值说明:返回0表示成功,返回其它值表示失败。
参考资源:接口调用示例,参见Profiling性能数据采集。
svp_acl_prof_get_op_name_len¶
函数功能:
获取算子名称的字符串长度,用于内存申请。同步接口。
建议用户新建一个线程,在新线程内调用该接口,否则可能阻塞主线程中的其它任务调度。
函数原型:
svp_acl_error svp_acl_prof_get_op_name_len(const void *op_info, size_t op_info_len, uint32_t index, size_t *op_name_len)
参数说明:
|
用户调用svp_acl_prof_get_op_num接口获取算子数量后,这个index的取值范围:[0, (算子数量-1)] |
||
返回值说明:返回0表示成功,返回其它值表示失败。
参考资源:接口调用示例,参见Profiling性能数据采集。
svp_acl_prof_get_op_name¶
函数功能:
获取指定算子的算子名称。同步接口。
建议用户新建一个线程,在新线程内调用该接口,否则可能阻塞主线程中的其它任务调度。
函数原型:
svp_acl_error svp_acl_prof_get_op_name(const void *op_info, size_t op_info_len, uint32_t index, char *op_name, size_t op_name_len)
参数说明:
|
用户调用svp_acl_prof_get_op_num接口获取算子数量后,这个index的取值范围:[0, (算子数量-1)] |
||
op_name的实际内存申请长度。取值范围建议不小于svp_acl_prof_get_op_name_len。 |
返回值说明:返回0表示成功,返回其它值表示失败。
参考资源:接口调用示例,参见Profiling性能数据采集。
svp_acl_prof_get_op_start¶
函数功能:
获取算子执行的开始时间,单位为ns。同步接口。
建议用户新建一个线程,在新线程内调用该接口,否则可能阻塞主线程中的其它任务调度。
函数原型:
uint64_t svp_acl_prof_get_op_start(const void *op_info, size_t op_info_len, uint32_t index)
参数说明:
|
用户调用svp_acl_prof_get_op_num接口获取算子数量后,这个index的取值范围:[0, (算子数量-1)] |
返回值说明:算子执行的开始时间。
参考资源:接口调用示例,参见Profiling性能数据采集。
svp_acl_prof_get_op_end¶
函数功能:
获取算子执行的结束时间,单位为ns。同步接口。
建议用户新建一个线程,在新线程内调用该接口,否则可能阻塞主线程中的其它任务调度。
函数原型:
uint64_t svp_acl_prof_get_op_end(const void *op_info, size_t op_info_len, uint32_t index)
参数说明:
|
用户调用svp_acl_prof_get_op_num接口获取算子数量后,这个index的取值范围:[0, (算子数量-1)] |
返回值说明:算子执行结束时间。
参考资源:接口调用示例,参见Profiling性能数据采集。
svp_acl_prof_get_op_duration¶
函数功能:
获取算子执行的耗时时间,单位为ns。同步接口。
建议用户新建一个线程,在新线程内调用该接口,否则可能阻塞主线程中的其它任务调度。
函数原型:
uint64_t svp_acl_prof_get_op_duration(const void *op_info, size_t op_info_len, uint32_t index)
参数说明:
|
用户调用svp_acl_prof_get_op_num接口获取算子数量后,这个index的取值范围:[0, (算子数量-1)] |
返回值说明:算子执行的耗时时间。
参考资源:接口调用示例,参见Profiling性能数据采集。
svp_acl_prof_get_model_id¶
函数功能:
获取指定算子所在模型的ID。同步接口。
建议用户新建一个线程,在新线程内调用该接口,否则可能阻塞主线程中的其它任务调度。
函数原型:
size_t svp_acl_prof_get_model_id(const void *op_info, size_t op_info_len, uint32_t index)
参数说明:
|
用户调用svp_acl_prof_get_op_num接口获取算子数量后,这个index的取值范围:[0, (算子数量-1)] |
返回值说明:模型的ID。
参考资源:接口调用示例,参见Profiling性能数据采集。
获取数据大小¶
svp_acl_data_type_size¶
函数功能:获取svp_acl_data_type数据的大小,单位bit,同步接口。
函数原型:
size_t svp_acl_data_type_size(svp_acl_data_type data_type)
参数说明:
返回值说明:返回svp_acl_data_type数据的大小,单位bit。
SoC扩展接口¶
svp_acl_ext_process_aacpu_task¶
函数功能:
获取模式识别CPU任务并执行。同步接口。
用户需新建一个线程,在线程函数内调用svp_acl_ext_process__aa_cpu_task接口。
约束说明:如果当前进程没有创建任何stream,会返回错误。
函数原型:
svp_acl_error svp_acl_ext_process_aacpu_task(int32_t timeout)
参数说明:
|
返回值说明:返回0表示成功,返回其它值表示失败。
svp_acl_ext_get_mdl_aacpu_task_num¶
函数功能:获取模型中模式识别CPU任务个数。同步接口。
函数原型:
svp_acl_error svp_acl_ext_get_mdl_aacpu_task_num(uint32_t model_id, uint32_t *num)
参数说明:
|
调用svp_acl_mdl_load_from_mem接口加载模型成功后,会返回模型ID。 |
||
返回值说明:返回0表示成功,返回其它值表示失败。
svp_acl_ext_get_mdl_net_type¶
函数功能:获取模型中的网络类型
函数原型:
svp_acl_error svp_acl_ext_get_mdl_net_type(uint32_t model_id, uint32_t *net_type)
参数说明:
|
调用svp_acl_mdl_load_from_mem接口加载模型成功后,会返回模型ID。 |
||
获取对应模型中的网络类型,当前模型中有RECURRENT网络会返回SVP_ACL_NET_TYPE_RECURRENT类型,其余的模型返回SVP_ACL_NET_TYPE_CNN类型。 #define SVP_ACL_NET_TYPE_CNN 0x1 #define SVP_ACL_NET_TYPE_RECURRENT (0x1 << 1) |
返回值说明:返回0表示成功,返回其它值表示失败。
数据类型及其操作接口¶
svp_acl_error¶
typedef int svp_acl_error;
表 1 返回码列表
请检查是否已调用svp_acl_init接口进行初始化,请确保已调用接口,且在其它SVP ACL接口之前调用。 |
||
#define SVP_ACL_ERROR_BIN_SELECTOR_ALREADY_REGISTERED 100030 |
||
请检查针对同一个Stream,是否重复调用svp_acl_rt_unsubscribe_report接口。 |
||
请检查是否已调用svp_acl_rt_subscribe_report接口。 |
||
请检查是否已调用svp_acl_rt_subscribe_report接口。 |
||
请检查是否已调用svp_acl_rt_launch_callback接口下发callback任务; 请检查svp_acl_rt_process_report接口中超时时间是否合理; 请检查callback任务是否已经处理完成,如果已处理完成,但还调用svp_acl_rt_process_report接口,则需优化代码逻辑。 |
||
请检查是否重复调用svp_acl_finalize接口进行去初始化。 |
||
|
||
请检查在调用Dump接口配置Dump信息前,是否已调用svp_acl_init接口配置Dump信息,如是,请调整代码逻辑,保留一种方式配置Dump信息即可。 |
||
请检查算子缓存信息老化配置,参考svp_acl_init处的配置说明及示例。 |
||
规则1:开发人员的环境异常或者代码逻辑错误,可以通过优化环境或代码逻辑的方式解决问题,此时返回码定义为:1XXXXX。
规则2:资源不足(Stream、内存等)、开发人员编程时使用的接口或参数与当前硬件不匹配,可以通过在编程时合理使用资源的方式解决,此时返回码定义为:2XXXXX。
规则3:业务功能异常,比如队列满、队列空等,此时返回码定义为3XXXXX。
规则4:软硬件内部异常,包括软件内部错误、Device执行失败等,用户无法解决问题,需要将问题反馈给软件工程师的,此时返回码定义为:5XXXXX。
规则5:无法识别的错误,当前都映射为500000。
svp_acl_data_type¶
typedef enum {
SVP_ACL_DT_UNDEFINED = -1, //未知数据类型,默认值。
SVP_ACL_FLOAT = 0,
SVP_ACL_FLOAT16 = 1,
SVP_ACL_INT8 = 2,
SVP_ACL_INT32 = 3,
SVP_ACL_UINT8 = 4,
SVP_ACL_INT16 = 6,
SVP_ACL_UINT16 = 7,
SVP_ACL_UINT32 = 8,
SVP_ACL_INT64 = 9,
SVP_ACL_UINT64 = 10,
SVP_ACL_DOUBLE = 11,
SVP_ACL_BOOL = 12,
SVP_ACL_STRING = 13,
SVP_ACL_INT10 = 100,
SVP_ACL_UINT10 = 101,
SVP_ACL_INT12 = 102,
SVP_ACL_UINT12 = 103,
SVP_ACL_INT14 = 104,
SVP_ACL_UINT14 = 105,
SVP_ACL_INT24 = 106,
SVP_ACL_UINT24 = 107,
} svp_acl_data_type;
svp_acl_float16¶
该数据类型仅用于数据传递,不能用于加减乘除等运算。
typedef uint16_t svp_acl_float16;
svp_acl_format¶
typedef enum {
SVP_ACL_FORMAT_UNDEFINED = -1,
SVP_ACL_FORMAT_NCHW = 0,
SVP_ACL_FORMAT_NHWC = 1,
SVP_ACL_FORMAT_ND = 2,
SVP_ACL_FORMAT_NC1HWC0 = 3,
SVP_ACL_FORMAT_FRACTAL_Z = 4,
SVP_ACL_FORMAT_NC1HWC0_C04 = 12,
SVP_ACL_FORMAT_FRACTAL_NZ = 29,
} svp_acl_format;
UNDEFINED:未知格式,默认值。
ND:表示支持任意格式,仅有Square、Tanh等这些单输入对自身处理的算子外,其它需要慎用。
NCHW:NCHW格式。
NHWC:NHWC格式。
NC1HWC0:自研的5维数据格式。其中,C0与微架构强相关,该值等于cube单元的size,例如16;C1是将C维度按照C0切分:C1=C/C0, 若结果不整除,最后一份数据需要padding到C0。
FRACTAL_Z:卷积的权重的格式。
NC1HWC0_C04:自研的5维数据格式。其中,C0固定为4,C1是将C维度按照C0切分:C1=C/C0, 若结果不整除,最后一份数据需要padding到C0。当前版本不支持。
FRACTAL_NZ:内部格式,用户目前无需使用。
svp_acl_rt_context¶
typedef void *svp_acl_rt_context;
svp_acl_rt_stream¶
typedef void *svp_acl_rt_stream;
svp_acl_rt_run_mode¶
typedef enum svp_acl_rt_run_mode {
SVP_ACL_DEVICE, /* 软件栈运行在Device的Control CPU或板端环境上 */
SVP_ACL_HOST, /* 软件栈运行在Host侧 */
} svp_acl_rt_run_mode;
svp_acl_mdl_io_dims¶
#define SVP_ACL_MAX_DIM_CNT 128
#define SVP_ACL_MAX_TENSOR_NAME_LEN 128
typedef struct svp_acl_mdl_io_dims {
char name[SVP_ACL_MAX_TENSOR_NAME_LEN]; /* tensor name */
size_t dim_count; /* Shape中的维度个数,如果为标量,则维度个数为0 */
int64_t dims[SVP_ACL_MAX_DIM_CNT]; /* 维度信息 */
} svp_acl_mdl_io_dims;
svp_acl_data_buffer¶
svp_acl_create_data_buffer¶
函数功能:创建svp_acl_data_buffer类型的数据,该数据类型用于描述内存地址、大小等内存信息。同步接口。
函数原型:
svp_acl_data_buffer *svp_acl_create_data_buffer(void *data, size_t size, size_t stride)
参数说明:
|
该内存需由用户自行管理,调用svp_acl_rt_malloc接口/svp_acl_rt_free接口申请/释放内存,或调用svp_acl_rt_malloc_host接口/svp_acl_rt_free_host接口申请/释放内存。 |
||
|
可参照svp_acl_mdl_get_input_size_by_index或svp_acl_mdl_get_output_size_by_index中描述的计算方法计算获取。 |
||
跨度大小,用于逻辑快速跳转到下一行,要求16字节对齐,单位Byte。 可参照svp_acl_mdl_get_input_default_stride或svp_acl_mdl_get_output_default_stride中的计算方法计算获得。 |
返回值说明:返回svp_acl_data_buffer类型的指针。
svp_acl_destroy_data_buffer¶
函数功能:
销毁svp_acl_data_buffer类型的数据。同步接口。
此处仅销毁svp_acl_data_buffer类型的数据,调用svp_acl_create_data_buffer接口创建svp_acl_data_buffer类型数据时传入的data的内存需由用户自行释放。
函数原型:
svp_acl_error svp_acl_destroy_data_buffer(const svp_acl_data_buffer *data_buffer)
参数说明:
返回值说明:返回0表示成功,返回非0表示失败。
svp_acl_get_data_buffer_addr¶
函数功能:获取svp_acl_data_buffer类型中的数据的内存地址。同步接口。
函数原型:
void *svp_acl_get_data_buffer_addr(const svp_acl_data_buffer *data_buffer)
参数说明:
返回值说明:返回svp_acl_data_buffer类型中的数据的内存地址。
svp_acl_get_data_buffer_size¶
函数功能:获取svp_acl_data_buffer类型中数据的内存大小,单位Byte。同步接口。
函数原型:
size_t svp_acl_get_data_buffer_size(const svp_acl_data_buffer *data_buffer)
参数说明:
返回值说明:svp_acl_data_buffer类型中数据的内存大小。
svp_acl_get_data_buffer_stride¶
函数功能:获取svp_acl_data_buffer类型中stride的大小,单位Byte。同步接口。
函数原型:
size_t svp_acl_get_data_buffer_stride(const svp_acl_data_buffer *data_buffer)
参数说明:
返回值说明:svp_acl_data_buffer类型中stride的大小。
svp_acl_update_data_buffer¶
函数功能:
更新svp_acl_data_buffer中数据的内存及大小。同步接口。
更新svp_acl_data_buffer后,之前svp_acl_data_buffer中存放数据的内存如果不使用,需及时释放,否则可能会导致内存泄漏。
函数原型:
svp_acl_error svp_acl_update_data_buffer(svp_acl_data_buffer *data_buffer, void *data, size_t size, size_t stride)
参数说明:
|
该内存需由用户自行管理,调用svp_acl_rt_malloc接口/svp_acl_rt_free接口申请/释放内存,或调用svp_acl_rt_malloc_host接口/svp_acl_rt_free_host接口申请/释放内存。 |
||
跨度大小,用于逻辑快速跳转到下一行,需要16字节对齐,单位Byte。 可参照svp_acl_mdl_get_input_default_stride或svp_acl_mdl_get_output_default_stride参照中的计算方法计算获得。 |
返回值说明:返回0表示成功,返回非0表示失败。
svp_acl_mdl_dataset¶
svp_acl_mdl_create_dataset¶
函数功能:创建svp_acl_mdl_dataset类型的数据,该数据类型用于描述模型推理时的输入数据、输出数据,模型可能存在多个输入、多个输出,每个输入/输出的内存地址、内存大小用svp_acl_data_buffer类型的数据来描述。同步接口。
函数原型:
svp_acl_mdl_dataset *svp_acl_mdl_create_dataset()
参数说明:无
返回值说明:返回svp_acl_mdl_dataset类型的指针。
svp_acl_mdl_destroy_dataset¶
函数功能:销毁svp_acl_mdl_dataset类型的数据。同步接口。
函数原型:
svp_acl_error svp_acl_mdl_destroy_dataset(const svp_acl_mdl_dataset *dataset)
参数说明:
返回值说明:返回0表示成功,返回非0表示失败。
svp_acl_mdl_add_dataset_buffer¶
函数功能:向svp_acl_mdl_dataset中增加svp_acl_data_buffer。同步接口。
约束说明:最多添加256个data_buffer。
函数原型:
svp_acl_error svp_acl_mdl_add_dataset_buffer(svp_acl_mdl_dataset *dataset, svp_acl_data_buffer *data_buffer)
参数说明:
返回值说明:返回0表示成功,返回非0表示失败。
svp_acl_mdl_get_dataset_num_buffers¶
函数功能:获取svp_acl_mdl_dataset中svp_acl_data_buffer的个数,同步接口。
函数原型:
size_t svp_acl_mdl_get_dataset_num_buffers(const svp_acl_mdl_dataset *dataset)
参数说明:
返回值说明:svp_acl_data_buffer的个数。
svp_acl_mdl_get_dataset_buffer¶
函数功能:获取svp_acl_mdl_dataset中的第n个svp_acl_data_buffer。同步接口。
函数原型:
svp_acl_data_buffer *svp_acl_mdl_get_dataset_buffer(const svp_acl_mdl_dataset *dataset, size_t index)
参数说明:
表明获取的是第几个svp_acl_data_buffer。 |
返回值说明:
获取成功,返回svp_acl_data_buffer的地址。
获取失败返回空地址。
svp_acl_mdl_desc¶
svp_acl_mdl_create_desc¶
函数功能:创建svp_acl_mdl_desc类型的数据,表示模型描述信息。同步接口。
函数原型:
svp_acl_mdl_desc *svp_acl_mdl_create_desc()
参数说明:无
返回值说明:返回svp_acl_mdl_desc类型的指针。
svp_acl_mdl_destroy_desc¶
函数功能:销毁svp_acl_mdl_desc类型的数据。同步接口。
函数原型:
svp_acl_error svp_acl_mdl_destroy_desc(svp_acl_mdl_desc *model_desc)
参数说明:
待销毁的svp_acl_mdl_desc类型的指针。 |
返回值说明:返回0表示成功,返回非0表示失败。
svp_acl_mdl_get_desc¶
函数功能:根据模型ID获取该模型的模型描述信息。同步接口。
函数原型:
svp_acl_error svp_acl_mdl_get_desc(svp_acl_mdl_desc *model_desc, uint32_t model_id)
参数说明:
svp_acl_mdl_desc类型数据的指针。 |
||
|
svp_acl_mdl_load_from_mem接口加载模型成功后,会返回模型ID。 |
返回值说明:返回0表示成功,返回非0表示失败。
svp_acl_mdl_get_num_inputs¶
函数功能:根据模型描述信息获取模型的输入个数。同步接口。
函数原型:
size_t svp_acl_mdl_get_num_inputs(const svp_acl_mdl_desc *model_desc)
参数说明:
svp_acl_mdl_desc类型数据的指针。 |
返回值说明:模型的输入个数。
svp_acl_mdl_get_num_outputs¶
函数功能:根据模型描述信息获取模型的输出个数。同步接口。
函数原型:
size_t svp_acl_mdl_get_num_outputs(const svp_acl_mdl_desc *model_desc)
参数说明:
svp_acl_mdl_desc类型数据的指针。 |
返回值说明:模型的输出个数。
svp_acl_mdl_get_input_size_by_index¶
函数功能:根据模型描述信息获取指定输入的大小,单位为Byte。同步接口。
函数原型:
size_t svp_acl_mdl_get_input_size_by_index(const svp_acl_mdl_desc *model_desc, size_t index)
参数说明:
svp_acl_mdl_desc类型数据的指针。 |
||
返回值说明:
返回指定输入单batch大小。单位是Byte。
非YVU输入的input_size = d_0 * d_1 *… * d_n-2 * default_stride;
YUV420SP_U8输入的input_size = d_0 * d_i * … * d_n-2 * default_stride / 2;
YUV422SP_U8输入的input_size = d_0 * d_i * … * d_n-2 * default_stride / 3 * 2;
其中d_i表示第i维长度,n表示指定输入的维度个数,default_stride为默认stride(详细请参见svp_acl_mdl_get_input_default_stride)。
实际使用中的stride可能不等于default_stride,实际输入大小actual_input_size可以通过input_size / default_stride * actual_stride换算得到,也可将上述的计算公式中的default_stride替换为actual_stride计算获得,其中actual_input_size表示实际所需输入内存大小,actual_stride表示实际stride大小。
svp_acl_mdl_get_output_size_by_index¶
函数功能:根据模型描述信息获取指定输出的大小,单位为Byte。同步接口。
函数原型:
size_t svp_acl_mdl_get_output_size_by_index(const svp_acl_mdl_desc *model_desc, size_t index)
参数说明:
svp_acl_mdl_desc类型数据的指针。 |
||
返回值说明:
返回指定输出的单batch大小。单位是Byte。
返回output_size = d_0 * d_1 *… * d_n-2 * default_stride,其中d_i表示第i维长度,n表示指定输出的维度个数,default_stride为默认stride(详细请参见svp_acl_mdl_get_output_default_stride)。
实际使用中的stride可能不等于default_stride,实际输出大小actual_output_size可以通过output_size / default_stride * actual_stride换算得到,也可将上述的计算公式中的default_stride替换为actual_stride计算获得。其中actual_output_size表示实际所需输出内存大小,actual_stride表示实际stride大小。
svp_acl_mdl_get_input_dims¶
函数功能:根据模型描述信息获取模型的输入tensor的维度信息。同步接口。
函数原型:
svp_acl_error svp_acl_mdl_get_input_dims(const svp_acl_mdl_desc *model_desc, size_t index, svp_acl_mdl_io_dims *dims)
参数说明:
表 1 图像输入维度定义规则
svp_acl_mdl_desc类型数据的指针。 |
||
返回值说明:返回0表示成功,返回非0表示失败。
svp_acl_mdl_get_output_dims¶
函数功能:根据模型描述信息获取指定的模型输出tensor的维度信息。同步接口。
函数原型:
svp_acl_error svp_acl_mdl_get_output_dims(const svp_acl_mdl_desc *model_desc, size_t index, svp_acl_mdl_io_dims *dims)
参数说明:
svp_acl_mdl_desc类型数据的指针。 |
||
返回值说明:返回0表示成功,返回非0表示失败。
svp_acl_mdl_get_input_name_by_index¶
函数功能:根据模型描述信息获取模型中指定输入的bottom名称。同步接口。
函数原型:
const char *svp_acl_mdl_get_input_name_by_index(const svp_acl_mdl_desc *model_desc, size_t index)
参数说明:
svp_acl_mdl_desc类型数据的指针。 |
||
返回值说明:返回指定输入的bottom名称,task_buf和work_buf返回的名称分别为“task_buf”和“work_buf”。
svp_acl_mdl_get_output_name_by_index¶
函数功能:根据模型描述信息获取模型中指定输出的top名称。同步接口。
函数原型:
const char *svp_acl_mdl_get_output_name_by_index(const svp_acl_mdl_desc *model_desc, size_t index)
参数说明:
svp_acl_mdl_desc类型数据的指针。 |
||
返回值说明:返回指定输出的top名称。
svp_acl_mdl_get_input_format¶
函数功能:根据模型描述信息获取模型中指定输入的Format。同步接口。
函数原型:
svp_acl_format svp_acl_mdl_get_input_format(const svp_acl_mdl_desc *model_desc, size_t index)
参数说明:
svp_acl_mdl_desc类型数据的指针。 |
||
返回值说明:返回指定输入的Format。
svp_acl_mdl_get_output_format¶
函数功能:根据模型描述信息获取模型中指定输出的Format。同步接口。
函数原型:
svp_acl_format svp_acl_mdl_get_output_format(const svp_acl_mdl_desc *model_desc, size_t index)
参数说明:
svp_acl_mdl_desc类型数据的指针。 |
||
返回值说明:返回指定输出的Format。
svp_acl_mdl_get_input_data_type¶
函数功能:根据模型描述信息获取模型中指定输入的数据类型。同步接口。
函数原型:
svp_acl_data_type svp_acl_mdl_get_input_data_type(const svp_acl_mdl_desc *model_desc, size_t index)
参数说明:
表 1 图像输入数据类型定义规则
svp_acl_mdl_desc类型数据的指针。 |
||
返回值说明:返回指定输入的数据类型。
svp_acl_mdl_get_output_data_type¶
函数功能:根据模型描述信息获取模型中指定输出的数据类型。同步接口。
函数原型:
svp_acl_data_type svp_acl_mdl_get_output_data_type(const svp_acl_mdl_desc *model_desc, size_t index)
参数说明:
svp_acl_mdl_desc类型数据的指针。 |
||
返回值说明:返回指定输出的数据类型。
svp_acl_mdl_get_input_index_by_name¶
函数功能:根据模型中的输入名称获取对应输入的索引编号。同步接口。
函数原型:
svp_acl_error svp_acl_mdl_get_input_index_by_name(const svp_acl_mdl_desc *model_desc, const char *name, size_t *index)
参数说明:
svp_acl_mdl_desc类型数据的指针。 |
||
返回值说明:返回0表示成功,返回非0表示失败。
svp_acl_mdl_get_output_index_by_name¶
函数功能:根据模型中的输出名称获取对应输出的索引编号。同步接口。
函数原型:
svp_acl_error svp_acl_mdl_get_output_index_by_name(const svp_acl_mdl_desc *model_desc, const char *name, size_t *index)
参数说明:
svp_acl_mdl_desc类型数据的指针。 |
||
返回值说明:返回0表示成功,返回非0表示失败。
svp_acl_mdl_get_input_default_stride¶
函数功能:根据模型描述信息获取模型中指定输入的默认stride。同步接口。
函数原型:
size_t svp_acl_mdl_get_input_default_stride(const svp_acl_mdl_desc *model_desc,size_t index)
参数说明:
svp_acl_mdl_desc类型数据的指针。 |
||
返回值说明:
返回指定输入的默认stride大小。单位是Byte。
默认stride = ceil (ceil(last_dim * svp_acl_data_type_size(data_type) / byte_bit_num) / default_align_byte) * default_align_byte。
其中ceil()函数表示向上取整;last_dim表示指定输入的最后一维长度;data_type表示指定输入的数据类型;byte_bit_num 表示一个字节所占bit数,数值为8;default_align_byte表示生成.om时[internal_stride]项所配置的对齐字节数,数值大于0且为16的整数倍(倍数需为2的非负整数次幂)并且不超过256。
如果实际使用中用户需要根据实际需要计算输入stride,可将上述计算中default_align_byte替换成实际所需的对齐字节数actual_align_byte,actual_align_byte不能为0并且为16的整数倍。
svp_acl_mdl_get_output_default_stride¶
函数功能:根据模型描述信息获取模型中指定输出的默认stride。同步接口。
函数原型:
size_t svp_acl_mdl_get_output_default_stride(const svp_acl_mdl_desc *model_desc, size_t index)
参数说明:
svp_acl_mdl_desc类型数据的指针。 |
||
返回值说明:
返回指定输出的默认stride大小。单位是Byte。
默认stride = ceil (ceil(last_dim * svp_acl_data_type_size(data_type) / byte_bit_num) / default_align_byte) * default_align_byte。
其中ceil()函数表示向上取整;last_dim表示指定输出的最后一维长度;data_type表示指定输出的数据类型;byte_bit_num 表示一个字节所占bit数,数值为8;default_align_byte表示生成.om时[internal_stride]项所配置的对齐字节数,数值为16的整数倍(倍数需为2的非负整数次幂)且不超过256。
如果实际使用中用户需要根据实际需要计算输出stride,可将上述计算中default_align_byte替换成实际所需的对齐字节数actual_align_byte,actual_align_byte不能为0并且为16的整数倍。
svp_acl_mdl_get_dynamic_hw¶
函数功能:
根据模型描述信息获取模型支持的动态宽高信息。同步接口。
函数原型:
svp_acl_error svp_acl_mdl_get_dynamic_hw(const svp_acl_mdl_desc *model_desc, size_t index, svp_acl_mdl_hw *hw)
参数说明:
svp_acl_mdl_desc类型数据的指针。 |
||
标识动态HW输入的输入index,当前固定为SVP_ACL_DYNAMIC_TENSOR_NAME的index,值为0。 |
||
#define SVP_ACL_MAX_HW_NUM 100 typedef struct { size_t hw_count; /* 模型中支持的宽高分档数 */ uint64_t hw[SVP_ACL_MAX_HW_NUM][2]; /* <div>模型中支持的具体分档,组分档中,数组下标为0代表的是高,下标为1代表的是宽 */ } svp_acl_mdl_hw; |
返回值说明:
返回0表示成功,返回非0表示失败。
svp_acl_prof_config¶
svp_acl_prof_create_config¶
函数功能:
创建svp_acl_prof_config类型的数据,表示创建Profiling配置数据。同步接口。
svp_acl_prof_config类型数据可以只创建一次、多处使用,用户需要保证数据的一致性和准确性。
如需销毁svp_acl_prof_config类型的数据,请参见svp_acl_prof_destroy_config。
函数原型:
svp_acl_prof_config *svp_acl_prof_create_config(const uint32_t *device_id_list, uint32_t device_num, svp_acl_prof_aacore_metrics aacore_metrics, const svp_acl_prof_aacore_events *aacore_events, uint64_t data_type_config)
参数说明:
Device的个数。需由用户保证device_id_list中的Device个数与device_num参数值一致,否则可能会导致后续业务异常。 |
||
用户选择如下多个宏进行逻辑或(例如:SVP_ACL_PROF_ACL_API | SVP_ACL_PROF_AACORE_METRICS),作为data_type_config参数值。每个宏表示某一类性能数据,详细说明如下: |
返回值说明:
返回svp_acl_prof_config类型的指针,表示成功。
返回nullptr,表示失败。
svp_acl_prof_destroy_config¶
函数功能:销毁通过svp_acl_prof_create_config接口创建的svp_acl_prof_config类型的数据。同步接口。
函数原型:
svp_acl_error svp_acl_prof_destroy_config(const svp_acl_prof_config *profiler_config)
参数说明:
返回值说明:返回0表示成功,返回非0表示失败。
svp_acl_prof_subscribe_config¶
svp_acl_prof_create_subscribe_config¶
函数功能:
创建svp_acl_prof_subscribe_config类型的数据,表示创建订阅配置信息。同步接口。
如需销毁svp_acl_prof_subscribe_config类型的数据,请参见svp_acl_prof_destroy_subscribe_config。
函数原型:
svp_acl_prof_subscribe_config *svp_acl_prof_create_subscribe_config(int8_t time_info_switch, svp_acl_prof_aacore_metrics aacore_metrics, const void *fd)
参数说明:
|
||
返回值说明:
返回svp_acl_prof_subscribe_config类型的指针,表示成功。
返回nullptr,表示失败。
svp_acl_prof_destroy_subscribe_config¶
函数功能:销毁通过svp_acl_prof_create_subscribe_config接口创建的svp_acl_prof_subscribe_config类型的数据。同步接口。
函数原型:
svp_acl_error svp_acl_prof_destroy_subscribe_config(const svp_acl_prof_subscribe_config *prof_subscribe_config)
参数说明:
待销毁的svp_acl_prof_subscribe_config类型的指针。 |
返回值说明:返回0表示成功,返回非0表示失败。
svp_acl_mdl_config_attr¶
typedef enum {
SVP_ACL_MDL_PRIORITY_INT32 = 0, //模型执行的优先级,高优先级任务会优先调度,不支持高优先级任务抢占低优先级任务,数字越小优先级越高,取值[0,7],可选项。默认值为0。
SVP_ACL_MDL_LOAD_TYPE_SIZET, //模型加载方式,见下文详细的取值说明,必选项。
SVP_ACL_MDL_PATH_PTR, //离线模型文件路径的指针,如果选择从文件加载模型,则该选项必选,目前不支持。
SVP_ACL_MDL_MEM_ADDR_PTR, //模型在内存中的起始地址,如果选择从内存加载模型,则该选项必选。
SVP_ACL_MDL_MEM_SIZET, //模型在内存中的大小,如果选择从内存加载模型,则该选项必选,与SVP_ACL_MDL_MEM_ADDR_PTR选项配合使用。
SVP_ACL_MDL_WEIGHT_ADDR_PTR, //Device上模型权值内存(存放权值数据)的指针,如果需要由用户管理权值内存,则该选项必选。若不配置该选项,则表示由系统管理内存,目前不支持。
SVP_ACL_MDL_WEIGHT_SIZET, //权值内存大小,单位为Byte,如果需要由用户管理权值内存,则该选项必选,与SVP_ACL_MDL_WEIGHT_ADDR_PTR选项配合使用,目前不支持。
SVP_ACL_MDL_WORKSPACE_ADDR_PTR, //Device上模型所需工作内存(存放模型输入/输出等数据)的指针,如果需要由用户管理工作内存,则该选项必选。若不配置该选项,则表示由系统管理内存,目前不支持。
SVP_ACL_MDL_WORKSPACE_SIZET, //模型所需工作内存的大小,单位为Byte,如果需要由用户管理权值内存,则该选项必选,与SVP_ACL_MDL_WORKSPACE_ADDR_PTR选项配合使用,目前不支持。
SVP_ACL_MDL_INPUTQ_NUM_SIZET, //模型输入队列大小 ,带队列加载模型时,该选项必选,与SVP_ACL_MDL_INPUTQ_ADDR_PTR选项配合使用。当前版本不支持该接口,目前不支持。
SVP_ACL_MDL_INPUTQ_ADDR_PTR, //模型输入队列ID的指针,带队列加载模型时,该选项必选,一个模型输入对应一个队列ID。当前版本不支持该接口,目前不支持。
SVP_ACL_MDL_OUTPUTQ_NUM_SIZET, //模型输出队列大小,带队列加载模型时,该选项必选,与SVP_ACL_MDL_OUTPUTQ_ADDR_PTR选项配置使用。当前版本不支持该接口,目前不支持。
SVP_ACL_MDL_OUTPUTQ_ADDR_PTR //模型输出队列ID的指针,带队列加载模型时,该选项必选,一个模型输出对应一个队列ID。当前版本不支持该接口,目前不支持。
} svp_acl_mdl_config_attr;
SVP_ACL_MDL_LOAD_TYPE_SIZET(表示模型加载方式)的取值使用如下宏:
SVP_ACL_MDL_LOAD_FROM_FILE (目前不支持)
#define SVP_ACL_MDL_LOAD_FROM_FILE 1SVP_ACL_MDL_LOAD_FROM_FILE_WITH_MEM (目前不支持)
#define SVP_ACL_MDL_LOAD_FROM_FILE_WITH_MEM 2SVP_ACL_MDL_LOAD_FROM_MEM
#define SVP_ACL_MDL_LOAD_FROM_MEM 3SVP_ACL_MDL_LOAD_FROM_MEM_WITH_MEM (目前不支持)
#define SVP_ACL_MDL_LOAD_FROM_MEM_WITH_MEM 4SVP_ACL_MDL_LOAD_FROM_FILE_WITH_Q (目前不支持)
#define SVP_ACL_MDL_LOAD_FROM_FILE_WITH_Q 5
svp_acl_mdl_config_handle¶
svp_acl_mdl_create_config_handle¶
函数功能:创建svp_acl_mdl_config_handle类型的数据,表示一个模型加载的配置对象,同步接口。如需销毁svp_acl_mdl_config_handle类型的数据,请参见svp_acl_mdl_destroy_config_handle。
函数原型:
svp_acl_mdl_config_handle *svp_acl_mdl_create_config_handle()
参数说明:无。
返回值说明:
返回svp_acl_mdl_config_handle类型的指针,表示成功。
返回nullptr,表示失败。
svp_acl_mdl_destroy_config_handle¶
函数功能:销毁通过svp_acl_mdl_create_config_handle接口创建的svp_acl_mdl_config_handle类型的数据。同步接口。
函数原型:
svp_acl_error svp_acl_mdl_destroy_config_handle (svp_acl_mdl_config_handle *handle)
参数说明:
待销毁的svp_acl_mdl_config_handle类型的指针。 |
返回值说明:返回0表示成功,返回非0表示失败。
svp_acl__aa_pp_input_format¶
支持的图片详情如下:
typedef enum {
SVP_ACL_YUV420SP_U8 = 0x1,
SVP_ACL_XRGB8888_U8 = 0x2,
SVP_ACL_RGB888_U8 = 0x3,
SVP_ACL_YUV400_U8 = 0x4,
SVP_ACL_NC1HWC0DI_FP16 = 0x5, /* not support */
SVP_ACL_NC1HWC0DI_S8 = 0x6, /* not support */
SVP_ACL_ARGB8888_U8 = 0x7, /* not support */
SVP_ACL_YUYV_U8 = 0x8, /* not support */
SVP_ACL_YUV422SP_U8 = 0x9,
SVP_ACL_AYUV444_U8 = 0xA, /* not support */
SVP_ACL_RAW10 = 0xB, /* not support */
SVP_ACL_RAW12 = 0xC, /* not support */
SVP_ACL_RAW16 = 0xD, /* not support */
SVP_ACL_RAW24 = 0xE, /* not support */
SVP_ACL_FEATURE_MAP_U8 = 0x100,
SVP_ACL_FEATURE_MAP_S8 = 0x101,
SVP_ACL_FEATURE_MAP_U16 = 0x102,
SVP_ACL_FEATURE_MAP_S16 = 0x103,
SVP_ACL_FEATURE_MAP_FP16 = 0x104,
SVP_ACL_FEATURE_MAP_FP32 = 0x105,
SVP_ACL_YVU420SP_U8 = 0x106,
SVP_ACL_YVU422SP_U8 = 0x107,
SVP_ACL_BGR_PLANAR_U8 = 0x108,
SVP_ACL_RGB_PLANAR_U8 = 0x109,
SVP_ACL_BGR_PACKAGE_U8 = 0x10A,
SVP_ACL_XRGB_PLANAR_U8 = 0x10B,
SVP_ACL_XBGR_PLANAR_U8 = 0x10C,
SVP_ACL_RGBX_PLANAR_U8 = 0x10D,
SVP_ACL_BGRX_PLANAR_U8 = 0x10E,
SVP_ACL_XBGR_PACKAGE_U8 = 0x10F,
SVP_ACL_RGBX_PACKAGE_U8 = 0x110,
SVP_ACL_BGRX_PACKAGE_U8 = 0x111,
SVP_ACL_AAPP_RESERVED = 0xFFFF
} svp_acl_aapp_input_format;
svp_acl__aa_pp_info¶
typedef struct svp_acl_aapp_info {
svp_acl_aapp_input_format input_format;
} svp_acl_aapp_info;
SVP ACL样例使用指导¶
总体说明¶
当前版本支持的样例以及样例在各形态的编译运行指导请参见如何获取Sample。
基于Caffe ResNet-50网络实现图片分类(同步推理)¶
样例介绍¶
获取样例¶
参考如何获取Sample,获取样例代码。
功能描述¶
该样例主要是基于Caffe ResNet-50网络(单输入、单Batch)实现图片分类的功能。
将Caffe ResNet-50网络的模型文件转换为适配SoC的离线模型(*.om文件),在样例中,加载该om文件,对2张*.jpg图片进行同步推理,分别得到推理结果后,再对推理结果进行处理,输出top5置信度的类别标识。
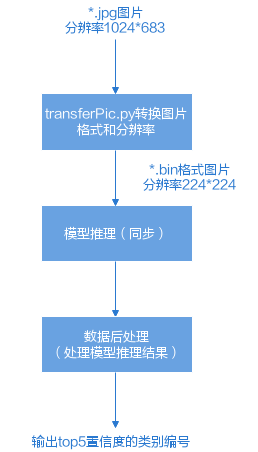
原理介绍¶
在该Sample中,涉及的关键功能点,如表1所示。API接口的详细介绍请参见SVP ACL API参考。
表 1 Sample中的关键功能点
目录结构¶
样例代码结构如下所示。
├── caffe_model
│ ├── resnet50.caffemodel //测试权重数据,需要按指导获取测试权重数据,放到caffe_model目录下
│ ├── resnet50.prototxt //测试模型网络,需要按指导获取测试模型网络,放到caffe_model目录下
│ ├── pixel_mean.txt //均值文件,数据归一化使用
├── data
│ ├── dog1_1024_683.jpg //测试数据,需要按指导获取测试图片,放到data目录下
│ ├── dog2_1024_683.jpg //测试数据,需要按指导获取测试图片,放到data目录下
│ ├── image_ref_list.txt //保存测试数据对应文件名的文件
├── inc
│ ├── model_process.h //声明模型处理相关函数的头文件
│ ├── sample_process.h //声明资源初始化/销毁相关函数的头文件
│ ├── utils.h //声明公共函数(例如:文件读取函数)的头文件
├── model //存放转换后模型目录
├── script
│ ├── transferPic.py //将*.jpg转换为*.bin,同时将图片从1024*683的分辨率缩放为224*224
├── src
│ ├── acl.json //系统初始化的配置文件
│ ├── CMakeLists.txt //编译脚本
│ ├── main.cpp //主函数,图片分类功能的实现文件
│ ├── model_process.cpp //模型处理相关函数的实现文件
│ ├── sample_process.cpp //资源初始化/销毁相关函数的实现文件
│ ├── utils.cpp //公共函数(例如:文件读取函数)的实现文件
├── .project //工程信息文件,包含工程类型、工程描述、运行目标设备类型等
├── CMakeLists.txt //编译脚本,调用src目录下的CMakeLists文件
├── resnet50_config.json //配置模型生成信息文件
├── README.md
编译及运行应用¶
模型转换
以运行用户登录开发环境。
参考《ATC工具使用指南》中的“使用入门”,执行“准备动作”,包括获取工具、设置环境变量。
准备数据。
从https://gitee.com/ascend/ModelZoo-TensorFlow/tree/master/TensorFlow/contrib/cv/resnet50/ATC_resnet50_caffe_AE 链接中获取ResNet-50网络的模型文件(.prototxt)、预训练模型文件(.caffemodel),并以运行用户将获取的文件上传至开发环境的“样例目录/caffe_model”目录下,也可查看README.md。如果目录不存在,需要自行创建。
请从以下链接获取该样例的输入图片,并以运行用户将获取的文件上传至开发环境的“样例目录/data”目录下。如果目录不存在,需自行创建。
https://c7xcode.obs.cn-north-4.myhuaweicloud.com/models/aclsample/dog1_1024_683.jpg
https://c7xcode.obs.cn-north-4.myhuaweicloud.com/models/aclsample/dog2_1024_683.jpg
在“样例目录/data”目录下,创建参考图片列表文件(image_ref_list.txt)并在其中填写图片路径data/ dog1_1024_683.jpg及data/ dog2_1024_683.jpg,各路径换行填写。
将ResNet-50网络转换为适配SoC的离线模型(*.om文件)。
切换到“样例目录”目录,执行如下命令:
atc --save_original_model="true" --soc_version=${soc_version} --log_level="0" --input_format="NCHW" --weight="./caffe_model/resnet50.caffemodel" --batch_num="256" --compile_mode="0" --image_list="data:./data/image_ref_list.txt" --input_shape="data:1,3,224,224" --online_model_type="0" --framework="0" --insert_op_conf="resnet50_insert_op.cfg" --dump_data="0" --output="./model/resnet50" --model="./caffe_model/resnet50.prototxt"--soc_version:SoC的版本,用户根据具体板端环境形态,选择对应的取值。
--insert_op_conf:插入图像预处理的配置。配置了图像预处理的Data层表示输入数据格式为图像,没有配置的为Feature Map,可参考《ATC工具使用指南》配置。
--output:生成的resnet50.om文件存放在“样例目录/model”目录下,建议使用命令中的默认设置,否则在编译代码前,您还需要修改sample_process.cpp中的omModelPath参数值。
const char* omModelPath = "../model/resnet50.om";
关于各参数的详细解释,请参见《ATC工具使用指南》。
编译代码
以运行用户登录开发环境。
设置环境变量,编译脚本CMakeLists.txt通过环境变量所设置的头文件、库文件的路径来编译代码。
如下为设置环境变量的示例,请将“$HOME/acl”替换为ACLlib组件的实际安装路径。
注意:stub路径中的库仅作为编译使用,在板端环境运行时请使用SDK包中的库。
export DDK_PATH=$HOME/acl/ascend-toolkit/svp_latest/x86_64-linux export NNN_HOST_LIB=$HOME/acl/ascend-toolkit/svp_latest/x86_64-linux/acllib/lib64/stub
切换到样例目录,创建目录用于存放编译文件,例如,本文中,创建的目录为“build/intermediates/soc”。
mkdir -p build/intermediates/soc切换到“build/intermediates/soc”目录,执行cmake生成编译文件。
“../../../src”表示CMakeLists.txt文件所在的目录,请根据实际目录层级修改。
cd build/intermediates/soc您需要根据所安装的交叉编译器,执行对应的cmake命令:
若在开发环境上安装的ACLlib软件包为Linux操作系统SoC-cs形态,则执行如下编译命令:
cmake ../../../src -DCMAKE_CXX_COMPILER=aarch64-mix410-linux-g++ -DCMAKE_SKIP_RPATH=TRUE执行make命令,生成的可执行文件main在“样例目录/out”目录下。
make
准备测试数据。
请参考步骤1,在“样例目录/data”目录下,存放测试图片dog1_1024_683.jpg和dog2_1024_683.jpg。
以运行用户登录开发环境。
切换到“样例目录/data”目录下,执行transferPic.py脚本,将*.jpg转换为*.bin,同时将图片从1024*683的分辨率缩放为224*224。在“样例目录/data”目录下生成2个*.bin文件。
python3.7.5 ../script/transferPic.py
说明:
如果执行脚本报错“ModuleNotFoundError: No module named 'PIL'”,则表示缺少Pillow库,请使用pip3.7.5 install Pillow --user命令安装Pillow库。运行可执行文件。
将开发环境的样例目录及目录下的文件上传到板端环境。
板端环境的操作系统为Linux时,以root用户将开发环境上的目录及其文件上传到板端环境的指定目录下,例如“/root/acl_resnet50”。
登录板端环境。
板端环境的操作系统为Linux时,以root用户登录板端环境。
设置环境变量。
板端环境的操作系统为Linux时,必须设置如下环境变量,并根据libsvp_acl.so和libsvp__aa_cpu.so文件所在的路径设置LD_LIBRARY_PATH环境变量。
export LD_LIBRARY_PATH=/home/demo/out/lib切换到可执行文件main所在的目录,例如“$HOME/acl_resnet50/out”,给该目录下的main文件加执行权限。
chmod +x main切换到可执行文件main所在的目录,例如“$HOME/acl_resnet50/out”,运行可执行文件。
./main执行成功后,在屏幕上的关键提示信息示例如下,index及其value会根据板端环境的实际情况有所不同:
[INFO] acl init success [INFO] open device 0 success [INFO] create context success [INFO] create stream success [INFO] load model ../model/resnet50.om success [INFO] create model description success [INFO] create model output success [INFO] start to process file:../data/dog1_1024_683.bin [INFO] model execute success [INFO] top 1: index[161] value[0.900391] [INFO] top 2: index[164] value[0.038666] [INFO] top 3: index[163] value[0.019287] [INFO] top 4: index[166] value[0.016357] [INFO] top 5: index[167] value[0.012161] [INFO] output data success [INFO] start to process file:../data/dog2_1024_683.bin [INFO] model execute success [INFO] top 1: index[267] value[0.974609] [INFO] top 2: index[266] value[0.013062] [INFO] top 3: index[265] value[0.010017] [INFO] top 4: index[129] value[0.000335] [INFO] top 5: index[372] value[0.000179] [INFO] output data success [INFO] Unload model success, modelId is 1 [INFO] execute sample success [INFO] end to destroy stream [INFO] end to destroy context [INFO] end to reset device is 0
基于Caffe ResNet-50网络实现图片分类(异步推理)¶
样例介绍¶
获取样例¶
参考如何获取Sample,获取样例代码。
功能描述¶
该样例主要是基于Caffe ResNet-50网络(单输入、单Batch)实现图片分类的功能。
将Caffe ResNet-50网络的模型文件转换为适配SoC的离线模型(*.om文件),在样例中,加载该om文件,对2张*.jpg图片进行n次异步推理(n作为运行应用的参数,由用户配置),分别得到n次推理结果后,再对推理结果进行处理,输出top1置信度的类别标识。
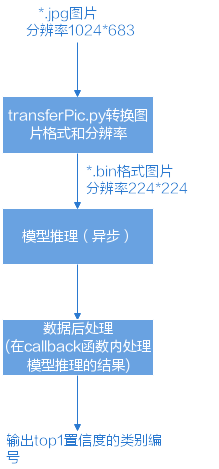
{kind=link}
{kind=link}
原理介绍¶
在该Sample中,涉及的关键功能点,如表1所示。API接口的详细介绍请参见SVP ACL API参考。
表 1 Sample中的关键功能点
目录结构¶
样例代码结构如下所示。
├── caffe_model
│ ├── resnet50.caffemodel //测试权重数据,需要按指导获取测试权重数据,放到caffe_model目录下
│ ├── resnet50.prototxt //测试模型网络,需要按指导获取测试模型网络,放到caffe_model目录下
│ ├── pixel_mean.txt //均值文件,数据归一化使用
├── data
│ ├── dog1_1024_683.jpg //测试数据,需要按指导获取测试图片,放到data目录下
│ ├── dog2_1024_683.jpg //测试数据,需要按指导获取测试图片,放到data目录下
│ ├── image_ref_list.txt //保存测试数据对应文件名的文件
├── inc
│ ├── memory_pool.h //声明内存池处理相关函数的头文件
│ ├── model_process.h //声明模型处理相关函数的头文件
│ ├── sample_process.h //声明资源初始化/销毁相关函数的头文件
│ ├── utils.h //声明公共函数(例如:文件读取函数)的头文件
├── model //存放转换后模型目录
├── script
│ ├── transferPic.py //将*.jpg转换为*.bin,同时将图片从1024*683的分辨率缩放为224*224
├── src
│ ├── acl.json //系统初始化的配置文件
│ ├── CMakeLists.txt //编译脚本
│ ├── main.cpp //主函数,图片分类功能的实现文件
│ ├── memory_pool.cpp //内存池处理相关函数的实现文件
│ ├── model_process.cpp //模型处理相关函数的实现文件
│ ├── sample_process.cpp //资源初始化/销毁相关函数的实现文件
│ ├── utils.cpp //公共函数(例如:文件读取函数)的实现文件
├── .project //工程信息文件,包含工程类型、工程描述、运行目标设备类型等
├── CMakeLists.txt //编译脚本,调用src目录下的CMakeLists文件
├── resnet50_config.json //配置模型生成信息文件
├── README.md
编译及运行应用¶
模型转换。
以运行用户登录开发环境。
参考《ATC工具使用指南》中的“使用入门”,执行“准备动作”,包括获取工具、设置环境变量。
准备数据。
从https://gitee.com/ascend/ModelZoo-TensorFlow/tree/master/TensorFlow/contrib/cv/resnet50/ATC_resnet50_caffe_AE 链接中获取ResNet-50网络的模型文件(.prototxt)、预训练模型文件(.caffemodel),并以运行用户将获取的文件上传至开发环境的“样例目录/caffe_model”目录下,也可查看README.md。如果目录不存在,需要自行创建。
请从以下链接获取该样例的输入图片,并以运行用户将获取的文件上传至开发环境的“样例目录/data”目录下。如果目录不存在,需自行创建。
https://c7xcode.obs.cn-north-4.myhuaweicloud.com/models/aclsample/dog1_1024_683.jpg
https://c7xcode.obs.cn-north-4.myhuaweicloud.com/models/aclsample/dog2_1024_683.jpg
在“样例目录/data”目录下,创建参考图片列表文件(image_ref_list.txt)并在其中填写图片路径data/ dog1_1024_683.jpg及data/ dog2_1024_683.jpg,各路径换行填写。
将ResNet-50网络转换为适配SoC的离线模型(*.om文件)。
切换到“样例目录”目录,执行如下命令:
atc --save_original_model="true" --soc_version=${soc_version} --log_level="0" --input_format="NCHW" --weight="./caffe_model/resnet50.caffemodel" --batch_num="256" --compile_mode="0" --image_list="data:./data/image_ref_list.txt" --input_shape="data:1,3,224,224" --online_model_type="0" --framework="0" --insert_op_conf="resnet50_insert_op.cfg" --dump_data="0" --output="./model/resnet50" --model="./caffe_model/resnet50.prototxt"--soc_version:SoC的版本,用户根据具体板端环境形态,选择对应的取值。
--insert_op_conf:插入图像预处理的配置。配置了图像预处理的Data层表示输入数据格式为图像,没有配置的为Feature Map,可参考《ATC工具使用指南》配置。
--output:生成的resnet50.om文件存放在“样例目录/model”目录下,建议使用命令中的默认设置,否则在编译代码前,您还需要修改sample_process.cpp中的omModelPath参数值。
const char* omModelPath = "../model/resnet50.om";关于各参数的详细解释,请参见《ATC工具使用指南》。
编译代码。
以运行用户登录开发环境。
设置环境变量,编译脚本CMakeLists.txt通过环境变量所设置的头文件、库文件的路径来编译代码。
如下为设置环境变量的示例,请将“$HOME/acl”替换为ACLlib组件的实际安装路径。
注意:stub路径中的库仅作为编译使用,在板端环境运行时请使用SDK包中的库。
export DDK_PATH=$HOME/acl/ascend-toolkit/svp_latest/x86_64-linux export NNN_HOST_LIB=$HOME/acl/ascend-toolkit/svp_latest/x86_64-linux/acllib/lib64/stub
切换到样例目录,创建目录用于存放编译文件,例如,本文中,创建的目录为“build/intermediates/soc”。
mkdir -p build/intermediates/soc切换到“build/intermediates/soc”目录,执行cmake生成编译文件。
“../../../src”表示CMakeLists.txt文件所在的目录,请根据实际目录层级修改。
cd build/intermediates/soc您需要根据所安装的交叉编译器,执行对应的cmake命令:
若在开发环境上安装的ACLlib软件包为Linux操作系统SoC-cs形态,则执行如下编译命令:
cmake ../../../src -DCMAKE_CXX_COMPILER=aarch64-mix410-linux-g++ -DCMAKE_SKIP_RPATH=TRUE执行make命令,生成的可执行文件main在“样例目录/out”目录下。
make
准备测试数据。
请参考步骤1,在“样例目录/data”目录下,存放测试图片dog1_1024_683.jpg和dog2_1024_683.jpg
以运行用户登录开发环境。
切换到“样例目录/data”目录下,执行transferPic.py脚本,将*.jpg转换为*.bin,同时将图片从1024*683的分辨率缩放为224*224。在“样例目录/data”目录下生成2个*.bin文件。
python3.7.5 ../script/transferPic.py
说明:
如果执行脚本报错“ModuleNotFoundError: No module named 'PIL'”,则表示缺少Pillow库,请使用pip3.7.5 install Pillow --user命令安装Pillow库。运行可执行文件。
将开发环境的样例目录及目录下的文件上传到板端环境。
板端环境的操作系统为Linux时,以root用户将开发环境上的目录及其文件上传到板端环境的指定目录下,例如“/root/acl_resnet50_async”。
登录板端环境。
板端环境的操作系统为Linux时,以root用户登录板端环境。
设置环境变量。
板端环境的操作系统为Linux时,必须设置如下环境变量,并根据libsvp_acl.so和libsvp__aa_cpu.so文件所在的路径设置LD_LIBRARY_PATH环境变量。
export LD_LIBRARY_PATH=/home/demo/out/lib切换到可执行文件main所在的目录,例如“$HOME/acl_resnet50_async/out”,给该目录下的main文件加执行权限。
chmod +x main切换到可执行文件main所在的目录,例如“$HOME/acl_resnet50_async/out”,运行可执行文件。
运行可执行文件,不带参数时:
执行模型异步推理的次数默认为10次;
callback间隔默认为,表示1次异步推理后,下发一次callback任务;
内存池中的内存块的个数默认为10个。
运行可执行文件,带参数时:
第一个参数表示执行模型异步推理的次数;
第二个参数表示下发callback间隔,参数值为0时表示不下发callback任务,参数值为非0值(例如m)时表示m次异步推理后下发一次callback任务;
第三个参数表示内存池中内存块的个数,内存块个数需大于等于模型异步推理的次数。
./main
执行成功后,在屏幕上的关键提示信息示例如下,index及其value会根据板端环境的实际情况有所不同:
备注:日志中出现“…… get callback task failed”,是因为执行过程中推理还没有开始执行就起线程进行callback处理,此为正常现象。
[INFO] ./main param1 param2 param3, param1 is execute model times(default 10), param2 is callback interval(default 1), param3 is memory pool size(default 10) [INFO] execute times = 10 [INFO] callback interval = 1 [INFO] memory pool size = 10 [INFO] acl init success [INFO] open device 0 success [INFO] create context success [INFO] create stream success [INFO] get run mode success [INFO] load model ../model/resnet50.om success [INFO] create model description success [INFO] init memory pool success [INFO] subscribe report success [INFO] top 1: index[267] value[0.889648] [INFO] top 1: index[161] value[0.836914] [INFO] top 1: index[267] value[0.889648] [INFO] top 1: index[161] value[0.836914] [INFO] top 1: index[161] value[0.836914] [INFO] top 1: index[267] value[0.889648] [INFO] top 1: index[161] value[0.836914] [INFO] top 1: index[267] value[0.889648] [INFO] top 1: index[161] value[0.836914] [INFO] top 1: index[267] value[0.889648] ...... [INFO] top 1: index[161] value[0.836914] [INFO] top 1: index[267] value[0.889648] [INFO] model execute success [INFO] unsubscribe report success [INFO] unload model success, modelId is 1 [INFO] execute sample success [INFO] end to destroy stream [INFO] end to destroy context [INFO] end to reset device is 0 [INFO] end to finalize acl
FAQ¶
SS928V100解决方案使用SVP__NNN_模块注意事项¶
hnr与svp__nnn_互斥:
两者不能同时使用,所依赖的ko(ot_pqp.ko/ot_svp_nnn.ko)为互斥,不能同时插入
当前版本默认都没有加载ko,使用svp__nnn_的进程需要手动更改加载脚本,或者手动insmod ot_svp_nnn.ko。如果ot_pqp.ko已经加载,需要rmmod ot_pqp.ko,然后加载ot_svp_nnn.ko
SVP__NNN_离线模型保护¶
当前svp__nnn_中未提供OM的完整性与机密性保护机制,需客户对OM的完整性与机密性进行保护。
第一次推理耗时长的问题¶
用户在进行第一次推理时,可能会碰到推理时间比后续推理耗时长的问题。这种现象可能是因为linux内存管理的缺页机制引发的。建议用户在申请内存时,对workbuf、output等内存进行初始化为0的操作,这样提前把缺页机制完成,使第一次推理耗时与后续的推理基本一致。